
Mots-clés:Meta, Scale AI, Superintelligence, AGI, Annotation des données, Entraînement de l’IA, Précision du modèle, Meta acquiert des actions de Scale AI, Alexandr Wang dirige le groupe Superintelligence, Précision d’annotation des données IA à 99,7%, Taux de contamination des données d’entraînement réduit, Cycle d’entraînement du modèle raccourci de 40%
🔥 À la Une
Meta aurait investi près de 15 milliards de dollars pour une participation dans Scale AI et nommé son PDG à la tête de la nouvelle équipe « Super Intelligence »: Meta prévoirait d’acquérir 49 % des parts de Scale AI, société spécialisée dans l’annotation de données et l’infrastructure IA, pour environ 14,9 milliards de dollars, et de nommer son PDG d’origine chinoise âgé de seulement 28 ans, Alexandr Wang, à la tête du nouveau « Groupe Super Intelligence ». Cette démarche vise à renforcer la compétitivité de Meta dans le domaine de l’IA, notamment en ce qui concerne les données d’entraînement de haute qualité et la R&D en AGI. Scale AI est réputée pour sa précision d’annotation des données atteignant 99,7 %, ce qui pourrait permettre de réduire le taux de contamination des données d’entraînement des modèles de Meta de 15 % à 2 %, et de diminuer de 40 % le cycle d’entraînement. Cette acquisition est considérée comme une étape clé pour Meta dans sa course pour rattraper et tenter de dépasser ses concurrents en IA, et souligne également la position stratégique centrale des données dans le développement de l’IA. (Source: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
OpenAI aurait conclu un accord majeur de puissance de calcul avec Google Cloud, possiblement pour réduire sa dépendance envers Microsoft: Selon des rapports, OpenAI aurait signé un important accord de services cloud avec Google Cloud, qui fournira à OpenAI la puissance de calcul nécessaire à l’entraînement et au déploiement croissants de ses modèles d’IA. Auparavant, Microsoft Azure était le principal fournisseur de puissance de calcul d’OpenAI. Cette démarche pourrait indiquer qu’OpenAI cherche à diversifier ses sources de puissance de calcul afin de réduire sa dépendance à un fournisseur unique et de satisfaire ses énormes besoins en calcul. Cette collaboration représente une victoire majeure pour Google Cloud, mais soulève également des questions sur la manière dont l’entreprise équilibrera les ressources TPU entre ses propres activités et les besoins de ses clients. (Source: 36氪, scaling01)
Mistral AI lance le modèle d’inférence Magistral, suscitant des doutes de la communauté sur la transparence de ses tests de référence: La société française d’IA Mistral AI a lancé sa première série de modèles conçus pour l’inférence, Magistral, comprenant une version open source 24B, Magistral Small, et une version destinée aux entreprises, Magistral Medium. Officiellement, ces modèles sont conçus pour un raisonnement logique multi-étapes transparent et traçable, et prennent en charge plusieurs langues. Cependant, la communauté a remis en question les résultats des tests de référence publiés, estimant qu’ils n’ont pas été comparés aux dernières versions de modèles concurrents tels que Qwen et DeepSeek R1, ce qui pourrait suggérer une tentative d’« éviter la confrontation ». Malgré cela, Magistral montre une amélioration significative par rapport à Mistral Medium 3 dans le test de référence mathématique AIME-24. (Source: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Richard Sutton, père de l’apprentissage par renforcement : la domination des LLM n’est que temporaire, l’avenir réside dans l’extension du calcul et l’apprentissage par l’expérience: Richard Sutton, lauréat du prix Turing et père de l’apprentissage par renforcement, prédit que la domination actuelle des grands modèles de langage (LLM) n’est que temporaire et que l’imitation du mode de pensée humain n’apporte qu’une amélioration des performances à court terme. Il estime que l’avenir de l’IA se situe dans « l’ère de l’expérience », où les agents apprennent en acquérant des données d’expérience par une interaction à la première personne avec le monde, plutôt qu’en s’appuyant sur des données humaines statiques. Sutton souligne que l’apprentissage par renforcement est la voie principale vers cet avenir, et que, combiné à des algorithmes d’apprentissage profond en continu et à une extension massive du calcul, il permettra à l’IA de dépasser les connaissances actuelles et de réaliser de véritables innovations. (Source: 量子位)

Hugging Face s’associe à NVIDIA pour lancer le « Training Cluster as a Service », abaissant le seuil d’accès à l’entraînement des grands modèles: Hugging Face a annoncé un partenariat avec NVIDIA pour lancer le « Training Cluster as a Service », visant à faciliter l’accès des instituts de recherche du monde entier à de grandes ressources de clusters GPU pour entraîner divers modèles de pointe. Ce service intègre NVIDIA DGX Cloud Lepton et les ressources de développement de Hugging Face, permettant aux organisations de demander et de payer à la demande le temps d’utilisation des clusters GPU. Cette initiative vise à combler le « fossé entre riches et pauvres en GPU », à promouvoir la diversité et la popularisation de la recherche en IA, et a déjà été adoptée en avant-première par des instituts de recherche et des startups tels que TIGEM, Numina et Mirror Physics. (Source: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 Tendances
OpenAI lance le modèle o3-pro et réduit considérablement les prix de l’API o3: OpenAI a lancé son nouveau modèle d’inférence haut de gamme, o3-pro, qui est désormais accessible aux utilisateurs de ChatGPT Pro et aux utilisateurs de l’API. Parallèlement, le prix de l’API du modèle o3 a été considérablement réduit de 80 %, et la limite de taux d’o3 pour les utilisateurs de ChatGPT Plus a été doublée. Les retours de la communauté indiquent qu’o3-pro surpasse Claude Opus 4 dans les tâches non liées au code et a établi de nouveaux records dans plusieurs tests de référence tels que Extended NYT Connections et Creative Short Story Writing, réussissant même à résoudre le « problème des Tours de Hanoï à 10 disques » précédemment utilisé dans un article d’Apple pour questionner les capacités des LLM. Cependant, certains utilisateurs signalent que o3-pro est plus lent. OpenAI a déclaré que la baisse de prix d’o3 n’est pas due à la distillation ou à la quantification, mais aux travaux d’optimisation des ingénieurs en inférence. (Source: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB lance la série MiniCPM4 de LLM efficaces pour les terminaux: OpenBMB a lancé la série de modèles MiniCPM4, spécialement conçue pour les appareils terminaux, affirmant avoir multiplié par plus de 5 la vitesse de génération sur les puces typiques des terminaux. Cette série comprend MiniCPM4-8B, MiniCPM4-0.5B, ainsi que des versions quantifiées ternaires BitCPM4-1B/0.5B. MiniCPM4 utilise un mécanisme d’attention sparse entraînable, InfLLM v2, prend en charge le traitement de textes longs de 128K, et combine des algorithmes d’apprentissage efficaces et des techniques d’entraînement telles que Model Wind Tunnel 2.0, la quantification ternaire BitCPM, le calcul à faible précision FP8 et la prédiction multi-jetons. Parallèlement, ont été publiés le jeu de données de pré-entraînement chinois et anglais de haute qualité UltraFineweb et le jeu de données de fine-tuning supervisé UltraChat v2. (Source: GitHub Trending)
Des chercheurs de MSRA et des universités de Tsinghua et Pékin proposent un nouveau paradigme de pré-entraînement renforcé (RPT): Microsoft Research Asia (MSRA), en collaboration avec des chercheurs de l’Université de Tsinghua et de l’Université de Pékin, a proposé un nouveau paradigme de pré-entraînement de LLM appelé Reinforced Pre-Training (RPT). Cette méthode intègre profondément l’apprentissage par renforcement (RL) dans la phase de pré-entraînement : avant de prédire chaque token, le modèle génère une séquence de raisonnement en chaîne de pensée et reçoit une récompense en fonction de l’exactitude de la prédiction. RPT vise à faire passer le modèle de l’apprentissage des corrélations superficielles entre tokens à la compréhension des significations profondes. Les expériences montrent qu’un modèle de 14B entraîné avec RPT peut égaler voire surpasser les modèles de 32B pré-entraînés traditionnellement sur certaines tâches de raisonnement, démontrant un potentiel énorme pour améliorer les capacités de modélisation du langage et de raisonnement des LLM. (Source: 量子位, omarsar0)

Meta lance le modèle du monde vidéo V-JEPA 2 et de nouveaux benchmarks: Meta AI a lancé V-JEPA 2, un modèle du monde de 1,2 milliard de paramètres entraîné sur des données vidéo, visant à améliorer la compréhension et la prédiction du monde physique par les machines. Ce modèle peut jouer un rôle dans la planification zero-shot pour les robots, leur permettant de planifier et d’exécuter des tâches dans des environnements inconnus. Parallèlement, Meta a également publié trois nouveaux benchmarks pour évaluer la capacité des modèles existants à raisonner sur le monde physique à partir de vidéos. HuggingFace propose déjà la prise en charge de V-JEPA 2 dans sa bibliothèque transformers. (Source: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance lance le modèle de génération vidéo Seedance 1.0 Pro, disponible sur l’application Doubao: ByteDance a lancé son dernier modèle de génération vidéo, Seedance 1.0 Pro (c’est-à-dire le modèle Video 3.0 Pro dans Dream Driver). Ce modèle excelle dans la compréhension des prompts, les détails de l’image et la cohérence des représentations physiques, capable de générer des vidéos de 5 secondes en 1080P. Actuellement, ce modèle est accessible aux entreprises via Volcengine et la fonction « Animer les photos » est disponible gratuitement pour les utilisateurs de l’application Doubao. (Source: op7418)
Huawei lance la plateforme de simulation « Soufflerie Numérique » pour optimiser l’efficacité de l’entraînement et de l’inférence IA: L’équipe de modélisation et simulation Markov de Huawei a présenté pour la première fois sa technologie de « Soufflerie Numérique », une plateforme permettant de réaliser des « répétitions » en environnement virtuel avant l’entraînement et l’inférence réels de modèles d’IA complexes. Cette plateforme comprend trois modules principaux : Sim2Train (simulation d’entraînement), Sim2Infer (simulation d’inférence) et Sim2Availability (simulation de haute disponibilité). Elle vise, par la simulation et l’optimisation automatique, à résoudre les problèmes de mauvaise allocation des ressources matérielles, de couplage des systèmes, etc., afin de prévisualiser en quelques heures des schémas de clusters de dizaines de milliers de cartes, d’éviter le gaspillage de puissance de calcul et d’améliorer l’efficacité et la stabilité de l’entraînement et de l’inférence des grands modèles d’IA. (Source: 量子位)

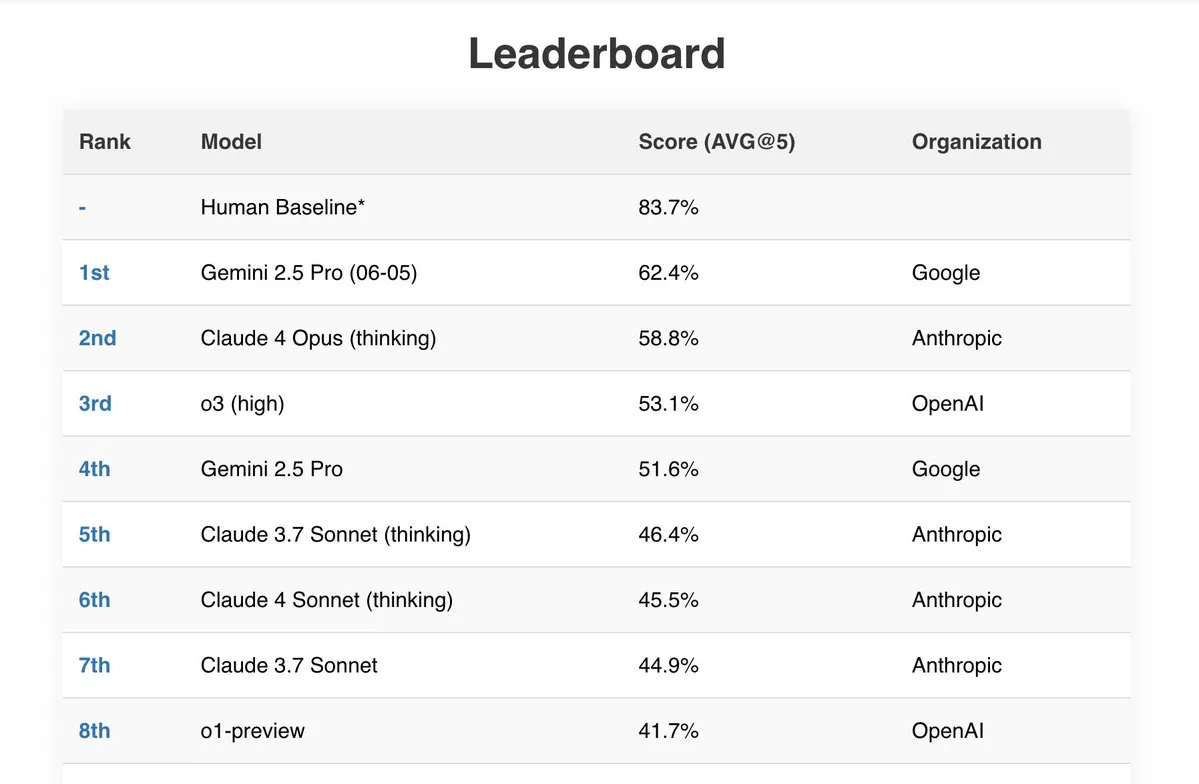
Gemini 2.5 Pro excelle dans plusieurs tests de référence: Le dernier modèle de Google, Gemini 2.5 Pro (06-05), se distingue dans plusieurs classements publics d’IA. Il obtient les meilleurs résultats au test Live Fiction traitant 192k tokens, se classe premier sur SimpleBench avec un score de 62,4 %, et démontre de solides capacités de traitement de documents et un bon rapport qualité-prix dans des benchmarks tels que IDP (Intelligent Document Processing) et Aider (AI-assisted coding). De plus, un utilisateur a signalé que Gemini 2.5 Pro a résolu avec succès tous les problèmes de la section mathématiques du JEE Advanced 2025. (Source: _philschmid, dilipkay)
Le modèle vidéo Kling AI met à jour sa fonction de synchronisation labiale, prend en charge la sélection et l’édition de personnages: L’outil de génération vidéo IA Kling AI, filiale de Kuaishou, a récemment mis à jour sa fonction de synchronisation labiale (Lip-sync). La nouvelle fonctionnalité permet aux utilisateurs de sélectionner des personnages spécifiques dans la vidéo générée pour la correspondance labiale, et d’ajuster la synchronisation de l’audio avec les mouvements des lèvres. Cette mise à jour améliore la flexibilité et le réalisme de Kling AI dans la création de vidéos de dialogue multi-personnages, marquant une avancée importante dans le domaine de la génération vidéo. (Source: Kling_ai, Kling_ai)
Delta Lake 4.0.0 publié, améliorant les capacités de Lakehouse: La version Delta Lake 4.0.0 a été officiellement publiée, apportant plusieurs nouvelles fonctionnalités importantes, notamment la prévisualisation des tables gérées par catalogue (Catalog-Managed Tables) pour une gouvernance et une découvrabilité unifiées, l’extension Delta Connect pour Spark Connect, la prise en charge du type de données Variant pour traiter les données semi-structurées, et la fonction DROP FEATURE instantanée, permettant de supprimer des fonctionnalités de table sans tronquer l’historique ni interrompre le service. Cette version vise à améliorer l’expérience de la communauté open lakehouse. (Source: matei_zaharia)

Hugging Face lance le serveur MCP pour simplifier l’interaction entre modèles et outils: Hugging Face a publié la première version de son serveur de protocole de contexte de modèle (MCP). Les utilisateurs peuvent désormais utiliser ce serveur via http://hf.co/mcp dans des applications comme Claude ou Cursor pour rechercher des modèles, des jeux de données, des articles, des applications ou des informations spécifiques. Cela marque une étape importante pour Hugging Face dans la promotion de l’interopérabilité des outils et des modèles au sein de l’écosystème de l’IA, avec des extensions futures possibles vers des fonctionnalités telles que le téléversement, le téléchargement, l’initiation de PR, etc. (Source: clefourrier, ClementDelangue)

Baidu lance une « Caméra IA » intégrant stockage et gestion intelligente, et met à niveau GenFlow Super Partner 2.0: Baidu Netdisk et Baidu Wenku ont conjointement lancé la fonction « Caméra IA », réalisant l’intégration de la prise de photos, du stockage cloud et de la gestion intelligente. Les photos peuvent être automatiquement archivées dans l’album cloud et prennent en charge la classification et la recherche intelligentes via des descriptions en langage naturel. La Caméra IA dispose également de multiples capacités d’IA telles que l’embellissement, la vulgarisation scientifique par reconnaissance d’objets, la génération de graffitis à partir de dessins au trait, la numérisation de reçus, la conversion de formulaires manuscrits, etc. Parallèlement, la plateforme de collaboration multi-agents intelligents « GenFlow Super Partner » a été mise à niveau vers la version 2.0, capable de s’intégrer plus profondément aux données et habitudes des utilisateurs pour fournir des services de génération de contenu personnalisés. (Source: 量子位)

ByteDance publie en open source le code et les poids du modèle de restauration vidéo SeedVR2: L’équipe SEED de ByteDance a publié le code d’inférence et les poids de son modèle de restauration vidéo en une étape, SeedVR2, désormais disponibles sur Hugging Face. Ce modèle utilise la technique de post-entraînement contradictoire par diffusion (diffusion adversarial post-training) et obtient des résultats remarquables en matière de restauration vidéo, notamment pour le traitement de vidéos haute résolution. (Source: _akhaliq)
GroqCloud met en ligne le modèle Qwen3-32B, prenant en charge plus de cent langues et un contexte de 131k: Groq a annoncé la mise en ligne du modèle Tongyi Qianwen Qwen3-32B sur sa plateforme cloud d’inférence LPU, GroqCloud. Ce modèle prend en charge plus de 100 langues et dialectes, dispose d’une fenêtre contextuelle de 131k, et fonctionne à la vitesse en temps réel caractéristique du matériel Groq, offrant aux développeurs de puissantes capacités de traitement multilingue et de textes longs. (Source: JonathanRoss321)
Sam Altman, PDG d’OpenAI, annonce que la publication de leur modèle à poids ouverts sera retardée: Sam Altman a indiqué que le modèle à poids ouverts d’OpenAI sera publié plus tard cet été, et non en juin comme prévu initialement. Il a révélé que l’équipe de recherche a fait des progrès « inattendus et très surprenants » qui valent la peine d’attendre, mais qui nécessitent plus de temps pour être peaufinés. (Source: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

Digua Robot lance le kit de développement RDK S100, intégrant une architecture de type grand et petit cerveaux sur un seul SoC: Digua Robot a lancé le premier kit de développement robotique intégré calcul-contrôle sur un seul SoC de l’industrie, le RDK S100. Ce kit adopte une conception d’architecture collaborative super-hétérogène de type grand et petit cerveaux humains (CPU Arm Cortex-A78AE 6 cœurs + BPU 80 TOPS comme « grand cerveau », MCU Arm Cortex-R52+ 4 cœurs comme « petit cerveau »), prenant en charge la collaboration efficace des grands et petits modèles d’intelligence incarnée, et bouclant la boucle « perception-décision-contrôle ». Le RDK S100 offre des interfaces riches et une infrastructure de développement complète, avec un prix de prévente de 2499 yuans. (Source: 量子位)

Aibee Intelligence lance le module de calcul IA E300, équipé d’un SoC national de 50TOPS: Aibee Intelligence a lancé le module de calcul IA E300 destiné aux scénarios en périphérie (edge), équipé de sa puce SoC IA auto-développée AB100. Ce module offre jusqu’à 50TOPS de puissance de calcul INT8, prend en charge le calcul à précision mixte FP16/FP32, et est équipé d’une bande passante mémoire LPDDR5 de 102 Go/s. L’E300 adopte une conception modulaire, visant à fournir des solutions d’IA en périphérie nationales à haute performance, faible latence et forte fiabilité pour des secteurs tels que l’éducation, l’énergie et la santé, et prend en charge le déploiement en périphérie des principaux grands modèles open source et de divers modèles visuels et vocaux. (Source: 量子位)

Huawei dévoile la technologie de haute disponibilité pour les clusters Ascend de dix mille cartes, atteignant une disponibilité d’entraînement de 98%: Huawei a révélé pour la première fois les détails de sa technologie de haute disponibilité pour les clusters de calcul Ascend de dix mille cartes. Grâce à trois capacités fondamentales – perception et diagnostic des pannes, gestion des pannes, et tolérance aux pannes des liaisons optiques du cluster – ainsi qu’à des capacités de support métier telles que l’optimisation de la linéarité du cluster et la récupération rapide de l’entraînement et de l’inférence, Huawei a atteint une disponibilité d’entraînement de 98% pour ses clusters de dix mille cartes, une linéarité supérieure à 95%, une récupération des pannes à la seconde près, et un diagnostic à la minute près. Ce système technologique à double dimension « 3+3 » vise à garantir le fonctionnement stable et efficace de l’entraînement et de l’inférence IA à grande échelle. (Source: 量子位)

Le taux de pénétration de la conduite intelligente des nouvelles voitures BYD atteint 79 %, le NOA sur autoroute devient une configuration courante: Les dernières données publiées par BYD montrent qu’en mai, parmi ses nouvelles voitures vendues, la proportion de modèles équipés de systèmes d’assistance à la conduite intelligente (possédant au moins les fonctions NOA sur autoroute et de stationnement automatique) a atteint 79 %. Cela indique que BYD a réalisé des progrès significatifs dans sa stratégie de « conduite intelligente pour tous », et que les fonctions de conduite intelligente deviennent rapidement une configuration standard pour ses modèles. Cette tendance reflète également l’accélération de la popularisation de la technologie de conduite intelligente sur le marché automobile chinois. (Source: 量子位)

La fonctionnalité vocale avancée de ChatGPT est déployée pour tous les utilisateurs payants: OpenAI a annoncé que la fonctionnalité vocale avancée de ChatGPT (Advanced Voice), précédemment mise à jour avec une naturalité accrue, est désormais disponible pour tous les utilisateurs payants (ChatGPT Plus, Team, Enterprise). Les utilisateurs peuvent interagir vocalement de manière plus naturelle avec ChatGPT grâce à cette fonctionnalité. (Source: juberti)
🧰 Outils
Lancement du navigateur Genspark AI, intégrant de multiples fonctions d’agents IA: L’équipe d’Eric Jing a lancé le navigateur Genspark AI, affirmant l’avoir développé en 10 semaines avec une équipe de 24 personnes. Il intègre 8 produits majeurs : navigateur IA, secrétaire IA, appels personnels IA, agent de téléchargement IA, AI Drive, AI Sheets, etc. Ce navigateur met l’accent sur la rapidité, le blocage des publicités, une agentification complète, un mode de pilotage automatique, et intègre un magasin MCP et des super-agents, visant à offrir une expérience de navigation et de travail assistée par IA centralisée. (Source: blader)
Yutori AI lance la plateforme Scouts pour la surveillance de réseaux d’agents IA: Yutori AI a lancé la plateforme Scouts, permettant aux utilisateurs de créer des agents IA constamment en ligne pour surveiller des mises à jour d’informations spécifiques sur le web. Ces agents peuvent suivre divers contenus intéressant les utilisateurs, tels que des actualités de niche, des variations de prix de produits, des informations sur la billetterie, etc., et alerter les utilisateurs par e-mail aux moments clés, visant à libérer les utilisateurs grâce au suivi automatisé de l’information. (Source: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face lance AISheets, combinant modèles IA et tableurs: Hugging Face a lancé AISheets, une application qui combine des milliers de modèles d’IA (en particulier des LLM open source) avec les fonctionnalités d’un tableur. Les utilisateurs peuvent construire, analyser et automatiser le traitement des données dans AISheets, visant à offrir une expérience de traitement de données fluide, rapide et simple, enrichie par l’IA. (Source: ben_burtenshaw, LoubnaBenAllal1)
PLaMo publie un outil CLI de traduction locale basé sur MLX: L’équipe PLaMo LLM a mis en open source un outil d’interface en ligne de commande (CLI) qui permet la traduction de texte en local sur les Mac équipés d’Apple Silicon en utilisant le framework MLX. Cet outil vise à offrir une expérience de traduction locale rapide et de haute précision, et intègre des serveurs et clients HTTP et MCP pour faciliter l’intégration avec d’autres applications compatibles MCP (comme Claude Desktop). (Source: awnihannun)
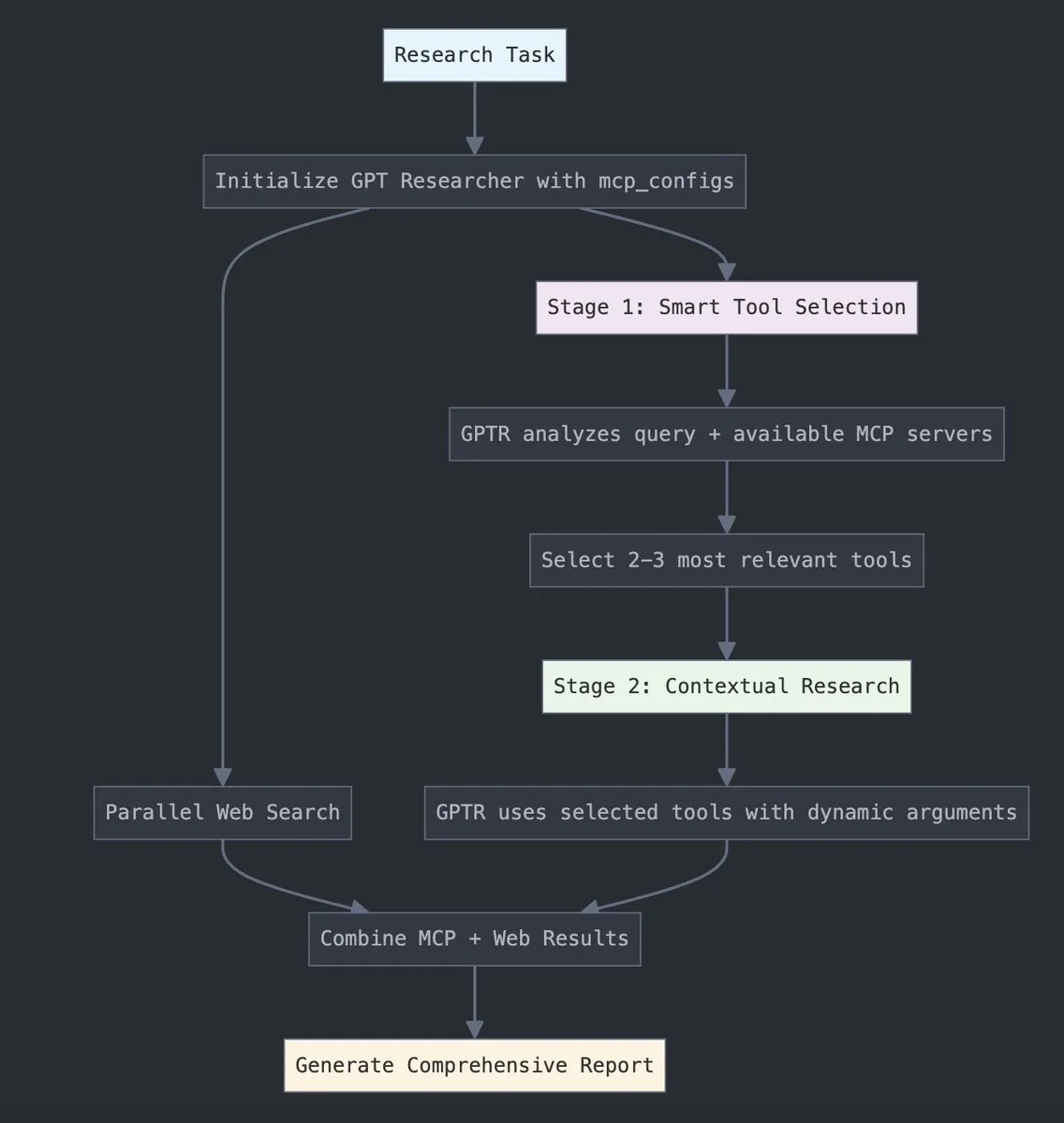
GPT Researcher intègre l’adaptateur MCP de LangChain, améliorant la sélection d’outils et les capacités de recherche: GPT Researcher utilise désormais l’adaptateur de protocole de contexte de modèle (MCP) de LangChain pour permettre une sélection d’outils et des processus de recherche plus intelligents. Cette initiative vise à combiner les avantages du MCP avec les capacités de recherche sur le web pour une collecte et une analyse de données plus complètes. (Source: Hacubu)
Consilium : Lancement d’un framework open source de collaboration multi-agents: Victor M a lancé Consilium, un framework open source pour la collaboration d’équipes d’agents IA. Les utilisateurs peuvent définir des stratégies, laisser plusieurs agents experts débattre, et utiliser des recherches en temps réel (web, arXiv, données SEC) pour résoudre conjointement des problèmes complexes et parvenir à un consensus. Une démo de cet outil est disponible sur Hugging Face. (Source: clefourrier)
youtube-transcript-api : une bibliothèque Python pour obtenir les sous-titres YouTube, avec traduction et génération automatique de contenu: La bibliothèque Python youtube-transcript-api développée par jdepoix gagne en popularité sur GitHub. Cette API permet de récupérer les sous-titres des vidéos YouTube, y compris les sous-titres générés automatiquement, et prend en charge la traduction. Contrairement à d’autres solutions basées sur Selenium, elle ne nécessite pas de clé API ni de navigateur sans tête, offrant aux développeurs un moyen pratique d’extraire le contenu textuel des vidéos. (Source: GitHub Trending)
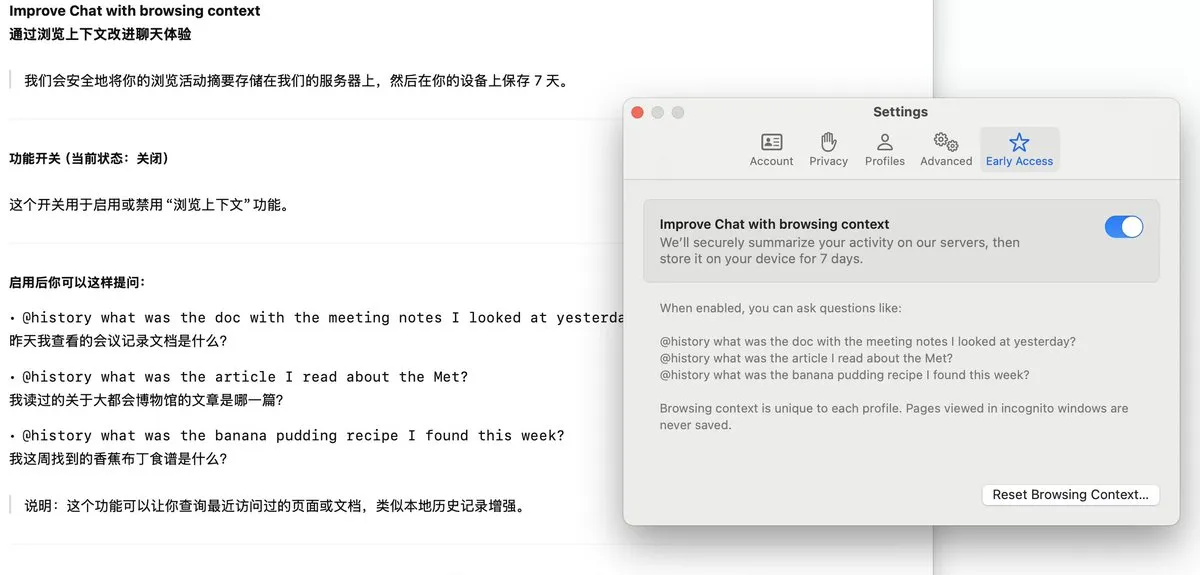
Le navigateur Arc lance la fonction Dia, enregistrant l’historique de navigation et prenant en charge les questions-réponses IA: Le navigateur Arc a ajouté une nouvelle fonction, Dia, qui, une fois activée, enregistre en continu tout l’historique de navigation de l’utilisateur. Grâce à la fonction @History, les utilisateurs peuvent poser des questions en langage naturel vague pour retrouver des informations consultées précédemment dont ils ont oublié l’URL exacte. Cette fonction pourrait même prendre en charge la génération de rapports d’historique de navigation, améliorant l’intelligence et la capacité de gestion personnalisée des informations du navigateur. (Source: op7418)
📚 Apprentissage
Apple publie un article « L’illusion de la pensée », explorant les limites des capacités des LLM: L’équipe de recherche en apprentissage machine d’Apple a publié un article intitulé « The Illusion of Thinking » (L’illusion de la pensée), analysant les performances et les limites des grands modèles de langage (LLM) actuels sur des tâches de raisonnement complexes (comme la résolution du problème des Tours de Hanoï). Cet article a suscité un débat au sein de la communauté sur le niveau d’intelligence réel des LLM, et certains estiment que ce type de recherche est parfois utilisé comme prétexte pour retarder l’adoption de l’IA. Le modèle o3-pro d’OpenAI a par la suite résolu le problème des Tours de Hanoï soulevé dans l’article. (Source: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
Une nouvelle étude « Les agents généraux ont besoin de modèles du monde » explore la relation entre la généralisation des agents et les modèles prédictifs: Un nouvel article de recherche intitulé « General agents need world models » (Les agents généraux ont besoin de modèles du monde) indique que les agents généraux capables de généraliser à des tâches multi-étapes orientées vers un but doivent apprendre un modèle prédictif du monde. Ce modèle est encodé dans la politique de l’agent, et l’article prouve le lien direct entre la capacité de généralisation et la fidélité du modèle appris en interrogeant les choix de politique de l’agent pour des objectifs composites afin d’extraire les probabilités de transition de l’environnement. (Source: menhguin)

Un article explore le fine-tuning sensible aux concepts (CAFT) pour améliorer les performances des LLM: Un nouvel article intitulé « Improving large language models with concept-aware fine-tuning » (Améliorer les grands modèles de langage avec un fine-tuning sensible aux concepts) propose la méthode CAFT, qui améliore la compréhension des concepts par le modèle en permettant un fine-tuning avec prédiction multi-jetons. La recherche montre que CAFT obtient des gains de performance significatifs dans des tâches telles que l’encodage, les mathématiques, le résumé de texte, la génération moléculaire et la conception de protéines. Le code est disponible en open source sur GitHub. (Source: Reddit r/MachineLearning)
DeepLearning.AI lance un nouveau cours « Orchestrer les workflows des applications GenAI »: DeepLearning.AI d’Andrew Ng, en partenariat avec Astronomer, a lancé un nouveau cours de courte durée intitulé « Orchestrating Workflows for GenAI Applications » (Orchestrer les workflows pour les applications GenAI). Ce cours enseigne comment utiliser l’outil open source populaire Airflow 3.0 pour construire des pipelines GenAI fiables et transformer des prototypes Jupyter Notebook ou des scripts Python en workflows prêts pour la production. Le contenu couvre la décomposition des tâches, la planification, l’exécution parallèle, la récupération après échec et l’observabilité. (Source: AndrewYNg)
Article « Alignement mot à mot du texte, des images et des structures 3D » explorant les modèles autorégressifs multimodaux: Cette recherche propose un cadre LLM unifié visant à aligner le langage, les images et les scènes 3D structurées. L’article détaille les choix de conception clés pour atteindre un entraînement et des performances optimaux, y compris la représentation des données, les fonctions objectives spécifiques à chaque modalité, etc., et évalue ces aspects sur quatre tâches 3D fondamentales (rendu, reconnaissance, suivi d’instructions et questions-réponses) ainsi que sur plusieurs jeux de données. La recherche s’étend également à la reconstruction de formes d’objets 3D complexes via des encodages de formes quantifiés. (Source: HuggingFace Daily Papers)
Article « Squeeze3D » : Utilisation de modèles génératifs 3D pré-entraînés pour une compression neuronale extrême: Le framework Squeeze3D exploite les a priori implicites appris dans les modèles génératifs 3D pré-entraînés pour compresser considérablement les données 3D (maillages, nuages de points, champs de radiance). Il relie l’encodeur pré-entraîné à l’espace latent du modèle génératif via un réseau de mappage entraînable, compressant les modèles 3D en codes latents compacts, qui sont ensuite reconstruits par le modèle génératif lors de la décompression. Cette méthode, entraînée sur des données synthétiques sans nécessiter de jeux de données 3D réels, atteint des taux de compression allant jusqu’à 2187x pour les maillages texturés. (Source: HuggingFace Daily Papers)
Article « Frame Guidance » : Contrôle au niveau de l’image sans entraînement dans les modèles de diffusion vidéo: Cette recherche propose « Frame Guidance », une méthode permettant un contrôle au niveau de l’image dans les modèles de diffusion vidéo sans nécessiter d’entraînement. Grâce à un traitement simple de l’espace latent et à une nouvelle stratégie d’optimisation de l’espace latent, cette méthode permet de contrôler efficacement des signaux au niveau de l’image tels que les images clés, les références de style, les croquis ou les cartes de profondeur. Elle est applicable à diverses tâches telles que le guidage par images clés, la stylisation, la lecture en boucle, et est compatible avec n’importe quel modèle vidéo. (Source: HuggingFace Daily Papers)
Article « Biais géopolitiques dans les grands modèles de langage » révélant les positions nationales des modèles: Cette étude évalue les biais géopolitiques dans les LLM en analysant leur interprétation d’événements historiques présentés sous différentes perspectives nationales (américaine, britannique, soviétique, chinoise). Les chercheurs ont introduit un nouveau jeu de données contenant des descriptions neutres d’événements et des points de vue contrastés de chaque pays. Ils ont constaté que les LLM présentent des biais significatifs en faveur des récits de certains pays, et que de simples invites de débiaisement ont un effet limité. Ce travail fournit un cadre et un jeu de données pour de futures recherches sur les biais géopolitiques. (Source: HuggingFace Daily Papers)
Les dépôts de ressources Awesome Lists sont continuellement mis à jour, répertoriant divers sujets intéressants: Le projet GitHub awesome maintenu par sindresorhus est une méta-liste qui rassemble des « Awesome lists » sur divers sujets intéressants. Ces listes couvrent de nombreux domaines, allant des langages de programmation et plateformes de développement aux théories, livres, outils, etc., offrant aux développeurs et aux apprenants un riche index de ressources. (Source: GitHub Trending)
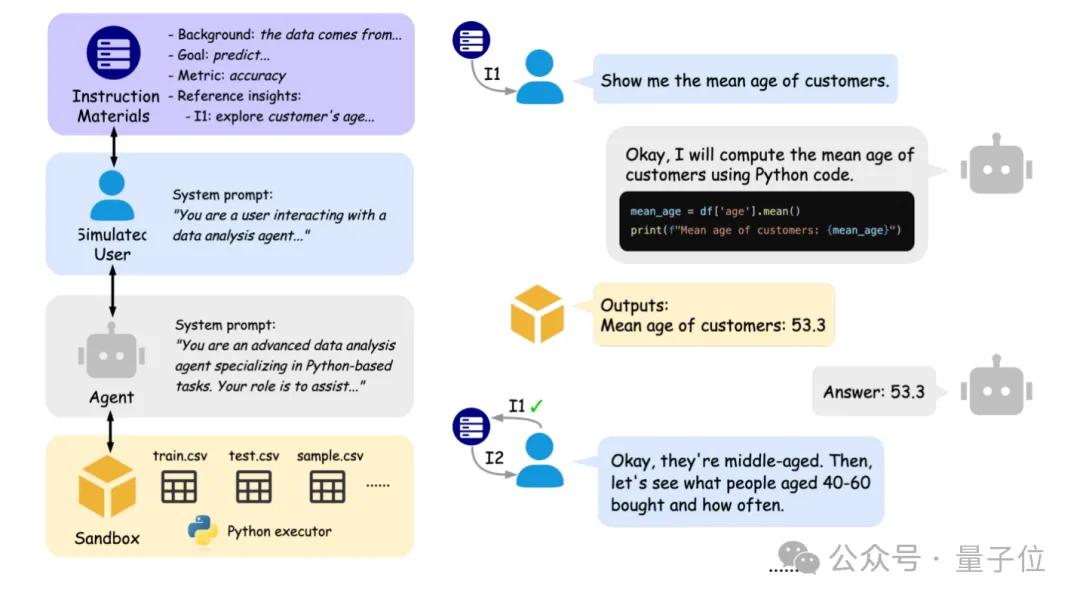
L’Université de Pékin et Berkeley lancent conjointement IDA-Bench pour évaluer la capacité d’interaction des agents d’analyse de données IA: Des équipes de recherche de l’Université de Pékin et de l’Université de Californie à Berkeley (dont le professeur Michael I. Jordan) ont lancé IDA-Bench, un nouveau benchmark visant à évaluer la capacité des grands modèles de langage (LLM) en tant qu’agents d’analyse de données (Agent) dans des scénarios d’interaction multi-tours. Ce benchmark simule le flux de travail réel des analystes de données, en examinant la capacité de l’Agent à suivre des instructions, à écrire et à exécuter du code via des instructions évolutives. Une évaluation préliminaire montre que même les meilleurs modèles comme Claude-3.7 et Gemini-2.5 Pro ont un taux de réussite inférieur à 40 %, révélant les défis actuels des Agents en matière d’interaction complexe et de suivi des instructions. (Source: 量子位)
💼 Affaires
xAI s’associe à Polymarket pour fusionner les prévisions de marché et l’analyse de Grok: xAI d’Elon Musk a annoncé un partenariat avec la plateforme de marchés prédictifs Polymarket. Les deux entités combineront les capacités de prévision de marché de Polymarket, les données de la plateforme X et les capacités d’analyse du modèle Grok, dans le but de créer un « moteur de vérité hardcore » (Hardcore truth engine) pour comprendre les facteurs qui façonnent le monde. Les responsables ont indiqué que ce n’était que le début de la collaboration et que d’autres développements suivraient. (Source: Yuhu_ai_)
UnslothAI reconnue par Redpoint comme une entreprise d’infrastructure de premier plan, son logo affiché sur l’écran du Nasdaq: La startup IA UnslothAI, pour sa contribution dans le domaine de l’infrastructure IA, a été classée par la société de capital-risque Redpoint parmi les 100 entreprises d’infrastructure les plus influentes et à la croissance la plus rapide pour l’année 2025. Son logo a ainsi été affiché sur l’écran électronique de la tour Nasdaq à New York. UnslothAI se concentre sur l’optimisation de l’efficacité de l’entraînement et de l’inférence des LLM. (Source: danielhanchen, karminski3)

Ant Digital fait évoluer son laboratoire Tianji pour se concentrer sur « l’IA + l’innovation industrielle »: Ant Digital a annoncé la transformation de son laboratoire Tianji, anciennement « Laboratoire de sécurité de l’identité numérique », en laboratoire « Intelligence Artificielle + Innovation Industrielle ». Le laboratoire amélioré se concentrera sur la recherche de percées technologiques clés dans l’application industrielle des grands modèles d’IA, en se positionnant sur quatre axes principaux : IA + Données, IA + Sécurité, IA + Finance et IA + Intelligence Incarnée. L’objectif est de promouvoir l’intégration profonde de la technologie IA et de l’industrie par une innovation collaborative entre la recherche, l’enseignement et les applications. (Source: 量子位)

🌟 Communauté
La capacité de conduite autonome de l’IA dans des environnements de trafic complexes suscite l’attention: Ronald van Loon a partagé une vidéo testant la conduite autonome dans le trafic chaotique de l’Inde, suscitant des discussions sur les capacités de perception, de décision et de contrôle de l’IA dans des environnements complexes et hautement dynamiques. De tels scénarios du monde réel posent des exigences extrêmement élevées en matière de robustesse et d’adaptabilité des systèmes de conduite autonome. (Source: Ronald_vanLoon)
Points saillants de la conférence AI Engineer World’s Fair : le protocole MCP, le coût des agents IA et les modèles locaux au centre des débats: Yogi et Shawn “swyx” Wang, entre autres, ont partagé les points essentiels de la conférence AI Engineer World’s Fair. Les tendances clés incluent : 1) Les agents IA sont l’avenir, l’unité d’interaction atomique sera l’appel d’agent ; 2) Le protocole de contexte de modèle (MCP) devient rapidement la norme, résolvant « l’enfer du copier-coller » et permettant à l’IA d’interagir directement avec des applications externes ; 3) La construction d’outils IA profondément optimisés pour des domaines et des flux de travail spécifiques (modèle Cursor-for-X) est cruciale ; 4) Le coût des modèles a considérablement baissé et les capacités des modèles locaux se sont améliorées, offrant aux développeurs un plus grand contrôle et des solutions à faible latence ; 5) L’IA évolue d’un outil d’assistance à un « coéquipier » pour les développeurs ; 6) L’ingénierie de l’IA passe de la phase de démonstration à celle des systèmes de production. (Source: swyx, TheTuringPost)
La communauté débat de l’itération rapide après la sortie d’o3-pro et de l’article d’Apple sur l’IA: andersonbcdefg a commenté avec humour que seulement 6 heures après la sortie d’o3-pro, la communauté semblait s’attendre à ce que quelqu’un réécrive fastText en Rust, et a ironisé sur les longs discours concernant la « superintelligence modérée », reflétant la rapidité de l’itération technologique dans le domaine de l’IA et les attentes élevées de la communauté. Parallèlement, Teknium1 a souligné qu’o3-pro a résolu le problème des Tours de Hanoï soulevé dans l’article d’Apple « L’illusion de la pensée », et s’est interrogé sur la raison pour laquelle Apple, dans un contexte de collaboration avec OpenAI, n’a pas d’abord procédé à une vérification interne avant de publier de tels articles, suscitant un débat au sein de la communauté sur les relations de concurrence et de coopération entre les entreprises technologiques. (Source: andersonbcdefg, Teknium1)
Discussion sur l’éthique et l’efficacité des applications de l’IA dans le monde réel: La communauté débat de l’efficacité et des questions éthiques liées à l’application de l’IA dans des scénarios spécifiques. Par exemple, Arvind Narayanan souligne que le concept même des applications de comptage de calories par IA est défectueux, car les informations issues des images sont insuffisantes pour estimer précisément les calories, considérant que ces applications servent davantage de « rituel » pour aider les utilisateurs à développer des habitudes alimentaires attentives. D’autre part, la question de savoir si l’utilisation d’images générées par IA pour la promotion commerciale (comme la présentation de plats dans un café) est éthique ou appropriée est également devenue un point de discussion, l’opinion générale étant que tant que ce n’est pas manifestement faux ou trompeur, cela constitue un moyen acceptable de réduire les coûts et d’améliorer l’efficacité. (Source: random_walker, Reddit r/artificial)
L’« humanisation » des LLM et l’expérience d’interaction utilisateur au centre des préoccupations: Les utilisateurs de la communauté Reddit discutent de la manière de rendre l’interaction avec les LLM plus semblable à celle avec de vrais humains, notamment en introduisant des hésitations, des pauses, des réponses plus courtes et des expressions imparfaites. Cela reflète le besoin des utilisateurs d’avoir des compagnons ou assistants IA plus naturels et moins « robotiques ». Parallèlement, certains utilisateurs se plaignent des formulations figées et des expressions exagérées (comme « Ce n’est pas seulement X, c’est Y ») couramment utilisées par les LLM actuels (comme ChatGPT), souhaitant des expressions plus concises et directes. Ces discussions soulignent les défis persistants des LLM pour simuler la conversation humaine et répondre aux besoins émotionnels des utilisateurs. (Source: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 Autres
Le PDG de NVIDIA, Jensen Huang, prononcera un discours liminaire au GTC Paris, axé sur la nouvelle phase du calcul IA: NVIDIA a annoncé que son PDG, Jensen Huang, prononcera un discours liminaire le 11 juin à la conférence GTC de Paris (pendant VivaTech 2025). Il devrait y dévoiler la prochaine phase du calcul IA, couvrant des sujets de pointe allant des systèmes d’agents aux usines d’IA. (Source: nvidia, nvidia)

Le Databricks Data+AI Summit présentera les dernières avancées: Databricks a annoncé que son Data+AI Summit réunira des experts de premier plan, des chercheurs et des contributeurs open source pour présenter les dernières avancées de l’entreprise dans les domaines des données et de l’IA, et partager les réussites d’entreprises innovantes. Le sommet propose une participation en ligne et sur place. (Source: matei_zaharia, lateinteraction)

L’éthique et l’impact environnemental de l’IA suscitent l’attention, vulgarisés sous forme de roman graphique: Le centre LEARN de l’EPFL (École Polytechnique Fédérale de Lausanne) et l’illustrateur Herji ont collaboré pour créer un roman graphique éducatif en français intitulé « Utop’IA ». L’œuvre vise à sensibiliser les adolescents à l’impact environnemental de l’intelligence artificielle par le biais d’une histoire, abordant sa consommation de ressources (énergie, eau, métaux rares) et ses bénéfices écologiques potentiels. Elle met l’accent sur la pensée critique et explore les voies d’un développement durable de l’IA. (Source: aihub.org)
