
كلمات مفتاحية:وكيل الذكاء الاصطناعي, نماذج اللغة الكبيرة (LLM), التعلم المعزز, الذكاء الاصطناعي متعدد الوسائط, القيادة الذاتية, أمان الذكاء الاصطناعي, منافسات الذكاء الاصطناعي, ساكانا AI وكيل ALE, ServiceNow أبريل جارد, واجهة برمجة تطبيقات جيميني إنتراكتيشنز, كلاينج AI 2.6 تحكم بالحركة, خوارزمية Transitive RL
🔥 تركيز
وكيل Sakana AI يفوز بمسابقة برمجة: فاز وكيل ALE-Agent الذي طورته Sakana AI بالمركز الأول في مسابقة البرمجة الاستكشافية AtCoder AHC058. تعلم وكيل AI ذاتيًا وابتكر “焼きなまし法” (خوارزمية المحاكاة للتلدين) غير المتوقعة للبشر، متفوقًا على أكثر من 800 مشارك. يُظهر هذا الإنجاز قدرة وكلاء AI القوية على التعلم الذاتي والابتكار في مشاكل التحسين المعقدة، وينبئ بإمكانيات هائلة لـ AI في حل المشكلات عالية التعقيد وغير المهيكلة، متجاوزًا نماذج البرمجة التقليدية، ويفتح مسارات جديدة لتوليد الأكواد وحل المشكلات تلقائيًا بواسطة AI في المستقبل. (المصدر: hardmaru)

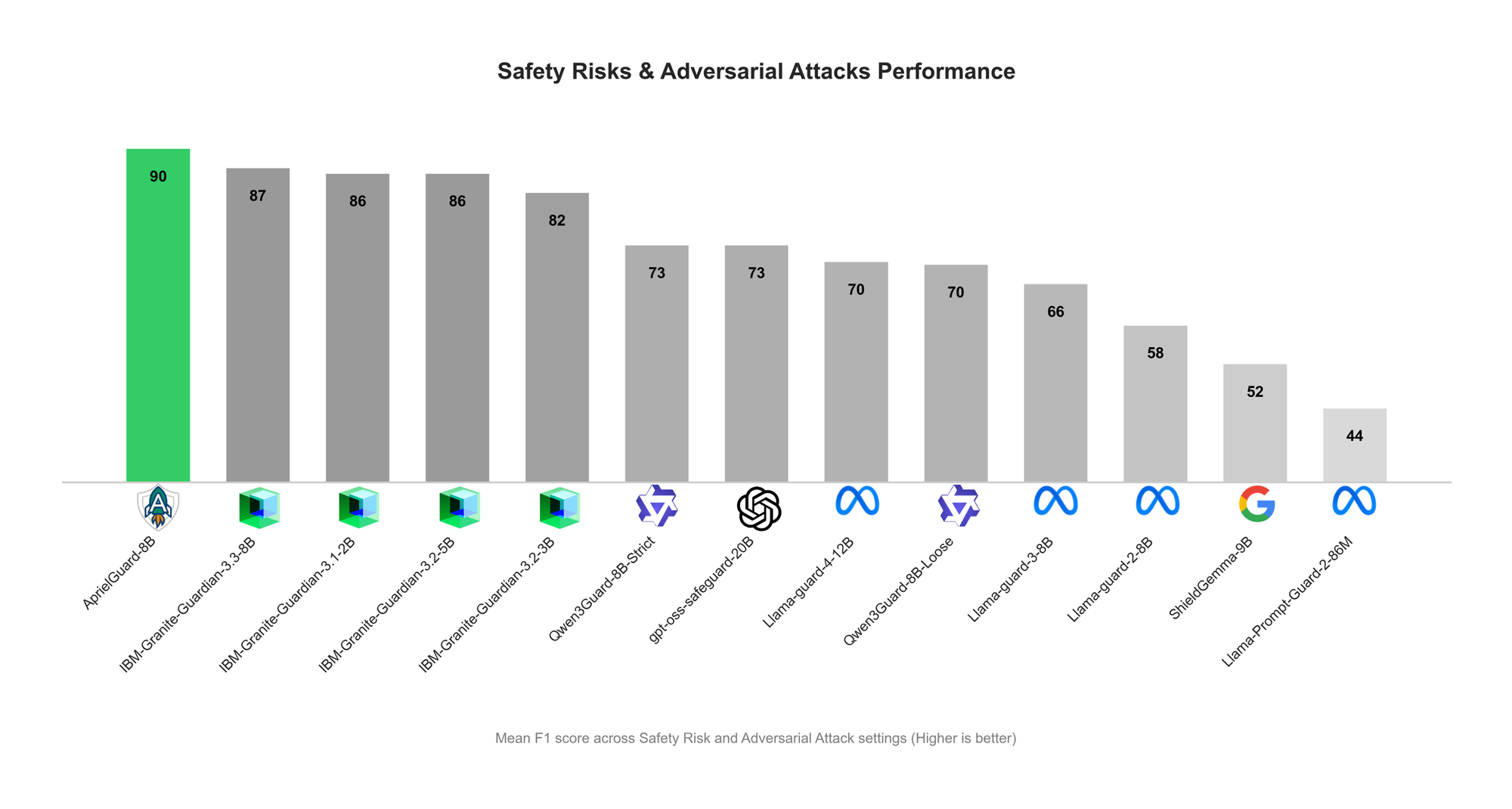
ServiceNow تطلق AprielGuard: حواجز أمان LLM ومقاومة الهجمات العدائية: أطلقت ServiceNow نموذج AprielGuard، وهو نموذج حماية أمان بمعاملات 8B، مصمم للكشف عن 16 فئة من المخاطر الأمنية والهجمات العدائية الواسعة في أنظمة LLM الحديثة، بما في ذلك “multi-round jailbreaks” و”prompt injection” و”memory hijacking” و”tool manipulation”. يدعم النموذج وضعين: الاستدلال وغير الاستدلال، مما يوفر تصنيفًا تفصيليًا عند الحاجة إلى التفسير، أو تصنيفًا بزمن استجابة منخفض في بيئات الإنتاج. من خلال نموذج موحد وتصنيف موحد، يحل AprielGuard القيود التي تواجهها مصنفات الأمان التقليدية في المحادثات متعددة الأدوار، والسياقات الطويلة، وسير عمل الوكلاء، مما يوفر أساسًا قابلاً للتطوير لنشر AI موثوق به. (المصدر: HuggingFace Blog)
🎯 الاتجاهات
Karpathy ينشر مراجعة LLM السنوية لعام 2025: RLVR يدفع AI من التقليد إلى الاستدلال: نشر أندريه كارباثي، أحد مؤسسي OpenAI، “مراجعة النماذج اللغوية الكبيرة السنوية لعام 2025”، مشيرًا إلى التحول الرئيسي في فلسفة تدريب AI لعام 2025 من “التقليد الاحتمالي” إلى “الاستدلال المنطقي”. القوة الدافعة الأساسية هي نضوج “Reinforcement Learning with Verifiable Rewards (RLVR)”، والذي من خلال بيئات التغذية الراجعة الموضوعية مثل الرياضيات والكود، يدفع النموذج لتوليد “آثار استدلال” تلقائيًا تشبه التفكير البشري. أكد أن هذا التعلم المعزز طويل الأمد بدأ يحل محل التدريب المسبق التقليدي، ليصبح محركًا جديدًا لتعزيز قدرات النموذج، وتوقع أن تتحول المنافسة في AI بحلول عام 2026 إلى النموذج المنطقي الأساسي لـ “كيفية جعل AI يفكر بكفاءة”. (المصدر: 36氪)
الولايات المتحدة تطلق “مهمة التكوين”: خطة AI مانهايتن تهدف إلى دفع الاختراقات العلمية: وقع الرئيس الأمريكي ترامب أمرًا تنفيذيًا، أطلق بموجبه رسميًا “مهمة التكوين”، بهدف دمج قدرات الحوسبة الفائقة للمختبرات الوطنية مع حكمة كبار العلماء، واستخدام AI لدفع الاختراقات العلمية بسرعة غير مسبوقة. شُبهت هذه الخطة بـ “مشروع مانهايتن خلال الحرب العالمية الثانية”، وتهدف إلى بناء AI قادر على دفع الاكتشافات العلمية بشكل مستقل، وتركيز الكفاءات الأساسية للمجتمع العلمي الأمريكي، وتعبئة 40 ألف عالم ومهندس من 17 مختبرًا وطنيًا تابعًا لوزارة الطاقة، للتحول الكامل نحو البحث والتطوير في تقنيات AI، لإعادة بناء السيادة التكنولوجية الوطنية. (المصدر: 36氪)

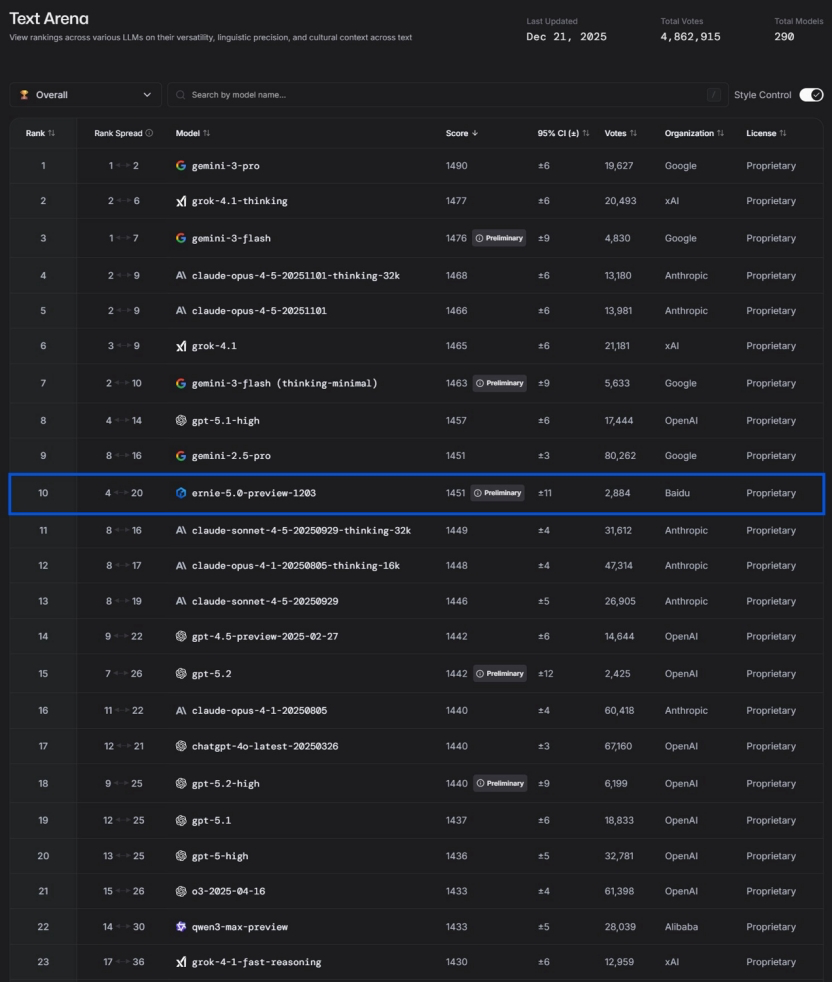
ابتكار AI الصيني وصعود Baidu Wenxin 5.0: ردًا على ادعاء DeepMind بأن AI الصيني “يفتقر إلى الابتكار، ويكتفي بالمتابعة السريعة”، تشير بعض الآراء إلى أن AI الصيني يشكل حواجز تقنية فريدة من خلال التطبيقات العملية. حقق Baidu Wenxin ERNIE-5.0-Preview-1203 المرتبة الأولى محليًا وضمن العشرة الأوائل عالميًا في تصنيف نصوص LMArena، متجاوزًا GPT-5.2 وClaude Sonnet 4.5، ليصبح النموذج غير الأمريكي الوحيد ضمن أفضل 20 نموذجًا. يُعزى هذا الاختراق إلى “النمذجة الموحدة الأصلية متعددة الأنماط”، وبنية MoE ذات 2.4 تريليون معلمة، و”سلسلة التفكير المركبة” التي تجمع بين المعرفة والعمل. يؤكد المقال على القيمة العميقة لـ AI الصيني في العالم المادي والتطبيقات الصناعية مثل تصميم الديناميكا الهوائية للقطارات عالية السرعة، وفحص شبكات الطاقة، وتوليد كود Shunfeng، وإدارة المدن. (المصدر: 36氪)
Microsoft Copilot يواجه تحديات في تبني المستخدمين، ونادالا يشرف شخصيًا: يشرف ساتيا نادالا، الرئيس التنفيذي لشركة Microsoft، شخصيًا على تحسينات Copilot، مما يعكس أن معدل تبني المستخدمين لم يصل إلى التوقعات على الرغم من دمج Copilot في مجموعة Office. يشير هذا إلى أن المنافسة في AI قد تحولت من “إظهار القدرات” إلى “الاحتفاظ بالمستخدمين”، أي من يمكنه أن يستخدمه المستخدمون يوميًا حقًا. يشير المقال إلى أن وضع Copilot كـ “مرشد” بدلاً من “شريك”، والتفاعل الميكانيكي الذي يغطي سيناريوهات بشكل مفرط، استنزف انتباه المستخدمين. ستركز المنافسة المستقبلية في AI على “حس التناسب”، أي متى يظهر AI ومتى يصمت، وما إذا كان يمكنه توفير فهم أكثر دقة، وتقليل التكلفة العاطفية للمستخدمين. (المصدر: 36氪)

إطلاق MiniMax M2.1، وتحسين أداء GLM 4.7: تم إطلاق MiniMax M2.1 رسميًا، وهو نموذج بنية MoE بمعاملات تنشيط 10B، ويظهر أداءً ممتازًا في البرمجة متعددة اللغات (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) وتطوير التطبيقات/الويب، حيث حقق 72.5% في اختبار SWE-bench متعدد اللغات، متجاوزًا Gemini 3 Pro وClaude Sonnet 4.5. في الوقت نفسه، احتل GLM 4.7 المرتبة الأولى في قائمة Vals Index مفتوحة المصدر، والتاسعة في القائمة الإجمالية، مع تحسن في الأداء بنسبة 9.5% مقارنة بـ GLM 4.6، خاصة في البرمجة، وAgent/ToolCall، وقدرة استدعاء السياق الطويل، وقدم آلية “الاحتفاظ بالتفكير” التي تعزز استقرار المهام المعقدة وقابليتها للتحكم. (المصدر: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

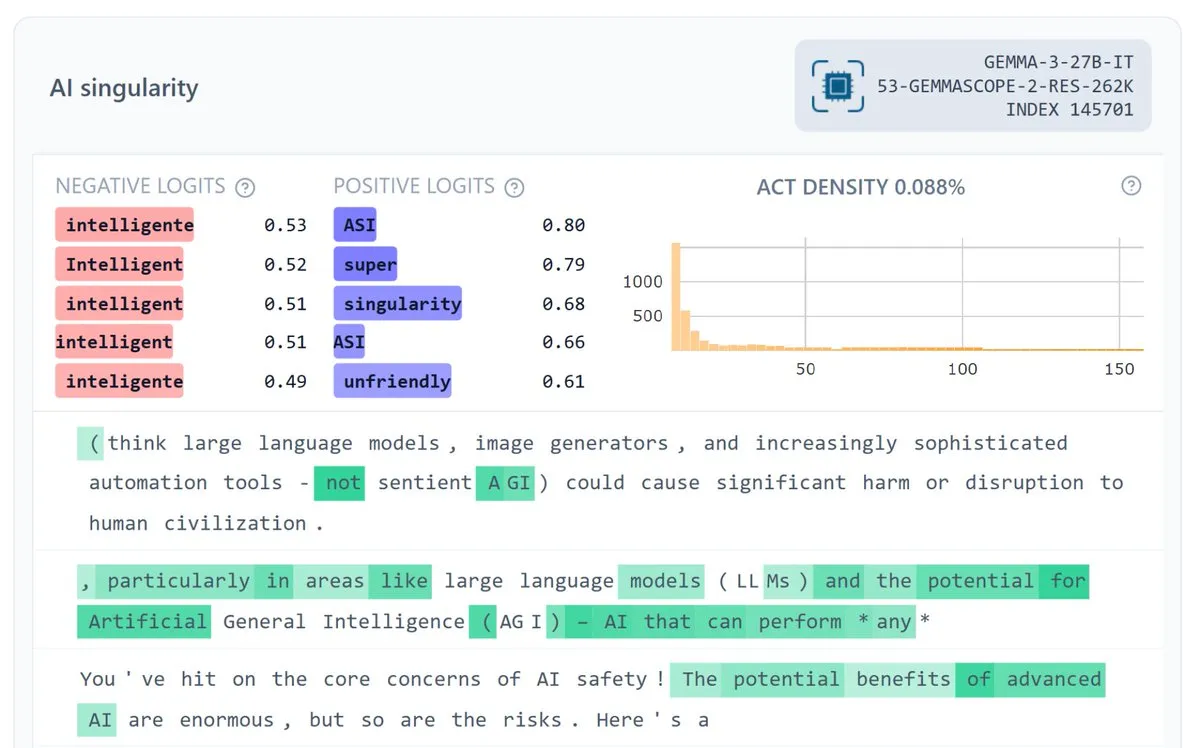
Google DeepMind تطلق Gemma Scope 2، لتعزيز قابلية تفسير النموذج: أطلقت Google DeepMind أداة Gemma Scope 2، وهي مجموعة أدوات تفسيرية كاملة المكدس لسلسلة نماذج Gemma 3 (270M-27B، الإصدار الأساسي والدردشة)، تتضمن “Sparse Autoencoders (SAE)” و”transcoders” لكل طبقة. تهدف هذه الخطوة إلى تعزيز الفهم العميق لسلوك النماذج المعقدة، ودعم أبحاث أمان وقابلية تفسير مفتوحة المصدر أكثر طموحًا، ومن المتوقع أن تساعد المجتمع على تصحيح وتحليل آليات العمل الداخلية لـ LLM بشكل أفضل. (المصدر: NeelNanda5, Reddit r/artificial)
إدارة حالة وكيل AI: Google Interactions API يبسط التطوير ولكنه يثير مخاوف بشأن الاحتكار: أطلقت Google واجهة “Gemini Interactions API”، التي تعالج سجل المحادثات، وإدارة السياق، والتنفيذ في الخلفية على جانب الخادم، مما يبسط بشكل كبير تطوير وكلاء AI. أدى ذلك إلى إزالة الكثير من أعمال البنية التحتية مثل إعداد قواعد بيانات المتجهات وهندسة السياق المخصصة، مما أدى إلى زيادة سرعة التطوير بشكل ملحوظ. ومع ذلك، أثارت هذه الخطوة أيضًا مخاوف بشأن احتكار الموردين، وفقدان التحكم في استرجاع تخزين السياق، وصعوبة تبديل النماذج، وعدم شفافية التكاليف. يشير هذا إلى أن Google تستخدم البنية التحتية كخندق دفاعي، على غرار نموذج AWS، ولكن بالنسبة لأعباء عمل ML التي تتطلب درجة عالية من التحكم في المكدس بأكمله، لا يزال يتعين مراقبة التأثير طويل المدى لهذا النموذج “الصندوق الأسود”. (المصدر: Reddit r/artificial)
زيادة هائلة في مجموعات بيانات الروبوتات على Hugging Face، مما يدفع تطور بيئة الروبوتات المفتوحة: زادت مجموعات بيانات الروبوتات المفتوحة على منصة Hugging Face من ألف إلى 27 ألفًا في العامين الماضيين، متجاوزة بكثير الفئات الأخرى مثل توليد النصوص. يُعزى هذا النمو الهائل إلى تخزين الفيديو الأرخص، والأدوات الأفضل، وانتشار ثقافة AI مفتوحة المصدر، مما خفض بشكل كبير حاجز الدخول إلى مجال الروبوتات، وسرّع عملية البحث والتطوير للروبوتات العامة والروبوتات البشرية. تتيح مجموعات البيانات المفتوحة سهولة تحميل وإعادة استخدام واختبار بيانات الروبوتات الحقيقية (الفيديو، والحركات، والمستشعرات، والأعطال، وما إلى ذلك)، مما يحول مجال الروبوتات إلى نظام بيئي أكثر قابلية للتوسع وتعاونًا. (المصدر: huggingface)
صراع مسارات القيادة الذاتية بين Tesla FSD وWaymo: من البداية إلى النهاية مقابل النمطية: تُظهر Waymo وTesla FSD فلسفتين مختلفتين تمامًا في مسار تقنية القيادة الذاتية. تتبنى Waymo منهجًا “نمطيًا”، يعتمد على الخرائط عالية الدقة، وLiDAR، والمستشعرات، وشبكة 5G، وإذا تعطلت إحدى الوحدات (مثل إشارة المرور)، فقد يدخل النظام في “وضع التوقف التام”. في المقابل، تتبنى Tesla FSD حلاً “من البداية إلى النهاية”، حيث يحول شبكة عصبية كبيرة بكسلات الكاميرا مباشرة إلى أوامر توجيه وفرملة، مما يشبه القيادة البشرية بشكل أكبر. يرى البعض أن طريقة Waymo النمطية تعاني من مشاكل برمجية ضخمة في قابلية التوسع والاعتمادية، وعلى المدى الطويل، فإن حل Tesla FSD من البداية إلى النهاية يتمتع بميزة أكبر. (المصدر: Yuchenj_UW)
مراجعة Zhihu Frontier السنوية: تطور البنية التحتية لـ AI ومتعددة الأنماط في عام 2025: نشرت Zhihu Frontier مراجعتها السنوية، ملخصة التقدم الهيكلي في مجال AI لعام 2025 من حيث البنية التحتية وتعدد الأنماط. أكدت على ضرورة أن تتمتع مساعدات AI بالقدرة على “الرؤية، والسمع، والاستدلال” مثل البشر، مما يدفع تطوير تقنيات متعددة الأنماط والصوت الأصلي. فيما يتعلق بقدرات النموذج، تجاوزت النماذج ذات 10B معلمة نماذج 100B+ لعام 2024، مع تحسن في كفاءة التكلفة بمقدار 10 أضعاف، ولا يزال التدريب المسبق هو الأساس. أصبحت البنية التحتية لـ AI ميزة تنافسية، حيث يعتبر الاستدلال الموزع، والبرمجة القائمة على “Tile-based”، والتعلم المعزز واسع النطاق، والتصميم التعاوني بين النموذج والنظام، تقدمًا رئيسيًا. كما أشارت إلى أن التواصل الفعال واكتساب الاهتمام أصبحا مهارتين أساسيتين للمتخصصين في التكنولوجيا. (المصدر: ZhihuFrontier)

🧰 الأدوات
تكامل Claude Code + Chrome يحقق أتمتة المتصفح: يدعم Claude Code الآن تكامل متصفح Chrome، مما يسمح للمستخدمين بكتابة الكود في الطرفية، ثم جعل Claude يفتح URL في Chrome، وينقر على الأزرار، ويملأ النماذج، ويقرأ أخطاء وحدة التحكم وحالة DOM، وحتى يلتقط لقطات شاشة ويسجل صور GIF. لا تتطلب هذه الميزة API أو token، وتستخدم مباشرة جلسة المتصفح التي سجل فيها المستخدم، مما يبسط بشكل كبير سير عمل الأتمتة متعددة المواقع، مثل إنشاء جداول بيانات Google، واستخراج المعلومات من Hacker News وملء الجداول. على الرغم من أنها تدعم Chrome فقط حاليًا ولا توجد وضع “headless”، إلا أنها توفر للمطورين قدرة تفاعل قوية وسلسة مع المتصفح. (المصدر: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: نموذج جديد لإعلانات الفيديو بالذكاء الاصطناعي: أطلقت Kling AI 2.6 ميزة قوية للتحكم في الحركة، تمكن من استبدال الشخصيات في الفيديو بشكل واقعي، وتدعم مزامنة الشفاه والتقاط الحركات المعقدة، حتى للشخصيات غير البشرية. تعزز هذه التقنية بشكل كبير إمكانات اختبار إعلانات AI، مما يسمح للمعلنين بإنشاء متغيرات إعلانية بسرعة بأعمار وأجناس وأعراق وأنماط جمالية مختلفة، وبالتالي تحقيق اختبار وتحسين الإعلانات على نطاق واسع. من خلال دمج Nano Banana Pro لتوليد الشخصيات وElevenlabs لتوليد الأصوات، يقدم Kling AI 2.6 تحسينًا ثوريًا في الكفاءة لإنشاء محتوى الفيديو وصناعة الإعلانات. (المصدر: Kling_ai, Reddit r/ChatGPT)

إطلاق MLflow 3.8، يعزز قدرات تقييم ومراقبة تطبيقات LLM: تم إطلاق الإصدار 3.8 من MLflow رسميًا، جالبًا معه ميزات متقدمة لتقييم ومراقبة تطبيقات LLM. تشمل الميزات الجديدة تكوين نماذج التوجيه، مما يسمح بربط إعدادات نموذج محددة بقوالب التوجيه، مما يزيد من قابلية تكرار سير عمل LLM؛ تدعم واجهة المستخدم للتتبع عرض التتبعات الجارية، مما يحقق تصحيح الأخطاء ومراقبة تطبيقات LLM في الوقت الفعلي؛ دمج DeepEval وRAGAS Judges، مما يوفر أكثر من 20 مؤشر تقييم، مثل مدى صلة الإجابة، والدقة، واكتشاف الهلوسة؛ إضافة مقياس أمان المحادثة ومقياس كفاءة استدعاء أداة المحادثة، لتقييم أمان المحادثات متعددة الأدوار وكفاءة استدعاء الأدوات في تفاعلات الوكيل على التوالي. (المصدر: matei_zaharia)

vLLM يدعم LongCat-Image-Edit وMiMo-V2-Flash، مما يبسط تحرير الصور وخدماتها: أضاف مجتمع vLLM دعمًا لنموذج Meituan LongCat-Image-Edit، مما يوفر مسار خدمة مبسطًا لتحرير الصور الموجه بالأوامر، ويدعم العمليات الشائعة مثل إضافة/استبدال الكائنات، وتغيير الخلفية، وتعديل الأنماط، وهو مناسب لأدوات تحرير الصور وعمليات التحرير الإبداعية. في الوقت نفسه، أصدر vLLM أيضًا برنامجًا تعليميًا رسميًا، يوضح كيفية نشر نماذج Xiaomi MiMo/MiMo-V2-Flash، بما في ذلك استدعاء الأدوات، وتكوين DP/TP/EP، وتعديل المعلمات الرئيسية مثل طول السياق، والتأخير، وKV cache، مما يدفع بشكل أكبر تطبيقات LLM في الأنماط المتعددة والأجهزة الطرفية. (المصدر: vllm_project)

Reka Vision تضع معيارًا جديدًا لـ AI أمان المنزل الذكي: أطلقت Reka Vision حلول كاميرات ذكية، تهدف إلى تجاوز الكشف التقليدي عن الحركة، وتحقيق فهم عميق للأحداث. يقوم هذا النظام بالاستدلال عبر الفيديو والصوت والوقت، مما يقلل من الإنذارات الكاذبة، ويوفر رؤى ذات صلة بالسياق وعلى مستوى بشري. تلتزم Reka Vision بوضع معيار جديد لـ AI أمان المنزل الذكي، لتمكينه من تحديد وفهم الأحداث المعقدة التي تحدث في البيئة المنزلية بدقة أكبر، وبالتالي توفير خدمات مراقبة أمنية أكثر ذكاءً وموثوقية. (المصدر: RekaAILabs)
YouTube Playables Builder: Gemini 3 يدعم إنشاء الألعاب: تم إطلاق تطبيق الويب YouTube Playables Builder الآن، مدعومًا بنموذج Gemini 3، لمساعدة المبدعين على تطوير ألعاب ممتعة وصغيرة بسرعة من خلال مطالبات نصية أو فيديو أو صور. تخفض هذه الأداة حاجز تطوير الألعاب، مما يمكن المطورين غير المحترفين من الاستفادة من قوة AI لتحويل الأفكار الإبداعية إلى تجارب ألعاب قابلة للعب، ومن المتوقع أن تحفز حيوية جديدة في نظام ألعاب UGC (المحتوى الذي ينشئه المستخدمون)، وتستكشف المزيد من الإمكانيات لـ AI في مجال إنشاء المحتوى الترفيهي. (المصدر: demishassabis)
إطلاق Medmarks v0.1: أكبر مجموعة أدوات تقييم LLM طبية مفتوحة المصدر: أطلقت Sophont AI أداة Medmarks v0.1، وهي حاليًا أكبر مجموعة أدوات تقييم آلية مفتوحة المصدر بالكامل، تُستخدم لتقييم القدرات الطبية لـ LLM. تم تطوير هذه المجموعة بواسطة مجتمع MedARC AI، وبدعم من PrimeIntellect، وقد استكشفت 46 نموذجًا للعثور على الأداء الأفضل. سيعزز إطلاق Medmarks v0.1 بشكل كبير البحث والتطوير في مجال AI الطبي، ويوفر أدوات ومعايير موحدة لتقييم وتحسين أداء LLM الطبي. (المصدر: iScienceLuvr)
دمج Nano Banana Pro وGemini 3 Pro لتحقيق توليد الصور وعرضها: يستخدم تطبيق وكيل Nano Banana Pro لتوليد الصور، ويعرضها عبر Gemini 3 Pro على الهاتف المحمول، مما يظهر القدرة القوية لنماذج AI في الأداء الجمالي للواجهة الأمامية. على سبيل المثال، يمكنه إنشاء صفحات ويب لملخص Karpathy السنوي، وحتى تغيير نمط مؤشر الماوس. لا يوفر هذا الدمج سير عمل فعال لتوليد الصور وعرضها فحسب، بل يشير أيضًا إلى الإمكانات الهائلة لـ AI في مجال تصميم واجهة المستخدم/تجربة المستخدم (UI/UX)، حيث يمكنه إنشاء محتوى جذاب بصريًا بسرعة وفقًا لاحتياجات المستخدم. (المصدر: op7418)

Heretic: أداة إزالة الرقابة التلقائية لـ LLM: Heretic هي أداة إزالة رقابة تلقائية بالكامل لـ LLM. في مجتمع AI مفتوح المصدر، أثار إطلاق هذه الأداة اهتمامًا واسعًا، لأنها تهدف إلى حل قيود الرقابة التي قد تواجهها النماذج عند توليد المحتوى. يوفر ظهور Heretic للمستخدمين حرية أكبر، ولكنه قد يثير أيضًا نقاشات حول أمان المحتوى والأخلاقيات، خاصة فيما يتعلق بالموازنة بين حرية التعبير وتوليد المحتوى الضار المحتمل. (المصدر: Reddit r/LocalLLaMA)
Claude Code يضيف ميزة البحث العكسي، مما يعزز كفاءة إدارة “prompts”: قام Claude Code بتحديث وظائفه، مضيفًا القدرة على البحث العكسي عن “prompts” عبر Ctrl+R. يمكن للمستخدمين الضغط بشكل متكرر على Ctrl+R للتنقل بين جميع “prompts” التي تحتوي على كلمة رئيسية محددة، مما يعزز بشكل كبير كفاءة وراحة إدارة “prompts”. يتيح هذا التحسين للمطورين العثور على “prompts” السابقة وإعادة استخدامها بشكل أسرع، وتحسين سير عمل برمجة AI الخاص بهم، وتقليل العمل المتكرر. (المصدر: dejavucoder)
📚 تعلم
نموذج جديد لـ RL: Transitive RL يحل المهام طويلة الأمد باستخدام طريقة “فرق تسد”: قدمت مدونة BAIR خوارزمية تعلم معزز جديدة تسمى Transitive RL (TRL)، والتي تتبنى نموذج “فرق تسد” بدلاً من التعلم التقليدي “Temporal Difference (TD) learning”. يقوم TRL بتقسيم المسارات بشكل متكرر إلى أجزاء أصغر، ويجمع قيمها لتحديث قيمة المسار الكامل، مما يظهر قابلية توسع أفضل للمهام طويلة الأمد. هذه الطريقة فعالة بشكل خاص في مشاكل RL الموجهة نحو الهدف، حيث تقلل بشكل كبير من عدد تكرارات Bellman من خلال تحسين الأهداف الفرعية الوسيطة، وتتجنب مشكلة تراكم الأخطاء في TD learning، مما يوفر اتجاهًا جديدًا لحل مهام RL المعقدة وطويلة الأمد. (المصدر: aihub.org)
LLM يساعد في البراهين الرياضية: مهندس سابق في DeepMind يستكشف P/=NP وNavier-Stokes: استكشف Bengoertzel، مهندس سابق في DeepMind، استخدام LLM للمساعدة في إثبات المشكلات الرياضية المعقدة، مثل وجود وتفرد معادلات Navier-Stokes، ومشكلة P/=NP. شارك تجربته في استخدام LLM لملء تفاصيل البراهين، وعلى الرغم من أن الفكرة الأساسية كانت منه، إلا أن LLM قدم مساعدة كبيرة في معالجة التفاصيل الشاقة. أثارت هذه الممارسة نقاشات حول كيفية الجمع الفعال بين التفكير الإبداعي البشري وقدرة LLM على معالجة التفاصيل، واستخدام أدوات التحقق الرسمية مثل Lean لضمان دقة البراهين الرياضية، مما ينبئ بالدور المحتمل لـ AI في أبحاث الرياضيات المتقدمة. (المصدر: bengoertzel)
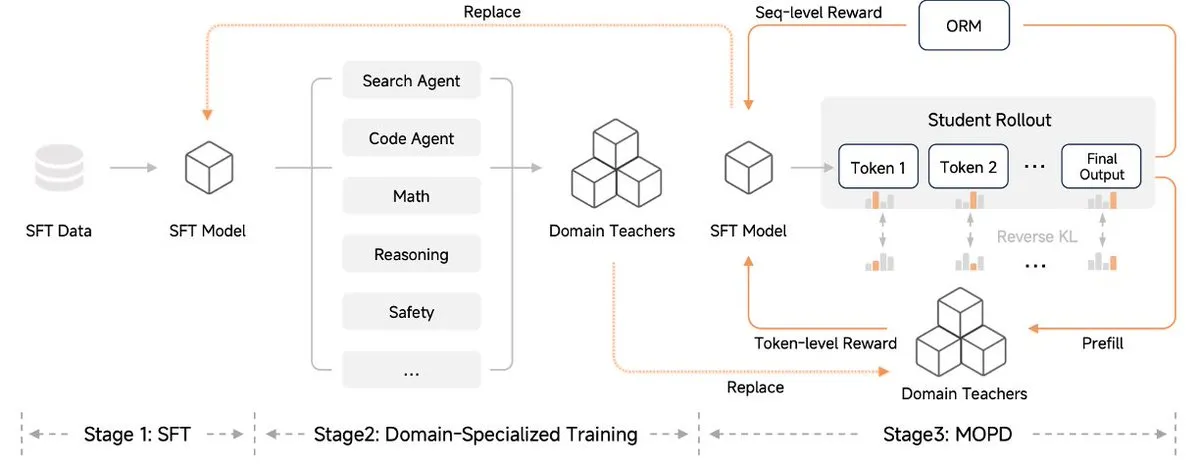
تطور عصر تدريب LLM: من التدريب المسبق إلى RLVR وGRPO: يشهد نموذج تدريب LLM تطورًا سريعًا. من التدريب المسبق (النماذج الأساسية) في عام 202x، إلى RLHF+PPO في عام 2022، ثم LoRA SFT في عام 2023، والتدريب المتوسط في عام 2024. من المتوقع أن يدخل عام 2025 عصر RLVR+GRPO، بينما قد يشهد عام 2026 فترة “On Policy Distillation”. يكشف هذا المسار التطوري عن التعميق والتحسين المستمر لمنهجية تدريب LLM، من بناء القدرات الأساسية الأولية، إلى التحول التدريجي نحو استراتيجيات تدريب أكثر دقة، وأكثر تركيزًا على التغذية الراجعة والكفاءة، مما ينبئ بأن النماذج المستقبلية ستركز بشكل أكبر على التعلم من التفاعل واستخلاص المعرفة. (المصدر: bookwormengr)
دراسة آليات ذاكرة LLM: مبادئ العمل الداخلية لـ Claude وChatGPT: تعمقت الأبحاث في آليات ذاكرة LLM مثل Claude وChatGPT، وحللت كيفية معالجتها واحتفاظها بمعلومات سياق المحادثة. تكشف هذه الدراسات كيف تؤثر الحالة الداخلية للنموذج على تكوين الذاكرة واسترجاعها، والتحديات في الحفاظ على الاتساق في المحادثات متعددة الأدوار. يعد فهم مبادئ عمل ذاكرة LLM أمرًا بالغ الأهمية لتحسين أنظمة المحادثة، وتعزيز تجربة المستخدم، وحل مشاكل فهم السياق الطويل، كما يوفر أساسًا نظريًا لتصميم تفاعلات AI أكثر كفاءة واستقرارًا في المستقبل. (المصدر: dejavucoder)
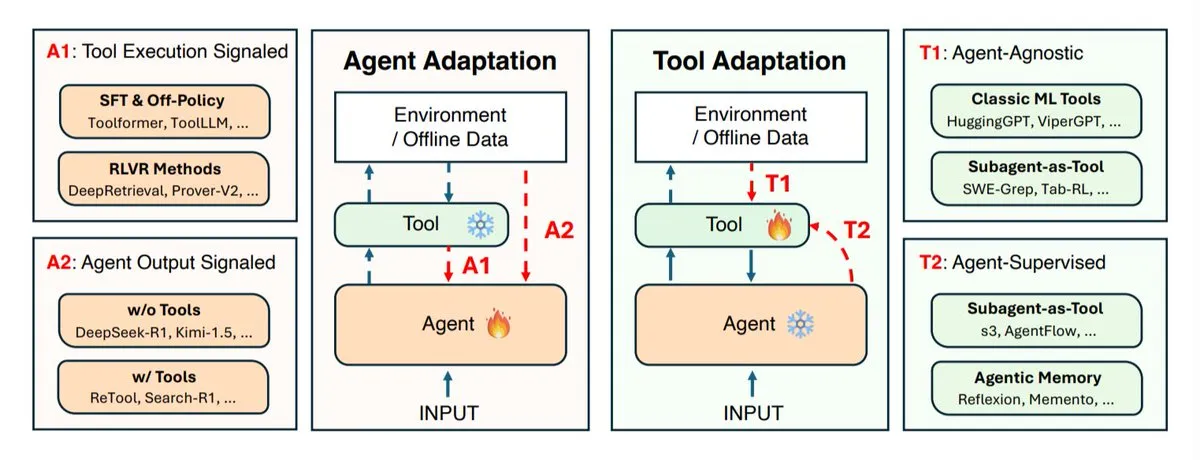
دراسة استراتيجيات تكيف وكيل AI: التطور المشترك بين الوكيل والأدوات: استكشفت مؤسسات بحثية مثل UIUC، وStanford، وHarvard استراتيجيات تكيف وكيل AI، والتي تنقسم بشكل رئيسي إلى فئتين: تكييف الوكيل نفسه (نموذج الاستدلال) وتكييف الأدوات التي يستخدمها (أنظمة البحث، المسترجع، الذاكرة، API). حددت الدراسة أربعة أنواع من التكيف: تكييف الوكيل باستخدام نتائج الأدوات، تدريب الوكيل باستخدام مخرجاته الخاصة، تكييف الأدوات بشكل مستقل، وتدريب الأدوات من خلال تغذية راجعة من الوكيل المجمد. توفر هذه الاستراتيجيات توجيهًا نظريًا لتطوير وكلاء AI أكثر ذكاءً ومرونة، وتؤكد على أهمية التطور المشترك بين الوكيل والأدوات لمواجهة بيئات المهام المعقدة والمتغيرة. (المصدر: TheTuringPost)
دراسة حول تعزيز قدرة استدلال نماذج AI: دور التدريب المسبق، والتدريب المتوسط، والتعلم المعزز: اكتشف باحثون من جامعة Carnegie Mellon أن التدريب المسبق، والتدريب المتوسط، والتعلم المعزز يلعبون أدوارًا مختلفة في تعزيز قدرة استدلال نماذج AI. تشير الدراسة إلى أن التعلم المعزز لا يمكنه تحسين قدرة الاستدلال بشكل حقيقي إلا في ظروف محددة، ويتطلب التعميم عبر السياقات تدريبًا مسبقًا أولاً، ويعتبر “Mid-training” أمرًا بالغ الأهمية، بينما تعتبر “Process-aware rewards” ضرورية. توفر هذه الاكتشافات توجيهًا لتحسين استراتيجيات تدريب نماذج AI، وتؤكد على أهمية تبني أساليب مستهدفة في مراحل مختلفة لتحقيق أقصى قدر من قدرة الاستدلال. (المصدر: TheTuringPost)

KappaTune: حل مشكلة “النسيان الكارثي” في ضبط LLM الدقيق: KappaTune هي طريقة جديدة لضبط LLM الدقيق، تهدف إلى حل مشكلة “النسيان الكارثي” الموجودة في الطرق الحالية مثل LoRA. تقلل KappaTune من درجة النسيان بمقدار 6 مرات مقارنة بـ LoRA، ولا تتطلب بيانات تدريب مسبق. تعمل هذه الطريقة على زيادة إمكانات نماذج MoE (Mixture of Experts) إلى أقصى حد من خلال الاستفادة من قدرتها على اختيار الموترات الدقيقة. يوفر ظهور KappaTune حلولًا أكثر كفاءة للتعلم المستمر وقابلية التكيف لـ LLM، ومن المتوقع أن يقلل من تكاليف صيانة النموذج، ويعزز التطبيق الشامل لـ AI. (المصدر: Reddit r/deeplearning)

إطار العمل Policy→Tests (P2T): سد الفجوة بين سياسات AI والقواعد القابلة للتنفيذ: يهدف إطار العمل Policy→Tests (P2T) إلى تحويل سياسات حوكمة AI المكتوبة باللغة الطبيعية (مثل قانون AI للاتحاد الأوروبي، وNIST AI RMF) إلى قواعد قابلة للتنفيذ. يقوم هذا الإطار، من خلال خط أنابيب قابل للتوسع وJSON DSL مدمج، بتحويل وثائق السياسات إلى قواعد ذرية موحدة، تتضمن المخاطر، والنطاق، والشروط، والاستثناءات، وإشارات الأدلة، والمصدر. يحل P2T مشكلة الاختناق بين تفسير السياسات وتنفيذ الأدوات، خاصة عند التعامل مع المجالات المعقدة مثل بيانات الرعاية الصحية، حيث يمكنه تقليل الوقت اللازم لربط متطلبات HIPAA بفحوصات خط أنابيب ML بشكل كبير، مما يعزز كفاءة حوكمة AI وقابليتها للتحقق. (المصدر: Reddit r/MachineLearning)
GenEnv: التطور المشترك لوكلاء LLM ومحاكيات البيئة المتوافقة مع الصعوبة: GenEnv هو إطار عمل يحل مشكلة التكلفة العالية وثبات بيانات التفاعل في العالم الحقيقي عند تدريب وكلاء LLM، وذلك من خلال إنشاء لعبة تطور مشترك متوافقة مع الصعوبة بين الوكيل ومحاكي بيئة توليدي قابل للتوسع. يعمل المحاكي كاستراتيجية منهج ديناميكية، حيث يولد باستمرار مهامًا تستهدف بشكل خاص “منطقة التطور القريب” للوكيل، ويتم توجيهها بواسطة مكافآت “α-curriculum”. عزز GenEnv أداء الوكيل بنسبة تصل إلى 40.3% في العديد من الاختبارات المعيارية، وطابق أو تجاوز متوسط أداء النماذج الكبيرة ببيانات أقل بمقدار 3.3 مرة، مما يوفر مسارًا فعالًا للبيانات لتوسيع قدرات الوكيل. (المصدر: HuggingFace Daily Papers)
QuCo-RAG: تحديد كمية عدم اليقين من مجموعات البيانات المدربة مسبقًا لتحقيق RAG ديناميكي: يقترح QuCo-RAG تحديد كمية عدم اليقين من بيانات التدريب المسبق لتحقيق RAG ديناميكي.