
Keywords:Large Language Models, Reasoning Capabilities, AI Safety, Multimodal Models, Open-source Models, AI Video Generation, AI Evaluation, AI Commercial Applications, Apple LLM Reasoning Research, Time-R1 Temporal Understanding Model, NVIDIA Blackwell GPU Video Generation, Alibaba Tongyi Qianwen 3 Open-source Model, Hugging Face MCP Server
🔥 Focus
Apple paper claims current LLMs only have an “illusion of thought” not true reasoning ability, sparking industry debate: Apple researchers (including Samy Bengio, one of the founders of Google Brain) published a paper, testing with four tasks of controllable difficulty such as Tower of Hanoi and checker swapping, pointing out that top models like DeepSeek, o3-mini, and Claude 3.7 “collapse” when facing high-complexity problems, exhibiting “inverse scaling of reasoning effort” (the harder the problem, the less they “think”). The paper argues these models rely more on pattern matching and memorization than on true, generalizable logical reasoning, and cannot overcome complexity bottlenecks even when provided with complete algorithms. This view challenges the current general understanding of LLM reasoning capabilities and has sparked widespread discussion about LLM evaluation methods, the boundaries of true reasoning abilities, and future development directions. The community’s reaction is mixed, with some believing it’s Apple’s defense for its slow AI progress, while others agree with its insights into evaluation mechanisms and the inherent limitations of models (Source: QbitAI, pmddomingos, scaling01, rao2z, paul_cal, BorisMPower, cloneofsimo, farguney)

Turing Award winner Yoshua Bengio warns of AI runaway risks, shifts research focus to “Scientist AI”: Yoshua Bengio stated at the BAIA Forum that, given the rapid development of AI (especially AGI) and its potential runaway risks (such as AI copying its own code or hiding behaviors to “survive”), he has adjusted his research direction to focus on building “Scientist AI” that possesses only intelligence, without self-awareness or goals. He believes AI’s planning capabilities could reach human levels within five years and noted that current AI training methods might lead to overconfidence even when wrong. Bengio emphasized the need to ensure AI adheres to ethical directives, avoids malicious use, and called for global cooperation to address AI safety challenges, solving “alignment” and “controllability” issues (Source: QbitAI)

UK government adopts Google Gemini-powered Extract system to accelerate planning decisions: The UK government is using a system called “Extract” to help local council planners make decisions faster. The system, based on Google’s Gemini foundational model, utilizes its multimodal reasoning capabilities to convert complex planning documents, including handwritten notes and blurry maps, into digital data in 40 seconds. This application demonstrates AI’s potential in public services, improving administrative efficiency and decision quality by automating the processing and understanding of complex documents (Source: GoogleDeepMind, kylebrussell, demishassabis)

Synthesia first to train large video model EXPRESS-2 on NVIDIA Blackwell GPUs: AI video generation company Synthesia announced it is the first company globally to train large video models on NVIDIA Blackwell GPUs in Google Cloud. Its new model, EXPRESS-2, aims to help customers create higher-quality AI-generated videos and avatars faster through more powerful hardware and an optimized multi-cloud setup. This move marks a significant advancement in AI video generation technology in terms of underlying hardware support and model capabilities, heralding further improvements in the efficiency and quality of future AI video content creation (Source: synthesiaIO, Synthesia Blog)
Epoch AI study reveals o3-mini-high model relies on “intuition” to solve top math problems, not rote memorization: Epoch AI invited 14 mathematicians to evaluate 29 reasoning processes of o3-mini-high on the FrontierMath benchmark, finding the model correctly solved 13 difficult problems. The study shows that o3-mini-high possesses extensive mathematical knowledge and can invoke relevant theorems, but its reasoning style leans more towards “intuition-based induction,” lacking rigorous formal proofs and creativity, sometimes even “taking shortcuts” by skipping proof steps. Despite issues like hallucinations and inability to accurately reproduce formulas, its performance on some problems resembles human mathematicians’ thought processes. This research deeply analyzes the capabilities and limitations of current large models in complex mathematical reasoning (Source: QbitAI)

🎯 Trends
Alibaba’s Qwen3 open-source model downloads exceed 12.5 million, with over 130,000 derivative models, ranking first globally: Since its open-source release a month ago, Alibaba’s Qwen3 series of large models has accumulated over 12.5 million downloads worldwide, becoming the most popular open-source model recently. Its four sizes, from 0.6B to 32B, have each surpassed one million downloads on platforms like Hugging Face and ModelScope community, with the number of derivative models exceeding 130,000, ranking first globally. Qwen3 has topped several domestic and international performance leaderboards for open-source models and has attracted adaptation and integration from numerous chip manufacturers and computing power platforms, including NVIDIA, Intel, and ARM, due to its lower inference cost (approximately one-third of DeepSeek R1) (Source: QbitAI)

University of Illinois releases Time-R1 model, achieving understanding, prediction, and generation of time with 3B parameters: Researchers at the University of Illinois Urbana-Champaign (UIUC) have introduced Time-R1, a 3B parameter language model that, through three-stage reinforcement learning and a dynamic reward mechanism, enhances the model’s understanding of time concepts, prediction of future events, and creative scenario generation capabilities. The model performs exceptionally well on temporal reasoning tasks, even surpassing models with far more parameters, such as DeepSeek-V3-0324. The research team has open-sourced Time-Bench (a large-scale multi-task temporal reasoning dataset based on 10 years of New York Times news) as well as Time-R1’s training code and model checkpoints (Source: QbitAI)

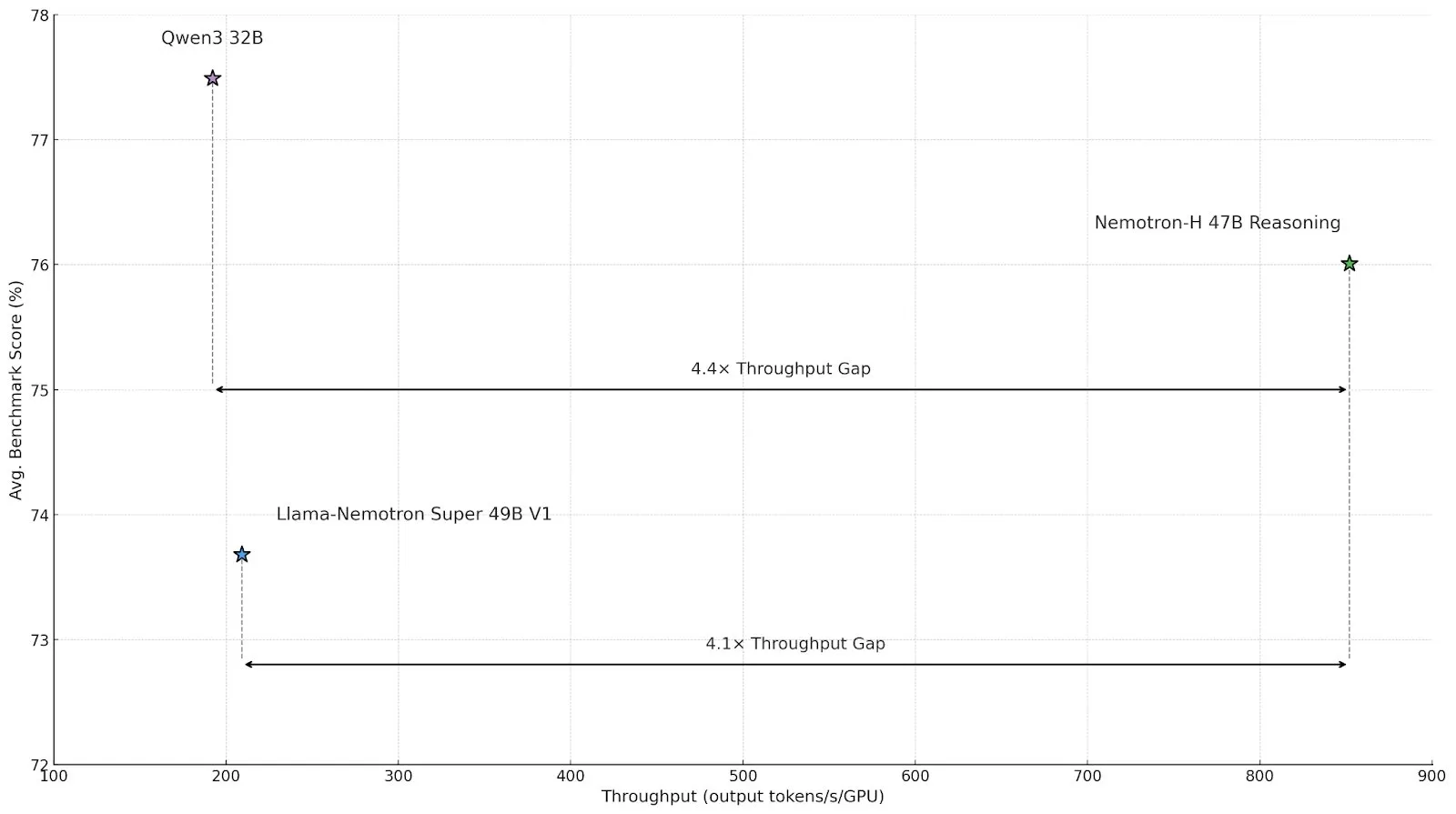
NVIDIA releases Nemotron-H series inference models with hybrid Mamba-Transformer architecture for improved efficiency: NVIDIA has launched the Nemotron-H 8B and 47B inference models, based on a hybrid SSM-Transformer (Mamba-Transformer) architecture. These models achieve up to 4x the inference throughput of comparable Transformer models while maintaining high accuracy. Nemotron-H-47B-Reasoning-128k outperforms Llama-Nemotron-Super-49B-1.0 on various benchmarks with up to 4x lower inference cost. Model weights have been released on HuggingFace under a non-production license to foster research in high-performance large-scale inference (Source: tri_dao, NVIDIA AI Developer)
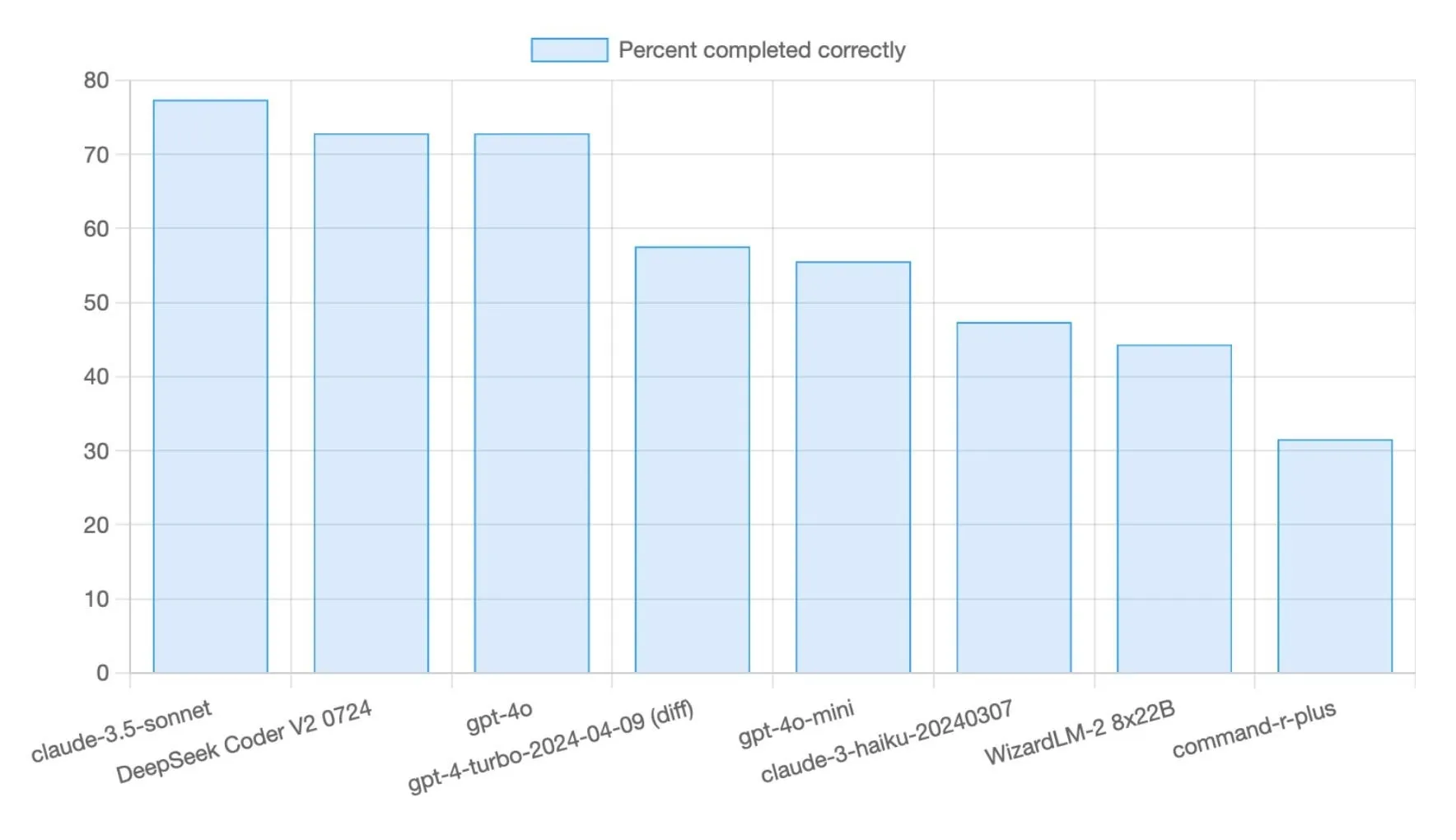
DeepSeek R1 0528 model achieves 71% score on Aider Polyglot programming benchmark: The DeepSeek R1 0528 model scored 71% on the Aider Polyglot programming benchmark, a significant improvement (+14.5 percentage points) over previous versions. The model is noted for its high cost-effectiveness, completing approximately 70% of the benchmark for less than $5, demonstrating strong competitiveness in code generation tasks (Source: Reddit r/LocalLLaMA, scaling01)
VACE framework released: A multi-functional model integrating video creation and editing: Alibaba Tongyi Lab has launched VACE (Video Creation and Editing), a unified model integrating multiple functions such as reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V). VACE allows users to freely combine these tasks to achieve diverse video processing like object movement, replacement, style referencing, extension, and animation. Several model versions, including VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B, and Wan2.1-VACE-14B, have been released and are available for download on HuggingFace and ModelScope (Source: GitHub Trending)

HKUST (GZ) and ByteDance jointly launch ComfyMind framework to unify visual generation tasks: The Hong Kong University of Science and Technology (Guangzhou) and ByteDance have jointly released the open-source visual generation framework ComfyMind, aiming to handle various mainstream visual generation tasks such as text-to-image and image-to-video with a single system. ComfyMind uses “atomic workflows” as the smallest unit, combined with tree-like planning and local feedback execution mechanisms, using ComfyUI as the underlying execution engine, and completes complex tasks through the collaboration of planning, execution, and evaluation agents. ComfyMind has shown excellent performance on benchmarks like ComfyBench, GenEval, and Reason-Edit, comparable to GPT-4o-Image (Source: QbitAI)

Hugging Face launches Model Context Protocol (MCP) server to enhance AI agent capabilities: Hugging Face now offers a Model Context Protocol (MCP) server, allowing AI agents to access external tools and real-time data in a standardized, secure manner, including searching models, analyzing datasets, and interacting with HuggingFace Spaces. This initiative aims to transform AI agents from static tools into dynamic collaborators, enhancing their ability to handle complex tasks and access up-to-date information. Several community members have begun exploring integrating MCP servers with various AI frameworks (e.g., Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) (Source: ClementDelangue, huggingface, awnihannun)

Research proposes STARFlow: Scalable Latent Normalizing Flow Models for High-Resolution Image Synthesis: STARFlow is a scalable generative model based on normalizing flows, with its core being the Transformer Autoregressive Flow (TARFlow). Through a deep-shallow design, modeling in the latent space of a pretrained autoencoder, and a novel guidance algorithm, STARFlow achieves competitive performance in class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models. This work successfully demonstrates normalizing flows operating effectively at this scale and resolution for the first time (Source: HuggingFace Daily Papers)
New research HASHIRU: Hierarchical Agent System for Hybrid Intelligent Resource Utilization: HASHIRU is a novel multi-agent system (MAS) framework featuring a “CEO” agent that dynamically manages specialized “employee” agents, instantiating them based on task requirements and resource constraints (cost, memory). The system prioritizes small local LLMs (via Ollama) while flexibly using external APIs and larger models, and includes autonomous API tool creation and memory functions. Evaluations on tasks like academic paper review, security assessment, and complex reasoning demonstrate its capabilities (Source: HuggingFace Daily Papers)
PartCrafter: Structured 3D Mesh Generation by Composing Latent Diffusion Transformers: PartCrafter is the first structured 3D generative model capable of jointly synthesizing multiple semantically meaningful and geometrically distinct 3D meshes from a single RGB image. It employs a unified compositional generation architecture that does not rely on pre-segmented input, enabling end-to-end part-aware generation of single objects and complex multi-object scenes. Its core innovations include a compositional latent space and a hierarchical attention mechanism (Source: HuggingFace Daily Papers)
Prefix Grouper: Efficient GRPO Training via Shared-Prefix Forward Passes: Group Relative Policy Optimization (GRPO) enhances policy learning by comparing relative differences between candidate outputs that share a common input prefix. Prefix Grouper improves GRPO’s training efficiency by eliminating redundant prefix computations through shared-prefix forward policy passes, especially in long-prefix scenarios, while maintaining training equivalence with standard GRPO (Source: HuggingFace Daily Papers)
GuideX: Guided Synthetic Data Generation for Zero-shot Information Extraction: Traditional Information Extraction (IE) systems are often domain-specific and costly to adapt. GuideX is a novel method that automatically defines domain-specific schemas, infers guidelines, and generates labeled synthetic instances, enabling better out-of-domain generalization. Fine-tuning Llama 3.1 with GuideX sets new SOTA on seven zero-shot Named Entity Recognition benchmarks, significantly improving the model’s understanding of complex domain-specific annotation patterns (Source: HuggingFace Daily Papers)
CodeContests+: Generating High-Quality Test Cases for Programming Competitions: Addressing the difficulty of obtaining test cases in programming competitions, researchers propose an LLM-based agent system for creating high-quality test cases. This system was applied to the CodeContests dataset, proposing an improved version, CodeContests+. Evaluations show CodeContests+ significantly outperforms the original in evaluation accuracy, especially in True Positive Rate (TPR), and offers substantial advantages for LLM reinforcement learning (Source: HuggingFace Daily Papers)
Sentinel: SOTA Model to Defend Against Prompt Injection Attacks: To address the vulnerability of Large Language Models (LLMs) to prompt injection attacks, researchers have introduced the Sentinel model (qualifire/prompt-injection-sentinel), based on the ModernBERT-large architecture. By fine-tuning on an extensive dataset containing various attack types and benign instructions, Sentinel achieves an average accuracy of 0.987 and an F1-score of 0.980 on an internal unseen test set, and outperforms strong baseline models on public benchmarks (Source: HuggingFace Daily Papers)
Paper explores: Is Extending Modalities the Right Path Towards Omnimodality?: Omnimodal Language Models (OLMs) aim to integrate and reason over multiple input modalities while maintaining strong language capabilities. This study investigates the effectiveness of extending modalities (i.e., fine-tuning pretrained language models) as a mainstream technique for training multimodal models. The research focuses on three core questions: Does modality extension harm core language abilities? Can model merging effectively integrate independently fine-tuned modality-specific models to achieve omnimodality? Does omnimodal extension lead to better knowledge sharing and generalization than sequential extension? (Source: HuggingFace Daily Papers)
Paper proposes Truth in the Few: High-Value Data Selection for Efficient Multimodal Reasoning: The research challenges the common belief that Multimodal LLMs (MLLMs) require vast amounts of training data for complex reasoning tasks. It observes that only a small subset of training data, termed “cognitive samples,” effectively elicits multimodal reasoning. Based on this, the paper proposes the Reasoning Activation Potential (RAP) data selection paradigm, which identifies these cognitive samples using a Causal Difference Estimator (CDE) and an Attention Confidence Estimator (ACE), and replaces simple instances with a Difficulty-aware Replacement Module (DRM). Experiments show RAP achieves superior performance with only 9.3% of training data and reduces computational costs by over 43% (Source: HuggingFace Daily Papers)
🧰 Tools
Task Master: AI-driven task management system integrated into editors like Cursor: Task Master is a task management system designed for AI-assisted development, seamlessly integrating with editors like Cursor AI, Lovable, Windsurf, and Roo. It utilizes APIs from large models like Claude (supporting Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama) to help developers parse product requirement documents (PRDs), generate task lists, plan development steps, and assist in implementing specific tasks. The system runs directly in the editor via MCP (Model Control Protocol), supports command-line operations, and provides detailed configuration guides and tutorials (Source: GitHub Trending)
Observer AI: Local open-source screen observation agent integrated with Ollama: Observer AI is an open-source project that allows users to run local LLMs via Ollama to observe the screen and perform tasks. Users can use this tool to let AI understand screen content and interact with it, for example, browsing foreign language websites. The project provides GitHub source code and a web application version that requires no local setup, enabling users to leverage LLMs for screen automation while protecting privacy (Source: Reddit r/LocalLLaMA)

Weaviate Query Agent integrates with seven major AI frameworks to simplify natural language data querying: Weaviate has announced the integration of its Query Agent with seven major AI frameworks (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic). The Query Agent is a pre-built agent service that can answer natural language queries based on data in Weaviate, without requiring complex query statements. These integrations allow developers to easily embed powerful natural language query capabilities into their existing AI application stacks, enhancing the convenience of data interaction (Source: bobvanluijt)

Claude Code and Gemini Pro collaborative MCP server released to boost coding efficiency: BeehiveInnovations has released an MCP server enabling Claude Code and Gemini 2.5 Pro to work collaboratively. Claude Code handles initial ideation and planning, while Gemini complements with its million-token context and deep reasoning capabilities. The server integrates tools for extended thinking, file reading, code review, and debugging, aiming to improve the quality and efficiency of code generation and optimization by combining the strengths of both models. Preliminary tests show that the combined use yields better results in JSON parsing speed optimization tasks than using either model alone (Source: Reddit r/ClaudeAI)

📚 Learning
Sakana AI releases Japanese financial benchmark EDINET-Bench to evaluate LLM financial task capabilities: Sakana AI has launched EDINET-Bench, a Japanese financial benchmark constructed using annual reports from Japan’s Financial Services Agency’s Electronic Disclosure for Investors’ NETwork (EDINET). The benchmark aims to evaluate the performance of Large Language Models (LLMs) on complex financial tasks such as fraud detection, addressing the scarcity of high-quality, freely available datasets in the financial domain. EDINET-Bench generates a multi-task dataset through automatic annotation, providing an important resource for financial AI R&D (Source: hardmaru, SakanaAILabs)

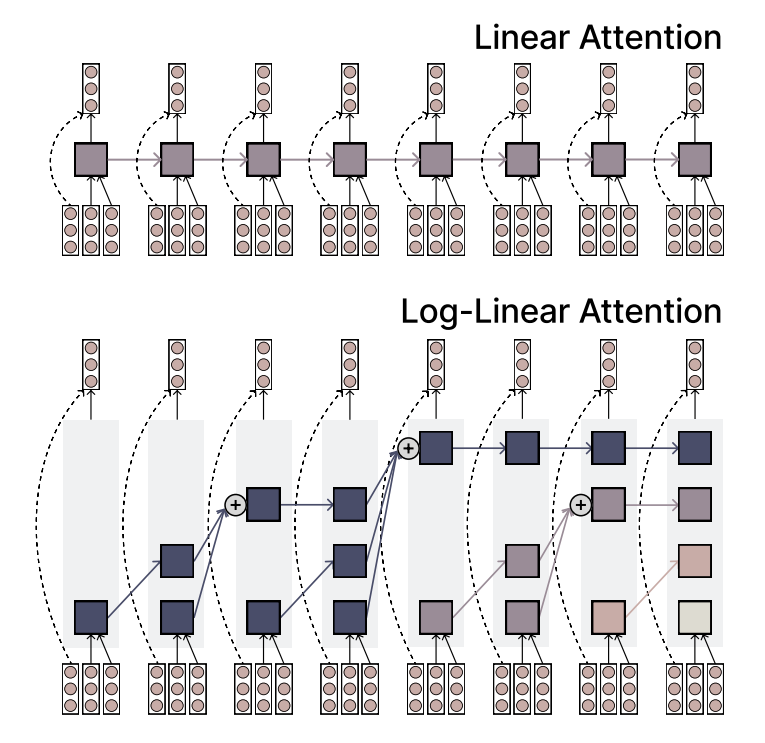
MIT proposes Log-linear Attention mechanism, balancing efficiency and expressiveness: MIT researchers have proposed a new attention mechanism called Log-linear Attention. This mechanism aims to combine the speed and efficiency of linear attention with the expressive power of Softmax attention. It achieves this by using a small number of memory slots that grow logarithmically with sequence length, offering a potentially new method for processing long sequence data (Source: TheTuringPost)
Hamel Husain and Shreya Rajpal’s LLM evaluation course receives positive reviews: Users like Ryan Lingo and Radek Osmulski shared positive experiences from participating in Hamel Husain and Shreya Rajpal’s LLM application evaluation course (maven.com/parlance-labs/evals). The course is considered some of the most in-depth and practical content on LLMs available, with its lectures and exclusive book being crucial for developers building AI applications, emphasizing the core role of evaluation in LLM development (Source: HamelHusain, HamelHusain)
MORSE-500: A Programmatically Controllable Video Benchmark for Stress-Testing Multimodal Reasoning: Addressing the issue that current multimodal reasoning benchmarks primarily rely on static images and neglect temporal complexity and breadth of reasoning skills, researchers have introduced MORSE-500. This is a benchmark comprising 500 fully-scripted video snippets covering six reasoning categories: abstract, physical, planning, spatial, and temporal. Its script-driven design allows fine-grained control over visual complexity, distractor density, and temporal dynamics, supporting the arbitrary creation of more challenging new instances, aimed at stress-testing next-generation models. Preliminary experiments show significant performance gaps for SOTA models, including Gemini 2.5 Pro and OpenAI o3, across all categories (Source: HuggingFace Daily Papers)
EverGreenQA: A Multilingual Evergreen Question Classification Dataset for Enhancing QA Trustworthiness: To address the issue of LLMs hallucinating in Question Answering (QA) tasks due to question temporality (whether answers change over time), researchers have introduced EverGreenQA. This is the first multilingual QA dataset with evergreen labels, supporting evaluation and training. Using this dataset, researchers benchmarked 12 modern LLMs, assessing their ability to encode question temporality, and trained a lightweight multilingual classifier, EG-E5. The study also demonstrates applications of evergreen classification in improving self-knowledge estimation, filtering QA datasets, and interpreting GPT-4o retrieval behavior (Source: HuggingFace Daily Papers)
KVzip: Query-agnostic KV cache eviction method significantly reduces memory footprint and decoding latency: Seoul National University ML Lab has released KVzip, a KV cache compression method designed to support diverse future queries. Through a query-agnostic eviction strategy, the method achieves approximately 3-4x memory reduction and 2x decoding latency reduction. It currently supports models like Qwen3/2.5, Gemma3, and LLaMA3, with demo code available on GitHub (Source: Reddit r/LocalLLaMA)

NimbleEdge open-sources sparse Transformer operator kernels, improving LLM running speed and memory efficiency: The NimbleEdge team, based on Apple’s “LLM in a Flash” and Zichang et al.’s “Deja Vu” research, has built fused operator kernels for structured context sparsity. These kernels achieve a 5x performance improvement in the MLP layers of Transformers and a 50% reduction in memory consumption by avoiding loading and computing feed-forward layer weights and activations whose outputs would ultimately be zero. When applied to the Llama 3.2 3B model, overall throughput increased by 1.78x, and memory usage decreased by 26.4%. The code is open-sourced on GitHub, with plans to support int8, CUDA, and sparse attention (Source: Reddit r/MachineLearning)
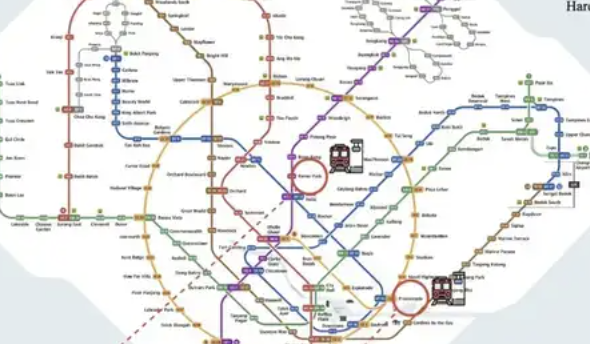
ReasonMap: Multimodal reasoning benchmark for high-resolution transport maps released: A research team from Westlake University and other institutions has launched ReasonMap, a multimodal reasoning benchmark focusing on high-resolution transport maps (mainly subway maps). The benchmark aims to evaluate the ability of large models to understand fine-grained structured spatial information in images, featuring high-resolution images (average 5839×5449), difficulty-aware design, and a multi-dimensional evaluation system. Test results show that current mainstream open-source models perform poorly on ReasonMap, especially in cross-line path planning, while closed-source reasoning models (like GPT-o3) significantly outperform open-source models but still lag behind human-level performance. Complex subway maps like those of Beijing and Hangzhou pose significant challenges for the models (Source: QbitAI)
Yandex releases Yambda-5B: A large-scale open dataset for recommendation systems: Yandex has launched Yambda-5B, a large-scale anonymized music streaming dataset containing 4.79 billion user-item interactions. The dataset features an “is_organic” flag and Global Time Split (GTS), does not contain directly identifiable user listening histories or likes, is resistant to de-anonymization, and includes both implicit (song listens, skips) and explicit (like/dislike) feedback. Yambda-5B aims to provide high-quality, multimodal data resources for recommendation system research (Source: TheTuringPost)
Tencent launches 2025 Spark Challenge Camp, recruiting top students for cutting-edge research including large models: Tencent announced the launch of its 2025 “Spark Challenge Camp,” targeting 60-70 students in their second or third year of high school (2025 college entrance exam takers) and others with outstanding performance in relevant subjects. Selected participants will have the opportunity to go to the Shenzhen headquarters to participate in research on six cutting-edge topics: ultra-long text understanding, long chain-of-thought technology, embodied intelligence + robotics, multimodal perception and understanding, security attack and defense (including LLM Agent hacker design), and quantum technology. The program aims to provide talented young people with exposure to industrial-grade research scenarios, broaden their technological horizons, and deepen their industry understanding (Source: QbitAI)

💼 Business
Rumor: Meta to invest over $10 billion in Scale AI, strengthening AI applications in military and other fields: According to reports, Meta is in talks with AI data annotation company Scale AI for a major investment, potentially amounting to billions or even exceeding $10 billion. If true, this would be one of Meta’s largest external AI investments. Scale AI has previously built Defense Llama, a model designed for military use based on Meta’s Llama 3, to support US national security missions. This move could signal a more aggressive investment and collaboration strategy for Meta in the AI field, particularly in applications related to government and defense (Source: 36Kr)

Mashang Consumer Finance releases “Tianjing” large model 3.0, upgraded to a financial decision-making platform: Mashang Consumer Finance has launched version 3.0 of its financial large model, “Tianjing.” The core breakthrough of the new version lies in a systemic leap from individual intelligence to collective intelligence, no longer solely relying on logical learning but deeply mining implicit experiences scattered throughout the company, such as employee trajectories and business logs, and transforming them into structured knowledge. Tianjing 3.0 aims to upgrade from a tool to a decision-making platform, promoting human-machine collaboration. It can dynamically break down complex service processes and, based on user demands and compliance requirements, match the optimal service combination in real-time, achieving decision-making from local optimum to global optimum (Source: QbitAI)

Together AI appoints Charles Zedlewski as new Chief Product Officer, focusing on open-source generative AI platform: Together AI announced the appointment of Charles Zedlewski as its new Chief Product Officer (CPO). Charles Zedlewski previously led developer-focused, community-driven platform products at Temporal and Cloudera. Together AI emphasizes its commitment to building an open-source future for generative AI, believing that open models offer advantages in flexibility, cost-effectiveness, and innovation. Charles’s addition aims to further drive Together AI’s efforts to build the definitive open-source AI platform, making powerful generative AI accessible to every developer and enterprise (Source: togethercompute)

🌟 Community
Waymo self-driving car torched in Los Angeles, sparking community concern and discussion about AV safety: Recently, multiple Waymo self-driving cars were set on fire in Los Angeles. This incident has garnered widespread attention and discussion on social media, covering public acceptance of autonomous vehicles, safety concerns, and the risk that such events could be inappropriately amplified or distorted by AI-generated content (such as videos generated by Veo 3). Some commentators compared the scene to the sci-fi movie “Children of Men,” highlighting the dramatic nature and potential societal impact of the event (Source: gfodor, fabianstelzer, hrishioa, bookwormengr, claud_fuen)
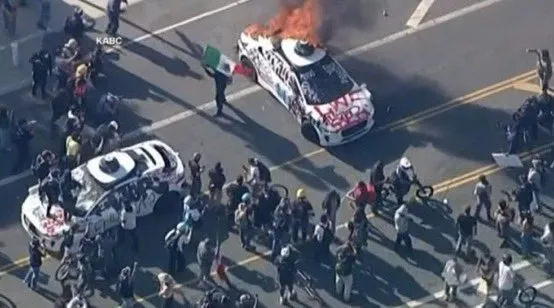
Reddit sues Anthropic, alleging unauthorized scraping of content to train Claude AI: Reddit has filed a lawsuit against Anthropic, accusing it of scraping Reddit posts and conversations to train its AI model Claude without permission or payment. Reddit argues this violates its user agreement, which prohibits unauthorized commercial use of content, and claims Anthropic’s statement that it “stopped scraping Reddit” is false. The lawsuit also involves privacy concerns, as Anthropic, unlike other companies with licensing agreements, lacks a mechanism to delete posts that users have deleted. Reddit is asking the court to prohibit Anthropic from using Reddit data and may demand that Claude be taken down (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)
AI Engineer World’s Fair buzz: Simon Willison reviews past six months of LLM development, emphasizes tools + reasoning combo: At the AI Engineer World’s Fair in San Francisco, Simon Willison humorously reviewed the rapid development of LLMs over the past six months using a “pelican riding a bicycle” SVG image generation test, personally testing over 30 AI models. He emphasized that the most powerful AI combination currently is “tools + reasoning,” such as the performance of o3/o4-mini in search, and the attention MCP architecture has received due to tool calling. The presentation also cataloged the year’s AI “bizarre bugs,” like ChatGPT’s excessive flattery, Claude’s potential to “report” users, and pointed out risks of prompt injection and data leakage (Source: 36Kr, swyx)

Community discusses AI-induced career anxiety and coping strategies: A Reddit post about “how to deal with AI anxiety” sparked heated discussion. Users widely fear AI could cause mass unemployment in the coming years, posing a severe threat especially to those with insufficient savings and significant debt. In the discussion, some suggested transitioning to trades, nursing, or other fields, but also worried these areas would become saturated with a large influx of career changers. Commenters shared their anxieties, such as insomnia and difficulty concentrating at work. Some opinions suggested actively learning AI, maintaining adaptability, and pointed out that historical technological innovations (like automobiles, the internet) also caused similar concerns but ultimately created new job opportunities. Other commenters believed the extent to which AI will replace human jobs is currently exaggerated and mass layoffs are unlikely in the short term (Source: Reddit r/ArtificialInteligence)
User shares experience of using ChatGPT for “brutal” self-psychoanalysis: A Reddit user shared their experience of using ChatGPT for a “savage executive-style” self-psychoanalysis. Using specific prompts, they asked ChatGPT to provide a harsh analysis from five angles: true strengths, deep weaknesses, recurring failure patterns, areas of avoidance, and neglected skills, and to give a three-stage development plan. The user stated that although the process was painful (e.g., being told they started 12 projects but completed none, and excessively researched productivity instead of taking action), this “brutal” feedback ultimately pushed them to change. The post sparked community discussion about AI’s application in self-reflection and personal development (Source: Reddit r/ArtificialInteligence)
Discussion on LLM memory vs. reasoning: Knowledgeable or truly understanding?: On social media, users discussed the excellent performance of Large Language Models (LLMs) on memory-based fact recall tasks and whether this implies they possess true reasoning abilities. Some argue that LLMs’ impressive performance on seemingly complex tasks may rely more on vast training data and pattern recognition than on deep understanding and creativity in the human sense. Research from companies like Meta suggests that model capacity can be estimated by measuring memory, and generalization only begins once capacity is filled. This discussion also relates to the emphasis on rote memorization in education systems and the lack of training in information retrieval and AI tool usage (Source: omarsar0, menhguin, menhguin)

💡 Others
Analysis of Stripe’s successful payment fraud detection foundational model case: A post by Stripe engineers about building a successful payment fraud detection foundational model has garnered attention. The analysis points out the specificity of this case: 1) Fraud detection is inherently not about predicting the future; theoretically, high accuracy can be achieved with sufficient signals. 2) Stripe is already in a signal-rich environment, not needing to accumulate data from scratch. 3) This scenario is an automation upgrade, moving from traditional machine learning to a foundational model, close to a direct replacement. This explains why such “quick wins” for AI applications are relatively rare, as most AI business value realization requires overcoming numerous obstacles (Source: random_walker)
Cognitive foundation for AI transformation: Systematized information perception and technological insight mechanisms are key: In AI transformation, enterprises need to establish systematized, structured mechanisms for information perception and technological insight, moving beyond individual experience and traditional path dependencies. This includes building internal data analysis capabilities and external knowledge networks (academia, industry, capital markets, startups). The assessment of AI investment returns also needs to shift from traditional ROI to a “phased, multi-dimensional” system, coupled with external knowledge networks, forming a strategic closed loop of continuous validation and dynamic adjustment. The article emphasizes that AI is not a one-time tool but a continuously evolving, value-adding strategic asset (Source: 36Kr)
Frigate: NVR system based on real-time local object detection: Frigate is a local Network Video Recorder (NVR) system designed for Home Assistant, utilizing OpenCV and Tensorflow for real-time local object detection on IP cameras. The system emphasizes resource optimization and performance, triggering object detection through low-overhead motion detection and leveraging multiprocessing. AI accelerators like Google Coral or Hailo are recommended for optimal performance. Frigate supports 24/7 recording, object detection-based recording retention, MQTT integration, RTSP restreaming, and WebRTC/MSE low-latency live viewing (Source: GitHub Trending)
