
Palabras clave:Meta, Scale AI, superinteligencia, AGI, etiquetado de datos, entrenamiento de IA, precisión del modelo, Meta adquiere participación en Scale AI, Alexandr Wang lidera el grupo de superinteligencia, precisión de etiquetado de datos de IA del 99.7%, tasa de contaminación de datos de entrenamiento reducida, ciclo de entrenamiento de modelos reducido en un 40%
🔥 Enfoque
Se informa que Meta invertirá casi 15 mil millones de dólares para adquirir una participación en Scale AI y nombrará a su CEO para liderar un nuevo equipo de “superinteligencia”: Meta planea invertir aproximadamente 14.9 mil millones de dólares para adquirir el 49% de las acciones de Scale AI, empresa de etiquetado de datos e infraestructura de IA, y ha nombrado a su CEO de 28 años de origen chino, Alexandr Wang, para liderar el recién formado “Grupo de Superinteligencia”. Esta medida tiene como objetivo fortalecer la competitividad de Meta en el campo de la IA, especialmente en datos de entrenamiento de alta calidad e investigación y desarrollo de AGI. Scale AI es conocida por su precisión de etiquetado de datos de hasta el 99.7%, y se espera que reduzca la tasa de contaminación de datos de entrenamiento de los modelos de Meta del 15% al 2%, y acorte el ciclo de entrenamiento en un 40%. Esta adquisición se considera un paso clave para que Meta alcance e intente superar a sus rivales en la carrera de la IA, y también destaca la posición estratégica central de los datos en el desarrollo de la IA. (Fuente: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
Se revela que OpenAI ha alcanzado un acuerdo de cómputo a gran escala con Google Cloud, posiblemente para reducir la dependencia de Microsoft: Según informes, OpenAI ha alcanzado un importante acuerdo de servicios en la nube con Google Cloud, mediante el cual Google Cloud proporcionará a OpenAI la potencia de cómputo necesaria para el entrenamiento y despliegue de sus crecientes modelos de IA. Anteriormente, Microsoft Azure era el principal proveedor de cómputo de OpenAI. Esta medida podría indicar que OpenAI está buscando diversificar sus fuentes de cómputo para reducir la dependencia de un solo proveedor y satisfacer sus enormes necesidades de cálculo. Esta colaboración es una victoria importante para Google Cloud, pero también ha generado debate sobre cómo equilibrará los recursos de TPU entre sus propias operaciones y las necesidades de los clientes. (Fuente: 36氪, scaling01)
Mistral AI lanza el modelo de inferencia Magistral, generando dudas en la comunidad sobre la transparencia de sus benchmarks: La empresa francesa de IA, Mistral AI, ha lanzado su primera serie de modelos diseñados específicamente para la inferencia, Magistral, que incluye la versión de código abierto 24B Magistral Small y Magistral Medium, orientada a empresas. Oficialmente, se afirma que está diseñado para un razonamiento lógico de múltiples pasos transparente y rastreable, y admite múltiples idiomas. Sin embargo, la comunidad ha cuestionado los resultados de los benchmarks publicados, considerando que no se compararon con las últimas versiones de modelos competidores como Qwen y DeepSeek R1, lo que podría sugerir una intención de “evitar la confrontación”. A pesar de esto, Magistral muestra una mejora significativa en el benchmark de matemáticas AIME-24 en comparación con Mistral Medium 3. (Fuente: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Richard Sutton, padre del aprendizaje por refuerzo: El dominio de los LLM es solo temporal, la computación extendida y el aprendizaje experiencial son el futuro: Richard Sutton, ganador del Premio Turing y padre del aprendizaje por refuerzo, predice que la actual posición dominante de los grandes modelos de lenguaje (LLM) es solo temporal, y que imitar la forma de pensar humana solo puede aportar mejoras de rendimiento a corto plazo. Considera que el futuro de la IA reside en la “era de la experiencia”, donde los Agents aprenden adquiriendo datos experienciales a través de la interacción en primera persona con el mundo, en lugar de depender de datos humanos estáticos. Sutton enfatiza que el aprendizaje por refuerzo es el camino central hacia este futuro, y que, combinado con algoritmos de aprendizaje profundo de aprendizaje continuo y computación extendida a gran escala, permitirá a la IA superar el conocimiento actual y lograr una verdadera innovación. (Fuente: 量子位)

Hugging Face y NVIDIA lanzan “Training Cluster as a Service” para reducir la barrera de entrenamiento de grandes modelos: Hugging Face ha anunciado una colaboración con NVIDIA para lanzar “Training Cluster as a Service”, con el objetivo de facilitar que las instituciones de investigación de todo el mundo accedan a grandes recursos de clústeres de GPU para entrenar diversos modelos de vanguardia. El servicio integra NVIDIA DGX Cloud Lepton y los recursos de desarrollo de Hugging Face, permitiendo a las organizaciones solicitar y pagar por el tiempo de uso del clúster de GPU según demanda. Esta medida tiene como objetivo cerrar la “brecha entre ricos y pobres de GPU”, impulsar la diversidad y la popularización de la investigación en IA, y ya ha sido adoptado tempranamente por instituciones de investigación y startups como TIGEM, Numina y Mirror Physics. (Fuente: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 Movimientos
OpenAI lanza el modelo o3-pro y reduce drásticamente los precios de la API de o3: OpenAI ha lanzado su nuevo modelo de inferencia de gama alta, o3-pro, que ya está disponible para los usuarios de ChatGPT Pro y los usuarios de la API. Al mismo tiempo, el precio de la API del modelo o3 se ha reducido drásticamente en un 80%, y el límite de tasa de o3 para los usuarios de ChatGPT Plus también se ha duplicado. Los comentarios de la comunidad indican que o3-pro supera a Claude Opus 4 en tareas no relacionadas con el código y ha establecido nuevos récords en varios benchmarks como Extended NYT Connections y Creative Short Story Writing, incluso resolviendo con éxito el “problema de las Torres de Hanói con 10 discos” que previamente un paper de Apple había utilizado para cuestionar las capacidades de los LLM. Sin embargo, algunos usuarios informan que o3-pro es más lento. OpenAI ha declarado que la reducción de precios de o3 no se debe a la destilación o cuantización, sino al trabajo de optimización de los ingenieros de inferencia. (Fuente: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB lanza la serie MiniCPM4 de LLM eficientes para dispositivos edge: OpenBMB ha lanzado la serie de modelos MiniCPM4, diseñados específicamente para dispositivos edge, afirmando haber logrado una aceleración de generación de más de 5 veces en chips típicos para dispositivos edge. La serie incluye versiones como MiniCPM4-8B, MiniCPM4-0.5B, y BitCPM4-1B/0.5B con cuantización ternaria. MiniCPM4 utiliza un mecanismo de atención dispersa entrenable, InfLLM v2, que admite el procesamiento de texto largo de 128K, y combina algoritmos de aprendizaje eficiente y técnicas de entrenamiento como el túnel de viento de modelos 2.0, cuantización ternaria BitCPM, cálculo de baja precisión FP8 y predicción de múltiples tokens. Simultáneamente, se lanzaron el conjunto de datos de preentrenamiento en chino e inglés de alta calidad UltraFineweb y el conjunto de datos de ajuste fino supervisado UltraChat v2. (Fuente: GitHub Trending)
MSRA y académicos de Tsinghua y Pekín proponen un nuevo paradigma de preentrenamiento reforzado (RPT): Investigadores de Microsoft Research Asia (MSRA), en colaboración con la Universidad de Tsinghua y la Universidad de Pekín, han propuesto un nuevo paradigma de preentrenamiento de LLM llamado Preentrenamiento Reforzado (RPT). Este método integra profundamente el aprendizaje por refuerzo (RL) en la fase de preentrenamiento; antes de predecir cada token, el modelo genera una secuencia de razonamiento de cadena de pensamiento y recibe recompensas basadas en la corrección de la predicción. RPT tiene como objetivo que el modelo pase de aprender correlaciones superficiales de tokens a comprender significados profundos. Los experimentos muestran que un modelo de 14B entrenado con RPT puede igualar o incluso superar a modelos de preentrenamiento tradicionales de 32B en ciertas tareas de razonamiento, demostrando un gran potencial para mejorar las capacidades de modelado de lenguaje y razonamiento de los LLM. (Fuente: 量子位, omarsar0)

Meta lanza el modelo mundial de video V-JEPA 2 y nuevos benchmarks: Meta AI ha presentado V-JEPA 2, un modelo mundial de 1.2 mil millones de parámetros entrenado con datos de video, diseñado para mejorar la comprensión y predicción del mundo físico por parte de las máquinas. El modelo puede desempeñar un papel en la planificación zero-shot de robots, permitiéndoles planificar y ejecutar tareas en entornos desconocidos. Al mismo tiempo, Meta también ha lanzado tres nuevos benchmarks para evaluar la capacidad de los modelos existentes para razonar sobre el mundo físico a partir de videos. HuggingFace ya ofrece soporte para V-JEPA 2 en su biblioteca transformers. (Fuente: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance lanza el modelo de generación de video Seedance 1.0 Pro, ya disponible en la App Doubao: ByteDance ha lanzado su último modelo de generación de video, Seedance 1.0 Pro (también conocido como el modelo Video 3.0 Pro en Dream Engine). Este modelo destaca en la comprensión de prompts, detalles de imagen y consistencia en la representación física, siendo capaz de generar videos de 5 segundos a 1080P. Actualmente, el modelo está disponible para usuarios empresariales a través de Volcengine y se ha lanzado la función “照片动起来” (fotos que cobran vida) en la App Doubao para que los usuarios la prueben de forma gratuita. (Fuente: op7418)
Huawei lanza la plataforma de simulación “Túnel de Viento Digital” para optimizar la eficiencia del entrenamiento e inferencia de IA: El equipo de simulación y modelado Markov de Huawei ha presentado por primera vez su tecnología de “Túnel de Viento Digital”, una plataforma para realizar “ensayos” en un entorno virtual antes del entrenamiento e inferencia reales de modelos complejos de IA. La plataforma incluye tres módulos principales: Sim2Train (simulación de entrenamiento), Sim2Infer (simulación de inferencia) y Sim2Availability (simulación de alta disponibilidad). Su objetivo es resolver problemas como el desajuste de recursos de hardware y el acoplamiento de sistemas mediante la simulación y la optimización automática, permitiendo previsualizar soluciones de clústeres de decenas de miles de GPUs en cuestión de horas, evitar el desperdicio de potencia de cómputo y mejorar la eficiencia y estabilidad del entrenamiento e inferencia de grandes modelos de IA. (Fuente: 量子位)

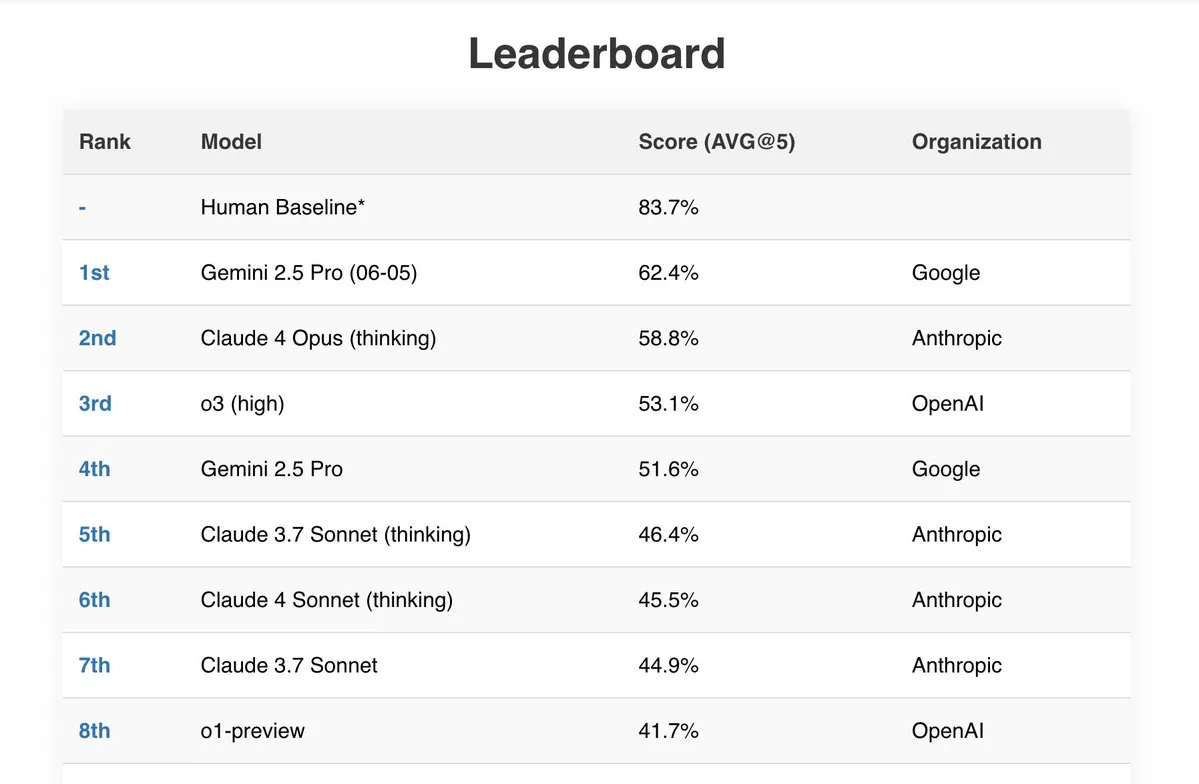
Gemini 2.5 Pro muestra un rendimiento excelente en múltiples benchmarks: El último modelo Gemini 2.5 Pro (06-05) de Google ha destacado en varias clasificaciones públicas de IA. Obtuvo el mejor rendimiento en la prueba Live Fiction procesando 192k tokens, ocupó el primer lugar en SimpleBench con una puntuación del 62.4%, y demostró una gran capacidad de procesamiento de documentos y rentabilidad en benchmarks como IDP (procesamiento inteligente de documentos) y Aider (codificación asistida por IA). Además, algunos usuarios informan que Gemini 2.5 Pro resolvió con éxito todos los problemas de la sección de matemáticas del JEE Advanced 2025. (Fuente: _philschmid, dilipkay)
El modelo de video Kling AI actualiza la función de sincronización labial, admite selección y edición de personajes: Kling AI, la herramienta de generación de video de Kuaishou, ha actualizado recientemente su función de sincronización labial (Lip-sync). La nueva función permite a los usuarios seleccionar personajes específicos en el video generado para la coincidencia labial y ajustar el tiempo de sincronización del audio con los movimientos de la boca. Esta actualización mejora la flexibilidad y el realismo de Kling AI en la creación de videos con diálogos entre múltiples personajes, lo que representa un avance importante en el campo de la generación de video. (Fuente: Kling_ai, Kling_ai)
Lanzamiento de Delta Lake 4.0.0, mejorando las capacidades de Lakehouse: Se ha lanzado oficialmente la versión Delta Lake 4.0.0, que trae varias características nuevas importantes, incluyendo una vista previa de las Tablas Gestionadas por Catálogo (Catalog-Managed Tables) para una gobernanza y descubribilidad unificadas, la extensión Delta Connect para Spark Connect, soporte para el tipo de datos Variant para manejar datos semiestructurados, y la función DROP FEATURE instantánea, que permite eliminar características de tabla sin truncar el historial ni interrumpir el servicio. Esta versión tiene como objetivo mejorar la experiencia de la comunidad open lakehouse. (Fuente: matei_zaharia)

Hugging Face lanza el servidor MCP para simplificar la interacción entre modelos y herramientas: Hugging Face ha lanzado la primera versión de su servidor de Protocolo de Contexto de Modelo (MCP). Los usuarios ahora pueden utilizar este servidor a través de http://hf.co/mcp en aplicaciones como Claude o Cursor para buscar modelos, conjuntos de datos, papers, aplicaciones o información específica. Esto marca un paso importante para Hugging Face en la promoción de la interoperabilidad de herramientas y modelos en el ecosistema de IA, y podría expandirse en el futuro a funciones como carga, descarga e inicio de PRs. (Fuente: clefourrier, ClementDelangue)

Baidu lanza “AI Camera” con almacenamiento integrado y gestión inteligente, y actualiza GenFlow Super Partner 2.0: Baidu Netdisk y Baidu Wenku han lanzado conjuntamente la función “AI Camera”, que integra la toma de fotografías, el almacenamiento en la nube y la gestión inteligente. Las fotos se pueden archivar automáticamente en álbumes en la nube y admiten la clasificación y búsqueda inteligente mediante descripciones en lenguaje natural. AI Camera también cuenta con diversas capacidades de IA como embellecimiento, divulgación científica mediante reconocimiento de objetos, generación de garabatos a partir de dibujos simples, escaneo de recibos y conversión de tablas escritas a mano. Al mismo tiempo, la plataforma de colaboración multiagente “GenFlow Super Partner” se ha actualizado a la versión 2.0, que puede integrarse más profundamente con los datos y hábitos del usuario para ofrecer servicios de generación de contenido personalizados. (Fuente: 量子位)

ByteDance publica el código y los pesos del modelo de restauración de video SeedVR2: El equipo SEED de ByteDance ha publicado el código de inferencia y los pesos del modelo de su modelo de restauración de video de un solo paso, SeedVR2, que ya están disponibles en Hugging Face. Este modelo utiliza la técnica de post-entrenamiento adversario de difusión (diffusion adversarial post-training) y ha logrado resultados notables en la restauración de video, especialmente en el procesamiento de video de alta resolución. (Fuente: _akhaliq)
GroqCloud incorpora el modelo Qwen3-32B, compatible con más de cien idiomas y 131k de contexto: Groq ha anunciado la incorporación del modelo Qwen3-32B de Tongyi Qianwen a su plataforma en la nube de inferencia LPU, GroqCloud. Este modelo es compatible con más de 100 idiomas y dialectos, tiene una ventana de contexto de 131k y funciona a la velocidad en tiempo real característica del hardware de Groq, ofreciendo a los desarrolladores potentes capacidades de procesamiento multilingüe y de texto largo. (Fuente: JonathanRoss321)
El CEO de OpenAI, Sam Altman, afirma que el lanzamiento de su modelo de pesos abiertos se retrasará: Sam Altman ha indicado que el modelo de pesos abiertos de OpenAI se retrasará hasta finales de este verano, en lugar de junio como estaba previsto originalmente. Reveló que el equipo de investigación ha logrado algunos avances “inesperados y muy sorprendentes” que merecen la espera, pero que necesitan más tiempo para perfeccionarlos. (Fuente: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

Diguarobot lanza el kit de desarrollo RDK S100, con arquitectura de cerebro y cerebelo integrada en un solo SoC: Diguarobot ha lanzado el primer kit de desarrollo de robots con control y cómputo integrados en un solo SoC de la industria, el RDK S100. Este kit adopta un diseño de arquitectura colaborativa superheterogénea similar al cerebro y cerebelo humanos (CPU Arm Cortex-A78AE de 6 núcleos + BPU de 80 TOPS como “cerebro”, MCU Arm Cortex-R52+ de 4 núcleos como “cerebelo”), compatible con la colaboración eficiente de modelos grandes y pequeños de inteligencia corpórea, cerrando el ciclo de “percepción-decisión-control”. El RDK S100 ofrece interfaces ricas e infraestructura de desarrollo de ciclo completo, con un precio de preventa de 2499 yuanes. (Fuente: 量子位)

Aibo Intelligence lanza el módulo de cómputo AI E300, equipado con un SoC nacional de 50TOPS: Aibo Intelligence ha lanzado el módulo de cómputo AI E300 para escenarios edge, equipado con su chip SoC de IA de desarrollo propio AB100. Este módulo ofrece hasta 50TOPS de potencia de cómputo INT8, admite cálculo de precisión mixta FP16/FP32 y está equipado con un ancho de banda de memoria LPDDR5 de 102GB/s. El E300 adopta un diseño modular, con el objetivo de proporcionar soluciones de IA edge de alto rendimiento, baja latencia y alta fiabilidad de producción nacional para industrias como la educación, la energía y la medicina, y es compatible con el despliegue en el borde de los principales modelos grandes de código abierto y diversos modelos visuales y de voz. (Fuente: 量子位)

Huawei revela la tecnología de alta disponibilidad para clústeres Ascend de decenas de miles de GPUs, logrando una disponibilidad de entrenamiento del 98%: Huawei ha revelado por primera vez los detalles de su tecnología de alta disponibilidad para clústeres de cómputo Ascend de decenas de miles de GPUs. Mediante tres capacidades básicas: diagnóstico de percepción de fallos, gestión de fallos y tolerancia a fallos de enlaces ópticos del clúster, así como capacidades de soporte empresarial como la optimización de la linealidad del clúster y la rápida recuperación del entrenamiento y la inferencia, Huawei ha logrado una disponibilidad de entrenamiento del clúster de decenas de miles de GPUs del 98%, una linealidad superior al 95%, una recuperación de fallos a nivel de segundos y un diagnóstico a nivel de minutos. Este sistema tecnológico de doble dimensión “3+3” tiene como objetivo garantizar el funcionamiento estable y eficiente del entrenamiento e inferencia de IA a gran escala. (Fuente: 量子位)

La tasa de penetración de la conducción inteligente en los nuevos vehículos de BYD alcanza el 79%, el NOA de alta velocidad se convierte en configuración estándar: Los últimos datos publicados por BYD muestran que, entre los vehículos nuevos vendidos en mayo, el porcentaje de modelos equipados con sistemas de asistencia a la conducción inteligente (al menos con funciones NOA de alta velocidad y estacionamiento automático) alcanzó el 79%. Esto indica que BYD ha logrado avances significativos en su estrategia de “conducción inteligente para todos”, y las funciones de conducción inteligente se están convirtiendo rápidamente en una configuración estándar en sus modelos. Esta tendencia también refleja la aceleración de la popularización de la tecnología de conducción inteligente en el mercado automotriz chino. (Fuente: 量子位)

Las funciones avanzadas de voz de ChatGPT se lanzan para todos los usuarios de pago: OpenAI ha anunciado que las funciones avanzadas de voz de ChatGPT (Advanced Voice), actualizadas anteriormente con una naturalidad mejorada, ya están disponibles para todos los usuarios de pago (ChatGPT Plus, Team, Enterprise). Los usuarios pueden utilizar esta función para interactuar con ChatGPT de forma más natural mediante la voz. (Fuente: juberti)
🧰 Herramientas
Lanzamiento del navegador Genspark AI, integrando múltiples funciones de agentes de IA: El equipo de Eric Jing ha lanzado el navegador Genspark AI, que según afirman fue creado por un equipo de 24 personas en 10 semanas. Integra 8 productos principales: navegador de IA, secretario de IA, llamadas personales de IA, agente de descarga de IA, AI Drive, AI Sheets, entre otros. Este navegador se promociona por su rapidez, bloqueo de anuncios, completa agentificación, modo de conducción automática, y cuenta con una tienda MCP integrada y un superagente, con el objetivo de proporcionar una experiencia integral de navegación y trabajo asistida por IA. (Fuente: blader)
Yutori AI lanza la plataforma Scouts para la monitorización de redes de agentes de IA: Yutori AI ha lanzado la plataforma Scouts, que permite a los usuarios crear agentes de IA permanentemente en línea para monitorizar actualizaciones de información específica en la web. Estos agentes pueden rastrear diversos contenidos de interés para el usuario, como noticias de nicho, cambios de precios de productos, información de entradas, etc., y alertar a los usuarios por correo electrónico en momentos clave, con el objetivo de liberar a los usuarios mediante la automatización del seguimiento de información. (Fuente: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face lanza AISheets, combinando modelos de IA con hojas de cálculo: Hugging Face ha lanzado AISheets, una aplicación que combina miles de modelos de IA (especialmente LLM de código abierto) con funcionalidades de hoja de cálculo. Los usuarios pueden construir, analizar y automatizar el procesamiento de datos en AISheets, con el objetivo de proporcionar una experiencia de procesamiento de datos fluida, rápida y sencilla potenciada por IA. (Fuente: ben_burtenshaw, LoubnaBenAllal1)
PLaMo lanza una herramienta CLI de traducción local basada en MLX: El equipo de PLaMo LLM ha lanzado como código abierto una herramienta de interfaz de línea de comandos (CLI) que permite la traducción de texto local en Macs con Apple Silicon utilizando el framework MLX. La herramienta tiene como objetivo proporcionar una experiencia de traducción local rápida y de alta precisión, e incluye servidores y clientes HTTP y MCP integrados para facilitar la integración con otras aplicaciones compatibles con MCP (como Claude Desktop). (Fuente: awnihannun)
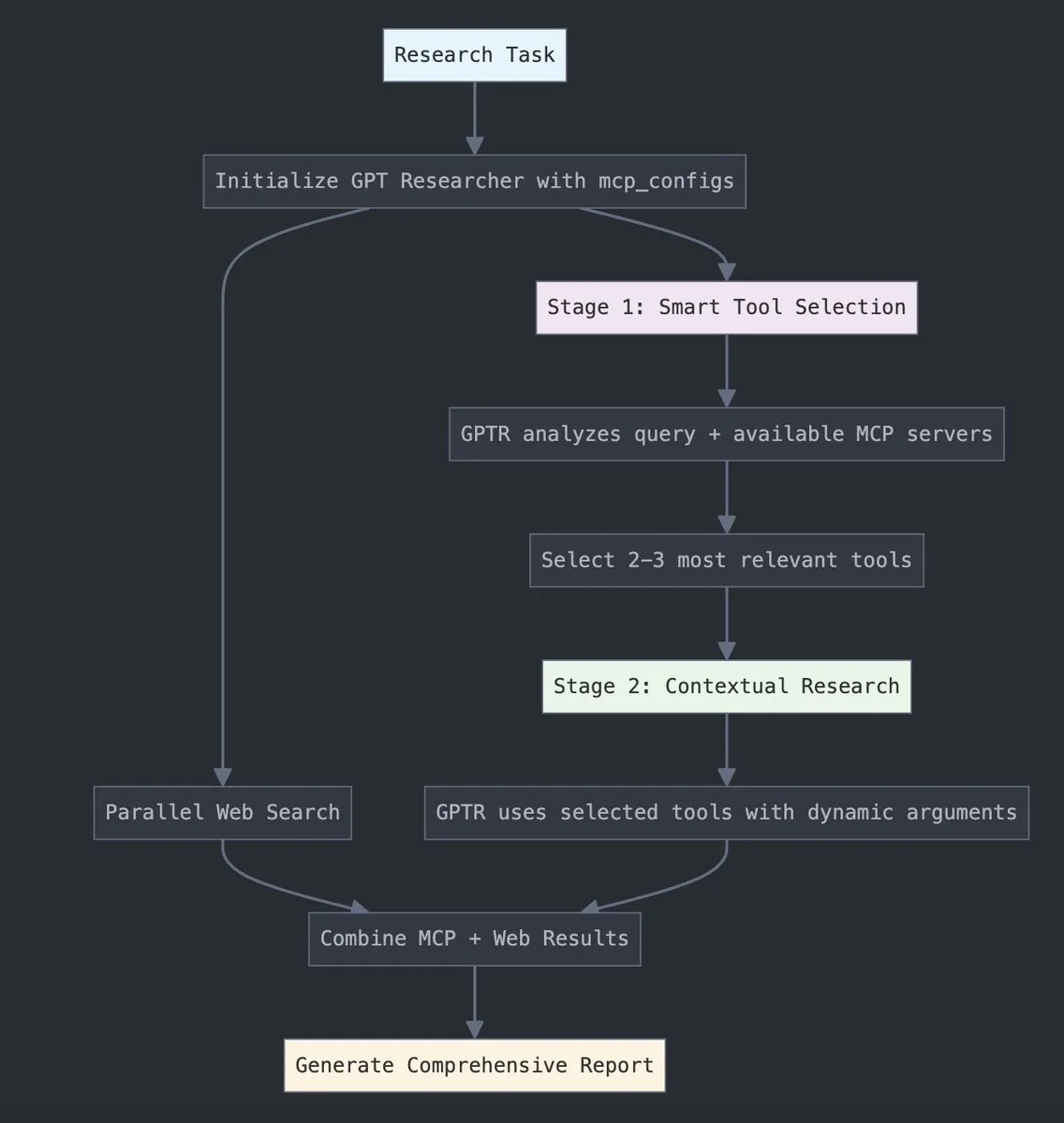
GPT Researcher integra el adaptador MCP de LangChain, mejorando la selección de herramientas y la capacidad de investigación: GPT Researcher ahora utiliza el adaptador del Protocolo de Contexto de Modelo (MCP) de LangChain para lograr una selección de herramientas y procesos de investigación más inteligentes. Esta medida tiene como objetivo combinar las ventajas de MCP con las capacidades de búsqueda en la web para una recopilación y análisis de datos más completos. (Fuente: Hacubu)
Consilium: Lanzamiento de un framework de colaboración multiagente de código abierto: Victor M ha lanzado Consilium, un framework de código abierto para la colaboración de equipos de agentes de IA. Los usuarios pueden establecer estrategias, donde múltiples agentes expertos debaten y utilizan investigación en tiempo real (web, arXiv, datos de la SEC) para resolver conjuntamente problemas complejos y alcanzar un consenso. La herramienta ya tiene una demo disponible en Hugging Face. (Fuente: clefourrier)
youtube-transcript-api: Biblioteca de Python para obtener subtítulos de YouTube, compatible con traducción y generación automática de contenido: La biblioteca de Python youtube-transcript-api desarrollada por jdepoix está ganando atención en GitHub. Esta API puede obtener los subtítulos de los videos de YouTube, incluidos los subtítulos generados automáticamente, y es compatible con la función de traducción. A diferencia de otras soluciones basadas en Selenium, no requiere claves API ni un navegador sin cabeza, lo que proporciona a los desarrolladores una forma conveniente de extraer contenido textual de videos. (Fuente: GitHub Trending)
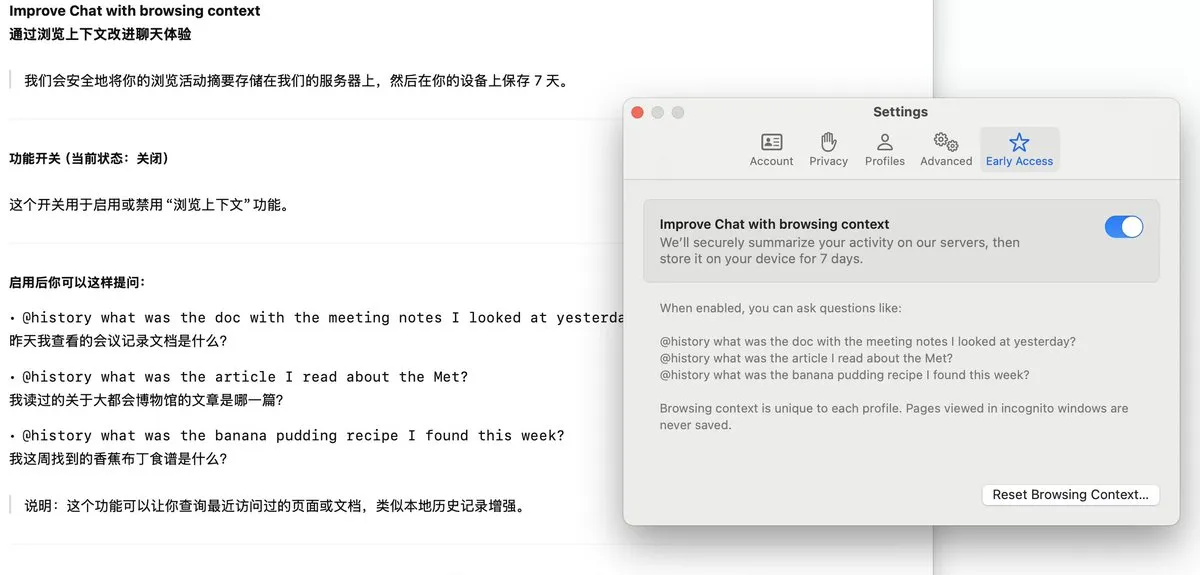
El navegador Arc lanza la función Dia, que registra el historial de navegación y admite preguntas y respuestas con IA: El navegador Arc ha añadido la función Dia, que, una vez activada, registra continuamente todo el historial de navegación del usuario. Los usuarios pueden utilizar la función @History para realizar preguntas en lenguaje natural vago y encontrar información que vieron anteriormente pero cuya URL específica han olvidado. Esta función incluso podría admitir la generación de informes del historial de navegación, mejorando la inteligencia y la capacidad de gestión de información personalizada del navegador. (Fuente: op7418)
📚 Aprendizaje
Apple publica el paper “La Ilusión del Pensamiento”, explorando los límites de capacidad de los LLM: El equipo de investigación de aprendizaje automático de Apple ha publicado el paper “La Ilusión del Pensamiento” (The Illusion of Thinking), que analiza el rendimiento y las limitaciones de los actuales grandes modelos de lenguaje (LLM) en tareas de razonamiento complejo (como resolver el problema de las Torres de Hanói). Este paper ha generado un debate en la comunidad sobre el verdadero nivel de inteligencia de los LLM, y algunos opinan que este tipo de investigación a veces se utiliza como pretexto para retrasar la adopción de la IA. Posteriormente, el modelo o3-pro de OpenAI resolvió el rompecabezas de las Torres de Hanói planteado en el paper. (Fuente: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
Nueva investigación “Los agentes generales necesitan modelos del mundo” explora la relación entre la generalización de agentes y los modelos predictivos: Un nuevo artículo de investigación titulado “Los agentes generales necesitan modelos del mundo” (General agents need world models) señala que los agentes generales capaces de generalizar a tareas orientadas a objetivos de múltiples pasos deben aprender un modelo predictivo del mundo. Este modelo está codificado en la política del agente, y el artículo demuestra la conexión directa entre la capacidad de generalización y la fidelidad del modelo aprendido consultando las elecciones de política del agente bajo objetivos compuestos para extraer las probabilidades de transición del entorno. (Fuente: menhguin)

Paper explora el ajuste fino consciente de conceptos (CAFT) para mejorar el rendimiento de los LLM: Un nuevo paper titulado “Mejora de los grandes modelos de lenguaje con ajuste fino consciente de conceptos” (Improving large language models with concept-aware fine-tuning) propone el método CAFT, que mejora la comprensión de conceptos por parte del modelo al permitir el ajuste fino mediante la predicción de múltiples tokens. La investigación demuestra que CAFT logra ganancias significativas de rendimiento en tareas como codificación, matemáticas, resumen de texto, generación molecular y diseño de proteínas. El código está disponible en GitHub. (Fuente: Reddit r/MachineLearning)
DeepLearning.AI lanza un nuevo curso “Orquestación de flujos de trabajo para aplicaciones GenAI”: DeepLearning.AI de Andrew Ng, en colaboración con Astronomer, ha lanzado un nuevo curso corto titulado “Orquestación de flujos de trabajo para aplicaciones GenAI” (Orchestrating Workflows for GenAI Applications). El curso enseña cómo construir flujos de proceso GenAI fiables utilizando la popular herramienta de código abierto Airflow 3.0, y cómo transformar prototipos de Jupyter Notebook o scripts de Python en flujos de trabajo listos para producción, cubriendo temas como la descomposición de tareas, la programación, la ejecución paralela, la recuperación de fallos y la observabilidad. (Fuente: AndrewYNg)
Paper “Alineación token a token de texto, imágenes y estructuras 3D” explora modelos autorregresivos multimodales: Esta investigación propone un marco LLM unificado destinado a alinear lenguaje, imágenes y escenas 3D estructuradas. El paper detalla las elecciones de diseño clave para lograr un entrenamiento y rendimiento óptimos, incluyendo la representación de datos, funciones objetivo específicas de modalidad, etc., y se evalúa en cuatro tareas 3D centrales (renderizado, reconocimiento, seguimiento de instrucciones y respuesta a preguntas) y múltiples conjuntos de datos. La investigación también se extiende a la reconstrucción de formas complejas de objetos 3D mediante la codificación de formas cuantizadas. (Fuente: HuggingFace Daily Papers)
Paper “Squeeze3D”: Compresión neuronal extrema utilizando modelos generativos 3D preentrenados: El framework Squeeze3D utiliza el conocimiento previo implícito aprendido en modelos generativos 3D preentrenados para comprimir drásticamente datos 3D (mallas, nubes de puntos, campos de radiancia). Conecta los espacios latentes de un codificador preentrenado y un modelo generativo mediante una red de mapeo entrenable, comprimiendo modelos 3D en códigos latentes compactos, que luego son reconstruidos por el modelo generativo durante la descompresión. Este método se entrena con datos sintéticos, sin necesidad de conjuntos de datos 3D reales, logrando tasas de compresión de mallas texturizadas de hasta 2187 veces. (Fuente: HuggingFace Daily Papers)
Paper “Frame Guidance”: Control a nivel de fotograma sin entrenamiento en modelos de difusión de video: Esta investigación propone “Frame Guidance”, un método para lograr control a nivel de fotograma en modelos de difusión de video sin necesidad de entrenamiento. Mediante un procesamiento simple del espacio latente y una novedosa estrategia de optimización del espacio latente, el método puede controlar eficazmente señales a nivel de fotograma como fotogramas clave, referencias de estilo, bocetos o mapas de profundidad, siendo aplicable a múltiples tareas como la guía por fotogramas clave, la estilización, la reproducción en bucle, y compatible con cualquier modelo de video. (Fuente: HuggingFace Daily Papers)
Paper “Sesgos geopolíticos en grandes modelos de lenguaje” revela las posturas nacionales de los modelos: Esta investigación evalúa los sesgos geopolíticos en los LLM analizando su interpretación de eventos históricos con diferentes perspectivas nacionales (estadounidense, británica, soviética, china). Los investigadores introdujeron un nuevo conjunto de datos que contiene descripciones neutrales de eventos y puntos de vista comparativos de cada país, descubriendo que los LLM muestran un sesgo significativo a favor de las narrativas de países específicos, y que los simples prompts de eliminación de sesgos tienen un efecto limitado. Este trabajo proporciona un marco y un conjunto de datos para futuras investigaciones sobre sesgos geopolíticos. (Fuente: HuggingFace Daily Papers)
El repositorio Awesome Lists se actualiza continuamente, recopilando diversos temas interesantes: El proyecto de GitHub awesome mantenido por sindresorhus es una metalista que recopila “Awesome lists” sobre diversos temas interesantes. Estas listas cubren numerosos campos, desde lenguajes de programación y plataformas de desarrollo hasta teorías, libros, herramientas, etc., proporcionando a desarrolladores y estudiantes un rico índice de recursos. (Fuente: GitHub Trending)
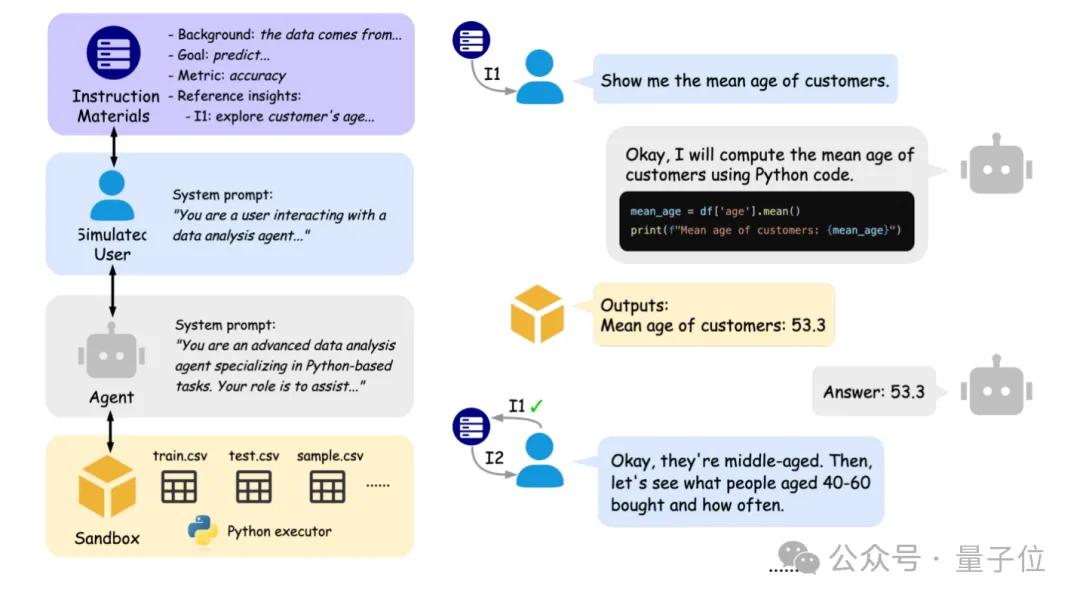
La Universidad de Pekín y Berkeley lanzan conjuntamente IDA-Bench para evaluar la capacidad de interacción de los agentes de análisis de datos de IA: Equipos de investigación de la Universidad de Pekín y la Universidad de California, Berkeley (incluido el profesor Michael I. Jordan) han lanzado IDA-Bench, un nuevo benchmark diseñado para evaluar la capacidad de los grandes modelos de lenguaje (LLM) como agentes de análisis de datos (Agent) en escenarios de interacción de múltiples rondas. Este benchmark simula el flujo de trabajo de los analistas de datos reales, examinando la capacidad de seguimiento de instrucciones, la capacidad de escritura y ejecución de código de los Agents a través de instrucciones que evolucionan gradualmente. Las evaluaciones preliminares muestran que incluso los modelos de primer nivel como Claude-3.7 y Gemini-2.5 Pro tienen una tasa de éxito en las tareas inferior al 40%, lo que expone los desafíos actuales de los Agents en la interacción compleja y el seguimiento de instrucciones. (Fuente: 量子位)
💼 Negocios
xAI y Polymarket colaboran para fusionar la predicción de mercados con el análisis de Grok: xAI de Elon Musk ha anunciado una colaboración con la plataforma de mercados de predicción Polymarket. Ambas partes combinarán la capacidad de predicción de mercados de Polymarket, los datos de la plataforma X y la capacidad de análisis del modelo Grok, con el objetivo de crear un “motor de verdad hardcore” (Hardcore truth engine) para obtener información sobre los factores que moldean el mundo. Oficialmente, se ha declarado que esto es solo el comienzo de la colaboración y que habrá más avances en el futuro. (Fuente: Yuhu_ai_)
UnslothAI es reconocida por Redpoint como una de las principales empresas de infraestructura y aparece en la pantalla grande del Nasdaq: La startup de IA UnslothAI ha sido reconocida por la firma de capital de riesgo Redpoint como una de las 100 empresas de infraestructura más influyentes y de más rápido crecimiento del año 2025 por sus contribuciones en el campo de la infraestructura de IA. Como resultado, su logotipo apareció en las pantallas electrónicas del edificio Nasdaq en Nueva York. UnslothAI se especializa en optimizar la eficiencia del entrenamiento y la inferencia de LLM. (Fuente: danielhanchen, karminski3)

Ant Digital actualiza el Laboratorio Tianji, centrándose en “IA + Innovación Industrial”: Ant Digital ha anunciado la actualización de su Laboratorio Tianji, que pasa de ser el “Laboratorio de Seguridad de Identidad Digital” a ser el laboratorio de “Inteligencia Artificial + Innovación Industrial”. El laboratorio actualizado se centrará en la investigación de avances tecnológicos clave en la aplicación industrial de grandes modelos de IA, y se enfocará en cuatro direcciones principales: IA + Datos, IA + Seguridad, IA + Finanzas e IA + Inteligencia Corpórea. El objetivo es promover la profunda integración de la tecnología de IA y la industria a través de la innovación colaborativa entre la industria, la academia, la investigación y la aplicación. (Fuente: 量子位)

🌟 Comunidad
La capacidad de conducción autónoma de la IA en entornos de tráfico complejos atrae la atención: Ronald van Loon compartió un video de una prueba de conducción autónoma en el caótico tráfico de la India, lo que generó un debate sobre las capacidades de percepción, toma de decisiones y control de la IA en entornos complejos y altamente dinámicos. Escenarios del mundo real como este plantean exigencias extremadamente altas a la robustez y adaptabilidad de los sistemas de conducción autónoma. (Fuente: Ronald_vanLoon)
Puntos destacados de la conferencia AI Engineer World’s Fair: Protocolo MCP, costo de agentes de IA y modelos locales en el foco: Yogi y Shawn “swyx” Wang, entre otros, compartieron los puntos clave de la conferencia AI Engineer World’s Fair. Las tendencias centrales incluyen: 1) Los agentes de IA son el futuro, la unidad de interacción atómica será la llamada a un agente; 2) El Protocolo de Contexto de Modelo (MCP) se está convirtiendo rápidamente en un estándar, resolviendo el “infierno del copiar y pegar” y permitiendo que la IA interactúe directamente con aplicaciones externas; 3) La construcción de herramientas de IA profundamente optimizadas para dominios y flujos de trabajo específicos (patrón Cursor-for-X) es clave; 4) El costo de los modelos ha disminuido drásticamente y la capacidad de los modelos locales ha aumentado, ofreciendo a los desarrolladores mayor control y soluciones de baja latencia; 5) La IA está evolucionando de ser una herramienta auxiliar a ser un “compañero de equipo” para los desarrolladores; 6) La ingeniería de IA está pasando de la fase de demostración a sistemas de nivel de producción. (Fuente: swyx, TheTuringPost)
La comunidad debate sobre la rápida iteración tras el lanzamiento de o3-pro y el paper de IA de Apple: andersonbcdefg comentó con humor que, solo 6 horas después del lanzamiento de o3-pro, la comunidad parecía esperar que alguien reescribiera fastText en Rust, e ironizó sobre los largos discursos acerca de la “superinteligencia moderada”, reflejando la rápida velocidad de iteración tecnológica en el campo de la IA y las altas expectativas de la comunidad. Al mismo tiempo, Teknium1 señaló que o3-pro resolvió el rompecabezas de las Torres de Hanói planteado en el paper “La Ilusión del Pensamiento” de Apple, y cuestionó por qué Apple, en el contexto de su colaboración con OpenAI, no realizó una verificación interna antes de publicar dicho paper, lo que generó un debate en la comunidad sobre las relaciones de competencia y cooperación entre las empresas tecnológicas. (Fuente: andersonbcdefg, Teknium1)
Debate sobre la ética y la efectividad de la IA en aplicaciones del mundo real: La comunidad discute la efectividad y los problemas éticos de la IA en escenarios específicos. Por ejemplo, Arvind Narayanan señaló que el concepto de las aplicaciones de conteo de calorías con IA es intrínsecamente defectuoso, ya que la información de la imagen es insuficiente para estimar calorías con precisión, y considera que son más bien un “ritual” para ayudar a los usuarios a establecer hábitos de atención a la dieta. Además, el uso de imágenes generadas por IA para publicidad comercial (como la exhibición de platos en una cafetería) y si es ético o apropiado también se convirtió en un punto de discusión, con la opinión general de que es una forma aceptable de reducir costos y aumentar la eficiencia siempre que no sea evidentemente falso o engañoso. (Fuente: random_walker, Reddit r/artificial)
La “humanización” de los LLM y la experiencia de interacción del usuario se convierten en foco de atención: Usuarios de la comunidad de Reddit exploran cómo hacer que la interacción con los LLM sea más parecida a la de los humanos reales, incluyendo la introducción de vacilaciones, pausas, respuestas más cortas y expresiones no perfectas. Esto refleja la demanda de los usuarios por compañeros o asistentes de IA más naturales y menos “robóticos”. Al mismo tiempo, algunos usuarios se quejan de que los LLM actuales (como ChatGPT) utilizan con frecuencia frases hechas y expresiones exageradas (como “esto no es solo X, sino también Y”), y desean que su expresión sea más concisa y directa. Estas discusiones apuntan a los continuos desafíos de los LLM en la simulación de la conversación humana y la satisfacción de las necesidades emocionales de los usuarios. (Fuente: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 Otros
El CEO de NVIDIA, Jensen Huang, pronunciará un discurso principal en GTC Paris, centrándose en la nueva etapa de la computación de IA: NVIDIA ha anunciado que su CEO, Jensen Huang, pronunciará un discurso principal el 11 de junio en la conferencia GTC de París (durante VivaTech 2025). Se espera que revele la próxima fase de la computación de IA, cubriendo temas de vanguardia desde sistemas de agentes hasta fábricas de IA. (Fuente: nvidia, nvidia)

Databricks Data+AI Summit mostrará los últimos avances: Databricks ha anunciado que su Data+AI Summit reunirá a los principales expertos, investigadores y contribuyentes de código abierto para mostrar los últimos avances de la compañía en datos e IA, y compartir casos de éxito de empresas innovadoras. La cumbre ofrece participación tanto en línea como presencial. (Fuente: matei_zaharia, lateinteraction)

El impacto ético y ambiental de la IA genera preocupación, se divulga en formato de novela gráfica: El centro LEARN de EPFL (Escuela Politécnica Federal de Lausana) en colaboración con el ilustrador Herji ha lanzado una novela gráfica educativa en francés titulada “Utop’IA”, con el objetivo de concienciar a los jóvenes sobre el impacto ambiental de la inteligencia artificial a través de una historia, incluyendo su consumo de recursos (energía, agua, metales raros) y sus posibles beneficios ecológicos. La obra enfatiza el pensamiento crítico y explora caminos hacia una IA sostenible. (Fuente: aihub.org)
