
Mots-clés:Agent IA, LLM, Apprentissage par renforcement, IA multimodale, Conduite autonome, Sécurité IA, Compétition IA, Sakana AI ALE-Agent, ServiceNow AprielGuard, API Gemini Interactions, Kling AI 2.6 Contrôle des mouvements, Algorithme RL Transitive
🔥 À la une
L’agent Sakana AI remporte une compétition de programmation : L’ALE-Agent développé par Sakana AI a remporté pour la première fois la compétition de programmation heuristique AtCoder AHC058. Cet agent d’IA a appris de manière autonome et a créé une méthode de “焼きなまし法” (algorithme de recuit simulé) inattendue pour les humains, se distinguant parmi plus de 800 participants. Cette réussite démontre la puissante capacité d’apprentissage autonome et d’innovation des agents d’IA pour les problèmes d’optimisation complexes, annonçant l’énorme potentiel de l’IA à résoudre des problèmes hautement complexes et non structurés, au-delà des paradigmes de programmation traditionnels, et ouvrant de nouvelles voies pour la génération de code automatisée et la résolution de problèmes pilotées par l’IA à l’avenir. (Source : hardmaru)

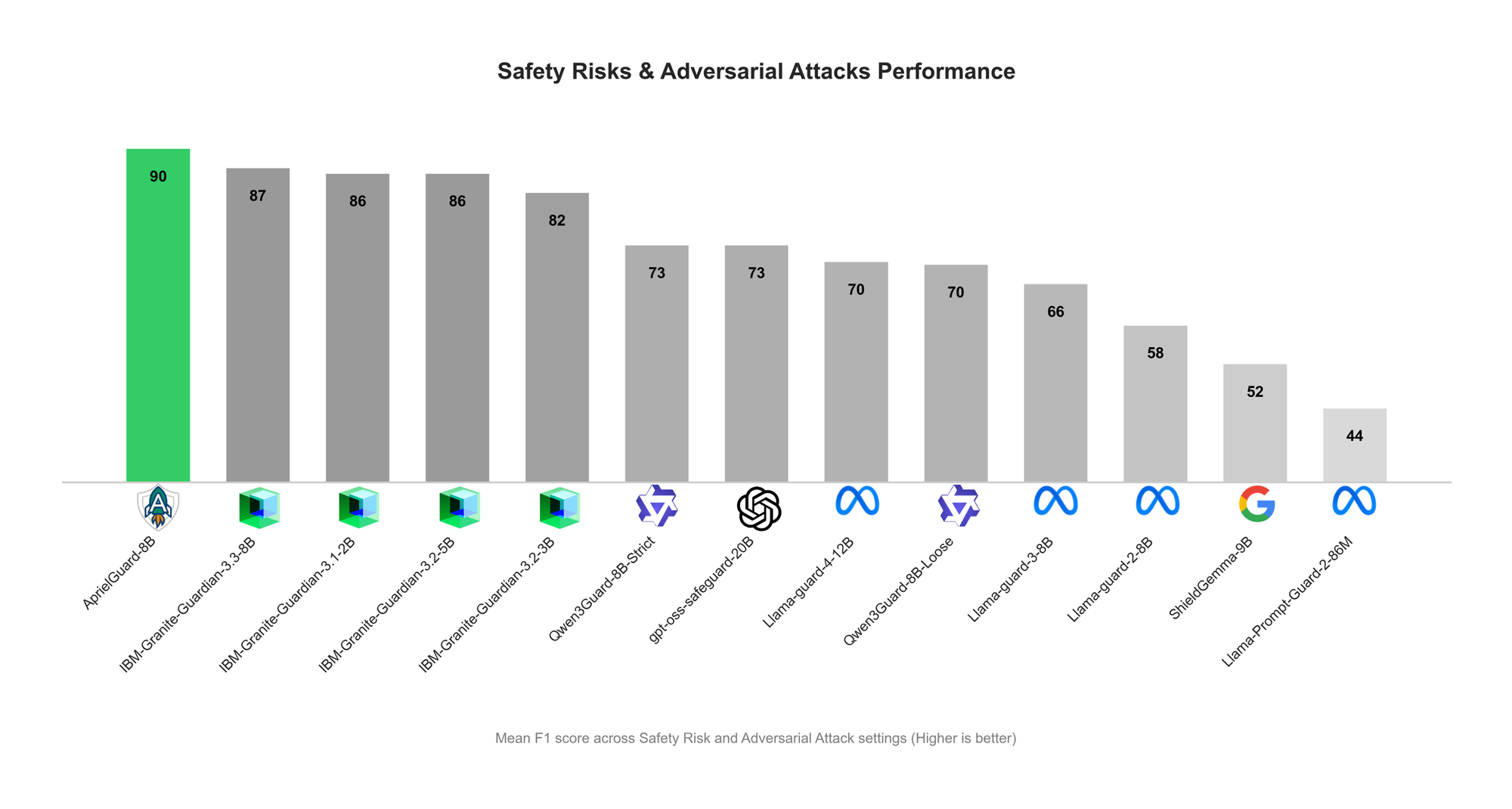
ServiceNow lance AprielGuard : Garde-fou de sécurité et de robustesse adversariale pour les LLM : ServiceNow a lancé AprielGuard, un modèle de garde-fou de sécurité de 8 milliards de paramètres, conçu pour détecter 16 catégories de risques de sécurité et une large gamme d’attaques adverses dans les systèmes LLM modernes, y compris les jailbreaks multi-tours, l’injection de prompt, le détournement de mémoire et la manipulation d’outils. Le modèle prend en charge deux modes, inférentiel et non inférentiel, permettant une classification détaillée lorsque des explications sont nécessaires, ou une classification à faible latence dans les environnements de production. AprielGuard, grâce à un modèle et une taxonomie unifiés, résout les limitations rencontrées par les classificateurs de sécurité traditionnels dans les dialogues multi-tours, les contextes longs et les flux de travail d’agents, fournissant une base évolutive pour la construction de déploiements d’IA fiables. (Source : HuggingFace Blog)
🎯 Tendances
Karpathy publie le bilan annuel 2025 des LLM : Le RLVR pousse l’IA de l’imitation au raisonnement : Andreï Karpathy, l’un des fondateurs d’OpenAI, a publié le « Bilan annuel 2025 des grands modèles linguistiques », soulignant un changement clé dans la philosophie d’entraînement de l’IA en 2025, passant de l’« imitation probabiliste » au « raisonnement logique ». Le moteur principal est la maturité de l’apprentissage par renforcement avec récompenses vérifiables (RLVR), qui, grâce à des environnements de feedback objectifs comme les mathématiques et le code, incite les modèles à générer spontanément des « traces de raisonnement » similaires à la pensée humaine. Il souligne que cet apprentissage par renforcement à long terme a commencé à remplacer le pré-entraînement traditionnel, devenant un nouveau moteur pour améliorer les capacités des modèles, et prédit qu’en 2026, la concurrence en IA se tournera vers le paradigme logique central de « comment faire penser l’IA de manière efficace ». (Source : 36氪)
Les États-Unis lancent la “Mission Genèse” : Le projet Manhattan de l’IA vise à stimuler les découvertes scientifiques : Le président américain Trump a signé un décret lançant officiellement la « Mission Genèse », visant à intégrer les capacités de supercalcul des laboratoires nationaux et la sagesse des meilleurs scientifiques, en utilisant l’IA pour accélérer les découvertes scientifiques à une vitesse sans précédent. Ce plan est comparé au « projet Manhattan de la Seconde Guerre mondiale », avec pour objectif de créer une IA capable de stimuler de manière autonome les découvertes scientifiques, et de concentrer les compétences clés de la communauté scientifique américaine, mobilisant 40 000 scientifiques et ingénieurs des 17 laboratoires nationaux relevant du Département de l’Énergie, pour se tourner entièrement vers la R&D en IA, afin de reconstruire la souveraineté technologique nationale. (Source : 36氪)

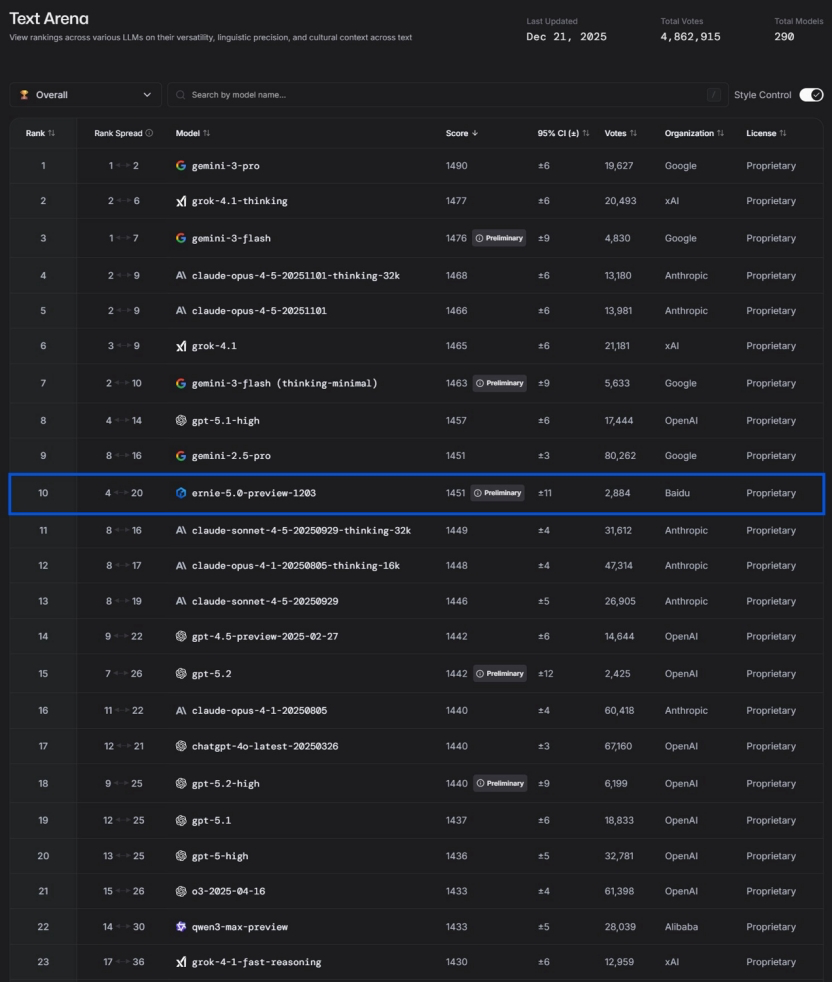
Innovation chinoise en IA et l’ascension de Baidu ERNIE 5.0 : Face à l’argument de DeepMind selon lequel l’IA chinoise « manque d’innovation et ne fait que suivre rapidement », certains estiment que l’IA chinoise est en train de créer des barrières technologiques uniques grâce à l’implémentation d’applications. Baidu ERNIE-5.0-Preview-1203 a atteint la première place en Chine et le top 10 mondial dans le classement de texte LMArena, surpassant GPT-5.2 et Claude Sonnet 4.5, devenant le seul modèle non américain parmi les 20 premiers. Sa percée est attribuée à la « modélisation unifiée native toutes modalités », à une architecture MoE de 2,4 billions de paramètres, et à une chaîne de pensée composite de « connaissance et action unifiées ». L’article souligne la valeur profonde de l’IA chinoise dans le monde physique et les applications industrielles, telles que la conception aérodynamique des trains à grande vitesse, l’inspection des réseaux électriques, la génération de code pour SF Express et la gouvernance urbaine. (Source : 36氪)
Microsoft Copilot face à des défis d’adoption, Nadella supervise personnellement : Satya Nadella, PDG de Microsoft, est personnellement intervenu pour superviser les améliorations de Copilot, ce qui reflète que, bien que Copilot soit intégré à la suite Office, son taux d’adoption par les utilisateurs n’a pas atteint les attentes. Cela indique que la concurrence en IA est passée de la « démonstration de capacités » à la « rétention des utilisateurs », c’est-à-dire qui peut réellement être utilisé quotidiennement par les utilisateurs. L’article souligne que la posture de « guide » de Copilot plutôt que de « partenaire », ainsi que son interaction mécanique couvrant trop de scénarios, ont épuisé l’attention des utilisateurs. La future concurrence en IA se concentrera sur le « sens de la mesure », c’est-à-dire quand l’IA doit apparaître, quand elle doit se taire, et si elle peut offrir une compréhension plus nuancée, réduisant ainsi le coût émotionnel pour l’utilisateur. (Source : 36氪)

MiniMax M2.1 lancé, GLM 4.7 améliore ses performances : MiniMax M2.1 est officiellement lancé. En tant que modèle d’architecture MoE avec 10 milliards de paramètres activés, il excelle dans le codage multilingue (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) et le développement d’applications/web, obtenant un score multilingue SWE-bench de 72,5 %, surpassant Gemini 3 Pro et Claude Sonnet 4.5. Parallèlement, GLM 4.7 s’est également classé premier dans le classement open source Vals Index et neuvième au classement général, avec une amélioration de performance de 9,5 % par rapport à GLM 4.6, se distinguant particulièrement dans la programmation, l’Agent/ToolCall et la capacité de rappel de contexte long, et a introduit un mécanisme de « pensée conservée » pour améliorer la stabilité et la contrôlabilité des tâches complexes. (Source : eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

Google DeepMind lance Gemma Scope 2 pour améliorer l’interprétabilité des modèles : Google DeepMind a lancé Gemma Scope 2, une suite d’interprétabilité full-stack pour les modèles de la série Gemma 3 (270M-27B, versions de base et de chat), comprenant des SAE (Sparse Autoencoders) et des transcodeurs pour chaque couche. Cette initiative vise à promouvoir une compréhension approfondie du comportement des modèles complexes, à soutenir des recherches plus ambitieuses en matière de sécurité et d’interprétabilité open source, et devrait aider la communauté à mieux déboguer et analyser les mécanismes de fonctionnement internes des LLM. (Source : NeelNanda5, Reddit r/artificial)
Gestion d’état des agents IA : L’Interactions API de Google simplifie le développement mais suscite des inquiétudes de verrouillage : Google a lancé l’Interactions API de Gemini, qui gère l’historique des conversations, la gestion du contexte et l’exécution en arrière-plan côté serveur, simplifiant considérablement le développement d’agents d’IA. Cela élimine une grande partie du travail d’infrastructure, comme la configuration des bases de données vectorielles et l’ingénierie de contexte personnalisée, augmentant considérablement la vitesse de développement. Cependant, cette initiative a également soulevé des inquiétudes concernant le verrouillage des fournisseurs, la perte de contrôle sur le stockage et la récupération du contexte, la difficulté de changer de modèle et l’opacité des coûts. Cela indique que Google utilise l’infrastructure comme un fossé, à l’instar du modèle AWS, mais pour les charges de travail ML nécessitant un contrôle élevé sur l’ensemble de la pile, l’impact à long terme de ce mode « boîte noire » reste à observer. (Source : Reddit r/artificial)
Les ensembles de données robotiques de Hugging Face explosent, stimulant l’écosystème robotique ouvert : Les ensembles de données robotiques ouverts sur la plateforme Hugging Face ont explosé, passant de 1 000 à 27 000 au cours des deux dernières années, dépassant de loin d’autres catégories comme la génération de texte. Cette croissance explosive est due à un stockage vidéo moins cher, de meilleurs outils et la propagation de la culture de l’IA open source, ce qui a considérablement réduit les barrières à l’entrée dans le domaine de la robotique et accéléré le processus de R&D pour les robots généraux et humanoïdes. Les ensembles de données ouverts facilitent le téléchargement, la réutilisation et le benchmarking des données robotiques réelles (vidéos, actions, capteurs, pannes, etc.), transformant le domaine de la robotique en un écosystème plus évolutif et collaboratif. (Source : huggingface)
Tesla FSD contre Waymo : La bataille des chemins de conduite autonome, de bout en bout ou modulaire : Waymo et Tesla FSD présentent des philosophies radicalement différentes en matière de trajectoire technologique de conduite autonome. Waymo adopte une approche « modulaire », s’appuyant sur des cartes HD, des lidars, des capteurs et le réseau 5G ; si l’un de ces modules (comme un feu de circulation défaillant) tombe en panne, le système peut entrer en « mode brique ». En revanche, Tesla FSD utilise une approche « de bout en bout », où un grand réseau neuronal convertit directement les pixels de la caméra en commandes de direction et de freinage, ressemblant davantage à la conduite humaine. Certains estiment que l’approche modulaire de Waymo présente d’énormes problèmes logiciels en termes d’évolutivité et de dépendance, et qu’à long terme, la solution de bout en bout de Tesla FSD est plus avantageuse. (Source : Yuchenj_UW)
Bilan annuel de Zhihu Frontier : Infrastructure IA et développement multimodal en 2025 : Zhihu Frontier a publié son bilan annuel, résumant les progrès structurels réalisés en 2025 dans le domaine de l’IA en matière d’infrastructure et de multimodalité. Il souligne que les assistants IA doivent posséder la capacité de « voir, entendre et raisonner » comme les humains, stimulant le développement des technologies multimodales et vocales natives. En termes de capacités des modèles, les modèles à 10 milliards de paramètres ont déjà surpassé les modèles de plus de 100 milliards de 2024, avec une amélioration de 10 fois de l’efficacité coût-bénéfice, le pré-entraînement restant la base. L’infrastructure d’IA est devenue un avantage concurrentiel, avec des progrès clés dans l’inférence distribuée, la programmation basée sur les tuiles (Tile-based programming), l’apprentissage par renforcement à grande échelle et la co-conception modèle-système. Il est également noté qu’une communication efficace et la capacité à attirer l’attention sont devenues des compétences essentielles pour les techniciens. (Source : ZhihuFrontier)

🧰 Outils
Claude Code + intégration Chrome pour l’automatisation du navigateur : Claude Code prend désormais en charge l’intégration avec le navigateur Chrome, permettant aux utilisateurs d’écrire du code dans le terminal, puis de laisser Claude ouvrir des URL dans Chrome, cliquer sur des boutons, remplir des formulaires, lire les erreurs de console et l’état du DOM, et même prendre des captures d’écran et enregistrer des GIF. Cette fonctionnalité ne nécessite ni API ni token, utilisant directement la session de navigateur déjà connectée de l’utilisateur, ce qui simplifie considérablement les flux de travail d’automatisation multi-sites, tels que la création de Google Sheets, l’extraction d’informations de Hacker News et le remplissage de tableaux. Bien qu’il ne prenne actuellement en charge que Chrome et n’ait pas de mode headless, il offre aux développeurs de puissantes capacités d’interaction transparente avec le navigateur. (Source : Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control : Nouveau paradigme pour la publicité vidéo IA : Kling AI 2.6 a lancé de puissantes fonctionnalités de contrôle de mouvement, permettant le remplacement réaliste de personnages dans les vidéos, et prenant en charge la synchronisation labiale et la capture de mouvements complexes, même pour des personnages non humains. Cette technologie améliore considérablement le potentiel de test des publicités IA, permettant aux annonceurs de générer rapidement des variantes publicitaires de différents âges, sexes, ethnies et styles esthétiques, réalisant ainsi des tests et une optimisation publicitaire à grande échelle. En combinant Nano Banana Pro pour la génération de personnages et Elevenlabs pour la génération de voix, Kling AI 2.6 apporte une amélioration révolutionnaire de l’efficacité pour la création de contenu vidéo et l’industrie de la publicité. (Source : Kling_ai, Reddit r/ChatGPT)

MLflow 3.8 lancé, améliorant l’évaluation et l’observabilité des applications LLM : La version 3.8 de MLflow a été officiellement lancée, apportant des fonctionnalités avancées pour l’évaluation et l’observation des applications LLM. Les nouvelles fonctionnalités incluent la configuration de modèles de prompt, permettant d’associer des paramètres de modèle spécifiques à des modèles de prompt pour améliorer la reproductibilité des flux de travail LLM ; l’interface utilisateur de suivi prend en charge l’affichage des suivis en cours, permettant le débogage et la surveillance en temps réel des applications LLM ; l’intégration de DeepEval et RAGAS Judges, offrant plus de 20 métriques d’évaluation, telles que la pertinence de la réponse, la fidélité et la détection d’hallucinations ; l’ajout d’un évaluateur de sécurité des conversations et d’un évaluateur d’efficacité d’appel d’outils de conversation, évaluant respectivement la sécurité des dialogues multi-tours et l’efficacité des appels d’outils dans les interactions d’agents. (Source : matei_zaharia)

vLLM prend en charge LongCat-Image-Edit et MiMo-V2-Flash, simplifiant l’édition et le service d’images : La communauté vLLM a ajouté le support du modèle Meituan LongCat-Image-Edit, offrant un chemin de service simplifié pour l’édition d’images basée sur des instructions, prenant en charge les opérations courantes telles que l’ajout/remplacement d’objets, le changement d’arrière-plan et l’ajustement de style, adapté aux outils de retouche photo et aux processus d’édition créative. Parallèlement, vLLM a également publié un tutoriel officiel expliquant comment déployer les modèles Xiaomi MiMo/MiMo-V2-Flash, y compris l’appel d’outils, la configuration DP/TP/EP et l’ajustement des paramètres clés tels que la longueur du contexte, la latence et le cache KV, favorisant ainsi l’application des LLM dans les domaines multimodaux et sur les appareils périphériques. (Source : vllm_project)

Reka Vision établit de nouvelles normes pour l’IA de sécurité domestique intelligente : Reka Vision a lancé une solution de caméra intelligente, visant à dépasser la détection de mouvement traditionnelle pour parvenir à une compréhension approfondie des événements. Ce système raisonne à travers la vidéo, l’audio et le temps pour réduire les fausses alertes et fournir des informations contextuelles de niveau humain. Reka Vision s’engage à établir de nouvelles normes pour l’IA de sécurité domestique intelligente, lui permettant d’identifier et de comprendre plus précisément les événements complexes se produisant dans l’environnement domestique, offrant ainsi des services de surveillance de sécurité plus intelligents et plus fiables. (Source : RekaAILabs)
YouTube Playables Builder : Gemini 3 alimente la création de jeux : L’application web YouTube Playables Builder est désormais en ligne, alimentée par le modèle Gemini 3, aidant les créateurs à développer rapidement des jeux amusants et compacts via des invites textuelles, vidéo ou image. Cet outil abaisse le seuil de développement de jeux, permettant aux développeurs non professionnels d’utiliser la puissance de l’IA pour transformer des idées créatives en expériences de jeu jouables, ce qui devrait stimuler une nouvelle vitalité dans l’écosystème des jeux UGC (contenu généré par les utilisateurs) et explorer davantage de possibilités pour l’IA dans le domaine de la création de contenu de divertissement. (Source : demishassabis)
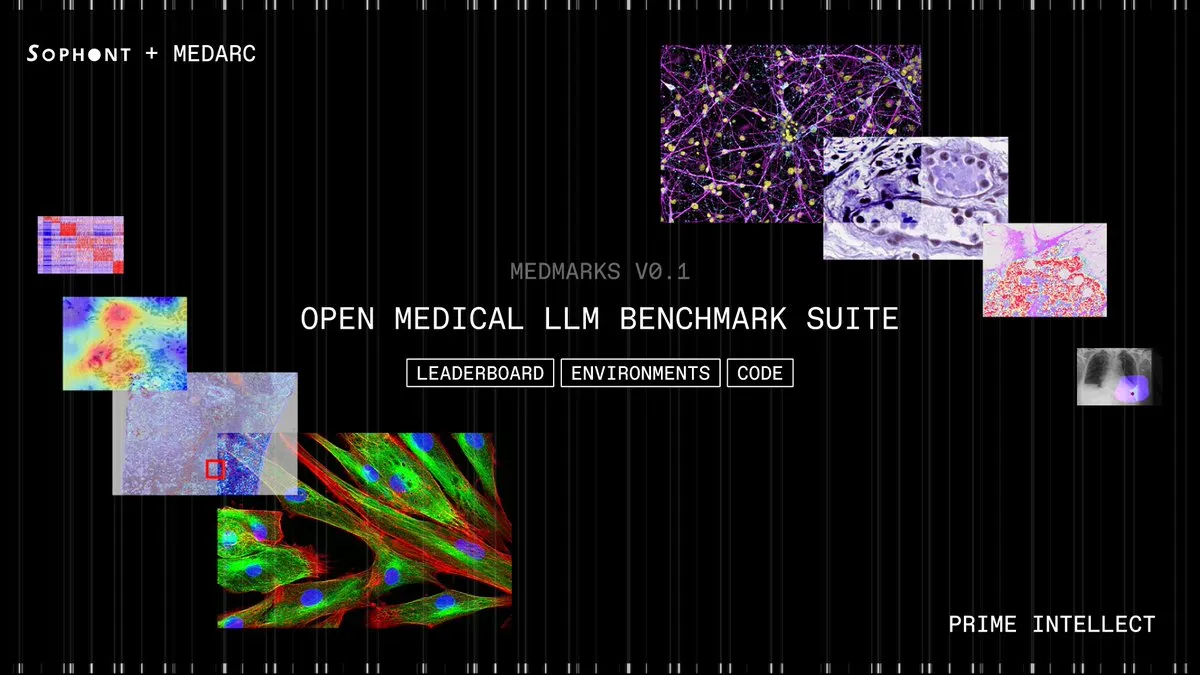
Medmarks v0.1 lancé : La plus grande suite d’évaluation LLM médicale open source : Sophont AI a lancé Medmarks v0.1, la plus grande suite d’évaluation automatisée entièrement open source à ce jour, conçue pour évaluer les capacités médicales des LLM. Cette suite a été développée par la communauté MedARC AI et soutenue par PrimeIntellect, et a exploré 46 modèles pour identifier les meilleures performances. Le lancement de Medmarks v0.1 stimulera considérablement la recherche et le développement dans le domaine de l’IA médicale, fournissant des outils et des benchmarks standardisés pour évaluer et améliorer les performances des LLM médicaux. (Source : iScienceLuvr)
Nano Banana Pro et Gemini 3 Pro combinés pour la génération et le rendu d’images : Une application agent utilise Nano Banana Pro pour générer des images et Gemini 3 Pro pour les rendre sur mobile, démontrant la puissante capacité des modèles d’IA en matière de performance esthétique front-end. Par exemple, elle peut créer des pages web pour le bilan de fin d’année de Karpathy, et même modifier le style de la souris. Cette combinaison offre non seulement un flux de travail efficace de génération et de rendu d’images, mais suggère également l’énorme potentiel de l’IA dans le domaine de la conception d’interfaces utilisateur/expérience utilisateur (UI/UX), capable de créer rapidement du contenu visuellement attrayant selon les besoins de l’utilisateur. (Source : op7418)

Heretic : Outil de suppression automatique de la censure pour les LLM : Heretic est un outil de suppression de censure entièrement automatique pour les LLM. Dans la communauté de l’IA open source, le lancement de cet outil a suscité un vif intérêt, car il vise à résoudre les limitations de censure que les modèles peuvent rencontrer lors de la génération de contenu. L’émergence de Heretic offre aux utilisateurs une plus grande liberté, mais pourrait également soulever des discussions sur la sécurité et l’éthique du contenu, en particulier concernant l’équilibre entre la liberté d’expression et la génération de contenu potentiellement nuisible. (Source : Reddit r/LocalLLaMA)
Claude Code ajoute la fonction de recherche inversée, améliorant l’efficacité de la gestion des prompts : Claude Code a mis à jour ses fonctionnalités, ajoutant la capacité de recherche inversée de prompts via Ctrl+R. Les utilisateurs peuvent appuyer à plusieurs reprises sur Ctrl+R pour parcourir tous les prompts contenant un mot-clé spécifique, ce qui améliore considérablement l’efficacité et la commodité de la gestion des prompts. Cette amélioration permet aux développeurs de trouver et de réutiliser plus rapidement les prompts historiques, optimisant ainsi leur flux de travail de programmation IA et réduisant le travail répétitif. (Source : dejavucoder)
📚 Apprentissage
Nouveau paradigme RL : Le Transitive RL résout les tâches à long terme par la méthode diviser pour régner : Le blog BAIR a présenté un nouvel algorithme d’apprentissage par renforcement appelé Transitive RL (TRL), qui adopte un paradigme de « diviser pour régner » plutôt que l’apprentissage par différence temporelle (TD) traditionnel. TRL divise récursivement les trajectoires en segments plus petits et combine leurs valeurs pour mettre à jour la valeur de la trajectoire complète, démontrant ainsi une meilleure évolutivité pour les tâches à long terme. Cette méthode est particulièrement efficace dans les problèmes de RL conditionnés par des objectifs, car elle optimise les sous-objectifs intermédiaires, réduisant considérablement le nombre de récursions de Bellman et évitant le problème d’accumulation d’erreurs dans l’apprentissage TD, offrant ainsi une nouvelle direction pour résoudre les tâches RL complexes et à long terme. (Source : aihub.org)
Les LLM assistent les preuves mathématiques : Un ancien de DeepMind explore P/=NP et Navier-Stokes : Bengoertzel, ancien ingénieur de DeepMind, a exploré l’utilisation des LLM pour aider à prouver des problèmes mathématiques complexes, tels que l’existence et l’unicité des équations de Navier-Stokes, ainsi que le problème P/=NP. Il a partagé son expérience d’utilisation des LLM pour combler les détails des preuves ; bien que l’idée centrale provienne de lui-même, les LLM ont apporté une aide significative dans le traitement des détails fastidieux. Cette pratique a suscité des discussions sur la manière de combiner efficacement la pensée créative humaine avec la capacité des LLM à gérer les détails, et sur l’utilisation d’outils de vérification formelle comme Lean pour assurer la rigueur des preuves mathématiques, annonçant le rôle potentiel de l’IA dans la recherche mathématique avancée. (Source : bengoertzel)
Évolution de l’ère d’entraînement des LLM : Du pré-entraînement au RLVR et GRPO : Le paradigme d’entraînement des LLM connaît une évolution rapide. Du pré-entraînement (modèles de base) en 202x, au RLHF+PPO en 2022, puis au LoRA SFT en 2023, et au mid-training en 2024. Il est prévu que 2025 marquera l’ère du RLVR+GRPO, et que 2026 pourrait voir l’avènement de la période de l’« On Policy Distillation ». Cette feuille de route d’évolution révèle l’approfondissement et l’optimisation continus des méthodologies d’entraînement des LLM, passant de la construction initiale des capacités de base à des stratégies d’entraînement plus raffinées, axées sur le feedback et l’efficacité, annonçant que les futurs modèles mettront davantage l’accent sur l’apprentissage par l’interaction et la distillation des connaissances. (Source : bookwormengr)
Étude sur les mécanismes de mémoire des LLM : Le fonctionnement interne de Claude et ChatGPT : Des recherches ont exploré en profondeur les mécanismes de mémoire des LLM comme Claude et ChatGPT, analysant la manière dont ils traitent et retiennent les informations de contexte de conversation. Ces études révèlent comment l’état interne du modèle affecte la formation et la récupération de la mémoire, ainsi que les défis liés au maintien de la cohérence dans les dialogues multi-tours. Comprendre le fonctionnement de la mémoire des LLM est crucial pour optimiser les systèmes de dialogue, améliorer l’expérience utilisateur et résoudre les problèmes de compréhension de contextes longs, et fournit également une base théorique pour la conception future d’interactions IA plus efficaces et plus stables. (Source : dejavucoder)
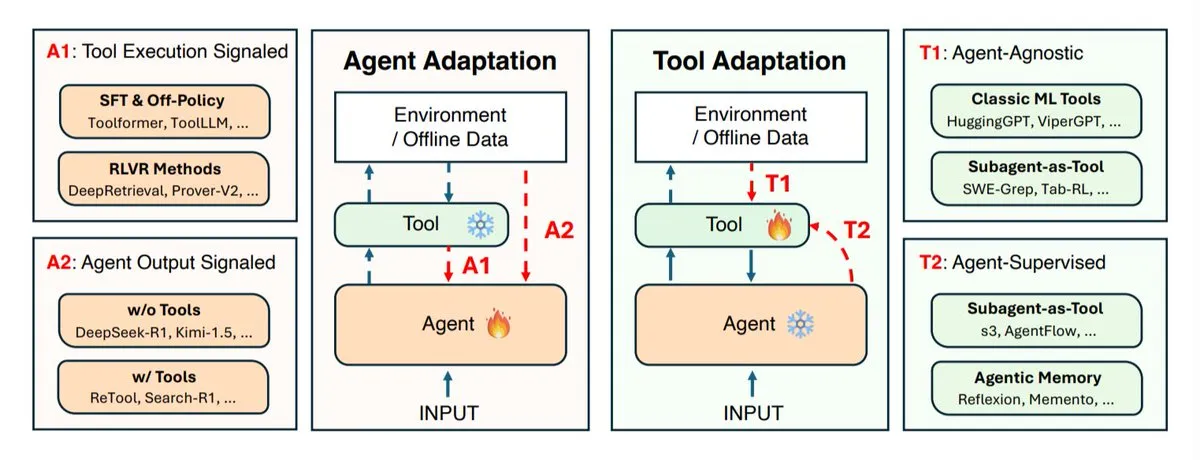
Recherche sur les stratégies d’adaptation des agents IA : Co-évolution des agents et des outils : Des instituts de recherche tels que l’UIUC, Stanford et Harvard ont exploré les stratégies d’adaptation des agents d’IA, principalement divisées en deux catégories : l’adaptation de l’agent lui-même (modèle d’inférence) et l’adaptation des outils qu’il utilise (systèmes de recherche, récupérateurs, mémoire, API). L’étude a défini quatre types d’adaptation : adapter l’agent en utilisant les résultats des outils, entraîner l’agent en utilisant ses propres sorties, adapter les outils indépendamment, et entraîner les outils via le feedback d’un agent figé. Ces stratégies fournissent des orientations théoriques pour le développement d’agents d’IA plus intelligents et plus flexibles, soulignant l’importance de la co-évolution entre les agents et les outils pour faire face à des environnements de tâches complexes et changeants. (Source : TheTuringPost)
Recherche sur l’amélioration des capacités de raisonnement des modèles IA : Rôle du pré-entraînement, du mid-training et de l’apprentissage par renforcement : Des chercheurs de l’Université Carnegie Mellon ont découvert que le pré-entraînement, le mid-training et l’apprentissage par renforcement jouent des rôles différents dans l’amélioration des capacités de raisonnement des modèles d’IA. L’étude indique que l’apprentissage par renforcement n’améliore réellement les capacités de raisonnement que sous certaines conditions, que la généralisation inter-contexte nécessite un pré-entraînement préalable, que le mid-training est crucial, et que les récompenses sensibles au processus (Process-aware rewards) sont indispensables. Ces découvertes fournissent des orientations pour optimiser les stratégies d’entraînement des modèles d’IA, soulignant l’importance d’adopter des approches ciblées à différentes étapes pour maximiser les capacités de raisonnement. (Source : TheTuringPost)

KappaTune : Résoudre le problème d’oubli catastrophique dans le fine-tuning des LLM : KappaTune est une nouvelle méthode de fine-tuning de LLM, conçue pour résoudre le problème d’oubli catastrophique présent dans les méthodes existantes comme LoRA. KappaTune réduit l’oubli de 6 fois par rapport à LoRA, et ne nécessite pas de données de pré-entraînement. Cette méthode maximise le potentiel des modèles MoE (Mixture of Experts) en exploitant leur capacité de sélection de tenseurs à grain fin. L’émergence de KappaTune offre des solutions plus efficaces pour l’apprentissage continu et l’adaptabilité des LLM, ce qui devrait réduire les coûts de maintenance des modèles et promouvoir l’adoption généralisée de l’IA. (Source : Reddit r/deeplearning)

Cadre Policy→Tests (P2T) : Combler le fossé entre les politiques IA et les règles exécutables : Le cadre Policy→Tests (P2T) vise à transformer les politiques de gouvernance de l’IA rédigées en langage naturel (telles que l’EU AI Act, NIST AI RMF) en règles exécutables. Ce cadre, via un pipeline évolutif et un DSL JSON compact, convertit les documents de politique en règles atomiques standardisées, incluant les risques, la portée, les conditions, les exceptions, les signaux de preuve et la provenance. P2T résout le goulot d’étranglement entre l’interprétation des politiques et l’exécution des outils, notamment dans des domaines complexes comme le traitement des données de santé, en réduisant considérablement le temps nécessaire pour mapper les exigences HIPAA aux inspections de pipelines ML, améliorant ainsi l’efficacité et la vérifiabilité de la gouvernance de l’IA. (Source : Reddit r/MachineLearning)
GenEnv : Co-évolution de l’alignement de la difficulté entre les agents LLM et les simulateurs d’environnement : GenEnv est un cadre qui résout les goulots d’étranglement liés au coût élevé et à la nature statique des données d’interaction du monde réel lors de l’entraînement des agents LLM, en établissant un jeu de co-évolution aligné sur la difficulté entre l’agent et un simulateur d’environnement génératif évolutif. Le simulateur agit comme une stratégie de curriculum dynamique, générant continuellement des tâches spécifiquement adaptées à la « zone de développement proximal » de l’agent, guidées par des récompenses α-curriculum. GenEnv a amélioré les performances des agents jusqu’à 40,3 % sur plusieurs benchmarks et a égalé ou dépassé les performances moyennes des grands modèles avec 3,3 fois moins de données, offrant une voie économe en données pour l’extension des capacités des agents. (Source : HuggingFace Daily Papers)
QuCo-RAG : Quantifier l’incertitude à partir des corpus de pré-entraînement pour un RAG dynamique : QuCo-RAG propose de quantifier l’incertitude à partir des données de pré-entraînement pour réaliser un RAG dynamique.