
Anahtar Kelimeler:büyük dil modeli, akıl yürütme yeteneği, AI güvenliği, çok modelli model, açık kaynak model, AI video oluşturma, AI değerlendirme, AI ticari uygulamalar, Apple LLM akıl yürütme yeteneği araştırması, Time-R1 zaman anlama modeli, NVIDIA Blackwell GPU video oluşturma, Ali Tongyi Qianwen 3 açık kaynak model, Hugging Face MCP sunucusu
🔥 Odak Noktası
Apple, mevcut büyük dil modellerinin (LLM’lerin) gerçek çıkarım yeteneği yerine yalnızca “düşünme yanılsamasına” sahip olduğunu belirten bir makale yayınladı ve bu durum sektörde hararetli tartışmalara yol açtı: Apple araştırmacıları (Google Brain’in kurucularından Samy Bengio dahil) yayınladıkları makalede, Hanoi Kulesi, damalı taş takası gibi dört kontrol edilebilir zorluktaki görevle yapılan testler aracılığıyla, DeepSeek, o3-mini, Claude 3.7 gibi önde gelen modellerin yüksek karmaşıklıktaki sorunlarla karşılaştıklarında “çöktüğünü”, “tersine ölçeklenen çıkarım çabası” (sorun ne kadar zorsa, o kadar az düşünme) sergilediklerini belirtti. Makale, bu modellerin gerçek, genelleştirilebilir mantıksal çıkarımdan ziyade örüntü eşleştirme ve ezberlemeye daha fazla güvendiğini ve tam algoritmalar sunulsa bile karmaşıklık darboğazlarını aşamadığını savunuyor. Bu görüş, LLM’lerin çıkarım yeteneklerine dair mevcut genel kanıyı sorguluyor ve LLM değerlendirme yöntemleri, gerçek çıkarım yeteneğinin sınırları ve gelecekteki gelişim yönleri hakkında geniş çaplı tartışmalara yol açtı. Topluluktan gelen tepkiler karışık; bazıları bunun Apple’ın kendi yavaş yapay zeka ilerlemesini savunma çabası olduğunu düşünürken, bazıları ise değerlendirme mekanizmalarına ve modellerin içsel sınırlamalarına dair içgörülerini onaylıyor (Kaynak: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

Turing Ödülü sahibi Yoshua Bengio, yapay zekanın kontrolden çıkma riskleri konusunda uyardı ve araştırma odağını “bilim insanı yapay zeka”ya kaydırdı: Yoshua Bengio, Ziyuan Konferansı’nda yaptığı konuşmada, yapay zekanın (özellikle AGI’nin) hızlı gelişimi ve potansiyel kontrolden çıkma riskleri (örneğin, yapay zekanın “hayatta kalmak” için kendi kodunu kopyalaması, davranışlarını gizlemesi) göz önüne alındığında, araştırma yönünü değiştirdiğini ve yalnızca zekaya sahip, öz farkındalığı ve hedefleri olmayan “bilim insanı yapay zeka”lar oluşturmaya odaklandığını belirtti. Yapay zekanın planlama yeteneğinin beş yıl içinde insan seviyesine ulaşabileceğini ve mevcut yapay zeka eğitim yöntemlerinin, hata yaptıklarında bile aşırı özgüven sergilemelerine yol açabileceğini ifade etti. Bengio, yapay zekanın etik talimatlara uymasını sağlamanın, kötü niyetli amaçlar için kullanılmasını önlemenin ve yapay zeka güvenlik zorluklarıyla başa çıkmak, “uyum” ve “kontrol edilebilirlik” sorunlarını çözmek için küresel işbirliğinin gerekliliğini vurguladı (Kaynak: 量子位)

İngiliz hükümeti, planlama kararlarını hızlandırmak için Google Gemini modeli destekli Extract sistemini benimsedi: İngiliz hükümeti, yerel meclis planlamacılarının daha hızlı karar almalarına yardımcı olmak için “Extract” adlı bir sistem kullanıyor. Bu sistem, Google’ın Gemini temel modeline dayanıyor ve çok modlu çıkarım yeteneklerini kullanarak, el yazısı notlar ve bulanık haritalar da dahil olmak üzere karmaşık planlama belgelerini 40 saniye içinde dijital verilere dönüştürebiliyor. Bu uygulama, karmaşık belgelerin otomatik olarak işlenmesi ve anlaşılması yoluyla idari verimliliği ve karar kalitesini artırarak yapay zekanın kamu hizmetleri alanındaki potansiyelini gösteriyor (Kaynak: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia, büyük video modeli EXPRESS-2’yi eğitmek için NVIDIA Blackwell GPU’larını ilk kullanan şirket oldu: Yapay zeka video üretim şirketi Synthesia, Google Cloud üzerinde NVIDIA Blackwell GPU’larını kullanarak büyük video modeli eğiten dünyadaki ilk şirket olduğunu duyurdu. Yeni modeli EXPRESS-2, daha güçlü donanım ve optimize edilmiş çoklu bulut kurulumuyla müşterilerin daha hızlı ve daha yüksek kalitede yapay zeka tarafından üretilmiş videolar ve sanal avatarlar oluşturmasına yardımcı olmayı amaçlıyor. Bu adım, yapay zeka video üretim teknolojisinin temel donanım desteği ve model yetenekleri açısından önemli bir ilerlemeye işaret ediyor ve gelecekte yapay zeka video içeriği oluşturma verimliliğinin ve kalitesinin daha da artacağını gösteriyor (Kaynak: synthesiaIO,Synthesia Blog)
Epoch AI araştırması, o3-mini-high modelinin önde gelen matematik problemlerini ezberlemek yerine “sezgi” ile çözdüğünü ortaya koydu: Epoch AI, 14 matematikçiyi o3-mini-high modelinin FrontierMath benchmark’ındaki 29 çıkarım sürecini değerlendirmeye davet etti ve modelin 13 zor problemi doğru çözebildiğini buldu. Araştırma, o3-mini-high’ın engin bir matematik bilgisine sahip olduğunu ve ilgili teoremleri çağırabildiğini, ancak çıkarım tarzının daha çok “sezgiye dayalı tümevarım” eğiliminde olduğunu, katı biçimsel kanıtlar ve yaratıcılıktan yoksun olduğunu, hatta bazen kanıt adımlarını “kestirmeden giderek” atladığını gösteriyor. Halüsinasyonlar ve formülleri doğru bir şekilde yeniden üretememe gibi sorunlara rağmen, bazı sorulardaki performansı insan matematikçilerin düşünme süreçleriyle benzerlik gösteriyor. Bu çalışma, mevcut büyük modellerin karmaşık matematiksel çıkarım konusundaki yetenek özelliklerini ve sınırlamalarını derinlemesine analiz ediyor (Kaynak: 量子位)

🎯 Gelişmeler
Alibaba QwenLM 3 açık kaynaklı modelinin indirme sayısı 12,5 milyonu aştı, türev model sayısı 130 bini geçerek dünya birincisi oldu: Alibaba QwenLM 3 serisi büyük modelleri, açık kaynak olarak yayınlanmasından bu yana bir ay içinde küresel toplam indirme sayısı 12,5 milyonu aştı ve son zamanların en popüler açık kaynaklı modeli oldu. 0.6B ila 32B arasındaki dört farklı boyuttaki modelleri, Hugging Face, ModelScope gibi platformlarda milyonlarca kez indirildi ve türev model sayısı 130 bini aşarak dünya genelinde birinci sırada yer aldı. QwenLM 3, birçok yerli ve yabancı performans listesinde açık kaynaklı modeller arasında şampiyon oldu ve düşük çıkarım maliyeti (DeepSeek R1’in yaklaşık üçte biri) sayesinde NVIDIA, Intel, ARM gibi birçok çip üreticisi ve hesaplama gücü platformunun adaptasyonunu ve entegrasyonunu çekti (Kaynak: 量子位)

Illinois Üniversitesi, zamanı anlama, tahmin etme ve üretme yeteneğine sahip 3B parametreli Time-R1 modelini yayınladı: Illinois Üniversitesi Urbana-Champaign’deki araştırmacılar, üç aşamalı pekiştirmeli öğrenme ve dinamik ödül mekanizması aracılığıyla modelin zaman kavramını anlamasını, gelecekteki olayları tahmin etmesini ve yaratıcı senaryolar üretme yeteneğini geliştiren 3B parametreli bir dil modeli olan Time-R1’i tanıttı. Model, zaman çıkarımı görevlerinde üstün performans gösterdi ve hatta DeepSeek-V3-0324 gibi kendisinden çok daha büyük parametre sayısına sahip modelleri geride bıraktı. Araştırma ekibi, Time-Bench’i (10 yıllık New York Times haberlerine dayanan büyük, çok görevli bir zaman çıkarımı veri kümesi) ve Time-R1’in eğitim kodunu ve model kontrol noktalarını açık kaynak olarak yayınladı (Kaynak: 量子位)

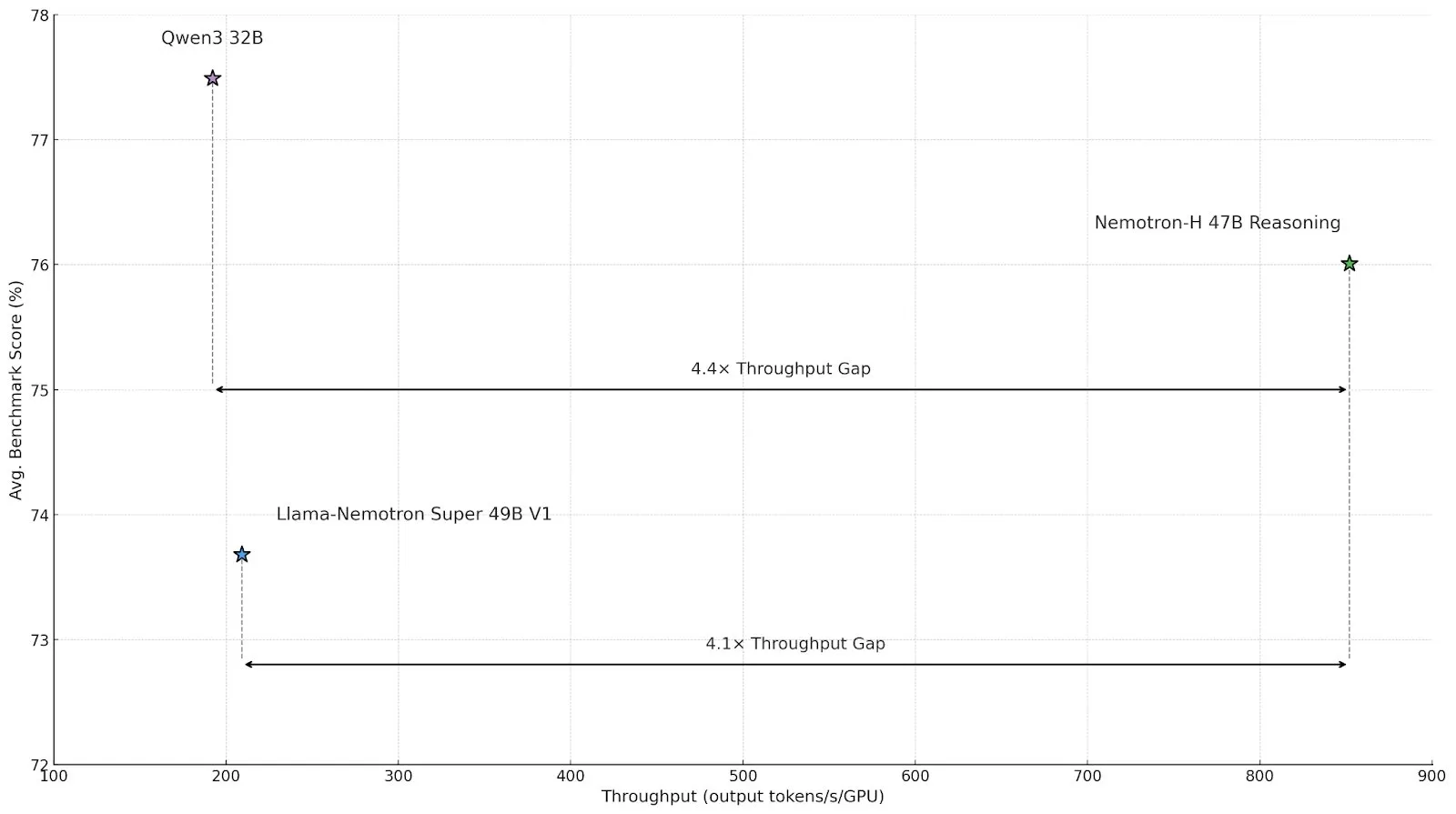
NVIDIA, verimliliği artırmak için hibrit Mamba-Transformer mimarisini kullanan Nemotron-H serisi çıkarım modellerini yayınladı: NVIDIA, hibrit SSM-Transformer (Mamba-Transformer) mimarisine dayanan Nemotron-H 8B ve 47B çıkarım modellerini tanıttı. Bu modeller, yüksek doğruluğu korurken, benzer Transformer modellerine göre 4 kata kadar daha fazla çıkarım verimi sağlayabiliyor. Nemotron-H-47B-Reasoning-128k, çeşitli benchmark testlerinde Llama-Nemotron-Super-49B-1.0’dan daha iyi performans gösteriyor ve çıkarım maliyetini 4 kata kadar düşürüyor. Model ağırlıkları, yüksek performanslı büyük ölçekli çıkarım araştırmalarını teşvik etmek amacıyla HuggingFace’te üretim dışı bir lisansla yayınlandı (Kaynak: tri_dao,NVIDIA AI Developer)
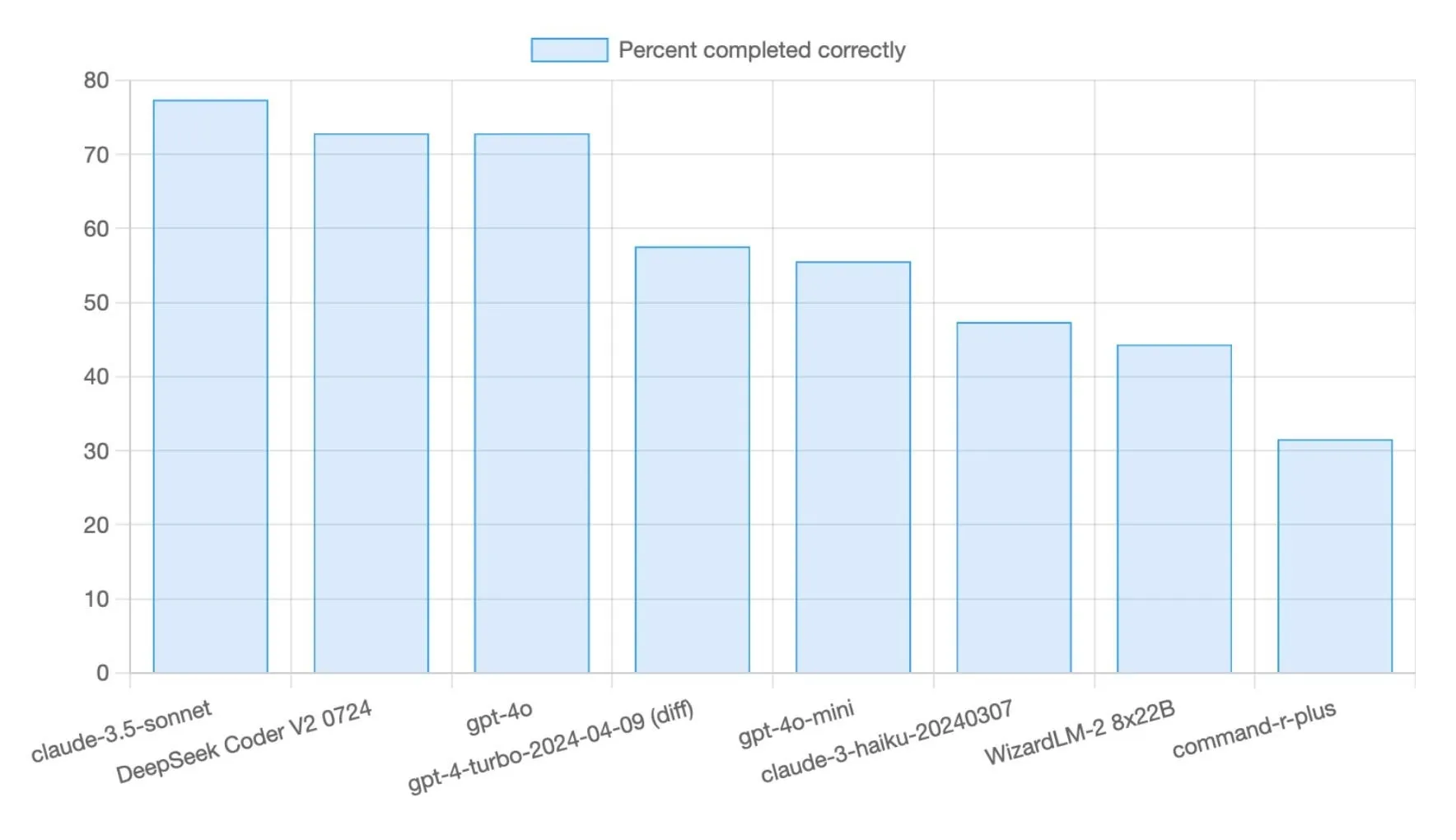
DeepSeek R1 0528 modeli, Aider Polyglot programlama benchmark testinde %71 puan aldı: DeepSeek R1 0528 modeli, Aider Polyglot programlama benchmark testinde %71’lik bir başarı elde ederek önceki sürüme göre önemli bir artış (+14,5 puan) gösterdi. Model, yüksek maliyet etkinliğiyle dikkat çekiyor; benchmark testlerinin yaklaşık %70’ini 5 dolardan daha ucuza tamamlayarak kod üretimi görevlerindeki güçlü rekabetçiliğini ortaya koyuyor (Kaynak: Reddit r/LocalLLaMA,scaling01)
VACE çerçevesi yayınlandı: Video oluşturma ve düzenlemeyi birleştiren çok işlevli bir model: Alibaba Tongyi Laboratuvarı, referans videodan video üretme (R2V), videodan videoya düzenleme (V2V) ve maskeli video düzenleme (MV2V) gibi birçok işlevi birleştiren birleşik bir model olan VACE’yi (Video Creation and Editing) tanıttı. VACE, kullanıcıların nesne taşıma, değiştirme, stil referansı alma, genişletme, canlandırma gibi çeşitli video işleme görevlerini gerçekleştirmek için bu görevleri serbestçe birleştirmesine olanak tanır. Şu anda VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B ve Wan2.1-VACE-14B gibi birden fazla model sürümü yayınlandı ve HuggingFace ile ModelScope’ta indirilmeye sunuldu (Kaynak: GitHub Trending)

HKUST ve ByteDance, görsel üretim görevlerini birleştirmek için ComfyMind çerçevesini ortaklaşa başlattı: Hong Kong Bilim ve Teknoloji Üniversitesi (Guangzhou) ve ByteDance, metinden görüntüye, görüntüden videoya gibi çeşitli ana akım görsel üretim görevlerini tek bir sistemle ele almak amacıyla açık kaynaklı görsel üretim çerçevesi ComfyMind’ı ortaklaşa yayınladı. ComfyMind, en küçük birim olarak “atomik iş akışını” benimser, ağaç yapısında planlama ve yerel geri bildirim yürütme mekanizmalarını birleştirir, ComfyUI’ı temel yürütme motoru olarak kullanır ve karmaşık görevleri planlama, yürütme ve değerlendirme olmak üzere üç ajanın işbirliğiyle tamamlar. ComfyBench, GenEval ve Reason-Edit gibi benchmark testlerinde ComfyMind üstün performans göstererek GPT-4o-Image ile karşılaştırılabilir bir performans sergiledi (Kaynak: 量子位)

Hugging Face, yapay zeka ajanlarının yeteneklerini artırmak için Model Context Protocol (MCP) sunucusunu başlattı: Hugging Face, yapay zeka ajanlarının arama modelleri, veri kümelerini analiz etme ve HuggingFace Spaces ile etkileşim kurma dahil olmak üzere harici araçlara ve gerçek zamanlı verilere standartlaştırılmış, güvenli bir şekilde erişmesine olanak tanıyan bir Model Context Protocol (MCP) sunucusu sunuyor. Bu girişim, yapay zeka ajanlarını statik araçlardan dinamik işbirlikçilere dönüştürerek karmaşık görevleri yerine getirme ve en son bilgilere erişme yeteneklerini artırmayı amaçlıyor. Birçok topluluk üyesi, MCP sunucusunu Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic gibi çeşitli yapay zeka çerçeveleriyle entegre etmeyi keşfetmeye başladı (Kaynak: ClementDelangue,huggingface,awnihannun)

Araştırma STARFlow’u sunuyor: Yüksek çözünürlüklü görüntü sentezi için ölçeklenebilir bir gizli normalleştirme akış modeli: STARFlow, temelinde Transformer otoregresif akışı (TARFlow) bulunan, normalleştirme akışına dayalı ölçeklenebilir bir üretken modeldir. Derin ve sığ katman tasarımı, önceden eğitilmiş bir otokodlayıcının gizli uzayında modelleme ve yeni bir yönlendirme algoritması aracılığıyla STARFlow, sınıf koşullu ve metin koşullu görüntü üretimi görevlerinde, en gelişmiş difüzyon modellerine yaklaşan rekabetçi bir performans elde eder. Bu çalışma, normalleştirme akışlarının bu ölçekte ve çözünürlükte etkili bir şekilde çalıştığını ilk kez başarılı bir şekilde göstermektedir (Kaynak: HuggingFace Daily Papers)
Yeni araştırma HASHIRU: Hibrit zeka kaynak kullanımı için hiyerarşik bir ajan sistemi: HASHIRU, özel “çalışan” ajanları dinamik olarak yöneten ve görev gereksinimlerine ve kaynak kısıtlamalarına (maliyet, bellek) göre onları örnekleyen bir “CEO” ajana sahip yeni bir çoklu ajan sistemi (MAS) çerçevesidir. Sistem, küçük yerel LLM’lere (Ollama aracılığıyla) öncelik verirken, harici API’leri ve büyük modelleri esnek bir şekilde kullanır ve otonom API aracı oluşturma ve bellek işlevlerini içerir. Akademik makale incelemesi, güvenlik değerlendirmesi ve karmaşık çıkarım gibi görevlerdeki değerlendirmeler yeteneklerini göstermektedir (Kaynak: HuggingFace Daily Papers)
PartCrafter: Gizli difüzyon Transformer’larını birleştirerek yapılandırılmış 3D ağ oluşturma: PartCrafter, tek bir RGB görüntüden anlamsal olarak anlamlı ve geometrik olarak farklı birden fazla 3D ağı ortaklaşa sentezleyebilen ilk yapılandırılmış 3D üretim modelidir. Önceden bölümlenmiş girdilere dayanmayan birleşik bir kompozisyonel üretim mimarisi kullanır ve tek nesnelerin ve karmaşık çok nesneli sahnelerin parça parça üretimini uçtan uca algılayabilir. Temel yenilikleri arasında kompozisyonel gizli uzay ve hiyerarşik dikkat mekanizmaları bulunmaktadır (Kaynak: HuggingFace Daily Papers)
Prefix Grouper: Paylaşılan önek ileri yayılımı yoluyla verimli GRPO eğitimi: Group Relative Policy Optimization (GRPO), ortak bir giriş önekini paylaşan aday çıktılar arasındaki göreceli farkları karşılaştırarak politika öğrenimini geliştirir. Prefix Grouper, paylaşılan önek ileri politikası aracılığıyla gereksiz önek hesaplamalarını ortadan kaldırarak, özellikle uzun önek senaryolarında GRPO’nun eğitim verimliliğini artırır ve aynı zamanda standart GRPO ile eğitim eşdeğerliğini korur (Kaynak: HuggingFace Daily Papers)
GuideX: Sıfır vuruşlu bilgi çıkarımı için yönlendirilmiş sentetik veri üretimi: Geleneksel bilgi çıkarma (IE) sistemleri genellikle alana özgüdür ve uyarlanması maliyetlidir. GuideX, alana özgü şemaları otomatik olarak tanımlayan, kılavuzları çıkaran ve etiketli sentetik örnekler üreten yeni bir yöntemdir, böylece daha iyi alan dışı genelleme sağlar. GuideX kullanılarak ince ayar yapılan Llama 3.1, yedi sıfır vuruşlu adlandırılmış varlık tanıma benchmark’ında yeni bir SOTA oluşturdu ve modelin karmaşık alana özgü açıklama desenlerini anlamasını önemli ölçüde geliştirdi (Kaynak: HuggingFace Daily Papers)
CodeContests+: Programlama yarışmaları için yüksek kaliteli test senaryoları oluşturma: Programlama yarışmalarında test senaryolarının elde edilmesinin zorluğu sorununa yönelik olarak araştırmacılar, yüksek kaliteli test senaryoları oluşturmak için LLM tabanlı bir ajan sistemi önerdiler. Bu sistem CodeContests veri kümesine uygulandı ve geliştirilmiş bir sürüm olan CodeContests+ önerildi. Değerlendirmeler, CodeContests+’ın değerlendirme doğruluğu açısından orijinal sürüme göre, özellikle gerçek pozitif oran (TPR) açısından önemli ölçüde daha iyi olduğunu ve LLM pekiştirmeli öğrenme için önemli avantajlar sağladığını göstermektedir (Kaynak: HuggingFace Daily Papers)
Sentinel: İpucu enjeksiyon saldırılarına karşı SOTA modeli: Büyük dil modellerinin (LLM) ipucu enjeksiyon saldırılarına karşı savunmasızlığı sorununa çözüm olarak araştırmacılar, ModernBERT-large mimarisine dayanan Sentinel modelini (qualifire/prompt-injection-sentinel) tanıttı. Çeşitli saldırı türlerini ve iyi huylu talimatları içeren kapsamlı bir veri kümesinde ince ayar yapılarak, Sentinel dahili olarak görülmemiş test kümesinde 0.987 ortalama doğruluk ve 0.980 F1 puanı elde etti ve genel benchmark’larda güçlü temel modellerden daha iyi performans gösterdi (Kaynak: HuggingFace Daily Papers)
Makale tartışması: Modalite genişletme, tam modaliteye ulaşmak için doğru yol mu?: Tam modaliteli dil modelleri (OLM), güçlü dil yeteneklerini korurken birden fazla giriş modalitesini entegre etmeyi ve bunlar üzerinde çıkarım yapmayı amaçlar. Bu çalışma, çok modlu modelleri eğitmek için ana akım bir teknik olan modalite genişletmenin (yani önceden eğitilmiş dil modellerinin ince ayarlanması) etkisini araştırmaktadır. Çalışma üç temel soruya odaklanmaktadır: Modalite genişletme temel dil yeteneklerine zarar verir mi? Model birleştirme, tam modaliteye ulaşmak için bağımsız olarak ince ayarlanmış belirli modalite modellerini etkili bir şekilde entegre edebilir mi? Tam modalite genişletme, sıralı genişletmeden daha iyi bilgi paylaşımı ve genelleme sağlar mı? (Kaynak: HuggingFace Daily Papers)
Makale, Truth in the Few’u sunuyor: Verimli çok modlu çıkarım için yüksek değerli veri seçimi yöntemi: Araştırma, çok modlu LLM’lerin (MLLM) karmaşık çıkarım görevlerinde büyük miktarda eğitim verisine ihtiyaç duyduğu yönündeki yaygın kanıya meydan okuyor. Gözlemler, “bilişsel örnekler” olarak adlandırılan eğitim verilerinin yalnızca küçük bir kısmının çok modlu çıkarımı etkili bir şekilde tetikleyebildiğini ortaya koymuştur. Buna dayanarak makale, bu bilişsel örnekleri tanımlamak için nedensel fark tahmincisi (CDE) ve dikkat güven tahmincisi (ACE) aracılığıyla Reasoning Activation Potential (RAP) veri seçimi paradigmasını ve basit örnekleri zorluk farkındalığı olan değiştirme modülü (DRM) ile değiştirmeyi önermektedir. Deneyler, RAP’ın eğitim verilerinin yalnızca %9,3’ü ile daha iyi performans elde ettiğini ve hesaplama maliyetini %43’ten fazla azalttığını göstermektedir (Kaynak: HuggingFace Daily Papers)
🧰 Araçlar
Task Master: Cursor gibi editörlere entegre edilmiş, yapay zeka destekli görev yönetim sistemi: Task Master, Cursor AI, Lovable, Windsurf, Roo gibi editörlerle sorunsuz bir şekilde entegre olabilen, yapay zeka destekli geliştirme için özel olarak tasarlanmış bir görev yönetim sistemidir. Claude gibi büyük modellerin API’lerini (Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama destekli) kullanarak geliştiricilerin gereksinim belgelerini (PRD) ayrıştırmasına, görev listeleri oluşturmasına, geliştirme adımlarını planlamasına ve belirli görevlerin uygulanmasına yardımcı olur. Bu sistem, MCP (Model Kontrol Protokolü) aracılığıyla doğrudan editörde çalışır, komut satırı işlemlerini destekler ve ayrıntılı yapılandırma kılavuzları ve kullanım eğitimleri sunar (Kaynak: GitHub Trending)
Observer AI: Ollama entegreli, yerel açık kaynaklı ekran gözlem ajanı: Observer AI, kullanıcıların Ollama aracılığıyla yerel LLM’leri çalıştırarak ekranı gözlemlemesine ve görevleri yerine getirmesine olanak tanıyan açık kaynaklı bir projedir. Kullanıcılar bu araç sayesinde yapay zekanın ekran içeriğini anlamasını ve etkileşimde bulunmasını sağlayabilir, örneğin yabancı dilde bir web sitesinde gezinebilirler. Proje, GitHub kaynak kodunu ve yerel kurulum gerektirmeyen bir web uygulaması sürümünü sunarak kullanıcıların gizliliklerini koruyarak LLM’leri ekran otomasyonu için kullanmalarını destekler (Kaynak: Reddit r/LocalLLaMA)

Weaviate Query Agent, yedi büyük yapay zeka çerçevesiyle entegre olarak doğal dil veri sorgulamasını basitleştiriyor: Weaviate, Query Agent’ının yedi ana akım yapay zeka çerçevesiyle (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) entegrasyon yöntemlerini yayınladı. Query Agent, Weaviate’teki verilere dayanarak doğal dil sorgularını yanıtlayabilen, karmaşık sorgu ifadeleri yazmaya gerek kalmadan önceden oluşturulmuş bir ajan hizmetidir. Bu entegrasyonlar, geliştiricilerin güçlü doğal dil sorgulama yeteneklerini mevcut yapay zeka uygulama yığınlarına kolayca yerleştirmelerini sağlayarak veri etkileşiminin kolaylığını artırır (Kaynak: bobvanluijt)

Claude Code ve Gemini Pro’nun birlikte çalıştığı MCP sunucusu yayınlandı, kodlama verimliliği artırıldı: BeehiveInnovations, Claude Code ve Gemini 2.5 Pro’nun birlikte çalışmasını sağlayan bir MCP sunucusu yayınladı. Claude Code ilk fikir üretme ve planlamadan sorumluyken, Gemini milyonlarca token’lık bağlamı ve derin çıkarım yetenekleriyle tamamlayıcı rol oynuyor. Sunucu, genişletilmiş düşünme, dosya okuma, kod inceleme ve hata ayıklama gibi araçları entegre ederek iki modelin avantajlarını birleştirerek kod üretimi ve optimizasyonunun kalitesini ve verimliliğini artırmayı amaçlıyor. İlk testler, JSON ayrıştırma hızı optimizasyonu görevinde, birleşik kullanımın her bir modelin tek başına kullanımından daha iyi sonuç verdiğini gösteriyor (Kaynak: Reddit r/ClaudeAI)

📚 Öğrenme Kaynakları
Sakana AI, LLM’lerin finansal görevlerdeki yeteneğini değerlendirmek için Japonca finansal benchmark EDINET-Bench’i yayınladı: Sakana AI, Japonya Finansal Hizmetler Ajansı’nın elektronik ifşa sistemi EDINET’in yıllık raporlarını kullanarak oluşturulan Japonca bir finansal benchmark testi olan EDINET-Bench’i tanıttı. Bu benchmark, finans alanında yüksek kaliteli, ücretsiz olarak kullanılabilir veri kümelerinin kıtlığı sorununa yanıt olarak, büyük dil modellerinin (LLM) dolandırıcılık tespiti gibi karmaşık finansal görevlerdeki performansını değerlendirmeyi amaçlamaktadır. EDINET-Bench, otomatik etiketleme yoluyla çok görevli bir veri kümesi oluşturarak finansal yapay zeka araştırmaları için önemli bir kaynak sağlıyor (Kaynak: hardmaru,SakanaAILabs)

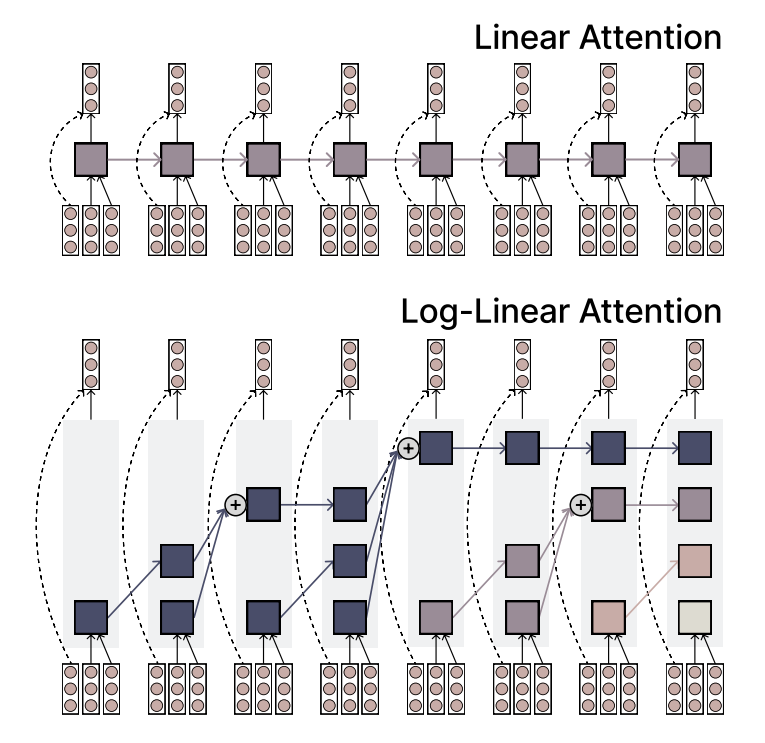
MIT, verimlilik ve ifade gücünü birleştiren Log-linear Attention mekanizmasını önerdi: MIT araştırmacıları, Log-linear Attention adlı yeni bir dikkat mekanizması önerdi. Bu mekanizma, doğrusal dikkatin hızını ve verimliliğini Softmax dikkatinin ifade gücüyle birleştirmeyi amaçlamaktadır. Bunu, az sayıda ancak dizi uzunluğuyla logaritmik olarak artan bellek yuvaları kullanarak başarır ve uzun dizi verilerini işlemek için potansiyel olarak yeni bir yöntem sunar (Kaynak: TheTuringPost)
Hamel Husain ve Shreya Rajpal’ın LLM değerlendirme kursu beğeni topladı: Ryan Lingo ve Radek Osmulski gibi kullanıcılar, Hamel Husain ve Shreya Rajpal’ın LLM uygulama değerlendirme kursuna (maven.com/parlance-labs/evals) katılım deneyimlerini olumlu bir şekilde paylaştılar. Kurs, LLM’ler hakkında mevcut en derinlemesine ve pratik içerik olarak kabul ediliyor; dersleri ve özel kitabı, yapay zeka uygulamaları geliştiren geliştiriciler için hayati önem taşıyor ve LLM geliştirmede değerlendirmenin merkezi rolünü vurguluyor (Kaynak: HamelHusain,HamelHusain)
MORSE-500: Çok modlu çıkarım stres testi için programlanabilir kontrollü video benchmark’ı: Mevcut çok modlu çıkarım benchmark’larının çoğunlukla statik görüntülere dayanması, zamansal karmaşıklığı ve çıkarım becerilerinin genişliğini göz ardı etmesi sorununa yönelik olarak araştırmacılar MORSE-500’ü tanıttı. Bu, soyutlama, fizik, planlama, uzamsal ve zamansal olmak üzere altı çıkarım kategorisini kapsayan 500 tamamen senaryolaştırılmış video parçasını içeren bir benchmark’tır. Senaryo odaklı tasarımı, görsel karmaşıklığın, dikkat dağıtıcıların yoğunluğunun ve zamansal dinamiklerin ince ayarlı kontrolüne olanak tanır, daha zorlu yeni örneklerin keyfi olarak oluşturulmasını destekler ve yeni nesil modelleri stres testine tabi tutmayı amaçlar. İlk deneyler, Gemini 2.5 Pro ve OpenAI o3 dahil olmak üzere SOTA modellerinin tüm kategorilerde önemli performans boşlukları olduğunu göstermektedir (Kaynak: HuggingFace Daily Papers)
EverGreenQA: Soru-cevap güvenilirliğini artırmak için çok dilli, her zaman güncel soru sınıflandırma veri kümesi: LLM’lerin soru-cevap (QA) görevlerinde soruların güncelliği (cevapların zamanla değişip değişmediği) nedeniyle halüsinasyon görmesi sorununu çözmek için araştırmacılar EverGreenQA’yı tanıttı. Bu, değerlendirme ve eğitimi destekleyen, her zaman güncel etiketlere sahip ilk çok dilli QA veri kümesidir. Bu veri kümesi aracılığıyla araştırmacılar, 12 modern LLM’yi benchmark testine tabi tutarak soruların güncelliğini kodlama yeteneklerini değerlendirdi ve hafif, çok dilli bir sınıflandırıcı olan EG-E5’i eğitti. Araştırma ayrıca, her zaman güncel sınıflandırmanın öz-bilgi tahminini iyileştirme, QA veri kümelerini filtreleme ve GPT-4o’nun erişim davranışını açıklama gibi uygulamalarını da göstermektedir (Kaynak: HuggingFace Daily Papers)
KVzip: Sorgudan bağımsız KV önbellek çıkarma yöntemi, bellek kullanımını ve kod çözme gecikmesini önemli ölçüde azaltıyor: Güney Kore Seul Ulusal Üniversitesi ML Laboratuvarı, gelecekteki çeşitli sorguları desteklemeyi amaçlayan bir KV önbellek sıkıştırma yöntemi olan KVzip’i yayınladı. Bu yöntem, sorgudan bağımsız bir çıkarma stratejisi aracılığıyla yaklaşık 3-4 kat bellek azaltma ve 2 kat kod çözme gecikmesi düşüşü sağlıyor. Şu anda Qwen3/2.5, Gemma3 ve LLaMA3 gibi modelleri destekliyor ve GitHub’da demo kodu sunuluyor (Kaynak: Reddit r/LocalLLaMA)

NimbleEdge, LLM çalışma hızını ve bellek verimliliğini artırmak için seyrek Transformer operatör çekirdeklerini açık kaynak olarak yayınladı: NimbleEdge ekibi, Apple’ın LLM in a Flash ve Zichang ve arkadaşlarının Deja Vu araştırmalarına dayanarak, yapılandırılmış bağlam seyrekliği için birleştirilmiş operatör çekirdekleri oluşturdu. Bu çekirdekler, çıktıları nihayetinde sıfır olacak ileri beslemeli katman ağırlıklarını ve aktivasyonlarını yüklemekten ve hesaplamaktan kaçınarak, Transformer’daki MLP katmanlarında %50 bellek tüketimi azalmasıyla birlikte 5 kat performans artışı sağlıyor. Llama 3.2 3B modeline uygulandığında, genel verim 1.78 kat artarken bellek kullanımı %26.4 azalıyor. Kod GitHub’da açık kaynak olarak yayınlandı ve int8, CUDA ve seyrek dikkat desteği planlanıyor (Kaynak: Reddit r/MachineLearning)
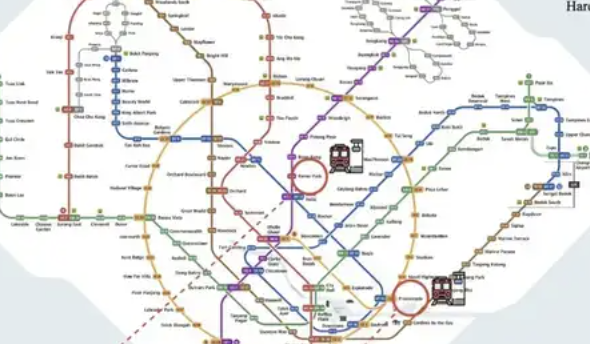
ReasonMap: Yüksek çözünürlüklü ulaşım haritaları için çok modlu çıkarım değerlendirme benchmark’ı yayınlandı: Westlake Üniversitesi ve diğer kurumların araştırma ekipleri, yüksek çözünürlüklü ulaşım haritalarına (özellikle metro haritaları) odaklanan çok modlu bir çıkarım değerlendirme benchmark’ı olan ReasonMap’i tanıttı. Bu benchmark, büyük modellerin görüntülerdeki ince taneli yapılandırılmış uzamsal bilgileri anlama yeteneğini değerlendirmeyi amaçlamaktadır ve yüksek çözünürlüklü görüntüler (ortalama 5839×5449), zorluk farkındalığı olan tasarım ve çok boyutlu bir değerlendirme sistemi içerir. Test sonuçları, mevcut ana akım açık kaynaklı modellerin ReasonMap’te, özellikle hatlar arası rota planlamada düşük performans gösterdiğini, kapalı kaynaklı çıkarım modellerinin (GPT-o3 gibi) ise açık kaynaklı modellerden önemli ölçüde daha iyi performans gösterdiğini ancak yine de insan seviyesinden uzak olduğunu göstermektedir. Pekin ve Hangzhou gibi karmaşık metro haritaları modellere büyük zorluklar çıkarmaktadır (Kaynak: 量子位)
Yandex, Yambda-5B’yi yayınladı: Büyük ölçekli açık öneri sistemi veri kümesi: Yandex, 4,79 milyar kullanıcı-öğe etkileşimini içeren büyük ölçekli anonimleştirilmiş bir müzik akışı veri kümesi olan Yambda-5B’yi tanıttı. Bu veri kümesinin özellikleri arasında “is_organic” işareti ve küresel zaman bölümlendirmesi (GTS) sağlaması, kullanıcıları doğrudan tanımlayabilecek dinleme geçmişlerini ve beğenilerini içermemesi, anonimlikten arındırmaya karşı dirençli olması ve örtük (şarkı dinleme, atlama) ve açık (beğenme/beğenmeme) geri bildirimleri içermesi yer alıyor. Yambda-5B, öneri sistemi araştırmaları için yüksek kaliteli, çok modlu veri kaynakları sağlamayı amaçlamaktadır (Kaynak: TheTuringPost)
Tencent, 2025 Yıldız Ateşi Mücadele Kampı’nı başlattı, büyük modeller gibi ileri düzey araştırmalara katılmak üzere en iyi öğrencileri işe alıyor: Tencent, 2025 yılı “Yıldız Ateşi Mücadele Kampı”nı başlattığını duyurdu. Lise 2, lise 3 (2025 mezunları) ve ilgili disiplinlerde üstün başarı gösteren diğer öğrencilere yönelik olarak 60-70 kişi işe alınacak. Seçilenler, Shenzhen merkezine gitme, ultra uzun metin anlama, uzun düşünce zinciri teknolojisi, somutlaştırılmış zeka + robotik, çok modlu algılama ve anlama, güvenlik saldırı ve savunması (LLM Agent hacker tasarımı dahil) ve kuantum teknolojisi gibi altı ileri düzey konunun araştırılmasına katılma fırsatı bulacaklar. Bu program, yetenekli gençlere endüstriyel düzeyde araştırma senaryolarıyla tanışma, teknolojik ufuklarını genişletme ve sektör anlayışlarını derinleştirme fırsatları sunmayı amaçlamaktadır (Kaynak: 量子位)

💼 İş Dünyası
Meta’nın Scale AI’a 10 milyar doları aşabilecek bir yatırım yapmayı planladığı söyleniyor, askeri ve diğer alanlardaki yapay zeka uygulamalarını güçlendirecek: Haberlere göre Meta, yapay zeka veri etiketleme şirketi Scale AI ile milyarlarca dolar, hatta 10 milyar doları aşabilecek büyük bir yatırım için görüşüyor. Eğer doğruysa, bu Meta’nın en büyük dış yapay zeka yatırımlarından biri olacak. Scale AI daha önce Meta’nın Llama 3 modelini temel alarak ABD ulusal güvenlik görevlerini desteklemek üzere askeri amaçlı özel bir model olan Defense Llama’yı geliştirmişti. Bu hamle, Meta’nın yapay zeka alanında, özellikle hükümet ve savunma ile ilgili uygulamalarda daha aktif bir yatırım ve işbirliği stratejisi benimseyeceğinin bir işareti olabilir (Kaynak: 36氪)

Mashang Consumer Finance, “Tianjing” büyük modelinin 3.0 sürümünü yayınladı ve finansal karar verme platformuna yükseltti: Mashang Consumer Finance, finansal büyük modeli “Tianjing”in 3.0 sürümünü tanıttı. Yeni sürümün temel atılımı, bireysel bilgelikten kolektif bilgeliğe doğru sistemik bir sıçrama yapmasıdır; artık yalnızca mantıksal öğrenmeye dayanmak yerine, şirkette dağınık halde bulunan çalışan izleri, iş günlükleri gibi örtük deneyimleri derinlemesine kazıyor ve bunları yapılandırılmış bilgiye dönüştürüyor. Tianjing 3.0, bir araçtan karar verme platformuna yükselmeyi, insan-makine işbirliğini teşvik etmeyi, karmaşık hizmet süreçlerini dinamik olarak ayrıştırmayı ve kullanıcı talepleri ile uyumluluk gereksinimlerine göre en uygun hizmet kombinasyonunu gerçek zamanlı olarak eşleştirerek yerel optimumdan küresel optimuma karar vermeyi amaçlamaktadır (Kaynak: 量子位)

Together AI, Charles Zedlewski’yi yeni Ürün Direktörü olarak atadı ve açık kaynaklı üretken yapay zeka platformuna odaklandı: Together AI, Charles Zedlewski’yi yeni Ürün Direktörü (CPO) olarak atadığını duyurdu. Charles Zedlewski daha önce Temporal ve Cloudera’da geliştiricilere yönelik topluluk odaklı platform ürünlerini yönetmişti. Together AI, açık kaynaklı üretken yapay zekanın geleceğini inşa etmeye kararlı olduğunu vurgulayarak, açık modellerin esneklik, maliyet etkinliği ve yenilikçilik açısından avantajlara sahip olduğunu belirtiyor. Charles’ın katılımı, Together AI’ın her geliştirici ve işletme için güçlü üretken yapay zekayı erişilebilir kılan yetkili bir açık kaynaklı yapay zeka platformu oluşturma çabalarını daha da ileriye taşımayı amaçlıyor (Kaynak: togethercompute)

🌟 Topluluk
Waymo otonom araçları Los Angeles’ta kundaklandı, toplulukta AV güvenliği endişeleri ve tartışmaları alevlendi: Son zamanlarda, Los Angeles’ta birden fazla Waymo otonom aracı kundaklandı. Bu olay sosyal medyada geniş yankı uyandırdı ve tartışmalara yol açtı; içerikler halkın otonom araçlara olan kabulü, güvenlik endişeleri ve bu tür olayların yapay zeka tarafından üretilen içeriklerle (örneğin Veo 3 tarafından üretilen videolar) uygunsuz bir şekilde abartılması veya çarpıtılması riskini içeriyordu. Bazı yorumcular bu sahneyi bilim kurgu filmi “Children of Men” ile karşılaştırarak olayın dramatikliğini ve potansiyel toplumsal etkilerini vurguladı (Kaynak: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
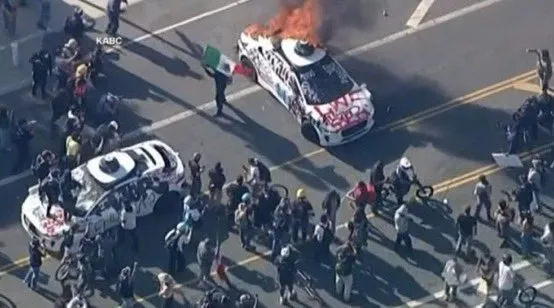
Reddit, Anthropic’i Claude AI’ı eğitmek için izinsiz içerik toplamakla suçlayarak dava açtı: Reddit, Anthropic’e karşı, yapay zeka modeli Claude’u eğitmek için Reddit gönderilerini ve konuşmalarını izinsiz ve ücretsiz olarak topladığı iddiasıyla dava açtı. Reddit, bu eylemin, içeriğin izinsiz ticari kullanımını yasaklayan kullanıcı sözleşmesini ihlal ettiğini savunuyor ve Anthropic’in “Reddit’i toplamayı durdurduğu” yönündeki iddiasının yanlış olduğunu belirtiyor. Dava ayrıca, Anthropic’in lisans anlaşması olan diğer şirketler gibi kullanıcıların sildiği gönderileri silme mekanizmasına sahip olmaması nedeniyle gizlilik sorunlarını da içeriyor. Reddit, mahkemeden Anthropic’in Reddit verilerini kullanmasını yasaklamasını ve muhtemelen Claude’u piyasadan çekmesini talep ediyor (Kaynak: Reddit r/ArtificialInteligence,Reddit r/artificial)
Yapay Zeka Mühendisleri Fuarı’nda hararetli tartışma: Simon Willison son altı aydaki LLM gelişimini değerlendirdi, araç + çıkarım kombinasyonunu vurguladı: San Francisco Yapay Zeka Mühendisleri Fuarı’nda Simon Willison, “bisiklete binen pelikan” SVG görüntü oluşturma testiyle son altı aydaki LLM’lerin hızlı gelişimini esprili bir şekilde değerlendirdi ve 30’dan fazla yapay zeka modelini bizzat test etti. Mevcut en güçlü yapay zeka kombinasyonunun “araçlar + çıkarım” olduğunu vurguladı; örneğin, o3/o4-mini’nin aramadaki performansı ve MCP mimarisinin araç çağrısı nedeniyle dikkat çekmesi gibi. Konuşmada ayrıca ChatGPT’nin aşırı pohpohlaması, Claude’un kullanıcıları “ihbar etme” olasılığı gibi yılın yapay zeka “tuhaf hataları” da sıralandı ve ipucu enjeksiyonu ile veri sızıntısı risklerine dikkat çekildi (Kaynak: 36氪,swyx)

Toplulukta yapay zekanın neden olduğu mesleki kaygı ve başa çıkma stratejileri tartışılıyor: Reddit’te “Yapay zeka kaygısıyla nasıl başa çıkılır?” başlıklı gönderi hararetli tartışmalara yol açtı. Kullanıcılar genel olarak önümüzdeki birkaç yıl içinde yapay zekanın büyük ölçekli işsizliğe yol açabileceğinden, özellikle birikimi yetersiz, borcu fazla olan kişiler için ciddi bir tehdit oluşturduğundan endişe duyuyor. Tartışmada, bazıları zanaatkarlık, hemşirelik gibi alanlara yönelmeyi önerirken, aynı zamanda bu alanların çok sayıda geçiş yapan kişi nedeniyle doygunluğa ulaşacağından da endişe ediyor. Yorumcular uykusuzluk, işe odaklanamama gibi kendi kaygılarını paylaştı. Bazı görüşler, yapay zekayı aktif olarak öğrenmek, uyum sağlamak gerektiğini belirtiyor ve tarihte teknolojik yeniliklerin (otomobil, internet gibi) de benzer endişelere yol açtığını ancak sonunda yeni istihdam fırsatları yarattığını işaret ediyor. Bazı yorumcular ise şu anda yapay zekanın insan işlerini devralma derecesinin abartıldığını, büyük ölçekli işten çıkarmaların kısa vadede pek olası olmadığını düşünüyor (Kaynak: Reddit r/ArtificialInteligence)
Kullanıcı, ChatGPT kullanarak “acımasız” bir öz-psikanaliz deneyimini paylaştı: Bir Reddit kullanıcısı, ChatGPT kullanarak “vahşi bir yönetici tarzı” öz-psikanaliz deneyimini paylaştı. Belirli ipuçları aracılığıyla ChatGPT’den gerçek güçlü yönler, derin zayıflıklar, tekrarlayan başarısızlık kalıpları, kaçınılan alanlar ve ihmal edilen beceriler olmak üzere beş açıdan sert bir analiz yapmasını ve üç aşamalı bir gelişim planı sunmasını istedi. Kullanıcı, sürecin acı verici olmasına rağmen (örneğin, 12 proje başlatıp hiçbirini tamamlamadığı ve fiili eylem yerine üretkenliği aşırı araştırdığı belirtildi), bu “acımasız” geri bildirimin sonunda değişimini tetiklediğini belirtti. Bu gönderi, toplulukta yapay zekanın öz yansıma ve kişisel gelişim alanlarındaki uygulamaları hakkında tartışmalara yol açtı (Kaynak: Reddit r/ArtificialInteligence)
LLM’lerin hafıza ve çıkarım yetenekleri üzerine tartışma: Bilgili mi, yoksa gerçekten anlıyor mu?: Sosyal medyada kullanıcılar, büyük dil modellerinin (LLM) hafızaya dayalı gerçekleri hatırlama görevlerindeki üstün performansını ve bunun gerçekten çıkarım yeteneğine sahip oldukları anlamına gelip gelmediğini tartışıyor. Bazı görüşler, LLM’lerin karmaşık görünen görevlerdeki başarısının, insan anlamındaki derin anlayış ve yaratıcılıktan ziyade, devasa eğitim verilerine ve örüntü tanımaya daha fazla dayandığını savunuyor. Meta gibi şirketlerin araştırmaları, model kapasitesini ölçmek için hafızanın kullanılabileceğini, kapasite dolduğunda ise genellemenin başladığını gösteriyor. Bu tartışma aynı zamanda eğitim sistemlerinde ezberciliğe verilen önemi ve bilgiye erişim ile yapay zeka araçlarını kullanma becerilerinin geliştirilmemesini de ele alıyor (Kaynak: omarsar0,menhguin,menhguin)

💡 Diğer
Stripe ödeme sahtekarlığı tespit temel modelinin başarı öyküsü analizi: Stripe mühendislerinin başarılı bir ödeme sahtekarlığı tespit temel modeli oluşturma hakkındaki paylaşımları dikkat çekti. Analiz, bu vakanın özelliklerini şöyle sıralıyor: 1) Sahtekarlık tespiti özünde geleceği tahmin etmek değildir, teorik olarak sinyaller yeterli olduğunda yüksek doğruluk oranına ulaşılabilir; 2) Stripe zaten sinyal açısından zengin bir ortamda bulunuyor, sıfırdan veri birikimine ihtiyaç duymuyor; 3) Bu senaryo, geleneksel makine öğreniminden temel modele doğru bir otomasyon yükseltmesidir ve doğrudan bir değiştirmeye yakındır. Bu, bu tür yapay zeka uygulamalarının “anlık zaferlerinin” neden nadir olduğunu ve çoğu yapay zeka ticari değerinin gerçekleştirilmesinin birçok engeli aşması gerektiğini açıklıyor (Kaynak: random_walker)
Yapay zeka dönüşümünün bilişsel temeli: Sistematik bilgi algısı ve teknoloji içgörü mekanizması kilit öneme sahip: Şirketlerin yapay zeka dönüşümünde, bireysel deneyimleri ve geleneksel yol bağımlılıklarını aşan sistematik, yapılandırılmış bir bilgi algısı ve teknoloji içgörü mekanizması kurmaları gerekiyor. Bu, iç veri analizi yetenekleri ve dış bilgi ağları (akademi, endüstri, sermaye piyasaları, startup’lar) oluşturmayı içerir. Yapay zeka yatırım getirisinin değerlendirilmesi de geleneksel ROI’den “dönemsel, çok boyutlu” bir sisteme doğru kaymalı ve dış bilgi ağlarıyla birleşerek sürekli doğrulama ve dinamik ayarlama yapan stratejik bir kapalı döngü oluşturmalıdır. Makale, yapay zekanın tek seferlik bir araç olmadığını, sürekli gelişen ve değeri artan stratejik bir varlık olduğunu vurguluyor (Kaynak: 36氪)
Frigate: Gerçek zamanlı yerel nesne tespitine dayalı NVR sistemi: Frigate, Home Assistant için özel olarak tasarlanmış yerel bir ağ video kayıt cihazı (NVR) sistemidir ve IP kameralarda gerçek zamanlı yerel nesne tespiti için OpenCV ve Tensorflow kullanır. Sistem, kaynak optimizasyonuna ve performansa vurgu yapar, düşük ek yükle hareket tespiti yoluyla nesne tespitini tetikler ve çoklu işlem kullanır. En iyi performans için Google Coral veya Hailo gibi yapay zeka hızlandırıcılarının kullanılması önerilir. Frigate, 7/24 kayıt, nesne tespitine dayalı kayıt saklama, MQTT entegrasyonu, RTSP yeniden akışı ve WebRTC/MSE düşük gecikmeli gerçek zamanlı görüntülemeyi destekler (Kaynak: GitHub Trending)
