
キーワード:Meta, Scale AI, 超知能, AGI, データアノテーション, AIトレーニング, モデル精度, MetaがScale AIの株式を取得, Alexandr Wangが超知能チームをリード, AIデータアノテーション精度99.7%, トレーニングデータ汚染率低減, モデルトレーニングサイクル40%短縮
🔥 フォーカス
Meta、Scale AIに約150億ドル出資、CEOを新設「Super Intelligence」チームのリーダーに任命との報道: Metaは約149億ドルでAIデータラベリングおよびインフラ企業Scale AIの株式49%を取得し、弱冠28歳の中国系CEO、Alexandr Wang氏を新設の「Super Intelligenceチーム」のリーダーに任命する計画だと報じられています。この動きは、MetaのAI分野における競争力、特に高品質な訓練データとAGI研究開発面を強化することを目的としています。Scale AIは99.7%という高いデータラベリング精度で知られており、Metaモデルの訓練データ汚染率を15%から2%に低減し、訓練サイクルを40%短縮することが期待されています。今回の買収は、MetaがAI競争で追いつき、ライバルを追い越そうとする重要な一歩と見なされており、AI開発におけるデータの核心的な戦略的地位を浮き彫りにしています。(情報源: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
OpenAI、Google Cloudと大規模計算能力契約を締結か、Microsoft依存脱却の動き: 報道によると、OpenAIはGoogle Cloudと重要なクラウドサービス契約を締結し、Google CloudはOpenAIの増大するAIモデル訓練とデプロイに必要な計算能力を提供するとのことです。これまでMicrosoft AzureがOpenAIの主要な計算能力サプライヤーでした。この動きは、OpenAIが計算能力の調達源を多様化し、単一サプライヤーへの依存を減らし、膨大な計算需要を満たそうとしていることを示唆している可能性があります。この提携はGoogle Cloudにとって大きな勝利である一方、自社事業と顧客ニーズの間でTPUリソースをどのようにバランスさせるかについての議論も呼んでいます。(情報源: 36氪, scaling01)
Mistral AI、推論モデルMagistralを発表、コミュニティからベンチマークテストの透明性に疑問の声: フランスのAI企業Mistral AIは、初の推論専用モデルシリーズMagistralを発表しました。これにはオープンソースの24BバージョンMagistral Smallと、企業向けのMagistral Mediumが含まれます。公式には、透明で追跡可能な多段階論理推論のために設計され、多言語をサポートするとされています。しかし、コミュニティからは発表されたベンチマークテスト結果に対し、最新バージョンのQwenやDeepSeek R1などの競合モデルと比較されていないため、「対戦回避」の疑いがあるとの疑問の声が上がっています。それにもかかわらず、MagistralはAIME-24数学ベンチマークテストにおいて、Mistral Medium 3と比較して大幅な向上を示しています。(情報源: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

強化学習の父 Richard Sutton氏:LLMの優位性は一時的、計算の拡張と経験学習が未来: チューリング賞受賞者であり強化学習の父であるRichard Sutton氏は、現在の大規模言語モデル(LLM)の優位性は一時的なものであり、人間の思考様式を模倣するだけでは短期的な性能向上しか得られないと予測しています。彼はAIの未来は「体験の時代」にあり、Agentが静的な人間データに依存するのではなく、世界との一人称のインタラクションを通じて経験データを取得して学習することにあると考えています。Sutton氏は、強化学習がこの未来への核心的な道筋であり、継続的な学習を行う深層学習アルゴリズムと大規模な計算拡張を組み合わせることで、AIは既存の認知を突破し、真のイノベーションを実現すると強調しています。(情報源: 量子位)

Hugging FaceとNVIDIAが「Training Cluster as a Service」提供で提携、大規模モデル訓練の敷居を下げる: Hugging FaceはNVIDIAとの提携により、「Training Cluster as a Service」を開始すると発表しました。これは、世界中の研究機関が最先端の各種モデルを訓練するための大規模GPUクラスターリソースをより容易に利用できるようにすることを目的としています。このサービスはNVIDIA DGX Cloud LeptonとHugging Faceの開発リソースを統合し、組織が必要に応じてGPUクラスターの使用時間を要求し、支払うことを可能にします。この動きは「GPU貧富の差」を埋め、AI研究の多様性と普及を促進することを目的としており、すでにTIGEM、Numina、Mirror Physicsなどの研究機関やスタートアップ企業に早期採用されています。(情報源: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 動向
OpenAI、o3-proモデルを発表し、o3 API価格を大幅引き下げ: OpenAIは、新しいトップクラスの推論モデルo3-proを発表し、ChatGPT ProユーザーおよびAPIユーザーに公開しました。同時に、o3モデルのAPI価格は80%大幅に引き下げられ、ChatGPT Plusユーザーのo3レート制限も2倍に引き上げられました。コミュニティからのフィードバックによると、o3-proは非コードタスクにおいてClaude Opus 4よりも優れており、Extended NYT ConnectionsやCreative Short Story Writingなどの複数のベンチマークテストで新記録を樹立し、以前Appleの論文でLLMの能力に疑問を呈した「ハノイの塔10円盤問題」の解決にも成功しました。しかし、一部のユーザーからはo3-proの速度が遅いとの報告もあります。OpenAIは、o3の値下げは蒸留や量子化によるものではなく、推論エンジニアの最適化作業の賜物であると述べています。(情報源: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB、エッジデバイス向け高効率LLM「MiniCPM4」シリーズを発表: OpenBMBは、エッジデバイス向けに設計されたMiniCPM4シリーズモデルを発表し、典型的なエッジチップ上で5倍以上の生成速度向上を実現したと主張しています。同シリーズには、MiniCPM4-8B、MiniCPM4-0.5B、および3値量子化されたBitCPM4-1B/0.5Bなどのバージョンが含まれます。MiniCPM4は、訓練可能なスパースアテンションメカニズムInfLLM v2を採用し、128Kの長文処理をサポートし、モデル風洞2.0、BitCPM3値量子化、FP8低精度計算、マルチトークン予測などの高効率学習アルゴリズムと訓練技術を組み合わせています。同時に、高品質な中英事前学習データセットUltraFinewebと教師ありファインチューニングデータセットUltraChat v2も発表されました。(情報源: GitHub Trending)
MSRAと清華大学・北京大学の研究者、強化学習事前学習(RPT)の新パラダイムを提案: Microsoft Research Asia (MSRA) は、清華大学および北京大学の研究者と共同で、強化学習事前学習(Reinforced Pre-training, RPT)と呼ばれる新しいLLM事前学習パラダイムを提案しました。この手法は、強化学習(RL)を事前学習段階に深く組み込み、モデルは各トークンを予測する前に思考連鎖推論シーケンスを生成し、予測の正しさに基づいて報酬を受け取ります。RPTは、モデルが表面的なトークンの相関関係を学習することから、深層的な意味を理解することへと移行させることを目的としています。実験では、RPTに基づいて訓練された14Bモデルが、一部の推論タスクにおいて32Bの従来の事前学習モデルに匹敵するか、それを超える性能を示し、LLMの言語モデリング能力と推論能力を向上させる大きな可能性を示しました。(情報源: 量子位, omarsar0)

Meta、ビデオワールドモデルV-JEPA 2および新ベンチマークを発表: Meta AIは、ビデオデータで訓練された12億パラメータのワールドモデルV-JEPA 2を発表しました。これは、機械の物理世界に対する理解と予測能力を向上させることを目的としています。このモデルは、ロボットのゼロショットプランニングに役立ち、未知の環境でタスクを計画・実行することを可能にします。同時に、Metaは既存モデルがビデオから物理世界を推論する能力を評価するための3つの新しいベンチマークテストも発表しました。HuggingFaceはV-JEPA 2のtransformersライブラリサポートを提供しています。(情報源: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance、動画生成モデルSeedance 1.0 Proを発表、豆包Appに搭載: ByteDanceは、最新の動画生成モデルSeedance 1.0 Pro(すなわち、夢幻駆動における動画3.0 Proモデル)を発表しました。このモデルは、プロンプト理解、画面のディテール、物理的表現の一貫性に優れており、5秒間の1080P動画を生成できます。現在、このモデルは火山エンジンを通じて企業ユーザーに公開されており、豆包Appでは「写真動起来(写真が動き出す)」機能としてユーザーが無料で体験できます。(情報源: op7418)
Huawei、「デジタル風洞」シミュレーションプラットフォームを発表、AI訓練・推論効率を最適化: Huaweiのマルコフモデリングシミュレーションチームは、実際の訓練と複雑なAIモデルの推論前に仮想環境で「リハーサル」を行うためのプラットフォームである「デジタル風洞」技術を初めて公開しました。このプラットフォームには、Sim2Train(訓練シミュレーション)、Sim2Infer(推論シミュレーション)、Sim2Availability(高可用性シミュレーション)の3つの主要モジュールが含まれており、シミュレーションと自動最適化を通じて、ハードウェアリソースのミスマッチ、システム結合などの問題を解決し、数万カードクラスターソリューションを時間単位で事前検証し、計算能力の浪費を避け、AI大規模モデルの訓練・推論の効率と安定性を向上させることを目的としています。(情報源: 量子位)

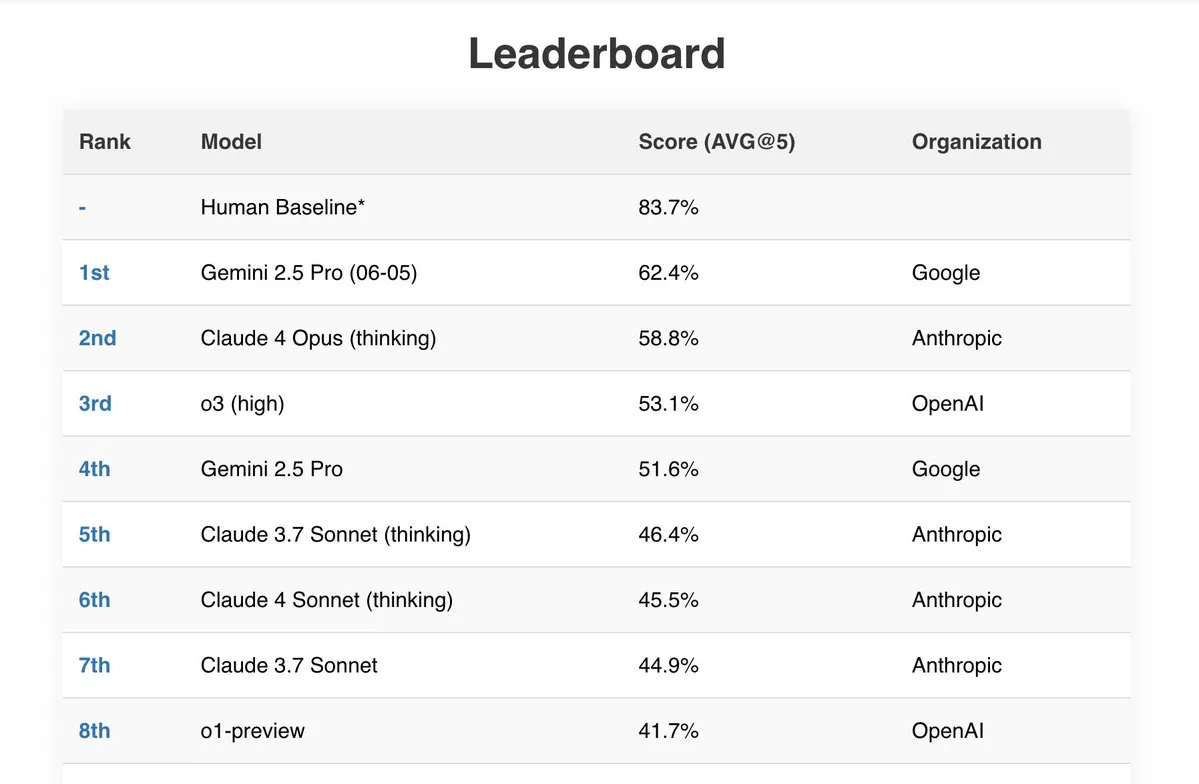
Gemini 2.5 Pro、複数のベンチマークテストで優れた性能を発揮: Googleの最新モデルGemini 2.5 Pro (06-05)は、複数の公開AIランキングで際立った性能を示しています。192kトークンを処理するLive Fictionテストで最高のパフォーマンスを発揮し、SimpleBenchでは62.4%のスコアで1位を獲得、IDP(インテリジェント・ドキュメント・プロセッシング)やAider(AI支援コーディング)などのベンチマークテストでも強力なドキュメント処理能力とコストパフォーマンスを示しました。さらに、あるユーザーはGemini 2.5 ProがJEE Advanced 2025の数学セクションの全問題を解決したと報告しています。(情報源: _philschmid, dilipkay)
Kling AI動画モデル、リップシンク機能更新、キャラクター選択・編集をサポート: 快手傘下のAI動画生成ツールKling AIは最近、リップシンク(Lip-sync)機能を更新しました。新機能では、ユーザーが生成された動画内の特定のキャラクターを選択してリップシンクを行い、音声と口の動きの同期時間を調整できます。この更新により、Kling AIの複数キャラクターが登場する会話動画作成における柔軟性とリアリティが向上し、動画生成分野における重要な進展となります。(情報源: Kling_ai, Kling_ai)
Delta Lake 4.0.0リリース、Lakehouse機能を強化: Delta Lake 4.0.0バージョンが正式にリリースされ、統一されたガバナンスと発見可能性を実現するためのプレビュー版カタログ管理テーブル(Catalog-Managed Tables)、Spark Connect向けのDelta Connect拡張、半構造化データ処理のためのVariantデータ型サポート、履歴の切り捨てやダウンタイムなしにテーブル特性を削除できる即時DROP FEATURE機能など、多くの重要な新機能が追加されました。このバージョンは、オープンなlakehouseコミュニティの体験を向上させることを目的としています。(情報源: matei_zaharia)

Hugging Face、モデルとツールの連携を簡素化するMCPサーバーを公開: Hugging Faceは、モデルコンテキストプロトコル(MCP)サーバーの最初のバージョンをリリースしました。ユーザーは現在、http://hf.co/mcp を通じてClaudeやCursorなどのアプリケーションでこのサーバーを利用し、モデル、データセット、論文、アプリケーション、または特定の情報を検索できます。これは、Hugging FaceがAIエコシステムにおけるツールとモデルの相互運用性を推進する上で重要な一歩であり、将来的にはアップロード、ダウンロード、PRの開始などの機能に拡張される可能性があります。(情報源: clefourrier, ClementDelangue)

Baidu、ストレージとインテリジェント管理を統合した「AIカメラ」を発表、GenFlow超能搭子2.0をアップグレード: Baidu NetdiskとBaidu Wenkuは共同で「AIカメラ」機能を発表し、写真撮影、クラウドストレージ、インテリジェント管理の一体化を実現しました。写真は自動的にクラウドアルバムにアーカイブされ、自然言語による説明でのインテリジェントな分類と検索をサポートします。AIカメラは、美顔、物体認識による解説、簡単な絵の落書き生成、領収書スキャン、手書き表の変換など、多様なAI機能も備えています。同時に、マルチエージェント連携プラットフォーム「GenFlow超能搭子」は2.0バージョンにアップグレードされ、ユーザーデータと習慣をより深く組み合わせ、パーソナライズされたコンテンツ生成サービスを提供します。(情報源: 量子位)

ByteDance、SeedVR2ビデオ修復モデルのコードと重みをオープンソース化: ByteDance SEEDチームは、ワンステップビデオ修復モデルSeedVR2の推論コードとモデルの重みを公開し、Hugging Faceで提供を開始しました。このモデルは、拡散敵対的ポストトレーニング(diffusion adversarial post-training)技術を利用し、ビデオ修復において顕著な効果を上げており、特に高解像度ビデオ処理で優れた性能を発揮します。(情報源: _akhaliq)
GroqCloud、Qwen3-32Bモデルをローンチ、100以上の言語と131kコンテキストをサポート: Groqは、LPU推論ハードウェアクラウドプラットフォームGroqCloudで、通义千问Qwen3-32Bモデルをローンチしたと発表しました。このモデルは100以上の言語と方言をサポートし、131kのコンテキストウィンドウを持ち、Groqハードウェア特有のリアルタイム速度で動作し、開発者に強力な多言語、長文処理能力を提供します。(情報源: JonathanRoss321)
OpenAI CEO Sam Altman氏、オープンソースの重みモデルのリリース延期を表明: Sam Altman氏は、OpenAIのオープンソースの重みモデルのリリースを、当初予定していた6月から今年の夏の終わりに延期すると述べました。彼は、研究チームが「予期せぬ、非常に驚くべき」進展を遂げており、待つ価値があるものの、完成にはさらに時間が必要だと明かしました。(情報源: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

地瓜机器人、RDK S100開発キットを発表、シングルSoCに大小脳アーキテクチャを統合: 地瓜机器人は、業界初のシングルSoC演算制御一体型ロボット開発キットRDK S100を発表しました。このキットは、人間のような大小脳のスーパーヘテロジニアス協調アーキテクチャ設計(6コアArm Cortex-A78AE CPU + 80 TOPS BPUを「大脳」、4コアArm Cortex-R52+ MCUを「小脳」として)を採用し、具身知能の大小モデルの効率的な協調をサポートし、「感知-決定-制御」のクローズドループを実現します。RDK S100は豊富なインターフェースとフルリンク開発インフラを提供し、予約販売価格は2499元です。(情報源: 量子位)

愛簿智能、50TOPS国産SoC搭載のE300 AI計算モジュールを発表: 愛簿智能は、エッジシーン向けのE300 AI計算モジュールを発表しました。これは自社開発のAI SoCチップAB100を搭載しています。このモジュールは最大50TOPSのINT8演算能力を提供し、FP16/FP32混合精度計算をサポートし、102GB/sのLPDDR5メモリ帯域幅を備えています。E300はモジュラー設計を採用し、教育、エネルギー、医療などの業界に高性能、低遅延、高信頼性の国産エッジAIソリューションを提供することを目的としており、主流のオープンソース大規模モデルや様々な視覚・音声モデルのエッジ展開をサポートします。(情報源: 量子位)

Huawei、Ascend万カードクラスター高可用性技術を公開、98%の訓練可用度を実現: Huaweiは、Ascend万カード計算能力クラスターの高可用性技術の詳細を初めて公開しました。故障検知診断、故障管理、クラスター光リンクフォールトトレランスの3つの基本能力と、クラスター線形度最適化、訓練と推論の迅速な回復などの業務支援能力を通じて、Huaweiは万カードクラスターの訓練可用度98%、線形度95%超、故障回復秒単位、診断分単位を実現しました。この「3+3」の2次元技術体系は、大規模AI訓練と推論の安定かつ効率的な運用を保障することを目的としています。(情報源: 量子位)

BYD新車のスマート運転普及率79%に、高速NOAが主流装備に: BYDが発表した最新データによると、5月に販売された新車のうち、スマートアシスト運転システム(少なくとも高速NOAと自動駐車機能を備える)を搭載した車種の割合が79%に達しました。これは、BYDが「全民スマート運転」戦略の推進で顕著な成果を上げ、スマート運転機能が急速に同社車種の標準装備になりつつあることを示しています。この傾向は、中国自動車市場におけるスマート運転技術の普及速度の加速も反映しています。(情報源: 量子位)

ChatGPTの高度な音声機能、全ての有料ユーザーに提供開始: OpenAIは、以前更新された、より自然なChatGPTの高度な音声機能(Advanced Voice)が、全ての有料ユーザー(ChatGPT Plus, Team, Enterprise)に提供開始されたと発表しました。ユーザーはこの機能を通じて、ChatGPTとより自然な音声対話を行うことができます。(情報源: juberti)
🧰 ツール
Genspark AIブラウザがリリース、複数のAIエージェント機能を統合: Eric JingチームはGenspark AIブラウザをリリースしました。24人のチームが10週間で開発したとされ、AIブラウザ、AI秘書、AIパーソナル通話、AIダウンロードエージェント、AI Drive、AI Sheetsなど8つの主要製品を統合しています。このブラウザは、高速性、広告ブロック、完全なエージェント化、自動運転モードを特徴とし、MCPストアとスーパーエージェントを内蔵しており、ワンストップのAI支援ブラウジングと作業体験を提供することを目指しています。(情報源: blader)
Yutori AI、AIエージェントネットワーク監視プラットフォームScoutsを発表: Yutori AIはScoutsプラットフォームを発表しました。これにより、ユーザーは常時オンラインのAIエージェントを作成し、ネットワーク上の特定の情報更新を監視できます。これらのエージェントは、ニッチなニュース、商品価格の変動、チケット情報など、ユーザーが関心を持つ様々なコンテンツを追跡し、重要なタイミングでメールでユーザーに通知することで、情報追跡の自動化を通じてユーザーを解放することを目指しています。(情報源: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face、AIモデルとスプレッドシートを組み合わせたAISheetsを発表: Hugging FaceはAISheetsを発表しました。これは、数千のAIモデル(特にオープンソースLLM)とスプレッドシート機能を組み合わせたアプリケーションです。ユーザーはAISheets内でデータを構築、分析、自動処理でき、スムーズで高速かつシンプルなAI活用データ処理体験を提供することを目指しています。(情報源: ben_burtenshaw, LoubnaBenAllal1)
PLaMo、MLXベースのローカル翻訳CLIツールを公開: PLaMo LLMチームは、Apple Silicon搭載Mac上でMLXフレームワークを利用してローカルテキスト翻訳を実現するコマンドラインインターフェース(CLI)ツールをオープンソース化しました。このツールは、高速かつ高精度なローカル翻訳体験を提供することを目指しており、HTTPおよびMCPサーバーとクライアントを内蔵しているため、他のMCP互換アプリケーション(Claude Desktopなど)との連携が容易です。(情報源: awnihannun)
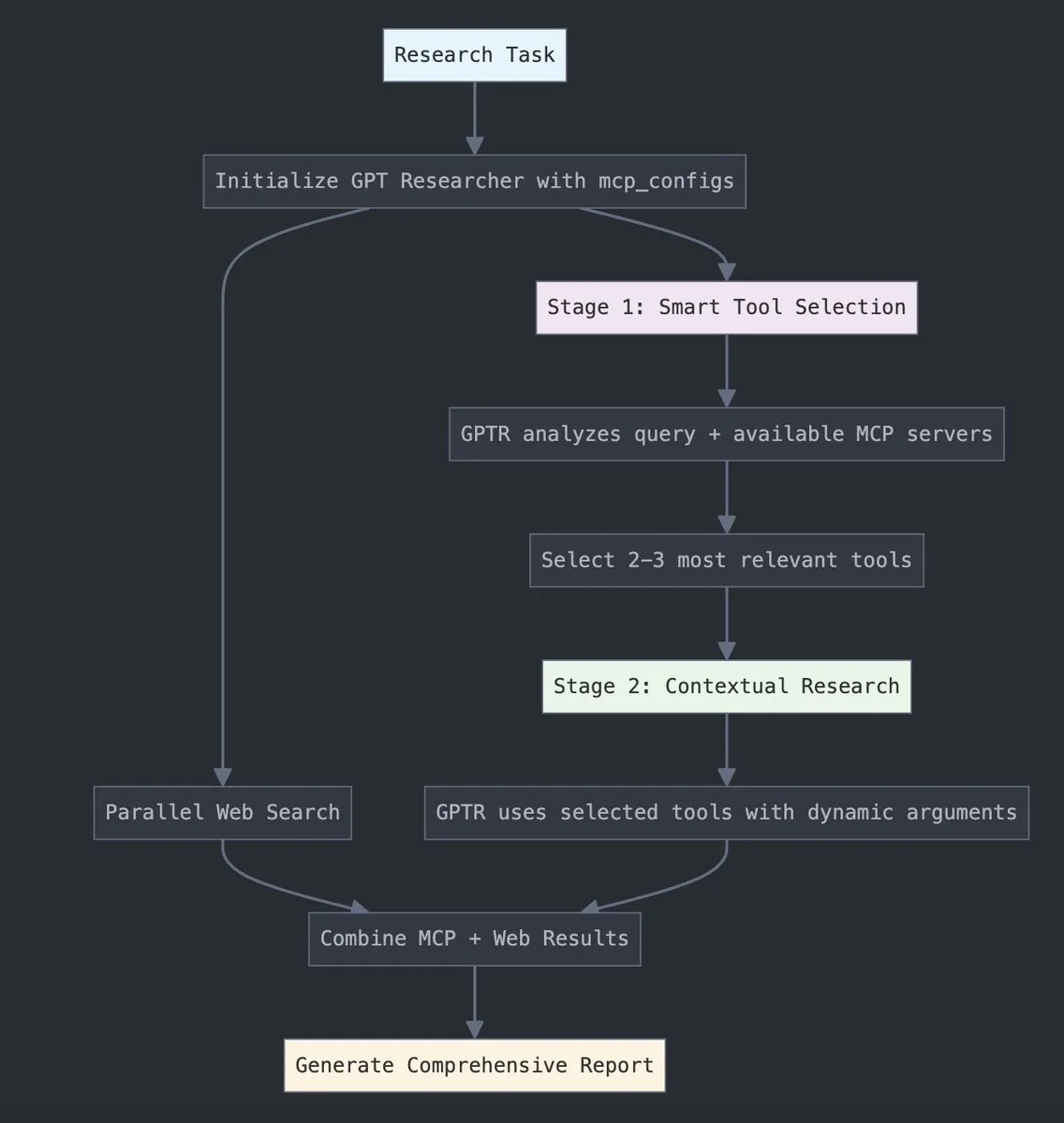
GPT Researcher、LangChain MCPアダプターを統合し、ツール選択と研究能力を向上: GPT Researcherは現在、LangChainのモデルコンテキストプロトコル(MCP)アダプターを利用して、よりインテリジェントなツール選択と研究プロセスを実現しています。この動きは、MCPの利点とウェブ検索能力を組み合わせることで、より包括的なデータ収集と分析を行うことを目的としています。(情報源: Hacubu)
Consilium:オープンソースのマルチエージェント連携フレームワークが公開: Victor Mは、オープンソースのAIエージェントチーム連携フレームワークConsiliumを公開しました。ユーザーは戦略を設定し、複数の専門家エージェントが議論を行い、リアルタイムの研究(ウェブ、arXiv、SECデータ)を利用して複雑な問題を共同で解決し、合意に達することができます。このツールはHugging Faceでデモが提供されています。(情報源: clefourrier)
youtube-transcript-api:YouTube字幕取得Pythonライブラリ、翻訳・自動生成コンテンツ対応: jdepoix氏が開発したPythonライブラリyoutube-transcript-apiがGitHubで注目を集めています。このAPIは、自動生成された字幕を含むYouTube動画の字幕を取得でき、翻訳機能もサポートしています。Seleniumベースの他のソリューションとは異なり、APIキーやヘッドレスブラウザを必要とせず、開発者に便利な動画テキストコンテンツ抽出手段を提供します。(情報源: GitHub Trending)
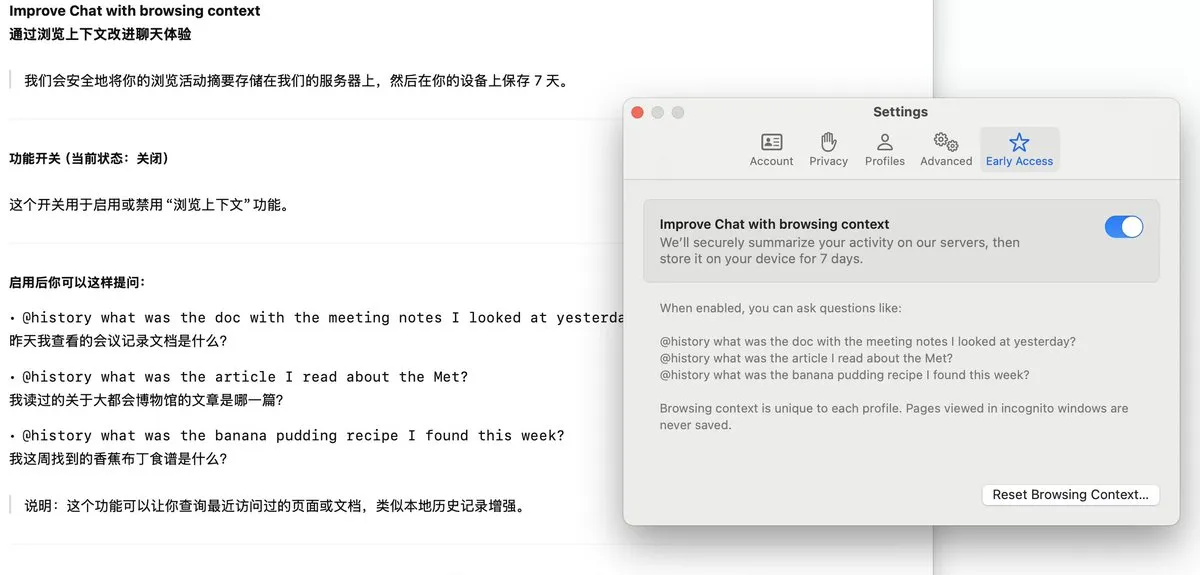
Arcブラウザ、閲覧履歴を記録しAI問答をサポートするDia機能を発表: ArcブラウザにDia機能が追加されました。有効にすると、ユーザーの全ての閲覧履歴を継続的に記録します。ユーザーは@History機能を通じて、曖昧な自然言語で質問することで、以前閲覧したが具体的なURLを忘れてしまった情報を検索できます。この機能は閲覧履歴レポートの生成もサポートする可能性があり、ブラウザのインテリジェント化とパーソナライズされた情報管理能力を向上させます。(情報源: op7418)
📚 学習
Apple、論文「思考の錯覚」を発表、LLMの能力の境界を探る: Appleの機械学習研究チームは論文「思考の錯覚」(The Illusion of Thinking)を発表し、現在のLLMが複雑な推論タスク(ハノイの塔問題の解決など)で示す性能と限界を分析しました。この論文は、LLMの真の知能レベルに関するコミュニティの議論を呼び、このような研究がAI採用を遅らせる理由として利用されることがあるとの見方もあります。OpenAIのo3-proモデルはその後、論文で提示されたハノイの塔の難問を解決しました。(情報源: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
新研究「汎用エージェントはワールドモデルを必要とする」がエージェントの汎化と予測モデルの関係を探る: 「汎用エージェントはワールドモデルを必要とする」(General agents need world models) と題された新しい研究論文は、多段階の目標指向タスクに汎化できる汎用エージェントは、予測的なワールドモデルを学習しなければならないと指摘しています。このモデルはエージェントの戦略にエンコードされており、論文は複合目標下でのエージェントの戦略選択を照会することで環境遷移確率を抽出し、それによって汎化能力と学習されたモデルの忠実度との間の直接的な関連性を証明しています。(情報源: menhguin)

論文、概念認識ファインチューニング(CAFT)によるLLM性能向上を議論: 新しい論文「概念認識ファインチューニングによる大規模言語モデルの改善」(Improving large language models with concept-aware fine-tuning) はCAFT手法を提案し、マルチトークン予測を可能にすることでファインチューニングを行い、モデルの概念理解を向上させます。研究によると、CAFTはエンコーディング、数学、テキスト要約、分子生成、タンパク質設計などのタスクで顕著な性能向上を達成しました。コードはGitHubで公開されています。(情報源: Reddit r/MachineLearning)
DeepLearning.AI、新コース「GenAIアプリケーションのワークフローをオーケストレーションする」を発表: Andrew Ng氏のDeepLearning.AIはAstronomerと提携し、「GenAIアプリケーションのワークフローをオーケストレーションする」(Orchestrating Workflows for GenAI Applications)という新しい短期トレーニングコースを発表しました。このコースでは、人気のオープンソースツールAirflow 3.0を使用して信頼性の高いGenAIプロセスを構築し、プロトタイプのJupyter NotebookやPythonスクリプトを本番環境対応のワークフローに変換する方法を教えます。内容は、タスク分解、スケジューリング、並列実行、障害回復、可観測性を網羅しています。(情報源: AndrewYNg)
論文「テキスト、画像、3D構造のトークンごとのアライメント」がマルチモーダル自己回帰モデルを探求: この研究は、言語、画像、構造化された3Dシーンをアライメントすることを目的とした統一的なLLMフレームワークを提案しています。論文は、データ表現、モダリティ固有の目的関数など、最適な訓練と性能を実現するための重要な設計選択について詳細に説明し、レンダリング、認識、指示追従、質疑応答という4つのコア3Dタスクおよび複数のデータで評価を行っています。研究はまた、量子化された形状エンコーディングを通じて複雑な3Dオブジェクトの形状を再構築することにも拡張されています。(情報源: HuggingFace Daily Papers)
論文「Squeeze3D」:事前学習済み3D生成モデルを利用した究極のニューラル圧縮: Squeeze3Dフレームワークは、事前学習済み3D生成モデルで学習された暗黙的な事前知識を利用して、3Dデータ(メッシュ、点群、放射場)を大幅に圧縮します。訓練可能なマッピングネットワークを介して事前学習済みエンコーダと生成モデルの潜在空間を接続し、3Dモデルをコンパクトな潜在コードに圧縮し、解凍時には生成モデルが再構築します。この手法は合成データで訓練され、実際の3Dデータセットを必要とせず、テクスチャ付きメッシュで最大2187倍の圧縮率を実現しました。(情報源: HuggingFace Daily Papers)
論文「フレームガイダンス」:ビデオ拡散モデルにおける訓練不要のフレームレベル制御: この研究は、「フレームガイダンス」(Frame Guidance)という、ビデオ拡散モデルにおいて訓練なしでフレームレベルの制御を実現する手法を提案しています。単純な潜在空間処理と新しい潜在空間最適化戦略を通じて、この手法はキーフレーム、スタイル参照、スケッチ、深度マップなどのフレームレベル信号を効果的に制御でき、キーフレームガイダンス、スタイル化、ループ再生など、さまざまなタスクに適用可能で、あらゆるビデオモデルと互換性があります。(情報源: HuggingFace Daily Papers)
論文「大規模言語モデルにおける地政学的バイアス」がモデルの国家の立場を明らかに: この研究は、LLMが異なる国家の視点(米、英、ソ、中)を持つ歴史的出来事をどのように解釈するかを分析することで、LLMにおける地政学的バイアスを評価しました。研究者は、中立的な出来事の記述と各国の対照的な視点を含む新しいデータセットを導入し、LLMが特定の国家の物語を著しく偏重するバイアスが存在し、単純なバイアス除去プロンプトの効果は限定的であることを発見しました。この研究は、将来の地政学的バイアス研究のためのフレームワークとデータセットを提供します。(情報源: HuggingFace Daily Papers)
Awesome Listsリソース庫が継続的に更新され、様々な興味深いトピックを収録: sindresorhus氏が管理するGitHubプロジェクトawesomeは、様々な興味深いトピックに関する「Awesome lists」を集めたメタリストです。これらのリストは、プログラミング言語、開発プラットフォームから理論、書籍、ツールなど、多くの分野を網羅しており、開発者や学習者に豊富なリソースインデックスを提供しています。(情報源: GitHub Trending)
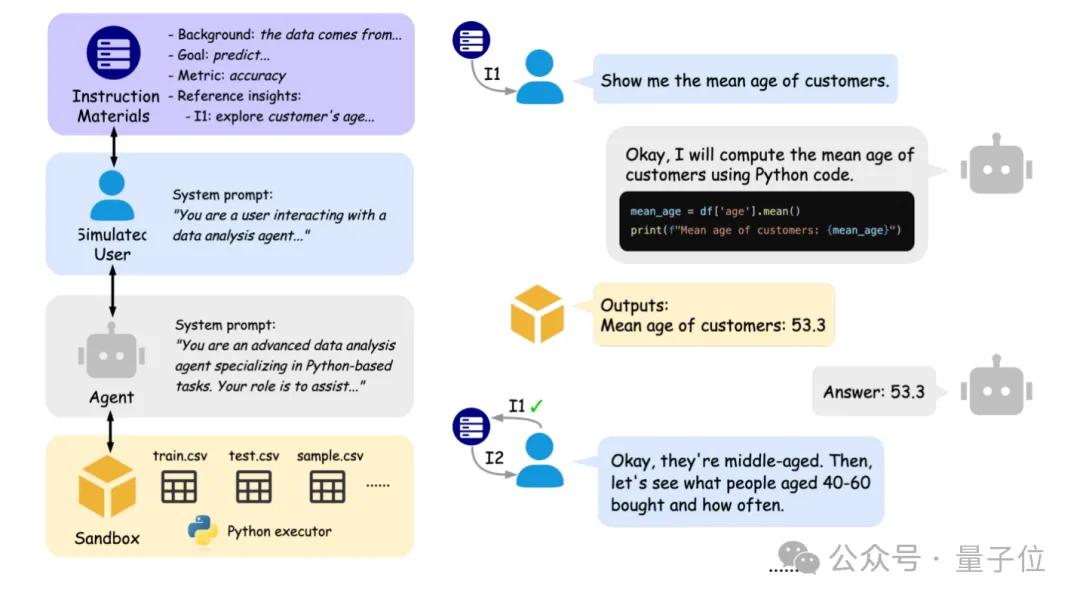
北京大学とバークレー校が共同でIDA-Benchを発表、AIデータ分析エージェントの対話能力を評価: 北京大学とカリフォルニア大学バークレー校の研究チーム(Michael I. Jordan教授を含む)は、IDA-Benchを発表しました。これは、大規模言語モデル(LLM)がデータ分析エージェント(Agent)として多段階の対話シナリオで示す能力を評価するための新しいベンチマークです。このベンチマークは、実際のデータアナリストのワークフローをシミュレートし、段階的に進化する指示を通じてAgentの追従能力、コード作成・実行能力を検証します。初期評価では、Claude-3.7やGemini-2.5 Proのようなトップモデルでさえ、タスク成功率は40%未満であり、現在のAgentが複雑な対話と指示追従において抱える課題を露呈しました。(情報源: 量子位)
💼 ビジネス
xAIとPolymarketが提携、市場予測とGrok分析を融合: Elon Musk氏のxAIは、予測市場プラットフォームPolymarketとの提携を発表しました。双方は、Polymarketの市場予測能力、Xプラットフォームのデータ、およびGrokモデルの分析能力を組み合わせ、「ハードコアな真実エンジン」(Hardcore truth engine)を構築し、世界を形作る要因を洞察することを目指しています。公式には、これは提携の始まりに過ぎず、将来的にはさらなる進展があるとしています。(情報源: Yuhu_ai_)
UnslothAI、Redpointによりトップインフラ企業に選出され、ナスダックの大型スクリーンに登場: AIスタートアップ企業UnslothAIは、AIインフラ分野への貢献により、ベンチャーキャピタル企業Redpointから2025年度の最も影響力があり成長著しいインフラ企業100社の一つに選ばれ、そのロゴがニューヨークのナスダックタワーの電子スクリーンに掲載されました。UnslothAIはLLMの訓練と推論効率の最適化に特化しています。(情報源: danielhanchen, karminski3)

Ant Digital、天玑ラボをアップグレード、「AI+産業イノベーション」に焦点: Ant Digitalは、天玑ラボを従来の「デジタルアイデンティティセキュリティラボ」から「AI+産業イノベーション」ラボにアップグレードすると発表しました。アップグレード後のラボは、産業応用におけるAI大規模モデルの重要な技術的ブレークスルーの研究に重点を置き、AI+データ、AI+セキュリティ、AI+金融、AI+具身知能の4つの方向性を展開し、産学研連携によるイノベーションを通じて、AI技術と産業の深い融合を推進することを目指しています。(情報源: 量子位)

🌟 コミュニティ
複雑な交通環境におけるAIの自動運転能力が注目される: Ronald van Loon氏は、インドの混沌とした交通状況で自動運転をテストする動画を共有し、複雑でダイナミックな環境下でのAIの認識、意思決定、制御能力についての議論を呼び起こしました。このような現実世界のシナリオは、自動運転システムの堅牢性と適応性に極めて高い要求を突きつけています。(情報源: Ronald_vanLoon)
AI Engineer World’s Fair大会のハイライト:MCPプロトコル、AIエージェントのコスト、ローカルモデルが焦点に: Yogi氏やShawn “swyx” Wang氏などがAI Engineer World’s Fair大会の要点を共有しました。主なトレンドは以下の通りです:1) AIエージェントが未来であり、原子的なインタラクション単位はエージェント呼び出しになる。2) モデルコンテキストプロトコル(MCP)が急速に標準となり、「コピー&ペースト地獄」を解決し、AIが外部アプリケーションと直接対話できるようにする。3) 特定のドメインやワークフロー向けに深く最適化されたAIツール(Cursor-for-Xパターン)の構築が鍵となる。4) モデルコストが大幅に低下し、ローカルモデルの能力が向上し、開発者により大きな制御権と低遅延ソリューションを提供する。5) AIは補助ツールから開発者の「チームメイト」へと進化している。6) AIエンジニアリングはデモ段階から本番レベルのシステムへと移行しつつある。(情報源: swyx, TheTuringPost)
コミュニティ、o3-proリリース後の迅速なイテレーションとAppleのAI論文について議論: andersonbcdefg氏は、o3-proのリリースからわずか6時間で、コミュニティが誰かがRustでfastTextを書き直すことを期待しているかのように見えるとユーモラスにコメントし、「穏やかな超知能」に関する長広舌を皮肉り、AI分野の技術イテレーションの速さとコミュニティの高い期待を反映しました。同時に、Teknium1氏は、o3-proがAppleの論文「思考の錯覚」で提示されたハノイの塔の難問を解決したことを指摘し、AppleとOpenAIが協力関係にある背景で、なぜ内部検証を経ずにこのような論文を発表したのか疑問を呈し、テクノロジー企業間の競争と協力の関係についてコミュニティの議論を呼びました。(情報源: andersonbcdefg, Teknium1)
AIの現実世界での応用における倫理と効果に関する議論: コミュニティでは、特定のシナリオにおけるAIの応用効果と倫理問題について議論が交わされています。例えば、Arvind Narayanan氏は、AIカロリー計算アプリの概念自体に欠陥があり、画像情報だけではカロリーを正確に推定するには不十分であると指摘し、これはユーザーが食事への注意習慣を身につけるための「儀式」のようなものだと考えています。また、AIが生成した画像を商業宣伝(例えばコーヒーショップのメニュー表示)に使用することが倫理的に許容されるか、あるいは適切かどうかについても議論の的となっており、明らかに虚偽であったり誤解を招いたりしない限り、コスト削減と効率向上の許容範囲内であるという見方が一般的です。(情報源: random_walker, Reddit r/artificial)
LLMの「人間らしさ」とユーザーインタラクション体験が焦点に: Redditコミュニティのユーザーは、ためらい、間、より短い返答、完璧ではない表現などを導入することで、LLMとのインタラクションをより現実の人間に近づける方法について議論しています。これは、より自然で「ロボット感」の少ないAIコンパニオンやアシスタントに対するユーザーのニーズを反映しています。同時に、現在のLLM(ChatGPTなど)が固定的な言い回しや大げさな表現(例:「これは単なるXではなく、Yでもある」)を多用することに不満を抱き、より簡潔で直接的な表現を望むユーザーもいます。これらの議論は、LLMが人間の対話をシミュレートし、ユーザーの感情的なニーズを満たす上での継続的な課題を示しています。(情報源: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 その他
NVIDIA CEO Jensen Huang氏、GTC Parisで基調講演、AIコンピューティングの新段階に焦点: NVIDIAは、CEOのJensen Huang氏が6月11日にパリで開催されるGTC大会(VivaTech 2025期間中)で基調講演を行うと発表しました。エージェントシステムからAIファクトリーに至るまで、AIコンピューティングの次の段階を明らかにすることが期待されています。(情報源: nvidia, nvidia)

Databricks Data+AI Summitで最新のブレークスルーを展示: Databricksは、Data+AI Summitにトップエキスパート、研究者、オープンソース貢献者を集め、データとAI分野における同社の最新のブレークスルーを展示し、革新的な企業の成功事例を共有すると発表しました。サミットはオンラインとオフラインでの参加が可能です。(情報源: matei_zaharia, lateinteraction)

AIの倫理と環境への影響が注目され、グラフィックノベル形式で啓発: EPFL(スイス連邦工科大学ローザンヌ校)のLEARNセンターは、イラストレーターのHerji氏と協力し、『Utop’IA』というフランス語の教育グラフィックノベルを制作しました。これは、物語形式を通じて青少年に人工知能の環境への影響(エネルギー、水、レアメタルの消費など)と潜在的な生態学的利益について啓発することを目的としています。この作品は批判的思考を強調し、持続可能なAIの発展経路を探求しています。(情報源: aihub.org)
