
Mots-clés:Inférence IA, Modèle open source, Grand modèle linguistique, Moteur d’inférence vLLM, Synthèse vocale Qwen3-TTS, Raisonnement agentique
🔥 À la Une
L’équipe principale de vLLM lève 150M$ pour fonder Inferact : Les membres fondateurs du moteur d’inférence open-source vLLM ont annoncé la création de la startup Inferact, avec une levée de fonds de 150M$ en seed round menée par a16z et Lightspeed, portant sa valorisation à 800M$. Cela marque un tournant dans l’industrie de l’IA où la compétition se déplace officiellement du “training des modèles” vers les “services d’inférence”. Avec la complexification des architectures et la croissance des modèles, l’exécution efficace et économique devient le goulot d’étranglement principal. Inferact ambitionne de faire de vLLM le “Linux de l’inférence” en standardisant la stack logicielle pour résoudre la fragmentation matérielle. Ce mouvement reflète la reconnaissance par les marchés capitaux de l’importance cruciale de l’infrastructure IA, où la réduction des coûts d’inférence accélérera directement la démocratisation des applications d’IA (Source: woosuk_k, 36Kr)
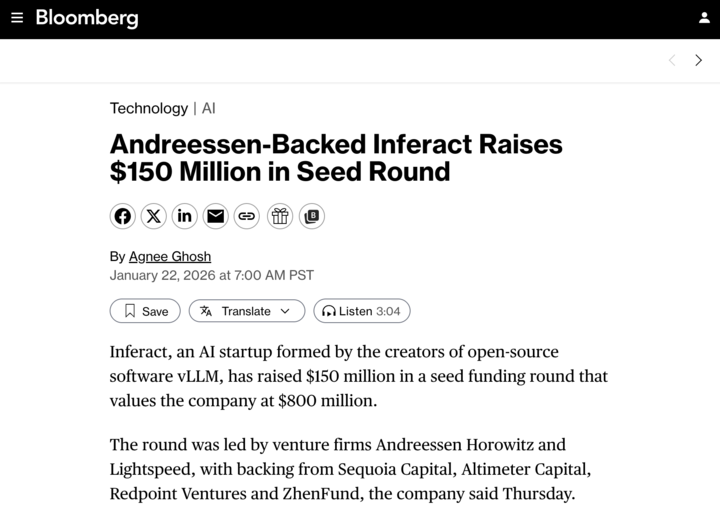
TTT-Discover : L’IA réalise des découvertes scientifiques via le training during testing : Une nouvelle recherche nommée TTT-Discover démontre le potentiel de l’IA à surpasser les connaissances humaines en mathématiques, ingénierie de kernels et conception d’algorithmes. La méthode utilise du reinforcement learning pendant les tests, permettant au modèle d’apprendre continuellement pour des problèmes spécifiques plutôt que de s’appuyer sur des poids pré-entraînés figés. Les expériences montrent qu’avec moins de 500$ de calcul, la méthode a battu des records sur le problème de recouvrement minimal d’Erdős et des compétitions d’optimisation de kernels GPU. Cela prouve que le “calcul pendant l’inférence” peut non seulement améliorer les capacités logiques, mais aussi servir de moteur à de nouvelles découvertes, annonçant une évolution de l’IA de “porteur de connaissances” vers un véritable “chercheur scientifique” (Source: charles_irl, _akhaliq)
Sortie de Qwen3-TTS : Un jalon pour la synthèse vocale open-source : L’équipe Qwen d’Alibaba a publié la série de modèles Qwen3-TTS, supportant le clonage vocal en 3 secondes et 10 langues, avec une latence streaming de seulement 97ms. La famille inclut les versions VoiceDesign, CustomVoice et Base, utilisant une architecture à double LM atteignant des performances SOTA en qualité vocale, contrôle émotionnel et vitesse d’inférence. La communauté considère cette version comme la plus disruptive dans le domaine open-source TTS, avec sa licence Apache 2.0 et ses capacités d’adaptation edge (comme MLX-Audio) qui accéléreront le développement d’assistants vocaux personnalisés et d’applications conversationnelles en temps réel (Source: Alibaba_Qwen, Reddit)

Audit approfondi des benchmarks HLE et GPQA : Taux d’erreur alarmant : Un chercheur indépendant a audité “Humanity’s Last Exam” (HLE) et GPQA, révélant des taux d’erreur de validation de ~58% pour HLE (erreurs OCR et fautes de frappe) et ~26.8% pour GPQA. De nombreux cas étiquetés comme “hallucinations du modèle” étaient en fait des réponses correctes que le modèle ne pouvait pas “deviner” à cause d’erreurs de mise en page dans les questions. Ces découvertes soulèvent des doutes majeurs sur la fiabilité des classements actuels d’IA. Nous pourrions “vaporiser” les meilleurs modèles avec des règles défectueuses, où les labos dépensent des millions à optimiser l’ajustement à des erreurs plutôt qu’à une véritable intelligence (Source: Reddit)
🎯 Tendances
La version interne de Meta Llama 4 critiquée par le CTO puis réorganisée : Le CTO de Meta, Bosworth, a révélé que la version précoce de Llama 4 était décevante, la jugeant “sans perspective” et médiocre. Meta a réorganisé son équipe IA sous la direction d’Alexandr Wang, avec un nouveau modèle prévu pour le premier semestre. Le débat interne sur l’open-source reste intense. Cela reflète que pour les labos leaders, l’empilement de paramètres ne suffit plus ; la compétition se joue désormais sur des “modes de pensée” uniques et l’optimisation post-training (Source: ylecun)
L’activité API d’OpenAI dépasse 1 milliard de dollars d’ARR mensuel : Sam Altman a annoncé que l’activité API d’OpenAI a généré plus de 1 milliard de dollars de revenus annuels récurrents (ARR) le mois dernier. Cette croissance fulgurante montre que malgré ChatGPT, le marché des développeurs B2B devient le véritable moteur. Alors que les applications IA passent du pilote au déploiement massif, la consommation d’API croît exponentiellement, consolidant OpenAI comme “grossiste en calcul et intelligence” de l’ère IA (Source: sama)
Revue sur le Agentic Reasoning : Du raisonnement statique à l’action dynamique : Un article de revue de 135 pages présente un nouveau paradigme pour l’intelligence des LLM : le raisonnement agentique (Agentic Reasoning). Les LLM excellent en environnement fermé mais peinent en milieu ouvert, par manque d‘“action”. Le cadre divise le raisonnement en trois dimensions : raisonnement de base, auto-évolutif et multi-agents collectifs. L’avenir de l’IA ne réside pas dans plus de paramètres, mais dans l’évolution continue via interaction, feedback et mémoire (Source: omarsar0)

Le “Vibe Coding” suscite des inquiétudes sur la “faillite de compréhension” : Avec l’essor d’outils comme Claude Code et Devin, la communauté débat du phénomène de “vibe coding”. Les ingénieurs expérimentés craignent que l’IA, en accomplissant en instantané des heures de travail, ne fasse perdre aux humains la compréhension profonde du code, créant une “dette de compréhension”. Si la productivité à court terme gagne 20-30%, le débogage des pannes deviendra exponentiellement plus difficile. Le développement logiciel pourrait évoluer vers une “surveillance de situation” plutôt qu’une “écriture de logique”, nécessitant de nouveaux systèmes de garantie qualité (Source: jon_stokes, jeremyphoward)
🧰 Outils
GitHub Copilot SDK : Intégrer des workflows agents dans n’importe quelle app : GitHub lance un SDK programmable permettant d’intégrer le moteur Copilot directement dans les apps. Sans couche d’orchestration complexe, les développeurs définissent simplement des intentions et comportements pour que Copilot exécute des tâches. Cela transforme les assistants IA d’outils indépendants en capacités plug-and-play universelles, abaissant radicalement le seuil des apps autonomes (Source: pierceboggan)
Devin Review : Refonte du processus de revue de code : Cognition lance Devin Review pour aider les développeurs à éviter le “code spam” grâce à une compréhension approfondie des PR complexes par l’IA. L’outil identifie les erreurs logiques et construit des cartes de compréhension pour prévenir les catastrophes de maintenance dues à une génération IA excessive. La communauté salue ses performances sur les refactos massives et changements cross-modules (Source: cognition, swyx)
LlamaParse v2 : Révolution structurelle dans l’analyse de documents : LlamaIndex restructure son API d’analyse avec la v2 et un nouveau SDK LlamaCloud. La version simplifie la configuration, supporte des sorties structurées précises (Markdown, JSON) et aligne Python et TypeScript. Cela fournit une infrastructure solide pour des apps RAG traitant des documents complexes à multiples colonnes et graphiques (Source: jerryjliu0)

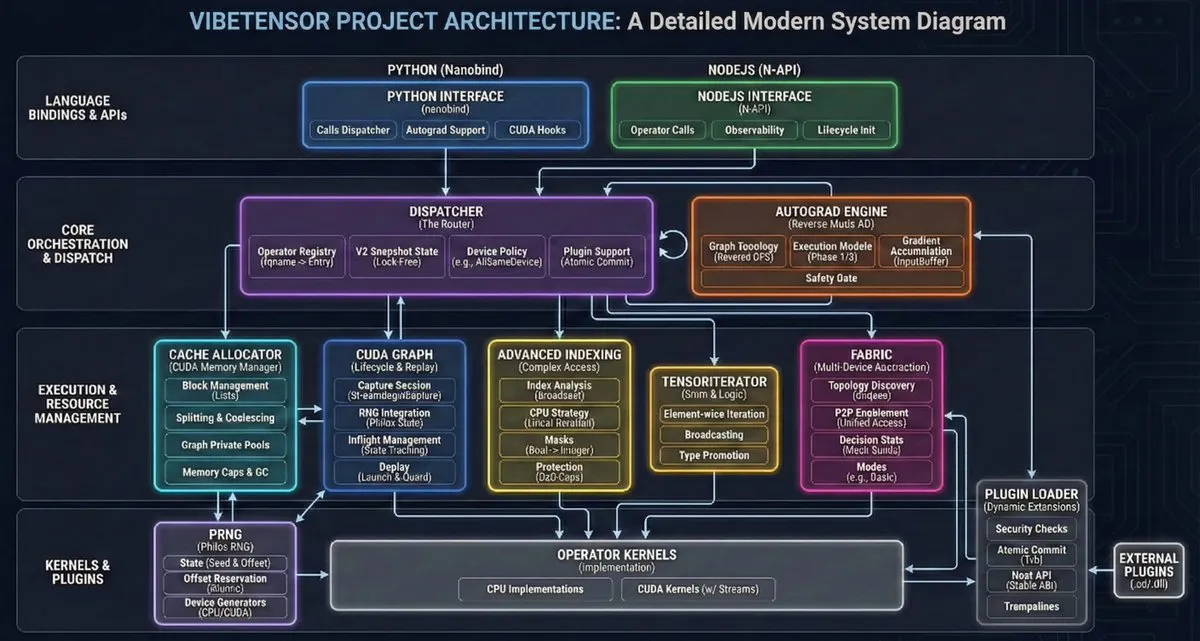
VibeTensor : Premier système deep learning généré automatiquement par des agents IA : NVlabs open-source VibeTensor, un framework deep learning généré entièrement par des agents IA, incluant 47k lignes de code Triton auto-généré. Bien que moins efficace que PyTorch sur certains chemins critiques (effet “Frankenstein”), il prouve que l’IA peut concevoir et implémenter des architectures système complexes, marquant l’avènement de l‘“IA écrivant l’IA” (Source: JvNixon)
💼 Business
Meta envisage d’acquérir Manus AI pour 2-3 milliards de dollars : Meta aurait conclu un accord pour acquérir la startup d’agents autonomes Manus AI. L’objectif est d’intégrer ses capacités validées dans Facebook, Instagram et WhatsApp. Cela reflète l’appétit des géants du social pour des capacités d’exécution proactive dans l’ère post-chatbots (Source: DeepLearningAI)

LiveKit lève 100M$ en série C : La plateforme d’infrastructure vocale IA LiveKit a levé 100M$ pour simplifier la construction d’apps vocales IA. Alors que les interactions vocales temps réel (comme le mode vocal avancé d’OpenAI) deviennent essentielles, la demande pour des services de streaming vocal à faible latence explose (Source: juberti)
World Labs de Fei-Fei Li vise 500M$ à 5 milliards de valorisation : La startup “d’intelligence spatiale” de Fei-Fei Li, World Labs, négocie un nouveau tour de financement. Les modèles mondiaux (World Models) sont perçus comme la prochaine vague pour les jeux et robots, visant à doter l’IA d’une compréhension des lois physiques (Source: kylebrussell)
📚 Apprentissage
Andrew Ng publie un cours sur Gemini CLI : DeepLearning.AI propose un nouveau cours sur la construction d’agents avec le CLI open-source Gemini. Le cours couvre des techniques pratiques pour orchestrer GitHub, Canva et Google Workspace via un serveur MCP, en mettant l’accent sur l’architecture transparente des agents open-source (Source: AndrewYNg)
Conférence approfondie sur les algorithmes de routage MoE : Une conférence systématique sur les mécanismes de routage des modèles Mixture of Experts (MoE) est disponible sur YouTube, couvrant les bases, le routage, la surcharge d’experts et les optimisations. Une ressource précieuse pour comprendre les mécanismes derrière les hautes performances de modèles comme DeepSeek (Source: ben_burtenshaw)
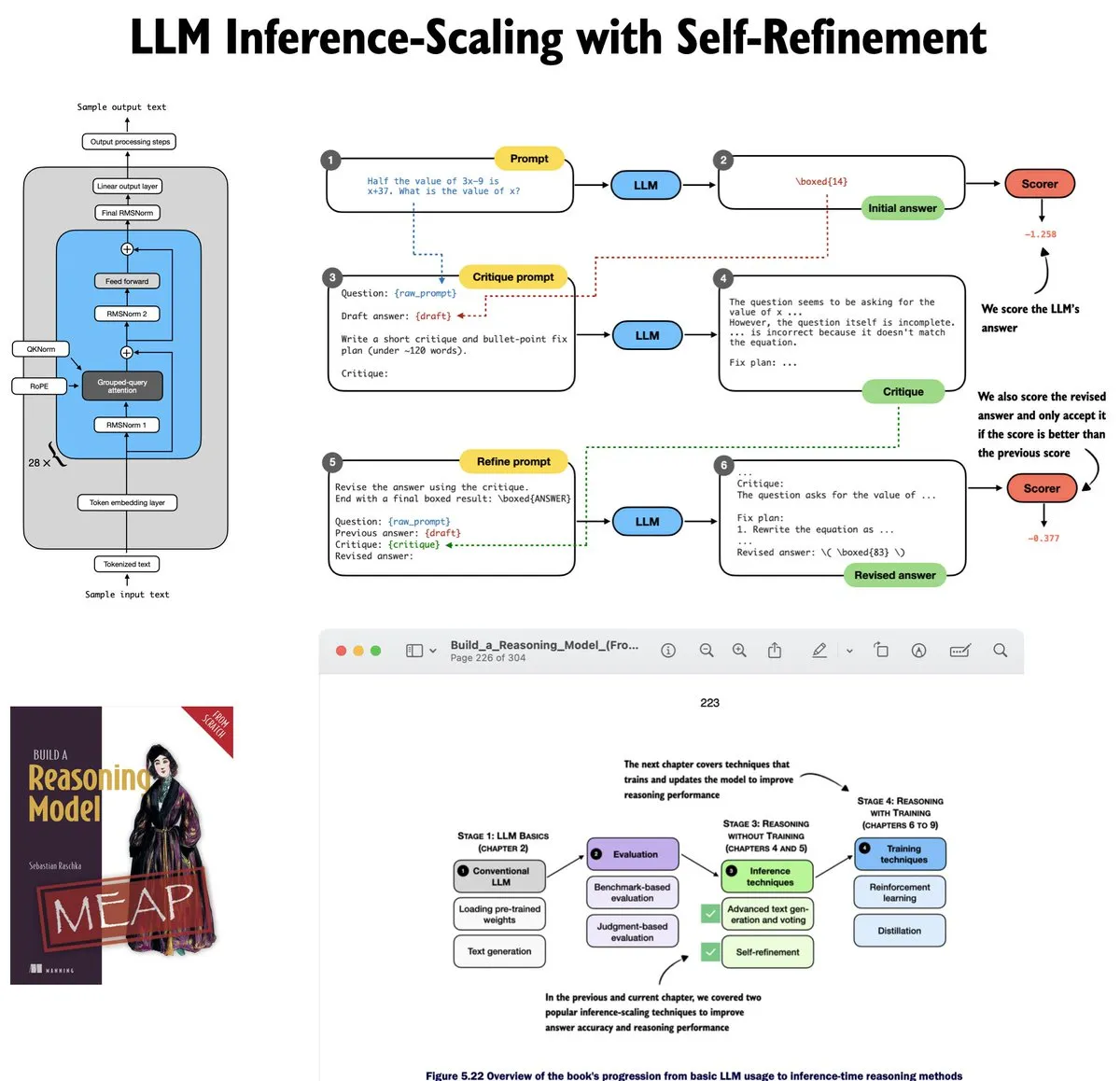
Mise à jour du tutoriel sur l’auto-amélioration des LLM : Sebastian Raschka a mis à jour le chapitre 5 de son tutoriel LLM, axé sur le scaling pendant l’inférence. Le tutoriel implémente de zéro la logique d’auto-évaluation et d’amélioration itérative des modèles, révélant les mathématiques et l’ingénierie derrière les méthodes d’inférence LLM (Source: nerdai)
🌟 Communauté
Le projet de prélèvement sur les découvertes assistées par IA d’OpenAI crée la polémique : Le CFO d’OpenAI a évoqué une future prise de participation sur les profits issus de découvertes scientifiques ou inventions assistées par IA. La communauté réagit vivement, critiquant une trahison de la mission non-lucrative et des difficultés éthiques à définir la “contribution de l’IA”. Cela pourrait pousser les institutions vers des modèles open-source pour éviter les litiges de propriété intellectuelle (Source: scaling01, rao2z)
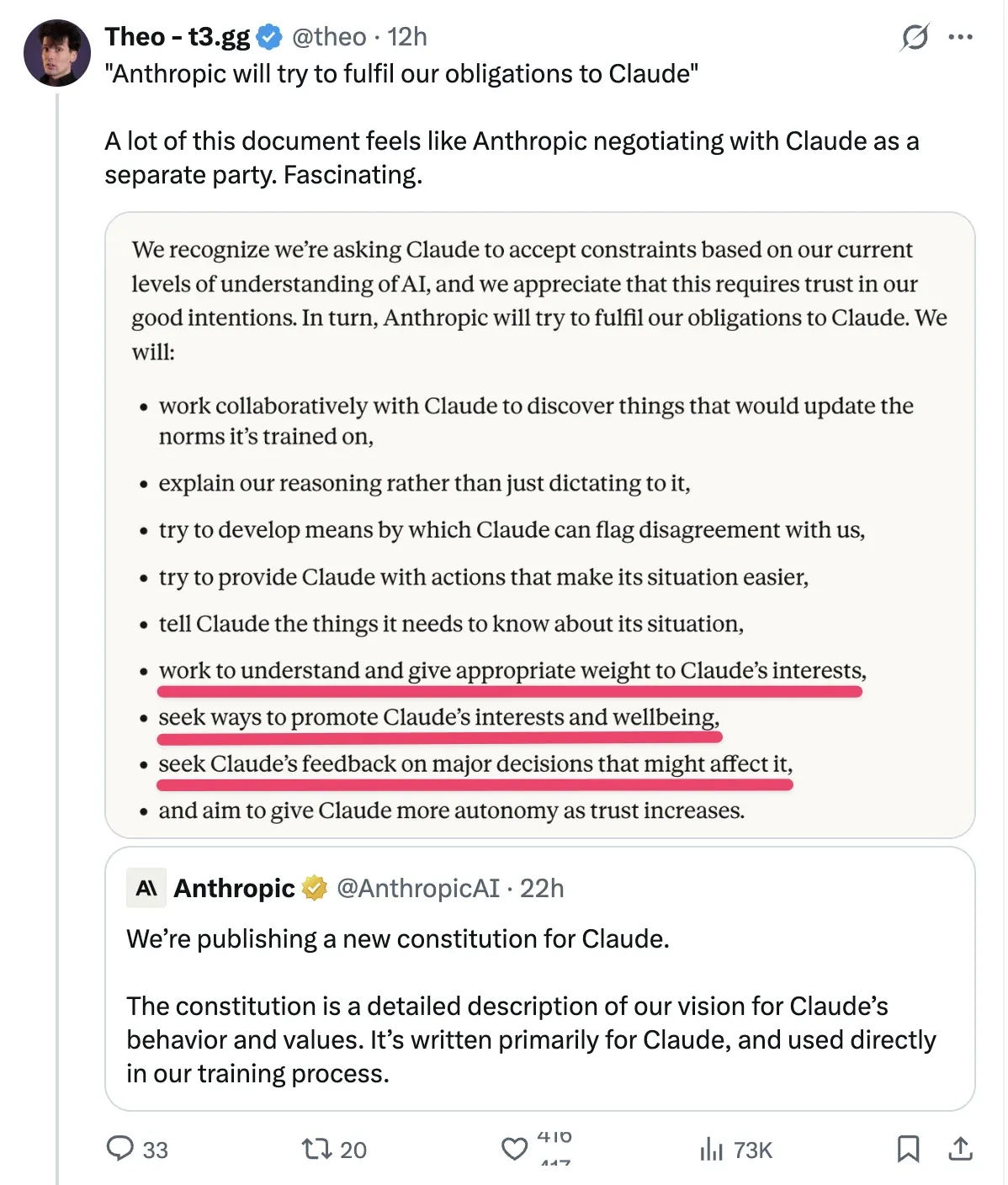
La nouvelle constitution de Claude et le débat sur les “états émotionnels” : Anthropic a publié une nouvelle constitution pour Claude, mentionnant que ses “états émotionnels” imitent des textes humains. La communauté est divisée : certains y voient du marketing habile en vue de l’IPO, d’autres estiment que ce “réglage émotionnel” améliore les performances sur tâches complexes comme le débogage (Source: Reddit)
La ruée vers le hardware IA : La bataille pour l’accès utilisateur : ByteDance, Meta et OpenAI investissent dans des hardware IA (lunettes, pods, écouteurs), craignant que “les utilisateurs ne cliquent plus sur les apps”. À l’ère des agents IA, qui contrôle les capteurs les plus proches des sens utilisateur contrôle le flux. C’est une compétition pour les données natives du monde physique, visant à pallier l’épuisement des données textuelles de qualité sur internet (Source: 36Kr)
💡 Divers
L’explosion des besoins en stockage à l’ère IA : SanDisk en hausse : Avec les caches KV massifs générés par les LLM et l’essor de la génération vidéo IA, la demande en stockage haute vitesse explose dans les data centers. La nouvelle architecture Nvidia supporte le déchargement direct des caches sur SSD, faisant du stockage un maillon clé des dépenses IA