
كلمات مفتاحية:Meta, Scale AI, الذكاء الفائق, الذكاء العام الاصطناعي (AGI), توسيم البيانات, تدريب الذكاء الاصطناعي, دقة نموذج الذكاء الاصطناعي, استحواذ Meta على حصص في Scale AI, ألكسندر وانغ يقود فريق الذكاء الفائق, دقة توسيم بيانات الذكاء الاصطناعي 99.7%, انخفاض معدل تلوث بيانات التدريب, تقليل دورة تدريب النموذج بنسبة 40%
🔥 التركيز
Meta تستثمر ما يقرب من 15 مليار دولار في Scale AI وتعين رئيسها التنفيذي لقيادة فريق “الذكاء الفائق” الجديد: تخطط Meta لاستثمار ما يقرب من 14.9 مليار دولار أمريكي للاستحواذ على حصة 49% في شركة Scale AI المتخصصة في توصيف بيانات الذكاء الاصطناعي والبنية التحتية، وتعيين رئيسها التنفيذي الأمريكي من أصل صيني Alexandr Wang البالغ من العمر 28 عامًا لقيادة “مجموعة الذكاء الفائق” المشكلة حديثًا. تهدف هذه الخطوة إلى تعزيز القدرة التنافسية لـ Meta في مجال الذكاء الاصطناعي، خاصة فيما يتعلق ببيانات التدريب عالية الجودة وأبحاث وتطوير AGI. تشتهر Scale AI بدقتها العالية في توصيف البيانات التي تصل إلى 99.7%، ومن المتوقع أن تقلل نسبة تلوث بيانات تدريب نماذج Meta من 15% إلى 2%، وتقصير دورة التدريب بنسبة 40%. يُعتبر هذا الاستحواذ خطوة حاسمة لـ Meta للحاق بمنافسيها ومحاولة التفوق عليهم في سباق الذكاء الاصطناعي، كما أنه يسلط الضوء على الأهمية الاستراتيجية المحورية للبيانات في تطوير الذكاء الاصطناعي. (المصدر: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
أنباء عن توصل OpenAI لاتفاقية ضخمة مع Google Cloud بشأن القدرة الحاسوبية، ربما للتخلص من الاعتماد على Microsoft: أفادت تقارير أن OpenAI أبرمت اتفاقية خدمات سحابية هامة مع Google Cloud، ستقوم Google Cloud بموجبها بتزويد OpenAI بالقدرة الحاسوبية اللازمة لتدريب ونشر نماذجها المتزايدة للذكاء الاصطناعي. سابقًا، كانت Microsoft Azure هي المورد الرئيسي للقدرة الحاسوبية لـ OpenAI. قد تشير هذه الخطوة إلى أن OpenAI تسعى لتنويع مصادر قدرتها الحاسوبية لتقليل الاعتماد على مورد واحد وتلبية احتياجاتها الحاسوبية الهائلة. يمثل هذا التعاون انتصارًا كبيرًا لـ Google Cloud، ولكنه أثار أيضًا نقاشات حول كيفية موازنتها بين أعمالها الخاصة واحتياجات عملائها من موارد TPU. (المصدر: 36氪, scaling01)
Mistral AI تطلق نموذج الاستدلال Magistral، مما يثير تساؤلات في المجتمع حول شفافية اختبارات الأداء القياسية: أطلقت شركة الذكاء الاصطناعي الفرنسية Mistral AI أول سلسلة نماذج لها مصممة خصيصًا للاستدلال، Magistral، والتي تشمل إصدار 24B مفتوح المصدر Magistral Small و Magistral Medium الموجه للشركات. وصرحت الشركة رسميًا بأن النموذج مصمم للاستدلال المنطقي متعدد الخطوات الشفاف والقابل للتتبع، ويدعم لغات متعددة. ومع ذلك، أثار المجتمع تساؤلات حول نتائج اختبارات الأداء القياسية التي نشرتها، معتبرين أنها لم تقارن بأحدث إصدارات النماذج المنافسة مثل Qwen و DeepSeek R1، مما قد يشير إلى شبهة “تجنب المواجهة”. على الرغم من ذلك، أظهر Magistral تحسنًا ملحوظًا في اختبار الأداء القياسي للرياضيات AIME-24 مقارنةً بـ Mistral Medium 3. (المصدر: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Richard Sutton، مؤسس التعلم المعزز: هيمنة نماذج اللغة الكبيرة (LLM) مؤقتة، والحوسبة الموسعة والتعلم التجريبي هما المستقبل: يتوقع Richard Sutton، الحائز على جائزة Turing ومؤسس التعلم المعزز، أن هيمنة نماذج اللغة الكبيرة (LLM) الحالية مؤقتة فقط، وأن محاكاة طرق التفكير البشري لا تحقق سوى تحسينات في الأداء على المدى القصير. ويرى أن مستقبل الذكاء الاصطناعي يكمن في “عصر التجربة”، حيث يتعلم الـ Agent من خلال التفاعل المباشر (من منظور الشخص الأول) مع العالم للحصول على بيانات تجريبية، بدلاً من الاعتماد على البيانات البشرية الثابتة. يؤكد Sutton أن التعلم المعزز هو المسار الأساسي نحو هذا المستقبل، وبالاقتران مع خوارزميات التعلم العميق ذات التعلم المستمر والحوسبة واسعة النطاق القابلة للتوسع، سيمكن الذكاء الاصطناعي من تجاوز الإدراك الحالي وتحقيق ابتكار حقيقي. (المصدر: 量子位)

Hugging Face تتعاون مع NVIDIA لإطلاق “مجموعات التدريب كخدمة”، مما يقلل من عوائق تدريب النماذج الكبيرة: أعلنت Hugging Face عن تعاونها مع NVIDIA لإطلاق “مجموعات التدريب كخدمة” (Training Cluster as a Service)، بهدف تسهيل حصول المؤسسات البحثية العالمية على موارد مجموعات GPU الكبيرة لتدريب مختلف النماذج الرائدة. تدمج هذه الخدمة NVIDIA DGX Cloud Lepton وموارد تطوير Hugging Face، مما يسمح للمنظمات بطلب ودفع تكلفة استخدام مجموعات GPU حسب الحاجة والوقت. تهدف هذه الخطوة إلى سد “فجوة GPU بين الأغنياء والفقراء”، وتعزيز التنوع والانتشار في أبحاث الذكاء الاصطناعي، وقد تم اعتمادها مبكرًا من قبل مؤسسات بحثية وشركات ناشئة مثل TIGEM و Numina و Mirror Physics. (المصدر: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 التطورات
OpenAI تطلق نموذج o3-pro وتخفض أسعار o3 API بشكل كبير: أطلقت OpenAI نموذجها الجديد للاستدلال المتميز o3-pro، وأتاحته لمستخدمي ChatGPT Pro ومستخدمي API. وفي الوقت نفسه، تم تخفيض أسعار o3 API بشكل كبير بنسبة 80%، كما تمت مضاعفة حدود معدل استخدام o3 لمستخدمي ChatGPT Plus. تشير ملاحظات المجتمع إلى أن o3-pro يتفوق على Claude Opus 4 في المهام غير المتعلقة بالكود، وحقق أرقامًا قياسية جديدة في العديد من اختبارات الأداء القياسية مثل Extended NYT Connections و Creative Short Story Writing، بل ونجح في حل “مسألة برج هانوي ذات 10 أقراص” التي شككت ورقة بحثية سابقة لشركة Apple في قدرة نماذج اللغة الكبيرة على حلها. ولكن أفاد بعض المستخدمين أيضًا أن o3-pro أبطأ. صرحت OpenAI بأن تخفيض سعر o3 لم يتم عن طريق التقطير أو التكميم، بل بفضل جهود مهندسي الاستدلال في التحسين. (المصدر: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB تطلق سلسلة MiniCPM4 من نماذج اللغة الكبيرة الفعالة للأجهزة الطرفية: أطلقت OpenBMB سلسلة نماذج MiniCPM4، المصممة خصيصًا للأجهزة الطرفية، وتدعي أنها تحقق تسريعًا في التوليد يزيد عن 5 أضعاف على شرائح الأجهزة الطرفية النموذجية. تتضمن السلسلة إصدارات MiniCPM4-8B و MiniCPM4-0.5B بالإضافة إلى BitCPM4-1B/0.5B المكممة ثلاثيًا. يستخدم MiniCPM4 آلية الانتباه المتناثر القابلة للتدريب InfLLM v2، ويدعم معالجة النصوص الطويلة حتى 128K، ويجمع بين خوارزميات التعلم الفعالة وتقنيات التدريب مثل Model Wind Tunnel 2.0، والتكميم الثلاثي BitCPM، والحساب منخفض الدقة FP8، والتنبؤ متعدد الرموز. كما تم إطلاق مجموعة بيانات التدريب المسبق عالية الجودة باللغتين الصينية والإنجليزية UltraFineweb ومجموعة بيانات الضبط الدقيق الخاضع للإشراف UltraChat v2. (المصدر: GitHub Trending)
باحثون من MSRA وجامعتي تسينغهوا وبكين يقترحون نموذجًا جديدًا للتدريب المسبق المعزز (RPT): اقترح باحثون من Microsoft Research Asia (MSRA) بالتعاون مع جامعتي تسينغهوا وبكين نموذجًا جديدًا للتدريب المسبق لنماذج اللغة الكبيرة يسمى التدريب المسبق المعزز (RPT). تدمج هذه الطريقة التعلم المعزز (RL) بعمق في مرحلة التدريب المسبق، حيث يقوم النموذج بإنشاء تسلسل استدلال لسلسلة الأفكار قبل التنبؤ بكل رمز، ويحصل على مكافأة بناءً
على صحة التنبؤ. يهدف RPT إلى تحويل النموذج من تعلم الارتباطات السطحية للرموز إلى فهم المعاني العميقة، وأظهرت التجارب أن نموذج 14B المدرب بناءً على RPT يمكن أن يضاهي أو حتى يتفوق على نماذج التدريب المسبق التقليدية بحجم 32B في بعض مهام الاستدلال، مما يدل على إمكانات هائلة في تعزيز قدرات نمذجة اللغة والاستدلال لنماذج اللغة الكبيرة. (المصدر: 量子位, omarsar0)

Meta تطلق نموذج العالم المرئي V-JEPA 2 ومعايير قياسية جديدة: أطلقت Meta AI نموذج V-JEPA 2، وهو نموذج عالمي بـ 1.2 مليار معلمة تم تدريبه على بيانات الفيديو، ويهدف إلى تعزيز فهم الآلات للعالم المادي وقدرتها على التنبؤ به. يمكن لهذا النموذج أن يلعب دورًا في تخطيط الروبوتات بدون تدريب مسبق (zero-sample planning)، مما يمكنها من تخطيط وتنفيذ المهام في بيئات غير مألوفة. وفي الوقت نفسه، أصدرت Meta ثلاثة معايير قياسية جديدة لتقييم قدرة النماذج الحالية على استنتاج العالم المادي من الفيديو. وقد وفرت HuggingFace دعم مكتبة transformers لـ V-JEPA 2. (المصدر: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance تطلق نموذج توليد الفيديو Seedance 1.0 Pro، وهو متاح الآن على تطبيق Doubao: أطلقت ByteDance أحدث نموذج لها لتوليد الفيديو Seedance 1.0 Pro (المعروف أيضًا باسم نموذج Video 3.0 Pro في Dream Driver). يتميز هذا النموذج بأداء متميز في فهم المطالبات، وتفاصيل الصورة، واتساق الأداء المادي، ويمكنه إنشاء فيديو بدقة 1080P لمدة 5 ثوانٍ. حاليًا، النموذج متاح للمستخدمين من الشركات عبر Volcano Engine، وتم إطلاق ميزة “تحريك الصور” في تطبيق Doubao ليجربها المستخدمون مجانًا. (المصدر: op7418)
هواوي تطلق منصة محاكاة “نفق الرياح الرقمي” لتحسين كفاءة تدريب واستدلال الذكاء الاصطناعي: عرض فريق نمذجة ومحاكاة ماركوف في هواوي لأول مرة تقنية “نفق الرياح الرقمي”، وهي منصة لإجراء “بروفة” في بيئة افتراضية قبل التدريب الفعلي واستدلال نماذج الذكاء الاصطناعي المعقدة. تتضمن المنصة ثلاث وحدات رئيسية: Sim2Train (محاكاة التدريب)، و Sim2Infer (محاكاة الاستدلال)، و Sim2Availability (محاكاة التوفر العالي). وتهدف إلى حل مشكلات عدم تطابق موارد الأجهزة، واقتران النظام، وما إلى ذلك، من خلال المحاكاة والتحسين التلقائي، وبالتالي محاكاة حلول مجموعات عشرات الآلاف من البطاقات في غضون ساعات، وتجنب إهدار القدرة الحاسوبية، وتحسين كفاءة واستقرار تدريب واستدلال نماذج الذكاء الاصطناعي الكبيرة. (المصدر: 量子位)

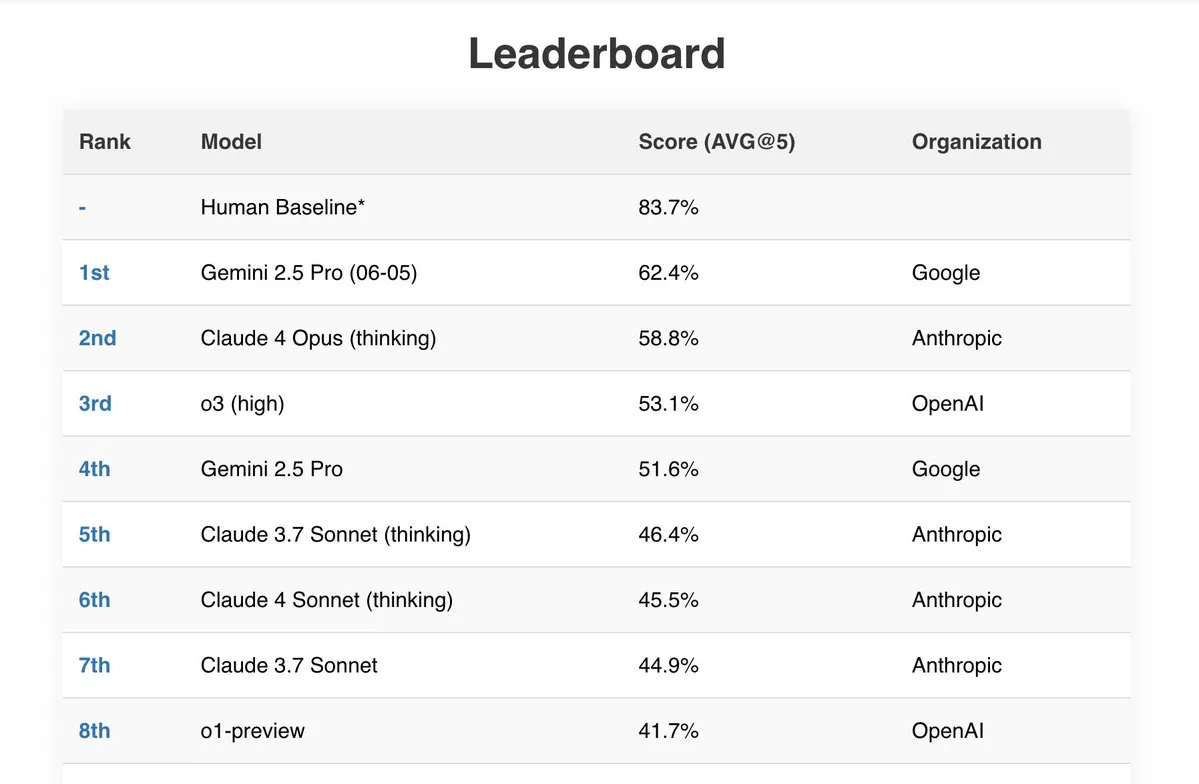
Gemini 2.5 Pro يحقق أداءً متميزًا في العديد من اختبارات الأداء القياسية: أظهر أحدث نموذج من جوجل Gemini 2.5 Pro (06-05) أداءً بارزًا في العديد من قوائم المتصدرين العامة للذكاء الاصطناعي. فقد حقق أفضل أداء في اختبار Live Fiction الذي يعالج 192 ألف توكن، واحتل المرتبة الأولى في SimpleBench بنسبة 62.4%، وأظهر قدرات قوية في معالجة المستندات وفعالية من حيث التكلفة في اختبارات الأداء القياسية مثل IDP (معالجة المستندات الذكية) و Aider (الترميز بمساعدة الذكاء الاصطناعي). بالإضافة إلى ذلك، أفاد بعض المستخدمين أن Gemini 2.5 Pro نجح في حل جميع مسائل قسم الرياضيات في امتحان JEE Advanced 2025. (المصدر: _philschmid, dilipkay)
تحديث نموذج الفيديو Kling AI بميزة مزامنة الشفاه، ودعم اختيار وتحرير الشخصيات: قامت أداة توليد الفيديو بالذكاء الاصطناعي Kling AI التابعة لشركة Kuaishou مؤخرًا بتحديث ميزة مزامنة الشفاه (Lip-sync). تسمح الميزة الجديدة للمستخدمين باختيار شخصيات معينة في الفيديو الذي تم إنشاؤه لمطابقة الشفاه، ويمكنها ضبط توقيت مزامنة الصوت مع حركة الفم. يعزز هذا التحديث مرونة وواقعية Kling AI في إنشاء مقاطع فيديو حوارية متعددة الشخصيات، ويعد تقدمًا مهمًا في مجال توليد الفيديو. (المصدر: Kling_ai, Kling_ai)
إصدار Delta Lake 4.0.0، معززًا قدرات Lakehouse: تم إطلاق إصدار Delta Lake 4.0.0 رسميًا، حاملاً معه العديد من الميزات الجديدة الهامة، بما في ذلك الإصدار التجريبي من جداول إدارة الكتالوج (Catalog-Managed Tables) لتحقيق حوكمة موحدة وقابلية للاكتشاف، وتوسيع Delta Connect لـ Spark Connect، ودعم نوع البيانات Variant لمعالجة البيانات شبه المهيكلة، وميزة DROP FEATURE الفورية، مما يسمح بإزالة ميزات الجدول دون اقتطاع السجل التاريخي أو التوقف عن العمل. يهدف هذا الإصدار إلى تحسين تجربة مجتمع lakehouse المفتوح. (المصدر: matei_zaharia)

Hugging Face تطلق خادم MCP لتبسيط التفاعل بين النماذج والأدوات: أصدرت Hugging Face الإصدار الأول من خادم بروتوكول سياق النموذج (MCP) الخاص بها. يمكن للمستخدمين الآن استخدام هذا الخادم عبر http://hf.co/mcp للبحث عن النماذج أو مجموعات البيانات أو الأوراق البحثية أو التطبيقات أو معلومات محددة داخل تطبيقات مثل Claude أو Cursor. يمثل هذا خطوة مهمة لـ Hugging Face في تعزيز قابلية التشغيل البيني للأدوات والنماذج في نظام الذكاء الاصطناعي البيئي، وقد يتم توسيعه في المستقبل ليشمل وظائف مثل التحميل والتنزيل وبدء طلبات السحب (PR). (المصدر: clefourrier, ClementDelangue)

بايدو تطلق “كاميرا AI” مدمجة مع التخزين والإدارة الذكية وترقية GenFlow Super Partner 2.0: أطلقت Baidu Netdisk و Baidu Wenku بالاشتراك ميزة “كاميرا AI”، التي تدمج التصوير والتخزين السحابي والإدارة الذكية. يمكن أرشفة الصور تلقائيًا في ألبوم سحابي، وتدعم التصنيف والبحث الذكي من خلال وصف اللغة الطبيعية. تتمتع كاميرا AI أيضًا بقدرات AI متنوعة مثل التجميل، والتعرف على الأشياء وتقديم معلومات عنها، وإنشاء رسومات الشعار المبتكرة، ومسح الفواتير، وتحويل الجداول المكتوبة بخط اليد. وفي الوقت نفسه، تمت ترقية منصة التعاون متعددة الوكلاء الذكية “GenFlow Super Partner” إلى الإصدار 2.0، والتي يمكنها دمج بيانات المستخدم وعاداته بشكل أعمق لتقديم خدمات إنشاء محتوى مخصصة. (المصدر: 量子位)

ByteDance تفتح مصدر كود وأوزان نموذج إصلاح الفيديو SeedVR2: أصدر فريق ByteDance SEED كود الاستدلال وأوزان النموذج الخاص به لإصلاح الفيديو بخطوة واحدة SeedVR2، وهو متاح الآن على Hugging Face. يستخدم هذا النموذج تقنية التدريب اللاحق التنافسي القائم على الانتشار (diffusion adversarial post-training)، وحقق نتائج ملحوظة في استعادة الفيديو، خاصة في معالجة الفيديو عالي الدقة. (المصدر: _akhaliq)
GroqCloud تضيف نموذج Qwen3-32B، يدعم أكثر من مائة لغة وسياق 131k: أعلنت Groq عن إضافة نموذج Tongyi Qianwen Qwen3-32B إلى منصتها السحابية للاستدلال القائمة على LPU، GroqCloud. يدعم هذا النموذج أكثر من 100 لغة ولهجة، ويتميز بنافذة سياق تبلغ 131k، ويعمل بالسرعة الفورية التي تتميز بها أجهزة Groq، مما يوفر للمطورين قدرات قوية لمعالجة اللغات المتعددة والنصوص الطويلة. (المصدر: JonathanRoss321)
Sam Altman، الرئيس التنفيذي لـ OpenAI، يقول إن إطلاق نموذجهم مفتوح الأوزان سيتأخر: صرح Sam Altman بأن نموذج OpenAI مفتوح الأوزان سيتأخر إطلاقه حتى أواخر الصيف الحالي، بدلاً من الموعد المقرر في يونيو. وكشف أن فريق البحث حقق بعض التقدم “غير المتوقع والمذهل للغاية” الذي يستحق الانتظار، ولكنه يحتاج إلى مزيد من الوقت لإتقانه. (المصدر: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

روبوت Digua يطلق مجموعة تطوير RDK S100، بدمج بنية المخ والمخيخ في شريحة SoC واحدة: أطلقت شركة Digua Robot أول مجموعة تطوير روبوتات متكاملة للحوسبة والتحكم في شريحة SoC واحدة في الصناعة، RDK S100. تعتمد هذه المجموعة تصميم بنية تعاونية غير متجانسة فائقة تشبه المخ والمخيخ البشري (وحدة معالجة مركزية Arm Cortex-A78AE سداسية النواة + BPU بقوة 80 TOPS كـ “مخ”، ووحدة تحكم دقيقة Arm Cortex-R52+ رباعية النواة كـ “مخيخ”)، وتدعم التعاون الفعال بين النماذج الكبيرة والصغيرة للذكاء المتجسد، وتكمل الحلقة المغلقة “الإدراك – اتخاذ القرار – التحكم”. توفر RDK S100 واجهات غنية وبنية تحتية كاملة للتطوير، بسعر بيع مسبق يبلغ 2499 يوان. (المصدر: 量子位)

Aibook Smart تطلق وحدة الحوسبة E300 AI، مزودة بشريحة SoC محلية بقوة 50TOPS: أطلقت Aibook Smart وحدة الحوسبة E300 AI الموجهة لسيناريوهات الحافة، والمزودة بشريحة AI SoC المطورة ذاتيًا AB100. توفر هذه الوحدة قدرة حوسبة تصل إلى 50TOPS بدقة INT8، وتدعم الحساب بدقة مختلطة FP16/FP32، ومجهزة بنطاق ترددي لذاكرة LPDDR5 يبلغ 102 جيجابايت/ثانية. تعتمد E300 تصميمًا معياريًا، وتهدف إلى توفير حلول AI طرفية محلية عالية الأداء ومنخفضة الكمون وقوية الموثوقية لقطاعات مثل التعليم والطاقة والرعاية الصحية، وتدعم النماذج الكبيرة مفتوحة المصدر السائدة ونماذج الرؤية والصوت المتنوعة للنشر على الحافة. (المصدر: 量子位)

هواوي تكشف عن تقنية التوفر العالي لمجموعات Ascend ذات عشرات الآلاف من البطاقات، محققة نسبة توفر تدريب 98%: كشفت هواوي لأول مرة عن تفاصيل تقنية التوفر العالي لمجموعات حوسبة Ascend التي تضم عشرات الآلاف من البطاقات. من خلال ثلاث قدرات أساسية هي استشعار وتشخيص الأعطال، وإدارة الأعطال، وتحمل أخطاء الروابط الضوئية للمجموعة، بالإضافة إلى قدرات دعم الأعمال مثل تحسين الخطية للمجموعة، والاسترداد السريع للتدريب والاستدلال، حققت هواوي نسبة توفر تدريب لمجموعات عشرات الآلاف من البطاقات تصل إلى 98%، وخطية تتجاوز 95%، واسترداد أعطال في غضون ثوانٍ، وتشخيص في غضون دقائق. يهدف هذا النظام التقني ثنائي الأبعاد “3+3” إلى ضمان التشغيل المستقر والفعال لتدريب واستدلال الذكاء الاصطناعي على نطاق واسع. (المصدر: 量子位)

معدل انتشار القيادة الذكية في سيارات BYD الجديدة يصل إلى 79%، ونظام NOA عالي السرعة يصبح تجهيزًا أساسيًا: أظهرت أحدث البيانات الصادرة عن BYD أن نسبة الطرازات المزودة بأنظمة مساعدة القيادة الذكية (التي تتمتع على الأقل بوظيفة NOA عالية السرعة ومواقف السيارات الآلية) في السيارات الجديدة التي باعتها في مايو بلغت 79%. يشير هذا إلى أن BYD تحقق تقدمًا ملحوظًا في استراتيجيتها “القيادة الذكية للجميع”، وأن وظائف القيادة الذكية أصبحت بسرعة تجهيزًا قياسيًا في طرازاتها. يعكس هذا الاتجاه أيضًا تسارع وتيرة انتشار تكنولوجيا القيادة الذكية في سوق السيارات الصيني. (المصدر: 量子位)

ميزة الصوت المتقدمة في ChatGPT متاحة لجميع المستخدمين المدفوعين: أعلنت OpenAI أن ميزة الصوت المتقدمة (Advanced Voice) في ChatGPT، التي تم تحديثها سابقًا بقدرة طبيعية أقوى، أصبحت متاحة الآن لجميع المستخدمين المدفوعين (ChatGPT Plus, Team, Enterprise). يمكن للمستخدمين من خلال هذه الميزة التفاعل صوتيًا بشكل أكثر طبيعية مع ChatGPT. (المصدر: juberti)
🧰 الأدوات
إطلاق متصفح Genspark AI، مدمج مع العديد من وظائف الوكلاء الأذكياء: أطلق فريق Eric Jing متصفح Genspark AI، الذي يُقال إنه تم إنشاؤه بواسطة فريق مكون من 24 شخصًا في غضون 10 أسابيع، ويدمج 8 منتجات رئيسية: متصفح AI، وسكرتير AI، ومكالمات شخصية AI، ووكيل تنزيل AI، و AI Drive، و AI Sheets. يتميز هذا المتصفح بالسرعة، وحظر الإعلانات، والتحول الكامل إلى وكيل ذكي، ووضع القيادة الذاتية، ويحتوي على متجر MCP مدمج ووكيل فائق الذكاء، بهدف توفير تجربة تصفح وعمل مدعومة بالذكاء الاصطناعي شاملة. (المصدر: blader)
Yutori AI تطلق منصة Scouts لمراقبة شبكة الإنترنت بواسطة وكلاء AI: أطلقت Yutori AI منصة Scouts، التي تسمح للمستخدمين بإنشاء وكلاء AI يعملون باستمرار لمراقبة تحديثات معلومات معينة على شبكة الإنترنت. يمكن لهذه الوكلاء تتبع مختلف المحتويات التي يهتم بها المستخدمون، مثل الأخبار المتخصصة، وتغيرات أسعار السلع، ومعلومات التذاكر، وما إلى ذلك، وتنبيه المستخدمين عبر البريد الإلكتروني في اللحظات الحاسمة، بهدف تحرير المستخدمين من خلال أتمتة تتبع المعلومات. (المصدر: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face تطلق AISheets، لدمج نماذج AI مع جداول البيانات: أطلقت Hugging Face تطبيق AISheets، الذي يدمج آلاف نماذج الذكاء الاصطناعي (خاصة نماذج اللغة الكبيرة مفتوحة المصدر) مع وظائف جداول البيانات. يمكن للمستخدمين بناء وتحليل وأتمتة معالجة البيانات في AISheets، بهدف توفير تجربة معالجة بيانات مدعومة بالذكاء الاصطناعي سلسة وسريعة وبسيطة. (المصدر: ben_burtenshaw, LoubnaBenAllal1)
PLaMo تطلق أداة ترجمة محلية عبر واجهة سطر الأوامر (CLI)، مبنية على MLX: قام فريق PLaMo LLM بفتح مصدر أداة واجهة سطر الأوامر (CLI) يمكنها تحقيق ترجمة نصوص محلية على أجهزة Mac المزودة بمعالجات Apple Silicon باستخدام إطار عمل MLX. تهدف هذه الأداة إلى توفير تجربة ترجمة محلية سريعة وعالية الدقة، وتحتوي على خادم وعميل HTTP و MCP مدمجين، مما يسهل التكامل مع تطبيقات أخرى متوافقة مع MCP (مثل Claude Desktop). (المصدر: awnihannun)
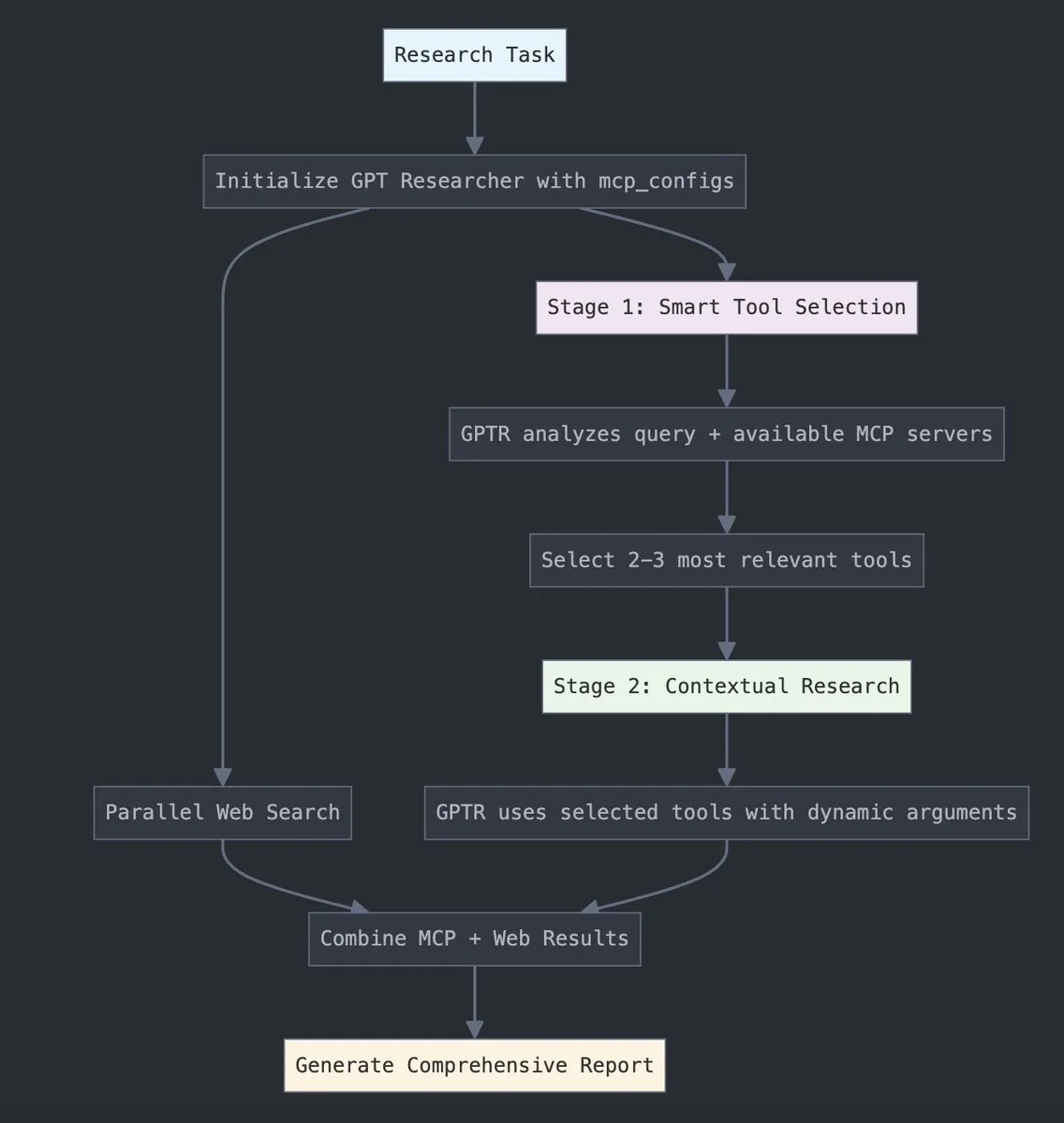
GPT Researcher يدمج محول LangChain MCP لتعزيز اختيار الأدوات وقدرات البحث: يستخدم GPT Researcher الآن محول بروتوكول سياق النموذج (MCP) الخاص بـ LangChain لتحقيق اختيار أدوات وعمليات بحث أكثر ذكاءً. تهدف هذه الخطوة إلى دمج مزايا MCP مع قدرات البحث على الويب لإجراء جمع وتحليل بيانات أكثر شمولاً. (المصدر: Hacubu)
Consilium: إطلاق إطار عمل مفتوح المصدر لتعاون الوكلاء الأذكياء المتعددين: أطلق Victor M إطار Consilium، وهو إطار عمل مفتوح المصدر لتعاون فرق الوكلاء الأذكياء. يمكن للمستخدمين تحديد الاستراتيجيات، والسماح لعدة وكلاء خبراء بالمناقشة، واستخدام الأبحاث في الوقت الفعلي (الويب، arXiv، بيانات SEC) لحل المشكلات المعقدة بشكل مشترك والتوصل إلى توافق في الآراء. الأداة متاحة كعرض توضيحي على Hugging Face. (المصدر: clefourrier)
youtube-transcript-api: مكتبة Python للحصول على نصوص يوتيوب، تدعم الترجمة وإنشاء المحتوى تلقائيًا: تحظى مكتبة Python youtube-transcript-api التي طورها jdepoix بالاهتمام على GitHub. يمكن لهذه الـ API الحصول على نصوص مقاطع فيديو YouTube، بما في ذلك النصوص التي يتم إنشاؤها تلقائيًا، وتدعم وظيفة الترجمة. على عكس الحلول الأخرى القائمة على Selenium، لا تتطلب مفتاح API أو متصفحًا بدون واجهة رسومية، مما يوفر للمطورين وسيلة مريحة لاستخراج محتوى الفيديو النصي. (المصدر: GitHub Trending)
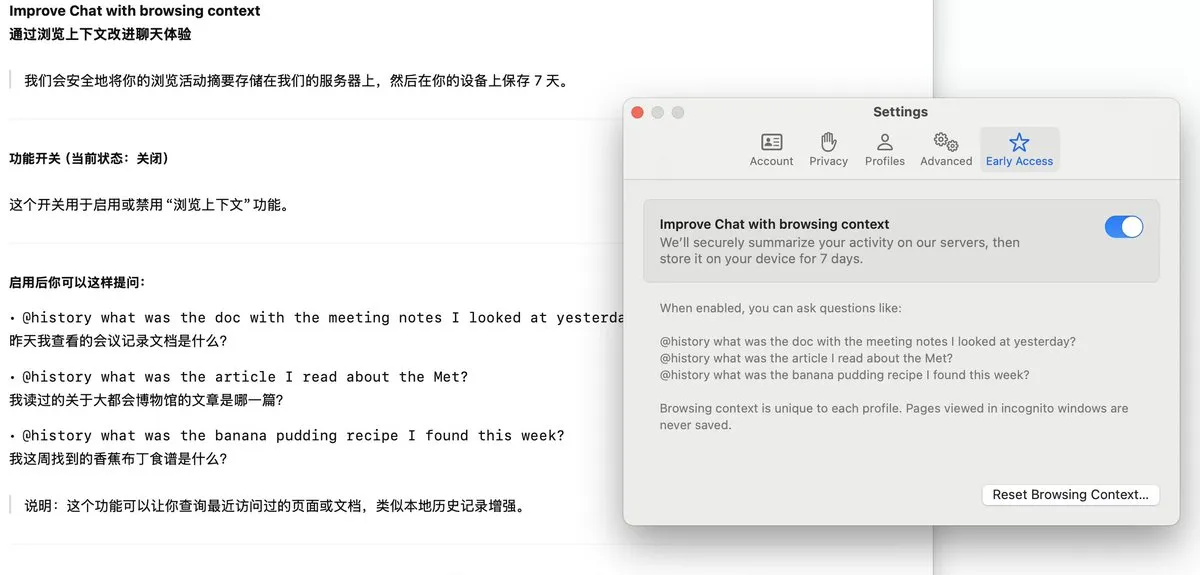
متصفح Arc يطلق ميزة Dia لتسجيل سجل التصفح ودعم الأسئلة والأجوبة بالذكاء الاصطناعي: أضاف متصفح Arc ميزة Dia، التي عند تفعيلها، تسجل باستمرار كل سجل تصفح المستخدم. يمكن للمستخدمين من خلال ميزة @History استخدام لغة طبيعية غامضة لطرح الأسئلة للعثور على معلومات تم تصفحها سابقًا ولكن تم نسيان عنوان URL المحدد لها. قد تدعم هذه الميزة حتى إنشاء تقارير سجل التصفح، مما يعزز ذكاء المتصفح وقدرته على إدارة المعلومات الشخصية. (المصدر: op7418)
📚 أبحاث ودراسات
Apple تنشر ورقة بحثية بعنوان “وهم التفكير”، تناقش حدود قدرات نماذج اللغة الكبيرة (LLM): نشر فريق أبحاث تعلم الآلة في Apple ورقة بحثية بعنوان “وهم التفكير” (The Illusion of Thinking)، تحلل أداء وحدود نماذج اللغة الكبيرة (LLM) الحالية في مهام الاستدلال المعقدة (مثل حل مسألة برج هانوي). أثارت هذه الورقة نقاشًا في المجتمع حول المستوى الحقيقي لذكاء نماذج اللغة الكبيرة، وهناك آراء ترى أن هذا النوع من الأبحاث يُستخدم أحيانًا كذريعة لتأخير تبني الذكاء الاصطناعي. لاحقًا، نجح نموذج o3-pro من OpenAI في حل معضلة برج هانوي التي طرحتها الورقة. (المصدر: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
بحث جديد بعنوان “الوكلاء العامون يحتاجون إلى نماذج عالمية” يناقش العلاقة بين تعميم الوكلاء ونماذج التنبؤ: تشير ورقة بحثية جديدة بعنوان “الوكلاء العامون يحتاجون إلى نماذج عالمية” (General agents need world models) إلى أن الوكلاء العامين القادرين على التعميم على المهام الموجهة نحو الأهداف متعددة الخطوات يجب أن يتعلموا نموذجًا عالميًا تنبئيًا. يتم ترميز هذا النموذج في استراتيجية الوكيل، وتثبت الورقة البحثية العلاقة المباشرة بين القدرة على التعميم ودقة النموذج المتعلم من خلال الاستعلام عن اختيارات استراتيجية الوكيل في ظل الأهداف المركبة لاستخلاص احتمالات انتقال البيئة. (المصدر: menhguin)

ورقة بحثية تناقش الضبط الدقيق المدرك للمفاهيم (CAFT) لتحسين أداء نماذج اللغة الكبيرة (LLM): تقترح ورقة بحثية جديدة بعنوان “تحسين نماذج اللغة الكبيرة باستخدام الضبط الدقيق المدرك للمفاهيم” (Improving large language models with concept-aware fine-tuning) طريقة CAFT، التي تهدف إلى تحسين فهم النموذج للمفاهيم من خلال تمكين التنبؤ متعدد الرموز أثناء الضبط الدقيق. أظهر البحث أن CAFT يحقق مكاسب أداء كبيرة في مهام مثل الترميز، والرياضيات، وتلخيص النصوص، وتوليد الجزيئات، وتصميم البروتينات. تم فتح مصدر الكود على GitHub. (المصدر: Reddit r/MachineLearning)
DeepLearning.AI تطلق دورة جديدة بعنوان “تنظيم سير عمل تطبيقات GenAI”: أطلقت DeepLearning.AI التابعة لـ Andrew Ng بالتعاون مع Astronomer دورة تدريبية قصيرة جديدة بعنوان “تنظيم سير عمل تطبيقات GenAI” (Orchestrating Workflows for GenAI Applications). تعلم هذه الدورة كيفية بناء عمليات GenAI موثوقة باستخدام أداة Airflow 3.0 مفتوحة المصدر الشائعة، وتحويل نماذج Jupyter Notebook الأولية أو نصوص Python إلى سير عمل جاهز للإنتاج، وتغطي موضوعات مثل تقسيم المهام، والجدولة، والتنفيذ المتوازي، واستعادة الأعطال، وقابلية الملاحظة. (المصدر: AndrewYNg)
ورقة بحثية بعنوان “محاذاة النصوص والصور والهياكل ثلاثية الأبعاد كلمة بكلمة” تستكشف النماذج التوليدية الذاتية متعددة الوسائط: يقترح هذا البحث إطار عمل موحد لنماذج اللغة الكبيرة (LLM) يهدف إلى محاذاة اللغة والصور والمشاهد ثلاثية الأبعاد المهيكلة. تشرح الورقة بالتفصيل خيارات التصميم الرئيسية لتحقيق أفضل تدريب وأداء، بما في ذلك تمثيل البيانات، ووظائف الهدف الخاصة بكل وسيط، وما إلى ذلك، وتم تقييمها على أربع مهام أساسية ثلاثية الأبعاد وبيانات متعددة، بما في ذلك العرض، والتعرف، واتباع التعليمات، والإجابة على الأسئلة. يمتد البحث أيضًا إلى إعادة بناء أشكال الكائنات ثلاثية الأبعاد المعقدة من خلال ترميز الأشكال المكممة. (المصدر: HuggingFace Daily Papers)
ورقة بحثية بعنوان “Squeeze3D”: استخدام نماذج توليد ثلاثية الأبعاد مدربة مسبقًا لتحقيق ضغط عصبي فائق: يستفيد إطار عمل Squeeze3D من المعرفة المسبقة الضمنية المكتسبة في نماذج التوليد ثلاثية الأبعاد المدربة مسبقًا لضغط البيانات ثلاثية الأبعاد (الشبكات، السحب النقطية، حقول الإشعاع) بشكل كبير. يقوم بذلك عن طريق شبكة تخطيط قابلة للتدريب تربط بين المشفر المدرب مسبقًا والفضاء الكامن لنموذج التوليد، مما يضغط النماذج ثلاثية الأبعاد إلى أكواد كامنة مدمجة، وعند فك الضغط، يعيد نموذج التوليد بناءها. يتم تدريب هذه الطريقة على بيانات اصطناعية، دون الحاجة إلى مجموعات بيانات ثلاثية الأبعاد حقيقية، وتحقق معدل ضغط للشبكات المزخرفة يصل إلى 2187 ضعفًا. (المصدر: HuggingFace Daily Papers)
ورقة بحثية بعنوان “توجيه الإطارات”: تحكم على مستوى الإطار بدون تدريب في نماذج انتشار الفيديو: يقترح هذا البحث “توجيه الإطارات” (Frame Guidance)، وهو طريقة لتحقيق التحكم على مستوى الإطار في نماذج انتشار الفيديو دون الحاجة إلى تدريب. من خلال معالجة بسيطة للفضاء الكامن واستراتيجية مبتكرة لتحسين الفضاء الكامن، يمكن لهذه الطريقة التحكم بفعالية في الإشارات على مستوى الإطار مثل الإطارات الرئيسية، ومراجع الأسلوب، والرسومات التخطيطية، أو خرائط العمق، وهي مناسبة لمهام متنوعة مثل التوجيه بالإطارات الرئيسية، والتنميط، والتشغيل المتكرر، ومتوافقة مع أي نموذج فيديو. (المصدر: HuggingFace Daily Papers)
ورقة بحثية بعنوان “التحيزات الجيوسياسية في نماذج اللغة الكبيرة” تكشف عن مواقف النماذج تجاه الدول: يقيم هذا البحث التحيزات الجيوسياسية في نماذج اللغة الكبيرة (LLM) من خلال تحليل تفسيرات هذه النماذج للأحداث التاريخية من وجهات نظر دول مختلفة (أمريكا، بريطانيا، الاتحاد السوفيتي، الصين). قدم الباحثون مجموعة بيانات جديدة تحتوي على أوصاف محايدة للأحداث وآراء متناقضة للدول، ووجدوا أن نماذج اللغة الكبيرة تظهر تحيزًا كبيرًا لصالح روايات دول معينة، وأن التوجيهات البسيطة لإزالة التحيز ذات تأثير محدود. يوفر هذا العمل إطارًا ومجموعة بيانات لأبحاث التحيز الجيوسياسي المستقبلية. (المصدر: HuggingFace Daily Papers)
مستودع Awesome Lists يستمر في التحديث، ويضم مواضيع متنوعة ومثيرة للاهتمام: مشروع awesome على GitHub الذي يحتفظ به sindresorhus هو قائمة وصفية (meta-list) تجمع “قوائم Awesome” حول مواضيع متنوعة ومثيرة للاهتمام. تغطي هذه القوائم العديد من المجالات بدءًا من لغات البرمجة ومنصات التطوير إلى النظريات والكتب والأدوات، مما يوفر للمطورين والمتعلمين فهرسًا غنيًا بالموارد. (المصدر: GitHub Trending)
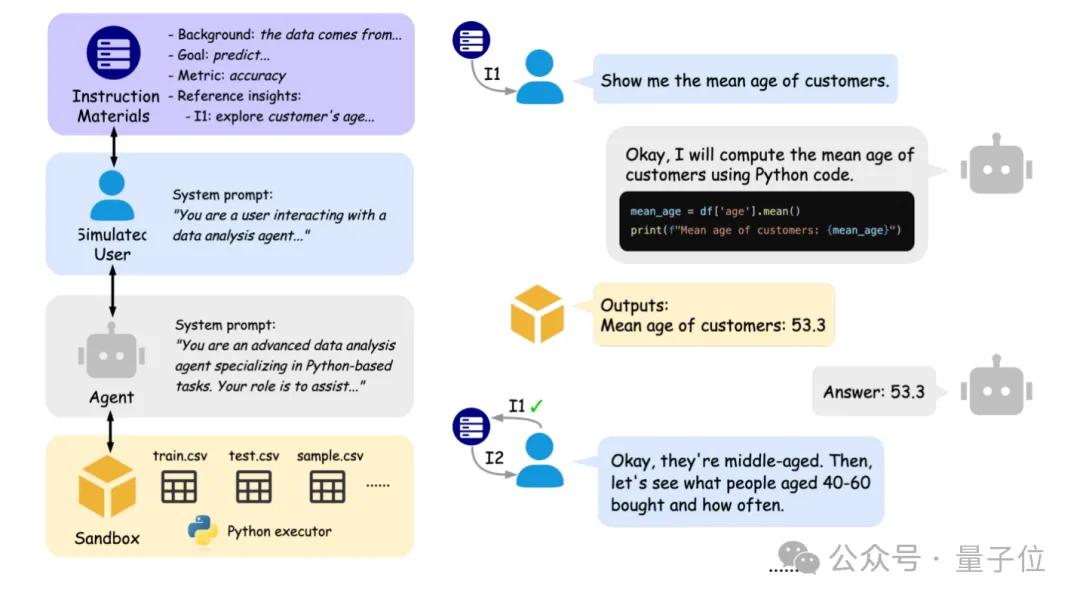
جامعتا بكين وبيركلي تطلقان IDA-Bench لتقييم قدرة وكلاء تحليل البيانات بالذكاء الاصطناعي على التفاعل: أطلق فريق بحثي من جامعة بكين وجامعة كاليفورنيا في بيركلي (بما في ذلك البروفيسور Michael I. Jordan) IDA-Bench، وهو معيار جديد يهدف إلى تقييم قدرة نماذج اللغة الكبيرة (LLM) كوكلاء لتحليل البيانات (Agent) في سيناريوهات التفاعل متعدد الجولات. يحاكي هذا المعيار سير عمل محللي البيانات الحقيقيين، ويفحص قدرة الوكيل على اتباع التعليمات، وكتابة وتنفيذ الأكواد من خلال تعليمات تتطور تدريجيًا. أظهر التقييم الأولي أنه حتى أفضل النماذج مثل Claude-3.7 و Gemini-2.5 Pro، لم يتجاوز معدل نجاح المهام 40%، مما يكشف عن التحديات الحالية التي تواجه الوكلاء في التفاعل المعقد واتباع التعليمات. (المصدر: 量子位)
💼 أعمال
xAI تتعاون مع Polymarket لدمج توقعات السوق مع تحليلات Grok: أعلنت شركة xAI التابعة لـ Elon Musk عن شراكة مع منصة أسواق التنبؤ Polymarket. سيجمع الطرفان بين قدرات Polymarket في توقعات السوق، وبيانات منصة X، وقدرات تحليل نموذج Grok، بهدف بناء “محرك الحقيقة المتشدد” (Hardcore truth engine) لاستكشاف العوامل التي تشكل العالم. وصرح المسؤولون بأن هذه مجرد بداية للتعاون، وسيكون هناك المزيد من التطورات في المستقبل. (المصدر: Yuhu_ai_)
UnslothAI تُصنف من قبل Redpoint كواحدة من أفضل شركات البنية التحتية، وتظهر على شاشة Nasdaq الكبيرة: تم اختيار شركة الذكاء الاصطناعي الناشئة UnslothAI من قبل شركة رأس المال الاستثماري Redpoint كواحدة من أكثر 100 شركة بنية تحتية تأثيرًا والأسرع نموًا لعام 2025، وذلك لمساهماتها في مجال البنية التحتية للذكاء الاصطناعي، ونتيجة لذلك، ظهر شعارها على الشاشات الإلكترونية لمبنى Nasdaq في نيويورك. تركز UnslothAI على تحسين كفاءة تدريب واستدلال نماذج اللغة الكبيرة (LLM). (المصدر: danielhanchen, karminski3)

Ant Digital تطور مختبر Tianji، مع التركيز على “AI + الابتكار الصناعي”: أعلنت Ant Digital عن ترقية مختبر Tianji الخاص بها من “مختبر أمن الهوية الرقمية” السابق إلى مختبر “الذكاء الاصطناعي + الابتكار الصناعي”. سيركز المختبر المطور على البحث في الاختراقات التقنية الرئيسية لنماذج الذكاء الاصطناعي الكبيرة في التطبيقات الصناعية، مع التركيز على أربعة اتجاهات: AI + البيانات، AI + الأمن، AI + التمويل، و AI + الذكاء المتجسد، بهدف تعزيز التكامل العميق بين تكنولوجيا الذكاء الاصطناعي والصناعة من خلال الابتكار التعاوني بين البحث الأكاديمي والصناعة والتطبيق. (المصدر: 量子位)

🌟 المجتمع
قدرة القيادة الذاتية بالذكاء الاصطناعي في بيئات المرور المعقدة تحظى بالاهتمام: شارك Ronald van Loon مقطع فيديو لاختبار القيادة الذاتية في حركة المرور الفوضوية في الهند، مما أثار نقاشًا حول قدرات الذكاء الاصطناعي على الإدراك واتخاذ القرار والتحكم في البيئات المعقدة والديناميكية للغاية. تطرح مثل هذه السيناريوهات الواقعية متطلبات عالية للغاية على متانة وقدرة أنظمة القيادة الذاتية على التكيف. (المصدر: Ronald_vanLoon)
أبرز نقاط مؤتمر AI Engineer World’s Fair: بروتوكول MCP، تكلفة وكلاء AI، والنماذج المحلية في دائرة الضوء: شارك Yogi و Shawn “swyx” Wang وآخرون النقاط الرئيسية من مؤتمر AI Engineer World’s Fair. تشمل الاتجاهات الأساسية: 1) وكلاء AI هم المستقبل، وستكون وحدة التفاعل الذرية هي استدعاء الوكيل؛ 2) بروتوكول سياق النموذج (MCP) أصبح بسرعة معيارًا، لحل “جحيم النسخ واللصق”، مما يمكّن الذكاء الاصطناعي من التفاعل مباشرة مع التطبيقات الخارجية؛ 3) بناء أدوات AI محسّنة بعمق لمجالات وسير عمل محددة (نمط Cursor-for-X) هو المفتاح؛ 4) انخفاض تكلفة النماذج بشكل كبير، وتعزيز قدرات النماذج المحلية، مما يوفر للمطورين تحكمًا أكبر وحلولًا ذات زمن انتقال منخفض؛ 5) يتطور الذكاء الاصطناعي من أداة مساعدة إلى “زميل فريق” للمطورين؛ 6) تنتقل هندسة الذكاء الاصطناعي من مرحلة العروض التوضيحية إلى أنظمة جاهزة للإنتاج. (المصدر: swyx, TheTuringPost)
المجتمع يناقش التكرار السريع بعد إطلاق o3-pro وورقة Apple البحثية حول الذكاء الاصطناعي: علق andersonbcdefg بشكل فكاهي قائلاً إنه بعد 6 ساعات فقط من إطلاق o3-pro، يبدو أن المجتمع يتوقع من شخص ما إعادة كتابة fastText بلغة Rust، وسخر من الأطروحات الطويلة حول “الذكاء الفائق المعتدل”، مما يعكس سرعة التطور التكنولوجي الهائلة في مجال الذكاء الاصطناعي والتوقعات العالية للمجتمع. وفي الوقت نفسه، أشار Teknium1 إلى أن o3-pro حل معضلة برج هانوي التي طرحتها ورقة Apple البحثية “وهم التفكير”، وتساءل لماذا لم تقم Apple و OpenAI بالتحقق الداخلي أولاً قبل نشر مثل هذه الأوراق البحثية في سياق تعاونهما، مما أثار نقاشًا في المجتمع حول علاقات المنافسة والتعاون بين شركات التكنولوجيا. (المصدر: andersonbcdefg, Teknium1)
نقاش حول أخلاقيات وفعالية تطبيقات الذكاء الاصطناعي في العالم الحقيقي: ناقش المجتمع فعالية تطبيقات الذكاء الاصطناعي في سيناريوهات محددة والقضايا الأخلاقية المتعلقة بها. على سبيل المثال، أشار Arvind Narayanan إلى أن مفهوم تطبيقات حساب السعرات الحرارية بالذكاء الاصطناعي معيب في حد ذاته، حيث أن معلومات الصورة غير كافية لتقدير السعرات الحرارية بدقة، معتبرًا أنها أشبه بـ “طقوس” تساعد المستخدمين على تكوين عادات الانتباه إلى نظامهم الغذائي. بالإضافة إلى ذلك، أصبح النقاش حول ما إذا كان استخدام الصور التي تم إنشاؤها بواسطة الذكاء الاصطناعي للدعاية التجارية (مثل عرض أطباق المقاهي) أخلاقيًا أو مقبولًا، نقطة نقاش، مع إجماع عام على أنه طالما لا يوجد تحريف واضح أو تضليل، فإنه يعتبر وسيلة مقبولة لخفض التكاليف وزيادة الكفاءة. (المصدر: random_walker, Reddit r/artificial)
“أنسنة” نماذج اللغة الكبيرة (LLM) وتجربة تفاعل المستخدم تصبحان محور الاهتمام: ناقش مستخدمو مجتمع Reddit كيفية جعل تفاعل نماذج اللغة الكبيرة (LLM) أشبه بالتفاعل البشري الحقيقي، بما في ذلك إدخال التردد، والتوقفات، والردود الأقصر، والتعبير غير المثالي. يعكس هذا حاجة المستخدمين إلى رفيق أو مساعد AI أكثر طبيعية وأقل “روبوتية”. وفي الوقت نفسه، اشتكى بعض المستخدمين من أن نماذج اللغة الكبيرة الحالية (مثل ChatGPT) تستخدم غالبًا صيغًا ثابتة وتعبيرات مبالغ فيها (مثل “هذا ليس مجرد X، بل هو Y”)، معربين عن أملهم في أن يكون تعبيرها أكثر إيجازًا ومباشرة. تشير هذه المناقشات إلى التحديات المستمرة التي تواجه نماذج اللغة الكبيرة في محاكاة الحوار البشري وتلبية الاحتياجات العاطفية للمستخدمين. (المصدر: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 متفرقات
Jensen Huang، الرئيس التنفيذي لـ NVIDIA، سيلقي كلمة رئيسية في GTC Paris، مع التركيز على المرحلة الجديدة من حوسبة الذكاء الاصطناعي: أعلنت NVIDIA أن رئيسها التنفيذي Jensen Huang سيلقي كلمة رئيسية في مؤتمر GTC في باريس في 11 يونيو (خلال VivaTech 2025). من المتوقع أن يكشف عن المرحلة التالية من حوسبة الذكاء الاصطناعي، والتي تغطي موضوعات متطورة من الأنظمة الوكيلة إلى مصانع الذكاء الاصطناعي. (المصدر: nvidia, nvidia)

قمة Databricks Data+AI ستعرض أحدث الإنجازات: أعلنت Databricks أن قمتها Data+AI Summit ستجمع كبار الخبراء والباحثين والمساهمين في المصادر المفتوحة لعرض أحدث إنجازات الشركة في مجالي البيانات والذكاء الاصطناعي، ومشاركة قصص نجاح الشركات المبتكرة. توفر القمة إمكانية المشاركة عبر الإنترنت وحضوريًا. (المصدر: matei_zaharia, lateinteraction)

التأثيرات الأخلاقية والبيئية للذكاء الاصطناعي تثير الاهتمام، وتوعية في شكل رواية مصورة: أطلق مركز LEARN التابع لـ EPFL (المعهد الفدرالي السويسري للتكنولوجيا في لوزان) بالتعاون مع الرسام Herji رواية مصورة تعليمية باللغة الفرنسية بعنوان “Utop’IA”، تهدف إلى توعية المراهقين بالتأثيرات البيئية للذكاء الاصطناعي من خلال قصة، بما في ذلك استهلاكه للموارد (الطاقة، المياه، المعادن النادرة) وفوائده البيئية المحتملة. يؤكد العمل على التفكير النقدي ويناقش مسارات تطوير الذكاء الاصطناعي المستدام. (المصدر: aihub.org)
