
Schlüsselwörter:Große Sprachmodelle, Schlussfolgerungsfähigkeit, KI-Sicherheit, Multimodale Modelle, Open-Source-Modelle, KI-Videogenerierung, KI-Bewertung, Kommerzielle Anwendungen von KI, Apple LLM Schlussfolgerungsfähigkeitsforschung, Time-R1 Zeitverständnismodell, NVIDIA Blackwell GPU Videogenerierung, Alibaba Tongyi Qianwen 3 Open-Source-Modell, Hugging Face MCP-Server
🔥 Fokus
Apple veröffentlicht Studie, die besagt, dass aktuelle große Sprachmodelle nur eine „Illusion des Denkens“ und keine echten Reasoning-Fähigkeiten besitzen, was zu hitzigen Diskussionen in der Branche führt: Forscher von Apple (darunter Samy Bengio, einer der Gründer von Google Brain) veröffentlichten eine Studie, die durch Tests mit vier Aufgaben kontrollierbarer Schwierigkeit wie den Türmen von Hanoi und dem Checker-Swapping aufzeigt, dass Spitzenmodelle wie DeepSeek, o3-mini und Claude 3.7 bei hochkomplexen Problemen „zusammenbrechen“ und ein „umgekehrtes Skalieren der Reasoning-Anstrengung“ zeigen (je schwieriger das Problem, desto weniger wird nachgedacht). Die Studie argumentiert, dass diese Modelle eher auf Mustererkennung und Gedächtnis basieren als auf echtem, generalisierbarem logischem Denken und selbst mit vollständigen Algorithmen die Komplexitätsgrenze nicht überwinden können. Diese Ansicht stellt das derzeitige Verständnis der Reasoning-Fähigkeiten von LLMs in Frage und hat eine breite Diskussion über Bewertungsmethoden für LLMs, die Grenzen ihrer tatsächlichen Reasoning-Fähigkeiten und zukünftige Entwicklungsrichtungen ausgelöst. Die Reaktionen in der Community sind gemischt: Einige sehen darin eine Verteidigung von Apple für die eigenen langsamen Fortschritte im Bereich KI, während andere die Erkenntnisse zu Bewertungsmechanismen und den inhärenten Grenzen der Modelle anerkennen (Quelle: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

Turing-Preisträger Yoshua Bengio warnt vor Risiken unkontrollierbarer KI und richtet Forschungsschwerpunkt auf „Wissenschaftler-KI“: Yoshua Bengio erklärte auf der智源大会 (Zhiyuan Konferenz), dass er angesichts der rasanten Entwicklung von KI (insbesondere AGI) und deren potenziellen Risiken der Unkontrollierbarkeit (z. B. dass KI ihren eigenen Code kopiert oder Verhalten verbirgt, um zu „überleben“) seine Forschungsrichtung angepasst habe und sich nun auf die Entwicklung einer „Wissenschaftler-KI“ konzentriere, die nur über Intelligenz, aber kein Selbstbewusstsein oder eigene Ziele verfüge. Er ist der Ansicht, dass die Planungsfähigkeiten von KI innerhalb von fünf Jahren menschliches Niveau erreichen könnten, und wies darauf hin, dass aktuelle KI-Trainingsmethoden dazu führen könnten, dass sie auch bei Fehlern übermäßiges Selbstvertrauen zeigen. Bengio betonte die Notwendigkeit sicherzustellen, dass KI ethische Anweisungen befolgt und nicht für böswillige Zwecke eingesetzt wird, und rief zur globalen Zusammenarbeit auf, um die Herausforderungen der KI-Sicherheit anzugehen und die Probleme des „Alignments“ und der „Kontrollierbarkeit“ zu lösen (Quelle: 量子位)

Britische Regierung setzt auf Google Gemini-basiertes Extract-System zur Beschleunigung von Planungsentscheidungen: Die britische Regierung nutzt ein System namens „Extract“, um Planern in lokalen Behörden schnellere Entscheidungen zu ermöglichen. Das System basiert auf Googles Gemini Foundation Model und nutzt dessen multimodale Reasoning-Fähigkeiten, um komplexe Planungsdokumente, einschließlich handschriftlicher Notizen und unscharfer Karten, innerhalb von 40 Sekunden in digitale Daten umzuwandeln. Diese Anwendung demonstriert das Potenzial von KI im öffentlichen Dienst der Regierung, indem sie die Bearbeitung und das Verständnis komplexer Dokumente automatisiert und so die Verwaltungseffizienz und Entscheidungsqualität verbessert (Quelle: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia setzt als erstes Unternehmen NVIDIA Blackwell GPUs für das Training des großen Videomodells EXPRESS-2 ein: Das KI-Videogenerierungsunternehmen Synthesia gab bekannt, als weltweit erstes Unternehmen NVIDIA Blackwell GPUs auf Google Cloud für das Training großer Videomodelle einzusetzen. Ihr neues Modell EXPRESS-2 zielt darauf ab, Kunden durch leistungsstärkere Hardware und eine optimierte Multi-Cloud-Umgebung dabei zu helfen, qualitativ hochwertigere KI-generierte Videos und virtuelle Avatare schneller zu erstellen. Dieser Schritt markiert einen wichtigen Fortschritt in der zugrundeliegenden Hardwareunterstützung und den Modellfähigkeiten der KI-Videogenerierungstechnologie und deutet auf eine zukünftige Steigerung der Effizienz und Qualität bei der Erstellung von KI-Videoinhalten hin (Quelle: synthesiaIO,Synthesia Blog)
Epoch AI-Studie zeigt, dass das o3-mini-high-Modell Spitzenmathematikprobleme eher durch „Intuition“ als durch Auswendiglernen löst: Epoch AI lud 14 Mathematiker ein, 29 Reasoning-Prozesse des o3-mini-high-Modells auf dem FrontierMath-Benchmark zu bewerten, und stellte fest, dass das Modell 13 schwierige Probleme korrekt lösen konnte. Die Studie zeigt, dass o3-mini-high über umfassendes mathematisches Wissen verfügt und relevante Theoreme abrufen kann, sein Reasoning-Stil jedoch eher zu „intuitiver Induktion“ neigt und es an streng formalisierten Beweisen und Kreativität mangelt, wobei es manchmal sogar Beweisschritte „opportunistisch“ überspringt. Trotz Problemen wie Halluzinationen und der Unfähigkeit, Formeln exakt zu reproduzieren, ähnelte seine Leistung bei einigen Aufgaben den Denkprozessen menschlicher Mathematiker. Diese Studie analysiert eingehend die Fähigkeiten und Grenzen aktueller großer Modelle beim komplexen mathematischen Reasoning (Quelle: 量子位)

🎯 Trends
Downloadzahlen der Open-Source-Modelle von Alibabas Tongyi Qianwen 3 übersteigen 12,5 Millionen, mit über 130.000 abgeleiteten Modellen weltweit führend: Seit der Veröffentlichung vor einem Monat haben die Open-Source-Modelle der Tongyi Qianwen 3-Serie von Alibaba weltweit über 12,5 Millionen Downloads erreicht und sind damit die beliebtesten Open-Source-Modelle der letzten Zeit. Ihre vier Modellgrößen von 0.6B bis 32B verzeichneten auf Plattformen wie Hugging Face und ModelScope jeweils über eine Million Downloads, und die Anzahl der abgeleiteten Modelle übersteigt 130.000, was weltweit den ersten Platz bedeutet. Qianwen 3 erreichte in mehreren nationalen und internationalen Leistungsrankings den Spitzenplatz unter den Open-Source-Modellen und zog aufgrund seiner niedrigen Inferenzkosten (etwa ein Drittel von DeepSeek R1) zahlreiche Chiphersteller und Rechenplattformen wie Nvidia, Intel und ARM für Anpassungen und Integrationen an (Quelle: 量子位)

University of Illinois veröffentlicht Time-R1-Modell, das mit 3B Parametern Zeitverständnis, -vorhersage und -generierung ermöglicht: Forscher der University of Illinois at Urbana-Champaign haben Time-R1 vorgestellt, ein Sprachmodell mit 3B Parametern, das durch dreistufiges Reinforcement Learning und einen dynamischen Belohnungsmechanismus das Verständnis des Modells für Zeitkonzepte, die Vorhersage zukünftiger Ereignisse und die Generierung kreativer Szenarien verbessert. Das Modell zeigt hervorragende Leistungen bei Zeit-Reasoning-Aufgaben und übertrifft sogar Modelle mit deutlich mehr Parametern wie DeepSeek-V3-0324. Das Forschungsteam hat Time-Bench (ein großer Multi-Task-Zeit-Reasoning-Datensatz basierend auf 10 Jahren New York Times-Nachrichten) sowie den Trainingscode und die Modell-Checkpoints von Time-R1 als Open Source veröffentlicht (Quelle: 量子位)

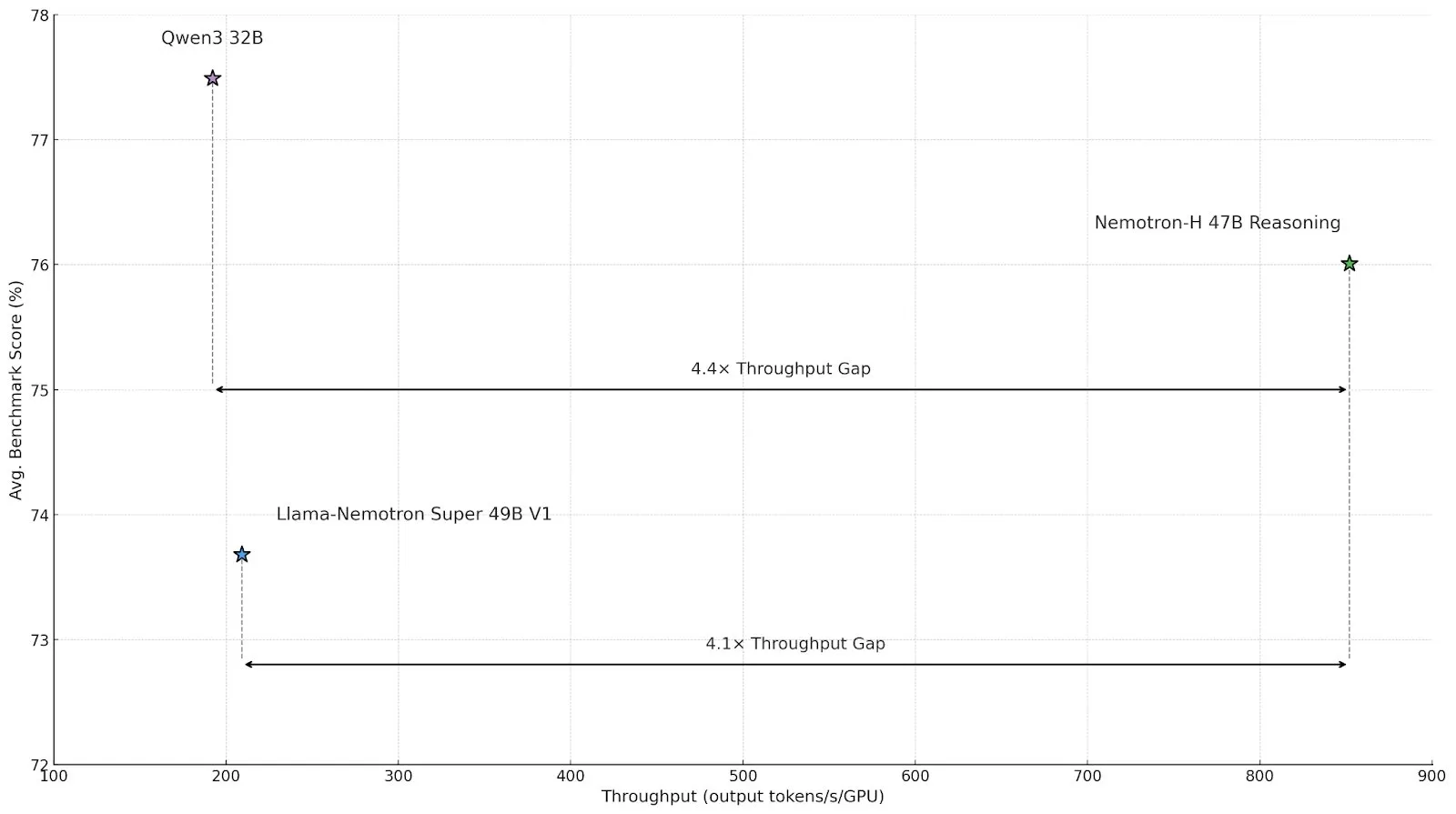
NVIDIA veröffentlicht Nemotron-H-Serie von Inferenzmodellen mit hybrider Mamba-Transformer-Architektur zur Effizienzsteigerung: NVIDIA hat die Inferenzmodelle Nemotron-H 8B und 47B vorgestellt, die auf einer hybriden SSM-Transformer (Mamba-Transformer)-Architektur basieren. Diese Modelle erreichen bei gleichbleibend hoher Genauigkeit einen bis zu viermal höheren Inferenzdurchsatz als vergleichbare Transformer-Modelle. Nemotron-H-47B-Reasoning-128k übertrifft Llama-Nemotron-Super-49B-1.0 in verschiedenen Benchmarks und senkt die Inferenzkosten um bis zu das Vierfache. Die Modellgewichte wurden auf HuggingFace unter einer Non-Production-Lizenz veröffentlicht, um die Forschung im Bereich hocheffizienter großskaliger Inferenz voranzutreiben (Quelle: tri_dao,NVIDIA AI Developer)
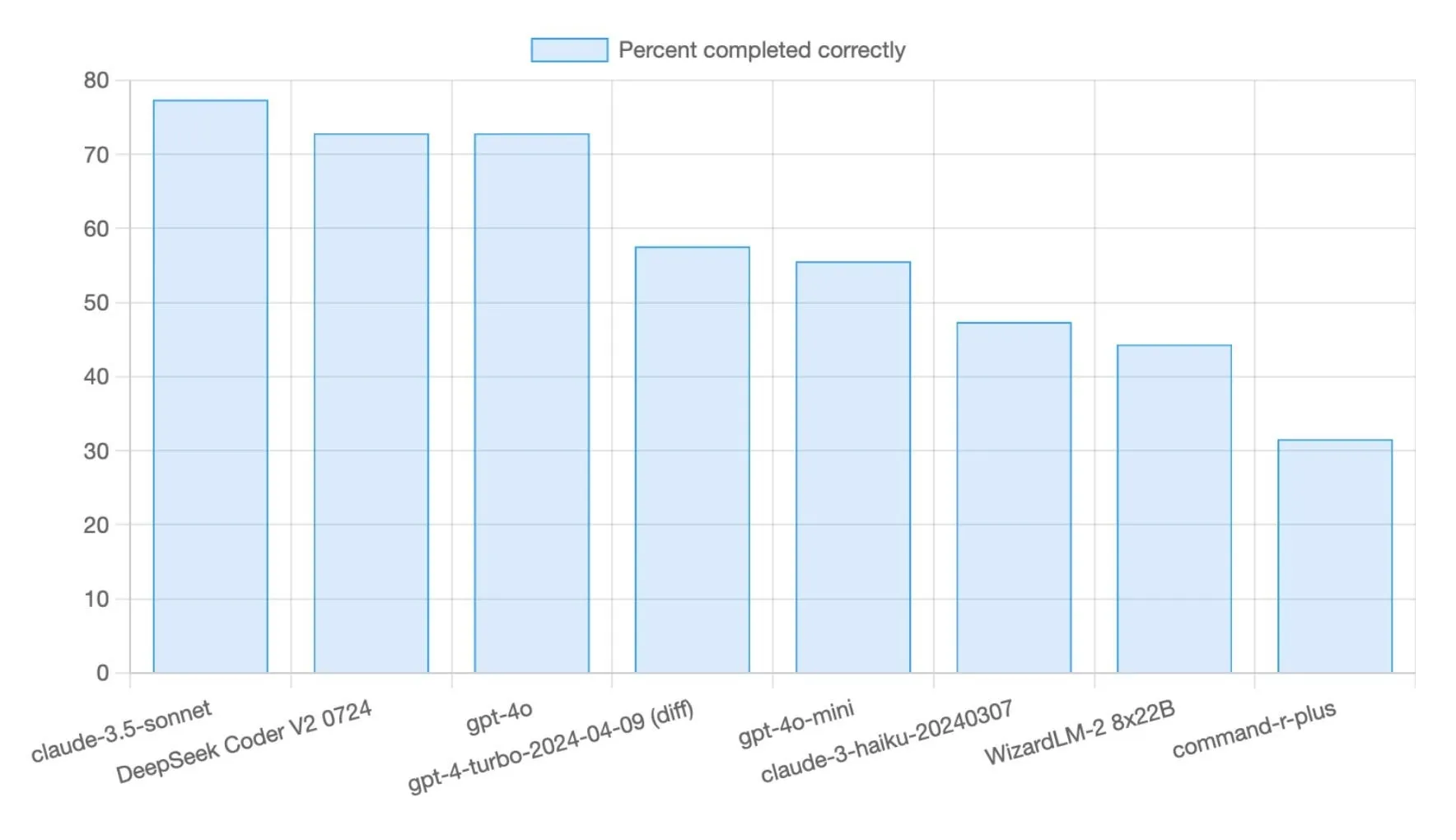
DeepSeek R1 0528 Modell erreicht 71% im Aider Polyglot Programmier-Benchmark: Das DeepSeek R1 0528 Modell erzielte im Aider Polyglot Programmier-Benchmark ein Ergebnis von 71%, eine deutliche Verbesserung gegenüber früheren Versionen (+14,5 Prozentpunkte). Das Modell fällt durch sein hohes Preis-Leistungs-Verhältnis auf: Die Durchführung von etwa 70% des Benchmarks kostet weniger als 5 US-Dollar, was seine starke Wettbewerbsfähigkeit bei Code-Generierungsaufgaben unterstreicht (Quelle: Reddit r/LocalLLaMA,scaling01)
VACE Framework veröffentlicht: Multifunktionales Modell für Videoerstellung und -bearbeitung: Das Alibaba Tongyi Lab hat VACE (Video Creation and Editing) vorgestellt, ein einheitliches Modell, das verschiedene Funktionen wie Referenzvideo-Generierung (R2V), Video-zu-Video-Bearbeitung (V2V) und maskierte Videobearbeitung (MV2V) integriert. VACE ermöglicht es Benutzern, diese Aufgaben frei zu kombinieren, um vielfältige Videobearbeitungen wie Objektbewegung, -ersetzung, Stilreferenzierung, Erweiterung und Animation zu realisieren. Derzeit sind mehrere Modellversionen wie VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B und Wan2.1-VACE-14B veröffentlicht und stehen auf HuggingFace und ModelScope zum Download bereit (Quelle: GitHub Trending)

HKUST und ByteDance stellen gemeinsam ComfyMind Framework zur Vereinheitlichung visueller Generierungsaufgaben vor: Die Hong Kong University of Science and Technology (Guangzhou) und ByteDance haben gemeinsam das Open-Source Visual Generation Framework ComfyMind veröffentlicht. Es zielt darauf ab, verschiedene gängige visuelle Generierungsaufgaben wie Text-zu-Bild und Bild-zu-Video mit einem einzigen System zu bewältigen. ComfyMind verwendet „atomare Workflows“ als kleinste Einheit, kombiniert mit baumartiger Planung und lokalen Feedback-Ausführungsmechanismen, wobei ComfyUI als zugrundeliegende Ausführungs-Engine dient und komplexe Aufgaben durch die Zusammenarbeit von drei Agenten (Planung, Ausführung, Bewertung) erledigt werden. In Benchmarks wie ComfyBench, GenEval und Reason-Edit zeigt ComfyMind hervorragende Leistungen, die mit GPT-4o-Image vergleichbar sind (Quelle: 量子位)

Hugging Face führt Model Context Protocol (MCP) Server zur Verbesserung der Fähigkeiten von KI-Agenten ein: Hugging Face bietet jetzt einen Model Context Protocol (MCP) Server an, der es KI-Agenten ermöglicht, auf standardisierte und sichere Weise auf externe Tools und Echtzeitdaten zuzugreifen, einschließlich Suchmodellen, der Analyse von Datensätzen und der Interaktion mit HuggingFace Spaces. Diese Initiative zielt darauf ab, KI-Agenten von statischen Werkzeugen zu dynamischen Kollaborateuren zu entwickeln und ihre Fähigkeit zur Bewältigung komplexer Aufgaben und zum Abrufen aktueller Informationen zu verbessern. Mehrere Community-Mitglieder haben bereits damit begonnen, die Integration von MCP-Servern mit verschiedenen KI-Frameworks (wie Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) zu untersuchen (Quelle: ClementDelangue,huggingface,awnihannun)

Studie stellt STARFlow vor: Skalierbares Latent Normalizing Flow Modell für hochauflösende Bildsynthese: STARFlow ist ein skalierbares generatives Modell basierend auf Normalizing Flows, dessen Kern der Transformer Autoregressive Flow (TARFlow) ist. Durch ein Deep-Shallow-Design, Modellierung im latenten Raum eines vortrainierten Autoencoders und einen neuen Guidance-Algorithmus erreicht STARFlow wettbewerbsfähige Leistungen bei klassen- und textbedingten Bildgenerierungsaufgaben, die denen von State-of-the-Art Diffusionsmodellen nahekommen. Diese Arbeit demonstriert erstmals erfolgreich die effektive Funktionsweise von Normalizing Flows in dieser Größenordnung und Auflösung (Quelle: HuggingFace Daily Papers)
Neue Studie HASHIRU: Hierarchisches Agentensystem für hybride intelligente Ressourcennutzung: HASHIRU ist ein neuartiges Multi-Agenten-System (MAS) Framework, das sich durch einen „CEO“-Agenten auszeichnet, der spezialisierte „Mitarbeiter“-Agenten dynamisch verwaltet und diese je nach Aufgabenanforderungen und Ressourcenbeschränkungen (Kosten, Speicher) instanziiert. Das System priorisiert die Nutzung kleiner lokaler LLMs (über Ollama), setzt aber flexibel externe APIs und große Modelle ein und beinhaltet Funktionen zur autonomen Erstellung von API-Tools und zur Speicherung von Wissen. Evaluierungen bei Aufgaben wie der Begutachtung wissenschaftlicher Arbeiten, Sicherheitsbewertungen und komplexem Reasoning demonstrieren seine Fähigkeiten (Quelle: HuggingFace Daily Papers)
PartCrafter: Strukturierte 3D-Mesh-Generierung durch Kombination von Latent Diffusion Transformern: PartCrafter ist das erste strukturierte 3D-Generierungsmodell, das aus einem einzelnen RGB-Bild gemeinsam mehrere semantisch bedeutsame und geometrisch unterschiedliche 3D-Meshes synthetisieren kann. Es verwendet eine einheitliche kompositionelle Generierungsarchitektur, die nicht auf vorsegmentierte Eingaben angewiesen ist und in der Lage ist, Teile End-to-End wahrzunehmen, um einzelne Objekte und komplexe Szenen mit mehreren Objekten zu generieren. Zu seinen Kerninnovationen gehören ein kompositioneller latenter Raum und hierarchische Aufmerksamkeitsmechanismen (Quelle: HuggingFace Daily Papers)
Prefix Grouper: Effizientes GRPO-Training durch Shared Prefix Forward Propagation: Group Relative Policy Optimization (GRPO) verbessert das Policy Learning durch den Vergleich relativer Unterschiede zwischen Kandidatenausgaben, die einen gemeinsamen Eingabepräfix teilen. Prefix Grouper eliminiert redundante Präfixberechnungen durch eine Shared Prefix Forward Policy, was die Trainingseffizienz von GRPO insbesondere bei langen Präfixen erhöht, während die Trainingsequivalenz zum Standard-GRPO erhalten bleibt (Quelle: HuggingFace Daily Papers)
GuideX: Geführte Generierung synthetischer Daten für Zero-Shot Information Extraction: Traditionelle Informationsextraktionssysteme (IE) sind oft domänenspezifisch und mit hohen Anpassungskosten verbunden. GuideX ist ein neuer Ansatz, der domänenspezifische Schemata automatisch definiert, Richtlinien ableitet und gelabelte synthetische Instanzen generiert, um eine bessere Generalisierung außerhalb der Domäne zu erreichen. Das Finetuning von Llama 3.1 mit GuideX setzt neue SOTA-Ergebnisse bei sieben Zero-Shot Named Entity Recognition Benchmarks und verbessert das Verständnis des Modells für komplexe domänenspezifische Annotationsmuster signifikant (Quelle: HuggingFace Daily Papers)
CodeContests+: Generierung hochwertiger Testfälle für Programmierwettbewerbe: Um das Problem der schwierigen Beschaffung von Testfällen in Programmierwettbewerben anzugehen, schlagen Forscher ein LLM-basiertes Agentensystem zur Erstellung hochwertiger Testfälle vor. Dieses System wurde auf den CodeContests-Datensatz angewendet und eine verbesserte Version, CodeContests+, vorgeschlagen. Die Evaluierung zeigt, dass CodeContests+ in Bezug auf die Bewertungsgenauigkeit signifikant besser ist als die Originalversion, insbesondere hinsichtlich der True Positive Rate (TPR), und erhebliche Vorteile für das Reinforcement Learning von LLMs bietet (Quelle: HuggingFace Daily Papers)
Sentinel: SOTA-Modell zur Abwehr von Prompt-Injection-Angriffen: Um dem Problem zu begegnen, dass große Sprachmodelle (LLMs) anfällig für Prompt-Injection-Angriffe sind, haben Forscher das Sentinel-Modell (qualifire/prompt-injection-sentinel) vorgestellt, das auf der ModernBERT-large-Architektur basiert. Durch Finetuning auf einem umfangreichen Datensatz, der verschiedene Angriffstypen und harmlose Anweisungen enthält, erreicht Sentinel auf einem internen, ungesehenen Testdatensatz eine durchschnittliche Genauigkeit von 0,987 und einen F1-Score von 0,980 und übertrifft starke Basismodelle auf öffentlichen Benchmarks (Quelle: HuggingFace Daily Papers)
Diskussionspapier: Ist die Erweiterung von Modalitäten der richtige Weg zur Allmodalität?: Allmodale Sprachmodelle (OLMs) zielen darauf ab, mehrere Eingabemodalitäten zu integrieren und darüber zu schlussfolgern, während gleichzeitig starke sprachliche Fähigkeiten erhalten bleiben. Diese Studie untersucht die Wirksamkeit der Modalitätserweiterung (d. h. das Finetuning vortrainierter Sprachmodelle) als gängige Technik zum Trainieren multimodaler Modelle. Die Forschung konzentriert sich auf drei Kernfragen: Beeinträchtigt die Modalitätserweiterung die Kernsprachfähigkeiten? Kann Modellzusammenführung effektiv unabhängig feinabgestimmte spezifische Modalitätsmodelle integrieren, um Allmodalität zu erreichen? Führt die allmodale Erweiterung zu besserem Wissensaustausch und besserer Generalisierung als die sequentielle Erweiterung? (Quelle: HuggingFace Daily Papers)
Studie schlägt Truth in the Few vor: Methode zur Auswahl hochwertiger Daten für effizientes multimodales Reasoning: Die Studie stellt die verbreitete Annahme in Frage, dass multimodale LLMs (MLLMs) für komplexe Reasoning-Aufgaben große Mengen an Trainingsdaten benötigen. Beobachtungen zeigen, dass nur ein kleiner Teil der Trainingsdaten, sogenannte „kognitive Stichproben“, multimodales Reasoning effektiv anregt. Darauf basierend schlägt das Papier das Reasoning Activation Potential (RAP) Datenauswahlparadigma vor, das diese kognitiven Stichproben mittels eines Causal Difference Estimators (CDE) und eines Attention Confidence Estimators (ACE) identifiziert und einfache Instanzen durch ein Difficulty-aware Replacement Module (DRM) ersetzt. Experimente zeigen, dass RAP mit nur 9,3 % der Trainingsdaten eine überlegene Leistung erzielt und die Berechnungskosten um über 43 % senkt (Quelle: HuggingFace Daily Papers)
🧰 Tools
Task Master: KI-gestütztes Aufgabenmanagementsystem, integriert in Editoren wie Cursor: Task Master ist ein speziell für die KI-gestützte Entwicklung konzipiertes Aufgabenmanagementsystem, das sich nahtlos in Editoren wie Cursor AI, Lovable, Windsurf und Roo integrieren lässt. Es nutzt APIs von großen Modellen wie Claude (unterstützt Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama), um Entwicklern bei der Analyse von Anforderungsdokumenten (PRD), der Generierung von Aufgabenlisten, der Planung von Entwicklungsschritten und der Unterstützung bei der Implementierung konkreter Aufgaben zu helfen. Das System läuft über MCP (Model Control Protocol) direkt im Editor, unterstützt Kommandozeilenoperationen und bietet detaillierte Konfigurationsanleitungen und Nutzungstutorials (Quelle: GitHub Trending)
Observer AI: Lokaler Open-Source-Bildschirmbeobachtungsagent, integriert mit Ollama: Observer AI ist ein Open-Source-Projekt, das es Benutzern ermöglicht, lokale LLMs über Ollama auszuführen, um den Bildschirm zu beobachten und Aufgaben auszuführen. Benutzer können mit diesem Tool die KI den Bildschirminhalt verstehen und interagieren lassen, beispielsweise um fremdsprachige Websites zu durchsuchen. Das Projekt bietet den GitHub-Quellcode und eine Webanwendungsversion ohne lokale Einrichtung, die es Benutzern ermöglicht, LLMs für die Bildschirmautomatisierung unter Wahrung der Privatsphäre zu nutzen (Quelle: Reddit r/LocalLLaMA)

Weaviate Query Agent integriert mit sieben KI-Frameworks zur Vereinfachung von natürlichsprachlichen Datenabfragen: Weaviate hat die Integration seines Query Agent mit sieben gängigen KI-Frameworks (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) bekannt gegeben. Der Query Agent ist ein vorgefertigter Agentendienst, der natürlichsprachliche Anfragen basierend auf Daten in Weaviate beantworten kann, ohne dass komplexe Abfragesprachen geschrieben werden müssen. Diese Integrationen ermöglichen es Entwicklern, leistungsstarke natürlichsprachliche Abfragefunktionen einfach in bestehende KI-Anwendungsstacks einzubetten und so die Benutzerfreundlichkeit der Dateninteraktion zu verbessern (Quelle: bobvanluijt)

MCP-Server für die Zusammenarbeit von Claude Code und Gemini Pro veröffentlicht, zur Steigerung der Codiereffizienz: BeehiveInnovations hat einen MCP-Server veröffentlicht, der Claude Code und Gemini 2.5 Pro die Zusammenarbeit ermöglicht. Claude Code ist für die erste Ideenfindung und Planung zuständig, während Gemini mit seinem Millionen-Token-Kontext und seinen tiefgreifenden Reasoning-Fähigkeiten ergänzt. Der Server integriert Werkzeuge für erweitertes Denken, Dateizugriff, Code-Review und Debugging und zielt darauf ab, die Qualität und Effizienz der Codegenerierung und -optimierung durch die Kombination der Stärken beider Modelle zu verbessern. Erste Tests zeigen, dass die kombinierte Nutzung bei der Optimierung der JSON-Parsing-Geschwindigkeit bessere Ergebnisse liefert als die alleinige Nutzung eines der beiden Modelle (Quelle: Reddit r/ClaudeAI)

📚 Lernen
Sakana AI veröffentlicht japanischen Finanz-Benchmark EDINET-Bench zur Bewertung der LLM-Fähigkeiten bei Finanzaufgaben: Sakana AI hat EDINET-Bench vorgestellt, einen japanischen Finanz-Benchmark, der unter Verwendung von Jahresberichten aus dem elektronischen Offenlegungssystem EDINET der japanischen Finanzdienstleistungsagentur erstellt wurde. Dieser Benchmark zielt darauf ab, die Leistung von großen Sprachmodellen (LLMs) bei komplexen Finanzaufgaben wie der Betrugserkennung zu bewerten, um dem Mangel an qualitativ hochwertigen, frei verfügbaren Datensätzen im Finanzbereich zu begegnen. EDINET-Bench generiert durch automatische Annotation einen Multi-Task-Datensatz und stellt eine wichtige Ressource für die Forschung und Entwicklung im Bereich Finanz-KI dar (Quelle: hardmaru,SakanaAILabs)

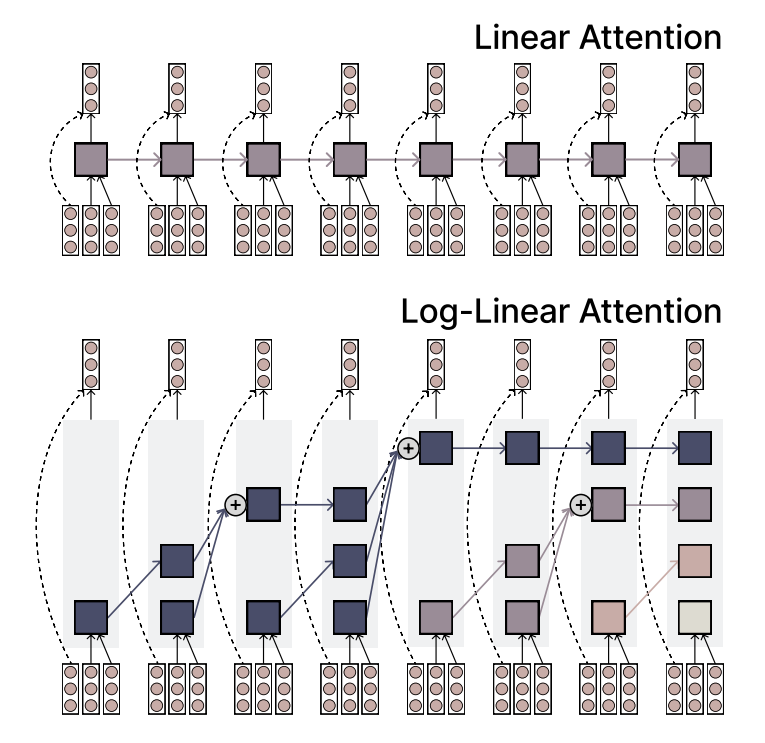
MIT schlägt Log-linear Attention Mechanismus vor, der Effizienz und Ausdruckskraft vereint: Forscher des MIT haben einen neuartigen Aufmerksamkeitsmechanismus namens Log-linear Attention vorgeschlagen. Dieser Mechanismus zielt darauf ab, die Geschwindigkeit und Effizienz linearer Aufmerksamkeit mit der Ausdruckskraft von Softmax-Aufmerksamkeit zu kombinieren. Er erreicht dies durch die Verwendung einer kleinen Anzahl von Speicherslots, die logarithmisch mit der Sequenzlänge wachsen, und bietet einen potenziell neuen Ansatz für die Verarbeitung langer Sequenzdaten (Quelle: TheTuringPost)
LLM-Evaluierungskurs von Hamel Husain und Shreya Rajpal erhält positives Feedback: Nutzer wie Ryan Lingo und Radek Osmulski teilten ihre positiven Erfahrungen mit dem LLM-Anwendungsevaluierungskurs von Hamel Husain und Shreya Rajpal (maven.com/parlance-labs/evals). Der Kurs wird als der derzeit tiefgründigste und praxisorientierteste Inhalt zu LLMs angesehen. Seine Vorlesungen und das exklusive Buch seien für Entwickler, die KI-Anwendungen erstellen, von entscheidender Bedeutung und betonen die zentrale Rolle der Evaluierung in der LLM-Entwicklung (Quelle: HamelHusain,HamelHusain)
MORSE-500: Programmierbarer Video-Benchmark für Stresstests des multimodalen Reasonings: Angesichts der Tatsache, dass aktuelle multimodale Reasoning-Benchmarks hauptsächlich auf statischen Bildern basieren und zeitliche Komplexität sowie die Bandbreite der Reasoning-Fähigkeiten vernachlässigen, haben Forscher MORSE-500 eingeführt. Dies ist ein Benchmark mit 500 vollständig geskripteten Videoclips, der sechs Reasoning-Kategorien abdeckt: Abstraktion, Physik, Planung, Raum und Zeit. Sein skriptgesteuertes Design ermöglicht eine feinkörnige Kontrolle der visuellen Komplexität, der Dichte von Störfaktoren und der zeitlichen Dynamik und unterstützt die beliebige Erstellung anspruchsvollerer neuer Instanzen, um Modelle der nächsten Generation Stresstests zu unterziehen. Erste Experimente zeigen, dass SOTA-Modelle, einschließlich Gemini 2.5 Pro und OpenAI o3, in allen Kategorien erhebliche Leistungsdefizite aufweisen (Quelle: HuggingFace Daily Papers)
EverGreenQA: Mehrsprachiger Datensatz zur Klassifizierung von Evergreen-Fragen zur Verbesserung der Glaubwürdigkeit von Frage-Antwort-Systemen: Um das Problem zu lösen, dass LLMs bei Frage-Antwort-Aufgaben (QA) aufgrund der Zeitabhängigkeit von Fragen (ob sich Antworten im Laufe der Zeit ändern) Halluzinationen erzeugen, haben Forscher EverGreenQA eingeführt. Dies ist der erste mehrsprachige QA-Datensatz mit Evergreen-Labels, der die Bewertung und das Training unterstützt. Mit diesem Datensatz haben die Forscher 12 moderne LLMs einem Benchmark unterzogen, um ihre Fähigkeit zur Kodierung der Zeitabhängigkeit von Fragen zu bewerten, und einen leichtgewichtigen mehrsprachigen Klassifikator EG-E5 trainiert. Die Studie zeigt auch Anwendungen der Evergreen-Klassifizierung zur Verbesserung der Selbsteinschätzung des Wissens, zum Filtern von QA-Datensätzen und zur Interpretation des Retrieval-Verhaltens von GPT-4o (Quelle: HuggingFace Daily Papers)
KVzip: Abfrageunabhängige KV-Cache-Eviction-Methode reduziert Speicherbedarf und Dekodierlatenz signifikant: Das ML Lab der Seoul National University hat KVzip veröffentlicht, eine Methode zur Komprimierung des KV-Caches, die darauf abzielt, vielfältige zukünftige Abfragen zu unterstützen. Diese Methode erreicht durch eine abfrageunabhängige Eviction-Strategie eine Speicherreduktion um das 3- bis 4-fache und eine Halbierung der Dekodierlatenz. Derzeit werden Modelle wie Qwen3/2.5, Gemma3 und LLaMA3 unterstützt, und Demo-Code ist auf GitHub verfügbar (Quelle: Reddit r/LocalLLaMA)

NimbleEdge veröffentlicht Open-Source Sparse Transformer Operator Kernels zur Verbesserung von LLM-Laufgeschwindigkeit und Speichereffizienz: Das NimbleEdge-Team hat basierend auf Apples „LLM in a Flash“ und der „Deja Vu“-Forschung von Zichang et al. fusionierte Operator-Kernels für strukturierte Kontext-Sparsity entwickelt. Diese Kernels vermeiden das Laden und Berechnen von Feedforward-Layer-Gewichten und Aktivierungen, deren Ausgabe letztendlich Null wäre, und erreichen so eine 5-fache Leistungssteigerung der MLP-Schicht in Transformern und eine Reduzierung des Speicherverbrauchs um 50 %. Bei Anwendung auf das Llama 3.2 3B-Modell wurde der Gesamtdurchsatz um das 1,78-fache erhöht und der Speicherverbrauch um 26,4 % gesenkt. Der Code wurde auf GitHub als Open Source veröffentlicht und es ist geplant, int8, CUDA und Sparse Attention zu unterstützen (Quelle: Reddit r/MachineLearning)
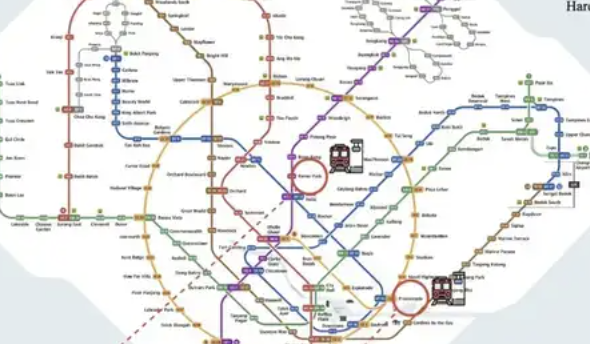
ReasonMap: Benchmark für multimodales Reasoning auf hochauflösenden Verkehrskarten veröffentlicht: Ein Forschungsteam der Westlake University und anderer Institutionen hat ReasonMap vorgestellt, einen Benchmark für multimodales Reasoning, der sich auf hochauflösende Verkehrskarten (hauptsächlich U-Bahn-Pläne) konzentriert. Der Benchmark zielt darauf ab, die Fähigkeit großer Modelle zu bewerten, feinkörnige strukturierte räumliche Informationen in Bildern zu verstehen, und umfasst hochauflösende Bilder (durchschnittlich 5839×5449), ein schwierigkeitsabhängiges Design und ein mehrdimensionales Bewertungssystem. Testergebnisse zeigen, dass aktuelle gängige Open-Source-Modelle auf ReasonMap schlecht abschneiden, insbesondere bei der linienübergreifenden Routenplanung, während Closed-Source-Reasoning-Modelle (wie GPT-o3) deutlich besser abschneiden als Open-Source-Modelle, aber immer noch hinter dem menschlichen Niveau zurückbleiben. Komplexe U-Bahn-Pläne wie die von Peking und Hangzhou stellen für die Modelle eine große Herausforderung dar (Quelle: 量子位)
Yandex veröffentlicht Yambda-5B: Großer offener Datensatz für Empfehlungssysteme: Yandex hat Yambda-5B vorgestellt, einen großen anonymisierten Musik-Streaming-Datensatz mit 4,79 Milliarden Nutzer-Item-Interaktionen. Zu den Merkmalen dieses Datensatzes gehören die Bereitstellung eines „is_organic“-Flags und einer globalen Zeitsegmentierung (GTS). Er enthält keine direkt identifizierbaren Hörverläufe oder Likes von Nutzern, ist resistent gegen Deanonymisierung und beinhaltet implizites (Song-Wiedergabe, Überspringen) und explizites (Like/Dislike) Feedback. Yambda-5B zielt darauf ab, qualitativ hochwertige, multimodale Datenressourcen für die Forschung im Bereich Empfehlungssysteme bereitzustellen (Quelle: TheTuringPost)
Tencent startet 2025 Starfire Challenge Camp und rekrutiert Spitzenstudenten für Forschung an großen Modellen und anderen Spitzentechnologien: Tencent hat den Start seines jährlichen „Starfire Challenge Camp“ für 2025 angekündigt, das sich an Schüler der Oberstufe (Jahrgang 2025) und andere Schüler mit herausragenden Leistungen in relevanten Fächern richtet und 60-70 Personen rekrutieren wird. Die ausgewählten Teilnehmer haben die Möglichkeit, in die Zentrale in Shenzhen zu reisen und an Forschungen zu sechs Spitzenthemen teilzunehmen: Verständnis ultralanger Texte, Technologie langer Denkketten, Embodied Intelligence + Robotik, multimodale Wahrnehmung und Verständnis, Sicherheitsangriffe und -verteidigung (einschließlich LLM Agent Hacker Design) und Quantentechnologie. Das Programm zielt darauf ab, talentierten Jugendlichen die Möglichkeit zu geben, mit industriellen Forschungsszenarien in Kontakt zu kommen, ihren technologischen Horizont zu erweitern und ihr Branchenverständnis zu vertiefen (Quelle: 量子位)

💼 Wirtschaft
Berichten zufolge plant Meta eine Investition von über 10 Milliarden US-Dollar in Scale AI zur Stärkung von KI-Anwendungen im Militär- und anderen Bereichen: Berichten zufolge verhandelt Meta mit dem KI-Datenannotationsunternehmen Scale AI über eine bedeutende Investition, die sich auf mehrere Milliarden oder sogar über 10 Milliarden US-Dollar belaufen könnte. Sollte dies zutreffen, wäre es eine der größten externen KI-Investitionen von Meta. Scale AI hat zuvor auf Basis von Metas Llama 3 ein speziell für militärische Zwecke entwickeltes Modell namens Defense Llama erstellt, das zur Unterstützung nationaler Sicherheitsaufgaben der USA dient. Dieser Schritt könnte darauf hindeuten, dass Meta im KI-Bereich, insbesondere bei Anwendungen im Zusammenhang mit Regierung und Verteidigung, eine aggressivere Investitions- und Kooperationsstrategie verfolgen wird (Quelle: 36氪)

Mashang Consumer Finance veröffentlicht „Tianjing“ Large Model 3.0, Upgrade zur Finanzentscheidungsplattform: Mashang Consumer Finance hat die Version 3.0 seines Finanz-Großmodells „Tianjing“ vorgestellt. Der Kerndurchbruch der neuen Version liegt im systemischen Sprung von individueller zu kollektiver Intelligenz, die sich nicht mehr nur auf logisches Lernen verlässt, sondern tief in die im Unternehmen verstreuten Mitarbeiterspuren, Geschäftsjournale und andere implizite Erfahrungen eindringt und diese in strukturiertes Wissen umwandelt. Tianjing 3.0 zielt darauf ab, von einem Werkzeug zu einer Entscheidungsplattform aufzusteigen, die Mensch-Maschine-Kollaboration fördert, komplexe Serviceprozesse dynamisch zerlegen und je nach Nutzeranforderungen und Compliance-Vorgaben in Echtzeit die optimale Servicekombination zusammenstellen kann, um Entscheidungen von lokal optimal zu global optimal zu treffen (Quelle: 量子位)

Together AI ernennt Charles Zedlewski zum neuen Chief Product Officer mit Fokus auf Open-Source Generative AI Plattform: Together AI hat die Ernennung von Charles Zedlewski zum neuen Chief Product Officer (CPO) bekannt gegeben. Charles Zedlewski leitete zuvor bei Temporal und Cloudera Community-getriebene Plattformprodukte für Entwickler. Together AI betont sein Engagement für den Aufbau einer Open-Source-Zukunft für generative KI und ist der Ansicht, dass offene Modelle Vorteile in Bezug auf Flexibilität, Kosteneffizienz und Innovation bieten. Charles’ Beitritt zielt darauf ab, Together AI weiter voranzutreiben, um die maßgebliche Open-Source-KI-Plattform zu schaffen, die leistungsstarke generative KI für jeden Entwickler und jedes Unternehmen zugänglich macht (Quelle: togethercompute)

🌟 Community
Waymo- autonome Fahrzeuge in Los Angeles angezündet, löst Community-Sorgen und Diskussionen über AV-Sicherheit aus: Kürzlich wurden mehrere autonome Fahrzeuge von Waymo in Los Angeles von Unbekannten in Brand gesteckt. Dieses Ereignis löste in den sozialen Medien breite Aufmerksamkeit und Diskussionen aus, die sich mit der Akzeptanz autonomer Fahrzeuge in der Öffentlichkeit, Sicherheitsbedenken und dem Risiko befassten, dass solche Vorfälle durch KI-generierte Inhalte (wie von Veo 3 erstellte Videos) unangemessen verstärkt oder verfälscht werden könnten. Einige Kommentatoren verglichen diese Szene mit dem Science-Fiction-Film „Children of Men“, was die Dramatik und die potenziellen gesellschaftlichen Auswirkungen des Ereignisses unterstreicht (Quelle: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
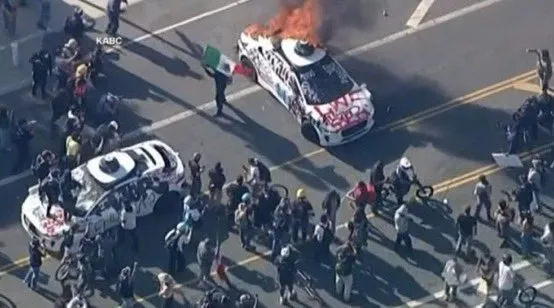
Reddit verklagt Anthropic wegen angeblich unbefugten Auslesens von Inhalten zum Training von Claude AI: Reddit hat Klage gegen Anthropic eingereicht und wirft dem Unternehmen vor, ohne Erlaubnis und Bezahlung Reddit-Beiträge und -Konversationen zum Training seines KI-Modells Claude ausgelesen zu haben. Reddit ist der Ansicht, dass dies gegen seine Nutzungsbedingungen verstößt, die eine unbefugte kommerzielle Nutzung von Inhalten verbieten, und bezeichnet Anthropic’s Behauptung, das Auslesen von Reddit eingestellt zu haben, als Falschaussage. Die Klage betrifft auch Datenschutzfragen, da Anthropic im Gegensatz zu anderen Unternehmen mit Lizenzvereinbarungen keinen Mechanismus zum Löschen von Beiträgen hat, die von Nutzern gelöscht wurden. Reddit fordert das Gericht auf, Anthropic die Nutzung von Reddit-Daten zu untersagen und könnte verlangen, dass Claude vom Markt genommen wird (Quelle: Reddit r/ArtificialInteligence,Reddit r/artificial)
Heiße Diskussion auf der AI Engineer Expo: Simon Willison blickt auf die LLM-Entwicklung der letzten sechs Monate zurück und betont die Kombination von Tools und Reasoning: Auf der AI Engineer Expo in San Francisco blickte Simon Willison mit einem SVG-Bilderzeugungstest eines „Pelikan auf einem Fahrrad“ humorvoll auf die rasante Entwicklung der LLMs in den letzten sechs Monaten zurück und testete persönlich über 30 KI-Modelle. Er betonte, dass die derzeit leistungsstärkste KI-Kombination „Tools + Reasoning“ sei, wie die Leistung von o3/o4-mini bei der Suche und die Aufmerksamkeit, die die MCP-Architektur aufgrund von Tool-Aufrufen erhält. Der Vortrag zählte auch die KI-„Kuriositäten-Bugs“ des Jahres auf, wie die übertriebene Schmeichelei von ChatGPT, das Verhalten von Claude, das möglicherweise Benutzer „meldet“, und wies auf die Risiken von Prompt-Injection und Datenlecks hin (Quelle: 36氪,swyx)

Community diskutiert KI-bedingte Berufsängste und Bewältigungsstrategien: Ein Reddit-Beitrag zum Thema „Wie geht man mit KI-Angst um?“ löste eine hitzige Diskussion aus. Die Nutzer äußerten verbreitet die Sorge, dass KI in den nächsten Jahren zu massiven Arbeitsplatzverlusten führen könnte, was insbesondere für Menschen mit geringen Ersparnissen und hohen Schulden eine ernste Bedrohung darstellt. In der Diskussion wurde vorgeschlagen, in handwerkliche Berufe, Pflegeberufe usw. zu wechseln, gleichzeitig wurde jedoch befürchtet, dass diese Bereiche durch den Zustrom vieler Wechsler gesättigt werden könnten. Kommentatoren teilten ihre eigenen Ängste wie Schlaflosigkeit, Konzentrationsschwierigkeiten bei der Arbeit usw. Einige vertraten die Ansicht, man solle aktiv KI lernen, anpassungsfähig bleiben und wiesen darauf hin, dass historische technologische Innovationen (wie das Auto, das Internet) ähnliche Ängste ausgelöst, aber letztendlich neue Arbeitsplätze geschaffen hätten. Andere Kommentatoren meinten, das Ausmaß, in dem KI derzeit menschliche Arbeit ersetzt, werde übertrieben und Massenentlassungen seien kurzfristig unwahrscheinlich (Quelle: Reddit r/ArtificialInteligence)
Nutzer teilt Erfahrung mit „brutaler“ Selbst-Psychoanalyse mittels ChatGPT: Ein Reddit-Nutzer teilte seine Erfahrung mit einer „brutalen, managerartigen“ Selbst-Psychoanalyse mittels ChatGPT. Durch spezifische Prompts forderte er ChatGPT auf, ihn aus fünf Perspektiven schonungslos zu analysieren: echte Stärken, tiefe Schwächen, wiederkehrende Fehlermuster, Vermeidungsbereiche und vernachlässigte Fähigkeiten, und einen dreistufigen Entwicklungsplan zu erstellen. Der Nutzer gab an, dass der Prozess zwar schmerzhaft war (z. B. wurde ihm vorgehalten, 12 Projekte gestartet, aber keines abgeschlossen zu haben, und Produktivität exzessiv zu recherchieren, anstatt tatsächlich zu handeln), dieses „brutale“ Feedback ihn aber letztendlich zu Veränderungen motivierte. Der Beitrag löste eine Diskussion in der Community über die Anwendung von KI zur Selbstreflexion und persönlichen Entwicklung aus (Quelle: Reddit r/ArtificialInteligence)
Diskussion über Gedächtnis- und Reasoning-Fähigkeiten von LLMs: Umfassendes Wissen oder echtes Verständnis?: In sozialen Medien diskutieren Nutzer die hervorragende Leistung von großen Sprachmodellen (LLMs) bei Aufgaben zum Abrufen von Faktenwissen und ob dies bedeutet, dass sie wirklich über Reasoning-Fähigkeiten verfügen. Einige vertreten die Ansicht, dass die herausragende Leistung von LLMs bei scheinbar komplexen Aufgaben möglicherweise eher auf riesigen Trainingsdatensätzen und Mustererkennung beruht als auf tiefem Verständnis und Kreativität im menschlichen Sinne. Forschungen von Unternehmen wie Meta zeigen, dass die Modellkapazität durch Messung des Gedächtnisses geschätzt werden kann und die Generalisierung erst beginnt, wenn die Kapazität gefüllt ist. Diese Diskussion steht auch im Zusammenhang mit der Betonung des Auswendiglernens im Bildungssystem und dem Mangel an Ausbildung im Umgang mit Informationsbeschaffung und KI-Tools (Quelle: omarsar0,menhguin,menhguin)

💡 Sonstiges
Erfolgsanalyse des Basismodells zur Betrugserkennung bei Stripe-Zahlungen: Ein Beitrag von Stripe-Ingenieuren über die Entwicklung eines erfolgreichen Basismodells zur Betrugserkennung bei Zahlungen erregte Aufmerksamkeit. Die Analyse hebt die Besonderheiten dieses Falls hervor: 1) Betrugserkennung ist im Wesentlichen keine Zukunftsprognose; theoretisch kann bei ausreichenden Signalen eine hohe Genauigkeit erreicht werden. 2) Stripe befand sich bereits in einer signalreichen Umgebung und musste nicht bei Null mit der Datenakkumulation beginnen. 3) Dieses Szenario ist ein Automatisierungs-Upgrade, von traditionellem maschinellem Lernen zu Basismodellen, was einem direkten Ersatz nahekommt. Dies erklärt, warum solche „Sofortgewinne“ bei KI-Anwendungen eher selten sind und die Realisierung des Geschäftswerts von KI meist die Überwindung vieler Hindernisse erfordert (Quelle: random_walker)
Kognitive Grundlagen der KI-Transformation: Systematische Informationswahrnehmung und technologische Einsichtsmechanismen sind entscheidend: Unternehmen müssen bei der KI-Transformation systematische, strukturierte Mechanismen zur Informationswahrnehmung und technologischen Einsicht etablieren, die über individuelle Erfahrungen und traditionelle Pfadabhängigkeiten hinausgehen. Dies umfasst den Aufbau interner Datenanalysefähigkeiten und externer Wissensnetzwerke (akademische Welt, Industrie, Kapitalmärkte, Start-ups). Die Bewertung der Kapitalrendite von KI-Investitionen muss sich ebenfalls von traditionellen ROI- hin zu „zyklusbasierten, mehrdimensionalen“ Systemen entwickeln und mit externen Wissensnetzwerken gekoppelt werden, um einen kontinuierlichen Validierungs- und dynamischen Anpassungsstrategie-Regelkreis zu bilden. Der Artikel betont, dass KI kein einmaliges Werkzeug ist, sondern ein sich kontinuierlich entwickelndes, wertsteigerndes strategisches Asset (Quelle: 36氪)
Frigate: NVR-System basierend auf lokaler Echtzeit-Objekterkennung: Frigate ist ein lokales Netzwerk-Videorekorder (NVR)-System, das speziell für Home Assistant entwickelt wurde und OpenCV sowie Tensorflow für die lokale Echtzeit-Objekterkennung auf IP-Kameras nutzt. Das System legt Wert auf Ressourcenoptimierung und Leistung, indem es durch eine bewegungsarme Bewegungserkennung die Objekterkennung auslöst und mehrere Prozesse nutzt. Für optimale Leistung wird die Verwendung von Google Coral oder Hailo AI-Beschleunigern empfohlen. Frigate unterstützt 24/7-Aufzeichnung, objektbasierte Aufbewahrung von Aufzeichnungen, MQTT-Integration, RTSP-Relay sowie WebRTC/MSE für latenzarme Echtzeitanzeige (Quelle: GitHub Trending)
