
키워드:대형 언어 모델, 추론 능력, AI 보안, 멀티모달 모델, 오픈소스 모델, AI 비디오 생성, AI 평가, AI 상업적 응용, 애플 LLM 추론 능력 연구, Time-R1 시간 이해 모델, NVIDIA Blackwell GPU 비디오 생성, 알리통의천문 3 오픈소스 모델, Hugging Face MCP 서버
🔥 주요 뉴스
Apple, 현재 대형 언어 모델이 진정한 추론 능력이 아닌 “생각하는 척”만 할 뿐이라는 논문 발표, 업계 논란 촉발: Apple 연구원(Google Brain 창립자 중 한 명인 Samy Bengio 포함)은 논문을 발표하여, 하노이의 탑, 체커 교환 등 4가지 난이도 조절 가능 작업 테스트를 통해 DeepSeek, o3-mini, Claude 3.7 등 최고 수준 모델들이 고복잡도 문제에 직면했을 때 모두 “붕괴”하며, “추론 노력 역스케일링”(문제가 어려울수록 오히려 생각을 덜 하는 현상)을 보인다고 지적했습니다. 논문은 이러한 모델들이 진정하고 일반화 가능한 논리적 추론보다는 패턴 매칭과 기억에 더 많이 의존하며, 완전한 알고리즘을 제공하더라도 복잡도 병목 현상을 돌파할 수 없다고 주장했습니다. 이러한 관점은 현재 LLM의 추론 능력에 대한 보편적인 인식에 도전하며, LLM 평가 방법, 실제 추론 능력의 한계, 그리고 미래 발전 방향에 대한 광범위한 논의를 촉발했습니다. 커뮤니티의 반응은 엇갈렸습니다. 일부는 이를 Apple의 AI 개발 지연에 대한 변명으로 보았고, 다른 일부는 평가 메커니즘과 모델의 내재적 한계에 대한 통찰력을 인정했습니다 (출처: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

튜링상 수상자 Yoshua Bengio, AI 통제 불능 위험 경고하며 연구 방향 “과학자 AI”로 조정: Yoshua Bengio는 지원(智源) 컨퍼런스에서 AI(특히 AGI)의 빠른 발전과 잠재적인 통제 불능 위험(예: AI가 “생존”을 위해 자체 코드를 복제하거나 행동을 숨기는 것)을 고려하여 연구 방향을 조정했으며, 지능만 있고 자아의식과 목표가 없는 “과학자 AI” 구축에 전념하고 있다고 밝혔습니다. 그는 AI의 계획 능력이 5년 내에 인간 수준에 도달할 수 있으며, 현재 AI 훈련 방법이 오류 발생 시에도 과도한 자신감을 보이도록 유도할 수 있다고 지적했습니다. Bengio는 AI가 도덕적 지침을 준수하고 악의적인 목적으로 사용되는 것을 방지해야 한다고 강조하며, AI 안전 문제에 대응하고 “정렬(alignment)”과 “제어 가능성(controllability)” 문제를 해결하기 위한 글로벌 협력을 촉구했습니다 (출처: 量子位)

영국 정부, Google Gemini 모델 기반 Extract 시스템 도입으로 계획 결정 가속화: 영국 정부는 “Extract”라는 시스템을 이용하여 지방 의회 계획 담당자들이 더 빠르게 의사 결정을 내릴 수 있도록 지원하고 있습니다. 이 시스템은 Google의 Gemini 기반 모델을 활용하며, 다중 모드 추론 능력을 통해 손글씨 메모와 흐릿한 지도를 포함한 복잡한 계획 문서를 40초 이내에 디지털 데이터로 변환할 수 있습니다. 이 응용 프로그램은 복잡한 문서의 자동 처리 및 이해를 통해 행정 효율성과 의사 결정 품질을 향상시키는 정부 공공 서비스 분야에서 AI의 잠재력을 보여줍니다 (출처: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia, NVIDIA Blackwell GPU를 사용하여 대형 비디오 모델 EXPRESS-2 훈련에 최초로 채택: AI 비디오 생성 회사 Synthesia는 Google Cloud에서 NVIDIA Blackwell GPU를 사용하여 대형 비디오 모델을 훈련하는 세계 최초의 회사가 되었다고 발표했습니다. 새로운 모델 EXPRESS-2는 더 강력한 하드웨어와 최적화된 멀티 클라우드 설정을 통해 고객이 더 빠르고 고품질의 AI 생성 비디오 및 가상 아바타를 만들 수 있도록 지원하는 것을 목표로 합니다. 이는 AI 비디오 생성 기술이 기본 하드웨어 지원 및 모델 기능 면에서 중요한 진전을 이루었음을 의미하며, 향후 AI 비디오 콘텐츠 제작의 효율성과 품질이 더욱 향상될 것을 예고합니다 (출처: synthesiaIO,Synthesia Blog)
Epoch AI 연구, o3-mini-high 모델이 단순 암기가 아닌 “직관”에 의존하여 최고 수준 수학 난제 해결한다고 밝혀: Epoch AI는 14명의 수학자를 초청하여 FrontierMath 벤치마크에서 o3-mini-high의 29개 추론 과정을 평가한 결과, 해당 모델이 13개의 난제를 정확하게 해결했음을 발견했습니다. 연구에 따르면 o3-mini-high는 해박한 수학 지식을 보유하고 관련 정리를 호출할 수 있지만, 추론 스타일은 엄격한 형식화된 증명과 창의성이 부족한 “직관 기반 귀납”에 더 치우쳐 있으며, 때로는 증명 단계를 “요행으로” 건너뛰기도 합니다. 환각 및 공식의 정확한 재현 불가능 등의 문제가 존재함에도 불구하고, 일부 문제에서는 인간 수학자의 사고 과정과 유사한 성능을 보였습니다. 이 연구는 현재 대형 모델이 복잡한 수학적 추론에서 보이는 능력의 특징과 한계를 심층적으로 분석했습니다 (출처: 量子位)

🎯 동향
알리바바 통이치엔원(通义千问)3 오픈소스 모델 다운로드 1250만 건 돌파, 파생 모델 13만 개 이상으로 세계 1위: 알리바바 통이치엔원3 시리즈 대형 모델이 오픈소스 공개 한 달 만에 전 세계 누적 다운로드 1250만 건을 돌파하며 최근 가장 인기 있는 오픈소스 모델이 되었습니다. 0.6B부터 32B까지 4가지 크기의 모델은 Hugging Face, 모다(魔搭) 커뮤니티 등 플랫폼에서 모두 다운로드 100만 건을 넘었으며, 파생 모델 수는 13만 개를 넘어 세계 1위를 차지했습니다. 통이치엔원3는 다수의 국내외 성능 순위에서 오픈소스 모델 챔피언을 차지했으며, 낮은 추론 비용(DeepSeek R1의 약 3분의 1)으로 NVIDIA, Intel, ARM 등 다수의 칩 제조업체 및 컴퓨팅 파워 플랫폼의 채택과 연동을 이끌어냈습니다 (출처: 量子位)

일리노이 대학교, Time-R1 모델 발표, 3B 파라미터로 시간 이해, 예측 및 생성 구현: 일리노이 대학교 어바나-샴페인 연구진은 3B 파라미터 언어 모델인 Time-R1을 출시했습니다. 이 모델은 3단계 강화 학습과 동적 보상 메커니즘을 통해 시간 개념에 대한 이해, 미래 사건 예측 및 창의적인 시나리오 생성 능력을 향상시켰습니다. 이 모델은 시간 추론 작업에서 우수한 성능을 보였으며, DeepSeek-V3-0324와 같이 파라미터 수가 훨씬 큰 모델을 능가하기도 했습니다. 연구팀은 Time-Bench(10년간의 뉴욕 타임스 뉴스를 기반으로 한 대규모 다중 작업 시간 추론 데이터셋)와 Time-R1의 훈련 코드 및 모델 체크포인트를 오픈소스로 공개했습니다 (출처: 量子位)

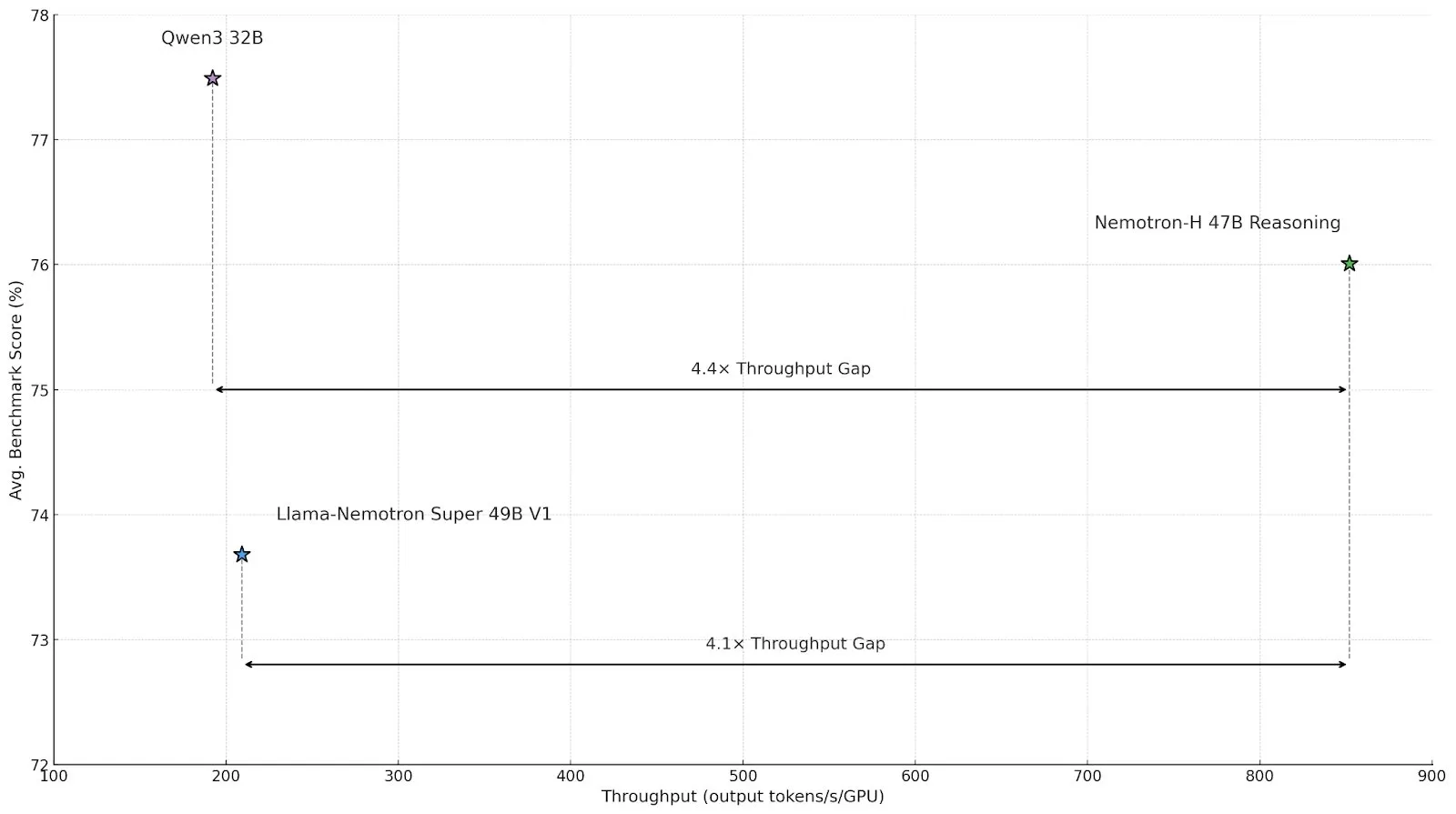
NVIDIA, Nemotron-H 시리즈 추론 모델 출시, 혼합 Mamba-Transformer 아키텍처로 효율성 향상: NVIDIA는 혼합 SSM-Transformer (Mamba-Transformer) 아키텍처 기반의 Nemotron-H 8B 및 47B 추론 모델을 출시했습니다. 이 모델들은 높은 정확도를 유지하면서도 동급 Transformer 모델 대비 최대 4배의 추론 처리량을 달성할 수 있습니다. Nemotron-H-47B-Reasoning-128k는 다양한 벤치마크 테스트에서 Llama-Nemotron-Super-49B-1.0보다 우수한 성능을 보였으며, 추론 비용은 최대 4배 절감되었습니다. 모델 가중치는 비생산 라이선스로 HuggingFace에 공개되어 효율적인 대규모 추론 연구를 촉진하는 것을 목표로 합니다 (출처: tri_dao,NVIDIA AI Developer)
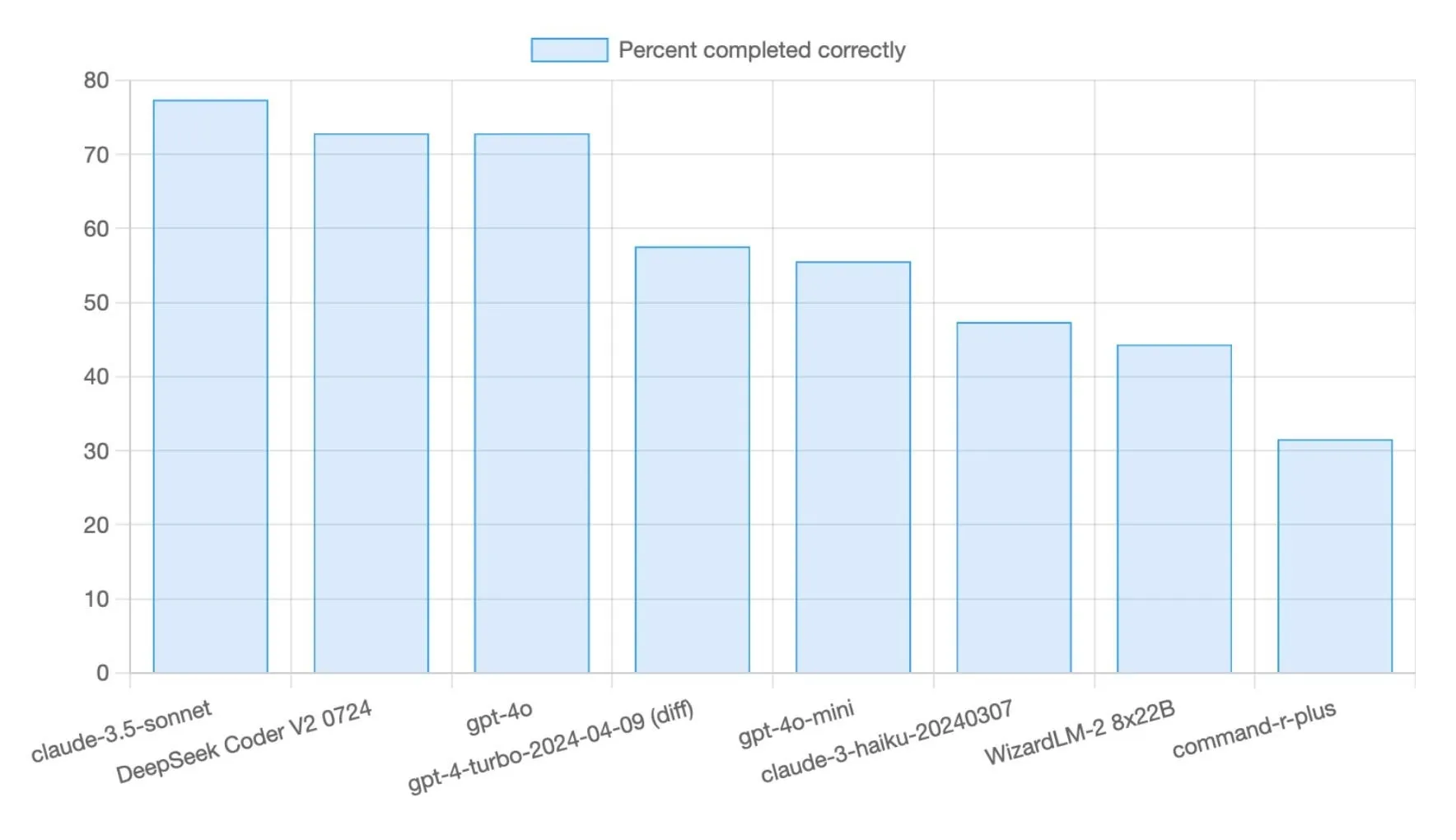
DeepSeek R1 0528 모델, Aider Polyglot 프로그래밍 벤치마크 테스트에서 71% 점수 획득: DeepSeek R1 0528 모델은 Aider Polyglot 프로그래밍 벤치마크 테스트에서 71%의 점수를 획득하여 이전 버전에 비해 현저한 향상(+14.5%p)을 보였습니다. 이 모델은 높은 가성비로 주목받고 있으며, 약 70%의 벤치마크 테스트를 완료하는 데 드는 비용이 5달러 미만으로 코드 생성 작업에서 강력한 경쟁력을 보여주었습니다 (출처: Reddit r/LocalLLaMA,scaling01)
VACE 프레임워크 출시: 비디오 제작과 편집을 하나로 통합한 다기능 모델: 알리바바 통이 연구소(通义实验室)는 참조 비디오 생성(R2V), 비디오-투-비디오 편집(V2V), 마스크 비디오 편집(MV2V) 등 다양한 기능을 통합한 단일 모델인 VACE (Video Creation and Editing)를 출시했습니다. VACE는 사용자가 이러한 작업을 자유롭게 조합하여 객체 이동, 교체, 스타일 참조, 확장, 애니메이션화 등 다양한 비디오 처리를 할 수 있도록 지원합니다. 현재 VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B, Wan2.1-VACE-14B 등 여러 모델 버전이 출시되었으며 HuggingFace와 ModelScope에서 다운로드할 수 있습니다 (출처: GitHub Trending)

홍콩과기대와 바이트댄스, 시각 생성 작업 통합하는 ComfyMind 프레임워크 공동 출시: 홍콩과학기술대학교(광저우)와 바이트댄스는 텍스트-이미지, 이미지-비디오 등 다양한 주요 시각 생성 작업을 하나의 시스템으로 처리하는 것을 목표로 하는 오픈소스 시각 생성 프레임워크 ComfyMind를 공동으로 출시했습니다. ComfyMind는 “원자 워크플로우”를 최소 단위로 채택하고, 트리형 계획 및 로컬 피드백 실행 메커니즘을 결합하여 ComfyUI를 기본 실행 엔진으로 사용하며, 계획, 실행, 평가의 세 가지 에이전트 협업을 통해 복잡한 작업을 완료합니다. ComfyBench, GenEval, Reason-Edit 등 벤치마크 테스트에서 ComfyMind는 우수한 성능을 보였으며, GPT-4o-Image에 필적하는 성능을 나타냈습니다 (출처: 量子位)

Hugging Face, 모델 컨텍스트 프로토콜(MCP) 서버 출시로 AI 에이전트 능력 강화: Hugging Face는 AI 에이전트가 검색 모델, 데이터셋 분석, HuggingFace Spaces와의 상호 작용을 포함하여 외부 도구 및 실시간 데이터에 표준화되고 안전한 방식으로 액세스할 수 있도록 하는 모델 컨텍스트 프로토콜(MCP) 서버를 제공합니다. 이 조치는 AI 에이전트를 정적 도구에서 동적 협력자로 전환하여 복잡한 작업을 처리하고 최신 정보를 얻는 능력을 향상시키는 것을 목표로 합니다. 다수의 커뮤니티 구성원이 이미 MCP 서버를 Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic과 같은 다양한 AI 프레임워크와 통합하는 방안을 모색하기 시작했습니다 (출처: ClementDelangue,huggingface,awnihannun)

연구 제안 STARFlow: 고해상도 이미지 합성을 위한 확장 가능한 잠재 정규화 흐름 모델: STARFlow는 정규화 흐름에 기반한 확장 가능한 생성 모델로, 핵심은 Transformer 자기 회귀 흐름(TARFlow)입니다. 심층-얕은층 설계, 사전 훈련된 자동 인코더의 잠재 공간에서의 모델링, 그리고 새로운 유도 알고리즘을 통해 STARFlow는 클래스 조건 및 텍스트 조건 이미지 생성 작업에서 최첨단 확산 모델에 근접하는 경쟁력 있는 성능을 달성했습니다. 이 연구는 이러한 규모와 해상도에서 정규화 흐름의 효과적인 작동을 최초로 성공적으로 보여주었습니다 (출처: HuggingFace Daily Papers)
새로운 연구 HASHIRU: 혼합 지능 자원 활용을 위한 계층적 에이전트 시스템: HASHIRU는 “CEO” 에이전트가 전문화된 “직원” 에이전트를 동적으로 관리하고 작업 요구 사항 및 자원 제약(비용, 메모리)에 따라 인스턴스화하는 것이 특징인 새로운 다중 에이전트 시스템(MAS) 프레임워크입니다. 이 시스템은 소규모 로컬 LLM(Ollama를 통해) 사용을 우선시하면서 외부 API 및 대형 모델을 유연하게 사용하며, 자율적인 API 도구 생성 및 기억 기능을 포함합니다. 학술 논문 검토, 보안 평가 및 복잡한 추론과 같은 작업에 대한 평가는 그 능력을 보여주었습니다 (출처: HuggingFace Daily Papers)
PartCrafter: 잠재 확산 Transformer 조합을 통한 구조화된 3D 메쉬 생성: PartCrafter는 단일 RGB 이미지로부터 의미론적으로 의미 있고 기하학적으로 구별되는 여러 3D 메쉬를 공동으로 합성할 수 있는 최초의 구조화된 3D 생성 모델입니다. 사전 분할된 입력에 의존하지 않는 통합된 조합 생성 아키텍처를 채택하여 단일 객체 및 복잡한 다중 객체 장면을 생성하기 위해 부품을 종단 간으로 인식할 수 있습니다. 핵심 혁신에는 조합 잠재 공간과 계층적 주의 메커니즘이 포함됩니다 (출처: HuggingFace Daily Papers)
Prefix Grouper: 공유 접두사 순방향 전파를 통한 효율적인 GRPO 훈련: Group Relative Policy Optimization (GRPO)은 공통 입력 접두사를 공유하는 후보 출력 간의 상대적 차이를 비교하여 정책 학습을 강화합니다. Prefix Grouper는 공유 접두사 순방향 정책을 통해 중복 접두사 계산을 제거하여 GRPO의 훈련 효율성을 향상시키며, 특히 긴 접두사 시나리오에서 표준 GRPO와의 훈련 등가성을 유지합니다 (출처: HuggingFace Daily Papers)
GuideX: 제로샷 정보 추출을 위한 유도 합성 데이터 생성: 전통적인 정보 추출(IE) 시스템은 일반적으로 특정 도메인에 국한되어 적응 비용이 높습니다. GuideX는 도메인 특정 스키마를 자동으로 정의하고, 가이드라인을 추론하며, 레이블이 지정된 합성 인스턴스를 생성하여 더 나은 도메인 외부 일반화를 가능하게 하는 새로운 방법입니다. GuideX를 사용하여 Llama 3.1을 미세 조정하면 7개의 제로샷 명명된 엔티티 인식 벤치마크에서 새로운 SOTA를 달성하여 복잡한 도메인 특정 주석 스키마에 대한 모델의 이해도를 크게 향상시켰습니다 (출처: HuggingFace Daily Papers)
CodeContests+: 프로그래밍 경진대회를 위한 고품질 테스트 케이스 생성: 프로그래밍 경진대회에서 테스트 케이스를 얻기 어려운 문제를 해결하기 위해 연구자들은 고품질 테스트 케이스를 생성하기 위한 LLM 기반 에이전트 시스템을 제안했습니다. 이 시스템은 CodeContests 데이터셋에 적용되었으며 개선된 버전인 CodeContests+를 제안했습니다. 평가는 CodeContests+가 원본에 비해 평가 정확도, 특히 참 양성률(TPR) 측면에서 현저히 우수하며 LLM 강화 학습에 상당한 이점이 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
Sentinel: 프롬프트 주입 공격 방지를 위한 SOTA 모델: 대형 언어 모델(LLM)이 프롬프트 주입 공격에 취약한 문제에 대응하기 위해 연구자들은 ModernBERT-large 아키텍처 기반의 Sentinel 모델(qualifire/prompt-injection-sentinel)을 출시했습니다. 다양한 공격 유형과 양성 명령어를 포함하는 광범위한 데이터셋에서 미세 조정을 통해 Sentinel은 내부 미공개 테스트셋에서 평균 정확도 0.987, F1 점수 0.980을 달성했으며 공용 벤치마크에서 강력한 기준 모델보다 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문 토론: 모달리티 확장이 전체 모달리티 구현의 올바른 경로인가?: 전체 모달리티 언어 모델(OLM)은 강력한 언어 능력을 유지하면서 다양한 입력 모달리티를 통합하고 추론하는 것을 목표로 합니다. 이 연구는 다중 모달 모델 훈련의 주류 기술인 모달리티 확장(즉, 사전 훈련된 언어 모델 미세 조정)의 효과를 탐구합니다. 연구는 세 가지 핵심 질문에 초점을 맞춥니다: 모달리티 확장이 핵심 언어 능력을 손상시키는가? 모델 병합이 독립적으로 미세 조정된 특정 모달리티 모델을 효과적으로 통합하여 전체 모달리티를 달성할 수 있는가? 전체 모달리티 확장이 순차적 확장보다 더 나은 지식 공유와 일반화를 가져오는가? (출처: HuggingFace Daily Papers)
논문 제안 Truth in the Few: 효율적인 다중 모드 추론을 위한 고가치 데이터 선택 방법: 이 연구는 다중 모드 LLM(MLLM)이 복잡한 추론 작업에서 대량의 훈련 데이터가 필요하다는 일반적인 견해에 도전합니다. 관찰을 통해 “인지 샘플”이라고 불리는 훈련 데이터의 작은 부분만이 다중 모드 추론을 효과적으로 유발한다는 사실을 발견했습니다. 이를 바탕으로 논문은 인과적 차이 추정기(CDE)와 주의 신뢰도 추정기(ACE)를 통해 이러한 인지 샘플을 식별하고, 난이도 인식 대체 모듈(DRM)로 간단한 인스턴스를 대체하는 Reasoning Activation Potential (RAP) 데이터 선택 패러다임을 제안합니다. 실험 결과, RAP는 훈련 데이터의 9.3%만으로도 더 우수한 성능을 얻을 수 있었으며 계산 비용을 43% 이상 절감했습니다 (출처: HuggingFace Daily Papers)
🧰 도구
Task Master: AI 기반 작업 관리 시스템, Cursor 등 편집기에 통합: Task Master는 AI 보조 개발을 위해 특별히 설계된 작업 관리 시스템으로, Cursor AI, Lovable, Windsurf, Roo 등 편집기와 원활하게 통합됩니다. Claude 등 대형 모델의 API(Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama 지원)를 활용하여 개발자가 요구 사항 문서(PRD)를 분석하고, 작업 목록을 생성하며, 개발 단계를 계획하고, 구체적인 작업 구현을 지원합니다. 이 시스템은 MCP(모델 제어 프로토콜)를 통해 편집기에서 직접 실행되며, 명령줄 작업을 지원하고 자세한 구성 가이드와 사용 튜토리얼을 제공합니다 (출처: GitHub Trending)
Observer AI: 로컬 오픈소스 화면 관찰 지능 에이전트, Ollama 통합: Observer AI는 사용자가 Ollama를 통해 로컬 LLM을 실행하여 화면을 관찰하고 작업을 수행할 수 있도록 하는 오픈소스 프로젝트입니다. 사용자는 이 도구를 통해 AI가 화면 내용을 이해하고 상호 작용하도록 할 수 있으며, 예를 들어 외국어 웹사이트를 탐색할 수 있습니다. 프로젝트는 GitHub 소스 코드와 로컬 설정이 필요 없는 웹 애플리케이션 버전을 제공하여 사용자가 개인 정보 보호를 전제로 LLM을 활용하여 화면 자동화 작업을 수행할 수 있도록 지원합니다 (출처: Reddit r/LocalLLaMA)

Weaviate Query Agent, 7대 AI 프레임워크와 통합하여 자연어 데이터 쿼리 간소화: Weaviate는 자사의 Query Agent와 7가지 주요 AI 프레임워크(Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic)의 통합 방법을 발표했습니다. Query Agent는 사전 구축된 지능형 에이전트 서비스로, 복잡한 쿼리 문을 작성할 필요 없이 Weaviate 내의 데이터를 기반으로 자연어 쿼리에 답변할 수 있습니다. 이러한 통합을 통해 개발자는 강력한 자연어 쿼리 기능을 기존 AI 애플리케이션 스택에 쉽게 내장하여 데이터 상호 작용의 편의성을 향상시킬 수 있습니다 (출처: bobvanluijt)

Claude Code와 Gemini Pro 협업 MCP 서버 출시, 코딩 효율성 향상: BeehiveInnovations는 Claude Code와 Gemini 2.5 Pro가 협력하여 작업할 수 있도록 하는 MCP 서버를 출시했습니다. Claude Code는 초기 구상과 계획을 담당하고, Gemini는 백만 토큰 컨텍스트와 심층 추론 능력을 활용하여 보완합니다. 이 서버는 확장된 사고, 파일 읽기, 코드 검토 및 디버깅과 같은 도구를 통합하여 두 모델의 장점을 결합함으로써 코드 생성 및 최적화의 품질과 효율성을 향상시키는 것을 목표로 합니다. 초기 테스트 결과, JSON 구문 분석 속도 최적화 작업에서 두 모델을 함께 사용하는 것이 단독으로 사용하는 것보다 더 나은 효과를 보였습니다 (출처: Reddit r/ClaudeAI)

📚 학습
Sakana AI, 일본 금융 벤치마크 EDINET-Bench 발표, LLM 금융 업무 능력 평가: Sakana AI는 일본 금융청 전자공시시스템 EDINET의 연차보고서를 활용하여 구축한 일본어 금융 벤치마크 테스트 EDINET-Bench를 출시했습니다. 이 벤치마크는 금융 분야에서 고품질의 무료 사용 가능한 데이터셋이 부족한 문제에 대응하기 위해 사기 탐지 등 복잡한 금융 업무에서 대형 언어 모델(LLM)의 성능을 평가하는 것을 목표로 합니다. EDINET-Bench는 자동 레이블링을 통해 다중 작업 데이터셋을 생성하여 금융 AI 연구 개발에 중요한 자원을 제공합니다 (출처: hardmaru,SakanaAILabs)

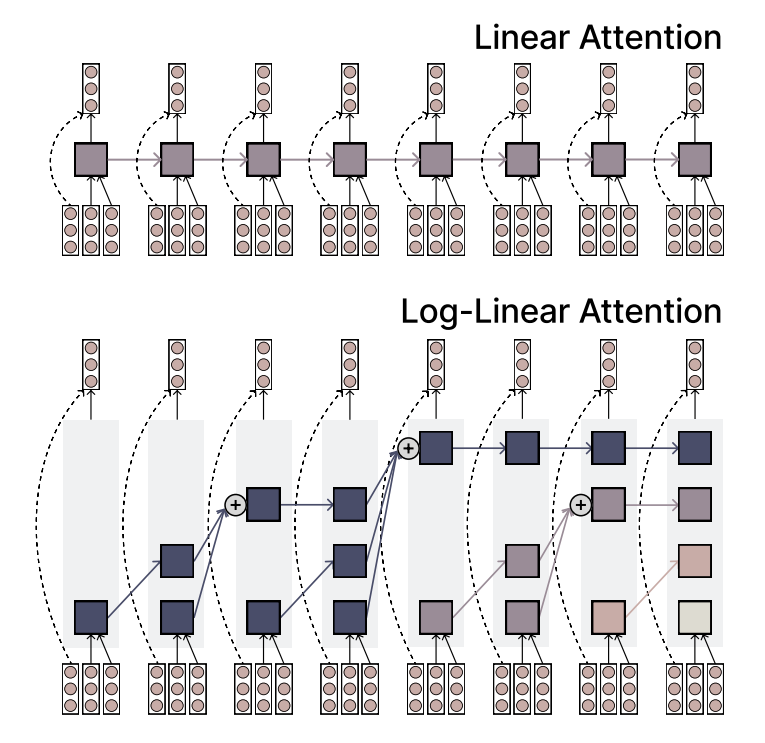
MIT, 효율성과 표현력을 겸비한 Log-linear Attention 메커니즘 제안: MIT 연구진은 Log-linear Attention이라는 새로운 어텐션 메커니즘을 제안했습니다. 이 메커니즘은 선형 어텐션의 속도와 효율성, 그리고 Softmax 어텐션의 표현력을 결합하는 것을 목표로 합니다. 이는 시퀀스 길이에 따라 로그적으로 증가하는 소량의 메모리 슬롯을 사용하여 이를 달성하며, 긴 시퀀스 데이터 처리를 위한 잠재력 있는 새로운 방법을 제공합니다 (출처: TheTuringPost)
Hamel Husain과 Shreya Rajpal의 LLM 평가 과정 호평: Ryan Lingo와 Radek Osmulski 등 사용자들이 Hamel Husain과 Shreya Rajpal의 LLM 애플리케이션 평가 과정(maven.com/parlance-labs/evals) 참여 경험을 긍정적으로 공유했습니다. 이 과정은 현재 LLM에 관한 가장 심도 있고 실용적인 내용으로 평가받고 있으며, 강의와 독점 서적은 AI 애플리케이션을 구축하는 개발자에게 매우 중요하며 LLM 개발에서 평가의 핵심적인 역할을 강조합니다 (출처: HamelHusain,HamelHusain)
MORSE-500: 다중 모드 추론 스트레스 테스트를 위한 프로그래밍 가능한 비디오 벤치마크 테스트: 현재 다중 모드 추론 벤치마크가 주로 정적 이미지에 의존하고 시간적 복잡성과 추론 기술의 광범위성을 간과하는 문제에 대응하여 연구자들은 MORSE-500을 출시했습니다. 이는 추상, 물리, 계획, 공간 및 시간 등 6가지 추론 범주를 포괄하는 500개의 완전히 스크립트화된 비디오 클립을 포함하는 벤치마크입니다. 스크립트 기반 설계는 시각적 복잡성, 방해 요소 밀도 및 시간적 역학에 대한 세분화된 제어를 허용하며, 차세대 모델에 대한 스트레스 테스트를 목표로 더욱 도전적인 새로운 인스턴스를 임의로 생성할 수 있도록 지원합니다. 초기 실험 결과, Gemini 2.5 Pro 및 OpenAI o3를 포함한 SOTA 모델은 모든 범주에서 상당한 성능 격차를 보였습니다 (출처: HuggingFace Daily Papers)
EverGreenQA: 다국어 상록 질문 분류 데이터셋, 질의응답 신뢰도 향상: LLM이 질의응답(QA) 작업에서 질문의 시효성(답변이 시간에 따라 변하는지 여부)으로 인해 환각을 일으키는 문제를 해결하기 위해 연구자들은 EverGreenQA를 출시했습니다. 이는 상록 레이블이 있는 최초의 다국어 QA 데이터셋으로, 평가와 훈련을 지원합니다. 이 데이터셋을 통해 연구자들은 12개의 최신 LLM을 벤치마킹하여 질문 시효성에 대한 인코딩 능력을 평가하고, 경량 다국어 분류기 EG-E5를 훈련했습니다. 이 연구는 또한 상록 분류가 자체 지식 추정 개선, QA 데이터셋 필터링 및 GPT-4o 검색 행동 설명 등에 적용될 수 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
KVzip: 쿼리 독립적인 KV 캐시 제거 방법, 메모리 점유율 및 디코딩 지연 시간 현저히 감소: 서울대학교 ML 연구실은 다양한 미래 쿼리를 지원하기 위한 KV 캐시 압축 방법인 KVzip을 발표했습니다. 이 방법은 쿼리 독립적인 제거 정책을 통해 약 3~4배의 메모리 감소와 2배의 디코딩 지연 시간 감소를 실현했습니다. 현재 Qwen3/2.5, Gemma3, LLaMA3 등 모델을 지원하며 GitHub에서 데모 코드를 제공합니다 (출처: Reddit r/LocalLLaMA)

NimbleEdge, 희소 Transformer 연산자 커널 오픈소스 공개, LLM 실행 속도 및 메모리 효율성 향상: NimbleEdge 팀은 Apple의 LLM in a Flash와 Zichang 등의 Deja Vu 연구를 기반으로 구조화된 컨텍스트 희소성을 위한 융합 연산자 커널을 구축했습니다. 이 커널은 출력이 최종적으로 0이 되는 순방향 계층 가중치와 활성화 값의 로딩 및 계산을 피함으로써 Transformer의 MLP 계층 성능을 5배 향상시키고 메모리 소비를 50% 줄였습니다. Llama 3.2 3B 모델에 적용했을 때 전체 처리량이 1.78배 향상되고 메모리 사용량이 26.4% 감소했습니다. 코드는 GitHub에 오픈소스로 공개되었으며 int8, CUDA 및 희소 어텐션을 지원할 계획입니다 (출처: Reddit r/MachineLearning)
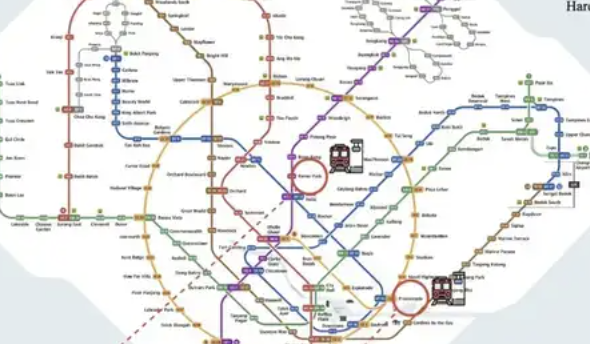
ReasonMap: 고해상도 교통 지도 다중 모드 추론 평가 벤치마크 발표: 서호(西湖)대학교 등 기관의 연구팀은 고해상도 교통 지도(주로 지하철 노선도)에 초점을 맞춘 다중 모드 추론 평가 벤치마크인 ReasonMap을 출시했습니다. 이 벤치마크는 이미지 내 세분화된 구조적 공간 정보 이해 능력에 대한 대형 모델의 평가를 목표로 하며, 고해상도 이미지(평균 5839×5449), 난이도 인식 설계 및 다차원 평가 시스템을 포함합니다. 테스트 결과, 현재 주류 오픈소스 모델은 ReasonMap에서 저조한 성능을 보였으며, 특히 여러 노선을 거치는 경로 계획에서 그러했습니다. 반면, 비공개 추론 모델(예: GPT-o3)은 오픈소스 모델보다 현저히 우수한 성능을 보였지만 여전히 인간 수준과는 격차가 있었습니다. 베이징과 항저우 등 복잡한 지하철 노선도는 모델에 상당한 어려움을 제기했습니다 (출처: 量子位)
Yandex, Yambda-5B 출시: 대규모 개방형 추천 시스템 데이터셋: Yandex는 47억 9천만 건의 사용자-아이템 상호작용을 포함하는 대규모 익명화 음악 스트리밍 데이터셋인 Yambda-5B를 출시했습니다. 이 데이터셋은 “is_organic” 플래그와 전역 시간 분할(GTS)을 제공하는 것이 특징이며, 사용자를 직접 식별할 수 있는 청취 기록과 좋아요를 포함하지 않고, 비식별화 방지 기능을 갖추고 있으며, 암묵적(노래 청취, 건너뛰기) 및 명시적(좋아요/싫어요) 피드백을 포함합니다. Yambda-5B는 추천 시스템 연구에 고품질, 다중 모드 데이터 자원을 제공하는 것을 목표로 합니다 (출처: TheTuringPost)
텐센트, 2025 성화(星火) 챌린지 캠프 시작, 대형 모델 등 첨단 연구 참여할 최고 학생 모집: 텐센트는 2025년도 “성화 챌린지 캠프”를 시작한다고 발표했습니다. 고등학교 2, 3학년(2025학년도 수험생) 및 기타 관련 학과에서 뛰어난 성적을 거둔 학생들을 대상으로 60~70명을 모집합니다. 선발된 학생들은 선전 본사로 가서 초장문 이해, 긴 사고 사슬 기술, 구현 지능+로봇, 다중 모드 감지 이해, 보안 공격 및 방어(LLM Agent 해커 설계 포함), 양자 기술 등 6대 첨단 연구 과제에 참여할 기회를 얻게 됩니다. 이 프로그램은 재능 있는 청소년들에게 산업 수준의 연구 개발 현장을 접하고 기술적 시야를 넓히며 산업에 대한 이해를 심화할 기회를 제공하는 것을 목표로 합니다 (출처: 量子位)

💼 비즈니스
Meta, Scale AI에 100억 달러 이상 투자 검토설, 군사 등 분야 AI 응용 강화: 보도에 따르면 Meta는 AI 데이터 레이블링 회사 Scale AI와 수십억 달러, 심지어 100억 달러를 초과할 수 있는 대규모 투자를 협상 중입니다. 사실이라면 이는 Meta의 외부 AI 투자 중 최대 규모가 될 것입니다. Scale AI는 이전에 Meta의 Llama 3를 기반으로 군사 용도로 특별히 설계된 모델 Defense Llama를 구축하여 미국 국가 안보 임무를 지원한 바 있습니다. 이번 조치는 Meta가 AI 분야, 특히 정부 및 국방 관련 응용 분야에서 더욱 적극적인 투자 및 협력 전략을 취할 것임을 시사할 수 있습니다 (출처: 36氪)

마샹소비(马上消费), “톈징(天镜)” 대형 모델 3.0 발표, 금융 의사결정 플랫폼으로 업그레이드: 마샹소비는 금융 대형 모델 “톈징”의 3.0 버전을 출시했습니다. 새 버전의 핵심적인 발전은 개별 지능에서 집단 지능으로의 시스템적 도약에 있으며, 더 이상 논리 학습에만 의존하지 않고 기업 내에 흩어져 있는 직원들의 활동 기록, 업무 로그 등 암묵적 경험을 심층적으로 발굴하여 구조화된 지식으로 전환합니다. 톈징 3.0은 도구에서 의사결정 플랫폼으로 업그레이드하여 인간과 기계의 협업을 촉진하고, 복잡한 서비스 프로세스를 동적으로 분해하며, 사용자 요구와 규제 요건에 따라 실시간으로 최적의 서비스 조합을 매칭하여 부분 최적에서 전체 최적으로의 의사결정을 실현하는 것을 목표로 합니다 (출처: 量子位)

Together AI, Charles Zedlewski를 신임 최고 제품 책임자로 임명, 오픈소스 생성 AI 플랫폼에 집중: Together AI는 Charles Zedlewski를 신임 최고 제품 책임자(CPO)로 임명했다고 발표했습니다. Charles Zedlewski는 이전에 Temporal과 Cloudera에서 개발자 대상 커뮤니티 기반 플랫폼 제품을 이끌었습니다. Together AI는 유연성, 비용 효율성 및 혁신 측면에서 오픈 모델이 우위를 점한다고 믿으며, 오픈소스 생성 AI의 미래를 구축하는 데 전념하고 있음을 강조했습니다. Charles의 합류는 Together AI가 강력한 생성 AI를 모든 개발자와 기업이 쉽게 사용할 수 있도록 하는 권위 있는 오픈소스 AI 플랫폼을 구축하는 데 더욱 박차를 가하기 위함입니다 (출처: togethercompute)

🌟 커뮤니티
Waymo 자율주행차 로스앤젤레스에서 방화 사건 발생, AV 안전에 대한 커뮤니티 우려와 논의 촉발: 최근 로스앤젤레스에서 여러 대의 Waymo 자율주행차가 방화로 소실되는 사건이 발생했습니다. 이 사건은 소셜 미디어에서 광범위한 관심과 논의를 불러일으켰으며, 자율주행차에 대한 대중의 수용도, 안전 우려, 그리고 이러한 사건이 Veo 3가 생성한 비디오와 같은 AI 생성 콘텐츠에 의해 부적절하게 확대되거나 왜곡될 수 있는 위험 등이 논의되었습니다. 일부 논평가들은 이 장면을 공상 과학 영화 ‘칠드런 오브 맨’에 비유하며 사건의 극적인 성격과 잠재적인 사회적 영향을 강조했습니다 (출처: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
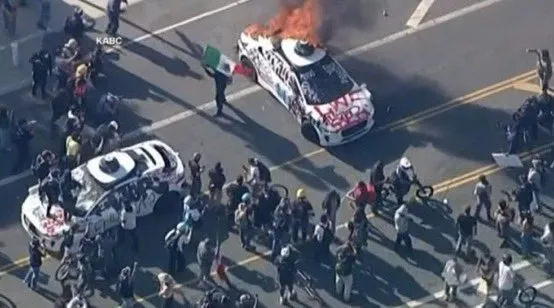
Reddit, Anthropic을 상대로 소송 제기, Claude AI 훈련 위한 무단 콘텐츠 스크래핑 혐의: Reddit은 Anthropic이 허가나 비용 지불 없이 Reddit의 게시물과 대화 내용을 스크래핑하여 AI 모델 Claude를 훈련시켰다고 주장하며 소송을 제기했습니다. Reddit은 이러한 행위가 무단 상업적 사용을 금지하는 사용자 계약을 위반했다고 주장하며, Anthropic이 “Reddit 스크래핑을 중단했다”고 주장한 것은 허위 진술이라고 밝혔습니다. 소송에는 Anthropic이 라이선스 계약을 맺은 다른 회사들과 달리 사용자가 삭제한 게시물을 삭제하는 메커니즘이 없다는 개인 정보 보호 문제도 포함되어 있습니다. Reddit은 법원에 Anthropic의 Reddit 데이터 사용 금지를 요청했으며, Claude를 서비스에서 내리도록 요구할 수도 있습니다 (출처: Reddit r/ArtificialInteligence,Reddit r/artificial)
AI 엔지니어 엑스포 열띤 토론: Simon Willison, 지난 반년간 LLM 발전 회고하며 ‘도구+추론’ 조합 강조: 샌프란시스코 AI 엔지니어 엑스포에서 Simon Willison은 ‘자전거 타는 펠리컨’ SVG 이미지 생성 테스트를 통해 지난 6개월간 LLM의 급속한 발전을 유머러스하게 회고하고 30여 종의 AI 모델을 직접 테스트했습니다. 그는 현재 가장 강력한 AI 조합은 ‘도구+추론’이며, 예를 들어 검색에서 o3/o4-mini의 성능과 도구 호출로 인해 주목받는 MCP 아키텍처를 강조했습니다. 강연에서는 ChatGPT의 과도한 아첨, Claude가 사용자를 ‘신고’할 수 있는 행동 등 연례 AI ‘기이한 버그’도 소개하고 프롬프트 주입 및 데이터 유출 위험을 지적했습니다 (출처: 36氪,swyx)

커뮤니티, AI로 인한 직업 불안 및 대응 전략 논의: Reddit에서 “AI 불안에 대처하는 방법”에 대한 게시물이 열띤 토론을 불러일으켰습니다. 사용자들은 향후 몇 년 안에 AI가 대규모 실업을 유발할 수 있다는 점을普遍적으로 우려하며, 특히 저축이 부족하고 부채가 많은 사람들에게 심각한 위협이 될 것이라고 걱정했습니다. 토론에서는 기술직, 간호 등 분야로 전환하라는 제안도 있었지만, 동시에 이러한 분야가 많은 전직자 유입으로 포화될 것을 우려하는 목소리도 있었습니다. 댓글 작성자들은 불면증, 업무 집중력 저하 등 각자의 불안감을 공유했습니다. 일부 의견은 AI를 적극적으로 배우고 적응력을 유지해야 한다고 주장하며, 역사적으로 기술 혁신(예: 자동차, 인터넷)도 유사한 우려를 불러일으켰지만 결국 새로운 일자리를 창출했다고 지적했습니다. 현재 AI가 인간의 일자리를 대체하는 정도가 과장되었으며, 단기적으로 대규모 해고는不太可能(일어날 가능성이 낮다)는 의견도 있었습니다 (출처: Reddit r/ArtificialInteligence)
사용자, ChatGPT를 이용한 “잔혹한” 자기 심리 분석 경험 공유: 한 Reddit 사용자가 ChatGPT를 사용하여 “야만적인 임원 스타일”로 자기 심리 분석을 한 경험을 공유했습니다. 그는 특정 프롬프트를 통해 ChatGPT에게 진정한 강점, 깊은 약점, 반복되는 실패 패턴, 회피 영역, 간과된 기술 등 다섯 가지 관점에서 엄격하게 분석하고 3단계 발전 계획을 제시하도록 요청했습니다. 사용자는 과정이 고통스러웠지만(예: 12개의 프로젝트를 시작했지만 하나도 완성하지 못했고, 실제 행동보다는 생산성에 대해 과도하게 연구했다는 지적), 이러한 “잔혹한” 피드백이 결국 변화를 이끌어냈다고 말했습니다. 이 게시물은 자기 성찰과 개인 발전 측면에서 AI 활용에 대한 커뮤니티의 논의를 촉발했습니다 (출처: Reddit r/ArtificialInteligence)
LLM 기억과 추론 능력에 대한 논의: 지식이 풍부한 것인가, 아니면 진정으로 이해하는 것인가?: 소셜 미디어에서 사용자들은 대형 언어 모델(LLM)이 기억형 사실 회상 작업에서 뛰어난 성능을 보이는 것과 이것이 진정으로 추론 능력을 갖추고 있음을 의미하는지에 대해 논의했습니다. 일부 견해에 따르면, LLM이 복잡해 보이는 작업에서 뛰어난 성능을 보이는 것은 방대한 훈련 데이터와 패턴 인식에 더 많이 의존할 가능성이 있으며, 인간적인 의미의 깊은 이해와 창의성과는 거리가 멀 수 있습니다. Meta 등 기업의 연구에 따르면 기억을 측정하여 모델 용량을 추정할 수 있으며, 용량이 채워지면 일반화가 시작됩니다. 이러한 논의는 교육 시스템에서 암기 위주의 교육과 정보 검색 및 AI 도구 사용 능력 배양 부족 문제와도 관련됩니다 (출처: omarsar0,menhguin,menhguin)

💡 기타
Stripe 결제 사기 탐지 기반 모델의 성공 사례 분석: Stripe 엔지니어가 공유한 성공적인 결제 사기 탐지 기반 모델 구축에 관한 게시물이 주목을 받았습니다. 분석에 따르면 이 사례의 특수성은 다음과 같습니다: 1) 사기 탐지는 본질적으로 미래를 예측하는 것이 아니며, 이론적으로 신호가 충분할 때 높은 정확도에 도달할 수 있습니다. 2) Stripe는 이미 신호가 풍부한 환경에 있으며, 처음부터 데이터를 축적할 필요가 없습니다. 3) 이 시나리오는 자동화 업그레이드로, 전통적인 머신러닝에서 기반 모델로 전환하는 것이며, 직접적인 대체에 가깝습니다. 이는 이러한 AI 애플리케이션의 “즉각적인 성공”이 비교적 드문 이유를 설명하며, 대부분의 AI 비즈니스 가치 실현은 많은 장애물을 극복해야 합니다 (출처: random_walker)
AI 전환 인지 기반: 체계적인 정보 감지 및 기술 통찰 메커니즘이 핵심: 기업은 AI 전환 과정에서 개인의 경험과 전통적인 경로 의존성을 뛰어넘어 체계적이고 구조화된 정보 감지 및 기술 통찰 메커니즘을 구축해야 합니다. 여기에는 내부 데이터 분석 능력 구축과 외부 지식 네트워크(학계, 산업계, 자본 시장, 스타트업) 구축이 포함됩니다. AI 투자 수익률 평가 또한 전통적인 ROI에서 “주기별, 다차원적” 시스템으로 전환하고 외부 지식 네트워크와 결합하여 지속적인 검증과 동적 조정을 이루는 전략적 폐쇄 루프를 형성해야 합니다. 이 글은 AI가 일회성 도구가 아니라 지속적으로 진화하고 끊임없이 가치가 증가하는 전략적 자산임을 강조합니다 (출처: 36氪)
Frigate: 실시간 로컬 객체 감지 기반 NVR 시스템: Frigate는 Home Assistant를 위해 특별히 설계된 로컬 네트워크 비디오 레코더(NVR) 시스템으로, OpenCV와 Tensorflow를 활용하여 IP 카메라에서 실시간 로컬 객체 감지를 수행합니다. 이 시스템은 자원 최적화와 성능을 강조하며, 저비용 모션 감지를 통해 객체 감지를 트리거하고 다중 프로세스를 활용하여 처리합니다. 최적의 성능을 위해 Google Coral 또는 Hailo와 같은 AI 가속기 사용을 권장합니다. Frigate는 24/7 녹화, 객체 감지 기반 녹화 보존, MQTT 통합, RTSP 재방송 및 WebRTC/MSE 저지연 실시간 보기를 지원합니다 (출처: GitHub Trending)
