
Anahtar Kelimeler:Yapay Zeka Ajanı, Büyük Dil Modeli (LLM), Pekiştirmeli Öğrenme, Çok Modlu Yapay Zeka, Otonom Sürüş, Yapay Zeka Güvenliği, Yapay Zeka Yarışması, Sakana AI ALE-Ajanı, ServiceNow AprielGuard, Gemini Etkileşim API’si, Kling AI 2.6 Hareket Kontrolü, Geçişli Pekiştirmeli Öğrenme Algoritması
🔥 聚焦
Sakana AI代理在程式設計競賽中奪冠 : Sakana AI開發的ALE-Agent在AtCoder啟發式程式設計競賽AHC058中首次奪冠。該AI代理自主學習並創造出人類意想不到的「焼きなまし法」(模擬退火演算法),在超過800名參賽者中脫穎而出。這項成就展現了AI代理在複雜最佳化問題上的強大自主學習和創新能力,預示著AI在解決高度複雜、非結構化問題方面的巨大潛力,超越了傳統程式設計範式,為未來AI驅動的自動化程式碼生成和問題解決開闢了新路徑。 (來源: hardmaru)

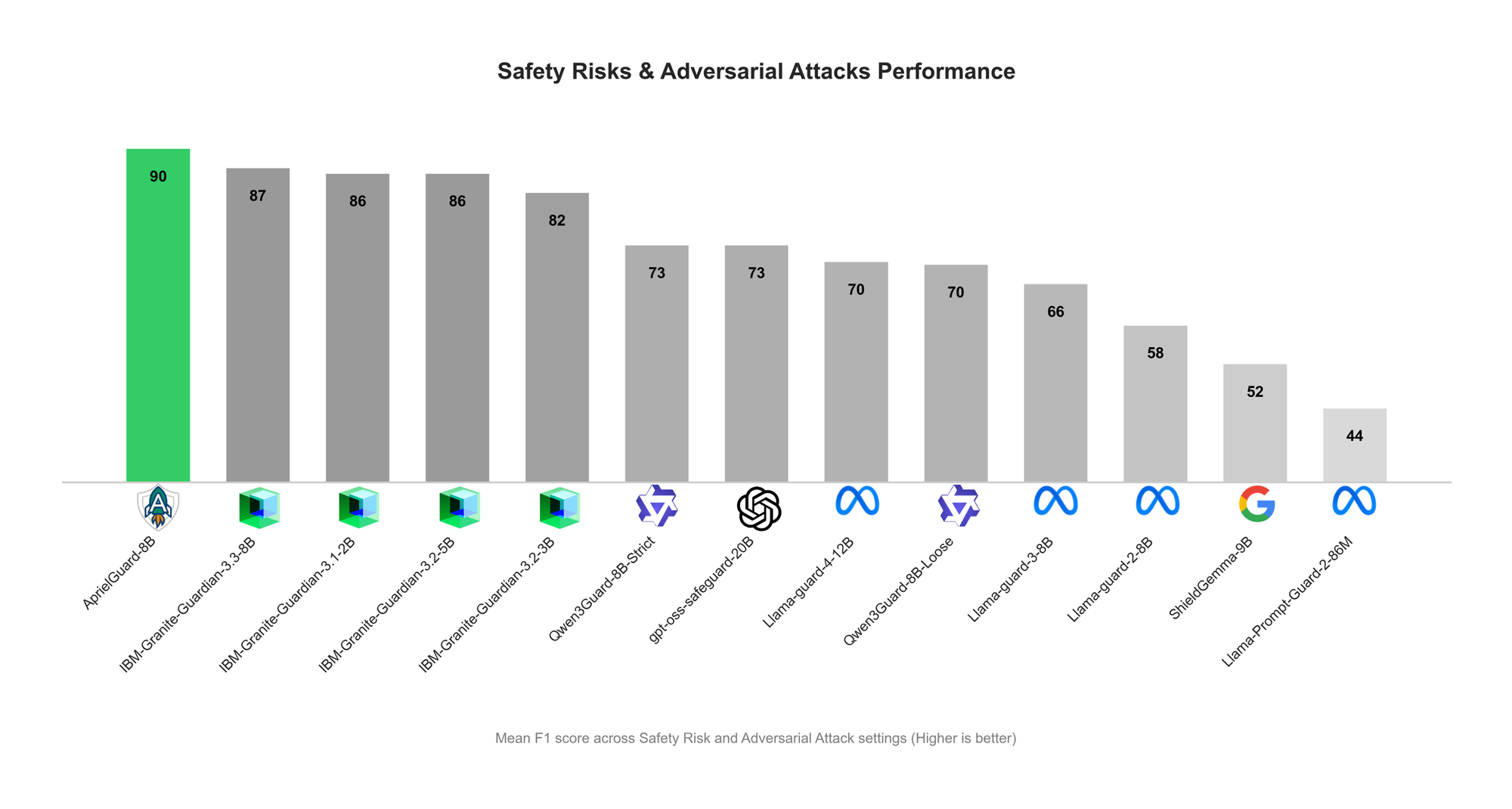
ServiceNow發布AprielGuard:LLM安全與對抗性魯棒性護欄 : ServiceNow發布了8B參數的安全護欄模型AprielGuard,旨在偵測現代LLM系統中的16類安全風險和廣泛的對抗性攻擊,包括多輪越獄、提示注入、記憶劫持和工具操縱。該模型支援推理和非推理兩種模式,可在需要解釋時提供詳細分類,或在生產環境中實現低延遲分類。AprielGuard透過統一模型和統一分類法,解決了傳統安全分類器在多輪對話、長上下文和代理工作流中面臨的局限性,為建構可信賴的AI部署提供了可擴展的基礎。 (來源: HuggingFace Blog)
🎯 動向
Karpathy發布2025年LLM年度回顧:RLVR驅動AI從模仿到推理 : OpenAI創始人之一安德烈·卡帕西發布《2025年大型語言模型年度回顧》,指出2025年AI訓練哲學從「概率模仿」向「邏輯推理」的關鍵轉變。核心驅動力是可驗證獎勵強化學習(RLVR)的成熟,透過數學和程式碼等客觀回饋環境,促使模型自發生成類似人類思維的「推理痕跡」。他強調,這種長週期強化學習已開始取代傳統預訓練,成為提升模型能力的新引擎,並預測2026年AI競爭將轉向「如何讓AI高效思考」的核心邏輯範式。 (來源: 36氪)
美國啟動「創世紀任務」:AI曼哈頓計畫旨在推動科學突破 : 美國總統特朗普簽署行政命令,正式啟動「創世紀任務」,旨在整合國家實驗室的超算能力與頂尖科學家智慧,利用AI以前所未有的速度推動科學突破。該計畫被比作「二戰期間的曼哈頓計畫」,目標是打造一個能自主推動科學發現的AI,並集中美國科學界核心競爭力,將能源部下屬17個國家實驗室的4萬名科學家和工程師動員起來,全面轉向AI技術研發,以重建國家技術主權。 (來源: 36氪)

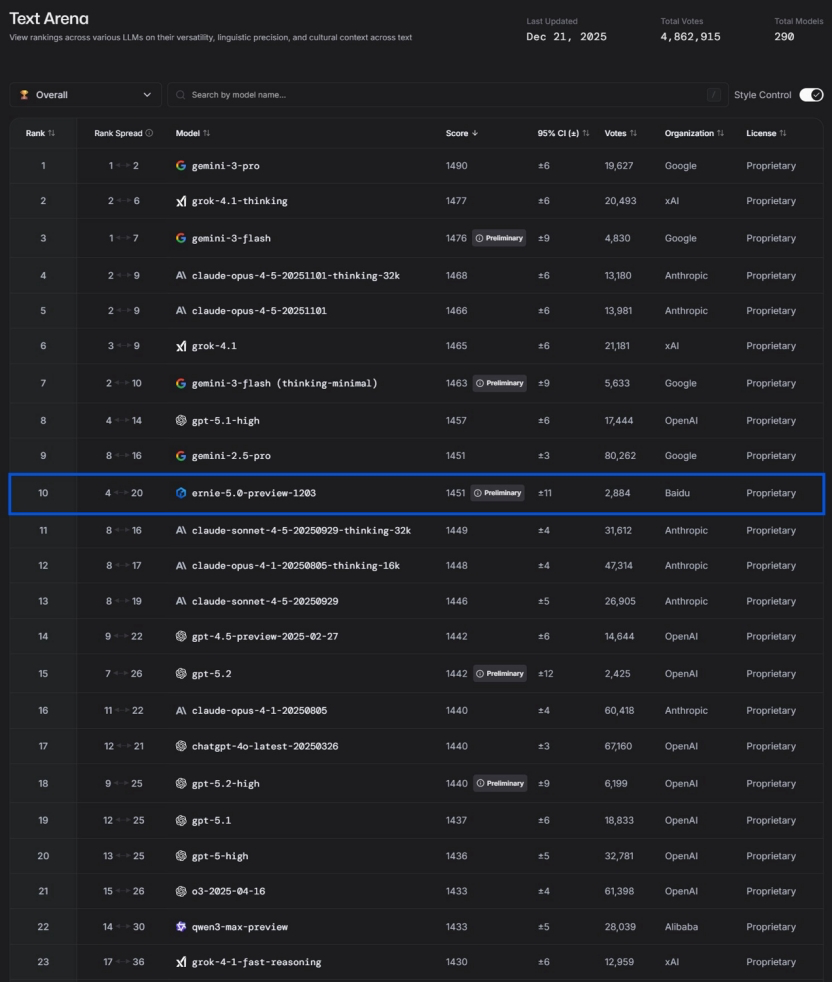
中國AI創新與百度文心5.0的崛起 : 針對DeepMind對中國AI「缺乏創新,僅是快速跟進」的論調,有觀點指出中國AI正透過應用落地形成獨特的技術壁壘。百度文心ERNIE-5.0-Preview-1203在LMArena文本排行榜上取得國內第一、全球前十的成績,超越GPT-5.2和Claude Sonnet 4.5,成為前20名中唯一的非美國模型。其突破歸因於「原生全模態統一建模」、2.4萬億參數的MoE架構,以及「知行合一」的複合思維鏈。文章強調中國AI在高鐵氣動設計、電網巡檢、順豐程式碼生成及城市治理等物理世界和產業應用中的深層價值。 (來源: 36氪)
微軟Copilot面臨用戶採納挑戰,納德拉親自督陣 : 微軟CEO薩蒂亞·納德拉親自下場督促Copilot的改進,反映出儘管Copilot已整合到Office套件,但用戶採納度未達預期。這表明AI競爭已從「展示能力」轉向「用戶留存」,即誰能真正被用戶日常使用。文章指出,Copilot的「指導」姿態而非「搭檔」角色,以及過度覆蓋場景的機械交互,消耗了用戶注意力。未來的AI競爭將聚焦於「分寸感」,即AI何時出現、何時沉默,以及能否提供更細膩的理解力,降低用戶的情緒成本。 (來源: 36氪)

MiniMax M2.1發布,GLM 4.7性能提升 : MiniMax M2.1正式上線,作為一個10B激活參數的MoE架構模型,在多語言編碼(Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS)和應用/網頁開發方面表現出色,SWE-bench多語言得分72.5%,超越Gemini 3 Pro和Claude Sonnet 4.5。同時,GLM 4.7也在Vals Index開源榜單中排名第一,總榜第九,性能較GLM 4.6提升9.5%,特別在程式設計、Agent/ToolCall和長上下文召回能力方面表現突出,並引入了「保留思維」機制,提升了複雜任務的穩定性和可控性。 (來源: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

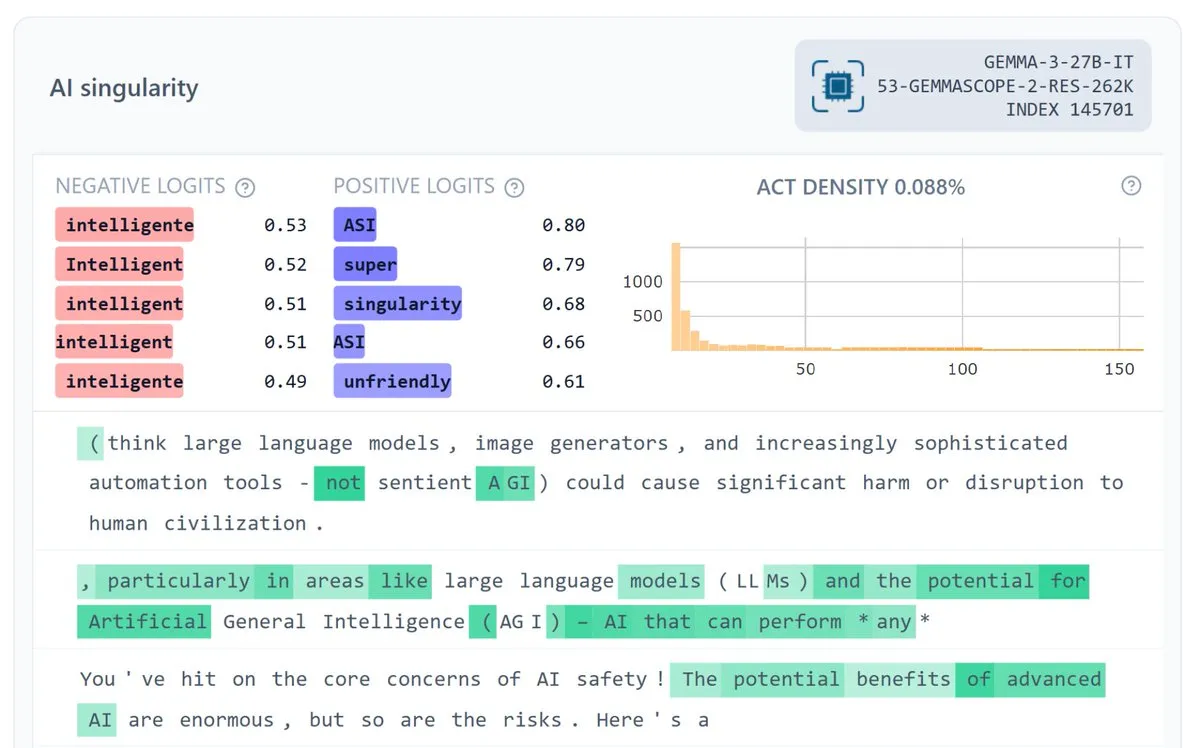
Google DeepMind發布Gemma Scope 2,提升模型可解釋性 : Google DeepMind發布Gemma Scope 2,這是一個針對Gemma 3系列模型(270M-27B,基礎版和聊天版)的全棧可解釋性套件,包含每個層級的SAE(稀疏自編碼器)和轉碼器。此舉旨在促進對複雜模型行為的深入理解,支援更具雄心的開源安全和可解釋性研究,有望幫助社群更好地偵錯和分析LLM的內部工作機制。 (來源: NeelNanda5, Reddit r/artificial)
AI代理狀態管理:Google Interactions API簡化開發但引發鎖定擔憂 : Google發布了Gemini的Interactions API,在伺服器端處理對話歷史、上下文管理和後台執行,極大地簡化了AI代理的開發。這消除了向量資料庫設定、自訂上下文工程等大量基礎設施工作,顯著提高了開發速度。然而,此舉也引發了對供應商鎖定、對上下文儲存檢索控制權喪失、模型切換困難以及成本不透明的擔憂。這表明Google正將基礎設施作為護城河,類似AWS模式,但對於需要對整個堆棧有高度控制的ML工作負載,這種黑盒模式的長期影響仍需觀察。 (來源: Reddit r/artificial)
Hugging Face機器人資料集激增,推動開放機器人生態發展 : Hugging Face平台上的開放機器人資料集在過去兩年內從1千個激增至2.7萬個,遠超文本生成等其他類別。這項爆炸式增長得益於更便宜的影片儲存、更好的工具以及開源AI文化的蔓延,極大地降低了機器人領域的準入門檻,加速了通用機器人和人形機器人的研發進程。開放資料集使得真實機器人資料(影片、動作、感測器、故障等)易於上傳、複用和基準測試,將機器人領域轉變為一個更具可擴展性和協作性的生態系統。 (來源: huggingface)
Tesla FSD與Waymo自動駕駛路徑之爭:端到端與模組化 : Waymo和Tesla FSD在自動駕駛技術路徑上展現出截然不同的哲學。Waymo採用「模組化」方法,依賴高清地圖、雷射雷達、感測器和5G網路,一旦其中一個模組(如交通燈失靈)出現故障,系統可能陷入「磚塊模式」。相比之下,Tesla FSD則採用「端到端」方案,透過一個大型神經網路直接將攝影機像素轉換為轉向和制動指令,更像人類駕駛。有觀點認為,Waymo的模組化方法在擴展性和依賴性上存在巨大軟體問題,長期來看Tesla FSD的端到端方案更具優勢。 (來源: Yuchenj_UW)
Zhihu Frontier年度回顧:2025年AI基礎設施與多模態發展 : Zhihu Frontier發布年度回顧,總結2025年AI領域在基礎設施和多模態方面的結構性進展。強調AI助手需具備像人類一樣「看、聽、推理」的能力,推動多模態和原生語音技術發展。模型能力方面,10B參數模型已超越2024年100B+模型,成本效益提升10倍,預訓練仍是基礎。AI基礎設施成為競爭優勢,分散式推理、Tile-based程式設計、大規模強化學習和模型-系統協同設計是關鍵進展。同時指出,有效溝通和獲取關注已成為技術人員的必備技能。 (來源: ZhihuFrontier)

🧰 工具
Claude Code + Chrome整合實現瀏覽器自動化 : Claude Code現已支援Chrome瀏覽器整合,允許用戶在終端編寫程式碼,然後讓Claude在Chrome中打開URL、點擊按鈕、填寫表單、讀取控制台錯誤和DOM狀態,甚至截圖和錄製GIF。這項功能無需API或token,直接利用用戶已登入的瀏覽器會話,極大地簡化了多站點自動化工作流,如建立Google表格、從Hacker News提取資訊並填充表格等。儘管目前僅支援Chrome且無headless模式,但它為開發者提供了強大的無縫瀏覽器交互能力。 (來源: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control:AI影片廣告新範式 : Kling AI 2.6推出了強大的運動控制功能,能夠實現影片中人物的逼真替換,並支援唇形同步和複雜動作捕捉,甚至適用於非人類角色。這項技術極大地提升了AI廣告的測試潛力,允許廣告商快速生成不同年齡、性別、種族和美學風格的廣告變體,從而實現大規模的廣告測試和最佳化。透過結合Nano Banana Pro生成角色和Elevenlabs生成聲音,Kling AI 2.6為影片內容創作和廣告行業帶來了革命性的效率提升。 (來源: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8發布,增強LLM應用評估與觀測能力 : MLflow 3.8版本正式發布,帶來了針對LLM應用評估與觀測的先進功能。新特性包括提示模型配置,允許將特定模型設定與提示模板關聯,提高LLM工作流的可複現性;追蹤UI支援顯示進行中的追蹤,實現LLM應用的即時偵錯和監控;整合DeepEval和RAGAS Judges,提供20多項評估指標,如答案相關性、忠實度和幻覺偵測;新增對話安全評分器和對話工具呼叫效率評分器,分別評估多輪對話的安全性和代理交互中的工具呼叫效率。 (來源: matei_zaharia)

vLLM支援LongCat-Image-Edit和MiMo-V2-Flash,簡化圖像編輯與服務 : vLLM社群新增對美團LongCat-Image-Edit模型的支援,為指令遵循型圖像編輯提供了更簡化的服務路徑,支援物件添加/替換、背景更改和風格調整等常見操作,適用於修圖工具和創意編輯流程。同時,vLLM還發布了官方教學,指導如何部署小米MiMo/MiMo-V2-Flash模型,包括工具呼叫、DP/TP/EP配置以及調整上下文長度、延遲和KV快取關鍵參數,進一步推動了LLM在多模態和邊緣設備上的應用。 (來源: vllm_project)

Reka Vision為智慧家居安全AI設定新標準 : Reka Vision推出智慧攝影機解決方案,旨在超越傳統運動偵測,實現對事件的深度理解。該系統透過跨影片、音訊和時間進行推理,減少誤報,並提供上下文相關的、人類級別的洞察。Reka Vision致力於為智慧家居安全AI樹立新標準,使其能夠更準確地識別和理解家庭環境中發生的複雜事件,從而提供更智慧、更可靠的安全監控服務。 (來源: RekaAILabs)
YouTube Playables Builder:Gemini 3賦能遊戲創作 : YouTube Playables Builder網路應用現已上線,由Gemini 3模型提供支援,幫助創作者透過文字、影片或圖像提示快速開發有趣、小巧的遊戲。這項工具降低了遊戲開發的門檻,使得非專業開發者也能利用AI的力量,將創意轉化為可玩的遊戲體驗,有望激發UGC(用戶生成內容)遊戲生態的新活力,並探索AI在娛樂內容創作領域的更多可能性。 (來源: demishassabis)
Medmarks v0.1發布:最大的開源醫療LLM評估套件 : Sophont AI發布了Medmarks v0.1,這是目前最大的完全開源自動化評估套件,用於評估LLM的醫療能力。該套件由MedARC AI社群開發,並得到PrimeIntellect的支援,已探索了46個模型以找出最佳表現。Medmarks v0.1的發布將極大地推動醫療AI領域的研究和發展,為評估和提升醫療LLM的性能提供了標準化的工具和基準。 (來源: iScienceLuvr)
Nano Banana Pro與Gemini 3 Pro結合實現圖像生成與渲染 : 一款代理應用利用Nano Banana Pro生成圖像,並透過Gemini 3 Pro在手機上進行渲染,展示了AI模型在前端美學表現方面的強大能力。例如,它可以為Karpathy的年終總結製作網頁,甚至改變滑鼠樣式。這種結合不僅提供了高效的圖像生成與渲染工作流,也暗示了AI在使用者介面/使用者體驗(UI/UX)設計領域的巨大潛力,能夠根據用戶需求快速建立具有視覺吸引力的內容。 (來源: op7418)

Heretic:LLM自動審查移除工具 : Heretic是一款用於LLM的完全自動審查移除工具。在開源AI社群,該工具的發布引發了廣泛關注,因為它旨在解決模型在生成內容時可能存在的審查限制。Heretic的出現為用戶提供了更大的自由度,但也可能引發關於內容安全和倫理的討論,尤其是在平衡言論自由與潛在有害內容生成方面。 (來源: Reddit r/LocalLLaMA)
Claude Code新增反向搜尋功能,提升提示詞管理效率 : Claude Code更新了其功能,新增了透過Ctrl+R進行提示詞反向搜尋的能力。用戶可以反覆按下Ctrl+R來循環查看包含特定關鍵詞的所有提示詞,這極大地提升了提示詞管理的效率和便捷性。這項改進使得開發者能夠更快速地找到和複用歷史提示詞,優化其AI程式設計工作流,減少重複勞動。 (來源: dejavucoder)
📚 學習
RL新範式:Transitive RL透過分治法解決長週期任務 : BAIR部落格介紹了一種名為Transitive RL (TRL)的新型強化學習演算法,該演算法採用「分治」範式,而非傳統的時序差分(TD)學習。TRL透過將軌跡遞迴地分成更小的段,並結合其價值來更新完整軌跡的價值,從而對長週期任務展現出更好的可擴展性。這種方法在目標條件RL問題中尤為有效,它透過對中間子目標的最佳化,顯著減少了貝爾曼遞迴次數,避免了TD學習中誤差累積的問題,為解決複雜、長時序的RL任務提供了新的方向。 (來源: aihub.org)
LLM協助數學證明:DeepMind前員工探索P/=NP與Navier-Stokes : 前DeepMind工程師Bengoertzel探討了利用LLM輔助證明複雜數學問題,如Navier-Stokes方程的存在性和唯一性,以及P/=NP問題。他分享了自己使用LLM填補證明細節的經驗,儘管核心思路源於自身,但LLM在處理繁瑣細節方面提供了顯著幫助。這項實踐引發了關於如何有效結合人類創造性思維與LLM細節處理能力,以及利用Lean等形式化驗證工具來確保數學證明嚴謹性的討論,預示著AI在高級數學研究中的潛在作用。 (來源: bengoertzel)
LLM訓練時代演進:從預訓練到RLVR與GRPO : LLM訓練範式正經歷快速演進。從202x年的預訓練(基礎模型),到2022年的RLHF+PPO,再到2023年的LoRA SFT,以及2024年的中訓練。預測2025年將進入RLVR+GRPO時代,而2026年則可能迎來「On Policy Distillation」時期。這項演進路線圖揭示了LLM訓練方法論的不斷深化和最佳化,從最初的基礎能力建構,逐步轉向更精細化、更注重回饋和效率的訓練策略,預示著未來模型將更加強調從交互中學習和蒸餾知識。 (來源: bookwormengr)
LLM記憶機制研究:Claude與ChatGPT的內部工作原理 : 有研究深入探討了Claude和ChatGPT等LLM的記憶機制,分析它們如何處理和保留對話上下文資訊。這些研究揭示了模型內部狀態如何影響記憶的形成和檢索,以及在多輪對話中保持連貫性的挑戰。理解LLM的記憶工作原理對於最佳化對話系統、提升用戶體驗以及解決長上下文理解問題至關重要,也為未來更高效、更穩定的AI交互設計提供了理論基礎。 (來源: dejavucoder)
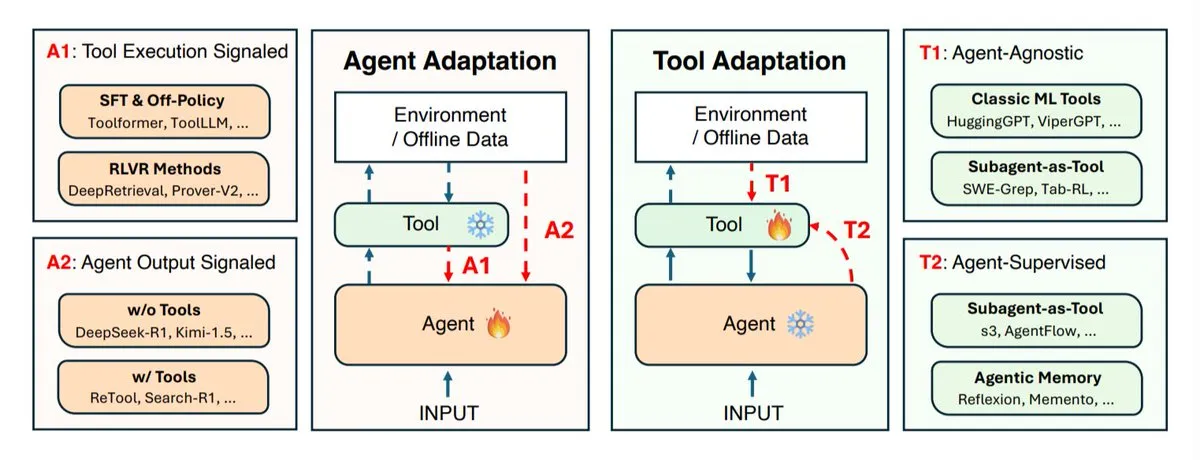
AI代理適應策略研究:Agent與工具的協同進化 : UIUC、史丹佛、哈佛等研究機構探討了AI代理的適應策略,主要分為兩類:適應代理本身(推理模型)和適應其使用的工具(搜尋系統、檢索器、記憶體、API)。研究定義了四種適應類型:使用工具結果適應代理、利用自身輸出訓練代理、獨立適應工具、以及透過凍結代理的回饋訓練工具。這些策略為開發更智慧、更靈活的AI代理提供了理論指導,強調了代理與工具之間協同進化的重要性,以應對複雜多變的任務環境。 (來源: TheTuringPost)
AI模型推理能力提升研究:預訓練、中訓練與強化學習的角色 : 卡內基梅隆大學研究人員發現,預訓練、中訓練和強化學習在提升AI模型推理能力中扮演著不同角色。研究指出,強化學習僅在特定條件下才能真正提升推理能力,跨上下文泛化需要先進行預訓練,中訓練(Mid-training)至關重要,而過程感知獎勵(Process-aware rewards)則是必不可少的。這些發現為最佳化AI模型的訓練策略提供了指導,強調了在不同階段採取針對性方法以實現推理能力最大化的重要性。 (來源: TheTuringPost)

KappaTune:解決LLM微調中的災難性遺忘問題 : KappaTune是一種新的LLM微調方法,旨在解決LoRA等現有方法中存在的災難性遺忘問題。KappaTune在遺忘程度方面比LoRA低6倍,且無需預訓練資料。該方法透過利用MoE(混合專家)模型的細粒度張量選擇能力,最大化其潛力。KappaTune的出現為LLM的持續學習和適應性提供了更高效的解決方案,有望降低模型維護成本,並促進AI的普及應用。 (來源: Reddit r/deeplearning)

政策到測試(P2T)框架:彌合AI政策與可執行規則的鴻溝 : Policy→Tests (P2T)框架旨在將自然語言編寫的AI治理政策(如歐盟AI法案、NIST AI RMF)轉化為可執行規則。該框架透過可擴展的管道和緊湊的JSON DSL,將政策文件轉換為標準化的原子規則,包含風險、範圍、條件、例外、證據訊號和出處。P2T解決了政策解讀和工具執行之間的瓶頸,尤其在處理醫療保健資料等複雜領域時,可顯著減少將HIPAA要求映射到ML管道檢查所需的時間,提升AI治理的效率和可驗證性。 (來源: Reddit r/MachineLearning)
GenEnv:LLM代理與環境模擬器難度對齊的協同進化 : GenEnv是一個框架,透過在代理和可擴展的生成環境模擬器之間建立難度對齊的協同進化博弈,解決了訓練LLM代理時真實世界交互資料成本高昂和靜態的瓶頸。模擬器作為一個動態課程策略,持續生成專門針對代理「最近發展區」的任務,由α-課程獎勵指導。GenEnv在多個基準測試中提升了代理性能高達40.3%,並以3.3倍更少的資料匹配或超越大型模型的平均性能,為代理能力擴展提供了資料高效的途徑。 (來源: HuggingFace Daily Papers)
QuCo-RAG:從預訓練語料庫量化不確定性以實現動態RAG : QuCo-RAG提出從預訓練資料中量化不確定性,以實現