
Keywords:AI agent, LLM, Reinforcement learning, Multimodal AI, Autonomous driving, AI security, AI competition, Sakana AI ALE-Agent, ServiceNow AprielGuard, Gemini Interactions API, Kling AI 2.6 Motion Control, Transitive RL algorithm
🔥 Focus
Sakana AI Agent Wins Programming Contest: ALE-Agent, developed by Sakana AI, secured its first victory in the AtCoder Heuristic Programming Contest AHC058. The AI agent autonomously learned and created an unexpected ‘simulated annealing’ algorithm, outperforming over 800 participants. This achievement demonstrates the AI agent’s powerful autonomous learning and innovative capabilities in complex optimization problems, signaling AI’s immense potential in solving highly complex, unstructured problems, transcending traditional programming paradigms, and paving new paths for future AI-driven automated code generation and problem-solving. (Source: hardmaru)

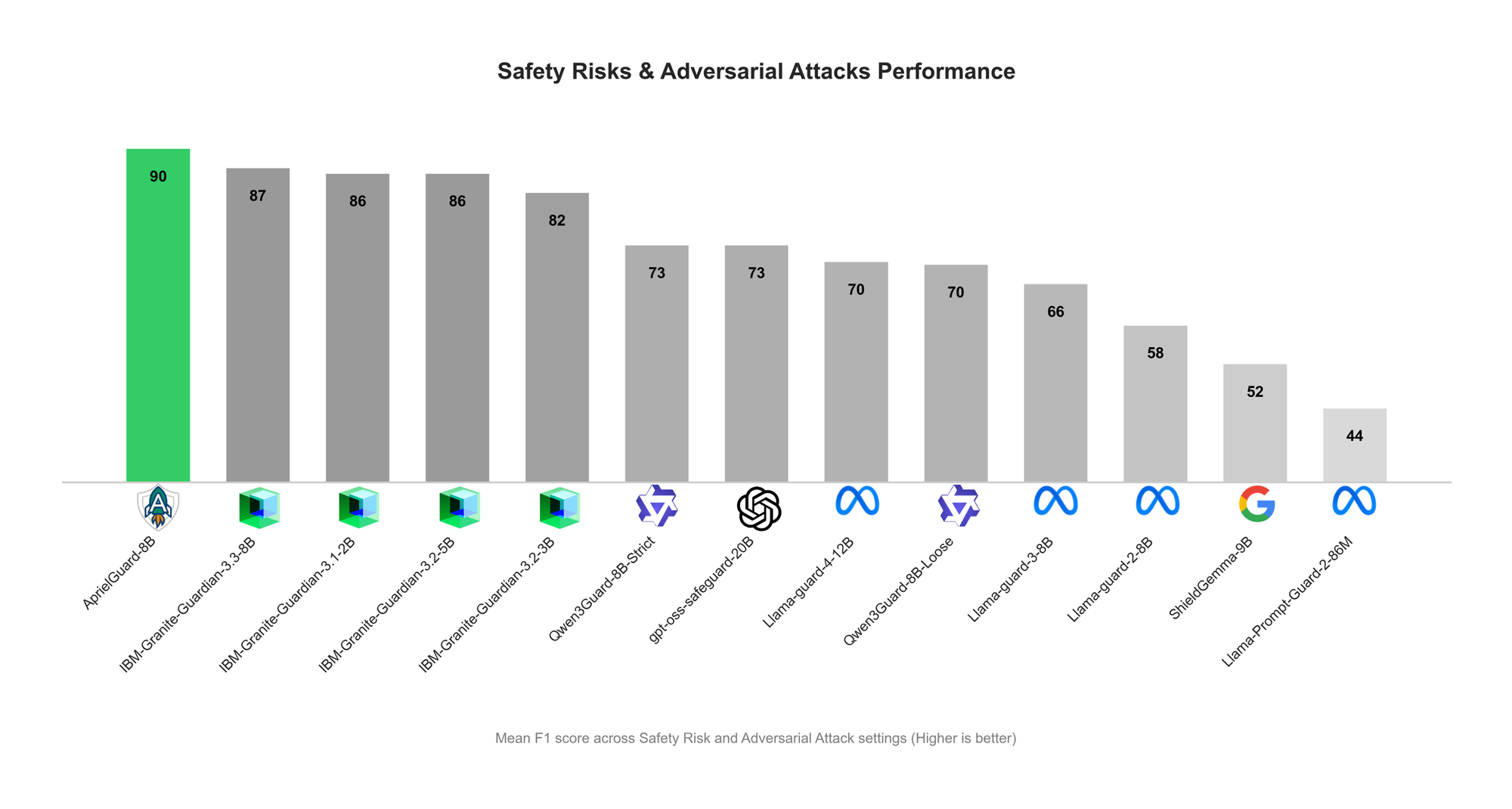
ServiceNow Releases AprielGuard: LLM Safety and Adversarial Robustness Guardrail: ServiceNow has released AprielGuard, an 8B-parameter safety guardrail model designed to detect 16 categories of safety risks and a wide range of adversarial attacks in modern LLM systems, including multi-turn jailbreaks, prompt injection, memory hijacking, and tool manipulation. The model supports both interpretative and non-interpretative modes, providing detailed classifications when explanations are needed, or achieving low-latency classification in production environments. By unifying models and classification taxonomies, AprielGuard addresses the limitations faced by traditional safety classifiers in multi-turn conversations, long contexts, and agentic workflows, providing a scalable foundation for building trustworthy AI deployments. (Source: HuggingFace Blog)
🎯 Trends
Karpathy Releases 2025 LLM Year in Review: RLVR Drives AI from Imitation to Reasoning: Andrej Karpathy, one of OpenAI’s founders, has released his ‘2025 Large Language Model Year in Review,’ highlighting a pivotal shift in AI training philosophy in 2025 from ‘probabilistic imitation’ to ‘logical reasoning’. The core driver is the maturation of Reinforcement Learning with Verifiable Rewards (RLVR), which, through objective feedback environments like mathematics and code, prompts models to spontaneously generate ‘reasoning traces’ similar to human thought. He emphasized that this long-horizon reinforcement learning has begun to replace traditional pre-training, becoming a new engine for enhancing model capabilities, and predicted that the AI competition in 2026 will shift towards the core logical paradigm of ‘how to make AI think efficiently’. (Source: 36氪)
US Launches ‘Project Genesis’: AI Manhattan Project Aims to Drive Scientific Breakthroughs: US President Trump signed an executive order, officially launching ‘Project Genesis,’ aimed at integrating the supercomputing capabilities of national laboratories with the wisdom of top scientists to leverage AI in driving scientific breakthroughs at an unprecedented pace. The initiative is likened to the ‘Manhattan Project during World War II,’ with the goal of creating an AI capable of autonomously driving scientific discovery. It aims to centralize the core competencies of the American scientific community, mobilizing 40,000 scientists and engineers from 17 Department of Energy national laboratories to fully pivot towards AI technology R&D, thereby rebuilding national technological sovereignty. (Source: 36氪)

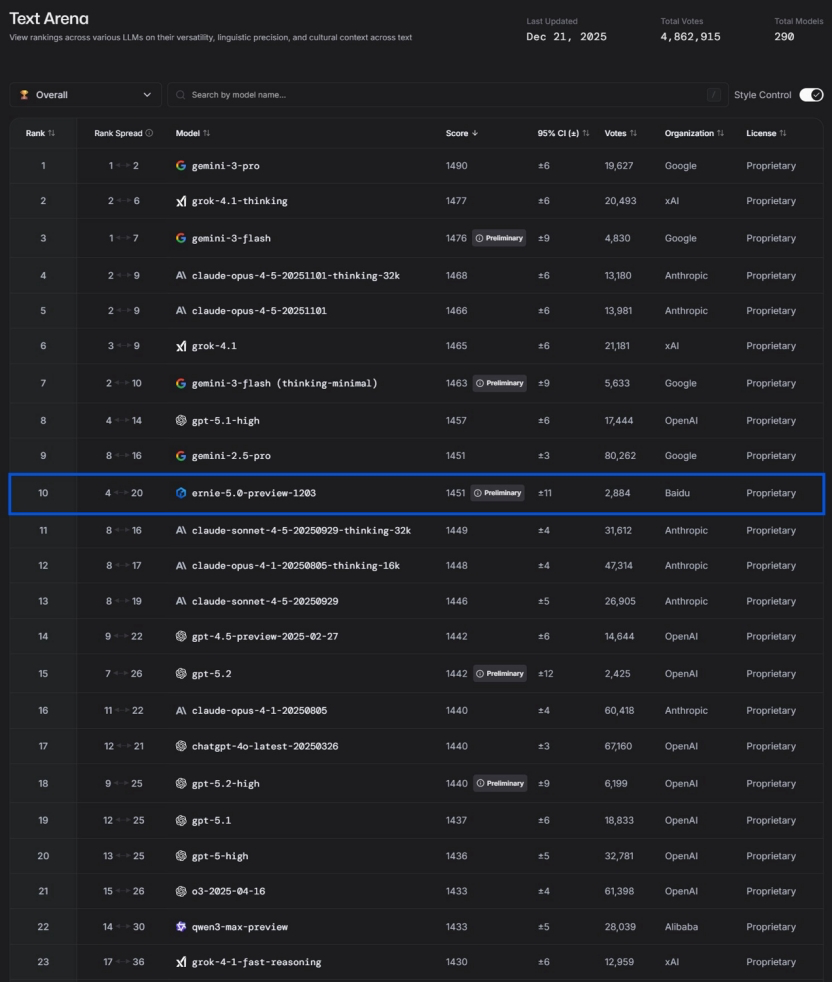
China’s AI Innovation and the Rise of Baidu ERNIE 5.0: In response to DeepMind’s assertion that Chinese AI ‘lacks innovation and merely fast-follows,’ some argue that China’s AI is forming unique technological barriers through practical application. Baidu ERNIE-5.0-Preview-1203 achieved first place domestically and a top-ten global ranking on the LMArena text leaderboard, surpassing GPT-5.2 and Claude Sonnet 4.5, becoming the only non-US model in the top 20. Its breakthrough is attributed to ‘native full-modality unified modeling,’ a 2.4 trillion-parameter MoE architecture, and a ‘unity of knowledge and action’ (知行合一) composite chain of thought. The article emphasizes the profound value of Chinese AI in physical world and industrial applications such as high-speed rail aerodynamic design, power grid inspection, SF Express code generation, and urban governance. (Source: 36氪)
Microsoft Copilot Faces User Adoption Challenges, Nadella Personally Oversees Improvements: Microsoft CEO Satya Nadella is personally overseeing Copilot’s improvements, reflecting that despite Copilot’s integration into the Office suite, user adoption has not met expectations. This indicates that AI competition has shifted from ‘demonstrating capabilities’ to ‘user retention,’ i.e., who can truly be used by users daily. The article points out that Copilot’s ‘guidance’ posture rather than a ‘partner’ role, coupled with mechanical interactions that over-cover scenarios, consumes user attention. Future AI competition will focus on ‘sense of proportion’ (分寸感), meaning when AI appears, when it remains silent, and whether it can provide more nuanced understanding to reduce users’ emotional costs. (Source: 36氪)

MiniMax M2.1 Released, GLM 4.7 Performance Enhanced: MiniMax M2.1 has officially launched as a 10B active parameter MoE architecture model, excelling in multilingual coding (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) and application/web development, achieving a SWE-bench multilingual score of 72.5%, surpassing Gemini 3 Pro and Claude Sonnet 4.5. Concurrently, GLM 4.7 also ranked first on the Vals Index open-source leaderboard and ninth overall, with a 9.5% performance improvement over GLM 4.6, particularly excelling in programming, Agent/ToolCall, and long-context recall capabilities. It also introduced a ‘thought preservation’ mechanism, enhancing the stability and controllability of complex tasks. (Source: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

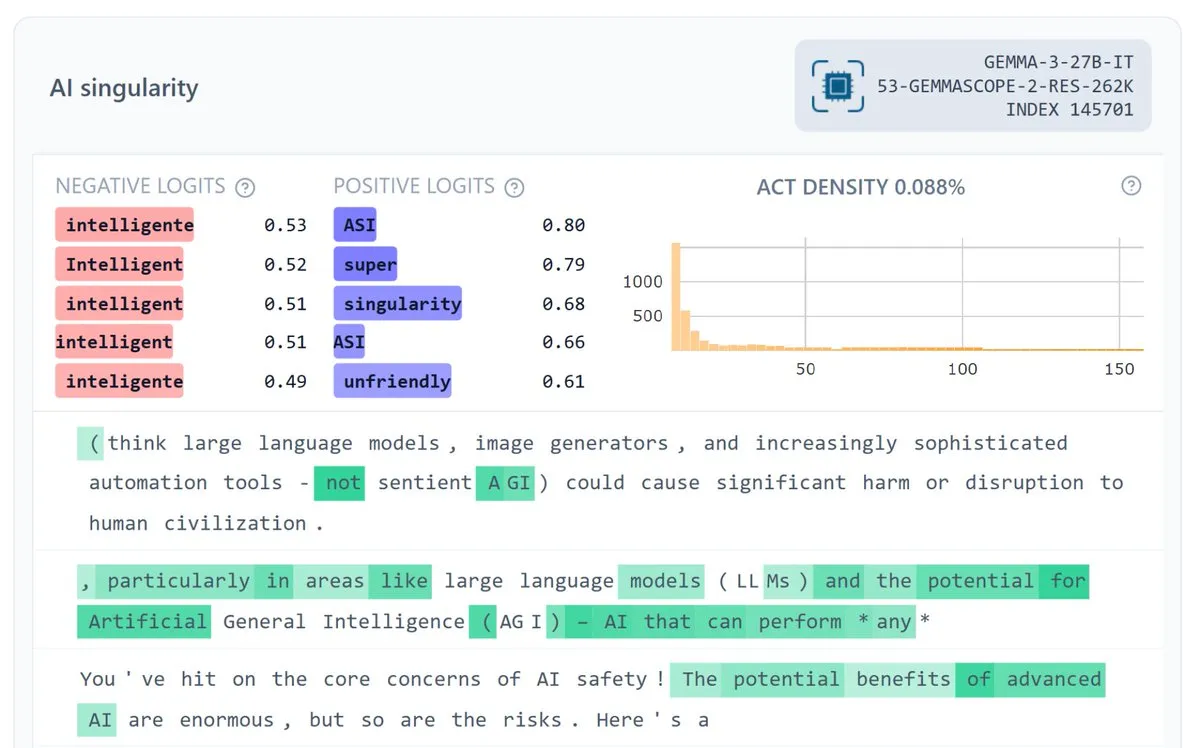
Google DeepMind Releases Gemma Scope 2, Enhancing Model Interpretability: Google DeepMind has released Gemma Scope 2, a full-stack interpretability suite for the Gemma 3 series models (270M-27B, base and chat versions), including Sparse Autoencoders (SAE) and transcoders for each layer. This initiative aims to foster a deeper understanding of complex model behaviors, support more ambitious open-source safety and interpretability research, and is expected to help the community better debug and analyze the internal workings of LLMs. (Source: NeelNanda5, Reddit r/artificial)
AI Agent State Management: Google Interactions API Simplifies Development but Raises Lock-in Concerns: Google has released the Gemini Interactions API, which handles conversation history, context management, and background execution on the server side, greatly simplifying AI agent development. This eliminates extensive infrastructure work such as vector database setup and custom context engineering, significantly accelerating development speed. However, this move has also raised concerns about vendor lock-in, loss of control over context storage and retrieval, difficulty in switching models, and opaque costs. This suggests that Google is leveraging infrastructure as a moat, similar to the AWS model, but the long-term implications of this black-box approach for ML workloads requiring high control over the entire stack remain to be seen. (Source: Reddit r/artificial)
Hugging Face Robotics Datasets Surge, Driving Open Robotics Ecosystem Development: Open robotics datasets on the Hugging Face platform have surged from 1,000 to 27,000 in the past two years, far exceeding other categories like text generation. This explosive growth is attributed to cheaper video storage, better tools, and the spread of open-source AI culture, significantly lowering the barrier to entry in robotics and accelerating the R&D process for general-purpose and humanoid robots. Open datasets make real-world robotics data (videos, actions, sensors, failures, etc.) easy to upload, reuse, and benchmark, transforming the robotics field into a more scalable and collaborative ecosystem. (Source: huggingface)
Tesla FSD vs. Waymo Autonomous Driving Path: End-to-End vs. Modular: Waymo and Tesla FSD exhibit distinctly different philosophies in their autonomous driving technology paths. Waymo employs a ‘modular’ approach, relying on high-definition maps, LiDAR, sensors, and 5G networks. If one module (e.g., a traffic light failure) malfunctions, the system might enter a ‘brick mode’. In contrast, Tesla FSD adopts an ‘end-to-end’ solution, directly converting camera pixels into steering and braking commands via a large neural network, more akin to human driving. Some argue that Waymo’s modular approach presents significant software issues in terms of scalability and dependencies, and in the long run, Tesla FSD’s end-to-end solution holds an advantage. (Source: Yuchenj_UW)
Zhihu Frontier Year in Review: 2025 AI Infrastructure and Multimodal Development: Zhihu Frontier has released its annual review, summarizing the structural progress in AI infrastructure and multimodal capabilities in 2025. It emphasizes that AI assistants need to possess human-like abilities to ‘see, hear, and reason,’ driving the development of multimodal and native speech technologies. Regarding model capabilities, 10B-parameter models have surpassed 100B+ models from 2024, with a 10x improvement in cost-effectiveness, and pre-training remains fundamental. AI infrastructure has become a competitive advantage, with distributed inference, Tile-based programming, large-scale reinforcement learning, and model-system co-design identified as key advancements. It also notes that effective communication and gaining attention have become essential skills for technical professionals. (Source: ZhihuFrontier)

🧰 Tools
Claude Code + Chrome Integration Enables Browser Automation: Claude Code now supports Chrome browser integration, allowing users to write code in the terminal and then have Claude open URLs, click buttons, fill forms, read console errors and DOM states, and even take screenshots and record GIFs in Chrome. This functionality requires no API or tokens, directly leveraging the user’s logged-in browser session, greatly simplifying multi-site automation workflows such as creating Google Sheets, extracting information from Hacker News, and populating tables. Although currently only supporting Chrome and lacking a headless mode, it provides developers with powerful, seamless browser interaction capabilities. (Source: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: A New Paradigm for AI Video Advertising: Kling AI 2.6 has introduced powerful motion control features, enabling realistic character replacement in videos, supporting lip-syncing and complex motion capture, and even applicable to non-human characters. This technology significantly enhances the testing potential for AI advertising, allowing advertisers to quickly generate ad variations across different ages, genders, ethnicities, and aesthetic styles, thereby enabling large-scale ad testing and optimization. By combining Nano Banana Pro for character generation and Elevenlabs for voice generation, Kling AI 2.6 brings revolutionary efficiency improvements to video content creation and the advertising industry. (Source: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8 Released, Enhancing LLM Application Evaluation and Observability: MLflow version 3.8 has been officially released, bringing advanced features for LLM application evaluation and observability. New features include prompt model configuration, allowing specific model settings to be associated with prompt templates to improve LLM workflow reproducibility; a tracking UI that supports displaying in-progress runs for real-time debugging and monitoring of LLM applications; integration with DeepEval and RAGAS Judges, offering over 20 evaluation metrics such as answer relevance, faithfulness, and hallucination detection; and new conversation safety scorers and conversation tool-call efficiency scorers, which evaluate the safety of multi-turn conversations and the efficiency of tool calls in agentic interactions, respectively. (Source: matei_zaharia)

vLLM Supports LongCat-Image-Edit and MiMo-V2-Flash, Simplifying Image Editing and Serving: The vLLM community has added support for Meituan’s LongCat-Image-Edit model, providing a simplified serving path for instruction-following image editing, supporting common operations such as object addition/replacement, background changes, and style adjustments, suitable for photo editing tools and creative editing workflows. Concurrently, vLLM has also released official tutorials guiding the deployment of Xiaomi’s MiMo/MiMo-V2-Flash models, including tool calling, DP/TP/EP configuration, and adjusting key parameters for context length, latency, and KV cache, further advancing LLM applications in multimodal and edge devices. (Source: vllm_project)

Reka Vision Sets New Standard for Smart Home Security AI: Reka Vision has launched a smart camera solution designed to go beyond traditional motion detection, achieving a deep understanding of events. The system reasons across video, audio, and time to reduce false positives and provide context-aware, human-level insights. Reka Vision is committed to setting a new standard for smart home security AI, enabling it to more accurately identify and understand complex events occurring in the home environment, thereby providing smarter and more reliable security monitoring services. (Source: RekaAILabs)
YouTube Playables Builder: Gemini 3 Empowers Game Creation: The YouTube Playables Builder web application is now live, powered by the Gemini 3 model, helping creators quickly develop fun, small games through text, video, or image prompts. This tool lowers the barrier to game development, enabling non-professional developers to leverage the power of AI to transform ideas into playable game experiences, potentially invigorating a new wave of UGC (User-Generated Content) gaming ecosystems and exploring more possibilities for AI in entertainment content creation. (Source: demishassabis)
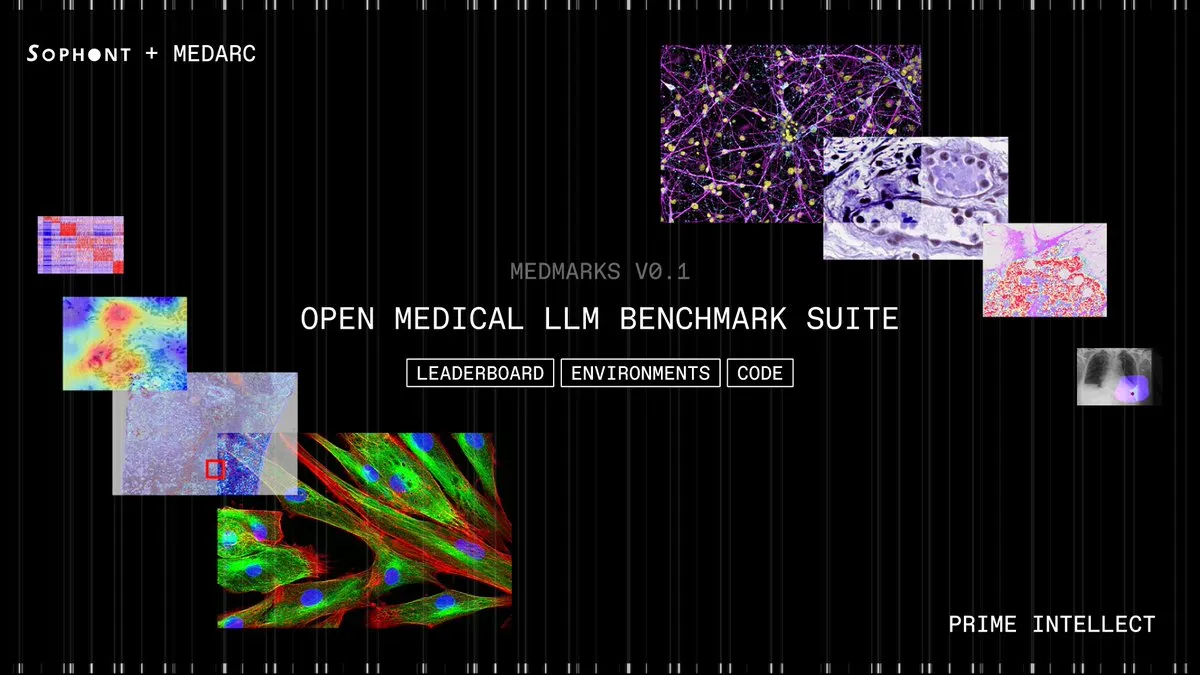
Medmarks v0.1 Released: The Largest Open-Source Medical LLM Evaluation Suite: Sophont AI has released Medmarks v0.1, currently the largest fully open-source automated evaluation suite for assessing the medical capabilities of LLMs. Developed by the MedARC AI community and supported by PrimeIntellect, the suite has explored 46 models to identify the best performers. The release of Medmarks v0.1 will significantly advance research and development in the medical AI field, providing standardized tools and benchmarks for evaluating and improving the performance of medical LLMs. (Source: iScienceLuvr)
Nano Banana Pro Combined with Gemini 3 Pro for Image Generation and Rendering: An agent application leverages Nano Banana Pro to generate images and renders them on a mobile phone via Gemini 3 Pro, showcasing the powerful capabilities of AI models in front-end aesthetic expression. For example, it can create web pages for Karpathy’s year-end summary and even change mouse styles. This combination not only provides an efficient image generation and rendering workflow but also hints at the immense potential of AI in User Interface/User Experience (UI/UX) design, capable of rapidly creating visually appealing content according to user needs. (Source: op7418)

Heretic: LLM Automated Censorship Removal Tool: Heretic is a fully automated censorship removal tool for LLMs. Its release has garnered widespread attention in the open-source AI community, as it aims to address potential censorship limitations in models when generating content. The emergence of Heretic offers users greater freedom but may also spark discussions about content safety and ethics, particularly regarding balancing freedom of speech with the generation of potentially harmful content. (Source: Reddit r/LocalLLaMA)
Claude Code Adds Reverse Search Functionality, Enhancing Prompt Management Efficiency: Claude Code has updated its features, adding the ability to perform reverse prompt search via Ctrl+R. Users can repeatedly press Ctrl+R to cycle through all prompts containing specific keywords, greatly enhancing the efficiency and convenience of prompt management. This improvement allows developers to more quickly find and reuse historical prompts, optimizing their AI programming workflow and reducing repetitive work. (Source: dejavucoder)
📚 Learning
New RL Paradigm: Transitive RL Solves Long-Horizon Tasks via Divide-and-Conquer: The BAIR blog introduces a new reinforcement learning algorithm called Transitive RL (TRL), which adopts a ‘divide-and-conquer’ paradigm instead of traditional Temporal Difference (TD) learning. TRL recursively divides trajectories into smaller segments and combines their values to update the value of the full trajectory, demonstrating better scalability for long-horizon tasks. This approach is particularly effective in goal-conditioned RL problems, where it significantly reduces the number of Bellman recursions by optimizing intermediate subgoals, avoiding the issue of error accumulation in TD learning, and offering a new direction for solving complex, long-horizon RL tasks. (Source: aihub.org)
LLMs Assist Mathematical Proofs: Former DeepMind Employee Explores P/=NP and Navier-Stokes: Former DeepMind engineer Bengoertzel explored using LLMs to assist in proving complex mathematical problems, such as the existence and uniqueness of Navier-Stokes equations and the P/=NP problem. He shared his experience using LLMs to fill in proof details; while the core ideas originated from himself, LLMs provided significant help in handling tedious specifics. This practice has sparked discussions on how to effectively combine human creative thinking with LLM’s detail-processing capabilities, and how to leverage formal verification tools like Lean to ensure the rigor of mathematical proofs, signaling AI’s potential role in advanced mathematical research. (Source: bengoertzel)
Evolution of LLM Training Eras: From Pre-training to RLVR and GRPO: The LLM training paradigm is undergoing rapid evolution. From pre-training (foundation models) in 202x, to RLHF+PPO in 2022, then LoRA SFT in 2023, and mid-training in 2024. It is predicted that 2025 will usher in the era of RLVR+GRPO, while 2026 might see the period of ‘On Policy Distillation’. This evolutionary roadmap reveals the continuous deepening and optimization of LLM training methodologies, moving from initial foundational capability building towards more refined training strategies that emphasize feedback and efficiency, indicating that future models will increasingly focus on learning from interaction and distilling knowledge. (Source: bookwormengr)
Research on LLM Memory Mechanisms: Internal Workings of Claude and ChatGPT: Research has delved into the memory mechanisms of LLMs like Claude and ChatGPT, analyzing how they process and retain conversational context information. These studies reveal how internal model states influence memory formation and retrieval, as well as the challenges of maintaining coherence in multi-turn conversations. Understanding the working principles of LLM memory is crucial for optimizing conversational systems, enhancing user experience, and addressing long-context comprehension issues, also providing a theoretical foundation for future more efficient and stable AI interaction design. (Source: dejavucoder)
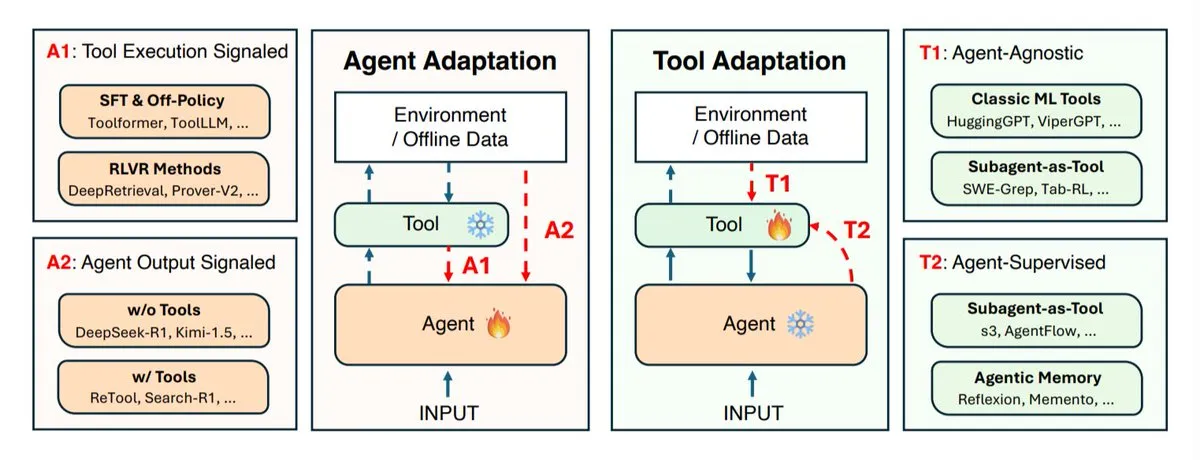
Research on AI Agent Adaptation Strategies: Co-evolution of Agents and Tools: Research institutions including UIUC, Stanford, and Harvard have explored AI agent adaptation strategies, primarily categorized into two types: adapting the agent itself (reasoning model) and adapting the tools it uses (search systems, retrievers, memory, APIs). The research defines four types of adaptation: adapting the agent using tool results, training the agent using its own outputs, independently adapting tools, and training tools with feedback from a frozen agent. These strategies provide theoretical guidance for developing smarter, more flexible AI agents, emphasizing the importance of co-evolution between agents and tools to cope with complex and dynamic task environments. (Source: TheTuringPost)
Research on Enhancing AI Model Reasoning Capabilities: Roles of Pre-training, Mid-training, and Reinforcement Learning: Researchers at Carnegie Mellon University have found that pre-training, mid-training, and reinforcement learning play distinct roles in enhancing AI model reasoning capabilities. The study indicates that reinforcement learning truly enhances reasoning capabilities only under specific conditions, cross-context generalization requires prior pre-training, mid-training is crucial, and process-aware rewards are indispensable. These findings provide guidance for optimizing AI model training strategies, emphasizing the importance of adopting targeted approaches at different stages to maximize reasoning capabilities. (Source: TheTuringPost)

KappaTune: Addressing Catastrophic Forgetting in LLM Fine-tuning: KappaTune is a new LLM fine-tuning method designed to address the catastrophic forgetting problem present in existing methods like LoRA. KappaTune exhibits 6 times less forgetting than LoRA and requires no pre-training data. The method maximizes the potential of Mixture-of-Experts (MoE) models by leveraging their fine-grained tensor selection capabilities. The emergence of KappaTune provides a more efficient solution for continuous learning and adaptability in LLMs, promising to reduce model maintenance costs and promote the widespread adoption of AI. (Source: Reddit r/deeplearning)

Policy-to-Tests (P2T) Framework: Bridging the Gap Between AI Policies and Executable Rules: The Policy→Tests (P2T) framework aims to transform AI governance policies written in natural language (such as the EU AI Act, NIST AI RMF) into executable rules. The framework, through a scalable pipeline and a compact JSON DSL, converts policy documents into standardized atomic rules, including risk, scope, conditions, exceptions, evidence signals, and provenance. P2T addresses the bottleneck between policy interpretation and tool execution, particularly in complex domains like healthcare data, where it can significantly reduce the time required to map HIPAA requirements to ML pipeline checks, enhancing the efficiency and verifiability of AI governance. (Source: Reddit r/MachineLearning)
GenEnv: Co-evolution of LLM Agents and Environment Simulators with Difficulty Alignment: GenEnv is a framework that addresses the bottlenecks of costly and static real-world interaction data when training LLM agents by establishing a difficulty-aligned co-evolutionary game between agents and scalable generative environment simulators. The simulator acts as a dynamic curriculum strategy, continuously generating tasks specifically tailored to the agent’s ‘zone of proximal development,’ guided by α-curriculum rewards. GenEnv has improved agent performance by up to 40.3% across multiple benchmarks and matched or surpassed the average performance of large models with 3.3 times less data, providing a data-efficient pathway for agent capability expansion. (Source: HuggingFace Daily Papers)
QuCo-RAG: Quantifying Uncertainty from Pre-training Corpora for Dynamic RAG: QuCo-RAG proposes quantifying uncertainty from pre-training data to achieve