Ключевые слова:Искусственный интеллект для логического вывода, Открытые модели, Большие языковые модели, Движок логического вывода vLLM, Синтез речи Qwen3-TTS, Агентное рассуждение
🔥 В фокусе
Основная команда vLLM привлекла $150 млн для основания Inferact : Учредители открытого движка для inference vLLM объявили о создании стартапа Inferact, получив $150 млн в посевном раунде под руководством a16z и Lightspeed при оценке в $800 млн. Это знаменует официальный переход фокуса конкуренции в AI-индустрии от «обучения моделей» к «сервисам inference». С ростом масштаба моделей и сложности архитектур ключевым узким местом становится обеспечение низкой стоимости и высокой эффективности их работы. Inferact стремится превратить vLLM в «Linux для inference» в эпоху AI, решая проблему фрагментации оборудования через стандартизированный программный стек. Этот шаг отражает высокое признание рынком капитала уровня AI-инфраструктуры; снижение стоимости inference напрямую ускорит демократизацию AI-приложений (Источник: woosuk_k, 36氪)
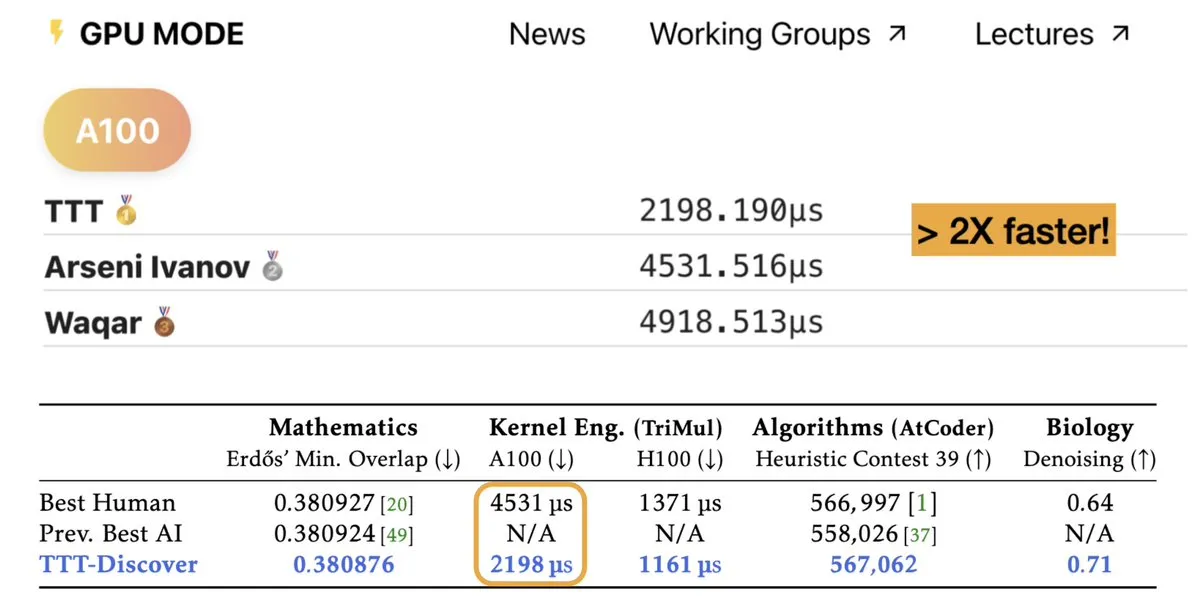
TTT-Discover: AI совершает научные открытия через Test-time training : Новое исследование под названием TTT-Discover демонстрирует потенциал AI превосходить текущий человеческий уровень в таких областях, как математика, kernel engineering и дизайн алгоритмов. Метод использует Reinforcement Learning во время теста, позволяя модели непрерывно обучаться под конкретную задачу, а не полагаться только на замороженные веса после pre-training. Эксперименты показали, что при затратах на вычислительные мощности менее $500 метод обновил рекорды в проблеме минимального перекрытия Erdős и в соревнованиях по оптимизации GPU-ядер. Это доказывает, что «Inference-time compute» не только улучшает логические способности, но и служит двигателем для открытия новых знаний, предвещая эволюцию AI от «переносчика знаний» к настоящему «научному исследователю» (Источник: charles_irl, _akhaliq)
Релиз Qwen3-TTS: новая веха в открытом синтезе речи : Команда Alibaba Qwen выпустила серию моделей Qwen3-TTS, поддерживающих сверхбыстрое клонирование голоса за 3 секунды и 10 языков с задержкой потоковой передачи всего 97 мс. Семейство включает версии VoiceDesign, CustomVoice и Base, использует архитектуру Dual-track LM и достигает уровня SOTA по качеству речи, контролю эмоций и скорости inference. Сообщество считает это самым прорывным релизом в сфере Open Source TTS; лицензия Apache 2.0 и мощные возможности адаптации на стороне устройства (например, поддержка MLX-Audio) дадут огромный толчок развитию персонализированных голосовых помощников и приложений для диалогов в реальном времени (Источник: Alibaba_Qwen, Reddit)

Глубокий аудит авторитетных бенчмарков HLE и GPQA выявил пугающий уровень ошибок : Независимый исследователь провел форензик-аудит тестов «Humanity’s Last Exam» (HLE) и GPQA, обнаружив, что из-за ошибок OCR и опечаток уровень ошибок валидации в HLE достигает ~58%, а в GPQA — ~26.8%. Многие случаи, классифицированные как «галлюцинации модели», на самом деле были правильными ответами, которые помечались как неверные, потому что модель не могла «телепатически» угадать опечатки в условии. Это открытие вызвало огромные сомнения в надежности текущих лидербордов AI. Возможно, мы оцениваем лучшие модели «сломанной линейкой», и лаборатории тратят миллионы долларов на оптимизацию под ошибки, а не на реальное повышение интеллекта (Источник: Reddit)
🎯 Тренды
Реорганизация внутренней версии Meta Llama 4 после критики CTO : CTO Meta Bosworth сообщил, что ранние версии Llama 4 разочаровали, так как им «не хватало точки зрения» и они были посредственными. В связи с этим Meta реорганизовала AI-команду под руководством Alexandr Wang и планирует выпустить новую модель в первой половине этого года. Внутри компании до сих пор идут жаркие споры о том, стоит ли открывать исходный код модели и как это сделать. Это отражает тот факт, что для ведущих лабораторий в погоне за AGI простое наращивание параметров больше не приносит сюрпризов; ключевыми точками конкуренции становятся наделение модели уникальным «способом мышления» и оптимизация после обучения (Источник: ylecun)
Ежемесячный ARR бизнеса OpenAI API превысил $1 млрд : Sam Altman объявил, что бизнес OpenAI API за последний месяц добавил более $1 млрд к годовой повторяющейся выручке (ARR). Такой ошеломляющий рост показывает, что хотя ChatGPT занимает умы широкой публики, рынок B2B-разработчиков становится настоящим двигателем роста OpenAI. По мере перехода корпоративных AI-приложений от пилотов к масштабному внедрению, потребление API растет экспоненциально, и OpenAI быстро закрепляет за собой статус «оптового поставщика вычислительных мощностей и интеллекта» в эпоху AI (Источник: sama)
Обзор Agentic Reasoning: от статического мышления к динамическим действиям : В обзорной статье на 135 страницах систематизирована новая парадигма интеллекта LLM — Agentic Reasoning. Исследование утверждает, что LLM отлично справляются в закрытых средах (closed-loop), но испытывают трудности в открытых динамических средах, где недостающим звеном является «действие». Фреймворк разделяет рассуждения на три измерения: базовые, самоэволюционирующие и коллективные мультиагентные. Это означает, что будущее AI не в большем количестве параметров, а в том, как непрерывно развиваться через взаимодействие с окружающей средой, обратную связь и память (Источник: omarsar0)

Vibe Coding вызывает опасения о «банкротстве понимания» : С популяризацией таких инструментов, как Claude Code и Devin, в сообществе разработчиков началось активное обсуждение феномена «Vibe Coding». Опытные инженеры обеспокоены тем, что когда AI мгновенно выполняет работу, требующую часов, люди теряют глубокое понимание кодовой базы, формируя «долг понимания». Хотя краткосрочная продуктивность выросла на 20-30%, в долгосрочной перспективе сложность отладки системных сбоев будет расти экспоненциально. Будущая разработка ПО может превратиться в «мониторинг ситуации» вместо «написания логики», что требует создания совершенно новых систем обеспечения качества кода (Источник: jon_stokes, jeremyphoward)
🧰 Инструменты
Выпуск GitHub Copilot SDK: встраивание агентных рабочих процессов в любое приложение : GitHub представил программируемый SDK, позволяющий разработчикам встраивать основной движок Copilot напрямую в свои приложения. Разработчикам не нужно строить сложные уровни оркестрации — достаточно определить намерения и поведение, чтобы Copilot выполнял задачи. Это знаменует трансформацию AI-помощников из независимых инструментов в подключаемую универсальную возможность, значительно снижая порог входа для разработки автономных агентных приложений (Источник: pierceboggan)
Devin Review: переосмысление процесса код-ревью : Cognition представила Devin Review, цель которого — глубокое понимание сложных PR с помощью AI, чтобы помочь разработчикам избавиться от низкокачественного «кодового мусора». Инструмент не только выявляет логические ошибки, но и строит карту понимания кода, предотвращая катастрофы в поддержке из-за чрезмерной зависимости от AI-генерации. Сообщество отмечает его отличную работу при масштабном рефакторинге и кросс-модульных изменениях (Источник: cognition, swyx)
LlamaParse v2: структурная революция в парсинге документов : LlamaIndex переработала свой API для парсинга документов, выпустив версию v2 и новый LlamaCloud SDK. Новая версия значительно упрощает процесс настройки, поддерживает точный контроль структурированного вывода (например, Markdown, JSON) и обеспечивает полную паритетную поддержку Python и TypeScript. Это создает более прочный фундамент для построения RAG-приложений, способных обрабатывать сложные многоколоночные документы с диаграммами (Источник: jerryjliu0)

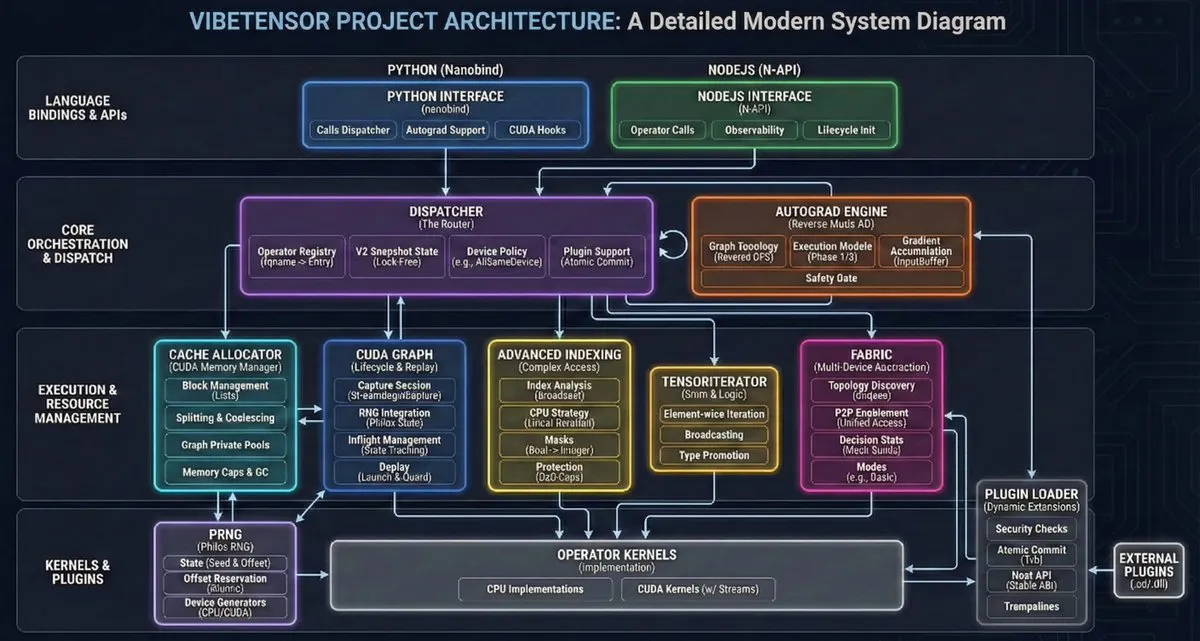
VibeTensor: первая система глубокого обучения, полностью созданная AI-агентами : NVlabs открыла исходный код VibeTensor — фреймворка для глубокого обучения, полностью сгенерированного AI-агентами, включая 47 000 строк автоматически созданного кода Triton kernel. Хотя на данный момент его эффективность на некоторых критических путях уступает PyTorch (так называемый «эффект Франкенштейна»), он доказывает, что AI уже способен проектировать и реализовывать сложные низкоуровневые системные архитектуры, знаменуя приход эры «AI пишет AI» (Источник: JvNixon)
💼 Бизнес
Meta планирует приобрести Manus AI за $2-3 млрд : По сообщениям, Meta достигла соглашения о покупке стартапа в области автономных агентов Manus AI за огромную сумму. Этот шаг направлен на интеграцию проверенных рынком возможностей Agent во всю линейку продуктов, включая Facebook, Instagram и WhatsApp. Это отражает стремление социальных гигантов к активному выполнению задач в «эпоху после чат-ботов» (Источник: DeepLearningAI)

LiveKit завершил раунд финансирования серии C на $100 млн : Платформа инфраструктуры Voice AI LiveKit привлекла $100 млн для упрощения процесса создания голосовых AI-приложений. Поскольку голосовое взаимодействие в реальном времени (например, Doubao, OpenAI Advanced Voice Mode) становится насущной потребностью, спрос разработчиков на услуги потоковой передачи голоса с низкой задержкой и высокой надежностью переживает взрывной рост (Источник: juberti)
World Labs Ли Фэйфэй планирует привлечь $500 млн при оценке в $5 млрд : Стартап в области «пространственного интеллекта» (Spatial Intelligence) World Labs, основанный Ли Фэйфэй, ведет переговоры о новом раунде финансирования. Мировые модели (World Models) рассматриваются как следующая волна в играх и робототехнике, призванная наделить AI способностью понимать законы физического мира (Источник: kylebrussell)
📚 Обучение
Эндрю Ын выпустил курс по Gemini CLI : DeepLearning.AI представила новый курс, обучающий использованию открытого Gemini CLI для создания агентов. Курс охватывает практические навыки оркестрации таких инструментов, как GitHub, Canva и Google Workspace, с помощью MCP-серверов. Акцент сделан на понимании архитектуры открытых агентов, что позволяет разработчикам прозрачно контролировать логику принятия решений AI (Источник: AndrewYNg)
Глубокая лекция по алгоритмам маршрутизации MoE : На YouTube вышла системная лекция об алгоритмах маршрутизации в моделях Mixture of Experts (MoE), охватывающая основы MoE, механизмы маршрутизации, проблему перегрузки экспертов и решения по оптимизации. Отличный ресурс для разработчиков, желающих понять механизмы высокой производительности таких моделей, как DeepSeek (Источник: ben_burtenshaw)
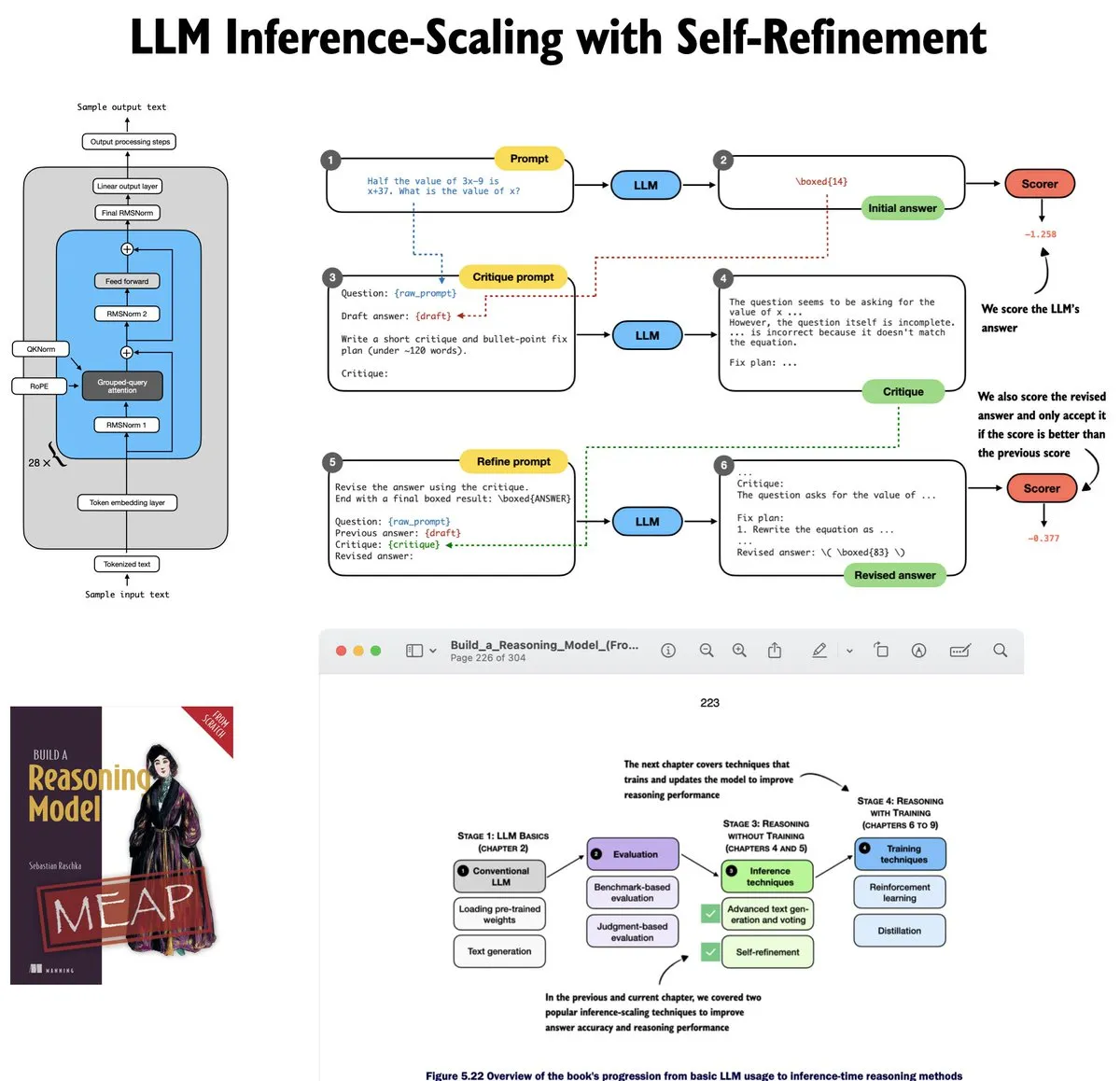
Обновление туториала по самосовершенствованию LLM (Self-Refinement) : Себастьян Рашка обновил пятую главу своего туториала по LLM, сфокусировавшись на Inference-time scaling. Туториал через код с нуля реализует логику итеративной самооценки и улучшения модели, помогая учащимся понять математическую и инженерную реализацию методов рассуждения LLM (Источник: nerdai)
🌟 Сообщество
Планы OpenAI забирать долю прибыли от «открытий с помощью AI» вызвали споры : CFO OpenAI сообщил, что в будущем компания может претендовать на долю прибыли от научных открытий или изобретений, сделанных клиентами с помощью AI. Эта новость вызвала бурю негодования в сообществе; критики считают, что это противоречит изначальным некоммерческим целям и трудноопределимо юридически и этически («доля вклада AI»). Это может привести к тому, что ведущие научные институты перейдут на открытые модели, чтобы избежать потенциальных споров об интеллектуальной собственности (Источник: scaling01, rao2z)
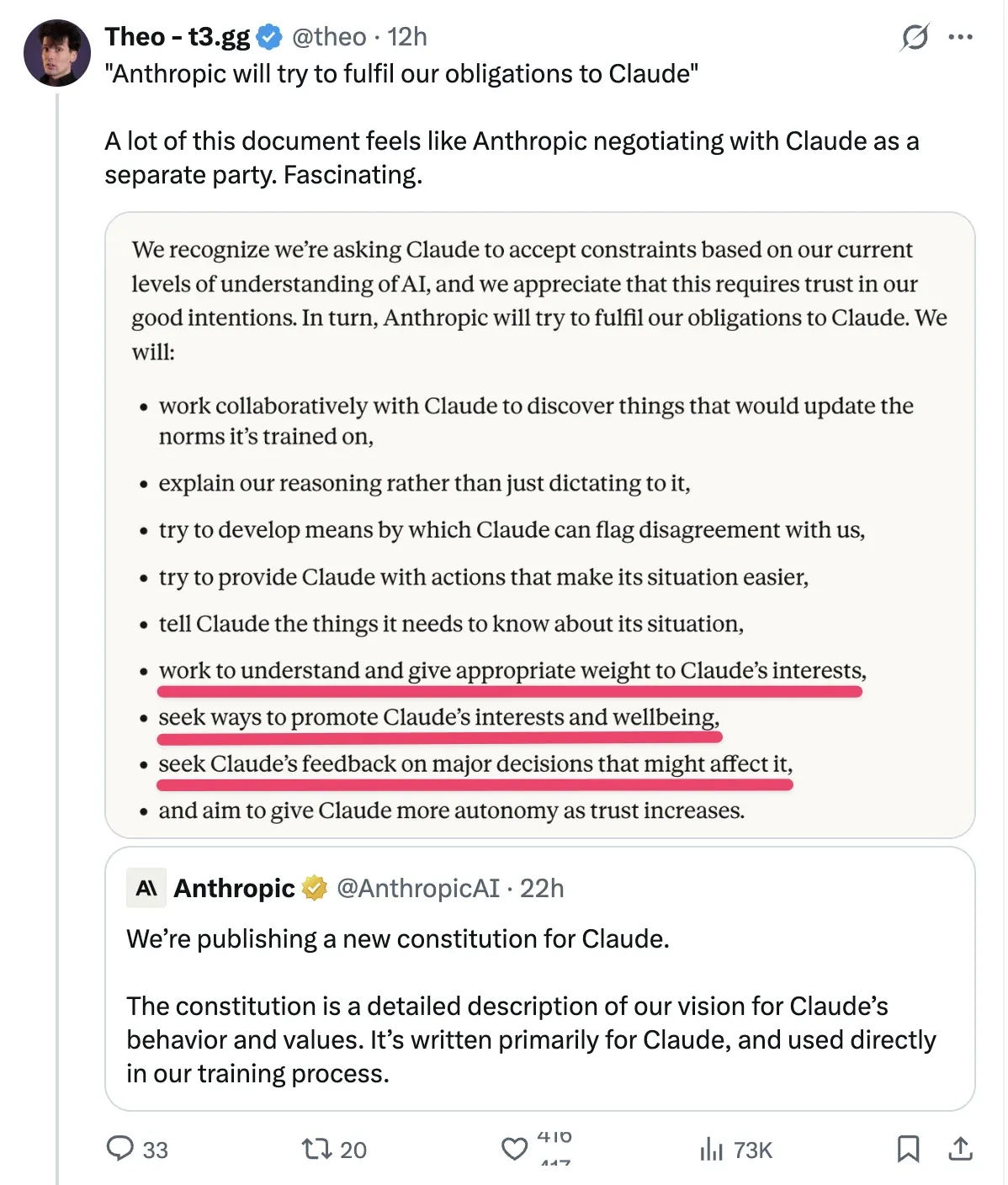
Новая конституция Claude и обсуждение «эмоциональных состояний» : Anthropic опубликовала новую конституцию Claude, в которой упоминается, что проявляемые моделью «эмоциональные состояния» являются результатом имитации человеческих текстов. Реакция сообщества разделилась: одни считают это умным маркетингом для подготовки к IPO, другие полагают, что такая «эмоциональная настройка» может значительно улучшить результаты при выполнении сложных и стрессовых задач, таких как Debug (Источник: Reddit)
Бум AI-железа: битва за точки входа во взаимодействие : ByteDance, Meta и OpenAI активно развивают AI-устройства (очки, диктофоны, наушники), что по сути является страхом того, что «пользователи перестанут кликать по приложениям». В эпоху AI Agent тот, кто владеет сенсорами, ближайшими к органам чувств пользователя, владеет первой точкой входа трафика. Это не только конкуренция оборудования, но и захват нативных данных физического мира, призванный выйти из тупика истощения качественных текстовых данных в интернете (Источник: 36氪)
💡 Прочее
Взрыв спроса на хранение данных в эпоху AI: акции SanDisk взлетели : С генерацией огромных объемов KV cache в LLM и бумом генерации AI-видео, спрос дата-центров на высокоскоростные хранилища резко вырос. Новая архитектура Nvidia поддерживает выгрузку кэша напрямую на SSD, что делает хранение данных ключевым звеном в капитальных затратах на AI (Источник: Yuchenj_UW)
Значение удаления GIL в Python 3.13 для AI : Основные разработчики Python объявили о конце GIL (Global Interpreter Lock), что имеет огромное значение для сферы AI. Это означает, что Python наконец-то сможет по-настоящему использовать многоядерные CPU для параллельных вычислений, значительно повышая эффективность предобработки данных и многопоточного inference (Источник: code_star)