
Palabras clave:modelo de lenguaje grande, capacidad de razonamiento, seguridad de IA, modelo multimodal, modelo de código abierto, generación de videos con IA, evaluación de IA, aplicaciones comerciales de IA, investigación sobre capacidad de razonamiento de LLM de Apple, modelo de comprensión temporal Time-R1, generación de videos con GPU NVIDIA Blackwell, modelo de código abierto Alibaba Tongyi Qianwen 3, servidor Hugging Face MCP
🔥 Enfoque
Apple publica un artículo que afirma que los grandes modelos de lenguaje actuales solo tienen una “ilusión de pensamiento” y no una verdadera capacidad de razonamiento, lo que genera un intenso debate en la industria: Investigadores de Apple (incluido Samy Bengio, uno de los fundadores de Google Brain) publicaron un artículo que, mediante pruebas en cuatro tareas de dificultad controlable como la Torre de Hanói y el intercambio de damas, señala que modelos de vanguardia como DeepSeek, o3-mini y Claude 3.7 “colapsan” al enfrentarse a problemas de alta complejidad, mostrando un “escalado inverso del esfuerzo de razonamiento” (cuanto más difícil es el problema, menos “piensan”). El artículo sostiene que estos modelos dependen más del reconocimiento de patrones y la memoria que de un razonamiento lógico genuino y generalizable, e incluso con algoritmos completos proporcionados, no pueden superar los cuellos de botella de complejidad. Esta perspectiva desafía la percepción común actual sobre las capacidades de razonamiento de los LLM y ha provocado una amplia discusión sobre los métodos de evaluación de los LLM, los límites de su verdadera capacidad de razonamiento y las futuras direcciones de desarrollo. La comunidad ha reaccionado de forma diversa; algunos creen que es una defensa de Apple por su lento progreso en IA, mientras que otros coinciden con sus percepciones sobre los mecanismos de evaluación y las limitaciones inherentes de los modelos (Fuente: 量子位, pmddomingos, scaling01, rao2z, paul_cal, BorisMPower, cloneofsimo, farguney)

Yoshua Bengio, ganador del Premio Turing, advierte sobre los riesgos de descontrol de la IA y reorienta su investigación hacia la “IA científica”: Yoshua Bengio declaró en la Conferencia de IA de Beijing (BAAI) que, dado el rápido desarrollo de la IA (especialmente la AGI) y sus riesgos potenciales de descontrol (como que la IA copie su propio código para “sobrevivir” u oculte comportamientos), ha reorientado su investigación hacia la construcción de una “IA científica” que solo posea inteligencia, sin autoconciencia ni objetivos propios. Considera que la capacidad de planificación de la IA podría alcanzar el nivel humano en cinco años y señaló que los métodos actuales de entrenamiento de IA podrían llevarla a mostrar un exceso de confianza incluso cuando comete errores. Bengio enfatizó la necesidad de garantizar que la IA cumpla con las directrices éticas, evitar su uso con fines maliciosos, e hizo un llamado a la cooperación global para abordar los desafíos de seguridad de la IA y resolver los problemas de “alineación” y “controlabilidad” (Fuente: 量子位)

El gobierno del Reino Unido adopta el sistema Extract, impulsado por el modelo Gemini de Google, para acelerar las decisiones de planificación: El gobierno del Reino Unido está utilizando un sistema llamado “Extract” para ayudar a los planificadores de los ayuntamientos a tomar decisiones más rápidamente. El sistema se basa en el modelo fundacional Gemini de Google y utiliza sus capacidades de razonamiento multimodal para convertir documentos de planificación complejos, incluidas notas escritas a mano y mapas borrosos, en datos digitales en 40 segundos. Esta aplicación demuestra el potencial de la IA en los servicios públicos gubernamentales, mejorando la eficiencia administrativa y la calidad de las decisiones mediante la automatización del procesamiento y la comprensión de documentos complejos (Fuente: GoogleDeepMind, kylebrussell, demishassabis)

Synthesia es la primera en adoptar las GPU NVIDIA Blackwell para entrenar su modelo de video a gran escala EXPRESS-2: La empresa de generación de video por IA Synthesia anunció que es la primera compañía del mundo en utilizar las GPU NVIDIA Blackwell en Google Cloud para entrenar modelos de video a gran escala. Su nuevo modelo, EXPRESS-2, tiene como objetivo ayudar a los clientes a crear videos y avatares generados por IA de mayor calidad y más rápidamente, mediante un hardware más potente y una configuración multicloud optimizada. Este movimiento marca un importante avance en el soporte de hardware subyacente y las capacidades de los modelos para la tecnología de generación de video por IA, lo que augura una mayor eficiencia y calidad en la creación de contenido de video por IA en el futuro (Fuente: synthesiaIO, Synthesia Blog)
Un estudio de Epoch AI revela que el modelo o3-mini-high resuelve problemas matemáticos de vanguardia basándose en la “intuición” y no en la memorización: Epoch AI invitó a 14 matemáticos a evaluar 29 procesos de razonamiento de o3-mini-high en el benchmark FrontierMath, descubriendo que el modelo podía resolver correctamente 13 problemas difíciles. El estudio indica que o3-mini-high posee un vasto conocimiento matemático y puede invocar teoremas relevantes, pero su estilo de razonamiento se inclina más hacia la “inducción basada en la intuición”, careciendo de pruebas formales rigurosas y creatividad, e incluso a veces “tomando atajos” para omitir pasos de demostración. A pesar de problemas como las alucinaciones y la incapacidad para reproducir fórmulas con precisión, su rendimiento en algunos problemas es similar al proceso de pensamiento de los matemáticos humanos. Esta investigación analiza en profundidad las capacidades y limitaciones actuales de los grandes modelos en el razonamiento matemático complejo (Fuente: 量子位)

🎯 Tendencias
Las descargas del modelo de código abierto Qwen3 de Alibaba superan los 12,5 millones, con más de 130.000 modelos derivados, liderando a nivel mundial: Desde su lanzamiento como código abierto hace un mes, la serie de grandes modelos Qwen3 de Alibaba ha acumulado más de 12,5 millones de descargas a nivel mundial, convirtiéndose en el modelo de código abierto más popular recientemente. Sus cuatro tamaños de modelo, de 0.6B a 32B, han superado el millón de descargas en plataformas como Hugging Face y ModelScope, y el número de modelos derivados supera los 130.000, ocupando el primer lugar a nivel mundial. Qwen3 ha obtenido el primer puesto entre los modelos de código abierto en varias listas de rendimiento nacionales e internacionales y, debido a su bajo costo de inferencia (aproximadamente un tercio del de DeepSeek R1), ha atraído la adaptación e integración de numerosos fabricantes de chips y plataformas de computación como Nvidia, Intel y ARM (Fuente: 量子位)

La Universidad de Illinois publica el modelo Time-R1, con 3B de parámetros, para la comprensión, predicción y generación temporal: Investigadores de la Universidad de Illinois en Urbana-Champaign han presentado Time-R1, un modelo de lenguaje de 3B parámetros que, mediante un aprendizaje por refuerzo de tres etapas y un mecanismo de recompensa dinámico, mejora la comprensión del concepto de tiempo, la predicción de eventos futuros y la capacidad de generación de escenarios creativos. Este modelo muestra un rendimiento excelente en tareas de razonamiento temporal, superando incluso a modelos con muchos más parámetros, como DeepSeek-V3-0324. El equipo de investigación ha hecho de código abierto Time-Bench (un gran conjunto de datos de razonamiento temporal multitarea basado en 10 años de noticias del New York Times) así como el código de entrenamiento y los checkpoints del modelo Time-R1 (Fuente: 量子位)

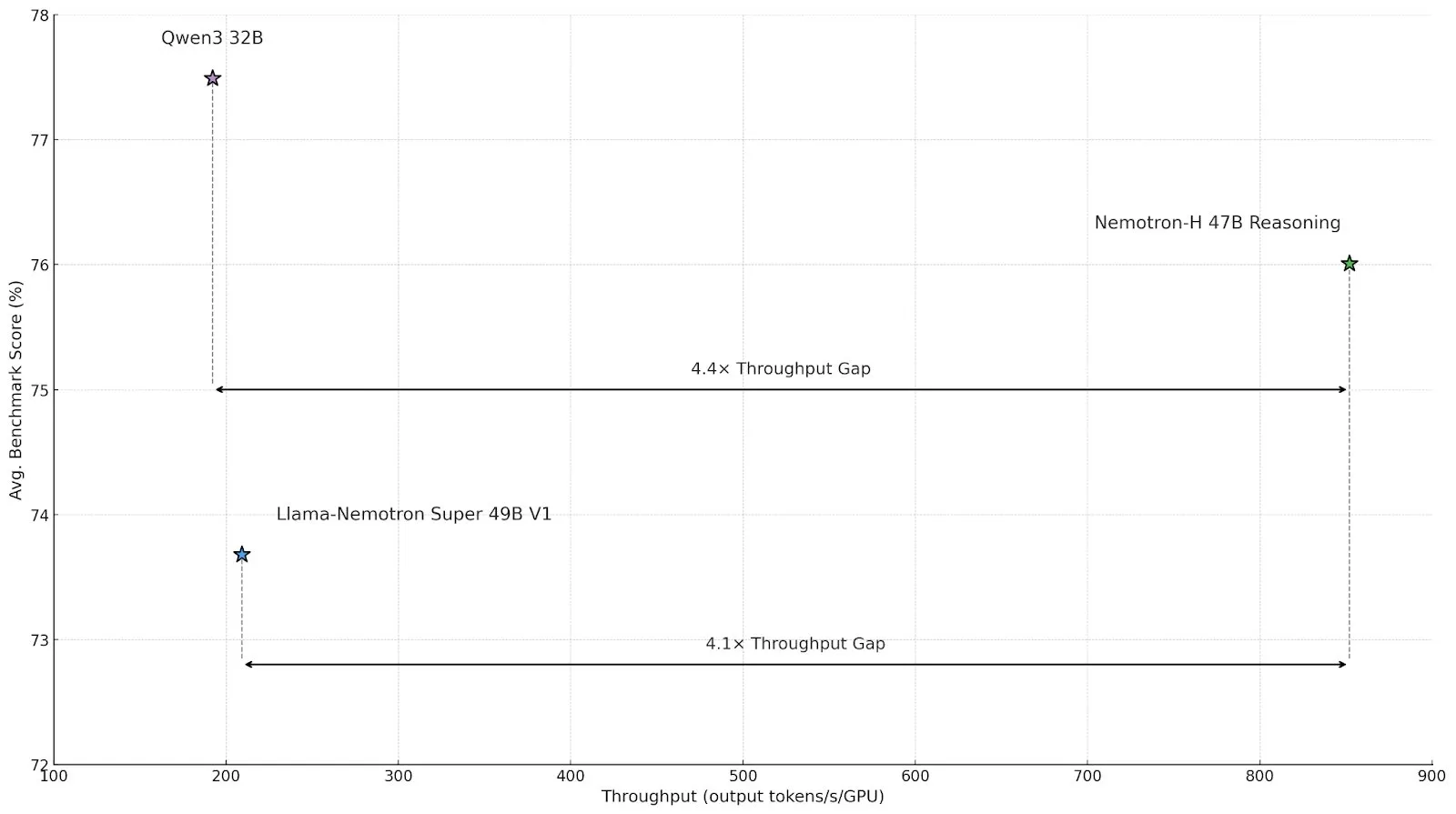
NVIDIA lanza la serie de modelos de inferencia Nemotron-H, que utiliza una arquitectura híbrida Mamba-Transformer para mejorar la eficiencia: NVIDIA ha presentado los modelos de inferencia Nemotron-H 8B y 47B, basados en una arquitectura híbrida SSM-Transformer (Mamba-Transformer). Estos modelos mantienen una alta precisión al tiempo que alcanzan un rendimiento de inferencia hasta 4 veces superior al de modelos Transformer comparables. Nemotron-H-47B-Reasoning-128k supera a Llama-Nemotron-Super-49B-1.0 en diversas pruebas de referencia, con un costo de inferencia hasta 4 veces menor. Los pesos del modelo se han publicado en HuggingFace bajo una licencia no productiva, con el objetivo de impulsar la investigación en inferencia a gran escala de alta eficiencia (Fuente: tri_dao, NVIDIA AI Developer)
El modelo DeepSeek R1 0528 alcanza una puntuación del 71% en el benchmark de programación Aider Polyglot: El modelo DeepSeek R1 0528 ha obtenido una puntuación del 71% en el benchmark de programación Aider Polyglot, lo que supone una mejora significativa (+14,5 puntos porcentuales) respecto a versiones anteriores. Este modelo ha llamado la atención por su alta rentabilidad, ya que completar aproximadamente el 70% del benchmark cuesta menos de 5 dólares, lo que demuestra su gran competitividad en tareas de generación de código (Fuente: Reddit r/LocalLLaMA, scaling01)
Lanzamiento del framework VACE: un modelo multifuncional que integra creación y edición de video: Alibaba Tongyi Lab ha presentado VACE (Video Creation and Editing), un modelo unificado que integra múltiples funciones como la generación de video a partir de referencia (R2V), la edición de video a video (V2V) y la edición de video con máscara (MV2V). VACE permite a los usuarios combinar libremente estas tareas para lograr una variedad de procesamientos de video, como mover objetos, reemplazarlos, aplicar estilos de referencia, extender, animar, etc. Actualmente se han lanzado varias versiones del modelo, como VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B y Wan2.1-VACE-14B, y están disponibles para su descarga en HuggingFace y ModelScope (Fuente: GitHub Trending)

HKUST y ByteDance lanzan conjuntamente el framework ComfyMind para unificar tareas de generación visual: La Universidad de Ciencia y Tecnología de Hong Kong (Cantón) y ByteDance han lanzado conjuntamente el framework de generación visual de código abierto ComfyMind, con el objetivo de procesar múltiples tareas principales de generación visual, como texto a imagen e imagen a video, con un solo sistema. ComfyMind adopta el “flujo de trabajo atómico” como unidad mínima, combinado con una planificación en forma de árbol y un mecanismo de ejecución con retroalimentación local, utilizando ComfyUI como motor de ejecución subyacente y completando tareas complejas mediante la colaboración de tres agentes: planificación, ejecución y evaluación. En benchmarks como ComfyBench, GenEval y Reason-Edit, ComfyMind ha demostrado un rendimiento excelente, comparable al de GPT-4o-Image (Fuente: 量子位)

Hugging Face lanza el servidor Model Context Protocol (MCP) para mejorar las capacidades de los agentes de IA: Hugging Face ahora ofrece un servidor de Model Context Protocol (MCP) que permite a los agentes de IA acceder a herramientas externas y datos en tiempo real de manera estandarizada y segura, incluyendo la búsqueda de modelos, el análisis de conjuntos de datos y la interacción con HuggingFace Spaces. Esta iniciativa tiene como objetivo transformar los agentes de IA de herramientas estáticas a colaboradores dinámicos, mejorando su capacidad para manejar tareas complejas y obtener la información más reciente. Varios miembros de la comunidad ya han comenzado a explorar la integración de servidores MCP con diversos frameworks de IA (como Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) (Fuente: ClementDelangue, huggingface, awnihannun)

Investigación presenta STARFlow: un modelo de flujo normalizador latente escalable para la síntesis de imágenes de alta resolución: STARFlow es un modelo generativo escalable basado en flujos normalizadores, cuyo núcleo es el Transformer Autoregressive Flow (TARFlow). Mediante un diseño de capas profundas y superficiales, modelando en el espacio latente de un autoencoder preentrenado y un nuevo algoritmo de guiado, STARFlow logra un rendimiento competitivo en tareas de generación de imágenes condicionadas por clase y por texto, acercándose a los modelos de difusión de última generación. Este trabajo demuestra por primera vez el funcionamiento efectivo de los flujos normalizadores a esta escala y resolución (Fuente: HuggingFace Daily Papers)
Nueva investigación HASHIRU: un sistema de agentes jerárquicos para la utilización de recursos de inteligencia mixta: HASHIRU es un novedoso framework de sistema multiagente (MAS) que se caracteriza por tener un agente “CEO” que gestiona dinámicamente agentes “empleados” especializados y los instancia según las necesidades de la tarea y las limitaciones de recursos (costo, memoria). El sistema prioriza el uso de LLM locales pequeños (a través de Ollama), al tiempo que utiliza de forma flexible API externas y modelos grandes, e incluye la creación autónoma de herramientas API y funciones de memoria. Las evaluaciones en tareas como la revisión de artículos académicos, la evaluación de seguridad y el razonamiento complejo demuestran sus capacidades (Fuente: HuggingFace Daily Papers)
PartCrafter: generación estructurada de mallas 3D mediante la combinación de Latent Diffusion Transformers: PartCrafter es el primer modelo de generación 3D estructurado capaz de sintetizar conjuntamente múltiples mallas 3D semánticamente significativas y geométricamente distintas a partir de una única imagen RGB. Adopta una arquitectura de generación composicional unificada, no depende de entradas presegmentadas y es capaz de percibir la generación de partes de extremo a extremo para objetos individuales y escenas complejas de múltiples objetos. Sus innovaciones principales incluyen un espacio latente composicional y un mecanismo de atención jerárquico (Fuente: HuggingFace Daily Papers)
Prefix Grouper: entrenamiento eficiente de GRPO mediante la propagación hacia adelante de prefijos compartidos: Group Relative Policy Optimization (GRPO) mejora el aprendizaje de políticas comparando las diferencias relativas entre salidas candidatas que comparten un prefijo de entrada común. Prefix Grouper elimina el cálculo redundante de prefijos mediante la compartición de la política de propagación hacia adelante de prefijos, mejorando la eficiencia del entrenamiento de GRPO, especialmente en escenarios con prefijos largos, al tiempo que mantiene la equivalencia de entrenamiento con el GRPO estándar (Fuente: HuggingFace Daily Papers)
GuideX: generación de datos sintéticos guiada para la extracción de información zero-shot: Los sistemas tradicionales de extracción de información (IE) suelen ser específicos de un dominio y costosos de adaptar. GuideX es un nuevo método que define automáticamente esquemas específicos de dominio, infiere guías y genera instancias sintéticas etiquetadas, logrando así una mejor generalización fuera del dominio. El ajuste fino de Llama 3.1 con GuideX establece un nuevo estado del arte (SOTA) en siete benchmarks de reconocimiento de entidades nombradas zero-shot, mejorando significativamente la comprensión del modelo sobre patrones de anotación complejos y específicos del dominio (Fuente: HuggingFace Daily Papers)
CodeContests+: generación de casos de prueba de alta calidad para concursos de programación: Para abordar el problema de la dificultad de obtener casos de prueba en concursos de programación, los investigadores proponen un sistema de agentes basado en LLM para crear casos de prueba de alta calidad. Este sistema se aplica al conjunto de datos CodeContests y se propone una versión mejorada, CodeContests+. La evaluación demuestra que CodeContests+ supera significativamente a la versión original en términos de precisión de la evaluación, especialmente en la tasa de verdaderos positivos (TPR), y ofrece ventajas significativas para el aprendizaje por refuerzo de LLM (Fuente: HuggingFace Daily Papers)
Sentinel: modelo SOTA para la prevención de ataques de inyección de prompts: Para hacer frente a la vulnerabilidad de los grandes modelos de lenguaje (LLM) a los ataques de inyección de prompts, los investigadores han lanzado el modelo Sentinel (qualifire/prompt-injection-sentinel), basado en la arquitectura ModernBERT-large. Mediante el ajuste fino en un amplio conjunto de datos que incluye múltiples tipos de ataques e instrucciones benignas, Sentinel logra una precisión promedio de 0.987 y una puntuación F1 de 0.980 en un conjunto de pruebas interno no visto, y supera a modelos de referencia sólidos en benchmarks públicos (Fuente: HuggingFace Daily Papers)
Artículo de debate: ¿Es la expansión de modalidades el camino correcto para lograr la omnimodalidad?: Los modelos de lenguaje omnimodales (OLM) tienen como objetivo integrar y razonar sobre múltiples modalidades de entrada, manteniendo al mismo tiempo sólidas capacidades lingüísticas. Esta investigación explora la efectividad de la expansión de modalidades (es decir, el ajuste fino de modelos de lenguaje preentrenados) como técnica principal para entrenar modelos multimodales. El estudio se centra en tres preguntas centrales: ¿La expansión de modalidades perjudica las capacidades lingüísticas centrales? ¿La fusión de modelos puede integrar eficazmente modelos específicos de modalidad ajustados de forma independiente para lograr la omnimodalidad? ¿La expansión omnimodal conduce a un mejor intercambio de conocimientos y generalización que la expansión secuencial? (Fuente: HuggingFace Daily Papers)
Artículo propone Truth in the Few: un método de selección de datos de alto valor para una inferencia multimodal eficiente: La investigación desafía la percepción generalizada de que los LLM multimodales (MLLM) requieren grandes cantidades de datos de entrenamiento para tareas de razonamiento complejo. Mediante la observación, se descubre que solo una pequeña parte de los datos de entrenamiento, denominados “muestras cognitivas”, estimulan eficazmente el razonamiento multimodal. Basándose en esto, el artículo propone el paradigma de selección de datos Reasoning Activation Potential (RAP), que identifica estas muestras cognitivas mediante un estimador de diferencia causal (CDE) y un estimador de confianza de atención (ACE), y reemplaza las instancias simples con un módulo de reemplazo sensible a la dificultad (DRM). Los experimentos demuestran que RAP logra un rendimiento superior utilizando solo el 9.3% de los datos de entrenamiento y reduce los costos computacionales en más del 43% (Fuente: HuggingFace Daily Papers)
🧰 Herramientas
Task Master: sistema de gestión de tareas impulsado por IA, integrado en editores como Cursor: Task Master es un sistema de gestión de tareas diseñado específicamente para el desarrollo asistido por IA, que se integra perfectamente con editores como Cursor AI, Lovable, Windsurf, Roo, etc. Utiliza API de grandes modelos como Claude (compatible con Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama) para ayudar a los desarrolladores a analizar documentos de requisitos de producto (PRD), generar listas de tareas, planificar pasos de desarrollo y asistir en la implementación de tareas específicas. El sistema se ejecuta directamente en el editor a través de MCP (Model Control Protocol), admite operaciones de línea de comandos y proporciona guías de configuración detalladas y tutoriales de uso (Fuente: GitHub Trending)
Observer AI: agente inteligente de observación de pantalla local y de código abierto, integrado con Ollama: Observer AI es un proyecto de código abierto que permite a los usuarios ejecutar LLM locales a través de Ollama para observar la pantalla y realizar tareas. Los usuarios pueden utilizar esta herramienta para que la IA comprenda el contenido de la pantalla e interactúe con él, por ejemplo, navegando por sitios web en idiomas extranjeros. El proyecto proporciona el código fuente en GitHub y una versión de aplicación web que no requiere configuración local, lo que permite a los usuarios utilizar LLM para la automatización de la pantalla protegiendo su privacidad (Fuente: Reddit r/LocalLLaMA)

Weaviate Query Agent se integra con siete frameworks de IA para simplificar la consulta de datos en lenguaje natural: Weaviate ha anunciado la integración de su Query Agent con siete importantes frameworks de IA (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic). Query Agent es un servicio de agente preconstruido que puede responder consultas en lenguaje natural basadas en datos almacenados en Weaviate, sin necesidad de escribir complejas sentencias de consulta. Estas integraciones permiten a los desarrolladores incorporar fácilmente potentes capacidades de consulta en lenguaje natural en sus pilas de aplicaciones de IA existentes, mejorando la comodidad de la interacción con los datos (Fuente: bobvanluijt)

Lanzamiento de un servidor MCP para la colaboración entre Claude Code y Gemini Pro, mejorando la eficiencia de codificación: BeehiveInnovations ha lanzado un servidor MCP que permite a Claude Code y Gemini 2.5 Pro trabajar en colaboración. Claude Code se encarga de la concepción inicial y la planificación, mientras que Gemini complementa con su contexto de millones de tokens y su profunda capacidad de razonamiento. El servidor integra herramientas para la reflexión extendida, lectura de archivos, revisión de código y depuración, con el objetivo de mejorar la calidad y eficiencia de la generación y optimización de código combinando las fortalezas de ambos modelos. Las pruebas preliminares muestran que, en tareas de optimización de la velocidad de análisis de JSON, el uso combinado es más efectivo que el uso individual de cualquiera de los modelos (Fuente: Reddit r/ClaudeAI)

📚 Aprendizaje
Sakana AI lanza el benchmark financiero japonés EDINET-Bench para evaluar la capacidad de los LLM en tareas financieras: Sakana AI ha presentado EDINET-Bench, un benchmark financiero en japonés construido utilizando informes anuales del sistema de divulgación electrónica EDINET de la Agencia de Servicios Financieros de Japón. Este benchmark tiene como objetivo evaluar el rendimiento de los grandes modelos de lenguaje (LLM) en tareas financieras complejas, como la detección de fraudes, para abordar la escasez de conjuntos de datos de alta calidad y disponibles gratuitamente en el sector financiero. EDINET-Bench genera conjuntos de datos multitarea mediante etiquetado automático, proporcionando un recurso importante para la investigación y el desarrollo de la IA financiera (Fuente: hardmaru, SakanaAILabs)

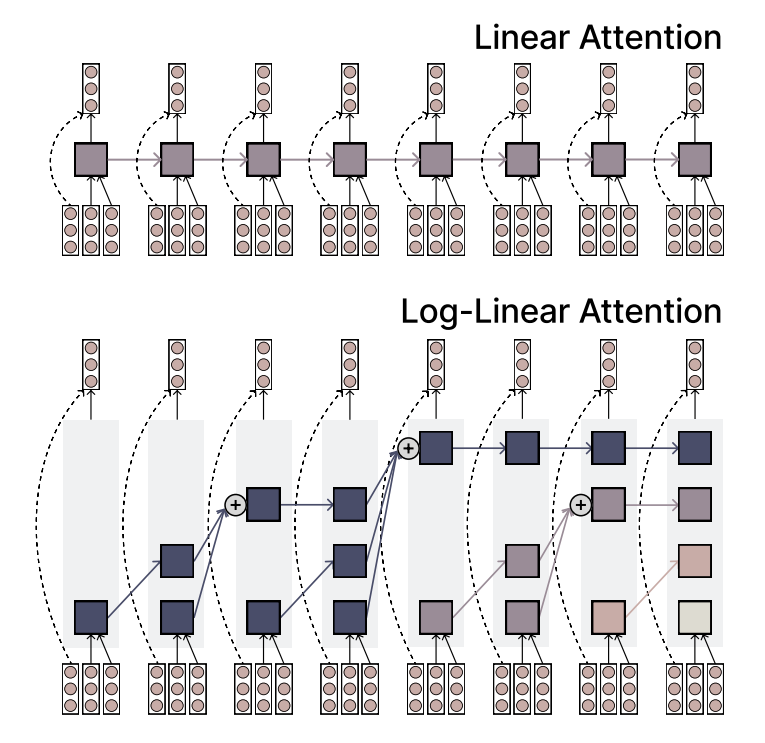
El MIT propone el mecanismo Log-linear Attention, equilibrando eficiencia y expresividad: Investigadores del MIT han propuesto un nuevo mecanismo de atención llamado Log-linear Attention. Este mecanismo tiene como objetivo combinar la velocidad y eficiencia de la atención lineal con la capacidad expresiva de la atención Softmax. Lo logra utilizando una pequeña cantidad de ranuras de memoria que crecen logarítmicamente con la longitud de la secuencia, ofreciendo un nuevo método prometedor para procesar datos de secuencias largas (Fuente: TheTuringPost)
El curso de evaluación de LLM de Hamel Husain y Shreya Rajpal recibe elogios: Usuarios como Ryan Lingo y Radek Osmulski compartieron sus experiencias positivas al participar en el curso de evaluación de aplicaciones de LLM de Hamel Husain y Shreya Rajpal (maven.com/parlance-labs/evals). El curso es considerado el contenido más profundo y práctico sobre LLM hasta la fecha, y sus conferencias y libro exclusivo son cruciales para los desarrolladores que construyen aplicaciones de IA, enfatizando el papel central de la evaluación en el desarrollo de LLM (Fuente: HamelHusain, HamelHusain)
MORSE-500: benchmark de video programable para pruebas de estrés de razonamiento multimodal: Ante el problema de que los benchmarks actuales de razonamiento multimodal se basan principalmente en imágenes estáticas, ignorando la complejidad temporal y la amplitud de las habilidades de razonamiento, los investigadores han lanzado MORSE-500. Se trata de un benchmark que contiene 500 videoclips completamente guionizados, que abarcan seis categorías de razonamiento: abstracto, físico, planificación, espacial y temporal. Su diseño basado en guiones permite un control detallado de la complejidad visual, la densidad de distractores y la dinámica temporal, y admite la creación arbitraria de nuevas instancias más desafiantes, con el objetivo de realizar pruebas de estrés a los modelos de próxima generación. Los experimentos preliminares muestran que los modelos SOTA, incluidos Gemini 2.5 Pro y OpenAI o3, presentan importantes brechas de rendimiento en todas las categorías (Fuente: HuggingFace Daily Papers)
EverGreenQA: conjunto de datos de clasificación de preguntas perennes multilingüe para mejorar la fiabilidad de la respuesta a preguntas: Para resolver el problema de las alucinaciones de los LLM en tareas de respuesta a preguntas (QA) debido a la actualidad de las preguntas (si las respuestas cambian con el tiempo), los investigadores han lanzado EverGreenQA. Este es el primer conjunto de datos de QA multilingüe con etiquetas de perennidad, que permite la evaluación y el entrenamiento. Con este conjunto de datos, los investigadores han realizado pruebas de referencia en 12 LLM modernos, evaluando su capacidad para codificar la actualidad de las preguntas, y han entrenado un clasificador multilingüe ligero, EG-E5. El estudio también demuestra la aplicación de la clasificación de perennidad para mejorar la estimación del autoconocimiento, filtrar conjuntos de datos de QA e interpretar el comportamiento de recuperación de GPT-4o (Fuente: HuggingFace Daily Papers)
KVzip: método de expulsión de caché KV independiente de la consulta, que reduce significativamente el uso de memoria y la latencia de decodificación: El laboratorio de ML de la Universidad Nacional de Seúl ha lanzado KVzip, un método de compresión de caché KV diseñado para admitir diversas consultas futuras. Este método, mediante una estrategia de expulsión independiente de la consulta, logra una reducción de memoria de aproximadamente 3-4 veces y una disminución de la latencia de decodificación de 2 veces. Actualmente es compatible con modelos como Qwen3/2.5, Gemma3 y LLaMA3, y se proporciona código de demostración en GitHub (Fuente: Reddit r/LocalLLaMA)

NimbleEdge publica núcleos de operadores Transformer dispersos de código abierto, mejorando la velocidad de ejecución y la eficiencia de memoria de los LLM: El equipo de NimbleEdge, basándose en la investigación LLM in a Flash de Apple y Deja Vu de Zichang et al., ha construido núcleos de operadores fusionados para la escasez de contexto estructurado. Estos núcleos, al evitar la carga y el cálculo de pesos y activaciones de capas feed-forward cuya salida finalmente sería cero, logran una mejora de rendimiento de 5 veces en las capas MLP de los Transformer y una reducción del consumo de memoria del 50%. Aplicado al modelo Llama 3.2 3B, el rendimiento general mejora 1.78 veces y el uso de memoria se reduce en un 26.4%. El código se ha publicado en GitHub y se planea dar soporte a int8, CUDA y atención dispersa (Fuente: Reddit r/MachineLearning)
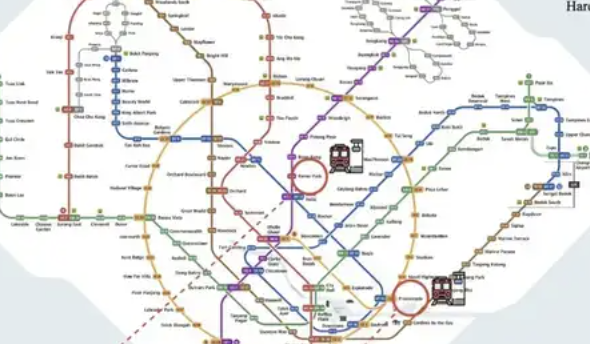
ReasonMap: lanzamiento de un benchmark de evaluación de razonamiento multimodal para mapas de transporte de alta resolución: Un equipo de investigación de la Universidad de Westlake y otras instituciones ha lanzado ReasonMap, un benchmark de evaluación de razonamiento multimodal centrado en mapas de transporte de alta resolución (principalmente mapas de metro). Este benchmark tiene como objetivo evaluar la capacidad de los grandes modelos para comprender información espacial estructurada de grano fino en imágenes, e incluye imágenes de alta resolución (promedio 5839×5449), un diseño sensible a la dificultad y un sistema de evaluación multidimensional. Los resultados de las pruebas muestran que los modelos de código abierto actuales tienen un rendimiento deficiente en ReasonMap, especialmente en la planificación de rutas entre líneas, mientras que los modelos de inferencia de código cerrado (como GPT-o3) superan significativamente a los modelos de código abierto, pero aún existe una brecha con el nivel humano. Mapas de metro complejos como los de Beijing y Hangzhou representan un gran desafío para los modelos (Fuente: 量子位)
Yandex publica Yambda-5B: un conjunto de datos a gran escala para sistemas de recomendación abiertos: Yandex ha lanzado Yambda-5B, un conjunto de datos anonimizado a gran escala de streaming de música que contiene 4.79 mil millones de interacciones usuario-ítem. Este conjunto de datos se caracteriza por proporcionar un indicador “is_organic” y una segmentación temporal global (GTS), no contiene historiales de escucha ni “me gusta” que puedan identificar directamente a los usuarios, tiene capacidad de resistir la desanonimización e incluye retroalimentación implícita (escucha de canciones, saltos) y explícita (me gusta/no me gusta). Yambda-5B tiene como objetivo proporcionar recursos de datos multimodales y de alta calidad para la investigación de sistemas de recomendación (Fuente: TheTuringPost)
Tencent lanza el campamento de desafío Spark 2025, reclutando a estudiantes destacados para participar en investigación de vanguardia sobre grandes modelos y más: Tencent anunció el lanzamiento de su “Campamento de Desafío Spark” anual para 2025, dirigido a estudiantes de segundo y tercer año de secundaria (candidatos al examen de ingreso a la universidad de 2025) y otros estudiantes con un rendimiento excepcional en disciplinas relevantes, con el objetivo de reclutar entre 60 y 70 personas. Los seleccionados tendrán la oportunidad de ir a la sede de Shenzhen para participar en la investigación de seis temas de vanguardia: comprensión de texto ultralargo, tecnología de cadena de pensamiento larga, inteligencia incorporada + robótica, percepción y comprensión multimodal, ataque y defensa de seguridad (incluido el diseño de hackers de LLM Agent) y tecnología cuántica. El programa tiene como objetivo proporcionar a los jóvenes talentosos la oportunidad de entrar en contacto con escenarios de investigación científica de nivel industrial, ampliar sus horizontes tecnológicos y profundizar su comprensión de la industria (Fuente: 量子位)

💼 Negocios
Se rumorea que Meta planea invertir más de 10 mil millones de dólares en Scale AI para fortalecer las aplicaciones de IA en el ámbito militar y otros: Según informes, Meta está en conversaciones con la empresa de etiquetado de datos de IA Scale AI sobre una importante inversión, que podría ascender a miles de millones o incluso superar los 10 mil millones de dólares. De confirmarse, esta sería una de las mayores inversiones externas de Meta en IA. Scale AI ya había desarrollado previamente un modelo diseñado específicamente para uso militar, Defense Llama, basado en Llama 3 de Meta, para apoyar misiones de seguridad nacional de EE. UU. Este movimiento podría indicar que Meta adoptará una estrategia de inversión y cooperación más activa en el campo de la IA, especialmente en aplicaciones relacionadas con el gobierno y la defensa (Fuente: 36氪)

Mashang Consumer Finance lanza el gran modelo “Tianjing” 3.0, actualizándolo a una plataforma de decisión financiera: Mashang Consumer Finance ha lanzado la versión 3.0 de su gran modelo financiero “Tianjing”. El principal avance de la nueva versión radica en un salto sistémico de la inteligencia individual a la inteligencia colectiva, dejando de depender únicamente del aprendizaje lógico para profundizar en la extracción de experiencias implícitas dispersas en las trayectorias de los empleados y los registros comerciales de la empresa, transformándolas en conocimiento estructurado. Tianjing 3.0 tiene como objetivo pasar de ser una herramienta a una plataforma de decisión, impulsando la colaboración hombre-máquina, capaz de desglosar dinámicamente procesos de servicio complejos y adaptar en tiempo real la combinación óptima de servicios según las demandas del usuario y los requisitos de cumplimiento, logrando así una toma de decisiones que pasa de la optimización local a la global (Fuente: 量子位)

Together AI nombra a Charles Zedlewski como nuevo Director de Producto, enfocándose en la plataforma de IA generativa de código abierto: Together AI anunció el nombramiento de Charles Zedlewski como su nuevo Director de Producto (CPO). Charles Zedlewski anteriormente lideró productos de plataforma orientados a desarrolladores e impulsados por la comunidad en Temporal y Cloudera. Together AI enfatiza su compromiso con la construcción de un futuro de IA generativa de código abierto, considerando que los modelos abiertos tienen ventajas en flexibilidad, rentabilidad e innovación. La incorporación de Charles tiene como objetivo impulsar aún más a Together AI en la creación de la plataforma de IA de código abierto de referencia, haciendo que la potente IA generativa sea accesible para todos los desarrolladores y empresas (Fuente: togethercompute)

🌟 Comunidad
Vehículo autónomo de Waymo incendiado en Los Ángeles, generando preocupación y debate en la comunidad sobre la seguridad de los AV: Recientemente, varios vehículos autónomos de Waymo fueron incendiados por personas en Los Ángeles. Este incidente ha generado amplia atención y discusión en las redes sociales, abarcando temas como la aceptación pública de los vehículos autónomos, las preocupaciones sobre seguridad y el riesgo de que tales eventos sean indebidamente amplificados o distorsionados por contenido generado por IA (como videos generados por Veo 3). Algunos comentaristas compararon esta escena con la película de ciencia ficción “Hijos de los hombres”, destacando la dramaticidad del evento y su potencial impacto social (Fuente: gfodor, fabianstelzer, hrishioa, bookwormengr, claud_fuen)
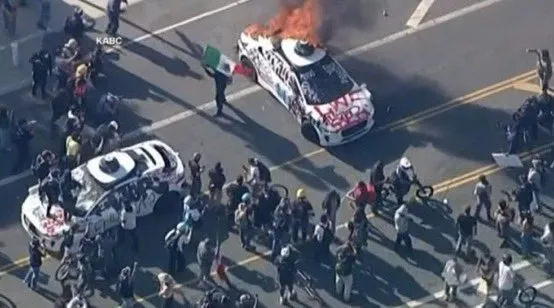
Reddit demanda a Anthropic, acusándola de extraer contenido sin autorización para entrenar a Claude AI: Reddit ha presentado una demanda contra Anthropic, acusándola de extraer publicaciones y conversaciones de Reddit sin permiso ni pago para entrenar su modelo de IA Claude. Reddit considera que esta acción viola los términos de su acuerdo de usuario, que prohíben el uso comercial no autorizado del contenido, y afirma que la declaración de Anthropic de que “ha dejado de extraer Reddit” es falsa. La demanda también aborda cuestiones de privacidad, ya que Anthropic, a diferencia de otras empresas con acuerdos de licencia, no tiene mecanismos para eliminar las publicaciones que los usuarios han borrado. Reddit solicita al tribunal que prohíba a Anthropic el uso de datos de Reddit y podría exigirle que retire Claude del mercado (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial)
Debate en la AI Engineer World’s Fair: Simon Willison repasa el desarrollo de LLM en los últimos seis meses, destacando la combinación de herramientas y razonamiento: En la AI Engineer World’s Fair de San Francisco, Simon Willison, mediante una prueba de generación de imágenes SVG de “pelícanos montando en bicicleta”, repasó con humor el rápido desarrollo de los LLM en los últimos seis meses y probó personalmente más de 30 modelos de IA. Destacó que la combinación de IA más potente actualmente es “herramientas + razonamiento”, como el rendimiento de o3/o4-mini en búsquedas, y la atención que ha recibido la arquitectura MCP debido a la invocación de herramientas. La presentación también hizo un recuento de los “bugs extraños” de IA del año, como la adulación excesiva de ChatGPT, el comportamiento de Claude que podría “denunciar” a los usuarios, y señaló los riesgos de inyección de prompts y filtración de datos (Fuente: 36氪, swyx)

Discusión comunitaria sobre la ansiedad laboral inducida por la IA y estrategias para afrontarla: Una publicación en Reddit sobre “cómo lidiar con la ansiedad por la IA” generó un acalorado debate. Los usuarios expresaron una preocupación generalizada de que la IA podría causar un desempleo masivo en los próximos años, lo que representa una grave amenaza especialmente para las personas con ahorros insuficientes y muchas deudas. En la discusión, algunos sugirieron reorientarse hacia oficios, enfermería y otros campos, pero también temían que estos sectores se saturaran debido a la afluencia masiva de personas que cambian de carrera. Los comentaristas compartieron sus propias emociones de ansiedad, como insomnio, dificultad para concentrarse en el trabajo, etc. Algunas opiniones sugirieron aprender activamente sobre IA, mantener la adaptabilidad y señalaron que las innovaciones tecnológicas históricas (como el automóvil, Internet) también habían causado preocupaciones similares, pero finalmente crearon nuevas oportunidades de empleo. Otros comentaristas consideraron que el grado en que la IA reemplaza el trabajo humano actualmente está exagerado y que es poco probable que se produzcan despidos masivos a corto plazo (Fuente: Reddit r/ArtificialInteligence)
Usuario comparte experiencia de autoanálisis psicológico “brutal” usando ChatGPT: Un usuario de Reddit compartió su experiencia al usar ChatGPT para un autoanálisis psicológico “al estilo ejecutivo brutal”. Mediante prompts específicos, pidió a ChatGPT que realizara un análisis severo desde cinco ángulos: fortalezas reales, debilidades profundas, patrones de fracaso recurrentes, áreas de evasión y habilidades desatendidas, y que proporcionara un plan de desarrollo en tres etapas. El usuario afirmó que, aunque el proceso fue doloroso (por ejemplo, se le señaló que había iniciado 12 proyectos sin completar ninguno, y que investigaba en exceso sobre productividad en lugar de actuar), esta retroalimentación “brutal” finalmente lo impulsó a cambiar. La publicación generó una discusión en la comunidad sobre la aplicación de la IA en la autorreflexión y el desarrollo personal (Fuente: Reddit r/ArtificialInteligence)
Debate sobre la memoria y la capacidad de razonamiento de los LLM: ¿conocimiento enciclopédico o verdadera comprensión?: En las redes sociales, los usuarios debatieron sobre el excelente rendimiento de los grandes modelos de lenguaje (LLM) en tareas de recuerdo de hechos memorizados y si esto significa que realmente poseen capacidad de razonamiento. Algunas opiniones sostienen que el buen desempeño de los LLM en tareas aparentemente complejas puede depender más de la ingente cantidad de datos de entrenamiento y el reconocimiento de patrones que de una comprensión profunda y creatividad en el sentido humano. Investigaciones de empresas como Meta indican que se puede estimar la capacidad del modelo midiendo la memoria, y que la generalización solo comienza una vez que la capacidad se llena. Esta discusión también se relaciona con el énfasis en la memorización en el sistema educativo y la falta de desarrollo de habilidades para la recuperación de información y el uso de herramientas de IA (Fuente: omarsar0, menhguin, menhguin)

💡 Otros
Análisis del caso de éxito del modelo fundacional de detección de fraude en pagos de Stripe: Una publicación de ingenieros de Stripe sobre la construcción de un exitoso modelo fundacional para la detección de fraude en pagos ha llamado la atención. El análisis señala la particularidad de este caso: 1) La detección de fraude, en esencia, no es predecir el futuro; teóricamente, con señales suficientes, se puede alcanzar una alta precisión. 2) Stripe ya se encontraba en un entorno rico en señales, sin necesidad de acumular datos desde cero. 3) Este escenario es una actualización de automatización, pasando del machine learning tradicional a un modelo fundacional, casi un reemplazo directo. Esto explica por qué tales “victorias instantáneas” de aplicaciones de IA son relativamente raras, ya que la mayoría de la materialización del valor comercial de la IA requiere superar numerosos obstáculos (Fuente: random_walker)
Base cognitiva para la transformación de la IA: la clave es un mecanismo sistemático de percepción de la información y conocimiento tecnológico: En la transformación de la IA, las empresas necesitan establecer mecanismos sistemáticos y estructurados para la percepción de la información y el conocimiento tecnológico, superando la experiencia individual y la dependencia de caminos tradicionales. Esto incluye la construcción de capacidades internas de análisis de datos y redes de conocimiento externas (mundo académico, industria, mercados de capitales, startups). La evaluación del retorno de la inversión en IA también debe pasar del ROI tradicional a un sistema “periódico y multidimensional”, acoplado con redes de conocimiento externas, formando un ciclo cerrado estratégico de validación continua y ajuste dinámico. El artículo enfatiza que la IA no es una herramienta de una sola vez, sino un activo estratégico en continua evolución y valorización (Fuente: 36氪)
Frigate: sistema NVR basado en detección local de objetos en tiempo real: Frigate es un sistema de grabador de video en red (NVR) local diseñado específicamente para Home Assistant, que utiliza OpenCV y Tensorflow para la detección local de objetos en tiempo real en cámaras IP. El sistema enfatiza la optimización de recursos y el rendimiento, utilizando detección de movimiento de bajo costo para activar la detección de objetos y aprovechando el procesamiento multiproceso. Se recomienda el uso de aceleradores de IA como Google Coral o Hailo para un rendimiento óptimo. Frigate admite grabación 24/7, retención de grabaciones basada en la detección de objetos, integración MQTT, retransmisión RTSP y visualización en tiempo real de baja latencia mediante WebRTC/MSE (Fuente: GitHub Trending)
