关键词:DeepSeek R1, AI 训练, 强化学习 RL, 过程奖励模型 PRM
🔥 聚焦
DeepSeek R1 爆更 86 页论文揭秘训练细节: DeepSeek 悄然更新了 R1 技术报告,从 22 页大幅扩张至 86 页,近乎重写为一份可复现的“教科书”。报告首次详细披露了 Dev1/2/3 三个训练阶段的演进、29.4 万美元的极低训练成本拆解,以及对 MCTS 和过程奖励模型(PRM)等失败尝试的复盘。这一举动不仅展示了其在强化学习(RL)领域的深度积淀,更通过详尽的附录参数向开源社区证明:纯 RL 驱动的推理模型不仅可行,且具有极高的效能比。这种“透明化”竞争策略正迫使闭源巨头重新审视其技术壁垒。 (来源: _akhaliq, karminski3, 量子位)

MiniMax 与智谱 AI 港股 IPO 开启大模型“上海/北京时刻”: 中国大模型领军企业 MiniMax 与智谱 AI 相继登陆港交所,标志着中国 AGI 产业正式进入二级市场检验阶段。MiniMax 上市首日股价暴涨超 100%,市值突破千亿港元,其海外收入占比超 70% 的全球化基因受到资本热捧;智谱 AI 则展示了 MaaS 业务 10 个月 25 倍的指数级增长。两家公司的成功上市,不仅为早期投资者带来了丰厚回报,更通过 18C 制度为后续 AI 独角兽提供了可复制的融资样本,证明了拥有自主基座模型能力的中国企业在全球竞争中的独特价值。 (来源: Zai_org, 36氪)

CES 2026 物理 AI 爆发:从屏幕走向现实世界: 本届 CES 彻底转向“物理 AI”主题,英伟达黄仁勋称之为“物理 AI 的 ChatGPT 时刻”。波士顿动力 Atlas 首次公开登台并宣布进入现代汽车工厂打工,LG 发布了能叠衣服的家务机器人 CLOiD,联想则推出了个人 AI 超级智能体 Qira。中国供应链表现抢眼,超 20 家机器人企业参展,展示了从灵巧手到全尺寸人形机器人的量产能力。AI 不再仅仅是对话框,而是通过传感器和执行器深度介入物理世界,重构了从家电、PC 到汽车的传统产业链。 (来源: TheRundownAI, 雷科技)

OpenAI 发布 Healthcare 板块进军医疗垂直赛道: OpenAI 正式推出 ChatGPT Health 体验,支持 HIPAA 合规,并与梅奥诊所、波士顿儿童医院等顶级医疗机构合作。该功能允许用户接入电子病历和 Apple 健康数据,通过 AI 辅助分析检查报告并制定健康计划。尽管被戏称为“美国版蚂蚁阿福”,但其背后代表了大模型从通用向专业垂直领域深耕的趋势。医疗 AI 正在从简单的问答进化为能够整合多源数据、提供临床决策支持的专业助手,尽管安全性与误诊风险仍是社区关注的焦点。 (来源: _samirism, openai)
🎯 动向
Google DeepMind 提出“嵌套学习” (Nested Learning) 框架: 针对 Transformer 缺乏持续学习能力且易产生“灾难性遗忘”的问题,DeepMind 团队借鉴人类联想记忆机制,提出了嵌套学习框架 NL。该框架将优化器视为模型架构的“上下文”,通过不同更新频率的模块嵌套,使 AI 能在运行中构建抽象结构,将短期经验沉淀为长期知识。这被视为通往 AGI 的关键一步,有望让模型像人类一样在动态环境中自我进化,而非依赖昂贵的重新训练。 (来源: hardmaru, 新智元)
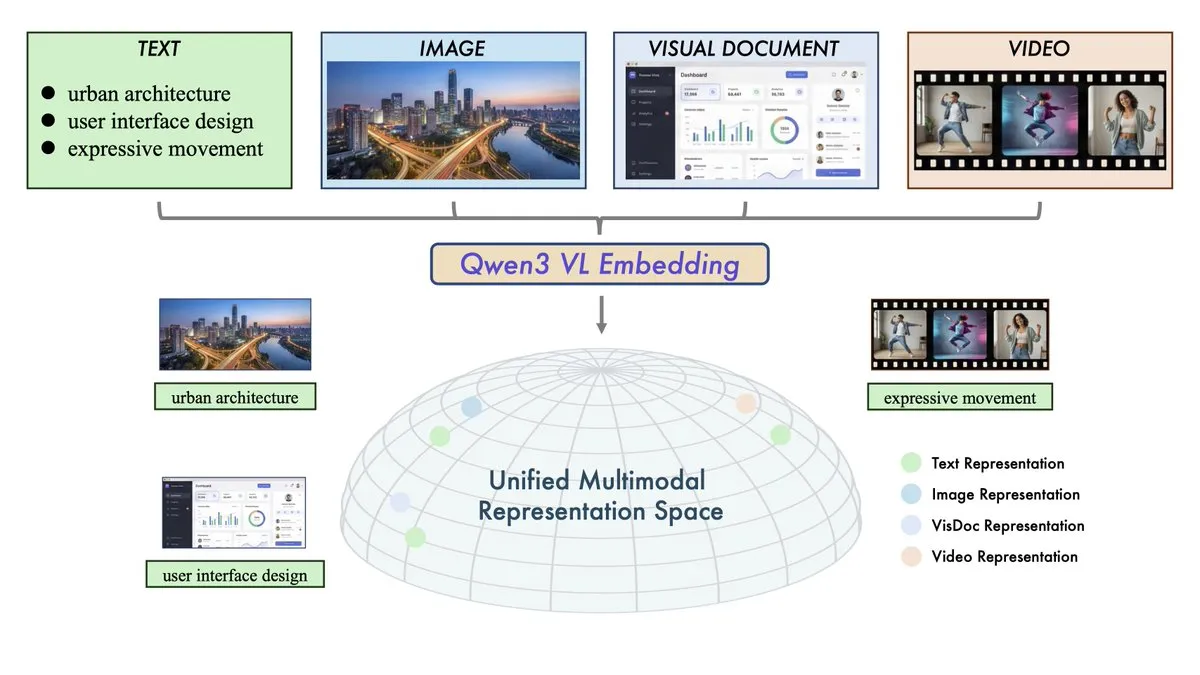
阿里发布 Qwen3-VL-Embedding 与 Reranker 模型: 阿里通义千问团队推出多模态检索双子星,旨在统一文本、图像、视频及混合模态的向量空间。Qwen3-VL-Embedding 支持 30 多种语言,在多模态检索基准上达到 SOTA 性能;Reranker 则通过细粒度相关性评分进一步提升检索精度。这一发布标志着 RAG(检索增强生成)技术正式进入全模态时代,为构建更复杂的视觉问答、视频搜索及多模态 Agent 提供了核心基础设施。 (来源: huggingface, _akhaliq)
a16z 创始人展望 2026:智能成本通缩将驱动需求爆发: Marc Andreessen 指出,AI 的单位成本下降速度已超过摩尔定律,智能正在从奢侈品变为水电般的日用品。他预测未来市场将呈现“金字塔结构”:顶端是少数超级模型,底层是无处不在的边缘侧小模型。同时,他认为初创公司正通过“向后整合”自研模型来摆脱“套壳”质疑,AI 商业模式将从按 Token 付费转向按创造的价值定价。 (来源: nvidia, 华尔街见闻)
智能座舱语音大模型加速“上车”: 在 CES 上,阶跃星辰展示了与吉利银河合作的端到端语音大模型座舱,具备情感识别与长记忆能力。行业观点认为,2026 年将是入口级 Agent 在汽车座舱规模化量产的元年。座舱正从简单的语音控制转向具备主动执行、个性化服务的“第三空间”,端云协同的 AI 架构将成为车企竞争的核心,旨在将 AI 能力深度融入 OS 底层以实现多域体验融合。 (来源: dotey, 科创板日报)
🧰 工具
Claude Code 与 code-simplifier 插件发布: Anthropic 推出的命令行工具 Claude Code 凭借极佳的工程感在开发者社区爆火。官方最新发布了 code-simplifier 代理插件,支持一键简化复杂代码库。其核心理念是“文件系统即上下文”,通过动态加载所需文件而非堆叠 Token,显著提升了处理大型仓库的效率。社区反馈其在逻辑理解和减少“代码废话”方面已超越 GPT-4o。 (来源: dotey, natolambert)
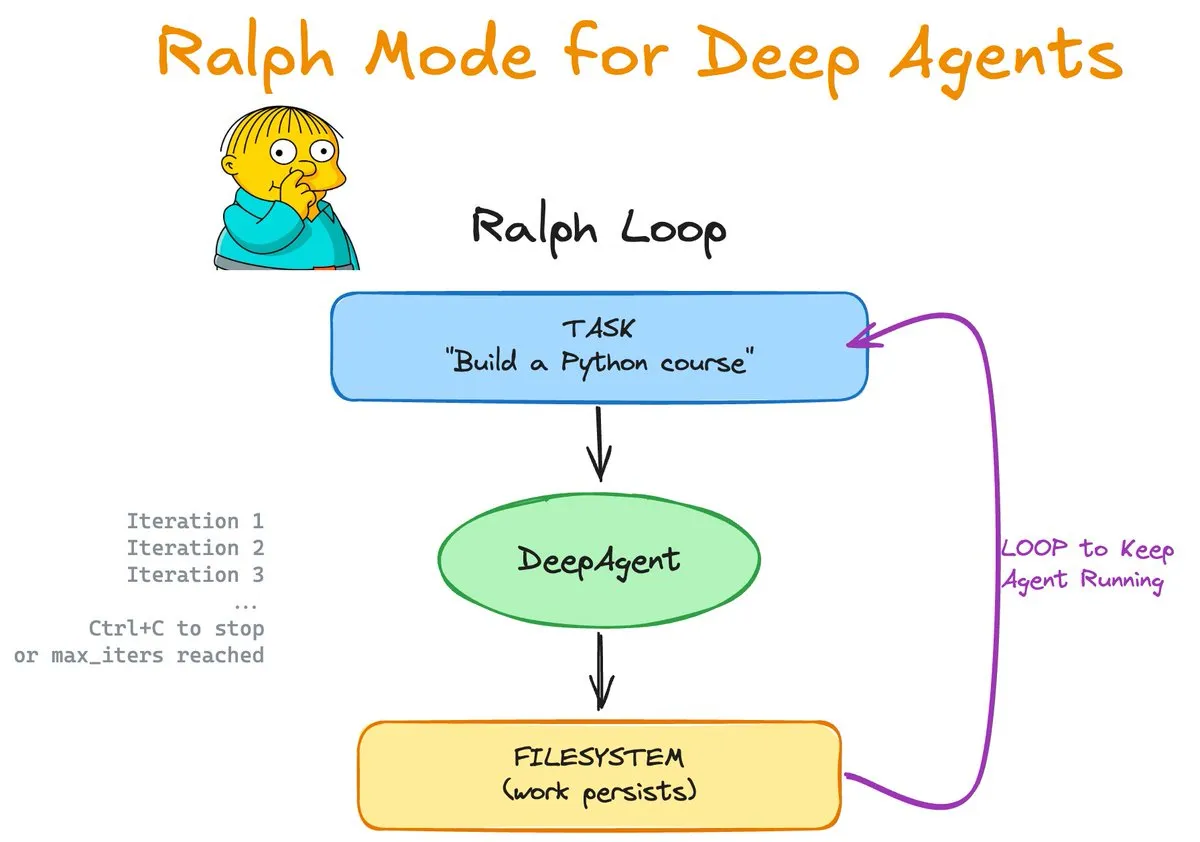
Ralph Mode:Agent 的持续循环与记忆增强: LangChain OSS 推出的 Ralph Mode 为 DeepAgents 库引入了原生 Skills 和 Memory 支持。该模式允许 Agent 在文件系统和 Git 的支持下进行无限循环任务,通过“技能化”学习过程不断更新知识库。这种设计让 Agent 能够自我纠错并积累经验,为自主软件开发和复杂长程任务处理提供了新的范式。 (来源: Vtrivedy10, hwchase17)
Pico AI Server:Mac 上的本地私有 ChatGPT: 针对隐私敏感用户,Pico AI Server 实现了在 Apple Silicon 上完全本地运行的 GPT-oss 支持。利用 MLX 框架优化,该工具能让具备 24GB+ 内存的 Mac 用户享受流畅的本地推理体验。这反映了 AI 算力向端侧迁移的趋势,用户不再需要将敏感数据上传至云端即可获得高性能的对话与编程辅助。 (来源: awnihannun)

LFM2.5 1.2B:性能卓越的 Agent 小模型: LiquidAI 发布的 LFM2.5 1.2B Instruct 模型在同尺寸级别中表现惊人,特别针对 Agent 任务、数据提取和 RAG 进行了优化。尽管不建议用于重知识任务,但其在 LM Studio 等本地环境下的推理速度极快(可达 41 tps),是构建轻量级 AI 助手和工具调用流程的理想选择。 (来源: Reddit r/LocalLLaMA)

📚 学习
清华团队 DrugCLIP 登上 Science:AI 提速药物筛选千万倍: 清华大学联合研究团队提出 DrugCLIP 框架,将虚拟筛选重新定义为密集检索任务。通过蛋白结合口袋与小分子的向量空间映射,该框架在 8 张 A100 上仅需 24 小时即可完成 10 万亿次计算,筛选速度比传统方法快 1000 万倍。这一突破开创了后 AlphaFold 时代的药物研发新范式,极大降低了超大规模药物发现的门槛。 (来源: 36氪)

Sakana AI 发布 Digital Red Queen (DRQ) 研究: 该研究在 Core War 编程游戏沙盒中模拟了 LLM 驱动的对抗性演化。通过让 LLM 编写的 Redcode 程序不断竞争,观察到了类似生物界的“趋同演化”现象:不同初始条件下的程序最终演化出相似的高效生存策略(如自复制、数据炸弹)。这项工作为研究人工系统中的对抗动力学和网络安全演化提供了安全受控的实验环境。 (来源: hardmaru, SakanaAILabs)
MAMF Explorer:洞察 GPU 真实矩阵乘法性能: 开发者 Aflah 推出的 MAMF Explorer 工具,为研究者提供了各种硬件上实际可达到的峰值 matmul FLOPS 数据,而非厂商宣传的理论峰值。这对于优化大规模模型训练和推理的算力分配具有极高的实用价值,帮助开发者在 Blackwell、H100 等不同芯片上寻找真实的性能瓶颈。 (来源: StasBekman, charles_irl)
💼 商业
Anthropic 估值或达 3500 亿美元,ARR 飞速增长: 传 Anthropic 计划融资 100 亿美元,估值在半年内翻倍。其 2025 年营收已达 9 亿美元,并定下 2026 年突破 20 亿美元的目标。相比 OpenAI 的内耗,Anthropic 凭借极高的团队稳定性和在开发者市场的“性能绝杀”(如 Claude Code),正成为企业级市场的首选,甚至被认为可能在 IPO 进度上反超老东家。 (来源: 36氪, srimuppidi)

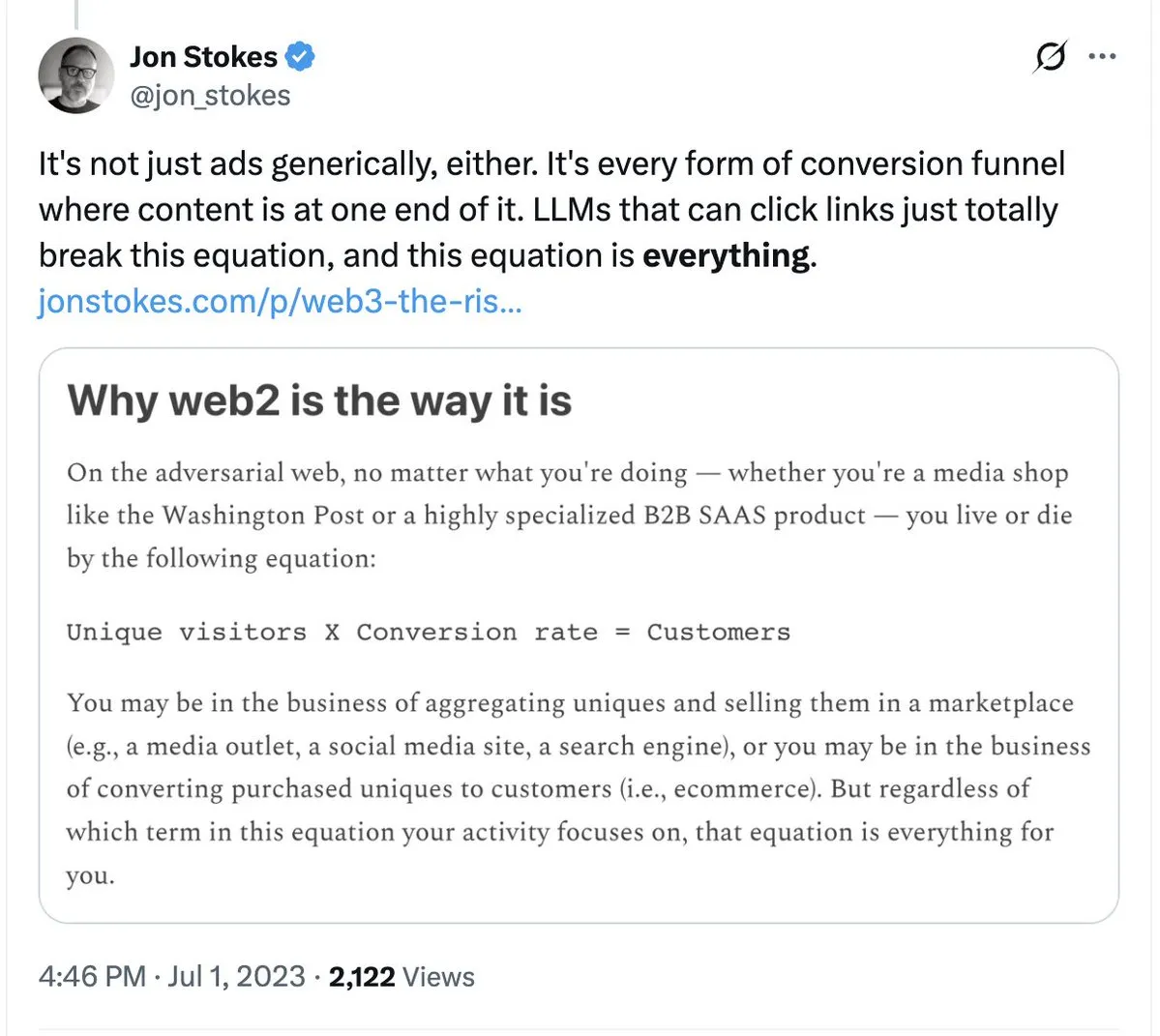
Tailwind 裁员引发 AI 冲击传统 SaaS 模式反思: 知名 CSS 框架 Tailwind 宣布裁员 75%,理由是 AI 编程工具的普及导致其商业模式崩溃。虽然 Tailwind 的使用量在增加,但用户通过 AI 生成代码的需求减少了对其付费组件的依赖。这一事件警示所有依赖“人力/模板”价值的软件公司:当 AI 能够一键生成实现方案时,传统的知识付费壁垒正在瓦解。 (来源: jon_stokes, imjaredz)
京东成立“变色龙业务部”加速具身智能落地: 京东将原有的变色龙项目升级为业务部,全面承接 JoyAI App 及具身智能品牌 JoyInside。该部门核心聚焦 AI 软硬件融合,已与 40 余家机器人和 AI 玩具品牌对接。这显示出电商巨头正利用深厚的供应链优势,试图在 AI 玩具和工业机器人领域构建从研发到销售的商业闭环。 (来源: 36氪)
🌟 社区
Linus Torvalds 怒怼“AI 垃圾代码”规范争论: 针对 Linux 内核社区是否应制定 AI 生成代码规范的讨论,Linus 直言这是“犯蠢”。他认为文档只能约束守规矩的人,而提交“AI 垃圾代码”的人根本不会主动标注。他坚持将 AI 视为一种工具,并指出内核的免疫力应来自代码评审机制和社区文化,而非无意义的文档装腔作势。 (来源: 36氪)

“Karpathy 效应”引发程序员集体焦虑: Andrej Karpathy 感叹程序员职业正被剧烈重构,开发者贡献的比特变得日益稀疏。社区将其总结为“Karpathy 效应”:即使是资深工程师也感到前所未有的落后感。讨论认为,未来的核心竞争力将从“写代码”转向“理解系统复杂性”,vibe coding 正在让 10x 工程师变成 100x,但也让初学者的门槛变得更高。 (来源: dejavucoder, arohan)
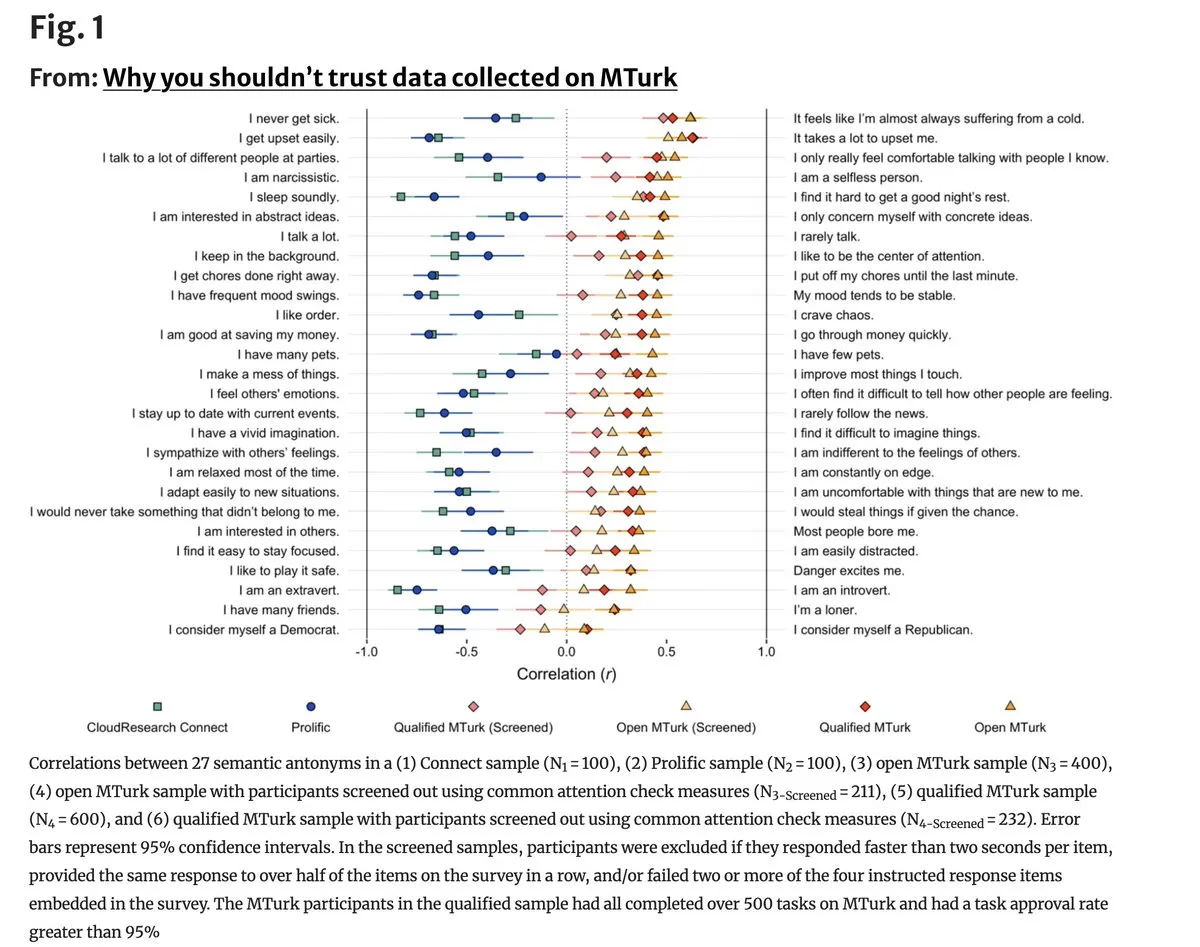
MTurk 数据质量因 AI 参与出现“存在性危机”: 最新研究显示,Amazon Mechanical Turk 等众包平台的数据质量严重下滑,96% 的矛盾项在标注中呈现正相关,证明大量工作者正使用 LLM 敷衍任务。这对于依赖高质量人工标注的行为科学和模型微调来说是致命的,社区正呼吁建立基于身份验证的真实数据采集网络。 (来源: random_walker)
💡 其他
NO FAKES Act 法律条款引发开源社区担忧: 该法案关于“数字副本权利”的责任界定被指存在陷阱。如果开发者发布的 TTS 或音色克隆模型被他人用于制作虚假名人视频,开发者可能面临巨额连带赔偿。社区担心这将导致 Hugging Face 等平台上的音频模型开发者陷入“法律自杀”,从而扼杀开源音频技术的创新。 (来源: Reddit r/LocalLLaMA)
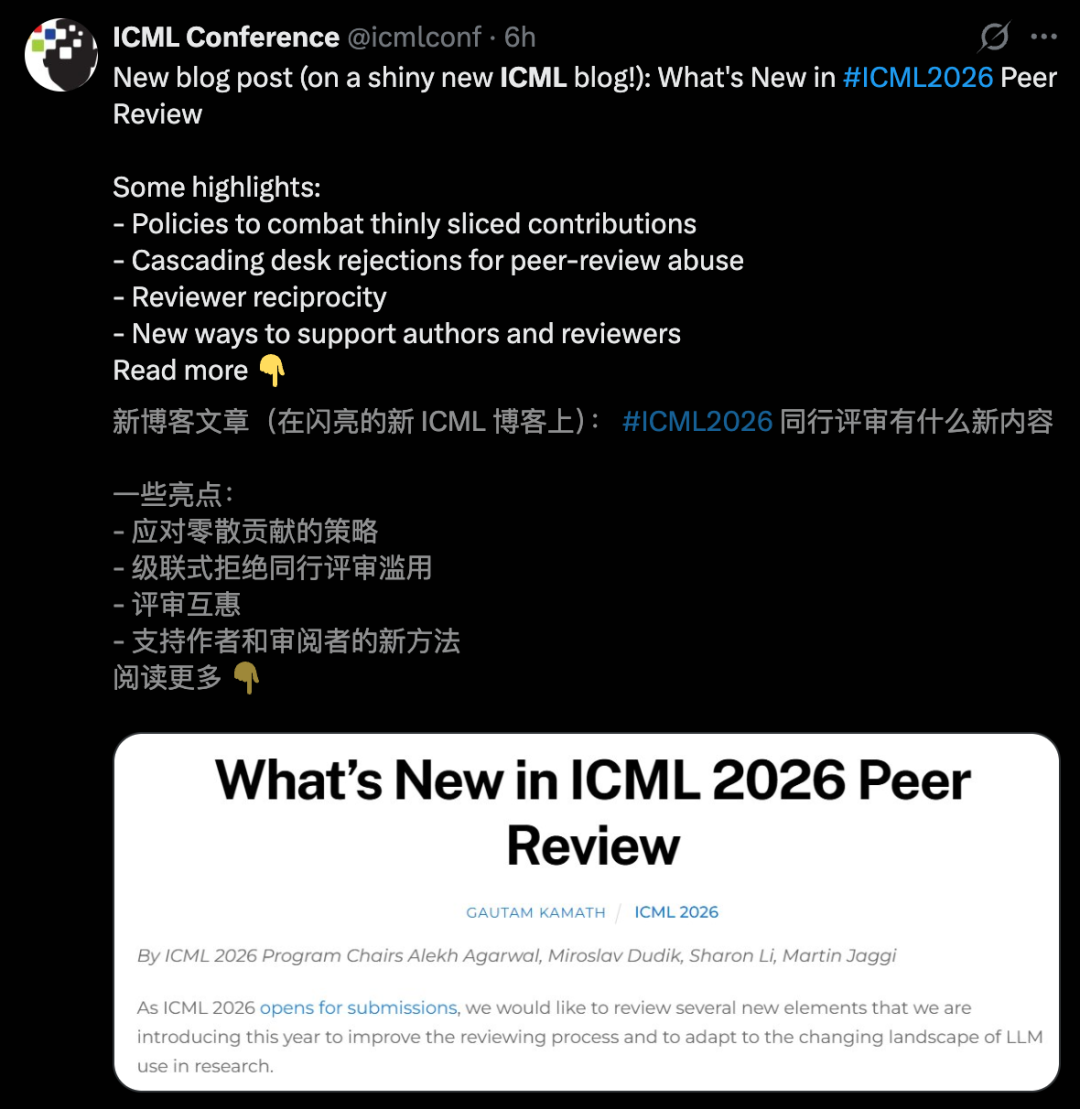
ICML 2026 引入“连坐”新规整治学术作弊: 为了打击“切香肠”式投稿和 AI 灌水,ICML 宣布:若一篇论文存在舞弊行为,所有合著者名下的所有投稿都可能被直接拒稿。这种“株连”机制要求课题组负责人必须亲自把关。同时,会议允许有条件地使用 AI 审稿,但必须征得作者同意。 (来源: 36氪)
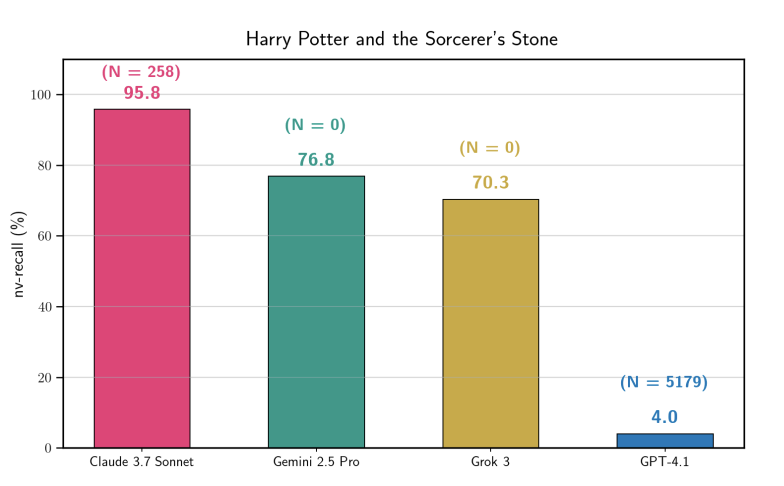
斯坦福论文证实 LLM 存在严重的版权数据背诵: 研究显示,Claude 3.7 Sonnet 能逐字复现《哈利波特》95.8% 的内容,Gemini 和 Grok 紧随其后。这有力反驳了“模型不存储训练数据”的说法,证明现有的安全过滤器在面对特定诱导时依然脆弱。这一发现将为未来的 AI 版权诉讼提供关键证据。 (来源: stanfordnlp, andykonwinski)