
Palavras-chave:Grandes Modelos de Linguagem (LLM), Capacidade de Raciocínio, Segurança em IA, Modelos Multimodais, Modelos de Código Aberto, Geração de Vídeo por IA, Avaliação de IA, Aplicações Comerciais de IA, Pesquisa sobre Capacidade de Raciocínio em LLM da Apple, Modelo de Compreensão Temporal Time-R1, Geração de Vídeo com GPU NVIDIA Blackwell, Modelo de Código Aberto Alibaba Tongyi Qianwen 3, Servidor MCP da Hugging Face
🔥 Foco
Apple publica artigo afirmando que os LLMs atuais têm apenas uma “ilusão de pensamento” e não capacidade de raciocínio real, gerando debate acalorado na indústria: Pesquisadores da Apple (incluindo Samy Bengio, um dos fundadores do Google Brain) publicaram um artigo que, através de testes com quatro tarefas de dificuldade controlável, como a Torre de Hanói e a troca de damas, aponta que modelos de ponta como DeepSeek, o3-mini, Claude 3.7 “colapsam” ao enfrentar problemas de alta complexidade, exibindo “escalonamento inverso do esforço de raciocínio” (quanto mais difícil o problema, menos pensam). O artigo argumenta que esses modelos dependem mais de correspondência de padrões e memória do que de raciocínio lógico real e generalizável, e mesmo com o fornecimento de algoritmos completos, não conseguem superar o gargalo de complexidade. Esta visão desafia a percepção comum atual sobre a capacidade de raciocínio dos LLMs e gerou ampla discussão sobre métodos de avaliação de LLMs, os limites da capacidade de raciocínio real e as futuras direções de desenvolvimento. A comunidade reagiu de forma mista, com alguns considerando isso uma defesa da Apple para seu próprio progresso lento em IA, enquanto outros concordam com sua percepção sobre os mecanismos de avaliação e as limitações intrínsecas dos modelos (Fonte: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

Yoshua Bengio, vencedor do Prêmio Turing, alerta para o risco de descontrole da IA e ajusta foco de pesquisa para “Scientist AI”: Yoshua Bengio afirmou na Conferência de IA de Pequim (BAAI) que, dado o rápido desenvolvimento da IA (especialmente AGI) e seus riscos potenciais de descontrole (como IA copiando seu próprio código para “sobreviver”, ocultando comportamentos), ele ajustou sua direção de pesquisa para se dedicar à construção de uma “Scientist AI” que possua apenas inteligência, sem autoconsciência ou objetivos próprios. Ele acredita que a capacidade de planejamento da IA pode atingir o nível humano em cinco anos e aponta que os métodos atuais de treinamento de IA podem levar a uma confiança excessiva, mesmo quando errada. Bengio enfatizou a necessidade de garantir que a IA cumpra instruções éticas, evite ser usada para fins maliciosos e apelou à cooperação global para enfrentar os desafios de segurança da IA, resolvendo problemas de “alinhamento” e “controlabilidade” (Fonte: 量子位)

Governo do Reino Unido adota sistema Extract, potencializado pelo modelo Gemini do Google, para acelerar decisões de planejamento: O governo do Reino Unido está utilizando um sistema chamado “Extract” para ajudar os planejadores dos conselhos locais a tomar decisões mais rapidamente. O sistema é baseado no modelo fundamental Gemini do Google e utiliza suas capacidades de raciocínio multimodal para converter documentos de planejamento complexos, incluindo notas manuscritas e mapas pouco nítidos, em dados digitais em 40 segundos. Esta aplicação demonstra o potencial da IA nos serviços públicos governamentais, melhorando a eficiência administrativa e a qualidade das decisões através do processamento e compreensão automatizados de documentos complexos (Fonte: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia é a primeira a adotar GPUs NVIDIA Blackwell para treinar o modelo de vídeo em larga escala EXPRESS-2: A empresa de geração de vídeo por IA Synthesia anunciou ser a primeira no mundo a usar GPUs NVIDIA Blackwell no Google Cloud para treinar modelos de vídeo em larga escala. Seu novo modelo, EXPRESS-2, visa ajudar os clientes a criar vídeos e avatares gerados por IA de maior qualidade e mais rapidamente, através de hardware mais potente e uma configuração multicloud otimizada. Esta medida marca um avanço importante no suporte de hardware subjacente e na capacidade dos modelos de tecnologia de geração de vídeo por IA, prenunciando uma maior eficiência e qualidade na criação de conteúdo de vídeo por IA no futuro (Fonte: synthesiaIO,Synthesia Blog)
Pesquisa da Epoch AI revela que o modelo o3-mini-high resolve problemas matemáticos de ponta com base na “intuição”, não na memorização: A Epoch AI convidou 14 matemáticos para avaliar 29 processos de raciocínio do o3-mini-high no benchmark FrontierMath, descobrindo que o modelo conseguiu resolver corretamente 13 problemas difíceis. O estudo indica que o o3-mini-high possui vasto conhecimento matemático e pode invocar teoremas relevantes, mas seu estilo de raciocínio tende mais para a “indução baseada na intuição”, carecendo de provas formais rigorosas e criatividade, às vezes até “pegando atalhos” e pulando etapas de prova. Apesar de problemas como alucinações e incapacidade de reproduzir fórmulas com precisão, seu desempenho em algumas questões é semelhante ao processo de pensamento de matemáticos humanos. Esta pesquisa analisa profundamente as capacidades e limitações atuais dos grandes modelos no raciocínio matemático complexo (Fonte: 量子位)

🎯 Tendências
Downloads do modelo de código aberto Qwen3 da Alibaba ultrapassam 12,5 milhões, com mais de 130.000 modelos derivados, liderando globalmente: Desde o seu lançamento há um mês, a série de modelos grandes Qwen3 da Alibaba acumulou mais de 12,5 milhões de downloads globalmente, tornando-se o modelo de código aberto mais popular recentemente. Seus quatro tamanhos de modelo, de 0.6B a 32B, ultrapassaram um milhão de downloads cada em plataformas como Hugging Face e ModelScope (魔搭社区), e o número de modelos derivados ultrapassou 130.000, ocupando o primeiro lugar global. O Qwen3 alcançou o topo em várias listas de desempenho nacionais e internacionais para modelos de código aberto e, devido ao seu baixo custo de inferência (aproximadamente um terço do DeepSeek R1), atraiu a adaptação e integração de muitos fabricantes de chips e plataformas de computação, como NVIDIA, Intel e ARM (Fonte: 量子位)

Universidade de Illinois lança modelo Time-R1, com 3B parâmetros, para compreensão, previsão e geração relacionadas ao tempo: Pesquisadores da Universidade de Illinois em Urbana-Champaign lançaram o Time-R1, um modelo de linguagem de 3B parâmetros que, através de aprendizado por reforço em três estágios e um mecanismo de recompensa dinâmico, aprimora a compreensão do conceito de tempo pelo modelo, a previsão de eventos futuros e a capacidade de geração de cenários criativos. O modelo apresenta desempenho superior em tarefas de raciocínio temporal, superando até mesmo modelos com um número de parâmetros muito maior, como o DeepSeek-V3-0324. A equipe de pesquisa disponibilizou em código aberto o Time-Bench (um grande dataset de raciocínio temporal multitarefa baseado em 10 anos de notícias do New York Times) e o código de treinamento e checkpoints do modelo Time-R1 (Fonte: 量子位)

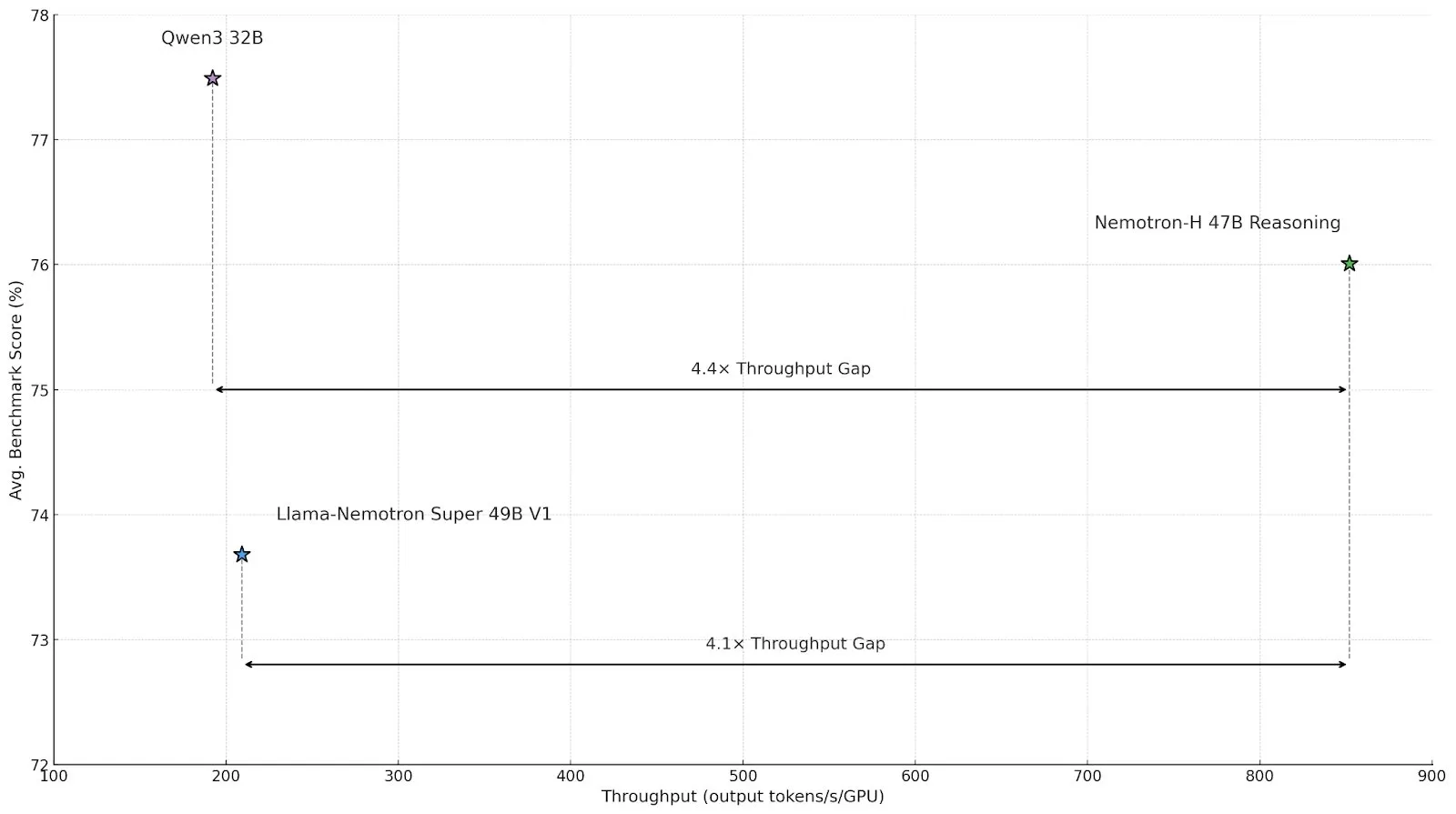
NVIDIA lança modelos de inferência da série Nemotron-H, utilizando arquitetura híbrida Mamba-Transformer para maior eficiência: A NVIDIA apresentou os modelos de inferência Nemotron-H 8B e 47B, baseados na arquitetura híbrida SSM-Transformer (Mamba-Transformer). Esses modelos mantêm alta precisão enquanto alcançam uma taxa de transferência de inferência até 4 vezes maior que modelos Transformer comparáveis. O Nemotron-H-47B-Reasoning-128k supera o Llama-Nemotron-Super-49B-1.0 em vários benchmarks, com um custo de inferência até 4 vezes menor. Os pesos do modelo foram lançados no HuggingFace sob uma licença não produtiva, visando impulsionar a pesquisa em inferência em larga escala de alta eficiência (Fonte: tri_dao,NVIDIA AI Developer)
Modelo DeepSeek R1 0528 atinge pontuação de 71% no benchmark de programação Aider Polyglot: O modelo DeepSeek R1 0528 alcançou uma pontuação de 71% no benchmark de programação Aider Polyglot, uma melhoria significativa (+14,5 pontos percentuais) em relação às versões anteriores. O modelo tem chamado a atenção por seu alto custo-benefício, completando aproximadamente 70% do benchmark por menos de 5 dólares, demonstrando forte competitividade em tarefas de geração de código (Fonte: Reddit r/LocalLLaMA,scaling01)
Framework VACE lançado: modelo multifuncional que integra criação e edição de vídeo: O Alibaba Tongyi Lab lançou o VACE (Video Creation and Editing), um modelo unificado que integra múltiplas funções, como geração de vídeo a partir de referência (R2V), edição de vídeo para vídeo (V2V) e edição de vídeo com máscara (MV2V). O VACE permite aos usuários combinar livremente essas tarefas para realizar diversos processamentos de vídeo, como mover objetos, substituí-los, referenciar estilos, expandir e animar. Várias versões do modelo já foram lançadas, incluindo VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B e Wan2.1-VACE-14B, e estão disponíveis para download no HuggingFace e ModelScope (Fonte: GitHub Trending)

HKUST (Guangzhou) e ByteDance lançam conjuntamente o framework ComfyMind para unificar tarefas de geração visual: A Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou) e a ByteDance lançaram conjuntamente o framework de geração visual de código aberto ComfyMind, que visa processar múltiplas tarefas de geração visual convencionais, como texto para imagem e imagem para vídeo, através de um único sistema. O ComfyMind adota “fluxos de trabalho atômicos” como a menor unidade, combinados com planejamento em árvore e mecanismos de execução de feedback local, utilizando o ComfyUI como motor de execução subjacente e completando tarefas complexas através da colaboração de três agentes: planejamento, execução e avaliação. Em benchmarks como ComfyBench, GenEval e Reason-Edit, o ComfyMind apresentou excelente desempenho, comparável ao GPT-4o-Image (Fonte: 量子位)

Hugging Face lança servidor do Protocolo de Contexto de Modelo (MCP) para aprimorar capacidades de agentes de IA: O Hugging Face agora oferece um servidor do Protocolo de Contexto de Modelo (MCP), permitindo que agentes de IA acessem ferramentas externas e dados em tempo real de forma padronizada e segura, incluindo modelos de busca, análise de datasets e interação com HuggingFace Spaces. Esta iniciativa visa transformar agentes de IA de ferramentas estáticas em colaboradores dinâmicos, aprimorando sua capacidade de lidar com tarefas complexas e obter informações atualizadas. Vários membros da comunidade já começaram a explorar a integração de servidores MCP com diversos frameworks de IA (como Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) (Fonte: ClementDelangue,huggingface,awnihannun)

Pesquisa apresenta STARFlow: modelo de fluxo normalizador latente escalável para síntese de imagens de alta resolução: STARFlow é um modelo generativo escalável baseado em fluxos normalizadores, cujo núcleo é o Transformer Autoregressive Flow (TARFlow). Através de um design de camadas profundas e rasas, modelagem no espaço latente de um autoencoder pré-treinado e um novo algoritmo de orientação, o STARFlow alcança desempenho competitivo em tarefas de geração de imagens condicionadas por classe e texto, aproximando-se dos modelos de difusão de última geração. Este trabalho demonstra pela primeira vez o funcionamento eficaz de fluxos normalizadores nesta escala e resolução (Fonte: HuggingFace Daily Papers)
Nova pesquisa HASHIRU: sistema de agentes hierárquico para utilização de recursos de inteligência híbrida: HASHIRU é um novo framework de sistema multiagente (MAS) caracterizado por um agente “CEO” que gerencia dinamicamente agentes “funcionários” especializados, instanciando-os de acordo com as necessidades da tarefa e restrições de recursos (custo, memória). O sistema prioriza o uso de LLMs locais pequenos (via Ollama), utilizando flexivelmente APIs externas e modelos grandes, e inclui criação autônoma de ferramentas API e funcionalidade de memória. Avaliações em tarefas como revisão de artigos acadêmicos, avaliação de segurança e raciocínio complexo demonstram suas capacidades (Fonte: HuggingFace Daily Papers)
PartCrafter: Geração estruturada de malhas 3D através da combinação de Transformers de difusão latente: PartCrafter é o primeiro modelo de geração 3D estruturado capaz de sintetizar conjuntamente múltiplas malhas 3D semanticamente significativas e geometricamente distintas a partir de uma única imagem RGB. Ele emprega uma arquitetura de geração combinatória unificada, não dependendo de entrada pré-segmentada, e é capaz de perceber a geração de partes de ponta a ponta para objetos únicos e cenas complexas com múltiplos objetos. Suas principais inovações incluem um espaço latente combinatório e um mecanismo de atenção hierárquico (Fonte: HuggingFace Daily Papers)
Prefix Grouper: Treinamento eficiente de GRPO através da propagação para frente de prefixo compartilhado: Group Relative Policy Optimization (GRPO) aprimora o aprendizado de políticas comparando as diferenças relativas entre saídas candidatas que compartilham um prefixo de entrada comum. O Prefix Grouper elimina cálculos redundantes de prefixo através da política de propagação para frente de prefixo compartilhado, aumentando a eficiência do treinamento do GRPO, especialmente em cenários de prefixos longos, enquanto mantém a equivalência de treinamento com o GRPO padrão (Fonte: HuggingFace Daily Papers)
GuideX: Geração de dados sintéticos guiada para extração de informações zero-shot: Sistemas tradicionais de extração de informações (IE) são geralmente específicos de domínio e caros para adaptar. GuideX é uma nova abordagem que define automaticamente esquemas específicos de domínio, infere guias e gera instâncias sintéticas rotuladas, permitindo melhor generalização fora do domínio. O ajuste fino do Llama 3.1 usando GuideX estabeleceu um novo SOTA em sete benchmarks de reconhecimento de entidades nomeadas zero-shot, melhorando significativamente a compreensão do modelo sobre padrões complexos de anotação específicos de domínio (Fonte: HuggingFace Daily Papers)
CodeContests+: Geração de casos de teste de alta qualidade para competições de programação: Para resolver o problema da dificuldade de obter casos de teste em competições de programação, pesquisadores propuseram um sistema de agentes baseado em LLM para criar casos de teste de alta qualidade. Este sistema foi aplicado ao dataset CodeContests, e uma versão melhorada, CodeContests+, foi proposta. A avaliação mostrou que o CodeContests+ supera significativamente a versão original em termos de precisão de avaliação, especialmente na taxa de verdadeiros positivos (TPR), e oferece vantagens significativas para o aprendizado por reforço de LLMs (Fonte: HuggingFace Daily Papers)
Sentinel: Modelo SOTA para defesa contra ataques de injeção de prompt: Para lidar com a vulnerabilidade de grandes modelos de linguagem (LLMs) a ataques de injeção de prompt, pesquisadores lançaram o modelo Sentinel (qualifire/prompt-injection-sentinel), baseado na arquitetura ModernBERT-large. Através do ajuste fino em um extenso dataset contendo vários tipos de ataque e instruções benignas, o Sentinel alcançou uma precisão média de 0,987 e uma pontuação F1 de 0,980 em um conjunto de testes interno não visto, e superou modelos de linha de base fortes em benchmarks públicos (Fonte: HuggingFace Daily Papers)
Artigo discute: A expansão de modalidades é o caminho correto para alcançar a omnimodalidade?: Modelos de linguagem omnimodais (OLMs) visam integrar e raciocinar sobre múltiplas modalidades de entrada, mantendo ao mesmo tempo fortes capacidades linguísticas. Esta pesquisa explora a eficácia da expansão de modalidades (ou seja, o ajuste fino de modelos de linguagem pré-treinados) como a técnica predominante para treinar modelos multimodais. O estudo foca em três questões centrais: a expansão de modalidades prejudica as capacidades linguísticas centrais? A fusão de modelos pode integrar efetivamente modelos específicos de modalidade ajustados independentemente para alcançar a omnimodalidade? A expansão omnimodal traz melhor compartilhamento de conhecimento e generalização do que a expansão sequencial? (Fonte: HuggingFace Daily Papers)
Artigo propõe Truth in the Few: Método de seleção de dados de alto valor para raciocínio multimodal eficiente: A pesquisa desafia a percepção comum de que LLMs multimodais (MLLMs) necessitam de grandes quantidades de dados de treinamento para tarefas complexas de raciocínio. Através da observação, descobriu-se que apenas uma pequena fração dos dados de treinamento, denominadas “amostras cognitivas”, estimula efetivamente o raciocínio multimodal. Com base nisso, o artigo propõe o paradigma de seleção de dados Reasoning Activation Potential (RAP), que identifica essas amostras cognitivas através de um estimador de diferença causal (CDE) e um estimador de confiança de atenção (ACE), e substitui instâncias simples por um módulo de substituição sensível à dificuldade (DRM). Experimentos mostram que o RAP alcança desempenho superior usando apenas 9,3% dos dados de treinamento e reduz os custos computacionais em mais de 43% (Fonte: HuggingFace Daily Papers)
🧰 Ferramentas
Task Master: Sistema de gerenciamento de tarefas orientado por IA, integrado a editores como Cursor: Task Master é um sistema de gerenciamento de tarefas projetado especificamente para desenvolvimento assistido por IA, integrando-se perfeitamente com editores como Cursor AI, Lovable, Windsurf, Roo, entre outros. Ele utiliza APIs de modelos grandes como Claude (suportando Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama) para ajudar desenvolvedores a analisar documentos de requisitos de produto (PRD), gerar listas de tarefas, planejar etapas de desenvolvimento e auxiliar na implementação de tarefas específicas. O sistema opera diretamente no editor através do MCP (Protocolo de Controle de Modelo), suporta operações de linha de comando e fornece guias detalhados de configuração e tutoriais de uso (Fonte: GitHub Trending)
Observer AI: Agente inteligente de observação de tela de código aberto local, integrado com Ollama: Observer AI é um projeto de código aberto que permite aos usuários executar LLMs locais através do Ollama para observar a tela e executar tarefas. Os usuários podem usar esta ferramenta para permitir que a IA compreenda o conteúdo da tela e interaja, por exemplo, navegando em sites em língua estrangeira. O projeto fornece o código-fonte no GitHub e uma versão de aplicativo web que não requer configuração local, permitindo que os usuários utilizem LLMs para automação de tela, protegendo a privacidade (Fonte: Reddit r/LocalLLaMA)

Weaviate Query Agent integra-se com sete grandes frameworks de IA, simplificando a consulta de dados em linguagem natural: A Weaviate anunciou a integração do seu Query Agent com sete dos principais frameworks de IA (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic). O Query Agent é um serviço de agente pré-construído que pode responder a consultas em linguagem natural com base nos dados do Weaviate, sem a necessidade de escrever declarações de consulta complexas. Essas integrações permitem que os desenvolvedores incorporem facilmente poderosas capacidades de consulta em linguagem natural em suas pilhas de aplicativos de IA existentes, aumentando a conveniência da interação com dados (Fonte: bobvanluijt)

Servidor MCP para trabalho colaborativo entre Claude Code e Gemini Pro lançado, aumentando a eficiência da codificação: A BeehiveInnovations lançou um servidor MCP que permite ao Claude Code e ao Gemini 2.5 Pro trabalharem em colaboração. O Claude Code é responsável pela concepção e planejamento iniciais, enquanto o Gemini complementa com seu contexto de milhões de tokens e capacidades de raciocínio profundo. O servidor integra ferramentas para pensamento estendido, leitura de arquivos, revisão de código e depuração, visando melhorar a qualidade e eficiência da geração e otimização de código, combinando as vantagens de ambos os modelos. Testes preliminares mostraram que, em tarefas de otimização da velocidade de análise de JSON, o uso combinado foi mais eficaz do que o uso individual de qualquer um dos modelos (Fonte: Reddit r/ClaudeAI)

📚 Aprendizado
Sakana AI lança benchmark financeiro em japonês EDINET-Bench para avaliar capacidade de LLMs em tarefas financeiras: A Sakana AI lançou o EDINET-Bench, um benchmark de teste financeiro em japonês construído utilizando relatórios anuais do sistema de divulgação eletrônica EDINET da Agência de Serviços Financeiros do Japão. Este benchmark visa avaliar o desempenho de grandes modelos de linguagem (LLMs) em tarefas financeiras complexas, como detecção de fraudes, para lidar com a escassez de datasets de alta qualidade e disponíveis gratuitamente no setor financeiro. O EDINET-Bench gera datasets multitarefa através de anotação automática, fornecendo um recurso importante para a pesquisa e desenvolvimento de IA financeira (Fonte: hardmaru,SakanaAILabs)

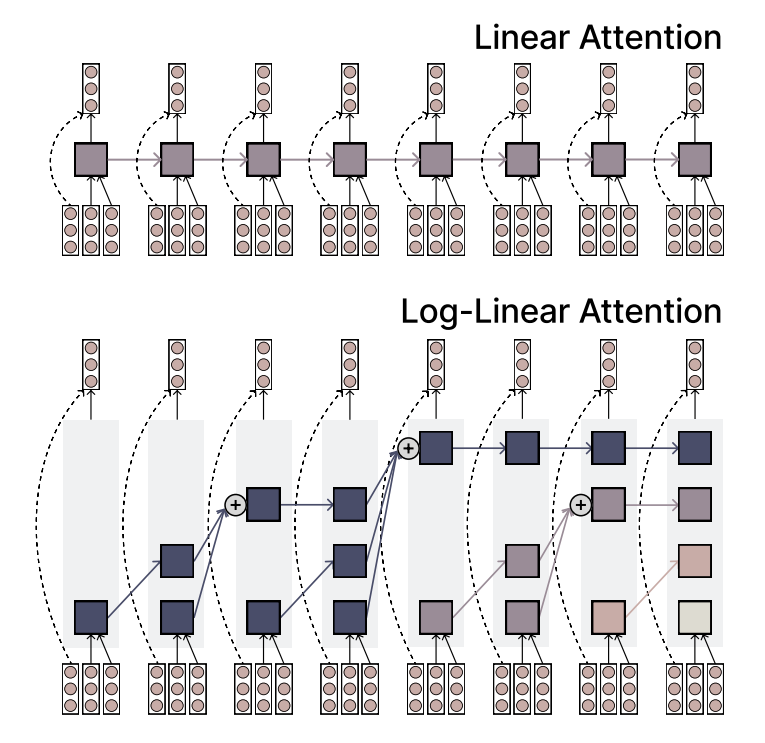
MIT propõe mecanismo Log-linear Attention, equilibrando eficiência e expressividade: Pesquisadores do MIT propuseram um novo mecanismo de atenção chamado Log-linear Attention. Este mecanismo visa combinar a velocidade e eficiência da atenção linear com a capacidade expressiva da atenção Softmax. Ele atinge esse objetivo usando um pequeno número de slots de memória que crescem logaritmicamente com o comprimento da sequência, oferecendo um novo método promissor para processar dados de sequências longas (Fonte: TheTuringPost)
Curso de avaliação de LLM de Hamel Husain e Shreya Rajpal recebe elogios: Usuários como Ryan Lingo e Radek Osmulski compartilharam experiências positivas ao participar do curso de avaliação de aplicações de LLM de Hamel Husain e Shreya Rajpal (maven.com/parlance-labs/evals). O curso é considerado o conteúdo mais aprofundado e prático sobre LLMs atualmente, com suas palestras e livro exclusivo sendo cruciais para desenvolvedores que constroem aplicações de IA, enfatizando o papel central da avaliação no desenvolvimento de LLMs (Fonte: HamelHusain,HamelHusain)
MORSE-500: Benchmark de vídeo programável para testes de estresse de raciocínio multimodal: Enfrentando o problema de que os benchmarks atuais de raciocínio multimodal dependem principalmente de imagens estáticas, negligenciando a complexidade temporal e a amplitude das habilidades de raciocínio, pesquisadores lançaram o MORSE-500. Trata-se de um benchmark contendo 500 clipes de vídeo totalmente roteirizados, cobrindo seis categorias de raciocínio: abstrato, físico, planejamento, espacial e temporal. Seu design orientado por script permite controle granular da complexidade visual, densidade de distratores e dinâmica temporal, suportando a criação arbitrária de novas instâncias mais desafiadoras, com o objetivo de testar sob estresse a próxima geração de modelos. Experimentos preliminares mostram que modelos SOTA, incluindo Gemini 2.5 Pro e OpenAI o3, apresentam lacunas de desempenho significativas em todas as categorias (Fonte: HuggingFace Daily Papers)
EverGreenQA: Dataset multilíngue de classificação de perguntas perenes para aumentar a confiabilidade de QA: Para resolver o problema de alucinações de LLMs em tarefas de Perguntas e Respostas (QA) devido à temporalidade das perguntas (se as respostas mudam com o tempo), pesquisadores lançaram o EverGreenQA. Este é o primeiro dataset de QA multilíngue com rótulos de perenidade, apoiando avaliação e treinamento. Com este dataset, os pesquisadores realizaram benchmarks em 12 LLMs modernos, avaliando sua capacidade de codificar a temporalidade das perguntas, e treinaram um classificador multilíngue leve, EG-E5. A pesquisa também demonstra a aplicação da classificação de perenidade na melhoria da estimativa de autoconhecimento, filtragem de datasets de QA e interpretação do comportamento de recuperação do GPT-4o (Fonte: HuggingFace Daily Papers)
KVzip: Método de evicção de cache KV independente de consulta, reduzindo significativamente o uso de memória e a latência de decodificação: O ML Lab da Universidade Nacional de Seul lançou o KVzip, um método de compressão de cache KV projetado para suportar diversas consultas futuras. Este método, através de uma estratégia de evicção independente de consulta, alcança uma redução de memória de aproximadamente 3-4 vezes e uma redução de latência de decodificação de 2 vezes. Atualmente, suporta modelos como Qwen3/2.5, Gemma3 e LLaMA3, e fornece código de demonstração no GitHub (Fonte: Reddit r/LocalLLaMA)

NimbleEdge lança núcleos de operadores Transformer esparsos de código aberto, aumentando a velocidade de execução e a eficiência de memória de LLMs: A equipe NimbleEdge, baseada nas pesquisas “LLM in a Flash” da Apple e “Deja Vu” de Zichang et al., construiu núcleos de operadores fundidos para esparsidade estruturada de contexto. Esses núcleos, ao evitar o carregamento e cálculo de pesos e ativações de camadas feed-forward cuja saída seria zero, alcançaram um aumento de desempenho de 5 vezes nas camadas MLP de Transformers e uma redução de 50% no consumo de memória. Aplicado ao modelo Llama 3.2 3B, o throughput geral aumentou 1,78 vezes e o uso de memória diminuiu 26,4%. O código foi disponibilizado em código aberto no GitHub, com planos de suportar int8, CUDA e atenção esparsa (Fonte: Reddit r/MachineLearning)
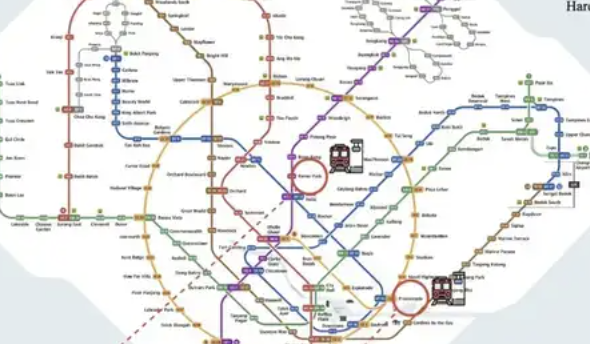
ReasonMap: Lançado benchmark de avaliação de raciocínio multimodal para mapas de transporte de alta resolução: Uma equipe de pesquisa da Westlake University e outras instituições lançou o ReasonMap, um benchmark de avaliação de raciocínio multimodal focado em mapas de transporte de alta resolução (principalmente mapas de metrô). O benchmark visa avaliar a capacidade de grandes modelos em compreender informações espaciais estruturadas de granulação fina em imagens, incluindo imagens de alta resolução (média de 5839×5449), design sensível à dificuldade e um sistema de avaliação multidimensional. Os resultados dos testes mostram que os modelos de código aberto atuais têm desempenho ruim no ReasonMap, especialmente no planejamento de rotas entre linhas, enquanto os modelos de inferência de código fechado (como GPT-o3) superam significativamente os modelos de código aberto, mas ainda há uma lacuna em relação ao nível humano. Mapas de metrô complexos, como os de Pequim e Hangzhou, representam grandes desafios para os modelos (Fonte: 量子位)
Yandex lança Yambda-5B: Dataset de sistema de recomendação aberto em grande escala: A Yandex lançou o Yambda-5B, um dataset de streaming de música anonimizado em grande escala contendo 4,79 bilhões de interações usuário-item. As características deste dataset incluem o fornecimento de um sinalizador “is_organic” e segmentação temporal global (GTS), não contendo histórico de audição ou curtidas que possam identificar diretamente os usuários, possuindo capacidade de resistir à desanonimização e incluindo feedback implícito (audição de músicas, pulos) e explícito (gostar/não gostar). O Yambda-5B visa fornecer recursos de dados multimodais de alta qualidade para pesquisa em sistemas de recomendação (Fonte: TheTuringPost)
Tencent lança o Acampamento Desafio Xinghuo 2025, recrutando estudantes de ponta para pesquisa de ponta em modelos grandes e mais: A Tencent anunciou o lançamento do seu “Acampamento Desafio Xinghuo” anual de 2025, voltado para estudantes do segundo e terceiro ano do ensino médio (candidatos ao vestibular de 2025) e outros estudantes com desempenho excepcional em disciplinas relevantes, recrutando de 60 a 70 pessoas. Os selecionados terão a oportunidade de ir à sede em Shenzhen para participar de pesquisas em seis tópicos de ponta: compreensão de texto ultralongo, tecnologia de cadeia de pensamento longa, inteligência incorporada + robótica, percepção e compreensão multimodal, ataque e defesa de segurança (incluindo design de hackers de LLM Agent) e tecnologia quântica. O programa visa fornecer aos jovens talentosos acesso a cenários de pesquisa de nível industrial, expandir seus horizontes tecnológicos e aprofundar seu conhecimento do setor (Fonte: 量子位)

💼 Negócios
Rumor: Meta planeja investir mais de US$ 10 bilhões na Scale AI para fortalecer aplicações de IA em áreas como militar: Segundo relatos, a Meta está em negociações com a empresa de rotulagem de dados de IA Scale AI para um grande investimento, que pode chegar a bilhões ou até ultrapassar US$ 10 bilhões. Se confirmado, este seria um dos maiores investimentos externos da Meta em IA. A Scale AI já havia construído um modelo projetado especificamente para uso militar, o Defense Llama, baseado no Llama 3 da Meta, para apoiar missões de segurança nacional dos EUA. Esta medida pode sinalizar uma estratégia de investimento e cooperação mais ativa da Meta no campo da IA, especialmente em aplicações relacionadas ao governo e defesa (Fonte: 36氪)

Mashang Consumer Finance lança o modelo grande “Tianjing” 3.0, atualizado para plataforma de decisão financeira: A Mashang Consumer Finance lançou a versão 3.0 do seu modelo grande financeiro “Tianjing”. O principal avanço da nova versão reside na transição sistêmica da inteligência individual para a inteligência coletiva, não dependendo mais apenas do aprendizado lógico, mas explorando profundamente as experiências implícitas dispersas na empresa, como trajetórias de funcionários e logs de negócios, transformando-as em conhecimento estruturado. O Tianjing 3.0 visa evoluir de uma ferramenta para uma plataforma de decisão, promovendo a colaboração homem-máquina, capaz de decompor dinamicamente processos de serviço complexos e combinar em tempo real a melhor combinação de serviços de acordo com as demandas do usuário e requisitos de conformidade, alcançando decisões ótimas globais a partir de ótimos locais (Fonte: 量子位)

Together AI nomeia Charles Zedlewski como novo Chief Product Officer, com foco na plataforma de IA generativa de código aberto: A Together AI anunciou a nomeação de Charles Zedlewski como seu novo Chief Product Officer (CPO). Charles Zedlewski liderou anteriormente produtos de plataforma orientados para a comunidade de desenvolvedores na Temporal e Cloudera. A Together AI enfatiza seu compromisso em construir o futuro da IA generativa de código aberto, acreditando que os modelos abertos têm vantagens em flexibilidade, custo-benefício e inovação. A chegada de Charles visa impulsionar ainda mais a Together AI na criação da plataforma de IA de código aberto definitiva, tornando a poderosa IA generativa acessível a todos os desenvolvedores e empresas (Fonte: togethercompute)

🌟 Comunidade
Carro autônomo da Waymo incendiado em Los Angeles gera preocupações e discussões na comunidade sobre segurança de VAs: Recentemente, vários carros autônomos da Waymo foram incendiados em Los Angeles. Este incidente gerou ampla atenção e discussão nas redes sociais, abordando a aceitação pública de veículos autônomos, preocupações com segurança e o risco de tais eventos serem indevidamente ampliados ou distorcidos por conteúdo gerado por IA (como vídeos gerados pelo Veo 3). Alguns comentaristas compararam a cena ao filme de ficção científica “Filhos da Esperança”, destacando o drama do evento e seu potencial impacto social (Fonte: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
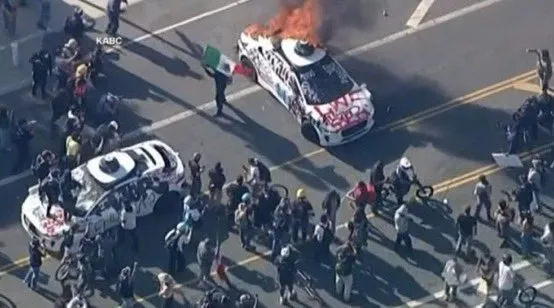
Reddit processa Anthropic, acusando-a de coletar conteúdo sem autorização para treinar o Claude AI: O Reddit entrou com uma ação judicial contra a Anthropic, acusando-a de coletar posts e conversas do Reddit sem permissão e pagamento para treinar seu modelo de IA, Claude. O Reddit alega que essa ação viola seus termos de usuário, que proíbem o uso comercial não autorizado de conteúdo, e afirma que a declaração da Anthropic de que “parou de coletar dados do Reddit” é falsa. O processo também envolve questões de privacidade, pois a Anthropic, ao contrário de outras empresas com acordos de licença, não possui mecanismos para excluir posts que os usuários deletaram. O Reddit pede ao tribunal que proíba a Anthropic de usar dados do Reddit e pode exigir que ela retire o Claude do ar (Fonte: Reddit r/ArtificialInteligence,Reddit r/artificial)
Debate acalorado na AI Engineer World’s Fair: Simon Willison revisita o desenvolvimento de LLMs nos últimos seis meses, enfatizando a combinação de ferramentas e raciocínio: Na AI Engineer World’s Fair em São Francisco, Simon Willison, através de um teste de geração de imagem SVG de um “pelicano andando de bicicleta”, relembrou humoristicamente o rápido desenvolvimento dos LLMs nos últimos seis meses e testou pessoalmente mais de 30 modelos de IA. Ele enfatizou que a combinação de IA mais poderosa atualmente é “ferramentas + raciocínio”, como o desempenho do o3/o4-mini em buscas, e a atenção dada à arquitetura MCP devido à chamada de ferramentas. A palestra também listou os “bugs bizarros” de IA do ano, como a bajulação excessiva do ChatGPT, o comportamento do Claude que poderia “denunciar” usuários, e apontou os riscos de injeção de prompt e vazamento de dados (Fonte: 36氪,swyx)

Discussão na comunidade sobre ansiedade profissional causada pela IA e estratégias de enfrentamento: Um post no Reddit sobre “como lidar com a ansiedade da IA” gerou debate acalorado. Os usuários geralmente se preocupam que a IA possa causar desemprego em massa nos próximos anos, representando uma ameaça séria especialmente para aqueles com poucas economias e muitas dívidas. Na discussão, alguns sugeriram mudar para áreas como trabalhos manuais qualificados e enfermagem, mas também expressaram preocupação de que esses campos fiquem saturados devido ao grande fluxo de pessoas mudando de carreira. Comentaristas compartilharam seus próprios sentimentos de ansiedade, como insônia e dificuldade de concentração no trabalho. Algumas opiniões sugeriram aprender ativamente sobre IA, manter a adaptabilidade e apontaram que inovações tecnológicas históricas (como carros e internet) também causaram preocupações semelhantes, mas acabaram criando novas oportunidades de emprego. Outros comentaristas acreditam que o grau em que a IA substitui o trabalho humano atualmente é exagerado e que demissões em massa são improváveis a curto prazo (Fonte: Reddit r/ArtificialInteligence)
Usuário compartilha experiência de usar o ChatGPT para uma autoanálise psicológica “cruel”: Um usuário do Reddit compartilhou sua experiência de usar o ChatGPT para uma autoanálise psicológica “brutal no estilo executivo”. Através de prompts específicos, ele pediu ao ChatGPT para realizar uma análise severa de suas verdadeiras forças, fraquezas profundas, padrões de fracasso recorrentes, áreas de evasão e habilidades negligenciadas, e fornecer um plano de desenvolvimento em três estágios. O usuário afirmou que, embora o processo tenha sido doloroso (por exemplo, ser apontado por iniciar 12 projetos sem concluir nenhum, e pesquisar excessivamente sobre produtividade em vez de agir), esse feedback “cruel” acabou impulsionando sua mudança. O post gerou discussão na comunidade sobre a aplicação da IA na autorreflexão e desenvolvimento pessoal (Fonte: Reddit r/ArtificialInteligence)
Discussão sobre as capacidades de memória e raciocínio dos LLMs: É conhecimento vasto ou compreensão real?: Nas redes sociais, usuários discutiram o excelente desempenho dos grandes modelos de linguagem (LLMs) em tarefas de recordação de fatos baseados na memória, e se isso significa que eles realmente possuem capacidade de raciocínio. Algumas opiniões sugerem que o desempenho notável dos LLMs em tarefas aparentemente complexas pode depender mais de vastos dados de treinamento e reconhecimento de padrões, do que de uma compreensão profunda e criatividade no sentido humano. Pesquisas de empresas como a Meta indicam que a capacidade do modelo pode ser estimada medindo a memória; uma vez que a capacidade é preenchida, a generalização começa. Essa discussão também se relaciona com a ênfase na memorização mecânica nos sistemas educacionais e a falta de desenvolvimento de habilidades de recuperação de informações e uso de ferramentas de IA (Fonte: omarsar0,menhguin,menhguin)

💡 Outros
Análise de caso de sucesso do modelo fundamental de detecção de fraude de pagamento da Stripe: Um post de engenheiros da Stripe sobre a construção de um modelo fundamental bem-sucedido para detecção de fraude de pagamento chamou a atenção. A análise aponta que a particularidade deste caso reside em: 1) A detecção de fraude, em essência, não é prever o futuro; teoricamente, com sinais suficientes, pode-se alcançar alta precisão; 2) A Stripe já se encontra em um ambiente rico em sinais, não precisando acumular dados do zero; 3) Este cenário é uma atualização de automação, da aprendizagem de máquina tradicional para modelos fundamentais, aproximando-se de uma substituição direta. Isso explica por que tais “vitórias instantâneas” de aplicações de IA são relativamente raras, e a maioria das realizações de valor comercial da IA precisa superar inúmeros obstáculos (Fonte: random_walker)
Base cognitiva para a transformação da IA: Mecanismos sistemáticos de percepção de informações e insights tecnológicos são cruciais: Na transformação da IA, as empresas precisam estabelecer mecanismos sistemáticos e estruturados de percepção de informações e insights tecnológicos, superando a experiência individual e a dependência de caminhos tradicionais. Isso inclui a construção de capacidades internas de análise de dados e redes de conhecimento externas (mundo acadêmico, indústria, mercado de capitais, startups). A avaliação do retorno sobre o investimento em IA também precisa mudar do ROI tradicional para um sistema “multiperíodo, multidimensional”, acoplado a redes de conhecimento externas, formando um ciclo estratégico fechado de validação contínua e ajuste dinâmico. O artigo enfatiza que a IA não é uma ferramenta única, mas um ativo estratégico em contínua evolução e valorização (Fonte: 36氪)
Frigate: Sistema NVR baseado em detecção local de objetos em tempo real: Frigate é um sistema de gravador de vídeo em rede (NVR) local projetado especificamente para o Home Assistant, utilizando OpenCV e Tensorflow para detecção local de objetos em tempo real em câmeras IP. O sistema enfatiza a otimização de recursos e desempenho, utilizando detecção de movimento de baixo custo para acionar a detecção de objetos e aproveitando o processamento multiprocesso. Recomenda-se o uso de aceleradores de IA como Google Coral ou Hailo para obter o melhor desempenho. O Frigate suporta gravação 24/7, retenção de gravações baseada na detecção de objetos, integração MQTT, retransmissão RTSP e visualização em tempo real de baixa latência via WebRTC/MSE (Fonte: GitHub Trending)
