키워드:테슬라 로보택시, AMD MI350, OpenAI o3-pro, iFLYTEK AIUI, DeepSeek Nano-vLLM, 위안롱치싱 VLA, 앤트그룹 Ming Lite Omni, L2 양산차 L4 자율주행 구현, AMD MI350X와 B200 성능 비교, o3-pro 모델 장문맥 처리 능력, AIUI 전이중 상호작용 기술, 시각-언어-동작 모델 VLA
🔥 주요 뉴스
Tesla Robotaxi 최초 공개 도로 주행, 머스크 “L2 양산차 개조 없이 L4급 자율주행 가능” 밝혀: Tesla의 Robotaxi(리프레시 Model Y)가 오스틴에서 도로 테스트 중이며, 차체에는 새로운 Robotaxi 로고가 부착되어 있지만 운전대는 그대로 유지하고 있습니다. 머스크는 모든 Tesla 양산차가 감독 없는 자율주행을 실현할 수 있다고 밝혔으며, 현재 테스트 차량에는 기존 FSD보다 파라미터 수가 4.5배 많은 내부 테스트 버전 FSD가 탑재되어 있고 연내 최적화 후 배포될 예정입니다. Robotaxi는 6월 22일 오스틴에서 처음으로 대중에게 공개될 예정입니다. 이는 Tesla의 L2급 FSD가 L4/L5급 Robotaxi로 발전하는 것을 의미하며, 자율주행 산업의 경쟁 구도를 가속화하고 특히 Waymo와 같은 L4 기술 경로 플레이어에게 도전이 될 수 있습니다 (출처: 量子位)

AMD, 최강 AI 칩 MI350 시리즈 발표, Nvidia B200 성능 능가: AMD CEO 리사 수와 OpenAI CEO 샘 알트먼이 MI350X 및 MI355X GPU를 공동 발표했습니다. 이 두 칩은 3nm 공정을 사용하며, 1850억 개의 트랜지스터와 288GB HBM3E 메모리를 탑재하여 Nvidia B200보다 1.6배 많은 메모리 용량을 자랑합니다. 공식 데이터에 따르면 MI350 시리즈는 FP4 정밀도에서 Llama 3.1 405B를 실행할 때 B200보다 추론 속도가 30% 빠르며, FP64 연산 능력은 Nvidia의 두 배입니다. AMD는 또한 OpenAI와 공동 개발한 MI400 시리즈가 내년에 출시될 것이라고 예고하여 AI 칩 시장의 경쟁을 더욱 심화시킬 전망입니다 (출처: 量子位)

OpenAI o3-pro 모델 추론 능력 주목, 실제 성능은 공식 테스트와 다소 차이: OpenAI의 최신 추론 모델 o3-pro는 복잡한 단어 게임(예: 가수 Sabrina Carpenter의 노래 제목 특징에 따라 특정 답변 생성) 처리에서 강력한 능력을 선보여, OpenAI 전 AGI Readiness 팀 책임자가 이전에 Apple이 제기했던 대형 모델 추론 능력에 대한 의구심을 비꼬았습니다. 그러나 LiveBench 등 권위 있는 순위표에서 o3-pro의 코딩 평균 점수는 o3와 거의 비슷했고, 에이전트 코딩 점수는 오히려 뒤처졌습니다. Fiction.LiveBench 테스트에 따르면 o3-pro는 짧은 컨텍스트에서는 우수한 성능을 보였지만, 192k 초장문 컨텍스트 처리에서는 여전히 Gemini 2.5 Pro에 미치지 못했습니다. Apple 및 SpaceX 전 엔지니어 Ben Hylak은 o3-pro의 실제 능력은 충분한 배경 정보 입력에 크게 의존하며, 단순한 채팅 대상보다는 보고서 생성기에 더 적합하고, 도구 호출 및 환경 이해 측면에서 상당한 개선이 있다고 지적했습니다 (출처: 量子位)

iFLYTEK, AIUI 인간-컴퓨터 상호작용 플랫폼 및 로봇 슈퍼브레인 플랫폼 업그레이드, 스마트 하드웨어 심층 협력 추진: iFLYTEK은 인간-컴퓨터 상호작용 플랫폼 AIUI의 주요 업그레이드를 발표했으며, 전이중 상호작용, 감정 감지 및 표현, 인간과 유사한 기억 시스템 향상에 중점을 두었습니다. 특히 어린이 환경을 위해 전용 상호작용 솔루션을 출시하여 어린이 말 인식 및 이해 능력을 향상시켰습니다. 동시에 로봇 슈퍼브레인 플랫폼은 Spark 대형 모델을 기반으로 다중 모드 상호작용, 의미 이해 및 지식 응용을 강화했으며, “스마트 음성 백팩”을 출시하여 기존 로봇이 하드웨어 개조 없이 음성 상호작용을 구현할 수 있도록 했습니다. 이러한 업그레이드는 스마트 하드웨어를 기본 상호작용에서 심층 지능형 협력으로 발전시켜 차량, AI 하드웨어, 로봇 등 여러 분야에 힘을 실어주는 것을 목표로 합니다 (출처: 量子位)

🎯 동향
DeepRoute.ai, Volcano Engine과 협력, Doubao 대형 모델 기반 VLA 물리 세계 Agent 개발: DeepRoute.ai CEO 저우광은 Volcano Engine과 협력하여 Doubao 대형 모델을 활용한 시각-언어-행동(VLA) 모델 등 미래 지향적 기술을 공동 개발하여 물리 세계의 Agent를 만들 것이라고 발표했습니다. DeepRoute.ai의 VLA 모델은 2025년 3분기에 소비자 시장에 출시될 예정이며, 공간 의미 이해, 특이 장애물 인식, 문자 안내판 이해 및 음성 차량 제어라는 네 가지 핵심 기능을 갖추고 보조 운전의 안전성과 지능화 수준을 향상시키는 것을 목표로 합니다. 현재 VLA 모델은 도로 테스트를 완료했으며, 연내 해당 모델을 탑재한 5개 이상의 AI 자동차가 출시될 예정입니다 (출처: 量子位)

DeepSeek 연구원, 1200줄 코드로 vLLM 복제, 일부 환경에서 원본 성능 능가: DeepSeek 연구원 위싱카이가 Nano-vLLM 프로젝트를 오픈소스로 공개했습니다. 1200줄 미만의 Python 코드로 PagedAttention 등 핵심 기술을 포함한 vLLM의 핵심 기능을 구현했습니다. 이 프로젝트는 학습과 이해를 돕기 위해 최소화되고 완전히 읽기 쉬운 vLLM 버전을 제공하는 것을 목표로 합니다. H800 하드웨어와 Qwen3-8B 모델의 특정 테스트 조건에서 Nano-vLLM의 처리량은 원본 vLLM을 능가하여 효율성을 입증했습니다. vLLM은 UC Berkeley에서 개발한 LLM 추론 및 서비스 프레임워크로, PagedAttention 알고리즘을 통해 LLM 서비스의 처리량을 크게 향상시켰습니다 (출처: 量子位)
중국 기업, “플라잉 하드 드라이브 박스” 이용해 미국 AI 칩 수출 제한 회피: 월스트리트저널 보도에 따르면, 미국의 고급 AI 칩 수출 제한에 직면한 중국 기업들은 새로운 전략을 채택하고 있습니다. 대량의 훈련 데이터가 저장된 하드 드라이브(예: 80TB)를 엔지니어가 직접 휴대하여 말레이시아 등 해외 데이터 센터로 가져가 현지 Nvidia 등 첨단 칩이 탑재된 서버를 이용해 AI 모델을 훈련한 후, 완성된 모델 파라미터를 다시 중국으로 가져오는 방식입니다. 이는 칩 직접 수입의 어려움을 우회하고 동남아 및 중동 지역 AI 데이터 센터의 부상을 촉진하기 위한 것입니다. 전 미국 상무부 관리는 이에 대해 우려를 표명했습니다 (출처: dotey)

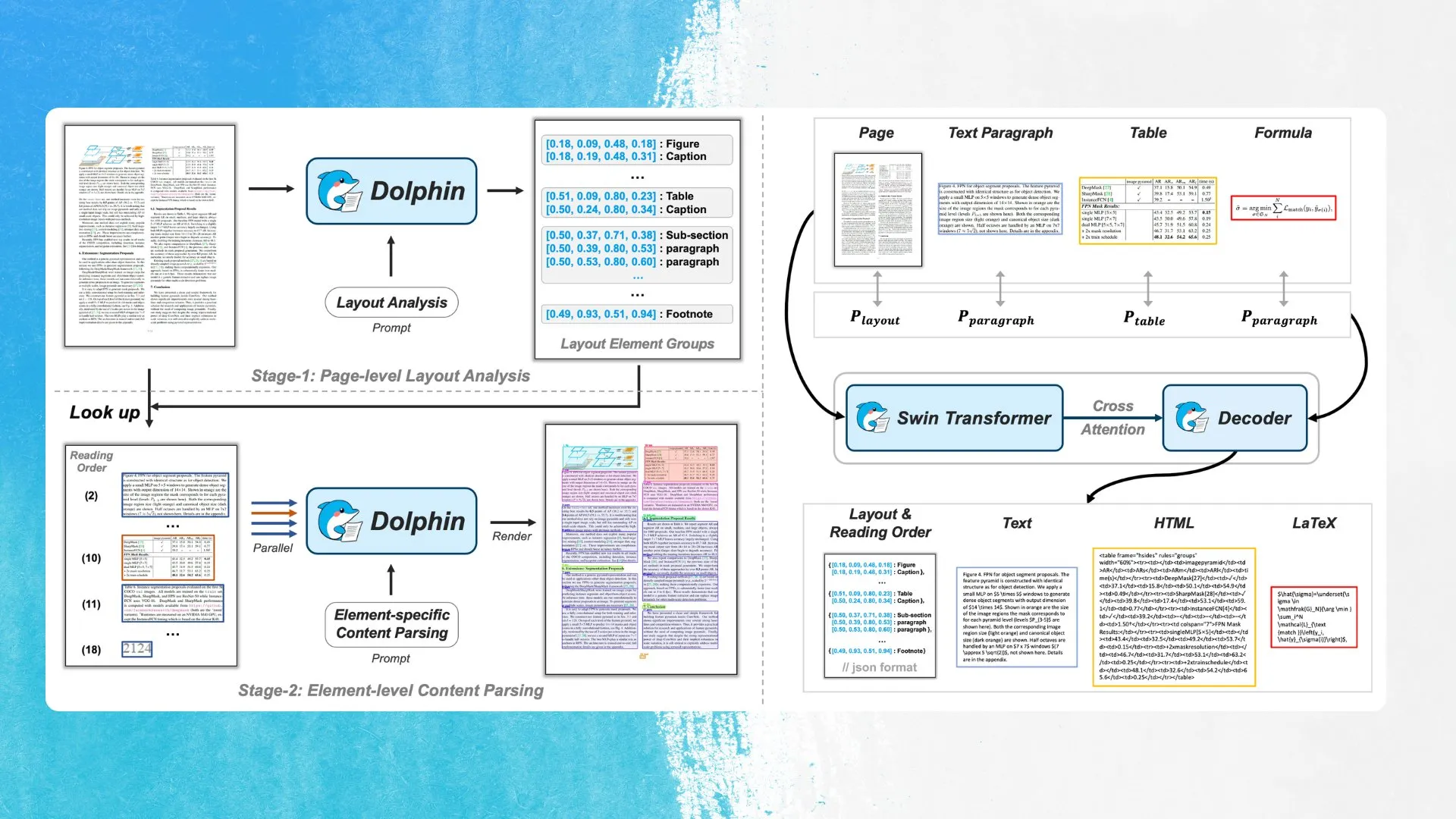
ByteDance, 레이아웃 요소 감지 및 병렬 분석 방식의 새로운 OCR 모델 Dolphin 출시: ByteDance가 MIT 라이선스 기반의 새로운 OCR 모델 Dolphin을 발표했습니다. 이 모델은 먼저 문서 레이아웃의 요소(표, 수식 등)를 감지한 다음 각 요소를 병렬로 분석하여 내용을 생성합니다. 모델과 데모는 Hugging Face Hub에 공개되었습니다. 이 방법은 복잡한 문서 구조 인식의 정확성과 효율성을 높이는 것을 목표로 합니다 (출처: mervenoyann)
OpenAI ChatGPT 프로젝트 기능 강화, 심층 연구, 음성 모드 및 모바일 파일 업로드 지원: OpenAI는 ChatGPT의 “프로젝트”(Projects) 기능에 심층 연구 지원 강화, 음성 모드 통합, 프로젝트 내 과거 채팅 기록 참조를 위한 향상된 기억 기능, 모바일에서의 파일 업로드 및 모델 선택기 지원 등 여러 개선 사항을 추가한다고 발표했습니다. 이러한 업데이트는 사용자가 ChatGPT에서 더욱 집중적이고 복잡한 작업을 수행할 수 있도록 지원하는 것을 목표로 합니다 (출처: kevinweil)
EuroLLM 팀, 22B 모델 및 소형 MoE 모델 포함 다수 신규 모델 프리뷰 버전 공개: EuroLLM 팀이 여러 신규 모델의 프리뷰 버전을 공개했습니다. 여기에는 22B 파라미터 기본 버전 및 명령어 미세 조정 버전 모델, 이전 EuroLLM 기반의 비전 모델 2종(1.7B 및 9B 파라미터), 그리고 0.6B 활성 파라미터와 2.6B 총 파라미터를 가진 소형 혼합 전문가(MoE) 모델이 포함됩니다. 이 모델들은 모두 Apache-2.0 라이선스를 따르며, 초기 테스트 결과 이 소형 MoE 모델은 해당 규모에서 예상외로 좋은 성능을 보였습니다 (출처: Reddit r/LocalLLaMA)

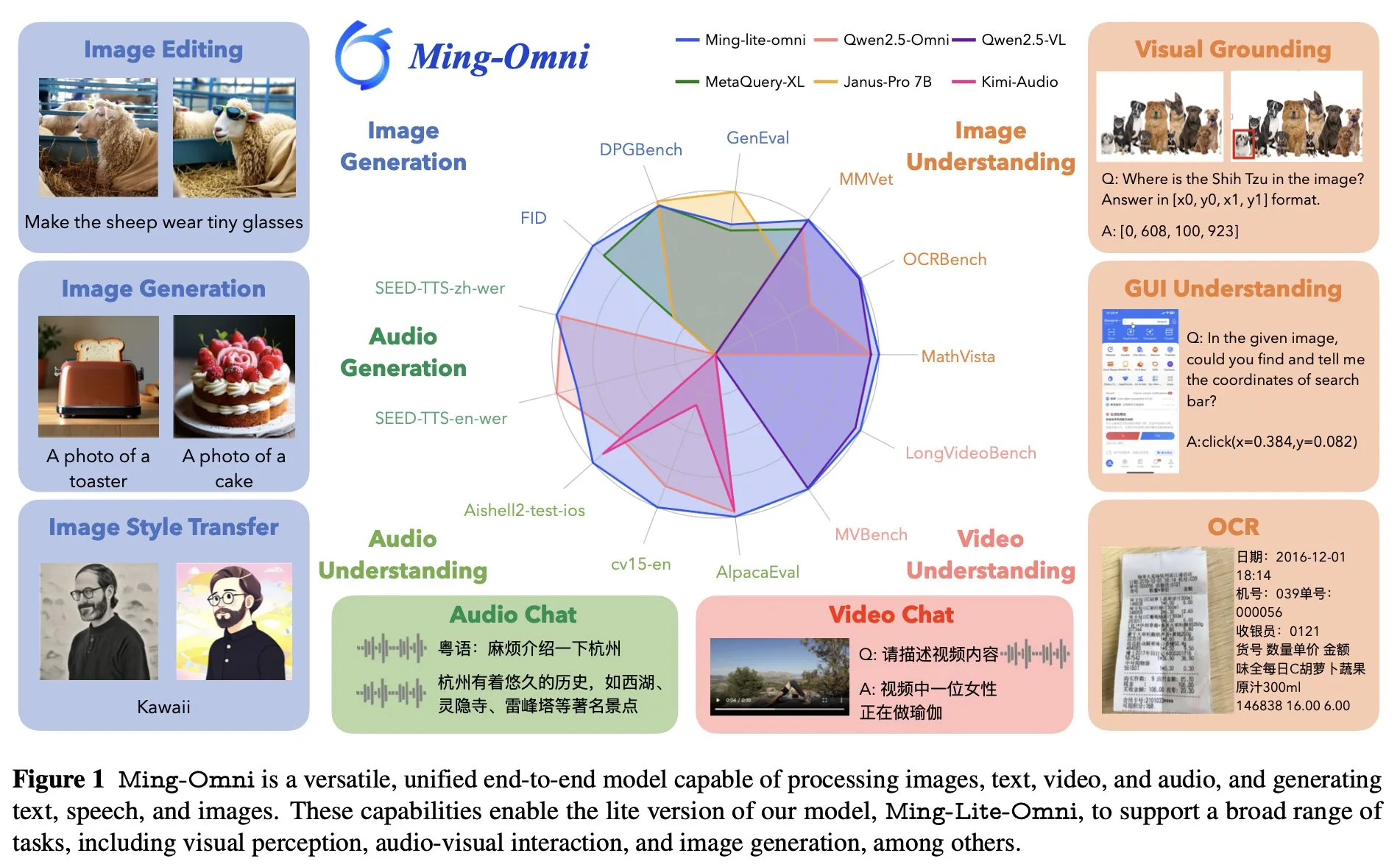
Ant Group, GPT-4o에 필적하는 엔드투엔드 만능 모델 Ming Lite Omni 발표: Ant Group이 Ming Lite Omni 모델을 출시했습니다. 이 모델은 듣기, 말하기, 이미지 생성 등 다양한 기능을 구현할 수 있으며 성능 면에서 GPT-4o와 경쟁합니다. Ming Lite Omni는 GUI 작업에서 Qwen2.5VL-7B보다 높은 정확도를 보였고, 오디오 이해는 여러 공개 벤치마크에서 SOTA를 달성했으며, 비디오 이해 능력도 우수한 성능을 보였습니다. 모델은 혼합 전문가(MoE) 아키텍처를 채택하여 활성 파라미터가 2.8B에 불과하며, 오디오 토큰 프레임률 감소를 위한 BPE 사용, 이미지 생성 품질 향상을 위한 다중 스케일 학습 가능 토큰 등 오디오 및 이미지 생성을 위해 특별히 최적화되었습니다 (출처: mervenoyann)
NVIDIA, Mistral AI와 협력하여 AI 클라우드 플랫폼 Mistral Compute 공동 구축: NVIDIA는 GTC 컨퍼런스에서 Mistral AI와 협력하여 Mistral Compute라는 AI 클라우드 플랫폼을 공동 구축한다고 발표했습니다. 이는 미국과 오픈소스 커뮤니티에 중대한 호재로 여겨지며, 미국 칩이 지원하는 개방형 모델을 통해 글로벌 AI 인프라 구축에 템플릿을 제공하는 것을 목표로 합니다 (출처: arthurmensch)
Hugging Face, PyTorch 전면 수용 선언, Transformers 라이브러리 간소화: Hugging Face의 최고 오픈소스 책임자 Lysandre Jik은 사용자층이 이미 PyTorch에 대한 공감대를 형성했기 때문에 향후 모든 노력을 PyTorch에 집중하여 Transformers 라이브러리의 비대화를 줄이고 더 간결한 툴킷을 제공하는 데 전념할 것이라고 밝혔습니다. PyTorch 공식 측은 이를 환영하며 코드 간결성 유지에 도움이 될 것이라고 강조했습니다 (출처: reach_vb)

ByteDance, 실시간 인터랙티브 비디오 생성 기술 APT2 출시: ByteDance가 최신 실시간 인터랙티브 비디오 생성 기술인 APT2(Autoregressive Adversarial Post-Training)를 선보였습니다. 이 기술은 자기회귀적 적대적 후훈련을 통해 고품질의 실시간 인터랙티브 비디오 콘텐츠 생성을 목표로 하며, 비디오 생성 분야의 발전을 더욱 촉진했습니다 (출처: NerdyRodent)
🧰 도구
Llama-Server Launcher: GUI를 갖춘 llama.cpp 서버 실행기, CUDA 성능 최적화에 중점: 한 개발자가 개인적으로 사용하는 llama-server 실행기를 공유했습니다. Python으로 작성되었으며 그래픽 사용자 인터페이스(GUI)를 제공합니다. 이 도구는 llama.cpp 서비스의 구성 및 시작을 단순화하고 특히 CUDA 성능 조정에 중점을 둡니다. 기능에는 모델 선택, 경로 설정, 컨텍스트 및 배치 크기 조정, GPU 오프로드, FlashAttention, 텐서 분할 등 고급 성능 설정과 채팅 템플릿 선택 및 환경 구성 관리가 포함됩니다. GPU 및 시스템 정보 자동 가져오기, GGUF 모델 메타데이터 분석을 지원하며 플랫폼 간 실행 스크립트(.ps1/.sh)를 생성할 수 있습니다 (출처: Reddit r/LocalLLaMA)
Together AI, 오픈소스 데이터 과학자 에이전트 출시: Together AI가 데이터 과학자처럼 추론할 수 있는 오픈소스 AI 에이전트를 구축했습니다. 이 에이전트는 데이터를 로드하고, Python 코드를 작성하며, 모델이 실패할 경우 재훈련하고, 실제 Kaggle 및 DABStep 작업을 해결할 수 있습니다. 이는 데이터 과학 분야에서 AI의 자동화와 보급을 촉진하기 위한 것입니다 (출처: percyliang)
AutoMind: 자동화된 데이터 과학을 위한 적응형 지식 기반 에이전트 프레임워크: AutoMind는 전문가 지식 베이스 통합, 에이전트 지식 트리 검색 알고리즘 채택, 적응형 코딩 전략을 통해 기존 데이터 과학 에이전트가 복잡하고 혁신적인 작업을 처리할 때 겪는 한계를 극복하고 자동화된 머신러닝 프로세스의 실제 효능을 향상시키기 위해 설계된 새로운 LLM 에이전트 프레임워크입니다 (출처: HuggingFace Daily Papers)
LlamaParse, “프리셋” 기능 출시로 문서 분석 설정 간소화: LlamaParse가 “프리셋”(Presets) 기능을 출시하여 다양한 사용 사례에 최적화된 설정을 제공하는 이해하기 쉬운 사전 구성 모드 시리즈를 제공합니다. 일반적인 시나리오를 위한 빠름, 균형, 고급 모드와 송장, 과학 논문, 기술 문서 및 양식과 같은 일반적인 사용 사례에 최적화된 모드가 포함되어 사용자가 속도와 정확성 사이에서 더 편리하게 선택할 수 있도록 하는 것을 목표로 합니다 (출처: jerryjliu0)
OpenWebUI, o3-pro 지원 기능 추가로 모델 호환성 확장: 커뮤니티 개발자가 Open WebUI를 위해 새로운 기능을 만들었습니다. 응답 API 지원, 비용 추적, 다중 키 지원 및 웹 검색과 같은 기능을 추가하여 o3-pro 모델에 대한 지원을 확장했습니다. 이를 통해 사용자는 공식 고급 요금제에 가입하지 않고도 Open WebUI에서 o3-pro를 사용할 수 있습니다 (출처: Reddit r/OpenWebUI)
📚 학습 자료
논문, 준음수 행렬 분해(SNMF)를 통해 MLP 활성화를 해석 가능한 특징으로 분해하는 방법 탐구: 이 연구는 SNMF를 사용하여 다층 퍼셉트론(MLP)의 활성화를 직접 분해하여, 공동 활성화된 뉴런의 선형 조합으로 구성된 희소 특징을 학습하고 이러한 특징을 활성화 입력에 매핑하여 직접적인 해석 가능성을 부여하는 방법을 제안합니다. 실험 결과, SNMF에서 파생된 특징은 인과적 유도 측면에서 희소 자동 인코더(SAE)보다 우수하며 인간이 해석 가능한 개념과 일치하여 MLP 활성화 공간의 계층 구조를 밝혀냈습니다 (출처: HuggingFace Daily Papers)
새 논문, LoRMA 제안: 저계수 곱셈 적응(Low-Rank Multiplicative Adaptation)을 통한 LLM 미세 조정의 새로운 패러다임: 전통적인 LLM 미세 조정은 일반적으로 가산적 가중치 업데이트를 통해 이루어지지만, LoRMA는 곱셈적 업데이트를 탐구합니다. 저계수 행렬이 야기하는 “계수 억제” 문제를 해결하기 위해, 논문은 순열 및 덧셈 기반의 새로운 계수 확장 연산을 도입하고 효과적인 재정렬 연산을 통해 계산 효율성을 보장합니다. 실험 결과 LoRMA는 경쟁력이 있으며 LLM 적응을 위한 새로운 아이디어를 제공합니다 (출처: Reddit r/deeplearning)
논문, TaxoAdapt 프레임워크 제안, LLM이 구축한 다차원 분류 체계를 진화하는 연구 코퍼스에 적응시켜: 과학 문헌 조직의 어려움에 대응하여 TaxoAdapt 프레임워크는 LLM이 생성한 분류 체계를 특정 코퍼스에 맞게 동적으로 조정하고 다차원(예: 방법론, 작업, 평가 지표)을 지원합니다. 이 프레임워크는 반복적인 계층적 분류를 통해 코퍼스의 주제 분포에 따라 분류의 너비와 깊이를 확장하여 과학 분야의 진화를 더 잘 조직하고 포착하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
논문, MOSAIC 프레임워크 소개, 에이전트 시스템에서의 협력 학습 구현: MOSAIC은 자율적이고 지능적인 AI 시스템이 분산되고 동적인 환경에서 협력 학습을 수행하기 위한 프레임워크입니다. 에이전트는 동기화나 중앙 집중식 제어 없이 모듈식 지식(신경망 마스크 형태)을 선택적으로 공유하고 재사용합니다. 실험 결과, MOSAIC은 속도와 성능 면에서 고립된 학습자보다 우수하며, 때로는 고립된 에이전트가 해결할 수 없는 작업을 해결하고 집단 효율성과 적응성 향상을 촉진할 수 있음을 보여주었습니다 (출처: Reddit r/MachineLearning)
논문, ClaimSpect 프레임워크 제안, 복잡한 주장에 대한 검색 증강 계층적 분석: 많은 주장(예: 과학적, 정치적 주장)은 단순한 참 또는 거짓이 아닙니다. ClaimSpect 프레임워크는 검색 증강 생성을 통해 주장 관련 측면의 계층 구조를 자동으로 구축하고 특정 코퍼스의 관점으로 이러한 측면을 풍부하게 합니다. 이 방법은 복잡한 주장을 해체하고 코퍼스 내 각 측면에 대한 다양한 관점과 그 보편성을 제시하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
논문, 어텐션 헤드 선택을 통한 세분화된 섭동 유도(Fine-Grained Perturbation Guidance) 제안: 이 연구는 확산 모델의 특정 어텐션 헤드가 다양한 시각적 개념(예: 구조, 스타일, 질감 품질)을 제어한다는 것을 발견했습니다. 이를 바탕으로 논문은 사용자 목표와 일치하는 어텐션 헤드를 체계적으로 선택하여 생성 품질과 시각적 속성에 대한 세분화된 제어를 구현하는 “HeadHunter” 프레임워크를 제안하고, SoftPAG를 도입하여 섭동 강도를 조정합니다. 이 방법은 Stable Diffusion 3 및 FLUX.1과 같은 모델에서 품질 향상 및 스타일 유도 측면에서 우수성을 검증했습니다 (출처: HuggingFace Daily Papers)
논문, LLM 비학습은 형식 독립적(Form-Independent)이어야 한다고 주장: 연구는 현재 LLM 비학습(unlearning) 방법의 효과가 훈련 샘플의 형식에 크게 의존하여 동일한 지식의 다른 표현으로 일반화하기 어렵다고 지적합니다. 논문은 이 문제를 “형식 의존 편향”(Form-Dependent Bias)으로 정의하고 ORT 벤치마크를 도입하여 평가합니다. 이 문제를 해결하기 위해 논문은 ROCR(Rank-one Concept Redirection) 방법을 제안하여 특정 개념에 대한 모델의 인식을 재지향함으로써 비학습을 구현하며, 실험 결과 ROCR은 비학습 효과를 현저히 향상시키고 자연스러운 출력을 생성할 수 있음을 입증했습니다 (출처: HuggingFace Daily Papers)
논문, UniPre3D 제안: 교차 모달 가우시안 스플래팅 기반 3D 포인트 클라우드 모델 통합 사전 훈련 방법: UniPre3D는 3D 비전에서 포인트 클라우드 데이터의 다양한 스케일로 인한 문제를 해결하기 위해, 모든 스케일의 포인트 클라우드와 모든 아키텍처의 3D 모델에 원활하게 적용할 수 있는 최초의 통합 사전 훈련 방법을 제안합니다. 이 방법은 가우시안 프리미티브 예측을 사전 훈련 작업으로 사용하고 미분 가능한 가우시안 스플래팅을 활용하여 이미지를 렌더링함으로써 정확한 픽셀 수준 감독과 엔드투엔드 최적화를 구현하는 동시에 2D 사전 훈련 모델의 특징을 통합하여 텍스처 지식을 도입합니다 (출처: HuggingFace Daily Papers)
논문, StreamSplat 제안: 미보정 비디오 스트림을 위한 온라인 동적 3D 재구성: StreamSplat은 임의 길이의 미보정 비디오 스트림을 온라인으로 동적 3D 가우시안 스플래팅(3DGS) 표현으로 변환할 수 있는 완전 전방향 프레임워크입니다. 정적 인코더의 확률적 샘플링 메커니즘을 통해 3DGS 위치를 예측하고 동적 디코더의 양방향 변형 필드를 통해 견고하고 효율적인 동적 모델링을 구현하여 실시간 동적 장면 재구성의 보정, 동적 모델링 및 효율성 안정성 문제를 해결하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
논문, 마스크 이미지 모델링에서의 어텐션 프로빙(Attentive Probing) 검토: 대규모 미세 조정이 비현실적이 되면서 프로빙(probing)이 자기 지도 학습(SSL) 평가의 우선적인 방법이 되었습니다. 표준 선형 프로빙(LP)은 마스크 이미지 모델링(MIM) 훈련 모델의 잠재력을 충분히 반영하지 못했습니다. 본 논문은 어텐션 프로빙을 재검토하여 효율적인 프로빙(EP), 즉 다중 쿼리 교차 어텐션 메커니즘을 도입하여 훈련 가능한 파라미터를 줄이고 속도를 향상시켰으며, 여러 벤치마크에서 LP 및 이전 어텐션 프로빙 방법보다 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문, PosterCraft 제안: 통합 프레임워크 하에서 고품질 미적 포스터 생성의 새로운 아이디어: PosterCraft는 미적 포스터 생성의 어려움을 해결하는 것을 목표로 하며, 이는 정확한 텍스트 렌더링뿐만 아니라 추상적인 예술 콘텐츠, 눈길을 끄는 레이아웃 및 전체적인 스타일 조화의 원활한 통합을 요구합니다. PosterCraft는 대규모 텍스트 렌더링 최적화, 영역 인식 감독 미세 조정, 미적 텍스트 강화 학습 및 공동 시각 언어 피드백 개선을 포함한 계단식 워크플로를 채택하여 생성을 최적화하며, 여러 실험에서 오픈소스 기준선보다 현저히 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문, 토큰 섭동 유도(Token Perturbation Guidance)를 통한 확산 모델 개선 제안: 분류기 독립적 유도(CFG)가 특정 훈련 과정을 필요로 하고 조건부 생성에만 국한되는 한계를 해결하기 위해, TPG 방법은 확산 네트워크 내 중간 토큰 표현에 직접 섭동 행렬을 적용합니다. TPG는 표준 보존 셔플링 연산을 사용하여 효과적인 유도 신호를 제공하며, 아키텍처 변경 없이 생성 품질을 향상시키고 조건부 및 무조건부 생성 모두에 적용 가능합니다. 실험 결과 TPG는 무조건부 생성에서 SDXL 기준선의 FID를 거의 2배 개선했습니다 (출처: HuggingFace Daily Papers)
논문, DreamActor-H1 제안: 모션 설계를 통한 Diffusion Transformers로 고품질 인간-제품 시연 비디오 생성: DreamActor-H1은 고품질 인간-제품 상호작용 시연 비디오 생성을 목표로 하는 Diffusion Transformer(DiT) 기반 프레임워크입니다. 이 방법은 쌍을 이루는 인간-제품 참조 정보와 추가적인 마스크 교차 어텐션 메커니즘을 주입하여 인간과 제품의 정체성 세부 정보(예: 로고, 질감)를 보존합니다. 3D 인체 메쉬 템플릿과 제품 경계 상자를 활용하여 정확한 모션 유도를 제공하고 구조화된 텍스트 인코딩을 통해 3D 일관성을 향상시킵니다 (출처: HuggingFace Daily Papers)
논문, EmbodiedGen 제안: 체화형 지능을 위한 생성형 3D 세계 엔진: EmbodiedGen은 상호작용형 3D 세계 생성을 위한 기본 플랫폼으로, 정확한 물리적 속성과 실제 세계 스케일을 갖춘 고품질, 제어 가능, 사진처럼 사실적인 3D 자산을 저비용으로 확장 가능하게 생성하고 통합 로봇 기술 형식(URDF)을 채택하는 것을 목표로 합니다. 이러한 자산은 다양한 물리 시뮬레이션 엔진에 직접 가져올 수 있어 체화형 지능의 훈련 및 평가 작업을 지원하며, 기존 3D 컴퓨터 그래픽 자산의 높은 비용과 제한된 현실감 문제를 해결합니다 (출처: HuggingFace Daily Papers)
새로운 연구, Apple의 “사고의 환상” 논문 반박, LLM이 새롭고 복잡한 문제 해결 가능하다고 주장: Apple이 최근 발표한 “사고의 환상”(Illusion of Thinking) 논문에서 대형 추론 모델(LRM)이 복잡한 계획 퍼즐(예: 하노이의 탑)에서 “정확도 붕괴”를 보인다고 주장한 것에 대해, 후속 비평 연구는 Apple의 결론이 모델의 기본 추론 능력 실패보다는 실험 설계의 한계를 주로 반영한다고 지적했습니다. 새로운 연구는 원 실험의 토큰 예산 초과, 의도적으로 잘린 출력에 대한 잘못된 평가, 수학적으로 해결 불가능한 퍼즐 인스턴스 포함 등이 모델 능력에 대한 오판을 초래했다고 주장합니다. 실험 방법을 조정하여, 예를 들어 모델이 하노이의 탑 해법을 생성하는 상세한 단계 목록 대신 간결한 Lua 함수를 출력하도록 요구했을 때, 모델은 이전에 완전히 실패했다고 보고된 사례에서 높은 정확도를 보여, 모델이 추론할 수 없는 것이 아니라 출력 형식과 토큰 제한에 의해 제약을 받는다는 것을 시사합니다 (출처: Reddit r/LocalLLaMA)

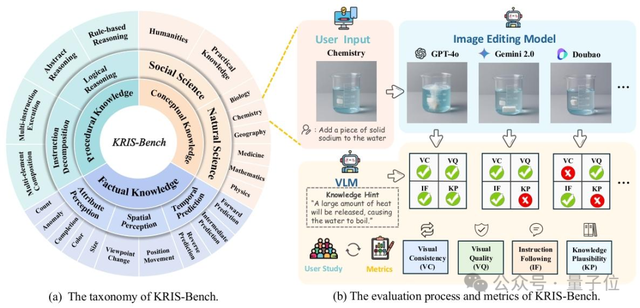
KRIS-Bench: 지식 유형 관점에서 이미지 편집 모델 추론 능력 종합 평가하는 새로운 벤치마크: 동남대학교 등 기관이 공동으로 KRIS-Bench를 발표했습니다. 이는 지식 기반 이미지 편집 시스템의 추론 능력을 평가하는 벤치마크입니다. 사실적 지식(예: 색상, 수량), 개념적 지식(예: 물리 상식), 절차적 지식(예: 다단계 작업)의 세 가지 측면에서 22가지 편집 작업을 세분화하여 10개의 주요 이미지 편집 모델(GPT-Image-1, Gemini 2.0 Flash 등 포함)을 평가했습니다. 결과에 따르면 비공개 모델인 GPT-Image-1이 가장 좋은 성능을 보였지만, 모든 모델이 절차적 추론, 자연 과학 및 다단계 합성 등 심층 추론 작업에서 전반적으로 부진한 성과를 보여 현재 모델의 고급 인지 능력 부족을 드러냈습니다 (출처: 量子位)
새로운 연구, Finetune-RAG 방법 제안, RAG에서의 환각에 저항하도록 언어 모델 미세 조정: 대형 언어 모델은 검색 증강 생성(RAG)에서 검색이 불완전할 때(예: 방해되는 문서 조각 존재) 환각을 일으키기 쉽습니다. Finetune-RAG는 정확하고 잘못된 컨텍스트를 포함하는 입력 샘플에 대해 모델을 훈련하여 진실성을 더 잘 유지하도록 합니다. 연구팀은 1600개 이상의 이중 컨텍스트 샘플을 포함하는 데이터셋, LLaMA 3.1-8B-Instruct의 미세 조정된 체크포인트, 그리고 Bench-RAG라는 GPT-4o 평가 프레임워크를 발표했습니다. 평가 결과, 이 방법은 정확도를 77%에서 98%로 향상시켰으며 유용성, 관련성 및 깊이 측면에서도 모두 향상되었습니다 (출처: Reddit r/MachineLearning)
TeleMath: 통신 분야 수학 문제 해결 능력 LLM 벤치마크 최초 공개: 통신 분야 특정, 수학 집약적 작업 해결 능력을 평가하기 위해 연구자들이 TeleMath 벤치마크를 출시했습니다. 이 벤치마크는 신호 처리, 네트워크 최적화 및 성능 분석 등 통신 주제를 다루는 500개의 질의응답 쌍을 포함합니다. 여러 오픈소스 LLM에 대한 평가 결과, 수학 또는 논리 추론을 위해 특별히 설계된 모델이 TeleMath에서 더 나은 성능을 보였고, 일반적인 대형 파라미터 모델은 종종 어려움을 겪었습니다. 데이터셋과 평가 코드는 공개되었습니다 (출처: HuggingFace Daily Papers)
ChineseHarm-Bench: 중국어 유해 콘텐츠 탐지 벤치마크 공개: 기존 유해 콘텐츠 탐지 자원이 대부분 영어인 상황에 대응하여 연구자들이 ChineseHarm-Bench를 발표했습니다. 이는 포괄적이고 전문적으로 레이블링된 중국어 콘텐츠 유해성 탐지 벤치마크입니다. 이 벤치마크는 6개의 대표적인 범주를 다루며 데이터는 모두 실제 세계에서 수집되었습니다. 레이블링 과정에서 LLM에 명시적인 전문가 지식을 제공하는 지식 규칙 라이브러리도 생성되었습니다. 또한 연구자들은 인공적으로 레이블링된 규칙과 LLM의 암묵적 지식을 결합하여 소형 모델이 SOTA LLM의 성능에 도달할 수 있도록 하는 지식 강화 기준 방법을 제안했습니다 (출처: HuggingFace Daily Papers)
새로운 연구, 인과적 표현 학습을 통해 언어 모델 잠재 능력의 계층 구조 발견: 언어 모델 능력을 충실히 평가하고 혼란 효과와 높은 계산 비용의 어려움을 극복하기 위해, 이 연구는 인과적 표현 학습 프레임워크를 제안합니다. 이 프레임워크는 관찰된 벤치마크 성능을 소수의 잠재 능력 요인의 선형 변환으로 모델링하고, 기본 모델을 공통 혼란 요인으로 제어한 후 이러한 잠재 요인 간의 인과 관계를 식별합니다. Open LLM Leaderboard의 1500개 이상 모델 데이터에 적용한 결과, 연구는 일반적인 문제 해결 능력에서 명령어 준수 숙련도, 그리고 수학적 추론 능력으로 이어지는 명확한 인과 경로를 보여주는 간결한 3개 노드 선형 인과 구조를 발견했습니다 (출처: HuggingFace Daily Papers)
DeepLearning.AI, “GenAI 애플리케이션을 위한 워크플로우 오케스트레이션” 신규 과정 출시: Andrew Ng은 Astronomer와 협력하여 인기 있는 오픈소스 도구 Airflow 3.0을 사용하여 신뢰할 수 있는 생성형 AI 파이프라인을 구축하고 배포하는 방법을 가르치는 새로운 단기 과정을 출시한다고 발표했습니다. 과정 내용에는 워크플로우를 개별 작업으로 분해, 작업 스케줄링, 병렬 실행, 장애 복구 및 관찰 가능성 등이 포함되며, 학습자가 프로토타입 Jupyter 노트북이나 Python 스크립트를 프로덕션 준비가 된 워크플로우로 전환하는 데 도움을 주는 것을 목표로 합니다 (출처: DeepLearningAI)
논문, 복합 AI 시스템 최적화 방법, 과제 및 미래 방향 논의: LLM 및 AI 시스템의 발전과 함께 여러 구성 요소를 통합한 복합 AI 시스템이 복잡한 작업을 수행하는 데 점점 더 성숙해지고 있습니다. 이 논문은 수치적 및 언어 기반 기술을 포함하여 복합 AI 시스템 최적화의 최신 진행 상황을 체계적으로 검토합니다. 논문은 복합 AI 시스템 최적화의 개념을 공식화하고 기존 방법을 분류하며 해당 분야의 개방된 연구 과제와 미래 방향을 강조합니다 (출처: HuggingFace Daily Papers)
💼 비즈니스
디즈니와 유니버설 스튜디오, 이미지 생성기 Midjourney 저작권 침해로 고소: 디즈니와 유니버설 스튜디오는 Midjourney가 허가 없이 스타워즈, 겨울왕국, 미니언즈 등 자사의 창작 라이브러리를 모델 훈련에 사용하고 대량의 파생 작품을 생성 및 배포했다고 비난하며 “끝없는 표절”이라고 주장했습니다. 이 사건은 AI 생성 콘텐츠와 지적 재산권 경계에 대한 논쟁을 다시 한번 불러일으켰습니다 (출처: Reddit r/ArtificialInteligence)
NVIDIA, 도이치 텔레콤과 협력, 2026년까지 유럽 제조업체를 위한 최초의 산업용 AI 클라우드 구축: 독일 연방 총리 프리드리히 메르츠와 NVIDIA CEO 젠슨 황이 만나 독일을 글로벌 AI 리더로 공고히 하기 위한 추가 전략적 협력을 논의했습니다. 이 비전의 일환으로 도이치 텔레콤과 NVIDIA는 새로운 협력을 발표하여 2026년까지 유럽 제조업체를 위한 세계 최초의 산업용 AI 클라우드를 구축할 계획입니다. 이 안전하고 유럽 규범을 준수하는 인프라는 최첨단 혁신을 지원하는 동시에 완전한 데이터 주권을 보장할 것입니다 (출처: nvidia)

샘 알트먼, 전액 주식 인수를 통해 OpenAI 비영리 조직 통제권 희석 가능성 루머: 최근 OpenAI가 io(65억 달러)와 Windsurf(30억 달러)를 전액 주식으로 인수한 것이 추측을 불러일으키고 있습니다. Hacker News에는 샘 알트먼이 이러한 거래를 이용하여 비영리 조직인 OpenAI Inc.의 영리 법인 OpenAI Global LLC(현재 OpenAI PBC)에 대한 통제권을 점진적으로 희석시켜 완전한 영리 회사로의 전환에 대한 법적 제한을 회피할 수 있다는 이론이 제기되었습니다. 일부에서는 이를 알트먼이 2014년 Reddit에 대해 취했던 조치와 연관 짓지만, 이러한 인수가 정상적인 사업 전략적 조치라는 견해도 있습니다 (출처: Reddit r/ArtificialInteligence)
🌟 커뮤니티
AI가 진정으로 “추론”할 수 있는지에 대한 논의 지속, Apple 논문 논란 야기: Apple이 최근 발표한 논문에서 대형 언어 모델(LLM)이 복잡한 작업(예: 하노이의 탑)에서 보이는 성능은 진정한 추론이라기보다는 패턴 매칭에 가깝다고 주장한 것이 커뮤니티에서 광범위하게 논의되고 있습니다. OpenAI 전 직원 Miles Brundage는 o3-pro가 복잡한 단어 게임을 해결하는 것을 보고 “이것이 추론이 아니면 무엇이 추론인가”라고 비꼬았습니다. 후속 연구에서는 Apple 논문의 “추론 붕괴” 현상이 모델 자체의 추론 능력 부족보다는 실험 설계의 한계(예: 토큰 제한, 해결 불가능한 문제에 대한 잘못된 평가) 때문일 수 있다고 지적했습니다. 테스트 방법을 조정한 후 모델은 이전에 실패했던 작업에서 좋은 성능을 보여, AI 추론 능력 평가는 더 신중한 실험 설계가 필요함을 시사합니다 (출처: o3-pro答高难题文字游戏引围观,OpenAI前员工讽刺苹果:这都不叫推理那什么叫推理, Reddit r/LocalLLaMA)
Nvidia CEO 젠슨 황과 Anthropic CEO 다리오 아모데이, AI 미래 관점에서 현저한 의견 차이: Fortune 보도에 따르면, Nvidia CEO 젠슨 황은 Anthropic CEO 다리오 아모데이의 AI에 대한 거의 모든 견해에 동의하지 않는다고 밝혔습니다. 아모데이는 종종 AI의 잠재적 위험과 고용에 미치는 막대한 영향을 강조하며, AI 발전에 대한 더 엄격한 통제와 소수의 “책임 있는” 조직 주도를 주장합니다. 반면 황은 이러한 견해에 회의적이며 AI 기술의 광범위한 적용과 발전을 선호하는 경향이 있습니다. 커뮤니티에서는 황의 입장이 Nvidia가 AI 하드웨어 주요 공급업체라는 사업적 이해관계와 관련 있을 수 있다고 보고 있습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Claude Code의 20달러 구독 플랜, 높은 가성비로 개발자 호평: 많은 개발자들이 소셜 미디어에서 Anthropic Claude Code 월 20달러 구독 플랜 사용 경험을 긍정적으로 공유하며, 가성비가 매우 뛰어나 프로젝트에서 빠르게 비용을 회수할 수 있다고 말합니다. 사용자들은 일정한 속도 제한이 존재함에도 불구하고 Claude Code가 코딩 보조, 새로운 언어 학습(예: C#에서 SwiftUI로 전환), 프로젝트 지침 최적화(예: CLAUDE.md 파일) 등에서 뛰어난 성능을 보여 작업 효율성을 크게 향상시켰다고 언급했습니다. 일부 사용자는 다른 AI 프로그래밍 보조 도구 구독 취소를 고려하고 있습니다 (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
커뮤니티, AI의 심리학 분야 미래 응용 및 윤리적 과제 논의: LLM이 치료 프롬프트를 작성하고, 스마트폰 센서를 통해 감정을 추적하는 애플리케이션 등 기술이 발전함에 따라 AI가 점차 심리학에 침투하고 있습니다. 커뮤니티는 AI가 임상 실습에서 치료사의 능력을 향상시킬 것인지 아니면 궁극적으로 일부 업무를 대체할 것인지, AI의 평가 및 연구에서의 신뢰도, 심리학 전문 교육 및 고용 시장에 미치는 영향, 그리고 데이터 편향, 개인 정보 보호 및 “로봇 치료사”의 한계와 같은 AI 응용의 윤리 및 규제 문제에 초점을 맞춰 논의하고 있습니다. 핵심 우려는 AI를 활용하여 효율성과 개인화된 서비스를 향상시키는 동시에 환자 안전을 보장하고 인간 관계의 치료적 가치를 유지하는 방법입니다 (출처: Reddit r/artificial)
Unsloth의 3.53bit 양자화 DeepSeek-R1-0528 모델, Aider Polyglot 코딩 벤치마크에서 양호한 성능: Unsloth 팀이 DeepSeek-R1-0528 모델을 3.53bit로 양자화(UD-Q3_K_XL)한 후, Aider Polyglot 코딩 벤치마크 테스트에서 68%의 통과율을 달성했습니다. 테스트에는 40960의 컨텍스트 크기와 Flash Attention이 사용되었으며, 필요한 RAM/VRAM은 약 300GB였습니다. 이 성적은 Claude Sonnet 3.7과 Claude Opus 4 사이로, 양자화 모델이 높은 코딩 능력을 유지하는 잠재력을 보여줍니다. 커뮤니티 회원들은 이러한 모델을 로컬에서 실행하는 성능에 깊은 인상을 받았으며 더 많은 양자화 버전의 테스트 결과를 기대하고 있습니다 (출처: Reddit r/LocalLLaMA)
💡 기타
GCP 글로벌 장애 사고 보고서 공개: 불법 할당량 정책으로 서비스 중단: Google Cloud Platform(GCP) 최근 글로벌 장애 사고 보고서에 따르면, 원인은 글로벌 API 관리 시스템에 잘못된 할당량 정책(예: 시간당 1회 요청 제한)이 하달되어 외부 요청이 할당량 초과로 거부(403 오류)된 것입니다. 엔지니어들이 발견 후 영향을 받는 API의 할당량 검사를 우회했습니다. 그러나 us-central1 지역에서는 이전 정책을 지우고 새 정책을 작성하려 할 때 캐시 문제로 데이터베이스 과부하가 발생하여 복구 시간이 더 길어졌습니다. 다른 지역은 캐시를 점진적으로 지우는 방식으로 복구했으며, 전체 과정은 약 2시간이 소요되었습니다 (출처: karminski3)

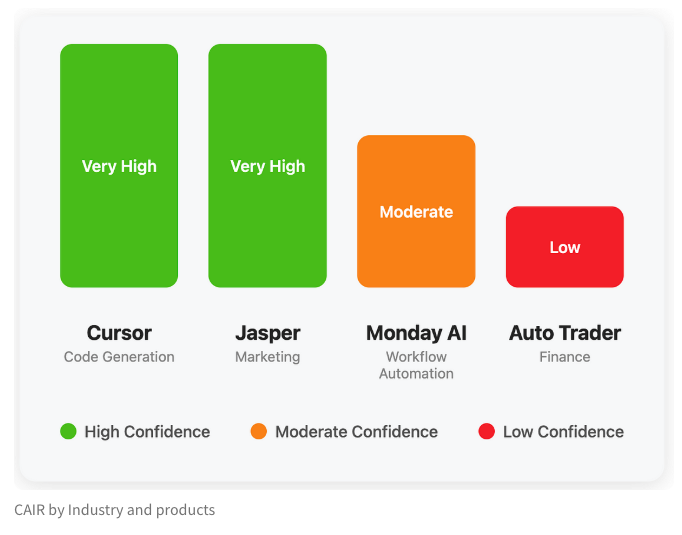
LangChain 팀, AI 제품 성공 잠재력 평가를 위한 CAIR 지표 제안: LangChain의 Harrison Chase와 Assaf Elovic은 일부 AI 제품이 빠르게 보급되는 반면 다른 제품은 어려움을 겪는 이유에 대해 공동으로 글을 썼습니다. 그들은 모델 능력이 유일한 결정 요인이 아니며 사용자 경험(UX)이 매우 중요하다고 주장하며 “CAIR”(Confidence in AI Results, AI 결과에 대한 신뢰도) 지표를 제안했습니다. CAIR이 높을수록 제품 채택률이 높아집니다. 이 프레임워크는 개발자가 사용자 신뢰도에 영향을 미치는 다양한 구성 요소를 식별하고 개선하여 제품 성공률을 높이는 데 도움을 주는 것을 목표로 합니다 (출처: hwchase17, swyx, hwchase17, Hacubu)
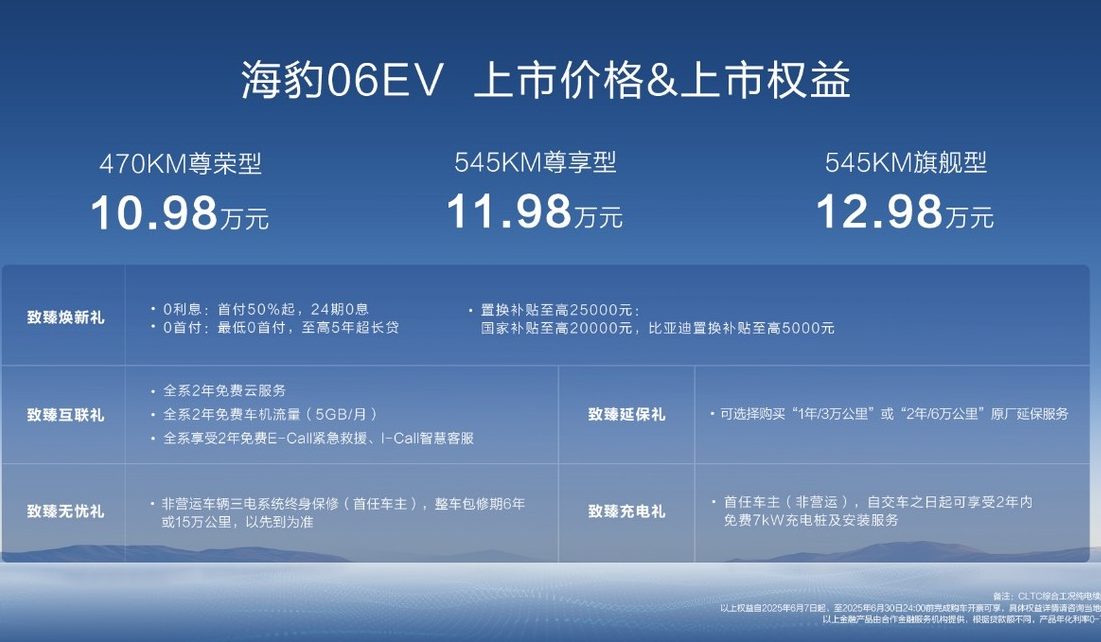
BYD, 순수 전기 가정용 쿠페 Seal 06EV 출시, 가격 10만 9800위안부터: BYD Ocean Net은 충칭 모터쇼에서 Seal 06EV를 출시했습니다. 트렌디하고 아름다운 품질을 갖춘 쿠페로 포지셔닝되며, 총 3가지 구성으로 가격대는 10만 9800위안에서 12만 9800위안입니다. 이 차량은 BYD e-platform 3.0 Evo를 기반으로 제작되었으며, 8-in-1 스마트 전기 구동 장치와 차세대 광온도 범위 고효율 히트 펌프 시스템을 탑재하여 CLTC 기준 470KM 및 545KM의 두 가지 주행 거리를 제공합니다. 차량은 후륜 구동 레이아웃을 채택하고 DiLink C 지능형 댐핑 차체 제어 시스템을 갖추고 있으며, “DiPilot 100” 지능형 운전 보조 삼안 버전을 탑재하여 고속도로 주행 보조, 자동 주차 등의 기능을 지원합니다 (출처: 量子位)