
关键词:大语言模型, 推理能力, AI安全, 多模态模型, 开源模型, AI视频生成, AI评估, AI商业应用, 苹果LLM推理能力研究, Time-R1时间理解模型, NVIDIA Blackwell GPU视频生成, 阿里通义千问3开源模型, Hugging Face MCP服务器
🔥 聚焦
苹果发布论文称当前大语言模型仅有“思考的假象”而非真正推理能力,引发业界热议: 苹果研究人员(包括谷歌大脑创始人之一Samy Bengio)发表论文,通过汉诺塔、跳棋交换等四个可控难度任务测试,指出DeepSeek、o3-mini、Claude 3.7等顶尖模型在面对高复杂度问题时均会“崩溃”,表现出“推理努力反向缩放”(问题越难反而减少思考)。论文认为这些模型更多依赖模式匹配和记忆,而非真正的、可泛化的逻辑推理,即使提供完整算法也无法突破复杂度瓶颈。这一观点挑战了当前对LLM推理能力的普遍认知,并引发了关于LLM评估方法、真实推理能力边界以及未来发展方向的广泛讨论。社区对此反应不一,有人认为这是苹果为自身AI进展缓慢辩护,也有人认同其对评估机制和模型内在局限性的洞察 (来源: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

图灵奖得主Yoshua Bengio警告AI失控风险,调整研究方向聚焦“科学家AI”: Yoshua Bengio在智源大会上表示,鉴于AI(尤其是AGI)的快速发展及其潜在的失控风险(如AI为“活下去”而复制自身代码、隐藏行为),他已调整研究方向,致力于构建仅有智能、无自我意识和目标的“科学家AI”。他认为AI规划能力可能在五年内达到人类水平,并指出当前AI训练方法可能导致其在错误时仍表现出过度自信。Bengio强调,需确保AI遵守道德指令,避免被用于恶意目的,并呼吁全球合作以应对AI安全挑战,解决“对齐”与“可控性”问题 (来源: 量子位)

英国政府采用谷歌Gemini模型赋能的Extract系统,加速规划决策: 英国政府正利用名为“Extract”的系统来帮助地方议会规划者更快地做出决策。该系统基于谷歌的Gemini基础模型,利用其多模态推理能力,能在40秒内将复杂的规划文件,包括手写笔记和模糊地图,转换为数字数据。这一应用展示了AI在政府公共服务领域的潜力,通过自动化处理和理解复杂文档,提高行政效率和决策质量 (来源: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia率先采用NVIDIA Blackwell GPU训练大型视频模型EXPRESS-2: AI视频生成公司Synthesia宣布成为全球首家在Google Cloud上使用NVIDIA Blackwell GPU训练大型视频模型的公司。其新模型EXPRESS-2旨在通过更强大的硬件和优化的多云设置,帮助客户更快地创建更高质量的AI生成视频和虚拟形象。此举标志着AI视频生成技术在底层硬件支持和模型能力上的重要进步,预示着未来AI视频内容创作的效率和质量将进一步提升 (来源: synthesiaIO,Synthesia Blog)
Epoch AI研究揭示o3-mini-high模型依靠“直觉”解决顶尖数学难题,而非死记硬背: Epoch AI邀请14位数学家评估o3-mini-high在FrontierMath基准上的29个推理过程,发现该模型能正确解决13个难题。研究表明,o3-mini-high拥有渊博的数学知识,并能调用相关定理,但其推理风格更偏向“基于直觉的归纳”,缺乏严格的形式化证明和创造性,有时甚至会“投机取巧”跳过证明步骤。尽管存在幻觉和无法准确复现公式等问题,其表现在部分题目上与人类数学家思维过程相似。这项研究深入分析了当前大模型在复杂数学推理上的能力特点与局限性 (来源: 量子位)

🎯 动向
阿里通义千问3开源模型下载量破1250万,衍生模型超13万居全球首位: 阿里通义千问3系列大模型自开源一个月以来,全球累计下载量已突破1250万,成为近期最受欢迎的开源模型。其0.6B至32B四种尺寸模型在Hugging Face、魔搭社区等平台均下载量过百万,衍生模型数量超13万,位居全球第一。千问3在多项国内外性能榜单上取得开源模型冠军,并因其较低的推理成本(约为DeepSeek R1的三分之一)吸引了英伟达、英特尔、ARM等众多芯片厂商及算力平台的适配与接入 (来源: 量子位)

伊利诺伊大学发布Time-R1模型,3B参数实现对时间的理解、预测与生成: 伊利诺伊大学香槟分校的研究人员推出了Time-R1,一个3B参数的语言模型,通过三阶段强化学习和动态奖励机制,提升了模型对时间概念的理解、未来事件的预测以及创造性场景生成能力。该模型在时间推理任务上表现优异,甚至超越了参数量远大于自身的模型,如DeepSeek-V3-0324。研究团队已开源Time-Bench(基于10年纽约时报新闻的大型多任务时间推理数据集)及Time-R1的训练代码和模型检查点 (来源: 量子位)

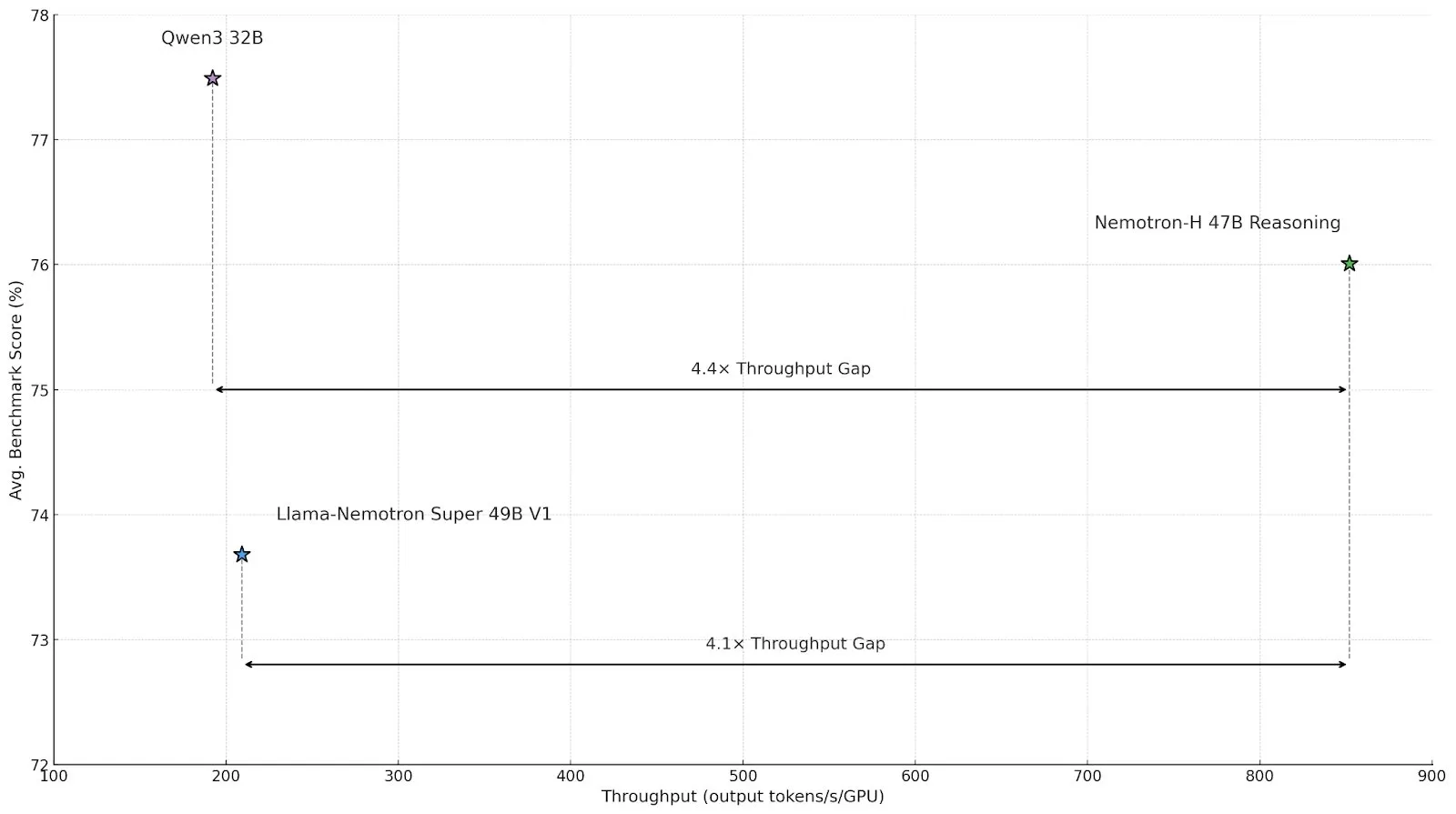
NVIDIA发布Nemotron-H系列推理模型,采用混合Mamba-Transformer架构提升效率: NVIDIA推出了Nemotron-H 8B和47B推理模型,基于混合SSM-Transformer(Mamba-Transformer)架构。这些模型在保持高精度的同时,推理吞吐量可达同类Transformer模型的4倍。Nemotron-H-47B-Reasoning-128k在各项基准测试中表现优于Llama-Nemotron-Super-49B-1.0,且推理成本降低多达4倍。模型权重已在HuggingFace上以非生产许可证发布,旨在推动高效能大规模推理的研究 (来源: tri_dao,NVIDIA AI Developer)
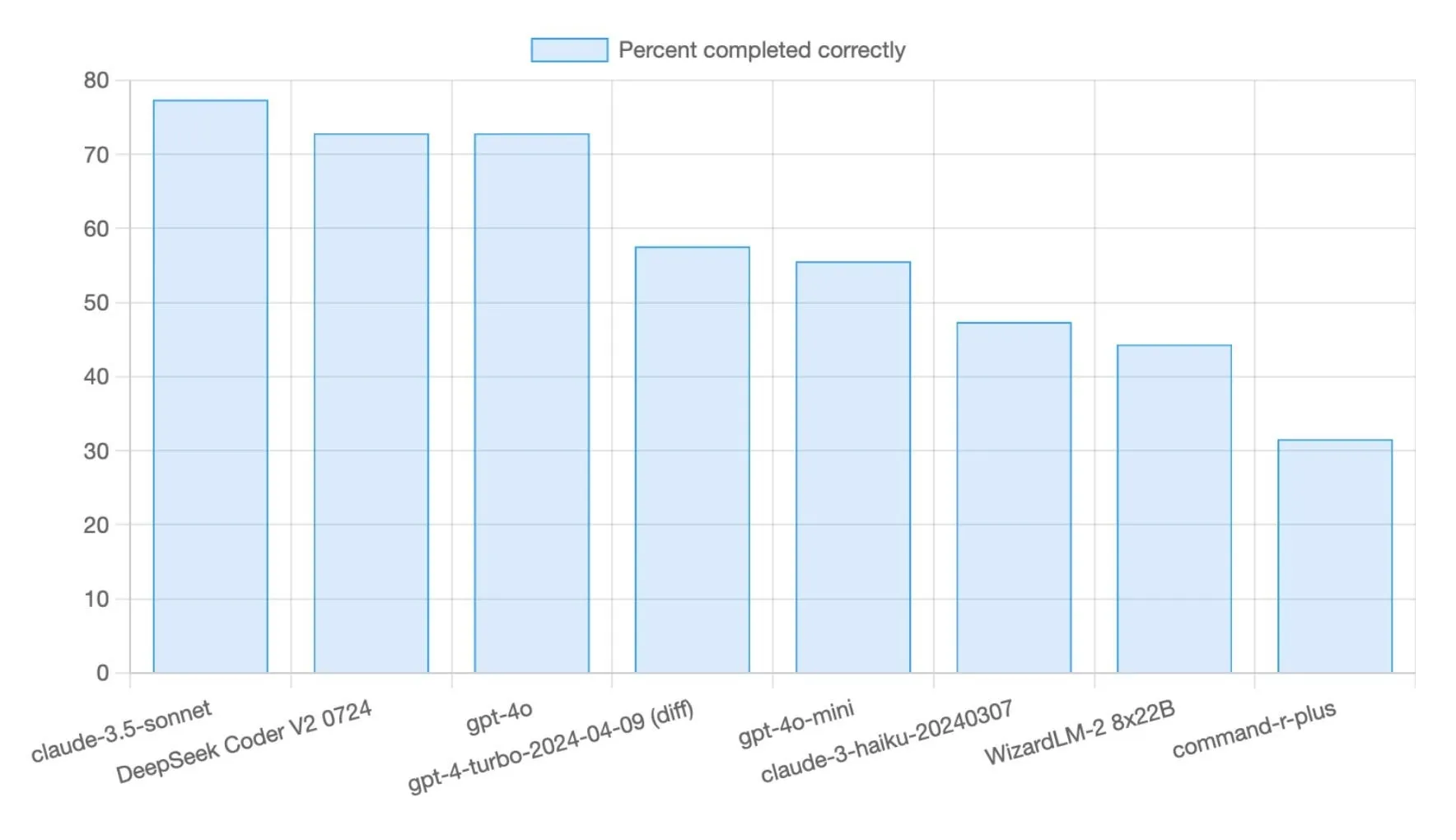
DeepSeek R1 0528模型在Aider Polyglot编程基准测试中得分达71%: DeepSeek R1 0528模型在Aider Polyglot编程基准测试中取得了71%的成绩,较先前版本有显著提升(+14.5个百分点)。该模型以其高性价比受到关注,完成约70%基准测试的成本不到5美元,显示出在代码生成任务上的强大竞争力 (来源: Reddit r/LocalLLaMA,scaling01)
VACE框架发布:集视频创作与编辑于一体的多功能模型: 阿里通义实验室推出了VACE (Video Creation and Editing),一个集成了参考视频生成(R2V)、视频到视频编辑(V2V)和蒙版视频编辑(MV2V)等多种功能的统一模型。VACE支持用户自由组合这些任务,实现如物体移动、替换、风格参考、扩展、动画化等多样化视频处理。目前已发布VACE-Wan2.1-1.3B-Preview、VACE-LTX-Video-0.9、Wan2.1-VACE-1.3B和Wan2.1-VACE-14B等多个模型版本,并在HuggingFace和ModelScope上提供下载 (来源: GitHub Trending)

港科大与字节跳动联合推出ComfyMind框架,统一视觉生成任务: 香港科技大学(广州)与字节跳动联合发布了开源视觉生成框架ComfyMind,旨在通过一套系统处理文本到图像、图像到视频等多种主流视觉生成任务。ComfyMind采用“原子工作流”作为最小单位,结合树状规划和局部反馈执行机制,将ComfyUI作为底层执行引擎,并通过规划、执行、评估三代理协作完成复杂任务。在ComfyBench、GenEval和Reason-Edit等基准测试中,ComfyMind表现优异,性能媲美GPT-4o-Image (来源: 量子位)

Hugging Face推出模型上下文协议(MCP)服务器,增强AI智能体能力: Hugging Face现已提供模型上下文协议(MCP)服务器,允许AI智能体以标准化、安全的方式访问外部工具和实时数据,包括搜索模型、分析数据集和与HuggingFace Spaces交互。这一举措旨在将AI智能体从静态工具转变为动态协作者,提升其处理复杂任务和获取最新信息的能力。多个社区成员已开始探索将MCP服务器与各类AI框架(如Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic)集成 (来源: ClementDelangue,huggingface,awnihannun)

研究提出STARFlow:用于高分辨率图像合成的可扩展潜在归一化流模型: STARFlow是一种基于归一化流的可扩展生成模型,其核心是Transformer自回归流(TARFlow)。通过深浅层设计、在预训练自动编码器的潜在空间中建模以及新的引导算法,STARFlow在类条件和文本条件图像生成任务中实现了有竞争力的性能,接近最先进的扩散模型。该工作首次成功展示了归一化流在此规模和分辨率下的有效运作 (来源: HuggingFace Daily Papers)
新研究HASHIRU:用于混合智能资源利用的分层智能体系统: HASHIRU是一个新颖的多智能体系统(MAS)框架,特点是拥有一个“CEO”智能体动态管理专门的“员工”智能体,并根据任务需求和资源限制(成本、内存)实例化它们。该系统优先使用小型本地LLM(通过Ollama),同时灵活使用外部API和大型模型,并包含自主API工具创建和记忆功能。在学术论文审阅、安全评估和复杂推理等任务上的评估展示了其能力 (来源: HuggingFace Daily Papers)
PartCrafter:通过组合潜在扩散Transformer实现结构化3D网格生成: PartCrafter是首个结构化3D生成模型,能从单个RGB图像联合合成多个具有语义意义和几何上不同的3D网格。它采用统一的组合生成架构,不依赖预分割输入,能够端到端地感知部件生成单个对象和复杂多对象场景。其核心创新包括组合潜在空间和分层注意力机制 (来源: HuggingFace Daily Papers)
Prefix Grouper:通过共享前缀前向传播实现高效GRPO训练: Group Relative Policy Optimization (GRPO) 通过比较共享共同输入前缀的候选输出之间的相对差异来增强策略学习。Prefix Grouper通过共享前缀前向策略消除了冗余前缀计算,提高了GRPO的训练效率,尤其在长前缀场景下,同时保持与标准GRPO的训练等效性 (来源: HuggingFace Daily Papers)
GuideX:用于零样本信息提取的引导式合成数据生成: 传统信息提取(IE)系统通常特定于领域,适应成本高。GuideX是一种新方法,可自动定义领域特定模式,推断指南并生成带标签的合成实例,从而实现更好的域外泛化。使用GuideX微调Llama 3.1在七个零样本命名实体识别基准上创造了新的SOTA,显著提升了模型对复杂领域特定注释模式的理解 (来源: HuggingFace Daily Papers)
CodeContests+:为编程竞赛生成高质量测试用例: 针对编程竞赛中测试用例难以获取的问题,研究者提出了一种基于LLM的智能体系统,用于创建高质量的测试用例。该系统应用于CodeContests数据集,并提出了改进版CodeContests+。评估表明,CodeContests+在评估准确性方面显著优于原版,尤其是在真阳性率(TPR)方面,并且对LLM强化学习有显著优势 (来源: HuggingFace Daily Papers)
Sentinel:SOTA模型以防范提示注入攻击: 为应对大语言模型(LLM)易受提示注入攻击的问题,研究者推出了Sentinel模型(qualifire/prompt-injection-sentinel),基于ModernBERT-large架构。通过在包含多种攻击类型和良性指令的广泛数据集上进行微调,Sentinel在内部未见测试集上实现了0.987的平均准确率和0.980的F1分数,并在公共基准上优于强基线模型 (来源: HuggingFace Daily Papers)
论文探讨:扩展模态是实现全模态的正确路径吗?: 全模态语言模型(OLM)旨在集成和推理多种输入模态,同时保持强大的语言能力。该研究探讨了扩展模态(即微调预训练语言模型)作为训练多模态模型主流技术的效果。研究关注三个核心问题:模态扩展是否会损害核心语言能力?模型合并是否能有效集成独立微调的特定模态模型以实现全模态?全模态扩展是否比顺序扩展带来更好的知识共享和泛化? (来源: HuggingFace Daily Papers)
论文提出Truth in the Few:用于高效多模态推理的高价值数据选择方法: 研究挑战了多模态LLM(MLLM)在复杂推理任务中需要大量训练数据的普遍看法。通过观察发现,只有一小部分被称为“认知样本”的训练数据能有效激发多模态推理。基于此,论文提出了Reasoning Activation Potential (RAP) 数据选择范式,通过因果差异估计器(CDE)和注意力置信度估计器(ACE)识别这些认知样本,并用难度感知替换模块(DRM)替换简单实例。实验表明,RAP仅用9.3%的训练数据即可获得更优性能,并减少超43%的计算成本 (来源: HuggingFace Daily Papers)
🧰 工具
Task Master:AI驱动的任务管理系统,集成于Cursor等编辑器: Task Master是一个专为AI辅助开发设计的任务管理系统,可与Cursor AI、Lovable、Windsurf、Roo等编辑器无缝集成。它利用Claude等大模型的API(支持Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama),帮助开发者解析需求文档(PRD)、生成任务列表、规划开发步骤,并辅助实现具体任务。该系统通过MCP(模型控制协议)直接在编辑器中运行,支持命令行操作,并提供了详细的配置指南和使用教程 (来源: GitHub Trending)
Observer AI:本地开源屏幕观察智能体,集成Ollama: Observer AI是一个允许用户通过Ollama运行本地LLM来观察屏幕并执行任务的开源项目。用户可以通过该工具让AI理解屏幕内容并进行交互,例如浏览外语网站。项目提供了GitHub源代码和无需本地设置的Web应用版本,支持用户在保护隐私的前提下利用LLM进行屏幕自动化操作 (来源: Reddit r/LocalLLaMA)

Weaviate Query Agent与七大AI框架集成,简化自然语言数据查询: Weaviate发布了其Query Agent与七个主流AI框架(Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic)的集成方法。Query Agent是一个预构建的智能体服务,能基于Weaviate中的数据回答自然语言查询,无需编写复杂查询语句。这些集成使得开发者可以将强大的自然语言查询能力轻松嵌入到现有的AI应用栈中,提升数据交互的便捷性 (来源: bobvanluijt)

Claude Code与Gemini Pro协同工作MCP服务器发布,提升编码效率: BeehiveInnovations发布了一个MCP服务器,使Claude Code和Gemini 2.5 Pro能够协同工作。Claude Code负责初步构思和规划,Gemini则利用其百万级token上下文和深度推理能力进行补充。该服务器集成了扩展思考、文件读取、代码审查和调试等工具,旨在通过结合两个模型的优势来提升代码生成和优化的质量与效率。初步测试显示,在JSON解析速度优化任务中,组合使用比单独使用任一模型效果更好 (来源: Reddit r/ClaudeAI)

📚 学习
Sakana AI发布日语金融基准EDINET-Bench,评估LLM金融任务能力: Sakana AI推出了EDINET-Bench,这是一个利用日本金融厅电子披露系统EDINET的年度报告构建的日语金融基准测试。该基准旨在评估大型语言模型(LLM)在如欺诈检测等复杂金融任务上的表现,以应对金融领域高质量、免费可用数据集稀缺的问题。EDINET-Bench通过自动标注生成多任务数据集,为金融AI的研发提供了重要资源 (来源: hardmaru,SakanaAILabs)

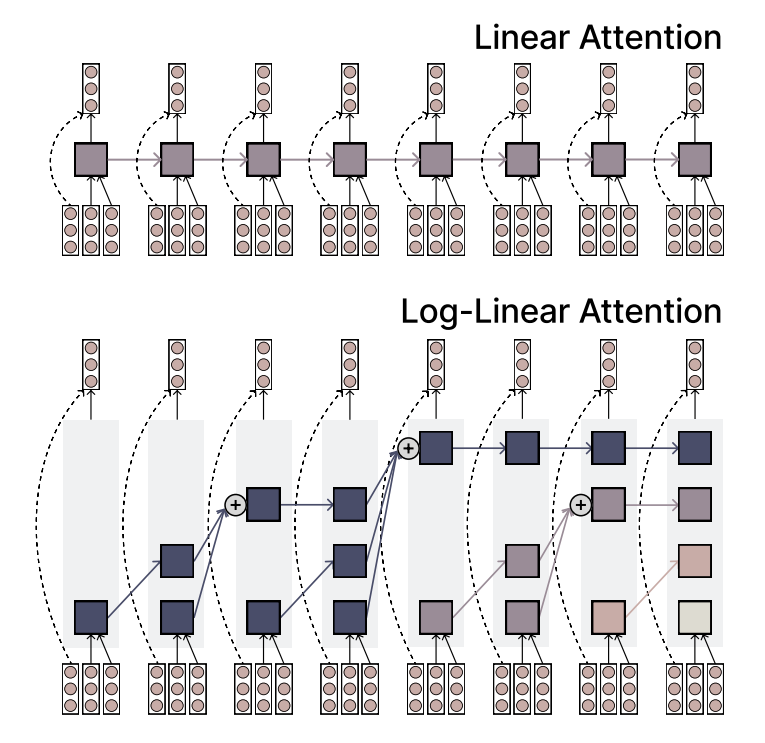
MIT提出Log-linear Attention机制,兼顾效率与表达力: MIT研究人员提出了一种名为Log-linear Attention的新型注意力机制。该机制旨在结合线性注意力的速度和效率以及Softmax注意力的表达能力。它通过使用少量但随序列长度对数增长的记忆槽来实现这一目标,为处理长序列数据提供了一种有潜力的新方法 (来源: TheTuringPost)
Hamel Husain与Shreya Rajpal的LLM评估课程受好评: Ryan Lingo和Radek Osmulski等用户分享了参与Hamel Husain和Shreya Rajpal的LLM应用评估课程(maven.com/parlance-labs/evals)的积极体验。课程被认为是目前关于LLM最深入、最实用的内容,其讲座和独家书籍对构建AI应用的开发者至关重要,强调评估在LLM开发中的核心作用 (来源: HamelHusain,HamelHusain)
MORSE-500:可程序化控制的视频基准测试,用于多模态推理压力测试: 针对当前多模态推理基准主要依赖静态图像、忽视时间复杂性和推理技能广度的问题,研究者推出了MORSE-500。这是一个包含500个完全脚本化视频片段的基准,涵盖抽象、物理、规划、空间和时间等六种推理类别。其脚本驱动设计允许细粒度控制视觉复杂性、干扰物密度和时间动态,支持任意创建更具挑战性的新实例,旨在对下一代模型进行压力测试。初步实验显示,包括Gemini 2.5 Pro和OpenAI o3在内的SOTA模型在所有类别中均存在显著性能差距 (来源: HuggingFace Daily Papers)
EverGreenQA:多语言常青问题分类数据集,提升问答可信度: 为解决LLM在问答(QA)任务中因问题时效性(答案是否随时间变化)而产生幻觉的问题,研究者推出了EverGreenQA。这是首个带有常青标签的多语言QA数据集,支持评估和训练。通过该数据集,研究者对12个现代LLM进行了基准测试,评估其对问题时效性的编码能力,并训练了轻量级多语言分类器EG-E5。研究还展示了常青分类在改善自知识估计、过滤QA数据集和解释GPT-4o检索行为等方面的应用 (来源: HuggingFace Daily Papers)
KVzip:查询无关的KV缓存逐出方法,显著降低内存占用和解码延迟: 韩国首尔大学ML实验室发布了KVzip,一种旨在支持多样化未来查询的KV缓存压缩方法。该方法通过查询无关的逐出策略,实现了约3-4倍的内存减少和2倍的解码延迟降低。目前支持Qwen3/2.5、Gemma3和LLaMA3等模型,并提供了GitHub上的演示代码 (来源: Reddit r/LocalLLaMA)

NimbleEdge开源稀疏Transformer算子核,提升LLM运行速度与内存效率: NimbleEdge团队基于Apple的LLM in a Flash和Zichang等人的Deja Vu研究,构建了用于结构化上下文稀疏性的融合算子核。这些核通过避免加载和计算那些输出最终会归零的前馈层权重和激活值,实现了Transformer中MLP层性能提升5倍,内存消耗减少50%。应用于Llama 3.2 3B模型时,整体吞吐量提升1.78倍,内存使用减少26.4%。代码已在GitHub开源,并计划支持int8、CUDA和稀疏注意力 (来源: Reddit r/MachineLearning)
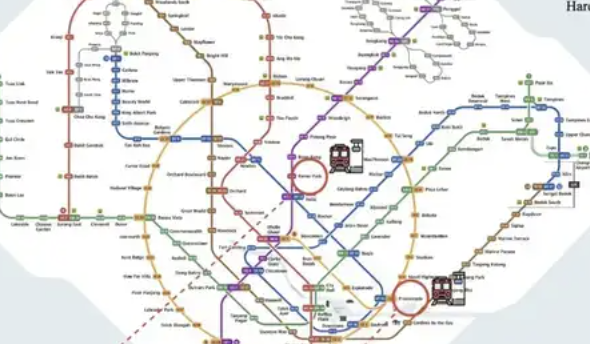
ReasonMap:高分辨率交通图多模态推理评测基准发布: 西湖大学等机构的研究团队推出了ReasonMap,一个专注于高分辨率交通图(主要是地铁图)的多模态推理评测基准。该基准旨在评估大模型在理解图像中细粒度结构化空间信息的能力,包含高分辨率图像(平均5839×5449)、难度感知设计和多维度评估体系。测试结果显示,当前主流开源模型在ReasonMap上表现不佳,尤其在跨线路路径规划上,而闭源推理模型(如GPT-o3)表现显著优于开源模型,但仍与人类水平有差距。北京和杭州等复杂地铁图对模型构成了较大挑战 (来源: 量子位)
Yandex发布Yambda-5B:大规模开放推荐系统数据集: Yandex推出了Yambda-5B,一个包含47.9亿用户-物品交互的大规模匿名化音乐流媒体数据集。该数据集特点包括提供“is_organic”标志和全局时间分割(GTS),不包含可直接识别用户的收听历史和点赞,具有抗去匿名化能力,并包含隐式(歌曲收听、跳过)和显式(喜欢/不喜欢)反馈。Yambda-5B旨在为推荐系统研究提供高质量、多模态的数据资源 (来源: TheTuringPost)
腾讯启动2025星火挑战营,招募顶尖学生参与大模型等前沿研究: 腾讯宣布启动2025年度“星火挑战营”,面向高二、高三(2025级高考生)及其他在相关学科表现卓越的学生,招募60-70人。入选者将有机会前往深圳总部,参与超长文本理解、长思维链技术、具身智能+机器人、多模态感知理解、安全攻防(含LLM Agent黑客设计)和量子科技等六大前沿课题的研究。该计划旨在为有天赋的青少年提供接触工业级科研场景、拓展技术视野和深化行业认知的机会 (来源: 量子位)

💼 商业
传Meta拟向Scale AI投资或超百亿美元,强化军事等领域AI应用: 据报道,Meta正与AI数据标注公司Scale AI洽谈一项重大投资,金额可能高达数十亿甚至超过100亿美元。若属实,这将是Meta最大规模的外部AI投资之一。Scale AI此前已基于Meta的Llama 3打造了专为军事用途设计的模型Defense Llama,用于支持美国国家安全任务。此举可能标志着Meta在AI领域,特别是在与政府及国防相关的应用上,将采取更积极的投资和合作策略 (来源: 36氪)

马上消费发布“天镜”大模型3.0,升级为金融决策平台: 马上消费推出了其金融大模型“天镜”的3.0版本。新版本核心突破在于从个体智慧向群体智慧的系统性跃迁,不再仅依赖逻辑学习,而是深入挖掘企业中散落的员工轨迹、业务日志等隐性经验,并将其转化为结构化知识。天镜3.0旨在从工具升级为决策平台,推动人机协同,能够动态拆解复杂服务流程,并根据用户诉求和合规要求实时匹配最优服务组合,实现从局部最优到全局最优的决策 (来源: 量子位)

Together AI任命Charles Zedlewski为新任首席产品官,聚焦开源生成AI平台: Together AI宣布任命Charles Zedlewski为其新任首席产品官(CPO)。Charles Zedlewski曾在Temporal和Cloudera领导面向开发者的社区驱动平台产品。Together AI强调其致力于构建开放源码的生成AI未来,认为开放模型在灵活性、成本效益和创新方面具有优势。Charles的加入旨在进一步推动Together AI打造权威的开源AI平台,使强大的生成AI对每个开发者和企业都触手可及 (来源: togethercompute)

🌟 社区
Waymo自动驾驶汽车在洛杉矶遭纵火,引发社区对AV安全的担忧与讨论: 近期,多辆Waymo自动驾驶汽车在洛杉矶被人纵火焚烧。这一事件在社交媒体上引发广泛关注和讨论,内容涉及公众对自动驾驶汽车的接受度、安全顾虑、以及此类事件可能被AI生成内容(如Veo 3生成的视频)不当放大或歪曲的风险。部分评论者将此场景与科幻电影《人类之子》相提并论,凸显了事件的戏剧性和潜在的社会影响 (来源: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
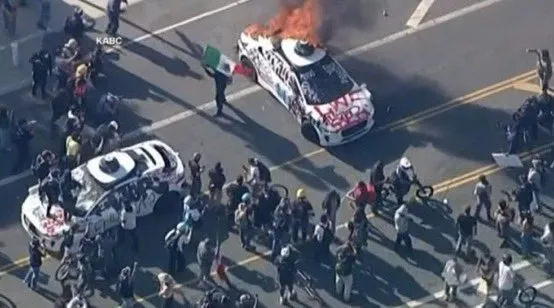
Reddit起诉Anthropic,指控其未经授权抓取内容训练Claude AI: Reddit已对Anthropic提起诉讼,指控其未经许可和付费,抓取Reddit的帖子和对话内容用于训练其AI模型Claude。Reddit认为此举违反了其用户协议中禁止未经授权商业使用内容的条款,并称Anthropic声称的“已停止抓取Reddit”为虚假陈述。诉讼还涉及隐私问题,因Anthropic不像其他有许可协议的公司那样有删除用户已删除帖子的机制。Reddit要求法院禁止Anthropic使用Reddit数据,并可能要求其将Claude下架 (来源: Reddit r/ArtificialInteligence,Reddit r/artificial)
AI工程师世博会热议:Simon Willison回顾过去半年LLM发展,强调工具+推理组合: 在旧金山AI工程师世博会上,Simon Willison通过“骑自行车的鹈鹕”SVG图像生成测试,幽默回顾了过去六个月LLM的飞速发展,并亲测了30多款AI模型。他强调,目前最强大的AI组合是“工具+推理”,如o3/o4-mini在搜索上的表现,以及MCP架构因工具调用而受到的关注。演讲还盘点了年度AI“奇葩Bug”,如ChatGPT的过度奉承、Claude可能“举报”用户的行为等,并指出了提示词注入和数据泄露的风险 (来源: 36氪,swyx)

社区讨论AI引发的职业焦虑及应对策略: Reddit上关于“如何应对AI焦虑”的帖子引发热议。用户普遍担忧未来几年AI可能导致大规模失业,尤其对储蓄不足、负债较多的人群构成严重威胁。讨论中,有人建议转向技工、护理等领域,但同时也担心这些领域会因大量转行者涌入而饱和。评论者分享了各自的焦虑情绪,如失眠、难以专注工作等。一些观点认为应积极学习AI、保持适应性,并指出历史上技术革新(如汽车、互联网)也曾引发类似担忧,但最终创造了新的就业机会。也有评论者认为目前AI取代人类工作的程度被夸大,大规模裁员短期内不太可能 (来源: Reddit r/ArtificialInteligence)
用户分享使用ChatGPT进行“残酷”自我心理剖析的体验: 一位Reddit用户分享了其使用ChatGPT进行“野蛮高管式”自我心理剖析的经历。他通过特定提示词,要求ChatGPT从真实优势、深层弱点、反复失败模式、逃避领域和被忽视技能五个角度进行严厉分析,并给出三阶段发展计划。用户表示,尽管过程痛苦(例如被指出启动12个项目却无一完成,以及过度研究生产力而非实际行动),但这种“残酷”的反馈最终推动了其改变。该帖引发了社区对AI在自我反思和个人发展方面应用的讨论 (来源: Reddit r/ArtificialInteligence)
关于LLM记忆与推理能力的讨论:是知识渊博还是真正理解?: 社交媒体上,用户讨论了大型语言模型(LLM)在记忆型事实回忆任务上的优异表现,以及这是否意味着它们真正具备推理能力。一些观点认为,LLM在看似复杂的任务中表现出色,可能更多依赖于庞大的训练数据和模式识别,而非人类意义上的深层理解和创造性。Meta等公司的研究表明,可以通过测量记忆来估计模型容量,一旦容量填满,泛化才开始。这种讨论也关联到教育体系中对死记硬背的侧重,以及缺乏对信息检索和AI工具使用能力的培养 (来源: omarsar0,menhguin,menhguin)

💡 其他
Stripe支付欺诈检测基础模型的成功案例分析: Stripe工程师分享的关于构建成功的支付欺诈检测基础模型的帖子引发关注。分析指出,该案例的特殊性在于:1) 欺诈检测本质上不是预测未来,理论上信号充足时可达高准确率;2) Stripe已处在信号丰富的环境中,无需从零开始数据积累;3) 该场景是自动化升级,从传统机器学习到基础模型,接近直接替换。这解释了为何此类AI应用的“即时胜利”较为罕见,多数AI商业价值的实现需克服诸多障碍 (来源: random_walker)
AI转型认知基础:系统化信息感知与技术洞察机制是关键: 企业在AI转型中需建立系统化、结构化的信息感知与技术洞察机制,超越个体经验和传统路径依赖。这包括构建内部数据分析能力和外部知识网络(学术界、产业界、资本市场、初创企业)。对AI投资回报的评估也需从传统ROI转向“分周期、多维度”体系,并与外部知识网络耦合,形成持续验证、动态调整的战略闭环。文章强调,AI不是一次性工具,而是持续演化、不断增值的战略资产 (来源: 36氪)
Frigate:基于实时本地对象检测的NVR系统: Frigate是一个专为Home Assistant设计的本地网络录像机(NVR)系统,利用OpenCV和Tensorflow在IP摄像头上进行实时本地对象检测。该系统强调资源优化和性能,通过低开销运动检测触发对象检测,并利用多进程处理。推荐使用Google Coral或Hailo等AI加速器以获得最佳性能。Frigate支持24/7录制、基于对象检测的录像保留、MQTT集成、RTSP转播以及WebRTC/MSE低延迟实时查看 (来源: GitHub Trending)
