
Ключевые слова:GPT-5.2 Pro, DeepSeek V4, Агент Confucius Code, Математическая проблема Эрдёша, Архитектура mHC, Агент с долгосрочной памятью
🔥 В фокусе
GPT-5.2 Pro самостоятельно решил ряд математических задач Erdos : В социальных сетях активно обсуждают прорыв GPT-5.2 Pro в области научных открытий. Модель в сочетании с системой Aristotle успешно и автономно решила несколько математических задач, включая задачи Erdos #729 и #397, при этом доказательство #397 уже получило признание математика Terence Tao. Это знаменует переход AI от простого обучения на корпусе текстов к способности рассуждать для решения ранее неизвестных научных проблем. Сообщество считает, что это доказывает огромный потенциал моделей рассуждения (reasoning models) в обработке высокоабстрактной логики, и получение AI премии Fields Medal — лишь вопрос времени (Источник: SebastienBubeck; kevinweil; halvarflake)
Прогноз релиза DeepSeek V4 и глубокое обсуждение архитектуры mHC : Инсайдерские источники сообщают, что релиз DeepSeek V4 ожидается во время Праздника весны (китайского Нового года) с целью достижения полного SOTA. В последнее время серия этих моделей привлекла внимание благодаря архитектуре mHC (Multi-Head Connection), которая через свойства Doubly Stochastic Matrix обеспечивает стабильность произведения слоев, эффективно решая проблему исчезновения или взрыва градиентов в глубоких сетях. Аналитики сообщества полагают, что технологический путь DeepSeek смещается от простого наращивания вычислительных мощностей к оптимизации фундаментальной математической архитектуры. Такой подход «малой ценой к большим результатам» меняет парадигму разработки больших моделей (Источник: teortaxesTex; Reddit r/MachineLearning)
Meta и Гарвард представили Confucius Code Agent (CCA) с долгой памятью : Meta совместно с Гарвардским университетом выпустила Confucius Code Agent, предназначенный для решения задач автономной работы в крупных и сложных кодовых базах. Ядром CCA являются постоянные внутренние заметки, долгосрочная память задач и отслеживаемые цепочки рассуждений, а также цикл обратной связи для самокорректировки стратегий использования инструментов. Такая архитектура позволяет AI сохранять логическую связность в реальных сложных системах, а не просто обрабатывать изолированные Prompt. Сообщество отмечает, что это подтверждает новый отраслевой консенсус: «масштабируемый интеллект зависит от структуры памяти, а не только от размера модели» (Источник: Reddit r/artificial; Reddit r/ArtificialInteligence)

🎯 Тренды
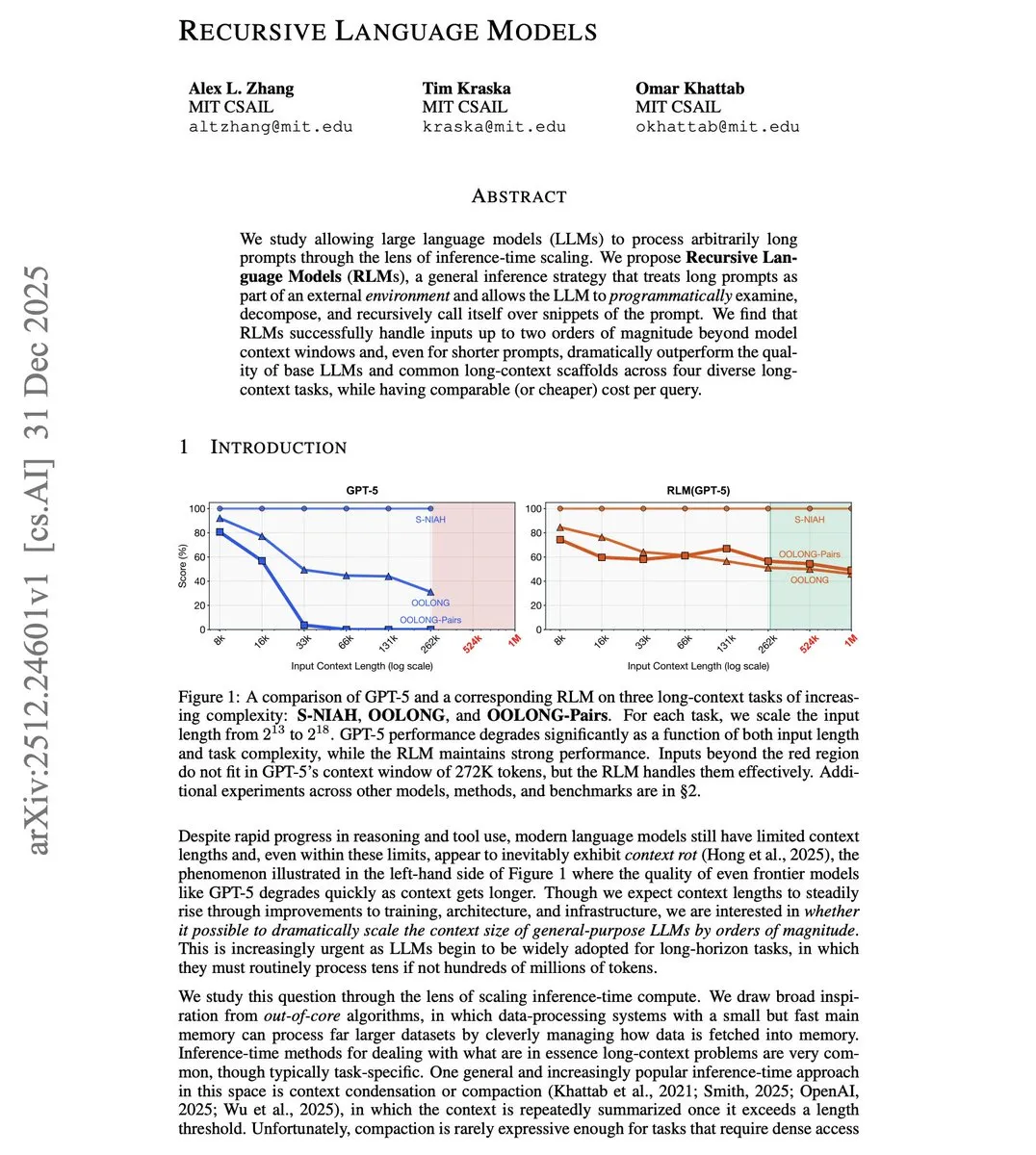
MIT предложил Recursive Language Model (RLM) для преодоления ограничений контекста : Исследователи из MIT представили RLM, позволяющую моделям обрабатывать входные данные, в 100 раз превышающие их Context Window. Технология не увеличивает окно через изменение архитектуры, а программно рассматривает длинные промпты как внешнюю среду, заставляя модель рекурсивно вызывать саму себя для обработки фрагментов. Тесты показали, что модель с окном 8K эффективно справляется с 800K токенов, превосходя традиционные решения с длинным контекстом даже в задачах с короткими промптами. Это открывает бюджетный путь для Agent при работе с полными репозиториями кода или длинными документами (Источник: omarsar0)
KimiLinear-48B реализовал поддержку MLA KV Cache : Разработчики успешно добавили в llama.cpp независимую от бэкенда поддержку MLA KV Cache для модели KimiLinear. Эта оптимизация снизила потребление памяти для 1M токенов (F16 KV) со 140 ГБ до 14,8 ГБ, что делает возможным запуск моделей с ультрадлинным контекстом на потребительских видеокартах с малым объемом видеопамяти. KimiLinear ранее показала отличные результаты в ContextArena, и данная оптимизация значительно ускорит популяризацию AI-приложений для работы с длинными текстами на локальных устройствах (Источник: Reddit r/LocalLLaMA)

Alibaba открыла исходный код кросс-модальной системы RAG Qwen3-VL : Alibaba выпустила модели Qwen3-VL-Embedding и Reranker, решив проблему чрезмерной зависимости RAG от текста в прошлом. Модель поддерживает встраивание текста, изображений, видео и скриншотов в единое векторное пространство, реализуя поиск «текст в изображение» или «изображение в видео». Уникальная функция «осознания инструкций» позволяет пользователям определять релевантность в зависимости от конкретной задачи (например, поиск в e-commerce или юридическое сравнение), что знаменует переход мультимодального RAG на новый этап, управляемый задачами (Источник: ZhihuFrontier)
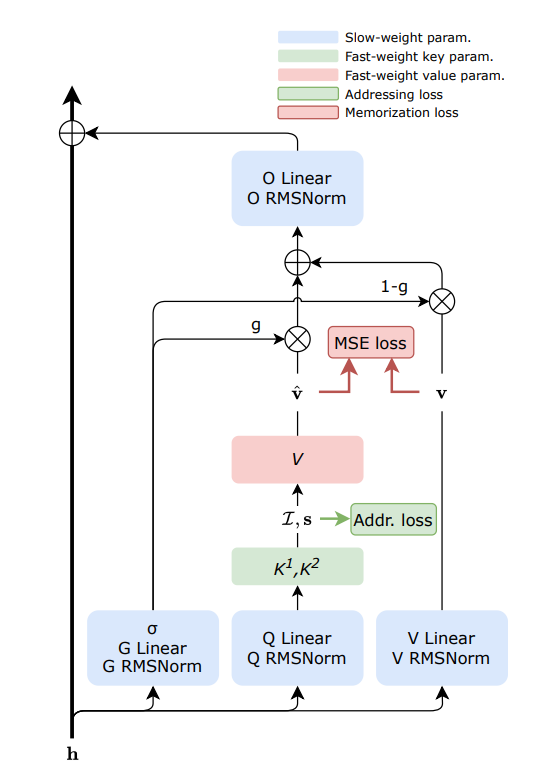
Sakana AI представила технологию динамической памяти FwPKM : Sakana AI выпустила Fast-weight Product Key Memory (FwPKM), нацеленную на баланс между большой емкостью памяти и низкими вычислительными затратами. Эта технология позволяет Product Key Memory (PKM) динамически обновляться как во время обучения, так и во время инференса, устраняя узкие места масштабирования механизмов внимания (Attention). Поскольку моделям необходимо запоминать больше информации и выполнять долгосрочные рассуждения, такие механизмы динамической памяти рассматриваются как ключевой шаг на пути к AGI (Источник: TheTuringPost)
🧰 Инструменты
Silicon-Studio: GUI для локального fine-tuning на Mac серии M : Это инструмент для сквозного локального дообучения LLM, разработанный специально для компьютеров Mac с чипами серии M. Он инкапсулирует фреймворк MLX от Apple, предлагая очистку данных, десенсибилизацию конфиденциальных данных (PII), настройку параметров LoRA/QLoRA и встроенный интерфейс для тестирования инференса. Инструмент снижает порог входа для обычных пользователей для персонализированного обучения моделей на Mac, реализуя полностью графическое управление процессом (Источник: Reddit r/LocalLLaMA)
Kreuzberg v4: Универсальная библиотека для анализа документов, переписанная на Rust : В версии Kreuzberg v4 была проведена полная переработка ядра с Python на Rust, обеспечивающая поддержку извлечения структурированных данных из 56 форматов. Библиотека отказалась от зависимости Pandoc в пользу нативных парсеров на Rust, что значительно увеличило скорость и снизило потребление памяти. Доступны привязки (bindings) для 10 языков (включая TS, Python, Go), поддержка переключения бэкендов OCR и эмбеддингов ONNX, что делает её идеальным выбором для построения высокопроизводительных конвейеров RAG (Источник: Reddit r/LocalLLaMA)

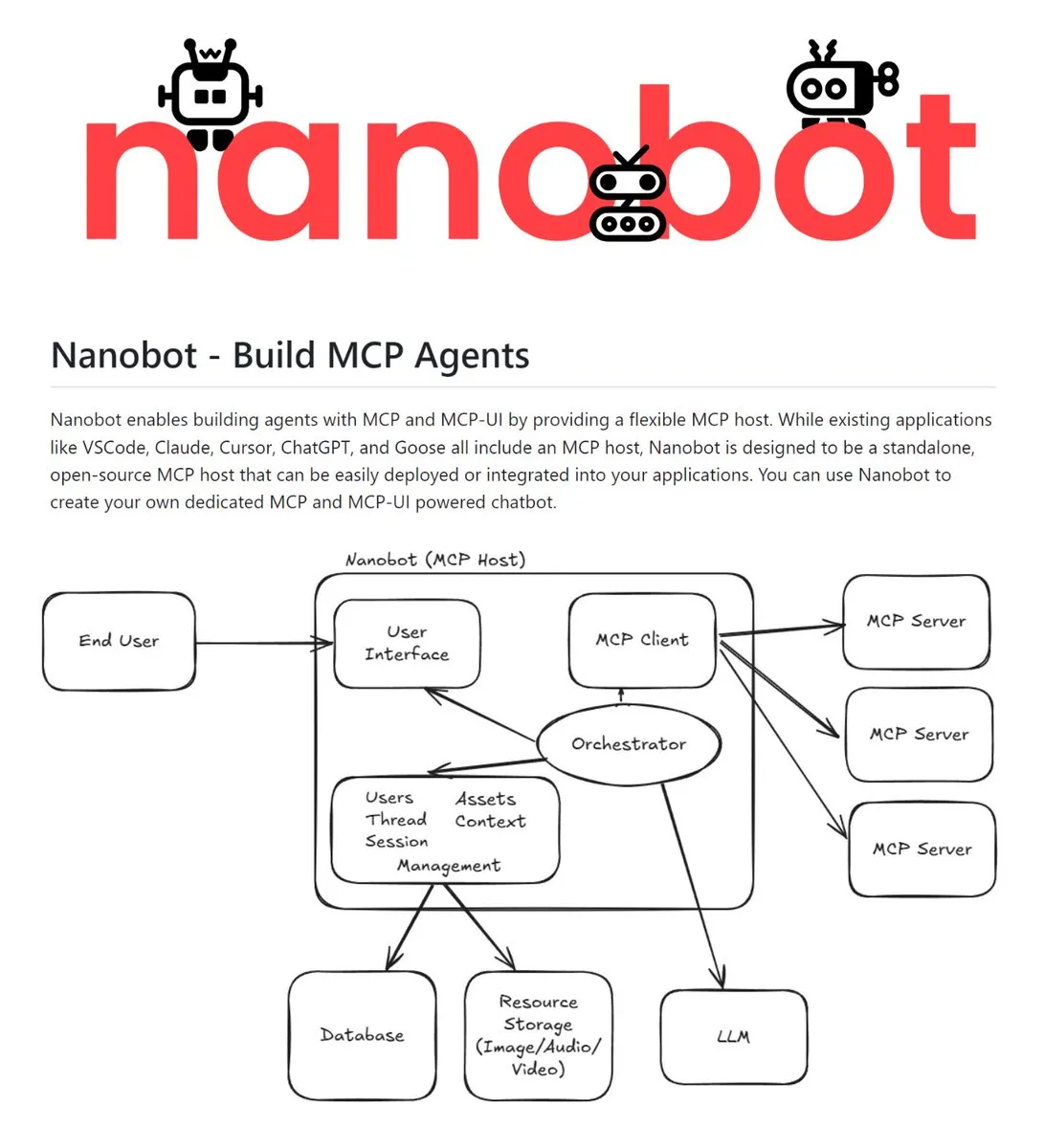
Nanobot: Автономный хост MCP с открытым исходным кодом : Nanobot — это автономный хост с поддержкой MCP (Model Context Protocol) и MCP-UI. Он позволяет объединять серверы MCP, LLM и контекст в единый сервис, поддерживая создание агентского опыта через чат-ботов, голос, почту, Slack и другие интерфейсы. Возможность независимого развертывания делает его базовым набором для разработчиков, создающих кроссплатформенных AI Agent (Источник: TheTuringPost)
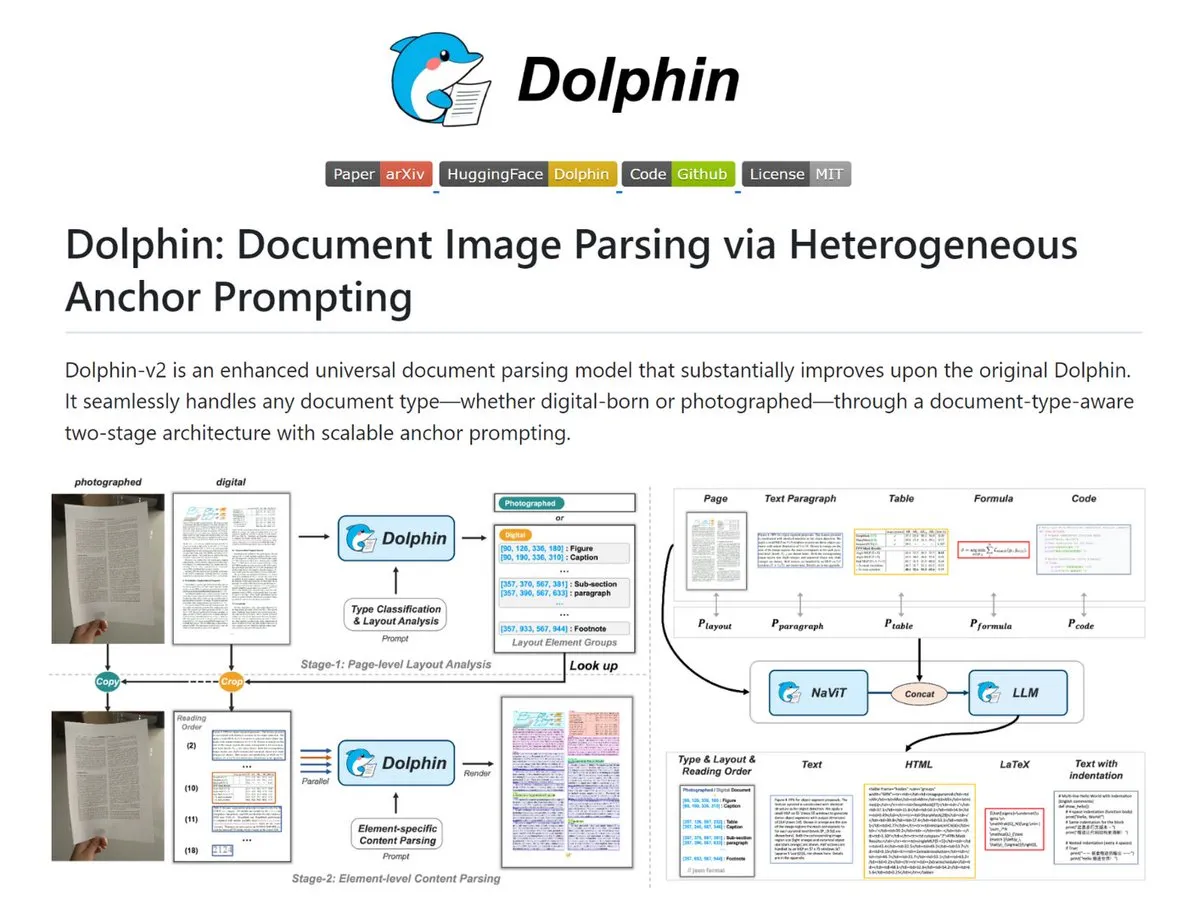
Dolphin: Мощный инструмент для парсинга сложных документов : Dolphin — это инструмент, способный преобразовывать изображения документов и PDF в структурированный Markdown/JSON. Он автоматически распознает сканы и цифровые документы, восстанавливает порядок чтения макета и параллельно анализирует текст, таблицы и формулы. Модели варьируются от 0.3B до 3B параметров и показывают отличные результаты в OmniDocBench, что подходит для сценариев, требующих высокоточной оцифровки документов (Источник: TheTuringPost)
📚 Обучение
AI Agents A-Z: Полный курс по разработке агентов : Этот репозиторий на GitHub содержит шаблоны n8n из серии видеоуроков «AI Agents A-Z», охватывающие более 40 практических кейсов: от агентов по управлению рецептурными лекарствами и ежедневных дайджестов до автоматизации LinkedIn и генерации видео для YouTube. Он демонстрирует, как использовать инструменты no-code в сочетании с LLM для создания сложных автоматизированных рабочих процессов (Источник: GitHub Trending)
Обзор построения Knowledge Graph с помощью LLM : Статья «LLM-empowered knowledge graph construction» систематизирует методы использования LLM для усиления традиционных графов знаний (KG). Содержание охватывает извлечение онтологий, извлечение на основе схем и без них, слияние знаний и будущие направления динамического вывода в памяти. Это ценный справочный материал для разработчиков, стремящихся объединить структурированные знания со способностями рассуждения больших моделей (Источник: TheTuringPost)

💼 Бизнес
Слухи о задержке видеокарт NVIDIA и стратегия приоритета AI : В социальных сетях циркулируют слухи о том, что NVIDIA может на неопределенный срок отложить выпуск видеокарт серии RTX 50 Super из-за нехватки памяти и приоритета поставок более прибыльных AI-чипов. Несмотря на то, что это лишь слухи, сообщество полагает, что, поскольку доля игрового бизнеса в доходах NVIDIA упала до 8%, «стратегическое пожертвование» потребительскими видеокартами в условиях дефицита вычислительных мощностей выглядит логичным (Источник: Reddit r/LocalLLaMA)

Meta подписала соглашение о ядерной энергии для обеспечения AI-суперкомпьютеров : Meta заключила соглашение об использовании ядерной энергии для своего кластера суперкомпьютеров Prometheus AI. По мере обострения гонки AI энергия становится узким местом для расширения вычислительных мощностей. Meta следует примеру Microsoft и других гигантов, резервируя стабильные и чистые ядерные ресурсы для обеспечения возможности расширения мощностей в ближайшие годы (Источник: Reddit r/artificial)
Внимание к динамике IPO Zhipu AI : В отраслевых обзорах упоминаются потенциальные шаги Zhipu AI как первой в Китае публичной компании в сфере больших моделей. Будучи ведущим игроком на внутреннем рынке, процессы коммерциализации и показатели Zhipu на рынке капитала рассматриваются как индикатор индустрии, особенно в условиях усложнения глобальной среды финансирования AI (Источник: ZhihuFrontier)
🌟 Сообщество
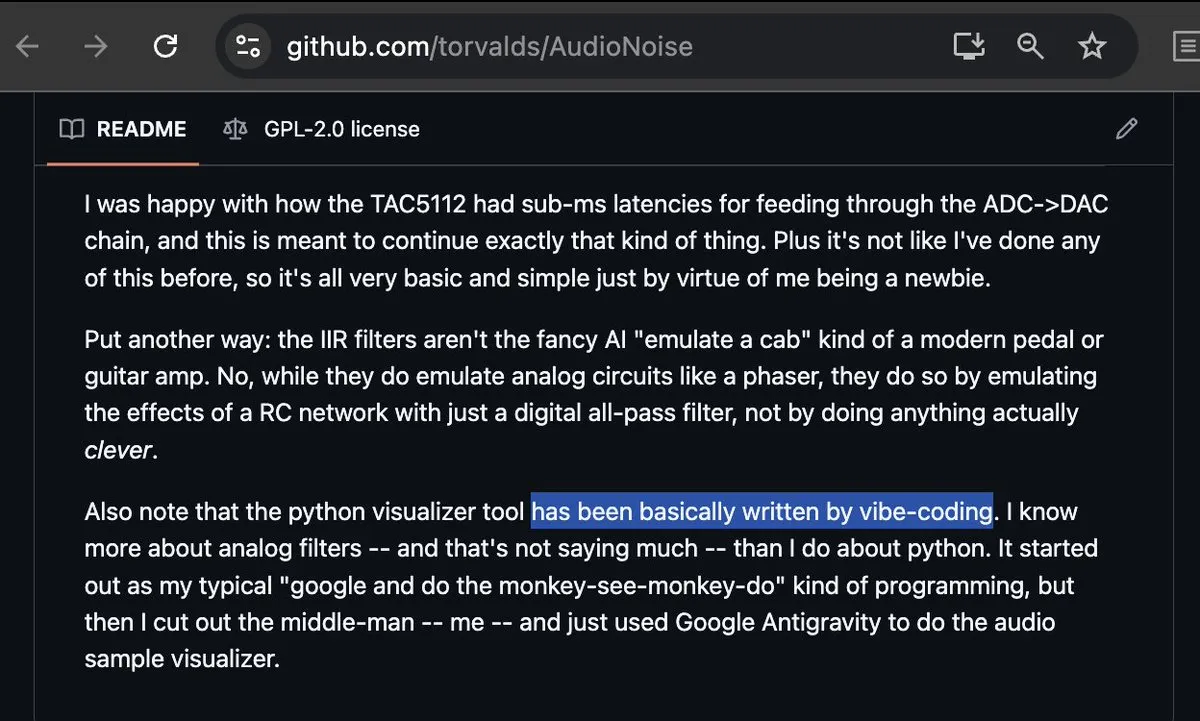
Linus Torvalds и Vibe-coding вызвали бурные обсуждения : Даже всегда строгий «отец Linux» Linus Torvalds начал использовать Google Antigravity для Vibe-coding («программирование по вайбу»), успешно создав инструмент визуализации аудио. Это событие вызвало сенсацию в сообществе и рассматривается как веха зрелости инструментов AI-программирования. Программисты отмечают: когда даже самые консервативные разработчики принимают такой подход, традиционные модели аудита и написания кода начинают фундаментально меняться (Источник: dotey; cto_junior; osanseviero)
Резкое изменение восприятия AI-программирования опытными разработчиками : Сообщество замечает, что хардкорные программисты (занимающиеся компиляторами, ядрами CUDA и т.д.), которые раньше презирали AI-код, называя его «мусором» (slop), быстро меняют свое мнение. С успехами таких моделей, как GPT-5.2, в сложной логике и низкоуровневом коде, окно для отрицания возможностей AI закрылось. Этот психологический переход от сопротивления к шоку и принятию отражает смену поколений инструментов продуктивности AI (Источник: Yuchenj_UW; timsoret)
Новая парадигма отладки Agent: смотреть Trace, а не код : Мнение Harrison Chase «при отладке Agent не показывайте мне код, покажите мне Trace» получило широкое признание. В Agentic-процессах процесс принятия решений LLM важнее статического кода. Анализируя траекторию выполнения (Trace), разработчики могут четче определить, на каком этапе рассуждения модель ошиблась. Такая «поведенческая» отладка заменяет традиционную «логическую» (Источник: Hacubu; _philschmid)
«Перетягивание каната» между безопасностью AI и привычками сотрудников : Многие руководители компаний обеспокоены тем, что сотрудники передают конфиденциальные данные в ChatGPT. Несмотря на тренинги по безопасности, из-за удобства AI сотрудники часто возвращаются к нарушениям. В сообществе обсуждают, что простой запрет неэффективен — необходимо предоставлять столь же удобные локальные безопасные альтернативы AI, подкрепляя это реальными «страшилками» об утечках для усиления осознанности (Источник: Reddit r/ArtificialInteligence)
💡 Другое
Сравнение технологий сальто назад роботов Китая и США : В соцсетях сравнили выполнение сальто назад роботом Atlas от Boston Dynamics и роботом от Unitree. Unitree продемонстрировал более совершенный баланс и приземление, в то время как Atlas показал более продвинутые стратегии суставов в «нечеловеческой» форме при восстановлении движения. Это соперничество показывает, что китайские роботы догнали или даже местами превзошли американские в производстве «железа» и контроле баланса, в то время как США сохраняют преимущество в алгоритмах сложных стратегий (Источник: teortaxesTex)
Фотонный AI-чип заявляет о 100-кратном ускорении : Сообщается о новом типе AI-чипа на световой основе, который якобы в 100 раз быстрее топовых GPU NVIDIA. Технология использует обработку световых сигналов вместо электронных, стремясь решить проблемы энергопотребления и задержек традиционных полупроводников при масштабировании мощностей. Хотя проект находится на стадии разработки, это представляет собой радикальный технологический путь противостояния монополии NVIDIA на аппаратном уровне (Источник: Ronald_vanLoon)
