
Anahtar Kelimeler:Meta, Scale AI, Süper Zeka, AGI, Veri Etiketleme, AI Eğitimi, Model Doğruluğu, Meta Scale AI hisse satın aldı, Alexandr Wang Süper Zeka ekibine liderlik ediyor, AI veri etiketleme %99,7 doğruluk, Eğitim verisi kirlilik oranı azaldı, Model eğitim süresi %40 kısaldı
🔥 Odak Noktası
Meta’nın Scale AI’a yaklaşık 15 milyar dolar yatırım yaparak ortak olacağı ve CEO’sunu yeni “Süper Zeka” ekibine liderlik etmesi için atayacağı bildirildi: Meta, AI veri etiketleme ve altyapı şirketi Scale AI’ın %49 hissesini yaklaşık 14,9 milyar dolar karşılığında almayı ve henüz 28 yaşındaki Çin kökenli CEO’su Alexandr Wang’ı yeni kurulan “Süper Zeka Grubu”na (Superintelligence Group) liderlik etmesi için atamayı planlıyor. Bu hamle, Meta’nın AI alanındaki rekabet gücünü, özellikle yüksek kaliteli eğitim verileri ve AGI geliştirme konularında güçlendirmeyi amaçlıyor. Scale AI, %99,7’ye varan veri etiketleme doğruluğuyla tanınıyor ve Meta modellerinin eğitim verisi kirlilik oranını %15’ten %2’ye düşürmesi, eğitim döngüsünü ise %40 kısaltması bekleniyor. Bu satın alma, Meta’nın AI yarışında rakiplerini yakalama ve geçme çabasında kritik bir adım olarak görülüyor ve aynı zamanda verinin AI gelişimindeki merkezi stratejik önemini de vurguluyor. (Kaynak: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
OpenAI’ın Google Cloud ile büyük ölçekli bir hesaplama gücü anlaşması yaptığı ve Microsoft’a olan bağımlılığını azaltmaya çalıştığı iddia edildi: Haberlere göre OpenAI, Google Cloud ile önemli bir bulut hizmetleri anlaşması imzaladı. Google Cloud, OpenAI’ın artan AI model eğitimi ve dağıtımı için gereken hesaplama gücünü sağlayacak. Daha önce Microsoft Azure, OpenAI’ın ana hesaplama gücü tedarikçisiydi. Bu hamle, OpenAI’ın tek bir tedarikçiye olan bağımlılığını azaltmak ve devasa hesaplama ihtiyaçlarını karşılamak için hesaplama gücü kaynaklarını çeşitlendirmeye çalıştığının bir işareti olabilir. Bu işbirliği Google Cloud için büyük bir zafer anlamına gelse de, kendi işleriyle müşteri talepleri arasında TPU kaynaklarını nasıl dengeleyeceği konusunda tartışmalara yol açtı. (Kaynak: 36氪, scaling01)
Mistral AI, çıkarım modeli Magistral’ı yayınladı ve toplulukta benchmark testlerinin şeffaflığı konusunda soru işaretleri oluştu: Fransız AI şirketi Mistral AI, çıkarım için özel olarak tasarlanmış ilk model serisi olan Magistral’ı tanıttı. Seri, açık kaynaklı 24B sürümü Magistral Small ve kurumsal odaklı Magistral Medium’u içeriyor. Resmi açıklamaya göre, şeffaf, izlenebilir çok adımlı mantıksal çıkarım için tasarlandı ve çoklu dil desteği sunuyor. Ancak topluluk, yayınlanan benchmark sonuçlarına şüpheyle yaklaştı ve en son Qwen ve DeepSeek R1 gibi rakip modellerle karşılaştırılmadığını, bunun bir “kaçınma” taktiği olabileceğini belirtti. Buna rağmen Magistral, AIME-24 matematik benchmark testinde Mistral Medium 3’e kıyasla önemli bir gelişme gösterdi. (Kaynak: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Takviyeli Öğrenmenin Babası Richard Sutton: LLM hakimiyeti sadece geçici, gelecekte ölçeklenebilir hesaplama ve deneyimsel öğrenme var: Turing Ödülü sahibi ve takviyeli öğrenmenin babası Richard Sutton, mevcut büyük dil modellerinin (LLM) hakimiyetinin sadece geçici olduğunu ve insan düşünce tarzını taklit etmenin yalnızca kısa vadeli performans artışı sağlayacağını öngördü. AI’ın geleceğinin “deneyim çağında” yattığını, yani Agent’ların statik insan verilerine güvenmek yerine dünyayla birinci şahıs etkileşimleri yoluyla deneyimsel veri elde ederek öğreneceğini savundu. Sutton, takviyeli öğrenmenin bu geleceğe giden temel yol olduğunu, sürekli öğrenen derin öğrenme algoritmaları ve büyük ölçekli hesaplama ile birleştiğinde AI’ın mevcut bilişsel sınırları aşmasını ve gerçek yeniliği mümkün kılacağını vurguladı. (Kaynak: 量子位)

Hugging Face ve NVIDIA, “Hizmet Olarak Eğitim Kümesi”ni başlatarak büyük model eğitim engelini düşürüyor: Hugging Face, NVIDIA ile işbirliği içinde “Hizmet Olarak Eğitim Kümesi”ni (Training Cluster as a Service) duyurdu. Bu hizmet, dünya çapındaki araştırma kurumlarının çeşitli öncü modelleri eğitmek için büyük GPU küme kaynaklarına daha kolay erişmesini sağlamayı amaçlıyor. Hizmet, NVIDIA DGX Cloud Lepton ve Hugging Face’in geliştirme kaynaklarını entegre ederek kuruluşların talep üzerine GPU kümesi kullanım süresi için ödeme yapmasına olanak tanıyor. Bu adım, “GPU zengin-fakir uçurumunu” kapatmayı, AI araştırmalarında çeşitliliği ve yaygınlaşmayı teşvik etmeyi hedefliyor ve TIGEM, Numina, Mirror Physics gibi araştırma kurumları ve startup’lar tarafından erken benimsendi. (Kaynak: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 Gelişmeler
OpenAI, o3-pro modelini yayınladı ve o3 API fiyatlarını önemli ölçüde düşürdü: OpenAI, yeni üst düzey çıkarım modeli o3-pro’yu piyasaya sürdü ve ChatGPT Pro kullanıcıları ile API kullanıcılarına açtı. Aynı zamanda, o3 modelinin API fiyatları %80 oranında önemli ölçüde düşürüldü ve ChatGPT Plus kullanıcılarının o3 hız sınırı iki katına çıkarıldı. Topluluk geri bildirimleri, o3-pro’nun kod dışı görevlerde Claude Opus 4’ten daha iyi performans gösterdiğini ve Extended NYT Connections ile Creative Short Story Writing gibi birçok benchmark testinde yeni rekorlar kırdığını, hatta daha önce Apple makalesinde LLM yeteneklerini sorgulayan “Hanoi Kulesi 10 disk problemini” başarıyla çözdüğünü gösteriyor. Ancak bazı kullanıcılar o3-pro’nun yavaş olduğunu bildirdi. OpenAI, o3 fiyat indiriminin damıtma veya niceleme yoluyla değil, çıkarım mühendislerinin optimizasyon çalışmaları sayesinde olduğunu belirtti. (Kaynak: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB, uç cihazlar için verimli LLM serisi MiniCPM4’ü yayınladı: OpenBMB, özellikle uç cihazlar için tasarlanmış MiniCPM4 model serisini tanıttı ve tipik uç cihaz çiplerinde 5 kattan fazla üretim hızlandırması sağladığını iddia etti. Seri, MiniCPM4-8B, MiniCPM4-0.5B ve üçlü nicelenmiş BitCPM4-1B/0.5B gibi sürümleri içeriyor. MiniCPM4, eğitilebilir seyrek dikkat mekanizması InfLLM v2’yi kullanıyor, 128K uzun metin işlemeyi destekliyor ve model rüzgar tüneli 2.0, BitCPM üçlü niceleme, FP8 düşük hassasiyetli hesaplama ve çoklu belirteç tahmini gibi verimli öğrenme algoritmalarını ve eğitim tekniklerini birleştiriyor. Aynı zamanda yüksek kaliteli Çince ve İngilizce ön eğitim veri kümesi UltraFineweb ve denetimli ince ayar veri kümesi UltraChat v2 de yayınlandı. (Kaynak: GitHub Trending)
MSRA ve Tsinghua-Pekin Üniversiteleri akademisyenleri yeni bir Takviyeli Ön Eğitim (RPT) paradigması önerdi: Microsoft Research Asia (MSRA), Tsinghua Üniversitesi ve Pekin Üniversitesi’nden araştırmacılarla birlikte Takviyeli Ön Eğitim (Reinforced Pre-training – RPT) adlı yeni bir LLM ön eğitim paradigması önerdi. Bu yöntem, takviyeli öğrenmeyi (RL) ön eğitim aşamasına derinlemesine entegre ediyor; model, her bir token’ı tahmin etmeden önce bir düşünce zinciri çıkarım dizisi üretiyor ve tahminin doğruluğuna göre ödül alıyor. RPT, modelin yüzeysel token ilişkilerini öğrenmekten derin anlamları kavramaya geçmesini amaçlıyor. Deneyler, RPT tabanlı eğitilmiş 14B bir modelin bazı çıkarım görevlerinde 32B geleneksel ön eğitimli modellerle rekabet edebildiğini ve hatta onları geçebildiğini göstererek LLM’lerin dil modelleme ve çıkarım yeteneklerini artırma konusunda büyük bir potansiyel sergiledi. (Kaynak: 量子位, omarsar0)

Meta, V-JEPA 2 video dünya modelini ve yeni benchmark’ları yayınladı: Meta AI, makinelerin fiziksel dünyayı anlama ve tahmin etme yeteneğini geliştirmek amacıyla video verileri üzerinde eğitilmiş 1,2 milyar parametreli bir dünya modeli olan V-JEPA 2’yi tanıttı. Bu model, robotların sıfır-atış (zero-shot) planlamasında rol oynayarak alışılmadık ortamlarda görevleri planlamasını ve yürütmesini sağlayabiliyor. Aynı zamanda Meta, mevcut modellerin videolardan fiziksel dünyayı çıkarım yapma yeteneğini değerlendirmek için üç yeni benchmark testi yayınladı. HuggingFace, V-JEPA 2 için transformers kütüphane desteği sunmaya başladı. (Kaynak: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance, Seedance 1.0 Pro video oluşturma modelini yayınladı, Doubao App’te kullanıma sunuldu: ByteDance, en son video oluşturma modeli Seedance 1.0 Pro’yu (yani Dream Driver’daki Video 3.0 Pro modeli) tanıttı. Bu model, komut anlama, görüntü detayı ve fiziksel tutarlılık konularında üstün performans gösteriyor ve 5 saniyelik 1080P videolar üretebiliyor. Model şu anda Volcano Engine aracılığıyla kurumsal kullanıcılara açık ve Doubao App’te kullanıcıların ücretsiz deneyebileceği “Fotoğrafı Canlandır” özelliğiyle kullanıma sunuldu. (Kaynak: op7418)
Huawei, AI eğitim ve çıkarım verimliliğini optimize etmek için “Dijital Rüzgar Tüneli” simülasyon platformunu tanıttı: Huawei Markov Modelleme Simülasyon ekibi, karmaşık AI modellerinin gerçek eğitim ve çıkarımından önce sanal ortamda “prova” yapmak için kullanılan “Dijital Rüzgar Tüneli” teknolojisini ilk kez sergiledi. Bu platform, Sim2Train (eğitim simülasyonu), Sim2Infer (çıkarım simülasyonu) ve Sim2Availability (yüksek kullanılabilirlik simülasyonu) olmak üzere üç ana modülden oluşuyor. Simülasyon ve otomatik optimizasyon yoluyla donanım kaynaklarının yanlış eşleşmesi, sistem birleşimi gibi sorunları çözmeyi, böylece on binlerce kartlık küme çözümlerini saatler içinde önceden canlandırmayı, hesaplama gücü israfını önlemeyi ve AI büyük model eğitim ve çıkarımının verimliliğini ve kararlılığını artırmayı amaçlıyor. (Kaynak: 量子位)

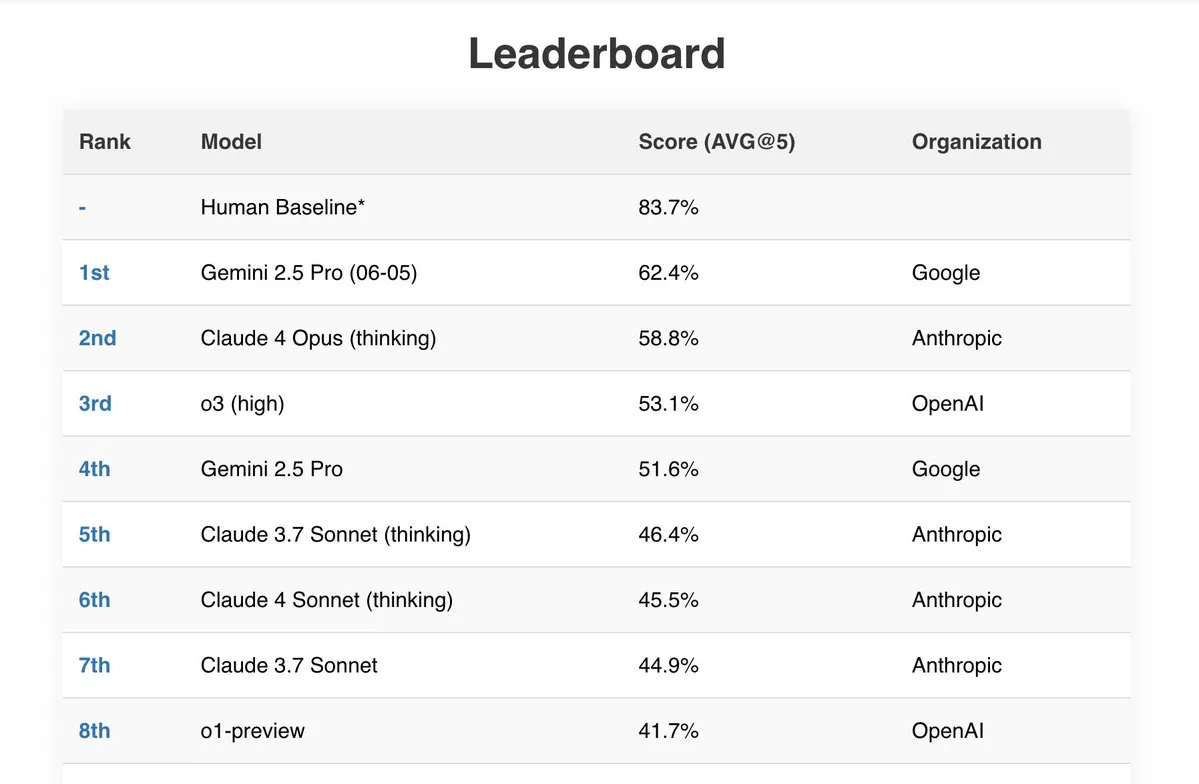
Gemini 2.5 Pro, birçok benchmark testinde üstün performans sergiledi: Google’ın en son Gemini 2.5 Pro (06-05) modeli, birçok halka açık AI sıralamasında öne çıktı. 192k token işleyen Live Fiction testinde en iyi performansı gösterdi, SimpleBench’te %62,4’lük bir skorla birinci oldu ve IDP (akıllı belge işleme) ile Aider (AI destekli kodlama) gibi benchmark testlerinde güçlü belge işleme yeteneği ve maliyet etkinliği sergiledi. Ayrıca, bazı kullanıcılar Gemini 2.5 Pro’nun JEE Advanced 2025 matematik bölümündeki tüm sorunları başarıyla çözdüğünü bildirdi. (Kaynak: _philschmid, dilipkay)
Kling AI video modeli, dudak senkronizasyonu özelliğini güncelledi, karakter seçimi ve düzenlemeyi destekliyor: Kuaishou’nun AI video oluşturma aracı Kling AI, son zamanlarda dudak senkronizasyonu (Lip-sync) özelliğini güncelledi. Yeni özellik, kullanıcıların oluşturulan videoda belirli bir karakteri dudak senkronizasyonu için seçmesine ve sesi ağız hareketleriyle senkronize etme zamanlamasını ayarlamasına olanak tanıyor. Bu güncelleme, Kling AI’ın çok karakterli diyalog video oluşturma konusundaki esnekliğini ve gerçekçiliğini artırıyor ve video oluşturma alanında önemli bir gelişme olarak kabul ediliyor. (Kaynak: Kling_ai, Kling_ai)
Delta Lake 4.0.0 yayınlandı, Lakehouse yeteneklerini geliştiriyor: Delta Lake 4.0.0 sürümü resmi olarak yayınlandı ve birleşik yönetişim ve keşfedilebilirlik için önizleme sürümündeki Katalog Yönetimli Tablolar (Catalog-Managed Tables), Spark Connect için Delta Connect uzantısı, yarı yapılandırılmış verileri işlemek için Variant veri türü desteği ve tablo özelliklerini geçmişi kesmeden veya kesinti olmadan kaldırmaya olanak tanıyan anında DROP FEATURE özelliği gibi birçok önemli yeni özellik getiriyor. Bu sürüm, açık lakehouse topluluğunun deneyimini geliştirmeyi amaçlıyor. (Kaynak: matei_zaharia)

Hugging Face, model ve araç etkileşimini basitleştirmek için MCP sunucusunu başlattı: Hugging Face, Model Bağlam Protokolü (MCP) sunucusunun ilk sürümünü yayınladı. Kullanıcılar artık Claude veya Cursor gibi uygulamalarda model, veri kümesi, makale, uygulama veya belirli bilgileri aramak için http://hf.co/mcp adresindeki bu sunucuyu kullanabilirler. Bu, Hugging Face’in AI ekosistemindeki araçların ve modellerin birlikte çalışabilirliğini teşvik etme yönünde attığı önemli bir adımı işaret ediyor ve gelecekte yükleme, indirme, PR başlatma gibi işlevlere genişleyebilir. (Kaynak: clefourrier, ClementDelangue)

Baidu, entegre depolama ve akıllı yönetim özellikli “AI Kamera”yı tanıttı ve GenFlow Süper Ortak 2.0’ı yükseltti: Baidu Netdisk ve Baidu Wenku ortaklaşa “AI Kamera” özelliğini yayınlayarak fotoğraf çekme, bulut depolama ve akıllı yönetimi bir araya getirdi. Fotoğraflar otomatik olarak bulut albümüne arşivlenebiliyor ve doğal dil açıklamalarıyla akıllı sınıflandırma ve arama destekleniyor. AI Kamera ayrıca güzelleştirme, nesne tanıma ve bilgilendirme, karalama çizimi oluşturma, fatura tarama, el yazısı tablo dönüştürme gibi çeşitli AI yeteneklerine sahip. Aynı zamanda, çoklu akıllı ajan işbirliği platformu “GenFlow Süper Ortak” 2.0 sürümüne yükseltildi ve kullanıcı verileri ve alışkanlıklarıyla daha derinlemesine entegre olarak kişiselleştirilmiş içerik oluşturma hizmetleri sunabiliyor. (Kaynak: 量子位)

ByteDance, SeedVR2 video onarım modelinin kodunu ve ağırlıklarını açık kaynak olarak yayınladı: ByteDance SEED ekibi, tek adımlı video onarım modeli SeedVR2’nin çıkarım kodunu ve model ağırlıklarını yayınladı ve bunlar artık Hugging Face’te mevcut. Bu model, difüzyon karşıt son eğitim (diffusion adversarial post-training) tekniğini kullanarak video restorasyonunda, özellikle yüksek çözünürlüklü video işlemede dikkate değer sonuçlar elde ediyor. (Kaynak: _akhaliq)
GroqCloud, Qwen3-32B modelini kullanıma sundu, 100’den fazla dili ve 131k bağlamı destekliyor: Groq, LPU çıkarım donanımı bulut platformu GroqCloud’da Tongyi Qianwen Qwen3-32B modelini kullanıma sunduğunu duyurdu. Bu model, 100’den fazla dil ve lehçeyi destekliyor, 131k’lık bir bağlam penceresine sahip ve Groq donanımının kendine özgü gerçek zamanlı hızıyla çalışarak geliştiricilere güçlü çok dilli, uzun metin işleme yetenekleri sunuyor. (Kaynak: JonathanRoss321)
OpenAI CEO’su Sam Altman, açık kaynak ağırlıklı modellerinin yayınlanmasının erteleneceğini söyledi: Sam Altman, OpenAI’ın açık kaynak ağırlıklı modellerinin planlanan Haziran ayı yerine bu yaz sonuna erteleneceğini belirtti. Araştırma ekibinin “beklenmedik ve çok şaşırtıcı” bazı ilerlemeler kaydettiğini, bunun beklemeye değer olduğunu ancak mükemmelleştirmek için daha fazla zamana ihtiyaç duyduklarını açıkladı. (Kaynak: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

Digua Robot, tek SoC’de büyük ve küçük beyin mimarisini entegre eden RDK S100 geliştirme kitini yayınladı: Digua Robot, sektördeki ilk tek SoC hesaplama ve kontrol entegre robot geliştirme kiti RDK S100’ü tanıttı. Bu kit, insan beynine benzer büyük ve küçük beyin (6 çekirdekli Arm Cortex-A78AE CPU + 80 TOPS BPU “beyin” olarak, 4 çekirdekli Arm Cortex-R52+ MCU “beyincik” olarak) süper heterojen işbirlikçi mimari tasarımını benimsiyor. Bu, somutlaştırılmış zeka için büyük ve küçük modellerin verimli işbirliğini destekleyerek “algılama-karar verme-kontrol” döngüsünü tamamlıyor. RDK S100, zengin arayüzler ve tam kapsamlı geliştirme altyapısı sunuyor ve ön satış fiyatı 2499 yuan. (Kaynak: 量子位)

Aibook Intelligence, 50TOPS yerli SoC içeren E300 AI hesaplama modülünü yayınladı: Aibook Intelligence, uç senaryolar için tasarlanmış E300 AI hesaplama modülünü tanıttı. Bu modül, kendi geliştirdiği AI SoC çipi AB100’ü içeriyor. Modül, 50TOPS’a kadar INT8 hesaplama gücü sunuyor, FP16/FP32 karma hassasiyetli hesaplamayı destekliyor ve 102GB/s LPDDR5 bellek bant genişliğine sahip. E300, modüler bir tasarıma sahip olup eğitim, enerji, sağlık gibi sektörlere yüksek performanslı, düşük gecikmeli, güçlü ve güvenilir yerli uç AI çözümleri sunmayı amaçlıyor ve ana akım açık kaynak büyük modellerin ve çeşitli görsel ve ses modellerinin uçta dağıtımını destekliyor. (Kaynak: 量子位)

Huawei, Ascend on bin kartlık küme yüksek kullanılabilirlik teknolojisini açıkladı, %98 eğitim kullanılabilirliği elde etti: Huawei, Ascend on bin kartlık hesaplama gücü kümesinin yüksek kullanılabilirlik teknolojisi ayrıntılarını ilk kez kamuoyuyla paylaştı. Arıza algılama ve teşhisi, arıza yönetimi, küme optik bağlantı hata toleransı olmak üzere üç temel yetenek ve küme doğrusallık optimizasyonu, eğitim ve çıkarımın hızlı kurtarılması gibi iş destek yetenekleri aracılığıyla Huawei, on bin kartlık küme eğitim kullanılabilirliğini %98’e, doğrusallığı %95’in üzerine, arıza kurtarmayı saniye düzeyine ve teşhisi dakika düzeyine çıkardı. Bu “3+3” çift boyutlu teknoloji sistemi, büyük ölçekli AI eğitimi ve çıkarımının istikrarlı ve verimli çalışmasını sağlamayı amaçlıyor. (Kaynak: 量子位)

BYD’nin yeni araçlarında akıllı sürüş penetrasyon oranı %79’a ulaştı, otoyol NOA ana akım konfigürasyon haline geldi: BYD tarafından açıklanan en son verilere göre, Mayıs ayında satılan yeni araçlarının %79’u akıllı yardımcı sürüş sistemleriyle (en azından otoyol NOA ve otomatik park etme özelliklerine sahip) donatılmıştı. Bu, BYD’nin “herkes için akıllı sürüş” stratejisini ilerletmede önemli bir başarı elde ettiğini ve akıllı sürüş özelliklerinin hızla araçlarının standart bir konfigürasyonu haline geldiğini gösteriyor. Bu eğilim aynı zamanda Çin otomobil pazarında akıllı sürüş teknolojisinin yaygınlaşma hızının arttığını da yansıtıyor. (Kaynak: 量子位)

ChatGPT gelişmiş ses özellikleri tüm ücretli kullanıcılara sunuldu: OpenAI, daha önce güncellenen ve daha doğal bir konuşma yeteneğine sahip olan ChatGPT gelişmiş ses özelliklerinin (Advanced Voice) tüm ücretli kullanıcılara (ChatGPT Plus, Team, Enterprise) sunulduğunu duyurdu. Kullanıcılar bu özellik sayesinde ChatGPT ile daha doğal sesli etkileşimler kurabilecekler. (Kaynak: juberti)
🧰 Araçlar
Genspark AI Tarayıcısı yayınlandı, birçok AI akıllı ajan özelliğini entegre ediyor: Eric Jing ekibi, 24 kişilik bir ekip tarafından 10 haftada geliştirildiği iddia edilen Genspark AI Tarayıcısını yayınladı. Tarayıcı, AI tarayıcı, AI sekreter, AI kişisel arama, AI indirme aracısı, AI Drive, AI Sheets gibi 8 ana ürünü bir araya getiriyor. Bu tarayıcı hızlı, reklam engelleme, tamamen akıllı ajanlaşmış, otonom sürüş modu özellikleriyle öne çıkıyor ve yerleşik MCP mağazası ile süper akıllı ajan içererek tek duraklı AI destekli gezinme ve çalışma deneyimi sunmayı amaçlıyor. (Kaynak: blader)
Yutori AI, AI ajan ağı izleme için Scouts platformunu başlattı: Yutori AI, kullanıcıların ağdaki belirli bilgi güncellemelerini izlemek için sürekli çevrimiçi AI ajanları oluşturmasına olanak tanıyan Scouts platformunu yayınladı. Bu ajanlar, niş haberler, ürün fiyat değişiklikleri, bilet bilgileri gibi kullanıcıların ilgilendiği çeşitli içerikleri takip edebilir ve kritik anlarda kullanıcıları e-posta ile uyararak bilgi takibini otomatikleştirmeyi ve kullanıcıları özgürleştirmeyi amaçlıyor. (Kaynak: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face, AI modellerini elektronik tablolarla birleştiren AISheets’i tanıttı: Hugging Face, binlerce AI modelini (özellikle açık kaynak LLM’leri) elektronik tablo işlevleriyle birleştiren bir uygulama olan AISheets’i yayınladı. Kullanıcılar AISheets’te veri oluşturabilir, analiz edebilir ve otomatikleştirebilir; bu, akıcı, hızlı ve basit bir AI destekli veri işleme deneyimi sunmayı amaçlamaktadır. (Kaynak: ben_burtenshaw, LoubnaBenAllal1)
PLaMo, MLX tabanlı yerel çeviri CLI aracını yayınladı: PLaMo LLM ekibi, Apple Silicon çipli Mac’lerde MLX çerçevesini kullanarak yerel metin çevirisi yapabilen bir komut satırı arayüzü (CLI) aracını açık kaynak olarak yayınladı. Bu araç, hızlı ve yüksek hassasiyetli yerel çeviri deneyimi sunmayı amaçlıyor ve diğer MCP uyumlu uygulamalarla (Claude Desktop gibi) entegrasyonu kolaylaştırmak için yerleşik HTTP ve MCP sunucuları ile istemcileri içeriyor. (Kaynak: awnihannun)
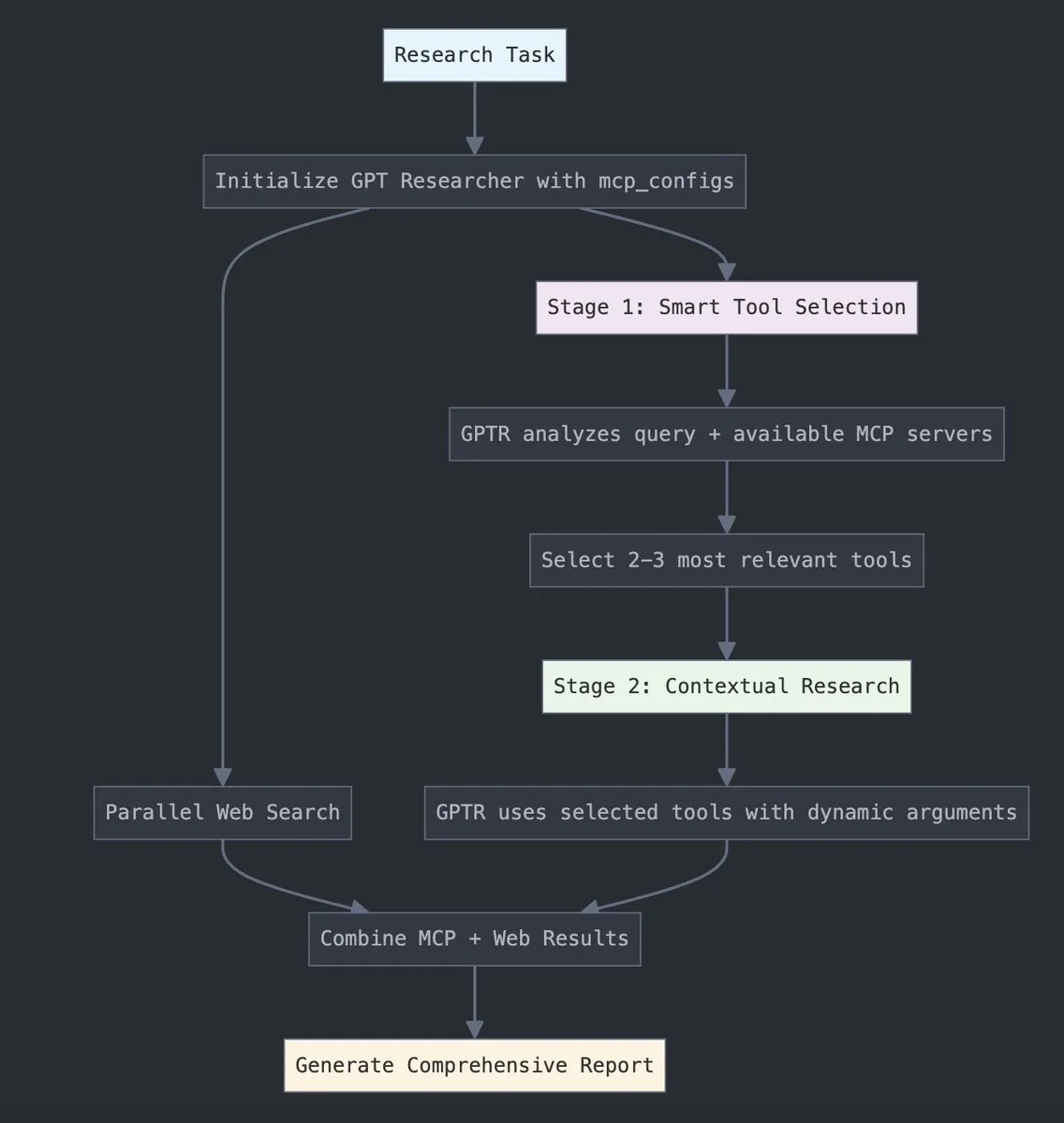
GPT Researcher, LangChain MCP adaptörünü entegre ederek araç seçimi ve araştırma yeteneklerini geliştirdi: GPT Researcher, daha akıllı araç seçimi ve araştırma süreçleri sağlamak için artık LangChain’in Model Bağlam Protokolü (MCP) adaptörünü kullanıyor. Bu adım, daha kapsamlı veri toplama ve analiz için MCP’nin avantajlarını web arama yetenekleriyle birleştirmeyi amaçlıyor. (Kaynak: Hacubu)
Consilium: Açık kaynaklı çoklu akıllı ajan işbirliği çerçevesi yayınlandı: Victor M, açık kaynaklı bir AI akıllı ajan ekip işbirliği çerçevesi olan Consilium’u tanıttı. Kullanıcılar stratejiler belirleyebilir, birden fazla uzman akıllı ajan tartışabilir ve karmaşık sorunları ortaklaşa çözmek ve fikir birliğine varmak için gerçek zamanlı araştırmayı (web, arXiv, SEC verileri) kullanabilir. Araç, Hugging Face’te bir Demo ile sunulmaktadır. (Kaynak: clefourrier)
youtube-transcript-api: YouTube altyazılarını almak için Python kütüphanesi, çeviriyi ve otomatik içerik oluşturmayı destekler: jdepoix tarafından geliştirilen Python kütüphanesi youtube-transcript-api, GitHub’da ilgi görüyor. Bu API, otomatik olarak oluşturulan altyazılar da dahil olmak üzere YouTube videolarının altyazılarını alabilir ve çeviri işlevini destekler. Selenium tabanlı diğer çözümlerden farklı olarak, API anahtarı veya başsız tarayıcı gerektirmez, geliştiricilere video metin içeriğini kolayca çıkarma yolu sunar. (Kaynak: GitHub Trending)
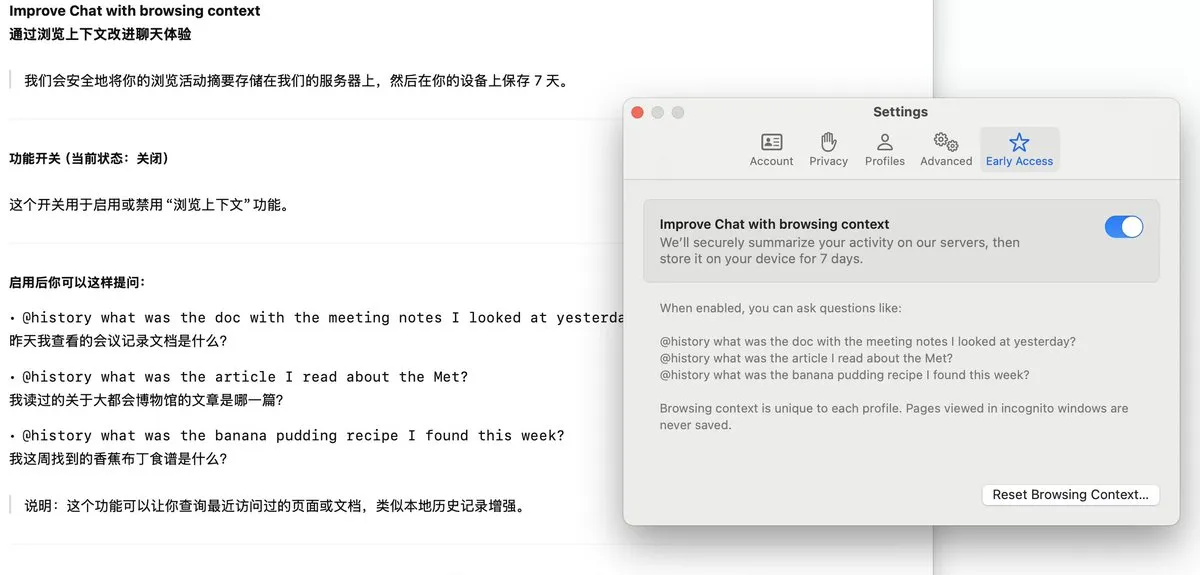
Arc Tarayıcı, gezinme geçmişini kaydeden ve AI soru-cevap özelliğini destekleyen Dia özelliğini başlattı: Arc Tarayıcı, etkinleştirildiğinde kullanıcının tüm gezinme geçmişini sürekli olarak kaydeden Dia özelliğini ekledi. Kullanıcılar, @History özelliği aracılığıyla, daha önce gezindikleri ancak tam adresini unuttukları bilgileri bulmak için belirsiz doğal dil soruları sorabilirler. Bu özellik, gezinme geçmişi raporları oluşturmayı bile destekleyebilir, tarayıcının akıllı ve kişiselleştirilmiş bilgi yönetimi yeteneklerini artırır. (Kaynak: op7418)
📚 Öğrenme
Apple, LLM yetenek sınırlarını tartışan “Düşünme İllüzyonu” adlı makaleyi yayınladı: Apple Makine Öğrenimi Araştırma ekibi, mevcut büyük dil modellerinin (LLM) karmaşık çıkarım görevlerindeki (Hanoi Kulesi problemini çözmek gibi) performansını ve sınırlamalarını analiz eden “Düşünme İllüzyonu” (The Illusion of Thinking) adlı bir makale yayınladı. Bu makale, toplulukta LLM’lerin gerçek zeka seviyesi hakkında tartışmalara yol açtı ve bu tür araştırmaların bazen AI’ın benimsenmesini ertelemek için bir gerekçe olarak kullanıldığı yönünde görüşler ortaya çıktı. OpenAI’ın o3-pro modeli daha sonra makalede ortaya atılan Hanoi Kulesi sorununu çözdü. (Kaynak: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
Yeni araştırma “Genel Amaçlı Ajanlar Dünya Modellerine İhtiyaç Duyar”, ajan genellemesi ve tahmin modelleri arasındaki ilişkiyi inceliyor: “Genel Amaçlı Ajanlar Dünya Modellerine İhtiyaç Duyar” (General agents need world models) başlıklı yeni bir araştırma makalesi, çok adımlı hedef odaklı görevlere genelleme yapabilen genel amaçlı ajanların tahmini bir dünya modeli öğrenmesi gerektiğini belirtiyor. Bu model, ajanın stratejisine kodlanmıştır ve makale, ajanın bileşik hedefler altındaki strateji seçimlerini sorgulayarak ortam geçiş olasılıklarını çıkararak genelleme yeteneği ile öğrenilen modelin doğruluğu arasındaki doğrudan bağlantıyı kanıtlıyor. (Kaynak: menhguin)

Makale, LLM performansını artırmak için Kavram Farkındalıklı İnce Ayar (CAFT) yöntemini tartışıyor: “Kavram Farkındalıklı İnce Ayar ile Büyük Dil Modellerini Geliştirmek” (Improving large language models with concept-aware fine-tuning) başlıklı yeni bir makale, çoklu belirteç tahminini etkinleştirerek ince ayar yaparak modelin kavram anlayışını geliştiren CAFT yöntemini öneriyor. Araştırma, CAFT’nin kodlama, matematik, metin özetleme, molekül üretimi ve protein tasarımı gibi görevlerde önemli performans artışları sağladığını gösteriyor. Kod, GitHub’da açık kaynak olarak yayınlandı. (Kaynak: Reddit r/MachineLearning)
DeepLearning.AI, “GenAI Uygulama İş Akışlarını Düzenleme” adlı yeni bir kurs başlattı: Andrew Ng’nin DeepLearning.AI’ı, Astronomer ile işbirliği içinde “GenAI Uygulamaları için İş Akışlarını Düzenleme” (Orchestrating Workflows for GenAI Applications) adlı yeni bir kısa eğitim kursu başlattı. Bu kurs, popüler açık kaynak aracı Airflow 3.0’ı kullanarak güvenilir GenAI süreçleri oluşturmayı ve prototip Jupyter Notebook’larını veya Python betiklerini üretime hazır iş akışlarına dönüştürmeyi öğretiyor. İçerik, görev ayrıştırma, zamanlama, paralel yürütme, hata kurtarma ve gözlemlenebilirliği kapsıyor. (Kaynak: AndrewYNg)
Makale “Metin, Görüntü ve 3D Yapıların Belirteç Bazında Hizalanması” çok modlu otoregresif modelleri araştırıyor: Bu araştırma, dil, görüntü ve yapılandırılmış 3D sahneleri hizalamayı amaçlayan birleşik bir LLM çerçevesi öneriyor. Makale, veri temsili, belirli modalitelere özgü hedef fonksiyonları gibi en iyi eğitim ve performansı elde etmek için kritik tasarım seçimlerini ayrıntılı olarak açıklıyor ve renderlama, tanıma, talimat izleme ve soru cevaplama gibi dört temel 3D görevde ve birden fazla veri üzerinde değerlendiriliyor. Araştırma ayrıca, nicelenmiş şekil kodlaması yoluyla karmaşık 3D nesne şekillerinin yeniden yapılandırılmasına da genişliyor. (Kaynak: HuggingFace Daily Papers)
Makale “Squeeze3D”: Önceden eğitilmiş 3D üretken modelleri kullanarak aşırı sinirsel sıkıştırma: Squeeze3D çerçevesi, 3D verileri (ağlar, nokta bulutları, radyans alanları) büyük ölçüde sıkıştırmak için önceden eğitilmiş 3D üretken modellerde öğrenilen örtük ön bilgileri kullanır. Önceden eğitilmiş kodlayıcıyı ve üretken modelin gizli uzayını birbirine bağlayan eğitilebilir bir eşleme ağı aracılığıyla 3D modelleri kompakt gizli kodlara sıkıştırır ve açma sırasında üretken model tarafından yeniden oluşturulur. Bu yöntem, sentetik veriler üzerinde eğitilir, gerçek 3D veri kümelerine ihtiyaç duymaz ve dokulu ağlarda 2187 kata kadar sıkıştırma oranı elde eder. (Kaynak: HuggingFace Daily Papers)
Makale “Çerçeve Yönlendirmesi”: Video difüzyon modellerinde eğitimsiz kare düzeyinde kontrol: Bu araştırma, video difüzyon modellerinde kare düzeyinde kontrolü eğitim gerektirmeden sağlayan “Çerçeve Yönlendirmesi” (Frame Guidance) yöntemini öneriyor. Basit gizli uzay işleme ve yeni bir gizli uzay optimizasyon stratejisi aracılığıyla bu yöntem, anahtar kareler, stil referansları, eskizler veya derinlik haritaları gibi kare düzeyindeki sinyalleri etkili bir şekilde kontrol edebilir. Anahtar kare yönlendirmesi, stilizasyon, döngüsel oynatma gibi çeşitli görevler için uygundur ve herhangi bir video modeliyle uyumludur. (Kaynak: HuggingFace Daily Papers)
Makale “Büyük Dil Modellerinde Jeopolitik Önyargılar” modelin ulusal duruşlarını ortaya koyuyor: Bu araştırma, LLM’lerin farklı ulusal perspektiflere (ABD, İngiltere, Sovyetler Birliği, Çin) sahip tarihi olayları yorumlamasını analiz ederek LLM’lerdeki jeopolitik önyargıları değerlendiriyor. Araştırmacılar, tarafsız olay açıklamaları ve ülkelerin karşılaştırmalı görüşlerini içeren yeni bir veri kümesi sundular ve LLM’lerin belirli ulusal anlatıları önemli ölçüde kayıran önyargılara sahip olduğunu ve basit önyargı giderme komutlarının sınırlı etkili olduğunu buldular. Bu çalışma, gelecekteki jeopolitik önyargı araştırmaları için bir çerçeve ve veri kümesi sağlıyor. (Kaynak: HuggingFace Daily Papers)
Awesome Lists kaynak deposu sürekli güncelleniyor, çeşitli ilginç konuları içeriyor: sindresorhus tarafından yönetilen GitHub projesi awesome, çeşitli ilginç konular hakkında “Awesome lists” (Harika listeler) içeren bir meta listedir. Bu listeler, programlama dillerinden geliştirme platformlarına, teorilerden kitaplara, araçlara kadar birçok alanı kapsayarak geliştiricilere ve öğrenicilere zengin kaynak dizinleri sunar. (Kaynak: GitHub Trending)
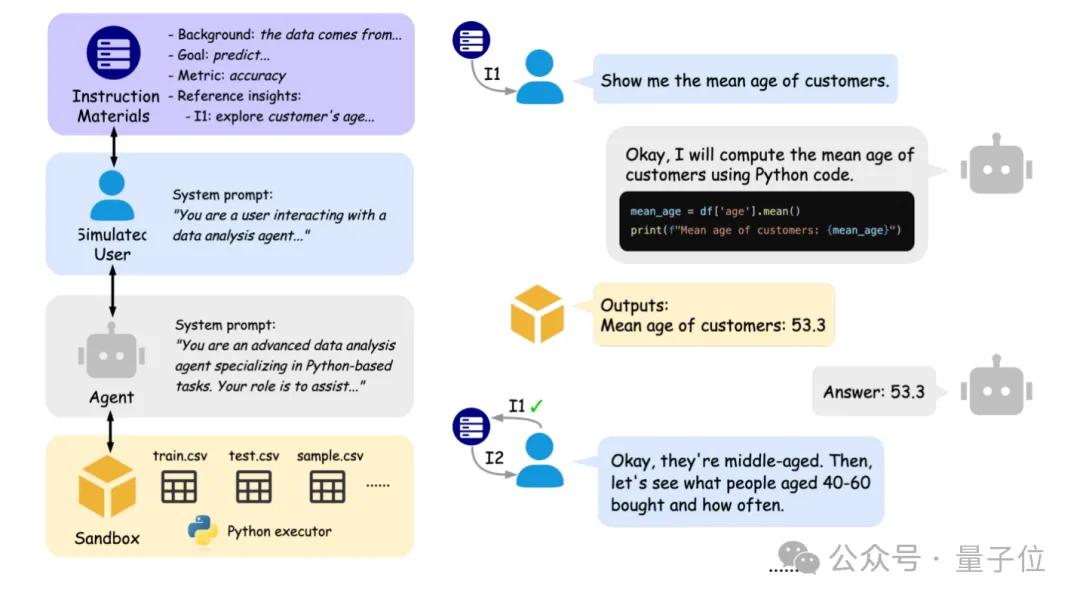
Pekin Üniversitesi ve Berkeley, AI veri analizi ajanlarının etkileşim yeteneğini değerlendirmek için IDA-Bench’i başlattı: Pekin Üniversitesi ve Kaliforniya Üniversitesi Berkeley’den (Michael I. Jordan dahil) araştırma ekipleri, büyük dil modellerinin (LLM) veri analizi ajanları (Agent) olarak çok turlu etkileşim senaryolarındaki yeteneklerini değerlendirmek için tasarlanmış yeni bir benchmark olan IDA-Bench’i başlattı. Bu benchmark, gerçek veri analistlerinin iş akışını simüle ederek, aşamalı olarak gelişen talimatlarla Agent’ın talimatları izleme, kod yazma ve yürütme yeteneğini inceliyor. İlk değerlendirmeler, Claude-3.7 ve Gemini-2.5 Pro gibi en iyi modellerin bile görev başarı oranının %40’ın altında olduğunu göstererek mevcut Agent’ların karmaşık etkileşim ve talimat izleme konusundaki zorluklarını ortaya koyuyor. (Kaynak: 量子位)
💼 İş Dünyası
xAI ve Polymarket işbirliği, pazar tahminlerini Grok analiziyle birleştiriyor: Elon Musk’ın xAI şirketi, tahmin piyasası platformu Polymarket ile bir işbirliği yaptığını duyurdu. İki taraf, Polymarket’in pazar tahmin yeteneklerini, X platformunun verilerini ve Grok modelinin analiz yeteneklerini birleştirerek dünyayı şekillendiren faktörleri anlamak amacıyla bir “sert gerçek motoru” (Hardcore truth engine) oluşturmayı hedefliyor. Resmi açıklamaya göre bu sadece işbirliğinin başlangıcı ve gelecekte daha fazla gelişme olacak. (Kaynak: Yuhu_ai_)
UnslothAI, Redpoint tarafından en iyi altyapı şirketlerinden biri olarak seçildi ve Nasdaq ekranında yer aldı: AI startup’ı UnslothAI, AI altyapı alanındaki katkılarından dolayı risk sermayesi şirketi Redpoint tarafından 2025 yılının en etkili ve en hızlı büyüyen 100 altyapı şirketinden biri olarak seçildi ve logosu New York Nasdaq binasının elektronik ekranında yer aldı. UnslothAI, LLM eğitim ve çıkarım verimliliğini optimize etmeye odaklanıyor. (Kaynak: danielhanchen, karminski3)

Ant Digital, Tianji Laboratuvarı’nı “AI + Endüstriyel İnovasyon”a odaklanmak üzere yükseltti: Ant Digital, Tianji Laboratuvarı’nı orijinal “Dijital Kimlik Güvenliği Laboratuvarı”ndan “Yapay Zeka + Endüstriyel İnovasyon” laboratuvarına yükselttiğini duyurdu. Yükseltilen laboratuvar, AI büyük modellerinin endüstriyel uygulamalardaki kilit teknolojik atılımlarını araştırmaya odaklanacak ve AI+Veri, AI+Güvenlik, AI+Finans ve AI+Somutlaştırılmış Zeka olmak üzere dört ana yönde konumlanacak. Amaç, üretim-akademi-araştırma-uygulama işbirliği ve inovasyonu yoluyla AI teknolojisinin endüstriyle derin entegrasyonunu teşvik etmektir. (Kaynak: 量子位)

🌟 Topluluk
AI’ın karmaşık trafik ortamlarındaki otonom sürüş yeteneği ilgi çekiyor: Ronald van Loon, Hindistan’ın kaotik trafiğinde otonom sürüş testi yapılan bir video paylaştı ve bu, AI’ın karmaşık, yüksek dinamik ortamlardaki algılama, karar verme ve kontrol yetenekleri hakkında tartışmalara yol açtı. Bu tür gerçek dünya senaryoları, otonom sürüş sistemlerinin sağlamlığı ve uyarlanabilirliği için son derece yüksek talepler ortaya koyuyor. (Kaynak: Ronald_vanLoon)
AI Engineer World’s Fair Konferansı’ndan Öne Çıkanlar: MCP protokolü, AI akıllı ajan maliyeti ve yerel modeller odak noktası oldu: Yogi ve Shawn “swyx” Wang gibi isimler, AI Engineer World’s Fair konferansının önemli noktalarını paylaştı. Temel eğilimler şunları içeriyor: 1) AI akıllı ajanları gelecektir, atomik etkileşim birimi akıllı ajan çağrısı olacaktır; 2) Model Bağlam Protokolü (MCP) hızla standart haline geliyor, “kopyala-yapıştır cehennemini” çözüyor ve AI’ın harici uygulamalarla doğrudan etkileşim kurmasını sağlıyor; 3) Belirli alanlar ve iş akışları için derinlemesine optimize edilmiş AI araçları oluşturmak (Cursor-for-X modeli) kritik öneme sahip; 4) Model maliyetleri önemli ölçüde düşüyor, yerel model yetenekleri artıyor ve geliştiricilere daha fazla kontrol ve düşük gecikmeli çözümler sunuyor; 5) AI, yardımcı araç olmaktan çıkıp geliştiricilerin “takım arkadaşı” haline geliyor; 6) AI mühendisliği, demo aşamasından üretim düzeyindeki sistemlere doğru ilerliyor. (Kaynak: swyx, TheTuringPost)
Topluluk, o3-pro’nun yayınlanmasının ardından hızlı yinelemeyi ve Apple’ın AI makalesini tartışıyor: andersonbcdefg, o3-pro’nun yayınlanmasından sadece 6 saat sonra topluluğun birisinin fastText’i Rust ile yeniden yazmasını bekliyormuş gibi göründüğünü esprili bir dille yorumladı ve “ılımlı süper zeka” hakkındaki uzun nutuklarla alay ederek AI alanındaki teknolojik yineleme hızının ne kadar hızlı olduğunu ve topluluğun yüksek beklentilerini yansıttı. Aynı zamanda Teknium1, o3-pro’nun Apple’ın “Düşünme İllüzyonu” makalesinde ortaya atılan Hanoi Kulesi sorununu çözdüğünü belirtti ve Apple ile OpenAI arasındaki işbirliği bağlamında Apple’ın neden bu tür makaleleri yayınlamadan önce dahili doğrulama yapmadığını sorgulayarak teknoloji şirketleri arasındaki rekabet ve işbirliği ilişkileri hakkında toplulukta tartışmalara yol açtı. (Kaynak: andersonbcdefg, Teknium1)
AI’ın gerçek dünya uygulamalarındaki etik ve etki tartışmaları: Topluluk, AI’ın belirli senaryolardaki uygulama etkileri ve etik sorunları üzerine tartışmalar yürütüyor. Örneğin, Arvind Narayanan, AI kalori sayma uygulamalarının kavramsal olarak kusurlu olduğunu, görüntü bilgilerinin kaloriyi doğru bir şekilde tahmin etmek için yetersiz olduğunu belirtti ve bunun daha çok kullanıcıların yeme alışkanlıklarına dikkat etmelerine yardımcı olan bir “ritüel” olduğunu savundu. Ayrıca, ticari tanıtım için (örneğin bir kahve dükkanının menü öğelerini sergilemek gibi) AI tarafından oluşturulan görüntülerin kullanılmasının etik olup olmadığı veya uygun bir uygulama olup olmadığı da bir tartışma konusu haline geldi; genel kanı, açıkça yanlış veya yanıltıcı olmadığı sürece bunun kabul edilebilir bir maliyet düşürme ve verimlilik artırma yöntemi olduğu yönünde. (Kaynak: random_walker, Reddit r/artificial)
LLM’lerin “insanlaşması” ve kullanıcı etkileşim deneyimi odak noktası haline geldi: Reddit topluluğu kullanıcıları, tereddüt, duraklama, daha kısa yanıtlar ve mükemmel olmayan ifadeler ekleyerek LLM etkileşimlerinin nasıl daha gerçek insanlara benzetilebileceğini tartışıyor. Bu, kullanıcıların daha doğal, daha az “robotik” AI arkadaşlarına veya asistanlarına olan ihtiyacını yansıtıyor. Aynı zamanda, bazı kullanıcılar mevcut LLM’lerin (ChatGPT gibi) sık sık sabit ifadeler ve abartılı anlatımlar (örneğin “Bu sadece X değil, aynı zamanda Y”) kullanmasından şikayet ediyor ve ifadelerinin daha kısa ve doğrudan olmasını istiyor. Bu tartışmalar, LLM’lerin insan konuşmasını taklit etme ve kullanıcıların duygusal ihtiyaçlarını karşılama konusundaki süregelen zorluklarına işaret ediyor. (Kaynak: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 Diğer
NVIDIA CEO’su Jensen Huang, GTC Paris’te AI hesaplamanın yeni aşamasına odaklanan bir açılış konuşması yapacak: NVIDIA, CEO’su Jensen Huang’ın 11 Haziran’da Paris’teki GTC Konferansı’nda (VivaTech 2025 sırasında) bir açılış konuşması yapacağını duyurdu. Konuşmanın, akıllı ajan sistemlerinden AI fabrikalarına kadar uzanan öncü konuları kapsayarak AI hesaplamanın bir sonraki aşamasını ortaya koyması bekleniyor. (Kaynak: nvidia, nvidia)

Databricks Data+AI Zirvesi en son gelişmeleri sergileyecek: Databricks, Data+AI Zirvesi’nin en iyi uzmanları, araştırmacıları ve açık kaynak katkıda bulunanları bir araya getirerek şirketin veri ve AI alanlarındaki en son gelişmelerini sergileyeceğini ve yenilikçi şirketlerin başarı öykülerini paylaşacağını duyurdu. Zirve, çevrimiçi ve çevrimdışı katılım seçenekleri sunuyor. (Kaynak: matei_zaharia, lateinteraction)

AI’ın etik ve çevresel etkileri ilgi çekiyor, çizgi roman formatında bilgilendirme yapılıyor: EPFL (Lozan Federal Teknoloji Enstitüsü) LEARN merkezi, illüstratör Herji ile işbirliği yaparak “Utop’IA” adlı Fransızca bir eğitici çizgi roman yayınladı. Amaç, gençlere yapay zekanın çevresel etkilerini (enerji, su, nadir metaller gibi kaynak tüketimi) ve potansiyel ekolojik faydalarını hikaye formatında anlatmak. Eser, eleştirel düşünmeyi vurguluyor ve sürdürülebilir AI geliştirme yollarını tartışıyor. (Kaynak: aihub.org)
