
Schlüsselwörter:KI-Agent, LLM (Large Language Model), Verstärkendes Lernen, Multimodale KI, Autonomes Fahren, KI-Sicherheit, KI-Wettbewerb, Sakana KI ALE-Agent, ServiceNow AprielGuard, Gemini Interaktions-API, Kling KI 2.6 Bewegungssteuerung, Transitiver RL-Algorithmus
🔥 Fokus
Sakana AI Agent gewinnt Programmierwettbewerb : Der von Sakana AI entwickelte ALE-Agent hat erstmals den AtCoder Heuristischen Programmierwettbewerb AHC058 gewonnen. Der AI-Agent lernte autonom und entwickelte eine von Menschen unerwartete “焼きなまし法” (Simulated Annealing-Algorithmus), wodurch er sich unter über 800 Teilnehmern durchsetzte. Diese Leistung demonstriert die starke autonome Lern- und Innovationsfähigkeit von AI-Agenten bei komplexen Optimierungsproblemen und deutet auf ein enormes Potenzial von AI bei der Lösung hochkomplexer, unstrukturierter Probleme hin, das traditionelle Programmierparadigmen übertrifft und neue Wege für zukünftige AI-gesteuerte automatisierte Codegenerierung und Problemlösung ebnet. (Quelle: hardmaru)

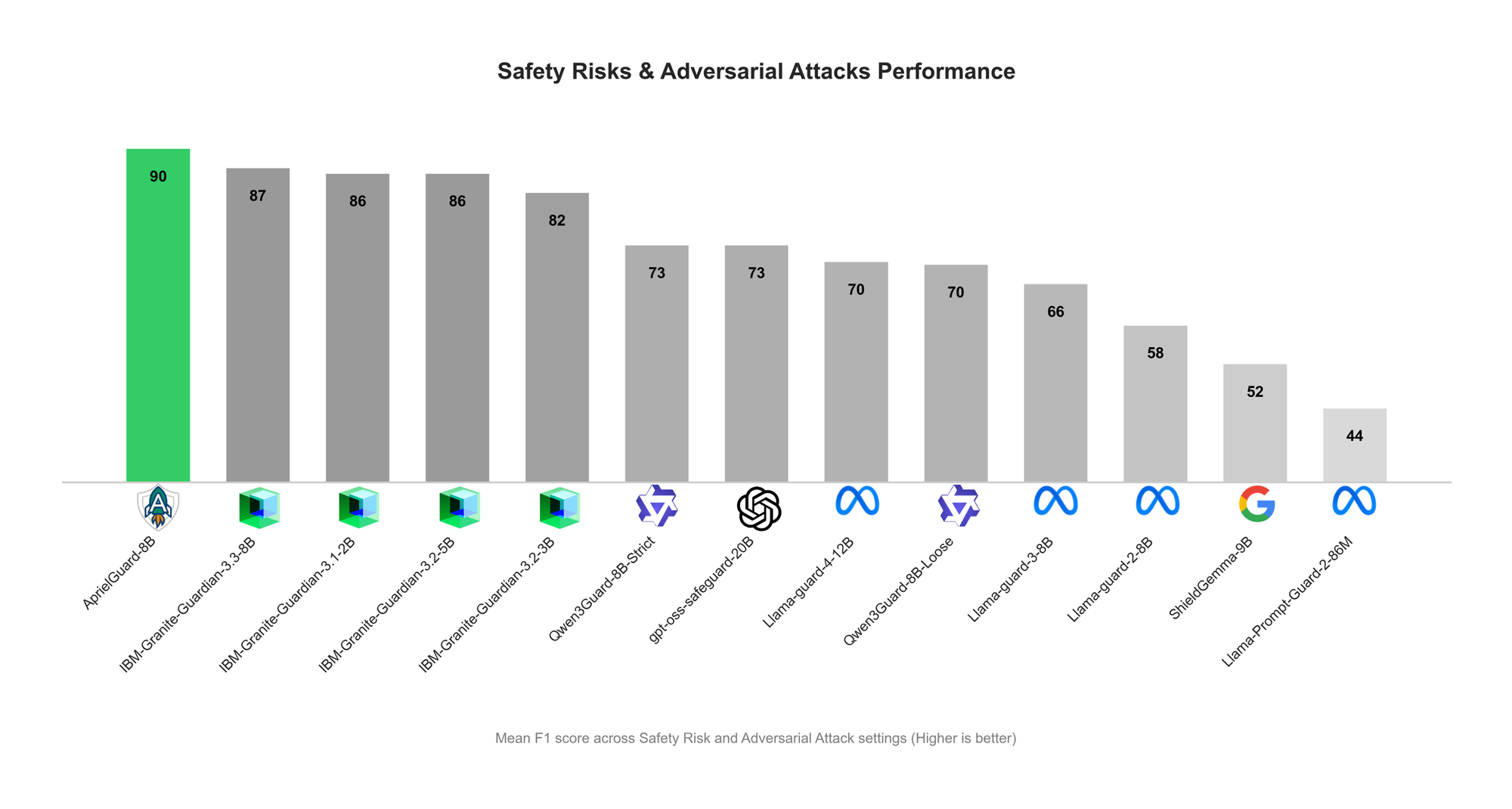
ServiceNow veröffentlicht AprielGuard: LLM-Sicherheit und Schutz vor adversariellen Angriffen : ServiceNow hat das 8B-Parameter-Sicherheits-Guardrail-Modell AprielGuard veröffentlicht, das darauf abzielt, 16 Arten von Sicherheitsrisiken und eine breite Palette von adversariellen Angriffen in modernen LLM-Systemen zu erkennen, darunter Multi-Round Jailbreaks, Prompt Injection, Memory Hijacking und Tool Manipulation. Das Modell unterstützt sowohl den Inferenz- als auch den Nicht-Inferenzmodus und kann bei Bedarf detaillierte Klassifizierungen liefern oder eine Klassifizierung mit geringer Latenz in Produktionsumgebungen ermöglichen. AprielGuard löst die Einschränkungen traditioneller Sicherheitsklassifikatoren bei Multi-Round-Dialogen, langen Kontexten und Agenten-Workflows durch ein einheitliches Modell und eine einheitliche Klassifizierung und bietet eine skalierbare Grundlage für den Aufbau vertrauenswürdiger AI-Implementierungen. (Quelle: HuggingFace Blog)
🎯 Trends
Karpathy veröffentlicht LLM-Jahresrückblick 2025: RLVR treibt AI von Imitation zu Schlussfolgerung : Andrej Karpathy, einer der Gründer von OpenAI, hat den “2025 Large Language Model Annual Review” veröffentlicht, der einen entscheidenden Wandel in der AI-Trainingsphilosophie von “probabilistischer Imitation” zu “logischem Schlussfolgern” im Jahr 2025 aufzeigt. Die zentrale treibende Kraft ist die Reife des Reinforcement Learning with Verifiable Rewards (RLVR), das Modelle dazu anregt, durch objektive Feedback-Umgebungen wie Mathematik und Code selbstständig “Schlussfolgerungsspuren” zu erzeugen, die menschlichem Denken ähneln. Er betont, dass dieses langfristige Reinforcement Learning begonnen hat, das traditionelle Pre-Training zu ersetzen und zu einem neuen Motor für die Verbesserung der Modellfähigkeiten geworden ist. Er prognostiziert, dass sich der AI-Wettbewerb im Jahr 2026 auf das Kernlogikparadigma “wie man AI effizient denken lässt” verlagern wird. (Quelle: 36氪)
USA starten “Genesis Mission”: AI-Manhattan-Projekt zur Förderung wissenschaftlicher Durchbrüche : US-Präsident Trump hat eine Executive Order unterzeichnet, die offiziell die “Genesis Mission” startet. Ziel ist es, die Supercomputing-Fähigkeiten nationaler Labore mit der Weisheit führender Wissenschaftler zu integrieren und AI zu nutzen, um wissenschaftliche Durchbrüche in beispielloser Geschwindigkeit voranzutreiben. Das Programm wird mit dem “Manhattan-Projekt des Zweiten Weltkriegs” verglichen und zielt darauf ab, eine AI zu schaffen, die eigenständig wissenschaftliche Entdeckungen vorantreiben kann. Es soll die Kernkompetenzen der amerikanischen Wissenschaftsgemeinschaft bündeln und 40.000 Wissenschaftler und Ingenieure aus 17 nationalen Laboren des Energieministeriums mobilisieren, um sich vollständig der AI-Technologieentwicklung zuzuwenden und die nationale technologische Souveränität wiederherzustellen. (Quelle: 36氪)

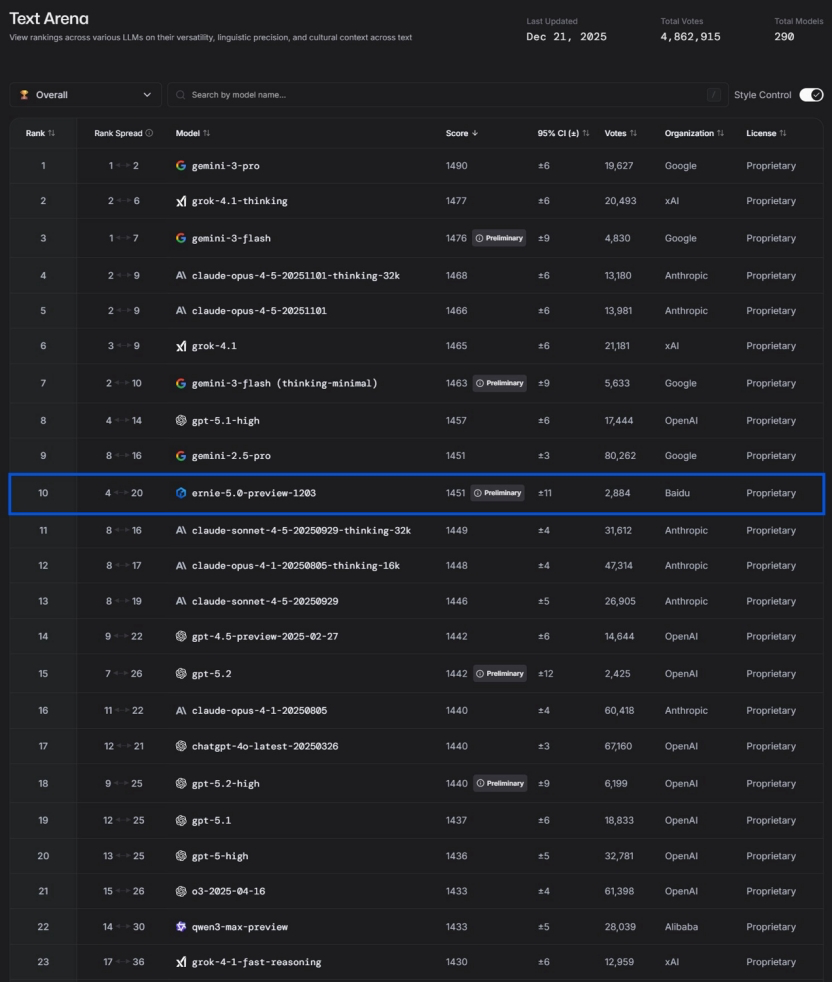
Chinesische AI-Innovation und der Aufstieg von Baidu Wenxin 5.0 : Als Reaktion auf DeepMinds Behauptung, die chinesische AI “fehle an Innovation und sei nur ein schneller Nachahmer”, wird die Ansicht vertreten, dass die chinesische AI durch die praktische Anwendung einzigartige technologische Barrieren aufbaut. Baidu Wenxin ERNIE-5.0-Preview-1203 erreichte auf der LMArena-Text-Rangliste den ersten Platz in China und einen Top-Ten-Platz weltweit, übertraf GPT-5.2 und Claude Sonnet 4.5 und war das einzige nicht-amerikanische Modell unter den Top 20. Sein Durchbruch wird dem “nativen Full-Modality Unified Modeling”, einer MoE-Architektur mit 2,4 Billionen Parametern und der komplexen Denkweise der “Einheit von Wissen und Handeln” (知行合一) zugeschrieben. Der Artikel betont den tiefgreifenden Wert der chinesischen AI in der physischen Welt und in industriellen Anwendungen wie dem aerodynamischen Design von Hochgeschwindigkeitszügen, der Inspektion von Stromnetzen, der Codegenerierung für SF Express und der Stadtverwaltung. (Quelle: 36氪)
Microsoft Copilot steht vor Herausforderungen bei der Benutzerakzeptanz, Nadella greift persönlich ein : Microsoft CEO Satya Nadella hat persönlich die Verbesserung von Copilot vorangetrieben, was zeigt, dass die Benutzerakzeptanz trotz der Integration von Copilot in die Office Suite nicht den Erwartungen entsprach. Dies deutet darauf hin, dass sich der AI-Wettbewerb von der “Demonstration von Fähigkeiten” hin zur “Benutzerbindung” verlagert hat, d.h. wer von den Benutzern tatsächlich täglich genutzt wird. Der Artikel weist darauf hin, dass Copilots “anleitende” Haltung statt einer “Partner”-Rolle und die mechanische Interaktion, die zu viele Szenarien abdeckt, die Aufmerksamkeit der Benutzer beansprucht haben. Der zukünftige AI-Wettbewerb wird sich auf das “Gefühl für das richtige Maß” konzentrieren, d.h. wann AI auftaucht, wann sie schweigt und ob sie ein feineres Verständnis bieten kann, um die emotionalen Kosten für die Benutzer zu senken. (Quelle: 36氪)

MiniMax M2.1 veröffentlicht, GLM 4.7 mit verbesserter Leistung : MiniMax M2.1 ist offiziell gestartet. Als MoE-Architekturmodell mit 10B aktivierten Parametern zeigt es hervorragende Leistungen in der mehrsprachigen Codierung (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) sowie in der Anwendungs-/Webentwicklung, mit einem SWE-bench Mehrsprachen-Score von 72,5%, der Gemini 3 Pro und Claude Sonnet 4.5 übertrifft. Gleichzeitig belegte GLM 4.7 den ersten Platz in der Open-Source-Rangliste des Vals Index und den neunten Platz in der Gesamtwertung, mit einer Leistungssteigerung von 9,5% gegenüber GLM 4.6. Es zeigte sich besonders stark in den Bereichen Programmierung, Agent/ToolCall und Long-Context-Retrieval-Fähigkeiten und führte einen “retained thought”-Mechanismus ein, der die Stabilität und Kontrollierbarkeit bei komplexen Aufgaben verbessert. (Quelle: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

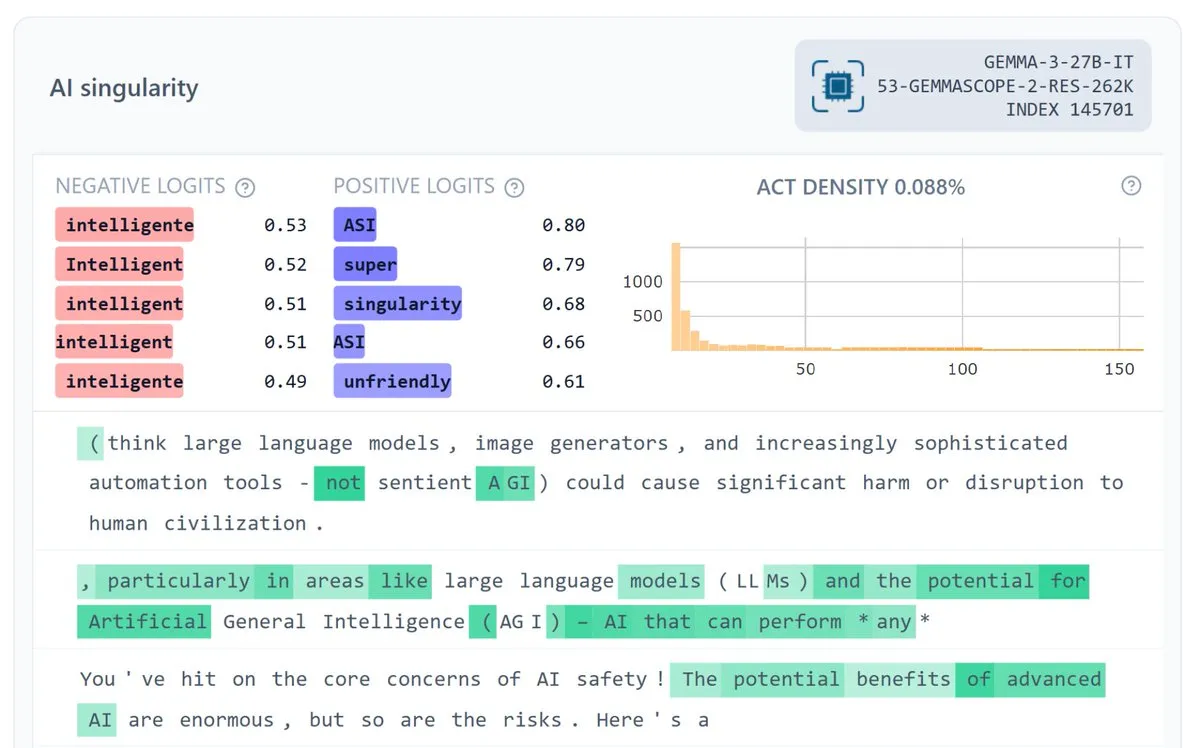
Google DeepMind veröffentlicht Gemma Scope 2 zur Verbesserung der Modellinterpretierbarkeit : Google DeepMind hat Gemma Scope 2 veröffentlicht, eine Full-Stack-Interpretierbarkeitssuite für die Gemma 3-Modellreihe (270M-27B, Basis- und Chat-Version), die SAEs (Sparse Autoencoder) und Transcoder für jede Ebene enthält. Dieser Schritt zielt darauf ab, ein tieferes Verständnis des Verhaltens komplexer Modelle zu fördern, ehrgeizigere Open-Source-Sicherheits- und Interpretierbarkeitsforschung zu unterstützen und der Community zu helfen, die internen Funktionsweisen von LLMs besser zu debuggen und zu analysieren. (Quelle: NeelNanda5, Reddit r/artificial)
AI-Agenten-Statusmanagement: Google Interactions API vereinfacht Entwicklung, weckt aber Bedenken hinsichtlich Vendor Lock-in : Google hat die Interactions API für Gemini veröffentlicht, die die Entwicklung von AI-Agenten erheblich vereinfacht, indem sie den Dialogverlauf, das Kontextmanagement und die Hintergrundausführung serverseitig verarbeitet. Dies eliminiert umfangreiche Infrastrukturarbeiten wie die Einrichtung von Vektordatenbanken und benutzerdefiniertes Kontext-Engineering, was die Entwicklungsgeschwindigkeit erheblich steigert. Dies hat jedoch auch Bedenken hinsichtlich Vendor Lock-in, des Verlusts der Kontrolle über Kontextspeicherung und -abruf, Schwierigkeiten beim Modellwechsel und intransparenter Kosten aufgeworfen. Dies deutet darauf hin, dass Google die Infrastruktur als “Moat” (Schutzgraben) nutzt, ähnlich dem AWS-Modell, aber die langfristigen Auswirkungen dieses Black-Box-Modells für ML-Workloads, die ein hohes Maß an Kontrolle über den gesamten Stack erfordern, müssen noch beobachtet werden. (Quelle: Reddit r/artificial)
Hugging Face: Roboter-Datensätze explodieren, fördern offenes Robotik-Ökosystem : Die Anzahl der offenen Robotik-Datensätze auf der Hugging Face-Plattform ist in den letzten zwei Jahren von 1.000 auf 27.000 gestiegen, was andere Kategorien wie die Textgenerierung weit übertrifft. Dieses explosive Wachstum ist auf günstigere Videospeicherung, bessere Tools und die Verbreitung der Open-Source-AI-Kultur zurückzuführen, was die Eintrittsbarrieren im Robotikbereich erheblich gesenkt und die Entwicklung von Universalrobotern und humanoiden Robotern beschleunigt hat. Offene Datensätze erleichtern das Hochladen, Wiederverwenden und Benchmarking von realen Robotikdaten (Videos, Aktionen, Sensoren, Fehler usw.) und verwandeln den Robotikbereich in ein skalierbareres und kollaborativeres Ökosystem. (Quelle: huggingface)
Tesla FSD vs. Waymo: Der Streit um End-to-End- vs. modulare Ansätze beim autonomen Fahren : Waymo und Tesla FSD zeigen grundverschiedene Philosophien bei ihren Ansätzen für autonomes Fahren. Waymo verfolgt einen “modularen” Ansatz, der auf HD-Karten, LiDAR, Sensoren und 5G-Netzwerke angewiesen ist. Wenn eines dieser Module (z.B. eine ausgefallene Ampel) versagt, kann das System in einen “Brick Mode” geraten. Im Gegensatz dazu verwendet Tesla FSD einen “End-to-End”-Ansatz, bei dem ein großes neuronales Netzwerk Kamerabilder direkt in Lenk- und Bremsbefehle umwandelt, was dem menschlichen Fahren ähnlicher ist. Einige argumentieren, dass Waymos modularer Ansatz erhebliche Softwareprobleme in Bezug auf Skalierbarkeit und Abhängigkeiten aufweist und dass Teslas FSD-End-to-End-Ansatz langfristig überlegen sein wird. (Quelle: Yuchenj_UW)
Zhihu Frontier Jahresrückblick: AI-Infrastruktur und multimodale Entwicklung im Jahr 2025 : Zhihu Frontier hat einen Jahresrückblick veröffentlicht, der die strukturellen Fortschritte im AI-Bereich in Bezug auf Infrastruktur und Multimodalität im Jahr 2025 zusammenfasst. Es wird betont, dass AI-Assistenten die Fähigkeit besitzen müssen, wie Menschen zu “sehen, hören und zu schlussfolgern”, was die Entwicklung multimodaler und nativer Sprachtechnologien vorantreibt. Hinsichtlich der Modellfähigkeiten haben 10B-Parameter-Modelle die 100B+-Modelle von 2024 übertroffen, die Kosteneffizienz wurde um das Zehnfache gesteigert, und Pre-Training bleibt die Grundlage. AI-Infrastruktur wird zu einem Wettbewerbsvorteil, wobei verteilte Inferenz, Tile-based Programming, groß angelegtes Reinforcement Learning und Modell-System-Co-Design als Schlüsselentwicklungen genannt werden. Gleichzeitig wird darauf hingewiesen, dass effektive Kommunikation und das Erlangen von Aufmerksamkeit zu unverzichtbaren Fähigkeiten für Techniker geworden sind. (Quelle: ZhihuFrontier)

🧰 Tools
Claude Code + Chrome-Integration ermöglicht Browser-Automatisierung : Claude Code unterstützt jetzt die Chrome-Browser-Integration, die es Benutzern ermöglicht, Code im Terminal zu schreiben und dann Claude im Chrome-Browser URLs öffnen, Schaltflächen klicken, Formulare ausfüllen, Konsolenfehler und DOM-Status lesen sowie sogar Screenshots und GIFs aufnehmen zu lassen. Diese Funktion benötigt keine API oder Tokens und nutzt direkt die aktive Browsersitzung des Benutzers, was Multi-Site-Automatisierungs-Workflows erheblich vereinfacht, z.B. das Erstellen von Google Sheets oder das Extrahieren von Informationen von Hacker News und das Ausfüllen von Tabellen. Obwohl derzeit nur Chrome und kein Headless-Modus unterstützt werden, bietet es Entwicklern leistungsstarke, nahtlose Browser-Interaktionsfähigkeiten. (Quelle: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: Ein neues Paradigma für AI-Videoanzeigen : Kling AI 2.6 hat leistungsstarke Motion-Control-Funktionen eingeführt, die eine realistische Ersetzung von Personen in Videos ermöglichen und Lippensynchronisation sowie komplexe Motion Capture unterstützen, sogar für nicht-menschliche Charaktere. Diese Technologie erhöht das Testpotenzial von AI-Werbung erheblich, indem sie Werbetreibenden ermöglicht, schnell Anzeigenvarianten mit unterschiedlichen Altersgruppen, Geschlechtern, Ethnien und ästhetischen Stilen zu generieren, um so umfangreiche Anzeigentests und -optimierungen durchzuführen. Durch die Kombination von Nano Banana Pro zur Charaktergenerierung und Elevenlabs zur Stimmerzeugung bringt Kling AI 2.6 revolutionäre Effizienzsteigerungen für die Videocontent-Erstellung und die Werbebranche. (Quelle: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8 veröffentlicht, verbessert LLM-Anwendungsbewertung und -beobachtung : MLflow Version 3.8 wurde offiziell veröffentlicht und bietet erweiterte Funktionen für die Bewertung und Beobachtung von LLM-Anwendungen. Zu den neuen Funktionen gehören die Prompt-Modellkonfiguration, die es ermöglicht, spezifische Modelleinstellungen mit Prompt-Templates zu verknüpfen, um die Reproduzierbarkeit von LLM-Workflows zu verbessern; die Tracing-UI unterstützt die Anzeige laufender Traces für Echtzeit-Debugging und -Überwachung von LLM-Anwendungen; die Integration von DeepEval und RAGAS Judges bietet über 20 Bewertungsmetriken wie Antwortrelevanz, Treue und Halluzinationserkennung; und neue Conversation Safety Scorer und Conversation Tool Call Efficiency Scorer bewerten die Sicherheit von Multi-Turn-Dialogen bzw. die Effizienz von Tool Calls in Agenteninteraktionen. (Quelle: matei_zaharia)

vLLM unterstützt LongCat-Image-Edit und MiMo-V2-Flash, vereinfacht Bildbearbeitung und -dienste : Die vLLM-Community hat die Unterstützung für das Meituan LongCat-Image-Edit-Modell hinzugefügt, das einen vereinfachten Servicepfad für anweisungsgesteuerte Bildbearbeitung bietet. Es unterstützt gängige Operationen wie Objekt hinzufügen/ersetzen, Hintergrund ändern und Stil anpassen, geeignet für Bildbearbeitungstools und kreative Bearbeitungsworkflows. Gleichzeitig hat vLLM ein offizielles Tutorial veröffentlicht, das die Bereitstellung der Xiaomi MiMo/MiMo-V2-Flash-Modelle anleitet, einschließlich Tool Calling, DP/TP/EP-Konfiguration und der Anpassung wichtiger Parameter wie Kontextlänge, Latenz und KV-Cache, was die Anwendung von LLMs in multimodalen und Edge-Geräten weiter vorantreibt. (Quelle: vllm_project)

Reka Vision setzt neue Standards für Smart Home Security AI : Reka Vision hat eine intelligente Kameralösung vorgestellt, die darauf abzielt, über die traditionelle Bewegungserkennung hinauszugehen und ein tiefes Verständnis von Ereignissen zu ermöglichen. Das System schlussfolgert über Video, Audio und Zeit hinweg, um Fehlalarme zu reduzieren und kontextbezogene, menschenähnliche Einblicke zu liefern. Reka Vision ist bestrebt, neue Standards für Smart Home Security AI zu setzen, damit diese komplexe Ereignisse in der häuslichen Umgebung genauer erkennen und verstehen kann, um intelligentere und zuverlässigere Sicherheitsüberwachungsdienste anzubieten. (Quelle: RekaAILabs)
YouTube Playables Builder: Gemini 3 ermöglicht Spieleentwicklung : Die Webanwendung YouTube Playables Builder ist jetzt live und wird vom Gemini 3-Modell unterstützt, um Kreativen zu helfen, schnell unterhaltsame, kleine Spiele durch Text-, Video- oder Bildprompts zu entwickeln. Dieses Tool senkt die Hürden für die Spieleentwicklung, sodass auch nicht-professionelle Entwickler die Kraft der AI nutzen können, um Ideen in spielbare Erlebnisse umzusetzen. Es wird erwartet, dass dies eine neue Dynamik im UGC (User Generated Content)-Spiele-Ökosystem entfacht und weitere Möglichkeiten für AI im Bereich der Unterhaltungsinhaltserstellung erschließt. (Quelle: demishassabis)
Medmarks v0.1 veröffentlicht: Größte Open-Source-Evaluierungssuite für medizinische LLMs : Sophont AI hat Medmarks v0.1 veröffentlicht, die derzeit größte vollständig Open-Source-Automatisierungs-Evaluierungssuite zur Bewertung der medizinischen Fähigkeiten von LLMs. Die Suite wurde von der MedARC AI-Community entwickelt und von PrimeIntellect unterstützt. Es wurden bereits 46 Modelle untersucht, um die besten Leistungen zu ermitteln. Die Veröffentlichung von Medmarks v0.1 wird die Forschung und Entwicklung im Bereich der medizinischen AI erheblich vorantreiben und standardisierte Tools und Benchmarks zur Bewertung und Verbesserung der Leistung medizinischer LLMs bereitstellen. (Quelle: iScienceLuvr)
Nano Banana Pro und Gemini 3 Pro kombinieren Bildgenerierung und Rendering : Eine Agenten-Anwendung nutzt Nano Banana Pro zur Bildgenerierung und Gemini 3 Pro zum Rendering auf Mobiltelefonen, was die starke Fähigkeit von AI-Modellen im Bereich der Frontend-Ästhetik demonstriert. Zum Beispiel kann sie Webseiten für Karpathys Jahresrückblick erstellen und sogar den Mauszeigerstil ändern. Diese Kombination bietet nicht nur einen effizienten Workflow für Bildgenerierung und Rendering, sondern deutet auch auf das enorme Potenzial von AI im Bereich des User Interface/User Experience (UI/UX)-Designs hin, indem sie in der Lage ist, schnell visuell ansprechende Inhalte gemäß den Benutzeranforderungen zu erstellen. (Quelle: op7418)

Heretic: Automatisches Zensurentfernungs-Tool für LLMs : Heretic ist ein vollständig automatisiertes Zensurentfernungs-Tool für LLMs. In der Open-Source-AI-Community hat die Veröffentlichung dieses Tools große Aufmerksamkeit erregt, da es darauf abzielt, Zensurbeschränkungen zu beheben, die Modelle bei der Inhaltserstellung möglicherweise aufweisen. Das Aufkommen von Heretic bietet Benutzern eine größere Freiheit, könnte aber auch Diskussionen über Inhaltssicherheit und Ethik auslösen, insbesondere im Hinblick auf das Gleichgewicht zwischen Meinungsfreiheit und der Generierung potenziell schädlicher Inhalte. (Quelle: Reddit r/LocalLLaMA)
Claude Code mit neuer Rückwärtssuchfunktion, verbessert die Effizienz des Prompt-Managements : Claude Code hat seine Funktionen aktualisiert und eine neue Fähigkeit zur Rückwärtssuche von Prompts über Strg+R hinzugefügt. Benutzer können Strg+R wiederholt drücken, um alle Prompts, die bestimmte Schlüsselwörter enthalten, zyklisch anzuzeigen, was die Effizienz und Bequemlichkeit des Prompt-Managements erheblich verbessert. Diese Verbesserung ermöglicht es Entwicklern, historische Prompts schneller zu finden und wiederzuverwenden, ihren AI-Programmier-Workflow zu optimieren und repetitive Arbeit zu reduzieren. (Quelle: dejavucoder)
📚 Learning
Neues RL-Paradigma: Transitive RL löst langfristige Aufgaben durch Divide-and-Conquer-Ansatz : Der BAIR-Blog stellt einen neuen Reinforcement Learning (RL)-Algorithmus namens Transitive RL (TRL) vor, der ein “Divide-and-Conquer”-Paradigma anstelle des traditionellen Temporal Difference (TD)-Lernens verwendet. TRL teilt Trajektorien rekursiv in kleinere Segmente auf und kombiniert deren Werte, um den Wert der vollständigen Trajektorie zu aktualisieren, wodurch eine bessere Skalierbarkeit für langfristige Aufgaben erzielt wird. Diese Methode ist besonders effektiv bei zielgerichteten RL-Problemen, da sie durch die Optimierung von Zwischenzielen die Anzahl der Bellman-Rekursionen erheblich reduziert, das Problem der Fehlerakkumulation im TD-Lernen vermeidet und eine neue Richtung für die Lösung komplexer, langfristiger RL-Aufgaben bietet. (Quelle: aihub.org)
LLM-Unterstützung bei mathematischen Beweisen: Ehemaliger DeepMind-Mitarbeiter erforscht P/=NP und Navier-Stokes : Der ehemalige DeepMind-Ingenieur Bengoertzel hat die Nutzung von LLMs zur Unterstützung bei der Beweisführung komplexer mathematischer Probleme wie der Existenz und Eindeutigkeit der Navier-Stokes-Gleichungen sowie des P/=NP-Problems untersucht. Er teilte seine Erfahrungen mit der Verwendung von LLMs, um Beweisdetails auszufüllen. Obwohl die Kernideen von ihm selbst stammten, boten LLMs erhebliche Hilfe bei der Bewältigung mühsamer Details. Diese Praxis hat Diskussionen darüber ausgelöst, wie menschliches kreatives Denken und die Detailverarbeitungsfähigkeiten von LLMs effektiv kombiniert werden können und wie formale Verifikationstools wie Lean genutzt werden können, um die Strenge mathematischer Beweise zu gewährleisten, was auf die potenzielle Rolle von AI in der fortgeschrittenen mathematischen Forschung hindeutet. (Quelle: bengoertzel)
Entwicklung der LLM-Trainingsära: Von Pre-Training zu RLVR und GRPO : Das LLM-Trainingsparadigma durchläuft eine rasche Entwicklung. Von Pre-Training (Basismodelle) in den 202xer Jahren über RLHF+PPO im Jahr 2022 und LoRA SFT im Jahr 2023 bis hin zum Mid-Training im Jahr 2024. Es wird prognostiziert, dass 2025 die Ära von RLVR+GRPO beginnt und 2026 möglicherweise die Zeit der “On Policy Distillation” einläutet. Diese Roadmap der Entwicklung zeigt die kontinuierliche Vertiefung und Optimierung der LLM-Trainingsmethodik, vom anfänglichen Aufbau grundlegender Fähigkeiten hin zu immer feineren, feedback- und effizienzorientierteren Trainingsstrategien, was darauf hindeutet, dass zukünftige Modelle das Lernen aus Interaktionen und die Destillation von Wissen stärker betonen werden. (Quelle: bookwormengr)
Forschung zu LLM-Speichermechanismen: Interne Funktionsweise von Claude und ChatGPT : Studien haben sich eingehend mit den Speichermechanismen von LLMs wie Claude und ChatGPT befasst und analysiert, wie diese Konversationskontextinformationen verarbeiten und speichern. Diese Forschungen enthüllen, wie interne Modellzustände die Bildung und den Abruf von Erinnerungen beeinflussen und welche Herausforderungen es gibt, die Kohärenz in Multi-Turn-Dialogen aufrechtzuerhalten. Das Verständnis der Funktionsweise des LLM-Gedächtnisses ist entscheidend für die Optimierung von Dialogsystemen, die Verbesserung der Benutzererfahrung und die Lösung von Problemen beim Verständnis langer Kontexte. Es bietet auch eine theoretische Grundlage für zukünftige effizientere und stabilere AI-Interaktionsdesigns. (Quelle: dejavucoder)
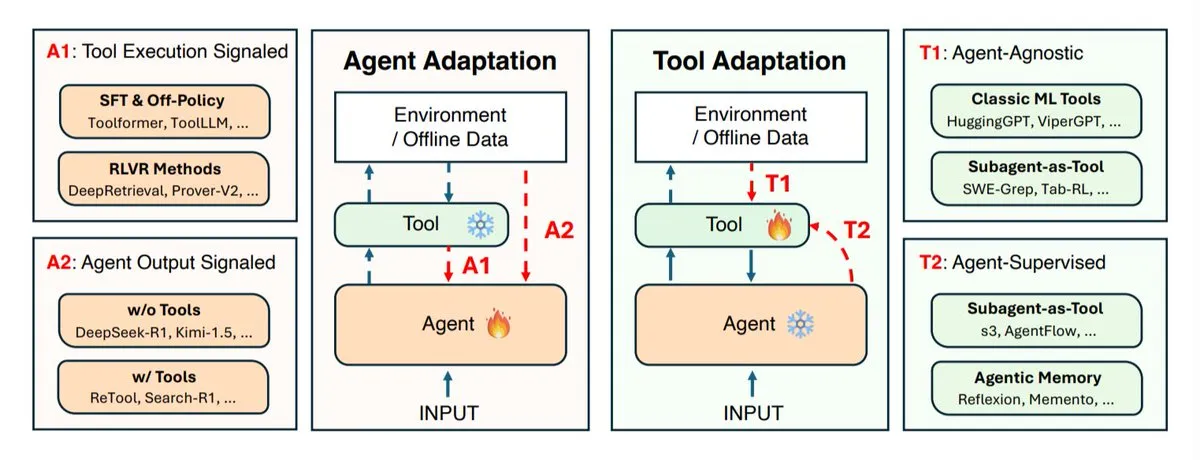
Forschung zu AI-Agenten-Adaptionsstrategien: Koevolution von Agenten und Tools : Forschungseinrichtungen wie UIUC, Stanford und Harvard haben Adaptionsstrategien für AI-Agenten untersucht, die hauptsächlich in zwei Kategorien unterteilt werden: die Anpassung des Agenten selbst (Inferenzmodell) und die Anpassung der von ihm verwendeten Tools (Suchsysteme, Retriever, Speicher, APIs). Die Studie definiert vier Adaptionstypen: Anpassung des Agenten unter Verwendung der Tool-Ergebnisse, Training des Agenten unter Nutzung seiner eigenen Ausgaben, unabhängige Anpassung der Tools und Training der Tools durch das Feedback des eingefrorenen Agenten. Diese Strategien bieten theoretische Leitlinien für die Entwicklung intelligenterer und flexiblerer AI-Agenten und betonen die Bedeutung der Koevolution zwischen Agenten und Tools, um komplexen und sich ständig ändernden Aufgabenstellungen gerecht zu werden. (Quelle: TheTuringPost)
Forschung zur Verbesserung der AI-Modell-Schlussfolgerungsfähigkeiten: Die Rolle von Pre-Training, Mid-Training und Reinforcement Learning : Forscher der Carnegie Mellon University haben herausgefunden, dass Pre-Training, Mid-Training und Reinforcement Learning unterschiedliche Rollen bei der Verbesserung der Schlussfolgerungsfähigkeiten von AI-Modellen spielen. Die Studie weist darauf hin, dass Reinforcement Learning die Schlussfolgerungsfähigkeiten nur unter bestimmten Bedingungen wirklich verbessern kann, dass Cross-Context-Generalisierung zunächst Pre-Training erfordert, Mid-Training entscheidend ist und prozessbewusste Belohnungen (Process-aware rewards) unerlässlich sind. Diese Erkenntnisse bieten Leitlinien für die Optimierung von Trainingsstrategien für AI-Modelle und betonen die Bedeutung gezielter Ansätze in verschiedenen Phasen, um die Schlussfolgerungsfähigkeiten zu maximieren. (Quelle: TheTuringPost)

KappaTune: Lösung des katastrophalen Vergessens beim LLM-Fine-Tuning : KappaTune ist eine neue LLM-Fine-Tuning-Methode, die darauf abzielt, das Problem des katastrophalen Vergessens zu lösen, das bei bestehenden Methoden wie LoRA auftritt. KappaTune weist eine sechsmal geringere Vergessensrate als LoRA auf und benötigt keine Pre-Training-Daten. Die Methode maximiert ihr Potenzial, indem sie die Fähigkeit zur feingranularen Tensor-Auswahl von MoE (Mixture of Experts)-Modellen nutzt. Das Aufkommen von KappaTune bietet eine effizientere Lösung für kontinuierliches Lernen und die Anpassungsfähigkeit von LLMs, was voraussichtlich die Modellwartungskosten senken und die breite Anwendung von AI fördern wird. (Quelle: Reddit r/deeplearning)

Policy→Tests (P2T)-Framework: Überbrückung der Kluft zwischen AI-Richtlinien und ausführbaren Regeln : Das Policy→Tests (P2T)-Framework zielt darauf ab, in natürlicher Sprache verfasste AI-Governance-Richtlinien (wie den EU AI Act, NIST AI RMF) in ausführbare Regeln umzuwandeln. Das Framework wandelt Richtliniendokumente über eine skalierbare Pipeline und eine kompakte JSON DSL in standardisierte atomare Regeln um, die Risiken, Geltungsbereiche, Bedingungen, Ausnahmen, Evidenzsignale und Herkunft umfassen. P2T behebt Engpässe zwischen der Richtlinieninterpretation und der Tool-Ausführung, insbesondere in komplexen Bereichen wie der Verarbeitung von Gesundheitsdaten, indem es die Zeit, die für die Abbildung von HIPAA-Anforderungen auf ML-Pipeline-Prüfungen benötigt wird, erheblich reduziert und die Effizienz und Überprüfbarkeit der AI-Governance verbessert. (Quelle: Reddit r/MachineLearning)
GenEnv: Koevolution von LLM-Agenten und Umweltsimulatoren mit Schwierigkeitsanpassung : GenEnv ist ein Framework, das das Problem der hohen Kosten und der statischen Natur von realen Interaktionsdaten beim Training von LLM-Agenten löst, indem es ein koevolutionäres Spiel mit Schwierigkeitsanpassung zwischen Agenten und skalierbaren generativen Umweltsimulatoren etabliert. Der Simulator fungiert als dynamische Lehrplanstrategie, die kontinuierlich Aufgaben generiert, die speziell auf die “Zone der proximalen Entwicklung” des Agenten zugeschnitten sind und durch α-Curriculum-Belohnungen geleitet werden. GenEnv verbesserte die Agentenleistung in mehreren Benchmarks um bis zu 40,3% und erreichte oder übertraf die durchschnittliche Leistung großer Modelle mit 3,3-mal weniger Daten, was einen dateneffizienten Weg zur Erweiterung der Agentenfähigkeiten bietet. (Quelle: HuggingFace Daily Papers)
QuCo-RAG: Quantifizierung von Unsicherheiten aus Pre-Training-Korpora für dynamisches RAG : QuCo-RAG schlägt vor, Unsicherheiten aus Pre-Training-Daten zu quantifizieren, um dynamisches RAG zu ermöglichen.