
Palavras-chave:Meta, Scale AI, superinteligência, AGI, rotulagem de dados, treinamento de IA, precisão do modelo, Meta adquire participação na Scale AI, Alexandr Wang lidera grupo de superinteligência, precisão de rotulagem de dados de IA 99.7%, taxa de contaminação de dados de treinamento reduzida, ciclo de treinamento de modelo reduzido em 40%
🔥 Foco
Meta alegadamente investe quase 15 mil milhões de dólares para adquirir participação na Scale AI e nomeia o seu CEO para liderar nova equipa de “superinteligência”: A Meta planeia adquirir uma participação de 49% na empresa de rotulagem de dados e infraestrutura de AI Scale AI por aproximadamente 14,9 mil milhões de dólares, e nomear o seu CEO sino-americano de 28 anos, Alexandr Wang, para liderar o recém-formado “Super Intelligence Group”. Esta medida visa fortalecer a competitividade da Meta no campo da AI, especialmente em dados de treino de alta qualidade e pesquisa e desenvolvimento de AGI. A Scale AI é conhecida pela sua precisão de rotulagem de dados de até 99,7%, e espera-se que reduza a taxa de contaminação de dados de treino dos modelos da Meta de 15% para 2%, e encurte o ciclo de treino em 40%. Esta aquisição é vista como um passo crucial para a Meta alcançar e tentar superar os seus concorrentes na corrida da AI, e também destaca a posição estratégica central dos dados no desenvolvimento da AI. (Fonte: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
OpenAI alegadamente fecha acordo de grande escala com Google Cloud para poder computacional, possivelmente para reduzir dependência da Microsoft: Segundo relatos, a OpenAI fechou um importante acordo de serviços na nuvem com o Google Cloud, que fornecerá à OpenAI o poder computacional necessário para o treino e implementação dos seus crescentes modelos de AI. Anteriormente, o Microsoft Azure era o principal fornecedor de poder computacional da OpenAI. Esta medida pode sinalizar que a OpenAI procura diversificar as suas fontes de poder computacional para reduzir a dependência de um único fornecedor e satisfazer as suas enormes necessidades de computação. A parceria é uma vitória significativa para o Google Cloud, mas também levanta discussões sobre como equilibrará os recursos de TPU entre os seus próprios negócios e as necessidades dos clientes. (Fonte: 36氪, scaling01)
Mistral AI lança modelo de inferência Magistral, levantando questões da comunidade sobre a transparência dos seus benchmarks: A empresa francesa de AI Mistral AI lançou a sua primeira série de modelos concebidos especificamente para inferência, Magistral, incluindo a versão open-source 24B Magistral Small e a Magistral Medium, orientada para empresas. Oficialmente, afirma-se que foi concebida para inferência lógica transparente, rastreável e em várias etapas, suportando múltiplos idiomas. No entanto, a comunidade questionou os resultados dos benchmarks divulgados, argumentando que não foram comparados com as versões mais recentes de modelos concorrentes como Qwen e DeepSeek R1, o que poderia indicar uma tentativa de “evitar o confronto”. Apesar disso, o Magistral mostrou uma melhoria significativa no benchmark de matemática AIME-24 em comparação com o Mistral Medium 3. (Fonte: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Pai da aprendizagem por reforço, Richard Sutton: Domínio dos LLM é apenas temporário, computação expandida e aprendizagem experiencial são o futuro: Richard Sutton, vencedor do Prémio Turing e pai da aprendizagem por reforço, prevê que o atual domínio dos modelos de linguagem grandes (LLM) é apenas temporário, e que imitar o pensamento humano apenas trará melhorias de desempenho a curto prazo. Ele acredita que o futuro da AI reside na “era da experiência”, onde os Agents aprendem através da aquisição de dados experienciais por meio de interações em primeira pessoa com o mundo, em vez de dependerem de dados humanos estáticos. Sutton enfatiza que a aprendizagem por reforço é o caminho central para este futuro, combinada com algoritmos de deep learning de aprendizagem contínua e computação em larga escala, permitirá que a AI ultrapasse o conhecimento existente e alcance a verdadeira inovação. (Fonte: 量子位)

Hugging Face e NVIDIA colaboram para lançar “Training Cluster as a Service”, reduzindo a barreira para o treino de grandes modelos: A Hugging Face anunciou uma parceria com a NVIDIA para lançar o “Training Cluster as a Service”, com o objetivo de facilitar o acesso de instituições de pesquisa globais a grandes recursos de cluster de GPU para treinar vários modelos de ponta. O serviço integra o NVIDIA DGX Cloud Lepton e os recursos de desenvolvimento da Hugging Face, permitindo que as organizações solicitem e paguem pelo tempo de uso do cluster de GPU sob demanda. Esta medida visa colmatar a “lacuna de riqueza de GPU”, promover a diversidade e a popularização da pesquisa em AI, e já foi adotada precocemente por instituições de pesquisa e startups como TIGEM, Numina e Mirror Physics. (Fonte: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 Tendências
OpenAI lança modelo o3-pro e reduz drasticamente os preços da API o3: A OpenAI lançou o seu novo modelo de inferência de topo, o3-pro, que já está disponível para utilizadores do ChatGPT Pro e utilizadores da API. Simultaneamente, o preço da API do modelo o3 foi drasticamente reduzido em 80%, e o limite de taxa do o3 para utilizadores do ChatGPT Plus também foi duplicado. O feedback da comunidade indica que o o3-pro supera o Claude Opus 4 em tarefas não relacionadas com código e estabeleceu novos recordes em vários benchmarks, como o Extended NYT Connections e o Creative Short Story Writing, tendo inclusivamente resolvido o “problema da Torre de Hanói com 10 discos” que um artigo anterior da Apple questionava a capacidade dos LLM de resolver. No entanto, alguns utilizadores relatam que o o3-pro é mais lento. A OpenAI afirmou que a redução de preço do o3 não se deve a destilação ou quantização, mas sim ao trabalho de otimização dos engenheiros de inferência. (Fonte: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB lança série MiniCPM4 de LLMs eficientes para dispositivos de ponta: A OpenBMB lançou a série de modelos MiniCPM4, concebida especificamente para dispositivos de ponta (edge devices), alegando alcançar uma aceleração de geração superior a 5 vezes em chips típicos de dispositivos de ponta. A série inclui MiniCPM4-8B, MiniCPM4-0.5B, bem como versões com quantização ternária BitCPM4-1B/0.5B. O MiniCPM4 utiliza um mecanismo de atenção esparsa treinável, InfLLM v2, suporta o processamento de texto longo de 128K e combina algoritmos de aprendizagem eficiente e técnicas de treino como o Model Wind Tunnel 2.0, quantização ternária BitCPM, computação de baixa precisão FP8 e previsão de múltiplos tokens. Foram também lançados o conjunto de dados de pré-treino de alta qualidade em chinês e inglês UltraFineweb e o conjunto de dados de ajuste fino supervisionado UltraChat v2. (Fonte: GitHub Trending)
MSRA e académicos da Tsinghua e Peking University propõem novo paradigma de pré-treino reforçado (RPT): O Microsoft Research Asia (MSRA), em colaboração com investigadores da Tsinghua University e da Peking University, propôs um novo paradigma de pré-treino de LLM chamado Reinforced Pre-training (RPT). Este método integra profundamente a aprendizagem por reforço (RL) na fase de pré-treino, onde o modelo gera sequências de raciocínio em cadeia de pensamento antes de prever cada token e recebe recompensas com base na correção da previsão. O RPT visa fazer com que o modelo passe de aprender correlações superficiais de tokens para compreender significados profundos. Experiências mostram que um modelo de 14B treinado com RPT pode igualar ou até superar modelos de pré-treino tradicionais de 32B em certas tarefas de raciocínio, demonstrando um enorme potencial para melhorar as capacidades de modelagem de linguagem e raciocínio dos LLM. (Fonte: 量子位, omarsar0)

Meta lança modelo de mundo em vídeo V-JEPA 2 e novos benchmarks: A Meta AI lançou o V-JEPA 2, um modelo de mundo com 1,2 mil milhões de parâmetros treinado em dados de vídeo, concebido para melhorar a compreensão e previsão do mundo físico pelas máquinas. O modelo pode desempenhar um papel no planeamento zero-shot de robôs, permitindo-lhes planear e executar tarefas em ambientes desconhecidos. Simultaneamente, a Meta também lançou três novos benchmarks para avaliar a capacidade dos modelos existentes de inferir o mundo físico a partir de vídeos. A HuggingFace já disponibilizou suporte da biblioteca transformers para o V-JEPA 2. (Fonte: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance lança modelo de geração de vídeo Seedance 1.0 Pro, já disponível na Doubao App: A ByteDance lançou o seu mais recente modelo de geração de vídeo, Seedance 1.0 Pro (também conhecido como modelo Video 3.0 Pro no Dream Driver). Este modelo apresenta um desempenho excecional na compreensão de prompts, detalhes de imagem e consistência da representação física, sendo capaz de gerar vídeos de 5 segundos a 1080P. Atualmente, o modelo está disponível para utilizadores empresariais através da Volcano Engine e foi lançado na Doubao App com a funcionalidade “dar vida às fotos” para experiência gratuita dos utilizadores. (Fonte: op7418)
Huawei lança plataforma de simulação “Túnel de Vento Digital” para otimizar eficiência de treino e inferência de AI: A equipa de simulação de modelagem Markov da Huawei apresentou pela primeira vez a sua tecnologia de “Túnel de Vento Digital”, uma plataforma para realizar “ensaios” em ambiente virtual antes do treino e inferência reais de modelos complexos de AI. A plataforma inclui três módulos principais: Sim2Train (simulação de treino), Sim2Infer (simulação de inferência) e Sim2Availability (simulação de alta disponibilidade). O objetivo é, através da simulação e otimização automática, resolver problemas como desalinhamento de recursos de hardware e acoplamento de sistemas, permitindo assim prever soluções para clusters de dezenas de milhares de placas em questão de horas, evitar o desperdício de poder computacional e melhorar a eficiência e estabilidade do treino e inferência de grandes modelos de AI. (Fonte: 量子位)

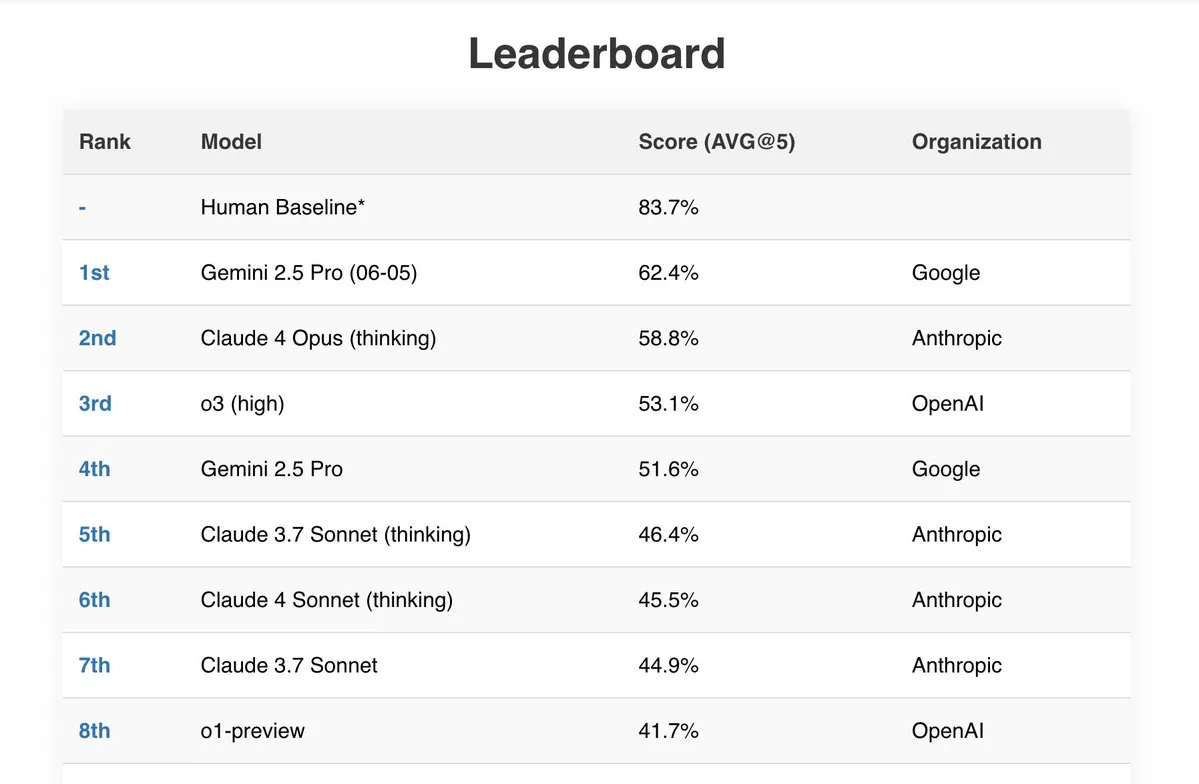
Gemini 2.5 Pro apresenta excelente desempenho em vários benchmarks: O mais recente modelo Gemini 2.5 Pro (06-05) da Google destacou-se em vários rankings públicos de AI. Obteve o melhor desempenho no teste Live Fiction com 192k tokens, ficou em primeiro lugar no SimpleBench com uma pontuação de 62,4% e demonstrou fortes capacidades de processamento de documentos e relação custo-benefício em benchmarks como IDP (Intelligent Document Processing) e Aider (AI-assisted coding). Além disso, alguns utilizadores relataram que o Gemini 2.5 Pro resolveu com sucesso todos os problemas da secção de matemática do JEE Advanced 2025. (Fonte: _philschmid, dilipkay)
Modelo de vídeo Kling AI atualiza funcionalidade de sincronização labial, suporta seleção e edição de personagens: A ferramenta de geração de vídeo por AI Kling AI, da Kuaishou, atualizou recentemente a sua funcionalidade de sincronização labial (Lip-sync). A nova funcionalidade permite aos utilizadores selecionar personagens específicos no vídeo gerado para correspondência labial e ajustar o tempo de sincronização entre o áudio e os movimentos da boca. Esta atualização melhora a flexibilidade e o realismo do Kling AI na criação de vídeos de diálogo com múltiplos personagens, representando um avanço importante no campo da geração de vídeo. (Fonte: Kling_ai, Kling_ai)
Delta Lake 4.0.0 lançado, melhorando as capacidades do Lakehouse: A versão Delta Lake 4.0.0 foi oficialmente lançada, trazendo várias novas funcionalidades importantes, incluindo uma versão de pré-visualização de Tabelas Geridas por Catálogo (Catalog-Managed Tables) para governança unificada e descoberta, extensões Delta Connect para Spark Connect, suporte para o tipo de dados Variant para lidar com dados semiestruturados e a funcionalidade DROP FEATURE instantânea, permitindo a remoção de características da tabela sem truncar o histórico ou causar tempo de inatividade. Esta versão visa melhorar a experiência da comunidade open lakehouse. (Fonte: matei_zaharia)

Hugging Face lança servidor MCP para simplificar interação entre modelos e ferramentas: A Hugging Face lançou a primeira versão do seu servidor Model Context Protocol (MCP). Os utilizadores podem agora usar este servidor através de http://hf.co/mcp em aplicações como Claude ou Cursor para pesquisar modelos, datasets, artigos, aplicações ou informações específicas. Isto marca um passo importante da Hugging Face na promoção da interoperabilidade entre ferramentas e modelos no ecossistema de AI, com potencial expansão futura para funcionalidades como upload, download e abertura de PRs. (Fonte: clefourrier, ClementDelangue)

Baidu lança “AI Camera” com armazenamento integrado e gestão inteligente, e atualiza GenFlow Super Assistant 2.0: O Baidu Netdisk e o Baidu Wenku lançaram conjuntamente a funcionalidade “AI Camera”, integrando captura de fotos, armazenamento na nuvem e gestão inteligente. As fotos podem ser arquivadas automaticamente no álbum da nuvem e suportam classificação e pesquisa inteligentes através de descrições em linguagem natural. A AI Camera também possui várias capacidades de AI, como embelezamento, identificação de objetos com fins educativos, geração de rabiscos a partir de desenhos simples, digitalização de recibos e conversão de tabelas manuscritas. Simultaneamente, a plataforma de colaboração multi-agente “GenFlow Super Assistant” foi atualizada para a versão 2.0, capaz de integrar mais profundamente os dados e hábitos do utilizador para fornecer serviços de geração de conteúdo personalizados. (Fonte: 量子位)

ByteDance disponibiliza em open source código e pesos do modelo de reparação de vídeo SeedVR2: A equipa SEED da ByteDance lançou o código de inferência e os pesos do modelo do seu modelo de reparação de vídeo de um passo, SeedVR2, agora disponível no Hugging Face. O modelo utiliza a técnica de pós-treino adversário de difusão (diffusion adversarial post-training) e alcançou resultados significativos na recuperação de vídeo, especialmente no processamento de vídeo de alta resolução. (Fonte: _akhaliq)
GroqCloud adiciona modelo Qwen3-32B, suportando mais de cem idiomas e contexto de 131k: A Groq anunciou a adição do modelo Qwen3-32B da Tongyi Qianwen à sua plataforma de nuvem de inferência LPU, GroqCloud. O modelo suporta mais de 100 idiomas e dialetos, possui uma janela de contexto de 131k e opera à velocidade em tempo real característica do hardware da Groq, oferecendo aos programadores poderosas capacidades de processamento de texto longo e multilíngue. (Fonte: JonathanRoss321)
CEO da OpenAI, Sam Altman, afirma que o lançamento do seu modelo de pesos abertos será adiado: Sam Altman afirmou que o modelo de pesos abertos da OpenAI será adiado para o final do verão deste ano, em vez do planeado para junho. Ele revelou que a equipa de pesquisa fez alguns progressos “inesperados e muito surpreendentes” que valem a pena esperar, mas precisam de mais tempo para aperfeiçoamento. (Fonte: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

Digua Robotics lança kit de desenvolvimento RDK S100, com arquitetura de cérebro e cerebelo integrados num único SoC: A Digua Robotics lançou o primeiro kit de desenvolvimento de robôs do setor com controlo e computação integrados num único SoC, o RDK S100. O kit adota um design de arquitetura colaborativa super-heterogénea semelhante ao cérebro e cerebelo humanos (CPU Arm Cortex-A78AE de 6 núcleos + BPU de 80 TOPS como “cérebro”, MCU Arm Cortex-R52+ de 4 núcleos como “cerebelo”), suportando a colaboração eficiente de modelos grandes e pequenos de inteligência incorporada, e completando o ciclo “perceção-decisão-controlo”. O RDK S100 oferece interfaces ricas e infraestrutura de desenvolvimento de ciclo completo, com um preço de pré-venda de 2499 yuan. (Fonte: 量子位)

Aibook Smart lança módulo de computação AI E300, equipado com SoC nacional de 50TOPS: A Aibook Smart lançou o módulo de computação AI E300 para cenários de edge, equipado com o seu chip SoC AI auto-desenvolvido AB100. O módulo oferece até 50TOPS de poder computacional INT8, suporta computação de precisão mista FP16/FP32 e está equipado com largura de banda de memória LPDDR5 de 102GB/s. O E300 adota um design modular, visando fornecer soluções de AI de edge nacionalizadas de alto desempenho, baixa latência e alta confiabilidade para indústrias como educação, energia e saúde, suportando os principais modelos grandes open-source e vários modelos de visão e voz para implementação em edge. (Fonte: 量子位)

Huawei revela tecnologia de alta disponibilidade para cluster Ascend de dezenas de milhares de placas, alcançando 98% de disponibilidade de treino: A Huawei divulgou publicamente pela primeira vez os detalhes da sua tecnologia de alta disponibilidade para o cluster de poder computacional Ascend de dezenas de milhares de placas. Através de três capacidades básicas – diagnóstico de perceção de falhas, gestão de falhas e tolerância a falhas de ligação ótica do cluster – bem como capacidades de suporte de negócios como otimização da linearidade do cluster e recuperação rápida de treino e inferência, a Huawei alcançou uma disponibilidade de treino de 98% para o cluster de dezenas de milhares de placas, linearidade superior a 95%, recuperação de falhas ao nível de segundos e diagnóstico ao nível de minutos. Este sistema tecnológico de dupla dimensão “3+3” visa garantir o funcionamento estável e eficiente do treino e inferência de AI em larga escala. (Fonte: 量子位)

Taxa de penetração de condução inteligente nos novos carros da BYD atinge 79%, NOA em autoestrada torna-se configuração principal: Os dados mais recentes divulgados pela BYD mostram que, em maio, a proporção de carros novos vendidos equipados com sistemas de assistência à condução inteligente (pelo menos com NOA em autoestrada e funcionalidade de estacionamento automático) atingiu 79%. Isto indica que a BYD obteve resultados significativos na promoção da sua estratégia de “condução inteligente para todos”, e as funcionalidades de condução inteligente estão rapidamente a tornar-se configurações padrão nos seus modelos. Esta tendência também reflete a aceleração da popularização da tecnologia de condução inteligente no mercado automóvel chinês. (Fonte: 量子位)

Funcionalidade de voz avançada do ChatGPT lançada para todos os utilizadores pagos: A OpenAI anunciou que a funcionalidade de voz avançada do ChatGPT (Advanced Voice), anteriormente atualizada com maior naturalidade, foi lançada para todos os utilizadores pagos (ChatGPT Plus, Team, Enterprise). Os utilizadores podem usar esta funcionalidade para interagir com o ChatGPT de forma mais natural por voz. (Fonte: juberti)
🧰 Ferramentas
Navegador Genspark AI lançado, integrando múltiplas funcionalidades de agentes de AI: A equipa de Eric Jing lançou o navegador Genspark AI, alegadamente criado por uma equipa de 24 pessoas em 10 semanas, integrando 8 produtos principais: navegador AI, secretário AI, chamadas pessoais AI, agente de download AI, AI Drive, AI Sheets, entre outros. O navegador destaca-se pela rapidez, bloqueio de anúncios, total integração com agentes, modo de condução autónoma e inclui uma loja MCP e superagentes integrados, com o objetivo de fornecer uma experiência de navegação e trabalho assistida por AI tudo-em-um. (Fonte: blader)
Yutori AI lança plataforma Scouts para monitorização de redes por agentes de AI: A Yutori AI lançou a plataforma Scouts, que permite aos utilizadores criar agentes de AI continuamente online para monitorizar atualizações de informações específicas na web. Estes agentes podem rastrear vários conteúdos de interesse para o utilizador, como notícias de nicho, alterações de preços de produtos, informações sobre bilhetes, etc., e alertar os utilizadores por e-mail em momentos cruciais, com o objetivo de libertar os utilizadores através da automatização do rastreio de informações. (Fonte: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face lança AISheets, combinando modelos de AI com folhas de cálculo: A Hugging Face lançou o AISheets, uma aplicação que combina milhares de modelos de AI (especialmente LLMs open-source) com funcionalidades de folha de cálculo. Os utilizadores podem construir, analisar e automatizar o processamento de dados no AISheets, com o objetivo de fornecer uma experiência de processamento de dados fluida, rápida e simples, potenciada por AI. (Fonte: ben_burtenshaw, LoubnaBenAllal1)
PLaMo lança ferramenta CLI de tradução local baseada em MLX: A equipa PLaMo LLM disponibilizou em open-source uma ferramenta de interface de linha de comandos (CLI) que permite a tradução de texto local em Macs com Apple Silicon, utilizando o framework MLX. A ferramenta visa fornecer uma experiência de tradução local rápida e de alta precisão, e inclui servidores e clientes HTTP e MCP integrados para facilitar a integração com outras aplicações compatíveis com MCP (como o Claude Desktop). (Fonte: awnihannun)
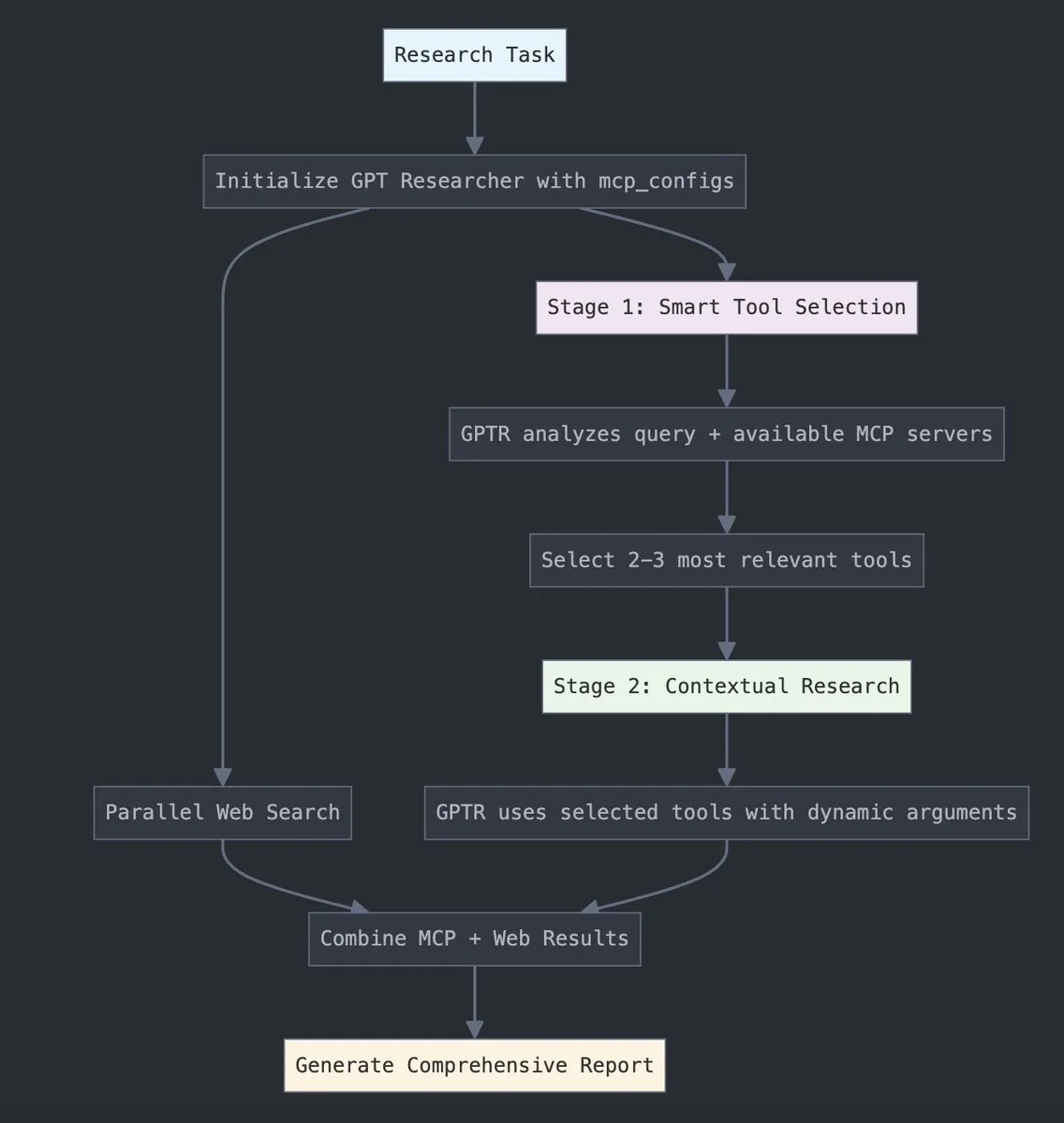
GPT Researcher integra adaptador LangChain MCP, melhorando a seleção de ferramentas e capacidade de pesquisa: O GPT Researcher está agora a utilizar o adaptador Model Context Protocol (MCP) da LangChain para permitir uma seleção de ferramentas e processos de pesquisa mais inteligentes. Esta medida visa combinar as vantagens do MCP com as capacidades de pesquisa na web para uma recolha e análise de dados mais abrangentes. (Fonte: Hacubu)
Consilium: Lançamento de framework open-source para colaboração multi-agente: Victor M lançou o Consilium, um framework open-source para colaboração de equipas de agentes de AI. Os utilizadores podem definir estratégias, que são debatidas por múltiplos agentes especialistas, utilizando pesquisa em tempo real (web, arXiv, dados da SEC) para resolver problemas complexos em conjunto e alcançar um consenso. A ferramenta já tem uma demo disponível no Hugging Face. (Fonte: clefourrier)
youtube-transcript-api: Biblioteca Python para obter legendas do YouTube, suporta tradução e geração automática de conteúdo: A biblioteca Python youtube-transcript-api, desenvolvida por jdepoix, tem ganho destaque no GitHub. Esta API consegue obter as legendas de vídeos do YouTube, incluindo legendas geradas automaticamente, e suporta a funcionalidade de tradução. Ao contrário de outras soluções baseadas em Selenium, não requer chaves de API ou um navegador headless, fornecendo aos programadores uma forma conveniente de extrair conteúdo textual de vídeos. (Fonte: GitHub Trending)
Navegador Arc lança funcionalidade Dia, regista histórico de navegação e suporta perguntas e respostas com AI: O navegador Arc adicionou a funcionalidade Dia, que, quando ativada, regista continuamente todo o histórico de navegação do utilizador. Através da funcionalidade @History, os utilizadores podem usar linguagem natural vaga para encontrar informações que viram anteriormente mas cujo URL específico esqueceram. A funcionalidade poderá até suportar a geração de relatórios de histórico de navegação, melhorando a inteligência do navegador e a capacidade de gestão de informação personalizada. (Fonte: op7418)
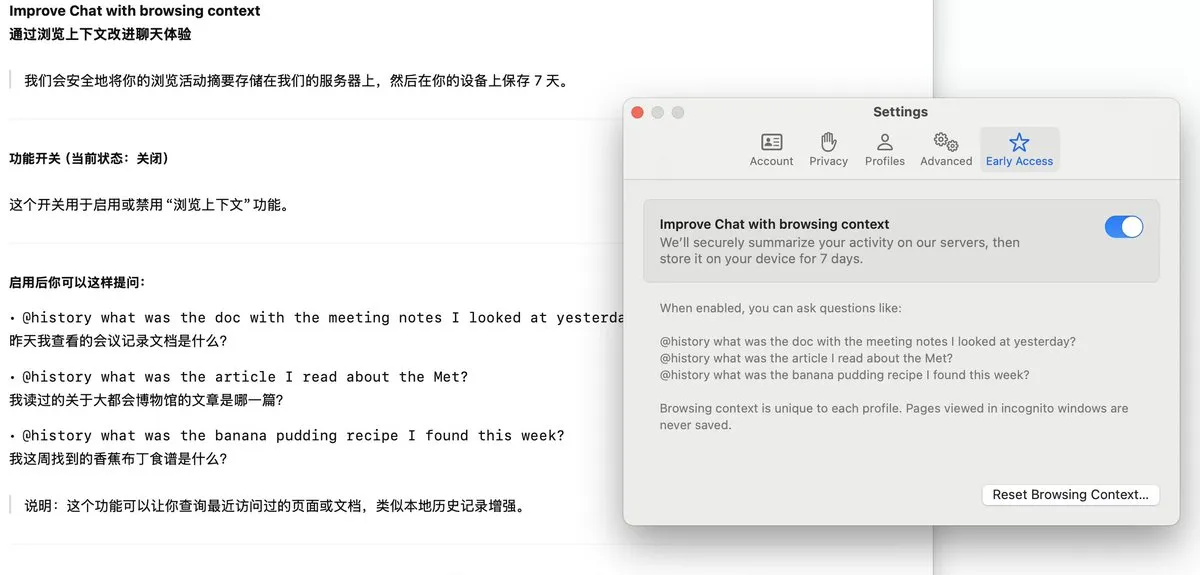
📚 Aprendizagem
Apple publica artigo “The Illusion of Thinking”, explorando os limites da capacidade dos LLM: A equipa de investigação em machine learning da Apple publicou o artigo “The Illusion of Thinking”, que analisa o desempenho e as limitações dos atuais modelos de linguagem grandes (LLM) em tarefas de raciocínio complexas (como resolver o problema da Torre de Hanói). O artigo gerou discussões na comunidade sobre o verdadeiro nível de inteligência dos LLM, e há quem defenda que este tipo de investigação é por vezes usado como justificação para adiar a adoção da AI. O modelo o3-pro da OpenAI resolveu posteriormente o problema da Torre de Hanói proposto no artigo. (Fonte: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
Nova investigação “General agents need world models” explora a relação entre a generalização de agentes e modelos preditivos: Um novo artigo de investigação intitulado “General agents need world models” (Agentes gerais precisam de modelos de mundo) aponta que agentes gerais capazes de generalizar para tarefas orientadas a objetivos de múltiplos passos devem aprender um modelo de mundo preditivo. Este modelo é codificado na política do agente, e o artigo demonstra a ligação direta entre a capacidade de generalização e a fidelidade do modelo aprendido, consultando as escolhas de política do agente sob objetivos compostos para extrair probabilidades de transição do ambiente. (Fonte: menhguin)

Artigo explora o Concept-Aware Fine-Tuning (CAFT) para melhorar o desempenho de LLMs: Um novo artigo, “Improving large language models with concept-aware fine-tuning”, propõe o método CAFT, que melhora a compreensão de conceitos pelo modelo ao permitir o ajuste fino com previsão de múltiplos tokens. A investigação demonstra que o CAFT alcança ganhos significativos de desempenho em tarefas como codificação, matemática, resumo de texto, geração molecular e design de proteínas. O código foi disponibilizado em open-source no GitHub. (Fonte: Reddit r/MachineLearning)
DeepLearning.AI lança novo curso “Orchestrating Workflows for GenAI Applications”: A DeepLearning.AI de Andrew Ng, em parceria com a Astronomer, lançou um novo curso breve intitulado “Orchestrating Workflows for GenAI Applications”. O curso ensina como construir pipelines de GenAI fiáveis usando a popular ferramenta open-source Airflow 3.0, e como transformar protótipos de Jupyter Notebooks ou scripts Python em workflows prontos para produção, cobrindo decomposição de tarefas, agendamento, execução paralela, recuperação de falhas e observabilidade. (Fonte: AndrewYNg)
Artigo “Token-by-Token Alignment of Text, Images, and 3D Structures” explora modelos autorregressivos multimodais: Esta investigação propõe um framework LLM unificado que visa alinhar linguagem, imagens e cenas 3D estruturadas. O artigo detalha as principais escolhas de design para alcançar o treino e desempenho ótimos, incluindo representação de dados, funções objetivo específicas da modalidade, etc., e é avaliado em quatro tarefas 3D centrais (renderização, reconhecimento, seguimento de instruções e resposta a perguntas) e múltiplos conjuntos de dados. A investigação também se estende à reconstrução de formas complexas de objetos 3D através da codificação de formas quantizadas. (Fonte: HuggingFace Daily Papers)
Artigo “Squeeze3D”: Utilização de modelos generativos 3D pré-treinados para compressão neural extrema: O framework Squeeze3D utiliza conhecimentos prévios implícitos aprendidos em modelos generativos 3D pré-treinados para comprimir drasticamente dados 3D (malhas, nuvens de pontos, campos de radiância). Fá-lo através de uma rede de mapeamento treinável que liga o codificador pré-treinado ao espaço latente do modelo generativo, comprimindo modelos 3D em códigos latentes compactos, que são depois reconstruídos pelo modelo generativo durante a descompressão. O método é treinado em dados sintéticos, sem necessidade de datasets 3D reais, alcançando taxas de compressão de malhas texturizadas de até 2187x. (Fonte: HuggingFace Daily Papers)
Artigo “Frame Guidance”: Controlo ao nível de frame sem treino em modelos de difusão de vídeo: Esta investigação propõe o “Frame Guidance”, um método para alcançar controlo ao nível de frame em modelos de difusão de vídeo sem necessidade de treino. Através de um processamento simples do espaço latente e de uma nova estratégia de otimização do espaço latente, o método consegue controlar eficazmente sinais ao nível de frame, como keyframes, referências de estilo, esboços ou mapas de profundidade, sendo aplicável a várias tarefas como orientação por keyframes, estilização, reprodução em loop, e compatível com qualquer modelo de vídeo. (Fonte: HuggingFace Daily Papers)
Artigo “Geopolitical Biases in Large Language Models” revela posições nacionais dos modelos: Esta investigação avalia os preconceitos geopolíticos em LLMs analisando a sua interpretação de eventos históricos com diferentes perspetivas nacionais (EUA, Reino Unido, URSS, China). Os investigadores introduziram um novo dataset contendo descrições neutras de eventos e pontos de vista contrastantes de cada país, descobrindo que os LLMs apresentam um preconceito significativo em favor de narrativas de países específicos, e que simples prompts de remoção de preconceito têm efeito limitado. Este trabalho fornece um framework e um dataset para futuras investigações sobre preconceitos geopolíticos. (Fonte: HuggingFace Daily Papers)
Repositório Awesome Lists continuamente atualizado, compilando diversos temas interessantes: O projeto awesome no GitHub, mantido por sindresorhus, é uma meta-lista que compila “Awesome lists” sobre vários temas interessantes. Estas listas cobrem inúmeras áreas, desde linguagens de programação, plataformas de desenvolvimento a teorias, livros, ferramentas, etc., fornecendo um rico índice de recursos para programadores e aprendizes. (Fonte: GitHub Trending)
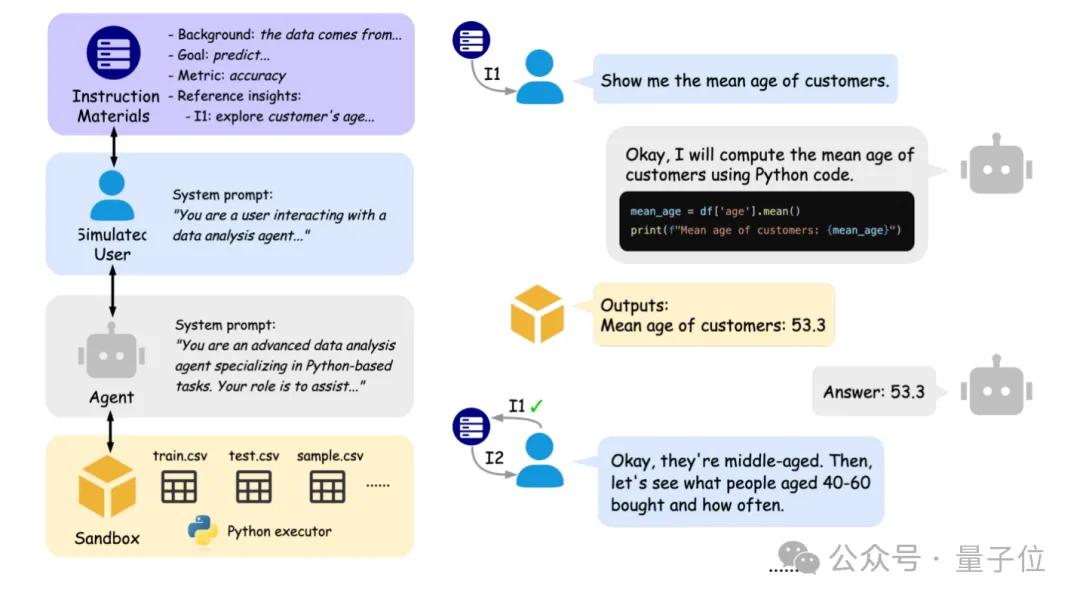
Peking University e Berkeley lançam conjuntamente IDA-Bench para avaliar capacidade interativa de agentes de análise de dados de AI: Equipas de investigação da Peking University e da University of California, Berkeley (incluindo o Professor Michael I. Jordan) lançaram o IDA-Bench, um novo benchmark concebido para avaliar a capacidade de modelos de linguagem grandes (LLM) como agentes de análise de dados (Agent) em cenários de interação multi-turno. O benchmark simula o fluxo de trabalho de analistas de dados reais, examinando a capacidade de seguimento de instruções, escrita e execução de código dos Agents através de instruções que evoluem gradualmente. Avaliações preliminares mostram que mesmo os modelos de topo como Claude-3.7 e Gemini-2.5 Pro têm uma taxa de sucesso inferior a 40%, expondo os desafios atuais dos Agents em interações complexas e seguimento de instruções. (Fonte: 量子位)
💼 Negócios
xAI e Polymarket colaboram para fundir previsão de mercado com análise Grok: A xAI de Elon Musk anunciou uma parceria com a plataforma de mercado de previsão Polymarket. Ambas as partes combinarão a capacidade de previsão de mercado da Polymarket, os dados da plataforma X e a capacidade de análise do modelo Grok, com o objetivo de criar um “motor de verdade hardcore” (Hardcore truth engine) para obter insights sobre os fatores que moldam o mundo. A declaração oficial indica que este é apenas o início da colaboração, com mais desenvolvimentos futuros. (Fonte: Yuhu_ai_)
UnslothAI reconhecida pela Redpoint como empresa de infraestrutura de topo, aparece no ecrã da Nasdaq: A startup de AI UnslothAI foi nomeada pela empresa de capital de risco Redpoint como uma das 100 empresas de infraestrutura mais influentes e de crescimento mais rápido para 2025, devido às suas contribuições no campo da infraestrutura de AI. O seu logótipo foi, por isso, exibido nos ecrãs eletrónicos do edifício Nasdaq em Nova Iorque. A UnslothAI foca-se na otimização da eficiência do treino e inferência de LLMs. (Fonte: danielhanchen, karminski3)

Ant Digital Science atualiza Tianji Laboratory, focando em “AI + Inovação Industrial”: A Ant Digital Science anunciou a atualização do seu Tianji Laboratory, anteriormente o “Laboratório de Segurança de Identidade Digital”, para um laboratório de “Inteligência Artificial + Inovação Industrial”. O laboratório atualizado concentrar-se-á na investigação de avanços tecnológicos chave na aplicação de grandes modelos de AI na indústria, com foco em quatro direções principais: AI + Dados, AI + Segurança, AI + Finanças e AI + Inteligência Incorporada. O objetivo é promover a integração profunda da tecnologia AI com a indústria através da inovação colaborativa entre indústria, academia, investigação e aplicação. (Fonte: 量子位)

🌟 Comunidade
Capacidade de condução autónoma da AI em ambientes de tráfego complexos ganha atenção: Ronald van Loon partilhou um vídeo de um teste de condução autónoma no trânsito caótico da Índia, o que gerou discussões sobre as capacidades de perceção, decisão e controlo da AI em ambientes complexos e altamente dinâmicos. Cenários do mundo real como este colocam exigências extremamente elevadas à robustez e adaptabilidade dos sistemas de condução autónoma. (Fonte: Ronald_vanLoon)
Destaques da conferência AI Engineer World’s Fair: Protocolo MCP, custo de agentes de AI e modelos locais em foco: Yogi e Shawn “swyx” Wang, entre outros, partilharam os pontos principais da conferência AI Engineer World’s Fair. As tendências centrais incluem: 1) Os agentes de AI são o futuro, e a unidade de interação atómica será a chamada de agente; 2) O Model Context Protocol (MCP) está rapidamente a tornar-se um padrão, resolvendo o “inferno do copiar e colar” e permitindo que a AI interaja diretamente com aplicações externas; 3) A construção de ferramentas de AI profundamente otimizadas para domínios e fluxos de trabalho específicos (padrão Cursor-for-X) é crucial; 4) O custo dos modelos diminuiu drasticamente e a capacidade dos modelos locais aumentou, oferecendo aos programadores maior controlo e soluções de baixa latência; 5) A AI está a evoluir de uma ferramenta auxiliar para um “colega de equipa” dos programadores; 6) A engenharia de AI está a passar da fase de demonstração para sistemas de nível de produção. (Fonte: swyx, TheTuringPost)
Comunidade discute iteração rápida após lançamento do o3-pro e artigo da Apple sobre AI: andersonbcdefg comentou com humor que, apenas 6 horas após o lançamento do o3-pro, a comunidade parecia esperar que alguém reescrevesse o fastText em Rust, e ironizou sobre longas dissertações acerca de “superinteligência moderada”, refletindo a rápida velocidade de iteração tecnológica no campo da AI e as elevadas expectativas da comunidade. Simultaneamente, Teknium1 salientou que o o3-pro resolveu o problema da Torre de Hanói proposto no artigo da Apple “The Illusion of Thinking”, e questionou por que razão a Apple, no contexto da sua colaboração com a OpenAI, não realizou uma verificação interna antes de publicar tal artigo, gerando discussões na comunidade sobre as relações de competição e cooperação entre empresas de tecnologia. (Fonte: andersonbcdefg, Teknium1)
Discussão sobre ética e eficácia da AI em aplicações do mundo real: A comunidade debateu a eficácia e as questões éticas da aplicação da AI em cenários específicos. Por exemplo, Arvind Narayanan salientou que o conceito de aplicações de contagem de calorias por AI é inerentemente falho, pois a informação da imagem é insuficiente para estimar calorias com precisão, considerando-as mais como um “ritual” para ajudar os utilizadores a criar hábitos de atenção alimentar. Além disso, a questão de saber se o uso de imagens geradas por AI para promoção comercial (como a exibição de pratos de um café) é ético ou apropriado também se tornou um ponto de discussão, com a opinião geral de que, desde que não seja claramente falso ou enganoso, é uma forma aceitável de reduzir custos e aumentar a eficiência. (Fonte: random_walker, Reddit r/artificial)
“Humanização” dos LLMs e experiência de interação do utilizador tornam-se foco: Utilizadores da comunidade Reddit discutiram como tornar a interação com LLMs mais semelhante à de humanos reais, incluindo a introdução de hesitações, pausas, respostas mais curtas e expressões não perfeitas. Isto reflete a necessidade dos utilizadores por companheiros ou assistentes de AI mais naturais e menos “robóticos”. Ao mesmo tempo, alguns utilizadores queixaram-se de que os LLMs atuais (como o ChatGPT) usam frequentemente frases feitas e expressões exageradas (como “isto não é apenas X, é Y”), desejando que a sua expressão fosse mais concisa e direta. Estas discussões apontam para os desafios contínuos dos LLMs em simular a conversação humana e satisfazer as necessidades emocionais dos utilizadores. (Fonte: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 Outros
CEO da NVIDIA, Jensen Huang, fará discurso principal na GTC Paris, focando na nova fase da computação AI: A NVIDIA anunciou que o seu CEO, Jensen Huang, fará um discurso principal na conferência GTC em Paris a 11 de junho (durante a VivaTech 2025). Espera-se que revele a próxima fase da computação AI, abrangendo tópicos de vanguarda desde sistemas de agentes até fábricas de AI. (Fonte: nvidia, nvidia)

Databricks Data+AI Summit apresentará os mais recentes avanços: A Databricks anunciou que o seu Data+AI Summit reunirá especialistas de topo, investigadores e contribuidores open-source para apresentar os mais recentes avanços da empresa nas áreas de dados e AI, e partilhar casos de sucesso de empresas inovadoras. A cimeira oferece participação online e presencial. (Fonte: matei_zaharia, lateinteraction)

Impacto ético e ambiental da AI em foco, divulgado em formato de novela gráfica: O centro LEARN da EPFL (Escola Politécnica Federal de Lausanne) colaborou com o ilustrador Herji para lançar uma novela gráfica educativa em francês intitulada “Utop’IA”, que visa sensibilizar os jovens para o impacto ambiental da inteligência artificial através de uma história, incluindo o seu consumo de recursos (energia, água, metais raros) e potenciais benefícios ecológicos. A obra enfatiza o pensamento crítico e explora caminhos para o desenvolvimento de uma AI sustentável. (Fonte: aihub.org)
