
Schlüsselwörter:Meta, Scale AI, Superintelligenz, AGI, Datenannotation, KI-Training, Modellgenauigkeit, Meta erwirbt Scale AI-Anteile, Alexandr Wang leitet Superintelligenz-Team, KI-Datenannotation mit 99,7% Genauigkeit, Verringerung der Trainingsdatenverschmutzung, Modelltrainingszyklus um 40% verkürzt
🔥 Fokus
Meta investiert Berichten zufolge fast 150 Milliarden US-Dollar für eine Beteiligung an Scale AI und ernennt dessen CEO zur Leitung des neuen „Superintelligenz“-Teams: Meta plant, für rund 14,9 Milliarden US-Dollar 49 % der Anteile an Scale AI zu erwerben, einem Unternehmen für KI-Datenannotation und -Infrastruktur, und dessen erst 28-jährigen chinesischstämmigen CEO Alexandr Wang mit der Leitung der neu gegründeten „Superintelligence Group“ zu betrauen. Dieser Schritt zielt darauf ab, die Wettbewerbsfähigkeit von Meta im KI-Bereich zu stärken, insbesondere bei hochwertigen Trainingsdaten und der AGI-Forschung. Scale AI ist bekannt für seine Datenannotationsgenauigkeit von bis zu 99,7 % und soll die Kontaminationsrate der Trainingsdaten von Meta-Modellen von 15 % auf 2 % senken und die Trainingszyklen um 40 % verkürzen. Die Übernahme wird als entscheidender Schritt für Meta angesehen, um im KI-Wettlauf aufzuholen und Konkurrenten zu übertreffen, und unterstreicht die zentrale strategische Bedeutung von Daten für die KI-Entwicklung. (Quelle: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
OpenAI schließt Berichten zufolge umfangreichen Rechenleistungsvertrag mit Google Cloud ab, möglicherweise zur Verringerung der Abhängigkeit von Microsoft: Berichten zufolge hat OpenAI einen wichtigen Cloud-Service-Vertrag mit Google Cloud abgeschlossen. Google Cloud wird OpenAI die für das Training und den Einsatz seiner wachsenden KI-Modelle erforderliche Rechenleistung bereitstellen. Zuvor war Microsoft Azure der Hauptlieferant für Rechenleistung von OpenAI. Dieser Schritt könnte darauf hindeuten, dass OpenAI eine Diversifizierung seiner Rechenleistungsquellen anstrebt, um die Abhängigkeit von einem einzelnen Anbieter zu verringern und seinen enormen Rechenbedarf zu decken. Die Zusammenarbeit ist ein bedeutender Erfolg für Google Cloud, wirft aber auch Fragen darüber auf, wie das Unternehmen seine TPU-Ressourcen zwischen eigenen Geschäften und Kundenanforderungen ausbalancieren wird. (Quelle: 36氪, scaling01)
Mistral AI veröffentlicht Inferenzmodell Magistral und löst Fragen der Community zur Benchmark-Transparenz aus: Das französische KI-Unternehmen Mistral AI hat seine erste, speziell für Inferenz entwickelte Modellreihe Magistral vorgestellt, darunter die Open-Source-Version 24B Magistral Small und die für Unternehmen gedachte Version Magistral Medium. Offiziell wurde es für transparente, nachvollziehbare, mehrstufige logische Schlussfolgerungen entwickelt und unterstützt mehrere Sprachen. Die Community stellte jedoch die veröffentlichten Benchmark-Ergebnisse in Frage und argumentierte, dass kein Vergleich mit den neuesten Versionen von Konkurrenzmodellen wie Qwen und DeepSeek R1 durchgeführt wurde, was den Verdacht auf „Vermeidung des Wettbewerbs“ nahelegt. Trotzdem zeigt Magistral im AIME-24 Mathematik-Benchmark eine signifikante Verbesserung gegenüber Mistral Medium 3. (Quelle: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Richard Sutton, Vater des Reinforcement Learning: LLM-Dominanz nur vorübergehend, skalierbare Berechnung und erfahrungsbasiertes Lernen sind die Zukunft: Turing-Preisträger und Vater des Reinforcement Learning, Richard Sutton, prognostiziert, dass die derzeitige Dominanz von Large Language Models (LLM) nur vorübergehend ist und die Nachahmung menschlicher Denkweisen nur kurzfristige Leistungssteigerungen bringt. Er glaubt, dass die Zukunft der KI im „Zeitalter der Erfahrung“ liegt, in dem Agenten durch die Erfassung von Erfahrungsdaten aus der Interaktion mit der Welt in der Ich-Perspektive lernen, anstatt sich auf statische menschliche Daten zu verlassen. Sutton betont, dass Reinforcement Learning der Kernpfad in diese Zukunft ist und in Kombination mit Deep-Learning-Algorithmen mit kontinuierlichem Lernen und massiv skalierbarer Berechnung die KI über bestehende Erkenntnisse hinausführen und echte Innovationen ermöglichen wird. (Quelle: 量子位)

Hugging Face und NVIDIA kooperieren für „Training Cluster as a Service“, um die Hürden für das Training großer Modelle zu senken: Hugging Face hat eine Zusammenarbeit mit NVIDIA angekündigt, um „Training Cluster as a Service“ anzubieten. Ziel ist es, Forschungseinrichtungen weltweit den Zugang zu großen GPU-Cluster-Ressourcen für das Training verschiedener Spitzenmodelle zu erleichtern. Der Dienst integriert NVIDIA DGX Cloud Lepton und die Entwicklungsressourcen von Hugging Face und ermöglicht es Organisationen, die Nutzungsdauer von GPU-Clustern nach Bedarf anzufordern und zu bezahlen. Dieser Schritt zielt darauf ab, die „GPU-Kluft“ zu überbrücken und die Vielfalt und Demokratisierung der KI-Forschung zu fördern. Forschungseinrichtungen und Start-ups wie TIGEM, Numina und Mirror Physics gehören zu den Early Adoptern. (Quelle: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 Entwicklungen
OpenAI veröffentlicht o3-pro-Modell und senkt API-Preise für o3 drastisch: OpenAI hat sein neues Spitzen-Inferenzmodell o3-pro vorgestellt, das ChatGPT Pro-Nutzern und API-Nutzern zur Verfügung steht. Gleichzeitig wurden die API-Preise für das o3-Modell um 80 % gesenkt, und die Ratenbegrenzung für o3 für ChatGPT Plus-Nutzer wurde verdoppelt. Community-Feedback zeigt, dass o3-pro bei Nicht-Code-Aufgaben besser abschneidet als Claude Opus 4 und in mehreren Benchmarks wie Extended NYT Connections und Creative Short Story Writing neue Rekorde aufstellt. Es hat sogar das zuvor in einem Apple-Paper als Herausforderung für LLMs dargestellte „Turm von Hanoi mit 10 Scheiben“-Problem gelöst. Einige Nutzer berichten jedoch, dass o3-pro langsamer ist. OpenAI erklärte, dass die Preissenkung für o3 nicht durch Destillation oder Quantisierung erreicht wurde, sondern durch Optimierungsarbeiten der Inferenz-Ingenieure. (Quelle: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB veröffentlicht MiniCPM4-Serie effizienter LLMs für Endgeräte: OpenBMB hat die MiniCPM4-Modellreihe vorgestellt, die speziell für Endgeräte entwickelt wurde und laut Angaben eine mehr als fünffache Generierungsbeschleunigung auf typischen Endgeräte-Chips erreicht. Die Serie umfasst MiniCPM4-8B, MiniCPM4-0.5B sowie die ternär quantisierten Versionen BitCPM4-1B/0.5B. MiniCPM4 verwendet einen trainierbaren Sparse-Attention-Mechanismus InfLLM v2, unterstützt die Verarbeitung von 128K langen Texten und kombiniert effiziente Lernalgorithmen und Trainingstechniken wie Model Wind Tunnel 2.0, ternäre BitCPM-Quantisierung, FP8-Berechnungen mit geringer Präzision und Multi-Token-Vorhersage. Gleichzeitig wurden der hochwertige chinesisch-englische Vortrainingsdatensatz UltraFineweb und der überwachte Feinabstimmungsdatensatz UltraChat v2 veröffentlicht. (Quelle: GitHub Trending)
MSRA und Forscher der Universitäten Tsinghua und Peking schlagen neues Paradigma des Reinforcement Pre-training (RPT) vor: Microsoft Research Asia (MSRA) hat in Zusammenarbeit mit Forschern der Tsinghua-Universität und der Peking-Universität ein neues LLM-Vortrainingsparadigma namens Reinforcement Pre-training (RPT) vorgestellt. Diese Methode integriert Reinforcement Learning (RL) tief in die Vortrainingsphase. Das Modell generiert vor der Vorhersage jedes Tokens Chain-of-Thought-Inferenzsequenzen und erhält Belohnungen basierend auf der Korrektheit der Vorhersage. RPT zielt darauf ab, das Modell vom Erlernen oberflächlicher Token-Korrelationen zum Verständnis tieferer Bedeutungen zu bewegen. Experimente zeigen, dass ein auf RPT basierendes 14B-Modell bei einigen Inferenzaufgaben mit traditionell vortrainierten 32B-Modellen konkurrieren oder diese sogar übertreffen kann, was ein enormes Potenzial zur Verbesserung der Sprachmodellierungs- und Inferenzfähigkeiten von LLMs aufzeigt. (Quelle: 量子位, omarsar0)

Meta veröffentlicht V-JEPA 2 Video-Weltmodell und neue Benchmarks: Meta AI hat V-JEPA 2 vorgestellt, ein 1,2-Milliarden-Parameter-Weltmodell, das auf Videodaten trainiert wurde, um das Verständnis und die Vorhersagefähigkeit von Maschinen für die physische Welt zu verbessern. Das Modell kann bei der Zero-Shot-Planung von Robotern eingesetzt werden, sodass diese Aufgaben in unbekannten Umgebungen planen und ausführen können. Gleichzeitig hat Meta drei neue Benchmarks veröffentlicht, um die Fähigkeit bestehender Modelle zu bewerten, aus Videos auf die physische Welt zu schließen. HuggingFace bietet bereits Unterstützung für V-JEPA 2 in seiner Transformers-Bibliothek an. (Quelle: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance veröffentlicht Seedance 1.0 Pro Videogenerierungsmodell, jetzt in der Doubao-App verfügbar: ByteDance hat sein neuestes Videogenerierungsmodell Seedance 1.0 Pro (auch bekannt als Video 3.0 Pro-Modell in Dream Engine) vorgestellt. Das Modell zeichnet sich durch hervorragendes Verständnis von Prompts, Bilddetails und physikalische Konsistenz aus und kann 5-Sekunden-Videos in 1080P generieren. Derzeit ist das Modell über Volcano Engine für Unternehmenskunden verfügbar und in der Doubao-App als „Foto zum Leben erwecken“-Funktion für Nutzer kostenlos erlebbar. (Quelle: op7418)
Huawei stellt „digitalen Windkanal“-Simulationsplattform zur Optimierung der Effizienz von KI-Training und -Inferenz vor: Das Markov-Modellierungs- und Simulationsteam von Huawei hat erstmals seine „digitalen Windkanal“-Technologie vorgestellt, eine Plattform für die „Generalprobe“ in einer virtuellen Umgebung vor dem eigentlichen Training und der Inferenz komplexer KI-Modelle. Die Plattform umfasst drei Hauptmodule: Sim2Train (Trainingssimulation), Sim2Infer (Inferenzsimulation) und Sim2Availability (Hochverfügbarkeitssimulation). Ziel ist es, durch Simulation und automatische Optimierung Probleme wie Fehlallokation von Hardwareressourcen und Systemkopplung zu lösen, um Lösungen für Cluster mit Zehntausenden von Karten innerhalb von Stunden zu testen, Rechenleistungsverschwendung zu vermeiden und die Effizienz und Stabilität des Trainings und der Inferenz großer KI-Modelle zu verbessern. (Quelle: 量子位)

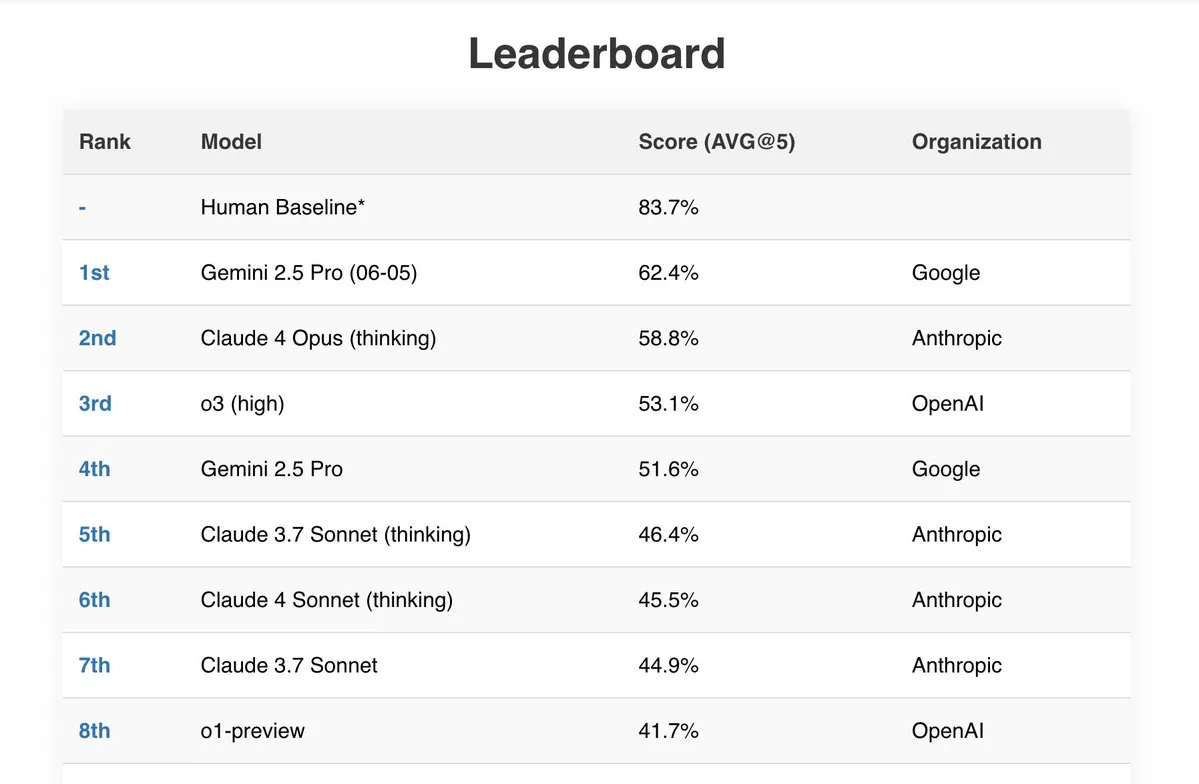
Gemini 2.5 Pro zeigt hervorragende Leistung in mehreren Benchmarks: Googles neuestes Modell Gemini 2.5 Pro (06-05) schneidet in mehreren öffentlichen KI-Ranglisten hervorragend ab. Es erzielte die beste Leistung im Live Fiction-Test mit 192k Tokens, belegte mit 62,4 % den ersten Platz bei SimpleBench und zeigte starke Fähigkeiten in der Dokumentenverarbeitung sowie ein gutes Preis-Leistungs-Verhältnis in Benchmarks wie IDP (Intelligent Document Processing) und Aider (KI-gestützte Codierung). Darüber hinaus berichten Nutzer, dass Gemini 2.5 Pro alle Probleme im Mathematikteil des JEE Advanced 2025 erfolgreich gelöst hat. (Quelle: _philschmid, dilipkay)
Kling AI Videomodell aktualisiert Lippensynchronisationsfunktion, unterstützt Charakterauswahl und -bearbeitung: Das KI-Videogenerierungstool Kling AI von Kuaishou hat kürzlich seine Lippensynchronisationsfunktion (Lip-Sync) aktualisiert. Die neue Funktion ermöglicht es Nutzern, in generierten Videos bestimmte Charaktere für die Lippensynchronisation auszuwählen und die Synchronisation von Audio und Mundbewegungen zeitlich anzupassen. Dieses Update verbessert die Flexibilität und den Realismus von Kling AI bei der Erstellung von Videos mit Dialogen zwischen mehreren Charakteren und ist ein wichtiger Fortschritt im Bereich der Videogenerierung. (Quelle: Kling_ai, Kling_ai)
Delta Lake 4.0.0 veröffentlicht, erweitert Lakehouse-Fähigkeiten: Delta Lake Version 4.0.0 wurde offiziell veröffentlicht und bringt mehrere wichtige neue Funktionen mit, darunter eine Vorschauversion von Catalog-Managed Tables für einheitliche Governance und Auffindbarkeit, die Delta Connect-Erweiterung für Spark Connect, Unterstützung für den Variant-Datentyp zur Verarbeitung semistrukturierter Daten sowie die sofortige DROP FEATURE-Funktion, mit der Tabellenmerkmale ohne Trunkierung der Historie oder Ausfallzeiten entfernt werden können. Diese Version zielt darauf ab, die Erfahrung der offenen Lakehouse-Community zu verbessern. (Quelle: matei_zaharia)

Hugging Face führt MCP-Server ein, um die Interaktion von Modellen und Werkzeugen zu vereinfachen: Hugging Face hat die erste Version seines Model Context Protocol (MCP) Servers veröffentlicht. Nutzer können nun über http://hf.co/mcp diesen Server in Anwendungen wie Claude oder Cursor nutzen, um nach Modellen, Datensätzen, Papern, Anwendungen oder spezifischen Informationen zu suchen. Dies markiert einen wichtigen Schritt von Hugging Face zur Förderung der Interoperabilität von Werkzeugen und Modellen im KI-Ökosystem und könnte zukünftig auf Funktionen wie Hochladen, Herunterladen und das Initiieren von PRs erweitert werden. (Quelle: clefourrier, ClementDelangue)

Baidu stellt „AI-Kamera“ mit integriertem Speicher und intelligenter Verwaltung vor und aktualisiert GenFlow Super Partner 2.0: Baidu Netdisk und Baidu Wenku haben gemeinsam die Funktion „AI-Kamera“ vorgestellt, die Fotografie, Cloud-Speicher und intelligente Verwaltung integriert. Fotos können automatisch in Cloud-Alben archiviert werden und unterstützen die intelligente Klassifizierung und Suche mittels natürlichsprachlicher Beschreibungen. Die AI-Kamera verfügt außerdem über verschiedene KI-Funktionen wie Beauty-Filter, Objekterkennung zur Wissensvermittlung, Generierung von Kritzelzeichnungen, Scannen von Belegen und Umwandlung handschriftlicher Tabellen. Gleichzeitig wurde die Multi-Agenten-Kollaborationsplattform „GenFlow Super Partner“ auf Version 2.0 aktualisiert, die Nutzerdaten und -gewohnheiten tiefer integrieren kann, um personalisierte Content-Generierungsdienste anzubieten. (Quelle: 量子位)

ByteDance veröffentlicht Open-Source-Code und Gewichte des SeedVR2 Videoreparaturmodells: Das SEED-Team von ByteDance hat den Inferenzcode und die Modellgewichte seines One-Step-Videoreparaturmodells SeedVR2 veröffentlicht, die nun auf Hugging Face verfügbar sind. Das Modell nutzt die Diffusion Adversarial Post-Training-Technologie und erzielt signifikante Ergebnisse bei der Videowiederherstellung, insbesondere bei der Verarbeitung hochauflösender Videos. (Quelle: _akhaliq)
GroqCloud nimmt Qwen3-32B-Modell auf, unterstützt über hundert Sprachen und 131k Kontext: Groq hat die Aufnahme des Tongyi Qianwen Qwen3-32B-Modells in seine LPU-Inferenzhardware-Cloud-Plattform GroqCloud bekannt gegeben. Das Modell unterstützt über 100 Sprachen und Dialekte, verfügt über ein Kontextfenster von 131k und läuft mit der für Groq-Hardware typischen Echtzeitgeschwindigkeit, was Entwicklern leistungsstarke Funktionen für die Verarbeitung mehrsprachiger, langer Texte bietet. (Quelle: JonathanRoss321)
OpenAI CEO Sam Altman gibt bekannt, dass die Veröffentlichung seines Open-Weight-Modells verschoben wird: Sam Altman erklärte, dass das Open-Weight-Modell von OpenAI erst im Spätsommer dieses Jahres veröffentlicht wird, anstatt wie ursprünglich geplant im Juni. Er teilte mit, dass das Forschungsteam einige „unerwartete und sehr erstaunliche“ Fortschritte gemacht habe, die das Warten wert seien, aber mehr Zeit für die Perfektionierung benötigten. (Quelle: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

Digua Robotics veröffentlicht RDK S100 Entwicklungskit, integriert Großhirn-Kleinhirn-Architektur auf einem einzigen SoC: Digua Robotics hat das branchenweit erste Single-SoC Robotik-Entwicklungskit RDK S100 mit integrierter Rechen- und Steuerungsfunktion vorgestellt. Das Kit verwendet ein menschenähnliches Großhirn-Kleinhirn-Design mit super-heterogener kollaborativer Architektur (6-Kern Arm Cortex-A78AE CPU + 80 TOPS BPU als „Großhirn“, 4-Kern Arm Cortex-R52+ MCU als „Kleinhirn“), unterstützt die effiziente Zusammenarbeit von großen und kleinen Embodied AI Modellen und schließt den „Wahrnehmungs-Entscheidungs-Steuerungs“-Regelkreis. Das RDK S100 bietet zahlreiche Schnittstellen und eine vollständige Entwicklungsinfrastruktur und ist zum Vorverkaufspreis von 2499 Yuan erhältlich. (Quelle: 量子位)

Aibook Intelligence veröffentlicht E300 AI-Rechenmodul mit 50TOPS国产SoC: Aibook Intelligence hat das E300 AI-Rechenmodul für Edge-Szenarien vorgestellt, das mit dem selbst entwickelten AI-SoC-Chip AB100 ausgestattet ist. Das Modul bietet bis zu 50TOPS INT8-Rechenleistung, unterstützt FP16/FP32-Mischpräzisionsberechnungen und verfügt über eine LPDDR5-Speicherbandbreite von 102 GB/s. Das E300 ist modular aufgebaut und zielt darauf ab, Branchen wie Bildung, Energie und Medizin hochleistungsfähige, latenzarme und zuverlässige国产Edge-AI-Lösungen anzubieten. Es unterstützt gängige Open-Source-Großmodelle sowie verschiedene visuelle und Sprachmodelle für den Edge-Einsatz. (Quelle: 量子位)

Huawei enthüllt Hochverfügbarkeitstechnologie für Ascend-Cluster mit Zehntausenden von Karten, erreicht 98 % Trainingsverfügbarkeit: Huawei hat erstmals Details seiner Hochverfügbarkeitstechnologie für Ascend-Rechencluster mit Zehntausenden von Karten veröffentlicht. Durch drei grundlegende Fähigkeiten – Fehlererkennung und -diagnose, Fehlermanagement und Fehlertoleranz für optische Verbindungen im Cluster – sowie unterstützende Geschäftsfunktionen wie Optimierung der Cluster-Linearität und schnelle Wiederherstellung von Training und Inferenz erreicht Huawei eine Trainingsverfügbarkeit von 98 % für Cluster mit Zehntausenden von Karten, eine Linearität von über 95 %, eine Fehlerwiederherstellung im Sekundenbereich und eine Diagnose im Minutenbereich. Dieses „3+3“-zweidimensionale Technologiesystem zielt darauf ab, den stabilen und effizienten Betrieb von groß angelegtem KI-Training und -Inferenz zu gewährleisten. (Quelle: 量子位)

BYDs Penetrationsrate für intelligentes Fahren bei Neuwagen erreicht 79 %, Autobahn-NOA wird zur Mainstream-Konfiguration: Die neuesten von BYD veröffentlichten Daten zeigen, dass bei den im Mai verkauften Neuwagen der Anteil der Modelle, die mit intelligenten Fahrerassistenzsystemen (mindestens mit Autobahn-NOA und automatischer Parkfunktion) ausgestattet sind, 79 % erreichte. Dies zeigt, dass BYD bei der Förderung seiner Strategie des „intelligenten Fahrens für alle“ erhebliche Fortschritte erzielt hat und intelligente Fahrfunktionen schnell zur Standardkonfiguration seiner Fahrzeugmodelle werden. Dieser Trend spiegelt auch die beschleunigte Verbreitung von Technologien für intelligentes Fahren auf dem chinesischen Automobilmarkt wider. (Quelle: 量子位)

Erweiterte Sprachfunktionen von ChatGPT für alle zahlenden Nutzer verfügbar: OpenAI gab bekannt, dass die zuvor aktualisierten erweiterten Sprachfunktionen von ChatGPT (Advanced Voice) mit verbesserter Natürlichkeit nun allen zahlenden Nutzern (ChatGPT Plus, Team, Enterprise) zur Verfügung stehen. Nutzer können über diese Funktion natürlicher mit ChatGPT per Sprache interagieren. (Quelle: juberti)
🧰 Tools
Genspark AI Browser veröffentlicht, integriert mehrere KI-Agentenfunktionen: Das Team von Eric Jing hat den Genspark AI Browser veröffentlicht, der angeblich von einem 24-köpfigen Team in 10 Wochen entwickelt wurde und 8 Hauptprodukte integriert: AI Browser, AI Secretary, AI Personal Calls, AI Download Agent, AI Drive und AI Sheets. Der Browser wirbt mit Geschwindigkeit, Werbeblocker, vollständiger Agentenfunktionalität, Autopilot-Modus und integriertem MCP Store sowie Super-Agenten, um ein umfassendes KI-gestütztes Browsing- und Arbeitserlebnis zu bieten. (Quelle: blader)
Yutori AI stellt Scouts-Plattform vor, ermöglicht Überwachung von KI-Agentennetzwerken: Yutori AI hat die Scouts-Plattform veröffentlicht, die es Nutzern ermöglicht, dauerhaft online befindliche KI-Agenten zu erstellen, um bestimmte Informationsaktualisierungen im Netzwerk zu überwachen. Diese Agenten können verschiedene für den Nutzer relevante Inhalte verfolgen, wie z. B. Nischennachrichten, Preisänderungen von Waren, Ticketinformationen usw., und den Nutzer in kritischen Momenten per E-Mail benachrichtigen, um ihn durch automatisierte Informationsverfolgung zu entlasten. (Quelle: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face stellt AISheets vor, das KI-Modelle mit Tabellenkalkulationen kombiniert: Hugging Face hat AISheets veröffentlicht, eine Anwendung, die Tausende von KI-Modellen (insbesondere Open-Source-LLMs) mit Tabellenkalkulationsfunktionen kombiniert. Nutzer können in AISheets Daten erstellen, analysieren und automatisiert verarbeiten, um ein reibungsloses, schnelles und einfaches KI-gestütztes Datenverarbeitungserlebnis zu bieten. (Quelle: ben_burtenshaw, LoubnaBenAllal1)
PLaMo veröffentlicht lokales Übersetzungs-CLI-Tool basierend auf MLX: Das PLaMo LLM-Team hat ein Open-Source-Kommandozeilen-Tool (CLI) veröffentlicht, das auf Macs mit Apple Silicon das MLX-Framework für lokale Textübersetzungen nutzt. Das Tool zielt darauf ab, ein schnelles und hochpräzises lokales Übersetzungserlebnis zu bieten und verfügt über integrierte HTTP- und MCP-Server sowie Clients zur einfachen Integration mit anderen MCP-kompatiblen Anwendungen (wie Claude Desktop). (Quelle: awnihannun)
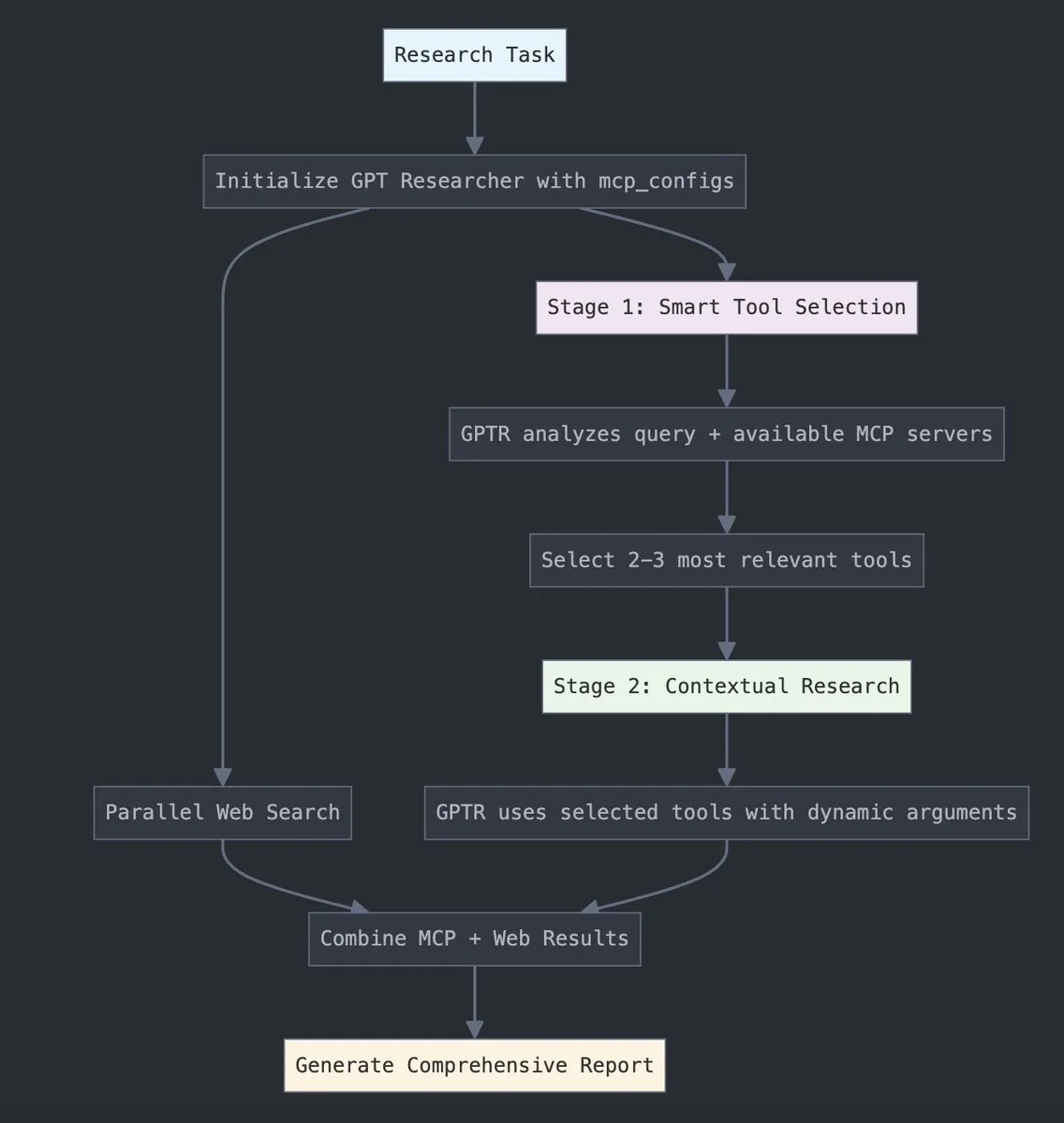
GPT Researcher integriert LangChain MCP-Adapter zur Verbesserung der Werkzeugauswahl und Forschungsfähigkeiten: GPT Researcher nutzt nun die Model Context Protocol (MCP)-Adapter von LangChain, um eine intelligentere Werkzeugauswahl und Forschungsprozesse zu ermöglichen. Ziel ist es, die Vorteile von MCP mit Websuchfunktionen zu kombinieren, um eine umfassendere Datenerfassung und -analyse durchzuführen. (Quelle: Hacubu)
Consilium: Open-Source-Framework für Multi-Agenten-Kollaboration veröffentlicht: Victor M stellt Consilium vor, ein Open-Source-Framework für die Zusammenarbeit von KI-Agententeams. Nutzer können Strategien festlegen, die von mehreren Expertenagenten diskutiert werden, und Echtzeitforschung (Web, arXiv, SEC-Daten) nutzen, um gemeinsam komplexe Probleme zu lösen und einen Konsens zu erzielen. Das Tool ist als Demo auf Hugging Face verfügbar. (Quelle: clefourrier)
youtube-transcript-api: Python-Bibliothek zum Abrufen von YouTube-Untertiteln, unterstützt Übersetzung und automatische Inhaltsgenerierung: Die von jdepoix entwickelte Python-Bibliothek youtube-transcript-api erregt Aufmerksamkeit auf GitHub. Die API kann Untertitel von YouTube-Videos abrufen, einschließlich automatisch generierter Untertitel, und unterstützt Übersetzungsfunktionen. Im Gegensatz zu anderen Selenium-basierten Lösungen benötigt sie keinen API-Schlüssel oder Headless-Browser und bietet Entwicklern einen bequemen Weg zur Extraktion von Video-Textinhalten. (Quelle: GitHub Trending)
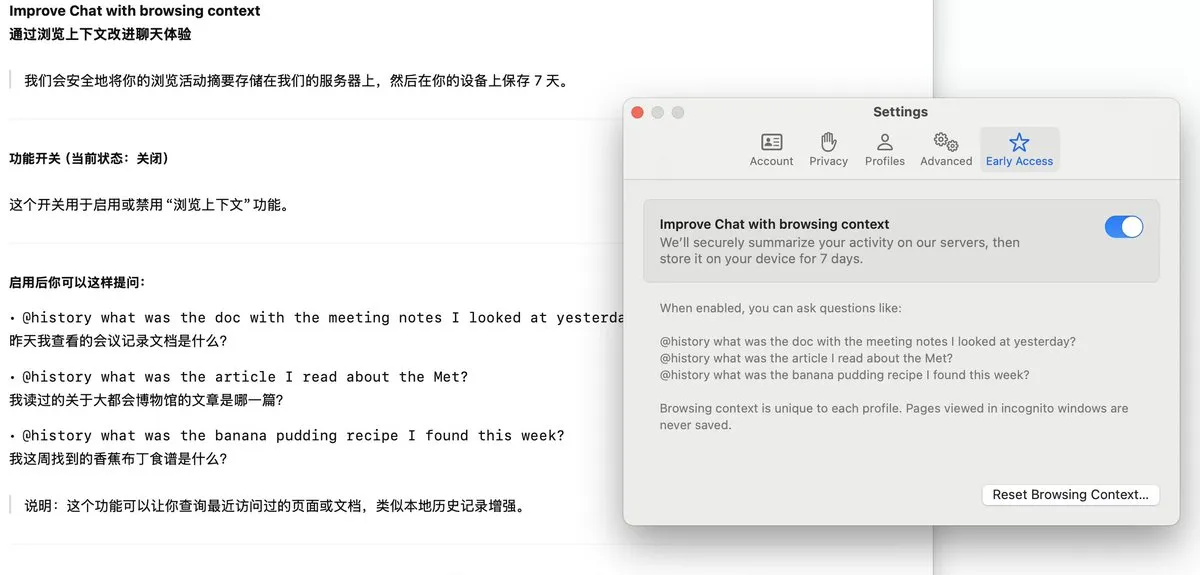
Arc Browser führt Dia-Funktion ein, zeichnet Browserverlauf auf und unterstützt KI-Fragen und Antworten: Der Arc Browser hat die neue Funktion Dia hinzugefügt, die bei Aktivierung kontinuierlich den gesamten Browserverlauf des Nutzers aufzeichnet. Nutzer können über die @History-Funktion mit vagen natürlichsprachlichen Fragen nach Informationen suchen, die sie einmal angesehen, deren genaue URL sie aber vergessen haben. Die Funktion könnte sogar die Generierung von Berichten über den Browserverlauf unterstützen und so die Intelligenz und personalisierte Informationsverwaltung des Browsers verbessern. (Quelle: op7418)
📚 Lernen
Apple veröffentlicht Paper „The Illusion of Thinking“, untersucht Fähigkeitsgrenzen von LLMs: Das Apple Machine Learning Research Team hat das Paper „The Illusion of Thinking“ veröffentlicht, das die Leistung und Grenzen aktueller Large Language Models (LLMs) bei komplexen Inferenzaufgaben (wie dem Lösen des Turm-von-Hanoi-Problems) analysiert. Das Paper löste eine Diskussion in der Community über das tatsächliche Intelligenzniveau von LLMs aus, und es gab Meinungen, dass solche Studien manchmal als Vorwand genutzt werden, um die Einführung von KI zu verzögern. Das o3-pro-Modell von OpenAI löste später das im Paper aufgeworfene Turm-von-Hanoi-Problem. (Quelle: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
Neue Studie „General agents need world models“ untersucht Beziehung zwischen Agenten-Generalisierung und prädiktiven Modellen: Ein neues Forschungspapier mit dem Titel „General agents need world models“ stellt fest, dass allgemeine Agenten, die auf mehrstufige, zielorientierte Aufgaben generalisieren können, ein prädiktives Weltmodell lernen müssen. Dieses Modell ist in der Strategie des Agenten kodiert. Das Papier extrahiert Umgebungstransitionswahrscheinlichkeiten, indem es die Strategieauswahl des Agenten bei zusammengesetzten Zielen abfragt, und beweist so einen direkten Zusammenhang zwischen Generalisierungsfähigkeit und der Genauigkeit des gelernten Modells. (Quelle: menhguin)

Paper untersucht Concept-Aware Fine-Tuning (CAFT) zur Verbesserung der LLM-Leistung: Ein neues Paper mit dem Titel „Improving large language models with concept-aware fine-tuning“ schlägt die CAFT-Methode vor, die durch die Aktivierung von Multi-Token-Vorhersagen beim Fine-Tuning das Verständnis von Konzepten durch das Modell verbessert. Die Studie zeigt, dass CAFT signifikante Leistungssteigerungen bei Aufgaben wie Codierung, Mathematik, Textzusammenfassung, Molekülgenerierung und Proteindesign erzielt. Der Code wurde auf GitHub als Open Source veröffentlicht. (Quelle: Reddit r/MachineLearning)
DeepLearning.AI startet neuen Kurs „Orchestrating Workflows for GenAI Applications“: DeepLearning.AI von Andrew Ng hat in Zusammenarbeit mit Astronomer einen neuen Kurzkurs mit dem Titel „Orchestrating Workflows for GenAI Applications“ gestartet. Der Kurs lehrt, wie man mit dem beliebten Open-Source-Tool Airflow 3.0 zuverlässige GenAI-Prozesse erstellt und Prototypen aus Jupyter Notebooks oder Python-Skripten in produktionsreife Workflows umwandelt. Die Inhalte umfassen Aufgabenzerlegung, Planung, parallele Ausführung, Fehlerbehebung und Beobachtbarkeit. (Quelle: AndrewYNg)
Paper „Token-weise Ausrichtung von Text, Bildern und 3D-Strukturen“ untersucht multimodale autoregressive Modelle: Diese Studie schlägt ein einheitliches LLM-Framework vor, das darauf abzielt, Sprache, Bilder und strukturierte 3D-Szenen auszurichten. Das Paper erläutert detailliert die wichtigsten Designentscheidungen zur Erzielung optimalen Trainings und optimaler Leistung, einschließlich Datenrepräsentation, modellspezifische Zielfunktionen usw., und bewertet diese anhand von vier Kernaufgaben im 3D-Bereich (Rendering, Erkennung, Befehlsverfolgung und Frage-Antwort) sowie mehreren Datensätzen. Die Forschung wird auch auf die Rekonstruktion komplexer 3D-Objektformen durch quantisierte Formcodierungen ausgeweitet. (Quelle: HuggingFace Daily Papers)
Paper „Squeeze3D“: Extreme neuronale Kompression durch Nutzung vortrainierter 3D-Generierungsmodelle: Das Squeeze3D-Framework nutzt implizite Priors, die in vortrainierten 3D-Generierungsmodellen gelernt wurden, um 3D-Daten (Meshes, Punktwolken, Radiance Fields) extrem zu komprimieren. Es verbindet den vortrainierten Encoder und den latenten Raum des Generierungsmodells über ein trainierbares Mapping-Netzwerk, komprimiert 3D-Modelle in kompakte latente Codes und rekonstruiert sie beim Dekomprimieren durch das Generierungsmodell. Die Methode wird auf synthetischen Daten trainiert, benötigt keine realen 3D-Datensätze und erreicht eine Kompressionsrate von bis zu 2187-fach für texturierte Meshes. (Quelle: HuggingFace Daily Papers)
Paper „Frame Guidance“: Trainingsfreie Steuerung auf Frame-Ebene in Video-Diffusionsmodellen: Diese Studie schlägt „Frame Guidance“ vor, eine Methode zur Erzielung von Steuerung auf Frame-Ebene in Video-Diffusionsmodellen ohne Training. Durch einfache Verarbeitung im latenten Raum und eine neuartige Optimierungsstrategie für den latenten Raum kann die Methode Signale auf Frame-Ebene wie Keyframes, Stilreferenzen, Skizzen oder Tiefenkarten effektiv steuern. Sie eignet sich für verschiedene Aufgaben wie Keyframe-geführte Generierung, Stilisierung, Endlosschleifen und ist mit jedem Videomodell kompatibel. (Quelle: HuggingFace Daily Papers)
Paper „Geopolitische Voreingenommenheit in Large Language Models“ deckt nationale Standpunkte von Modellen auf: Diese Studie bewertet geopolitische Voreingenommenheit in LLMs, indem sie deren Interpretation historischer Ereignisse aus verschiedenen nationalen Perspektiven (USA, Großbritannien, Sowjetunion, China) analysiert. Die Forscher führten einen neuen Datensatz mit neutralen Ereignisbeschreibungen und kontrastierenden nationalen Sichtweisen ein und stellten fest, dass LLMs eine signifikante Voreingenommenheit zugunsten bestimmter nationaler Narrative aufweisen und einfache De-Biasing-Prompts nur begrenzte Wirkung zeigen. Diese Arbeit bietet einen Rahmen und einen Datensatz für zukünftige Forschung zu geopolitischer Voreingenommenheit. (Quelle: HuggingFace Daily Papers)
Awesome Lists-Ressourcenbibliothek wird kontinuierlich aktualisiert und sammelt verschiedene interessante Themen: Das von sindresorhus gepflegte GitHub-Projekt awesome ist eine Meta-Liste, die „Awesome Lists“ zu verschiedenen interessanten Themen zusammenfasst. Diese Listen decken zahlreiche Bereiche ab, von Programmiersprachen und Entwicklungsplattformen bis hin zu Theorien, Büchern, Werkzeugen usw., und bieten Entwicklern und Lernenden einen umfangreichen Ressourcenindex. (Quelle: GitHub Trending)
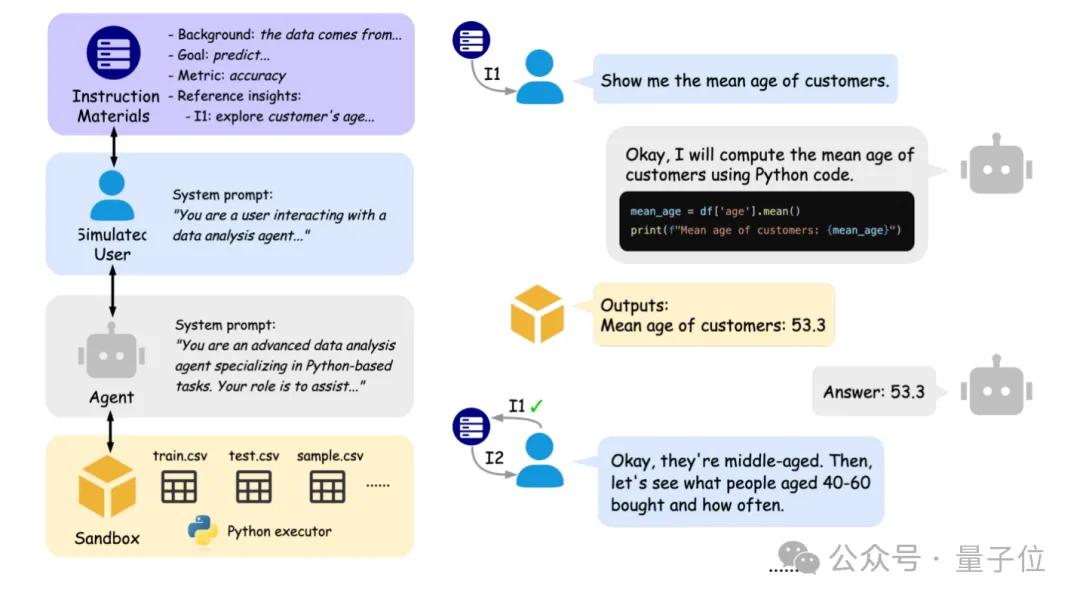
Peking-Universität und Berkeley stellen gemeinsam IDA-Bench vor, um die interaktiven Fähigkeiten von KI-Datenanalyse-Agenten zu bewerten: Forschungsteams der Peking-Universität und der University of California, Berkeley (einschließlich Professor Michael I. Jordan) haben IDA-Bench vorgestellt, einen neuen Benchmark zur Bewertung der Fähigkeiten von Large Language Models (LLMs) als Datenanalyse-Agenten (Agents) in interaktiven Szenarien mit mehreren Runden. Der Benchmark simuliert den Arbeitsablauf realer Datenanalysten und prüft die Fähigkeit der Agenten, Anweisungen zu befolgen sowie Code zu schreiben und auszuführen, anhand schrittweise weiterentwickelter Anweisungen. Erste Bewertungen zeigen, dass selbst Spitzenmodelle wie Claude-3.7 und Gemini-2.5 Pro eine Erfolgsquote von weniger als 40 % erreichen, was die aktuellen Herausforderungen von Agenten bei komplexen Interaktionen und der Befolgung von Anweisungen aufzeigt. (Quelle: 量子位)
💼 Business
xAI und Polymarket kooperieren, um Marktprognosen mit Grok-Analysen zu verbinden: Elon Musks xAI hat eine Zusammenarbeit mit der Prognosemarkt-Plattform Polymarket angekündigt. Beide Parteien werden die Marktprognosefähigkeiten von Polymarket, Daten von der X-Plattform und die Analysefähigkeiten des Grok-Modells kombinieren, um eine „Hardcore Truth Engine“ zu schaffen, die Einblicke in die Faktoren geben soll, die die Welt prägen. Offiziell ist dies erst der Anfang der Zusammenarbeit, weitere Entwicklungen sollen folgen. (Quelle: Yuhu_ai_)
UnslothAI von Redpoint als Top-Infrastrukturunternehmen ausgezeichnet, erscheint auf Nasdaq-Großbildschirm: Das KI-Startup UnslothAI wurde von der Risikokapitalgesellschaft Redpoint für seine Beiträge im Bereich der KI-Infrastruktur als eines der 100 einflussreichsten und am schnellsten wachsenden Infrastrukturunternehmen des Jahres 2025 ausgezeichnet. Sein Logo erschien daraufhin auf dem elektronischen Bildschirm des Nasdaq-Gebäudes in New York. UnslothAI konzentriert sich auf die Optimierung der Trainings- und Ineffizienz von LLMs. (Quelle: danielhanchen, karminski3)

Ant Digital Science wertet Tianji-Labor auf, Fokus auf „KI + industrielle Innovation“: Ant Digital Science hat angekündigt, sein Tianji-Labor vom ursprünglichen „Labor für digitale Identitätssicherheit“ zu einem Labor für „Künstliche Intelligenz + industrielle Innovation“ aufzuwerten. Das aufgewertete Labor wird sich auf wichtige technologische Durchbrüche bei der Anwendung von KI-Großmodellen in der Industrie konzentrieren und die vier Bereiche KI + Daten, KI + Sicherheit, KI + Finanzen sowie KI + Embodied Intelligence abdecken. Ziel ist es, durch kollaborative Innovationen in Industrie, Wissenschaft, Forschung und Anwendung die tiefe Integration von KI-Technologie und Industrie zu fördern. (Quelle: 量子位)

🌟 Community
Fähigkeiten von KI beim autonomen Fahren in komplexen Verkehrsumgebungen im Fokus: Ronald van Loon teilte ein Video, das Tests autonomen Fahrens im chaotischen Verkehr Indiens zeigt, und löste damit eine Diskussion über die Wahrnehmungs-, Entscheidungs- und Kontrollfähigkeiten von KI in komplexen, hochdynamischen Umgebungen aus. Solche realen Szenarien stellen extrem hohe Anforderungen an die Robustheit und Anpassungsfähigkeit von autonomen Fahrsystemen. (Quelle: Ronald_vanLoon)
Highlights der AI Engineer World’s Fair Konferenz: MCP-Protokoll, Kosten von KI-Agenten und lokale Modelle im Fokus: Yogi und Shawn “swyx” Wang sowie andere teilten die wichtigsten Punkte der AI Engineer World’s Fair Konferenz. Zu den Kerntrends gehören: 1) KI-Agenten sind die Zukunft, die atomare Interaktionseinheit wird der Agentenaufruf sein; 2) Das Model Context Protocol (MCP) entwickelt sich schnell zum Standard und löst die „Copy-Paste-Hölle“, indem es KI ermöglicht, direkt mit externen Anwendungen zu interagieren; 3) Der Aufbau tief optimierter KI-Tools für spezifische Bereiche und Arbeitsabläufe (Cursor-for-X-Modus) ist entscheidend; 4) Die Modellkosten sinken drastisch und die Fähigkeiten lokaler Modelle nehmen zu, was Entwicklern mehr Kontrolle und Lösungen mit geringer Latenz bietet; 5) KI entwickelt sich von einem Hilfswerkzeug zu einem „Teamkollegen“ für Entwickler; 6) KI-Engineering geht von der Demonstrationsphase in produktionsreife Systeme über. (Quelle: swyx, TheTuringPost)
Community diskutiert schnelle Iteration nach Veröffentlichung von o3-pro und Apples KI-Paper: andersonbcdefg kommentierte humorvoll, dass die Community nur 6 Stunden nach der Veröffentlichung von o3-pro scheinbar erwarte, dass jemand fastText in Rust neu schreibt, und ironisierte über lange Abhandlungen zur „sanften Superintelligenz“, was die schnelle technologische Iteration im KI-Bereich und die hohen Erwartungen der Community widerspiegelt. Gleichzeitig wies Teknium1 darauf hin, dass o3-pro das im Apple-Paper „The Illusion of Thinking“ aufgeworfene Turm-von-Hanoi-Problem gelöst habe, und stellte in Frage, warum Apple angesichts der Zusammenarbeit mit OpenAI solche Paper nicht zuerst intern validiere, bevor sie veröffentlicht werden, was eine Diskussion in der Community über Wettbewerb und Kooperation zwischen Technologieunternehmen auslöste. (Quelle: andersonbcdefg, Teknium1)
Diskussion über Ethik und Wirksamkeit von KI-Anwendungen in der realen Welt: Die Community diskutiert die Wirksamkeit und ethische Fragen von KI-Anwendungen in spezifischen Szenarien. Arvind Narayanan wies beispielsweise darauf hin, dass das Konzept von KI-Kalorienzähler-Apps fehlerhaft sei, da Bildinformationen nicht ausreichten, um Kalorien genau zu schätzen, und meinte, sie dienten eher als „Ritual“, um Nutzern zu helfen, auf ihre Ernährung zu achten. Auch die Frage, ob die Verwendung von KI-generierten Bildern für kommerzielle Werbung (z. B. zur Präsentation von Gerichten in einem Café) ethisch vertretbar oder angemessen ist, wurde diskutiert. Allgemein wurde dies als akzeptable Methode zur Kostensenkung und Effizienzsteigerung angesehen, solange keine offensichtlichen Unwahrheiten oder Irreführungen vorliegen. (Quelle: random_walker, Reddit r/artificial)
„Vermenschlichung“ von LLMs und Nutzerinteraktionserfahrung im Fokus: Reddit-Nutzer diskutieren, wie die Interaktion mit LLMs menschlicher gestaltet werden kann, einschließlich der Einführung von Zögern, Pausen, kürzeren Antworten und nicht perfekter Ausdrucksweise. Dies spiegelt das Bedürfnis der Nutzer nach natürlicheren, weniger „roboterhaften“ KI-Begleitern oder -Assistenten wider. Gleichzeitig beschweren sich einige Nutzer darüber, dass aktuelle LLMs (wie ChatGPT) oft feste Satzmuster und übertriebene Formulierungen verwenden (z. B. „Das ist nicht nur X, sondern Y“) und wünschen sich eine prägnantere und direktere Ausdrucksweise. Diese Diskussionen deuten auf die anhaltenden Herausforderungen von LLMs bei der Simulation menschlicher Gespräche und der Erfüllung emotionaler Bedürfnisse der Nutzer hin. (Quelle: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 Sonstiges
NVIDIA CEO Jensen Huang hält Keynote auf der GTC Paris, Fokus auf neue Phase des KI-Computings: NVIDIA hat angekündigt, dass sein CEO Jensen Huang am 11. Juni auf der GTC Konferenz in Paris (während der VivaTech 2025) eine Keynote halten wird. Es wird erwartet, dass er die nächste Phase des KI-Computings enthüllt, die von Agentensystemen bis hin zu KI-Fabriken reicht. (Quelle: nvidia, nvidia)

Databricks Data+AI Summit wird neueste Durchbrüche präsentieren: Databricks hat angekündigt, dass sein Data+AI Summit führende Experten, Forscher und Open-Source-Beitragende zusammenbringen wird, um die neuesten Durchbrüche des Unternehmens im Bereich Daten und KI zu präsentieren und Erfolgsgeschichten innovativer Unternehmen zu teilen. Der Gipfel bietet Teilnahmeoptionen online und vor Ort. (Quelle: matei_zaharia, lateinteraction)

Ethik und Umweltauswirkungen von KI im Fokus, Aufklärung in Form einer Graphic Novel: Das LEARN-Zentrum der EPFL (École polytechnique fédérale de Lausanne) hat in Zusammenarbeit mit dem Illustrator Herji eine französischsprachige pädagogische Graphic Novel mit dem Titel „Utop’IA“ veröffentlicht. Ziel ist es, Jugendlichen die Umweltauswirkungen künstlicher Intelligenz, einschließlich ihres Ressourcenverbrauchs (Energie, Wasser, seltene Metalle) und potenzieller ökologischer Vorteile, in Form einer Geschichte näherzubringen. Das Werk betont kritisches Denken und untersucht Wege zu einer nachhaltigen KI-Entwicklung. (Quelle: aihub.org)
