Ключевые слова:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, Yuanrong Qixing VLA, DeepSeek Nano-vLLM, Ant Group Ming Lite Omni, Реализация автономного вождения уровня L4 в серийных автомобилях уровня L2, Сравнение производительности AMD MI350X и B200, Способность модели o3-pro обрабатывать длинный контекст, Технология полнодуплексного взаимодействия AIUI, Модель визуально-языкового действия (VLA)
🔥 В центре внимания
Robotaxi от Tesla впервые выехал на дороги общего пользования, Маск заявил, что серийные автомобили с L2 могут достичь L4 уровня автопилота без модификаций: Robotaxi от Tesla (обновленная Model Y) уже проходит испытания на дорогах Остина, автомобиль имеет новый логотип Robotaxi, но сохраняет рулевое колесо. Маск заявил, что все серийные автомобили Tesla способны достичь полностью автономного вождения без контроля со стороны водителя. Текущие тестовые автомобили оснащены внутренней тестовой версией FSD с количеством параметров в 4,5 раза большим, чем у текущей версии FSD, и ожидается, что она будет выпущена после оптимизации в этом году. Планируется, что Robotaxi станет доступен для общественности 22 июня, начиная с Остина. Этот шаг знаменует собой переход Tesla от FSD уровня L2 к Robotaxi уровня L4/L5, что может ускорить конкуренцию в индустрии автономного вождения, особенно бросая вызов игрокам, следующим технологическому маршруту L4, таким как Waymo (Источник: 量子位)

AMD представила мощнейшие ИИ-чипы серии MI350, превосходящие по производительности Nvidia B200: CEO AMD Лиза Су и CEO OpenAI Сэм Альтман совместно анонсировали GPU MI350X и MI355X. Эти два чипа изготовлены по 3-нм техпроцессу, содержат 185 миллиардов транзисторов и 288 ГБ памяти HBM3E, что в 1,6 раза больше объема памяти у Nvidia B200. Официальные данные показывают, что серия MI350 при работе с Llama 3.1 405B с точностью FP4 выполняет инференс на 30% быстрее, чем B200, и вдвое превосходит Nvidia по вычислительной мощности FP64. AMD также анонсировала серию MI400, разрабатываемую совместно с OpenAI, которая появится в следующем году, что еще больше обострит конкуренцию на рынке ИИ-чипов (Источник: 量子位)

Способности к логическому выводу модели OpenAI o3-pro привлекли внимание, фактическая производительность незначительно отличается от официальных тестов: Новейшая модель для логического вывода от OpenAI, o3-pro, продемонстрировала мощные способности при решении сложных текстовых игр (например, генерация специфических ответов на основе особенностей названий песен певицы Sabrina Carpenter), что вызвало иронию со стороны бывшего руководителя команды AGI Readiness в OpenAI по поводу предыдущих сомнений Apple в способностях больших моделей к логическому выводу. Однако в авторитетных рейтингах, таких как LiveBench, средний балл o3-pro за кодирование практически совпадает с o3, а оценка за кодирование агентом даже ниже. Тестирование Fiction.LiveBench показывает, что o3-pro отлично справляется с короткими контекстами, но все еще уступает Gemini 2.5 Pro в обработке сверхдлинных контекстов (192k). Бывший инженер Apple и SpaceX Бен Хайлак (Ben Hylak) отметил, что реальные возможности o3-pro сильно зависят от предоставления достаточной фоновой информации, и модель больше подходит для генерации отчетов, чем для простого чата, при этом у нее значительно улучшены вызов инструментов и понимание окружения (Источник: 量子位)

iFLYTEK обновляет платформу человеко-машинного взаимодействия AIUI и платформу робототехники Robot Super Brain, способствуя глубокой кооперации интеллектуального оборудования: iFLYTEK объявила о значительном обновлении своей платформы человеко-машинного взаимодействия AIUI, сосредоточив внимание на улучшении полнодуплексного взаимодействия, восприятия и выражения эмоций, а также системы памяти, подобной человеческой. Специально для детских сценариев было представлено эксклюзивное решение для взаимодействия, улучшающее распознавание и понимание детской речи. В то же время, ее платформа робототехники Robot Super Brain, основанная на большой модели Spark, усилила мультимодальное взаимодействие, семантическое понимание и применение знаний, а также представила «интеллектуальный голосовой рюкзак», позволяющий существующим роботам осуществлять голосовое взаимодействие без аппаратной модификации. Эти обновления направлены на переход интеллектуального оборудования от базового взаимодействия к глубокой интеллектуальной кооперации, расширяя возможности в таких областях, как автомобилестроение, аппаратное обеспечение ИИ и робототехника (Источник: 量子位)

🎯 Новости и тенденции
DeepRoute.ai и Volcano Engine сотрудничают в разработке VLA-агента для физического мира на базе большой модели Doubao: CEO DeepRoute.ai Чжоу Гуан объявил о сотрудничестве с Volcano Engine для совместной разработки перспективных технологий, таких как модель «зрение-язык-действие» (VLA), с использованием большой модели Doubao, с целью создания агента для физического мира. Модель VLA от DeepRoute.ai будет выпущена на потребительский рынок в третьем квартале 2025 года и будет обладать четырьмя основными функциями: понимание пространственной семантики, распознавание нестандартных препятствий, понимание текстовых указателей и голосовое управление автомобилем, направленными на повышение безопасности и интеллектуальности вспомогательного вождения. В настоящее время модель VLA прошла дорожные испытания, и ожидается, что в течение года на рынок выйдет более 5 моделей автомобилей с ИИ, оснащенных этой моделью (Источник: 量子位)

Исследователь из DeepSeek воспроизвел vLLM на 1200 строках кода, в некоторых сценариях производительность превзошла оригинал: Исследователь из DeepSeek Юй Синкай (俞星凯) открыл исходный код проекта Nano-vLLM, реализовав ключевые функции vLLM, включая такие важные технологии, как PagedAttention, менее чем на 1200 строках кода Python. Цель проекта — предоставить минималистичную и полностью читаемую версию vLLM для облегчения изучения и понимания. В определенных тестовых условиях на оборудовании H800 и с моделью Qwen3-8B пропускная способность Nano-vLLM даже превысила оригинальную vLLM, демонстрируя ее эффективность. vLLM — это фреймворк для инференса и обслуживания LLM, разработанный UC Berkeley, который значительно повышает пропускную способность сервисов LLM благодаря своему алгоритму PagedAttention (Источник: 量子位)
Китайские компании используют «летающие жесткие диски» для обхода ограничений США на экспорт ИИ-чипов: По сообщению The Wall Street Journal, столкнувшись с ограничениями США на экспорт высокопроизводительных ИИ-чипов, китайские компании применяют новую стратегию: инженеры перевозят жесткие диски с большими объемами обучающих данных (например, 80 ТБ) в зарубежные дата-центры, такие как Малайзия, для обучения моделей ИИ на серверах, оснащенных передовыми чипами, такими как Nvidia. После завершения обучения параметры модели возвращаются в Китай. Этот шаг направлен на обход трудностей с прямым импортом чипов и способствует росту дата-центров ИИ в Юго-Восточной Азии и на Ближнем Востоке. Бывший чиновник Министерства торговли США выразил обеспокоенность по этому поводу (Источник: dotey)

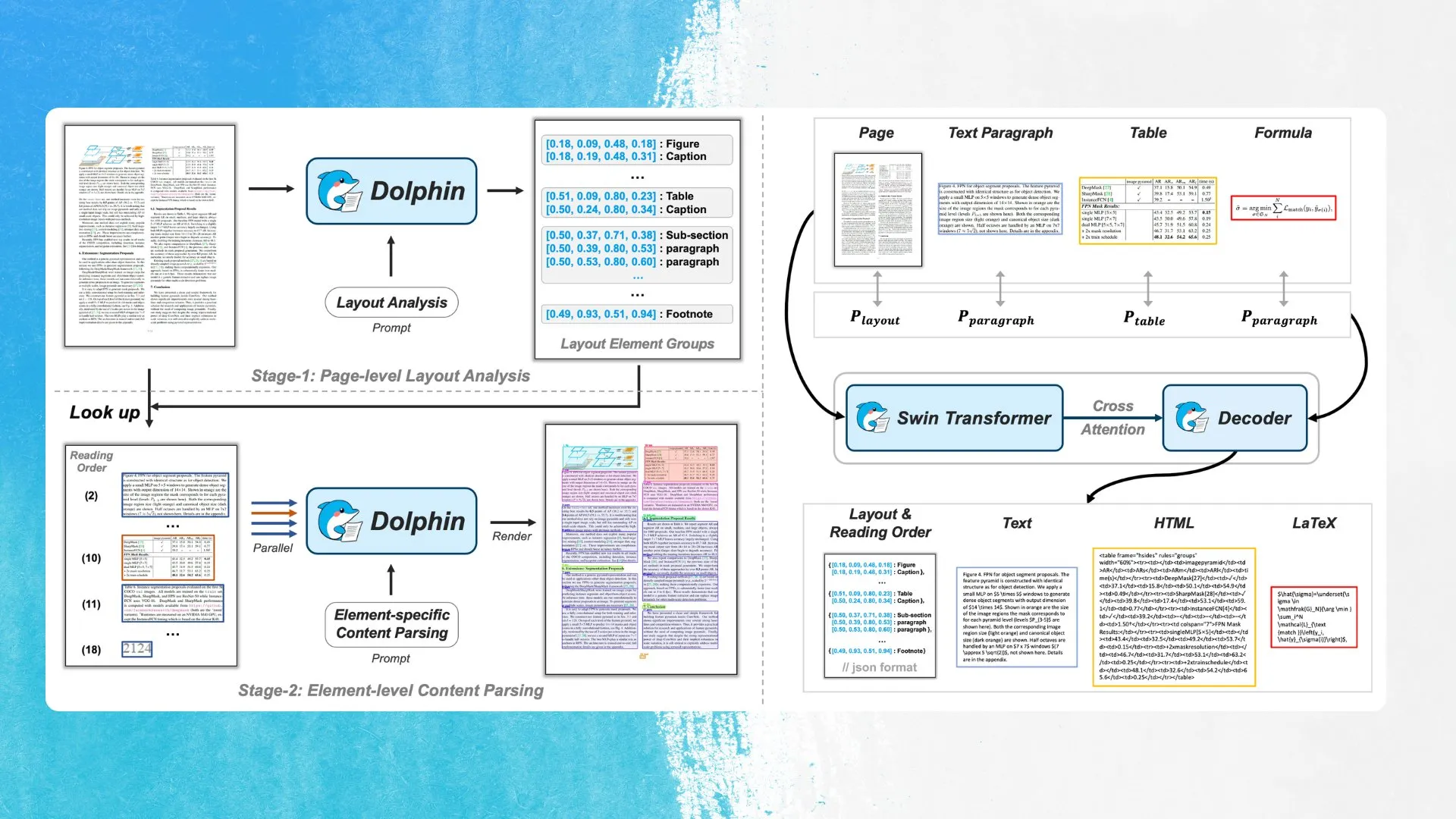
ByteDance выпускает новую модель OCR Dolphin, использующую обнаружение элементов макета и параллельный анализ: ByteDance выпустила новую модель OCR Dolphin под лицензией MIT. Модель сначала обнаруживает элементы в макете документа (такие как таблицы, формулы и т. д.), а затем параллельно анализирует каждый элемент для генерации содержимого. Модель и демонстрация доступны на Hugging Face Hub. Этот метод направлен на повышение точности и эффективности распознавания сложных структур документов (Источник: mervenoyann)
Функциональность проектов OpenAI ChatGPT расширена, добавлена поддержка углубленных исследований, голосового режима и загрузки файлов с мобильных устройств: OpenAI объявила о нескольких улучшениях функции «Проекты» (Projects) в ChatGPT, включая расширенную поддержку углубленных исследований, интеграцию голосового режима, улучшенную функцию памяти для ссылок на прошлые чаты в рамках проекта, а также поддержку загрузки файлов и выбора модели на мобильных устройствах. Эти обновления направлены на повышение способности пользователей выполнять более сфокусированную и сложную работу в ChatGPT (Источник: kevinweil)
Команда EuroLLM выпустила предварительные версии нескольких новых моделей, включая модель на 22B параметров и небольшую модель MoE: Команда EuroLLM выпустила предварительные версии нескольких новых моделей, включая базовую версию и версию с инструктивной донастройкой на 22B параметров, две визуальные модели на базе старой версии EuroLLM (1.7B и 9B параметров), а также небольшую модель «смесь экспертов» (MoE) с 0.6B активных параметров и 2.6B общих параметров. Все эти модели распространяются под лицензией Apache-2.0, и предварительные тесты показывают, что небольшая модель MoE демонстрирует неожиданно хорошие результаты для своего размера (Источник: Reddit r/LocalLLaMA)

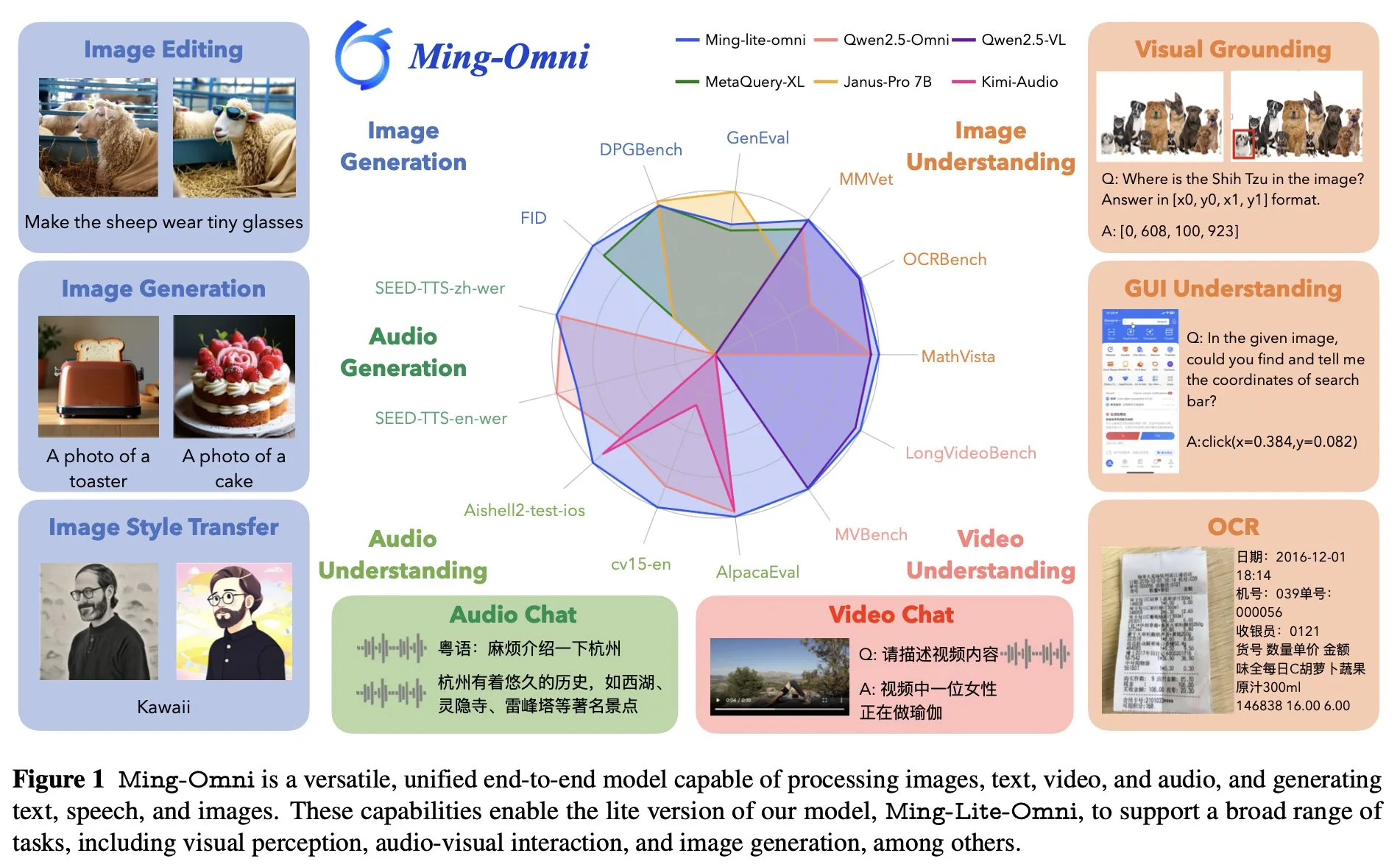
Ant Group выпустила универсальную модель Ming Lite Omni, конкурирующую с GPT-4o: Ant Group представила модель Ming Lite Omni, способную выполнять множество функций, таких как прослушивание, говорение, генерация изображений, и по производительности конкурирующую с GPT-4o. Ming Lite Omni превосходит Qwen2.5VL-7B по точности в задачах GUI, достигает SOTA в нескольких публичных бенчмарках по пониманию аудио, а также демонстрирует отличные способности в понимании видео. Модель использует архитектуру «смесь экспертов» (MoE) с всего 2.8B активных параметров и специально оптимизирована для генерации аудио и изображений, например, за счет использования BPE для снижения частоты кадров аудио-токенов и многомасштабных обучаемых токенов для улучшения качества генерации изображений (Источник: mervenoyann)
NVIDIA и Mistral AI сотрудничают для создания облачной ИИ-платформы Mistral Compute: На конференции GTC NVIDIA объявила о сотрудничестве с Mistral AI для совместного создания облачной ИИ-платформы под названием Mistral Compute. Этот шаг рассматривается как значительное преимущество для США и сообщества открытого исходного кода, направленное на предоставление шаблона для создания глобальной инфраструктуры ИИ с помощью открытых моделей, поддерживаемых американскими чипами (Источник: arthurmensch)
Hugging Face объявляет о полной поддержке PyTorch, упрощая библиотеку Transformers: Главный специалист по открытому исходному коду Hugging Face, Лисандр Джик (Lysandre Jik), заявил, что, учитывая сложившийся консенсус пользовательской базы вокруг PyTorch, в будущем все усилия будут сосредоточены на PyTorch, чтобы уменьшить раздутость библиотеки Transformers и предоставить более лаконичный инструментарий. Официальные представители PyTorch приветствовали этот шаг и подчеркнули, что он поможет поддерживать чистоту кода (Источник: reach_vb)

ByteDance представляет технологию генерации интерактивного видео в реальном времени APT2: ByteDance продемонстрировала свою новейшую технологию генерации интерактивного видео в реальном времени APT2 (Autoregressive Adversarial Post-Training). Эта технология, основанная на авторегрессионном состязательном пост-обучении, направлена на создание высококачественного интерактивного видеоконтента в реальном времени, что способствует дальнейшему развитию области генерации видео (Источник: NerdyRodent)
🧰 Инструменты
Llama-Server Launcher: лаунчер для сервера llama.cpp с GUI, ориентированный на оптимизацию производительности CUDA: Разработчик поделился своим личным лаунчером для llama-server, написанным на Python и предоставляющим графический пользовательский интерфейс (GUI). Инструмент предназначен для упрощения конфигурации и запуска сервисов llama.cpp, с особым вниманием к настройке производительности CUDA. Функции включают выбор модели, установку путей, настройку размера контекста и пакета, выгрузку на GPU, FlashAttention, разделение тензоров и другие расширенные настройки производительности, а также выбор шаблона чата и управление конфигурацией среды. Поддерживает автоматическое получение информации о GPU и системе, анализ метаданных модели GGUF и может генерировать кроссплатформенные скрипты запуска (.ps1/.sh) (Источник: Reddit r/LocalLLaMA)
Together AI выпускает опенсорсного ИИ-агента для специалистов по данным: Together AI создала опенсорсного ИИ-агента, способного рассуждать как специалист по данным. Агент может загружать данные, писать код на Python, переобучать модель в случае сбоя и решать реальные задачи из Kaggle и DABStep. Этот шаг направлен на продвижение автоматизации и популяризации ИИ в области науки о данных (Источник: percyliang)
AutoMind: адаптивный фреймворк интеллектуальных агентов на основе знаний для автоматизации науки о данных: AutoMind — это новый фреймворк для LLM-агентов, разработанный для преодоления ограничений существующих агентов в области науки о данных при решении сложных и инновационных задач путем интеграции экспертных баз знаний, использования алгоритма поиска по дереву знаний агента и адаптивных стратегий кодирования, тем самым повышая реальную эффективность автоматизированных процессов машинного обучения (Источник: HuggingFace Daily Papers)
LlamaParse выпускает функцию «пресетов» для упрощения конфигурации парсинга документов: LlamaParse представила функцию «пресетов» (Presets), предлагающую ряд легко понятных предварительно сконфигурированных режимов для оптимизации настроек под различные сценарии использования. Включает быстрый, сбалансированный и расширенный режимы для общих сценариев, а также оптимизированные режимы для распространенных случаев, таких как счета-фактуры, научные статьи, техническая документация и формы, с целью предоставить пользователям более удобный выбор между скоростью и точностью (Источник: jerryjliu0)
OpenWebUI добавляет поддержку o3-pro, расширяя совместимость моделей: Разработчик сообщества создал новую функцию для Open WebUI, расширяющую поддержку модели o3-pro путем добавления поддержки API ответов, отслеживания затрат, поддержки нескольких ключей и веб-поиска. Это позволяет пользователям использовать o3-pro в Open WebUI без подписки на официальный премиум-пакет (Источник: Reddit r/OpenWebUI)
📚 Обучение
Статья исследует разложение активаций MLP на интерпретируемые признаки с помощью полунеотрицательной матричной факторизации (SNMF): В исследовании предлагается использовать SNMF для прямого разложения активаций многослойного перцептрона (MLP) с целью изучения разреженных признаков, состоящих из линейных комбинаций совместно активируемых нейронов, и сопоставления этих признаков с их активирующими входами, что делает их непосредственно интерпретируемыми. Эксперименты показывают, что признаки, полученные с помощью SNMF, превосходят разреженные автоэнкодеры (SAE) в каузальном управлении и согласуются с человеко-интерпретируемыми концепциями, выявляя иерархическую структуру в пространстве активаций MLP (Источник: HuggingFace Daily Papers)
Новая статья предлагает LoRMA: новую парадигму дообучения LLM посредством низкоранговой мультипликативной адаптации (Low-Rank Multiplicative Adaptation): Традиционное дообучение LLM обычно обновляет веса аддитивно, в то время как LoRMA исследует мультипликативные обновления. Для решения проблемы «подавления ранга», вызванной низкоранговыми матрицами, в статье вводятся новые операции расширения ранга на основе перестановок и сложения, а также обеспечивается вычислительная эффективность за счет эффективных операций переупорядочения. Эксперименты показывают конкурентоспособность LoRMA, предлагая новые идеи для адаптации LLM (Источник: Reddit r/deeplearning)
Статья предлагает фреймворк TaxoAdapt, позволяющий адаптировать многомерные таксономии, построенные LLM, к развивающимся исследовательским корпусам: Для решения проблемы организации научной литературы фреймворк TaxoAdapt способен динамически корректировать таксономии, сгенерированные LLM, для адаптации к конкретным корпусам, а также поддерживает несколько измерений (например, методология, задачи, метрики оценки). Фреймворк расширяет широту и глубину классификации в соответствии с тематическим распределением корпуса посредством итеративной иерархической классификации, с целью лучшей организации и отражения эволюции научных областей (Источник: HuggingFace Daily Papers)
Статья представляет фреймворк MOSAIC, реализующий совместное обучение в системах агентов: MOSAIC — это фреймворк для автономных, интеллектуальных систем ИИ-агентов, осуществляющих совместное обучение в децентрализованных, динамичных средах. Агенты избирательно делятся и повторно используют модульные знания (в виде масок нейронных сетей) без синхронизации или централизованного управления. Эксперименты показывают, что MOSAIC превосходит изолированных обучающихся по скорости и производительности, иногда решая задачи, неразрешимые для изолированных агентов, и способствует повышению коллективной эффективности и адаптивности (Источник: Reddit r/MachineLearning)
Статья предлагает фреймворк ClaimSpect для иерархического анализа сложных утверждений с использованием поиска и дополнения: Многие утверждения (например, научные, политические) не являются просто истинными или ложными. Фреймворк ClaimSpect посредством генерации с поиском и дополнением автоматически строит иерархическую структуру аспектов, связанных с утверждением, и обогащает эти аспекты перспективами из конкретного корпуса. Этот метод направлен на деконструкцию сложных утверждений и представление различных точек зрения на каждый аспект, содержащихся в корпусе, а также их распространенности (Источник: HuggingFace Daily Papers)
Статья предлагает мелкозернистое управление пертурбациями (Fine-Grained Perturbation Guidance) путем выбора голов внимания: Исследование показало, что определенные головы внимания в диффузионных моделях контролируют различные визуальные концепции (такие как структура, стиль, качество текстуры). Основываясь на этом, в статье предлагается фреймворк “HeadHunter”, который систематически выбирает головы внимания, соответствующие целям пользователя, для достижения мелкозернистого контроля над качеством генерации и визуальными атрибутами, а также вводит SoftPAG для настройки интенсивности пертурбаций. Метод продемонстрировал свое превосходство в улучшении качества и управлении стилем на таких моделях, как Stable Diffusion 3 и FLUX.1 (Источник: HuggingFace Daily Papers)
Статья исследует, что «забывание» в LLM должно быть независимым от формы (Form-Independent): Исследование указывает, что эффективность текущих методов «забывания» (unlearning) в LLM сильно зависит от формы обучающих примеров и с трудом обобщается на различные представления одного и того же знания. В статье эта проблема определяется как «смещение, зависимое от формы» (Form-Dependent Bias) и вводится бенчмарк ORT для ее оценки. Для решения этой проблемы в статье предлагается метод ROCR (Rank-one Concept Redirection), который осуществляет «забывание» путем перенаправления восприятия моделью определенных концепций. Эксперименты показывают, что ROCR значительно улучшает эффект «забывания» и способен генерировать естественный вывод (Источник: HuggingFace Daily Papers)
Статья предлагает UniPre3D: унифицированный метод предварительного обучения моделей 3D-облаков точек на основе кросс-модального Gaussian Splatting: UniPre3D направлен на решение проблем, связанных с разнообразием масштабов данных облаков точек в 3D-зрении, и предлагает первый унифицированный метод предварительного обучения, который может без проблем применяться к облакам точек любого масштаба и к 3D-моделям любой архитектуры. Метод использует предсказание гауссовых примитивов в качестве задачи предварительного обучения и применяет дифференцируемый рендеринг Gaussian Splatting для изображений, обеспечивая точный надзор на уровне пикселей и сквозную оптимизацию, одновременно интегрируя признаки из предварительно обученных 2D-моделей для введения знаний о текстурах (Источник: HuggingFace Daily Papers)
Статья предлагает StreamSplat: онлайн-реконструкцию динамических 3D-сцен из некалиброванных видеопотоков: StreamSplat — это полностью прямой (feed-forward) фреймворк, способный в режиме онлайн преобразовывать некалиброванные видеопотоки произвольной длины в динамическое представление 3D Gaussian Splatting (3DGS). Он использует механизм вероятностной выборки в статическом кодировщике для предсказания позиций 3DGS, а также двунаправленное поле деформации в динамическом декодере, обеспечивая надежное и эффективное динамическое моделирование. Цель — решить проблемы калибровки, динамического моделирования и стабильности эффективности при реконструкции динамических сцен в реальном времени (Источник: HuggingFace Daily Papers)
Статья рассматривает внимательное зондирование (Attentive Probing) в моделировании маскированных изображений: Поскольку крупномасштабное дообучение становится непрактичным, зондирование (probing) стало предпочтительным методом оценки самообучающихся моделей (SSL). Стандартное линейное зондирование (LP) не в полной мере отражает потенциал моделей, обученных с помощью моделирования маскированных изображений (MIM). В данной статье пересматривается внимательное зондирование и вводится эффективное зондирование (EP) — механизм перекрестного внимания с несколькими запросами, который сокращает количество обучаемых параметров и повышает скорость, превосходя LP и предыдущие методы внимательного зондирования в нескольких бенчмарках (Источник: HuggingFace Daily Papers)
Статья предлагает PosterCraft: новый подход к генерации высококачественных эстетичных постеров в рамках единого фреймворка: PosterCraft направлен на решение проблем генерации эстетичных постеров, что требует не только точного рендеринга текста, но и бесшовной интеграции абстрактного художественного контента, привлекательного макета и общей гармонии стиля. PosterCraft использует каскадный рабочий процесс для оптимизации генерации, включая крупномасштабную оптимизацию рендеринга текста, дообучение с учетом регионального надзора, обучение с подкреплением для эстетичного текста и совместную доработку с обратной связью по визуальным и языковым аспектам, и значительно превосходит открытые базовые модели в нескольких экспериментах (Источник: HuggingFace Daily Papers)
Статья предлагает улучшение диффузионных моделей с помощью управления пертурбациями токенов (Token Perturbation Guidance): Для решения проблемы, заключающейся в том, что бесклассификаторное управление (CFG) требует специфического процесса обучения и ограничено условной генерацией, метод TPG применяет матрицы пертурбаций непосредственно к промежуточным представлениям токенов внутри диффузионной сети. TPG использует операцию перемешивания с сохранением нормы для предоставления эффективного управляющего сигнала, улучшая качество генерации без изменений архитектуры и подходя как для условной, так и для безусловной генерации. Эксперименты показывают, что TPG почти в 2 раза улучшает FID для базовой модели SDXL при безусловной генерации (Источник: HuggingFace Daily Papers)
Статья предлагает DreamActor-H1: генерация высококачественных демонстрационных видео взаимодействия человека с товаром с помощью Diffusion Transformers, управляемых дизайном движения: DreamActor-H1 — это фреймворк на основе Diffusion Transformer (DiT), предназначенный для генерации высококачественных демонстрационных видео взаимодействия человека с продуктом. Метод использует инъекцию парной эталонной информации о человеке и продукте, а также дополнительный механизм маскированного перекрестного внимания, сохраняя при этом детали идентичности человека и продукта (такие как логотипы, текстуры). Он использует шаблоны 3D-сетки человека и ограничивающие рамки продукта для точного управления движением и усиливает 3D-согласованность с помощью структурированного кодирования текста (Источник: HuggingFace Daily Papers)
Статья предлагает EmbodiedGen: генеративный движок 3D-миров для воплощенного интеллекта: EmbodiedGen — это базовая платформа для генерации интерактивных 3D-миров, предназначенная для масштабируемого создания высококачественных, управляемых, фотореалистичных 3D-ассетов с низкими затратами, которые обладают точными физическими свойствами и реальными масштабами, а также используют унифицированный формат описания роботов (URDF). Эти ассеты могут быть напрямую импортированы в различные движки физического моделирования, поддерживая задачи обучения и оценки воплощенного интеллекта, и решая проблемы высокой стоимости и ограниченной реалистичности традиционных 3D-ассетов компьютерной графики (Источник: HuggingFace Daily Papers)
Новое исследование опровергает статью Apple об «иллюзии мышления», утверждая, что LLM способны решать новые сложные проблемы: В ответ на недавнюю статью Apple «Иллюзия мышления» (Illusion of Thinking), в которой утверждалось, что большие модели рассуждений (LRM) испытывают «коллапс точности» при решении сложных задач планирования (таких как Ханойская башня), последующее обзорное исследование указало, что выводы Apple в основном отражают ограничения дизайна эксперимента, а не фундаментальный провал способности моделей к рассуждению. Новое исследование утверждает, что превышение бюджета токенов в исходном эксперименте, неверная оценка намеренно усеченных выходных данных и включение математически неразрешимых примеров головоломок совместно привели к неверной оценке способностей моделей. При изменении методов эксперимента, например, когда модель просят сгенерировать компактную функцию на Lua для решения Ханойской башни вместо подробного списка шагов, модели демонстрируют высокую точность в случаях, ранее сообщавшихся как полный провал, что указывает на то, что модели способны рассуждать, но ограничены форматом вывода и лимитом токенов (Источник: Reddit r/LocalLLaMA)

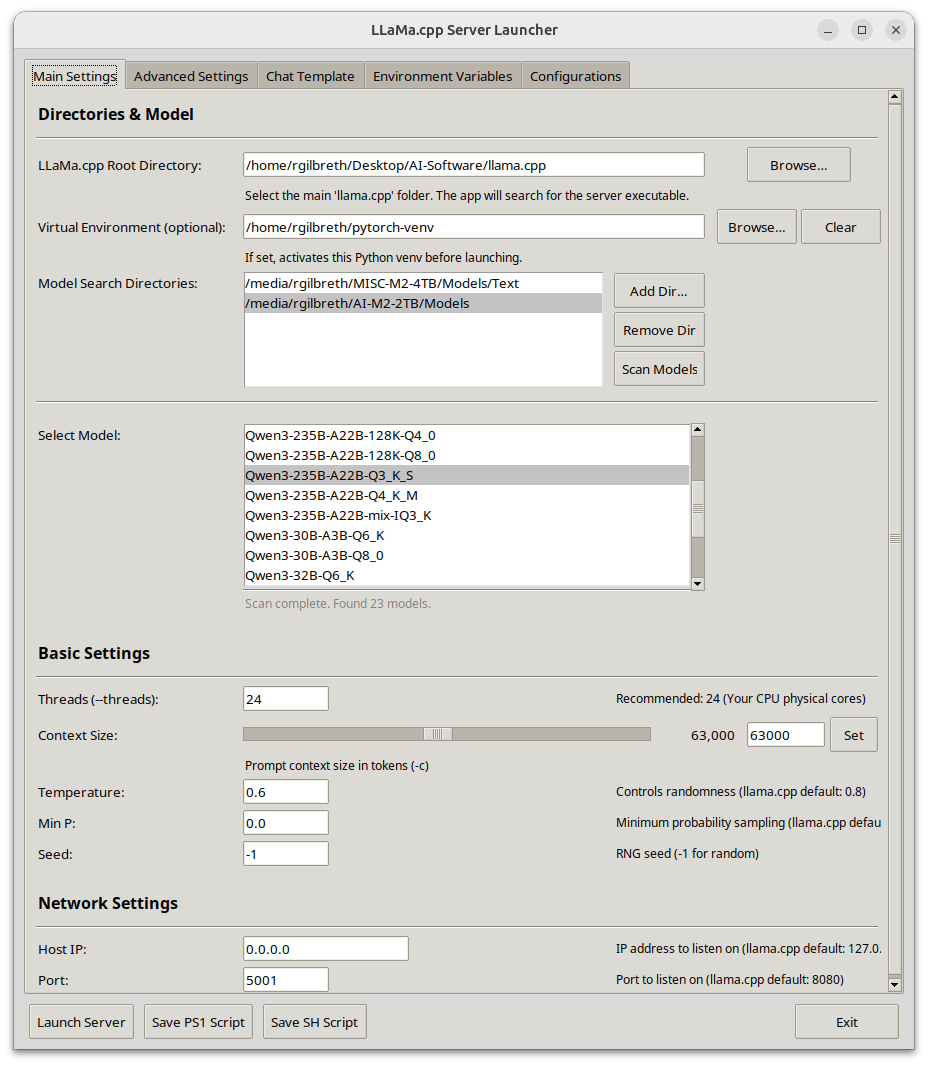
KRIS-Bench: новый бенчмарк для всесторонней оценки способности моделей редактирования изображений к логическому выводу с точки зрения типов знаний: Юго-Восточный университет и другие учреждения совместно выпустили KRIS-Bench, бенчмарк для оценки способности систем редактирования изображений на основе знаний к логическому выводу. Он оценивает 10 основных моделей редактирования изображений (включая GPT-Image-1, Gemini 2.0 Flash и др.) по трем уровням: фактические знания (например, цвет, количество), концептуальные знания (например, здравый смысл в физике) и процедурные знания (например, многошаговые операции), разделенные на 22 типа задач редактирования. Результаты показывают, что закрытая модель GPT-Image-1 показала наилучшие результаты, но все модели в целом плохо справляются с задачами процедурного вывода, естественных наук и многошагового синтеза, что выявляет недостатки текущих моделей в продвинутых когнитивных способностях (Источник: 量子位)
Новое исследование предлагает метод Finetune-RAG, дообучение языковых моделей для противодействия галлюцинациям в RAG: Большие языковые модели в системах генерации с дополненной выборкой (RAG) склонны к галлюцинациям, когда выборка несовершенна (например, присутствуют отвлекающие фрагменты документов). Finetune-RAG обучает модель на входных данных, содержащих как правильный, так и неправильный контекст, что позволяет ей лучше сохранять достоверность. Исследовательская группа выпустила набор данных, содержащий более 1600 примеров с двойным контекстом, дообученную контрольную точку LLaMA 3.1-8B-Instruct, а также фреймворк для оценки GPT-4o под названием Bench-RAG. Оценка показала, что этот метод повысил точность с 77% до 98%, а также улучшил полезность, релевантность и глубину (Источник: Reddit r/MachineLearning)
TeleMath: выпущен первый бенчмарк для оценки способности LLM решать математические задачи в области телекоммуникаций: Для оценки способности больших языковых моделей решать специфические, математически насыщенные задачи в области телекоммуникаций, исследователи представили бенчмарк TeleMath. Бенчмарк содержит 500 пар вопросов и ответов, охватывающих такие темы телекоммуникаций, как обработка сигналов, оптимизация сетей и анализ производительности. Оценка различных LLM с открытым исходным кодом показала, что модели, специально разработанные для математического или логического вывода, лучше справляются с TeleMath, в то время как универсальные модели с большим количеством параметров часто испытывают трудности. Набор данных и код для оценки доступны (Источник: HuggingFace Daily Papers)
ChineseHarm-Bench: выпущен бенчмарк для обнаружения вредоносного контента на китайском языке: В связи с тем, что существующие ресурсы для обнаружения вредоносного контента в основном англоязычные, исследователи выпустили ChineseHarm-Bench, всеобъемлющий, профессионально аннотированный бенчмарк для обнаружения вредоносного контента на китайском языке. Бенчмарк охватывает шесть репрезентативных категорий, данные полностью взяты из реального мира. В процессе аннотирования также была создана база знаний правил, предоставляющая LLM явные экспертные знания. Кроме того, исследователи предложили базовый метод, усиленный знаниями, который сочетает правила, аннотированные вручную, и неявные знания LLM, позволяя небольшим моделям достигать производительности SOTA LLM (Источник: HuggingFace Daily Papers)
Новое исследование выявляет иерархическую структуру скрытых способностей языковых моделей с помощью каузального обучения представлений: Для достоверной оценки способностей языковых моделей и преодоления эффектов смешения и высоких вычислительных затрат, данное исследование предлагает фреймворк каузального обучения представлений. Этот фреймворк моделирует наблюдаемую производительность на бенчмарках как линейное преобразование небольшого числа факторов скрытых способностей и, после контроля базовой модели как общего фактора смешения, идентифицирует каузальные связи между этими скрытыми факторами. Применив его к данным более 1500 моделей из Open LLM Leaderboard, исследование выявило лаконичную трех-узловую линейную каузальную структуру, раскрывающую четкий каузальный путь от общих способностей к решению проблем к мастерству следования инструкциям, и далее к способностям математического вывода (Источник: HuggingFace Daily Papers)
DeepLearning.AI запускает новый курс «Оркестровка рабочих процессов для приложений GenAI»: Эндрю Ын (Andrew Ng) объявил о запуске нового краткосрочного курса в сотрудничестве с Astronomer, который научит создавать и развертывать надежные конвейеры генеративного ИИ с использованием популярного инструмента с открытым исходным кодом Airflow 3.0. Содержание курса включает разложение рабочих процессов на дискретные задачи, планирование задач, параллельное выполнение, восстановление после сбоев и наблюдаемость, с целью помочь учащимся превратить прототипы Jupyter-ноутбуков или Python-скриптов в готовые к производству рабочие процессы (Источник: DeepLearningAI)
Статья рассматривает методы оптимизации композитных систем ИИ, проблемы и будущие направления: С развитием LLM и систем ИИ, композитные системы ИИ, интегрирующие несколько компонентов, становятся все более зрелыми в выполнении сложных задач. В данной статье систематически рассматриваются последние достижения в оптимизации композитных систем ИИ, включая численные и языковые методы. Статья формализует концепцию оптимизации композитных систем ИИ, классифицирует существующие методы и подчеркивает открытые исследовательские проблемы и будущие направления в этой области (Источник: HuggingFace Daily Papers)
💼 Бизнес
Disney и Universal Studios подали в суд на генератор изображений Midjourney за нарушение авторских прав: Disney и Universal Studios обвинили Midjourney в несанкционированном использовании их творческих библиотек (включая персонажей из «Звездных войн», «Холодного сердца», «Миньонов» и др.) для обучения модели, а также в создании и распространении большого количества производных работ, назвав это «бездонной ямой плагиата». Этот случай вновь вызвал дискуссию о границах между контентом, генерируемым ИИ, и интеллектуальной собственностью (Источник: Reddit r/ArtificialInteligence)
NVIDIA и Deutsche Telekom сотрудничают для создания первого промышленного облака ИИ для европейских производителей к 2026 году: Федеральный канцлер Германии Фридрих Мерц встретился с CEO NVIDIA Дженсеном Хуангом для обсуждения дальнейшего стратегического сотрудничества с целью укрепления позиций Германии как мирового лидера в области ИИ. В рамках этого видения Deutsche Telekom и NVIDIA объявили о новом сотрудничестве, планируя к 2026 году создать первое в мире промышленное облако ИИ для европейских производителей. Эта безопасная и соответствующая европейским нормам инфраструктура будет поддерживать передовые инновации, обеспечивая при этом полный суверенитет данных (Источник: nvidia)

Слухи: Сэм Альтман может размыть некоммерческий контроль над OpenAI путем приобретения компаний за акции: Недавние приобретения OpenAI компаний io (за 6,5 млрд долларов) и Windsurf (за 3 млрд долларов) полностью за акции вызвали предположения. На Hacker News существует теория, что Сэм Альтман может использовать эти сделки для постепенного размывания контроля некоммерческой организации OpenAI Inc. над коммерческой структурой OpenAI Global LLC (ныне OpenAI PBC), тем самым потенциально обходя юридические ограничения на преобразование в полностью коммерческую компанию. Некоторые связывают этот шаг с действиями Альтмана в отношении Reddit в 2014 году, однако есть и мнения, что эти приобретения являются обычной стратегией развития бизнеса (Источник: Reddit r/ArtificialInteligence)
🌟 Сообщество
Дискуссия о том, может ли ИИ действительно «рассуждать», продолжается, статья Apple вызвала споры: Недавняя статья Apple, утверждающая, что производительность больших языковых моделей (LLM) в сложных задачах (таких как Ханойская башня) не является настоящим рассуждением, а скорее сопоставлением с образцом, вызвала широкое обсуждение в сообществе. Бывший сотрудник OpenAI Майлз Брандейдж (Miles Brundage), комментируя решение o3-pro сложной текстовой игры, иронично спросил: «Если это не называется рассуждением, то что тогда называется?». Последующие исследования указали, что явление «коллапса рассуждений» в статье Apple могло быть вызвано ограничениями дизайна эксперимента (такими как лимит токенов, неверная оценка неразрешимых проблем), а не отсутствием у самой модели способности к рассуждению. После корректировки методов тестирования модель хорошо справилась с задачами, на которых ранее терпела неудачу, что указывает на необходимость более тщательного дизайна экспериментов для оценки способностей ИИ к рассуждению (Источник: o3-pro答高难题文字游戏引围观,OpenAI前员工讽刺苹果:这都不叫推理那什么叫推理, Reddit r/LocalLLaMA)
CEO Nvidia Дженсен Хуанг и CEO Anthropic Дарио Амодей имеют значительные расхождения во взглядах на будущее ИИ: Fortune сообщает, что CEO Nvidia Дженсен Хуанг заявил, что он практически не согласен почти со всеми взглядами CEO Anthropic Дарио Амодея на ИИ. Амодей часто подчеркивает потенциальные риски ИИ и его огромное влияние на занятость, а также выступает за более строгий контроль над развитием ИИ и доминирование нескольких «ответственных» организаций. Хуанг, напротив, скептически относится к таким взглядам и склонен способствовать широкому применению и развитию технологий ИИ. В сообществе комментируют, что позиция Хуанга может быть связана с его коммерческими интересами, поскольку Nvidia является основным поставщиком аппаратного обеспечения для ИИ (Источник: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Подписка Claude Code за 20 долларов получила высокую оценку разработчиков за соотношение цены и качества: Многие разработчики поделились в социальных сетях своим положительным опытом использования ежемесячной подписки Anthropic Claude Code за 20 долларов, назвав ее чрезвычайно выгодной и быстро окупающейся в проектах. Пользователи отмечают, что, несмотря на определенные ограничения по скорости, Claude Code отлично справляется с помощью в кодировании, изучении новых языков (например, переход с C# на SwiftUI) и оптимизации инструкций для проектов (например, файл CLAUDE.md), значительно повышая эффективность работы. Некоторые пользователи даже рассматривают возможность отмены подписок на другие ИИ-инструменты для программирования (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Сообщество обсуждает будущее применение ИИ в психологии и этические проблемы: По мере развития технологий, таких как LLM, составляющие терапевтические подсказки, и приложения, отслеживающие эмоции с помощью датчиков телефона, ИИ постепенно проникает в психологию. Обсуждение в сообществе сосредоточено на том, будет ли ИИ в клинической практике усиливать возможности терапевтов или в конечном итоге заменит часть их работы, на достоверности ИИ в оценке и исследованиях, на влиянии на профессиональную подготовку и рынок труда в психологии, а также на этических и регуляторных вопросах применения ИИ, особенно на предвзятости данных, конфиденциальности и ограничениях «роботов-терапевтов». Основная обеспокоенность заключается в том, как использовать ИИ для повышения эффективности и персонализации услуг, одновременно обеспечивая безопасность пациентов и сохраняя терапевтическую ценность межличностных связей (Источник: Reddit r/artificial)
3,53-битная квантованная модель DeepSeek-R1-0528 от Unsloth хорошо показала себя на бенчмарке кодирования Aider Polyglot: Команда Unsloth провела 3,53-битную квантизацию (UD-Q3_K_XL) модели DeepSeek-R1-0528, которая достигла 68% успешных прохождений на бенчмарке кодирования Aider Polyglot. В тесте использовался контекст размером 40960 и Flash Attention, требуемый объем RAM/VRAM составил около 300 ГБ. Этот результат находится между Claude Sonnet 3.7 и Claude Opus 4, демонстрируя потенциал квантованных моделей в сохранении высокой способности к кодированию. Члены сообщества впечатлены производительностью таких моделей при локальном запуске и ожидают результатов тестирования большего количества квантованных версий (Источник: Reddit r/LocalLLaMA)
💡 Прочее
Отчет о глобальном сбое GCP раскрыл причину: неверная политика квот привела к прерыванию обслуживания: Отчет о недавнем глобальном сбое Google Cloud Platform (GCP) показал, что причиной стала ошибочная политика квот, примененная к глобальной системе управления API (например, ограничение до 1 запроса в час), что привело к отклонению внешних запросов из-за превышения квоты (ошибка 403). Инженеры, обнаружив проблему, обошли проверку квот для затронутых API. Однако в регионе us-central1 при попытке очистить старую политику и записать новую из-за проблем с кэшированием произошла перегрузка базы данных, что увеличило время восстановления. В других регионах для восстановления использовался постепенный метод очистки кэша, и весь процесс занял около 2 часов (Источник: karminski3)

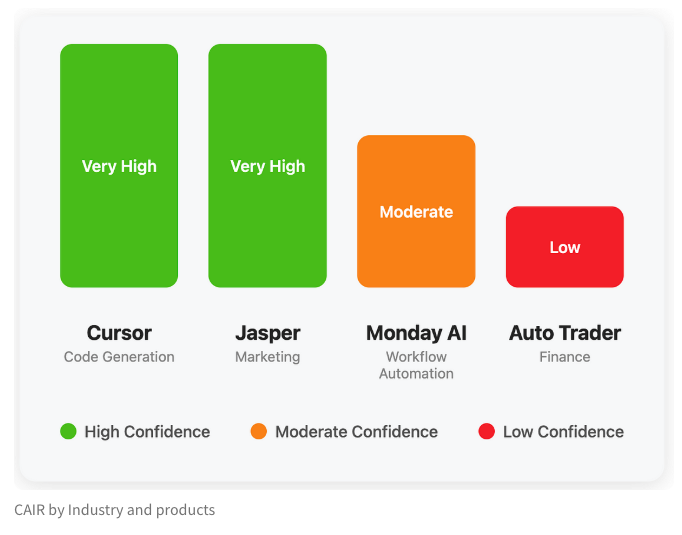
Команда LangChain предложила метрику CAIR для оценки потенциала успеха ИИ-продуктов: Харрисон Чейз (Harrison Chase) из LangChain совместно с Ассафом Эловичем (Assaf Elovic) написали статью, в которой обсуждается, почему некоторые ИИ-продукты быстро набирают популярность, а другие сталкиваются с трудностями. Они считают, что возможности модели не являются единственным определяющим фактором, решающее значение имеет пользовательский опыт (UX), и предложили метрику «CAIR» (Confidence in AI Results, уверенность в результатах ИИ). Чем выше CAIR, тем выше уровень принятия продукта. Этот фреймворк призван помочь разработчикам выявлять и улучшать компоненты, влияющие на уверенность пользователей, тем самым повышая шансы на успех продукта (Источник: hwchase17, swyx, hwchase17, Hacubu)
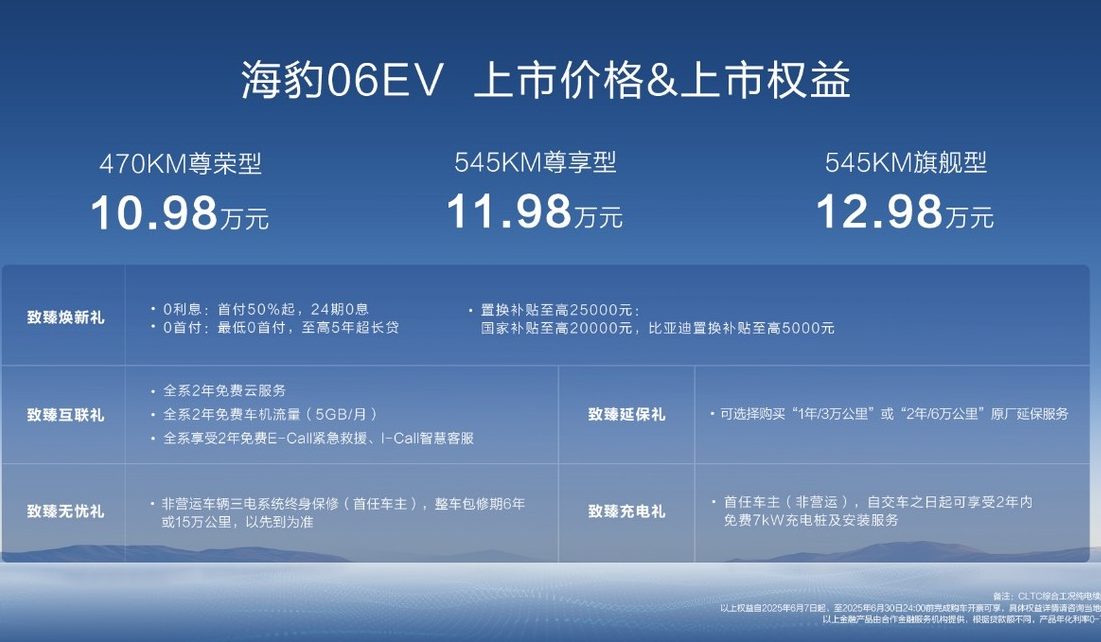
BYD выпустила новый полностью электрический семейный седан-купе Seal 06EV по цене от 109 800 юаней: На автосалоне в Чунцине подразделение BYD Ocean представило Seal 06EV, позиционируемый как стильный и качественный седан-купе, доступный в 3 комплектациях по цене от 109 800 до 129 800 юаней. Автомобиль построен на платформе BYD e-platform 3.0 Evo, оснащен интеллектуальным электроприводом «восемь в одном» и новой широкотемпературной эффективной системой теплового насоса, обеспечивая запас хода по CLTC 470 км и 545 км. Автомобиль имеет задний привод, оснащен интеллектуальной системой управления демпфированием кузова Cloud Chariot-C и интеллектуальной системой помощи водителю «Глаз Бога C» (трехкамерная версия), поддерживающей функции навигации по шоссе, автоматической парковки и др. (Источник: 量子位)