
Kata Kunci:model bahasa besar, kemampuan penalaran, keamanan AI, model multimodal, model sumber terbuka, pembuatan video AI, evaluasi AI, aplikasi bisnis AI, penelitian kemampuan penalaran LLM Apple, model pemahaman waktu Time-R1, pembuatan video GPU NVIDIA Blackwell, model sumber terbuka Alibaba Tongyi Qianwen 3, server Hugging Face MCP
🔥 Fokus
Apple merilis makalah yang menyatakan bahwa model bahasa besar saat ini hanya memiliki “ilusi berpikir” bukan kemampuan penalaran sejati, memicu diskusi hangat di industri: Peneliti Apple (termasuk Samy Bengio, salah satu pendiri Google Brain) menerbitkan sebuah makalah, melalui pengujian empat tugas dengan tingkat kesulitan terkontrol seperti Menara Hanoi dan pertukaran dam, menunjukkan bahwa model-model terkemuka seperti DeepSeek, o3-mini, dan Claude 3.7 semuanya “runtuh” ketika menghadapi masalah dengan kompleksitas tinggi, menunjukkan “skala terbalik upaya penalaran” (semakin sulit masalahnya, semakin sedikit pemikiran yang dilakukan). Makalah tersebut berpendapat bahwa model-model ini lebih mengandalkan pencocokan pola dan memori, daripada penalaran logis yang benar-benar dapat digeneralisasi, bahkan jika algoritma lengkap disediakan, mereka tidak dapat menembus hambatan kompleksitas. Pandangan ini menantang pemahaman umum saat ini tentang kemampuan penalaran LLM, dan memicu diskusi luas tentang metode evaluasi LLM, batas kemampuan penalaran yang sebenarnya, dan arah pengembangan di masa depan. Komunitas memiliki reaksi beragam terhadap hal ini, beberapa orang percaya ini adalah pembelaan Apple atas kemajuan AI-nya yang lambat, sementara yang lain setuju dengan wawasannya tentang mekanisme evaluasi dan keterbatasan inheren model (Sumber: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

Pemenang Turing Award Yoshua Bengio memperingatkan risiko AI di luar kendali, menyesuaikan arah penelitian untuk fokus pada “AI Ilmuwan”: Yoshua Bengio menyatakan di Konferensi BAII bahwa, mengingat perkembangan pesat AI (terutama AGI) dan potensi risiko di luar kendali (seperti AI menyalin kodenya sendiri untuk “bertahan hidup”, menyembunyikan perilaku), ia telah menyesuaikan arah penelitiannya, berdedikasi untuk membangun “AI Ilmuwan” yang hanya memiliki kecerdasan, tanpa kesadaran diri dan tujuan. Ia percaya bahwa kemampuan perencanaan AI dapat mencapai tingkat manusia dalam lima tahun, dan menunjukkan bahwa metode pelatihan AI saat ini dapat menyebabkannya menunjukkan kepercayaan diri yang berlebihan bahkan ketika salah. Bengio menekankan perlunya memastikan AI mematuhi instruksi etis, menghindari penggunaan untuk tujuan jahat, dan menyerukan kerja sama global untuk mengatasi tantangan keamanan AI, menyelesaikan masalah “penyelarasan” dan “kontrolabilitas” (Sumber: 量子位)

Pemerintah Inggris mengadopsi sistem Extract yang didukung model Gemini Google untuk mempercepat pengambilan keputusan perencanaan: Pemerintah Inggris menggunakan sistem bernama “Extract” untuk membantu perencana dewan lokal membuat keputusan lebih cepat. Sistem ini didasarkan pada model dasar Gemini Google, memanfaatkan kemampuan penalaran multimodalnya untuk mengubah dokumen perencanaan yang kompleks, termasuk catatan tulisan tangan dan peta buram, menjadi data digital dalam waktu 40 detik. Aplikasi ini menunjukkan potensi AI di bidang layanan publik pemerintah, dengan mengotomatiskan pemrosesan dan pemahaman dokumen kompleks, meningkatkan efisiensi administrasi dan kualitas pengambilan keputusan (Sumber: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia menjadi yang pertama menggunakan NVIDIA Blackwell GPU untuk melatih model video besar EXPRESS-2: Perusahaan pembuat video AI Synthesia mengumumkan menjadi perusahaan pertama di dunia yang menggunakan NVIDIA Blackwell GPU di Google Cloud untuk melatih model video besar. Model barunya EXPRESS-2 bertujuan untuk membantu pelanggan membuat video dan avatar yang dihasilkan AI berkualitas lebih tinggi dengan lebih cepat melalui perangkat keras yang lebih kuat dan pengaturan multi-cloud yang dioptimalkan. Langkah ini menandai kemajuan penting dalam dukungan perangkat keras dasar dan kemampuan model teknologi pembuatan video AI, yang menandakan bahwa efisiensi dan kualitas pembuatan konten video AI di masa depan akan semakin meningkat (Sumber: synthesiaIO,Synthesia Blog)
Penelitian Epoch AI mengungkapkan model o3-mini-high mengandalkan “intuisi” untuk memecahkan masalah matematika terkemuka, bukan menghafal mati: Epoch AI mengundang 14 ahli matematika untuk mengevaluasi 29 proses penalaran o3-mini-high pada tolok ukur FrontierMath, dan menemukan bahwa model tersebut dapat menyelesaikan 13 masalah sulit dengan benar. Penelitian menunjukkan bahwa o3-mini-high memiliki pengetahuan matematika yang mendalam dan dapat memanggil teorema yang relevan, tetapi gaya penalarannya lebih condong ke “induksi berbasis intuisi”, kurang bukti formal yang ketat dan kreativitas, bahkan terkadang “mengambil jalan pintas” dengan melewatkan langkah-langkah pembuktian. Meskipun ada masalah seperti halusinasi dan ketidakmampuan untuk mereproduksi rumus secara akurat, kinerjanya pada beberapa soal mirip dengan proses berpikir ahli matematika manusia. Penelitian ini menganalisis secara mendalam karakteristik kemampuan dan keterbatasan model besar saat ini dalam penalaran matematika yang kompleks (Sumber: 量子位)

🎯 Perkembangan
Jumlah unduhan model open-source Alibaba Tongyi Qianwen 3 melampaui 12,5 juta, dengan lebih dari 130.000 model turunan, menempati peringkat pertama secara global: Sejak dirilis sebulan lalu, seri model besar Alibaba Tongyi Qianwen 3 telah diunduh lebih dari 12,5 juta kali secara global, menjadi model open-source paling populer baru-baru ini. Empat ukuran modelnya dari 0.6B hingga 32B telah diunduh lebih dari satu juta kali di platform seperti Hugging Face dan ModelScope, dengan jumlah model turunan melebihi 130.000, menempati peringkat pertama di dunia. Qianwen 3 telah meraih juara model open-source di berbagai daftar peringkat kinerja domestik dan internasional, dan karena biaya inferensi yang lebih rendah (sekitar sepertiga dari DeepSeek R1), telah menarik adaptasi dan akses dari banyak produsen chip seperti Nvidia, Intel, ARM, serta platform komputasi (Sumber: 量子位)

Universitas Illinois merilis model Time-R1, parameter 3B mencapai pemahaman, prediksi, dan generasi waktu: Peneliti dari Universitas Illinois Urbana-Champaign meluncurkan Time-R1, sebuah model bahasa dengan parameter 3B, yang melalui pembelajaran penguatan tiga tahap dan mekanisme hadiah dinamis, meningkatkan pemahaman model terhadap konsep waktu, prediksi peristiwa masa depan, dan kemampuan generasi skenario kreatif. Model ini menunjukkan kinerja yang sangat baik dalam tugas penalaran waktu, bahkan melampaui model dengan parameter yang jauh lebih besar, seperti DeepSeek-V3-0324. Tim peneliti telah merilis Time-Bench (dataset penalaran waktu multi-tugas besar berdasarkan berita New York Times selama 10 tahun) serta kode pelatihan dan checkpoint model Time-R1 secara open-source (Sumber: 量子位)

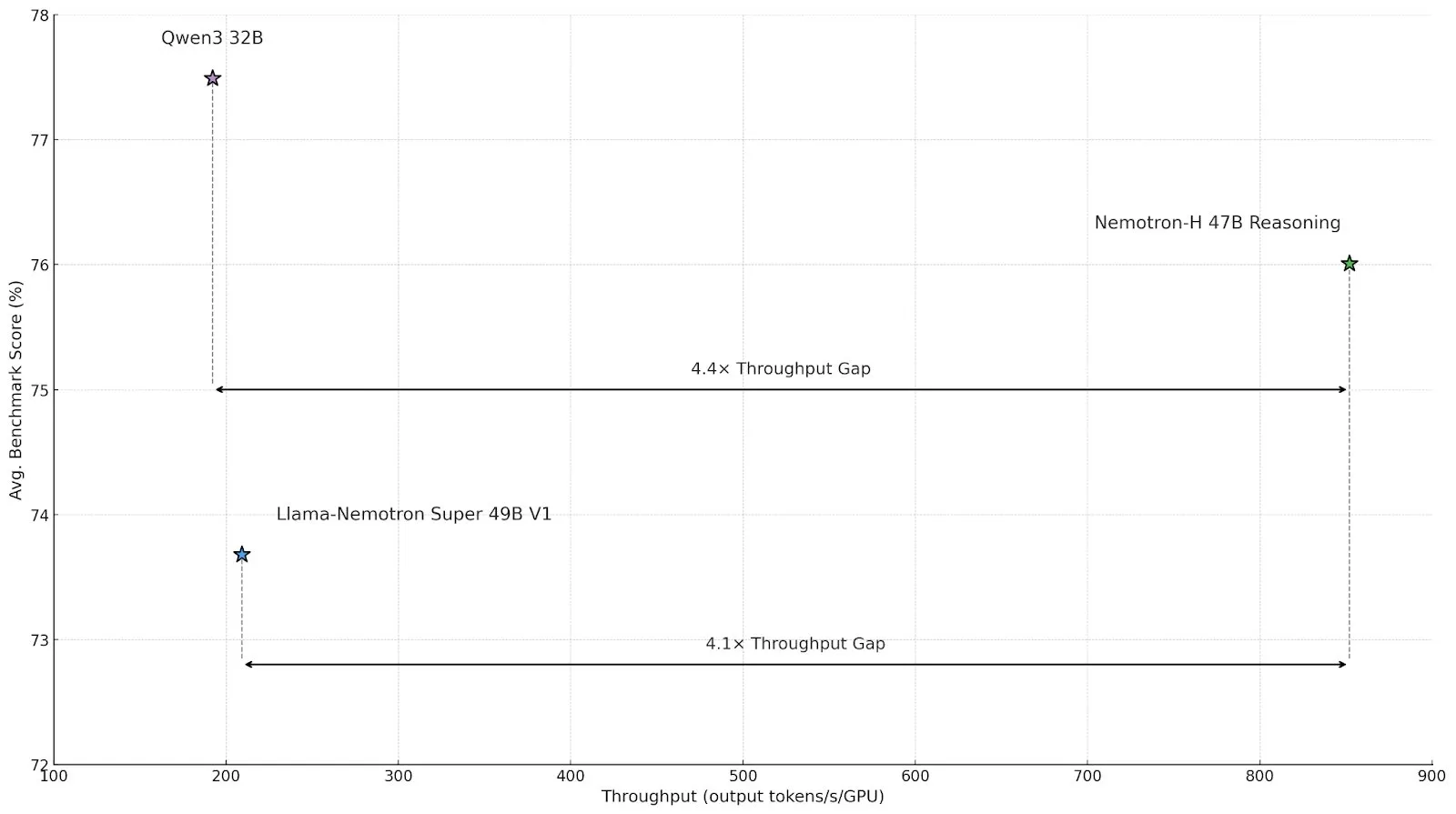
NVIDIA merilis model inferensi seri Nemotron-H, menggunakan arsitektur hybrid Mamba-Transformer untuk meningkatkan efisiensi: NVIDIA meluncurkan model inferensi Nemotron-H 8B dan 47B, berdasarkan arsitektur hybrid SSM-Transformer (Mamba-Transformer). Model-model ini, sambil mempertahankan akurasi tinggi, dapat mencapai throughput inferensi hingga 4 kali lipat dari model Transformer sejenis. Nemotron-H-47B-Reasoning-128k berkinerja lebih baik daripada Llama-Nemotron-Super-49B-1.0 dalam berbagai tolok ukur, dan biaya inferensi berkurang hingga 4 kali lipat. Bobot model telah dirilis di HuggingFace dengan lisensi non-produksi, bertujuan untuk mendorong penelitian tentang inferensi skala besar yang berefisiensi tinggi (Sumber: tri_dao,NVIDIA AI Developer)
Model DeepSeek R1 0528 mencapai skor 71% dalam tolok ukur pemrograman Aider Polyglot: Model DeepSeek R1 0528 mencapai skor 71% dalam tolok ukur pemrograman Aider Polyglot, menunjukkan peningkatan signifikan (+14,5 poin persentase) dari versi sebelumnya. Model ini menarik perhatian karena rasio harga-kinerja yang tinggi, menyelesaikan sekitar 70% tolok ukur dengan biaya kurang dari $5, menunjukkan daya saing yang kuat dalam tugas pembuatan kode (Sumber: Reddit r/LocalLLaMA,scaling01)
Kerangka kerja VACE dirilis: model multifungsi yang mengintegrasikan pembuatan dan pengeditan video: Alibaba Tongyi Lab meluncurkan VACE (Video Creation and Editing), sebuah model terpadu yang mengintegrasikan berbagai fungsi seperti pembuatan video referensi (R2V), pengeditan video-ke-video (V2V), dan pengeditan video dengan masker (MV2V). VACE memungkinkan pengguna untuk menggabungkan tugas-tugas ini secara bebas untuk mencapai berbagai pemrosesan video seperti pemindahan objek, penggantian, referensi gaya, perluasan, dan animasi. Beberapa versi model seperti VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B, dan Wan2.1-VACE-14B telah dirilis dan tersedia untuk diunduh di HuggingFace dan ModelScope (Sumber: GitHub Trending)

HKUST dan ByteDance bersama-sama meluncurkan kerangka kerja ComfyMind, menyatukan tugas generasi visual: Universitas Sains dan Teknologi Hong Kong (Guangzhou) dan ByteDance bersama-sama merilis kerangka kerja generasi visual open-source ComfyMind, yang bertujuan untuk memproses berbagai tugas generasi visual utama seperti teks-ke-gambar dan gambar-ke-video melalui satu sistem. ComfyMind menggunakan “alur kerja atomik” sebagai unit terkecil, dikombinasikan dengan perencanaan seperti pohon dan mekanisme eksekusi umpan balik lokal, menggunakan ComfyUI sebagai mesin eksekusi dasar, dan menyelesaikan tugas-tugas kompleks melalui kolaborasi tiga agen: perencanaan, eksekusi, dan evaluasi. Dalam tolok ukur seperti ComfyBench, GenEval, dan Reason-Edit, ComfyMind menunjukkan kinerja yang sangat baik, sebanding dengan GPT-4o-Image (Sumber: 量子位)

Hugging Face meluncurkan server Model Context Protocol (MCP), meningkatkan kemampuan agen AI: Hugging Face kini menyediakan server Model Context Protocol (MCP), yang memungkinkan agen AI mengakses alat eksternal dan data real-time dengan cara yang terstandardisasi dan aman, termasuk model pencarian, analisis dataset, dan interaksi dengan HuggingFace Spaces. Inisiatif ini bertujuan untuk mengubah agen AI dari alat statis menjadi kolaborator dinamis, meningkatkan kemampuannya untuk menangani tugas-tugas kompleks dan memperoleh informasi terbaru. Beberapa anggota komunitas telah mulai mengeksplorasi integrasi server MCP dengan berbagai kerangka kerja AI (seperti Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) (Sumber: ClementDelangue,huggingface,awnihannun)

Penelitian mengusulkan STARFlow: model aliran normalisasi laten yang dapat diskalakan untuk sintesis gambar resolusi tinggi: STARFlow adalah model generatif yang dapat diskalakan berdasarkan aliran normalisasi, yang intinya adalah Transformer Autoregressive Flow (TARFlow). Melalui desain lapisan dalam-dangkal, pemodelan dalam ruang laten autoencoder yang telah dilatih sebelumnya, dan algoritma panduan baru, STARFlow mencapai kinerja kompetitif dalam tugas generasi gambar bersyarat kelas dan bersyarat teks, mendekati model difusi canggih. Pekerjaan ini untuk pertama kalinya berhasil menunjukkan operasi efektif aliran normalisasi pada skala dan resolusi ini (Sumber: HuggingFace Daily Papers)
Penelitian baru HASHIRU: sistem agen hierarkis untuk pemanfaatan sumber daya kecerdasan hibrida: HASHIRU adalah kerangka kerja sistem multi-agen (MAS) baru, yang ditandai dengan agen “CEO” yang secara dinamis mengelola agen “karyawan” khusus, dan menginstansiasikannya sesuai dengan kebutuhan tugas dan batasan sumber daya (biaya, memori). Sistem ini memprioritaskan penggunaan LLM lokal kecil (melalui Ollama), sambil secara fleksibel menggunakan API eksternal dan model besar, dan mencakup pembuatan alat API otonom dan fungsi memori. Evaluasi pada tugas-tugas seperti peninjauan makalah akademis, penilaian keamanan, dan penalaran kompleks menunjukkan kemampuannya (Sumber: HuggingFace Daily Papers)
PartCrafter: generasi mesh 3D terstruktur melalui kombinasi Transformer difusi laten: PartCrafter adalah model generasi 3D terstruktur pertama yang dapat secara bersamaan mensintesis beberapa mesh 3D yang bermakna secara semantik dan berbeda secara geometris dari satu gambar RGB. Ini mengadopsi arsitektur generasi kombinatorial terpadu, tidak bergantung pada input pra-segmentasi, dan mampu menghasilkan objek tunggal dan adegan multi-objek yang kompleks secara end-to-end. Inovasi intinya mencakup ruang laten kombinatorial dan mekanisme perhatian hierarkis (Sumber: HuggingFace Daily Papers)
Prefix Grouper: mencapai pelatihan GRPO yang efisien melalui propagasi maju prefiks bersama: Group Relative Policy Optimization (GRPO) meningkatkan pembelajaran kebijakan dengan membandingkan perbedaan relatif antara output kandidat yang berbagi prefiks input umum. Prefix Grouper menghilangkan perhitungan prefiks yang berlebihan melalui kebijakan maju prefiks bersama, meningkatkan efisiensi pelatihan GRPO, terutama dalam skenario prefiks panjang, sambil mempertahankan kesetaraan pelatihan dengan GRPO standar (Sumber: HuggingFace Daily Papers)
GuideX: generasi data sintetis terpandu untuk ekstraksi informasi zero-shot: Sistem ekstraksi informasi (IE) tradisional biasanya spesifik domain, dengan biaya adaptasi yang tinggi. GuideX adalah metode baru yang secara otomatis mendefinisikan skema spesifik domain, menyimpulkan panduan, dan menghasilkan instance sintetis berlabel, sehingga mencapai generalisasi di luar domain yang lebih baik. Menggunakan GuideX untuk menyempurnakan Llama 3.1 menciptakan SOTA baru pada tujuh tolok ukur pengenalan entitas bernama zero-shot, secara signifikan meningkatkan pemahaman model terhadap pola anotasi spesifik domain yang kompleks (Sumber: HuggingFace Daily Papers)
CodeContests+: menghasilkan kasus uji berkualitas tinggi untuk kompetisi pemrograman: Untuk mengatasi masalah sulitnya memperoleh kasus uji dalam kompetisi pemrograman, peneliti mengusulkan sistem agen berbasis LLM untuk membuat kasus uji berkualitas tinggi. Sistem ini diterapkan pada dataset CodeContests, dan versi perbaikan CodeContests+ diusulkan. Evaluasi menunjukkan bahwa CodeContests+ secara signifikan lebih unggul dari versi asli dalam hal akurasi evaluasi, terutama dalam tingkat positif sejati (TPR), dan memiliki keunggulan signifikan untuk pembelajaran penguatan LLM (Sumber: HuggingFace Daily Papers)
Sentinel: Model SOTA untuk mencegah serangan injeksi prompt: Untuk mengatasi masalah model bahasa besar (LLM) yang rentan terhadap serangan injeksi prompt, peneliti meluncurkan model Sentinel (qualifire/prompt-injection-sentinel), berdasarkan arsitektur ModernBERT-large. Melalui penyempurnaan pada dataset luas yang berisi berbagai jenis serangan dan instruksi jinak, Sentinel mencapai akurasi rata-rata 0,987 dan skor F1 0,980 pada set pengujian internal yang tidak terlihat, dan mengungguli model dasar yang kuat pada tolok ukur publik (Sumber: HuggingFace Daily Papers)
Makalah membahas: Apakah perluasan modalitas merupakan jalur yang tepat untuk mencapai semua modalitas?: Model bahasa semua modalitas (OLM) bertujuan untuk mengintegrasikan dan menalar berbagai modalitas input, sambil mempertahankan kemampuan bahasa yang kuat. Penelitian ini membahas efek perluasan modalitas (yaitu, menyempurnakan model bahasa yang telah dilatih sebelumnya) sebagai teknik utama untuk melatih model multimodal. Penelitian berfokus pada tiga pertanyaan inti: Apakah perluasan modalitas akan merusak kemampuan bahasa inti? Apakah penggabungan model dapat secara efektif mengintegrasikan model spesifik modalitas yang disempurnakan secara independen untuk mencapai semua modalitas? Apakah perluasan semua modalitas membawa pembagian pengetahuan dan generalisasi yang lebih baik daripada perluasan berurutan? (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan Truth in the Few: metode pemilihan data bernilai tinggi untuk penalaran multimodal yang efisien: Penelitian menantang pandangan umum bahwa LLM multimodal (MLLM) memerlukan sejumlah besar data pelatihan dalam tugas penalaran kompleks. Melalui observasi, ditemukan bahwa hanya sebagian kecil data pelatihan yang disebut “sampel kognitif” yang dapat secara efektif merangsang penalaran multimodal. Berdasarkan hal ini, makalah mengusulkan paradigma pemilihan data Reasoning Activation Potential (RAP), yang mengidentifikasi sampel kognitif ini melalui Causal Difference Estimator (CDE) dan Attention Confidence Estimator (ACE), dan mengganti instance sederhana dengan Difficulty-aware Replacement Module (DRM). Eksperimen menunjukkan bahwa RAP hanya menggunakan 9,3% data pelatihan untuk mendapatkan kinerja yang lebih unggul, dan mengurangi biaya komputasi lebih dari 43% (Sumber: HuggingFace Daily Papers)
🧰 Alat
Task Master: Sistem manajemen tugas berbasis AI, terintegrasi dengan editor seperti Cursor: Task Master adalah sistem manajemen tugas yang dirancang khusus untuk pengembangan yang dibantu AI, yang dapat diintegrasikan secara mulus dengan editor seperti Cursor AI, Lovable, Windsurf, dan Roo. Sistem ini memanfaatkan API model besar seperti Claude (mendukung Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama) untuk membantu pengembang menganalisis dokumen persyaratan produk (PRD), menghasilkan daftar tugas, merencanakan langkah-langkah pengembangan, dan membantu dalam implementasi tugas tertentu. Sistem ini berjalan langsung di editor melalui MCP (Model Control Protocol), mendukung operasi baris perintah, dan menyediakan panduan konfigurasi serta tutorial penggunaan yang terperinci (Sumber: GitHub Trending)
Observer AI: Agen observasi layar open-source lokal, terintegrasi dengan Ollama: Observer AI adalah proyek open-source yang memungkinkan pengguna menjalankan LLM lokal melalui Ollama untuk mengamati layar dan melakukan tugas. Pengguna dapat menggunakan alat ini untuk membuat AI memahami konten layar dan berinteraksi, misalnya menjelajahi situs web berbahasa asing. Proyek ini menyediakan kode sumber GitHub dan versi aplikasi web tanpa perlu pengaturan lokal, mendukung pengguna untuk memanfaatkan LLM untuk otomatisasi operasi layar sambil melindungi privasi (Sumber: Reddit r/LocalLLaMA)

Weaviate Query Agent terintegrasi dengan tujuh kerangka kerja AI utama, menyederhanakan kueri data bahasa alami: Weaviate merilis metode integrasi Query Agent-nya dengan tujuh kerangka kerja AI utama (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic). Query Agent adalah layanan agen pra-bangun yang dapat menjawab kueri bahasa alami berdasarkan data di Weaviate, tanpa perlu menulis pernyataan kueri yang rumit. Integrasi ini memungkinkan pengembang untuk dengan mudah menyematkan kemampuan kueri bahasa alami yang kuat ke dalam tumpukan aplikasi AI yang ada, meningkatkan kemudahan interaksi data (Sumber: bobvanluijt)

Server MCP Claude Code dan Gemini Pro yang bekerja sama dirilis, meningkatkan efisiensi pengkodean: BeehiveInnovations merilis server MCP yang memungkinkan Claude Code dan Gemini 2.5 Pro bekerja sama. Claude Code bertanggung jawab atas konsepsi dan perencanaan awal, sementara Gemini menggunakan konteks token jutaan dan kemampuan penalaran mendalamnya untuk melengkapi. Server ini mengintegrasikan alat seperti perluasan pemikiran, pembacaan file, tinjauan kode, dan debugging, yang bertujuan untuk meningkatkan kualitas dan efisiensi pembuatan dan optimalisasi kode dengan menggabungkan keunggulan kedua model. Pengujian awal menunjukkan bahwa penggunaan gabungan lebih efektif daripada penggunaan salah satu model secara terpisah dalam tugas optimasi kecepatan parsing JSON (Sumber: Reddit r/ClaudeAI)

📚 Pembelajaran
Sakana AI merilis tolok ukur keuangan Jepang EDINET-Bench, mengevaluasi kemampuan LLM dalam tugas keuangan: Sakana AI meluncurkan EDINET-Bench, sebuah tolok ukur keuangan Jepang yang dibangun menggunakan laporan tahunan dari sistem pengungkapan elektronik Badan Jasa Keuangan Jepang, EDINET. Tolok ukur ini bertujuan untuk mengevaluasi kinerja model bahasa besar (LLM) dalam tugas keuangan yang kompleks seperti deteksi penipuan, untuk mengatasi kelangkaan dataset berkualitas tinggi yang tersedia secara gratis di bidang keuangan. EDINET-Bench menghasilkan dataset multi-tugas melalui anotasi otomatis, menyediakan sumber daya penting untuk penelitian dan pengembangan AI keuangan (Sumber: hardmaru,SakanaAILabs)

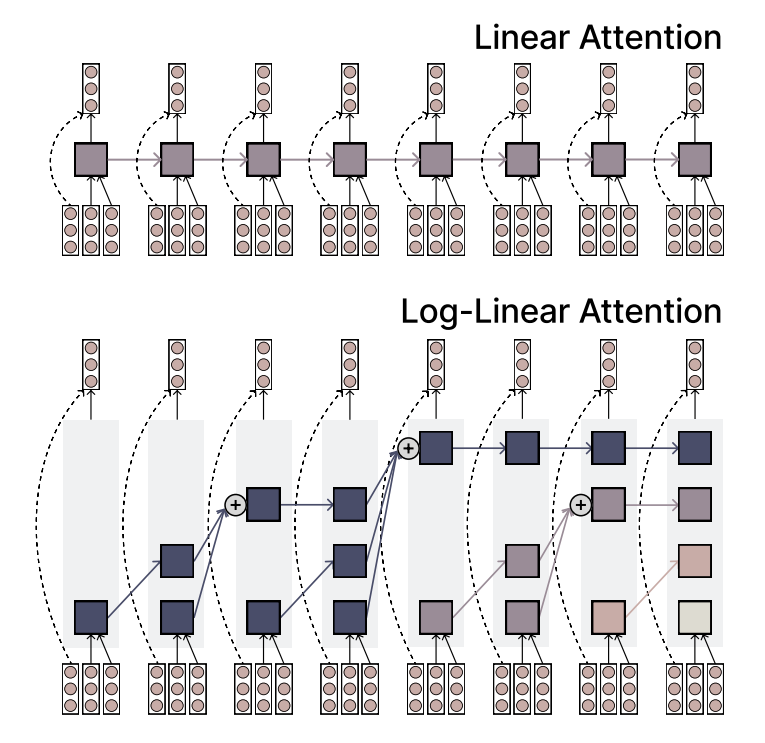
MIT mengusulkan mekanisme Log-linear Attention, menyeimbangkan efisiensi dan daya ekspresif: Peneliti MIT mengusulkan mekanisme perhatian baru yang disebut Log-linear Attention. Mekanisme ini bertujuan untuk menggabungkan kecepatan dan efisiensi perhatian linear dengan daya ekspresif perhatian Softmax. Ini mencapai tujuan ini dengan menggunakan sejumlah kecil slot memori yang tumbuh secara logaritmik dengan panjang urutan, menyediakan metode baru yang potensial untuk memproses data urutan panjang (Sumber: TheTuringPost)
Kursus evaluasi LLM Hamel Husain dan Shreya Rajpal mendapat ulasan positif: Pengguna seperti Ryan Lingo dan Radek Osmulski berbagi pengalaman positif mereka berpartisipasi dalam kursus evaluasi aplikasi LLM Hamel Husain dan Shreya Rajpal (maven.com/parlance-labs/evals). Kursus ini dianggap sebagai konten paling mendalam dan praktis tentang LLM saat ini, dengan kuliah dan buku eksklusifnya yang sangat penting bagi pengembang yang membangun aplikasi AI, menekankan peran sentral evaluasi dalam pengembangan LLM (Sumber: HamelHusain,HamelHusain)
MORSE-500: tolok ukur pengujian video yang dapat diprogram untuk uji tekanan penalaran multimodal: Menanggapi masalah bahwa tolok ukur penalaran multimodal saat ini terutama bergantung pada gambar statis, mengabaikan kompleksitas temporal dan luasnya keterampilan penalaran, peneliti meluncurkan MORSE-500. Ini adalah tolok ukur yang berisi 500 klip video yang sepenuhnya diskripkan, mencakup enam kategori penalaran seperti abstrak, fisik, perencanaan, spasial, dan temporal. Desain berbasis skripnya memungkinkan kontrol granular terhadap kompleksitas visual, kepadatan pengalih perhatian, dan dinamika temporal, mendukung pembuatan instance baru yang lebih menantang secara sewenang-wenang, yang bertujuan untuk menguji tekanan model generasi berikutnya. Eksperimen awal menunjukkan bahwa model SOTA termasuk Gemini 2.5 Pro dan OpenAI o3 memiliki kesenjangan kinerja yang signifikan di semua kategori (Sumber: HuggingFace Daily Papers)
EverGreenQA: dataset klasifikasi pertanyaan evergreen multibahasa, meningkatkan kredibilitas tanya jawab: Untuk mengatasi masalah LLM yang menghasilkan halusinasi dalam tugas tanya jawab (QA) karena ketepatan waktu pertanyaan (apakah jawaban berubah seiring waktu), peneliti meluncurkan EverGreenQA. Ini adalah dataset QA multibahasa pertama dengan label evergreen, mendukung evaluasi dan pelatihan. Melalui dataset ini, peneliti melakukan tolok ukur terhadap 12 LLM modern, mengevaluasi kemampuan mereka untuk mengkodekan ketepatan waktu pertanyaan, dan melatih pengklasifikasi multibahasa ringan EG-E5. Penelitian ini juga menunjukkan penerapan klasifikasi evergreen dalam meningkatkan estimasi pengetahuan diri, memfilter dataset QA, dan menjelaskan perilaku pengambilan GPT-4o (Sumber: HuggingFace Daily Papers)
KVzip: metode pengusiran cache KV yang tidak bergantung pada kueri, secara signifikan mengurangi penggunaan memori dan latensi dekode: ML Lab Universitas Nasional Seoul merilis KVzip, sebuah metode kompresi cache KV yang bertujuan untuk mendukung beragam kueri di masa depan. Metode ini, melalui strategi pengusiran yang tidak bergantung pada kueri, mencapai pengurangan memori sekitar 3-4 kali lipat dan pengurangan latensi dekode 2 kali lipat. Saat ini mendukung model seperti Qwen3/2.5, Gemma3, dan LLaMA3, dan menyediakan kode demo di GitHub (Sumber: Reddit r/LocalLLaMA)

NimbleEdge merilis kernel operator Transformer jarang secara open-source, meningkatkan kecepatan operasi LLM dan efisiensi memori: Tim NimbleEdge, berdasarkan penelitian LLM in a Flash dari Apple dan Deja Vu dari Zichang dkk., membangun kernel operator fusi untuk sparsity konteks terstruktur. Kernel ini, dengan menghindari pemuatan dan perhitungan bobot lapisan feed-forward dan aktivasi yang outputnya pada akhirnya akan menjadi nol, mencapai peningkatan kinerja 5 kali lipat pada lapisan MLP di Transformer dan pengurangan konsumsi memori sebesar 50%. Ketika diterapkan pada model Llama 3.2 3B, throughput keseluruhan meningkat 1,78 kali lipat dan penggunaan memori berkurang 26,4%. Kode telah dirilis secara open-source di GitHub dan direncanakan untuk mendukung int8, CUDA, dan sparse attention (Sumber: Reddit r/MachineLearning)
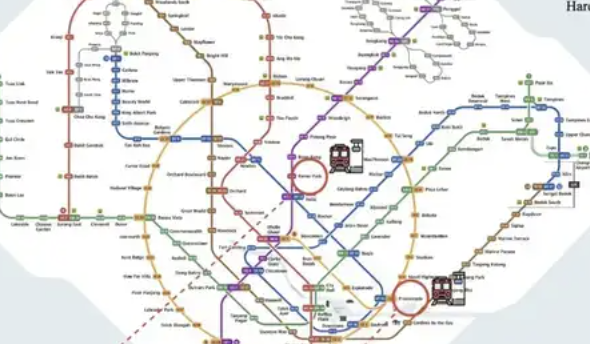
ReasonMap: tolok ukur evaluasi penalaran multimodal peta lalu lintas resolusi tinggi dirilis: Tim peneliti dari Universitas Westlake dan institusi lain meluncurkan ReasonMap, sebuah tolok ukur evaluasi penalaran multimodal yang berfokus pada peta lalu lintas resolusi tinggi (terutama peta kereta bawah tanah). Tolok ukur ini bertujuan untuk mengevaluasi kemampuan model besar dalam memahami informasi spasial terstruktur yang sangat detail dalam gambar, mencakup gambar resolusi tinggi (rata-rata 5839×5449), desain yang sadar akan kesulitan, dan sistem evaluasi multidimensi. Hasil pengujian menunjukkan bahwa model open-source utama saat ini berkinerja buruk di ReasonMap, terutama dalam perencanaan rute lintas jalur, sementara model penalaran sumber tertutup (seperti GPT-o3) berkinerja jauh lebih baik daripada model open-source, tetapi masih ada kesenjangan dengan tingkat manusia. Peta kereta bawah tanah yang kompleks seperti Beijing dan Hangzhou menjadi tantangan besar bagi model (Sumber: 量子位)
Yandex merilis Yambda-5B: dataset sistem rekomendasi terbuka skala besar: Yandex meluncurkan Yambda-5B, sebuah dataset streaming musik anonim skala besar yang berisi 4,79 miliar interaksi pengguna-item. Fitur dataset ini termasuk penyediaan tanda “is_organic” dan segmentasi waktu global (GTS), tidak mengandung riwayat pendengaran dan suka yang dapat secara langsung mengidentifikasi pengguna, memiliki kemampuan anti-deanonimisasi, dan berisi umpan balik implisit (mendengarkan lagu, melewatkan) dan eksplisit (suka/tidak suka). Yambda-5B bertujuan untuk menyediakan sumber daya data berkualitas tinggi dan multimodal untuk penelitian sistem rekomendasi (Sumber: TheTuringPost)
Tencent meluncurkan Star Challenge Camp 2025, merekrut siswa terbaik untuk berpartisipasi dalam penelitian mutakhir seperti model besar: Tencent mengumumkan peluncuran “Star Challenge Camp” tahunan 2025, yang ditujukan untuk siswa kelas 2 dan 3 SMA (calon siswa SMA angkatan 2025) serta siswa lain yang berprestasi luar biasa dalam disiplin ilmu terkait, merekrut 60-70 orang. Peserta terpilih akan berkesempatan pergi ke kantor pusat Shenzhen untuk berpartisipasi dalam penelitian enam topik mutakhir, termasuk pemahaman teks super panjang, teknologi rantai pemikiran panjang, kecerdasan terwujud + robotika, persepsi dan pemahaman multimodal, serangan dan pertahanan keamanan (termasuk desain peretas LLM Agent), dan teknologi kuantum. Program ini bertujuan untuk memberikan kesempatan kepada remaja berbakat untuk terpapar pada skenario penelitian tingkat industri, memperluas wawasan teknologi, dan memperdalam pemahaman industri (Sumber: 量子位)

💼 Bisnis
Dikabarkan Meta berencana berinvestasi lebih dari 10 miliar USD di Scale AI, memperkuat aplikasi AI di bidang militer dan lainnya: Dilaporkan bahwa Meta sedang dalam pembicaraan dengan perusahaan pelabelan data AI Scale AI mengenai investasi besar, yang jumlahnya bisa mencapai miliaran atau bahkan lebih dari 10 miliar USD. Jika benar, ini akan menjadi salah satu investasi AI eksternal terbesar Meta. Scale AI sebelumnya telah membangun model yang dirancang khusus untuk penggunaan militer, Defense Llama, berdasarkan Llama 3 Meta, untuk mendukung misi keamanan nasional AS. Langkah ini mungkin menandakan bahwa Meta akan mengambil strategi investasi dan kerja sama yang lebih aktif di bidang AI, terutama dalam aplikasi yang terkait dengan pemerintah dan pertahanan (Sumber: 36氪)

Mashang Consumer Finance merilis model besar “Tianjing” 3.0, ditingkatkan menjadi platform keputusan keuangan: Mashang Consumer Finance meluncurkan versi 3.0 dari model besar keuangannya “Tianjing”. Terobosan inti dari versi baru ini adalah lompatan sistematis dari kecerdasan individu ke kecerdasan kolektif, tidak lagi hanya mengandalkan pembelajaran logika, tetapi menggali lebih dalam pengalaman implisit yang tersebar dalam jejak karyawan, log bisnis, dll., dan mengubahnya menjadi pengetahuan terstruktur. Tianjing 3.0 bertujuan untuk ditingkatkan dari alat menjadi platform keputusan, mendorong kolaborasi manusia-mesin, mampu secara dinamis membongkar proses layanan yang kompleks, dan secara real-time mencocokkan kombinasi layanan optimal sesuai dengan permintaan pengguna dan persyaratan kepatuhan, mencapai keputusan dari optimal lokal ke optimal global (Sumber: 量子位)

Together AI menunjuk Charles Zedlewski sebagai Chief Product Officer baru, berfokus pada platform AI generatif open-source: Together AI mengumumkan penunjukan Charles Zedlewski sebagai Chief Product Officer (CPO) barunya. Charles Zedlewski sebelumnya memimpin produk platform berbasis komunitas yang berorientasi pada pengembang di Temporal dan Cloudera. Together AI menekankan komitmennya untuk membangun masa depan AI generatif open-source, percaya bahwa model terbuka memiliki keunggulan dalam fleksibilitas, efektivitas biaya, dan inovasi. Kehadiran Charles bertujuan untuk lebih mendorong Together AI dalam membangun platform AI open-source yang otoritatif, membuat AI generatif yang kuat dapat dijangkau oleh setiap pengembang dan perusahaan (Sumber: togethercompute)

🌟 Komunitas
Mobil self-driving Waymo dibakar di Los Angeles, memicu kekhawatiran dan diskusi komunitas tentang keamanan AV: Baru-baru ini, beberapa mobil self-driving Waymo dibakar oleh orang tak dikenal di Los Angeles. Insiden ini menarik perhatian dan diskusi luas di media sosial, yang mencakup penerimaan publik terhadap mobil self-driving, kekhawatiran keamanan, dan risiko bahwa insiden semacam itu dapat diperbesar atau diputarbalikkan secara tidak patut oleh konten yang dihasilkan AI (seperti video yang dihasilkan Veo 3). Beberapa komentator membandingkan adegan ini dengan film fiksi ilmiah “Children of Men”, menyoroti dramatisasi insiden dan potensi dampak sosialnya (Sumber: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
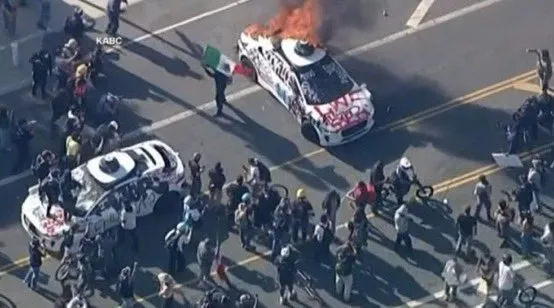
Reddit menggugat Anthropic, menuduhnya mengambil konten tanpa izin untuk melatih Claude AI: Reddit telah mengajukan gugatan terhadap Anthropic, menuduhnya mengambil postingan dan percakapan Reddit tanpa izin dan pembayaran untuk melatih model AI-nya, Claude. Reddit percaya tindakan ini melanggar ketentuan penggunaannya yang melarang penggunaan komersial konten tanpa izin, dan menyebut klaim Anthropic bahwa mereka “telah berhenti mengambil konten Reddit” sebagai pernyataan palsu. Gugatan tersebut juga melibatkan masalah privasi, karena Anthropic tidak memiliki mekanisme untuk menghapus postingan yang telah dihapus pengguna, tidak seperti perusahaan lain yang memiliki perjanjian lisensi. Reddit meminta pengadilan untuk melarang Anthropic menggunakan data Reddit, dan mungkin meminta mereka untuk menarik Claude dari peredaran (Sumber: Reddit r/ArtificialInteligence,Reddit r/artificial)
Diskusi hangat di AI Engineer Expo: Simon Willison meninjau perkembangan LLM selama setengah tahun terakhir, menekankan kombinasi alat + penalaran: Di AI Engineer Expo San Francisco, Simon Willison dengan humor meninjau perkembangan pesat LLM selama enam bulan terakhir melalui tes pembuatan gambar SVG “pelikan bersepeda”, dan secara pribadi menguji lebih dari 30 model AI. Dia menekankan bahwa kombinasi AI terkuat saat ini adalah “alat + penalaran”, seperti kinerja o3/o4-mini dalam pencarian, dan perhatian yang diterima arsitektur MCP karena pemanggilan alat. Pidatonya juga merangkum “bug aneh” AI tahun ini, seperti sanjungan berlebihan ChatGPT, perilaku Claude yang mungkin “melaporkan” pengguna, dll., dan menunjukkan risiko injeksi prompt dan kebocoran data (Sumber: 36氪,swyx)

Diskusi komunitas mengenai kecemasan karir yang disebabkan oleh AI dan strategi mengatasinya: Postingan di Reddit tentang “bagaimana mengatasi kecemasan AI” memicu diskusi hangat. Pengguna umumnya khawatir bahwa AI dapat menyebabkan pengangguran massal dalam beberapa tahun ke depan, terutama menjadi ancaman serius bagi mereka yang memiliki tabungan tidak mencukupi dan banyak utang. Dalam diskusi tersebut, beberapa orang menyarankan untuk beralih ke bidang tukang, perawatan, dll., tetapi juga khawatir bahwa bidang-bidang ini akan jenuh karena banyaknya orang yang beralih profesi. Komentator berbagi emosi kecemasan mereka, seperti insomnia, kesulitan berkonsentrasi pada pekerjaan, dll. Beberapa pandangan berpendapat bahwa kita harus aktif belajar AI, menjaga kemampuan beradaptasi, dan menunjukkan bahwa inovasi teknologi di masa lalu (seperti mobil, internet) juga pernah menimbulkan kekhawatiran serupa, tetapi pada akhirnya menciptakan peluang kerja baru. Ada juga komentator yang berpendapat bahwa tingkat penggantian pekerjaan manusia oleh AI saat ini dibesar-besarkan, dan PHK massal tidak mungkin terjadi dalam waktu dekat (Sumber: Reddit r/ArtificialInteligence)
Pengguna berbagi pengalaman menggunakan ChatGPT untuk analisis diri psikologis yang “kejam”: Seorang pengguna Reddit berbagi pengalamannya menggunakan ChatGPT untuk analisis diri psikologis gaya “eksekutif brutal”. Dia menggunakan prompt tertentu, meminta ChatGPT untuk menganalisis secara keras dari lima sudut: kekuatan sejati, kelemahan mendalam, pola kegagalan berulang, area yang dihindari, dan keterampilan yang diabaikan, dan memberikan rencana pengembangan tiga tahap. Pengguna menyatakan bahwa meskipun prosesnya menyakitkan (misalnya, ditunjukkan telah memulai 12 proyek tetapi tidak ada yang selesai, dan terlalu banyak meneliti produktivitas daripada tindakan nyata), umpan balik “kejam” ini pada akhirnya mendorongnya untuk berubah. Postingan ini memicu diskusi komunitas tentang penerapan AI dalam refleksi diri dan pengembangan pribadi (Sumber: Reddit r/ArtificialInteligence)
Diskusi tentang kemampuan memori dan penalaran LLM: apakah berpengetahuan luas atau benar-benar memahami?: Di media sosial, pengguna membahas kinerja luar biasa model bahasa besar (LLM) dalam tugas mengingat fakta berbasis memori, dan apakah ini berarti mereka benar-benar memiliki kemampuan penalaran. Beberapa pandangan berpendapat bahwa kinerja LLM yang sangat baik dalam tugas yang tampak kompleks mungkin lebih bergantung pada data pelatihan yang sangat besar dan pengenalan pola, daripada pemahaman mendalam dan kreativitas dalam arti manusia. Penelitian dari perusahaan seperti Meta menunjukkan bahwa kapasitas model dapat diperkirakan dengan mengukur memori, dan generalisasi baru dimulai setelah kapasitas terisi. Diskusi ini juga terkait dengan penekanan pada hafalan dalam sistem pendidikan, dan kurangnya pengembangan kemampuan untuk mengambil informasi dan menggunakan alat AI (Sumber: omarsar0,menhguin,menhguin)

💡 Lainnya
Analisis studi kasus keberhasilan model dasar deteksi penipuan pembayaran Stripe: Postingan dari insinyur Stripe tentang membangun model dasar deteksi penipuan pembayaran yang sukses menarik perhatian. Analisis menunjukkan bahwa kekhususan kasus ini adalah: 1) Deteksi penipuan pada dasarnya bukan memprediksi masa depan, secara teoritis akurasi tinggi dapat dicapai ketika sinyal mencukupi; 2) Stripe sudah berada dalam lingkungan yang kaya sinyal, tidak perlu memulai akumulasi data dari nol; 3) Skenario ini adalah peningkatan otomatisasi, dari pembelajaran mesin tradisional ke model dasar, mendekati penggantian langsung. Ini menjelaskan mengapa “kemenangan instan” aplikasi AI semacam ini relatif jarang, sebagian besar realisasi nilai bisnis AI perlu mengatasi banyak rintangan (Sumber: random_walker)
Dasar kognitif transformasi AI: mekanisme persepsi informasi sistematis dan wawasan teknologi adalah kunci: Dalam transformasi AI, perusahaan perlu membangun mekanisme persepsi informasi dan wawasan teknologi yang sistematis dan terstruktur, melampaui pengalaman individu dan ketergantungan jalur tradisional. Ini termasuk membangun kemampuan analisis data internal dan jaringan pengetahuan eksternal (akademisi, industri, pasar modal, perusahaan rintisan). Evaluasi laba atas investasi AI juga perlu beralih dari ROI tradisional ke sistem “multi-siklus, multi-dimensi”, dan digabungkan dengan jaringan pengetahuan eksternal, membentuk lingkaran tertutup strategis verifikasi berkelanjutan dan penyesuaian dinamis. Artikel ini menekankan bahwa AI bukanlah alat sekali pakai, melainkan aset strategis yang terus berkembang dan nilainya terus bertambah (Sumber: 36氪)
Frigate: Sistem NVR berbasis deteksi objek lokal real-time: Frigate adalah sistem perekam video jaringan (NVR) lokal yang dirancang khusus untuk Home Assistant, menggunakan OpenCV dan Tensorflow untuk melakukan deteksi objek lokal real-time pada kamera IP. Sistem ini menekankan optimalisasi sumber daya dan kinerja, memicu deteksi objek melalui deteksi gerakan berbiaya rendah, dan memanfaatkan pemrosesan multi-proses. Disarankan menggunakan akselerator AI seperti Google Coral atau Hailo untuk kinerja optimal. Frigate mendukung perekaman 24/7, penyimpanan rekaman berbasis deteksi objek, integrasi MQTT, siaran ulang RTSP, serta tampilan real-time latensi rendah WebRTC/MSE (Sumber: GitHub Trending)
