
كلمات مفتاحية:الذكاء الاصطناعي يونيكورن, النماذج الكبيرة, أدوات الذكاء الاصطناعي, إدراج تشايتشات الذكاء الاصطناعي في البورصة, ريبليت فيب للبرمجة, كلود كود النسخة الثالثة
🔥 تسليط الضوء
إدراج شركتي Zhipu AI و MiniMax في بورصة هونغ كونغ تباعاً: في أوائل عام 2026، أُدرجت شركتا Zhipu AI و MiniMax في بورصة هونغ كونغ خلال 48 ساعة، مما يمثل دخول منافسة النماذج الكبيرة في الصين مرحلة الحسم القائمة على “رأس المال العالي والهندسة الثقيلة”. حققت Zhipu AI اكتتاباً تجاوز المعروض بألف مرة بفضل مسار البنية التحتية للمؤسسات الحكومية والخاصة، بينما تضاعف سعر سهم MiniMax في اليوم الأول بفضل النمو الانفجاري لتطبيقات المستهلكين مثل Talkie. تعكس موجة الإدراج هذه محدودية نموذج تمويل VC، حيث بدأت الأسواق العامة في توفير آلية “دعم مالي” مستقرة للاستثمار طويل الأمد في أبحاث النماذج الكبيرة، مما يدفع السلسلة الصناعية للانتقال من “سباق المعايير” إلى مرحلة التعاون بين “الكفاءة والانغلاق التجاري” (المصدر: 产业家)
Replit تحصل على تمويل بقيمة 400 مليون دولار، وتقود تحول نموذج “Vibe Coding”: تخطط منصة البرمجة Replit لجمع 400 مليون دولار بتقييم يصل إلى 9 مليارات دولار، حيث قفز الـ ARR الخاص بها من 10 ملايين دولار إلى 144 مليون دولار في غضون ستة أشهر. يكمن نجاح Replit في تخليها الحاسم عن سوق “المطورين المحترفين” والتوجه نحو تمكين “المستخدمين غير التقنيين” عبر Replit Agent. هذا النموذج الجديد المعروف بـ “Vibe Coding”، يركز على بناء التطبيقات من خلال وصف النوايا بدلاً من كتابة الأكواد البرمجية. لا يلغي هذا التحول الحاجة إلى مديري المنتجات المبتدئين فحسب، بل ينبئ بتحول جذري في تطوير البرمجيات من “الصناعة اليدوية” إلى “الأتمتة المدفوعة بالنوايا” (المصدر: 36氪؛ TheRundownAI)
تقرير مؤشر Anthropic الاقتصادي: الوظائف ذات المؤهلات العليا تواجه أزمة “إلغاء المهارات” بسبب AI: كشف أحدث تقرير صادر عن Anthropic عن اتجاه غير متوقع: تأثير تسريع AI للمهام المعقدة يتجاوز بكثير المهام البسيطة. رفع Claude كفاءة المهام التي تتطلب شهادة جامعية بمقدار 12 مرة، بينما بلغت الزيادة للمهام التي تتطلب شهادة ثانوية 9 مرات فقط. يشير التقرير إلى أن AI يفرغ بشكل منهجي “القيمة الجوهرية” للوظائف عالية الذكاء، مما يؤدي إلى ظاهرة “إلغاء المهارات” (De-skilling) – حيث يحتفظ البشر فقط بالأعمال الإدارية التافهة، بينما يُترك التحليل والتخطيط الأساسي لـ AI. بالإضافة إلى ذلك، من خلال التعاون بين الإنسان والآلة، يمكن تمديد المهلة الزمنية لنجاح AI في معالجة الهندسة المعقدة من ساعتين إلى 19 ساعة، مما يحدد “قانون مور الجديد” لمكان العمل في المستقبل (المصدر: Anthropic؛ 新智元)
Higgsfield Cinema Studio: فهم AI لقواعد السينما يثير ضجة في Hollywood: أصدرت شركة Higgsfield، وهي شركة يونيكورن بتقييم 1.3 مليار دولار، تحديثاً رئيسياً يحول كاميرات السينما والعدسات وأساليب حركة الكاميرا الاحترافية إلى وحدات AI رقمية. لم يعد HCS يعتمد على Prompt غامض، بل يتيح لـ AI استيعاب “نية المخرج” عبر نموذج DOP I2V، لتحقيق تأثيرات احترافية مثل جودة IMAX وحركات Steadicam. هذا “التكافؤ التقني” يسمح للمبدعين الأفراد بإنتاج أفلام بصرية بمستوى Hollywood بتكلفة منخفضة جداً، مما يجبر صناعة السينما على إعادة التفكير: عندما تختفي الحواجز المهنية، كيف ستتم إعادة تعريف القيمة الجوهرية للإبداع (المصدر: 极客电影)
🎯 التوجهات
DeepSeek تطلق DeepGEMM وتحدث مسار معمارية V4: أطلقت DeepSeek رسمياً مكتبة DeepGEMM مفتوحة المصدر لضرب المصفوفات بكفاءة، والمحسنة خصيصاً لمعمارية Hopper. في الوقت نفسه، اكتشف المجتمع دعم HyperConnection في قاعدة الأكواد الخاصة بها، مما يشير إلى أن نموذج V4 القادم سيعزز دقة الاستدلال من خلال اتصالات شبكية أعمق. تلتزم DeepSeek بدعم SOTA منذ اليوم الأول، محاولةً التفوق على النماذج المغلقة الحالية في كفاءة استخدام القدرة الحسابية من خلال تحسين المشغلات الأساسية (المصدر: teortaxesTex؛ You Jiacheng)

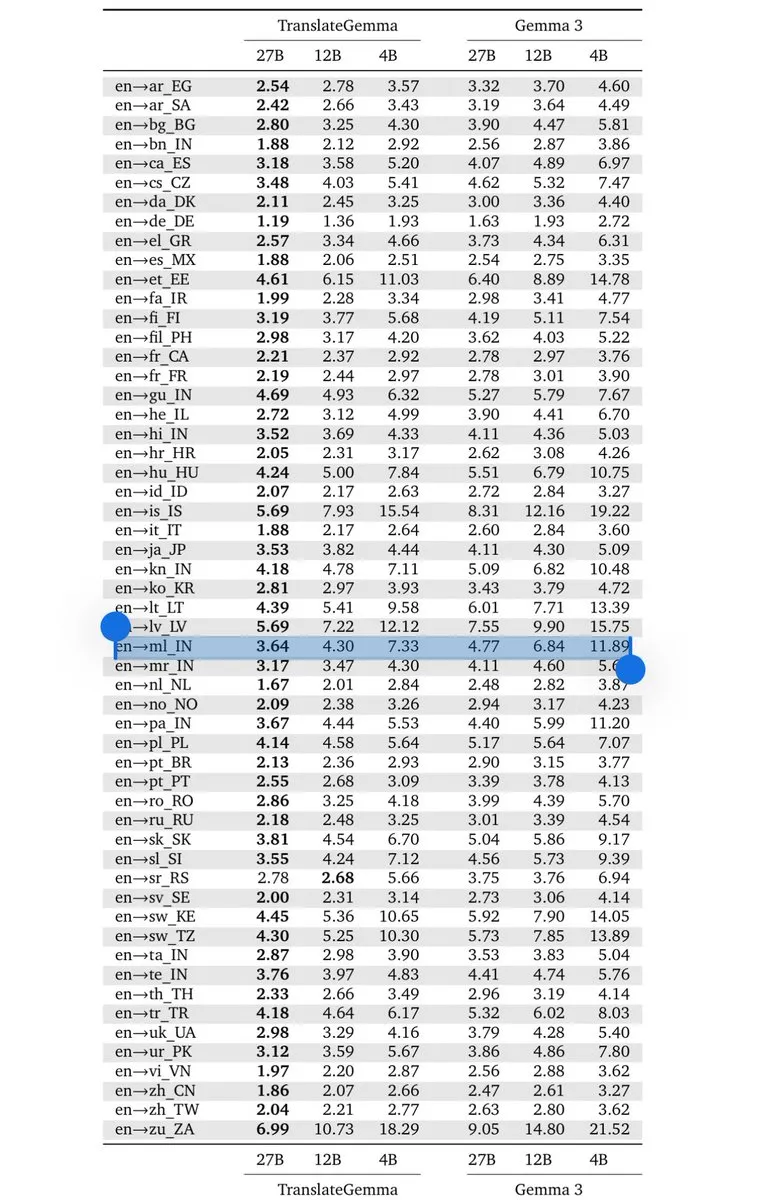
Google DeepMind تطلق TranslateGemma: معيار جديد للترجمة على الأجهزة: بناءً على معمارية Gemma 3، أطلقت Google سلسلة نماذج TranslateGemma (بأحجام 4B/12B/27B). من خلال تقطير المعرفة (Knowledge Distillation) المولد بواسطة Gemini، تدعم هذه النماذج 55 لغة مع الحفاظ على خفة الوزن، مما يسمح للمطورين ببناء أدوات ترجمة منخفضة التأخير تعمل بالكامل على الأجهزة. هذا يمثل أهمية كبرى للأسواق ذات الطلب القوي على معالجة اللغات المتعددة مثل الهند، ويشير إلى أن قدرة الاستدلال للنماذج ذات المعايير الصغيرة في مجالات محددة قد اقتربت من النماذج الرائدة (المصدر: arohan؛ Google DeepMind)
NVIDIA تطلق KVzap مفتوح المصدر: تقنية تقليم KV Cache لتحقيق ضغط بدون فقدان: أطلقت NVIDIA AI طريقة KVzap لتقليم KV Cache بمستوى SOTA. تتيح هذه التقنية ضغط ذاكرة التخزين المؤقت KV بمقدار 2x-4x مع ضمان عدم فقدان الجودة تقريباً. ومع تحول مهام الـ Agent ذات الحوارات الطويلة والاستدلال المعقد إلى الاتجاه السائد، أصبح KV Cache عنق الزجاجة الأساسي في تكلفة الاستدلال. سيؤدي إطلاق KVzap إلى تقليل استهلاك ذاكرة الفيديو وتأخير الاستجابة للمهام ذات السياق الطويل بشكل كبير، مما يحسن إنتاجية أنظمة الاستدلال (المصدر: Reddit r/artificial؛ Sudden-Dog2918)
Zhipu و Huawei تطلقان GLM-Image: أول نموذج متعدد الوسائط تم تدريبه بالكامل على رقائق صينية: أطلقت Zhipu AI بالتعاون مع Huawei نموذج GLM-Image، وهو أول نموذج رائد يتم تدريبه بالكامل من المعالجة المسبقة إلى التدريب الكامل على رقائق Ascend 910 الصينية. يعتمد النموذج على معمارية Autoregressive + Diffusion Decoder، محققاً مستوى SOTA في عرض النصوص الصينية، ويدعم توليد الصور بدقة 1024-2048 بأي نسبة عرض إلى ارتفاع. يُزعم أن كفاءة الاستدلال الخاصة به أعلى بنسبة 60% من H200، مما يثبت إمكانية تدريب نماذج متعددة الوسائط ذات تنافسية صناعية حتى بدون الاعتماد على منظومة NVIDIA (المصدر: Reddit r/MachineLearning؛ karminski3)
Microsoft تطلق FrogMini-14B: تعزيز قدرات تصحيح الأكواد عبر SFT: أصدرت Microsoft نموذج FrogMini-14B على Hugging Face، المبني على Qwen3، والذي حقق نتيجة Pass@1 بلغت 45.0% في اختبار SWE-Bench Verified. تكمن التقنية الأساسية في استخدام مسارات تصحيح الأخطاء الناجحة المولدة بواسطة نماذج قوية مثل Claude لإجراء الضبط الدقيق الخاضع للإشراف (SFT). يشير هذا التوجه إلى أنه من خلال البيانات الاصطناعية عالية الجودة والتدريب الموجه للمهام، يمكن للنماذج متوسطة الحجم (14B) إظهار فائدة استثنائية في مهام هندسة البرمجيات المحددة (المصدر: NerdyRodent)
🧰 الأدوات
إطلاق Claude Code V3: إدخال LSP لتحقيق فهم دلالي بمستوى IDE: قامت Anthropic بتحديث Claude Code بشكل كبير، ليدعم رسمياً بروتوكول خادم اللغة (LSP). هذا يعني أن Claude يمتلك الآن قدرات فهم الأكواد الدلالية مثل الانتقال إلى التعريف، والبحث عن المراجع، والتشخيص في الوقت الفعلي، مع زيادة سرعة التنقل عبر المكتبات بمقدار 900 مرة. يدمج إصدار V3 أيضاً Commands مع Skills، ويستخدم ملف CLAUDE.md كبوابة أمان ومخطط للمشروع، مما يرفع برمجة AI من مجرد تلاعب بالنصوص إلى فهم عميق للمعمارية (المصدر: TheDecipherist؛ GeckoLogic)

FLUX.2 [klein]: تحقيق ذكاء بصري تفاعلي في أقل من ثانية: أطلقت Black Forest Labs سلسلة نماذج FLUX.2 [klein]. صُمم هذا النموذج (4B/9B) خصيصاً للتوليد والتحرير في الوقت الفعلي، مع تأخير استدلال أقل من 0.5 ثانية على الأجهزة الحديثة. يتطلب إصدار 4B ذاكرة فيديو سعة 13 جيجابايت فقط للعمل على وحدات GPU الاستهلاكية، ويعتمد بروتوكول Apache 2.0. يمثل إطلاق هذه الأداة تحول توليد صور AI من “وضع الانتظار” إلى “الوضع التفاعلي”، مما يوسع بشكل كبير سيناريوهات التصميم الفوري وتطوير النماذج الأولية السريعة (المصدر: Black Forest Labs؛ vllm_project)

AionUi: واجهة رسومية مفتوحة المصدر للتعاون بين الـ Agents المتعددة: AionUi هو تطبيق مكتبي مجاني ومفتوح المصدر يهدف لتوفير مساحة عمل رسومية موحدة لأدوات AI التي تعمل عبر سطر الأوامر مثل Gemini CLI و Claude Code و Codex. يدعم التطبيق المعالجة المتوازية لجلسات متعددة، وتشفير البيانات محلياً، ويحتوي على لوحة معاينة فورية تدعم أكثر من 9 تنسيقات. يحل AionUi مشكلة عدم قدرة أدوات CLI على حفظ الجلسات وصعوبة تشغيلها، موفراً منصة تعاون فعالة بـ AI للمطورين والمستخدمين الإداريين (المصدر: iOfficeAI؛ AionUI)

Claude Flow v3: بناء منصة أسراب الـ Agents المتعددة: تمت إعادة بناء Claude Flow v3 بالكامل باستخدام TypeScript و WASM، بهدف تحويل Claude Code إلى منصة تعاونية للـ Agents المتعددة. يستخدم RuVector لتحقيق ذاكرة مشتركة، ويدعم تفكيك المهام، والوصول إلى إجماع، والتعلم المستمر. يركز إصدار v3 بشكل خاص على تحسين حصص الاشتراك، مدعياً تقليل استهلاك الـ Tokens بنسبة 80%. يدعم النظام النماذج المحلية والتشغيل دون اتصال بالإنترنت، مما يسمح للمستخدمين بتشغيل حلقات تحسين ومهام تدقيق أمني مستمرة في الخلفية (المصدر: ruvnet؛ MichaelT_KC)

📚 التعلم
Agent-as-a-Judge: نموذج جديد لتقييم المهام المعقدة: لمواجهة قيود LLM-as-a-Judge مثل التحيز ونقص التحقق في الوقت الفعلي في المهام المعقدة، اقترحت مراجعة حديثة مفهوم Agent-as-a-Judge. يقدم هذا النموذج قدرات التخطيط واستدعاء الأدوات والذاكرة، مما يسمح للمقيم بتقييم المهام من خلال سلوكيات نشطة مثل تشغيل الأكواد والتحقق من المخرجات، مما يوفر خارطة طريق لتقييم AI قوي وقابل للتحقق (المصدر: TheTuringPost؛ Ksenia_TuringPost)

Thoughtology: الكشف عن “المنطقة المثالية” لسلسلة أفكار نماذج الاستدلال: حللت دراسة ميكانيكية مكونة من 135 صفحة بعنوان “Thoughtology” سلسلة أفكار نماذج الاستدلال مثل GPT-OSS و Qwen3 و R1. وجدت الدراسة أن التفكير الأطول ليس دائماً الأفضل، حيث توجد “منطقة مثالية” (Sweet Spot) للاستدلال لكل سؤال، وقد يؤدي التفكير المفرط إلى انخفاض الدقة. بالإضافة إلى ذلك، يرتبط التفكير المتكرر (Rumination) عادةً بالإجابات الخاطئة. توفر هذه الدراسة بيانات أساسية لتحسين تكلفة الاستدلال ورفع جودة المخرجات لنماذج الاستدلال (المصدر: YejinChoinka؛ Sara Vera Marjanović)

MatchTIR: تحقيق إشراف دقيق للاستدلال المتكامل بالأدوات عبر مطابقة الرسم البياني الثنائي: يقدم إطار MatchTIR توزيع مكافآت على مستوى الـ Turn بناءً على مطابقة الرسم البياني الثنائي لمعالجة مشكلة تخصيص الائتمان التقريبي في الاستدلال المتكامل بالأدوات (TIR). يمكن لهذه الطريقة التمييز بفعالية بين استدعاءات الأدوات الصالحة والزائدة، وتؤدي بشكل ممتاز في المهام الطويلة متعددة الجولات. أظهرت التجارب أن نموذج 4B الخاص بها تفوق على معظم نماذج 8B في اختبارات مرجعية متعددة، مما يثبت الإمكانات الهائلة للإشراف الدقيق في تحسين معدل نجاح مهام الـ Agent (المصدر: quchangle1؛ HuggingFace Daily Papers)
💼 الأعمال
OpenAI تستثمر في Merge Labs، شركة واجهة الدماغ والحاسوب الناشئة لـ Sam Altman: شاركت OpenAI في تمويل شركة Merge Labs المتخصصة في واجهة الدماغ والحاسوب (BCI)، والتي أسسها رئيسها التنفيذي Sam Altman. تُعتبر هذه الخطوة توجهاً استباقياً من OpenAI في شكل أجهزة AGI، في محاولة لربط الوعي البشري مباشرة بنماذج AI عبر تقنية BCI، لتحدي شركة Neuralink التابعة لـ Elon Musk. أثار هذا الاستثمار مجدداً النقاشات حول الحدود بين المصالح الشخصية لـ Altman وقرارات الشركة (المصدر: unusual_whales؛ scaling01)
Wikipedia تتوصل لاتفاقيات تعاون مع Microsoft و Meta و Perplexity بمناسبة ذكرى تأسيسها الـ 25: وقعت Wikipedia رسمياً اتفاقيات ترخيص بيانات AI مع Microsoft و Meta و Perplexity في ذكرى تأسيسها الخامسة والعشرين. تهدف هذه الشراكات لضمان تقديم نماذج AI لمصادر دقيقة عند الاقتباس من محتوى Wikipedia، وتوفير تمويل تشغيلي مستدام لمؤسسة Wikimedia. يمثل هذا تحولاً استراتيجياً لمنصات المعرفة في عصر AI من “الزحف السلبي” إلى “التعاون النشط” (المصدر: AP News؛ Reddit r/artificial)
🌟 المجتمع
“It Takes Two”: تحسين المشاريع عبر تنافس النماذج: يناقش المجتمع تقنية Prompt تسمى “Dueling Idea Wizards”. من خلال جعل نموذجين مختلفين (مثل Claude Opus 4.5 و GPT-5.2) يراجعان مقترحات تحسين بعضهما البعض ويقيمانها (من 0 إلى 1000 نقطة)، وجد المطورون أن هناك اختلافات وتواطؤات مثيرة للاهتمام بين النماذج. المقترحات التي يتفق عليها النموذجان بشدة هي عادةً حلول عالية الجودة ذات قيمة عملية حقيقية، وهذا الاستدلال التنافسي يحسن كفاءة تصفية الأفكار بشكل كبير (المصدر: doodlestein)
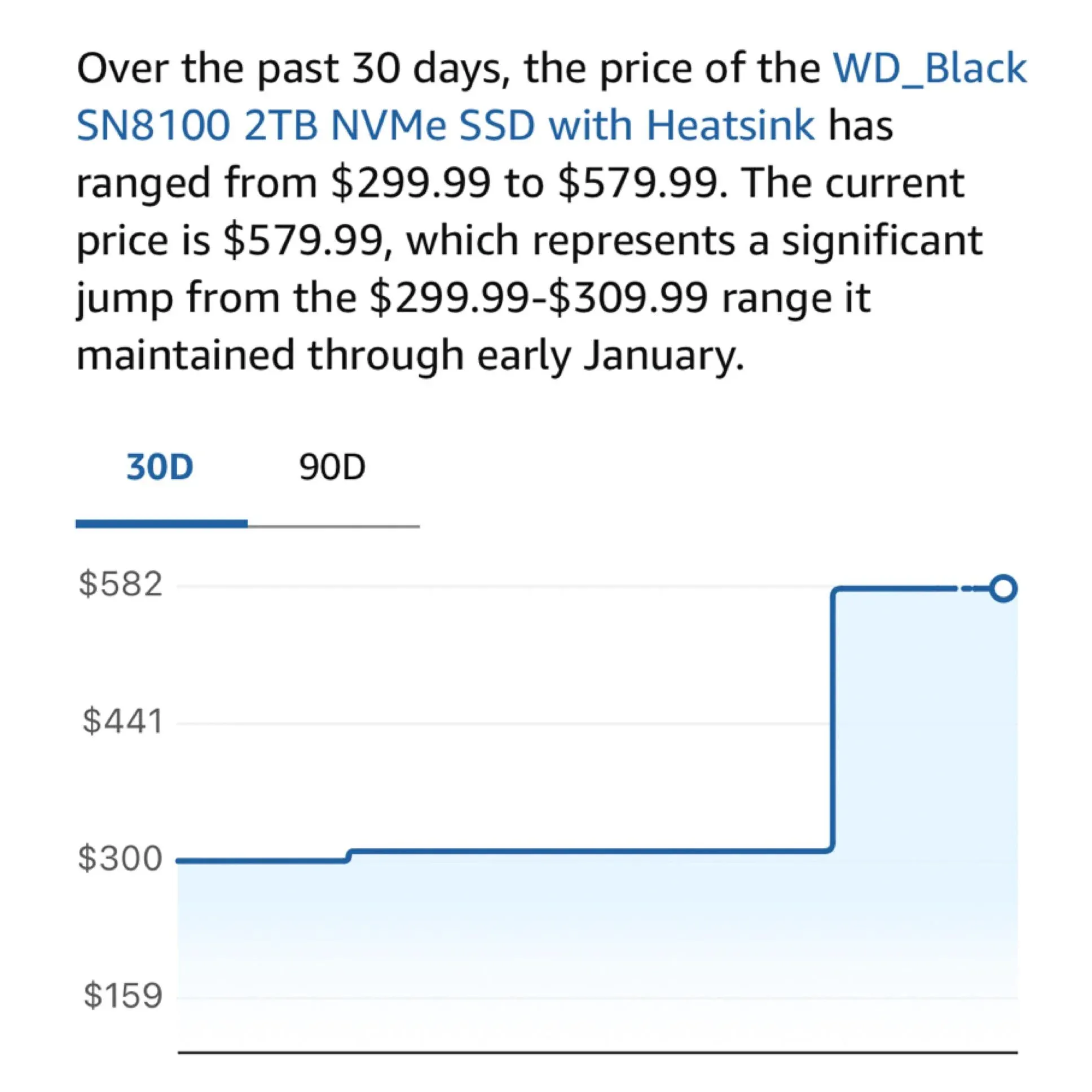
قلق الأجهزة: ارتفاع أسعار M2 SSD يؤثر على مستخدمي AI المحليين: يشتكي مستخدمو المجتمع من الارتفاع الكبير في أسعار M2 SSD والذاكرة مؤخراً، حيث تضاعفت أسعار بعض الموديلات ثلاث مرات في عام واحد. مع زيادة الطلب على تشغيل نماذج 100B+ محلياً (مثل DeepSeek و Qwen)، يزداد اعتماد المستخدمين على التخزين عالي السرعة والسعة الكبيرة. أصبح قرار Samsung و Micron بتقليص الإمدادات الاستهلاكية العائق الأكبر لهواة LLM المحليين في بناء “مراكز حسابية منزلية” (المصدر: Reddit r/LocalLLaMA؛ dgibbons0)
إضافة “خوار” Claude Code تثير نقاشاً حول ردود فعل تفاعل AI: شارك مطور إضافة تسمى claude-code-moo تصدر صوت “خوار بقرة” عندما يحتاج Claude Code إلى إذن المستخدم لأوامر Bash. حلت هذه الأداة الهزلية مشكلة تفويت المطورين لتنبيهات AI بعد تبديل النوافذ. أطلق هذا نقاشاً عميقاً في المجتمع حول كيفية حفاظ AI Agent على مشاركة البشر في المهام الطويلة عبر ردود فعل غير اقتحامية (صوتية، لمسية) (المصدر: Reddit r/ClaudeAI؛ iefnaf)

💡 أخرى
Galbot S1 من Galbot: كسر الحد الأقصى لحمولة الروبوتات الذكية المجسدة: أطلقت Galbot روبوت الحمولة الثقيلة Galbot S1، بحمولة قصوى للذراعين تصل إلى 50 كجم، ويمكنه حمل 32 كجم عندما تكون الأذرع ممدودة، وهو ما يتجاوز بكثير متوسط الصناعة. تم تطبيق الروبوت بالفعل في مصانع CATL، محققاً عمليات ذاتية بالكامل دون تحكم عن بعد عبر نموذج حمل مجسد. يمثل هذا دخول الذكاء المجسد من مرحلة استعراض “صنع القهوة” إلى جوهر الإنتاج الصناعي عالي الكثافة وطويل الدورة (المصدر: 银河通用؛ 36氪)

تصوير هلوسة AI: التأثير السلبي لحجم المهمة على الاتساق: أظهر مستخدم في المجتمع كيف تتدهور هلوسة AI مع زيادة حجم المهمة من خلال توليد صور تحتوي على 10 و 50 و 100 شخصية. وجدت التجربة أنه مع زيادة عدد الشخصيات، ينهار AI بوضوح في معالجة الخصائص الوطنية، وهجاء الكلمات، وهياكل الأطراف. يذكر هذا المطورين بضرورة تقليل العبء المعرفي لـ Prompt واحد من خلال تفكيك المهام (Decomposition) عند بناء مهام Agent معقدة (المصدر: Reddit r/ChatGPT؛ haneke86)
إطلاق Raspberry Pi AI HAT+ 2: آلة استدلال لنماذج 1B على الحافة: أطلقت Raspberry Pi إضافة AI HAT+ 2 بسعر 130 دولاراً، مزودة بمسرع Hailo-10H وذاكرة 8 جيجابايت. صُمم هذا الجهاز خصيصاً لتشغيل LLM و VLM محلياً بقدرة حسابية 40 TOPS دون الاعتماد على السحابة. يعتبر المجتمع هذا الخيار مثالياً لبناء آلات استدلال Agent محلية صغيرة، قادرة على تشغيل نماذج 1B المكممة بسلاسة، مما يعزز انتشار AI في إنترنت الأشياء والسيناريوهات الحساسة للخصوصية (المصدر: ben_burtenshaw؛ Raspberry Pi)
