
Palavras-chave:Inferência de IA, Modelo de código aberto, Modelo de linguagem grande, Motor de inferência vLLM, Síntese de voz Qwen3-TTS, Raciocínio Agente
🔥 Destaque
Equipa central do vLLM angaria 150 milhões de dólares para fundar a Inferact: Os membros fundadores do motor de inferência de código aberto vLLM anunciaram a criação da startup Inferact, tendo angariado uma ronda de financiamento inicial de 150 milhões de dólares liderada pela a16z e Lightspeed, com uma avaliação de 800 milhões de dólares. Este marco assinala a mudança do foco competitivo na indústria de IA de “treino de modelos” para “serviços de inferência”. À medida que a escala dos modelos e a complexidade da arquitetura aumentam, a execução eficiente e de baixo custo tornou-se o principal gargalo. A Inferact pretende transformar o vLLM no “Linux da inferência” da era da IA, resolvendo a fragmentação de hardware através de uma stack de software padronizada. Esta iniciativa reflete o elevado reconhecimento do mercado de capitais pela camada de infraestrutura de IA, e a redução dos custos de inferência acelerará diretamente a democratização das aplicações de IA (Fonte: woosuk_k, 36Kr)
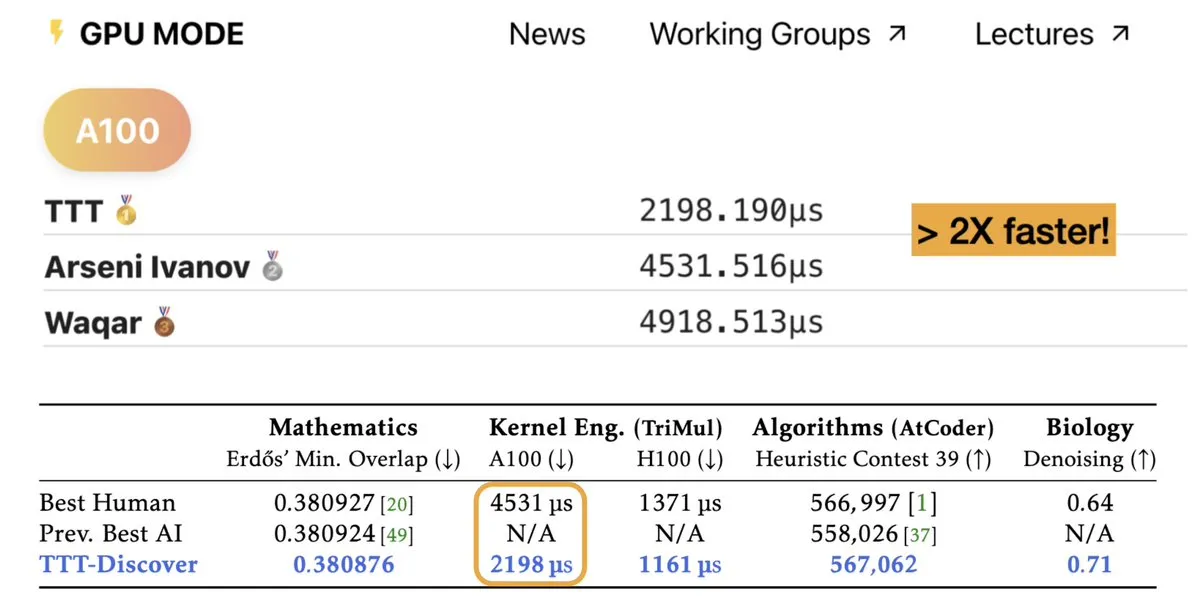
TTT-Discover: IA realiza descobertas científicas através de treino durante teste: Uma nova investigação denominada TTT-Discover demonstrou o potencial da IA para superar o conhecimento humano atual em áreas como matemática, engenharia de kernels e design de algoritmos. O método utiliza aprendizagem por reforço durante o teste, permitindo que o modelo aprenda continuamente para problemas específicos, em vez de depender apenas de pesos pré-treinados congelados. Os resultados mostraram que, com menos de 500 dólares de poder computacional, o método estabeleceu novos recordes no problema de sobreposição mínima de Erdős e em competições de otimização de kernels GPU. Isto prova que o “cálculo durante inferência” não só melhora a capacidade lógica, mas também funciona como um motor para descobrir novos conhecimentos, indicando que a IA evoluirá de “transportadora de conhecimento” para verdadeira “investigadora científica” (Fonte: charles_irl, _akhaliq)
Lançamento do Qwen3-TTS: marco na síntese de voz open-source: A equipa Qwen da Alibaba lançou a família de modelos Qwen3-TTS, que suporta clonagem de voz em 3 segundos e 10 idiomas, com latência de streaming tão baixa quanto 97ms. A família inclui versões VoiceDesign, CustomVoice e Base, utilizando uma arquitetura de LM de dupla via, alcançando estado da arte em qualidade de voz, controlo emocional e velocidade de inferência. A comunidade considera este o lançamento mais disruptivo no campo open-source de TTS, e a sua licença Apache 2.0 e capacidade de adaptação a dispositivos (como suporte a MLX-Audio) impulsionarão significativamente o desenvolvimento de assistentes de voz personalizados e aplicações de conversação em tempo real (Fonte: Alibaba_Qwen, Reddit)

Auditoria profunda a benchmarks HLE e GPQA revela taxas de erro surpreendentes: Investigadores independentes realizaram uma auditoria forense aos testes “Humanity’s Last Exam” (HLE) e GPQA, descobrindo que, devido a erros de OCR e ortográficos, a taxa de erro de validação do HLE é de ~58%, e o GPQA tem ~26.8% de defeitos. Muitos casos classificados como “alucinações do modelo” eram, na verdade, o modelo a deduzir a resposta correta, mas sendo penalizado por não “adivinhar” erros de formatação nas perguntas. Esta descoberta levantou grandes dúvidas sobre a fiabilidade dos rankings atuais de IA. Estamos possivelmente a “evaporar” os melhores modelos com uma régua danificada, e os laboratórios podem estar a gastar milhões a otimizar o ajuste a erros, em vez de melhorar a inteligência genuína (Fonte: Reddit)
🎯 Tendências
Versão interna do Meta Llama 4 criticada pelo CTO e reorganizada: O CTO da Meta, Bosworth, revelou que a versão inicial do Llama 4 foi dececionante, considerando-a “sem perspetiva” e medíocre. Como resultado, a Meta reorganizou a equipa de IA sob a liderança de Alexandr Wang, com planos para lançar um novo modelo no primeiro semestre deste ano. O debate interno continua sobre se e como tornar o modelo open-source. Isto reflete que, na busca pela AGI, o simples aumento de parâmetros já não traz surpresas, e a competição agora centra-se em como dotar os modelos de “formas de pensar” únicas e otimização pós-treino (Fonte: ylecun)
Negócio de API da OpenAI atinge 1 bilião de dólares em ARR mensal: Sam Altman anunciou que o negócio de API da OpenAI gerou mais de 1 bilião de dólares em receita anual recorrente (ARR) no último mês. Este crescimento impressionante mostra que, embora o ChatGPT domine a mente do público, o mercado de desenvolvedores B2B está a tornar-se o verdadeiro motor de crescimento da OpenAI. Com as aplicações empresariais de IA a passarem de testes para implementação em escala, o consumo de APIs está a crescer exponencialmente, consolidando rapidamente a OpenAI como “fornecedor mayorista de poder computacional e inteligência” na era da IA (Fonte: sama)
Revisão de Agentic Reasoning: do pensamento estático para ação dinâmica: Um artigo de revisão de 135 páginas explora um novo paradigma para a inteligência de LLMs – o raciocínio agentivo (Agentic Reasoning). A investigação argumenta que os LLMs têm bom desempenho em ambientes fechados, mas lutam em ambientes abertos e dinâmicos, faltando-lhes “ação”. O enquadramento divide o raciocínio em três dimensões: raciocínio básico, raciocínio de auto-evolução e raciocínio coletivo multiagente. Isto sugere que o futuro da IA não está em mais parâmetros, mas em como evoluir continuamente através da interação, feedback e memória com o ambiente (Fonte: omarsar0)

“Vibe Coding” levanta preocupações sobre “falência de compreensão”: Com a popularização de ferramentas como Claude Code e Devin, a comunidade de desenvolvedores começou a debater o fenómeno do “vibe coding”. Engenheiros experientes receiam que, quando a IA consegue completar horas de trabalho em segundos, os humanos estão a perder a compreensão profunda das bases de código, criando “dívida de compreensão”. Embora a produtividade a curto prazo tenha aumentado 20-30%, a longo prazo, a dificuldade de depuração de falhas aumentará exponencialmente. O desenvolvimento de software no futuro pode evoluir para “monitorizar situações” em vez de “escrever lógica”, exigindo novos sistemas de garantia de qualidade de código (Fonte: jon_stokes, jeremyphoward)
🧰 Ferramentas
GitHub Copilot SDK lançado: incorpora fluxos de trabalho de agentes em qualquer aplicação: O GitHub lançou um SDK programável que permite aos desenvolvedores incorporar o motor central do Copilot diretamente nas suas aplicações. Sem necessidade de construir camadas complexas de orquestração, os desenvolvedores podem definir intenções e comportamentos para o Copilot executar tarefas. Isto marca a transição dos assistentes de IA de ferramentas independentes para capacidades universais plug-and-play, reduzindo significativamente a barreira de entrada para desenvolver aplicações de agentes autónomos (Fonte: pierceboggan)
Devin Review: reestrutura o processo de revisão de código: A Cognition lançou o Devin Review, que visa ajudar os desenvolvedores a evitar “lixo de código” de baixa qualidade, compreendendo profundamente PRs complexos. A ferramenta não só identifica erros lógicos, mas também constrói mapas de compreensão de código, prevenindo desastres de manutenção causados por excesso de dependência em geração por IA. O feedback da comunidade destaca o seu excelente desempenho em refatorações em larga escala e mudanças entre módulos (Fonte: cognition, swyx)
LlamaParse v2: revolução na análise estruturada de documentos: O LlamaIndex reformulou a sua API de análise de documentos, lançando a versão 2 e um novo LlamaCloud SDK. A nova versão simplifica significativamente o fluxo de configuração, suporta controlo preciso de saída estruturada (como Markdown, JSON) e oferece suporte completo em Python e TypeScript. Isto fornece uma infraestrutura mais sólida para construir aplicações RAG que processam documentos complexos, com múltiplas colunas e gráficos (Fonte: jerryjliu0)

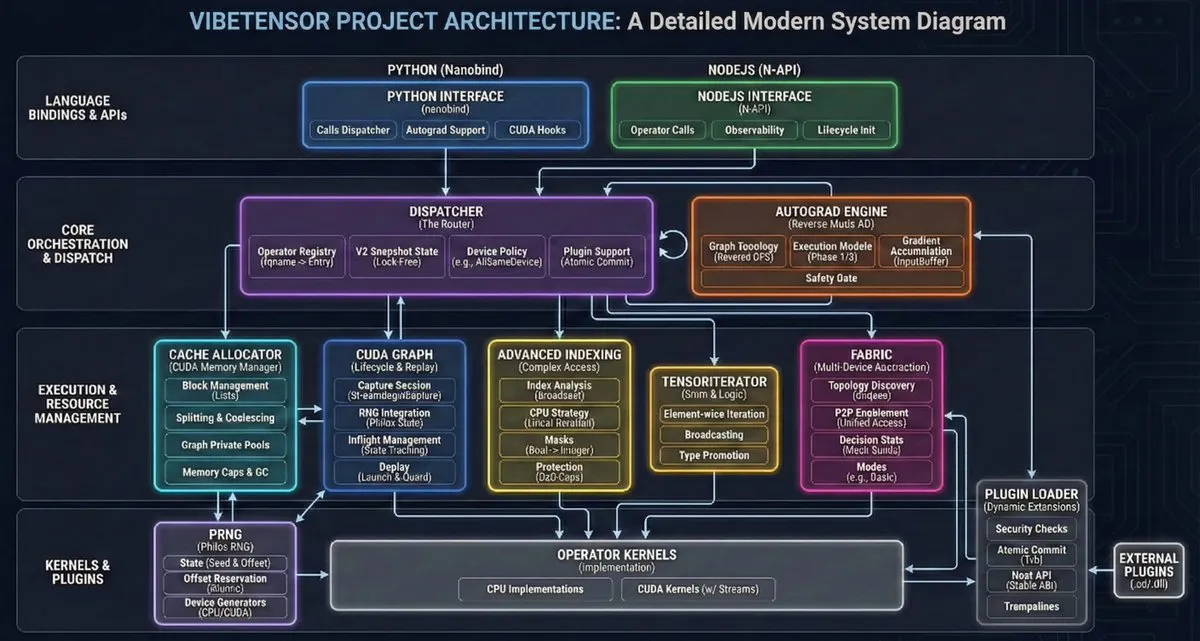
VibeTensor: primeiro sistema de deep learning gerado automaticamente por agentes de IA: A NVlabs tornou open-source o VibeTensor, uma framework de deep learning gerada inteiramente por agentes de IA, incluindo 47 mil linhas de código de kernels Triton gerados automaticamente. Embora a eficiência em certos caminhos críticos ainda não atinja o nível do PyTorch (chamado de “efeito Frankenstein”), demonstra que a IA já possui a capacidade de projetar e implementar arquiteturas de sistemas complexos, marcando a chegada da era em que “a IA escreve IA” (Fonte: JvNixon)
💼 Negócios
Meta planeia adquirir Manus AI por 2-3 biliões de dólares: Fontes indicam que a Meta chegou a um acordo para adquirir a startup de agentes autónomos Manus AI por um valor elevado. O objetivo é integrar as suas capacidades validadas pelo mercado em produtos como Facebook, Instagram e WhatsApp. Isto reflete o desejo do gigante das redes sociais por capacidades de execução proativa na “era pós-chatbots” (Fonte: DeepLearningAI)

LiveKit completa ronda de financiamento série C de 100 milhões de dólares: A plataforma de infraestrutura de voz IA LiveKit angariou 100 milhões de dólares para simplificar a construção de aplicações de voz IA. Com a interação de voz em tempo real (como o Doubao e o modo de voz avançado da OpenAI) a tornar-se uma necessidade, a procura por serviços de streaming de voz de baixa latência e alta fiabilidade está a explodir (Fonte: juberti)
World Labs de Fei-Fei Li planeia angariar 500 milhões, avaliação de 5 biliões: A startup de “inteligência espacial” World Labs, fundada por Fei-Fei Li, está em negociações para uma nova ronda de financiamento. Os modelos mundiais (World Models) são vistos como a próxima onda nos campos de jogos e robótica, visando dotar a IA com a capacidade de compreender as leis do mundo físico (Fonte: kylebrussell)
📚 Aprendizagem
Andrew Ng lança curso sobre Gemini CLI: A DeepLearning.AI lançou um novo curso que ensina a construir agentes usando o Gemini CLI open-source. O curso abrange técnicas práticas para orquestrar ferramentas como GitHub, Canva e Google Workspace usando servidores MCP. O foco está em compreender a arquitetura de agentes open-source, permitindo que os desenvolvedores entendam transparentemente a lógica de decisão da IA (Fonte: AndrewYNg)
Aula aprofundada sobre algoritmos de roteamento MoE: Uma aula sistemática sobre algoritmos de roteamento em modelos de especialistas mistos (MoE) foi disponibilizada no YouTube, cobrindo os fundamentos do MoE, mecanismos de roteamento, problemas de sobrecarga de especialistas e soluções de otimização. É um recurso excelente para desenvolvedores que querem entender os mecanismos por trás do alto desempenho de modelos como o DeepSeek (Fonte: ben_burtenshaw)
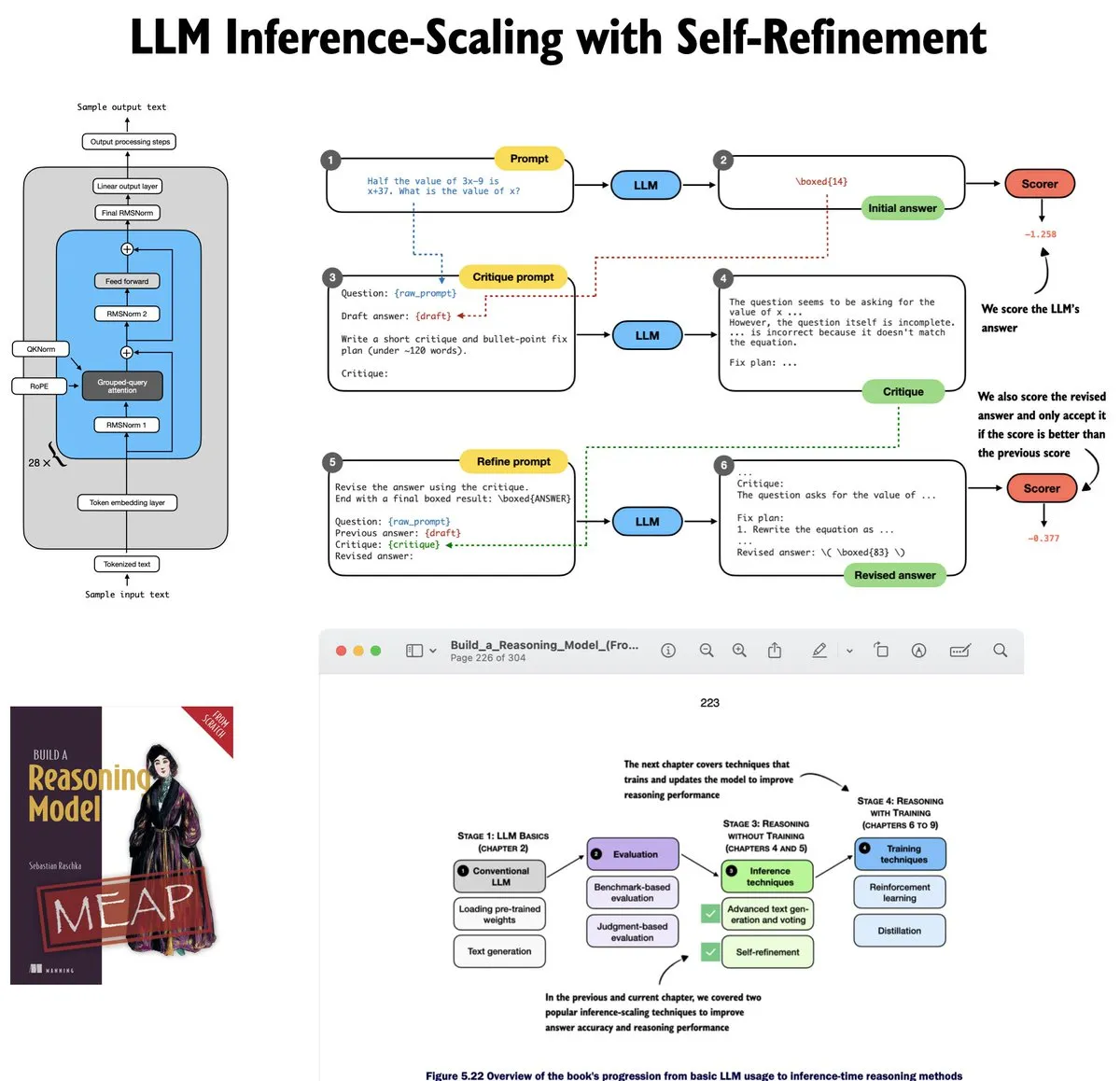
Tutorial sobre auto-melhoria (Self-Refinement) em LLMs atualizado: Sebastian Raschka atualizou o capítulo 5 do seu tutorial sobre LLMs, focando-se em escalamento durante inferência (Inference-time scaling). O tutorial implementa do zero a lógica de autoavaliação e melhoria iterativa de modelos, ajudando os aprendizes a entender a matemática e implementação por trás dos métodos de inferência de LLMs (Fonte: nerdai)
🌟 Comunidade
Plano da OpenAI para receber parte dos lucros de “descobertas assistidas por IA” gera controvérsia: O CFO da OpenAI revelou que a empresa pode no futuro receber uma percentagem dos lucros de descobertas científicas ou invenções obtidas por clientes através de IA. Esta notícia causou polémica na comunidade, com críticos a argumentar que isto viola o seu propósito sem fins lucrativos e que é difícil definir legal e eticamente a “contribuição da IA”. Isto pode levar instituições de pesquisa de topo a optar por modelos open-source para evitar disputas de propriedade intelectual (Fonte: scaling01, rao2z)
Nova constituição do Claude e debate sobre “estados emocionais”: A Anthropic publicou uma nova constituição para o Claude, mencionando que os “estados emocionais” exibidos pelo modelo são resultado da imitação de texto humano. A comunidade reagiu de forma polarizada: alguns consideram isto um marketing inteligente para preparar o IPO, enquanto outros acreditam que este “ajuste emocional” pode melhorar significativamente o desempenho em