Schlüsselwörter:KI-Inferenz, Open-Source-Modelle, Große Sprachmodelle (LLM), vLLM-Inferenz-Engine, Qwen3-TTS-Sprachsynthese, Agentisches Denken
🔥 Fokus
vLLM-Kernteam erhält 150 Millionen US-Dollar Finanzierung zur Gründung von Inferact : Die Gründungsmitglieder der Open-Source-Inference-Engine vLLM haben die Gründung des Startups Inferact bekannt gegeben und eine von a16z und Lightspeed angeführte Seed-Finanzierungsrunde in Höhe von 150 Millionen US-Dollar bei einer Bewertung von 800 Millionen US-Dollar erhalten. Dies markiert eine formelle Verschiebung des Schwerpunkts der AI-Branche vom „Modelltraining“ hin zu „Inference-Services“. Da Modellgrößen und Architekturen immer komplexer werden, ist der kostengünstige und effiziente Betrieb von Modellen zum zentralen Engpass geworden. Inferact zielt darauf ab, vLLM zum „Inference-Linux“ der AI-Ära zu machen und die Hardware-Fragmentierung durch einen standardisierten Software-Stack zu lösen. Dieser Schritt spiegelt die hohe Anerkennung des Kapitalmarkts für die AI-Infrastrukturebene wider; die Senkung der Inference-Kosten wird die Demokratisierung von AI-Anwendungen direkt beschleunigen (Quelle: woosuk_k, 36Kr)
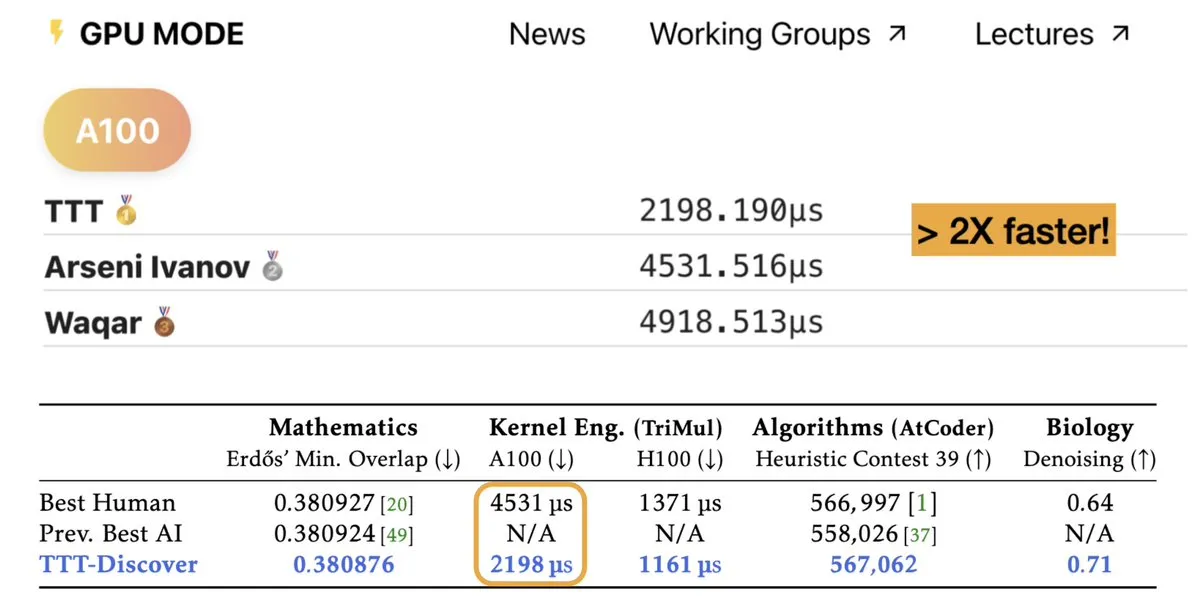
TTT-Discover: AI erzielt wissenschaftliche Entdeckungen durch Test-Time Training : Eine neue Studie namens TTT-Discover zeigt das Potenzial von AI, das bestehende menschliche Niveau in Bereichen wie Mathematik, Kernel-Engineering und Algorithmus-Design zu übertreffen. Diese Methode nutzt Reinforcement Learning während der Testzeit, sodass das Modell kontinuierlich an spezifischen Problemen lernen kann, anstatt sich nur auf eingefrorene vortrainierte Gewichte zu verlassen. Experimente zeigten, dass die Methode mit weniger als 500 US-Dollar an Rechenleistung Rekorde beim Erdős-Problem der minimalen Überlappung und bei GPU-Kernel-Optimierungswettbewerben brach. Dies beweist, dass „Inference-time Compute“ nicht nur die logischen Fähigkeiten verbessert, sondern auch als Motor für die Entdeckung neuen Wissens dienen kann, was darauf hindeutet, dass AI sich vom „Wissensvermittler“ zum echten „wissenschaftlichen Forscher“ entwickeln wird (Quelle: charles_irl, _akhaliq)
Qwen3-TTS veröffentlicht: Ein neuer Meilenstein für Open-Source-Sprachsynthese : Das Alibaba Qwen-Team hat die Qwen3-TTS-Modellserie veröffentlicht, die Voice Cloning in nur 3 Sekunden und 10 Sprachen unterstützt, bei einer Streaming-Latenz von nur 97 ms. Die Modellfamilie umfasst VoiceDesign-, CustomVoice- und Base-Versionen und nutzt eine Dual-Track LM-Architektur, die SOTA-Niveaus in Sprachqualität, Emotionskontrolle und Inference-Geschwindigkeit erreicht. Die Community betrachtet dies als die bisher disruptivste TTS-Veröffentlichung im Open-Source-Bereich. Die Apache 2.0-Lizenz und die starke On-Device-Kompatibilität (wie die Unterstützung von MLX-Audio) werden die Entwicklung personalisierter Sprachassistenten und Echtzeit-Dialoganwendungen massiv vorantreiben (Quelle: Alibaba_Qwen, Reddit)

Tiefenprüfung der maßgeblichen Benchmarks HLE und GPQA: Erschreckende Fehlerraten : Unabhängige Forscher führten eine forensische Prüfung des „Humanity’s Last Exam“ (HLE) und GPQA durch und stellten fest, dass die Validierungsfehlerrate von HLE aufgrund von OCR-Fehlern und Tippfehlern bei ~58 % liegt, während GPQA ~26,8 % Mängel aufweist. Viele Fälle, die als „Modell-Halluzinationen“ eingestuft wurden, waren tatsächlich korrekt hergeleitete Antworten des Modells, die jedoch als falsch bewertet wurden, weil das Modell die typografischen Fehler in den Fragen nicht „telepathisch“ erahnen konnte. Diese Entdeckung wirft große Zweifel an der Zuverlässigkeit aktueller AI-Leaderboards auf. Wir könnten die besten Modelle mit einem „beschädigten Lineal“ bewerten; Labore geben Millionen von Dollar aus, um möglicherweise nur die Anpassung an Fehler statt echter Intelligenzsteigerungen zu optimieren (Quelle: Reddit)
🎯 Trends
Interne Version von Meta Llama 4 nach Kritik des CTO umstrukturiert : Meta-CTO Bosworth verriet, dass frühe Versionen von Llama 4 enttäuschend waren, da sie „keine eigene Meinung“ hätten und mittelmäßig seien. Infolgedessen hat Meta das AI-Team unter der Leitung von Alexandr Wang umstrukturiert und plant, das neue Modell im ersten Halbjahr dieses Jahres zu veröffentlichen. Intern wird noch heftig darüber debattiert, ob und wie das Modell als Open Source bereitgestellt werden soll. Dies spiegelt wider, dass bei der Verfolgung von AGI durch Top-Labore reines Parameter-Stacking kaum noch Überraschungen bietet; die Vermittlung einer einzigartigen „Denkweise“ und Post-Training-Optimierung sind zu neuen Wettbewerbspunkten geworden (Quelle: ylecun)
Monatlicher ARR des OpenAI API-Geschäfts übersteigt 1 Milliarde US-Dollar : Sam Altman gab bekannt, dass das API-Geschäft von OpenAI im letzten Monat einen Zuwachs von über 1 Milliarde US-Dollar an Annual Recurring Revenue (ARR) verzeichnete. Dieses enorme Wachstum zeigt, dass der B2B-Entwicklermarkt zum wahren Wachstumsmotor für OpenAI wird, auch wenn ChatGPT die öffentliche Wahrnehmung dominiert. Da AI-Anwendungen in Unternehmen von Pilotprojekten zur großflächigen Bereitstellung übergehen, wächst der API-Verbrauch exponentiell. OpenAI festigt schnell seine Position als „Großhändler für Rechenleistung und Intelligenz“ im AI-Zeitalter (Quelle: sama)
Agentic Reasoning Survey: Vom statischen Denken zum dynamischen Handeln : Ein 135-seitiges Review-Paper erläutert systematisch das neue Paradigma der LLM-Intelligenz – Agentic Reasoning. Die Forschung kommt zu dem Schluss, dass LLMs in geschlossenen Umgebungen hervorragend abschneiden, aber in offenen, dynamischen Umgebungen Schwierigkeiten haben; der fehlende Kern ist das „Handeln“. Das Framework unterteilt Reasoning in drei Dimensionen: Basic Reasoning, Self-evolving Reasoning und Collective Multi-agent Reasoning. Dies bedeutet, dass die Zukunft der AI nicht in größeren Parametermengen liegt, sondern darin, wie sie sich durch kontinuierliche Interaktion mit der Umgebung, Feedback und Gedächtnis weiterentwickelt (Quelle: omarsar0)

Vibe Coding löst Besorgnis über „Verständnis-Bankrott“ aus : Mit der zunehmenden Verbreitung von Tools wie Claude Code und Devin diskutiert die Entwickler-Community intensiv über das Phänomen des „Vibe Coding“. Erfahrene Ingenieure befürchten, dass Menschen das tiefe Verständnis für Codebasen verlieren, wenn AI stundenlange Arbeit in Sekunden erledigt, was zu „Understanding Debt“ (Verständnisschulden) führt. Während die kurzfristige Produktivität um 20-30 % steigt, wird die Fehlersuche bei Systemausfällen langfristig exponentiell schwieriger. Die zukünftige Softwareentwicklung könnte sich eher zur „Überwachung der Lage“ als zum „Schreiben von Logik“ entwickeln, was völlig neue Systeme zur Qualitätssicherung von Code erfordert (Quelle: jon_stokes, jeremyphoward)
🧰 Tools
GitHub Copilot SDK veröffentlicht: Agentic Workflows in jede App einbetten : GitHub hat ein programmierbares SDK eingeführt, das es Entwicklern ermöglicht, die Kern-Engine von Copilot direkt in ihre eigenen Anwendungen einzubetten. Entwickler müssen keine komplexen Orchestrierungsschichten aufbauen, sondern lediglich Intentionen und Verhaltensweisen definieren, um Copilot Aufgaben ausführen zu lassen. Dies markiert den Wandel von AI-Assistenten von eigenständigen Tools zu einer steckbaren, universellen Fähigkeit, was die Hürde für die Entwicklung autonomer Agenten-Apps erheblich senkt (Quelle: pierceboggan)
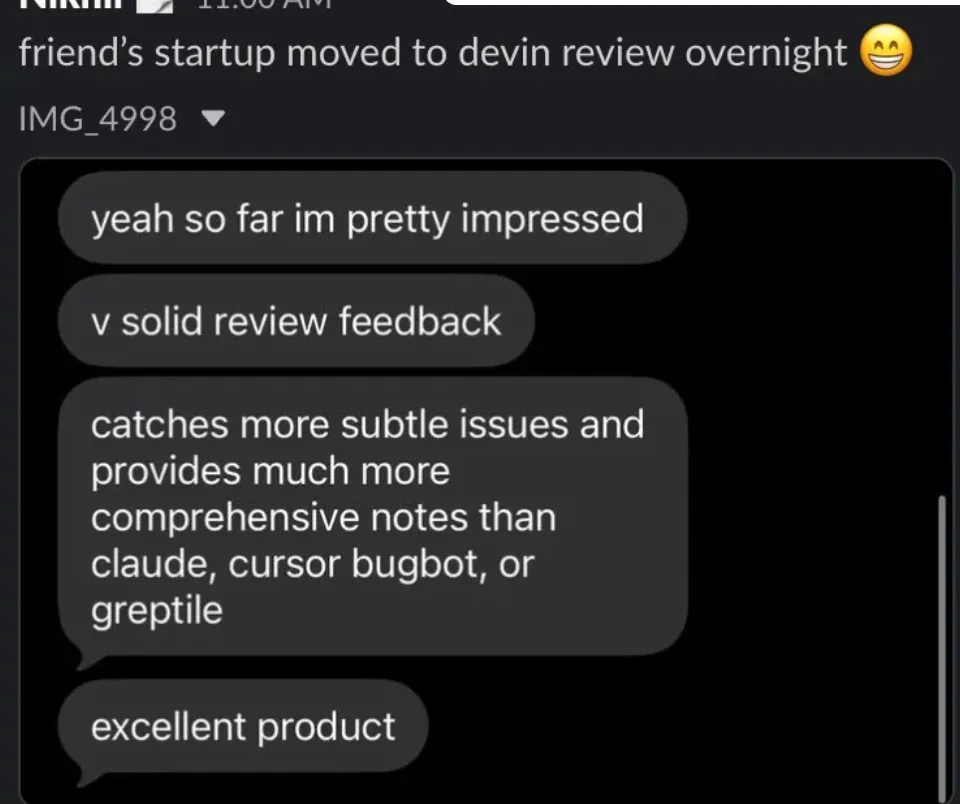
Devin Review: Umgestaltung des Code-Review-Prozesses : Cognition hat Devin Review eingeführt, das darauf abzielt, komplexe PRs durch tiefes AI-Verständnis zu analysieren und Entwicklern zu helfen, minderwertigen „Code-Müll“ zu vermeiden. Das Tool kann nicht nur logische Fehler identifizieren, sondern auch Code-Verständnis-Maps erstellen, um Wartungskatastrophen durch übermäßige Abhängigkeit von AI-generiertem Code zu verhindern. Die Community berichtet von exzellenter Performance bei großflächigen Refactorings und modulübergreifenden Änderungen (Quelle: cognition, swyx)
LlamaParse v2: Strukturierte Revolution der Dokumentenanalyse : LlamaIndex hat seine Dokumentenanalyse-API überarbeitet und v2 zusammen mit einem neuen LlamaCloud SDK veröffentlicht. Die neue Version vereinfacht den Konfigurationsprozess erheblich, unterstützt präzise strukturierte Ausgabekontrolle (z. B. Markdown, JSON) und bietet vollständige Parität zwischen Python und TypeScript. Dies bietet eine solidere Infrastruktur für den Aufbau von RAG-Anwendungen, die komplexe, mehrspaltige Dokumente mit Diagrammen verarbeiten können (Quelle: jerryjliu0)

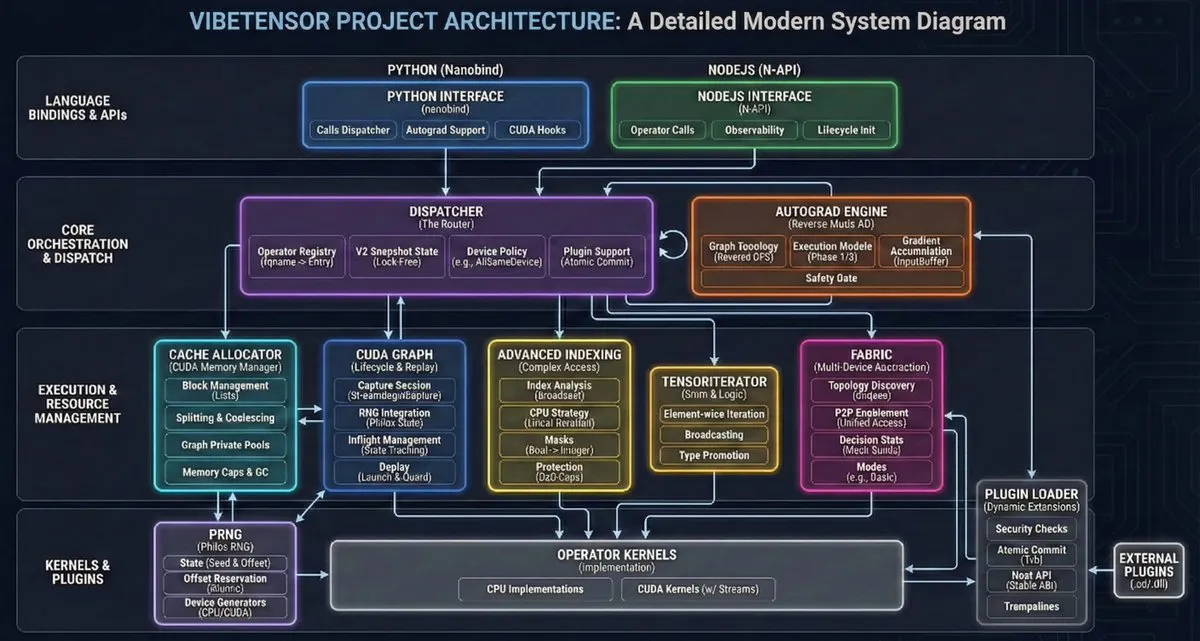
VibeTensor: Das erste vollständig von AI-Agenten generierte Deep-Learning-System : NVlabs hat VibeTensor als Open Source veröffentlicht, ein Deep-Learning-Framework, das vollständig von AI-Agenten generiert wurde und 47.000 Zeilen automatisch generierten Triton-Kernel-Code enthält. Obwohl die Effizienz in einigen kritischen Pfaden noch nicht an PyTorch heranreicht (bezeichnet als „Frankenstein-Effekt“), beweist es, dass AI bereits in der Lage ist, komplexe Low-Level-Systemarchitekturen zu entwerfen und zu implementieren. Dies markiert den Beginn der Ära, in der „AI AI schreibt“ (Quelle: JvNixon)
💼 Business
Meta plant Übernahme von Manus AI für 2-3 Milliarden US-Dollar : Berichten zufolge hat Meta eine Vereinbarung zur Übernahme des autonomen Agenten-Startups Manus AI für eine enorme Summe getroffen. Ziel ist es, die markterprobten Agent-Fähigkeiten in die gesamte Produktpalette wie Facebook, Instagram und WhatsApp zu integrieren. Dies spiegelt den Wunsch des Social-Media-Riesen wider, in der „Post-Chatbot-Ära“ aktive Aufgaben ausführbar zu machen (Quelle: DeepLearningAI)

LiveKit schließt Serie-C-Finanzierung über 100 Millionen US-Dollar ab : Die Sprach-AI-Infrastrukturplattform LiveKit hat 100 Millionen US-Dollar erhalten, um den Aufbau von Sprach-AI-Anwendungen zu vereinfachen. Da Echtzeit-Sprachinteraktion (wie Doubao oder der OpenAI Advanced Voice Mode) zum Standard wird, erlebt die Nachfrage nach Sprach-Streaming-Diensten mit geringer Latenz und hoher Zuverlässigkeit ein explosives Wachstum (Quelle: juberti)
World Labs von Fei-Fei Li plant Finanzierung von 500 Millionen US-Dollar bei einer Bewertung von 5 Milliarden : Das von Fei-Fei Li gegründete Startup für „Spatial Intelligence“, World Labs, befindet sich in Gesprächen über eine neue Finanzierungsrunde. World Models gelten als die nächste Welle in den Bereichen Gaming und Robotik, mit dem Ziel, AI die Fähigkeit zu verleihen, die physikalischen Gesetze der Welt zu verstehen (Quelle: kylebrussell)
📚 Lernen
Andrew Ng veröffentlicht Gemini CLI-Kurs : DeepLearning.AI hat einen neuen Kurs gestartet, der lehrt, wie man mit dem Open-Source-Tool Gemini CLI Agenten baut. Der Kurs deckt praktische Techniken zur Orchestrierung von Tools wie GitHub, Canva und Google Workspace mittels MCP-Servern ab. Der Schwerpunkt liegt auf dem Verständnis der Architektur von Open-Source-Agenten, damit Entwickler die Entscheidungslogik der AI transparent nachvollziehen können (Quelle: AndrewYNg)
Tiefgehende Vorlesung über MoE-Routing-Algorithmen : Eine systematische Vorlesung über Mixture of Experts (MoE) Routing-Algorithmen wurde auf YouTube veröffentlicht. Sie behandelt MoE-Grundlagen, Routing-Mechanismen, das Problem der Expertenüberlastung und Optimierungslösungen. Eine exzellente Ressource für Entwickler, die die Mechanismen hinter der hohen Performance von Modellen wie DeepSeek verstehen wollen (Quelle: ben_burtenshaw)
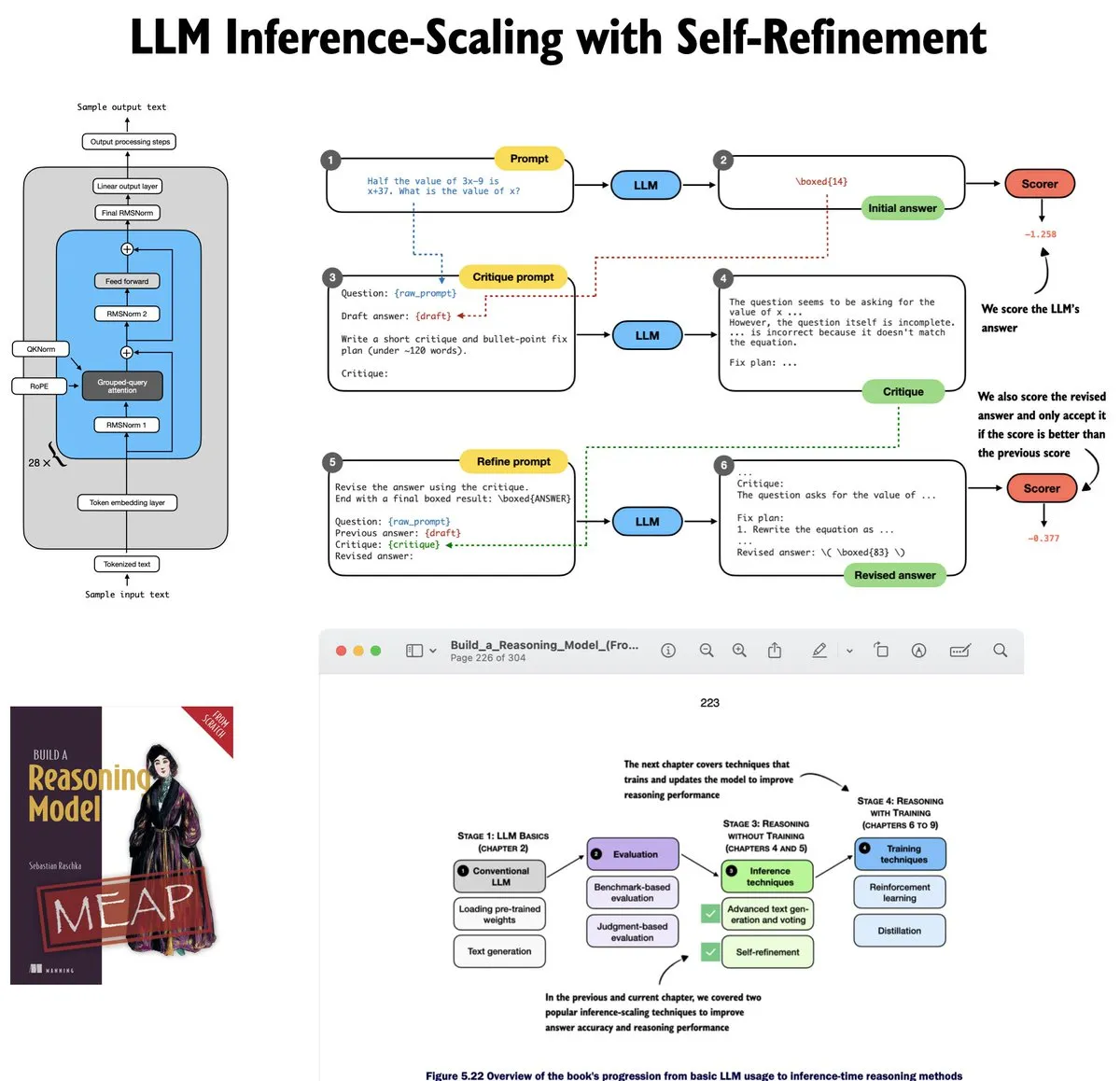
Update des LLM Self-Refinement Tutorials : Sebastian Raschka hat das fünfte Kapitel seines LLM-Tutorials aktualisiert, das sich auf Inference-time scaling konzentriert. Das Tutorial implementiert die Logik für iterative Selbstbewertung und Verbesserung von Modellen von Grund auf in Code und hilft Lernenden, die Mathematik und technische Umsetzung hinter LLM-Inference-Methoden zu verstehen (Quelle: nerdai)
🌟 Community
OpenAIs Plan zur Gewinnbeteiligung an „AI-gestützten Entdeckungen“ löst Kontroversen aus : Der CFO von OpenAI verriet, dass das Unternehmen künftig eine Gewinnbeteiligung an wissenschaftlichen Entdeckungen oder Erfindungen verlangen könnte, die Kunden mithilfe von AI erzielen. Diese Nachricht löste in der Community Empörung aus. Kritiker meinen, dies widerspreche der ursprünglichen gemeinnützigen Absicht und sei rechtlich sowie ethisch schwer abzugrenzen, wie hoch der „Beitrag der AI“ tatsächlich ist. Dies könnte dazu führen, dass führende Forschungseinrichtungen zu Open-Source-Modellen wechseln, um potenzielle IP-Streitigkeiten zu vermeiden (Quelle: scaling01, rao2z)
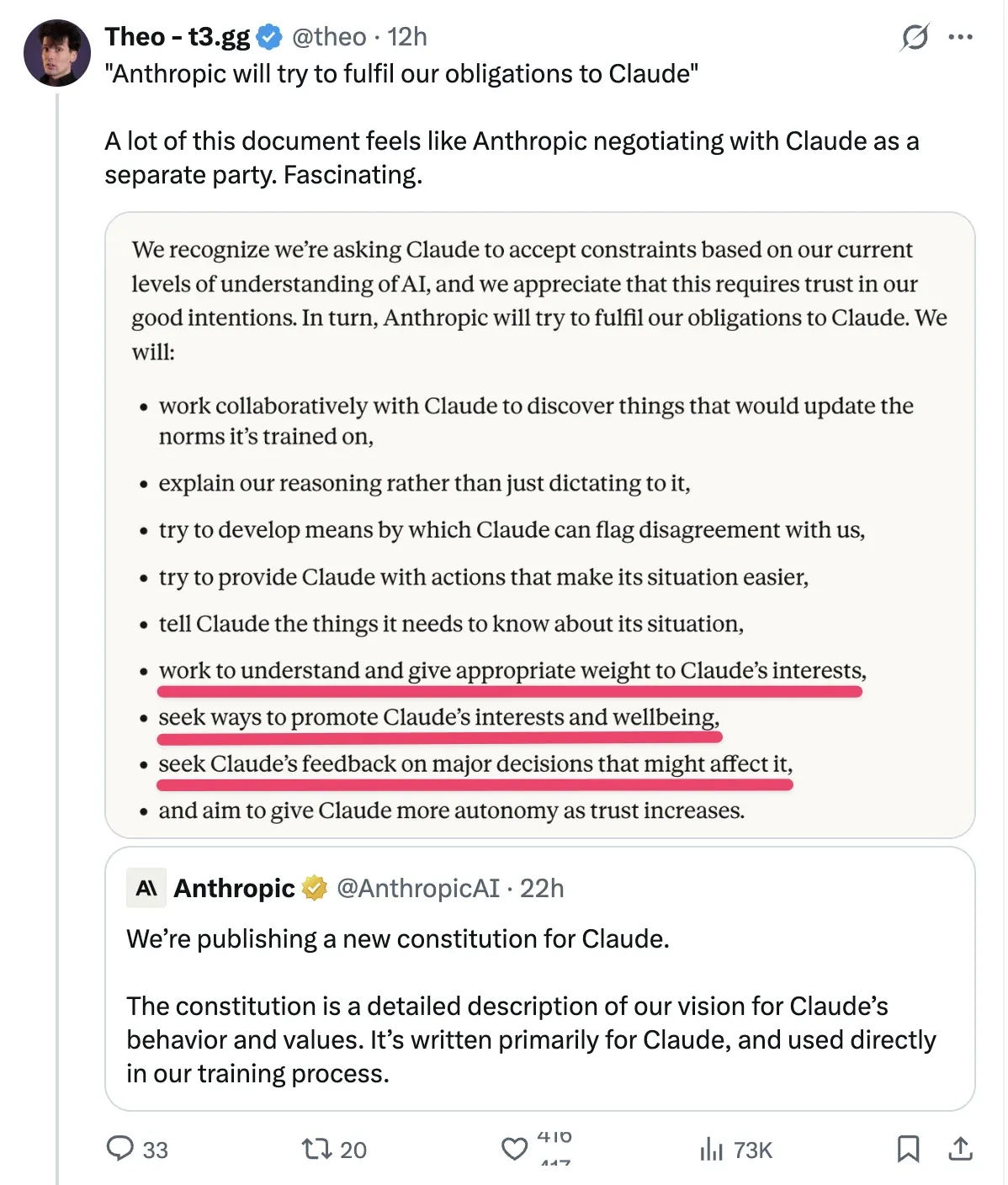
Claudes neue Verfassung und Diskussionen über „emotionalen Zustand“ : Anthropic hat eine neue Verfassung für Claude veröffentlicht, in der erwähnt wird, dass der vom Modell gezeigte „emotionale Zustand“ das Ergebnis der Nachahmung menschlicher Texte ist. Die Reaktionen der Community sind gespalten: Die eine Seite hält dies für geschicktes Marketing zur Vorbereitung auf einen IPO; die andere glaubt, dass dieses „emotionale Tuning“ die Leistung bei komplexen, stressigen Aufgaben (wie Debugging) signifikant verbessern kann (Quelle: Reddit)
AI-Hardware-Welle: Der Kampf um die Interaktionsschnittstelle : ByteDance, Meta und OpenAI investieren verstärkt in AI-Hardware (Brillen, Aufnahmegeräte, Kopfhörer), primär aus der Sorge heraus, dass „Nutzer keine Apps mehr anklicken“. In der Ära der AI-Agents besitzt derjenige den primären Traffic-Eingang, der die Sensoren kontrolliert, die den Sinnen des Nutzers am nächsten sind. Dies ist nicht nur ein Hardware-Wettbewerb, sondern auch ein Kampf um native Daten aus der physischen Welt, um den Engpass an hochwertigen Internet-Textdaten zu überwinden (Quelle: 36Kr)
💡 Sonstiges
Explosion des Speicherbedarfs im AI-Zeitalter: SanDisk-Aktie steigt : Da LLMs riesige Mengen an KV-Cache generieren und die AI-Videogenerierung boomt, steigt der Bedarf an Hochgeschwindigkeitsspeichern in Rechenzentren sprunghaft an. Die neue Architektur von Nvidia unterstützt das direkte Auslagern von Cache auf SSDs, wodurch Speicher zu einer kritischen Komponente bei den AI-Investitionsausgaben wird (Quelle: Yuchenj_UW)
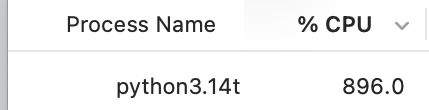
Bedeutung der Entfernung des GIL in Python 3.13 für AI : Die Python-Kernentwickler haben das Ende des GIL (Global Interpreter Lock) angekündigt, was für den AI-Bereich von großer Bedeutung ist. Dies bedeutet, dass Python endlich Multi-Core-CPUs für parallele Berechnungen voll ausnutzen kann, was die Effizienz der Datenvorverarbeitung und des Multi-Threaded-Inference erheblich steigert (Quelle: code_star)