
关键词:Engram模块, Cowork, Gemini合作, Transformer知识查找机制, AI Agent任务执行, TTT-E2E测试时训练
🔥 聚焦
DeepSeek发布Engram模块,实现存储与计算解耦 : DeepSeek联合北大发表论文,推出“条件记忆”模块Engram。该技术通过现代化的哈希N-gram嵌入,为Transformer补齐了原生的“知识查找”机制,实现近似O(1)的确定性检索。实验显示,Engram-27B在严格等参数和等计算量下显著优于纯MoE模型,不仅提升了知识储备,更因解放了浅层注意力的“死记硬背”负担,使深层网络能专注于复杂推理,代码和数学能力大幅跃升。这种将海量参数卸载至主机内存(CPU)且推理损耗低于3%的工程路线,被视为下一代稀疏大模型的核心原语,极有可能集成在即将发布的DeepSeek-V4中(来源: GitHub)

Anthropic发布战略级产品Cowork,开启“数字同事”时代 : Anthropic正式推出Cowork(研究预览版),将Claude Code的底层能力封装为面向非技术人员的图形化工具。Cowork允许Claude直接访问本地文件夹,具备读取、编辑和创建文件的权限。它不再仅仅是聊天机器人,而是一个能自主规划步骤、并行处理任务(如整理下载文件夹、从截图中提取数据生成Excel、撰写报告初稿)的智能协作体。产品内置虚拟机隔离环境以确保安全,并支持浏览器自动化。社区普遍认为,这标志着AI从“内容生成”向“任务执行”的范式转变,可能对大量初创AI应用造成降维打击(来源: Anthropic)

苹果与谷歌达成Gemini合作协议,Siri迎来“外脑” : 苹果与谷歌发布联合声明,确认未来的Apple Foundation Models将基于谷歌Gemini模型和云技术构建,以驱动今年晚些时候推出的个性化Siri。据称苹果每年将支付约10亿美元。此次合作被视为苹果在自研模型跳票背景下的“过渡性低头”,Gemini将负责摘要和规划等复杂任务,而设备端基础功能仍由苹果自研模型支持。此举使谷歌市值首次突破4万亿美元,同时也引发了马斯克对“权力过度集中”的抨击,以及OpenAI在苹果生态中地位被边缘化的讨论(来源: Google)

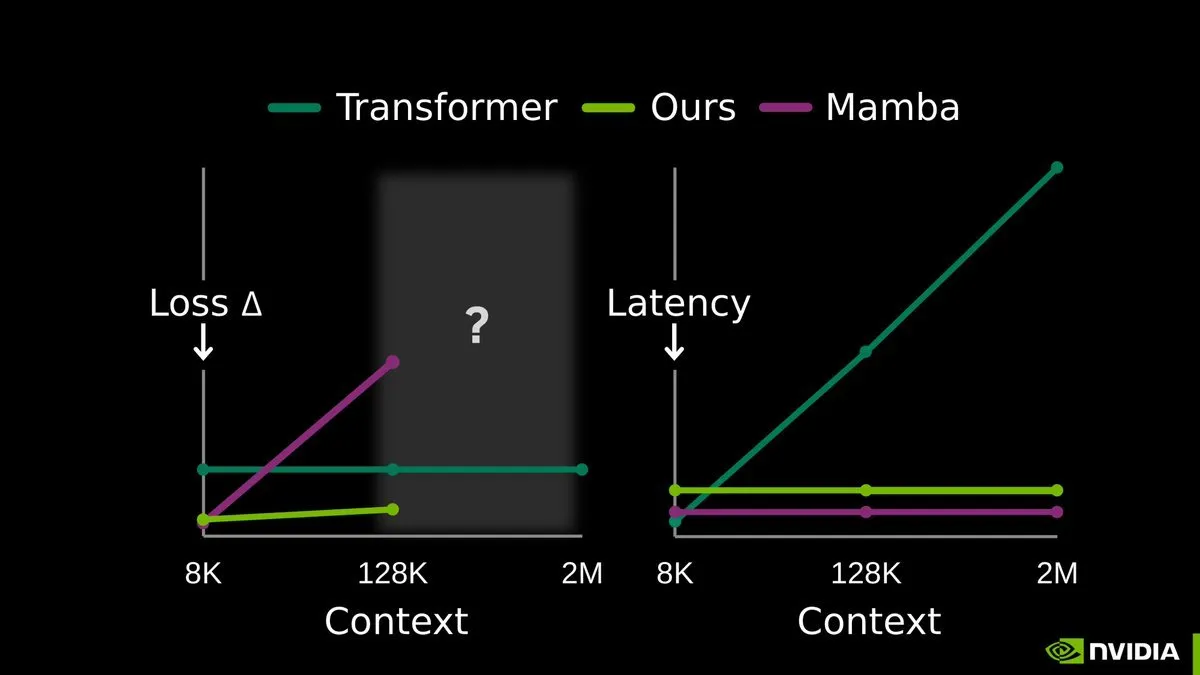
TTT-E2E:端到端测试时训练开启LLM长记忆新纪元 : 由NVIDIA、斯坦福和Astera研究院联合发布的End-to-End Test-Time Training (TTT-E2E) 研究引起轰动。该技术主张无需激进的新架构,而是通过在推理阶段(测试时)利用上下文作为训练数据,通过下一Token预测持续更新模型权重。这种方式将长上下文经验压缩进模型权重中,有效解决了KV缓存随序列长度爆炸的问题。TTT使模型成为真正的“持续学习者”,在处理数百万Token的超长序列时表现出极强的稳定性,被认为是通往纯子二次方序列建模的最具前景路径(来源: arXiv)
🎯 动向
Sakana AI推出DroPE:丢弃位置嵌入实现长文本外推 : Transformer核心作者Llion Jones团队开源DroPE技术,提出位置嵌入只是训练的“辅助轮”。DroPE在推理阶段丢弃旋转位置编码(RoPE),仅需不到1%的预训练预算进行简短校准,即可解锁海量上下文窗口。实验显示,该方法在LongBench和大海捞针测试中显著优于传统的RoPE缩放,为低成本扩展长文本能力提供了新思路(来源: arXiv)
BabyVision评测集:顶尖大模型视觉能力尚不及3岁儿童 : 红杉中国xbench与UniPatAI发布的BabyVision评测显示,在严格控制语言依赖的视觉任务中,绝大多数模型表现远逊于3岁儿童。即使是表现最好的Gemini 3 Pro也仅勉强过线。研究指出,模型过度依赖语言推理掩盖了其在空间感知、轨迹追踪和几何直觉上的系统性缺失,未来的多模态智能必须从根本上重建视觉能力(来源: 36氪)

Recursive Language Models (RLM):DeepMind探索无RAG完美记忆 : DeepMind研究员提出的递归语言模型(RLM)通过让模型自省、拆分并递归调用自身来处理数百万Token。这种机制打破了传统上下文窗口的限制,模型不再依赖外部RAG,而是通过递归聚合结果实现对海量信息的“完美记忆”。这一进展预示着未来AI处理超长文档的方式将发生质变(来源: HuggingFace)

字节跳动AI出海进入“效率工具”新阶段 : 字节跳动近期在海外密集布局,推出对标Manus的工作场景Agent AnyGen,主打文档撰写、数据分析等高质量交付成果。同时,海外AI助手Dola日活已突破千万。字节正试图从“输出快乐”(TikTok)转向“出售效率”,在办公Agent赛道与OpenAI、Anthropic展开贴身肉搏(来源: 36氪)

🧰 工具
Distil-Text2SQL:4B小模型本地实现685B级精度 : Distil-labs通过对Qwen3-4B进行精调,使其在Text2SQL任务上达到了DeepSeek-V3(685B)的语义准确率,且在“精确匹配”指标上实现超越。该模型支持本地运行,处理CSV数据无需上传云端,响应时间低于2秒,展示了小模型在垂直任务中替代超大模型的巨大潜力(来源: GitHub)
LlamaParse升级:低成本实现图表与图像的精准OCR : LlamaIndex对其解析工具LlamaParse进行了Agentic模式升级,专门针对文档中复杂的视觉元素(如折线图、饼图、流程图)进行优化。相比直接将整页截图喂给VLM,该工具能识别子元素的边界框并提取数值逻辑,将其转化为高质量Markdown,是目前处理专业文档中非文字信息最经济高效的方案之一(来源: jerryjliu0)
Wobo:基于AI Agent的“求职版Tinder” : Wobo是一款利用AI Agent自动化投递简历的iOS应用。用户只需上传一次简历,AI会分析其“职场人格”,并在用户“右滑”心仪职位时,自动导航至复杂的外部官网,生成个性化求职信并回答筛选问题。该工具旨在终结繁琐的重复填表过程,将20分钟的申请流程缩短至2秒(来源: Reddit)
📚 学习
斯坦福CS224N 2026回归:新增Agent与推理专题 : 经典的自然语言处理课程CS224N宣布回归。今年的课程由Diyi Yang和Yejin Choi共同执教,除了涵盖神经网络NLP基础,还将重点增加关于AI Agent、工具使用以及两场专门针对“推理(Reasoning)”的讲座,紧跟大模型前沿趋势(来源: Stanford)
Andrew Ng发布《Build with Andrew》:零代码构建Web应用 : 吴恩达在最新的The Batch周报中推出新课程,指导初学者如何仅通过自然语言描述创意,利用AI工具构建并发布可运行的Web应用程序。课程强调“AI作为开发者”的范式,降低了普通人进入软件开发领域的门槛(来源: DeepLearningAI)
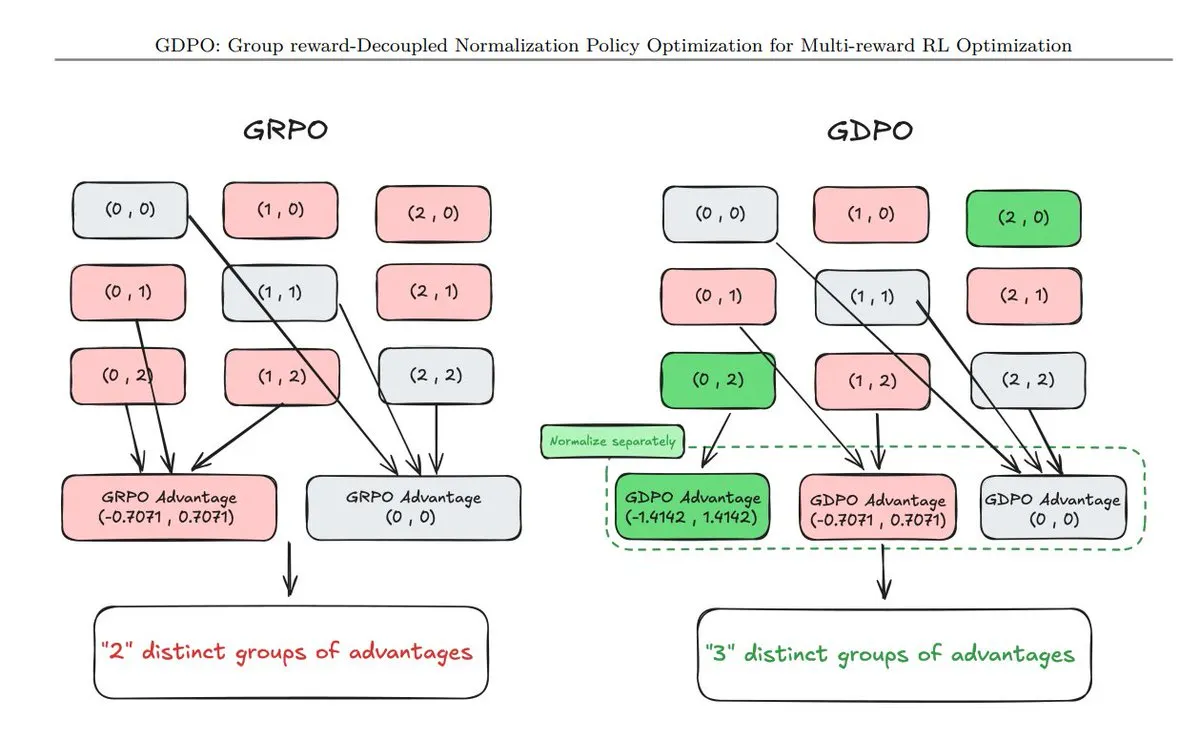
11种新型策略优化技术总结 : TuringPost汇总了近期出现的11种策略优化(Policy Optimization)技术,包括GDPO(奖励脱钩归一化)、AT²PO(基于树搜索的Agent回合制PO)以及备受关注的PC-GRPO(拼图课程GRPO)。这些技术是提升大模型逻辑链和任务对齐能力的核心(来源: TuringPost)
💼 商业
OpenAI收购医疗初创公司Torch : OpenAI宣布收购Torch,这是一家整合实验结果、药物记录和就诊录音的医疗AI初创公司。Torch团队将加入ChatGPT Health部门。此举显示OpenAI正加速推进AI在健康管理和临床辅助领域的商业化落地,力图将ChatGPT打造为全球最专业的个人健康助手(来源: OpenAI)

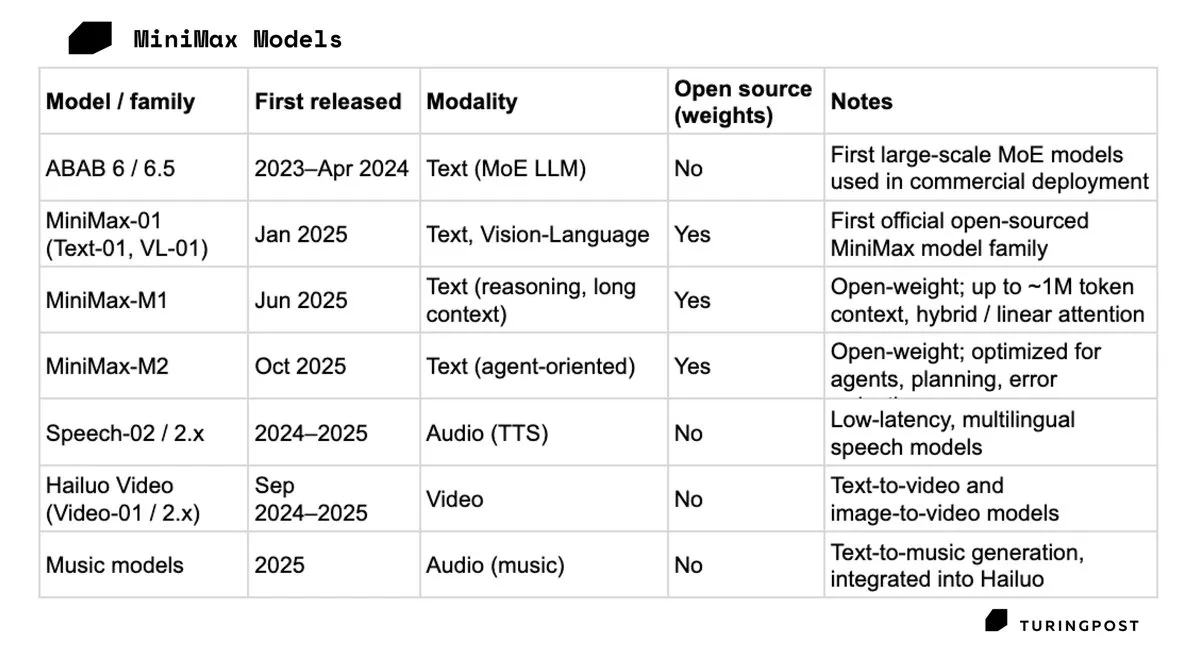
MiniMax在港上市,首日大涨109% : 中国AI独角兽MiniMax于2026年1月9日在香港上市,首日股价飙升109%,市值突破1500亿港元。MiniMax凭借Talkie和海螺AI在C端市场的成功,证明了不依赖大客户合同、深耕消费者多模态产品的路径在资本市场的吸引力。此次IPO被视为其在激烈的算力竞赛中获取“氧气”的关键一步(来源: TuringPost)
xAI日烧2800万美元,估值冲向2300亿 : 尽管xAI在2025年前三季度亏损高达78亿美元,但其近期完成200亿美元融资,估值达2300亿美元。马斯克正全力推动“Macrohard”计划,旨在构建能驱动特斯拉机器人的自主AI系统。这种“暴力投入”模式反映了顶级AI玩家在基建和人才上的极高准入门槛(来源: 36氪)
🌟 社区
Vibe Coding/Working 引发职业身份大讨论 : 随着Claude Cowork和各种Agent工具的普及,“氛围办公(Vibe Working)”成为热词。社区讨论认为,这并非简单的效率提升,而是“变现大脑中的领域知识”。未来工程师的价值将从“写10万行代码”转向“设计让AI写10万行代码的系统”。然而,也有人担忧这会导致代码质量的“粗制滥造(Slop)”和对AI黑盒的过度依赖(来源: nearcyan, amasad)
AI检测器被指为“纯粹的骗局” : Reddit社区对GPTZero等AI检测工具发起猛烈抨击,指出其误报率极高,甚至将《独立宣言》标记为90% AI生成。用户认为这些工具衡量的是“统计熟悉度”而非来源,导致大量原创作者和学生被误伤。教育界呼吁停止“猎巫行动”,转向考察学生对内容的理解和应用能力(来源: Reddit)
DeepSeek创始人梁文锋被封为“AI界扫地僧” : 社区热议DeepSeek创始人梁文锋的量化基金背景。其执掌的幻方量化在2025年回报率高达56.6%,远超行业平均水平。网友感叹其用量化赚的钱“YOLO”式投入AI,且在技术路线上不走寻常路(如MLA、Engram),展现了极高的架构品味和工程效率,被视为中国AI对抗硅谷巨头的关键变量(来源: teortaxesTex)
💡 其他
AI耳机Sweetpea或于9月发布 : 传闻OpenAI的首款硬件产品——代号为Sweetpea的AI耳机,由Jony Ive团队操刀,外形酷似金属卵石,内置2nm芯片以支持本地推理。OpenAI预估首年销量将冲刺5000万部,直接挑战AirPods的市场地位(来源: 36氪)

AI安全成为2026年企业选型新标配 : 随着AI代理权限扩张,企业对安全的关注从“可选项”转为“前置条件”。调查显示,43%的企业将安全视为AI落地的首要障碍。2026年的趋势是安全能力“内建化”,即在模型调用和Agent编排阶段默认启用审计和权限隔离(来源: 36氪)