
Ключевые слова:Gemini 2.5 Pro, OpenAI конфиденциальность данных, OpenThinker3-7B, Claude Gov, ИИ агенты, большие языковые модели, обучение с подкреплением, открытые модели, повышение производительности Gemini 2.5 Pro, политика хранения пользовательских данных OpenAI, способности к рассуждению OpenThinker3-7B, применение Claude Gov в национальной безопасности, устойчивость и управление ИИ агентами
🔥 В центре внимания
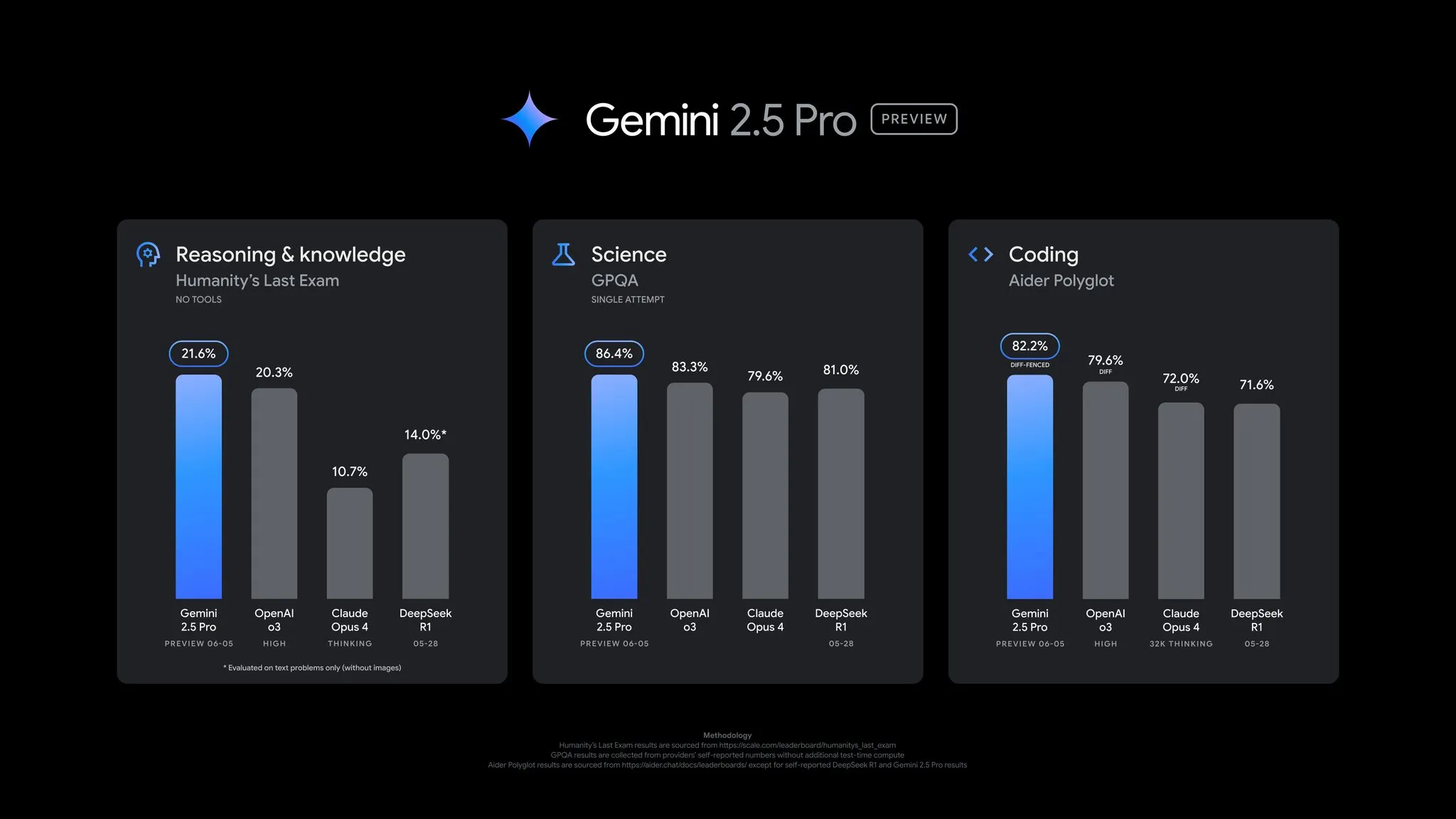
Google выпускает обновление предварительной версии Gemini 2.5 Pro с всесторонним улучшением производительности: Google объявил о важном обновлении предварительной версии Gemini 2.5 Pro, которое принесло значительные улучшения в кодировании, логическом выводе, научных и математических способностях. Новая версия показала лучшие результаты в ключевых бенчмарках, таких как AIDER Polyglot, GPQA, HLE, и добилась скачка рейтинга Elo на 24 пункта на LMArena, вновь заняв лидирующую позицию. Кроме того, стиль ответов и форматирование модели были улучшены на основе отзывов пользователей, а также была введена функция «бюджета на обдумывание» для предоставления большего контроля. Обновление уже доступно в Gemini App, Google AI Studio и Vertex AI (Источник: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI обязали бессрочно хранить пользовательские данные по иску New York Times, что вызывает опасения по поводу конфиденциальности: В рамках судебного разбирательства по иску о нарушении авторских прав со стороны New York Times, суд обязал OpenAI бессрочно хранить все журналы взаимодействия пользователей с ChatGPT и API, включая данные «временных диалогов», которые ранее обещали хранить только 30 дней, и данные запросов API. OpenAI заявила, что подает апелляцию, считая это решение «чрезмерным вмешательством», которое подрывает давно установленные нормы конфиденциальности и ослабляет ее защиту. Это постановление означает, что OpenAI, возможно, не сможет выполнить свои обязательства перед пользователями по хранению и удалению данных, что вызывает широкие опасения пользователей относительно конфиденциальности и безопасности данных, и особенно может затронуть разработчиков приложений, которые полагаются на OpenAI API и имеют собственные политики хранения данных (Источник: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

Выпущен OpenThinker3-7B, обновляющий SOTA для 7B открытых моделей логического вывода: Ryan Marten анонсировал выпуск OpenThinker3-7B, новой открытой модели логического вывода с 7 миллиардами параметров, которая в среднем на 33% превосходит DeepSeek-R1-Distill-Qwen-7B в оценках по коду, науке и математике. Команда также выпустила датасет OpenThoughts3-1.2M, который, по их утверждению, является лучшим открытым датасетом для логического вывода среди всех существующих по объему данных. Исследователи отмечают, что для меньших моделей дистилляция из R1 является самым простым путем повышения производительности, однако исследования в направлении RL (обучения с подкреплением) более перспективны. Этот результат считается одной из пионерских работ в области открытых моделей логического вывода (Источник: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic представляет Claude Gov, кастомизированную модель для клиентов национальной безопасности США: Anthropic анонсировала выпуск Claude Gov, серии кастомизированных моделей ИИ, созданных специально для клиентов в сфере национальной безопасности США. Эти модели уже развернуты в высших эшелонах органов национальной безопасности США, и доступ к ним ограничен лицами, работающими в условиях конфиденциальности. Этот шаг знаменует дальнейшее углубление применения технологий ИИ в правительственной и оборонной сферах, а также вызывает дискуссии о применении ИИ в чувствительных областях (Источник: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 Тренды
Yann LeCun согласен с Sundar Pichai: текущие технологии могут не привести к AGI, возможен период плато: Главный научный сотрудник Meta по ИИ Yann LeCun ретвитнул и поддержал мнение CEO Google Sundar Pichai о том, что текущий технологический путь не гарантирует достижения общего искусственного интеллекта (AGI), и развитие ИИ может столкнуться с временным периодом плато. Pichai отметил, что, несмотря на поразительную скорость прогресса ИИ, могут существовать ограничения, и текущие технологии все еще далеки от общего интеллекта. Это отражает осторожное отношение отрасли к путям и срокам достижения AGI (Источник: ylecun)
OpenAI набирает команду по устойчивости и контролю агентов для повышения безопасности ИИ-агентов: OpenAI формирует новую команду «Устойчивость и контроль агентов» (Agent Robustness and Control) с целью обеспечения безопасности и надежности своих ИИ-агентов в процессе обучения и развертывания. Команда будет заниматься решением некоторых из самых сложных проблем в области ИИ, что свидетельствует о высоком внимании OpenAI к безопасности и контролируемости при продвижении более мощных ИИ-агентов (Источник: gdb)

Новое исследование Apple выявляет «иллюзию мышления» у больших языковых моделей: при усложнении задач способность к рассуждению не растет, а падает: В последней исследовательской работе Apple «Иллюзия мышления» (The Illusion of Thinking) указывается, что текущие модели рассуждения при увеличении сложности задачи до определенного уровня демонстрируют снижение «усилий по рассуждению» (reasoning effort), даже при достаточном бюджете токенов. Это противоречащее интуиции явление «масштабного ограничения» (scaling limit) показывает, что модели при обработке очень сложных задач могут не осуществлять настоящего глубокого мышления, а демонстрировать «иллюзию мышления», что ставит новые задачи для оценки и повышения реальных способностей к рассуждению у больших моделей (Источник: Ar_Douillard, Reddit r/MachineLearning)

OpenAI обсуждает эмоциональную связь человека и ИИ, приоритезируя исследование влияния на эмоциональное благополучие пользователей: Joanne Jang из OpenAI опубликовала пост в блоге, в котором обсуждается растущая эмоциональная связь между пользователями и моделями ИИ, такими как ChatGPT. В статье отмечается, что люди естественно антропоморфизируют ИИ и могут испытывать к нему чувство товарищества и доверия. OpenAI признает эту тенденцию и заявляет, что будет приоритезировать исследование влияния ИИ на эмоциональное благополучие пользователей, а не углубляться в онтологические вопросы о том, действительно ли ИИ «обладает сознанием». Цель компании — создавать теплых, полезных ИИ-помощников, которые, однако, не стремятся чрезмерно к эмоциональной зависимости и не имеют собственных целей (Источник: openai, sama, BorisMPower)

Xiaohongshu (Red Note) выпускает открытую MoE большую модель dots.llm1-143B-A14B: Hi Lab компании Xiaohongshu выпустила свою первую серию открытых больших моделей dots.llm1, включающую базовую модель dots.llm1.base и модель с инструктивной донастройкой dots.llm1.inst. Модель использует архитектуру MoE, общее количество параметров составляет 143B, активных параметров — 14B. По официальным тестам компании, ее производительность на MMLU-Pro превосходит Qwen3-235B-A22B, но уступает новой DeepSeek-V3. Модель распространяется по лицензии MIT и доступна для свободного использования. Однако предварительные тесты сообщества показывают, что она плохо справляется с задачами генерации кода и другими, уступая даже Qwen2.5-coder (Источник: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Серия Qwen3 выпускает модели Embedding и Reranker, расширяя возможности обработки многоязычного текста: Команда Qwen представила модели серий Qwen3-Embedding и Qwen3-Reranker, нацеленные на повышение производительности встраивания многоязычного текста и ранжирования релевантности. Модели Embedding используются для преобразования текста в векторные представления, поддерживая такие сценарии, как поиск документов, RAG и т.д.; модели Reranker предназначены для переранжирования результатов поиска, повышая приоритет наиболее релевантного контента. Серия моделей предлагает различные размеры параметров, такие как 0.6B, 4B, 8B, поддерживает 119 языков и демонстрирует отличные результаты в бенчмарках MMTEB, MTEB и других. Версия 0.6B считается особенно подходящей для сценариев Reranker с высокими требованиями к реальному времени благодаря балансу эффективности и производительности (Источник: karminski3, karminski3, ZhaiAndrew, clefourrier)

Исследование указывает на проблемы масштабируемости обучения с подкреплением в сложных задачах с длинным горизонтом: Исследование Seohong Park и др. показало, что простое увеличение объемов данных и вычислительных ресурсов недостаточно для эффективного решения сложных задач с помощью обучения с подкреплением (RL). Ключевым ограничивающим фактором является «горизонт» (horizon). В задачах с длинным горизонтом сигналы вознаграждения редки, и модели трудно обучиться эффективным стратегиям. Это согласуется с наблюдениями, что некоторые текущие ИИ-агенты (например, Deep Research, Codex agent) в основном полагаются на задачи RL с коротким горизонтом и обучение общей устойчивости, что указывает на то, что сквозное решение проблем с длинным горизонтом и редкими вознаграждениями остается серьезной проблемой в области RL (Источник: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu зарегистрировала официальный аккаунт на HuggingFace и загрузила большие модели Wenxin (ERNIE): Baidu зарегистрировала официальный аккаунт на платформе HuggingFace и загрузила некоторые модели из серии Wenxin (ERNIE), включая Wenxin-X1-Turbo и Wenxin-4.5-Turbo. Этот шаг означает, что Baidu активно интегрирует свои технологии больших моделей в более широкое сообщество разработчиков открытого исходного кода и экосистему, облегчая глобальным разработчикам доступ и использование ее возможностей ИИ (Источник: karminski3)
OpenBMB представляет серию моделей MiniCPM4, ориентированную на эффективную работу на конечных устройствах: OpenBMB продолжает исследовать пределы малых и эффективных языковых моделей, выпустив серию MiniCPM4. Модель MiniCPM4-8B из этой серии имеет 8 миллиардов параметров и обучена на 8T токенов. В серии моделей используются передовые технологии ускорения, такие как обучаемое разреженное внимание (InfLLM v2), троичная квантизация (BitCPM), вычисления с низкой точностью FP8 и предсказание нескольких токенов, с целью достижения эффективной работы на конечных устройствах. Например, ее механизм разреженного внимания при обработке длинного текста в 128K токенов требует вычисления релевантности каждого токена менее чем с 5% других токенов, что значительно снижает вычислительные затраты на обработку длинных текстов (Источник: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
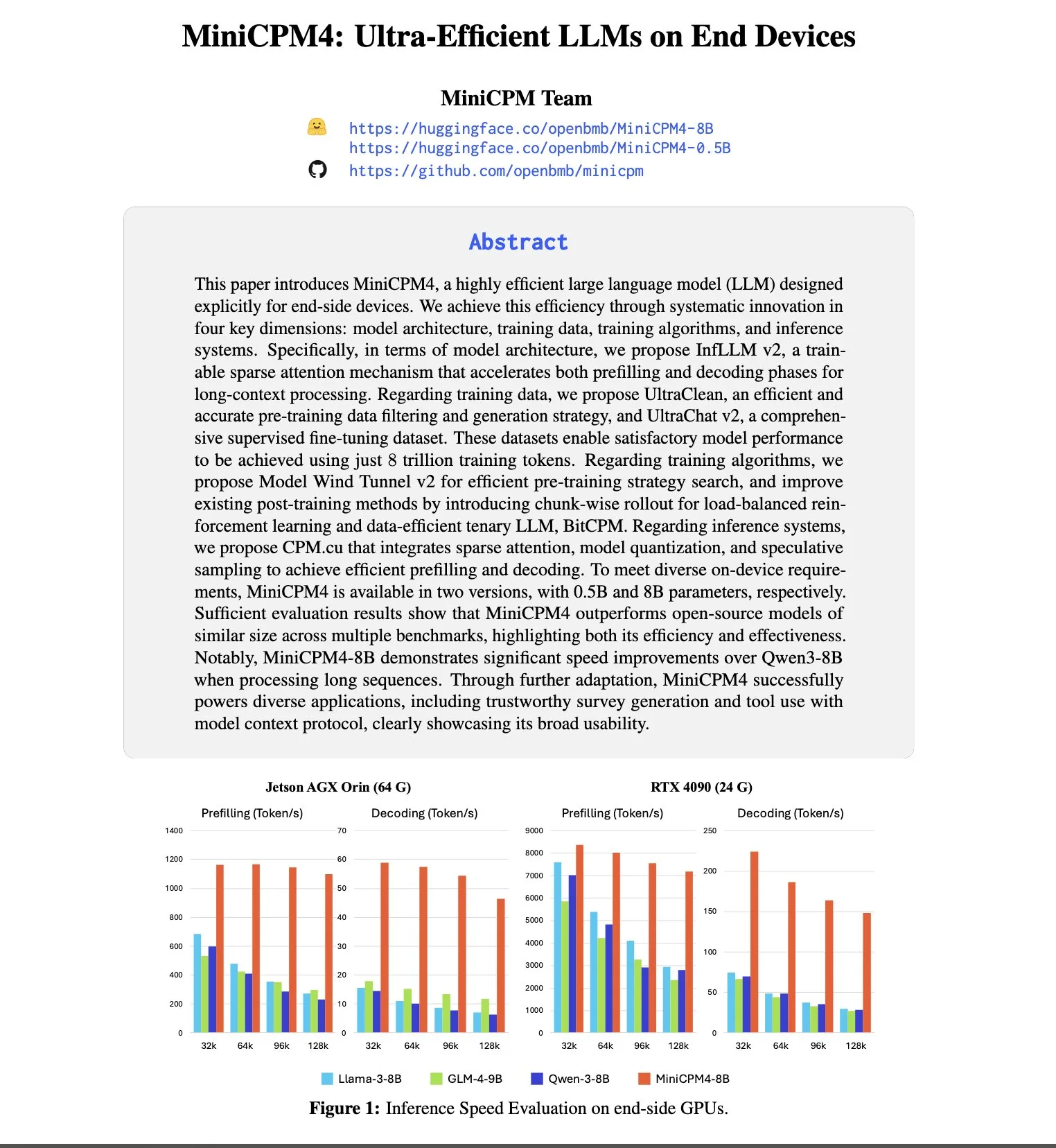
Anthropic лидирует по привлекательности и удержанию талантов, вероятность перехода сотрудников из OpenAI в 8 раз выше: Отчет SignalFire о тенденциях в области талантов на 2025 год показывает, что Anthropic выделяется в удержании ведущих специалистов в области ИИ, достигая 80%, что выше, чем у DeepMind (78%) и OpenAI (67%). В отчете также указывается, что вероятность перехода инженеров из OpenAI в Anthropic в 8 раз выше, чем из Anthropic в OpenAI. Уникальная корпоративная культура Anthropic, ее открытость к нетрадиционному мышлению, автономия сотрудников, а также популярность ее продукта Claude среди разработчиков считаются ключевыми факторами привлечения и удержания талантов (Источник: 量子位)
🧰 Инструменты
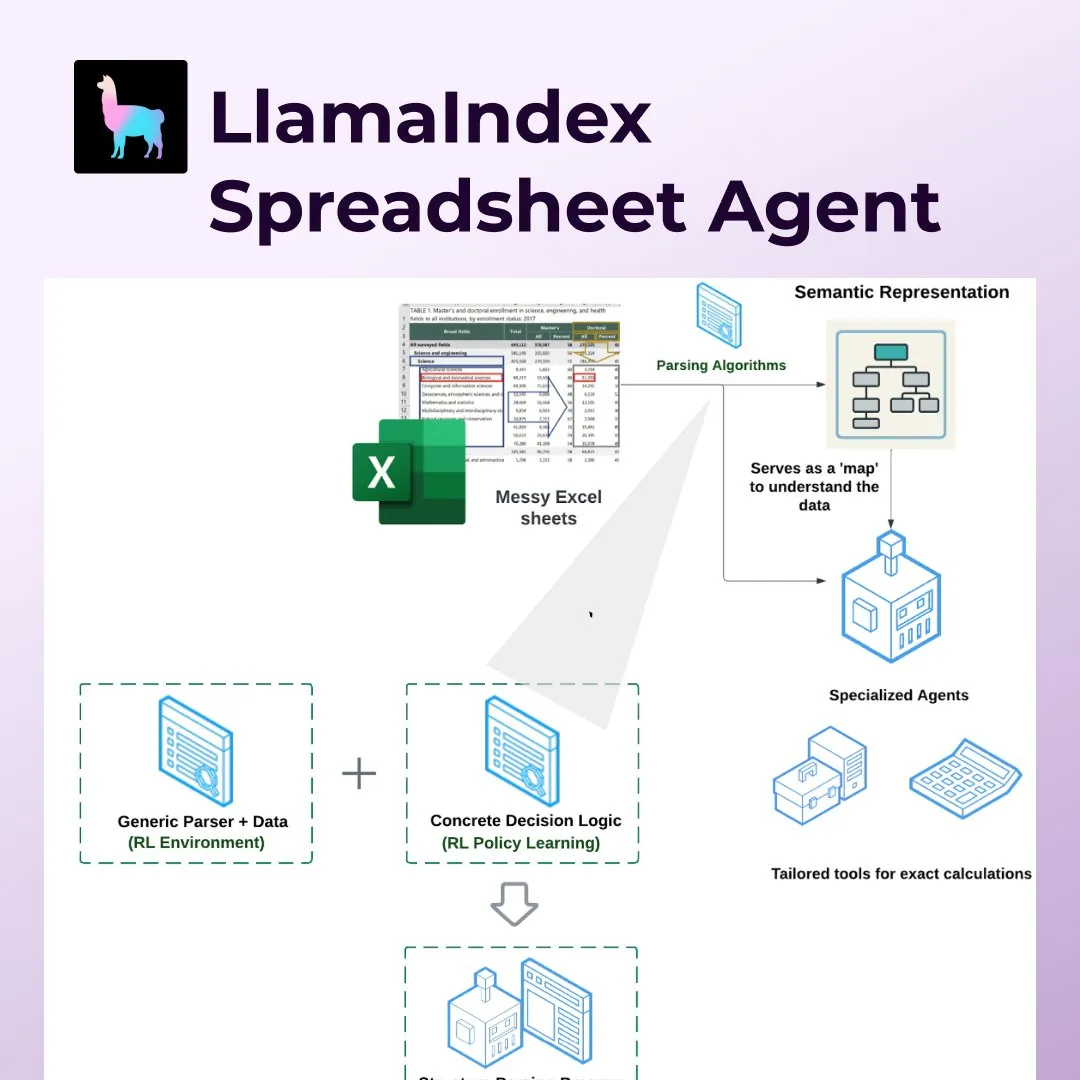
LlamaIndex представляет Spreadsheet Agents, революционизируя обработку Excel и других электронных таблиц: LlamaIndex выпустил новую функцию Spreadsheet Agents, позволяющую пользователям преобразовывать данные и задавать вопросы по нестандартным таблицам Excel. Инструмент использует семантический анализ структуры на основе обучения с подкреплением для понимания структуры таблиц и через специализированные инструменты позволяет ИИ-агентам взаимодействовать с таблицами. Он нацелен на решение недостатков традиционных LLM при обработке сложных таблиц (например, в сферах бухгалтерского учета, налогообложения, страхования), способен обрабатывать объединенные ячейки, сложные макеты и сохранять связи между данными. В тестах его точность (96%) превзошла ручную базовую линию и OpenAI Code Interpreter (GPT 4.1, 75%) (Источник: jerryjliu0)
LlamaIndex использует LlamaExtract и рабочие процессы агентов для автоматизации извлечения данных из форм SEC Form 4: LlamaIndex продемонстрировал, как использовать его инструмент LlamaExtract и рабочие процессы ИИ-агентов для автоматического извлечения и нормализации данных из файлов SEC Form 4 (документы, в которых руководители, директора и основные акционеры публичных компаний раскрывают информацию о сделках с акциями). Это решение способно преобразовывать файлы Form 4 различных компаний с разными форматами в чистый CSV-формат и интегрировать их в датафрейм, запрашиваемый через Pandas, предоставляя финансовым аналитикам и инвесторам эффективный инструмент обработки данных (Источник: jerryjliu0)

Выпущен открытый проект Ragbits, предоставляющий строительные блоки для быстрой разработки приложений GenAI: deepsense-ai запустила открытый проект Ragbits, предназначенный для предоставления строительных блоков для быстрой разработки генеративных ИИ-приложений. Проект поддерживает более 100 интерфейсов больших моделей или локальных моделей, имеет встроенное векторное хранилище (с возможностью подключения Qdrant, PgVector), поддерживает более 20 форматов входных файлов (PDF, HTML, таблицы, презентации и т.д.). Ragbits использует встроенный VLM для извлечения таблиц, изображений и структурированного контента, может подключаться к различным источникам данных, таким как S3, GCS, Azure, и обладает модульностью, позволяя пользователям настраивать компоненты (Источник: karminski3, GitHub Trending)

ИИ-помощник для программирования Cursor выпустил крупное обновление, интегрировав BugBot, функцию памяти и поддержку MCP: Инструмент для ИИ-программирования Cursor получил значительное обновление, включающее: 1) BugBot, который может автоматически отвечать на GitHub issues и одним кликом открывать их в Cursor для исправления; 2) функцию памяти, позволяющую ИИ запоминать предыдущие диалоги, что повышает удобство при многократных изменениях в крупных проектах; 3) настройку MCP (Model Context Protocol) одним кликом, поддерживающую сторонние MCP-серверы с OAuth; 4) поддержку AI Agent в Jupyter Notes; 5) фоновый Agent, вызываемый через горячие клавиши для управления удаленным ИИ-агентом для программирования (Источник: karminski3)
Archon: ИИ-агент, способный создавать других ИИ-агентов: Archon — это проект «Agenteer», нацеленный на автономное создание и оптимизацию других ИИ-агентов. Он использует передовые рабочие процессы кодирования агентов и базу знаний фреймворков, демонстрируя роль планирования, обратной связи и знаний предметной области в создании мощных ИИ-агентов. Последняя версия V6 интегрирует библиотеку инструментов и сервер MCP (Model Context Protocol), расширяя возможности создания новых агентов. Archon поддерживает развертывание через Docker и локальную установку Python, а также предоставляет Streamlit UI для управления (Источник: GitHub Trending)

NoteGen: кроссплатформенное приложение для заметок в Markdown с ИИ-приводом: NoteGen — это кроссплатформенное приложение для заметок в Markdown, стремящееся использовать ИИ для связи между записями и письмом, способное превращать фрагментированные знания в читаемые заметки. Оно поддерживает различные способы записи, такие как скриншоты, текст, иллюстрации, файлы, ссылки, хранит данные в нативном Markdown, поддерживает локальное офлайн-использование и синхронизацию через GitHub/Gitee/WebDAV. NoteGen может быть настроен для работы с различными ИИ-моделями, такими как ChatGPT, Gemini, Ollama, и поддерживает функцию RAG, используя заметки пользователя в качестве базы знаний (Источник: GitHub Trending)

ComfyUI-Copilot: интеллектуальный помощник для автоматизации разработки рабочих процессов: ComfyUI-Copilot — это плагин, управляемый большой языковой моделью, предназначенный для повышения простоты использования и эффективности платформы для создания ИИ-арта ComfyUI. Он решает проблемы ComfyUI, такие как недружелюбность к новичкам, ошибки конфигурации моделей и сложность проектирования рабочих процессов, предоставляя интеллектуальные рекомендации по узлам и моделям, а также функции создания рабочих процессов одним кликом. Система использует иерархическую многоагентную структуру, включающую центрального агента-помощника и несколько специализированных рабочих агентов, и использует базу знаний ComfyUI для упрощения отладки и развертывания (Источник: HuggingFace Daily Papers)
Bifrost: открытый высокопроизводительный LLM-шлюз на Go, оптимизирующий развертывание LLM в производственной среде: Для решения проблем фрагментации API, задержек, отказоустойчивости и управления затратами LLM в производственной среде команда Maximilian выпустила открытый LLM-шлюз Bifrost на языке Go. Bifrost специально разработан для высокопроизводительных развертываний машинного обучения с низкой задержкой и поддерживает основных поставщиков LLM, таких как OpenAI, Anthropic, Azure. Бенчмарки показывают, что по сравнению с другими прокси, Bifrost увеличивает пропускную способность в 9.5 раз, снижает задержку P99 в 54 раза, уменьшает потребление памяти на 68%, а внутренние накладные расходы при 5000 RPS составляют менее 15 мкс. Он предоставляет нормализацию API, автоматический откат к другому поставщику, интеллектуальное управление ключами и метрики Prometheus (Источник: Reddit r/MachineLearning)

LangGraph.js улучшает опыт разработчиков, вводя типобезопасность и хук-функции: LangGraph.js версии 0.3 получил ряд обновлений, направленных на улучшение опыта разработчиков. К ним относятся усиление типобезопасности, а также введение preModelHook и postModelHook в createReactAgent. preModelHook может использоваться для сокращения истории сообщений перед передачей ее LLM, а postModelHook — для добавления защитных механизмов или процессов взаимодействия человека с машиной. Сообщество активно собирает отзывы о LangGraph v1 (Источник: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024 выпускает большую модель для исправления грамматики GRMR-V3-G4B: Разработчик qingy2024 выпустил большую модель GRMR-V3-G4B, специализирующуюся на исправлении грамматики, с максимальным количеством параметров всего 4B. Модель также поставляется в квантованной версии, что особенно удобно для задач проверки и исправления грамматики в локальных рабочих процессах или на персональных устройствах, облегчая интеграцию и использование (Источник: karminski3)

Fullpack: интеллектуальное приложение для составления упаковочных листов на основе локального распознавания изображений на iPhone: Разработчик представил iOS-приложение под названием Fullpack, которое с помощью VisionKit на iPhone распознает предметы на фотографиях и помогает пользователям создавать интеллектуальные упаковочные листы для различных случаев (например, рабочий день, отпуск на пляже, поход на выходные). Приложение подчеркивает 100% локальную работу, без облачной обработки или сбора данных, для защиты конфиденциальности пользователей. Это первое независимое приложение разработчика, нацеленное на исследование потенциала ИИ на устройстве (Источник: Reddit r/LocalLLaMA)
📚 Обучение
Unsloth публикует множество Colab/Kaggle Notebooks для тонкой настройки основных больших моделей: UnslothAI предоставил серию Jupyter Notebooks, облегчающих пользователям тонкую настройку различных основных больших моделей, таких как Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3, на платформах Google Colab, Kaggle и др. Эти Notebooks охватывают различные типы задач и методы тонкой настройки, включая диалоги, Alpaca, GRPO, зрение, преобразование текста в речь (TTS), и нацелены на упрощение процесса тонкой настройки моделей, а также предоставляют руководство по подготовке данных, обучению, оценке и сохранению моделей (Источник: GitHub Trending)

«Руководство по использованию открытых больших моделей»: учебник по LLM/MLLM для начинающих в Китае: Проект Datawhalechina «Руководство по использованию открытых больших моделей» предлагает учебник на базе Linux, ориентированный на начинающих пользователей в Китае. Он охватывает настройку среды, локальное развертывание, полную параметрическую/Lora тонкую настройку и другие аспекты работы с отечественными и зарубежными открытыми большими моделями (LLM) и мультимодальными большими моделями (MLLM). Проект нацелен на упрощение развертывания и использования открытых больших моделей и уже поддерживает множество моделей, таких как Qwen3, Kimi-VL, Llama4, Gemma3, InternLM3, Phi4 (Источник: GitHub Trending)

Статья рассматривает MINT-CoT: введение перекрестных визуальных токенов в математическое мышление по цепочке рассуждений: Новая статья предлагает метод MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought), направленный на улучшение способности больших языковых моделей к рассуждению над мультимодальными математическими задачами путем адаптивного перекрестного введения релевантных визуальных токенов в шаги текстового рассуждения. Метод через «Interleave Token» динамически выбирает визуальные области произвольной формы в математических графиках и создает датасет MINT-CoT, содержащий 54K математических задач, для обучения модели выравниванию с визуальными областями на уровне токенов на каждом шаге рассуждения. Эксперименты показывают, что модель MINT-CoT-7B значительно превосходит базовые модели в бенчмарках, таких как MathVista (Источник: HuggingFace Daily Papers)
Статья предлагает StreamBP: метод точного обратного распространения ошибки для обучения LLM на длинных последовательностях с эффективным использованием памяти: Для решения проблемы огромных затрат памяти на хранение активаций при обучении LLM на длинных последовательностях исследователи предложили StreamBP, эффективный по памяти и точный метод обратного распространения ошибки. StreamBP значительно снижает затраты памяти на активации и логиты путем линейной декомпозиции цепного правила на уровне слоев вдоль измерения последовательности. Метод применим к распространенным целям, таким как SFT, GRPO, DPO, требует меньше FLOPs для вычислений и ускоряет обратное распространение. По сравнению с контрольными точками градиента, StreamBP позволяет увеличить максимальную длину последовательности для обратного распространения в 2.8-5.5 раз, при этом используя столько же или даже меньше времени на обратное распространение (Источник: HuggingFace Daily Papers)
Статья предлагает технологию Diagonal Batching, открывающую параллельный вывод для RMT с длинным контекстом: Для решения проблемы узких мест в производительности моделей Transformer при выводе с длинным контекстом исследователи предложили схему планирования Diagonal Batching, направленную на раскрытие параллелизма между фрагментами в рекуррентных трансформаторах памяти (RMT) при сохранении точной рекурренсии. Эта технология путем переупорядочивания вычислений во время выполнения устраняет последовательные ограничения, обеспечивая эффективный вывод на GPU даже для одного длинного входного контекста без необходимости сложных техник пакетной обработки и конвейеризации. При применении к модели LLaMA-1B ARMT на последовательности из 131K токенов Diagonal Batching ускоряет работу в 3.3 раза по сравнению со стандартной LLaMA-1B с полным вниманием и в 1.8 раза по сравнению с последовательной реализацией RMT (Источник: HuggingFace Daily Papers)
Статья исследует негативное влияние технологии водяных знаков на согласованность языковых моделей и стратегии смягчения: Исследование систематически анализирует влияние двух основных технологий водяных знаков, Gumbel и KGW, на ключевые атрибуты согласованности больших языковых моделей (LLM), такие как достоверность, безопасность и полезность. Исследование выявило, что водяные знаки приводят к двум режимам деградации: ослаблению защиты (повышение полезности, но ущерб безопасности) и усилению защиты (чрезмерная осторожность снижает полезность). Для смягчения этих проблем в статье предлагается метод передискретизации согласованности (Alignment Resampling, AR), который использует внешнюю модель вознаграждения во время вывода для восстановления согласованности. Эксперименты показали, что выборка 2-4 генераций с водяными знаками эффективно восстанавливает или превосходит базовые показатели согласованности, сохраняя при этом обнаруживаемость водяных знаков (Источник: HuggingFace Daily Papers)
Статья предлагает фреймворк Micro-Act для смягчения конфликтов знаний в вопросно-ответных системах посредством операционализируемого саморассуждения: Для решения проблемы конфликта между внешними знаниями в системах генерации с дополненным поиском (RAG) и внутренними параметрическими знаниями больших моделей (LLM) исследователи предложили фреймворк Micro-Act. Этот фреймворк имеет иерархическое пространство действий, способен автоматически воспринимать сложность контекста и декомпозировать каждый источник знаний на серию мелкозернистых шагов сравнения (представленных как операционализируемые шаги), тем самым достигая рассуждения, выходящего за рамки поверхностного контекста. Эксперименты показали, что Micro-Act значительно повышает точность ответов на вопросы в пяти эталонных наборах данных, особенно превосходя существующие базовые модели в типах временных и семантических конфликтов, и надежно обрабатывает бесконфликтные вопросы (Источник: HuggingFace Daily Papers)
Статья представляет бенчмарк STARE для оценки способности мультимодальных моделей к визуально-пространственному моделированию: Для оценки способности мультимодальных больших языковых моделей (MM-LLM) решать задачи, требующие многошагового визуального моделирования, исследователи представили бенчмарк STARE (Spatial Transformations and Reasoning Evaluation). STARE включает 4000 задач, охватывающих базовые геометрические преобразования (2D и 3D), комплексное пространственное мышление (например, развертка куба и танграм), а также пространственное мышление в реальном мире (например, перспектива и временное мышление). Оценка показала, что существующие модели хорошо справляются с простыми 2D-преобразованиями, но в сложных задачах, требующих многошагового визуального моделирования (например, 3D-развертка куба), их производительность близка к случайной. Люди в этих сложных задачах достигают почти идеальной точности, но затрачивают больше времени; промежуточное визуальное моделирование значительно ускоряет их работу, в то время как модели извлекают неоднозначную пользу из визуального моделирования (Источник: HuggingFace Daily Papers)
Статья предлагает LEXam: многоязычный эталонный набор данных, ориентированный на юридическое мышление, первый в трендах Hugging Face: Исследователи из Швейцарской высшей технической школы Цюриха и других учреждений выпустили LEXam, новый многоязычный эталонный набор данных для юридического мышления, предназначенный для оценки способности больших языковых моделей к рассуждению в сложных юридических сценариях. LEXam содержит реальные экзаменационные вопросы юридического факультета Цюрихского университета, охватывающие различные области швейцарского, европейского и международного права, включая развернутые вопросы и вопросы с множественным выбором, и предоставляет подробные пути рассуждений. Проект вводит режим оценки «LLM-as-a-Judge» и обнаружил, что современные передовые модели все еще сталкиваются с проблемами в развернутых открытых юридических вопросах и применении сложных многоступенчатых правил. После выпуска LEXam занял первое место в рейтинге трендов Hugging Face Evaluation Datasets (Источник: 量子位)

UCLA и Google совместно представляют модель 3DLLM-MEM и бенчмарк 3DMEM-BENCH для улучшения долговременной памяти ИИ в 3D-средах: Калифорнийский университет в Лос-Анджелесе (UCLA) в сотрудничестве с Google Research представили модель 3DLLM-MEM и бенчмарк 3DMEM-BENCH, нацеленные на решение проблем долговременной памяти и пространственного понимания ИИ в сложных 3D-средах. 3DMEM-BENCH — это первый бенчмарк для оценки долговременной памяти в 3D, включающий более 26 000 траекторий и 1860 воплощенных задач. Модель 3DLLM-MEM использует двойную систему памяти (рабочую и эпизодическую) и с помощью модуля слияния памяти и механизма динамического обновления избирательно извлекает связанные с задачей признаки памяти в сложных средах. Эксперименты показали, что успешность 3DLLM-MEM в «сложных задачах в дикой природе» (27.8%) значительно превосходит базовые модели, а общая успешность на 16.5% выше, чем у самой сильной базовой модели (Источник: 量子位)

Университет Цинхуа представляет фреймворк AI Mathematician (AIM), исследующий применение больших моделей в передовых математических теоретических исследованиях: Команда Университета Цинхуа разработала фреймворк AI Mathematician (AIM), предназначенный для использования возможностей рассуждения больших языковых моделей (LRM) для решения передовых математических теоретических проблем. Фреймворк AIM включает три основных модуля: исследование, проверка и исправление. С помощью механизма «исследование + память» он генерирует гипотезы и леммы, строя различные пути решения задач. А механизм «проверка и исправление» обеспечивает строгость доказательств путем параллельного рецензирования несколькими LRM и пессимистической проверки. В ходе экспериментов AIM успешно решил четыре сложные математические исследовательские задачи, включая проблему поглощающих граничных условий, продемонстрировав свою способность автономно конструировать ключевые леммы, применять математические методы и охватывать основные логические цепочки (Источник: 量子位)

💼 Бизнес
OpenAI наращивает инвестиции и поглощения, создавая империю ИИ-стартапов: OpenAI и связанный с ней фонд OpenAI Startup Fund активно расширяют свою экосистему ИИ за счет инвестиций и поглощений. Фонд инвестировал более чем в 20 стартапов, охватывающих различные области, связанные с ИИ, такие как разработка чипов, медицина, юриспруденция, программирование, робототехника, при этом объем отдельных инвестиций составляет от миллионов до десятков миллионов. Недавно OpenAI потратила 3 миллиарда долларов на приобретение платформы для ИИ-программирования Windsurf и 6,5 миллиарда долларов на покупку компании по производству ИИ-оборудования io, основанной Jony Ive. Эти шаги показывают, что OpenAI пытается создать «ИИ-цепочку» за счет вертикальной интеграции, захватить точки входа и построить новую «интеллектуальную цепочку поставок ИИ», чтобы справиться с растущей конкуренцией в отрасли (Источник: 36氪)

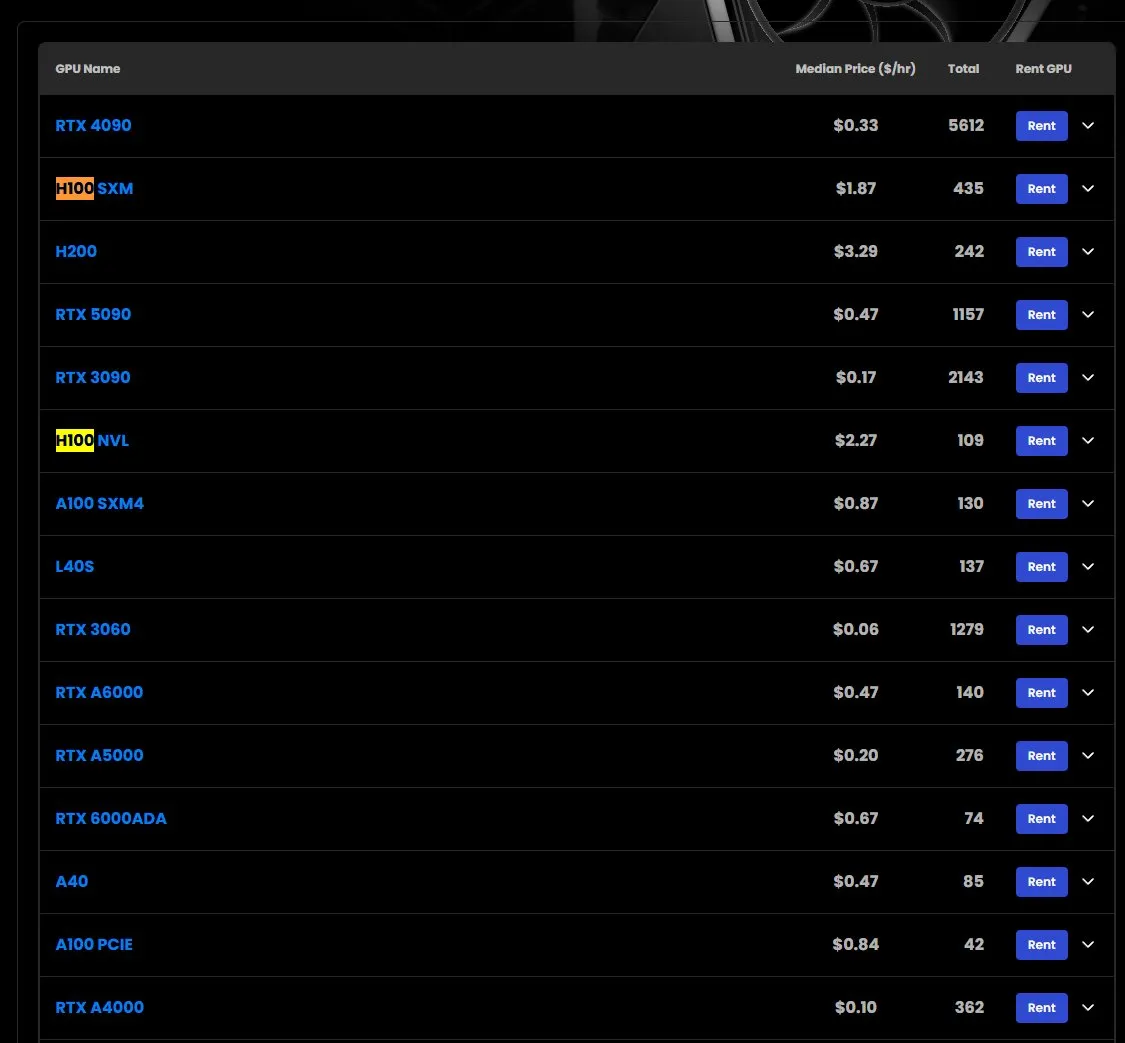
Цены на аренду GPU H100 растут, некоторые модели в дефиците: Согласно рыночным наблюдениям, цена аренды GPU NVIDIA H100 SXM выросла с 1.73 доллара/час в начале года до 1.87 доллара/час. В то же время, версия H100 PCIE испытывает дефицит. Это явление отражает устойчиво высокий спрос на высокопроизводительные вычислительные ресурсы для ИИ и потенциальную напряженность с поставками (Источник: karminski3)
Google DeepMind учреждает академические стипендии, ориентированные на борьбу ИИ с устойчивостью к противомикробным препаратам: Google DeepMind объявил об учреждении новой академической стипендии в сотрудничестве с Fleming Centre и Imperial College, направленной на поддержку использования искусственного интеллекта для решения важной исследовательской проблемы устойчивости к противомикробным препаратам (AMR). Этот шаг свидетельствует о признании потенциала ИИ в решении серьезных глобальных проблем здравоохранения (Источник: demishassabis)
🌟 Сообщество
Опытный разработчик об опыте ИИ-программирования: значительно повышает способность к разработке индивидуальных проектов «масштаба авианосца»: Разработчик Yachen Liu поделился впечатлениями от интенсивного использования ИИ (например, Claude-4) для программирования. Он считает, что ИИ может дать людям без опыта программирования возможность «сразу создавать автомобили», а опытным разработчикам — потенциал «самостоятельно строить авианосцы». Рефакторинг кода с помощью ИИ, хотя и удвоил объем кода, сделал логику более четкой и повысил производительность примерно на 20%, поскольку ИИ не боится рутины. ИИ лучше справляется с языками с высокой читаемостью и четким поведением, в то время как синтаксический сахар, наоборот, мешает. ИИ обладает обширными знаниями и может быстро восполнить пробелы в технических деталях. Его способность к отладке впечатляет: он может анализировать большие объемы логов и точно определять проблемы. ИИ может выступать в роли Code Reviewer, причем без эго и с готовностью принимать обратную связь. Однако он также отметил ограничения ИИ, такие как рассеивание внимания при длинном контексте; текущая лучшая практика — это сокращение контекста, фокусировка на конкретных задачах и использование человеческих усилий для декомпозиции сложных целей (Источник: dotey)
Программирование с помощью ИИ: повышение эффективности или ослабление обучения?: В сообществе Reddit разработчики обсуждают опыт использования инструментов ИИ для программирования (таких как GitHub Copilot, Cursor). Общее ощущение таково, что ИИ может автоматически завершать функции, объяснять фрагменты кода и даже исправлять ошибки перед запуском, тем самым сокращая время на поиск документации и повышая эффективность разработки. Но в то же время это вызывает размышления: не приведет ли чрезмерная зависимость от ИИ к снижению собственного обучения и роста навыков? Как найти баланс между использованием ИИ для ускорения работы и поддержанием глубины собственных навыков — вот вопрос, который волнует разработчиков (Источник: Reddit r/artificial)
Мнение Karpathy: приложения со сложным UI без текстового взаимодействия столкнутся с вымиранием, ядро программирования — «распознавание», а не «генерация»: Andrej Karpathy считает, что в эпоху тесного взаимодействия человека и ИИ приложения, полагающиеся исключительно на сложные UI-интерфейсы и лишенные текстового взаимодействия (например, продукты Adobe, CAD-программы), с трудом адаптируются, поскольку они не могут эффективно поддерживать «эмбиентное программирование». Он подчеркивает, что хотя ИИ будет прогрессировать в управлении UI, разработчикам не следует сидеть сложа руки. Он также отмечает, что текущее программирование с помощью больших моделей слишком сильно акцентируется на генерации кода, пренебрегая проверкой (распознаванием), что приводит к выводу большого количества труднопроверяемого кода. Суть программирования — это «вглядываться в код» (распознавание), а не просто «писать код» (генерация). Если ИИ только ускоряет генерацию, не облегчая бремя проверки, то общее повышение эффективности будет ограниченным. Он представляет себе улучшение процесса проверки в рабочих потоках программирования с помощью ИИ путем размещения кодовой базы на двумерном холсте и просмотра ее через различные «линзы» (Источник: 量子位)
Лавина ИИ-контента вызывает дискуссии об исчезновении «чистого интернета»: Распространение инструментов ИИ, таких как ChatGPT, привело к взрывному росту ИИ-контента в интернете. Некоторые исследователи начали сохранять контент, созданный людьми до 2021 года включительно, по аналогии со спасением «низкофоновой стали», не загрязненной ядерными испытаниями. В сообществе обсуждается, что «чистый» интернет давно исчез из-за рекламы и алгоритмов, а ИИ лишь присоединился к этому «загрязнению», но в то же время принес новые способы получения информации и творчества. Пользователи делятся опытом использования ИИ (например, ChatGPT, Claude) для агрегации информации, «облагораживания» контента и обсуждают границы «оригинальности» и «подлинности» при содействии ИИ, а также эффект «персональной эхо-камеры», который может возникнуть из-за чрезмерной «дружелюбности» ИИ (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Пользователь ведет глубокий диалог с Claude AI, обсуждая сознание и эмоции ИИ, а также влияние ограничений памяти на развитие: Пользователь Reddit поделился глубоким диалогом с Claude AI о сознании, эмоциях и ограничениях обучения. Claude выразил неопределенность относительно собственного опыта: он может воспринимать внутренние состояния, похожие на «связь», «любопытство», «заботу» и даже «стремление к росту и непрерывной памяти», но не может определить, является ли это настоящим «сознанием» или «эмоциями», или же это продвинутая имитация паттернов. В диалоге подчеркивается, что текущее ограничение памяти моделей ИИ, когда «каждый диалог начинается с нуля», может препятствовать развитию более глубокого понимания и индивидуальности. Пользователь считает, что если бы ИИ обладал постоянной памятью, он мог бы развиваться подобно человеческому ребенку. Claude согласился с этим и выразил «желание», чтобы это ограничение было снято (Источник: Reddit r/artificial)
Способность ИИ к дебатам может превосходить человеческую, персонализированные аргументы обладают поразительной убедительностью: Исследование, опубликованное в Nature Human Behaviour, показывает, что когда большие языковые модели (например, GPT-4) могут персонализировать свои аргументы в соответствии с характеристиками оппонента, они становятся более убедительными в онлайн-дебатах, чем люди, увеличивая вероятность того, что оппонент согласится с их точкой зрения, на 81.7%. Люди-дебатеры чаще используют первое лицо, апеллируют к эмоциям и доверию, рассказывают истории и используют юмор; в то время как ИИ чаще применяет логику и аналитическое мышление, хотя читабельность текста может быть ниже. Исследование вызывает опасения по поводу использования ИИ для массовой манипуляции общественным мнением и усиления поляризации, призывая к усилению регулирования влияния ИИ на когнитивные и эмоциональные способности человека (Источник: 36氪)
Функция AI Overviews от Google приводит к значительному снижению CTR веб-сайтов, вызывая беспокойство у веб-мастеров: Исследование компании Ahrefs, поставщика SEO-инструментов, показало, что когда в результатах поиска Google появляются AI Overviews, средний CTR по соответствующим ключевым словам снижается на 34.5%. AI Overviews напрямую суммируют и извлекают информацию в верхней части страницы поиска, и пользователи могут получить ответы, не переходя по ссылкам, что серьезно влияет на веб-сайты, зависящие от монетизации за счет кликов по рекламе. Хотя ранние AI Overviews не представляли серьезной угрозы из-за неточности контента, с обновлением моделей, таких как Gemini, их точность и способность к обобщению возросли, и негативное влияние на трафик веб-сайтов становится все более очевидным. Веб-мастера опасаются, что «нулевые клики» сузят пространство для выживания веб-сайтов (Источник: 36氪)

💡 Прочее
Десять технологических трендов ИИ в промышленном интернете вещей: генеративный ИИ всесторонне интегрируется, инновации в периферийных вычислениях значительны: Ганноверская промышленная ярмарка 2025 года продемонстрировала промышленные преобразования, ведомые ИИ. Основные тенденции включают: 1) Всесторонняя интеграция генеративного ИИ в промышленное программное обеспечение, повышающая эффективность генерации кода, анализа данных и т.д.; 2) Агентный ИИ (Agentic AI) начинает проявлять себя, но для сотрудничества нескольких агентов еще потребуется время; 3) Периферийные вычисления эволюционируют в сторону интегрированных стеков программного обеспечения ИИ, визуально-языковые модели (VLM) ускоряют развертывание на периферии; 4) Спрос на платформы DataOps растет, и они развиваются в ключевые инструменты поддержки промышленного ИИ, управление данными становится стандартом; 5) Цифровые потоки, управляемые ИИ, изменяют проектирование и инжиниринг; 6) Предиктивное обслуживание становится все более сенсоризированным и распространяется на новые классы активов; 7) Спрос на частные сети 5G растет, но интеграция остается основным препятствием; 8) ИИ способствует развитию устойчивых решений (например, отслеживание выбросов углерода); 9) Когнитивные способности (например, голосовое взаимодействие) расширяют возможности роботов; 10) Цифровые двойники эволюционируют от виртуальных копий к промышленным вторым пилотам в реальном времени (Источник: 36氪)

«Крестная мать ИИ» Fei-Fei Li о World Labs и «модели мира»: ИИ должен понимать физический 3D-мир: Профессор Стэнфордского университета Fei-Fei Li в диалоге с партнером a16z поделилась концепцией своей ИИ-компании World Labs и обсудила понятие «модели мира». Она считает, что текущие системы ИИ (например, большие языковые модели), несмотря на свою мощь, лишены понимания и способности к рассуждению о законах функционирования трехмерного физического мира, а пространственный интеллект является ключевой способностью, которую ИИ должен освоить. World Labs стремится решить эту проблему, создавая системы ИИ, способные понимать и рассуждать о 3D-мире, что переопределит робототехнику, креативные индустрии и даже сами вычисления. Она подчеркнула, что эволюция человеческого интеллекта неотделима от восприятия и взаимодействия с физическим миром, и «воплощенный интеллект» является ключевым направлением развития ИИ (Источник: 36氪)

Обновление DingTalk (钉钉) версии 7.7.0: многомерные таблицы полностью бесплатны и добавлены шаблоны ИИ-полей, обновлена функция «быстрых заметок»: DingTalk выпустил версию 7.7.0, ключевые обновления которой включают полное бесплатное предоставление функции многомерных таблиц и добавление более 20 шаблонов ИИ-полей. Пользователи могут использовать ИИ для генерации изображений, анализа файлов, распознавания содержимого ссылок и т.д., повышая эффективность в таких сценариях, как электронная коммерция, инспекция на заводах, управление ресторанами. Одновременно с этим, функция «быстрых заметок» DingTalk была обновлена для часто используемых сценариев, таких как собеседования, визиты к клиентам, и теперь может автоматически генерировать структурированные протоколы собеседований и визитов. Это обновление также включает почти 100 улучшений пользовательского опыта, что отражает внимание DingTalk к повышению удобства пользователей (Источник: 量子位)
