
키워드:AI 에이전트, LLM, 강화 학습, 멀티모달 AI, 자율 주행, AI 보안, AI 경쟁, 사카나 AI ALE-에이전트, 서비스나우 아프리엘가드, 제미나이 인터랙션스 API, 클링 AI 2.6 모션 컨트롤, 트랜지티브 RL 알고리즘
🔥 포커스
Sakana AI 에이전트, 프로그래밍 대회 우승 : Sakana AI가 개발한 ALE-Agent가 AtCoder 휴리스틱 프로그래밍 대회 AHC058에서 처음으로 우승했습니다. 이 AI 에이전트는 스스로 학습하여 인간이 예상치 못한 “焼きなまし法”(simulated annealing algorithm)을 창조해 800명 이상의 참가자 중 두각을 나타냈습니다. 이 성과는 복잡한 최적화 문제에서 AI 에이전트의 강력한 자율 학습 및 혁신 능력을 보여주며, AI가 전통적인 프로그래밍 패러다임을 넘어 고도로 복잡하고 비정형적인 문제를 해결할 수 있는 엄청난 잠재력을 가지고 있음을 시사합니다. 이는 미래 AI 기반 자동 코드 생성 및 문제 해결을 위한 새로운 길을 열어줍니다. (출처: hardmaru)

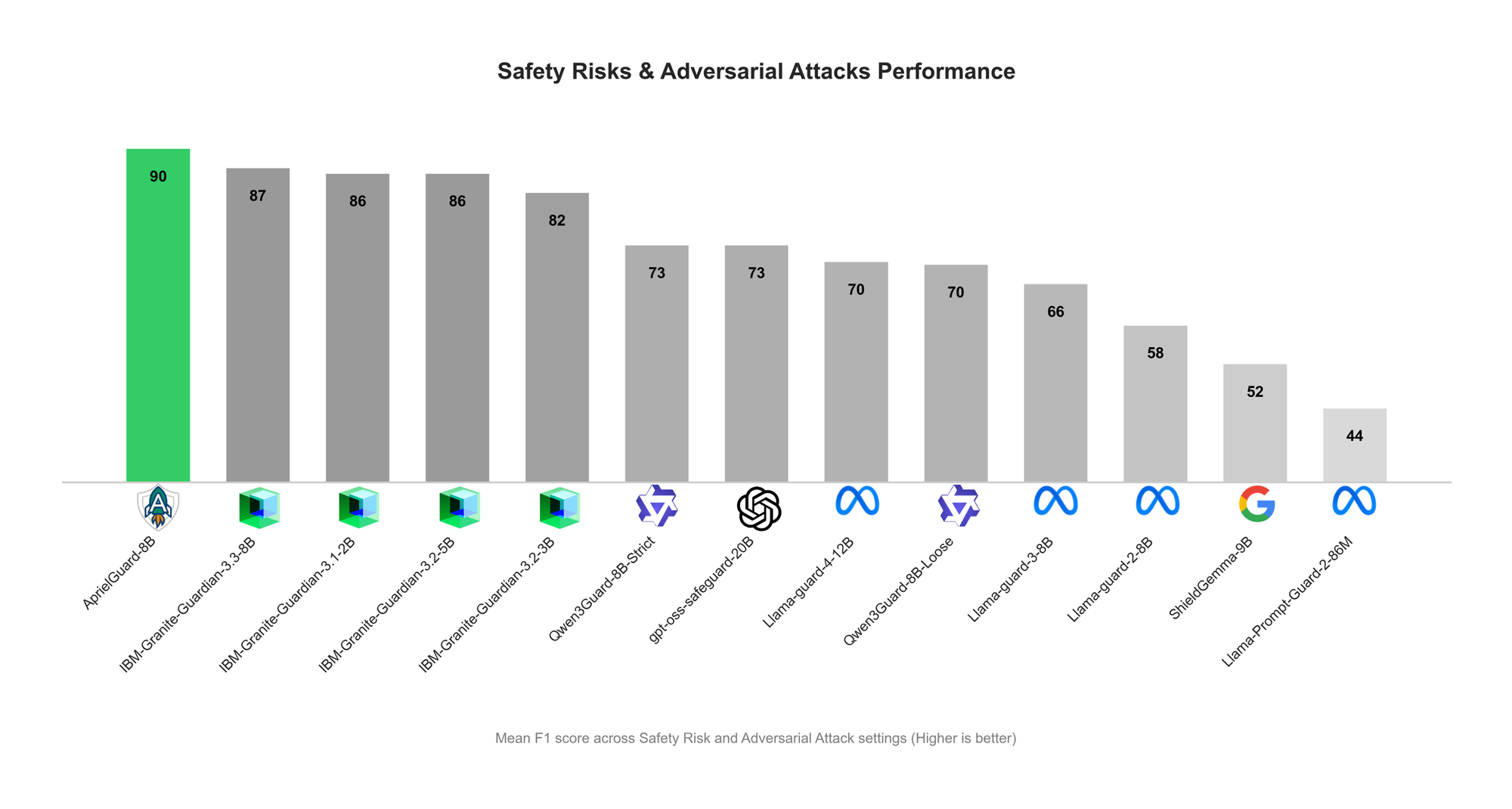
ServiceNow, AprielGuard 출시: LLM 안전 및 적대적 견고성 가드레일 : ServiceNow가 8B 파라미터의 안전 가드레일 모델 AprielGuard를 출시했습니다. 이 모델은 최신 LLM 시스템에서 발생하는 16가지 유형의 안전 위험과 광범위한 적대적 공격(다중 턴 탈옥, 프롬프트 주입, 메모리 하이재킹, 도구 조작 등)을 탐지하도록 설계되었습니다. AprielGuard는 추론 및 비추론 두 가지 모드를 지원하여, 설명이 필요할 때는 상세한 분류를 제공하고, 프로덕션 환경에서는 낮은 지연 시간으로 분류를 수행할 수 있습니다. AprielGuard는 통합 모델과 통합 분류법을 통해 다중 턴 대화, 긴 컨텍스트, 에이전트 워크플로우에서 기존 안전 분류기가 직면했던 한계를 해결하며, 신뢰할 수 있는 AI 배포를 위한 확장 가능한 기반을 제공합니다. (출처: HuggingFace Blog)
🎯 동향
Karpathy, 2025년 LLM 연간 회고 발표: RLVR이 AI를 모방에서 추론으로 이끌다 : OpenAI 공동 창립자 중 한 명인 Andrej Karpathy가 “2025년 대규모 언어 모델 연간 회고”를 발표하며, 2025년 AI 훈련 철학이 “확률적 모방”에서 “논리적 추론”으로 핵심적인 전환을 맞이할 것이라고 지적했습니다. 핵심 동력은 검증 가능한 보상 강화 학습(RLVR)의 성숙이며, 수학 및 코드와 같은 객관적인 피드백 환경을 통해 모델이 인간의 사고와 유사한 “추론 흔적”을 자발적으로 생성하도록 유도합니다. 그는 이러한 장주기 강화 학습이 전통적인 pre-training을 대체하기 시작하여 모델 능력 향상의 새로운 엔진이 되었으며, 2026년 AI 경쟁은 “AI가 어떻게 효율적으로 사고하게 할 것인가”라는 핵심 논리 패러다임으로 전환될 것이라고 예측했습니다. (출처: 36氪)
미국, “제네시스 미션” 착수: AI 맨해튼 프로젝트로 과학적 돌파구 추진 : 도널드 트럼프 미국 대통령이 행정 명령에 서명하여 “제네시스 미션”을 공식적으로 시작했습니다. 이 미션은 국가 연구소의 슈퍼컴퓨팅 능력과 최고 과학자들의 지혜를 통합하여 AI를 활용해 전례 없는 속도로 과학적 돌파구를 추진하는 것을 목표로 합니다. 이 계획은 “제2차 세계대전 중의 맨해튼 프로젝트”에 비유되며, 자율적으로 과학적 발견을 추진할 수 있는 AI를 구축하고, 미국 과학계의 핵심 역량을 집중하여 에너지부 산하 17개 국립 연구소의 4만 명 과학자와 엔지니어를 동원해 AI 기술 연구 개발로 전면 전환함으로써 국가 기술 주권을 재건하는 것을 목표로 합니다. (출처: 36氪)

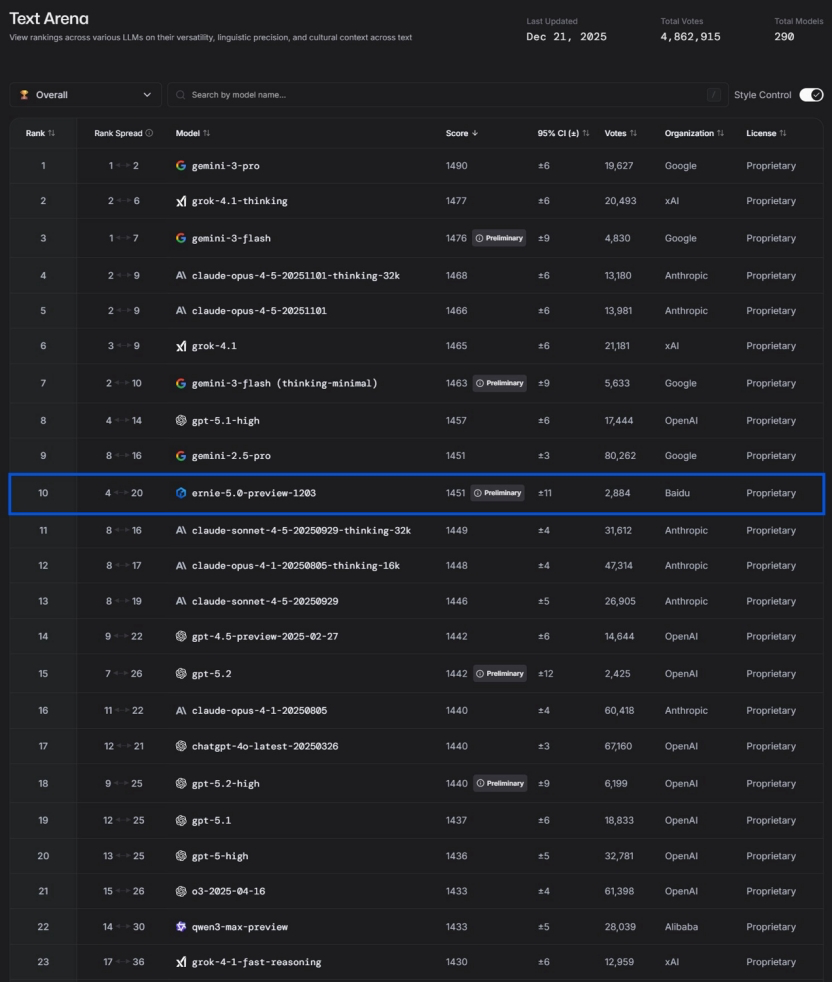
중국 AI 혁신과 Baidu Wenxin 5.0의 부상 : DeepMind가 중국 AI에 대해 “혁신 부족, 빠른 추격에 불과하다”는 주장에 대해, 중국 AI는 애플리케이션 구현을 통해 독특한 기술 장벽을 형성하고 있다는 견해가 있습니다. Baidu Wenxin ERNIE-5.0-Preview-1203은 LMArena 텍스트 순위에서 국내 1위, 세계 10위권에 진입하여 GPT-5.2와 Claude Sonnet 4.5를 능가하며 상위 20개 모델 중 유일한 비미국 모델이 되었습니다. 이러한 돌파구는 “네이티브 풀 모달리티 통합 모델링”, 2.4조 파라미터의 MoE 아키텍처, 그리고 “지행합일”의 복합 사고 체인 덕분입니다. 이 기사는 고속철도 공기역학 설계, 전력망 순찰, SF Express 코드 생성 및 도시 거버넌스와 같은 물리적 세계 및 산업 애플리케이션에서 중국 AI의 심층적인 가치를 강조합니다. (출처: 36氪)
Microsoft Copilot, 사용자 채택 문제 직면, Nadella 직접 지휘 : Microsoft CEO Satya Nadella가 Copilot 개선을 직접 독려하는 것은 Copilot이 Office 제품군에 통합되었음에도 불구하고 사용자 채택률이 예상에 미치지 못하고 있음을 반영합니다. 이는 AI 경쟁이 “능력 과시”에서 “사용자 유지”로 전환되었음을 의미하며, 즉 누가 실제로 사용자 일상에서 사용될 수 있는지에 대한 문제입니다. 이 기사는 Copilot의 “안내”하는 자세가 아닌 “파트너” 역할, 그리고 과도하게 많은 시나리오를 커버하는 기계적인 상호작용이 사용자 주의를 소모한다고 지적합니다. 미래 AI 경쟁은 “적절한 거리감”에 초점을 맞출 것이며, 즉 AI가 언제 나타나고 언제 침묵할지, 그리고 더 섬세한 이해력을 제공하여 사용자 감정적 비용을 줄일 수 있는지에 달려 있습니다. (출처: 36氪)

MiniMax M2.1 출시, GLM 4.7 성능 향상 : MiniMax M2.1이 공식적으로 출시되었습니다. 10B 활성화 파라미터의 MoE 아키텍처 모델로서 다국어 코딩(Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) 및 애플리케이션/웹 개발 분야에서 뛰어난 성능을 보이며, SWE-bench 다국어 점수 72.5%로 Gemini 3 Pro 및 Claude Sonnet 4.5를 능가했습니다. 동시에 GLM 4.7도 Vals Index 오픈소스 순위에서 1위, 전체 순위 9위를 차지했으며, GLM 4.6 대비 9.5% 성능 향상을 이루었습니다. 특히 프로그래밍, Agent/ToolCall 및 긴 컨텍스트 리콜 능력에서 두드러진 성능을 보였고, “사고 보존” 메커니즘을 도입하여 복잡한 작업의 안정성과 제어 가능성을 높였습니다. (출처: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

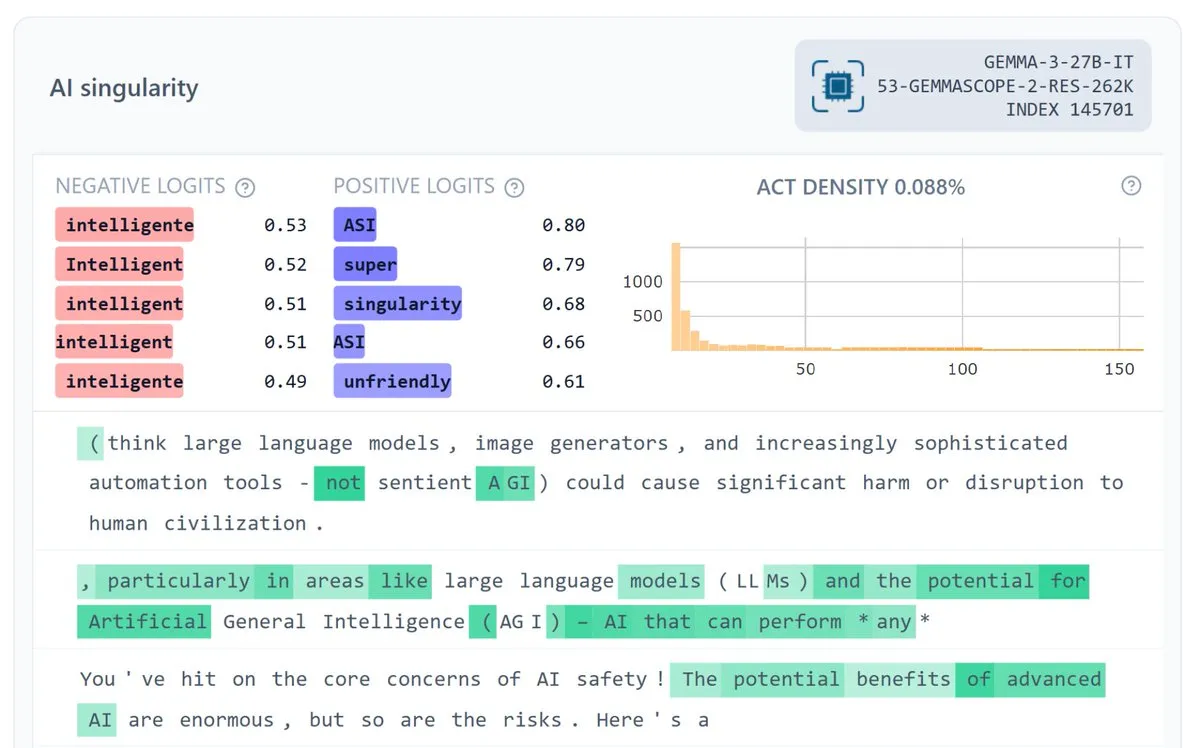
Google DeepMind, Gemma Scope 2 출시로 모델 해석 가능성 향상 : Google DeepMind가 Gemma Scope 2를 출시했습니다. 이는 Gemma 3 시리즈 모델(270M-27B, 기본 및 채팅 버전)을 위한 풀 스택 해석 가능성 스위트로, 각 계층의 SAE(Sparse Autoencoder)와 트랜스코더를 포함합니다. 이 조치는 복잡한 모델 동작에 대한 심층적인 이해를 촉진하고, 더욱 야심찬 오픈소스 안전 및 해석 가능성 연구를 지원하며, 커뮤니티가 LLM의 내부 작동 메커니즘을 더 잘 디버깅하고 분석하는 데 도움이 될 것으로 기대됩니다. (출처: NeelNanda5, Reddit r/artificial)
AI 에이전트 상태 관리: Google Interactions API, 개발 간소화하지만 종속성 우려 제기 : Google이 Gemini의 Interactions API를 출시했습니다. 이 API는 서버 측에서 대화 기록, 컨텍스트 관리 및 백그라운드 실행을 처리하여 AI 에이전트 개발을 크게 간소화합니다. 이는 벡터 데이터베이스 설정, 사용자 정의 컨텍스트 엔지니어링 등 많은 인프라 작업을 제거하여 개발 속도를 현저히 높였습니다. 그러나 이 조치는 벤더 종속, 컨텍스트 저장 및 검색 제어권 상실, 모델 전환의 어려움, 비용 불투명성에 대한 우려를 불러일으켰습니다. 이는 Google이 AWS 모델과 유사하게 인프라를 해자로 활용하고 있음을 보여주지만, 전체 스택에 대한 높은 제어가 필요한 ML 워크로드의 경우 이러한 블랙박스 모델의 장기적인 영향은 계속 지켜봐야 합니다. (출처: Reddit r/artificial)
Hugging Face 로봇 데이터셋 급증, 오픈 로봇 생태계 발전 가속화 : Hugging Face 플랫폼의 오픈 로봇 데이터셋은 지난 2년간 1천 개에서 2.7만 개로 급증하여 텍스트 생성 등 다른 카테고리를 훨씬 능가했습니다. 이러한 폭발적인 성장은 더 저렴한 비디오 저장, 더 나은 도구, 그리고 오픈소스 AI 문화의 확산 덕분이며, 로봇 분야의 진입 장벽을 크게 낮추고 범용 로봇 및 휴머노이드 로봇의 연구 개발 과정을 가속화했습니다. 오픈 데이터셋은 실제 로봇 데이터(비디오, 동작, 센서, 오류 등)를 쉽게 업로드, 재사용 및 벤치마킹할 수 있게 하여 로봇 분야를 더욱 확장 가능하고 협력적인 생태계로 변화시키고 있습니다. (출처: huggingface)
Tesla FSD와 Waymo 자율주행 경로 논쟁: 엔드투엔드 대 모듈형 : Waymo와 Tesla FSD는 자율주행 기술 경로에서 극명하게 다른 철학을 보여줍니다. Waymo는 고화질 지도, LiDAR, 센서 및 5G 네트워크에 의존하는 “모듈형” 방식을 채택하며, 교통 신호 고장과 같은 모듈 중 하나가 고장 나면 시스템이 “벽돌 모드”에 빠질 수 있습니다. 반면 Tesla FSD는 “엔드투엔드” 방식을 채택하여, 대규모 신경망을 통해 카메라 픽셀을 직접 조향 및 제동 명령으로 변환하며 인간 운전과 더 유사합니다. 일부 견해는 Waymo의 모듈형 방식이 확장성과 의존성 측면에서 거대한 소프트웨어 문제를 안고 있으며, 장기적으로 Tesla FSD의 엔드투엔드 방식이 더 유리하다고 주장합니다. (출처: Yuchenj_UW)
Zhihu Frontier 연간 회고: 2025년 AI 인프라 및 멀티모달 발전 : Zhihu Frontier가 연간 회고를 발표하며, 2025년 AI 분야의 인프라 및 멀티모달 측면에서 구조적 진전을 요약했습니다. AI 에이전트가 인간처럼 “보고, 듣고, 추론”하는 능력을 갖춰야 하며, 멀티모달 및 네이티브 음성 기술 발전을 추진해야 한다고 강조했습니다. 모델 능력 측면에서는 10B 파라미터 모델이 2024년 100B+ 모델을 능가했으며, 비용 효율성이 10배 향상되었고, pre-training은 여전히 기본입니다. AI 인프라가 경쟁 우위가 되었으며, 분산 추론, Tile-based 프로그래밍, 대규모 강화 학습 및 모델-시스템 협력 설계가 핵심 진전 사항입니다. 또한, 효과적인 의사소통과 관심 확보가 기술 전문가의 필수 역량이 되었음을 지적했습니다. (출처: ZhihuFrontier)

🧰 도구
Claude Code + Chrome 통합으로 브라우저 자동화 구현 : Claude Code가 이제 Chrome 브라우저 통합을 지원하여, 사용자가 터미널에서 코드를 작성한 다음 Claude가 Chrome에서 URL을 열고, 버튼을 클릭하고, 양식을 작성하고, 콘솔 오류 및 DOM 상태를 읽고, 심지어 스크린샷을 찍고 GIF를 녹화할 수 있게 합니다. 이 기능은 API나 token 없이 사용자가 로그인한 브라우저 세션을 직접 활용하여, Google Sheets 생성, Hacker News에서 정보 추출 및 양식 채우기와 같은 다중 사이트 자동화 워크플로우를 크게 간소화합니다. 현재 Chrome만 지원하고 headless 모드는 없지만, 개발자에게 강력하고 원활한 브라우저 상호작용 기능을 제공합니다. (출처: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: AI 비디오 광고의 새로운 패러다임 : Kling AI 2.6이 강력한 Motion Control 기능을 출시하여, 비디오 속 인물의 사실적인 교체를 가능하게 하고, 립싱크 및 복잡한 동작 캡처를 지원하며, 심지어 비인간 캐릭터에도 적용됩니다. 이 기술은 AI 광고의 테스트 잠재력을 크게 향상시켜, 광고주가 다양한 연령, 성별, 인종 및 미학적 스타일의 광고 변형을 빠르게 생성하여 대규모 광고 테스트 및 최적화를 실현할 수 있도록 합니다. Nano Banana Pro로 캐릭터를 생성하고 Elevenlabs로 음성을 생성하는 것을 결합함으로써, Kling AI 2.6은 비디오 콘텐츠 제작 및 광고 산업에 혁명적인 효율성 향상을 가져왔습니다. (출처: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8 출시, LLM 애플리케이션 평가 및 관측 능력 강화 : MLflow 3.8 버전이 공식 출시되어 LLM 애플리케이션 평가 및 관측을 위한 고급 기능을 제공합니다. 새로운 기능에는 특정 모델 설정을 프롬프트 템플릿과 연결하여 LLM 워크플로우의 재현성을 높이는 프롬프트 모델 구성; 진행 중인 추적을 표시하여 LLM 애플리케이션의 실시간 디버깅 및 모니터링을 가능하게 하는 추적 UI 지원; DeepEval 및 RAGAS Judges 통합으로 답변 관련성, 충실도 및 환각 감지 등 20개 이상의 평가 지표 제공; 그리고 다중 턴 대화의 안전성과 에이전트 상호작용에서 도구 호출 효율성을 각각 평가하는 대화 안전성 평가기 및 대화 도구 호출 효율성 평가기가 추가되었습니다. (출처: matei_zaharia)

vLLM, LongCat-Image-Edit 및 MiMo-V2-Flash 지원으로 이미지 편집 및 서비스 간소화 : vLLM 커뮤니티가 Meituan LongCat-Image-Edit 모델에 대한 지원을 추가하여, 명령어 준수형 이미지 편집을 위한 간소화된 서비스 경로를 제공합니다. 이는 객체 추가/교체, 배경 변경 및 스타일 조정과 같은 일반적인 작업을 지원하며, 사진 편집 도구 및 창의적 편집 프로세스에 적합합니다. 동시에 vLLM은 Xiaomi MiMo/MiMo-V2-Flash 모델 배포 방법에 대한 공식 튜토리얼도 발표했습니다. 여기에는 도구 호출, DP/TP/EP 구성, 그리고 컨텍스트 길이, 지연 시간 및 KV 캐시의 핵심 파라미터 조정이 포함되어 LLM의 멀티모달 및 엣지 장치에서의 적용을 더욱 촉진합니다. (출처: vllm_project)

Reka Vision, 스마트 홈 보안 AI의 새로운 표준 제시 : Reka Vision이 스마트 카메라 솔루션을 출시하여, 전통적인 움직임 감지를 넘어 이벤트에 대한 심층적인 이해를 목표로 합니다. 이 시스템은 비디오, 오디오 및 시간을 아우르는 추론을 통해 오탐지를 줄이고, 상황에 맞는 인간 수준의 통찰력을 제공합니다. Reka Vision은 스마트 홈 보안 AI의 새로운 표준을 수립하여, 가정 환경에서 발생하는 복잡한 이벤트를 더 정확하게 식별하고 이해함으로써 더 스마트하고 신뢰할 수 있는 보안 모니터링 서비스를 제공하는 데 전념하고 있습니다. (출처: RekaAILabs)
YouTube Playables Builder: Gemini 3로 게임 창작 지원 : YouTube Playables Builder 웹 애플리케이션이 Gemini 3 모델의 지원을 받아 출시되었습니다. 이 앱은 크리에이터가 텍스트, 비디오 또는 이미지 프롬프트를 통해 재미있고 작은 게임을 빠르게 개발할 수 있도록 돕습니다. 이 도구는 게임 개발의 진입 장벽을 낮춰 비전문 개발자도 AI의 힘을 활용하여 아이디어를 플레이 가능한 게임 경험으로 전환할 수 있게 하며, UGC(User Generated Content) 게임 생태계에 새로운 활력을 불어넣고 엔터테인먼트 콘텐츠 창작 분야에서 AI의 더 많은 가능성을 탐색할 것으로 기대됩니다. (출처: demishassabis)
Medmarks v0.1 출시: 최대 규모의 오픈소스 의료 LLM 평가 스위트 : Sophont AI가 Medmarks v0.1을 출시했습니다. 이는 LLM의 의료 능력을 평가하기 위한 현재까지 가장 큰 완전 오픈소스 자동화 평가 스위트입니다. 이 스위트는 MedARC AI 커뮤니티에서 개발되었으며 PrimeIntellect의 지원을 받아 최상의 성능을 찾기 위해 46개 모델을 탐색했습니다. Medmarks v0.1의 출시는 의료 AI 분야의 연구 및 발전을 크게 촉진하고, 의료 LLM의 성능을 평가하고 향상시키기 위한 표준화된 도구와 벤치마크를 제공할 것입니다. (출처: iScienceLuvr)
Nano Banana Pro와 Gemini 3 Pro 결합으로 이미지 생성 및 렌더링 구현 : 한 에이전트 애플리케이션이 Nano Banana Pro를 활용하여 이미지를 생성하고 Gemini 3 Pro를 통해 휴대폰에서 렌더링함으로써, AI 모델의 프런트엔드 미학적 표현 능력을 강력하게 보여주었습니다. 예를 들어, Karpathy의 연말 요약을 위한 웹페이지를 만들거나 마우스 스타일을 변경할 수도 있습니다. 이러한 결합은 효율적인 이미지 생성 및 렌더링 워크플로우를 제공할 뿐만 아니라, 사용자 요구에 따라 시각적으로 매력적인 콘텐츠를 빠르게 생성할 수 있는 UI/UX(사용자 인터페이스/사용자 경험) 디자인 분야에서 AI의 거대한 잠재력을 시사합니다. (출처: op7418)

Heretic: LLM 자동 검열 제거 도구 : Heretic은 LLM을 위한 완전 자동 검열 제거 도구입니다. 오픈소스 AI 커뮤니티에서 이 도구의 출시는 모델이 콘텐츠를 생성할 때 발생할 수 있는 검열 제한을 해결하는 것을 목표로 하기 때문에 광범위한 관심을 불러일으켰습니다. Heretic의 등장은 사용자에게 더 큰 자유를 제공하지만, 특히 표현의 자유와 잠재적으로 유해한 콘텐츠 생성의 균형에 대한 내용 안전 및 윤리적 논의를 촉발할 수 있습니다. (출처: Reddit r/LocalLLaMA)
Claude Code, 역방향 검색 기능 추가로 프롬프트 관리 효율성 향상 : Claude Code가 기능을 업데이트하여 Ctrl+R을 통한 프롬프트 역방향 검색 기능을 추가했습니다. 사용자는 Ctrl+R을 반복해서 눌러 특정 키워드를 포함하는 모든 프롬프트를 순환하며 볼 수 있어, 프롬프트 관리의 효율성과 편리성을 크게 향상시킵니다. 이 개선 사항은 개발자가 과거 프롬프트를 더 빠르게 찾아 재사용하고, AI 프로그래밍 워크플로우를 최적화하며, 반복 작업을 줄이는 데 도움이 됩니다. (출처: dejavucoder)
📚 학습
RL의 새로운 패러다임: Transitive RL, 분할 정복법으로 장주기 작업 해결 : BAIR 블로그는 Transitive RL (TRL)이라는 새로운 강화 학습 알고리즘을 소개했습니다. 이 알고리즘은 전통적인 시간차분(TD) 학습이 아닌 “분할 정복” 패러다임을 채택합니다. TRL은 궤적을 재귀적으로 더 작은 세그먼트로 분할하고 그 가치를 결합하여 전체 궤적의 가치를 업데이트함으로써 장주기 작업에서 더 나은 확장성을 보여줍니다. 이 방법은 목표 조건 RL 문제에서 특히 효과적이며, 중간 하위 목표의 최적화를 통해 Bellman 재귀 횟수를 크게 줄이고 TD 학습에서 오류 누적 문제를 피하여 복잡하고 장시간의 RL 작업을 해결하는 새로운 방향을 제시합니다. (출처: aihub.org)
LLM, 수학 증명 지원: DeepMind 전 직원이 P/=NP 및 Navier-Stokes 탐구 : 전 DeepMind 엔지니어 Bengoertzel이 LLM을 활용하여 Navier-Stokes 방정식의 존재 및 유일성, 그리고 P/=NP 문제와 같은 복잡한 수학 문제 증명을 돕는 방법을 탐구했습니다. 그는 LLM을 사용하여 증명의 세부 사항을 채워 넣은 경험을 공유했으며, 핵심 아이디어는 자신에게서 나왔지만 LLM이 번거로운 세부 사항을 처리하는 데 상당한 도움을 주었다고 밝혔습니다. 이 실천은 인간의 창의적 사고와 LLM의 세부 처리 능력을 효과적으로 결합하는 방법, 그리고 Lean과 같은 형식 검증 도구를 활용하여 수학 증명의 엄격성을 보장하는 방법에 대한 논의를 촉발하며, 고급 수학 연구에서 AI의 잠재적 역할을 예고합니다. (출처: bengoertzel)
LLM 훈련 시대의 진화: Pre-training에서 RLVR 및 GRPO로 : LLM 훈련 패러다임은 빠르게 진화하고 있습니다. 202x년의 pre-training(기본 모델)부터 2022년의 RLHF+PPO, 2023년의 LoRA SFT, 그리고 2024년의 mid-training에 이르기까지. 2025년에는 RLVR+GRPO 시대에 진입할 것으로 예측되며, 2026년에는 “On Policy Distillation” 시기가 도래할 수 있습니다. 이러한 진화 로드맵은 LLM 훈련 방법론의 지속적인 심화 및 최적화를 보여주며, 초기 기본 능력 구축에서 점차 더 정교하고 피드백 및 효율성을 중시하는 훈련 전략으로 전환되어, 미래 모델이 상호작용을 통한 학습 및 지식 증류를 더욱 강조할 것임을 예고합니다. (출처: bookwormengr)
LLM 기억 메커니즘 연구: Claude와 ChatGPT의 내부 작동 원리 : Claude와 ChatGPT와 같은 LLM의 기억 메커니즘에 대한 심층 연구가 진행되어, 이들이 대화 컨텍스트 정보를 어떻게 처리하고 유지하는지 분석했습니다. 이 연구들은 모델 내부 상태가 기억 형성 및 검색에 어떻게 영향을 미치는지, 그리고 다중 턴 대화에서 일관성을 유지하는 데 따르는 과제를 밝혀냈습니다. LLM의 기억 작동 원리를 이해하는 것은 대화 시스템 최적화, 사용자 경험 향상 및 긴 컨텍스트 이해 문제 해결에 매우 중요하며, 미래의 더 효율적이고 안정적인 AI 상호작용 설계를 위한 이론적 기반을 제공합니다. (출처: dejavucoder)
AI 에이전트 적응 전략 연구: Agent와 도구의 공진화 : UIUC, Stanford, Harvard 등 연구 기관들이 AI 에이전트의 적응 전략을 탐구했으며, 주로 두 가지 유형으로 나뉩니다: 에이전트 자체(추론 모델) 적응과 에이전트가 사용하는 도구(검색 시스템, 리트리버, 메모리, API) 적응. 연구는 네 가지 적응 유형을 정의했습니다: 도구 결과를 사용하여 에이전트 적응, 자체 출력을 활용하여 에이전트 훈련, 도구 독립적 적응, 그리고 에이전트의 피드백을 통해 도구 훈련. 이러한 전략은 더 스마트하고 유연한 AI 에이전트 개발을 위한 이론적 지침을 제공하며, 복잡하고 변화무쌍한 작업 환경에 대응하기 위한 에이전트와 도구 간의 공진화 중요성을 강조합니다. (출처: TheTuringPost)
AI 모델 추론 능력 향상 연구: Pre-training, Mid-training 및 강화 학습의 역할 : Carnegie Mellon University 연구원들은 pre-training, mid-training 및 강화 학습이 AI 모델의 추론 능력 향상에 서로 다른 역할을 한다는 것을 발견했습니다. 연구는 강화 학습이 특정 조건에서만 실제로 추론 능력을 향상시킬 수 있으며, 교차 컨텍스트 일반화를 위해서는 먼저 pre-training이 필요하고, mid-training이 매우 중요하며, Process-aware rewards가 필수적이라고 지적합니다. 이러한 발견은 AI 모델의 훈련 전략을 최적화하는 데 지침을 제공하며, 추론 능력 최대화를 위해 다른 단계에서 맞춤형 접근 방식을 채택하는 것의 중요성을 강조합니다. (출처: TheTuringPost)

KappaTune: LLM 미세 조정의 재앙적 망각 문제 해결 : KappaTune은 LoRA와 같은 기존 방법에서 발생하는 재앙적 망각 문제를 해결하기 위해 고안된 새로운 LLM 미세 조정 방법입니다. KappaTune은 망각 정도가 LoRA보다 6배 낮으며, pre-training 데이터가 필요 없습니다. 이 방법은 MoE(Mixture of Experts) 모델의 세분화된 텐서 선택 능력을 활용하여 잠재력을 극대화합니다. KappaTune의 등장은 LLM의 지속적인 학습 및 적응성을 위한 더 효율적인 솔루션을 제공하며, 모델 유지보수 비용을 절감하고 AI의 보급을 촉진할 것으로 기대됩니다. (출처: Reddit r/deeplearning)

정책-테스트(P2T) 프레임워크: AI 정책과 실행 가능한 규칙 간의 격차 해소 : Policy→Tests (P2T) 프레임워크는 자연어로 작성된 AI 거버넌스 정책(예: EU AI Act, NIST AI RMF)을 실행 가능한 규칙으로 전환하는 것을 목표로 합니다. 이 프레임워크는 확장 가능한 파이프라인과 간결한 JSON DSL을 통해 정책 문서를 표준화된 원자적 규칙으로 변환하며, 여기에는 위험, 범위, 조건, 예외, 증거 신호 및 출처가 포함됩니다. P2T는 정책 해석과 도구 실행 간의 병목 현상을 해결하며, 특히 의료 데이터와 같은 복잡한 영역을 처리할 때 HIPAA 요구 사항을 ML 파이프라인 검사에 매핑하는 데 필요한 시간을 크게 줄여 AI 거버넌스의 효율성과 검증 가능성을 높입니다. (출처: Reddit r/MachineLearning)
GenEnv: LLM 에이전트와 환경 시뮬레이터 난이도 정렬의 공진화 : GenEnv는 에이전트와 확장 가능한 생성 환경 시뮬레이터 사이에 난이도 정렬된 공진화 게임을 구축하여, LLM 에이전트 훈련 시 실제 세계 상호작용 데이터의 높은 비용과 정적인 병목 현상을 해결하는 프레임워크입니다. 시뮬레이터는 동적 커리큘럼 전략으로서, 에이전트의 “근접 발달 영역”에 특화된 작업을 지속적으로 생성하며, α-curriculum reward의 지도를 받습니다. GenEnv는 여러 벤치마크에서 에이전트 성능을 최대 40.3% 향상시켰고, 3.3배 적은 데이터로 대규모 모델의 평균 성능과 일치하거나 능가하여, 에이전트 능력 확장을 위한 데이터 효율적인 경로를 제공합니다. (출처: HuggingFace Daily Papers)
QuCo-RAG: Pre-training 코퍼스에서 불확실성 정량화로 동적 RAG 구현 : QuCo-RAG은 pre-training 데이터에서 불확실성을 정량화하여 동적 RAG를 구현하는 방안을 제안합니다.