
关键词:AI曼哈顿计划, Gemini 3 Flash, GPT-5.2-Codex, 可控核聚变, AI科研工程, AI Agent, 多模态模型, 开源AI模型, 美国能源部创世纪任务, Gemini 3 Flash编码测试, GPT-5.2-Codex网络安全防御, T5Gemma 2多模态模型, Perception Encoder Audiovisual音频分离
🔥 聚焦
美国“AI曼哈顿计划”启动 : 美国能源部正式启动“创世纪任务”,这是一项国家级AI科研工程,旨在将顶尖AI技术与国家实验室科研能力结合,加速科学发现。该计划集结了微软、谷歌、英伟达、OpenAI、DeepMind、Anthropic等24家科技巨头,将AI模型和超级计算能力应用于可控核聚变、能源材料、气候模拟等领域,目标是到2030年将美国科学生产力翻倍,标志着美国在科技领域的国家级战略调整。(来源:36氪, nvidia, AnthropicAI, GoogleDeepMind, OpenAI Newsroom)
Hinton与Jeff Dean对话现代AI : 神经网络奠基人Geoffrey Hinton与Google首席科学家Jeff Dean在NeurIPS大会上对谈,探讨现代AI从实验室走向数十亿用户的关键因素。他们认为,AI的突破并非单一奇迹,而是算法(如Transformer)、硬件(如GPU、TPU)和工程(如JAX、Pathways)系统性成熟的共同结果。对话还指出AI规模化面临能效、记忆(长上下文)和创造力(联想能力)三大门槛,强调基础研究与持续投入的重要性。(来源:36氪, JeffDean, geoffreyhinton)
Sam Altman访谈:OpenAI战略与融资 : Sam Altman在最新访谈中指出,Google仍是OpenAI的最大威胁,但OpenAI将通过AI原生软件、个性化与记忆功能、加速企业市场拓展及1.4万亿美元的基础设施投资来巩固优势。他预测GPT-6或将在明年Q1亮相,并强调AI未来将重塑软件使用方式,成为不可替代的“数字伙伴”,而非简单嵌入旧产品。(来源:36氪, sama)
Google发布Gemini 3 Flash模型 : Google推出Gemini 3 Flash,该模型以极高的性价比和速度,在多项基准测试中表现出色,甚至在SWE-bench编码测试中超越GPT-5.2。Google计划将其深度整合到搜索、YouTube、Gmail等生态产品中,旨在通过生态优势而非单纯模型参数竞争,重塑AI市场格局。此次发布被视为对OpenAI的“精准打击”,引发了行业对模型竞争和AI应用普及的广泛讨论。(来源:36氪, MS_BASE44, GeminiApp, scaling01)
OpenAI发布GPT-5.2-Codex编程模型 : OpenAI发布GPT-5.2-Codex,号称其迄今最强的AI智能体编程模型,专为复杂软件工程和网络安全优化。该模型提升了长程任务执行、大规模代码变更、Windows环境兼容及网络安全防御能力。尽管在基准测试中表现强势,但有用户实测其在某些任务中不及Gemini 3 Flash,引发市场对其真实效能和竞争力的讨论。(来源:36氪, sama, scaling01)
🎯 动向
Google开源T5Gemma 2和FunctionGemma : Google开源T5Gemma 2和FunctionGemma两款小模型,均基于Gemma 3家族。T5Gemma 2是首个多模态长上下文编码器-解码器模型,最小规模为270M-270M,专注于架构效率和多模态能力。FunctionGemma是专为函数调用优化的270M模型,可在手机等边缘设备上运行,旨在解决大模型落地中“能聊不能干”的问题,为智能体和工具使用提供专用大脑。(来源:36氪, huggingface, osanseviero, ImazAngel, danielhanchen)

字节豆包1.8模型实测 : 字节跳动发布豆包大模型1.8,作为其新一代主力模型,在教育、客服、金融、法律等多个场景测评中处于领先水平。实测显示,豆包1.8在Agent能力(多工具调用、多轮指令遵循、OS Agent)、256K超长上下文管理和多模态理解(视频理解能力提升至20分钟)方面表现突出,尤其适合搭建复杂Agent和跑真实流程,被视为推动企业级Agent和端侧Agent发展的关键一步。(来源:WeChat)

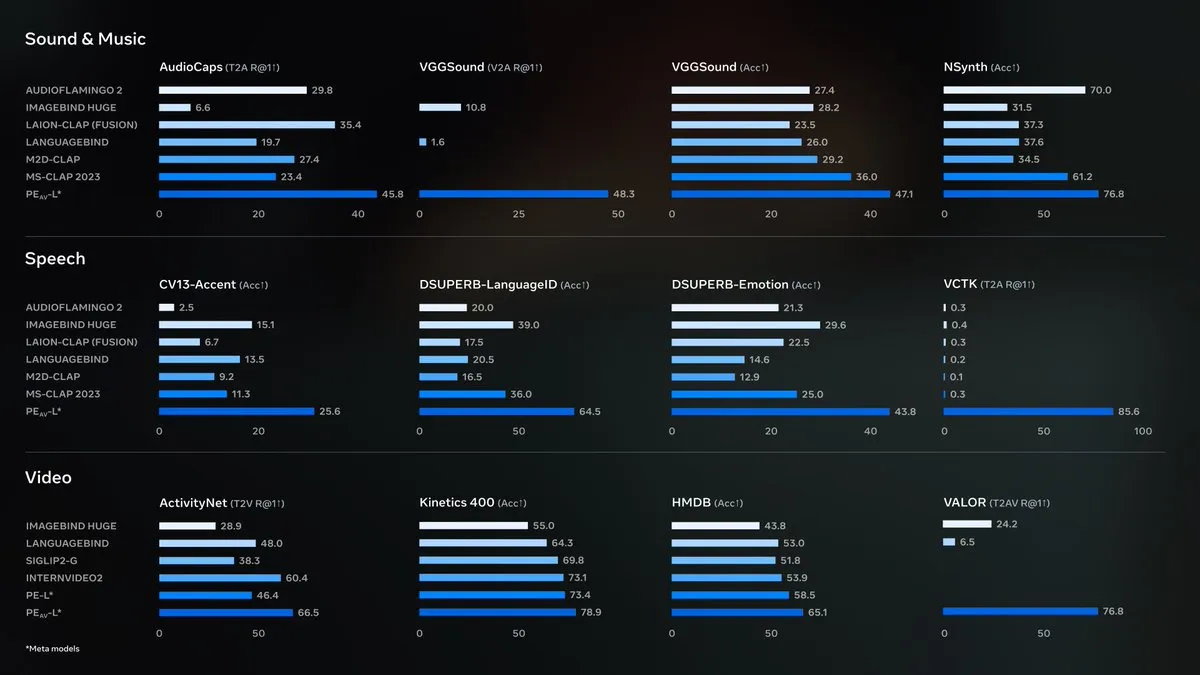
Meta开源Perception Encoder Audiovisual (PE-AV) : Meta开源了Perception Encoder Audiovisual (PE-AV),这是SAM Audio背后的核心技术引擎,旨在实现最先进的音频分离。PE-AV基于Meta早前发布的Perception Encoder模型,将音频与视觉感知深度融合,在广泛的音频和视频基准测试中取得了顶尖成果,有望通过多模态支持提升声音检测和视听场景理解能力。(来源:AIatMeta, Reddit r/LocalLLaMA)
Runway推出Gen-4.5和GWM-1模型 : Runway发布Gen-4.5视频生成模型,新增音频和多镜头编辑功能,同时推出GWM-1(通用世界模型)系列,包括GWM Worlds(可导航场景)、GWM Robotics(机器人视角模拟)和GWM Avatars(唇语同步角色),旨在实现实时、可控的世界模型视频生成,预示着视频生成技术向通用模拟的重大飞跃。(来源:c_valenzuelab, DeepLearningAI)
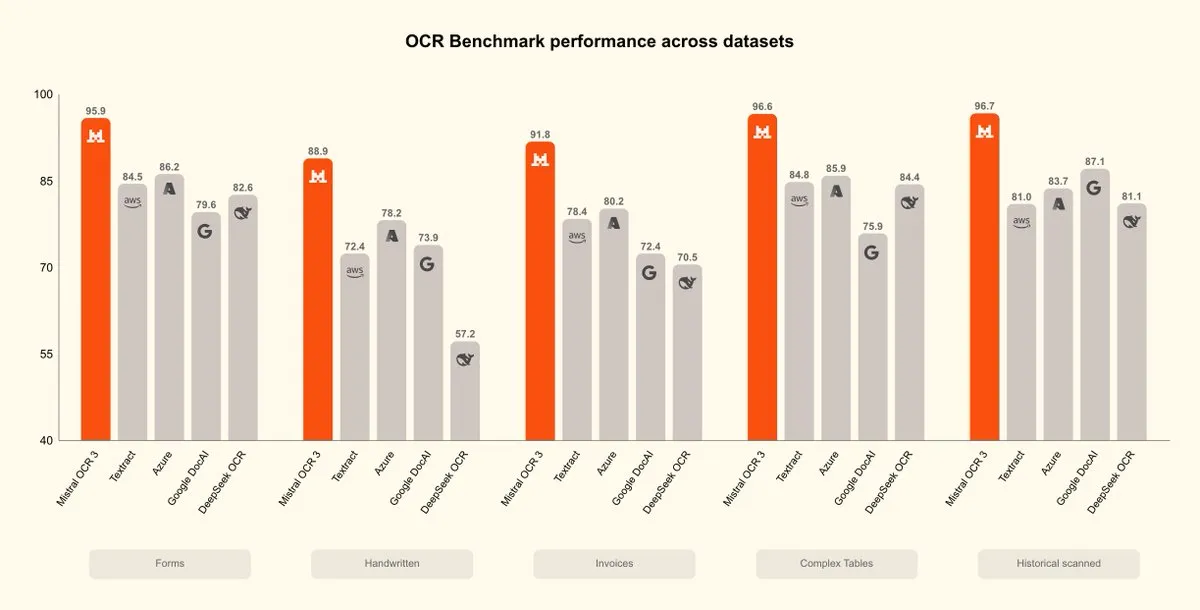
Mistral OCR 3发布,文档智能新突破 : Mistral AI发布Mistral OCR 3模型,在准确性和效率方面树立了新标杆,超越了现有的企业文档处理解决方案和AI原生OCR。该模型在处理手写内容、低质量扫描件以及企业文档中常见的复杂表格和表单方面进行了大量优化,标志着文档智能领域的新进展。(来源:qtnx_, GuillaumeLample)
Hugging Face Transformers v5 Tokenization重构 : Hugging Face的Transformers v5对分词器(tokenizer)工作方式进行了重大重新设计。新版本将分词器架构与训练词汇表分离,提高了透明度、模块化,并简化了从零开始训练模型特定分词器的过程。这一改进使得分词器更易于检查、定制和训练,解决了v4中分词器不透明且紧密耦合的问题。(来源:HuggingFace Blog, huggingface)

Firefox宣布AI转型引发用户争议 : 火狐浏览器宣布将转型为AI浏览器,支持一系列新的软件。此举在Reddit等社区引发了大量用户的不满,尤其是那些重视隐私和极简主义的硬核用户,他们认为Firefox正在背离其核心价值。此次转型反映了Mozilla在“搜索已死”时代寻求新增长点的战略,但如何在AI功能与用户隐私之间取得平衡,是其面临的巨大挑战。(来源:36氪)

ChatGPT推出聊天置顶功能 : OpenAI宣布ChatGPT现已推出聊天置顶功能,用户可在iOS、Android和Web端将重要对话置顶,方便快速访问。这一更新旨在提升用户体验,简化对话管理。(来源:openai, Reddit r/ChatGPT)
Claude for Chrome扩展功能升级 : Claude for Chrome扩展现已向所有付费用户开放,并集成了Claude Code功能。用户现在可以直接在浏览器中通过Claude Code进行代码测试和调试,无需离开当前页面。这一更新旨在提升开发者的工作效率和体验,同时Anthropic也强调了在设计和测试中对安全性的考量。(来源:Reddit r/ClaudeAI, Reddit r/ClaudeAI)

🧰 工具
Agent Skills成为开放标准 : Anthropic的Agent Skills现已成为开放标准,允许AI Agent学习和执行跨平台的重复性工作流。这一举措旨在简化技能的部署、发现和构建,促进AI工具生态系统的互操作性。开发者现在可以创建一次技能,在多个AI平台上使用,从而提高Agent的专业化能力和效率。(来源:omarsar0, code, Reddit r/ClaudeAI)
LangChain Academy推出新课程 : LangChain Academy发布了“LangChain入门(Python)”新课程,旨在帮助开发者学习如何使用LangChain框架构建AI Agent。课程涵盖Agent的创建、核心构建模块(模型、消息、记忆、工具)的使用,以及如何利用LangSmith进行行为调试,最终目标是让学员能够组建一个完整的个人助理团队。(来源:LangChainAI, hwchase17)

Claude Code CLI高级开发设置 : 一位开发者分享了其“过度工程化”的Claude Code CLI设置,该设置结合了MCP服务器、自定义技能和严格的CLAUDE.md文件,实现了生产级代码的“Vibe Coding”。该方法通过质量门禁、迭代循环和浏览器内测试,有效防止Agent偏离轨道,并实现高效重构,解决了传统Agent在实际开发中遇到的痛点。(来源:Reddit r/ClaudeAI)
OpenRouter推出LLM JSON输出修复功能 : OpenRouter引入了“响应修复”(Response Healing)功能,可自动修复大型语言模型(LLM)生成的结构化JSON输出中的错误。该功能显著降低了Gemini 2 Flash和Qwen3 235B等模型的缺陷率,提高了LLM在需要精确JSON格式输出场景下的可靠性。(来源:xanderatallah)

AssemblyAI音频转录工具支持URL输入 : AssemblyAI Playground更新,现支持直接从URL转录音频。用户无需下载文件即可测试播客、云端音频或大型文件(如财报电话会议),极大地简化了原型开发和集成验证流程,提升了Speech AI能力的测试效率。(来源:AssemblyAI)
jax-js:浏览器端机器学习库 : jax-js是一个开源的机器学习库,用纯JavaScript重新实现了JAX,并支持JIT编译到WebGPU,使其能在浏览器中运行神经网络。该库提供了自动求导、JIT编译等功能,旨在提供与PyTorch和JAX类似的高效和灵活的编程模型,并已通过MNIST训练和MobileCLIP推理等自包含演示验证其交互性。(来源:Vtrivedy10, Reddit r/MachineLearning)

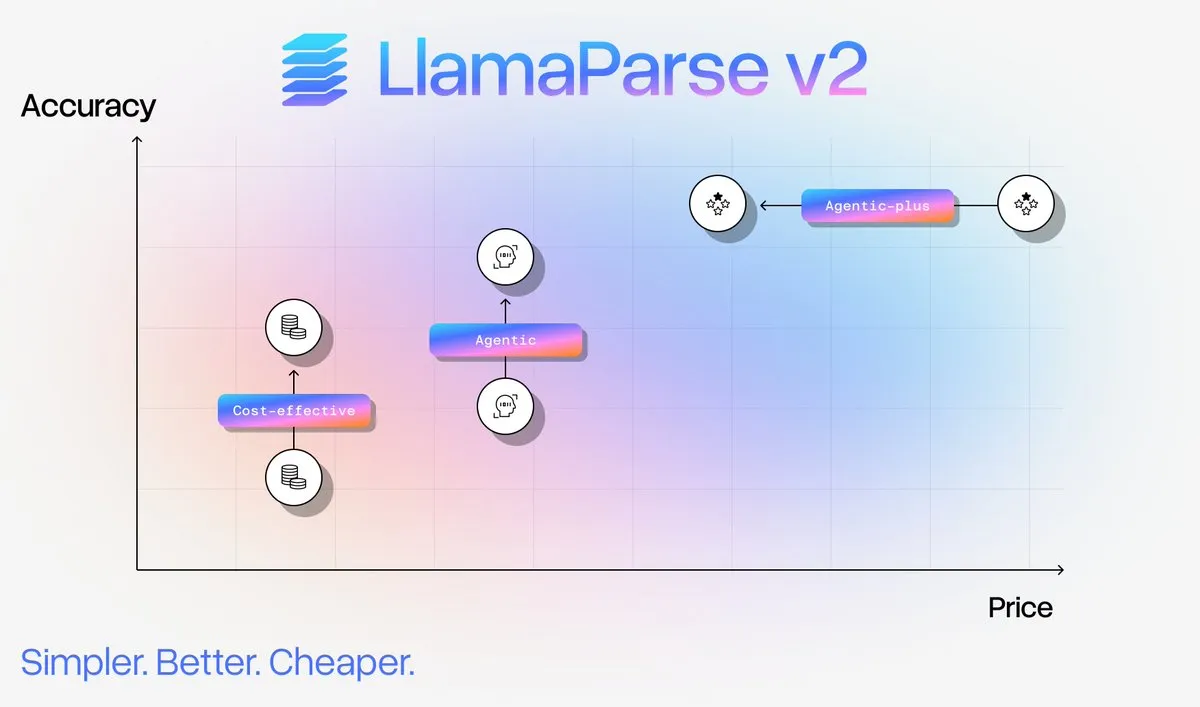
LlamaParse v2文档解析服务升级 : LlamaIndex发布LlamaParse v2,显著简化了文档解析配置,提升了性能,并为复杂文档解析带来了高达50%的成本削减。新版本引入了Fast、Cost Effective、Agentic和Agentic Plus四种固定层级,增强了多模态内容的准确性,减少了幻觉,使用户无需成为解析专家即可实现生产级文档摄取。(来源:jerryjliu0)
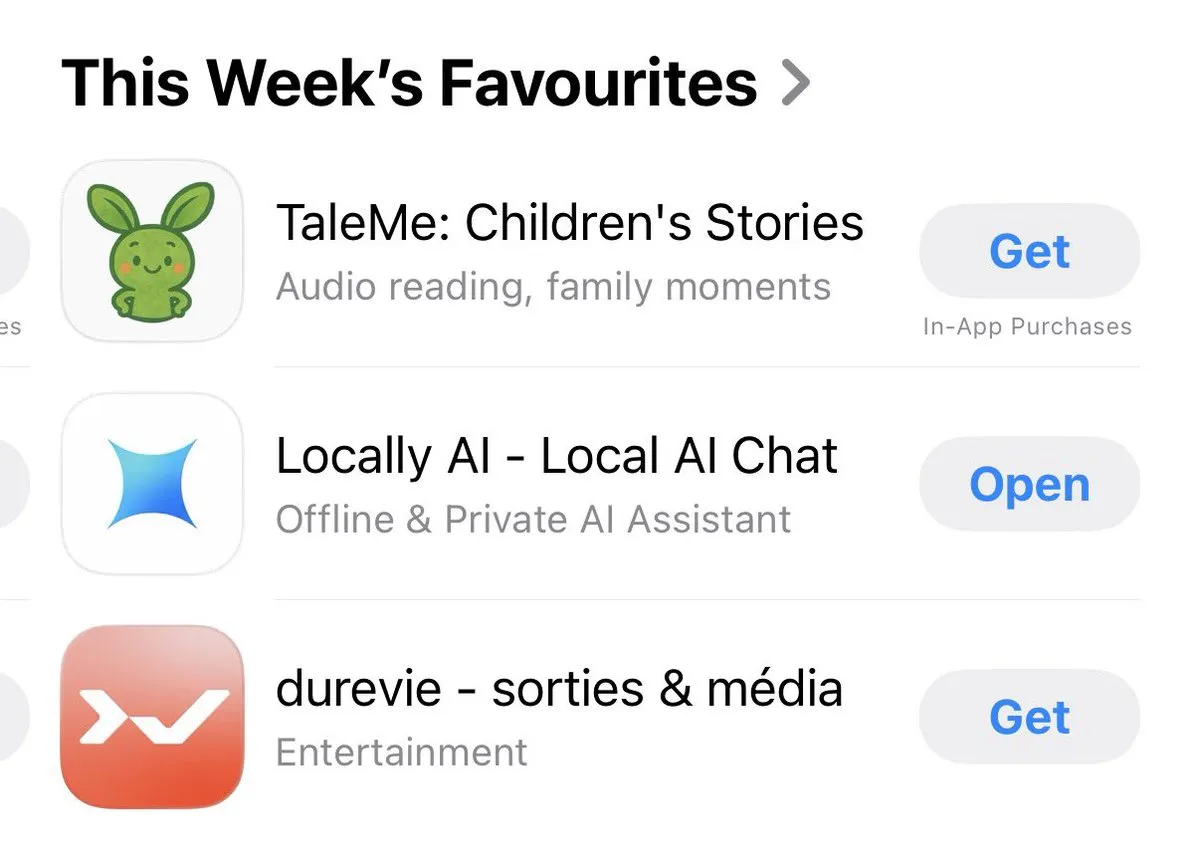
Locally AI:本地运行AI模型的应用 : Locally AI是一款允许用户在日常设备上本地运行AI模型的应用,因其便捷性被App Store列入“本周最爱”榜单。该应用旨在降低AI使用门槛,让更多人能轻松地与本地AI模型进行交互,强调了本地AI的易用性和可访问性。(来源:adrgrondin)
Google Flow图像生成支持高分辨率下载 : Google Flow的Nano Banana Pro功能现已支持下载2K和4K分辨率的AI生成图片。这一更新满足了用户对更高分辨率图像的需求,无论是用于创作素材、帧序列还是视觉效果,都可获得更清晰、更精细的AI生成内容。(来源:op7418)

OpenWebUI用户报告RAG功能问题 : OpenWebUI用户报告RAG(检索增强生成)功能存在问题,尤其是在处理大于1MB的PDF文件时,模型无法将文件内容传递到上下文,导致“未找到来源”错误。尽管文件上传、文本提取和嵌入成功,但查询生成步骤失败,阻碍了PDF内容被用于模型推理,影响了结构化数据提取等任务。(来源:Reddit r/OpenWebUI, Reddit r/OpenWebUI)

AI文本冒险游戏Glif Agent : Glif agent提供了一种文本冒险游戏体验,用户可以直接沉浸其中,无需复杂的指南。这款AI工具展示了LLM在创造互动叙事和沉浸式体验方面的潜力,让玩家通过自然语言指令探索虚拟世界。(来源:NerdyRodent)

Cass:编码Agent会话搜索工具 : Cass工具被誉为编码Agent的“救星”,能显著节省时间和精力。它能自动检测、摄取并索引所有编码CLI会话,提供即时搜索和“机器人模式”,使用户能快速查找、管理和重用Agent的痕迹,极大提升了使用编码Agent的效率。(来源:doodlestein)
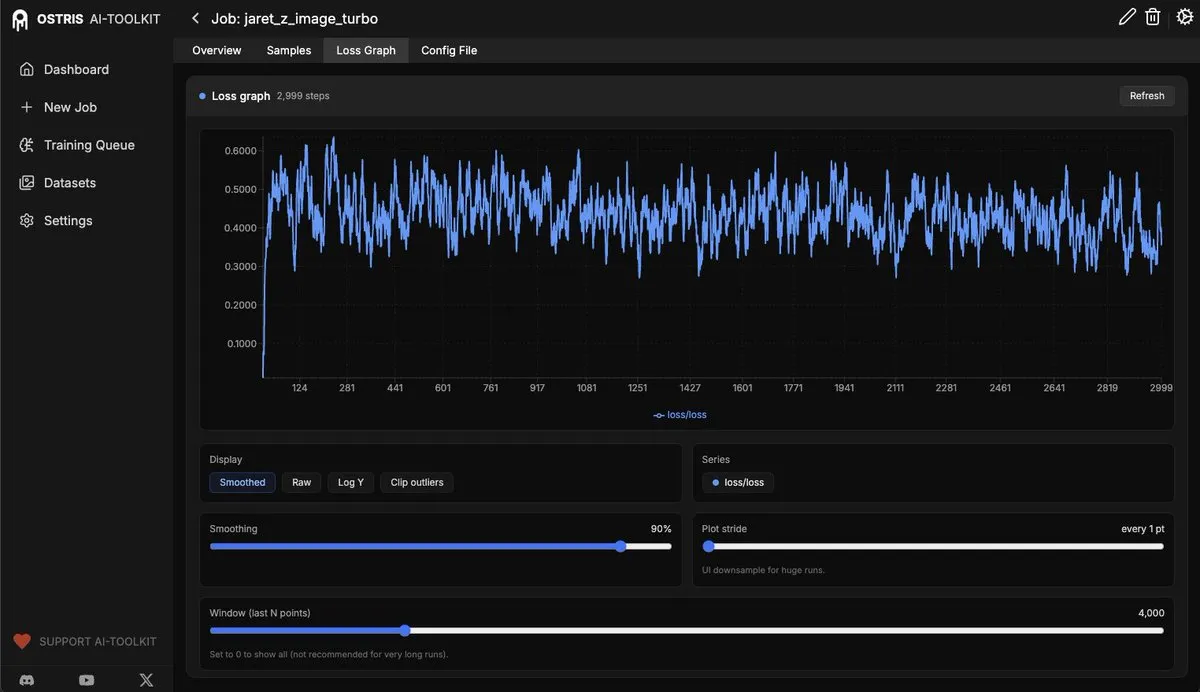
AI Toolkit UI新增损失图功能 : AI Toolkit UI更新,新增了损失图(loss graph)功能,用于监测扩散模型(diffusion models)的微调过程。该功能将为用户提供更直观的模型训练反馈,未来还将添加更多功能,以提升AI模型开发和调试的效率。(来源:ostrisai)
📚 学习
Nvidia NeMo Agent Toolkit新课程 : DeepLearning.AI推出Nvidia NeMo Agent Toolkit新课程,由NVIDIA专家Brian教导如何利用该工具包构建可靠、生产级的AI Agent。课程涵盖配置驱动的工作流、通过追踪实现可观测性、利用黄金标准数据集进行系统评估,以及部署多Agent系统,旨在帮助开发者将Agent原型转化为可靠的生产系统。(来源:AndrewYNg)
AI学习资源与概念回顾 : 一系列AI学习资源被分享,包括Deep Learning Weekly最新一期,涵盖自优化Agent、AI基准测试中的Bug、RL训练指南等;此外还有掌握Agentic AI的路线图、2025年AI核心概念回顾(强化学习、RLHF变体、持续学习、神经符号AI、AI硬件等),以及AI安全研究的最新进展。(来源:dl_weekly, TheTuringPost, Ronald_vanLoon, AndrewYNg, ajeya_cotra)
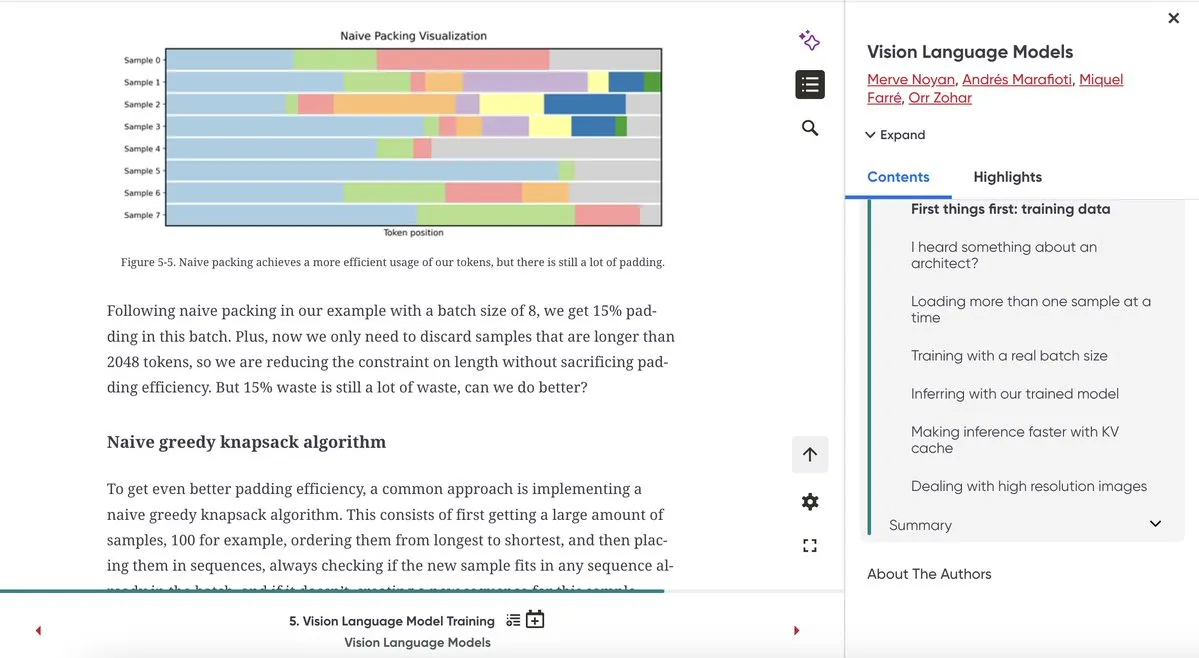
《视觉语言模型》书籍章节发布 : 《视觉语言模型》一书的第五章已发布,内容聚焦预训练,并提供了插图和实践指导。这为AI学习者深入理解视觉语言模型的预训练机制提供了宝贵的资源。(来源:algo_diver)
AI驱动研究系统(ADRS)论文更新 : AI驱动研究系统(ADRS)发布了更新论文,评估了三个开源框架在解决10个真实世界系统性能问题上的表现。研究表明,AI生成的解决方案在负载均衡方面可实现13倍加速,在云调度方面可节省35%成本,甚至超越人类专家,为AI在系统研究中的应用提供了强有力证据。(来源:matei_zaharia)

💼 商业
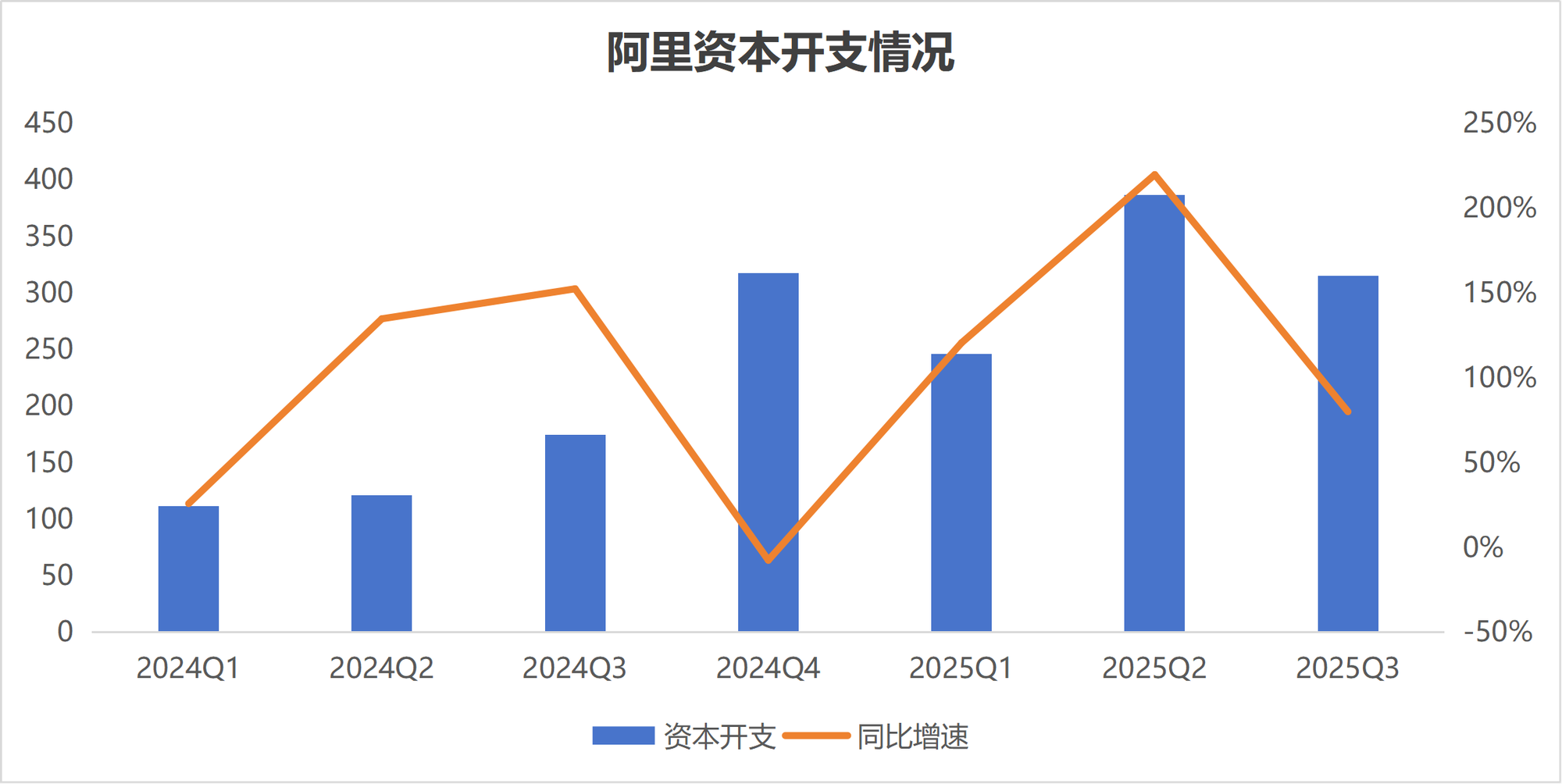
AI投资分歧:阿里与腾讯策略迥异 : 面对AI浪潮,中国两大科技巨头阿里巴巴和腾讯的投资策略出现明显分歧。阿里巴巴正加速投入AI基础设施建设,计划未来三年投入超3800亿元,旨在成为提供AI“水电煤”的基础设施公司。而腾讯则趋于“冷静”,下调了资本支出指引,更侧重AI在应用端的赋能,并引入前OpenAI科学家姚顺雨强化AI战略向应用侧倾斜。这种分歧反映了双方对AI时代商业化路径的不同判断。(来源:36氪)
甲骨文百亿项目融资“告吹”引发AI泡沫担忧 : 甲骨文在美国数据中心项目的百亿融资“告吹”,主要支持者Blue Owl Capital撤资,引发市场对AI泡沫的恐慌。该事件凸显了AI基建周期中,投资者对巨额投入成本和变现时间表的不确定性。分析师质疑OpenAI能否兑现对甲骨文的算力支付承诺,以及甲骨文资产负债表扩张过快的问题,预示AI竞争正进入“现金流检验期”。(来源:36氪)
Brett Adcock成立新AI实验室Hark : Figure AI首席执行官Brett Adcock宣布成立新的AI实验室Hark,并投入1亿美元个人资金。Hark实验室将专注于“以人为本的AI”研究,而Adcock将继续担任Figure AI的职务。此举标志着AI领域对人机交互和伦理的持续关注,也为AI研究注入了新的私人资本。(来源:steph_palazzolo)
🌟 社区
LLM性能与用户体验争议 : 社交媒体上对GPT-5.2的实际表现存在广泛争议,许多用户抱怨其日常使用体验不佳,出现幻觉,或在简单任务中表现平庸,与基准测试中的“更聪明”形成对比。这种脱节引发了对AI模型开发方向的讨论:是追求竞赛级智能还是日常实用性?同时,有用户分享了Opus 4.5模型性能下降的担忧,以及LLM在调试和理解用户意图方面的挑战,例如Claude Code在处理复杂代码时的困境。(来源:VictorTaelin, aidan_mclau, 36氪, dbreunig, Reddit r/ChatGPT, Reddit r/artificial)
AI对工作与社会影响 : 社交媒体广泛讨论AI对就业市场的冲击,包括白领工作可能面临“塌陷”的担忧,以及AI在提升生产力方面的潜力。同时,公众对AI的认知水平参差不齐,许多人误以为ChatGPT通过数据库查找答案。此外,AI技术也降低了虚假信息和欺诈的门槛,引发了关于平台审核机制和个人自证成本的担忧。也有观点认为,AI的进步更像是“新火车跑在旧铁轨上”,实际应用中的瓶颈更多是社会、经济和政治因素。(来源:random_walker, Reddit r/ArtificialInteligence, Plinz, doodlestein, amasad, 36氪, gfodor, Reddit r/ArtificialInteligence)
AI伦理与安全 : 社交媒体上围绕AI伦理与安全的讨论热烈。包括对Hinton等AI先驱涉嫌抄袭的指控,AI模型在面部识别等应用中导致误捕的案例,以及AI生成内容(如WSJ测试的AI自动售货机失控)带来的风险。OpenAI发布了《模型规范》以指导模型行为,Google DeepMind则推出SynthID水印技术以检测AI生成视频。此外,关于AI的巨大环境足迹(水和碳排放)也引发关注,以及AI在提供情感支持时的伦理考量。(来源:SchmidhuberAI, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Ronald_vanLoon, AnthropicAI, ajeya_cotra, Reddit r/MachineLearning)
AI Agent发展与挑战 : AI Agent的开发和应用成为热点,讨论涵盖其架构(可组合模块、记忆管理)、开放标准(Agent Skills)、以及在机器人(Reachy Mini、Grek机器人、Bipedal Gait机器人、自主移动机器人)和编程(Claude MCP Agent)等领域的实践。挑战包括如何提升Agent的可信度、处理长上下文、优化基础设施以支持多Agent协作,以及如何确保Agent在复杂任务中的稳定性和避免“死循环”。(来源:Vtrivedy10, julesagent, LangChainAI, TheTuringPost, Ronald_vanLoon, Sentdex, ClementDelangue, doodlestein, corbtt, Ronald_vanLoon)
LLM研究与模型特性 : AI社区对LLM研究的讨论涵盖了强化学习(RL)中的价值函数、LoRA RL的实用性、GPT-4的能力评估、RL与后训练LLM的辩论、LLM在数学研究中的应用、以及对AI意识和“思想食粮”等哲学问题的探讨。此外,还关注了新的LLM架构(如扩散LLM、DexWM世界模型)、模型密度法则、长上下文处理的挑战,以及Kimi K2和MiMo-V2等特定模型的性能评估。(来源:natolambert, vllm_project, SebastienBubeck, sarahcat21, karpathy, riemannzeta, _akhaliq, code_star, DeepLearningAI, ollama, gdb, yacinelearning, ylecun, pmddomingos, matei_zaharia, TheTuringPost, yacinelearning, MiniMax__AI, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/LocalLLaMA)
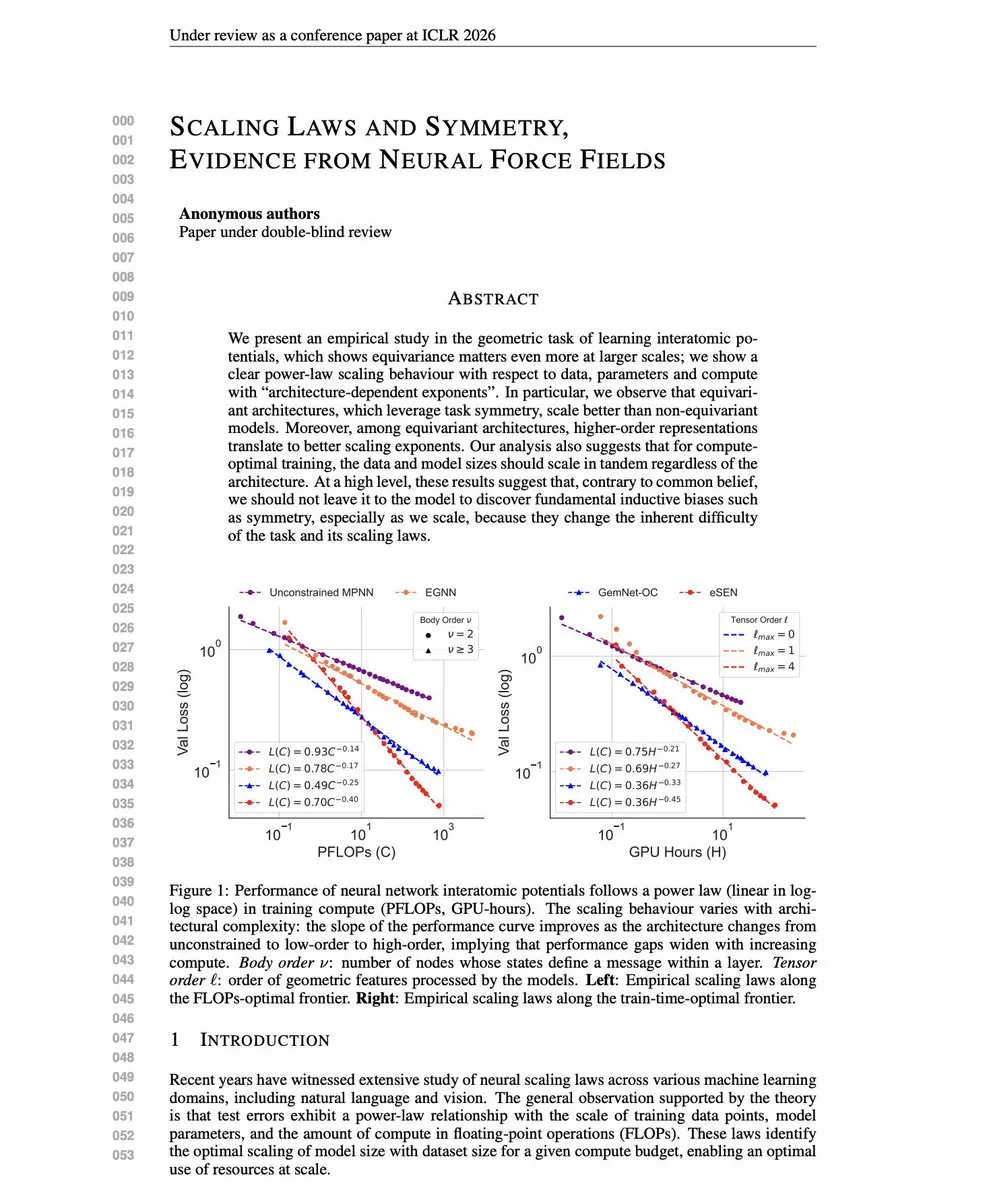
AI基础设施与硬件 : AI基础设施和硬件是热门话题,包括MLX框架在Mac上实现低延迟张量并行推理,Qdrant和Turbopuffer等向量数据库在Agentic时代的重要性,以及构建GPU集群(如8x B200或Mac Studio集群)的成本和挑战。讨论还涉及分布式训练优化(SonicMoE)、服务器less后端对Agent的瓶颈,以及AI数据中心能源消耗的担忧。(来源:awnihannun, qdrant_engine, TheEthanDing, Dorialexander, halvarflake, matei_zaharia, togethercompute, andersonbcdefg, idavidrein, Reddit r/deeplearning, Reddit r/MachineLearning, Reddit r/LocalLLaMA, Reddit r/MachineLearning, StasBekman, HuggingFace Daily Papers)

Generative AI艺术与应用 : 讨论围绕生成式AI在艺术和应用领域的进展。Runway Gen-4.5和GWM-1模型推动视频生成向通用世界模拟发展,DALL-E 3和Gemini被用于图像生成,包括提升图像真实感、3D内容创作和艺术风格转换。社区还探讨了AI生成内容(AIGC)的感知,例如当AI创作的媒体作品质量极高,以至于观众怀疑是否由AI生成时,是赞美还是冒犯。此外,AI在数学问题解决和代码转换等研究应用也受到关注。(来源:c_valenzuelab, BlackHC, nptacek, yupp_ai, nptacek, claud_fuen, dotey, ylecun, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 其他
AI工程化原则 : 社交媒体讨论强调,AI工程化应遵循传统工程学的核心原则,如版本控制、测试和生产可观测性。观点认为,LLM的使用不应改变这些基本实践,而是要将它们融入AI开发流程,以确保系统的可靠性和质量。(来源:imjaredz)
LLM大规模数据处理 : 讨论LLM大规模数据处理这一被低估的议题。强调在处理海量数据时,需要将LLM视为数据库操作符,采用语义映射、过滤和归约等技术。同时,通过任务级联等成本优化策略,可以在保证准确性的前提下,大幅降低LLM处理数据的成本,实现效率与经济性的平衡。(来源:HamelHusain)
AI对人类认知与学习的洞察 : 一位AI研究员通过5000小时的《铁拳》游戏经验,探讨人类如何在极端时间限制下建立预测模型,以及这与AI世界模型和预测学习的关联。他认为,格斗游戏迫使玩家预测而非单纯反应,这映射了AI研究中构建内部世界模型、从部分信息中读取模式并适应预测失败的挑战,为理解超越游戏AI的智能提供了独特视角。(来源:Reddit r/MachineLearning, Reddit r/ArtificialInteligence)