Palabras clave:Inferencia de IA, Modelos de lenguaje grande, Modelos de código abierto, Motor de inferencia vLLM, Síntesis de voz Qwen3-TTS, Razonamiento agentivo
🔥 Enfoque
El equipo principal de vLLM recauda 150 millones de dólares para fundar Inferact : Los miembros fundadores del motor de inferencia de código abierto vLLM anunciaron la creación de la startup Inferact, tras cerrar una ronda de financiación semilla de 150 millones de dólares liderada por a16z y Lightspeed, con una valoración de 800 millones de dólares. Esto marca un cambio oficial en el centro de gravedad de la industria de la AI, pasando del “entrenamiento de modelos” a los “servicios de inferencia”. A medida que la escala de los modelos y la complejidad de las arquitecturas aumentan, la ejecución eficiente y a bajo costo se ha convertido en el principal cuello de botella. Inferact busca convertir a vLLM en el “Linux de la inferencia” para la era de la AI, resolviendo la fragmentación del hardware mediante un stack de software estandarizado. Este movimiento refleja el alto reconocimiento del mercado de capitales hacia la capa de infraestructura de AI; la reducción de los costos de inferencia acelerará directamente la democratización de las aplicaciones de AI (Fuente: woosuk_k, 36kr)
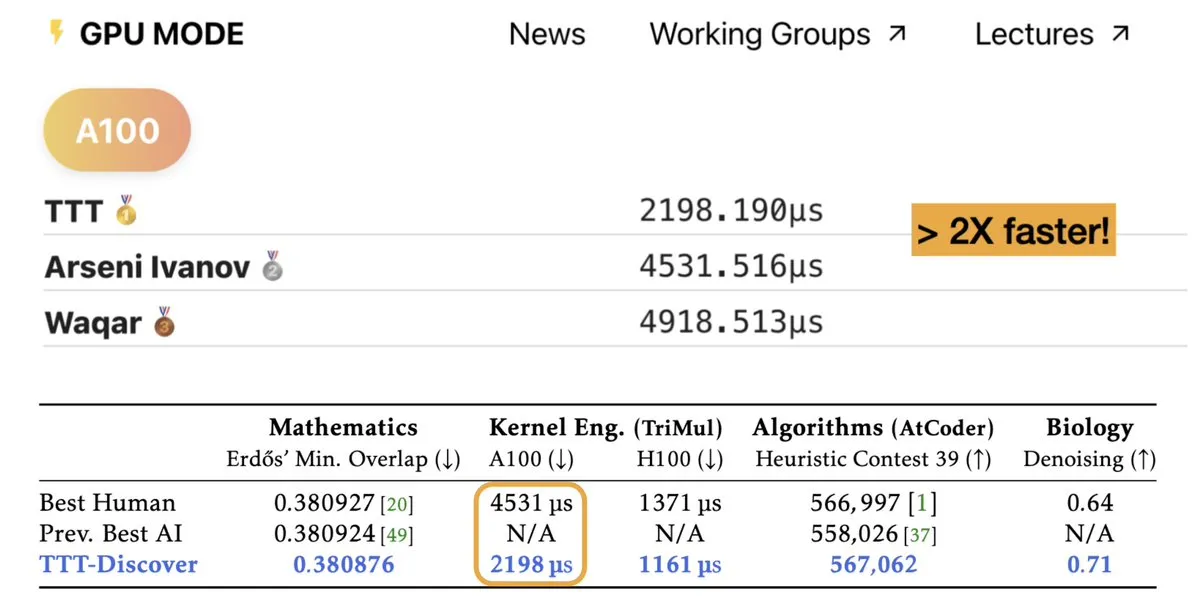
TTT-Discover: La AI logra descubrimientos científicos mediante Test-Time Training : Una nueva investigación titulada TTT-Discover demuestra el potencial de la AI para superar los niveles humanos actuales en campos como las matemáticas, la ingeniería de kernels y el diseño de algoritmos. Este método utiliza Reinforcement Learning durante el tiempo de prueba (test-time), permitiendo que el modelo aprenda continuamente para problemas específicos en lugar de depender únicamente de pesos pre-entrenados estáticos. Los experimentos mostraron que, con menos de 500 dólares en potencia de cómputo, el método rompió récords en el problema de superposición mínima de Erdős y en competencias de optimización de kernels de GPU. Esto prueba que el “Inference-time compute” no solo mejora la capacidad lógica, sino que sirve como motor para descubrir nuevo conocimiento, vaticinando la evolución de la AI de “transportador de conocimiento” a un verdadero “investigador científico” (Fuente: charles_irl, _akhaliq)
Lanzamiento de Qwen3-TTS: Un nuevo hito en la síntesis de voz de código abierto : El equipo Qwen de Alibaba lanzó la serie de modelos Qwen3-TTS, que admite clonación de voz ultrarrápida en 3 segundos y 10 idiomas, con una latencia de streaming de tan solo 97ms. La familia de modelos incluye las versiones VoiceDesign, CustomVoice y Base, utilizando una arquitectura Dual-track LM, alcanzando niveles SOTA en calidad de voz, control emocional y velocidad de inferencia. La comunidad considera este el lanzamiento de TTS más disruptivo en el ámbito del código abierto hasta la fecha; su licencia Apache 2.0 y su fuerte capacidad de adaptación en dispositivos finales (como el soporte para MLX-Audio) impulsarán enormemente el desarrollo de asistentes de voz personalizados y aplicaciones de diálogo en tiempo real (Fuente: Alibaba_Qwen, Reddit)

Auditoría profunda de los benchmarks HLE y GPQA revela tasas de error alarmantes : Investigadores independientes realizaron una auditoría forense de “Humanity’s Last Exam” (HLE) y GPQA, descubriendo que debido a errores de OCR y faltas de ortografía, la tasa de error de validación de HLE llega al ~58%, mientras que GPQA presenta un ~26.8% de defectos. Muchos casos clasificados como “alucinaciones del modelo” fueron en realidad situaciones donde el modelo derivó la respuesta correcta, pero fue penalizado por no poder “adivinar” los errores tipográficos del enunciado. Este hallazgo genera grandes dudas sobre la confiabilidad de los rankings de AI actuales. Es posible que estemos evaluando los mejores modelos con una “regla dañada”, y que los laboratorios estén gastando millones de dólares optimizando el ajuste a errores en lugar de una mejora real de la inteligencia (Fuente: Reddit)
🎯 Tendencias
La versión interna de Meta Llama 4 recibe críticas del CTO y es reestructurada : El CTO de Meta, Bosworth, reveló que las versiones tempranas de Llama 4 fueron decepcionantes, calificándolas de “mediocres” y con “falta de punto de vista”. Debido a esto, Meta ha reestructurado su equipo de AI bajo el liderazgo de Alexandr Wang, con planes de lanzar el nuevo modelo en la primera mitad de este año. Actualmente, existe un intenso debate interno sobre si el modelo debe ser de código abierto y cómo hacerlo. Esto refleja que, en la búsqueda de la AGI, el simple apilamiento de parámetros ya no garantiza sorpresas; dotar al modelo de una “forma de pensar” única y la optimización post-entrenamiento se han convertido en los nuevos puntos de competencia (Fuente: ylecun)
El ARR mensual del negocio de OpenAI API supera los 1.000 millones de dólares : Sam Altman anunció que el negocio de API de OpenAI ha sumado más de 1.000 millones de dólares en ingresos recurrentes anuales (ARR) solo en el último mes. Este crecimiento asombroso indica que, aunque ChatGPT domina la mente del público general, el mercado de desarrolladores B2B se está convirtiendo en el verdadero motor de crecimiento de OpenAI. A medida que las aplicaciones de AI empresariales pasan de pilotos a despliegues a escala, el consumo de API crece exponencialmente, consolidando a OpenAI como el “mayorista de cómputo e inteligencia” de la era de la AI (Fuente: sama)
Resumen de Agentic Reasoning: Del pensamiento estático a la acción dinámica : Un artículo de revisión de 135 páginas sistematiza el nuevo paradigma de inteligencia de los LLM: el Razonamiento Agéntico (Agentic Reasoning). La investigación sostiene que, aunque los LLM rinden bien en entornos cerrados, tienen dificultades en entornos abiertos y dinámicos; la pieza faltante es la “acción”. El marco divide el razonamiento en tres dimensiones: razonamiento base, razonamiento de auto-evolución y razonamiento colectivo multi-agente. Esto implica que el futuro de la AI no reside en mayores parámetros, sino en cómo evolucionar continuamente mediante la interacción, retroalimentación y memoria con el entorno (Fuente: omarsar0)

El “Vibe Coding” genera preocupación por la “quiebra de la comprensión” : Con la popularización de herramientas como Claude Code y Devin, la comunidad de desarrolladores debate el fenómeno del “Vibe Coding”. Ingenieros veteranos temen que, cuando la AI puede completar instantáneamente horas de trabajo, los humanos pierdan la comprensión profunda de las bases de código, creando una “deuda de comprensión”. Aunque la productividad a corto plazo aumenta un 20-30%, a largo plazo, la dificultad para depurar fallos del sistema aumentará exponencialmente. El desarrollo de software futuro podría evolucionar hacia el “monitoreo de la situación” en lugar de “escribir lógica”, lo que exige establecer nuevos sistemas de garantía de calidad de código (Fuente: jon_stokes, jeremyphoward)
🧰 Herramientas
Lanzamiento de GitHub Copilot SDK: Integración de flujos de trabajo agénticos en cualquier aplicación : GitHub presentó un SDK programable que permite a los desarrolladores integrar el motor principal de Copilot directamente en sus propias aplicaciones. Los desarrolladores no necesitan construir capas de orquestación complejas; basta con definir intenciones y comportamientos para que Copilot ejecute tareas. Esto marca la transición de los asistentes de AI de herramientas independientes a capacidades universales conectables, reduciendo drásticamente la barrera para desarrollar aplicaciones de agentes autónomos (Fuente: pierceboggan)
Devin Review: Reestructurando el proceso de revisión de código : Cognition lanzó Devin Review, diseñado para ayudar a los desarrolladores a evitar la “basura de código” de baja calidad mediante la comprensión profunda de PR complejos por parte de la AI. La herramienta no solo identifica errores lógicos, sino que construye mapas de comprensión del código para prevenir desastres de mantenimiento causados por la dependencia excesiva de la generación por AI. La comunidad reporta un excelente desempeño en refactorizaciones a gran escala y cambios entre módulos (Fuente: cognition, swyx)
LlamaParse v2: La revolución estructurada del análisis de documentos : LlamaIndex ha reestructurado su API de análisis de documentos con el lanzamiento de la versión v2 y el nuevo LlamaCloud SDK. La nueva versión simplifica significativamente el proceso de configuración, admite un control preciso de la salida estructurada (como Markdown y JSON) y logra una paridad total entre Python y TypeScript. Esto proporciona una infraestructura más sólida para construir aplicaciones RAG capaces de manejar documentos complejos, de múltiples columnas y con gráficos (Fuente: jerryjliu0)

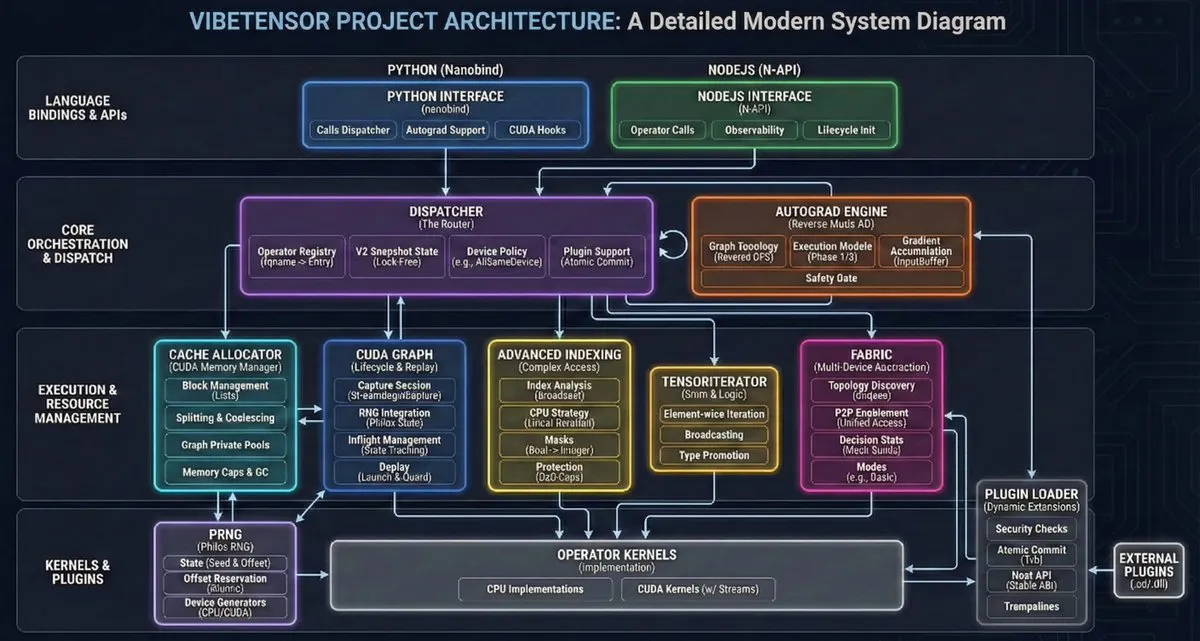
VibeTensor: El primer sistema de Deep Learning generado totalmente por agentes de AI : NVlabs liberó VibeTensor, un framework de Deep Learning generado íntegramente por agentes de AI, que incluye 47,000 líneas de código de kernels Triton generadas automáticamente. Aunque su eficiencia en ciertas rutas críticas aún no alcanza a PyTorch (fenómeno llamado “efecto Frankenstein”), demuestra que la AI ya posee la capacidad de diseñar e implementar arquitecturas de sistemas complejos de bajo nivel, marcando el inicio de la era de “AI escribiendo AI” (Fuente: JvNixon)
💼 Negocios
Meta planea adquirir Manus AI por 2.000-3.000 millones de dólares : Según informes, Meta ha llegado a un acuerdo para adquirir la startup de agentes autónomos Manus AI por una suma millonaria. El objetivo es integrar sus capacidades de agentes validadas por el mercado en toda su línea de productos, incluyendo Facebook, Instagram y WhatsApp. Esto refleja el deseo de los gigantes de las redes sociales por capacidades de ejecución de tareas proactivas en la “era post-chatbot” (Fuente: DeepLearningAI)

LiveKit completa una ronda de financiación Serie C de 100 millones de dólares : La plataforma de infraestructura de AI de voz LiveKit obtuvo 100 millones de dólares para simplificar el proceso de construcción de aplicaciones de AI de voz. Con la interacción de voz en tiempo real convirtiéndose en una necesidad básica (como en OpenAI Advanced Voice Mode), la demanda de servicios de streaming de voz de baja latencia y alta confiabilidad está experimentando un crecimiento explosivo (Fuente: juberti)
World Labs de Fei-Fei Li busca recaudar 500 millones de dólares, con una valoración de 5.000 millones : La startup de “inteligencia espacial” fundada por Fei-Fei Li, World Labs, está en negociaciones para una nueva ronda de financiación. Los Modelos de Mundo (World Models) se consideran la próxima gran ola en los campos de los videojuegos y la robótica, con el fin de dotar a la AI de la capacidad de comprender las leyes del mundo físico (Fuente: kylebrussell)
📚 Aprendizaje
Andrew Ng lanza curso de Gemini CLI : DeepLearning.AI presentó un nuevo curso sobre cómo construir agentes utilizando la herramienta de código abierto Gemini CLI. El curso cubre técnicas prácticas para orquestar herramientas como GitHub, Canva y Google Workspace mediante servidores MCP. El enfoque está en comprender la arquitectura de los agentes de código abierto para que los desarrolladores dominen la lógica de decisión de la AI de forma transparente (Fuente: AndrewYNg)
Conferencia magistral sobre algoritmos de enrutamiento MoE : Se ha publicado en YouTube una conferencia sistemática sobre los algoritmos de enrutamiento en modelos de mezcla de expertos (MoE), que abarca los fundamentos de MoE, mecanismos de enrutamiento, problemas de sobrecarga de expertos y soluciones de optimización. Es un recurso excelente para desarrolladores que deseen comprender los mecanismos detrás del alto rendimiento de modelos como DeepSeek (Fuente: ben_burtenshaw)
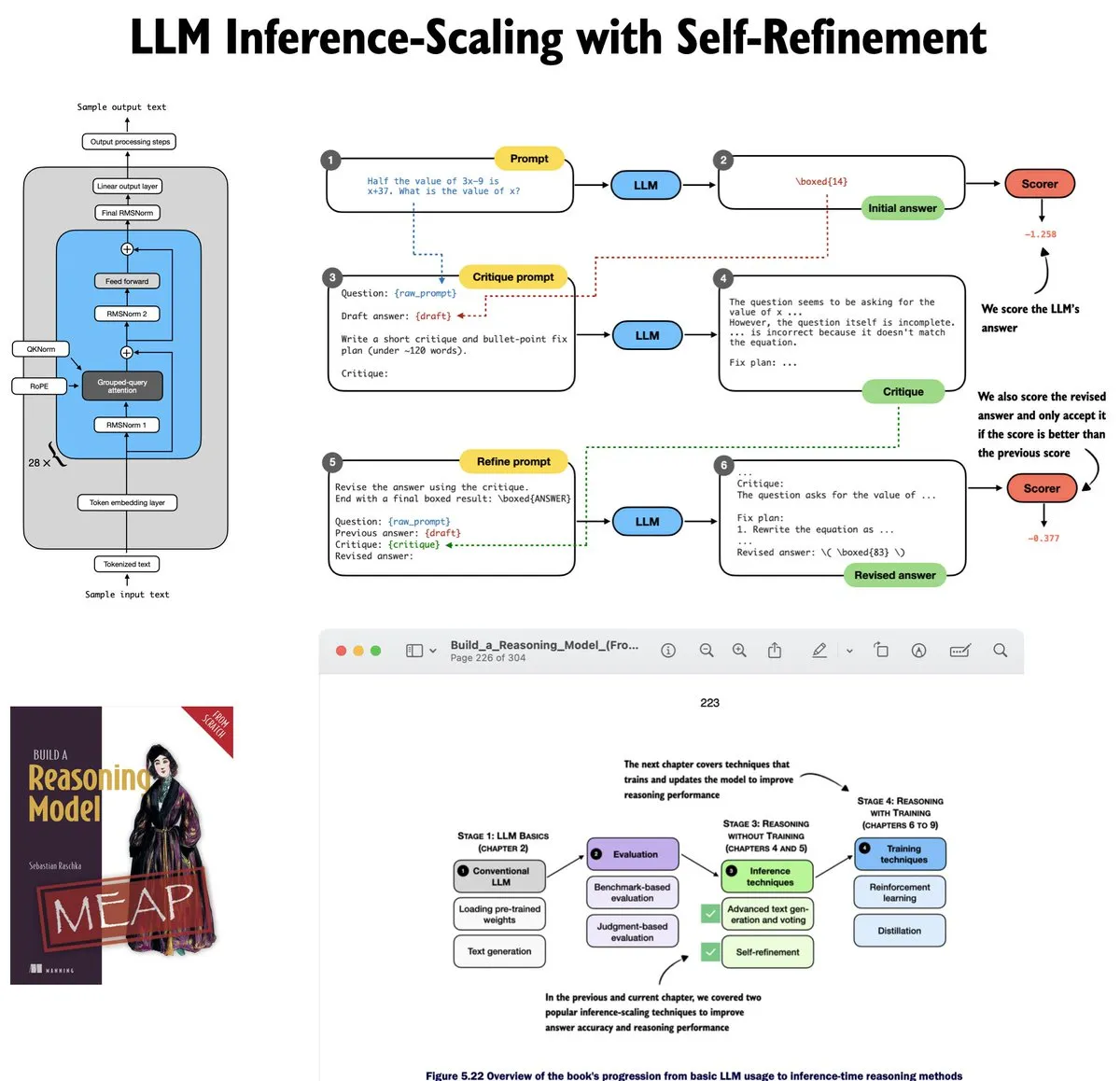
Actualización del tutorial de auto-mejora de LLM (Self-Refinement) : Sebastian Raschka actualizó el quinto capítulo de su tutorial de LLM, centrándose en el escalado en tiempo de inferencia (Inference-time scaling). El tutorial implementa desde cero la lógica de autoevaluación iterativa y mejora del modelo, ayudando a los estudiantes a comprender la implementación matemática y de ingeniería detrás de los métodos de inferencia de LLM (Fuente: nerdai)
🌟 Comunidad
La intención de OpenAI de cobrar comisiones por descubrimientos asistidos por AI genera controversia : El CFO de OpenAI reveló que la empresa podría en el futuro participar en las ganancias de descubrimientos científicos o inventos realizados por clientes mediante su AI. La noticia causó un gran revuelo en la comunidad; los críticos consideran que esto contradice su propósito original sin fines de lucro y que es difícil definir legal y éticamente la “proporción de contribución de la AI”. Esto podría llevar a instituciones de investigación de élite a optar por modelos de código abierto para evitar posibles disputas de propiedad intelectual (Fuente: scaling01, rao2z)
Nueva constitución de Claude y debate sobre “estados emocionales” : Anthropic publicó la nueva constitución de Claude, mencionando que los “estados emocionales” mostrados por el modelo son resultado de la imitación de textos humanos. La reacción de la comunidad está dividida: unos lo ven como una estrategia de marketing astuta para preparar una IPO, mientras que otros creen que este “ajuste emocional” mejora significativamente el rendimiento en tareas complejas y de alta presión como el Debugging (Fuente: Reddit)
Ola de hardware de AI: La batalla por el control de la interfaz : ByteDance, Meta y OpenAI están desplegando hardware de AI (gafas, grabadoras, auriculares), motivados por el temor de que “los usuarios dejen de hacer clic en las Apps”. En la era de los AI Agents, quien controle los sensores más cercanos a los sentidos del usuario controlará la puerta de entrada al tráfico. No es solo una competencia de hardware, sino una captura de datos nativos del mundo físico para romper el estancamiento de la escasez de datos de texto de alta calidad en internet (Fuente: 36kr)
💡 Otros
Explosión de la demanda de almacenamiento en la era de la AI: Las acciones de SanDisk se disparan : Con la generación masiva de KV cache por los LLM y la explosión de la generación de video por AI, la demanda de almacenamiento de alta velocidad en los centros de datos se ha disparado. La nueva arquitectura de Nvidia permite descargar el caché directamente a SSD, convirtiendo al almacenamiento en un eslabón crítico del gasto de capital en AI (Fuente: Yuchenj_UW)
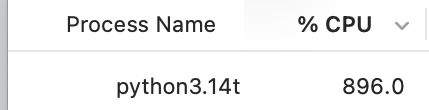
Significado para la AI de la eliminación del GIL en Python 3.13 : Los desarrolladores principales de Python anunciaron el fin del GIL (Global Interpreter Lock), lo cual es trascendental para el campo de la AI. Esto significa que Python finalmente podrá aprovechar verdaderamente las CPUs multinúcleo para computación paralela, mejorando significativamente la eficiencia en el preprocesamiento de datos y la inferencia multihilo (Fuente: code_star)