
キーワード:SAM 3, Gemini 3 Flash, AI動画生成, エンボディドAI, 大規模言語モデル, AIエージェント, 3Dデジタルヒューマン, Meta SAM 3画像セグメンテーション, Google Gemini 3 Flashの性能, Alibaba万相2.6動画生成, 深度機智状況データ収集, Xiaomi MiMo-V2-Flashオープンソース
🔥 注目
MetaがSAM 3モデルを発表 : Facebook Researchは、統一された画像およびビデオのプロンプト可能なセグメンテーション基盤モデルであるSAM 3を発表しました。テキストまたは視覚的なプロンプトを通じてオブジェクトの検出、セグメンテーション、トラッキングを行い、オープンボキャブラリー概念のインスタンスセグメンテーション能力を導入し、SA-COベンチマークで75-80%の人間のパフォーマンスを達成しました。このモデルは、400万以上のユニークな概念を自動的にアノテーションした革新的なデータエンジンによって駆動され、識別力と効率を向上させるために、存在トークンとデカップリングされた検出器-トラッカーを含む新しいアーキテクチャ設計を採用しています。(出典: GitHub Trending)

GoogleがGemini 3 Flashモデルを発表 : Googleは、これまでのAIモデルで最速となるGemini 3 Flashを発表しました。これは速度のために特別に設計され、最先端のインテリジェンスを維持しています。このモデルは、GPQA DiamondやHumanity’s Last Examといった博士レベルの推論および知識ベンチマークテストで優れたパフォーマンスを示し、SWE-bench VerifiedコーディングベンチマークテストではGemini 3 Proをも上回りました。Gemini 3 Flashは、Gemini 2.5 Proの3倍の速度を低コスト(入力トークン100万あたり0.50ドル、出力3ドル)で提供し、Google検索のAIモードのデフォルトモデルとして世界中で展開されており、企業アプリケーションおよび開発者エコシステムにおけるAIの普及を推進することを目指しています。(出典: WeChat)
🎯 動向
AI動画生成モデルの継続的な進化 : AlibabaのWanxiang 2.6、ByteDanceのSeedance 1.5 Pro、Kling 2.6などのモデルが相次いで発表されました。Wanxiang 2.6は、音声と映像の一貫性のあるキャラクターカスタマイズとマルチショットの絵コンテ制御を実現し、1回の生成で最大15秒の動画を作成できます。Seedance 1.5 Proは、高精度な音声と映像の同期および多言語対応を特徴としています。Kling 2.6は、音色制御とMotion Control機能を強化しました。これらの進展は、AI動画制作が「ガチャ」時代から、正確に制御可能な映画レベルの制作という新しい段階へと移行していることを示しています。(出典: WeChat, WeChat, Kling_ai, Alibaba_Wan)
具身智能技術と戦略の深化 : DeepMindは、人間の第一視点データを通じて汎用性の課題を解決する具身智能「コンテキストデータ収集」モードを発表しました。Horizon Roboticsは、スマートカーと汎用ロボットを強化する「BPU+コンパイラ+基盤モデル」のWintel戦略を発表しました。中山大学の王広潤博士チームは、物理モデルと空間モデルのデカップリングを強調し、少量のサンプルでのファインチューニングによる汎化を実現するE0具身大規模モデルを発表しました。これらの進展は、具身智能が機械的な模倣から論理的な理解と物理世界との相互作用へと移行するのを共同で推進しています。(出典: WeChat, WeChat, WeChat)
XiaomiとSenseTimeが最先端の大規模モデルを発表 : Xiaomiは、MoEアーキテクチャを採用し、Agentおよびコードシナリオ向けに設計されたMiMo-V2-Flash大規模モデルをオープンソース化し、極めて高い推論効率と低コストで世界のオープンソースモデルのトップティアに参入しました。SenseTimeは、純粋な言語モデルが物理世界を理解する上での限界を解決することを目指し、ネイティブなマルチモーダルとクロスビュー予測を通じて空間知能を向上させるSenseNova-SIモデルとNEOアーキテクチャを発表しました。(出典: WeChat, WeChat)
AI PCと特定のアプリケーションシナリオの融合 : Covestroは、非接触型rPPG技術を利用して非接触で血圧や皮膚の検出を行い、Intel NPUと連携してローカルで効率的な計算を行うAI PCパーソナルヘルスアシスタントを発表しました。同時に、Yunpeng Technologyは、AIヘルスケア大規模モデルスマート冷蔵庫やデジタル化された未来のキッチンラボを含むAI+ヘルスケア新製品を発表し、AIを日常の健康管理と家庭テクノロジーに統合しました。(出典: WeChat, 36氪)

Moore ThreadsのLiteGS技術が3Dグラフィックスレンダリングを突破 : Moore Threadsは、SIGGRAPH Asia 2025の3DGS再構築チャレンジで銀賞を受賞し、自社開発のLiteGS技術をオープンソース化しました。LiteGSは3D Gaussian Splattingの基本ライブラリであり、フルリンク協調最適化を通じて、トレーニング効率と再構築品質において顕著なリードを達成し、3DGS技術の3D再構築、リアルタイムレンダリング、具身智能トレーニングシナリオへの応用を推進しています。(出典: WeChat)

小規模LLMのデータ効率的な事前学習における新たな進展 : 韓国の独立研究エンジニアが、1.5Bパラメータの韓英バイリンガル基盤LLMであるGuminiを発表しました。これはわずか3.14Bのトレーニングトークンで韓国のベンチマークテストで上位にランクインしました。この進展は、アーキテクチャとトレーニング戦略を最適化することで、LLMの事前学習がデータ効率的になり、「より多くのデータ+より多くの計算能力」というパラダイム以外の新しい道を小規模チームや独立研究者に提供することを示しています。(出典: Reddit r/LocalLLaMA)

マルチモーダルAIの特定分野での深化する応用 : MiraTTSは、高品質で高速なTTSモデルとして、リアルタイムの100倍以上の速度でリアルな音声を生成でき、多言語をサポートしています。同時に、多言語RAGシステムが農業生態系意思決定支援に導入され、低リソースで高度に専門的な分野におけるLLMの挙動を研究し、すでに1年間本番環境で稼働しています。これらは、マルチモーダルAIが音声生成と垂直分野の意思決定支援において成熟した応用を示しています。(出典: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Taobao Technologyがモバイル3Dデジタルヒューマン再構築システムを発表 : Taobao TechnologyのMetaチームは、SIGGRAPH AsiaでHRM²Avatarシステムを発表しました。これにより、ユーザーは携帯電話の単眼ビデオだけで、高忠実度のリアルタイム3Dデジタルヒューマンを作成およびレンダリングできます。このシステムは、明示的な服装メッシュとガウス表現を組み合わせ、モバイルデバイス上でのリアルタイム駆動とレンダリングをサポートし、視覚的なリアリズム、クロス姿勢の一貫性、モバイル性能において優れたパフォーマンスを発揮し、3Dデジタルヒューマン作成の敷居を下げることを目指しています。(出典: WeChat)

🧰 ツール
Letta:ステートフルAIエージェント構築プラットフォーム : Letta (旧MemGPT) は、ステートフルAIエージェントを構築するためのプラットフォームであり、その核となるのは高度なメモリ管理です。これにより、AIエージェントは時間とともに学習し、自己改善することができます。このプラットフォームは、Python/TypeScript SDK、ノーコードADE環境、ローカルデスクトップ版、およびクラウドサービスを提供し、メモリ階層、メモリブロック、エージェントコンテキストエンジニアリングなどのコア概念をサポートし、複数のエージェントによるメモリ共有とバックグラウンドで実行される「スリープタイムエージェント」を実現します。Maestroは、AIエージェントをオーケストレーションするための無料オープンソースのクロスプラットフォームデスクトップアプリケーションであり、ファイルシステムメモリとツール作成をサポートし、「自動実行」機能を備えています。Toadは、統一されたAIコーディングエージェントターミナルインターフェースとして、異なるAIコーディングツールとの統合を簡素化します。(出典: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
MiaodaノーコードAIプログラミングツールが非プログラマーを支援 : Miaodaは、リリースから8ヶ月で50億元以上の価値を生み出したノーコードAIプログラミングツールであり、主なユーザーは非プログラマーです。このツールは、「プロダクトマネージャーエージェント」を通じて複数回の要件ヒアリングを行い、曖昧な要件を構造化された製品ドキュメントに変換し、その後「開発エージェント」が実装します。Miaodaはバックエンド構築の課題を克服し、AIとデータベースの深い統合を実現し、精密な戦略を通じてコスト削減と効率向上を達成し、「コードの山」を回避しています。(出典: WeChat)

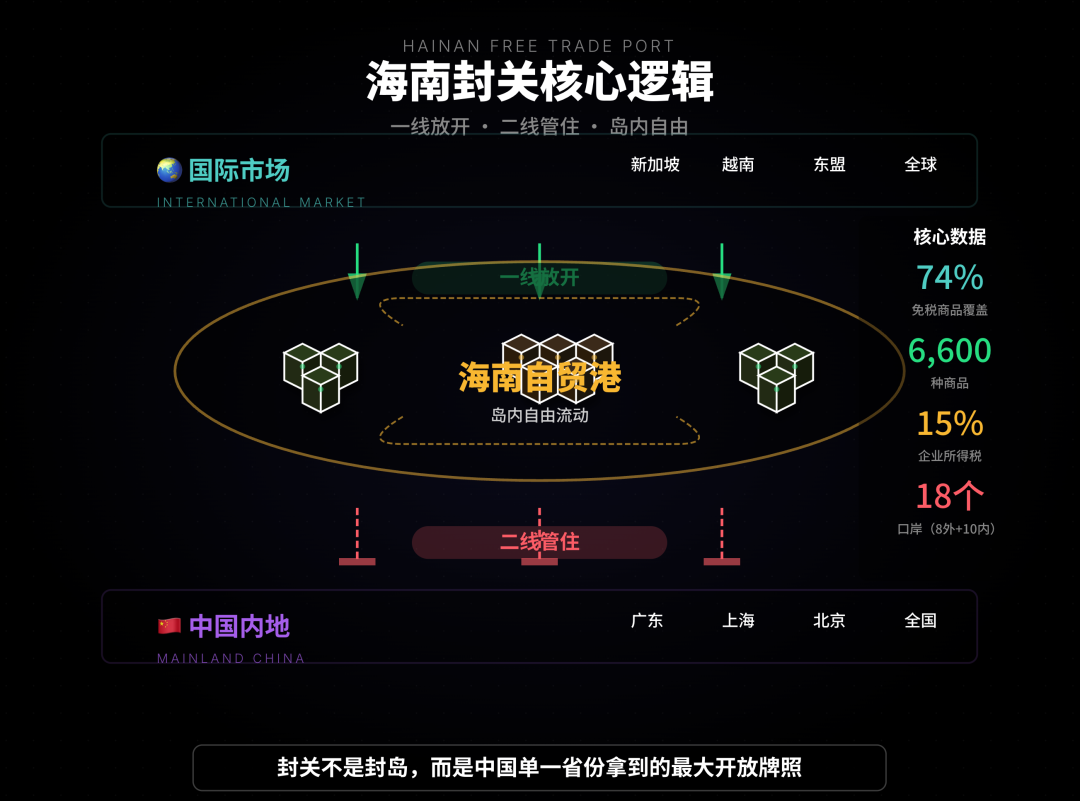
AI支援分析と販売自動化ツール : この記事では、AIが「海南封鎖」政策のトレンド分析をどのように支援するかを示しています。多チャネル情報の統合、分類、および推論を通じて、ユーザーが複雑な情報を整理するのに役立ちます。QuickHookは、Gemini 3とSearch Groundingに基づいた販売自動化ツールであり、15分間の手動調査を10秒の自動化に変換でき、コールドアウトリーチにおける「AI調」の問題を解決することを目的としています。(出典: WeChat, Reddit r/artificial)
OpenWebUI APIとローカルSTTシステム : OpenWebUIはAPIインターフェースを提供し、開発者がWearOS上の音声モードアプリケーションのようなカスタムクライアントアプリケーションを作成し、パーソナライズされたAIインタラクション体験を実現できるようにします。Kroko-onnx-home-assistantは、Home Assistant向けに設計されたオープンソースのローカルストリーミング音声テキスト変換(STT)パイプラインであり、高品質、リアルタイムストリーミング処理、100%ローカル化などの特徴を持ち、低リソースデバイスでも効率的に動作します。(出典: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
複数のLLM連携によるゲーム開発効率の向上 : 開発者はOpenAI Realtime APIを利用してゲームの要件を収集し、Gemini 3 Proを通じてMarkdown仕様を生成し、さらにAnthropic Opus 4.5によってアプリケーションをコーディングすることで、カスタマイズされたスマートボールゲームの開発を実現しました。この複数のLLMが連携するワークフローは、異なるLLMの利点を最適化し、要件からコードまでの開発効率と品質を向上させ、複雑なプロジェクトに新しい開発パラダイムを提供します。(出典: Reddit r/artificial)

📚 学習
Transformerアーキテクチャの最適化と正規化の革新 : プリンストン大学のLiu Zhuangチームは、TransformerにおけるLayerNormをガウス誤差関数(erf)に基づくDerf演算子に置き換えることを提案し、視覚、生成、遺伝子配列モデリングなどのタスクで既存の手法を全面的に上回りました。同時に、南洋理工大学と復旦大学はEFLA(Error-Free Linear Attention)を提案し、解析解を通じて長系列における線形アテンションの数値ドリフトを排除し、安定性と性能の同時向上を実現しました。(出典: WeChat, WeChat)

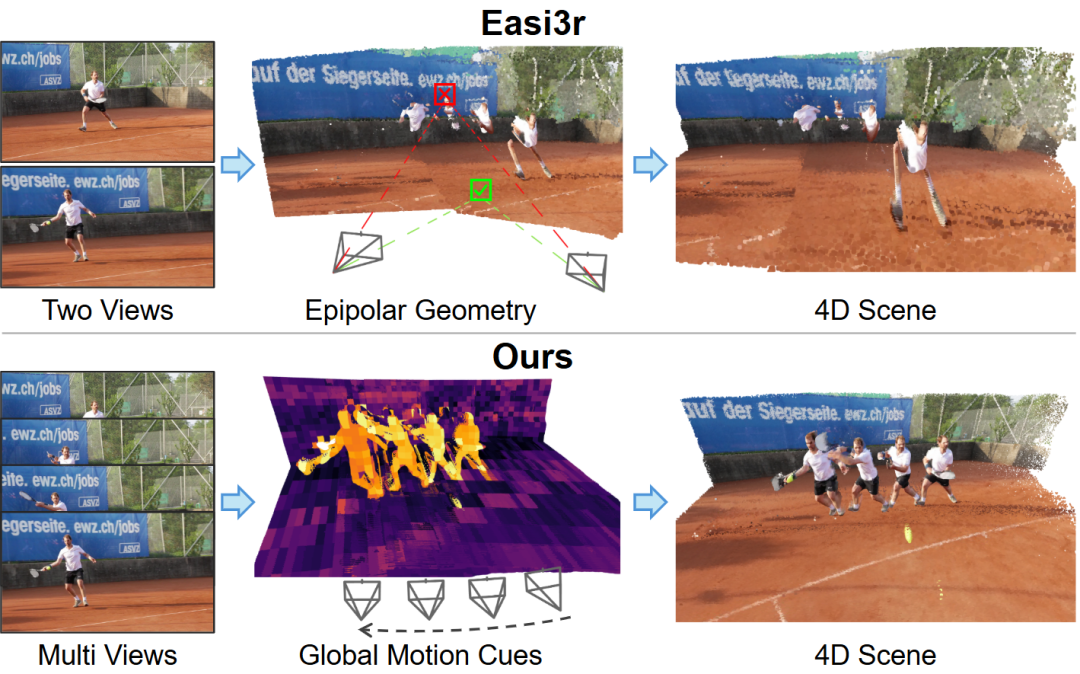
マルチモーダルとビデオ理解の最先端研究 : DiffusionVLフレームワークは、自己回帰モデルを拡散視覚言語モデルに変換し、性能を大幅に向上させ、推論を高速化します。SAGEシステムは、強化学習を利用して長尺ビデオの多段階推論を実現し、オープンエンドのビデオタスクで優れたパフォーマンスを発揮します。MMSI-Video-Benchは、ビデオ空間知能の総合ベンチマークとして、MLLMが幾何学的推論や運動グラウンディングなどで体系的に失敗していることを明らかにしました。VGGT4Dは、Transformer内部の運動手がかりを掘り起こすことで動的シーンを処理する、トレーニング不要の4Dシーン再構築フレームワークを提案しています。(出典: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
AIエージェントとLLMメモリの最適化 : 南京理工大学とBaiduなどの機関は、ViLoMemを提案しました。これは、デュアルストリームセマンティックメモリ(視覚ストリーム+論理ストリーム)を通じて、マルチモーダル大規模モデルが「教訓を記憶できない」という問題を解決し、推論パフォーマンスを大幅に向上させます。LightSearcherフレームワークは、経験的メモリを通じてRL駆動のエージェントツール呼び出しを最適化し、呼び出し回数を39.6%削減し、推論時間を48.6%短縮しながら、精度を維持します。MEM1フレームワークも、RLを通じてエージェントを訓練し、長期間のタスクで一定のメモリを維持します。(出典: WeChat, WeChat, omarsar0)
LLM評価とデータセット構築 : LikeBenchは、マルチセッション動的評価フレームワークとして、LLMのパーソナライズされた好み度を初めて7つの診断指標に分解し、ユーザーの好みに適応するモデルの能力を測定します。VOYAGERは、トレーニング不要の方法で、LLMを利用して多様なデータセットを生成し、多様性を1.5〜3倍に大幅に向上させます。FiNERwebデータセット作成パイプラインは、91言語と25スクリプトに対応するスケーラブルな多言語固有表現認識リソースを提供します。NVIDIAもNemotron 3 Nanoの完全な評価ガイドを公開し、LLM評価の透明性と再現性を向上させました。(出典: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

AIセキュリティと説明可能性の研究 : この研究では、ディープフェイクの課題に対処するため、マルチメディアコンテンツの真偽を堅牢かつ正確に検出するための再合成フレームワークを提案しています。同時に、Hybrid Attribution Priorsフレームワークは、Class-Aware Attribution Prior (CAP)を通じて言語モデルが微細なカテゴリ区別を捉えるように誘導し、モデルの説明可能性と堅牢性を強化します。Hyper++は、双曲深層強化学習を改善し、エージェントの学習安定性を向上させました。(出典: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
深層学習学習リソースと研究機会 : AIhubは、2025年AAAI/ACM SIGAI博士課程学生フォーラムのインタビュー集を公開し、多分野にわたるAIの最先端研究を網羅しています。同時に、MLシステムとGPUプログラミングに関する新しいコースが予告されており、実践を通じてDLスタックを深く理解することを目指しています。PyTorch/vLLMハードウェアチャレンジは、開発者にバグ修正を奨励し、コンピュータビジョンの学習ロードマップの提案もあり、学習者がキャリアパスを計画するのに役立ちます。(出典: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

3D/XRとヒューマンコンピュータインタラクションモデリング : TIMARフレームワークは、インタラクティブな3D対話における頭部ダイナミクスを因果的にモデリングすることを提案し、マルチモーダル情報を融合して連続的な3D頭部ダイナミクスを予測します。SARからRGB画像への変換研究では、深層学習モデルを通じて鮮明な画像を生成する方法が探求されています。就学前児童のアルファベット手書き採点アルゴリズム研究では、テンプレートマッチング手法を用いて子供の手書き品質を正確に評価する方法が模索されています。(出典: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
Scaling Lawsとモデル融合理論 : この研究は、「Scaling Lawが帰納バイアスよりも優れている」という見解に異議を唱え、対称性をエンコードするアーキテクチャがより優れたScaling Exponentsを持つことを発見しました。同時に、多タスクモデル融合の競合解決策(TATR、CAT Merging、LOT Merging)は、競合する次元を特定してフィルタリングしたり、投影または加重融合したりすることで、知識の競合を効果的に緩和し、多タスクの性能と堅牢性を向上させます。(出典: dair_ai, WeChat)
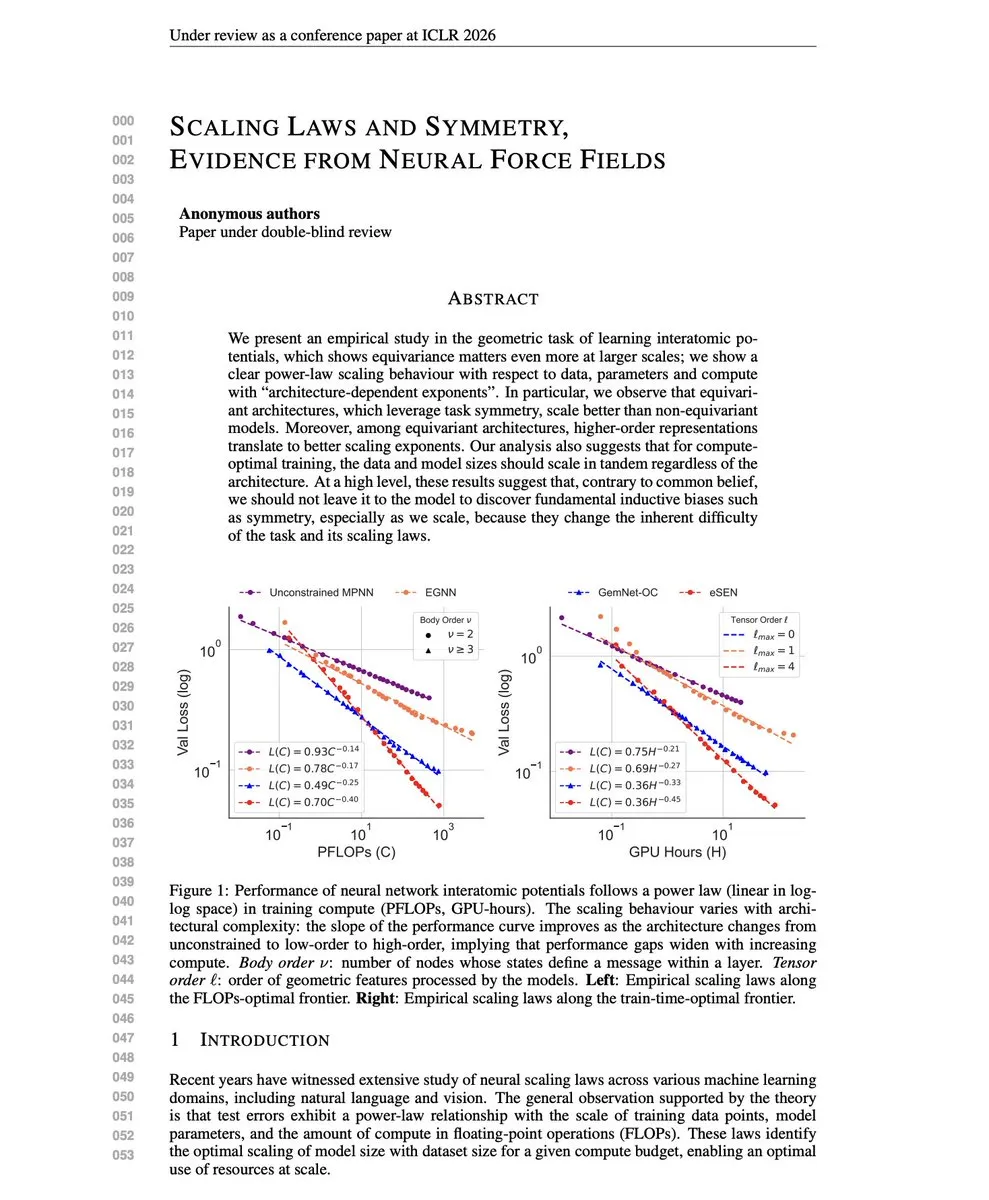
自己回帰ビデオ拡散のEnd-to-Endトレーニング : この研究では、「リサンプリング強制」(Resampling Forcing)フレームワークを導入し、自己回帰ビデオ拡散モデルのEnd-to-Endトレーニングを実現しました。推論時にモデルが過去のフレームで犯すエラーをシミュレートし、疎な因果マスクと履歴ルーティングメカニズムを組み合わせることで、この方法は時間的一貫性を維持しながら、蒸留ベースラインに匹敵する性能を達成し、効率的な長距離生成をサポートします。(出典: HuggingFace Daily Papers)
LLM評価と再現性に関する議論 : Redditコミュニティでは、LLM評価の課題と再現性の問題について議論されています。ユーザーは、信頼できる評価基準を確立し、異なる研究やモデル間の結果の比較可能性を確保する方法、そして急速に進化するLLM分野において、科学的進歩を促進するために評価方法とデータセットを効果的に管理・共有する方法について関心を寄せています。(出典: Reddit r/deeplearning)
💼 ビジネス
Zhipu AIとMiniMaxが香港IPOを目指す : 国内の大規模モデル企業であるMiniMaxとZhipu AIは、中国証券監督管理委員会の登録を完了し、香港証券取引所のリスニングに参加しました。MiniMaxは2026年1月に上場する予定です。Zhipu AIは推定評価額約400億元で、GtoCおよびBtoB、マルチモーダルAgentに焦点を当てています。MiniMaxは推定評価額約300億元で、マルチモーダル能力を核とした製品主導型モデルです。両社とも上場前に戦略の収束とチームの調整を行っており、大規模モデル業界が「資本と効率の二重制約期」に入ったことを示しています。(出典: 36氪)
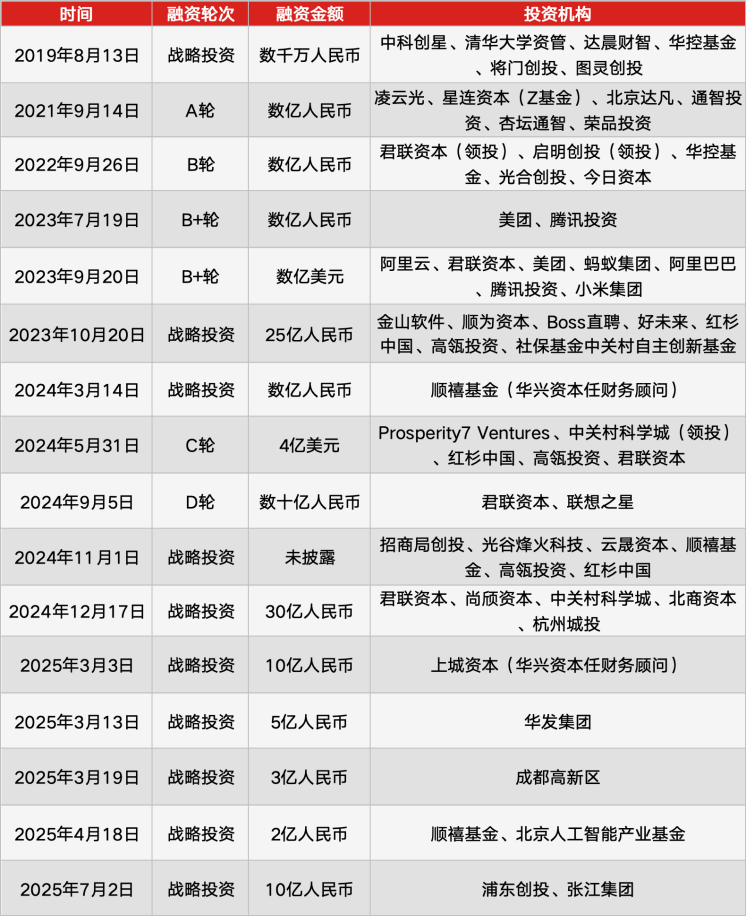
AmazonがOpenAIに100億ドルを投資予定 : AmazonはOpenAIに少なくとも100億ドルを投資する計画であり、この動きには、OpenAIがAmazonのTrainiumシリーズAIチップを使用し、ChatGPTなどのモデルやツールを実行するためにより多くのデータセンター容量を借りることが含まれると予想されています。この投資は、両社のAIインフラストラクチャとモデル展開における協力を深めることを目的としています。(出典: Reddit r/ArtificialInteligence)

Birun Technologyが香港市場の汎用GPU初の株式を目指す : 評価額209億の汎用GPUユニコーン企業であるBirun Technologyは、香港証券取引所のリスニングを通過し、香港市場における「国産GPU初の株式」となる予定です。同社はハーバード大学法学博士のZhang Wenによって設立され、自社開発のGPGPUアーキテクチャに基づくハードウェアシステム(BIREN 106、110、166チップ)とBIRENSUPAソフトウェアプラットフォームを核製品としており、AIトレーニングと推論のフルスタックサポートを提供し、顧客は通信、フィンテックなどの高計算能力産業をカバーしています。(出典: WeChat)
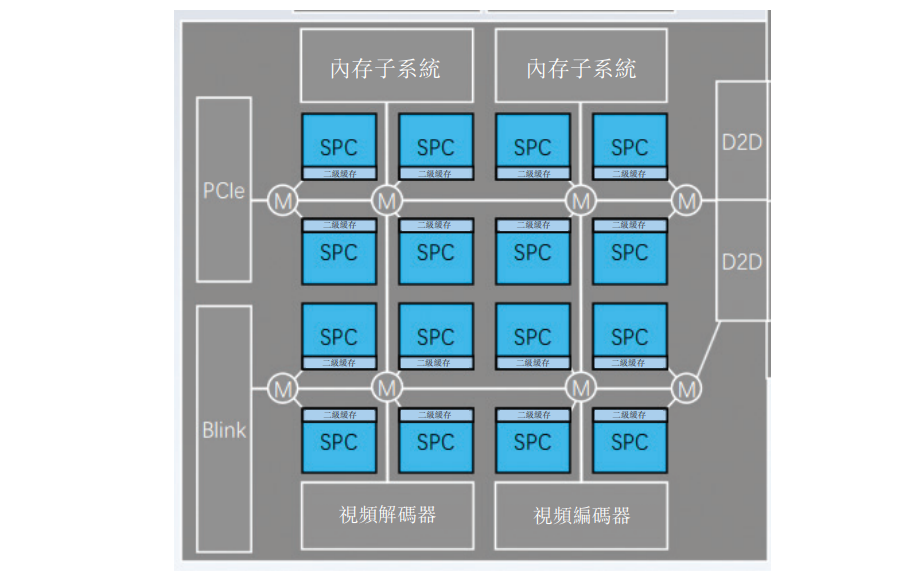
🌟 コミュニティ
AI生成コンテンツの品質とインターネットの「slop」現象 : ソーシャルメディアでは、AI生成コンテンツの品質がまちまちである「slop」現象が広く議論されており、これが今年の言葉に選ばれたことは、AIコンテンツの氾濫と低品質問題を反映しています。これは、インターネット広告プラットフォームの利益追求に対する批判と、AIコンテンツ作成の敷居をどのように高めるかについての考察を引き起こしました。(出典: 36氪)

AIが労働市場と開発者の働き方に与える影響 : ソーシャルメディアでは、AIが雇用市場と開発者の働き方をどのように変革するかについて深く議論されています。AIは強力な生産性ツールと見なされており、開発者の役割を純粋なコード記述からシステム設計、エージェントのオーケストレーション、コード検証とデバッグへとシフトさせ、より高度なスキルを習得する必要があるとしています。LinkedInはAI採用アシスタントを導入し、求職と採用プロセスを変革しています。同時に、AIは写真などの分野で効率を大幅に向上させていますが、AIコーディングエージェントの生産準備性には依然として課題が残っています。(出典: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

AIが教育、医療などの分野で応用される際の課題 : 教師がAI検出ソフトウェアを使用して生徒がAIを使用したかどうかを判断することは、教育倫理上の論争を引き起こし、教育システムが生徒の理解に焦点を当てるべきであり、ツールの使用ではないと呼びかけています。ChatGPTは医療健康分野で補助診断や健康アドバイス提供の可能性を示していますが、慎重な使用が必要です。Glass 5.0などのプラットフォームは、AIを臨床意思決定支援に応用し、医療AIをチャットボットからパートナーへと転換させています。(出典: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

LLMの性能、コスト、ユーザー体験に関する継続的な議論 : ソーシャルメディアユーザーは、Gemini 3 Flash、Claude Opus 4.5などのLLMの性能、コスト、実際の使用体験について活発な議論を交わしています。焦点は、モデルのコーディング、ツール呼び出し、推論能力の進歩、および性能劣化、ハルシネーション率などの問題にあります。ユーザーは異なるモデルの費用対効果を比較し、AIモデルの価格戦略とモデル価値に対するユーザーの認識について議論しています。(出典: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
AI倫理、哲学、AGIに関する深い考察 : ソーシャルメディアでは、AIの倫理的および社会的影響について議論されており、AIが「神の空白」を埋めているのか、AGIの真の定義、物理学研究におけるAIの可能性と限界などが含まれます。ユーザーはまた、AIベンチマークの再現性、AI研究の質の批判、AIモデルと人間の知能の本質的な違いに関する哲学的考察にも注目しています。(出典: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

AIモデルアーキテクチャ、効率、インフラ最適化 : ソーシャルメディアでは、AIモデルのアーキテクチャと効率について議論されており、MoEモデルのMFU効率、nmoeの超疎MoEトレーニング、LLM推論の簡素化(mini-SGLangなど)が含まれます。ユーザーは、長文コンテキスト処理、メモリ管理、ハードウェア最適化(MLX分散バックエンド、vLLMサービングなど)におけるモデルの進歩に注目し、AIシステム全体の性能とスケーラビリティを向上させています。(出典: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

AI企業の戦略、市場競争、人材流動 : ソーシャルメディアでは、AI企業の戦略と市場競争について議論されており、AmazonがトップAI研究者を雇用したこと、Thinking Machinesがモデル発表を計画していること、Meta AIの投資対効果、OpenAIが直面する組織問題などが含まれます。ユーザーはまた、NVIDIAのオープンソースAI分野におけるリーダーシップ、そのハードウェア駆動戦略、Anthropicの研究者がTencentに加わったことなどの重要な人材流動にも注目しています。(出典: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

AIコーディング現状レポートと業界トレンド : Greptileは「2025年AIプログラミング現状レポート」を発表し、開発者の月間コード生産量が76%増加し、PRのボリュームが膨張していること、AIツールの収益分配が不均一であることを指摘しました。レポートでは、OpenAI、Anthropic、Googleのモデルの初回トークン応答時間、スループット、コストにおけるパフォーマンスも比較し、ベクトルデータベースとAIメモリツールの市場競争状況を明らかにしています。(出典: dotey)

AIモデル評価と再現性 : Redditコミュニティでは、LLM評価の課題と再現性の問題について議論されています。ユーザーは、信頼できる評価基準を確立し、異なる研究やモデル間の結果の比較可能性を確保する方法、そして急速に進化するLLM分野において、科学的進歩を促進するために評価方法とデータセットを効果的に管理・共有する方法について関心を寄せています。(出典: Reddit r/deeplearning)
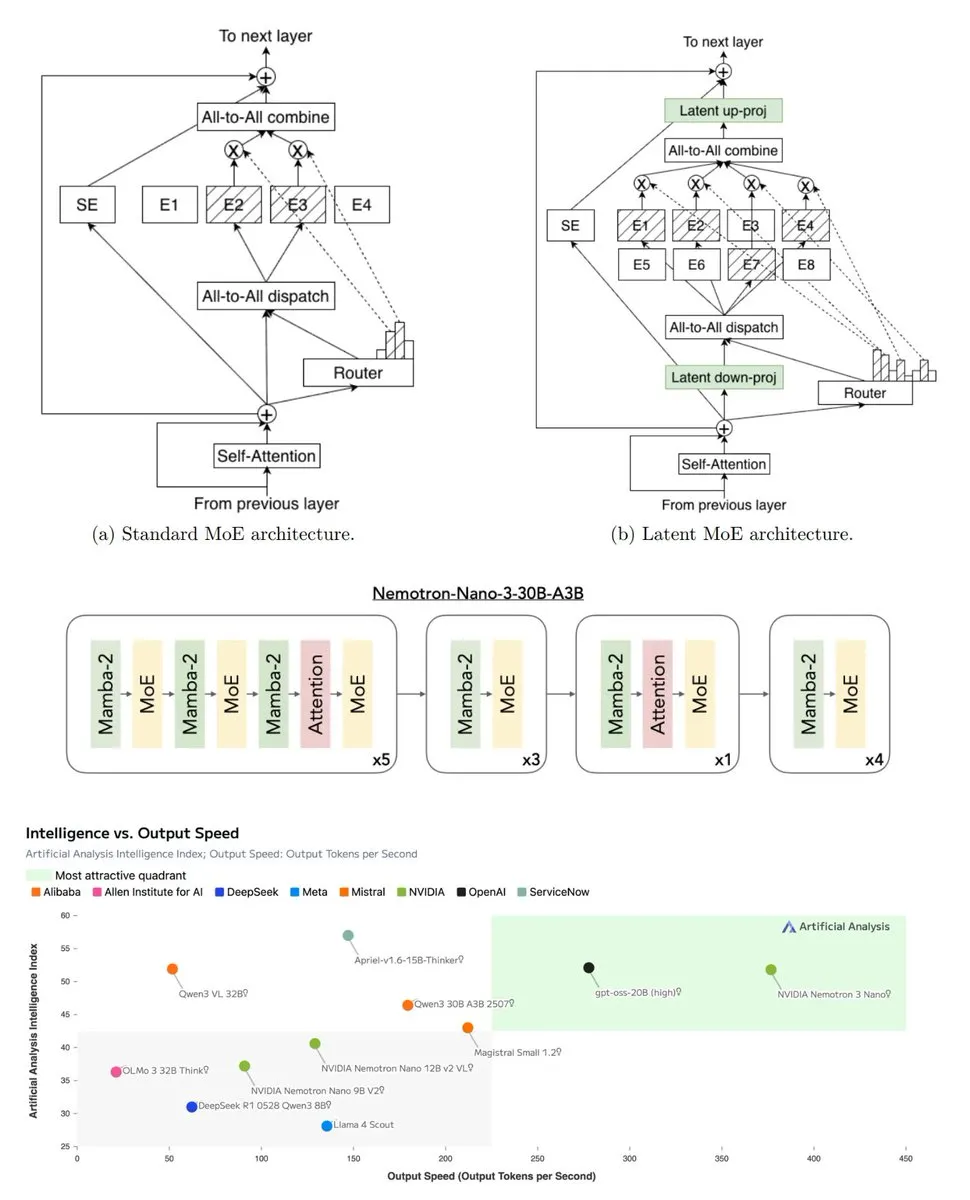
オープンAIとハードウェア駆動戦略 : NVIDIA Nemotron 3の発表は、オープンソースAIのリーダーシップにおける転換点を象徴しています。このモデルは、大規模な事前学習データ、RLデータセット、および新しいハイブリッドアーキテクチャを通じて、NVIDIAハードウェアの計算消費を最適化しました。この戦略は、オープンソースAIが「ビッグテックの慈善事業」時代から「ハードウェアがAIを定義する」時代へと移行していることを示しており、モデルのリリースは特定のハードウェアの計算消費を拡大することを目的としています。(出典: TheTuringPost, teortaxesTex)
AI画像・動画生成ツールの比較と応用 : ソーシャルメディアユーザーは、ChatGPT、Gemini、Midjourney、Grok、Nano Banana ProなどのAI画像・動画生成ツールの性能と応用について議論しています。議論は、AIアート作品のリアリズム、ゲームキャラクターの変換、映画制作におけるAI動画の応用をカバーしています。ユーザーはまた、AI生成コンテンツの品質、コスト、効率、および創作プロセスへの破壊的な影響にも注目しています。(出典: dotey, swyx, karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Kling_ai)

AIの金融分野における応用とトレンド : ソーシャルメディアでは、AIの金融分野における応用について議論されており、不正検出、リスク管理、顧客サービスなど26の具体的な事例が取り上げられています。これらの応用は、機械学習と人工知能が金融業界をどのように強化し、効率を向上させ、意思決定を最適化し、新しいビジネス価値を創造するかを示しています。(出典: Ronald_vanLoon)

AIエージェントと知識グラフの結合 : SAPのAI科学者は、知識グラフを通じてAIエージェントの発見と実行を改善する方法について議論しました。知識グラフはAIエージェントに意味的およびプロセス的なコンテキストを提供し、企業システム内のツールやAPIをより効果的に発見・呼び出すことを可能にし、複雑な企業環境におけるエージェントの効率を高めます。(出典: DeepLearningAI)

LLM評価と再現性に関する議論 : Redditコミュニティでは、LLM評価の課題と再現性の問題について議論されています。ユーザーは、信頼できる評価基準を確立し、異なる研究やモデル間の結果の比較可能性を確保する方法、そして急速に進化するLLM分野において、科学的進歩を促進するために評価方法とデータセットを効果的に管理・共有する方法について関心を寄せています。(出典: Reddit r/deeplearning)
EUにおけるAIモデルの性能と規制の影響 : Redditユーザーは、EU地域でビデオおよび画像AIモデルが規制のために「賢くなくなった」かどうかについて議論しています。一般的な見解では、モデルのコア品質は影響を受けないものの、EUの厳格なセキュリティ層とコンプライアンス要件により、機能のリリースが遅れたり、フィルタリングが厳しくなったり、デフォルト設定が異なったりする可能性があり、それがユーザー体験に影響を与えるのであって、モデル自体の知能が低下するわけではないとされています。(出典: Reddit r/ArtificialInteligence)
💡 その他
AIの芸術・エンターテイメント分野への融合 : Desdemona Robotとそのバンドは、1月11日にサンフランシスコでパフォーマンスを行い、AIと芸術を融合させ、パフォーマーとしてのロボットの可能性を探ります。同時に、ユーザーからはバンドがSunoなどのAIツールを使って曲を生成し、ライブで演奏するのを見たいという声も上がっており、これは音楽制作やライブエンターテイメントにおけるAIの新たな応用トレンドを反映しています。(出典: bengoertzel, fabianstelzer)
ComfyUIが「シンプルモード」でワークフロー簡素化を模索 : ComfyUIは、複雑なワークフローをより簡単に共有・反復できるようにすることを目的とした新しい「シンプルモード」を模索しており、基盤となるノードグラフではなく結果に焦点を当てています。このモードは、大規模なグラフを理解するのが難しいと感じるユーザー向けに、使用の敷居を下げ、ユーザー体験と作業効率を向上させることを特に意図しています。(出典: NerdyRodent)