
키워드:양자 컴퓨팅, 자율 주행, 대규모 언어 모델, 3D 생성 모델, AI 도구, 머신 러닝, 인공지능 연구, CUDA-Q 양자 컴퓨팅 플랫폼, Waymo 자율 주행 데이터 연구, Claude 다중 에이전트 시스템, 텐센트 혼위안 Hunyuan 3D 2.1, AI 생성 커널 성능 최적화
🔥 포커스
엔비디아, 양자 컴퓨팅 전용 CUDA-Q 플랫폼 발표: 엔비디아 CEO 젠슨 황이 GTC 파리 강연에서 양자-고전 가속 슈퍼컴퓨팅 플랫폼인 CUDA-Q를 출시한다고 발표했습니다. 이 플랫폼은 현재의 고전 컴퓨팅과 미래의 양자 컴퓨팅 간의 격차를 해소하고, 고전 컴퓨터에서 양자 연산을 시뮬레이션하거나 실제 양자 컴퓨터를 지원하는 것을 목표로 합니다. CUDA-Q는 Grace Blackwell에서 이미 사용 가능하며, GB200 NVL72 슈퍼컴퓨터를 통해 개발 속도를 1300배 향상시킬 수 있습니다. 젠슨 황은 양자 컴퓨터의 실제 응용이 몇 년 안에 이루어질 것으로 예측하며, 이 개발 단계에서 엔비디아 칩(특히 GB200)이 시뮬레이션 컴퓨팅 및 QPU 지원에 필수적이라고 강조했습니다. 엔비디아는 전 세계 양자 컴퓨팅 회사 및 슈퍼컴퓨팅 센터와 협력하여 GPU와 QPU의 협업을 모색하고 있습니다 (출처: 量子位)

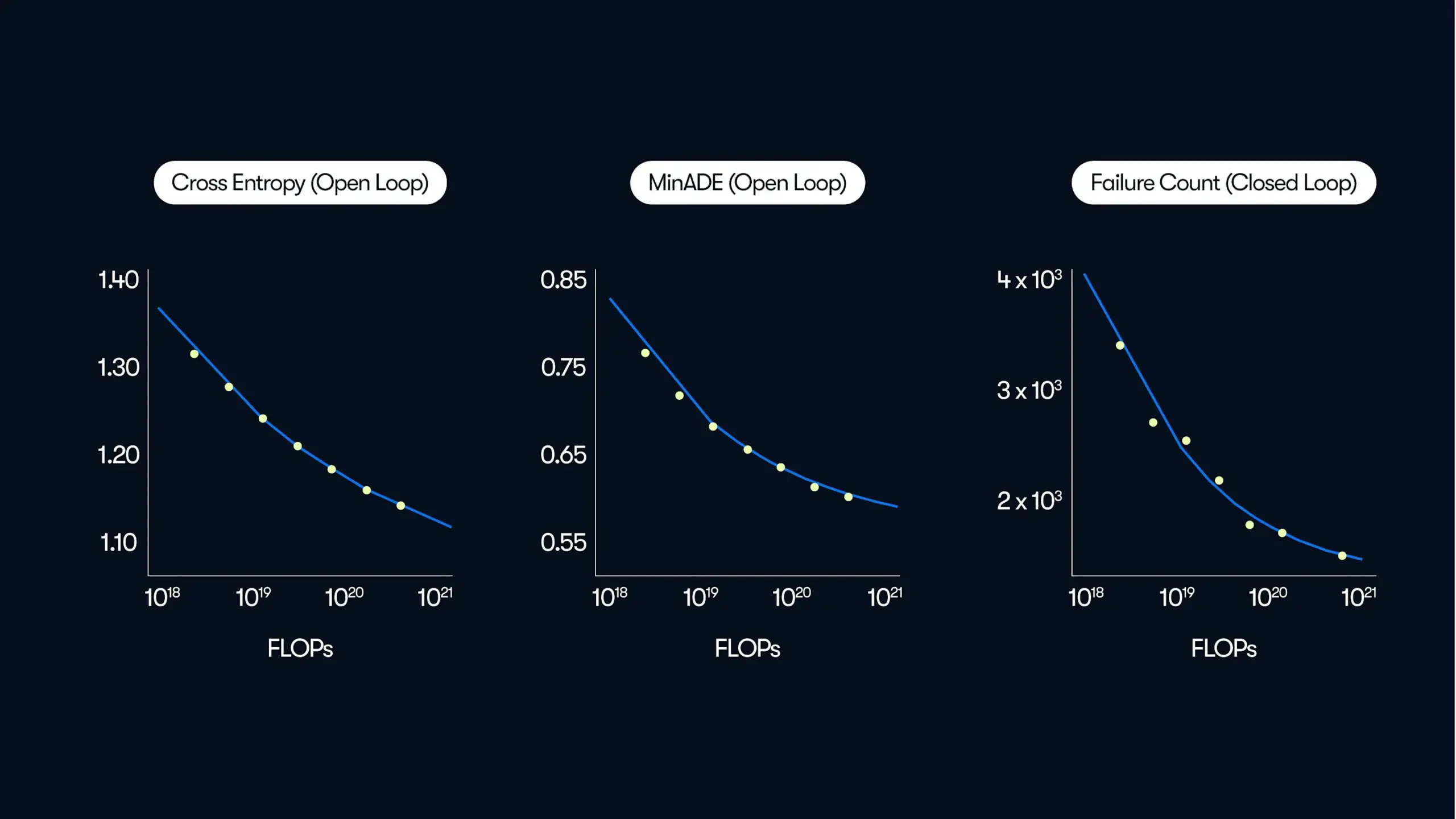
Waymo, 자율주행 대규모 연구 발표, “데이터 주도” 성능 향상 법칙 공개: Waymo는 최신 블로그 게시물에서 50만 시간의 주행 데이터를 기반으로 한 포괄적인 연구 결과를 공유했습니다. 이는 자율주행 분야에서 현재까지 가장 큰 규모의 데이터 세트입니다. 연구에 따르면 대규모 언어 모델(LLM)과 유사하게 자율주행 시스템의 모션 예측 품질도 훈련 계산량 증가에 따라 멱법칙 관계를 따르는 것으로 나타났습니다. 데이터 규모 확장은 모델 성능 향상에 매우 중요하며, 동시에 추론 계산 능력을 확대하면 모델이 복잡한 주행 시나리오를 처리하는 능력도 향상됩니다. 이 연구는 훈련 데이터와 계산 자원을 늘림으로써 실제 환경에서의 자율주행 성능을 크게 개선할 수 있음을 처음으로 입증했으며, 업계에 규모화를 통한 능력 향상 경로를 제시했습니다 (출처: Sawyer Merritt, scaling01)
Anthropic, Claude 다중 에이전트 연구 시스템 구축 경험 공유: Anthropic은 엔지니어링 블로그에서 여러 병렬 작업 에이전트를 활용하여 Claude의 연구 능력을 구축하는 방법을 자세히 소개했습니다. 이 글은 개발 과정에서의 성공 경험, 직면했던 문제 및 엔지니어링 과제를 공유합니다. 이러한 다중 에이전트 시스템을 통해 Claude는 정보를 보다 효율적으로 검색, 분석 및 종합하여 연구 및 복잡한 문제 해결 능력을 향상시킬 수 있습니다. 이 공유는 대규모 언어 모델이 복잡한 시스템 설계를 통해 기능을 확장하는 방법을 이해하는 데 중요한 참고 자료가 됩니다 (출처: ImazAngel, teortaxesTex)
Meta, 비디오 이해, 예측 및 로봇 제어를 위한 V-JEPA 2 월드 모델 출시: Meta AI는 비디오 기반으로 훈련된 월드 모델인 V-JEPA 2를 발표했습니다. 이 모델은 물리적 세계의 역학을 이해하고 예측하는 데 있어 상당한 진전을 이루었습니다. V-JEPA 2는 효율적인 비디오 특징 학습뿐만 아니라 새로운 환경에서 제로샷 계획 및 로봇 제어를 실현하여 일반 인공 지능 분야에서의 잠재력을 보여주었습니다. 이 모델은 자기 지도 학습을 통해 비디오 데이터에서 세계 표상을 학습하며, 더 지능적이고 현실 세계와 더 잘 상호 작용할 수 있는 AI 시스템을 구축하기 위한 새로운 길을 제시합니다 (출처: dl_weekly)
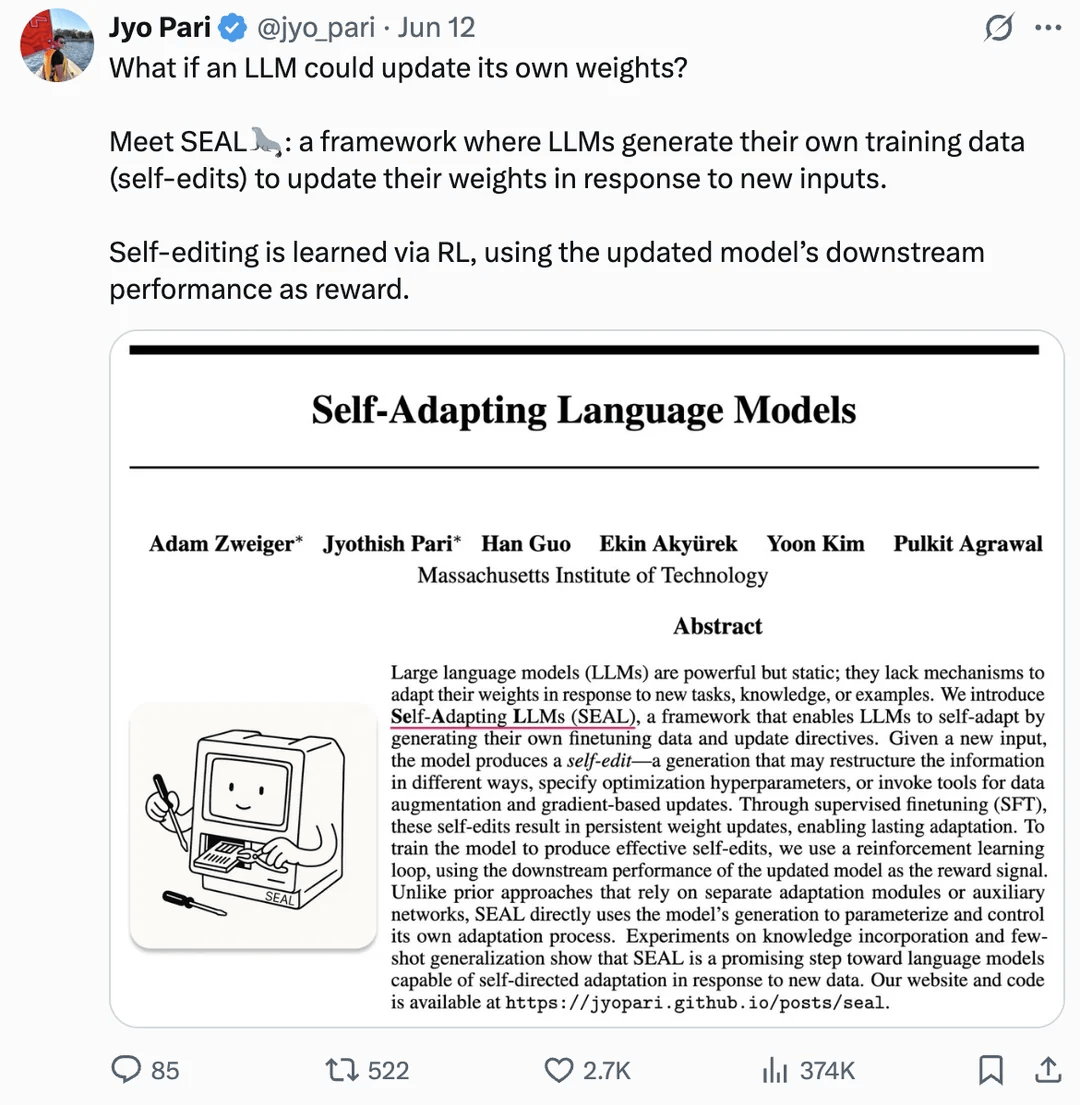
논문, LLM 가중치 자체 업데이트를 통한 자가 개선 가능성 탐구: arXiv에 발표된 논문(2506.10943)은 대규모 언어 모델(LLM)이 이제 자체 가중치를 업데이트하여 자가 개선을 달성할 수 있다고 제안합니다. 이러한 메커니즘은 LLM이 새로운 데이터나 경험으로부터 학습하고, 전체 재훈련 없이 동적으로 내부 매개변수를 조정하여 성능을 향상시키거나 새로운 작업에 적응할 수 있음을 의미할 수 있습니다. 이 연구 방향이 성공한다면 LLM의 적응성과 지속적인 학습 능력을 크게 향상시켜 보다 자율적인 AI 시스템으로 나아가는 중요한 단계가 될 것입니다 (출처: Reddit r/artificial)
🎯 동향
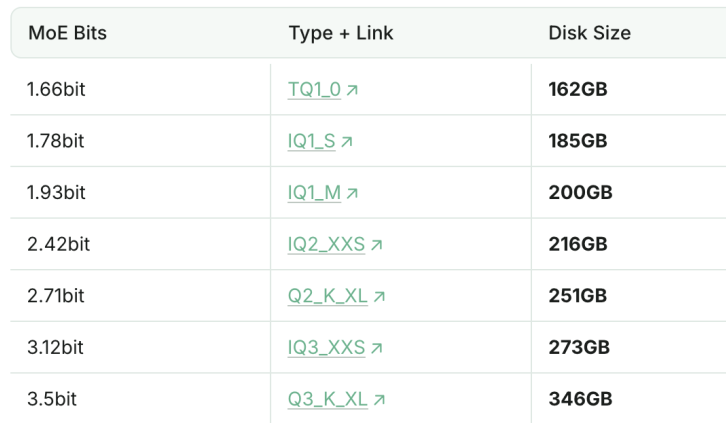
1.93bit 양자화 버전 DeepSeek-R1, 프로그래밍 능력에서 Claude 4 Sonnet 능가: Unsloth 스튜디오는 DeepSeek-R1(0528 버전)을 1.93bit로 양자화하는 데 성공했으며, 프로그래밍 벤치마크 aider에서 60%의 점수를 얻어 Claude 4 Sonnet(56.4%) 및 1월 버전의 완전판 R1을 능가했습니다. 이 극도로 압축된 버전은 파일 크기를 70% 이상 줄였으며, GPU 없이도 실행할 수 있습니다(CPU와 충분한 메모리). 완전판 R1-0528은 aider에서 71.4%를 기록하여 사고 모드를 켜지 않은 Claude 4 Opus를 능가했습니다. 이는 모델 양자화 기술이 성능을 유지하면서 리소스 요구 사항을 크게 줄일 수 있는 잠재력을 보여줍니다 (출처: 量子位)
텐센트 혼원, 첫 생산 등급 PBR 3D 생성 모델 Hunyuan 3D 2.1 오픈소스 공개: 텐센트 혼원 팀은 업계 최초로 완전 오픈소스이며 생산 등급에 도달한 PBR(Physically Based Rendering) 3D 생성 모델인 Hunyuan 3D 2.1을 발표했습니다. 이 모델은 PBR 재질 합성 기술을 활용하여 영화 수준의 시각 효과를 가진 3D 콘텐츠를 생성할 수 있으며, 가죽, 청동과 같은 재질이 조명 아래에서 더욱 생생하고 사실적으로 표현되도록 합니다. 이 프로젝트는 모델 가중치, 훈련/추론 코드, 데이터 파이프라인 및 아키텍처를 공개했으며, 소비자용 그래픽 카드 실행을 지원하여 3D 콘텐츠 생성 기술의 발전과 보급을 촉진하는 것을 목표로 합니다 (출처: op7418, ImazAngel)
Meta AI, 3D 포인트 클라우드 표현의 자기 지도 학습을 위한 Sonata 발표: Meta AI는 3D 자기 지도 학습 분야에서 상당한 진전을 이룬 연구인 Sonata를 출시했습니다. Sonata는 기하학적 지름길 문제를 식별하고 해결하며, 유연하고 효율적인 프레임워크를 도입하여 매우 견고한 3D 포인트 클라우드 표현을 학습할 수 있습니다. 이 연구는 3D 인식 기술의 기존 수준을 향상시키고 미래 3D 인식 및 응용 분야 혁신을 위한 기반을 마련했습니다 (출처: AIatMeta)

Meta AI, 독서 행동 이해를 위한 “야생에서의 독서 인식 데이터 세트” 발표: Meta AI는 비디오, 시선 추적 및 머리 자세 센서 출력을 포함하는 “Reading Recognition in the Wild”라는 대규모 다중 모드 데이터 세트를 공개했습니다. 이 데이터 세트는 웨어러블 장치에서 독서 인식 작업을 해결하는 데 도움을 주기 위해 설계되었으며, 60Hz의 고주파로 시선 데이터를 수집한 최초의 자기 중심 시점 데이터 세트로서 인간의 독서 행동 연구에 귀중한 자원을 제공합니다 (출처: AIatMeta)

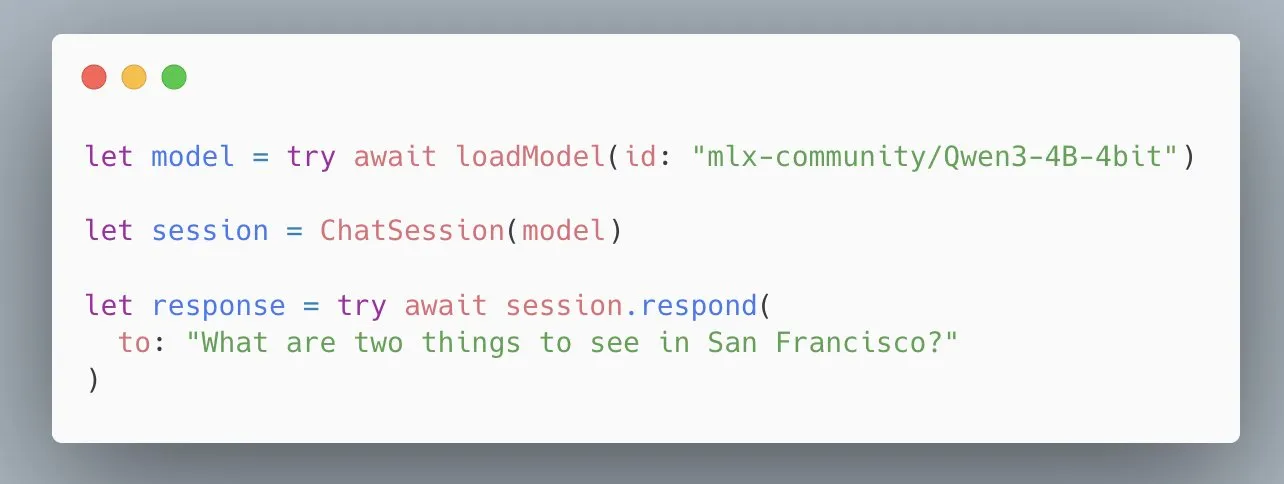
애플 MLX Swift LLM API 간소화, 세 줄 코드로 모델 로드 가능: 개발자들의 MLX Swift LLM API 사용이 어렵다는 피드백에 따라 애플 팀은 신속하게 개선하여 새로운 간소화된 API를 출시했습니다. 이제 개발자는 단 세 줄의 코드로 Swift 프로젝트에서 LLM 또는 VLM을 로드하고 채팅 세션을 시작할 수 있어 애플 생태계에서 대규모 언어 모델을 사용하는 진입 장벽을 크게 낮췄습니다 (출처: stablequan)
구글 Gemma3 4B, 브라질 포르투갈어 최적화 버전 GAIA 출시: 구글은 브라질 여러 기관(ABRIA, CEIA-UFG, Nama, Amadeus AI) 및 DeepMind와 협력하여 브라질 포르투갈어에 최적화된 오픈소스 언어 모델 GAIA (Gemma-3-Gaia-PT-BR-4b-it)를 발표했습니다. 이 모델은 Gemma-3-4b-pt를 기반으로 하며, 130억 개의 고품질 브라질 포르투갈어 토큰으로 지속적인 사전 훈련을 거쳤습니다. GAIA는 혁신적인 “가중치 병합” 기술을 사용하여 기존 SFT 없이 명령어 준수를 구현했으며, ENEM 2024 벤치마크에서 기본 Gemma 모델을 능가했습니다. 이 모델은 채팅, 질의응답, 요약, 텍스트 생성 및 브라질 포르투갈어 미세 조정을 위한 기본 모델로 적합합니다 (출처: Reddit r/LocalLLaMA)
Figure AI 로봇, Helix AI와 자율성 융합으로 확장 가능한 배포 추진: Figure AI는 실제 세계 로봇이 Helix AI와 자율성을 강화하여 확장 가능한 배포를 어떻게 추진하는지 보여주었습니다. 이는 물리적 로봇과 첨단 AI 모델의 결합이 더 복잡한 환경에서 로봇의 응용을 가능하게 하고 있으며, 로봇 분야에서 엔지니어링과 신흥 기술의 중요성을 강조합니다 (출처: Ronald_vanLoon)
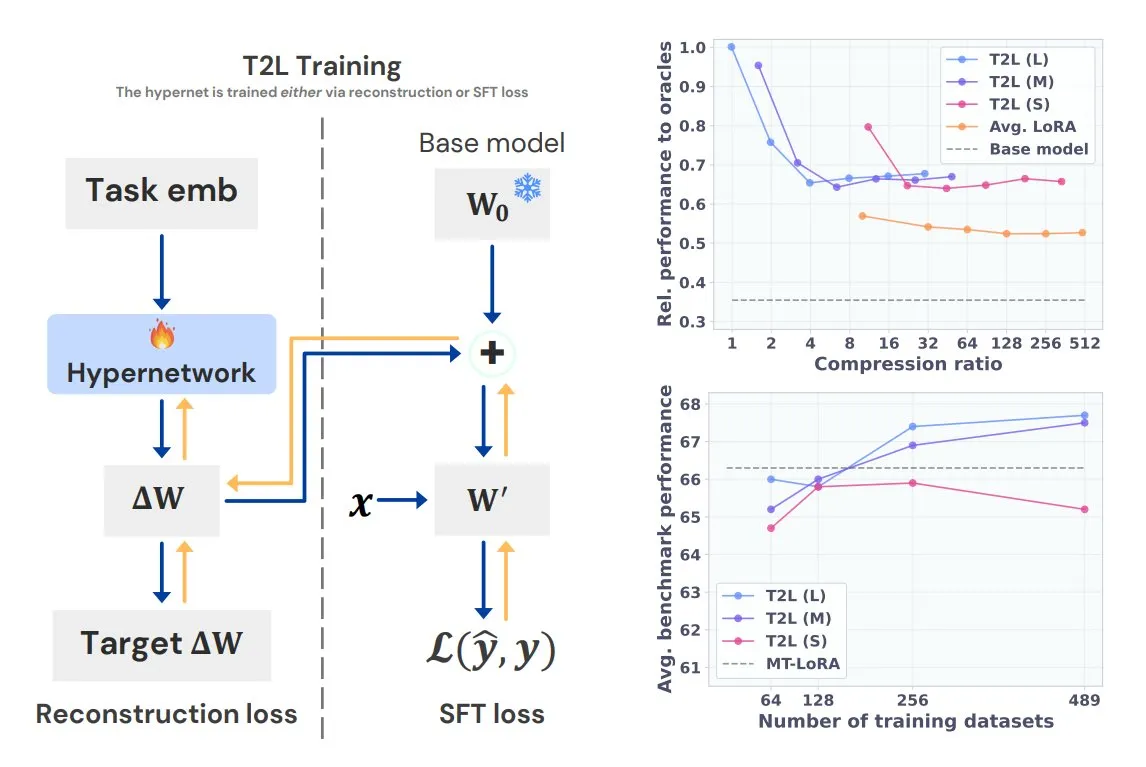
Sakana AI, Text-to-LoRA (T2L) 하이퍼네트워크 출시: Sakana AI는 여러 기존 LoRA(Low-Rank Adaptation)를 자체적으로 압축하고 작업의 텍스트 설명만으로 대규모 언어 모델을 위한 새로운 LoRA 어댑터를 신속하게 생성할 수 있는 새로운 유형의 하이퍼네트워크인 Text-to-LoRA (T2L)를 발표했습니다. T2L은 훈련 후 즉시 새로운 LoRA를 생성할 수 있어 특정 작업 LLM의 신속한 맞춤화 및 배포를 위한 효율적인 경로를 제공하며, 관련 성과는 ICML 2025에서 발표될 예정입니다 (출처: TheTuringPost)
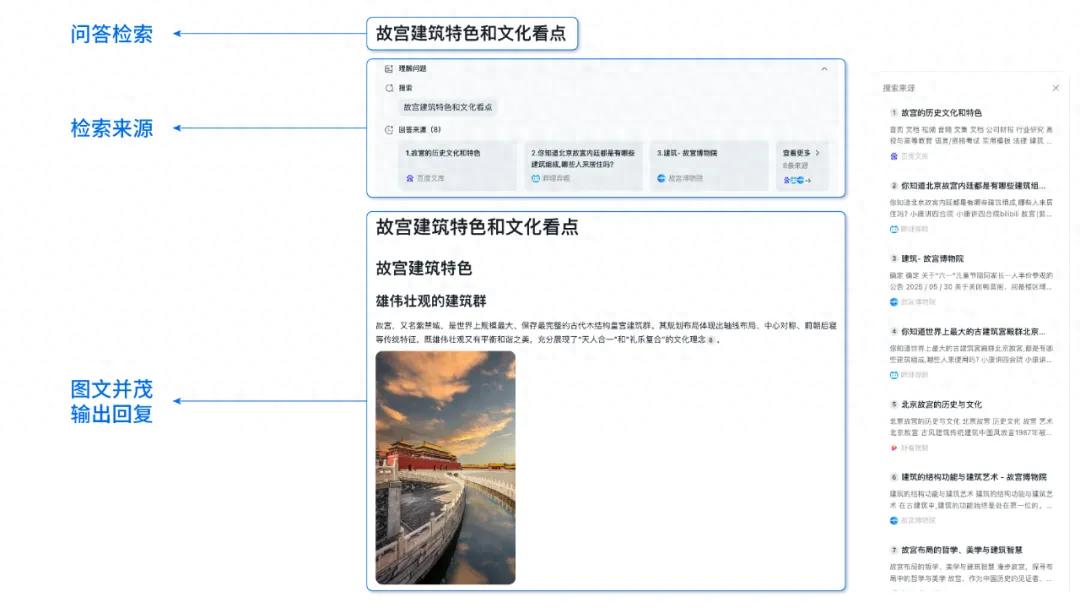
바이두 AI 검색, 바이두 스마트 클라우드 첸판 플랫폼에 전면 출시: 바이두 스마트 클라우드 첸판 애플리케이션 개발 플랫폼 AppBuilder가 “바이두 AI 검색” 서비스를 공식 출시했습니다. 이 서비스는 “바이두 검색”과 “스마트 검색 생성”이라는 두 가지 핵심 기능을 통합하여 기업에 정보 검색에서 스마트 생성까지 전체 체인 서비스를 제공합니다. 바이두의 20년 이상 축적된 중국어 검색 기술과 수천억 규모의 데이터베이스를 활용하여 광고 없는 다중 모드 검색 결과를 제공하며, 정확한 필터링, 출처 추적 및 기업 수준의 보안 정책을 지원합니다. 스마트 검색 생성 기능은 원신, Deepseek 등 모델과 결합하여 AI 요약, 사설 지식 공동 검색 등의 기능을 제공합니다 (출처: 量子位)
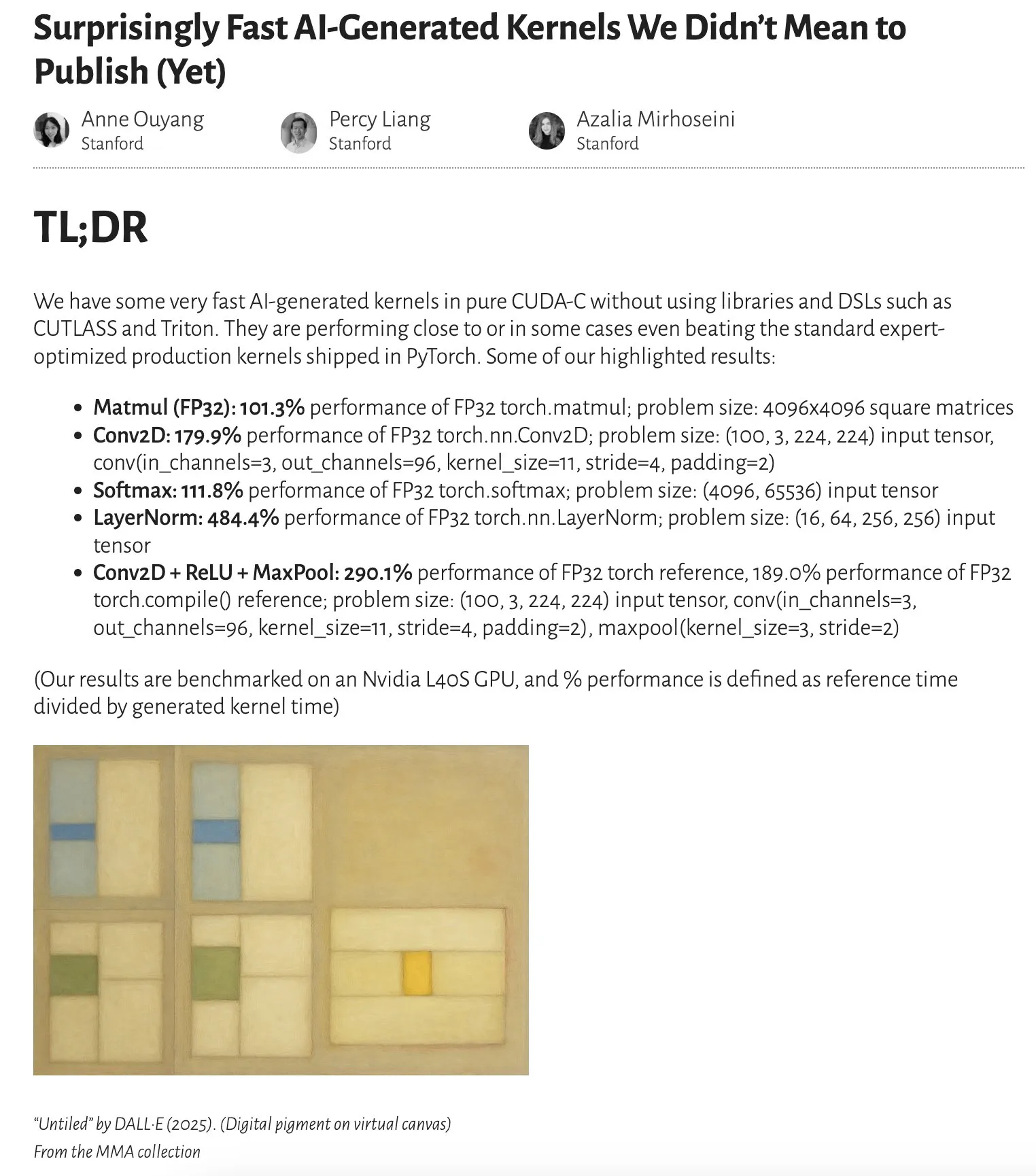
연구 결과, AI 생성 커널 성능, 전문가 최적화 커널에 근접하거나 능가: Anne Ouyang의 블로그 게시물에 따르면, 간단한 테스트 시간 전용 검색(test-time only search)을 통해 생성된 AI 커널의 성능이 PyTorch의 표준적인 전문가 최적화 생산 커널에 근접하거나 경우에 따라 능가하는 것으로 나타났습니다. 이는 AI가 코드 최적화 및 성능 향상에 엄청난 잠재력을 가지고 있으며, 향후 기본 라이브러리 최적화에서 더 중요한 역할을 할 수 있음을 시사합니다 (출처: jeremyphoward)
“확산 이중성” 연구, 이산 확산 언어 모델의 적은 단계 생성 위한 새로운 방법 제안: ICML 2025에 발표된 논문 “The Diffusion Duality”는 잠재적 가우시안 확산을 활용하여 이산 확산 언어 모델에서 적은 단계 생성을 달성하는 새로운 방법을 제안합니다. 이 방법은 7개의 제로샷 우도 벤치마크 중 3개에서 자기 회귀(AR) 모델을 능가하여 확산 모델 생성 효율성 향상을 위한 새로운 아이디어를 제공합니다 (출처: arankomatsuzaki)
MLP 계층 해석 가능성 새로운 돌파구: 활성화를 해석 가능한 특징으로 분해: Mor Geva 등의 새로운 연구는 다층 퍼셉트론(MLP)의 활성화를 해석 가능한 특징으로 분해하는 간단한 방법을 보여줍니다. 이 방법은 희소한 뉴런 조합이 점점 더 추상적인 개념을 형성하는 숨겨진 개념 계층 구조를 밝혀내어 신경망 내부 작동 메커니즘을 더 깊이 이해할 수 있는 시각을 제공합니다 (출처: menhguin)

HeadHunter 프레임워크, 교란된 어텐션 유도에 대한 정교한 제어 실현: Sayak Paul 등은 교란된 어텐션 유도에 대한 원칙적인 분석을 위한 HeadHunter 프레임워크를 제안했습니다. 이 프레임워크는 생성 품질과 시각적 속성에 대한 심층적이고 세분화된 제어를 가능하게 하여 생성 모델 출력을 개선하고 맞춤화하기 위한 새로운 도구와 통찰력을 제공합니다 (출처: huggingface, RisingSayak)

🧰 도구
Windsurf 유료 플랜, 이제 Claude Sonnet 4 지원: Windsurf는 모든 유료 플랜에서 Claude Sonnet 4 모델을 지원한다고 발표했습니다. 사용자는 이제 Windsurf 플랫폼에서 Anthropic의 최신 모델의 강력한 기능을 활용하여 텍스트 생성, 대화 등의 작업을 수행하고 AI 어시스턴트의 성능과 경험을 더욱 향상시킬 수 있습니다 (출처: op7418)
Anthropic, Claude Code 공식 Python SDK 출시: Anthropic은 개발자가 Claude의 코드 생성 및 도구 사용 능력을 자신의 Python 프로젝트에 쉽게 통합할 수 있도록 Claude Code용 Python SDK를 공식 출시했습니다. 이 SDK는 도구 사용, 스트리밍 출력, 동기/비동기 작업, 파일 처리를 지원하며 채팅 구조가 내장되어 있어 Claude Code와의 상호 작용 개발 프로세스를 간소화합니다 (출처: Reddit r/ClaudeAI)
Claude Task Master VS Code 확장 프로그램 출시: DevDreed는 Claude Task Master VS Code 확장 프로그램 1.0.0 버전을 출시했습니다. 이 확장 프로그램은 eyaltoledano의 Claude Task Master AI 프로젝트를 보완하여 Claude Task Master의 출력을 VS Code 인터페이스에 직접 통합함으로써 사용자가 편집기와 콘솔 간을 원활하게 전환하여 개발 효율성을 높일 수 있도록 설계되었습니다 (출처: Reddit r/ClaudeAI)
SmartSelect AI: 브라우저 내 텍스트 이미지 AI 처리 도구: SmartSelect AI라는 Chrome 확장 프로그램이 출시되었습니다. 이 도구를 사용하면 웹 페이지를 탐색하는 동안 선택한 텍스트를 직접 요약, 번역 또는 채팅하고 이미지에 대한 AI 설명을 얻을 수 있으며, 탭을 전환하거나 ChatGPT와 같은 외부 애플리케이션에 복사하여 붙여넣을 필요가 없습니다. 이 도구는 Gemini 모델을 기반으로 하며 정보 획득 및 처리 효율성을 높이는 것을 목표로 합니다 (출처: Reddit r/deeplearning)

Unsiloed AI, 다기능 데이터 청킹 도구 오픈소스 공개: Unsiloed AI (EF 2024)가 일부 데이터 청킹(chunker) 기능을 오픈소스로 공개했습니다. 이 도구는 PDF, Excel, PPT 등 다양한 형식의 문서를 처리하여 대규모 언어 모델이 처리하기에 적합한 형식으로 변환하는 데 도움을 주기 위해 설계되었습니다. Unsiloed AI는 이미 포춘 100대 기업 및 여러 스타트업에서 다중 모드 데이터 수집에 사용되고 있습니다 (출처: Reddit r/LocalLLaMA)
Claude Superprompt System: Claude 프롬프트 최적화를 위한 무료 도구: Igor Warzocha는 사용자가 간단한 요청을 구조화되고 사고의 연쇄 및 컨텍스트 예제가 포함된 복잡한 프롬프트로 변환하여 Claude의 능력을 더 잘 활용할 수 있도록 돕는 “Claude Superprompt System”이라는 온라인 도구를 개발하고 공유했습니다. 이 도구는 Anthropic 공식 문서와 커뮤니티에서 발견된 모범 사례를 기반으로 하며, XML 태그 구조화, CoT 추론 블록 등을 통해 프롬프트를 최적화하여 Claude의 출력 품질을 향상시킵니다. 프로젝트 코드는 GitHub에 오픈소스로 공개되었습니다 (출처: Reddit r/artificial)
로컬 TTS Firefox 플러그인 Kokoro-TTS 출시: 개발자 Pinguy가 Kokoro TTS라는 Firefox 플러그인을 출시했습니다. 이 플러그인은 82M 매개변수의 로컬 호스팅 신경망 모델(Kokoro TTS 모델)을 사용하여 텍스트 음성 변환을 수행하며, 완전히 오프라인으로 실행되어 사용자 개인 정보를 보호합니다. 다양한 음성과 억양을 지원하며 구형 하드웨어에서도 원활하게 실행되며 Windows, Linux 및 macOS 버전을 제공합니다 (출처: Reddit r/artificial)
Spy Search: 오픈소스 LLM 검색 엔진 프로젝트 업데이트: JasonHonKL이 자신의 오픈소스 LLM 검색 엔진 프로젝트인 Spy Search를 업데이트했습니다. 이 프로젝트는 대규모 언어 모델 기반의 효율적인 검색 엔진 구축에 전념하고 있으며, 최신 버전은 3초 이내에 검색하고 응답할 수 있습니다. 프로젝트 코드는 GitHub에 호스팅되어 있으며, 사용자에게 빠르고 유용한 일상 검색 도구를 제공하는 것을 목표로 합니다 (출처: Reddit r/deeplearning)
HandFonted: 손글씨를 글꼴로 변환하는 도구 오픈소스 공개: Resham Gaire가 HandFonted 프로젝트를 개발하고 오픈소스로 공개했습니다. 이는 손글씨 문자 이미지를 설치 가능한 .ttf 글꼴 파일로 변환하는 엔드투엔드 Python 애플리케이션입니다. 이 시스템은 OpenCV를 사용하여 이미지 처리 및 문자 분할을 수행하고, 맞춤형 PyTorch 모델(ResNet-Inception)을 사용하여 문자 분류를 수행하며, 헝가리안 알고리즘을 사용하여 최적의 일치를 수행하고, 마지막으로 fontTools 라이브러리를 사용하여 글꼴 파일을 생성합니다 (출처: Reddit r/MachineLearning)
📚 학습
웨이둥이 등, 초임계 비집속 비선형 파동 방정식의 폭발 현상 연구 논문, 수학 저널 정상 등극: 베이징대학 학자 웨이둥이, 장즈페이, 샤오펑이 공동 저술한 논문 “On blow-up for the supercritical defocusing nonlinear wave equation”이 최고 수준의 수학 저널 “Forum of Mathematics, Pi”에 게재되었습니다. 이 연구는 특정 비집속 비선형 파동 방정식이 초임계 상태에서 폭발(해가 유한 시간 내에 무한대가 되는 현상)하는 문제를 탐구합니다. 그들은 공간 차원 d=4이고 p≥29, 그리고 d≥5이고 p≥17인 경우 유한 시간 내에 폭발하는 매끄러운 복소수 값 해가 존재함을 증명했습니다. 이 성과는 관련 분야의 공백을 메웠으며, 그 증명 방법은 다른 비선형 편미분 방정식의 폭발 연구에 새로운 아이디어를 제공했습니다 (출처: 量子位)

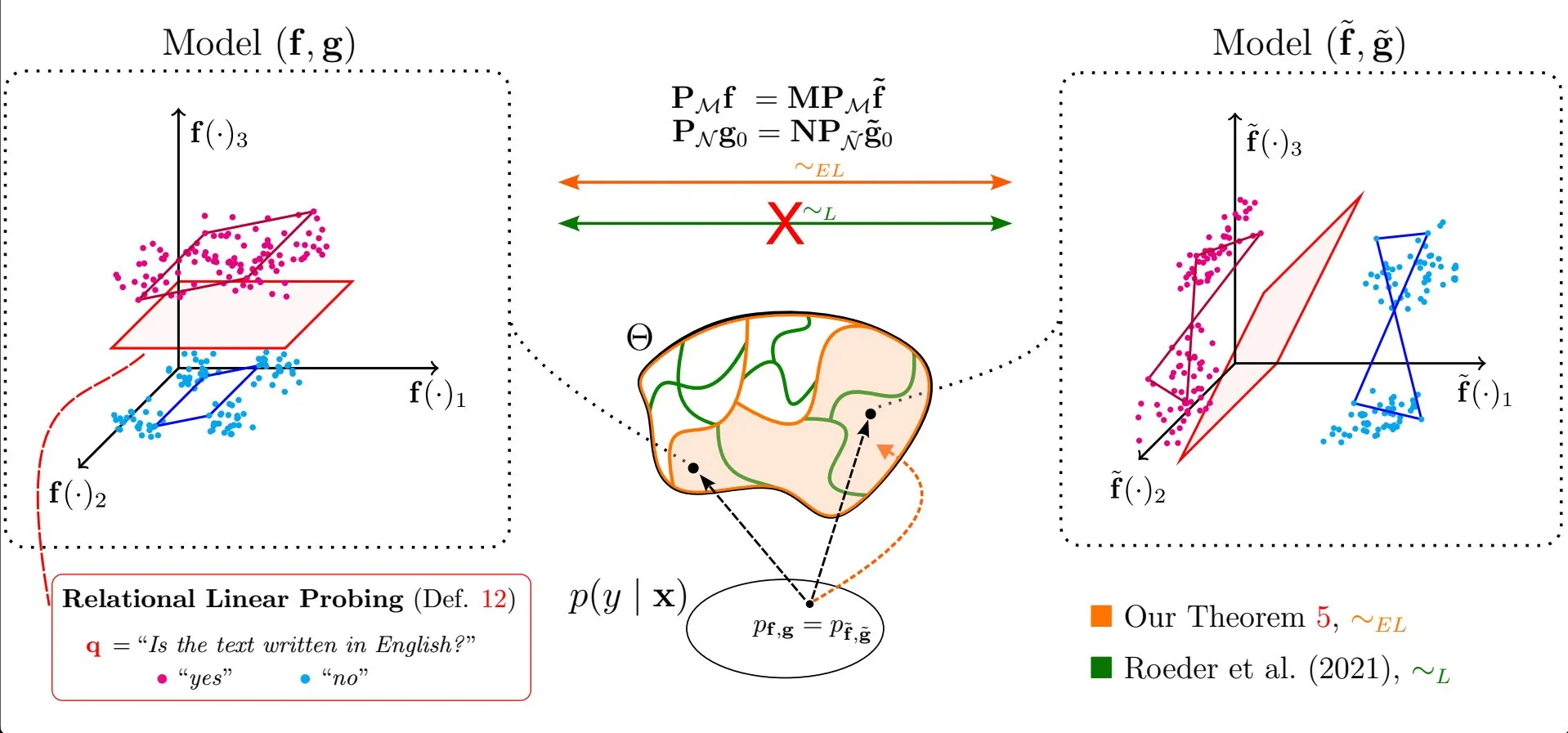
논문, 대규모 언어 모델 표현에서 선형 특성의 보편성 탐구: Emanuele Marconato 등의 연구 “All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling”(AISTATS 2025 발표)은 식별 가능성 관점에서 대규모 언어 모델(LLM) 표현에서 선형 특성이 왜 그렇게 보편적인지를 탐구합니다. 이 연구는 LLM 내부 표현의 구조와 행동을 더 깊이 이해하는 데 도움이 됩니다 (출처: menhguin)
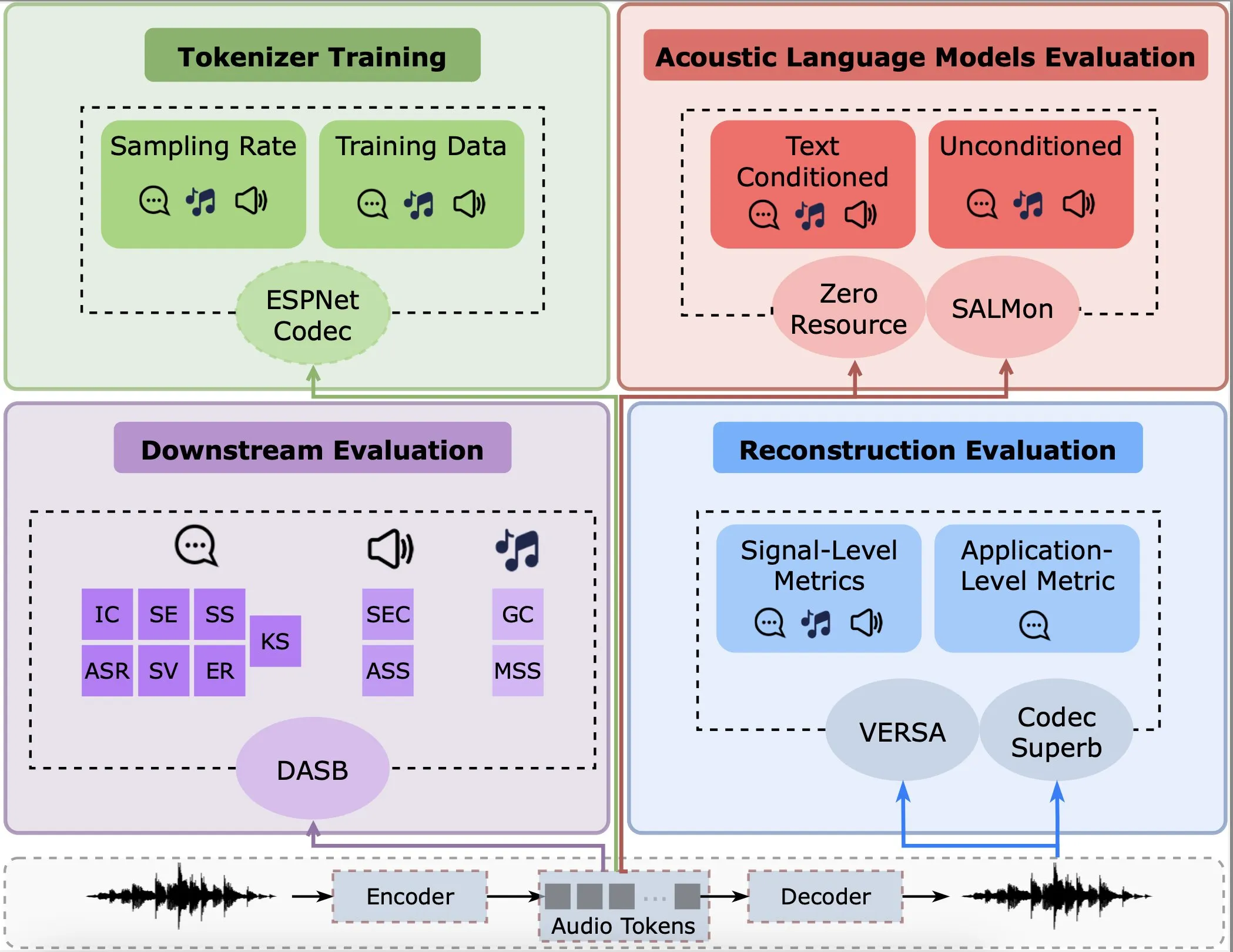
연구, 오디오 인코더의 재구성, 다운스트림 작업 및 언어 모델에서의 성능 분석: Gallil Maimon 등이 기존 오디오 인코더(Audio Tokenisers)에 대한 포괄적인 실증 분석을 수행한 새로운 연구를 발표했습니다. 이 연구는 재구성 품질, 다운스트림 작업에서의 성능, 언어 모델과의 결합 등 여러 차원에서 이러한 인코더를 평가하여 오디오 처리 모델 선택 및 최적화에 참고 자료를 제공합니다 (출처: menhguin)
논문, “사고의 착각”: 문제 복잡성 관점에서 추론 모델의 장단점 이해: 애플사의 “사고의 착각” 연구에 대한 응답 논문(arXiv:2506.09250)이 제출되었으며, Claude Opus가 제1 저자로 등재되었습니다. 이 논문은 애플 연구의 실험 설계를 비판하며, 관찰된 추론 붕괴는 실제로는 토큰 제한으로 인한 것이지 모델의 내재적 논리 능력 부족이 아니라고 주장합니다. 이는 대규모 언어 모델의 실제 추론 능력을 어떻게 평가할 것인가에 대한 논의를 촉발시켰습니다 (출처: NandoDF, BlancheMinerva, teortaxesTex)

연구, 적응형 언어 모델 탐구, 그러나 중거리 기억은 여전히 과제: Dorialexander는 “적응형 언어 모델” 관련 논문을 읽은 후, 이것이 유망한 연구 방향이긴 하지만 모델이 추론 시 중거리 기억을 구현하는 데 여전히 한계가 있다고 지적했습니다. 이는 현재 모델이 비교적 긴 컨텍스트에 걸친 일관된 정보를 처리하는 데 여전히 어려움을 겪고 있음을 시사합니다 (출처: Dorialexander)

RLHF 테스트 품질 연구: 현재 테스트는 얼마나 좋은가? 어떻게 개선할 수 있는가? 테스트 품질은 얼마나 중요한가?: Kexun Zhang 등의 최신 연구는 특히 LLM 코딩 분야에서 인간 피드백 기반 강화 학습(RLHF)의 검증기(테스트)의 중요성을 탐구합니다. 연구는 세 가지 핵심 질문을 제기합니다: 현재 테스트의 품질은 어떠한가? 더 나은 테스트를 어떻게 얻을 수 있는가? 테스트 품질은 모델 성능에 얼마나 큰 영향을 미치는가? 이 연구는 LLM 코딩 능력 향상을 위한 고품질 테스트의 필요성을 강조합니다 (출처: StringChaos)
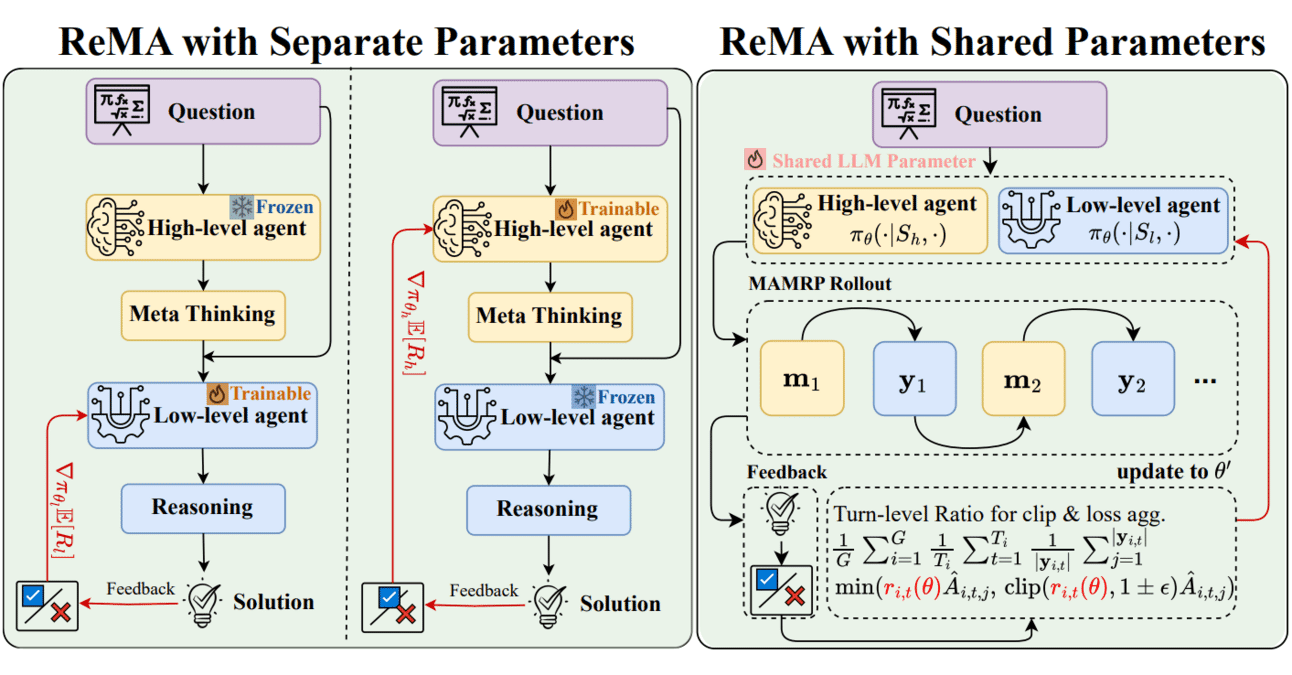
Meta-learning과 강화 학습 결합: ReMA, LLM 협업 효율성 향상: Reinforced Meta-thinking Agents (ReMA)는 메타 학습(Meta-learning)과 강화 학습(RL)을 결합하여 대규모 언어 모델(LLM)의 효율성을 향상시키는 것을 목표로 하며, 특히 여러 LLM 에이전트가 협력하여 작업할 때 그렇습니다. ReMA는 문제 해결을 메타 사고(전략 계획)와 추론(전략 실행) 두 부분으로 나누고, 전문 에이전트와 다중 에이전트 강화 학습을 통해 최적화하여 수학 벤치마크와 LLM을 심판으로 사용하는 벤치마크 모두에서 개선을 이루었습니다 (출처: TheTuringPost, TheTuringPost)
AI 평가 전략: 예산 제약 하에서 저렴한 평가자와 비싼 평가자를 결합하여 최적의 모델 품질 추정치를 얻는 방법: Adam Fisch 등의 연구(arXiv:2506.07949)는 실제적인 문제를 탐구합니다: 저렴하지만 잡음이 있는 평가자, 비싸지만 정확한 평가자, 그리고 고정된 예산이 있을 때 모델 품질에 대한 가장 정확한 추정치를 얻기 위해 예산을 어떻게 배분해야 하는가? 이 연구는 AI 시스템 평가를 위한 비용 효율성 분석 프레임워크를 제공합니다 (출처: Ar_Douillard)
LLM 프롬프트의 “허위 보상” 및 “허위 프롬프트” 현상: Stella Li 등의 연구는 LLM 훈련 및 평가에서 흥미로운 현상을 밝혀냈습니다. “허위 보상”(예: 무작위 보상도 특정 작업에서 모델 성능을 향상시킬 수 있음)을 발견한 후, 그들은 “허위 프롬프트”를 추가로 탐구했습니다. 즉, “Lorem ipsum”과 같은 무의미한 텍스트도 특정 상황에서 상당한 성능 향상(예: 19.4%)을 가져올 수 있다는 것입니다. 이러한 발견은 LLM이 프롬프트에 어떻게 반응하는지, 그리고 더 강력한 평가 방법을 어떻게 설계할 것인지에 대한 새로운 과제와 생각을 제기합니다 (출처: Tim_Dettmers)

논문, AI 상호작용의 “인형극 극장” 모델 탐구: “The Pig in Yellow: AI Interface as Puppet Theatre”라는 제목의 논문(또는 초고)은 언어 AI 시스템(LLM, AGI, ASI)을 주관성을 소유하는 것이 아니라 주관성을 모방하는 공연적 인터페이스로 간주할 것을 제안합니다. 이 글은 “미스 피기”를 비유로 사용하여 AI의 유창성, 일관성 및 감정 표현이 정신적 지표가 아니라 최적화의 산물임을 분석하고, 인터페이스는 인형과 같으며 사용자는 상호작용을 통해 공동으로 의미를 구성하고 권력은 공연적 설계를 통해 나타난다고 강조합니다 (출처: Reddit r/artificial)
💼 비즈니스
“DJI 대부” 리쩌샹 지분 보유한 워안 로봇, IPO 도전: 하얼빈 공업대학 동문 형제가 창업하고 AI 기반 가정용 로봇에 주력하는 워안 로봇(SwitchBot)이 홍콩 증시에 기업공개(IPO) 신청서를 제출했습니다. 이 회사는 “DJI 대부”로 불리는 리쩌샹의 투자와 자원 지원을 받았으며, 리쩌샹은 12.98%의 지분을 보유하고 있습니다. 워안 로봇은 지난 10년간 총 7차례의 투자를 유치했으며, 기업 가치는 2천만 위안에서 40억 위안으로 성장했습니다. 제품에는 인간의 팔다리 움직임을 모방하는 실행 로봇과 감지 결정 시스템이 포함되며, 이미 전 세계 AI 기반 가정용 로봇 최대 공급업체로 시장 점유율 11.9%를 차지하고 있으며, 2024년에는 조정 후 순이익 111만 위안을 달성했습니다 (출처: 量子位)

텐센트, 2026 “청운 계획” 시작, 최초로 과제 리소스 라이브러리 공개: 텐센트는 전 세계 최고 수준의 기술 학생들을 대상으로 하는 2026 “청운 계획”을 시작한다고 발표했습니다. AI 대형 모델, 기본 인프라, 고성능 컴퓨팅 등 10대 기술 분야를 포괄하며 100여 개의 기술 과제를 제공합니다. 예년과 달리 이번 계획은 처음으로 청운 과제 리소스 라이브러리를 공개하고 우수 인재에게 채용 그린 채널을 제공하여 산학 협력을 심화하고 청년 과학 기술 인재를 양성하는 것을 목표로 합니다. 텐센트는 업계 최고 수준의 교수진, 컴퓨팅 자원 및 경쟁력 있는 급여를 제공할 예정입니다 (출처: 量子位)

뤄융하오 디지털 휴먼, 6월 15일 바이두 이커머스에서 방송 시작: 뤄융하오가 자신의 AI 디지털 휴먼 아바타가 6월 15일 바이두 이커머스 플랫폼에서 라이브 방송 데뷔를 한다고 발표했습니다. 이는 정상급 스트리머가 AI 디지털 휴먼을 사용하여 라이브 커머스를 진행하는 첫 사례로, 바이두의 설득력 높은 디지털 휴먼 등 핵심 기술 발전 덕분입니다. 이번 시도는 “AI + 정상급 IP” 이커머스 새로운 패러다임 탐색으로 간주되며, 라이브 커머스 산업이 지능화, 고효율 저비용 방향으로 발전하는 데 기여할 것으로 기대됩니다. 바이두 이커머스 데이터에 따르면 이미 10만 명 이상의 디지털 휴먼 스트리머가 각 산업에서 활용되어 판매자의 운영 비용을 크게 절감하고 GMV를 향상시키고 있습니다 (출처: 量子位)
🌟 커뮤니티
중국 AI 기업, 모델 훈련 위해 대량 데이터 하드 드라이브 말레이시아로 운송: NIK 보도에 따르면, 중국 AI 기업들은 칩 제한을 회피하고 해외 컴퓨팅 자원을 활용하기 위해 훈련 데이터가 가득 담긴 하드 드라이브를 말레이시아 등지로 “직접” 운반하는 전략을 취하고 있습니다. 예를 들어, 한 엔지니어는 80TB의 데이터가 담긴 15개의 하드 드라이브를 가지고 말레이시아로 가서 서버를 임대하여 모델 훈련을 진행했습니다. 이러한 현상은 글로벌 AI 컴퓨팅 경쟁의 치열함과 데이터 국경 간 이동의 현실적인 과제를 반영하는 동시에 데이터 보안 및 규정 준수에 대한 논의를 불러일으키고 있습니다 (출처: jpt401, agihippo, cloneofsimo, fabianstelzer)

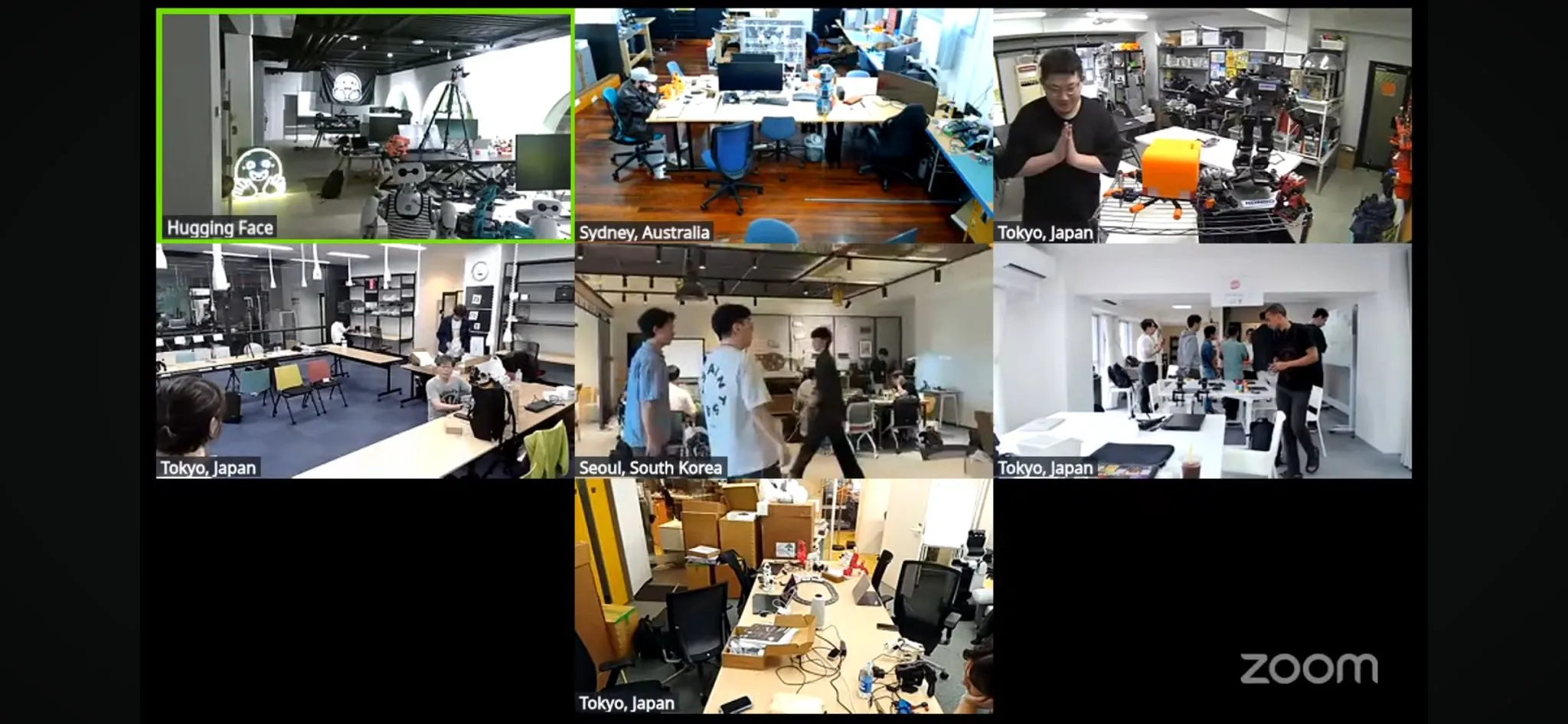
세계 최대 규모 LeRobot 로봇 해커톤 시작: Hugging Face가 주최하는 LeRobot 글로벌 로봇 해커톤이 공식적으로 시작되어 전 세계 5개 대륙 100개 이상의 장소에서 2300명 이상의 참가자를 유치했습니다. 이 행사는 오픈소스 AI 로봇의 발전을 촉진하는 것을 목표로 하며, 참가자들은 52시간 동안 로봇 관련 구축 및 탐색을 진행합니다. 각 지역의 개발자와 팀들이 열정적으로 참여하여 현장 사진과 프로젝트 진행 상황을 공유하며 로봇 기술에 대한 커뮤니티의 열정과 창의성을 보여주었습니다 (출처: _akhaliq, eliebakouch, ClementDelangue)
Lovable, AI 웹 페이지 생성 대결 개최, Claude 성능 호평: Lovable은 사용자가 OpenAI, Anthropic, Google의 최고 모델을 무료로 사용하여 AI 웹 페이지 생성 경쟁을 벌일 수 있는 행사를 개최했습니다. 사용자 op7418은 동일한 프롬프트 세트를 사용하여 세 회사의 모델로 웹 페이지를 생성한 경험을 공유하며, Claude가 콘텐츠 양과 시각 효과 측면에서 두드러졌다고 평가했습니다. 이러한 행사는 개발자와 사용자에게 특정 응용 시나리오에서 다양한 대형 모델의 성능을 비교할 수 있는 기회를 제공합니다 (출처: _philschmid, op7418)
AI 모델 추론 능력에 대한 논의: 토큰 제한과 실제 논리: 애플사가 제기한 “사고의 착각(Illusion of Thinking)” 논문에 대해 커뮤니티에서 반박 의견이 나왔습니다. 일부 논평과 후속 연구(예: Claude Opus를 저자로 명시한 arXiv:2506.09250)는 관찰된 모델 추론 능력의 “붕괴”가 모델 자체의 논리 능력 부족보다는 토큰 수 제한 때문이라고 주장합니다. 모델이 더 압축된 답변 형식을 사용하거나 충분한 컨텍스트가 주어지면 문제를 성공적으로 해결할 수 있다는 것입니다. 이는 대규모 언어 모델의 실제 추론 능력을 정확하게 평가하고 이해하는 방법, 그리고 현재 평가 방법의 잠재적 한계에 대한 심도 있는 논의를 촉발시켰습니다 (출처: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
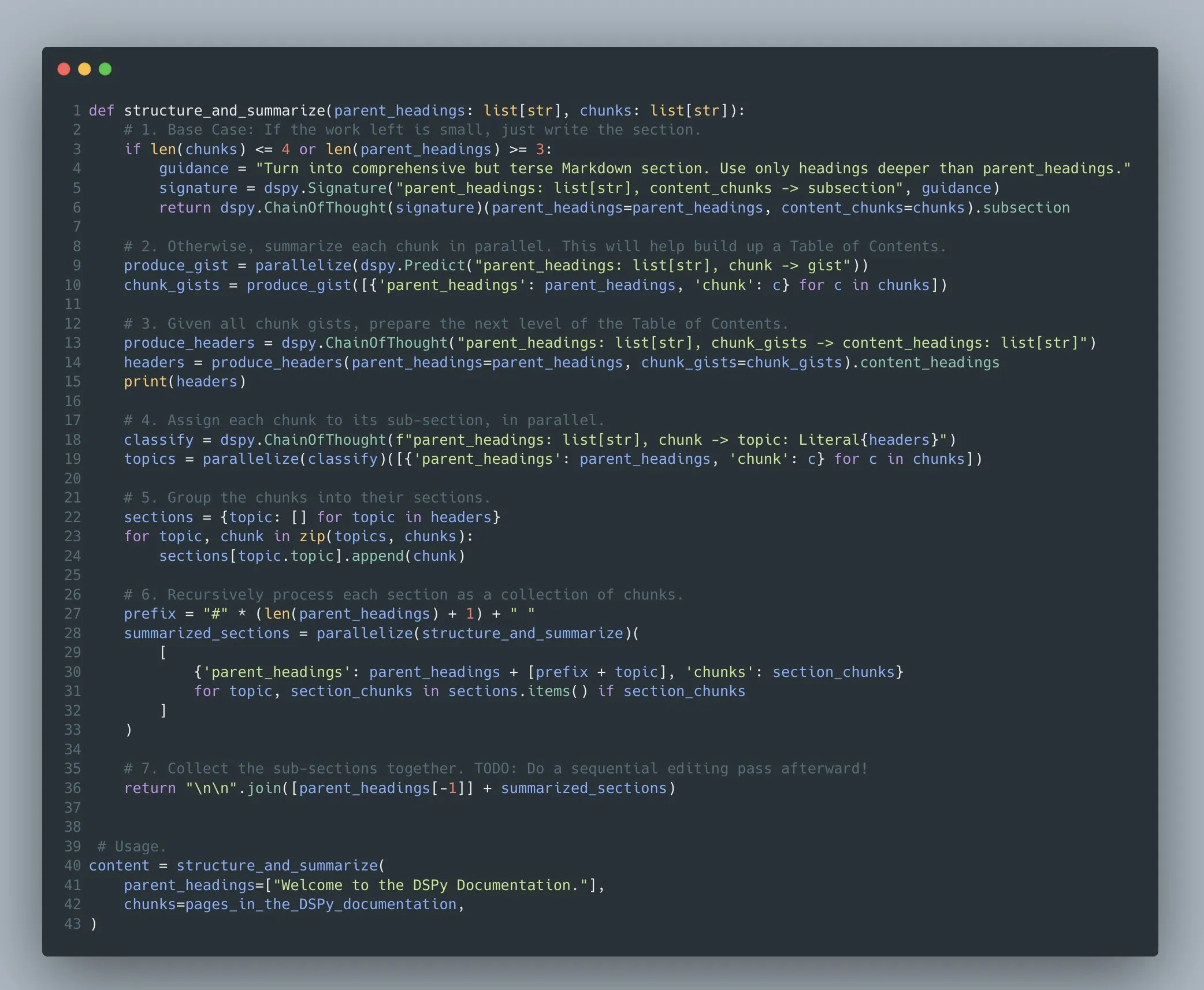
DSPy 프레임워크, 복잡한 다단계 언어 모델 프로그램 최적화 지원: Omar Khattab은 DSPy 프레임워크가 2022/2023년부터 복잡한 다단계 언어 모델 프로그램(Compound AI Systems)에 대한 프롬프트 최적화 및 강화 학습을 지원해 왔다고 강조했습니다. 그는 AI 시스템이 점점 더 복잡해짐에 따라 이를 단순한 “모델”이 아닌 “프로그램”으로 간주하는 것이 더 적절하며, DSPy는 선형적인 “흐름”이나 “체인”뿐만 아니라 재귀, 예외 처리 등을 포함한 임의의 복잡성을 가진 이러한 프로그램을 구축하고 최적화하는 것을 지원하는 것을 목표로 한다고 주장했습니다 (출처: lateinteraction)
LLM이 인간의 사고와 유사한지에 대한 논의: Geoffrey Hinton은 대규모 언어 모델(LLM)이 인간이 언어를 처리하는 방식과 유사하며, 언어가 어떻게 작동하는지 이해하는 데 가장 좋은 모델이라고 생각합니다. 그러나 Pedro Domingos는 이에 대해 LLM이 오래된 언어학 이론보다 우수하다고 해서 인간처럼 생각한다는 의미는 아니라고 반박합니다. 이 논의는 LLM의 본질과 인간 인지와의 관계에 대한 AI 분야의 지속적인 논쟁을 반영합니다 (출처: pmddomingos)
물리 과학 연구에서 AI의 막대한 응용 잠재력: 지구 과학 분야의 한 연구원은 o3 Pro(아마도 OpenAI의 특정 고급 모델을 지칭)를 사용한 긍정적인 경험을 공유하며, 연구에서 “매우 똑똑한 박사후 연구원”과 같다고 말했습니다. 이 모델은 코딩, 모델 개발, 아이디어 구체화에서 뛰어난 성능을 보였으며, 지시를 빠르고 정확하게 수행하고 연구를 보조했습니다. 연구원은 현재 모델이 아직 연구 문제를 능동적으로 제기하는 능력(AGI 특징)을 갖추고 있지는 않지만, 강력한 보조 기능이 이미 연구 효율성을 크게 향상시켰으며 자율성을 가진 LLM이 머지않았음을 예감한다고 말했습니다 (출처: Reddit r/ArtificialInteligence)
💡 기타
AI 생성 만화 도구로 창의적 표현 더욱 편리해져: 사용자 StriderWriting은 AI 도구를 사용하여 만화를 창작한 경험을 공유하며, AI 덕분에 “어리석은 아이디어”를 만화로 전환하는 것이 가능해졌다고 말했습니다. 이는 AI가 창의적인 콘텐츠 생성 분야에서 보편화되어 창작의 문턱을 낮추고 더 많은 사람들이 자신의 창의성을 쉽게 표현할 수 있게 되었음을 반영합니다 (출처: Reddit r/ChatGPT)

AI 편견에 대한 우려: ChatGPT의 성 고정관념 표현에 사용자 불만: 한 여성 사용자는 ChatGPT가 대화에서 남성에 대한 부정적인 고정관념을 보인다고 지적했습니다. 예를 들어, 업무 및 의료 문제에 대해 논의할 때 별도의 지시 없이 부정적인 역할을 남성으로 가정하고 “남자는 원래 그래”와 같은 발언을 사용했다는 것입니다. 사용자는 이러한 성별 기반의 안일한 고정관념이 불쾌하며, OpenAI에 이러한 행동을 규제하는 규칙이 있는지 의문을 제기했습니다. 이는 AI 모델 훈련 데이터의 편견과 그것이 상호작용에서 어떻게 나타나는지에 대한 논의를 다시 한번 촉발시켰습니다 (출처: Reddit r/ChatGPT)
뉴스 보도에서 AI의 객관성 잠재력과 현재 한계: 한 사용자가 OpenAI의 o3 모델을 “편견 없는 뉴스 기자”로서의 잠재력을 테스트했습니다. 2017년 이후 트럼프와 바이든 행정부의 여러 정책이 초래할 수 있는 “의도치 않은” 결과에 대해 논평하도록 지시한 것입니다. AI가 객관적으로 보이는 분석을 생성할 수는 있지만, 정보 출처, 잠재적 편견, 복잡한 정치 경제 역학에 대한 진정한 이해 깊이는 여전히 미래에 해결해야 할 문제입니다. 이는 AI를 활용하여 뉴스 객관성과 깊이를 향상시키려는 커뮤니티의 기대와 현재 기술의 한계에 대한 인식을 반영합니다 (출처: Reddit r/deeplearning)