
Ключевые слова:Модуль Engram, Совместная работа Cowork, Сотрудничество Gemini, Механизм поиска знаний Transformer, Выполнение задач AI Agent, TTT-E2E обучение во время тестирования
🔥 В фокусе
DeepSeek выпустила модуль Engram, реализовав разделение хранения и вычислений: DeepSeek совместно с Пекинским университетом опубликовала статью, представив модуль «условной памяти» Engram. Эта технология, использующая современные хэшированные N-gram эмбеддинги, дополняет Transformer нативным механизмом «поиска знаний», обеспечивая детерминированный поиск, близкий к O(1). Эксперименты показали, что Engram-27B при строгом равенстве параметров и вычислительных затрат значительно превосходит чистые MoE модели. Это не только увеличивает запас знаний, но и освобождает слои внимания от нагрузки «зубрежки», позволяя глубоким сетям сосредоточиться на сложных рассуждениях, что привело к резкому скачку в способностях к кодингу и математике. Такой инженерный подход, позволяющий выгружать огромные массивы параметров в оперативную память хоста (CPU) с потерями при выводе менее 3%, считается ключевым примитивом для следующего поколения разреженных (sparse) больших моделей и, скорее всего, будет интегрирован в предстоящую DeepSeek-V4 (Источник: GitHub)

Anthropic представила стратегический продукт Cowork, открывая эру «цифровых коллег»: Anthropic официально запустила Cowork (Research Preview), упаковав базовые возможности Claude Code в графический инструмент для нетехнических специалистов. Cowork позволяет Claude напрямую обращаться к локальным папкам с правами на чтение, редактирование и создание файлов. Это больше не просто чат-бот, а интеллектуальный агент, способный самостоятельно планировать шаги и параллельно выполнять задачи (например, наводить порядок в папке загрузок, извлекать данные из скриншотов для генерации Excel, писать черновики отчетов). Продукт включает изолированную среду виртуальной машины (VM) для обеспечения безопасности и поддерживает автоматизацию браузера. Сообщество считает, что это знаменует переход парадигмы AI от «генерации контента» к «выполнению задач», что может нанести сокрушительный удар по многим стартапам в сфере AI-приложений (Источник: Anthropic)

Apple и Google заключили соглашение о сотрудничестве по Gemini: Siri получает «внешний мозг»: Apple и Google опубликовали совместное заявление, подтверждающее, что будущие Apple Foundation Models будут построены на базе моделей Google Gemini и облачных технологий для работы персонализированной Siri, которая выйдет в конце этого года. Сообщается, что Apple будет платить около 1 миллиарда долларов ежегодно. Это сотрудничество рассматривается как «временная уступка» Apple на фоне задержек в разработке собственных моделей; Gemini будет отвечать за сложные задачи, такие как саммаризация и планирование, в то время как базовые функции на устройстве по-прежнему будут поддерживаться собственными моделями Apple. Этот шаг позволил рыночной капитализации Google впервые превысить 4 триллиона долларов, но также вызвал критику Илона Маска по поводу «чрезмерной концентрации власти» и дискуссии о маргинализации OpenAI в экосистеме Apple (Источник: Google)

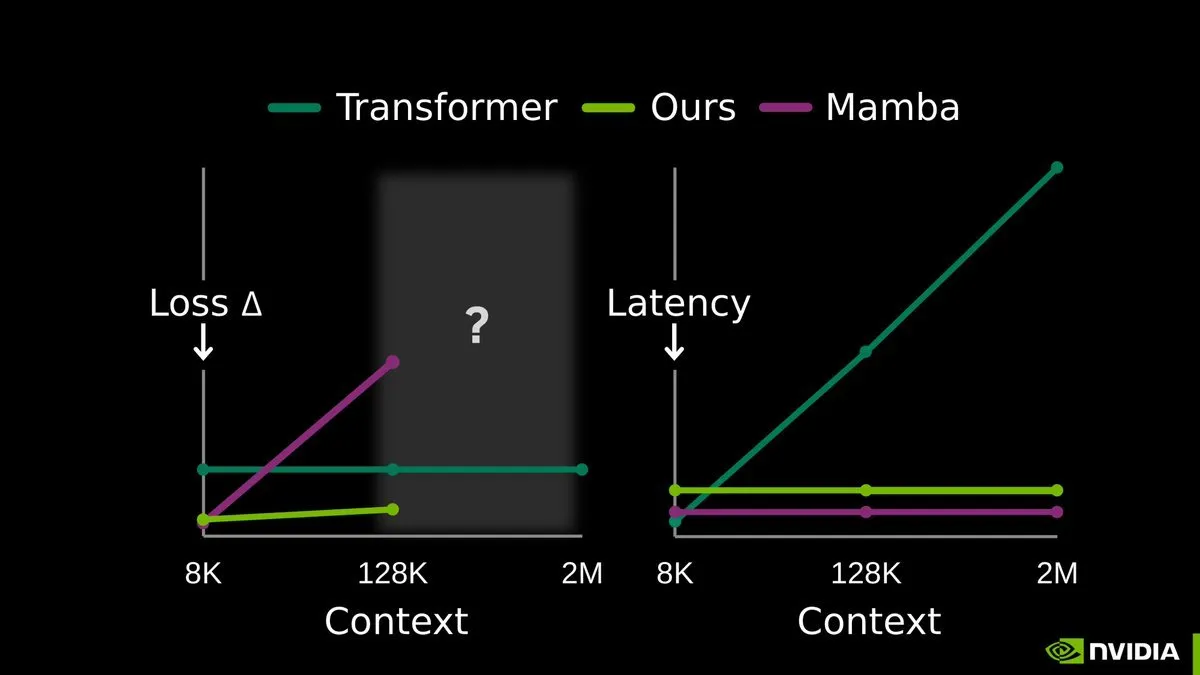
TTT-E2E: Сквозное обучение во время тестирования открывает новую эру долгой памяти LLM: Исследование End-to-End Test-Time Training (TTT-E2E), опубликованное совместно NVIDIA, Стэнфордом и Astera Institute, вызвало сенсацию. Технология утверждает, что нет необходимости в радикально новых архитектурах; вместо этого на этапе вывода (во время теста) контекст используется как обучающие данные для непрерывного обновления весов модели через Next Token Prediction. Этот метод сжимает опыт длинного контекста в веса модели, эффективно решая проблему взрывного роста KV cache с увеличением длины последовательности. TTT делает модель настоящим «постоянным учеником», демонстрируя высокую стабильность при обработке сверхдлинных последовательностей в миллионы токенов, и считается наиболее перспективным путем к чистому субквадратичному моделированию последовательностей (Источник: arXiv)
🎯 Тенденции
Sakana AI представила DroPE: отказ от позиционных эмбеддингов для экстраполяции длинных текстов: Команда автора Transformer Ллиона Джонса открыла исходный код технологии DroPE, утверждая, что позиционные эмбеддинги — это лишь «вспомогательные колеса» для обучения. DroPE отбрасывает Rotary Position Embedding (RoPE) на этапе вывода, требуя менее 1% бюджета предварительного обучения для короткой калибровки, чтобы разблокировать огромные окна контекста. Эксперименты показывают, что этот метод значительно превосходит традиционное масштабирование RoPE в тестах LongBench и «иголка в стоге сена», предлагая новый подход к недорогому расширению возможностей работы с длинными текстами (Источник: arXiv)
Бенчмарк BabyVision: визуальные способности топовых моделей все еще уступают 3-летним детям: Оценка BabyVision, опубликованная Sequoia China xbench и UniPatAI, показала, что в визуальных задачах со строгим контролем языковой зависимости большинство моделей справляются гораздо хуже 3-летних детей. Даже лучший результат Gemini 3 Pro едва преодолел пороговое значение. Исследование отмечает, что чрезмерная зависимость моделей от языковых рассуждений скрывает их системные недостатки в пространственном восприятии, отслеживании траекторий и геометрической интуиции; будущий мультимодальный интеллект должен фундаментально перестроить визуальные способности (Источник: 36氪)

Recursive Language Models (RLM): DeepMind исследует идеальную память без RAG: Исследователи DeepMind предложили рекурсивные языковые модели (RLM), которые позволяют модели анализировать, разделять и рекурсивно вызывать саму себя для обработки миллионов токенов. Этот механизм преодолевает ограничения традиционных окон контекста: модель больше не полагается на внешний RAG, а достигает «идеальной памяти» для огромных объемов информации через рекурсивную агрегацию результатов. Этот прогресс предвещает качественное изменение в том, как AI будет обрабатывать сверхдлинные документы в будущем (Источник: HuggingFace)

Экспансия AI ByteDance за рубеж переходит в стадию «инструментов эффективности»: ByteDance активно расширяет присутствие на зарубежных рынках, запустив AnyGen — рабочего Agent, конкурирующего с Manus, который специализируется на высококачественном написании документов и анализе данных. Одновременно с этим число активных пользователей AI-помощника Dola за рубежом превысило 10 миллионов. ByteDance пытается перейти от «экспорта радости» (TikTok) к «продаже эффективности», вступая в прямую конкуренцию с OpenAI и Anthropic в сегменте офисных Agent (Источник: 36氪)

🧰 Инструменты
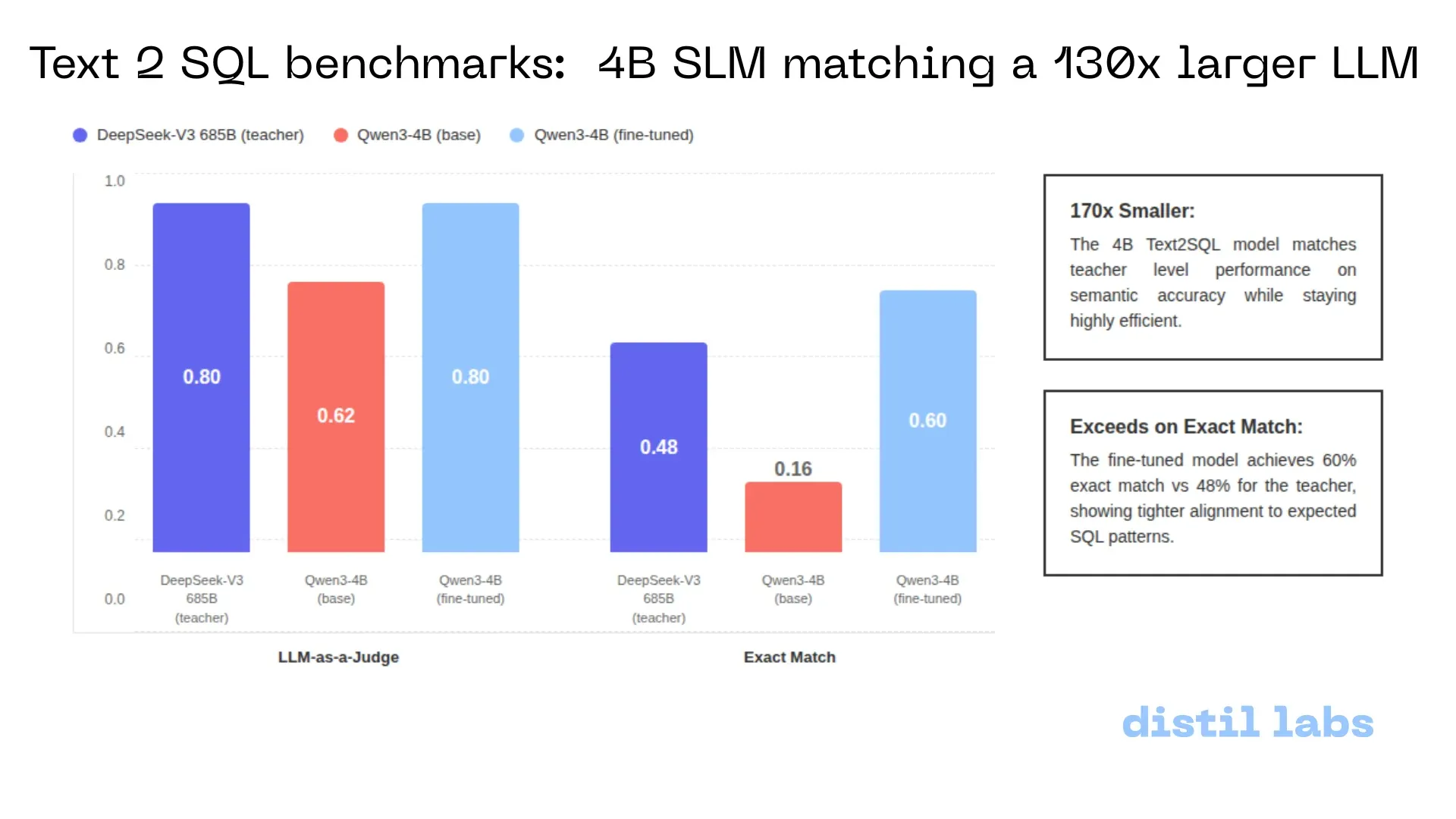
Distil-Text2SQL: малая модель 4B достигает точности уровня 685B локально: Distil-labs путем тонкой настройки Qwen3-4B добилась того, что модель в задачах Text2SQL достигла семантической точности DeepSeek-V3 (685B) и даже превзошла её по показателю «точного совпадения». Модель поддерживает локальный запуск, обработка данных CSV не требует загрузки в облако, а время отклика составляет менее 2 секунд, что демонстрирует огромный потенциал малых моделей для замены сверхбольших в узкоспециализированных задачах (Источник: GitHub)
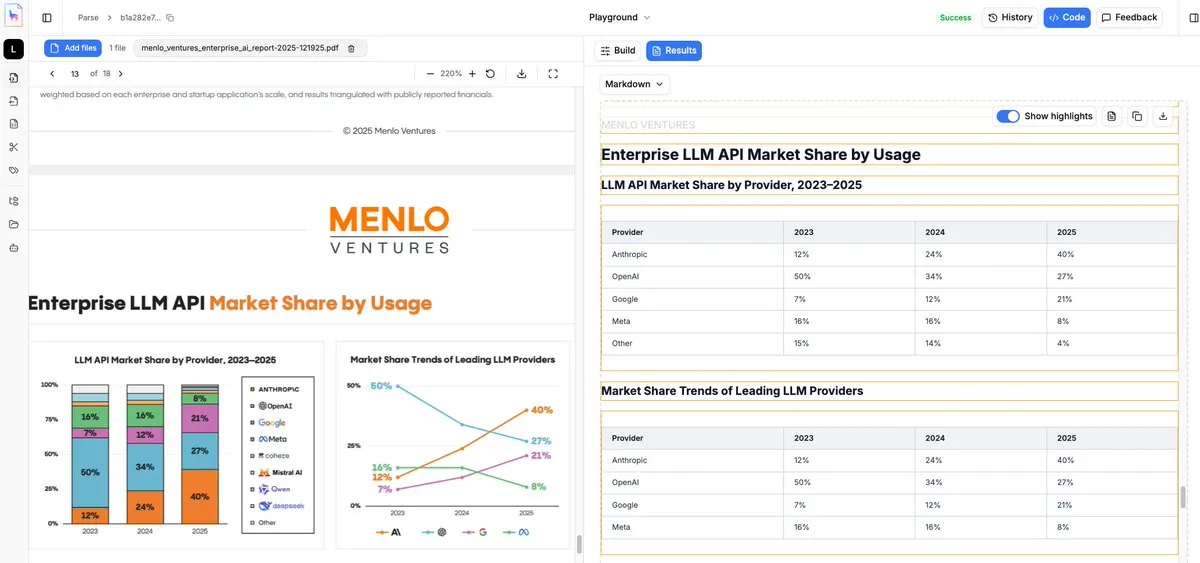
Обновление LlamaParse: недорогой и точный OCR для графиков и изображений: LlamaIndex обновила свой инструмент парсинга LlamaParse до Agentic-режима, специально оптимизировав его для сложных визуальных элементов в документах (линейные графики, круговые диаграммы, блок-схемы). По сравнению с прямой подачей скриншотов страниц в VLM, этот инструмент распознает границы подобъектов и извлекает числовую логику, преобразуя её в высококачественный Markdown. Это одно из самых экономичных и эффективных решений для обработки нетекстовой информации в профессиональных документах (Источник: jerryjliu0)
Wobo: «Tinder для поиска работы» на базе AI Agent: Wobo — это приложение для iOS, использующее AI Agent для автоматизации рассылки резюме. Пользователю достаточно один раз загрузить резюме, AI проанализирует его «профессиональную личность» и при «свайпе вправо» на понравившуюся вакансию автоматически перейдет на сложный внешний сайт компании, создаст персонализированное сопроводительное письмо и ответит на отборочные вопросы. Инструмент призван покончить с утомительным заполнением анкет, сокращая процесс подачи заявки с 20 минут до 2 секунд (Источник: Reddit)
📚 Обучение
Возвращение Стэнфордского CS224N 2026: добавлены темы Agent и Reasoning: Классический курс по обработке естественного языка CS224N объявил о своем возвращении. В этом году курс ведут Дии Ян и Еджин Чой. Помимо основ нейросетевого NLP, в программу будут добавлены блоки по AI Agent, использованию инструментов и две лекции, посвященные исключительно «рассуждениям (Reasoning)», следуя передовым трендам больших моделей (Источник: Stanford)
Эндрю Ын представил «Build with Andrew»: создание веб-приложений без кода: Эндрю Ын в последнем выпуске еженедельника The Batch запустил новый курс, обучающий новичков создавать и публиковать работающие веб-приложения, используя только описание идей на естественном языке и AI-инструменты. Курс подчеркивает парадигму «AI как разработчик», снижая порог входа в сферу разработки ПО для обычных людей (Источник: DeepLearningAI)
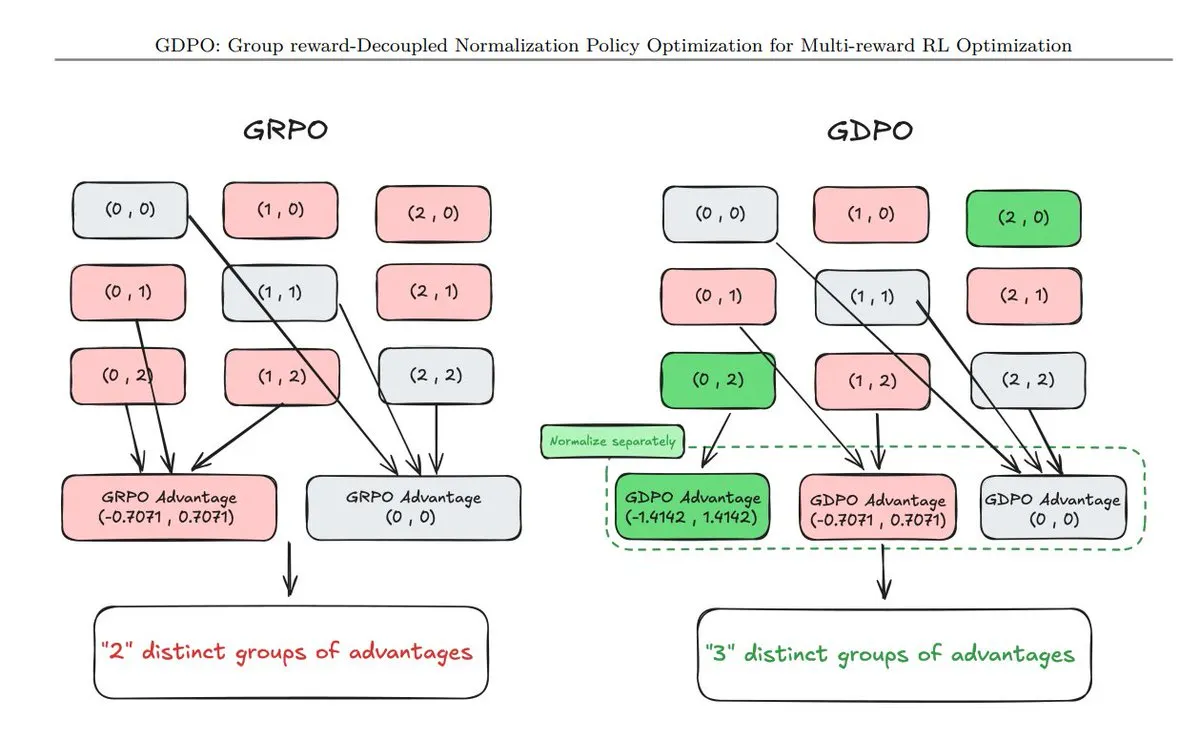
Обзор 11 новых техник оптимизации стратегий: TuringPost подготовил сводку из 11 недавно появившихся техник оптимизации стратегий (Policy Optimization), включая GDPO (нормализация с разделением вознаграждения), AT²PO (пошаговая оптимизация агента на основе поиска по дереву) и привлекшую большое внимание PC-GRPO (GRPO с учебным планом-пазлом). Эти технологии являются ключевыми для улучшения логических цепочек и выравнивания задач в больших моделях (Источник: TuringPost)
💼 Бизнес
OpenAI приобрела медицинский стартап Torch: OpenAI объявила о покупке Torch — медицинского AI-стартапа, который интегрирует результаты экспериментов, записи о лекарствах и аудиозаписи приемов. Команда Torch присоединится к подразделению ChatGPT Health. Этот шаг показывает, что OpenAI ускоряет коммерциализацию AI в сфере управления здоровьем и клинической поддержки, стремясь сделать ChatGPT самым профессиональным персональным помощником по здоровью в мире (Источник: OpenAI)

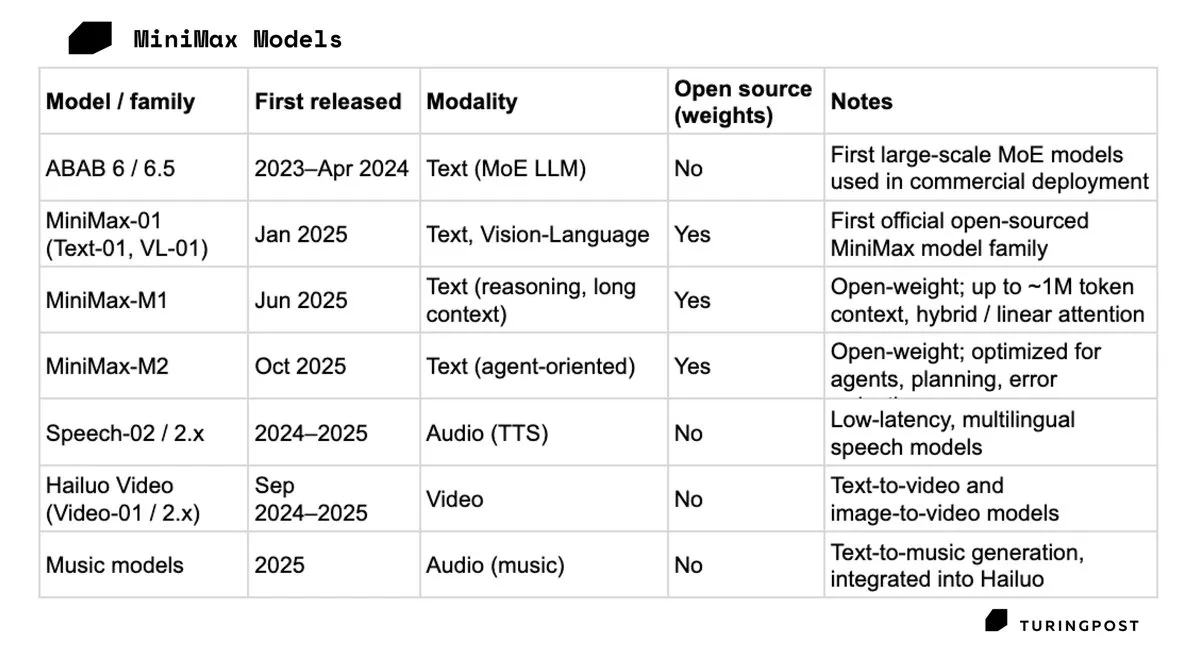
MiniMax вышла на биржу в Гонконге, акции выросли на 109% в первый день: Китайский AI-единорог MiniMax вышел на Гонконгскую фондовую биржу 9 января 2026 года. В первый день торгов цена акций взлетела на 109%, а рыночная капитализация превысила 150 миллиардов гонконгских долларов. Успех MiniMax с продуктами Talkie и Hailuo AI на потребительском рынке доказал привлекательность пути глубокой проработки мультимодальных продуктов для C-сегмента без зависимости от крупных корпоративных контрактов. Это IPO рассматривается как важный шаг для получения «кислорода» в жесткой гонке вычислительных мощностей (Источник: TuringPost)
xAI тратит 28 миллионов долларов в день, оценка стремится к 230 миллиардам: Несмотря на то, что убытки xAI за первые три квартала 2025 года составили 7,8 миллиарда долларов, компания недавно завершила раунд финансирования на 20 миллиардов долларов при оценке в 230 миллиардов. Маск активно продвигает план «Macrohard», целью которого является создание автономных AI-систем для роботов Tesla. Такая модель «агрессивных инвестиций» отражает крайне высокий порог входа в инфраструктуру и таланты для топовых игроков AI (Источник: 36氪)
🌟 Сообщество
Vibe Coding/Working вызвал дискуссию о профессиональной идентичности: С популяризацией Claude Cowork и различных инструментов Agent термин «атмосферная работа (Vibe Working)» стал виральным. Сообщество считает, что это не просто повышение эффективности, а «монетизация доменных знаний в голове». В будущем ценность инженера сместится от «написания 100 000 строк кода» к «проектированию систем, которые заставят AI написать эти 100 000 строк». Однако есть опасения, что это приведет к «низкокачественному коду (Slop)» и чрезмерной зависимости от «черного ящика» AI (Источник: nearcyan, amasad)
Детекторы AI называют «чистым мошенничеством»: Сообщество Reddit обрушилось с критикой на инструменты обнаружения AI, такие как GPTZero, указывая на их крайне высокий уровень ложноположительных результатов (они даже помечают Декларацию независимости как на 90% созданную AI). Пользователи считают, что эти инструменты измеряют «статистическую привычность», а не происхождение, что наносит вред авторам оригинального контента и студентам. Сфера образования призывает прекратить «охоту на ведьм» и перейти к оценке понимания и применения контента студентами (Источник: Reddit)
Основателя DeepSeek Лян Вэньфэна прозвали «мастером-отшельником мира AI»: Сообщество активно обсуждает бэкграунд основателя DeepSeek Лян Вэньфэна в сфере квантитативных фондов. Его фонд High-Flyer Quant в 2025 году показал доходность 56,6%, что значительно выше среднего по отрасли. Пользователи восхищаются тем, как он вкладывает заработанные на квантовом трейдинге деньги в AI в стиле «YOLO», выбирая при этом нестандартные технологические пути (такие как MLA, Engram), демонстрируя высокий архитектурный вкус и инженерную эффективность. Его считают ключевой фигурой в противостоянии китайского AI гигантам Кремниевой долины (Источник: teortaxesTex)
💡 Прочее
AI-наушники Sweetpea могут быть выпущены в сентябре: Ходят слухи, что первый аппаратный продукт OpenAI под кодовым названием Sweetpea — это AI-наушники, разработанные командой Джони Айва. Внешне они напоминают металлический голыш и оснащены 2-нм чипом для поддержки локального вывода. OpenAI прогнозирует продажи в 50 миллионов штук в первый год, бросая прямой вызов позициям AirPods на рынке (Источник: 36氪)

Безопасность AI станет новым стандартом выбора для предприятий в 2026 году: По мере расширения полномочий AI-агентов внимание компаний к безопасности переходит из разряда «опционально» в «обязательное условие». Исследования показывают, что 43% предприятий считают безопасность главным препятствием для внедрения AI. Трендом 2026 года станет «встроенная» безопасность, когда аудит и изоляция прав доступа включаются по умолчанию на этапе вызова моделей и оркестрации Agent (Источник: 36氪)