
Palabras clave:Agente de IA, LLM (Modelo de Lenguaje Grande), Aprendizaje por refuerzo, IA multimodal, Conducción autónoma, Seguridad de IA, Competencia de IA, Sakana AI ALE-Agent, ServiceNow AprielGuard, API de Gemini Interactions, Kling AI 2.6 Control de Movimiento, Algoritmo Transitive RL
🔥 Destacado
El agente de Sakana AI gana concurso de programación : El ALE-Agent, desarrollado por Sakana AI, ganó por primera vez el concurso de programación heurística AHC058 de AtCoder. Este agente de IA aprendió de forma autónoma y creó un “焼きなまし法” (algoritmo de recocido simulado) inesperado para los humanos, destacándose entre más de 800 participantes. Este logro demuestra la potente capacidad de autoaprendizaje e innovación de los agentes de IA en problemas de optimización complejos, lo que presagia el enorme potencial de la IA para resolver problemas altamente complejos y no estructurados, trascendiendo los paradigmas de programación tradicionales y abriendo nuevas vías para la generación automatizada de código y la resolución de problemas impulsada por la IA en el futuro. (Fuente: hardmaru)

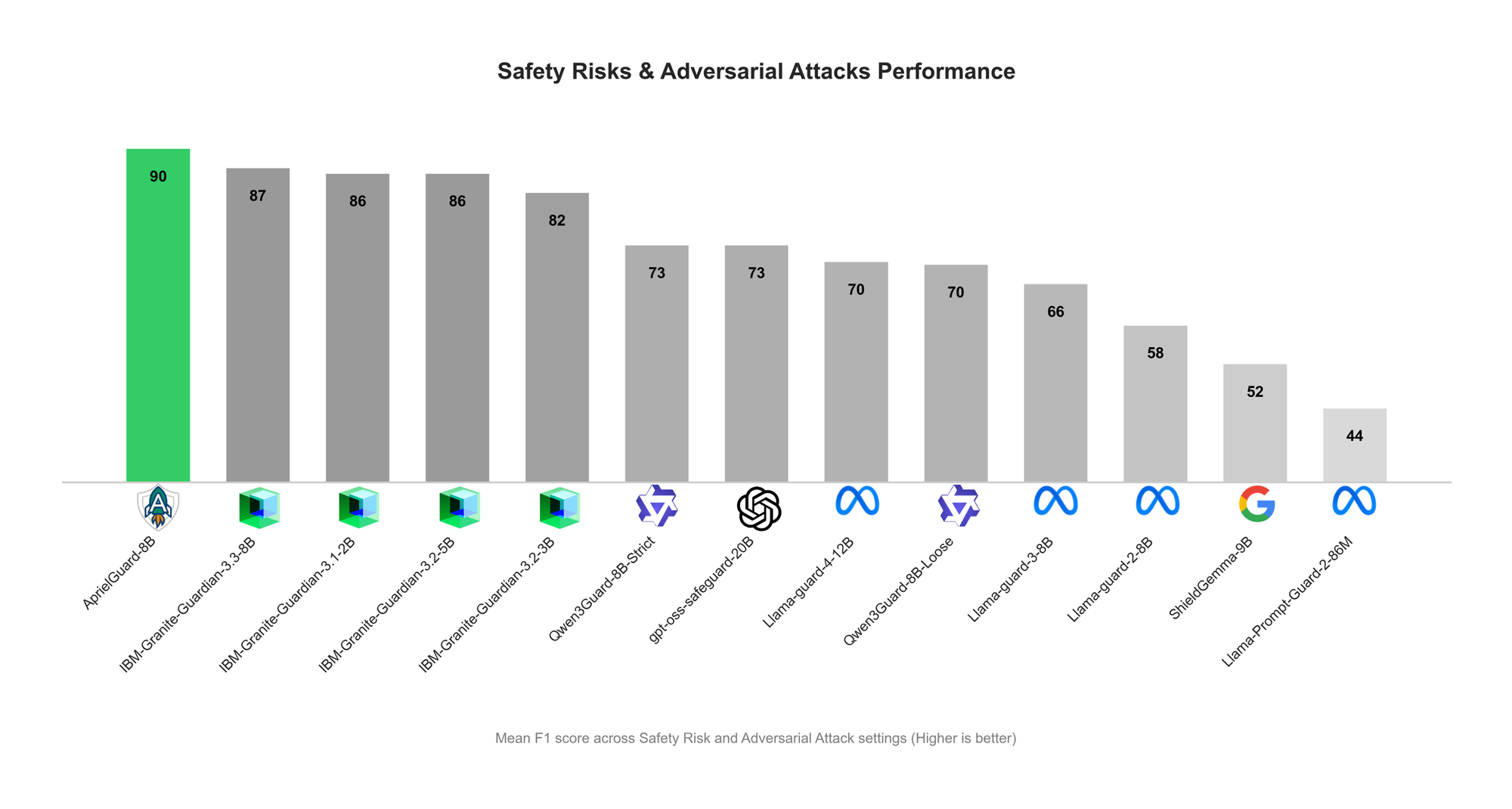
ServiceNow lanza AprielGuard: Barrera de seguridad y robustez adversarial para LLM : ServiceNow ha lanzado AprielGuard, un modelo de barrera de seguridad de 8B parámetros, diseñado para detectar 16 categorías de riesgos de seguridad y una amplia gama de ataques adversarios en sistemas LLM modernos, incluyendo jailbreaks multivuelta, inyección de prompts, secuestro de memoria y manipulación de herramientas. El modelo soporta dos modos: inferencia y no inferencia, lo que permite una clasificación detallada cuando se requiere explicación, o una clasificación de baja latencia en entornos de producción. AprielGuard aborda las limitaciones que enfrentan los clasificadores de seguridad tradicionales en diálogos multivuelta, contextos largos y flujos de trabajo de agentes, a través de un modelo y una taxonomía unificados, proporcionando una base escalable para construir implementaciones de IA confiables. (Fuente: HuggingFace Blog)
🎯 Tendencias
Karpathy publica la Revisión Anual de LLM 2025: RLVR impulsa la IA de la imitación al razonamiento : Andrej Karpathy, cofundador de OpenAI, ha publicado la “Revisión Anual de Grandes Modelos de Lenguaje 2025”, señalando un cambio clave en la filosofía de entrenamiento de la IA en 2025, de la “imitación probabilística” al “razonamiento lógico”. El motor principal es la madurez del Aprendizaje por Refuerzo con Recompensas Verificables (RLVR), que, a través de entornos de retroalimentación objetivos como las matemáticas y el código, impulsa a los modelos a generar espontáneamente “rastros de razonamiento” similares al pensamiento humano. Subraya que este aprendizaje por refuerzo de ciclo largo ha comenzado a reemplazar el preentrenamiento tradicional, convirtiéndose en un nuevo motor para mejorar las capacidades de los modelos, y predice que la competencia de IA en 2026 se centrará en el paradigma lógico central de “cómo hacer que la IA piense de manera eficiente”. (Fuente: 36氪)
EE. UU. lanza la “Misión Génesis”: Un Plan Manhattan de IA para impulsar avances científicos : El presidente de EE. UU., Trump, ha firmado una orden ejecutiva que lanza oficialmente la “Misión Génesis”, con el objetivo de integrar la capacidad de supercomputación de los laboratorios nacionales con la sabiduría de los científicos de élite, utilizando la IA para impulsar avances científicos a una velocidad sin precedentes. El plan se compara con el “Proyecto Manhattan de la Segunda Guerra Mundial”, con el objetivo de crear una IA capaz de impulsar descubrimientos científicos de forma autónoma y concentrar la competitividad central de la comunidad científica estadounidense, movilizando a 40.000 científicos e ingenieros de los 17 laboratorios nacionales del Departamento de Energía para que se dediquen por completo a la investigación y desarrollo de tecnología de IA, con el fin de reconstruir la soberanía tecnológica nacional. (Fuente: 36氪)

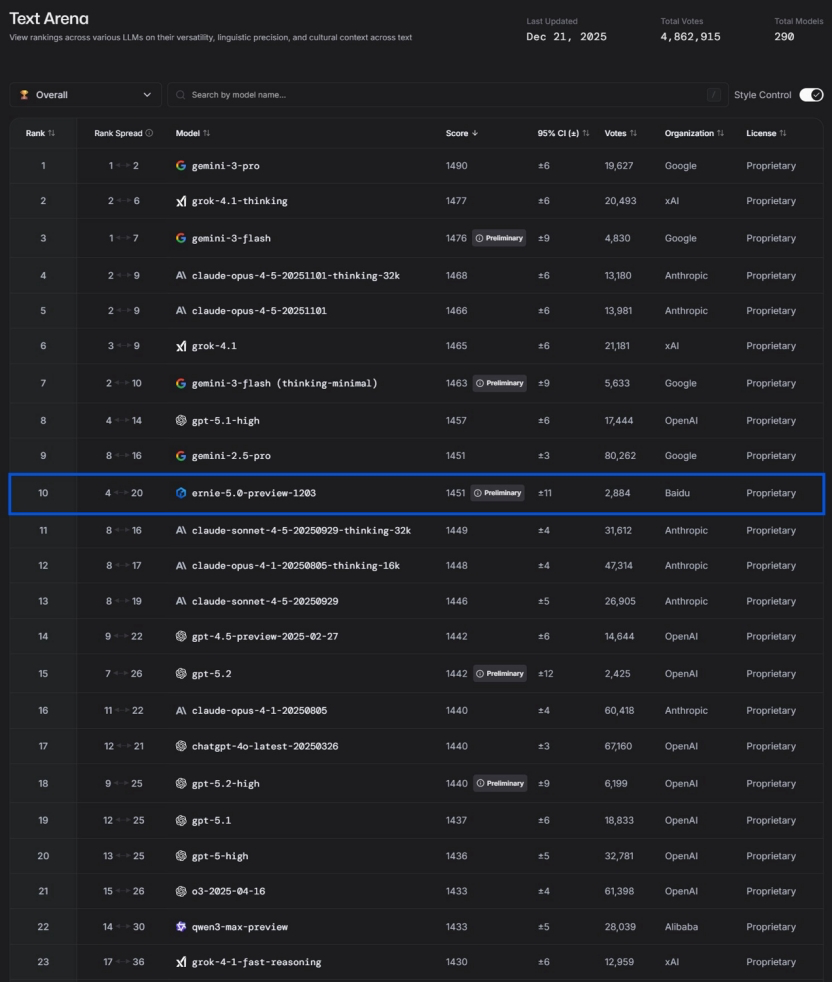
Innovación china en IA y el ascenso de Baidu ERNIE 5.0 : Frente a la afirmación de DeepMind de que la IA china “carece de innovación y solo sigue rápidamente”, hay quienes señalan que la IA china está formando barreras tecnológicas únicas a través de la implementación de aplicaciones. Baidu ERNIE-5.0-Preview-1203 ha logrado el primer puesto a nivel nacional y se ha situado entre los diez primeros a nivel mundial en la clasificación de texto de LMArena, superando a GPT-5.2 y Claude Sonnet 4.5, convirtiéndose en el único modelo no estadounidense entre los 20 primeros. Su avance se atribuye al “modelado unificado multimodal nativo”, una arquitectura MoE de 2.4 billones de parámetros, y una cadena de pensamiento compuesta de “unidad de conocimiento y acción”. El artículo destaca el profundo valor de la IA china en el mundo físico y las aplicaciones industriales, como el diseño aerodinámico de trenes de alta velocidad, la inspección de redes eléctricas, la generación de código para SF Express y la gobernanza urbana. (Fuente: 36氪)
Microsoft Copilot enfrenta desafíos de adopción por parte de los usuarios, Nadella supervisa personalmente : Satya Nadella, CEO de Microsoft, ha intervenido personalmente para impulsar las mejoras de Copilot, lo que refleja que, a pesar de su integración en la suite de Office, la tasa de adopción por parte de los usuarios no ha cumplido las expectativas. Esto indica que la competencia en IA ha pasado de “demostrar capacidades” a “retener usuarios”, es decir, quién puede ser utilizado realmente por los usuarios en su día a día. El artículo señala que la postura de “guía” de Copilot en lugar de “compañero”, así como su interacción mecánica que cubre excesivamente los escenarios, consume la atención del usuario. La futura competencia en IA se centrará en el “sentido de la medida”, es decir, cuándo debe aparecer la IA, cuándo debe permanecer en silencio, y si puede ofrecer una comprensión más sutil, reduciendo el costo emocional para el usuario. (Fuente: 36氪)

MiniMax M2.1 lanzado, mejora del rendimiento de GLM 4.7 : MiniMax M2.1 ha sido lanzado oficialmente como un modelo con arquitectura MoE de 10B parámetros activados, destacando en codificación multilingüe (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) y desarrollo de aplicaciones/web, con una puntuación multilingüe SWE-bench del 72.5%, superando a Gemini 3 Pro y Claude Sonnet 4.5. Al mismo tiempo, GLM 4.7 también ha ocupado el primer lugar en la lista de código abierto de Vals Index y el noveno en la clasificación general, con una mejora del rendimiento del 9.5% respecto a GLM 4.6, destacando especialmente en programación, Agent/ToolCall y capacidad de recuperación de contexto largo, e introduciendo un mecanismo de “pensamiento retenido” que mejora la estabilidad y controlabilidad en tareas complejas. (Fuente: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

Google DeepMind lanza Gemma Scope 2 para mejorar la interpretabilidad del modelo : Google DeepMind ha lanzado Gemma Scope 2, una suite de interpretabilidad de pila completa para los modelos de la serie Gemma 3 (270M-27B, versiones base y chat), que incluye SAE (autoencoders dispersos) y transcodificadores para cada capa. Esta iniciativa tiene como objetivo promover una comprensión profunda del comportamiento de los modelos complejos, apoyar una investigación más ambiciosa en seguridad y interpretabilidad de código abierto, y se espera que ayude a la comunidad a depurar y analizar mejor los mecanismos de trabajo internos de los LLM. (Fuente: NeelNanda5, Reddit r/artificial)
Gestión de estado de agentes de IA: Google Interactions API simplifica el desarrollo pero genera preocupaciones de bloqueo : Google ha lanzado la Interactions API de Gemini, que maneja el historial de conversaciones, la gestión de contexto y la ejecución en segundo plano en el lado del servidor, simplificando enormemente el desarrollo de agentes de IA. Esto elimina una gran cantidad de trabajo de infraestructura, como la configuración de bases de datos vectoriales y la ingeniería de contexto personalizada, acelerando significativamente la velocidad de desarrollo. Sin embargo, esta medida también ha generado preocupaciones sobre el bloqueo de proveedores, la pérdida de control sobre el almacenamiento y recuperación de contexto, la dificultad para cambiar de modelo y la falta de transparencia en los costos. Esto sugiere que Google está utilizando la infraestructura como una barrera, similar al modelo de AWS, pero el impacto a largo plazo de este modelo de “caja negra” para cargas de trabajo de ML que requieren un alto grado de control sobre toda la pila aún debe ser observado. (Fuente: Reddit r/artificial)
Los conjuntos de datos de robótica de Hugging Face se disparan, impulsando el desarrollo del ecosistema de robótica abierta : Los conjuntos de datos de robótica abierta en la plataforma Hugging Face se han disparado de 1.000 a 27.000 en los últimos dos años, superando con creces otras categorías como la generación de texto. Este crecimiento explosivo se debe a un almacenamiento de video más económico, mejores herramientas y la proliferación de la cultura de IA de código abierto, lo que ha reducido drásticamente las barreras de entrada en el campo de la robótica y ha acelerado el proceso de I+D de robots generales y humanoides. Los conjuntos de datos abiertos facilitan la carga, reutilización y evaluación comparativa de datos reales de robots (videos, acciones, sensores, fallos, etc.), transformando el campo de la robótica en un ecosistema más escalable y colaborativo. (Fuente: huggingface)
La disputa entre Tesla FSD y Waymo sobre las rutas de conducción autónoma: de extremo a extremo vs. modular : Waymo y Tesla FSD muestran filosofías completamente diferentes en sus rutas tecnológicas de conducción autónoma. Waymo adopta un enfoque “modular”, dependiendo de mapas de alta definición, LiDAR, sensores y redes 5G; si uno de los módulos (como un semáforo defectuoso) falla, el sistema puede entrar en “modo ladrillo”. En contraste, Tesla FSD utiliza una solución “de extremo a extremo”, donde una gran red neuronal convierte directamente los píxeles de la cámara en comandos de dirección y frenado, de manera más similar a la conducción humana. Algunos argumentan que el enfoque modular de Waymo presenta enormes problemas de software en términos de escalabilidad y dependencia, y que a largo plazo, la solución de extremo a extremo de Tesla FSD tiene una ventaja. (Fuente: Yuchenj_UW)
Revisión Anual de Zhihu Frontier: Infraestructura de IA y desarrollo multimodal en 2025 : Zhihu Frontier ha publicado su revisión anual, resumiendo los avances estructurales en el campo de la IA en 2025 en términos de infraestructura y multimodalidad. Se enfatiza que los asistentes de IA necesitan tener la capacidad de “ver, escuchar y razonar” como los humanos, impulsando el desarrollo de tecnologías multimodales y de voz nativa. En cuanto a las capacidades del modelo, los modelos de 10B parámetros ya han superado a los modelos de 100B+ de 2024, con una mejora de 10 veces en la rentabilidad, y el preentrenamiento sigue siendo fundamental. La infraestructura de IA se ha convertido en una ventaja competitiva, con avances clave en inferencia distribuida, programación basada en Tiles, aprendizaje por refuerzo a gran escala y diseño colaborativo modelo-sistema. También se señala que la comunicación efectiva y la capacidad de captar atención se han convertido en habilidades esenciales para el personal técnico. (Fuente: ZhihuFrontier)

🧰 Herramientas
Integración de Claude Code + Chrome para automatización del navegador : Claude Code ahora soporta la integración con el navegador Chrome, permitiendo a los usuarios escribir código en la terminal y luego hacer que Claude abra URLs en Chrome, haga clic en botones, rellene formularios, lea errores de consola y el estado del DOM, e incluso tome capturas de pantalla y grabe GIFs. Esta función no requiere API ni tokens, utilizando directamente la sesión del navegador del usuario ya iniciada, lo que simplifica enormemente los flujos de trabajo de automatización multisitio, como crear hojas de cálculo de Google, extraer información de Hacker News y rellenar tablas. Aunque actualmente solo soporta Chrome y no tiene modo headless, ofrece a los desarrolladores potentes capacidades de interacción con el navegador sin interrupciones. (Fuente: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: Nuevo paradigma para la publicidad en video con IA : Kling AI 2.6 ha lanzado potentes funciones de control de movimiento, capaces de lograr el reemplazo realista de personajes en videos, y soporta la sincronización labial y la captura de movimientos complejos, incluso aplicable a personajes no humanos. Esta tecnología mejora enormemente el potencial de prueba de los anuncios de IA, permitiendo a los anunciantes generar rápidamente variantes de anuncios con diferentes edades, géneros, etnias y estilos estéticos, logrando así pruebas y optimización de anuncios a gran escala. Al combinar Nano Banana Pro para la generación de personajes y Elevenlabs para la generación de sonido, Kling AI 2.6 aporta una mejora revolucionaria en la eficiencia para la creación de contenido de video y la industria publicitaria. (Fuente: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8 lanzado, mejora las capacidades de evaluación y observación de aplicaciones LLM : La versión MLflow 3.8 ha sido lanzada oficialmente, trayendo funciones avanzadas para la evaluación y observación de aplicaciones LLM. Las nuevas características incluyen la configuración de modelos de prompt, que permite asociar configuraciones específicas del modelo con plantillas de prompt para mejorar la reproducibilidad de los flujos de trabajo de LLM; la interfaz de usuario de seguimiento soporta la visualización de seguimientos en curso, permitiendo la depuración y monitoreo en tiempo real de aplicaciones LLM; la integración de DeepEval y RAGAS Judges, que proporciona más de 20 métricas de evaluación, como la relevancia de la respuesta, la fidelidad y la detección de alucinaciones; y la adición de un calificador de seguridad de diálogo y un calificador de eficiencia de llamadas a herramientas de diálogo, que evalúan respectivamente la seguridad de los diálogos multivuelta y la eficiencia de las llamadas a herramientas en las interacciones de agentes. (Fuente: matei_zaharia)

vLLM soporta LongCat-Image-Edit y MiMo-V2-Flash, simplificando la edición y el servicio de imágenes : La comunidad vLLM ha añadido soporte para el modelo LongCat-Image-Edit de Meituan, proporcionando una ruta de servicio más simplificada para la edición de imágenes basada en instrucciones, soportando operaciones comunes como añadir/reemplazar objetos, cambiar fondos y ajustar estilos, adecuado para herramientas de retoque fotográfico y flujos de trabajo de edición creativa. Al mismo tiempo, vLLM también ha publicado tutoriales oficiales que guían sobre cómo desplegar los modelos MiMo/MiMo-V2-Flash de Xiaomi, incluyendo llamadas a herramientas, configuración de DP/TP/EP y ajuste de parámetros clave como la longitud del contexto, la latencia y la caché KV, impulsando aún más la aplicación de LLM en multimodalidad y dispositivos de borde. (Fuente: vllm_project)

Reka Vision establece un nuevo estándar para la IA de seguridad en el hogar inteligente : Reka Vision ha lanzado una solución de cámara inteligente, diseñada para ir más allá de la detección de movimiento tradicional y lograr una comprensión profunda de los eventos. El sistema razona a través de video, audio y tiempo, reduciendo las falsas alarmas y proporcionando información contextualizada a nivel humano. Reka Vision se compromete a establecer un nuevo estándar para la IA de seguridad en el hogar inteligente, permitiéndole identificar y comprender con mayor precisión eventos complejos que ocurren en el entorno doméstico, proporcionando así servicios de monitoreo de seguridad más inteligentes y confiables. (Fuente: RekaAILabs)
YouTube Playables Builder: Gemini 3 potencia la creación de juegos : La aplicación web YouTube Playables Builder ya está disponible, impulsada por el modelo Gemini 3, ayudando a los creadores a desarrollar rápidamente juegos divertidos y pequeños a través de prompts de texto, video o imagen. Esta herramienta reduce la barrera de entrada para el desarrollo de juegos, permitiendo a los desarrolladores no profesionales aprovechar el poder de la IA para transformar ideas creativas en experiencias de juego jugables, con el potencial de estimular una nueva vitalidad en el ecosistema de juegos UGC (contenido generado por el usuario) y explorar más posibilidades de la IA en la creación de contenido de entretenimiento. (Fuente: demishassabis)
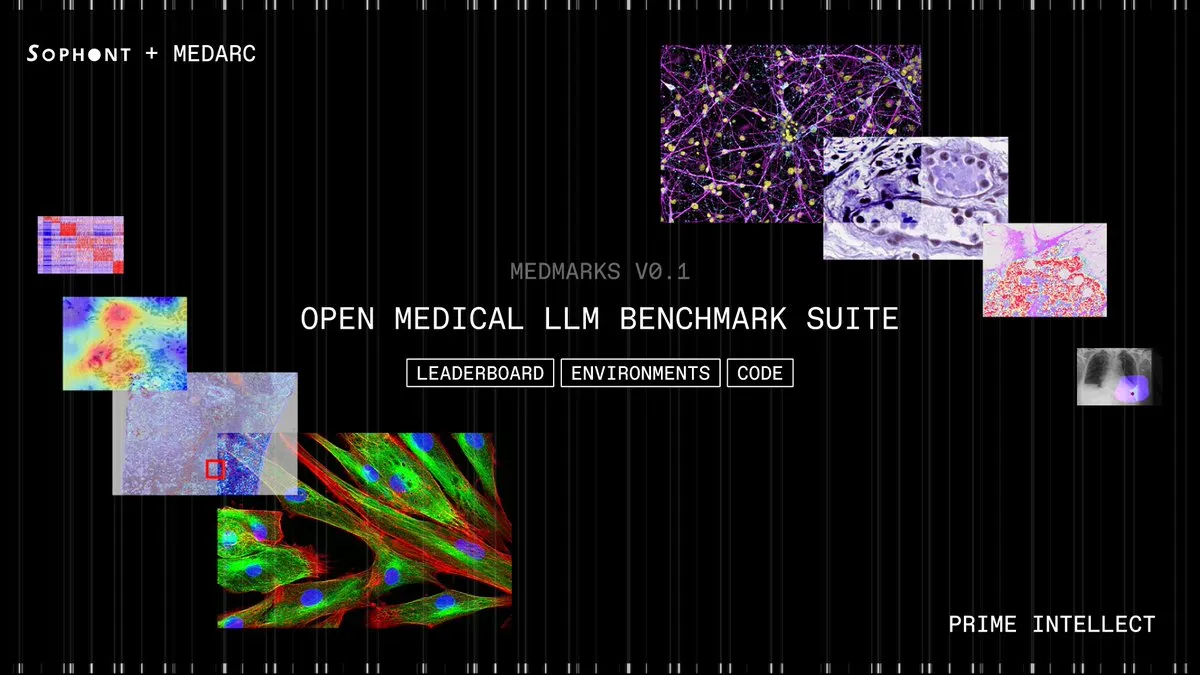
Medmarks v0.1 lanzado: El mayor conjunto de evaluación de LLM médicos de código abierto : Sophont AI ha lanzado Medmarks v0.1, el conjunto de evaluación automatizado completamente de código abierto más grande hasta la fecha, utilizado para evaluar las capacidades médicas de los LLM. Este conjunto, desarrollado por la comunidad MedARC AI y apoyado por PrimeIntellect, ha explorado 46 modelos para identificar el mejor rendimiento. El lanzamiento de Medmarks v0.1 impulsará enormemente la investigación y el desarrollo en el campo de la IA médica, proporcionando herramientas y puntos de referencia estandarizados para evaluar y mejorar el rendimiento de los LLM médicos. (Fuente: iScienceLuvr)
Nano Banana Pro y Gemini 3 Pro se combinan para la generación y renderizado de imágenes : Una aplicación de agente utiliza Nano Banana Pro para generar imágenes y las renderiza en un teléfono móvil a través de Gemini 3 Pro, demostrando la potente capacidad de los modelos de IA en la expresión estética de frontend. Por ejemplo, puede crear páginas web para el resumen de fin de año de Karpathy e incluso cambiar el estilo del cursor. Esta combinación no solo proporciona un flujo de trabajo eficiente de generación y renderizado de imágenes, sino que también insinúa el enorme potencial de la IA en el campo del diseño de interfaz de usuario/experiencia de usuario (UI/UX), siendo capaz de crear rápidamente contenido visualmente atractivo según las necesidades del usuario. (Fuente: op7418)

Heretic: Herramienta de eliminación automática de censura para LLM : Heretic es una herramienta de eliminación de censura completamente automática para LLM. En la comunidad de IA de código abierto, el lanzamiento de esta herramienta ha generado una amplia atención, ya que busca abordar las limitaciones de censura que pueden existir en los modelos al generar contenido. La aparición de Heretic ofrece a los usuarios una mayor libertad, pero también podría provocar debates sobre la seguridad y la ética del contenido, especialmente en lo que respecta al equilibrio entre la libertad de expresión y la generación de contenido potencialmente dañino. (Fuente: Reddit r/LocalLLaMA)
Claude Code añade función de búsqueda inversa, mejorando la eficiencia de gestión de prompts : Claude Code ha actualizado sus funciones, añadiendo la capacidad de realizar búsquedas inversas de prompts mediante Ctrl+R. Los usuarios pueden presionar Ctrl+R repetidamente para ciclar a través de todos los prompts que contienen una palabra clave específica, lo que mejora enormemente la eficiencia y conveniencia de la gestión de prompts. Esta mejora permite a los desarrolladores encontrar y reutilizar prompts históricos más rápidamente, optimizando sus flujos de trabajo de programación de IA y reduciendo el trabajo repetitivo. (Fuente: dejavucoder)
📚 Aprendizaje
Nuevo paradigma de RL: Transitive RL resuelve tareas de ciclo largo mediante el método de divide y vencerás : El blog de BAIR presenta un nuevo algoritmo de aprendizaje por refuerzo llamado Transitive RL (TRL), que adopta un paradigma de “divide y vencerás” en lugar del aprendizaje tradicional por diferencia temporal (TD). TRL demuestra una mejor escalabilidad para tareas de ciclo largo al dividir recursivamente las trayectorias en segmentos más pequeños y combinar sus valores para actualizar el valor de la trayectoria completa. Este método es particularmente efectivo en problemas de RL condicionados por objetivos, ya que optimiza los subobjetivos intermedios, reduciendo significativamente el número de recursiones de Bellman y evitando el problema de acumulación de errores en el aprendizaje TD, ofreciendo una nueva dirección para resolver tareas de RL complejas y de larga duración. (Fuente: aihub.org)
LLM asiste en pruebas matemáticas: Ex empleado de DeepMind explora P/=NP y Navier-Stokes : Bengoertzel, ex ingeniero de DeepMind, ha explorado el uso de LLM para asistir en la demostración de problemas matemáticos complejos, como la existencia y unicidad de las ecuaciones de Navier-Stokes, y el problema P/=NP. Compartió su experiencia utilizando LLM para rellenar los detalles de las pruebas; aunque las ideas centrales surgieron de él mismo, los LLM proporcionaron una ayuda significativa en el manejo de detalles tediosos. Esta práctica ha provocado debates sobre cómo combinar eficazmente el pensamiento creativo humano con la capacidad de procesamiento de detalles de los LLM, y cómo utilizar herramientas de verificación formal como Lean para garantizar el rigor de las pruebas matemáticas, lo que presagia el papel potencial de la IA en la investigación matemática avanzada. (Fuente: bengoertzel)
Evolución de la era de entrenamiento de LLM: Del preentrenamiento a RLVR y GRPO : El paradigma de entrenamiento de LLM está experimentando una rápida evolución. Desde el preentrenamiento (modelos base) en 202x, pasando por RLHF+PPO en 2022, LoRA SFT en 2023, y el entrenamiento intermedio en 2024. Se predice que 2025 marcará el comienzo de la era RLVR+GRPO, y 2026 podría ver el período de “On Policy Distillation”. Esta hoja de ruta de evolución revela la profundización y optimización continua de la metodología de entrenamiento de LLM, pasando de la construcción inicial de capacidades básicas a estrategias de entrenamiento más refinadas, que priorizan la retroalimentación y la eficiencia, lo que presagia que los modelos futuros enfatizarán aún más el aprendizaje a partir de la interacción y la destilación de conocimiento. (Fuente: bookwormengr)
Estudio sobre mecanismos de memoria de LLM: Funcionamiento interno de Claude y ChatGPT : Investigaciones han explorado en profundidad los mecanismos de memoria de LLM como Claude y ChatGPT, analizando cómo procesan y retienen la información del contexto de la conversación. Estos estudios revelan cómo los estados internos del modelo afectan la formación y recuperación de la memoria, así como los desafíos para mantener la coherencia en diálogos multivuelta. Comprender el funcionamiento de la memoria de los LLM es crucial para optimizar los sistemas de diálogo, mejorar la experiencia del usuario y resolver problemas de comprensión de contextos largos, y también proporciona una base teórica para el diseño de interacciones de IA más eficientes y estables en el futuro. (Fuente: dejavucoder)
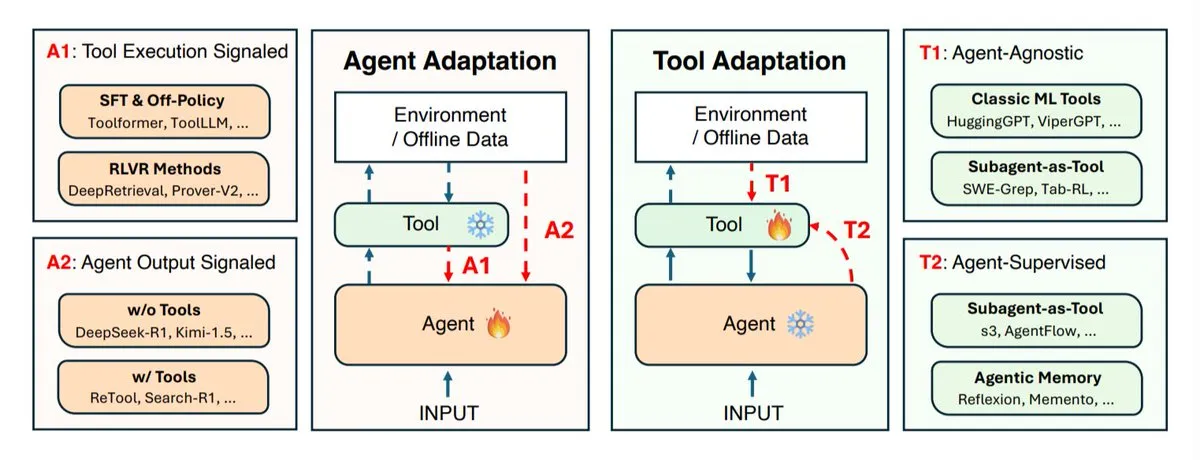
Estudio sobre estrategias de adaptación de agentes de IA: Coevolución de agentes y herramientas : Instituciones de investigación como UIUC, Stanford y Harvard han explorado estrategias de adaptación para agentes de IA, divididas principalmente en dos categorías: adaptar el propio agente (modelo de razonamiento) y adaptar las herramientas que utiliza (sistemas de búsqueda, recuperadores, memoria, API). El estudio define cuatro tipos de adaptación: adaptar el agente utilizando los resultados de las herramientas, entrenar el agente utilizando sus propias salidas, adaptar las herramientas de forma independiente, y entrenar las herramientas a través de la retroalimentación del agente congelado. Estas estrategias proporcionan una guía teórica para el desarrollo de agentes de IA más inteligentes y flexibles, enfatizando la importancia de la coevolución entre agentes y herramientas para hacer frente a entornos de tareas complejos y cambiantes. (Fuente: TheTuringPost)
Estudio sobre la mejora de la capacidad de razonamiento de los modelos de IA: El papel del preentrenamiento, el entrenamiento intermedio y el aprendizaje por refuerzo : Investigadores de la Universidad Carnegie Mellon han descubierto que el preentrenamiento, el entrenamiento intermedio y el aprendizaje por refuerzo desempeñan diferentes roles en la mejora de la capacidad de razonamiento de los modelos de IA. El estudio señala que el aprendizaje por refuerzo solo puede mejorar realmente la capacidad de razonamiento bajo ciertas condiciones, la generalización entre contextos requiere preentrenamiento previo, el entrenamiento intermedio (Mid-training) es crucial, y las recompensas conscientes del proceso (Process-aware rewards) son indispensables. Estos hallazgos proporcionan orientación para optimizar las estrategias de entrenamiento de los modelos de IA, enfatizando la importancia de adoptar enfoques específicos en diferentes etapas para maximizar la capacidad de razonamiento. (Fuente: TheTuringPost)

KappaTune: Abordando el problema del olvido catastrófico en el ajuste fino de LLM : KappaTune es un nuevo método de ajuste fino de LLM diseñado para resolver el problema del olvido catastrófico presente en métodos existentes como LoRA. KappaTune es 6 veces menos propenso al olvido que LoRA y no requiere datos de preentrenamiento. Este método maximiza el potencial de los modelos MoE (Mixture of Experts) al aprovechar su capacidad de selección de tensores de grano fino. La aparición de KappaTune proporciona una solución más eficiente para el aprendizaje continuo y la adaptabilidad de los LLM, con el potencial de reducir los costos de mantenimiento del modelo y promover la aplicación generalizada de la IA. (Fuente: Reddit r/deeplearning)

Marco de Política a Pruebas (P2T): Cerrando la brecha entre las políticas de IA y las reglas ejecutables : El marco Policy→Tests (P2T) tiene como objetivo transformar las políticas de gobernanza de IA escritas en lenguaje natural (como la Ley de IA de la UE, NIST AI RMF) en reglas ejecutables. Este marco, a través de un pipeline escalable y un DSL JSON compacto, convierte los documentos de política en reglas atómicas estandarizadas que incluyen riesgos, alcance, condiciones, excepciones, señales de evidencia y procedencia. P2T aborda el cuello de botella entre la interpretación de políticas y la ejecución de herramientas, especialmente al tratar con dominios complejos como los datos de atención médica, reduciendo significativamente el tiempo necesario para mapear los requisitos de HIPAA a las comprobaciones del pipeline de ML, mejorando la eficiencia y verificabilidad de la gobernanza de la IA. (Fuente: Reddit r/MachineLearning)
GenEnv: Coevolución de agentes LLM y simuladores de entorno con alineación de dificultad : GenEnv es un marco que aborda los cuellos de botella del alto costo y la naturaleza estática de los datos de interacción del mundo real al entrenar agentes LLM, estableciendo un juego de coevolución con alineación de dificultad entre el agente y un simulador de entorno generativo escalable. El simulador actúa como una estrategia de currículo dinámico, generando continuamente tareas adaptadas a la “zona de desarrollo próximo” del agente, guiado por recompensas de currículo α. GenEnv ha mejorado el rendimiento del agente hasta en un 40.3% en múltiples benchmarks y ha igualado o superado el rendimiento promedio de modelos grandes con 3.3 veces menos datos, proporcionando una vía eficiente en datos para la expansión de las capacidades del agente. (Fuente: HuggingFace Daily Papers)
QuCo-RAG: Cuantificación de la incertidumbre a partir de corpus preentrenados para RAG dinámico : QuCo-RAG propone cuantificar la incertidumbre a partir de datos preentrenados para lograr un RAG dinámico.