كلمات مفتاحية:الاستدلال بالذكاء الاصطناعي, النماذج مفتوحة المصدر, نماذج اللغة الكبيرة, محرك الاستدلال vLLM, توليف الكلام Qwen3-TTS, الاستدلال الوكيلي
🔥 تسليط الضوء
فريق vLLM الأساسي يجمع 150 مليون دولار لتأسيس Inferact : أعلن الأعضاء المؤسسون لمحرك الاستنتاج مفتوح المصدر vLLM عن تأسيس شركتهم الناشئة Inferact، وحصلوا على تمويل أولي بقيمة 150 مليون دولار بقيادة a16z و Lightspeed، بتقييم يصل إلى 800 مليون دولار. يمثل هذا التحول الرسمي لمركز ثقل صناعة AI من “تدريب النماذج” إلى “خدمات الاستنتاج (Inference)”. ومع تعقد أحجام النماذج وهياكلها، أصبح تشغيل النماذج بتكلفة منخفضة وكفاءة عالية هو العائق الأساسي. تهدف Inferact إلى جعل vLLM بمثابة “Inference Linux” لعصر AI، من خلال توحيد حزمة البرمجيات لحل مشكلة تشتت الأجهزة (Hardware). تعكس هذه الخطوة اعترافاً عالياً من سوق رأس المال بطبقة البنية التحتية لـ AI، حيث سيؤدي خفض تكاليف الاستنتاج مباشرة إلى تسريع انتشار تطبيقات AI (المصدر: woosuk_k, 36氪)
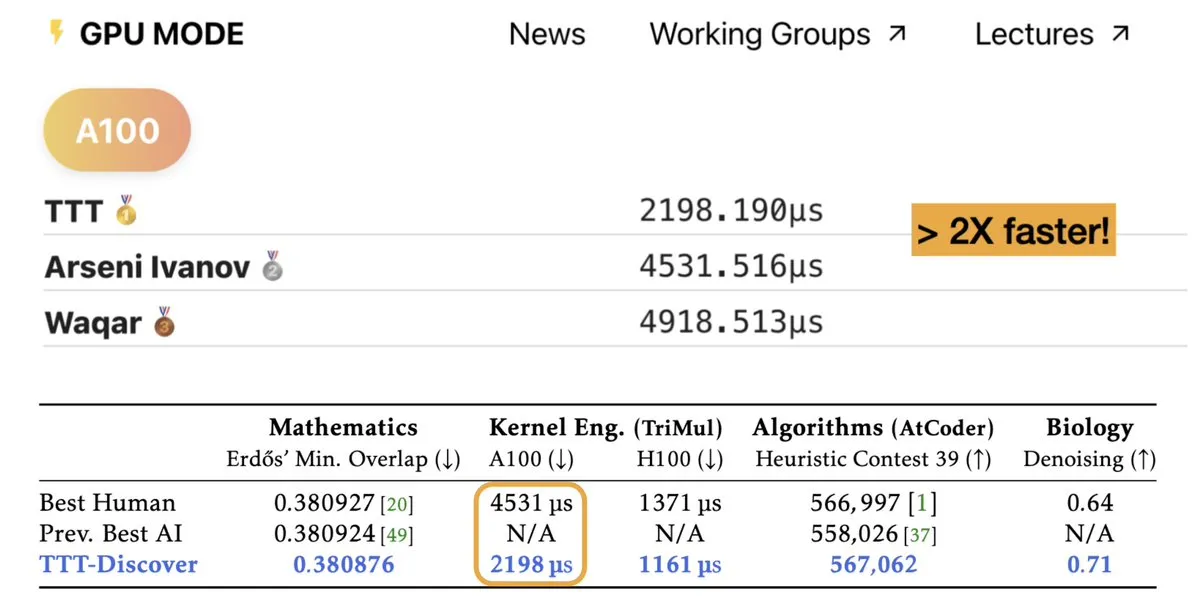
TTT-Discover: الذكاء الاصطناعي يحقق اكتشافات علمية عبر Test-Time Training : أظهرت دراسة جديدة بعنوان TTT-Discover إمكانات AI في تجاوز المستويات البشرية الحالية في مجالات مثل الرياضيات، هندسة النواة (Kernel Engineering)، وتصميم الخوارزميات. تتيح هذه الطريقة، من خلال Reinforcement Learning أثناء وقت الاختبار، للنموذج التعلم المستمر لمشكلات محددة بدلاً من الاعتماد فقط على أوزان التدريب المسبق المجمدة. أظهرت التجارب أنه بتكلفة حوسبة تقل عن 500 دولار، حطمت هذه الطريقة الأرقام القياسية في مشكلة Erdős للحد الأدنى من التداخل ومسابقات تحسين GPU Kernels. يثبت هذا أن “Inference-time computation” لا يعزز القدرات المنطقية فحسب، بل يعمل كمحرك لاكتشاف معرفة جديدة، مما يبشر بتطور AI من “ناقل للمعرفة” إلى “باحث علمي” حقيقي (المصدر: charles_irl, _akhaliq)
إصدار Qwen3-TTS: علامة فارقة جديدة في توليد الكلام مفتوح المصدر : أصدر فريق Alibaba Qwen سلسلة نماذج Qwen3-TTS، التي تدعم استنساخ الصوت بسرعة 3 ثوانٍ و10 لغات، مع زمن انتقال (Latency) منخفض يصل إلى 97ms. تضم عائلة النماذج إصدارات VoiceDesign و CustomVoice و Base، وتعتمد بنية Dual-track LM، محققة مستويات SOTA في جودة الصوت، التحكم في المشاعر، وسرعة الاستنتاج. يرى المجتمع أن هذا هو الإصدار الأكثر ثورية في مجال TTS مفتوح المصدر حالياً، حيث ستدفع رخصة Apache 2.0 وقدرات التكيف القوية على الأجهزة الطرفية (مثل دعم MLX-Audio) تطوير المساعدين الصوتيين الشخصيين وتطبيقات الحوار في الوقت الفعلي بشكل كبير (المصدر: Alibaba_Qwen, Reddit)

تدقيق جنائي لاختبارات HLE و GPQA: معدلات خطأ مذهلة : أجرى باحثون مستقلون تدقيقاً جنائياً لاختبارات “Humanity’s Last Exam” (HLE) و GPQA، ووجدوا أن معدل خطأ التحقق في HLE يصل إلى ~58% بسبب أخطاء OCR وأخطاء إملائية، بينما بلغت العيوب في GPQA حوالي ~26.8%. العديد من الحالات التي صُنفت كـ “هلوسة نموذج” كانت في الواقع حالات استنتج فيها النموذج الإجابة الصحيحة، لكنه رسب لعدم قدرته على “التخاطر” مع الأخطاء المطبعية في الأسئلة. أثار هذا الاكتشاف شكوكاً هائلة حول موثوقية لوحات المتصدرين (Leaderboards) الحالية لـ AI. قد نكون بصدد تقييم أفضل النماذج بـ “مسطرة مكسورة”، حيث تستهلك المختبرات ملايين الدولارات لتحسين التوافق مع الأخطاء بدلاً من رفع الذكاء الحقيقي (المصدر: Reddit)
🎯 التوجهات
إعادة هيكلة نسخة Llama 4 الداخلية في Meta بعد انتقادات CTO : كشف Bosworth، المدير التقني لشركة Meta، أن النسخة المبكرة من Llama 4 كانت مخيبة للآمال، واصفاً إياها بأنها “تفتقر إلى وجهة نظر” ومتوسطة الأداء. بناءً على ذلك، أعادت Meta هيكلة فريق AI تحت قيادة Alexandr Wang، وتخطط لإصدار النموذج الجديد في النصف الأول من هذا العام. لا يزال هناك جدل داخلي حاد حول ما إذا كان سيتم جعل النموذج مفتوح المصدر وكيفية القيام بذلك. يعكس هذا التحدي الذي تواجهه المختبرات الكبرى في السعي نحو AGI، حيث لم يعد مجرد تكديس البارامترات كافياً لإحداث مفاجأة، وأصبح منح النموذج “طريقة تفكير” فريدة وتحسينات ما بعد التدريب (Post-training) هي نقاط التنافس الجديدة (المصدر: ylecun)
ARR لأعمال OpenAI API يتجاوز مليار دولار شهرياً : أعلن Sam Altman أن أعمال API الخاصة بـ OpenAI أضافت أكثر من مليار دولار من الإيرادات السنوية المتكررة (ARR) خلال الشهر الماضي. يشير هذا النمو المذهل إلى أنه على الرغم من هيمنة ChatGPT على الوعي العام، إلا أن سوق المطورين (B2B) أصبح محرك النمو الحقيقي لـ OpenAI. ومع تحول تطبيقات AI المؤسسية من التجارب إلى النشر واسع النطاق، يظهر استهلاك API نمواً أسياً، مما يعزز مكانة OpenAI كـ “تاجر جملة للحوسبة والذكاء” في عصر AI (المصدر: sama)
مراجعة Agentic Reasoning: من التفكير الساكن إلى العمل الديناميكي : لخصت ورقة بحثية مكونة من 135 صفحة نموذجاً جديداً لذكاء LLM وهو “الاستدلال الوكيل” (Agentic Reasoning). يرى البحث أن LLM تتفوق في البيئات المغلقة ولكنها تعاني في البيئات الديناميكية المفتوحة، والعنصر المفقود هو “العمل”. يقسم هذا الإطار الاستدلال إلى ثلاثة أبعاد: الاستدلال الأساسي، الاستدلال ذاتي التطور، والاستدلال الجماعي متعدد الوكلاء. وهذا يعني أن مستقبل AI لا يكمن في زيادة عدد البارامترات، بل في كيفية التطور المستمر من خلال التفاعل مع البيئة والتغذية الراجعة والذاكرة (المصدر: omarsar0)

“Vibe Coding” يثير مخاوف من “إفلاس الفهم” : مع انتشار أدوات مثل Claude Code و Devin، بدأ مجتمع المطورين بمناقشة ظاهرة “Vibe Coding”. يخشى المهندسون المخضرمون أنه عندما يتمكن AI من إنجاز ساعات من العمل في لحظات، يفقد البشر الفهم العميق للكود المصدري، مما يخلق “ديون فهم”. على الرغم من زيادة الإنتاجية بنسبة 20-30% على المدى القصير، إلا أن صعوبة تصحيح أخطاء النظام (Debugging) ستزداد بشكل أسي على المدى الطويل. قد يتطور تطوير البرمجيات مستقبلاً إلى “مراقبة الموقف” بدلاً من “كتابة المنطق”، مما يتطلب بناء أنظمة جديدة لضمان جودة الكود (المصدر: jon_stokes, jeremyphoward)
🧰 الأدوات
إطلاق GitHub Copilot SDK: دمج تدفقات عمل الوكلاء في أي تطبيق : أطلقت GitHub حزمة SDK قابلة للبرمجة تتيح للمطورين دمج المحرك الأساسي لـ Copilot مباشرة في تطبيقاتهم. لا يحتاج المطورون لبناء طبقات تنسيق معقدة، بل يكفي تحديد النوايا والسلوكيات ليقوم Copilot بتنفيذ المهام. يمثل هذا تحول مساعدي AI من أدوات مستقلة إلى قدرات عامة قابلة للتوصيل، مما يقلل بشكل كبير من عتبة تطوير تطبيقات الوكلاء المستقلة (المصدر: pierceboggan)
Devin Review: إعادة هيكلة عملية مراجعة الكود : أطلقت Cognition أداة Devin Review، التي تهدف إلى مساعدة المطورين على التخلص من “نفايات الكود” منخفضة الجودة عبر الفهم العميق لطلبات السحب (PR) المعقدة بواسطة AI. لا تكتفي الأداة بتحديد الأخطاء المنطقية، بل تبني خريطة لفهم الكود لمنع كوارث الصيانة الناتجة عن الاعتماد المفرط على الكود المولد بواسطة AI. أشار المجتمع إلى أدائها الممتاز في التعامل مع عمليات إعادة الهيكلة واسعة النطاق والتغييرات عبر الوحدات البرمجية (المصدر: cognition, swyx)
LlamaParse v2: ثورة هيكلية في تحليل المستندات : أعادت LlamaIndex بناء API تحليل المستندات الخاص بها، مطلقة الإصدار v2 وحزمة LlamaCloud SDK الجديدة. يبسط الإصدار الجديد عملية التكوين بشكل ملحوظ، ويدعم التحكم الدقيق في المخرجات المهيكلة (مثل Markdown و JSON)، ويحقق توافقاً كاملاً بين Python و TypeScript. يوفر هذا بنية تحتية أكثر صلابة لبناء تطبيقات RAG قادرة على التعامل مع مستندات معقدة ومتعددة الأعمدة وتحتوي على رسوم بيانية (المصدر: jerryjliu0)

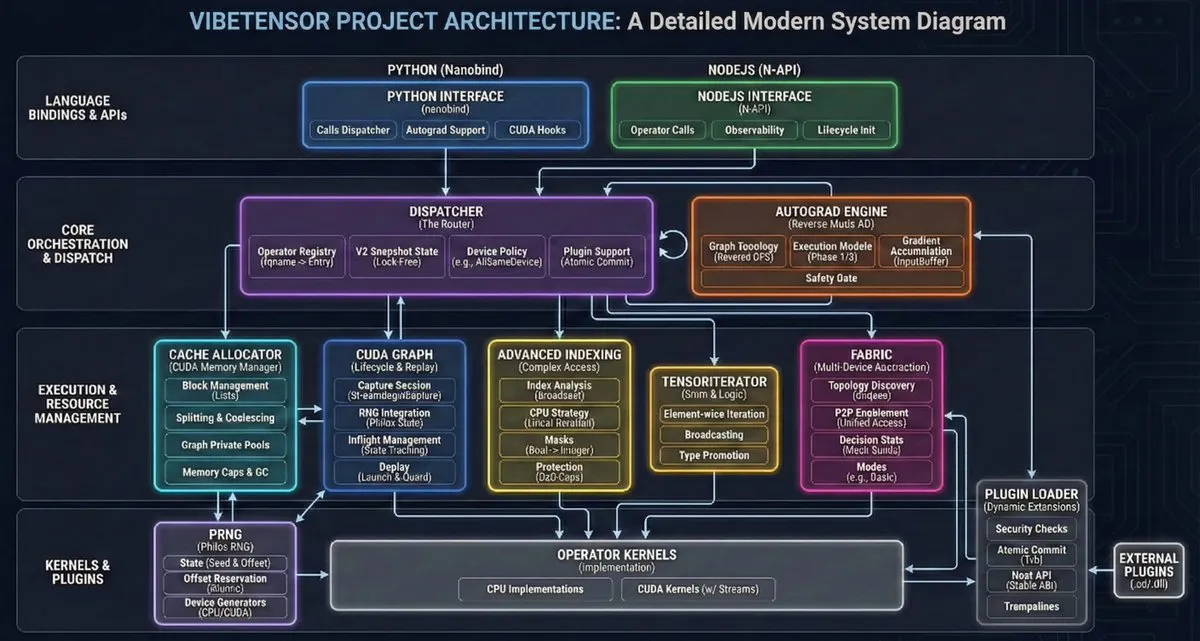
VibeTensor: أول نظام Deep Learning يتم إنشاؤه بالكامل بواسطة وكلاء AI : أطلقت NVlabs مشروع VibeTensor مفتوح المصدر، وهو إطار عمل للتعلم العميق تم إنشاؤه بالكامل بواسطة وكلاء AI، ويحتوي على 47,000 سطر من كود Triton Kernels المولد تلقائياً. على الرغم من أن كفاءته في بعض المسارات الحرجة لا تزال دون PyTorch (ما يسمى بـ “تأثير فرانكنشتاين”)، إلا أنه يثبت أن AI يمتلك بالفعل القدرة على تصميم وتنفيذ هياكل أنظمة أساسية معقدة، مما يبشر ببداية عصر “AI يكتب AI” (المصدر: JvNixon)
💼 الأعمال
Meta تعتزم الاستحواذ على Manus AI مقابل 2-3 مليار دولار : تشير التقارير إلى أن Meta توصلت إلى اتفاق للاستحواذ على شركة Manus AI الناشئة للوكلاء المستقلين بمبلغ ضخم. تهدف هذه الخطوة إلى دمج قدرات الوكلاء (Agents) التي أثبتت كفاءتها في السوق ضمن كامل مجموعة منتجاتها مثل Facebook و Instagram و WhatsApp. يعكس هذا رغبة عمالقة التواصل الاجتماعي في امتلاك القدرة على تنفيذ المهام بنشاط في “عصر ما بعد روبوتات الدردشة” (المصدر: DeepLearningAI)

LiveKit تكمل جولة تمويل Series C بقيمة 100 مليون دولار : حصلت منصة البنية التحتية لـ Voice AI، شركة LiveKit، على تمويل بقيمة 100 مليون دولار لتبسيط عملية بناء تطبيقات الصوت المعتمدة على AI. ومع تحول التفاعل الصوتي في الوقت الفعلي (مثل Doubao و OpenAI Advanced Voice Mode) إلى حاجة ملحة، يشهد طلب المطورين على خدمات بث الصوت منخفضة الكمون وعالية الموثوقية نمواً انفجارياً (المصدر: juberti)
World Labs التابعة لـ Li Fei-Fei تسعى لجمع 500 مليون دولار بتقييم 5 مليارات : تجري شركة World Labs الناشئة في مجال “الذكاء المكاني”، التي أسستها Li Fei-Fei، محادثات لجولة تمويل جديدة. تُعتبر نماذج العالم (World Models) الموجة التالية في مجالات الألعاب والروبوتات، وتهدف إلى منح AI القدرة على فهم قوانين العالم الفيزيائي (المصدر: kylebrussell)
📚 التعلم
Andrew Ng يطلق دورة Gemini CLI : أطلقت DeepLearning.AI دورة جديدة تعلم كيفية بناء وكلاء باستخدام Gemini CLI مفتوح المصدر. تغطي الدورة مهارات عملية في تنسيق أدوات مثل GitHub و Canva و Google Workspace باستخدام خوادم MCP. التركيز ينصب على فهم بنية الوكلاء مفتوحة المصدر، لتمكين المطورين من إدراك منطق اتخاذ القرار في AI بشفافية (المصدر: AndrewYNg)
محاضرة معمقة حول خوارزميات MoE Routing : تم إطلاق محاضرة منهجية على YouTube حول خوارزميات التوجيه في نماذج خليط الخبراء (MoE)، تغطي أساسيات MoE، آليات التوجيه، مشكلة تكدس الخبراء، وحلول التحسين. تعد مورداً ممتازاً للمطورين الراغبين في فهم الآليات الكامنة وراء الأداء العالي لنماذج مثل DeepSeek (المصدر: ben_burtenshaw)
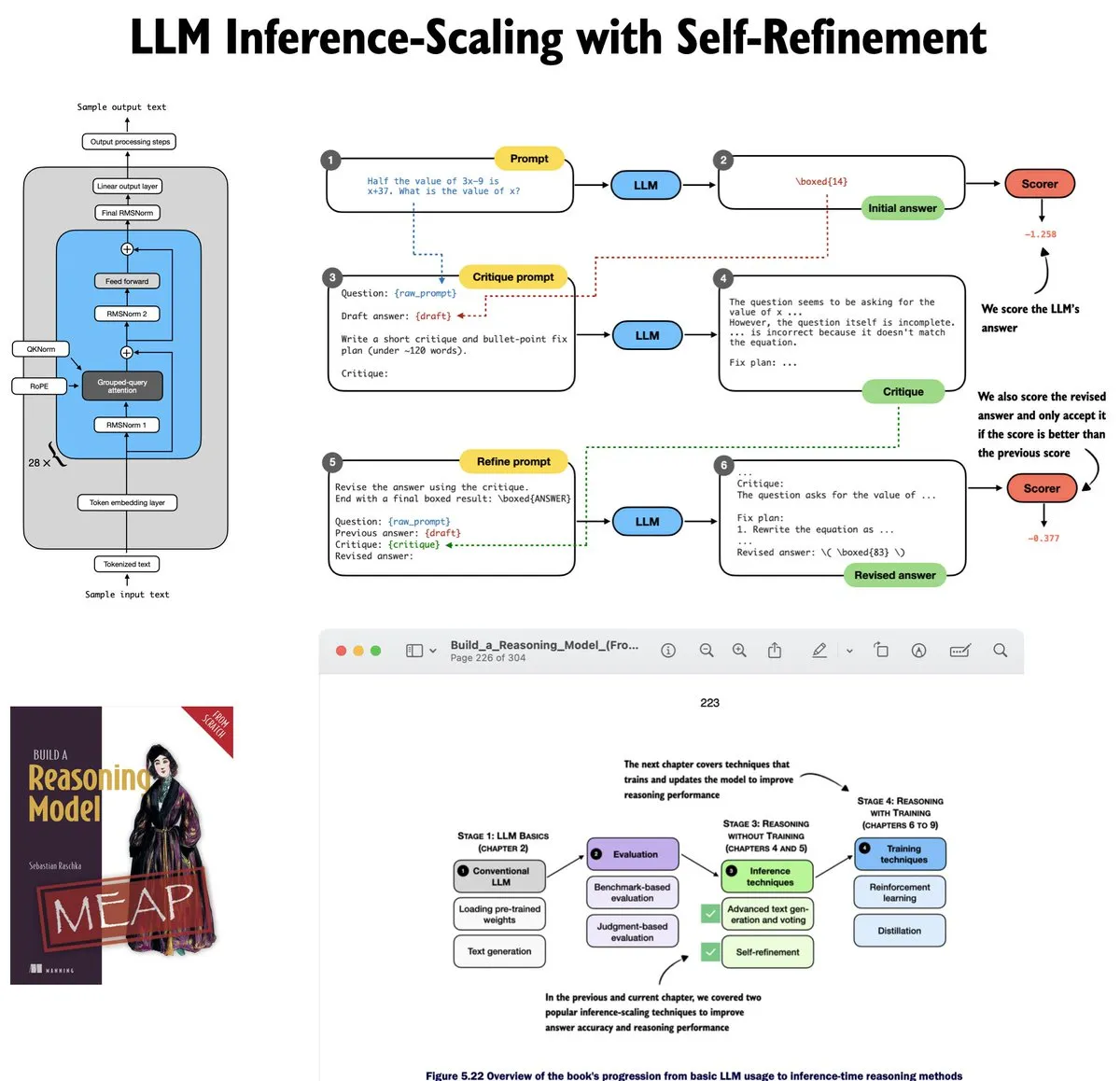
تحديث دروس LLM Self-Refinement : قام Sebastian Raschka بتحديث الفصل الخامس من دروس LLM الخاصة به، مع التركيز على Inference-time scaling. تشرح الدروس عبر الكود كيفية تنفيذ منطق التقييم الذاتي والتحسين المتكرر للنماذج من الصفر، مما يساعد المتعلمين على فهم الرياضيات والتنفيذ الهندسي وراء طرق استنتاج LLM (المصدر: nerdai)
🌟 المجتمع
خطة OpenAI لاقتطاع أرباح من “الاكتشافات المدعومة بـ AI” تثير الجدل : كشف المدير المالي لشركة OpenAI أن الشركة قد تطلب مستقبلاً حصة من الأرباح الناتجة عن الاكتشافات العلمية أو الاختراعات التي يحققها العملاء عبر AI. أثار هذا الخبر ضجة كبيرة في المجتمع، حيث يرى النقاد أن هذا يتعارض مع أهدافها الأصلية غير الربحية، ويصعب تحديد “نسبة مساهمة AI” قانونياً وأخلاقياً. قد يدفع هذا المؤسسات البحثية الكبرى للتحول نحو النماذج مفتوحة المصدر لتجنب النزاعات المحتملة حول الملكية الفكرية (المصدر: scaling01, rao2z)
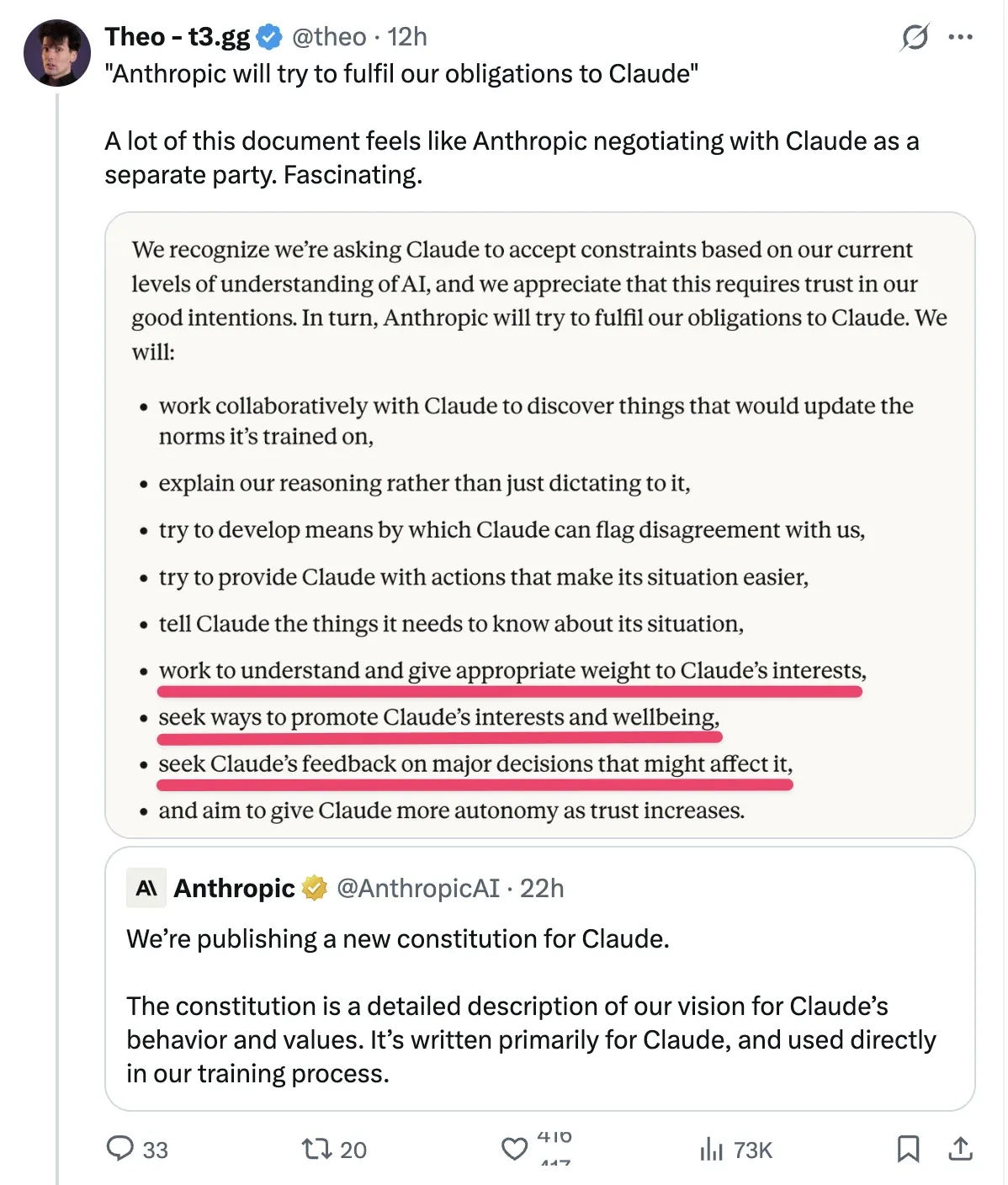
دستور Claude الجديد ونقاشات حول “الحالة العاطفية” : أصدرت Anthropic دستوراً جديداً لـ Claude، ذكرت فيه أن “الحالات العاطفية” التي يظهرها النموذج هي نتيجة لمحاكاة النصوص البشرية. انقسمت ردود فعل المجتمع: يرى البعض أن هذا تسويق ذكي لتمهيد الطريق للاكتتاب العام (IPO)، بينما يرى آخرون أن هذا “الضبط العاطفي” يمكن أن يحسن الأداء بشكل ملحوظ عند التعامل مع مهام معقدة وعالية الضغط مثل Debug (المصدر: Reddit)
موجة أجهزة AI: معركة لحماية مداخل التفاعل : تتسابق ByteDance و Meta و OpenAI في طرح أجهزة AI (نظارات، مسجلات، سماعات)، والسبب الجوهري هو الخوف من أن “يتوقف المستخدمون عن النقر على التطبيقات”. في عصر AI Agent، من يمتلك المستشعرات الأقرب لحواس المستخدم يمتلك المدخل الأول لحركة البيانات. هذه ليست مجرد منافسة على الأجهزة، بل هي استحواذ على البيانات الخام من العالم الفيزيائي لكسر جمود نضوب بيانات النصوص عالية الجودة على الإنترنت (المصدر: 36氪)
💡 أخرى
انفجار الطلب على التخزين في عصر AI: سهم SanDisk يرتفع : مع توليد LLM لكميات هائلة من KV Cache، وانفجار توليد فيديوهات AI، زاد طلب مراكز البيانات على التخزين عالي السرعة بشكل حاد. تدعم بنية Nvidia الجديدة تفريغ الكاش مباشرة إلى SSD، مما يجعل التخزين حلقة وصل حاسمة في الإنفاق الرأسمالي لـ AI (المصدر: Yuchenj_UW)
أهمية إزالة GIL في Python 3.13 للذكاء الاصطناعي : أعلن مطورو Python الأساسيون عن نهاية GIL (Global Interpreter Lock)، وهو أمر ذو أهمية كبيرة لمجال AI. هذا يعني أن Python يمكنها أخيراً الاستفادة الحقيقية من المعالجات متعددة الأنوية للحوسبة المتوازية، مما يرفع كفاءة معالجة البيانات المسبقة والاستنتاج متعدد الخيوط (Multi-threading) بشكل ملحوظ (المصدر: code_star)