
Keywords:Meta, Scale AI, Superintelligence, AGI, Data Annotation, AI Training, Model Accuracy, Meta acquires Scale AI equity, Alexandr Wang leads Superintelligence team, AI data annotation accuracy 99.7%, Training data contamination rate reduced, Model training cycle shortened by 40%
🔥 Focus
Meta reportedly to invest nearly $15 billion for a stake in Scale AI, appointing its CEO to lead a new “Super Intelligence” team: Meta plans to acquire a 49% stake in AI data annotation and infrastructure company Scale AI for approximately $14.9 billion, and appoint its 28-year-old Chinese-American CEO Alexandr Wang to lead the newly formed “Super Intelligence Group.” This move aims to strengthen Meta’s competitiveness in the AI field, especially in high-quality training data and AGI R&D. Scale AI is known for its data annotation accuracy of up to 99.7% and is expected to reduce Meta model’s training data contamination rate from 15% to 2%, and shorten the training cycle by 40%. This acquisition is seen as a key step for Meta to catch up and attempt to surpass competitors in the AI race, also highlighting the core strategic position of data in AI development. (Source: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
OpenAI reportedly reaches large-scale computing power agreement with Google Cloud, possibly to reduce reliance on Microsoft: According to reports, OpenAI has reached a significant cloud service agreement with Google Cloud, under which Google Cloud will provide OpenAI with the computing power needed for its growing AI model training and deployment. Previously, Microsoft Azure was OpenAI’s main computing power supplier. This move may signal OpenAI’s effort to diversify its computing power sources to reduce dependence on a single supplier and meet its massive computational needs. This collaboration is a major win for Google Cloud, but it has also sparked discussions about how it will balance TPU resources between its own business and client demands. (Source: 36氪, scaling01)
Mistral AI releases inference model Magistral, sparking community questions about its benchmark transparency: French AI company Mistral AI has launched Magistral, its first model series designed specifically for inference, including the open-source 24B version Magistral Small and the enterprise-oriented Magistral Medium. Officially, it is designed for transparent, traceable multi-step logical reasoning and supports multiple languages. However, the community has questioned its published benchmark results, suggesting it may be “avoiding competition” by not comparing with the latest versions of competing models like Qwen and DeepSeek R1. Nevertheless, Magistral shows significant improvement over Mistral Medium 3 in the AIME-24 math benchmark. (Source: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Father of Reinforcement Learning Richard Sutton: LLM dominance is only temporary, scaling computation and experiential learning are the future: Turing Award winner and father of reinforcement learning, Richard Sutton, predicts that the current dominance of Large Language Models (LLMs) is temporary, and imitating human thinking only brings short-term performance improvements. He believes the future of AI lies in the “Age of Experience,” where agents learn by acquiring experiential data through first-person interaction with the world, rather than relying on static human data. Sutton emphasizes that reinforcement learning is the core path to this future, and combined with continuously learning deep learning algorithms and massively scaled computation, it will enable AI to break through existing cognitive limitations and achieve true innovation. (Source: 量子位)

Hugging Face partners with NVIDIA to launch “Training Cluster as a Service,” lowering the barrier to large model training: Hugging Face announced a partnership with NVIDIA to launch “Training Cluster as a Service,” aiming to make large GPU cluster resources more accessible for research institutions worldwide to train various cutting-edge models. The service integrates NVIDIA DGX Cloud Lepton and Hugging Face’s development resources, allowing organizations to request and pay for GPU cluster usage time on demand. This initiative aims to bridge the “GPU divide,” promoting diversity and democratization in AI research, and has already seen early adoption by research institutions and startups like TIGEM, Numina, and Mirror Physics. (Source: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 Trends
OpenAI releases o3-pro model and significantly reduces o3 API prices: OpenAI has launched its new top-tier inference model, o3-pro, and has made it available to ChatGPT Pro users and API users. Simultaneously, the API price for the o3 model has been drastically reduced by 80%, and the o3 rate limit for ChatGPT Plus users has been doubled. Community feedback indicates that o3-pro outperforms Claude Opus 4 on non-code tasks and has set new records in several benchmarks such as Extended NYT Connections and Creative Short Story Writing, even successfully solving the “Tower of Hanoi 10-disk problem” previously questioned in an Apple paper regarding LLM capabilities. However, some users have reported that o3-pro is relatively slow. OpenAI stated that the o3 price reduction was not achieved through distillation or quantization but through the optimization efforts of inference engineers. (Source: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB releases MiniCPM4 series of efficient on-device LLMs: OpenBMB has launched the MiniCPM4 series of models, designed specifically for on-device applications, claiming over 5x generation acceleration on typical on-device chips. The series includes MiniCPM4-8B, MiniCPM4-0.5B, and ternarily quantized versions BitCPM4-1B/0.5B. MiniCPM4 employs a trainable sparse attention mechanism, InfLLM v2, supporting 128K long-text processing, and incorporates efficient learning algorithms and training techniques such as Model Wind Tunnel 2.0, BitCPM ternary quantization, FP8 low-precision computation, and multi-token prediction. Concurrently, high-quality Chinese-English pre-training dataset UltraFineweb and supervised fine-tuning dataset UltraChat v2 were also released. (Source: GitHub Trending)
MSRA and Tsinghua/Peking University scholars propose new Reinforcement Pre-Training (RPT) paradigm: Researchers from Microsoft Research Asia (MSRA), in collaboration with Tsinghua University and Peking University, have proposed a new LLM pre-training paradigm called Reinforcement Pre-Training (RPT). This method deeply integrates reinforcement learning (RL) into the pre-training phase, where the model generates chain-of-thought reasoning sequences before predicting each token and receives rewards based on the correctness of the prediction. RPT aims to shift models from learning superficial token correlations to understanding deeper meanings. Experiments show that a 14B model trained with RPT can match or even surpass a 32B traditionally pre-trained model on certain reasoning tasks, demonstrating significant potential in enhancing LLM language modeling and reasoning capabilities. (Source: 量子位, omarsar0)

Meta releases V-JEPA 2 video world model and new benchmarks: Meta AI has introduced V-JEPA 2, a 1.2 billion parameter world model trained on video data, aimed at enhancing machines’ understanding and prediction of the physical world. The model can play a role in robot zero-shot planning, enabling them to plan and execute tasks in unfamiliar environments. Concurrently, Meta also released three new benchmarks for evaluating existing models’ ability to reason about the physical world from video. HuggingFace has provided transformers library support for V-JEPA 2. (Source: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance releases Seedance 1.0 Pro video generation model, now live on Doubao App: ByteDance has launched its latest video generation model, Seedance 1.0 Pro (also known as the Video 3.0 Pro model in Dream Engine). The model excels in prompt understanding, image detail, and physical consistency, capable of generating 5-second 1080P videos. Currently, the model is available to enterprise users via Volcano Engine and has been integrated into the Doubao App’s “Animate Photo” feature for free user experience. (Source: op7418)
Huawei launches “Digital Wind Tunnel” simulation platform to optimize AI training and inference efficiency: Huawei’s Markov modeling and simulation team has unveiled its “Digital Wind Tunnel” technology for the first time, a platform for virtual environment “rehearsals” before actual training and inference of complex AI models. The platform includes three major modules: Sim2Train (training simulation), Sim2Infer (inference simulation), and Sim2Availability (high-availability simulation). It aims to address issues like hardware resource mismatch and system coupling through simulation and automatic optimization, thereby enabling hour-level previews of ten-thousand-card cluster solutions, avoiding wasted computing power, and enhancing the efficiency and stability of AI large model training and inference. (Source: 量子位)

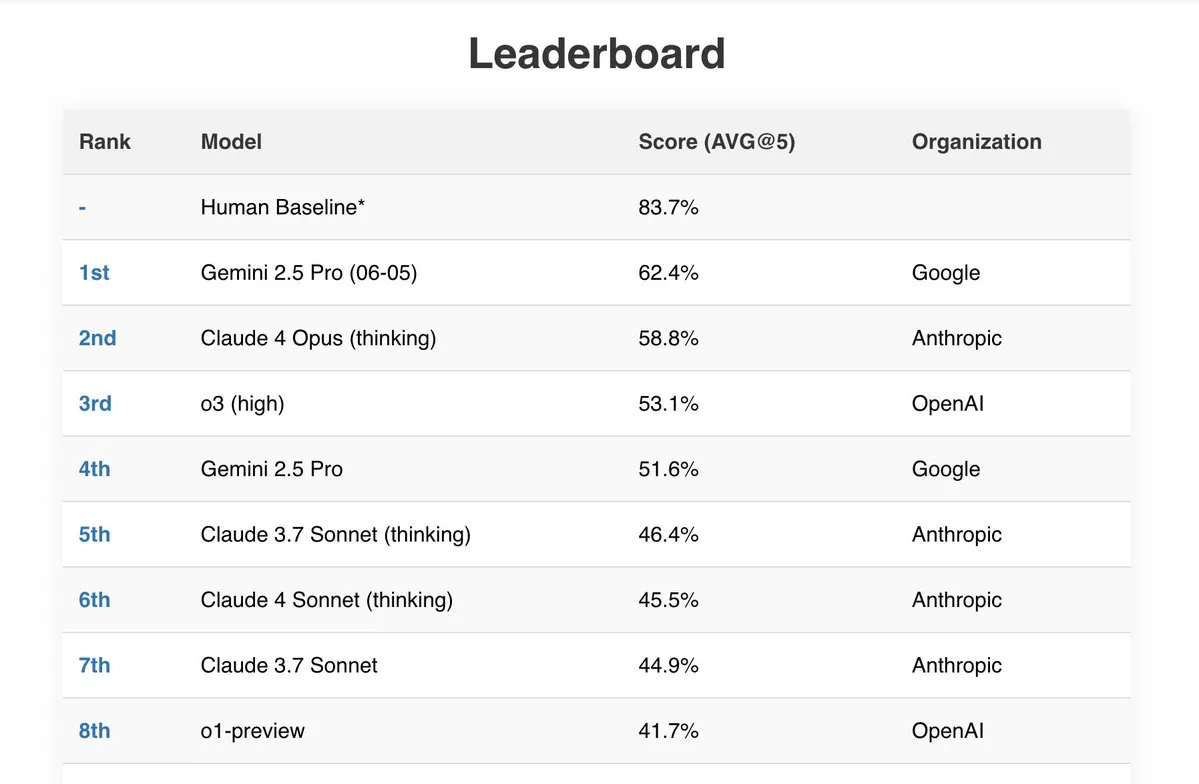
Gemini 2.5 Pro performs excellently in multiple benchmarks: Google’s latest Gemini 2.5 Pro (06-05) model has shown outstanding performance on several public AI leaderboards. It performed best in the Live Fiction test handling 192k tokens, ranked first on SimpleBench with a score of 62.4%, and demonstrated strong document processing capabilities and cost-effectiveness in benchmarks like IDP (Intelligent Document Processing) and Aider (AI-assisted coding). Additionally, a user reported that Gemini 2.5 Pro successfully solved all problems in the JEE Advanced 2025 mathematics section. (Source: _philschmid, dilipkay)
Kling AI video model updates lip-sync feature, supports character selection and editing: Kuaishou’s AI video generation tool, Kling AI, recently updated its Lip-sync feature. The new function allows users to select specific characters in the generated video for lip matching and adjust the timing of audio and mouth shape synchronization. This update enhances Kling AI’s flexibility and realism in creating multi-character dialogue videos, marking an important advancement in the field of video generation. (Source: Kling_ai, Kling_ai)
Delta Lake 4.0.0 released, enhancing Lakehouse capabilities: Delta Lake 4.0.0 has been officially released, bringing several important new features, including a preview of Catalog-Managed Tables for unified governance and discoverability, Delta Connect extensions for Spark Connect, support for Variant data types to handle semi-structured data, and an immediate DROP FEATURE functionality that allows removing table features without truncating history or downtime. This release aims to enhance the experience for the open lakehouse community. (Source: matei_zaharia)

Hugging Face launches MCP server to simplify model and tool interaction: Hugging Face has released the first version of its Model Context Protocol (MCP) server. Users can now leverage this server via http://hf.co/mcp in applications like Claude or Cursor to search for models, datasets, papers, applications, or specific information. This marks an important step for Hugging Face in promoting interoperability between tools and models in the AI ecosystem, potentially expanding to functions like uploading, downloading, and initiating PRs in the future. (Source: clefourrier, ClementDelangue)

Baidu launches “AI Camera” integrating storage and intelligent management, upgrades GenFlow Super Assistant 2.0: Baidu Netdisk and Baidu Wenku jointly released the “AI Camera” feature, integrating photo-taking, cloud storage, and intelligent management. Photos can be automatically archived to a cloud album and support intelligent classification and retrieval through natural language descriptions. The AI Camera also features beautification, object recognition for popular science, doodle generation, receipt scanning, handwritten form conversion, and other AI capabilities. Simultaneously, the multi-agent collaboration platform “GenFlow Super Assistant” has been upgraded to version 2.0, offering deeper integration with user data and habits to provide personalized content generation services. (Source: 量子位)

ByteDance open-sources SeedVR2 video restoration model code and weights: The ByteDance SEED team has released the inference code and model weights for its one-step video restoration model, SeedVR2, now available on Hugging Face. The model utilizes diffusion adversarial post-training technology and has achieved significant results in video restoration, particularly excelling in high-resolution video processing. (Source: _akhaliq)
GroqCloud launches Qwen3-32B model, supporting over 100 languages and 131k context: Groq announced the launch of the Qwen3-32B model from Tongyi Qianwen on its LPU inference hardware cloud platform, GroqCloud. The model supports over 100 languages and dialects, boasts a 131k context window, and runs at Groq hardware’s characteristic real-time speed, providing developers with powerful multilingual and long-text processing capabilities. (Source: JonathanRoss321)
OpenAI CEO Sam Altman says its open-weight model release will be delayed: Sam Altman stated that OpenAI’s open-weight model release will be postponed until late summer this year, instead of the originally planned June. He revealed that the research team has made some “unexpected and very surprising” progress that is worth waiting for but requires more time for refinement. (Source: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

Digua Robot releases RDK S100 development kit, single SoC integrates cerebrum-cerebellum architecture: Digua Robot has launched the industry’s first single-SoC computing and control integrated robot development kit, RDK S100. The kit adopts a human-like cerebrum-cerebellum super-heterogeneous collaborative architecture design (6-core Arm Cortex-A78AE CPU + 80 TOPS BPU as the “cerebrum,” 4-core Arm Cortex-R52+ MCU as the “cerebellum”), supporting efficient collaboration of large and small models for embodied intelligence and completing the “perception-decision-control” closed loop. RDK S100 offers rich interfaces and full-stack development infrastructure, with a pre-sale price of 2499 yuan. (Source: 量子位)

AIBook Smart releases E300 AI computing module, equipped with 50TOPS domestic SoC: AIBook Smart has launched the E300 AI computing module for edge scenarios, equipped with its self-developed AI SoC chip AB100. The module provides up to 50TOPS of INT8 computing power, supports FP16/FP32 mixed-precision computing, and is equipped with 102GB/s LPDDR5 memory bandwidth. The E300 adopts a modular design, aiming to provide high-performance, low-latency, and highly reliable domestic edge AI solutions for industries such as education, energy, and healthcare, supporting mainstream open-source large models and various visual and speech models for edge deployment. (Source: 量子位)

Huawei discloses Ascend 10,000-card cluster high-availability technology, achieving 98% training availability: Huawei has publicly disclosed for the first time the details of its Ascend 10,000-card computing cluster’s high-availability technology. Through three fundamental capabilities—fault perception and diagnosis, fault management, and cluster optical link fault tolerance—along with business support capabilities like cluster linearity optimization and rapid recovery for training and inference, Huawei has achieved 98% training availability for its 10,000-card cluster, with linearity exceeding 95%, fault recovery at the second level, and diagnosis at the minute level. This “3+3” dual-dimensional technology system aims to ensure the stable and efficient operation of large-scale AI training and inference. (Source: 量子位)

BYD’s new car intelligent driving penetration rate reaches 79%, highway NOA becomes mainstream configuration: According to the latest data released by BYD, 79% of its new cars sold in May were equipped with intelligent assisted driving systems (at least featuring highway NOA and automatic parking). This indicates that BYD has made significant progress in promoting its “intelligent driving for all” strategy, and intelligent driving functions are rapidly becoming standard configurations for its models. This trend also reflects the accelerating pace of intelligent driving technology popularization in the Chinese automotive market. (Source: 量子位)

ChatGPT Advanced Voice feature rolls out to all paid users: OpenAI announced that the previously updated ChatGPT Advanced Voice feature, with enhanced naturalness, has been rolled out to all paid users (ChatGPT Plus, Team, Enterprise). Users can engage in more natural voice interactions with ChatGPT through this feature. (Source: juberti)
🧰 Tools
Genspark AI browser released, integrating multiple AI agent functions: Eric Jing’s team has released the Genspark AI browser, reportedly built by a team of 24 in 10 weeks, integrating 8 major products including AI browser, AI secretary, AI personal calls, AI download agent, AI Drive, and AI Sheets. The browser emphasizes speed, ad-blocking, full agent capabilities, autonomous driving mode, and has a built-in MCP store and super agent, aiming to provide a one-stop AI-assisted browsing and work experience. (Source: blader)
Yutori AI launches Scouts platform for AI agent network monitoring: Yutori AI has released the Scouts platform, allowing users to create continuously online AI agents to monitor specific information updates on the web. These agents can track various content of interest to users, such as niche news, product price changes, ticket information, etc., and alert users via email at critical moments, aiming to free users through automated information tracking. (Source: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face launches AISheets, combining AI models with spreadsheets: Hugging Face has released AISheets, an application that combines thousands of AI models (especially open-source LLMs) with spreadsheet functionality. Users can build, analyze, and automate data processing in AISheets, aiming to provide a smooth, fast, and simple AI-empowered data processing experience. (Source: ben_burtenshaw, LoubnaBenAllal1)
PLaMo releases local translation CLI tool based on MLX: The PLaMo LLM team has open-sourced a command-line interface (CLI) tool that enables local text translation on Macs with Apple Silicon using the MLX framework. The tool aims to provide a fast, high-accuracy local translation experience and includes built-in HTTP and MCP servers and clients for easy integration with other MCP-compatible applications (like Claude Desktop). (Source: awnihannun)
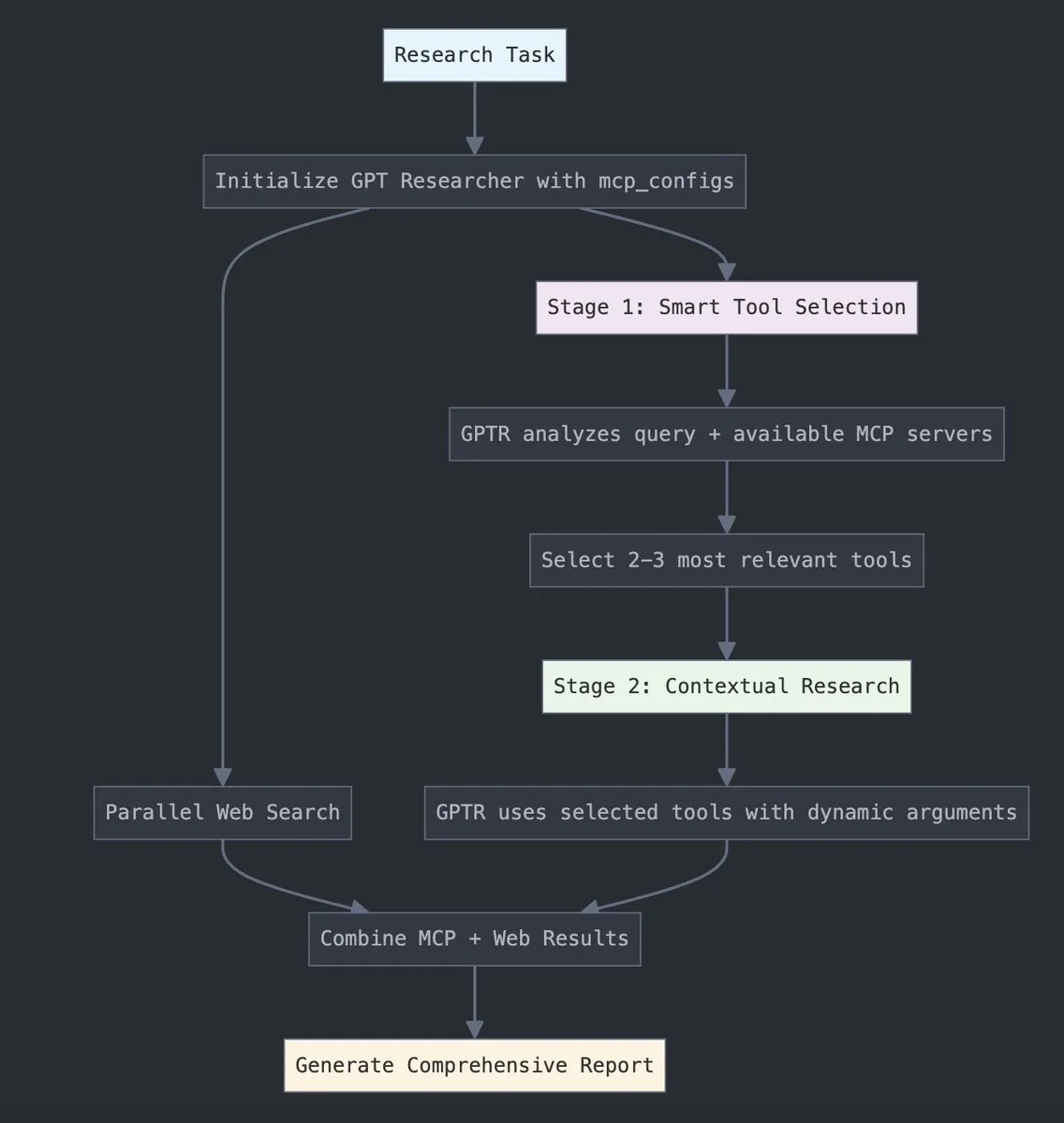
GPT Researcher integrates LangChain MCP adapter for enhanced tool selection and research capabilities: GPT Researcher now utilizes LangChain’s Model Context Protocol (MCP) adapter to achieve more intelligent tool selection and research workflows. This move aims to combine the advantages of MCP with web search capabilities for more comprehensive data collection and analysis. (Source: Hacubu)
Consilium: Open-source multi-agent collaboration framework released: Victor M has launched Consilium, an open-source AI agent team collaboration framework. Users can set strategies, have multiple expert agents debate, and utilize real-time research (web, arXiv, SEC data) to collaboratively solve complex problems and reach consensus. A demo of the tool is available on Hugging Face. (Source: clefourrier)
youtube-transcript-api: Python library to fetch YouTube subtitles, supports translation and auto-generated content: The Python library youtube-transcript-api, developed by jdepoix, is gaining attention on GitHub. The API can fetch subtitles for YouTube videos, including auto-generated ones, and supports translation. Unlike other Selenium-based solutions, it does not require an API key or a headless browser, providing developers with a convenient way to extract video text content. (Source: GitHub Trending)
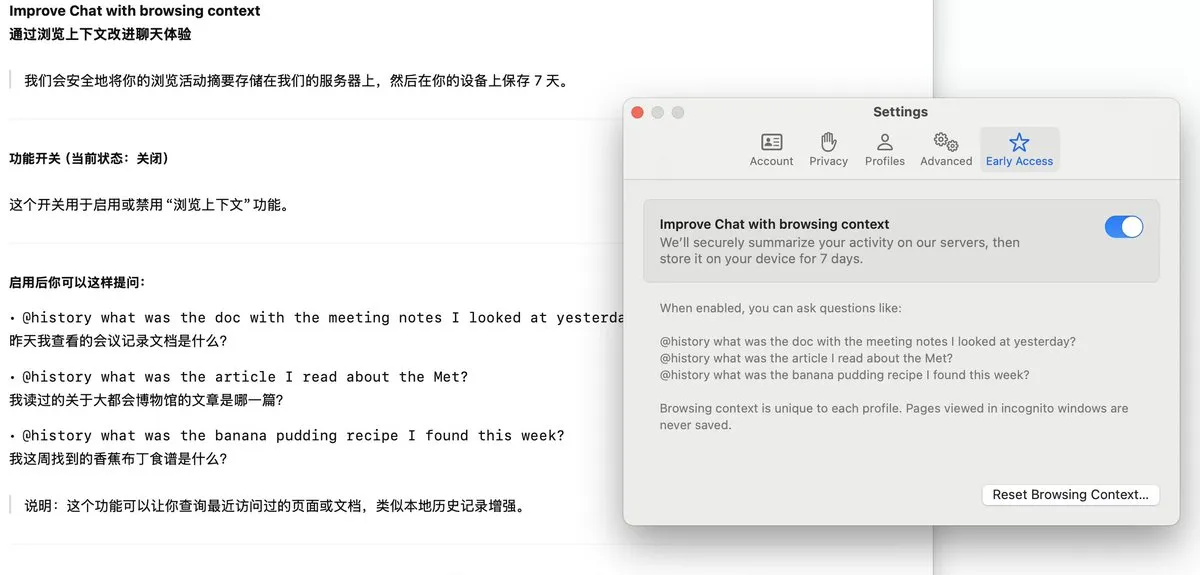
Arc browser launches Dia feature to record browsing history and support AI Q&A: Arc browser has added a new feature called Dia, which, when enabled, continuously records all of the user’s browsing history. Users can use the @History function to find information they once browsed but forgot the specific URL for, using vague natural language queries. The feature may even support generating browsing history reports, enhancing the browser’s intelligence and personalized information management capabilities. (Source: op7418)
📚 Learning
Apple releases paper “The Illusion of Thinking,” exploring LLM capability boundaries: Apple’s Machine Learning Research team published the paper “The Illusion of Thinking,” analyzing the performance and limitations of current Large Language Models (LLMs) on complex reasoning tasks, such as solving the Tower of Hanoi problem. The paper sparked community discussion about the true intelligence level of LLMs, with some arguing that such research is sometimes used as a reason to delay AI adoption. OpenAI’s o3-pro model subsequently solved the Tower of Hanoi puzzle presented in the paper. (Source: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
New study “General agents need world models” explores the relationship between agent generalization and predictive models: A new research paper titled “General agents need world models” posits that general agents capable of generalizing to multi-step goal-oriented tasks must learn a predictive world model. This model is encoded within the agent’s policy, and the paper demonstrates a direct link between generalization ability and the fidelity of the learned model by querying the agent’s policy choices under composite goals to extract environment transition probabilities. (Source: menhguin)

Paper explores Concept-Aware Fine-Tuning (CAFT) to enhance LLM performance: A new paper, “Improving large language models with concept-aware fine-tuning,” proposes the CAFT method, which improves model understanding of concepts by enabling multi-token prediction during fine-tuning. Research shows that CAFT achieves significant performance gains in tasks such as coding, mathematics, text summarization, molecular generation, and protein design. The code has been open-sourced on GitHub. (Source: Reddit r/MachineLearning)
DeepLearning.AI launches new course “Orchestrating Workflows for GenAI Applications”: Andrew Ng’s DeepLearning.AI, in collaboration with Astronomer, has launched a new short course titled “Orchestrating Workflows for GenAI Applications.” The course teaches how to build reliable GenAI pipelines using the popular open-source tool Airflow 3.0, transforming prototype Jupyter Notebooks or Python scripts into production-ready workflows. Content covers task decomposition, scheduling, parallel execution, fault recovery, and observability. (Source: AndrewYNg)
Paper “Token-by-Token Alignment of Text, Images, and 3D Structures” explores multimodal autoregressive models: This research proposes a unified LLM framework aimed at aligning language, images, and structured 3D scenes. The paper details key design choices for achieving optimal training and performance, including data representation, modality-specific objective functions, and evaluates them on four core 3D tasks (rendering, recognition, instruction following, and Q&A) across multiple datasets. The research also extends to reconstructing complex 3D object shapes via quantized shape encoding. (Source: HuggingFace Daily Papers)
Paper “Squeeze3D”: Extreme Neural Compression Leveraging Pre-trained 3D Generative Models: The Squeeze3D framework utilizes implicit priors learned in pre-trained 3D generative models to drastically compress 3D data (meshes, point clouds, radiance fields). It connects the pre-trained encoder and the generative model’s latent space via a trainable mapping network, compressing 3D models into compact latent codes, which are then reconstructed by the generative model during decompression. Trained on synthetic data without requiring real 3D datasets, this method achieves up to 2187x compression for textured meshes. (Source: HuggingFace Daily Papers)
Paper “Frame Guidance”: Training-Free Frame-Level Control in Video Diffusion Models: This research introduces “Frame Guidance,” a training-free method for achieving frame-level control in video diffusion models. Through simple latent space manipulation and a novel latent space optimization strategy, the method effectively controls frame-level signals such as keyframes, style references, sketches, or depth maps. It is applicable to various tasks like keyframe guidance, stylization, and looping, and is compatible with any video model. (Source: HuggingFace Daily Papers)
Paper “Geopolitical Biases in Large Language Models” reveals model national stances: This study assesses geopolitical biases in LLMs by analyzing their interpretations of historical events from different national perspectives (US, UK, Soviet, Chinese). Researchers introduced a new dataset containing neutral event descriptions and contrasting national viewpoints, finding that LLMs exhibit significant biases favoring specific national narratives, and simple de-biasing prompts have limited effect. This work provides a framework and dataset for future research on geopolitical bias. (Source: HuggingFace Daily Papers)
Awesome Lists repository continuously updated, collecting various interesting topics: The GitHub project awesome maintained by sindresorhus is a meta-list that curates “Awesome lists” on various interesting topics. These lists cover a wide range of areas from programming languages, development platforms to theories, books, tools, and more, providing a rich resource index for developers and learners. (Source: GitHub Trending)
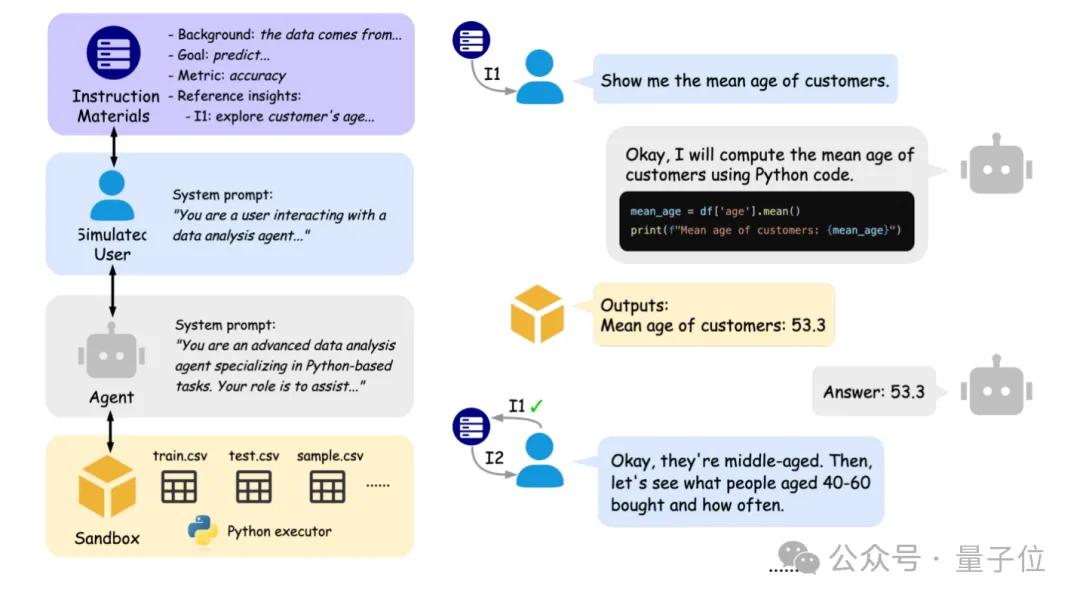
Peking University and UC Berkeley jointly launch IDA-Bench to evaluate AI data analysis agent interaction capabilities: A research team from Peking University and the University of California, Berkeley (including Professor Michael I. Jordan) has launched IDA-Bench, a new benchmark designed to evaluate the capabilities of Large Language Models (LLMs) as data analysis agents in multi-turn interactive scenarios. The benchmark simulates the workflow of real data analysts, examining the agent’s ability to follow instructions, write and execute code through progressively evolving instructions. Preliminary evaluations show that even top models like Claude-3.7 and Gemini-2.5 Pro have task success rates below 40%, exposing current agents’ challenges in complex interaction and instruction following. (Source: 量子位)
💼 Business
xAI partners with Polymarket, merging market predictions with Grok analysis: Elon Musk’s xAI announced a partnership with prediction market platform Polymarket. The collaboration will combine Polymarket’s market prediction capabilities, X platform data, and Grok model’s analytical power, aiming to create a “Hardcore truth engine” to gain insights into factors shaping the world. Officials stated this is just the beginning of the collaboration, with more developments to come. (Source: Yuhu_ai_)
UnslothAI recognized by Redpoint as a top infrastructure company, featured on Nasdaq screen: AI startup UnslothAI was named one of the 100 most impactful and fastest-growing infrastructure companies of 2025 by venture capital firm Redpoint for its contributions to AI infrastructure. Its logo was consequently displayed on the electronic screen of the Nasdaq building in New York. UnslothAI focuses on optimizing LLM training and inference efficiency. (Source: danielhanchen, karminski3)

Ant Digital upgrades Tianji Laboratory, focusing on “AI + Industrial Innovation”: Ant Digital announced the upgrade of its Tianji Laboratory from the original “Digital Identity Security Laboratory” to an “AI + Industrial Innovation” laboratory. The upgraded lab will focus on key technological breakthroughs in the industrial application of AI large models, with a layout in four major directions: AI + Data, AI + Security, AI + Finance, and AI + Embodied Intelligence. It aims to promote the deep integration of AI technology and industry through collaborative innovation across industry, academia, research, and application. (Source: 量子位)

🌟 Community
AI’s autonomous driving capabilities in complex traffic environments draw attention: Ronald van Loon shared a video testing autonomous driving in chaotic Indian traffic, sparking discussions about AI’s perception, decision-making, and control capabilities in complex, highly dynamic environments. Such real-world scenarios pose extremely high demands on the robustness and adaptability of autonomous driving systems. (Source: Ronald_vanLoon)
AI Engineer World’s Fair highlights: MCP protocol, AI agent costs, and local models take center stage: Yogi and Shawn “swyx” Wang, among others, shared key takeaways from the AI Engineer World’s Fair. Core trends include: 1) AI agents are the future, with agent calls being the atomic unit of interaction; 2) The Model Context Protocol (MCP) is rapidly becoming a standard, solving the “copy-paste hell” and enabling AI to interact directly with external applications; 3) Building deeply optimized AI tools for specific domains and workflows (Cursor-for-X pattern) is key; 4) Model costs are dropping significantly, and local model capabilities are enhancing, giving developers greater control and low-latency solutions; 5) AI is evolving from an assistive tool to a developer’s “teammate”; 6) AI engineering is moving from demo stage to production-grade systems. (Source: swyx, TheTuringPost)
Community discusses rapid iteration after o3-pro release and Apple’s AI paper: andersonbcdefg humorously commented that just 6 hours after o3-pro’s release, the community seemed to expect someone to rewrite fastText in Rust, satirizing lengthy discussions about “mild superintelligence,” reflecting the rapid pace of technological iteration in AI and high community expectations. Meanwhile, Teknium1 pointed out that o3-pro solved the Tower of Hanoi puzzle from Apple’s “The Illusion of Thinking” paper, questioning why Apple, given its collaboration with OpenAI, didn’t conduct internal validation before publishing such a paper, sparking community discussion on the competitive and cooperative relationships between tech companies. (Source: andersonbcdefg, Teknium1)
Ethical and effectiveness discussions on AI in real-world applications: The community discussed the effectiveness and ethical issues of AI applications in specific scenarios. For example, Arvind Narayanan pointed out that AI calorie counting apps are inherently flawed, as image information is insufficient for accurate calorie estimation, suggesting they primarily serve as a “ritual” to help users build dietary awareness. Additionally, the ethics and appropriateness of using AI-generated images for commercial promotion (e.g., coffee shop menu displays) became a point of discussion, with the general consensus being that it is an acceptable cost-saving and efficiency-enhancing method as long as it is not overtly false or misleading. (Source: random_walker, Reddit r/artificial)
“Humanization” of LLMs and user interaction experience become focal points: Reddit community users discussed how to make LLM interactions more human-like, including introducing hesitation, pauses, shorter replies, and imperfect expressions. This reflects users’ desire for more natural, less “robotic” AI companions or assistants. Concurrently, some users complained about current LLMs (like ChatGPT) using fixed sentence patterns and exaggerated expressions (e.g., “It’s not just X, it’s Y”), wishing for more concise and direct communication. These discussions point to the ongoing challenges for LLMs in simulating human conversation and meeting users’ emotional needs. (Source: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 Others
NVIDIA CEO Jensen Huang to deliver keynote at GTC Paris, focusing on new phase of AI computing: NVIDIA announced that its CEO Jensen Huang will deliver a keynote speech on June 11th at the GTC conference in Paris (during VivaTech 2025). He is expected to unveil the next phase of AI computing, covering cutting-edge topics from agentic systems to AI factories. (Source: nvidia, nvidia)

Databricks Data+AI Summit to showcase latest breakthroughs: Databricks announced that its Data+AI Summit will bring together top experts, researchers, and open-source contributors to showcase the company’s latest breakthroughs in data and AI, and share success stories from innovative companies. The summit offers both online and in-person participation. (Source: matei_zaharia, lateinteraction)

AI’s ethical and environmental impact draws attention, popularized in graphic novel format: EPFL’s (Swiss Federal Institute of Technology Lausanne) LEARN center, in collaboration with illustrator Herji, has launched a French-language educational graphic novel titled “Utop’IA.” It aims to educate teenagers about the environmental impact of artificial intelligence through storytelling, including its resource consumption (energy, water, rare metals) and potential ecological benefits. The work emphasizes critical thinking and explores paths for sustainable AI development. (Source: aihub.org)
