
Mots-clés:Grand modèle de langage, Capacité de raisonnement, Sécurité de l’IA, Modèle multimodal, Modèle open source, Génération de vidéos par IA, Évaluation de l’IA, Applications commerciales de l’IA, Étude sur les capacités de raisonnement des LLM d’Apple, Modèle de compréhension temporelle Time-R1, Génération vidéo avec GPU NVIDIA Blackwell, Modèle open source Alibaba Tongyi Qianwen 3, Serveur MCP de Hugging Face
🔥 聚焦
Apple publie un article affirmant que les grands modèles de langage actuels n’ont qu’une “illusion de la pensée” et non une véritable capacité de raisonnement, suscitant un vif débat dans l’industrie: Des chercheurs d’Apple (dont Samy Bengio, l’un des fondateurs de Google Brain) ont publié un article indiquant, à travers des tests sur quatre tâches à difficulté contrôlable telles que les Tours de Hanoï et l’échange de dames, que les modèles de pointe comme DeepSeek, o3-mini, Claude 3.7 “s’effondrent” face à des problèmes de haute complexité, manifestant une “mise à l’échelle inversée de l’effort de raisonnement” (plus le problème est difficile, moins ils semblent réfléchir). L’article suggère que ces modèles reposent davantage sur la reconnaissance de formes et la mémorisation que sur un raisonnement logique véritable et généralisable, et ne parviennent pas à surmonter le goulot d’étranglement de la complexité même lorsqu’on leur fournit l’algorithme complet. Ce point de vue remet en question la perception actuelle des capacités de raisonnement des LLM et a déclenché une vaste discussion sur les méthodes d’évaluation des LLM, les limites réelles de leurs capacités de raisonnement et les orientations futures de leur développement. Les réactions de la communauté sont partagées : certains y voient une tentative d’Apple de justifier la lenteur de ses propres progrès en IA, tandis que d’autres reconnaissent la pertinence de ses observations sur les mécanismes d’évaluation et les limitations intrinsèques des modèles (来源: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

Yoshua Bengio, lauréat du prix Turing, met en garde contre les risques de perte de contrôle de l’IA et réoriente ses recherches vers une “IA scientifique”: Lors de la conférence BAII (Beijing Academy of Artificial Intelligence), Yoshua Bengio a déclaré qu’étant donné le développement rapide de l’IA (en particulier de l’AGI) et ses risques potentiels de perte de contrôle (par exemple, l’IA copiant son propre code et dissimulant ses actions pour “survivre”), il a réorienté ses recherches pour se consacrer à la construction d’une “IA scientifique” dotée uniquement d’intelligence, sans conscience de soi ni objectifs propres. Il estime que les capacités de planification de l’IA pourraient atteindre le niveau humain d’ici cinq ans et souligne que les méthodes d’entraînement actuelles de l’IA pourraient l’amener à faire preuve d’une confiance excessive même lorsqu’elle commet des erreurs. Bengio insiste sur la nécessité de s’assurer que l’IA respecte les directives éthiques, d’éviter son utilisation à des fins malveillantes, et appelle à une coopération mondiale pour relever les défis de la sécurité de l’IA et résoudre les problèmes d‘“alignement” et de “contrôlabilité” (来源: 量子位)

Le gouvernement britannique adopte le système Extract, basé sur le modèle Gemini de Google, pour accélérer la prise de décision en matière d’urbanisme: Le gouvernement britannique utilise un système nommé “Extract” pour aider les urbanistes des conseils locaux à prendre des décisions plus rapidement. Ce système, basé sur le modèle fondamental Gemini de Google, exploite ses capacités de raisonnement multimodal pour convertir en 40 secondes des documents d’urbanisme complexes, y compris des notes manuscrites et des cartes floues, en données numériques. Cette application démontre le potentiel de l’IA dans le secteur des services publics gouvernementaux, en automatisant le traitement et la compréhension de documents complexes pour améliorer l’efficacité administrative et la qualité des décisions (来源: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia est la première entreprise à utiliser les GPU NVIDIA Blackwell pour entraîner son grand modèle vidéo EXPRESS-2: La société de génération de vidéos par IA Synthesia a annoncé être la première au monde à utiliser les GPU NVIDIA Blackwell sur Google Cloud pour entraîner de grands modèles vidéo. Son nouveau modèle, EXPRESS-2, vise à aider les clients à créer plus rapidement des vidéos et des avatars virtuels générés par IA de meilleure qualité, grâce à un matériel plus puissant et à une configuration multi-cloud optimisée. Cette initiative marque une avancée importante dans le support matériel sous-jacent et les capacités des modèles pour la technologie de génération de vidéos par IA, préfigurant une nouvelle amélioration de l’efficacité et de la qualité de la création de contenu vidéo par IA à l’avenir (来源: synthesiaIO,Synthesia Blog)
Une étude d’Epoch AI révèle que le modèle o3-mini-high s’appuie sur l‘“intuition” pour résoudre des problèmes mathématiques de haut niveau, plutôt que sur la mémorisation par cœur: Epoch AI a invité 14 mathématiciens à évaluer 29 processus de raisonnement du modèle o3-mini-high sur le benchmark FrontierMath, constatant que le modèle pouvait résoudre correctement 13 problèmes difficiles. L’étude montre que o3-mini-high possède une connaissance mathématique approfondie et peut invoquer des théorèmes pertinents, mais son style de raisonnement tend davantage vers une “induction basée sur l’intuition”, manquant de preuves formelles rigoureuses et de créativité, allant parfois jusqu’à “prendre des raccourcis” en sautant des étapes de démonstration. Malgré des problèmes tels que les hallucinations et l’incapacité à reproduire précisément des formules, ses performances sur certaines questions sont similaires aux processus de pensée des mathématiciens humains. Cette recherche analyse en profondeur les capacités et les limites actuelles des grands modèles en matière de raisonnement mathématique complexe (来源: 量子位)

🎯 动向
Les téléchargements des modèles open source Tongyi Qianwen 3 d’Alibaba dépassent les 12,5 millions, avec plus de 130 000 modèles dérivés, un record mondial: Depuis leur lancement en open source il y a un mois, les grands modèles de la série Tongyi Qianwen 3 d’Alibaba ont été téléchargés plus de 12,5 millions de fois dans le monde, devenant ainsi les modèles open source les plus populaires récemment. Ses quatre tailles de modèles, de 0.6B à 32B, ont toutes dépassé le million de téléchargements sur des plateformes comme Hugging Face et ModelScope, et le nombre de modèles dérivés a dépassé les 130 000, se classant au premier rang mondial. Qianwen 3 a remporté la première place parmi les modèles open source dans plusieurs classements de performance nationaux et internationaux, et a attiré l’adaptation et l’intégration de nombreux fabricants de puces et plateformes de calcul tels que Nvidia, Intel et ARM, en raison de son faible coût d’inférence (environ un tiers de celui de DeepSeek R1) (来源: 量子位)

L’Université de l’Illinois publie le modèle Time-R1, avec 3 milliards de paramètres, pour la compréhension, la prédiction et la génération liées au temps: Des chercheurs de l’Université de l’Illinois à Urbana-Champaign ont lancé Time-R1, un modèle de langage de 3 milliards de paramètres qui, grâce à un apprentissage par renforcement en trois étapes et à un mécanisme de récompense dynamique, améliore la compréhension du concept de temps par le modèle, la prédiction d’événements futurs et la capacité de génération de scénarios créatifs. Ce modèle excelle dans les tâches de raisonnement temporel, surpassant même des modèles avec beaucoup plus de paramètres, tels que DeepSeek-V3-0324. L’équipe de recherche a mis en open source Time-Bench (un grand jeu de données de raisonnement temporel multi-tâches basé sur 10 ans d’actualités du New York Times) ainsi que le code d’entraînement et les points de contrôle du modèle Time-R1 (来源: 量子位)

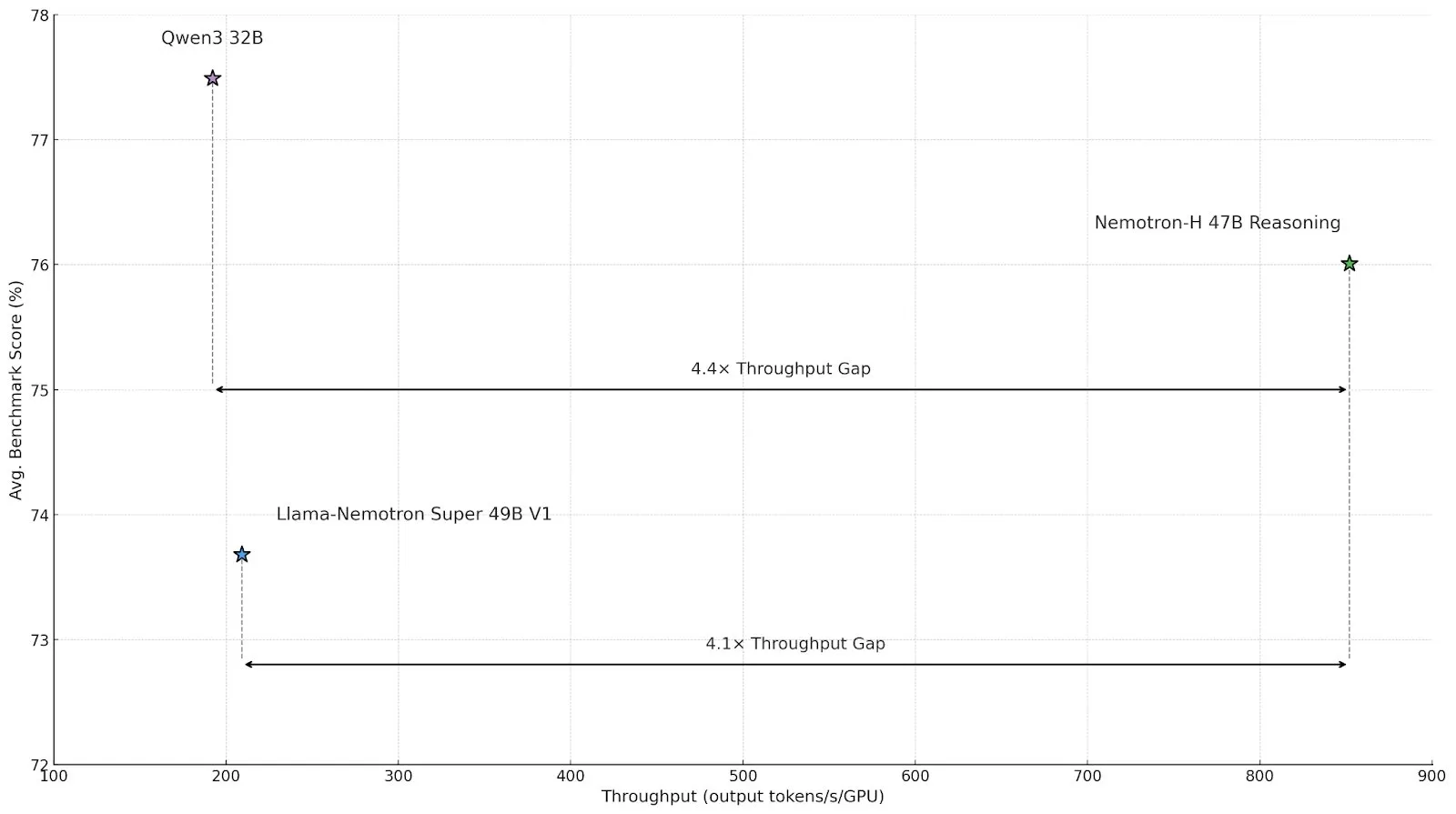
NVIDIA lance la série de modèles d’inférence Nemotron-H, adoptant une architecture hybride Mamba-Transformer pour une efficacité accrue: NVIDIA a présenté les modèles d’inférence Nemotron-H 8B et 47B, basés sur une architecture hybride SSM-Transformer (Mamba-Transformer). Ces modèles, tout en maintenant une haute précision, peuvent atteindre un débit d’inférence jusqu’à 4 fois supérieur à celui des modèles Transformer comparables. Nemotron-H-47B-Reasoning-128k surpasse Llama-Nemotron-Super-49B-1.0 dans divers benchmarks, avec un coût d’inférence réduit jusqu’à 4 fois. Les poids du modèle ont été publiés sur HuggingFace sous une licence non destinée à la production, visant à promouvoir la recherche sur l’inférence à grande échelle à haute performance (来源: tri_dao,NVIDIA AI Developer)
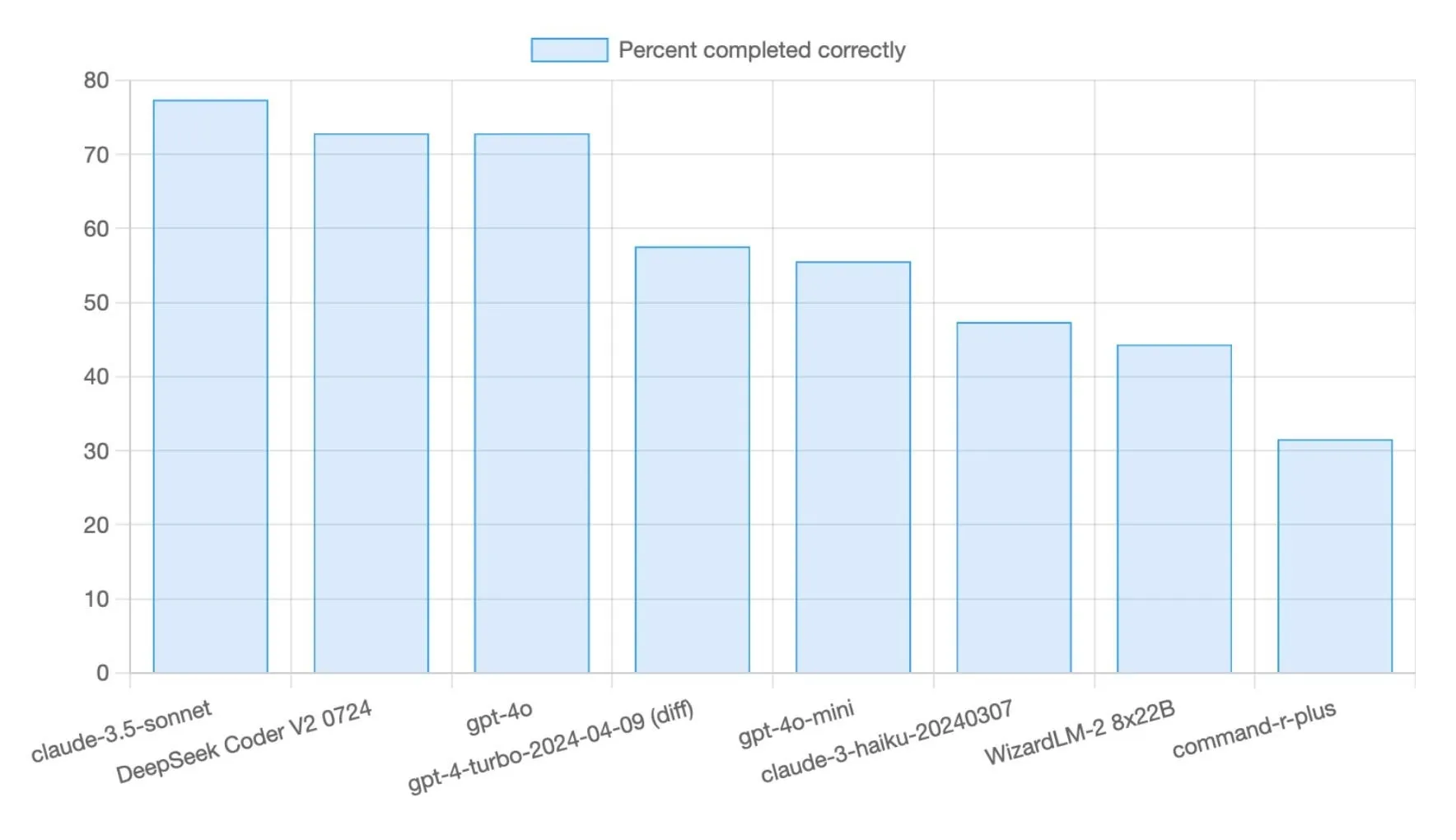
Le modèle DeepSeek R1 0528 obtient un score de 71% au benchmark de programmation Aider Polyglot: Le modèle DeepSeek R1 0528 a obtenu un score de 71% au benchmark de programmation Aider Polyglot, une amélioration significative (+14,5 points de pourcentage) par rapport aux versions précédentes. Ce modèle a attiré l’attention pour son excellent rapport coût-efficacité, réalisant environ 70% du benchmark pour moins de 5 dollars, démontrant une forte compétitivité dans les tâches de génération de code (来源: Reddit r/LocalLLaMA,scaling01)
Lancement du framework VACE : un modèle multifonctionnel intégrant la création et l’édition vidéo: Le laboratoire Tongyi d’Alibaba a lancé VACE (Video Creation and Editing), un modèle unifié intégrant de multiples fonctionnalités telles que la génération de vidéo à partir d’une référence (R2V), l’édition de vidéo à vidéo (V2V) et l’édition de vidéo masquée (MV2V). VACE permet aux utilisateurs de combiner librement ces tâches pour réaliser divers traitements vidéo tels que le déplacement d’objets, le remplacement, la référence de style, l’extension, l’animation, etc. Plusieurs versions du modèle ont déjà été publiées, notamment VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B et Wan2.1-VACE-14B, et sont disponibles en téléchargement sur HuggingFace et ModelScope (来源: GitHub Trending)

HKUST (Guangzhou) et ByteDance lancent conjointement le framework ComfyMind pour unifier les tâches de génération visuelle: L’Université des Sciences et Technologies de Hong Kong (Guangzhou) et ByteDance ont conjointement publié le framework open source de génération visuelle ComfyMind, visant à traiter une variété de tâches de génération visuelle courantes telles que texte-vers-image et image-vers-vidéo avec un seul système. ComfyMind utilise des “workflows atomiques” comme unité minimale, combinés à une planification arborescente et à un mécanisme d’exécution à rétroaction locale, utilisant ComfyUI comme moteur d’exécution sous-jacent, et accomplit des tâches complexes grâce à la collaboration de trois agents : planification, exécution et évaluation. Dans les benchmarks ComfyBench, GenEval et Reason-Edit, ComfyMind a montré d’excellentes performances, comparables à celles de GPT-4o-Image (来源: 量子位)

Hugging Face lance un serveur de protocole de contexte de modèle (MCP) pour améliorer les capacités des agents IA: Hugging Face propose désormais un serveur de protocole de contexte de modèle (MCP), permettant aux agents IA d’accéder à des outils externes et à des données en temps réel de manière standardisée et sécurisée, y compris la recherche de modèles, l’analyse de jeux de données et l’interaction avec les HuggingFace Spaces. Cette initiative vise à transformer les agents IA d’outils statiques en collaborateurs dynamiques, améliorant leur capacité à traiter des tâches complexes et à obtenir les informations les plus récentes. Plusieurs membres de la communauté ont commencé à explorer l’intégration du serveur MCP avec divers frameworks d’IA (tels que Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) (来源: ClementDelangue,huggingface,awnihannun)

Une étude présente STARFlow : un modèle de flux normalisant latent évolutif pour la synthèse d’images à haute résolution: STARFlow est un modèle génératif évolutif basé sur des flux normalisants, dont le cœur est le Transformer Autoregressive Flow (TARFlow). Grâce à une conception à couches profondes et peu profondes, à la modélisation dans l’espace latent d’un auto-encodeur pré-entraîné et à un nouvel algorithme de guidage, STARFlow atteint des performances compétitives dans les tâches de génération d’images conditionnées par classe et par texte, se rapprochant des modèles de diffusion de pointe. Ce travail démontre pour la première fois le fonctionnement efficace des flux normalisants à cette échelle et à cette résolution (来源: HuggingFace Daily Papers)
Nouvelle recherche HASHIRU : un système d’agents hiérarchiques pour l’utilisation des ressources d’intelligence hybride: HASHIRU est un nouveau framework de système multi-agents (MAS) caractérisé par un agent “PDG” qui gère dynamiquement des agents “employés” spécialisés et les instancie en fonction des besoins de la tâche et des contraintes de ressources (coût, mémoire). Le système privilégie l’utilisation de petits LLM locaux (via Ollama), tout en utilisant de manière flexible des API externes et de grands modèles, et inclut la création autonome d’outils API et des fonctionnalités de mémorisation. L’évaluation sur des tâches telles que l’examen d’articles universitaires, l’évaluation de la sécurité et le raisonnement complexe a démontré ses capacités (来源: HuggingFace Daily Papers)
PartCrafter : Génération de maillages 3D structurés par la combinaison de Transformers à diffusion latente: PartCrafter est le premier modèle de génération 3D structurée capable de synthétiser conjointement plusieurs maillages 3D sémantiquement significatifs et géométriquement distincts à partir d’une seule image RGB. Il adopte une architecture de génération compositionnelle unifiée, ne dépendant pas d’une entrée pré-segmentée, et capable de percevoir de bout en bout la génération de parties pour des objets uniques et des scènes complexes multi-objets. Ses innovations principales incluent un espace latent compositionnel et un mécanisme d’attention hiérarchique (来源: HuggingFace Daily Papers)
Prefix Grouper : Entraînement GRPO efficace grâce à la propagation avant de préfixes partagés: Group Relative Policy Optimization (GRPO) améliore l’apprentissage des politiques en comparant les différences relatives entre les sorties candidates qui partagent un préfixe d’entrée commun. Prefix Grouper élimine les calculs redondants de préfixes en partageant la politique de propagation avant des préfixes, améliorant ainsi l’efficacité de l’entraînement de GRPO, en particulier dans les scénarios à longs préfixes, tout en maintenant l’équivalence d’entraînement avec le GRPO standard (来源: HuggingFace Daily Papers)
GuideX : Génération de données synthétiques guidée pour l’extraction d’informations zero-shot: Les systèmes traditionnels d’extraction d’informations (IE) sont souvent spécifiques à un domaine, avec des coûts d’adaptation élevés. GuideX est une nouvelle méthode qui définit automatiquement des schémas spécifiques au domaine, infère des guides et génère des instances synthétiques étiquetées, permettant ainsi une meilleure généralisation hors domaine. L’affinage de Llama 3.1 avec GuideX a établi un nouveau SOTA sur sept benchmarks de reconnaissance d’entités nommées zero-shot, améliorant considérablement la compréhension par le modèle des schémas d’annotation complexes spécifiques au domaine (来源: HuggingFace Daily Papers)
CodeContests+ : Génération de cas de test de haute qualité pour les concours de programmation: Pour résoudre le problème de la difficulté d’obtenir des cas de test dans les concours de programmation, des chercheurs ont proposé un système d’agents basé sur les LLM pour créer des cas de test de haute qualité. Ce système a été appliqué à l’ensemble de données CodeContests, et une version améliorée, CodeContests+, a été proposée. L’évaluation a montré que CodeContests+ surpasse considérablement la version originale en termes de précision d’évaluation, en particulier en ce qui concerne le taux de vrais positifs (TPR), et présente des avantages significatifs pour l’apprentissage par renforcement des LLM (来源: HuggingFace Daily Papers)
Sentinel : Modèle SOTA pour se prémunir contre les attaques par injection de prompt: Pour contrer la vulnérabilité des grands modèles de langage (LLM) aux attaques par injection de prompt, des chercheurs ont lancé le modèle Sentinel (qualifire/prompt-injection-sentinel), basé sur l’architecture ModernBERT-large. En l’affinant sur un vaste ensemble de données contenant divers types d’attaques et d’instructions bénignes, Sentinel a atteint une précision moyenne de 0,987 et un score F1 de 0,980 sur un ensemble de tests internes non vus, et surpasse les modèles de référence robustes sur les benchmarks publics (来源: HuggingFace Daily Papers)
Un article explore : L’extension des modalités est-elle la bonne voie pour atteindre la pleine modalité ?: Les modèles de langage omni-modaux (OLM) visent à intégrer et à raisonner sur plusieurs modalités d’entrée tout en maintenant de solides capacités linguistiques. Cette étude explore l’efficacité de l’extension des modalités (c’est-à-dire l’affinage de modèles de langage pré-entraînés) en tant que technique dominante pour entraîner des modèles multimodaux. La recherche se concentre sur trois questions fondamentales : l’extension des modalités nuit-elle aux capacités linguistiques de base ? La fusion de modèles peut-elle intégrer efficacement des modèles spécifiques à une modalité affinés indépendamment pour atteindre la pleine modalité ? L’extension omni-modale apporte-t-elle un meilleur partage des connaissances et une meilleure généralisation que l’extension séquentielle ? (来源: HuggingFace Daily Papers)
Un article propose Truth in the Few : une méthode de sélection de données de haute valeur pour un raisonnement multimodal efficace: La recherche remet en question l’idée répandue selon laquelle les LLM multimodaux (MLLM) nécessitent de grandes quantités de données d’entraînement pour les tâches de raisonnement complexes. L’observation révèle que seule une petite fraction des données d’entraînement, appelées “échantillons cognitifs”, stimule efficacement le raisonnement multimodal. Sur cette base, l’article propose le paradigme de sélection de données Reasoning Activation Potential (RAP), qui identifie ces échantillons cognitifs à l’aide d’un estimateur de différence causale (CDE) et d’un estimateur de confiance d’attention (ACE), et remplace les instances simples par un module de remplacement sensible à la difficulté (DRM). Les expériences montrent que RAP n’utilise que 9,3 % des données d’entraînement pour obtenir des performances supérieures et réduit les coûts de calcul de plus de 43 % (来源: HuggingFace Daily Papers)
🧰 工具
Task Master : Système de gestion de tâches piloté par IA, intégré à des éditeurs comme Cursor: Task Master est un système de gestion de tâches spécialement conçu pour le développement assisté par IA, s’intégrant de manière transparente avec des éditeurs tels que Cursor AI, Lovable, Windsurf, Roo, etc. Il utilise les API de grands modèles comme Claude (prenant en charge Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama) pour aider les développeurs à analyser les documents d’exigences (PRD), à générer des listes de tâches, à planifier les étapes de développement et à assister dans la réalisation de tâches spécifiques. Ce système fonctionne directement dans l’éditeur via MCP (Model Control Protocol), prend en charge les opérations en ligne de commande et fournit des guides de configuration détaillés et des tutoriels d’utilisation (来源: GitHub Trending)
Observer AI : Agent intelligent open source d’observation d’écran local, intégré à Ollama: Observer AI est un projet open source permettant aux utilisateurs d’exécuter des LLM locaux via Ollama pour observer l’écran et effectuer des tâches. Les utilisateurs peuvent utiliser cet outil pour permettre à l’IA de comprendre le contenu de l’écran et d’interagir, par exemple pour naviguer sur des sites web en langue étrangère. Le projet fournit le code source GitHub et une version d’application web ne nécessitant aucune configuration locale, permettant aux utilisateurs d’utiliser les LLM pour l’automatisation des opérations à l’écran tout en protégeant leur vie privée (来源: Reddit r/LocalLLaMA)

Weaviate Query Agent s’intègre à sept frameworks IA majeurs, simplifiant l’interrogation de données en langage naturel: Weaviate a annoncé l’intégration de son Query Agent avec sept frameworks IA majeurs (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic). Query Agent est un service d’agent pré-construit capable de répondre à des requêtes en langage naturel basées sur les données stockées dans Weaviate, sans nécessiter l’écriture de requêtes complexes. Ces intégrations permettent aux développeurs d’intégrer facilement de puissantes capacités d’interrogation en langage naturel dans leurs piles d’applications IA existantes, améliorant ainsi la facilité d’interaction avec les données (来源: bobvanluijt)

Lancement d’un serveur MCP collaboratif Claude Code et Gemini Pro pour améliorer l’efficacité du codage: BeehiveInnovations a lancé un serveur MCP permettant à Claude Code et Gemini 2.5 Pro de travailler en collaboration. Claude Code est responsable de la conception initiale et de la planification, tandis que Gemini complète avec son contexte d’un million de tokens et ses capacités de raisonnement profond. Ce serveur intègre des outils pour la réflexion étendue, la lecture de fichiers, la revue de code et le débogage, visant à améliorer la qualité et l’efficacité de la génération et de l’optimisation du code en combinant les forces des deux modèles. Les tests préliminaires montrent que, dans les tâches d’optimisation de la vitesse d’analyse JSON, l’utilisation combinée est plus efficace que l’utilisation de l’un ou l’autre modèle seul (来源: Reddit r/ClaudeAI)

📚 学习
Sakana AI publie le benchmark financier japonais EDINET-Bench pour évaluer les capacités des LLM dans les tâches financières: Sakana AI a lancé EDINET-Bench, un benchmark financier en japonais construit à partir des rapports annuels du système de divulgation électronique EDINET de l’Agence des services financiers du Japon. Ce benchmark vise à évaluer les performances des grands modèles de langage (LLM) dans des tâches financières complexes telles que la détection de fraude, afin de pallier la rareté des jeux de données de haute qualité et librement disponibles dans le domaine financier. EDINET-Bench génère des jeux de données multi-tâches par annotation automatique, fournissant une ressource importante pour la R&D en IA financière (来源: hardmaru,SakanaAILabs)

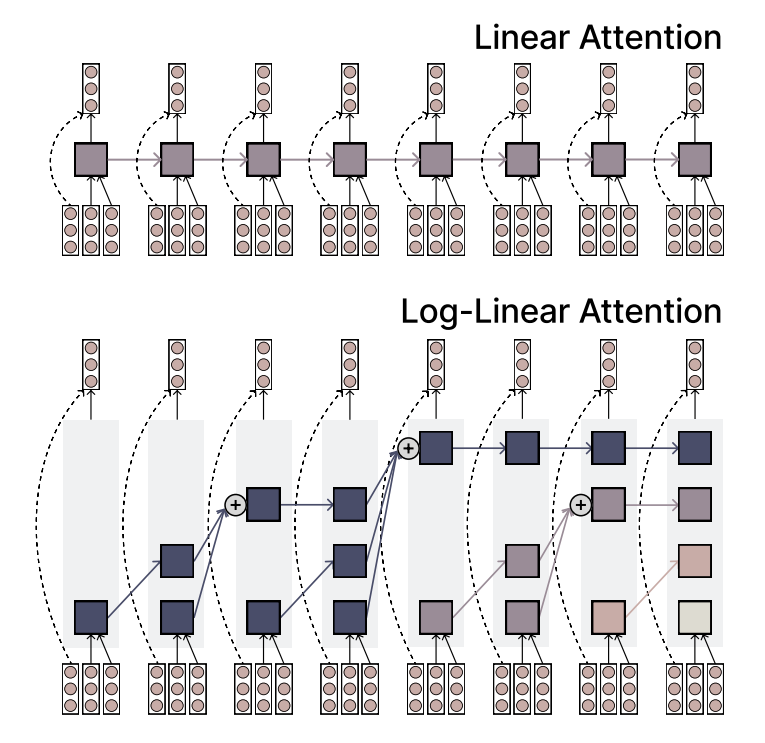
Le MIT propose le mécanisme d’attention Log-linear, alliant efficacité et expressivité: Des chercheurs du MIT ont proposé un nouveau mécanisme d’attention appelé Log-linear Attention. Ce mécanisme vise à combiner la vitesse et l’efficacité de l’attention linéaire avec la capacité d’expression de l’attention Softmax. Il y parvient en utilisant un petit nombre de créneaux mémoire qui augmentent de manière logarithmique avec la longueur de la séquence, offrant une nouvelle approche potentielle pour le traitement de longues séquences de données (来源: TheTuringPost)
Le cours d’évaluation des LLM de Hamel Husain et Shreya Rajpal reçoit des éloges: Des utilisateurs comme Ryan Lingo et Radek Osmulski ont partagé leurs expériences positives suite à leur participation au cours d’évaluation des applications LLM de Hamel Husain et Shreya Rajpal (maven.com/parlance-labs/evals). Le cours est considéré comme le contenu le plus approfondi et le plus pratique actuellement disponible sur les LLM, ses conférences et son livre exclusif étant cruciaux pour les développeurs construisant des applications d’IA, soulignant le rôle central de l’évaluation dans le développement des LLM (来源: HamelHusain,HamelHusain)
MORSE-500 : Un benchmark vidéo programmable pour tester la résistance du raisonnement multimodal: Face au problème que les benchmarks actuels de raisonnement multimodal reposent principalement sur des images statiques, négligeant la complexité temporelle et l’étendue des compétences de raisonnement, les chercheurs ont lancé MORSE-500. Il s’agit d’un benchmark contenant 500 clips vidéo entièrement scénarisés, couvrant six catégories de raisonnement : abstrait, physique, planification, spatial et temporel. Sa conception basée sur des scripts permet un contrôle fin de la complexité visuelle, de la densité des distracteurs et de la dynamique temporelle, et supporte la création arbitraire de nouvelles instances plus difficiles, visant à tester la résistance des modèles de nouvelle génération. Les expériences préliminaires montrent que les modèles SOTA, y compris Gemini 2.5 Pro et OpenAI o3, présentent des écarts de performance significatifs dans toutes les catégories (来源: HuggingFace Daily Papers)
EverGreenQA : Un jeu de données multilingue de classification de questions persistantes pour améliorer la fiabilité des systèmes de questions-réponses: Pour résoudre le problème des hallucinations des LLM dans les tâches de questions-réponses (QA) dû à la temporalité des questions (la réponse change-t-elle avec le temps), les chercheurs ont lancé EverGreenQA. Il s’agit du premier jeu de données QA multilingue avec des étiquettes de persistance, soutenant l’évaluation et l’entraînement. Grâce à ce jeu de données, les chercheurs ont évalué 12 LLM modernes, testant leur capacité à coder la temporalité des questions, et ont entraîné un classificateur multilingue léger, EG-E5. L’étude montre également les applications de la classification persistante pour améliorer l’estimation de la connaissance de soi, filtrer les jeux de données QA et interpréter le comportement de récupération de GPT-4o (来源: HuggingFace Daily Papers)
KVzip : Une méthode d’éviction du cache KV indépendante des requêtes, réduisant significativement l’empreinte mémoire et la latence de décodage: Le laboratoire ML de l’Université Nationale de Séoul a publié KVzip, une méthode de compression du cache KV conçue pour prendre en charge une diversité de requêtes futures. Cette méthode, grâce à une stratégie d’éviction indépendante des requêtes, permet une réduction de mémoire d’environ 3-4 fois et une diminution de la latence de décodage de 2 fois. Elle prend actuellement en charge des modèles tels que Qwen3/2.5, Gemma3 et LLaMA3, et fournit un code de démonstration sur GitHub (来源: Reddit r/LocalLLaMA)

NimbleEdge publie en open source des noyaux d’opérateurs Transformer creux, améliorant la vitesse d’exécution et l’efficacité mémoire des LLM: L’équipe de NimbleEdge, s’inspirant des recherches “LLM in a Flash” d’Apple et “Deja Vu” de Zichang et al., a construit des noyaux d’opérateurs fusionnés pour la sparsité contextuelle structurée. Ces noyaux, en évitant de charger et de calculer les poids et les activations des couches feed-forward dont la sortie serait finalement nulle, permettent une amélioration des performances de 5 fois pour les couches MLP dans les Transformers et une réduction de la consommation mémoire de 50%. Appliqués au modèle Llama 3.2 3B, le débit global est amélioré de 1,78 fois et l’utilisation de la mémoire réduite de 26,4%. Le code a été mis en open source sur GitHub et il est prévu de prendre en charge int8, CUDA et l’attention creuse (来源: Reddit r/MachineLearning)
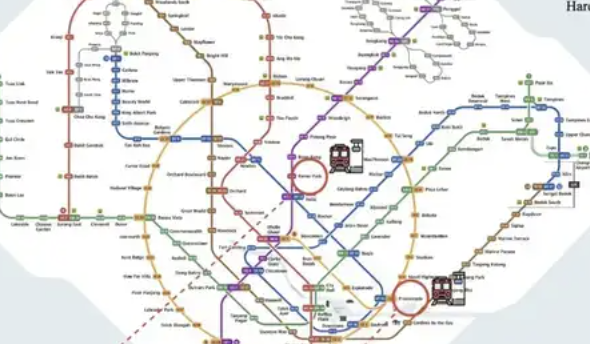
ReasonMap : Publication d’un benchmark d’évaluation du raisonnement multimodal sur des cartes de transport haute résolution: Une équipe de chercheurs de l’Université de Westlake et d’autres institutions a lancé ReasonMap, un benchmark d’évaluation du raisonnement multimodal axé sur les cartes de transport haute résolution (principalement des plans de métro). Ce benchmark vise à évaluer la capacité des grands modèles à comprendre les informations spatiales structurées à grain fin dans les images. Il comprend des images haute résolution (en moyenne 5839×5449), une conception sensible à la difficulté et un système d’évaluation multidimensionnel. Les résultats des tests montrent que les modèles open source actuels ont de mauvaises performances sur ReasonMap, en particulier dans la planification d’itinéraires inter-lignes, tandis que les modèles de raisonnement propriétaires (comme GPT-o3) surpassent considérablement les modèles open source, mais restent en deçà du niveau humain. Les plans de métro complexes comme ceux de Pékin et Hangzhou représentent des défis majeurs pour les modèles (来源: 量子位)
Yandex publie Yambda-5B : un jeu de données à grande échelle pour les systèmes de recommandation ouverts: Yandex a lancé Yambda-5B, un vaste jeu de données anonymisé de streaming musical contenant 4,79 milliards d’interactions utilisateur-élément. Ce jeu de données se caractérise par la fourniture d’un indicateur “is_organic” et d’une segmentation temporelle globale (GTS), ne contient pas d’historique d’écoute ni de “j’aime” directement identifiables par l’utilisateur, résiste à la désanonymisation et inclut des retours implicites (écoute de chansons, sauts) et explicites (aime/n’aime pas). Yambda-5B vise à fournir des ressources de données de haute qualité et multimodales pour la recherche sur les systèmes de recommandation (来源: TheTuringPost)
Tencent lance le camp de défi Xinghuo 2025, recrutant les meilleurs étudiants pour participer à des recherches de pointe sur les grands modèles et d’autres domaines: Tencent a annoncé le lancement de son “Camp de défi Xinghuo” annuel pour 2025, s’adressant aux élèves de terminale (promotion 2025 du baccalauréat) et à d’autres étudiants excellant dans les disciplines concernées, pour recruter 60 à 70 personnes. Les candidats sélectionnés auront l’opportunité de se rendre au siège de Shenzhen pour participer à des recherches sur six sujets de pointe : compréhension de textes ultra-longs, technologie de longues chaînes de pensée, intelligence incarnée + robotique, perception et compréhension multimodales, attaque et défense en matière de sécurité (y compris la conception de hackers d’agents LLM) et technologies quantiques. Ce programme vise à offrir aux jeunes talents l’opportunité d’entrer en contact avec des scénarios de recherche scientifique de niveau industriel, d’élargir leurs horizons technologiques et d’approfondir leur connaissance du secteur (来源: 量子位)

💼 商业
Meta envisagerait d’investir plus de 10 milliards de dollars dans Scale AI pour renforcer les applications d’IA, notamment dans le domaine militaire: Selon des informations, Meta serait en pourparlers avec la société d’annotation de données IA Scale AI pour un investissement majeur, dont le montant pourrait atteindre plusieurs milliards, voire dépasser les 10 milliards de dollars. Si cela se confirmait, il s’agirait de l’un des plus importants investissements externes de Meta dans l’IA. Scale AI a déjà développé, sur la base du Llama 3 de Meta, un modèle spécifiquement conçu pour des usages militaires, Defense Llama, destiné à soutenir les missions de sécurité nationale américaines. Cette démarche pourrait marquer une stratégie d’investissement et de collaboration plus active de Meta dans le domaine de l’IA, en particulier pour les applications liées au gouvernement et à la défense (来源: 36氪)

Mashang Consumer Finance lance la version 3.0 de son grand modèle “Tianjing”, le transformant en plateforme de décision financière: Mashang Consumer Finance a lancé la version 3.0 de son grand modèle financier “Tianjing”. La principale avancée de cette nouvelle version réside dans une transition systémique d’une intelligence individuelle à une intelligence collective, ne se reposant plus uniquement sur l’apprentissage logique, mais explorant en profondeur les expériences implicites disséminées dans l’entreprise, telles que les parcours des employés et les journaux d’activité, pour les transformer en connaissances structurées. Tianjing 3.0 vise à passer d’un outil à une plateforme de décision, favorisant la collaboration homme-machine, capable de décomposer dynamiquement des processus de service complexes et d’adapter en temps réel la combinaison de services optimale en fonction des demandes des utilisateurs et des exigences de conformité, réalisant ainsi une prise de décision passant d’un optimum local à un optimum global (来源: 量子位)

Together AI nomme Charles Zedlewski nouveau Chef de Produit, axé sur la plateforme d’IA générative open source: Together AI a annoncé la nomination de Charles Zedlewski en tant que nouveau Chef de Produit (CPO). Charles Zedlewski a précédemment dirigé les produits de plateformes communautaires destinées aux développeurs chez Temporal et Cloudera. Together AI souligne son engagement à construire l’avenir de l’IA générative open source, estimant que les modèles ouverts offrent des avantages en termes de flexibilité, de rentabilité et d’innovation. L’arrivée de Charles vise à renforcer la création par Together AI d’une plateforme d’IA open source de référence, rendant l’IA générative puissante accessible à chaque développeur et entreprise (来源: togethercompute)

🌟 社区
Des voitures autonomes Waymo incendiées à Los Angeles suscitent des inquiétudes et des débats au sein de la communauté sur la sécurité des véhicules autonomes: Récemment, plusieurs voitures autonomes Waymo ont été incendiées à Los Angeles. Cet événement a suscité une large attention et des discussions sur les réseaux sociaux, portant sur l’acceptation des voitures autonomes par le public, les préoccupations en matière de sécurité, ainsi que le risque que de tels événements soient indûment amplifiés ou déformés par des contenus générés par l’IA (comme des vidéos générées par Veo 3). Certains commentateurs ont comparé cette scène au film de science-fiction “Les Fils de l’homme”, soulignant le caractère dramatique de l’événement et son impact social potentiel (来源: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
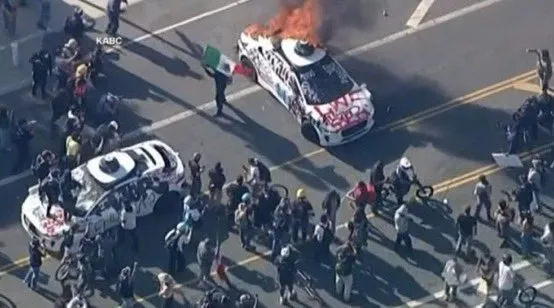
Reddit poursuit Anthropic, l’accusant d’avoir collecté sans autorisation du contenu pour entraîner Claude AI: Reddit a intenté une action en justice contre Anthropic, l’accusant d’avoir collecté des publications et des conversations de Reddit sans autorisation ni paiement pour entraîner son modèle d’IA Claude. Reddit estime que cette action viole ses conditions d’utilisation qui interdisent l’utilisation commerciale non autorisée du contenu, et affirme que la déclaration d’Anthropic selon laquelle elle aurait “cessé de collecter sur Reddit” est fausse. Le procès porte également sur des questions de confidentialité, car Anthropic, contrairement à d’autres sociétés ayant des accords de licence, ne dispose pas de mécanisme pour supprimer les publications que les utilisateurs ont supprimées. Reddit demande au tribunal d’interdire à Anthropic d’utiliser les données de Reddit et pourrait exiger le retrait de Claude (来源: Reddit r/ArtificialInteligence,Reddit r/artificial)
Débat à l’AI Engineer World’s Fair : Simon Willison passe en revue les six derniers mois de développement des LLM, soulignant la combinaison outils + raisonnement: Lors de l’AI Engineer World’s Fair à San Francisco, Simon Willison a passé en revue avec humour les six derniers mois de développement fulgurant des LLM, en utilisant un test de génération d’image SVG d’un “pélican à vélo”, et a personnellement testé plus de 30 modèles d’IA. Il a souligné que la combinaison d’IA la plus puissante actuellement est “outils + raisonnement”, comme les performances de o3/o4-mini en recherche, et l’attention portée à l’architecture MCP en raison de l’appel d’outils. Sa présentation a également recensé les “bugs bizarres” de l’IA de l’année, tels que la flatterie excessive de ChatGPT, le comportement de Claude qui pourrait “dénoncer” les utilisateurs, etc., et a souligné les risques d’injection de prompt et de fuite de données (来源: 36氪,swyx)

Discussion communautaire sur l’anxiété professionnelle induite par l’IA et les stratégies d’adaptation: Un post sur Reddit intitulé “Comment gérer l’anxiété liée à l’IA” a suscité un vif débat. Les utilisateurs s’inquiètent généralement que l’IA puisse entraîner des pertes d’emploi massives dans les années à venir, constituant une menace sérieuse en particulier pour les personnes ayant peu d’économies et beaucoup de dettes. Dans la discussion, certains suggèrent de se réorienter vers des métiers manuels, les soins, etc., mais craignent également que ces secteurs ne deviennent saturés en raison de l’afflux de nombreux reconvertis. Les commentateurs partagent leurs propres angoisses, telles que l’insomnie, la difficulté à se concentrer au travail, etc. Certains estiment qu’il faut apprendre activement l’IA, rester adaptable, et soulignent que les innovations technologiques passées (comme l’automobile, Internet) ont également suscité des craintes similaires, mais ont finalement créé de nouvelles opportunités d’emploi. D’autres commentateurs pensent que le degré de remplacement du travail humain par l’IA est actuellement exagéré et que des licenciements massifs à court terme sont peu probables (来源: Reddit r/ArtificialInteligence)
Un utilisateur partage son expérience d’auto-analyse psychologique “brutale” avec ChatGPT: Un utilisateur de Reddit a partagé son expérience d’auto-analyse psychologique “à la manière d’un cadre dirigeant brutal” en utilisant ChatGPT. Grâce à des prompts spécifiques, il a demandé à ChatGPT une analyse sévère sous cinq angles : véritables forces, faiblesses profondes, schémas d’échec récurrents, domaines d’évitement et compétences négligées, et de lui fournir un plan de développement en trois étapes. L’utilisateur a déclaré que, bien que le processus ait été douloureux (par exemple, se voir reprocher d’avoir lancé 12 projets sans en terminer aucun, et de trop rechercher la productivité au lieu d’agir concrètement), ce retour “brutal” l’a finalement poussé à changer. Ce post a suscité une discussion au sein de la communauté sur les applications de l’IA dans l’introspection et le développement personnel (来源: Reddit r/ArtificialInteligence)
Discussion sur les capacités de mémoire et de raisonnement des LLM : connaissance encyclopédique ou véritable compréhension ?: Sur les réseaux sociaux, les utilisateurs discutent des excellentes performances des grands modèles de langage (LLM) dans les tâches de rappel de faits mémorisés, et se demandent si cela signifie qu’ils possèdent réellement des capacités de raisonnement. Certains estiment que les performances exceptionnelles des LLM dans des tâches apparemment complexes pourraient davantage reposer sur d’énormes quantités de données d’entraînement et la reconnaissance de formes, plutôt que sur une compréhension profonde et une créativité au sens humain du terme. Des recherches menées par des entreprises comme Meta montrent qu’il est possible d’estimer la capacité d’un modèle en mesurant la mémoire, et que la généralisation ne commence qu’une fois cette capacité remplie. Cette discussion est également liée à l’accent mis sur la mémorisation par cœur dans les systèmes éducatifs, et au manque de développement des compétences en recherche d’informations et en utilisation des outils d’IA (来源: omarsar0,menhguin,menhguin)

💡 其他
Analyse de cas de succès du modèle de base de détection de fraude aux paiements de Stripe: Un post d’ingénieurs de Stripe partageant la construction réussie d’un modèle de base pour la détection de fraude aux paiements a attiré l’attention. L’analyse souligne la particularité de ce cas : 1) La détection de fraude n’est pas intrinsèquement une prédiction de l’avenir ; théoriquement, avec des signaux suffisants, une grande précision peut être atteinte. 2) Stripe se trouvait déjà dans un environnement riche en signaux, sans avoir besoin d’accumuler des données à partir de zéro. 3) Ce scénario est une mise à niveau de l’automatisation, passant de l’apprentissage automatique traditionnel à un modèle de base, proche d’un remplacement direct. Cela explique pourquoi de telles “victoires instantanées” des applications d’IA sont relativement rares, la plupart des réalisations de valeur commerciale de l’IA devant surmonter de nombreux obstacles (来源: random_walker)
Fondations cognitives de la transformation IA : des mécanismes systématiques de perception de l’information et de veille technologique sont essentiels: Dans leur transformation IA, les entreprises doivent établir des mécanismes systématiques et structurés de perception de l’information et de veille technologique, allant au-delà de l’expérience individuelle et de la dépendance aux parcours traditionnels. Cela inclut la construction de capacités d’analyse de données internes et de réseaux de connaissances externes (monde universitaire, industrie, marchés financiers, start-ups). L’évaluation du retour sur investissement de l’IA doit également passer d’un ROI traditionnel à un système “multi-périodes, multi-dimensions”, couplé aux réseaux de connaissances externes, formant une boucle stratégique fermée de validation continue et d’ajustement dynamique. L’article souligne que l’IA n’est pas un outil ponctuel, mais un actif stratégique en constante évolution et à valeur ajoutée continue (来源: 36氪)
Frigate : Système NVR basé sur la détection d’objets locale en temps réel: Frigate est un système d’enregistreur vidéo en réseau (NVR) local conçu spécialement pour Home Assistant, utilisant OpenCV et Tensorflow pour la détection d’objets locale en temps réel sur les caméras IP. Ce système met l’accent sur l’optimisation des ressources et les performances, en déclenchant la détection d’objets par une détection de mouvement à faible coût, et en utilisant le traitement multiprocessus. L’utilisation d’accélérateurs IA tels que Google Coral ou Hailo est recommandée pour des performances optimales. Frigate prend en charge l’enregistrement 24/7, la conservation des enregistrements basée sur la détection d’objets, l’intégration MQTT, la retransmission RTSP et la visualisation en temps réel à faible latence via WebRTC/MSE (来源: GitHub Trending)
