
Kata Kunci:Agen AI, LLM, Pembelajaran Penguatan, AI Multimodal, Mengemudi Otonom, Keamanan AI, Kompetisi AI, Sakana AI ALE-Agent, ServiceNow AprielGuard, Gemini Interactions API, Kling AI 2.6 Kontrol Gerak, Algoritma RL Transitive
🔥 Fokus Utama
Agen Sakana AI Meraih Kemenangan dalam Kompetisi Pemrograman : ALE-Agent yang dikembangkan oleh Sakana AI berhasil meraih kemenangan pertamanya dalam kompetisi pemrograman heuristik AtCoder AHC058. Agen AI ini belajar secara mandiri dan menciptakan “焼きなまし法” (algoritma simulated annealing) yang tidak terduga oleh manusia, mengungguli lebih dari 800 peserta. Pencapaian ini menunjukkan kemampuan belajar mandiri dan inovasi yang kuat dari agen AI dalam masalah optimasi yang kompleks, mengindikasikan potensi besar AI dalam memecahkan masalah yang sangat kompleks dan tidak terstruktur, melampaui paradigma pemrograman tradisional, serta membuka jalan baru bagi generasi kode otomatis dan pemecahan masalah yang didorong AI di masa depan. (来源: hardmaru)

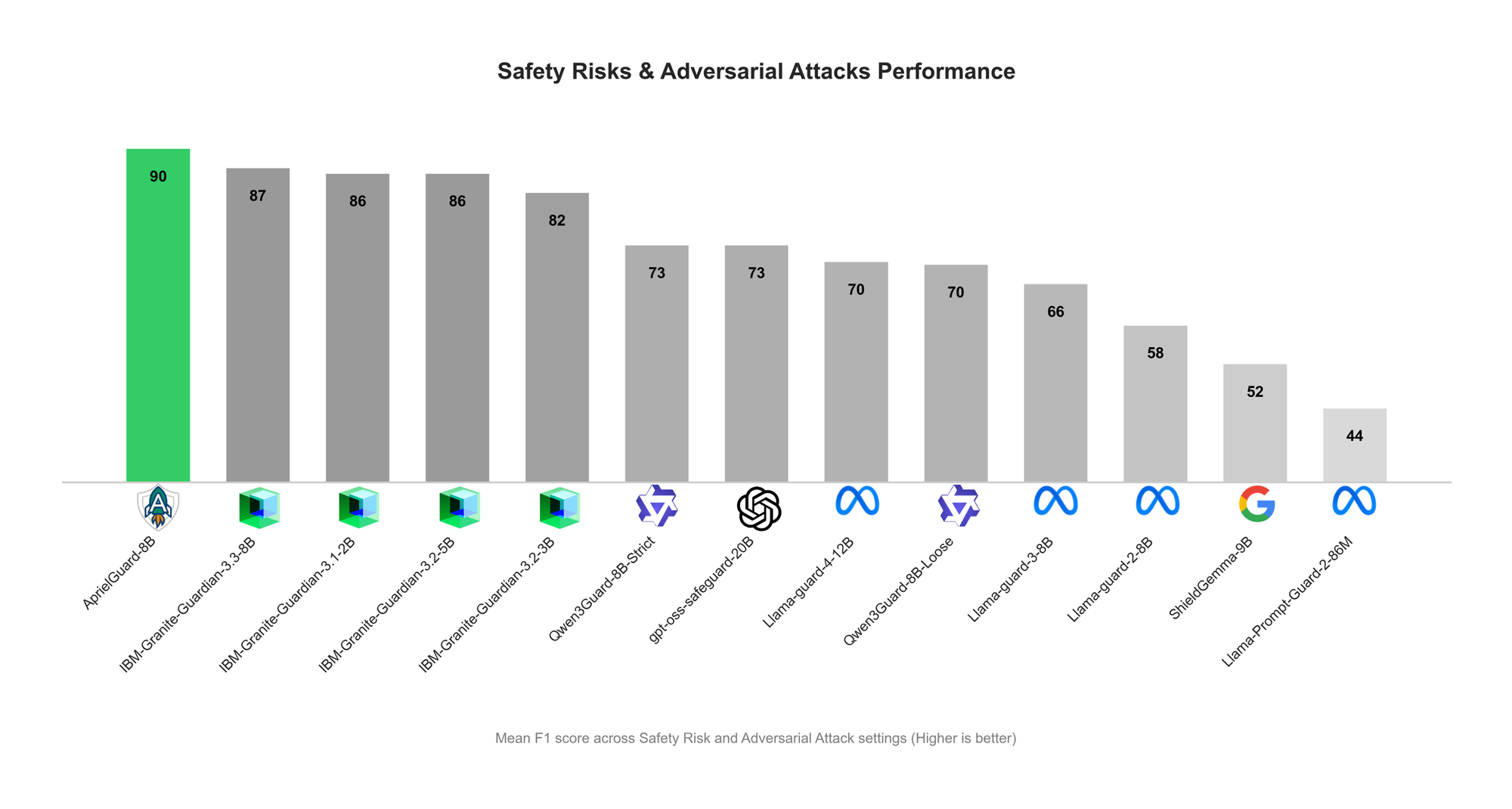
ServiceNow Merilis AprielGuard: Guardrail Keamanan LLM dan Ketahanan Adversarial : ServiceNow telah merilis model guardrail keamanan 8B parameter, AprielGuard, yang dirancang untuk mendeteksi 16 kategori risiko keamanan dan berbagai serangan adversarial dalam sistem LLM modern, termasuk multi-turn jailbreak, prompt injection, memory hijacking, dan tool manipulation. Model ini mendukung mode inferensi dan non-inferensi, dapat memberikan klasifikasi terperinci saat diperlukan penjelasan, atau mencapai klasifikasi latensi rendah di lingkungan produksi. AprielGuard, melalui model terpadu dan taksonomi terpadu, mengatasi keterbatasan yang dihadapi oleh klasifikasi keamanan tradisional dalam percakapan multi-turn, konteks panjang, dan alur kerja agen, menyediakan fondasi yang dapat diskalakan untuk membangun deployment AI yang dapat dipercaya. (来源: HuggingFace Blog)
🎯 Tren
Karpathy Merilis Ulasan Tahunan LLM 2025: RLVR Mendorong AI dari Imitasi ke Penalaran : Salah satu pendiri OpenAI, Andrej Karpathy, merilis “Ulasan Tahunan Model Bahasa Besar 2025”, menyoroti pergeseran kunci dalam filosofi pelatihan AI pada tahun 2025 dari “imitasi probabilistik” menjadi “penalaran logis”. Pendorong utamanya adalah kematangan Reinforcement Learning with Verifiable Rewards (RLVR), yang melalui lingkungan umpan balik objektif seperti matematika dan kode, mendorong model untuk secara spontan menghasilkan “jejak penalaran” yang mirip dengan pemikiran manusia. Dia menekankan bahwa reinforcement learning jangka panjang ini telah mulai menggantikan pre-training tradisional, menjadi mesin baru untuk meningkatkan kemampuan model, dan memprediksi bahwa persaingan AI pada tahun 2026 akan beralih ke paradigma logis inti “bagaimana membuat AI berpikir secara efisien”. (来源: 36氪)
AS Meluncurkan “Misi Genesis”: Proyek Manhattan AI Bertujuan Mendorong Terobosan Ilmiah : Presiden AS Donald Trump menandatangani perintah eksekutif, secara resmi meluncurkan “Misi Genesis”, yang bertujuan untuk mengintegrasikan kemampuan superkomputer laboratorium nasional dengan kebijaksanaan ilmuwan top, memanfaatkan AI untuk mendorong terobosan ilmiah dengan kecepatan yang belum pernah terjadi sebelumnya. Program ini disamakan dengan “Proyek Manhattan selama Perang Dunia II”, dengan tujuan menciptakan AI yang dapat secara mandiri mendorong penemuan ilmiah, dan memusatkan kompetensi inti komunitas ilmiah AS, memobilisasi 40.000 ilmuwan dan insinyur dari 17 laboratorium nasional di bawah Departemen Energi, untuk sepenuhnya beralih ke penelitian dan pengembangan teknologi AI, guna membangun kembali kedaulatan teknologi nasional. (来源: 36氪)

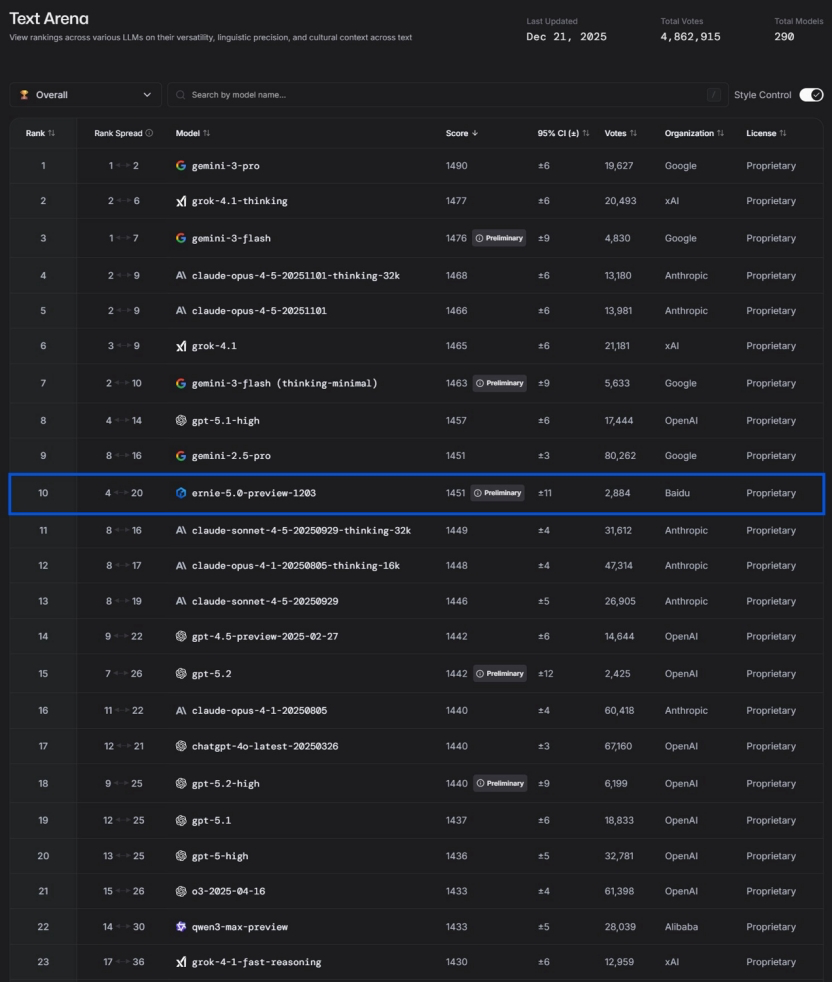
Inovasi AI Tiongkok dan Kebangkitan Baidu Wenxin 5.0 : Menanggapi argumen DeepMind bahwa AI Tiongkok “kurang inovasi, hanya cepat mengikuti”, ada pandangan yang menunjukkan bahwa AI Tiongkok sedang membentuk hambatan teknis yang unik melalui implementasi aplikasi. Baidu Wenxin ERNIE-5.0-Preview-1203 meraih peringkat pertama di Tiongkok dan sepuluh besar global dalam peringkat teks LMArena, melampaui GPT-5.2 dan Claude Sonnet 4.5, menjadi satu-satunya model non-AS di antara 20 besar. Terobosannya dikaitkan dengan “pemodelan terpadu multimodalitas asli”, arsitektur MoE dengan 2,4 triliun parameter, serta rantai pemikiran komposit “kesatuan pengetahuan dan tindakan”. Artikel ini menekankan nilai mendalam AI Tiongkok dalam dunia fisik dan aplikasi industri seperti desain aerodinamis kereta cepat, inspeksi jaringan listrik, generasi kode SF Express, dan tata kelola kota. (来源: 36氪)
Microsoft Copilot Menghadapi Tantangan Adopsi Pengguna, Nadella Turun Tangan Langsung : CEO Microsoft Satya Nadella secara pribadi turun tangan untuk mendesak perbaikan Copilot, mencerminkan bahwa meskipun Copilot telah terintegrasi ke dalam suite Office, tingkat adopsi pengguna belum mencapai ekspektasi. Ini menunjukkan bahwa persaingan AI telah bergeser dari “menunjukkan kemampuan” menjadi “retensi pengguna”, yaitu siapa yang benar-benar dapat digunakan oleh pengguna sehari-hari. Artikel ini menunjukkan bahwa sikap “membimbing” Copilot daripada peran “mitra”, serta interaksi mekanis yang terlalu banyak mencakup skenario, telah menguras perhatian pengguna. Persaingan AI di masa depan akan berfokus pada “rasa proporsi”, yaitu kapan AI muncul, kapan AI diam, dan apakah AI dapat memberikan pemahaman yang lebih halus, mengurangi biaya emosional pengguna. (来源: 36氪)

MiniMax M2.1 Dirilis, Kinerja GLM 4.7 Meningkat : MiniMax M2.1 resmi diluncurkan, sebagai model arsitektur MoE dengan 10B parameter aktif, menunjukkan kinerja luar biasa dalam pengkodean multibahasa (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) dan pengembangan aplikasi/web, dengan skor multibahasa SWE-bench 72,5%, melampaui Gemini 3 Pro dan Claude Sonnet 4.5. Pada saat yang sama, GLM 4.7 juga menduduki peringkat pertama dalam daftar open-source Vals Index, dan peringkat kesembilan secara keseluruhan, dengan peningkatan kinerja 9,5% dibandingkan GLM 4.6, terutama menonjol dalam pemrograman, Agent/ToolCall, dan kemampuan recall konteks panjang, serta memperkenalkan mekanisme “thought preservation” yang meningkatkan stabilitas dan kontrol tugas kompleks. (来源: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

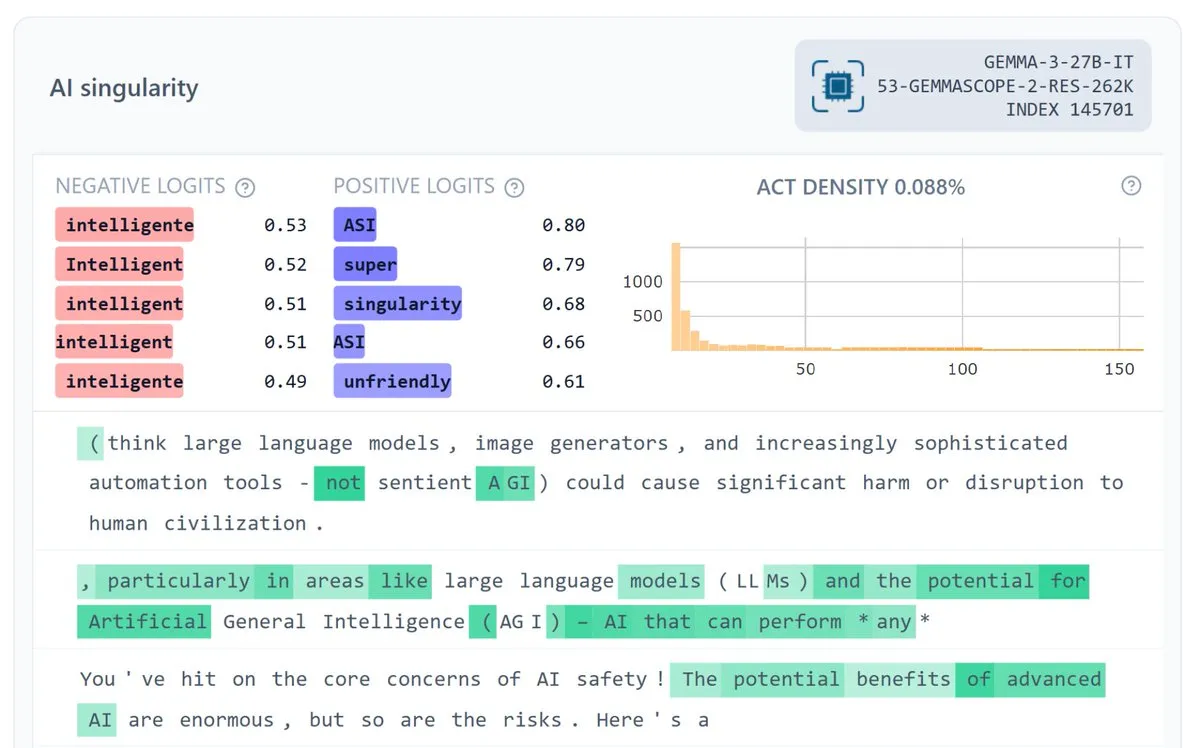
Google DeepMind Merilis Gemma Scope 2, Meningkatkan Interpretasi Model : Google DeepMind merilis Gemma Scope 2, sebuah suite interpretasi full-stack untuk model seri Gemma 3 (270M-27B, versi dasar dan chat), yang mencakup SAE (Sparse Autoencoders) dan transcoder di setiap lapisan. Langkah ini bertujuan untuk mempromosikan pemahaman mendalam tentang perilaku model kompleks, mendukung penelitian keamanan dan interpretasi open-source yang lebih ambisius, dan diharapkan dapat membantu komunitas untuk lebih baik dalam melakukan debug dan menganalisis mekanisme kerja internal LLM. (来源: NeelNanda5, Reddit r/artificial)
Manajemen Status Agen AI: Google Interactions API Menyederhanakan Pengembangan tetapi Menimbulkan Kekhawatiran Lock-in : Google merilis Interactions API untuk Gemini, yang menangani riwayat percakapan, manajemen konteks, dan eksekusi latar belakang di sisi server, sangat menyederhanakan pengembangan agen AI. Ini menghilangkan banyak pekerjaan infrastruktur seperti pengaturan database vektor, rekayasa konteks kustom, dan secara signifikan meningkatkan kecepatan pengembangan. Namun, langkah ini juga menimbulkan kekhawatiran tentang vendor lock-in, hilangnya kontrol atas penyimpanan dan pengambilan konteks, kesulitan dalam beralih model, dan biaya yang tidak transparan. Ini menunjukkan bahwa Google sedang menjadikan infrastruktur sebagai parit pertahanan, mirip dengan model AWS, tetapi dampak jangka panjang dari mode “kotak hitam” ini masih perlu diamati untuk beban kerja ML yang membutuhkan kontrol tinggi atas seluruh stack. (来源: Reddit r/artificial)
Dataset Robotika Hugging Face Melonjak, Mendorong Pengembangan Ekosistem Robotika Terbuka : Dataset robotika terbuka di platform Hugging Face telah melonjak dari 1.000 menjadi 27.000 dalam dua tahun terakhir, jauh melampaui kategori lain seperti generasi teks. Pertumbuhan eksplosif ini didorong oleh penyimpanan video yang lebih murah, alat yang lebih baik, dan penyebaran budaya AI open-source, yang secara signifikan menurunkan hambatan masuk ke bidang robotika, mempercepat proses penelitian dan pengembangan robot umum dan humanoid. Dataset terbuka memungkinkan data robotika nyata (video, gerakan, sensor, kegagalan, dll.) mudah diunggah, digunakan kembali, dan di-benchmark, mengubah bidang robotika menjadi ekosistem yang lebih skalabel dan kolaboratif. (来源: huggingface)
Persaingan Jalur Autonomous Driving Tesla FSD dan Waymo: End-to-End vs. Modular : Waymo dan Tesla FSD menunjukkan filosofi yang sangat berbeda dalam jalur teknologi autonomous driving. Waymo mengadopsi pendekatan “modular”, mengandalkan peta HD, LiDAR, sensor, dan jaringan 5G. Jika salah satu modul (misalnya, lampu lalu lintas rusak) mengalami kegagalan, sistem dapat masuk ke “mode bata”. Sebaliknya, Tesla FSD menggunakan solusi “end-to-end”, yang secara langsung mengubah piksel kamera menjadi instruksi kemudi dan pengereman melalui jaringan saraf besar, lebih mirip dengan cara manusia mengemudi. Ada pandangan yang menyatakan bahwa metode modular Waymo memiliki masalah perangkat lunak besar dalam skalabilitas dan ketergantungan, dan dalam jangka panjang, solusi end-to-end Tesla FSD lebih unggul. (来源: Yuchenj_UW)
Ulasan Tahunan Zhihu Frontier: Infrastruktur AI dan Pengembangan Multimodal pada Tahun 2025 : Zhihu Frontier merilis ulasan tahunan, merangkum kemajuan struktural di bidang AI pada tahun 2025 dalam hal infrastruktur dan multimodalitas. Menekankan bahwa asisten AI perlu memiliki kemampuan “melihat, mendengar, dan bernalar” seperti manusia, mendorong pengembangan teknologi multimodalitas dan suara asli. Dalam hal kemampuan model, model 10B parameter telah melampaui model 100B+ pada tahun 2024, dengan peningkatan efisiensi biaya 10 kali lipat, dan pre-training tetap menjadi dasar. Infrastruktur AI menjadi keunggulan kompetitif, dengan inferensi terdistribusi, pemrograman berbasis Tile, reinforcement learning skala besar, dan desain kolaboratif model-sistem sebagai kemajuan kunci. Pada saat yang sama, disebutkan bahwa komunikasi yang efektif dan menarik perhatian telah menjadi keterampilan penting bagi personel teknis. (来源: ZhihuFrontier)

🧰 Alat
Integrasi Claude Code + Chrome Mewujudkan Otomatisasi Browser : Claude Code kini mendukung integrasi browser Chrome, memungkinkan pengguna menulis kode di terminal, lalu meminta Claude membuka URL, mengklik tombol, mengisi formulir, membaca kesalahan konsol dan status DOM di Chrome, bahkan mengambil tangkapan layar dan merekam GIF. Fungsi ini tidak memerlukan API atau token, langsung memanfaatkan sesi browser yang sudah login, sangat menyederhanakan alur kerja otomatisasi multi-situs, seperti membuat Google Sheets, mengekstrak informasi dari Hacker News, dan mengisi tabel. Meskipun saat ini hanya mendukung Chrome dan tanpa mode headless, ini memberikan kemampuan interaksi browser yang mulus dan kuat bagi pengembang. (来源: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: Paradigma Baru Iklan Video AI : Kling AI 2.6 meluncurkan fitur kontrol gerak yang kuat, mampu melakukan penggantian karakter yang realistis dalam video, serta mendukung sinkronisasi bibir dan penangkapan gerakan kompleks, bahkan berlaku untuk karakter non-manusia. Teknologi ini secara signifikan meningkatkan potensi pengujian iklan AI, memungkinkan pengiklan dengan cepat menghasilkan varian iklan dengan usia, jenis kelamin, ras, dan gaya estetika yang berbeda, sehingga mencapai pengujian dan optimasi iklan skala besar. Dengan menggabungkan Nano Banana Pro untuk menghasilkan karakter dan Elevenlabs untuk menghasilkan suara, Kling AI 2.6 membawa peningkatan efisiensi revolusioner untuk pembuatan konten video dan industri periklanan. (来源: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8 Dirilis, Meningkatkan Kemampuan Evaluasi dan Observasi Aplikasi LLM : Versi MLflow 3.8 resmi dirilis, membawa fitur-fitur canggih untuk evaluasi dan observasi aplikasi LLM. Fitur baru termasuk konfigurasi model prompt, yang memungkinkan pengaturan model tertentu dikaitkan dengan template prompt, meningkatkan reproduksibilitas alur kerja LLM; UI pelacakan mendukung tampilan pelacakan yang sedang berlangsung, memungkinkan debugging dan pemantauan real-time aplikasi LLM; integrasi DeepEval dan RAGAS Judges, menyediakan lebih dari 20 metrik evaluasi, seperti relevansi jawaban, fidelitas, dan deteksi halusinasi; penambahan penilai keamanan percakapan dan penilai efisiensi panggilan alat percakapan, yang masing-masing mengevaluasi keamanan percakapan multi-turn dan efisiensi panggilan alat dalam interaksi agen. (来源: matei_zaharia)

vLLM Mendukung LongCat-Image-Edit dan MiMo-V2-Flash, Menyederhanakan Pengeditan dan Layanan Gambar : Komunitas vLLM telah menambahkan dukungan untuk model Meituan LongCat-Image-Edit, menyediakan jalur layanan yang lebih sederhana untuk pengeditan gambar berbasis instruksi, mendukung operasi umum seperti penambahan/penggantian objek, perubahan latar belakang, dan penyesuaian gaya, cocok untuk alat pengeditan gambar dan alur kerja pengeditan kreatif. Pada saat yang sama, vLLM juga merilis tutorial resmi yang memandu cara deployment model Xiaomi MiMo/MiMo-V2-Flash, termasuk panggilan alat, konfigurasi DP/TP/EP, serta penyesuaian parameter kunci seperti panjang konteks, latensi, dan KV cache, lebih lanjut mendorong aplikasi LLM dalam multimodalitas dan perangkat edge. (来源: vllm_project)

Reka Vision Menetapkan Standar Baru untuk AI Keamanan Rumah Pintar : Reka Vision meluncurkan solusi kamera pintar, yang bertujuan untuk melampaui deteksi gerakan tradisional dan mencapai pemahaman mendalam tentang peristiwa. Sistem ini melakukan inferensi lintas video, audio, dan waktu, mengurangi false positive, dan memberikan wawasan tingkat manusia yang relevan dengan konteks. Reka Vision berkomitmen untuk menetapkan standar baru untuk AI keamanan rumah pintar, memungkinkannya mengidentifikasi dan memahami peristiwa kompleks yang terjadi di lingkungan rumah dengan lebih akurat, sehingga menyediakan layanan pemantauan keamanan yang lebih cerdas dan andal. (来源: RekaAILabs)
YouTube Playables Builder: Gemini 3 Memberdayakan Kreasi Game : Aplikasi web YouTube Playables Builder kini telah diluncurkan, didukung oleh model Gemini 3, membantu kreator dengan cepat mengembangkan game yang menarik dan kecil melalui prompt teks, video, atau gambar. Alat ini menurunkan hambatan pengembangan game, memungkinkan pengembang non-profesional untuk memanfaatkan kekuatan AI, mengubah ide kreatif menjadi pengalaman game yang dapat dimainkan, diharapkan dapat memicu vitalitas baru dalam ekosistem game UGC (User-Generated Content), dan mengeksplorasi lebih banyak kemungkinan AI dalam bidang pembuatan konten hiburan. (来源: demishassabis)
Medmarks v0.1 Dirilis: Suite Evaluasi LLM Medis Open-Source Terbesar : Sophont AI merilis Medmarks v0.1, suite evaluasi otomatis open-source terbesar saat ini, yang digunakan untuk mengevaluasi kemampuan medis LLM. Suite ini dikembangkan oleh komunitas MedARC AI dan didukung oleh PrimeIntellect, telah mengeksplorasi 46 model untuk menemukan kinerja terbaik. Perilisan Medmarks v0.1 akan secara signifikan mendorong penelitian dan pengembangan di bidang AI medis, menyediakan alat dan benchmark terstandardisasi untuk mengevaluasi dan meningkatkan kinerja LLM medis. (来源: iScienceLuvr)
Kombinasi Nano Banana Pro dan Gemini 3 Pro Mewujudkan Generasi dan Rendering Gambar : Sebuah aplikasi agen memanfaatkan Nano Banana Pro untuk menghasilkan gambar, dan merendernya di ponsel melalui Gemini 3 Pro, menunjukkan kemampuan kuat model AI dalam ekspresi estetika frontend. Misalnya, ia dapat membuat halaman web untuk ringkasan akhir tahun Karpathy, bahkan mengubah gaya kursor mouse. Kombinasi ini tidak hanya menyediakan alur kerja generasi dan rendering gambar yang efisien, tetapi juga mengisyaratkan potensi besar AI dalam bidang desain antarmuka pengguna/pengalaman pengguna (UI/UX), mampu dengan cepat membuat konten yang menarik secara visual sesuai kebutuhan pengguna. (来源: op7418)

Heretic: Alat Penghapus Sensor Otomatis LLM : Heretic adalah alat penghapus sensor otomatis sepenuhnya untuk LLM. Dalam komunitas AI open-source, perilisan alat ini menarik perhatian luas karena bertujuan untuk mengatasi batasan sensor yang mungkin ada pada model saat menghasilkan konten. Kehadiran Heretic memberikan kebebasan yang lebih besar kepada pengguna, tetapi juga dapat memicu diskusi tentang keamanan dan etika konten, terutama dalam menyeimbangkan kebebasan berbicara dengan potensi generasi konten berbahaya. (来源: Reddit r/LocalLLaMA)
Claude Code Menambahkan Fitur Pencarian Terbalik, Meningkatkan Efisiensi Manajemen Prompt : Claude Code memperbarui fungsinya, menambahkan kemampuan pencarian terbalik prompt melalui Ctrl+R. Pengguna dapat berulang kali menekan Ctrl+R untuk melihat semua prompt yang berisi kata kunci tertentu secara berulang, yang sangat meningkatkan efisiensi dan kenyamanan manajemen prompt. Peningkatan ini memungkinkan pengembang untuk lebih cepat menemukan dan menggunakan kembali prompt historis, mengoptimalkan alur kerja pemrograman AI mereka, dan mengurangi pekerjaan berulang. (来源: dejavucoder)
📚 Pembelajaran
Paradigma RL Baru: Transitive RL Memecahkan Tugas Jangka Panjang Melalui Divide and Conquer : Blog BAIR memperkenalkan algoritma reinforcement learning baru bernama Transitive RL (TRL), yang mengadopsi paradigma “divide and conquer”, bukan pembelajaran Temporal Difference (TD) tradisional. TRL menunjukkan skalabilitas yang lebih baik untuk tugas jangka panjang dengan secara rekursif membagi lintasan menjadi segmen yang lebih kecil dan menggabungkan nilainya untuk memperbarui nilai lintasan lengkap. Metode ini sangat efektif dalam masalah RL berbasis tujuan, di mana ia secara signifikan mengurangi jumlah rekursi Bellman melalui optimasi sub-tujuan perantara, menghindari masalah akumulasi kesalahan dalam pembelajaran TD, dan menyediakan arah baru untuk memecahkan tugas RL yang kompleks dan berurutan panjang. (来源: aihub.org)
Bantuan LLM dalam Pembuktian Matematika: Mantan Karyawan DeepMind Menjelajahi P/=NP dan Navier-Stokes : Mantan insinyur DeepMind, Bengoertzel, membahas penggunaan LLM untuk membantu membuktikan masalah matematika kompleks, seperti keberadaan dan keunikan persamaan Navier-Stokes, serta masalah P/=NP. Dia berbagi pengalamannya menggunakan LLM untuk mengisi detail bukti, meskipun ide intinya berasal dari dirinya sendiri, LLM memberikan bantuan signifikan dalam menangani detail yang rumit. Praktik ini memicu diskusi tentang bagaimana secara efektif menggabungkan pemikiran kreatif manusia dengan kemampuan pemrosesan detail LLM, serta penggunaan alat verifikasi formal seperti Lean untuk memastikan ketelitian bukti matematika, mengisyaratkan peran potensial AI dalam penelitian matematika tingkat lanjut. (来源: bengoertzel)
Evolusi Era Pelatihan LLM: Dari Pre-training ke RLVR dan GRPO : Paradigma pelatihan LLM sedang mengalami evolusi cepat. Dari pre-training (model dasar) pada tahun 202x, ke RLHF+PPO pada tahun 2022, lalu LoRA SFT pada tahun 2023, dan mid-training pada tahun 2024. Diprediksi tahun 2025 akan memasuki era RLVR+GRPO, dan tahun 2026 mungkin akan menyambut periode “On Policy Distillation”. Peta jalan evolusi ini mengungkapkan pendalaman dan optimasi metodologi pelatihan LLM yang berkelanjutan, dari pembangunan kemampuan dasar awal, secara bertahap beralih ke strategi pelatihan yang lebih halus, lebih berfokus pada umpan balik dan efisiensi, mengisyaratkan bahwa model masa depan akan lebih menekankan pembelajaran dari interaksi dan distilasi pengetahuan. (来源: bookwormengr)
Penelitian Mekanisme Memori LLM: Cara Kerja Internal Claude dan ChatGPT : Ada penelitian yang mendalami mekanisme memori LLM seperti Claude dan ChatGPT, menganalisis bagaimana mereka memproses dan mempertahankan informasi konteks percakapan. Penelitian ini mengungkapkan bagaimana status internal model memengaruhi pembentukan dan pengambilan memori, serta tantangan dalam menjaga koherensi dalam percakapan multi-turn. Memahami prinsip kerja memori LLM sangat penting untuk mengoptimalkan sistem percakapan, meningkatkan pengalaman pengguna, dan memecahkan masalah pemahaman konteks panjang, serta menyediakan dasar teoretis untuk desain interaksi AI yang lebih efisien dan stabil di masa depan. (来源: dejavucoder)
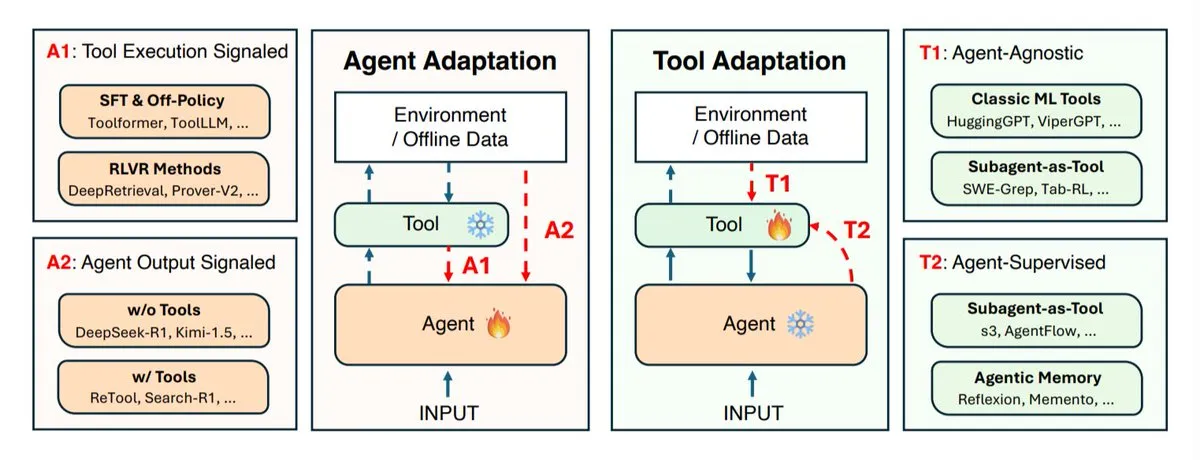
Penelitian Strategi Adaptasi Agen AI: Ko-evolusi Agen dan Alat : Institusi penelitian seperti UIUC, Stanford, Harvard, dll., telah membahas strategi adaptasi agen AI, yang terutama dibagi menjadi dua kategori: adaptasi agen itu sendiri (model inferensi) dan adaptasi alat yang digunakannya (sistem pencarian, retriever, memori, API). Penelitian ini mendefinisikan empat jenis adaptasi: mengadaptasi agen menggunakan hasil alat, melatih agen menggunakan outputnya sendiri, mengadaptasi alat secara independen, dan melatih alat melalui umpan balik dari agen yang dibekukan. Strategi-strategi ini memberikan panduan teoretis untuk mengembangkan agen AI yang lebih cerdas dan fleksibel, menekankan pentingnya evolusi kolaboratif antara agen dan alat untuk menghadapi lingkungan tugas yang kompleks dan bervariasi. (来源: TheTuringPost)
Penelitian Peningkatan Kemampuan Penalaran Model AI: Peran Pre-training, Mid-training, dan Reinforcement Learning : Peneliti dari Carnegie Mellon University menemukan bahwa pre-training, mid-training, dan reinforcement learning memainkan peran yang berbeda dalam meningkatkan kemampuan penalaran model AI. Penelitian menunjukkan bahwa reinforcement learning hanya dapat benar-benar meningkatkan kemampuan penalaran dalam kondisi tertentu, generalisasi lintas konteks memerlukan pre-training terlebih dahulu, mid-training sangat penting, dan process-aware rewards adalah hal yang tak terpisahkan. Penemuan ini memberikan panduan untuk mengoptimalkan strategi pelatihan model AI, menekankan pentingnya mengadopsi metode yang ditargetkan pada tahap yang berbeda untuk memaksimalkan kemampuan penalaran. (来源: TheTuringPost)

KappaTune: Mengatasi Masalah Catastrophic Forgetting dalam Fine-tuning LLM : KappaTune adalah metode fine-tuning LLM baru yang dirancang untuk mengatasi masalah catastrophic forgetting yang ada pada metode seperti LoRA. KappaTune memiliki tingkat lupa 6 kali lebih rendah dibandingkan LoRA, dan tidak memerlukan data pre-training. Metode ini memaksimalkan potensinya dengan memanfaatkan kemampuan pemilihan tensor berbutir halus dari model MoE (Mixture of Experts). Kehadiran KappaTune menyediakan solusi yang lebih efisien untuk pembelajaran berkelanjutan dan adaptabilitas LLM, diharapkan dapat mengurangi biaya pemeliharaan model, dan mempromosikan aplikasi AI yang lebih luas. (来源: Reddit r/deeplearning)

Kerangka Kerja Policy→Tests (P2T): Menjembatani Kesenjangan antara Kebijakan AI dan Aturan yang Dapat Dieksekusi : Kerangka kerja Policy→Tests (P2T) bertujuan untuk mengubah kebijakan tata kelola AI yang ditulis dalam bahasa alami (seperti EU AI Act, NIST AI RMF) menjadi aturan yang dapat dieksekusi. Kerangka kerja ini, melalui pipeline yang dapat diskalakan dan JSON DSL yang ringkas, mengubah dokumen kebijakan menjadi aturan atomik yang terstandardisasi, mencakup risiko, cakupan, kondisi, pengecualian, sinyal bukti, dan asal-usul. P2T mengatasi hambatan antara interpretasi kebijakan dan eksekusi alat, terutama saat menangani bidang kompleks seperti data perawatan kesehatan, dapat secara signifikan mengurangi waktu yang diperlukan untuk memetakan persyaratan HIPAA ke pemeriksaan pipeline ML, meningkatkan efisiensi dan verifikasi tata kelola AI. (来源: Reddit r/MachineLearning)
GenEnv: Ko-evolusi Penyelarasan Kesulitan Agen LLM dan Simulator Lingkungan : GenEnv adalah kerangka kerja yang mengatasi hambatan biaya tinggi dan sifat statis data interaksi dunia nyata saat melatih agen LLM, dengan membangun permainan evolusi ko-adaptif yang selaras kesulitan antara agen dan simulator lingkungan generatif yang dapat diskalakan. Simulator bertindak sebagai strategi kurikulum dinamis, terus-menerus menghasilkan tugas yang secara khusus menargetkan “zona perkembangan proksimal” agen, dipandu oleh reward kurikulum-α. GenEnv meningkatkan kinerja agen hingga 40,3% dalam beberapa benchmark, dan mencocokkan atau melampaui kinerja rata-rata model besar dengan data 3,3 kali lebih sedikit, menyediakan jalur yang efisien data untuk perluasan kemampuan agen. (来源: HuggingFace Daily Papers)
QuCo-RAG: Mengkuantifikasi Ketidakpastian dari Korpus Pre-training untuk RAG Dinamis : QuCo-RAG mengusulkan untuk mengkuantifikasi ketidakpastian dari data pre-training untuk mencapai RAG dinamis.