
Palavras-chave:Agente de IA, LLM, Aprendizagem por Reforço, IA Multimodal, Condução Autônoma, Segurança de IA, Competição de IA, Sakana AI ALE-Agent, ServiceNow AprielGuard, API Gemini Interactions, Kling AI 2.6 Controle de Movimento, Algoritmo Transitive RL
🔥 Foco
Agente Sakana AI vence competição de programação : O ALE-Agent, desenvolvido pela Sakana AI, conquistou o primeiro lugar na competição de programação heurística AtCoder AHC058. O agente de IA aprendeu de forma autônoma e criou um método inesperado para humanos, o “焼きなまし法” (algoritmo de recozimento simulado), destacando-se entre mais de 800 participantes. Esta conquista demonstra a poderosa capacidade de aprendizagem autônoma e inovação dos agentes de IA em problemas de otimização complexos, prenunciando o enorme potencial da IA na resolução de problemas altamente complexos e não estruturados, superando os paradigmas de programação tradicionais e abrindo novos caminhos para a geração automatizada de código e resolução de problemas impulsionada por IA no futuro. (Fonte: hardmaru)

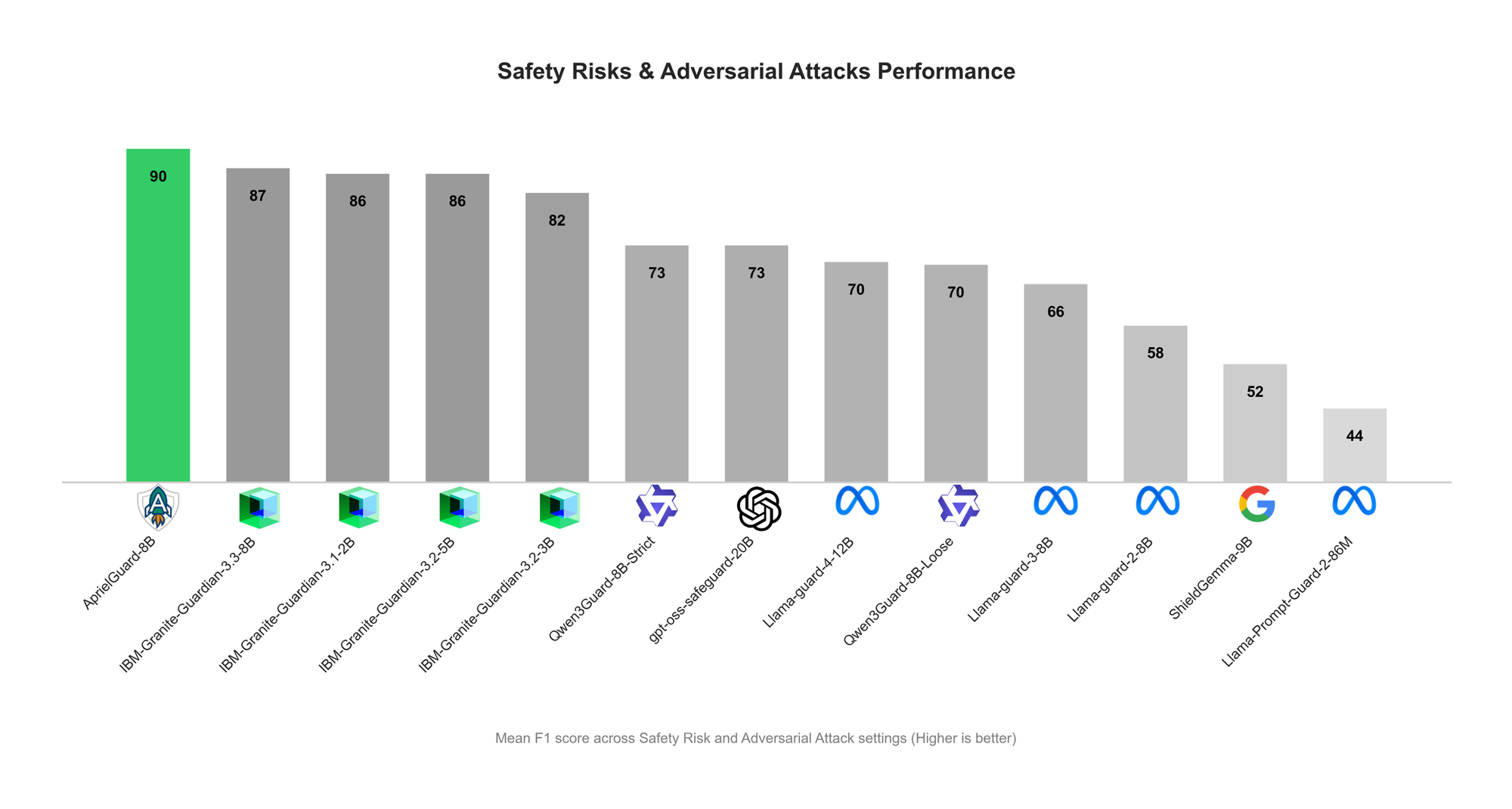
ServiceNow lança AprielGuard: Guardrail de segurança e robustez adversarial para LLMs : A ServiceNow lançou o AprielGuard, um modelo de guardrail de segurança de 8B parâmetros, projetado para detectar 16 categorias de riscos de segurança e uma ampla gama de ataques adversariais em sistemas LLM modernos, incluindo jailbreaks multi-turn, prompt injection, memory hijacking e tool manipulation. O modelo suporta modos de inferência e não inferência, fornecendo classificação detalhada quando a explicação é necessária, ou classificação de baixa latência em ambientes de produção. AprielGuard, através de um modelo unificado e taxonomia unificada, aborda as limitações que os classificadores de segurança tradicionais enfrentam em diálogos multi-turn, contextos longos e fluxos de trabalho de agente, fornecendo uma base escalável para a construção de implantações de IA confiáveis. (Fonte: HuggingFace Blog)
🎯 Tendências
Karpathy lança Revisão Anual de LLMs de 2025: RLVR impulsiona a IA da imitação ao raciocínio : Andrej Karpathy, um dos fundadores da OpenAI, lançou a “Revisão Anual de Grandes Modelos de Linguagem de 2025”, apontando para uma mudança fundamental na filosofia de treinamento de IA em 2025, da “imitação probabilística” para o “raciocínio lógico”. A força motriz central é a maturidade da aprendizagem por reforço com recompensa verificável (RLVR), que, através de ambientes de feedback objetivo como matemática e código, leva os modelos a gerar espontaneamente “rastros de raciocínio” semelhantes ao pensamento humano. Ele enfatiza que esta aprendizagem por reforço de longo ciclo começou a substituir o pré-treinamento tradicional, tornando-se um novo motor para melhorar a capacidade do modelo, e prevê que a competição de IA em 2026 se voltará para o paradigma lógico central de “como fazer a IA pensar de forma eficiente”. (Fonte: 36氪)
EUA lançam “Missão Gênesis”: Plano Manhattan da IA visa impulsionar descobertas científicas : O presidente dos EUA, Trump, assinou uma ordem executiva, lançando oficialmente a “Missão Gênesis”, que visa integrar as capacidades de supercomputação dos laboratórios nacionais com a sabedoria de cientistas de ponta, utilizando a IA para impulsionar descobertas científicas a uma velocidade sem precedentes. O plano é comparado ao “Projeto Manhattan da Segunda Guerra Mundial”, com o objetivo de criar uma IA capaz de impulsionar descobertas científicas de forma autônoma e concentrar a competitividade central da comunidade científica dos EUA, mobilizando 40.000 cientistas e engenheiros dos 17 laboratórios nacionais do Departamento de Energia para mudar completamente para a pesquisa e desenvolvimento de tecnologia de IA, a fim de reconstruir a soberania tecnológica nacional. (Fonte: 36氪)

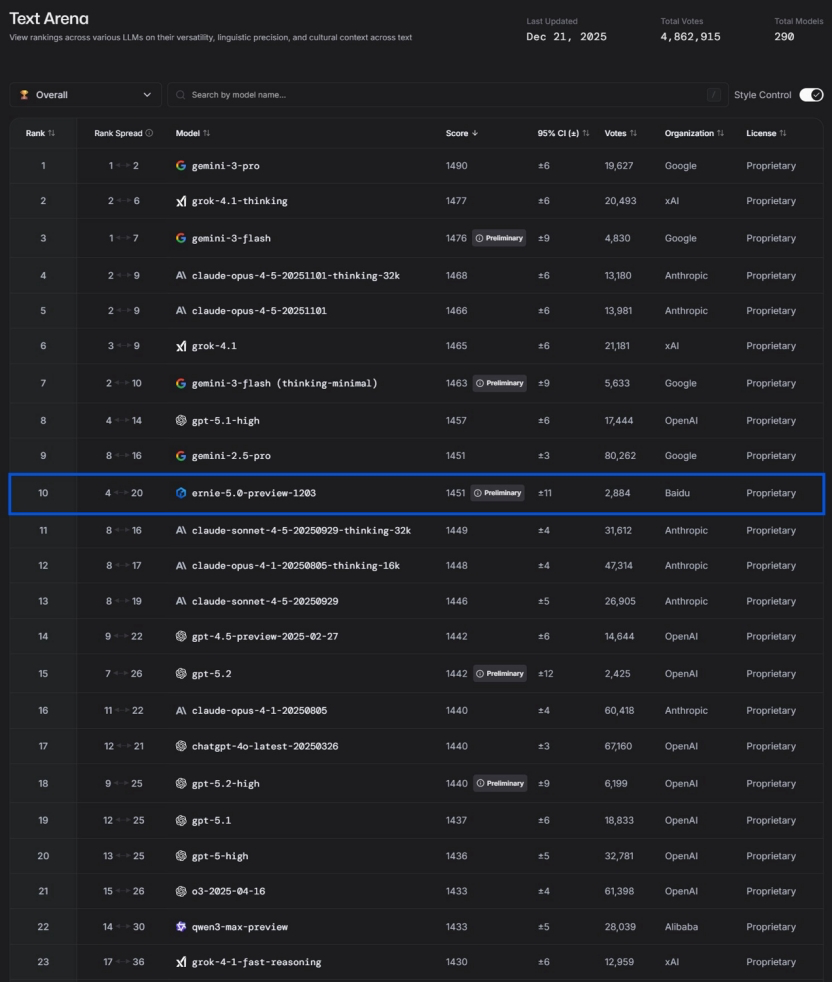
Inovação chinesa em IA e a ascensão do Baidu Wenxin 5.0 : Em resposta à afirmação de DeepMind de que a IA chinesa “carece de inovação, sendo apenas um seguidor rápido”, há quem aponte que a IA chinesa está formando barreiras tecnológicas únicas através da implementação de aplicações. O Baidu Wenxin ERNIE-5.0-Preview-1203 alcançou o primeiro lugar nacional e entre os dez primeiros globalmente no ranking de texto LMArena, superando GPT-5.2 e Claude Sonnet 4.5, tornando-se o único modelo não americano entre os 20 primeiros. Seu avanço é atribuído à “modelagem unificada multimodal nativa”, uma arquitetura MoE de 2,4 trilhões de parâmetros, e uma “cadeia de pensamento composta” de “conhecimento e ação unificados”. O artigo destaca o valor profundo da IA chinesa no mundo físico e em aplicações industriais, como design aerodinâmico de trens de alta velocidade, inspeção de redes elétricas, geração de código para SF Express e governança urbana. (Fonte: 36氪)
Microsoft Copilot enfrenta desafios de adoção pelo usuário, Satya Nadella supervisiona pessoalmente : Satya Nadella, CEO da Microsoft, está pessoalmente supervisionando as melhorias do Copilot, refletindo que, embora o Copilot esteja integrado ao pacote Office, a taxa de adoção pelo usuário não atingiu as expectativas. Isso indica que a competição de IA mudou da “demonstração de capacidade” para a “retenção de usuários”, ou seja, quem pode realmente ser usado pelos usuários no dia a dia. O artigo aponta que a postura de “guia” do Copilot, em vez de um papel de “parceiro”, e as interações mecânicas que cobrem excessivamente os cenários, consomem a atenção do usuário. A futura competição de IA focará no “senso de proporção”, ou seja, quando a IA deve aparecer, quando deve permanecer em silêncio, e se pode fornecer uma compreensão mais sutil, reduzindo o custo emocional do usuário. (Fonte: 36氪)

MiniMax M2.1 lançado, desempenho do GLM 4.7 aprimorado : O MiniMax M2.1 foi oficialmente lançado, como um modelo de arquitetura MoE com 10B parâmetros ativados, destacando-se em codificação multilíngue (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) e desenvolvimento de aplicativos/web, com uma pontuação de 72,5% no SWE-bench multilíngue, superando Gemini 3 Pro e Claude Sonnet 4.5. Simultaneamente, o GLM 4.7 também ficou em primeiro lugar no ranking de código aberto Vals Index e em nono lugar na classificação geral, com um desempenho 9,5% superior ao GLM 4.6, destacando-se particularmente em programação, Agent/ToolCall e capacidade de recuperação de contexto longo, e introduziu um mecanismo de “retenção de pensamento”, melhorando a estabilidade e controlabilidade de tarefas complexas. (Fonte: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

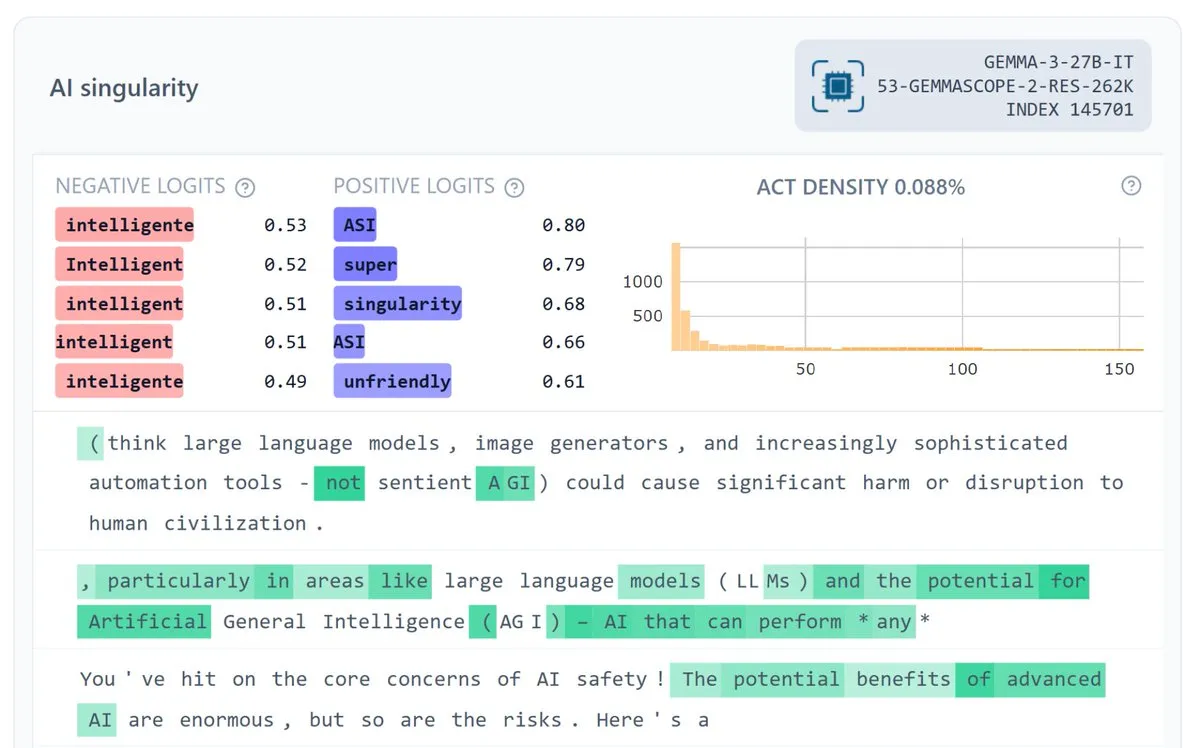
Google DeepMind lança Gemma Scope 2, melhorando a interpretabilidade do modelo : Google DeepMind lançou Gemma Scope 2, um pacote de interpretabilidade full-stack para os modelos da série Gemma 3 (270M-27B, versões base e chat), contendo SAEs (sparse autoencoders) e transcodificadores para cada camada. Esta iniciativa visa promover uma compreensão aprofundada do comportamento de modelos complexos, apoiar pesquisas mais ambiciosas de segurança e interpretabilidade de código aberto, e espera-se que ajude a comunidade a depurar e analisar melhor os mecanismos internos de funcionamento dos LLMs. (Fonte: NeelNanda5, Reddit r/artificial)
Gerenciamento de estado de agentes de IA: Google Interactions API simplifica o desenvolvimento, mas levanta preocupações de bloqueio : O Google lançou a Interactions API do Gemini, que processa o histórico de conversas, gerenciamento de contexto e execução em segundo plano no lado do servidor, simplificando enormemente o desenvolvimento de agentes de IA. Isso eliminou muito trabalho de infraestrutura, como configuração de banco de dados vetorial e engenharia de contexto personalizada, aumentando significativamente a velocidade de desenvolvimento. No entanto, esta iniciativa também levantou preocupações sobre bloqueio de fornecedor, perda de controle sobre o armazenamento e recuperação de contexto, dificuldade na troca de modelos e custos não transparentes. Isso indica que o Google está usando a infraestrutura como um fosso, semelhante ao modelo AWS, mas para cargas de trabalho de ML que exigem alto controle sobre toda a pilha, o impacto a longo prazo deste modo caixa-preta ainda precisa ser observado. (Fonte: Reddit r/artificial)
Conjuntos de dados de robótica do Hugging Face aumentam drasticamente, impulsionando o desenvolvimento de um ecossistema de robótica aberta : Os conjuntos de dados de robótica aberta na plataforma Hugging Face aumentaram de 1.000 para 27.000 nos últimos dois anos, superando em muito outras categorias como geração de texto. Este crescimento explosivo é atribuído ao armazenamento de vídeo mais barato, melhores ferramentas e à disseminação da cultura de IA de código aberto, que reduziu drasticamente as barreiras de entrada no campo da robótica, acelerando o processo de P&D de robôs gerais e humanoides. Os conjuntos de dados abertos tornaram os dados reais de robôs (vídeos, ações, sensores, falhas, etc.) fáceis de carregar, reutilizar e testar, transformando o campo da robótica em um ecossistema mais escalável e colaborativo. (Fonte: huggingface)
Disputa de caminho da condução autônoma: Tesla FSD vs. Waymo: End-to-end vs. modular : Waymo e Tesla FSD exibem filosofias de tecnologia de condução autônoma marcadamente diferentes. Waymo adota uma abordagem “modular”, dependendo de mapas de alta definição, LiDAR, sensores e rede 5G. Uma vez que um desses módulos (como um semáforo com defeito) falhe, o sistema pode entrar em “modo tijolo”. Em contraste, o Tesla FSD adota uma solução “end-to-end”, convertendo diretamente os pixels da câmera em comandos de direção e frenagem através de uma grande rede neural, mais parecido com a condução humana. Há quem argumente que o método modular da Waymo apresenta enormes problemas de software em termos de escalabilidade e dependência, e que a longo prazo, a solução end-to-end do Tesla FSD é mais vantajosa. (Fonte: Yuchenj_UW)
Revisão Anual Zhihu Frontier: Infraestrutura de IA e desenvolvimento multimodal em 2025 : Zhihu Frontier lançou sua revisão anual, resumindo os avanços estruturais no campo da IA em 2025 em termos de infraestrutura e multimodalidade. Enfatiza que os assistentes de IA precisam ter a capacidade de “ver, ouvir e raciocinar” como humanos, impulsionando o desenvolvimento de tecnologias multimodais e de voz nativas. Em termos de capacidade do modelo, modelos de 10B parâmetros já superaram modelos de 100B+ de 2024, com uma melhoria de 10 vezes na eficiência de custo, e o pré-treinamento continua sendo a base. A infraestrutura de IA tornou-se uma vantagem competitiva, com inferência distribuída, programação baseada em Tile, aprendizagem por reforço em larga escala e design colaborativo modelo-sistema sendo avanços chave. Também aponta que a comunicação eficaz e a obtenção de atenção se tornaram habilidades essenciais para profissionais de tecnologia. (Fonte: ZhihuFrontier)

🧰 Ferramentas
Integração Claude Code + Chrome para automação de navegador : O Claude Code agora suporta integração com o navegador Chrome, permitindo aos usuários escrever código no terminal e, em seguida, fazer com que Claude abra URLs no Chrome, clique em botões, preencha formulários, leia erros de console e o estado do DOM, e até mesmo tire screenshots e grave GIFs. Esta funcionalidade não requer API ou token, utilizando diretamente a sessão do navegador logada do usuário, simplificando enormemente os fluxos de trabalho de automação multi-site, como criar Google Sheets, extrair informações do Hacker News e preencher tabelas. Embora atualmente suporte apenas Chrome e não tenha modo headless, oferece aos desenvolvedores poderosas capacidades de interação contínua com o navegador. (Fonte: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: Novo paradigma para anúncios em vídeo com IA : O Kling AI 2.6 lançou poderosas funcionalidades de controle de movimento, permitindo a substituição realista de pessoas em vídeos, e suportando sincronização labial e captura de movimento complexa, e até mesmo para personagens não humanos. Esta tecnologia aumentou drasticamente o potencial de teste de anúncios de IA, permitindo aos anunciantes gerar rapidamente variantes de anúncios de diferentes idades, gêneros, etnias e estilos estéticos, alcançando assim testes e otimização de anúncios em larga escala. Ao combinar Nano Banana Pro para gerar personagens e Elevenlabs para gerar vozes, o Kling AI 2.6 trouxe um aumento revolucionário na eficiência para a criação de conteúdo de vídeo e a indústria de publicidade. (Fonte: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8 lançado, aprimora as capacidades de avaliação e observabilidade de aplicações LLM : A versão MLflow 3.8 foi oficialmente lançada, trazendo funcionalidades avançadas para a avaliação e observabilidade de aplicações baseadas em LLM. As novas funcionalidades incluem configuração de modelo de prompt, permitindo associar configurações específicas do modelo a templates de prompt para melhorar a reprodutibilidade do fluxo de trabalho LLM; a UI de rastreamento suporta a exibição de rastreamentos em andamento, permitindo depuração e monitoramento em tempo real de aplicações LLM; integra DeepEval e RAGAS Judges, fornecendo mais de 20 métricas de avaliação, como relevância da resposta, fidelidade e detecção de alucinações; adiciona um avaliador de segurança de diálogo e um avaliador de eficiência de chamada de ferramenta de diálogo, avaliando respectivamente a segurança de diálogos multi-turn e a eficiência da chamada de ferramentas em interações de agente. (Fonte: matei_zaharia)

vLLM suporta LongCat-Image-Edit e MiMo-V2-Flash, simplificando a edição e o serviço de imagens : A comunidade vLLM adicionou suporte para o modelo Meituan LongCat-Image-Edit, fornecendo um caminho de serviço mais simplificado para edição de imagem orientada por instruções, suportando operações comuns como adição/substituição de objetos, mudança de fundo e ajuste de estilo, adequado para ferramentas de edição de fotos e fluxos de trabalho de edição criativa. Simultaneamente, o vLLM também lançou tutoriais oficiais, orientando como implantar os modelos Xiaomi MiMo/MiMo-V2-Flash, incluindo chamada de ferramenta, configuração DP/TP/EP e ajuste de parâmetros chave como comprimento de contexto, latência e cache KV, impulsionando ainda mais as aplicações de LLM em multimodalidade e dispositivos de borda. (Fonte: vllm_project)

Reka Vision estabelece um novo padrão para IA de segurança em casas inteligentes : Reka Vision lançou uma solução de câmera inteligente, visando ir além da detecção de movimento tradicional para alcançar uma compreensão profunda dos eventos. O sistema raciocina através de vídeo, áudio e tempo, reduzindo falsos positivos e fornecendo insights contextuais e de nível humano. Reka Vision dedica-se a estabelecer um novo padrão para IA de segurança em casas inteligentes, permitindo que ela identifique e compreenda com mais precisão eventos complexos que ocorrem no ambiente doméstico, proporcionando assim serviços de monitoramento de segurança mais inteligentes e confiáveis. (Fonte: RekaAILabs)
YouTube Playables Builder: Gemini 3 capacita a criação de jogos : O aplicativo web YouTube Playables Builder foi lançado, alimentado pelo modelo Gemini 3, ajudando criadores a desenvolver rapidamente jogos divertidos e pequenos através de prompts de texto, vídeo ou imagem. Esta ferramenta reduziu a barreira de entrada para o desenvolvimento de jogos, permitindo que desenvolvedores não profissionais também aproveitem o poder da IA para transformar ideias criativas em experiências de jogo jogáveis, e espera-se que estimule nova vitalidade no ecossistema de jogos UGC (conteúdo gerado pelo usuário) e explore mais possibilidades da IA na criação de conteúdo de entretenimento. (Fonte: demishassabis)
Medmarks v0.1 lançado: O maior conjunto de avaliação de LLM médico de código aberto : A Sophont AI lançou o Medmarks v0.1, o maior conjunto de avaliação automatizada totalmente de código aberto atualmente, para avaliar as capacidades médicas de LLMs. O conjunto, desenvolvido pela comunidade MedARC AI e apoiado pela PrimeIntellect, explorou 46 modelos para encontrar o melhor desempenho. O lançamento do Medmarks v0.1 impulsionará enormemente a pesquisa e o desenvolvimento no campo da IA médica, fornecendo ferramentas e benchmarks padronizados para avaliar e melhorar o desempenho dos LLMs médicos. (Fonte: iScienceLuvr)
Nano Banana Pro e Gemini 3 Pro combinam para alcançar geração e renderização de imagens : Um aplicativo de agente utiliza Nano Banana Pro para gerar imagens e as renderiza em telefones via Gemini 3 Pro, demonstrando a poderosa capacidade dos modelos de IA em termos de desempenho estético de front-end. Por exemplo, ele pode criar páginas web para o resumo de fim de ano de Karpathy e até mesmo mudar o estilo do cursor. Esta combinação não só oferece fluxos de trabalho eficientes de geração e renderização de imagens, mas também sugere o enorme potencial da IA no campo do design de interface de usuário/experiência de usuário (UI/UX), capaz de criar rapidamente conteúdo visualmente atraente de acordo com as necessidades do usuário. (Fonte: op7418)

Heretic: Ferramenta de remoção automática de censura para LLMs : Heretic é uma ferramenta de remoção de censura totalmente automatizada para LLMs. Na comunidade de IA de código aberto, o lançamento desta ferramenta gerou ampla atenção, pois visa resolver as limitações de censura que os modelos podem ter ao gerar conteúdo. O surgimento de Heretic oferece aos usuários maior liberdade, mas também pode levantar discussões sobre segurança e ética do conteúdo, especialmente no equilíbrio entre a liberdade de expressão e a geração de conteúdo potencialmente prejudicial. (Fonte: Reddit r/LocalLLaMA)
Claude Code adiciona função de busca reversa, melhorando a eficiência do gerenciamento de prompts : O Claude Code atualizou suas funcionalidades, adicionando a capacidade de busca reversa de prompts via Ctrl+R. Os usuários podem pressionar repetidamente Ctrl+R para percorrer e visualizar todos os prompts que contêm palavras-chave específicas, o que melhorou enormemente a eficiência e conveniência do gerenciamento de prompts. Esta melhoria permite que os desenvolvedores encontrem e reutilizem prompts históricos mais rapidamente, otimizando seus fluxos de trabalho de programação de IA e reduzindo o trabalho repetitivo. (Fonte: dejavucoder)
📚 Aprendizagem
Novo paradigma de RL: Transitive RL resolve tarefas de longo ciclo através do método de dividir e conquistar : O blog BAIR apresentou um novo algoritmo de aprendizagem por reforço chamado Transitive RL (TRL), que adota um paradigma de “dividir e conquistar”, em vez da aprendizagem por diferença temporal (TD) tradicional. O TRL, dividindo recursivamente as trajetórias em segmentos menores e combinando seus valores para atualizar o valor da trajetória completa, demonstra assim melhor escalabilidade para tarefas de longo ciclo. Este método é particularmente eficaz em problemas de RL condicionados por objetivos, pois, otimizando sub-objetivos intermediários, reduz significativamente o número de recursões de Bellman e evita o problema de acumulação de erros na aprendizagem TD, oferecendo uma nova direção para resolver tarefas de RL complexas e de longo prazo. (Fonte: aihub.org)
LLM auxilia na prova matemática: Ex-funcionário da DeepMind explora P/=NP e Navier-Stokes : Bengoertzel, ex-engenheiro da DeepMind, explorou o uso de LLMs para auxiliar na prova de problemas matemáticos complexos, como a existência e unicidade das equações de Navier-Stokes, e o problema P/=NP. Ele compartilhou sua experiência no uso de LLMs para preencher detalhes de provas, e embora a ideia central tenha vindo dele, os LLMs forneceram ajuda significativa no tratamento de detalhes tediosos. Esta prática gerou discussões sobre como combinar efetivamente o pensamento criativo humano com a capacidade de processamento de detalhes dos LLMs, e o uso de ferramentas de verificação formal como Lean para garantir o rigor das provas matemáticas, prenunciando o papel potencial da IA na pesquisa matemática avançada. (Fonte: bengoertzel)
Evolução da era de treinamento de LLMs: Do pré-treinamento ao RLVR e GRPO : O paradigma de treinamento de LLMs está passando por uma rápida evolução. Do pré-treinamento (modelos base) em 202x, para RLHF+PPO em 2022, LoRA SFT em 2023, e mid-training em 2024. Prevê-se que 2025 entrará na era de RLVR+GRPO, e 2026 poderá inaugurar o período de “On Policy Distillation”. Este roteiro de evolução revela o aprofundamento e a otimização contínuos da metodologia de treinamento de LLMs, desde a construção inicial de capacidades básicas, gradualmente mudando para estratégias de treinamento mais refinadas, focadas em feedback e eficiência, prenunciando que os modelos futuros enfatizarão mais aprender com interações e destilar conhecimento. (Fonte: bookwormengr)
Pesquisa sobre mecanismos de memória de LLMs: Princípios de funcionamento internos de Claude e ChatGPT : Pesquisas aprofundaram-se na exploração dos mecanismos de memória de LLMs como Claude e ChatGPT, analisando como eles processam e retêm informações de contexto de diálogo. Estes estudos revelam como o estado interno do modelo afeta a formação e recuperação da memória, e os desafios de manter a coerência em diálogos multi-turn. A compreensão dos princípios de funcionamento da memória dos LLMs é crucial para otimizar sistemas de diálogo, melhorar a experiência do usuário e resolver problemas de compreensão de contexto longo, e fornece uma base teórica para um design de interação de IA mais eficiente e estável no futuro. (Fonte: dejavucoder)
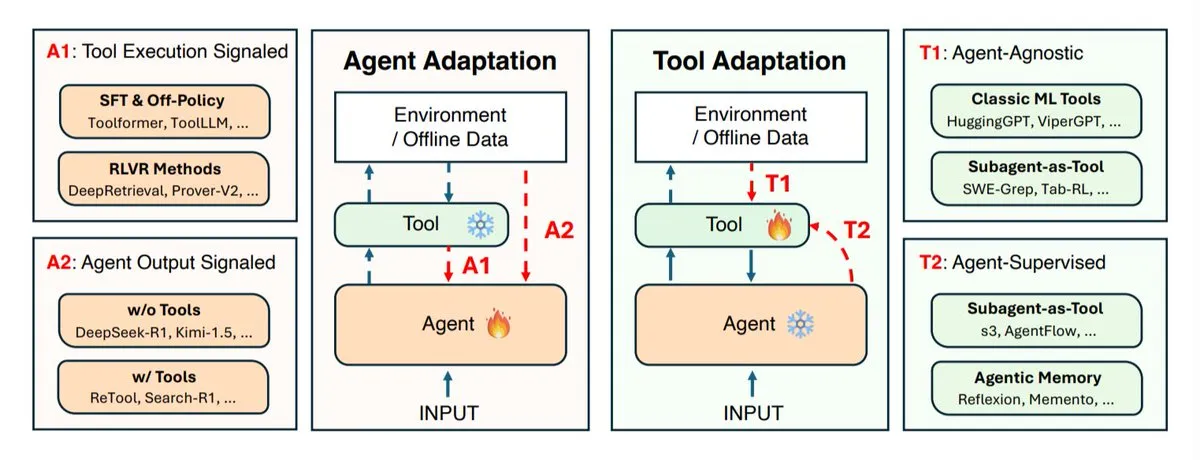
Pesquisa sobre estratégias de adaptação de agentes de IA: Co-evolução de agentes e ferramentas : Instituições de pesquisa como UIUC, Stanford e Harvard exploraram as estratégias de adaptação de agentes de IA, divididas principalmente em duas categorias: adaptar o próprio agente (modelo de inferência) e adaptar as ferramentas que ele usa (sistemas de busca, recuperadores, memória, API). O estudo define quatro tipos de adaptação: adaptar o agente usando os resultados da ferramenta, treinar o agente usando sua própria saída, adaptar a ferramenta independentemente, e treinar a ferramenta através do feedback do agente congelado. Estas estratégias fornecem orientação teórica para o desenvolvimento de agentes de IA mais inteligentes e flexíveis, enfatizando a importância da co-evolução entre agentes e ferramentas para lidar com ambientes de tarefa complexos e variáveis. (Fonte: TheTuringPost)
Pesquisa sobre aprimoramento da capacidade de raciocínio de modelos de IA: O papel do pré-treinamento, mid-training e aprendizagem por reforço : Pesquisadores da Carnegie Mellon University descobriram que o pré-treinamento, o mid-training e a aprendizagem por reforço desempenham papéis diferentes no aprimoramento da capacidade de raciocínio de modelos de IA. O estudo aponta que a aprendizagem por reforço só pode realmente melhorar a capacidade de raciocínio sob condições específicas, a generalização entre contextos requer pré-treinamento inicial, o mid-training é crucial, e as recompensas conscientes do processo (Process-aware rewards) são indispensáveis. Estas descobertas fornecem orientação para otimizar as estratégias de treinamento de modelos de IA, enfatizando a importância de adotar abordagens direcionadas em diferentes estágios para maximizar a capacidade de raciocínio. (Fonte: TheTuringPost)

KappaTune: Aborda o problema de esquecimento catastrófico no fine-tuning de LLMs : KappaTune é um novo método de fine-tuning de LLM projetado para resolver o problema de esquecimento catastrófico presente em métodos existentes como LoRA. KappaTune apresenta 6 vezes menos esquecimento do que LoRA e não requer dados de pré-treinamento. O método maximiza seu potencial ao aproveitar a capacidade de seleção de tensor de granularidade fina de modelos MoE (Mistura de Especialistas). O surgimento de KappaTune oferece uma solução mais eficiente para a aprendizagem contínua e adaptabilidade de LLMs, e espera-se que reduza os custos de manutenção do modelo e promova a aplicação generalizada da IA. (Fonte: Reddit r/deeplearning)

Estrutura Policy→Tests (P2T): Preenche a lacuna entre políticas de IA e regras executáveis : A estrutura Policy→Tests (P2T) visa transformar políticas de governança de IA escritas em linguagem natural (como a Lei de IA da UE, NIST AI RMF) em regras executáveis. A estrutura, através de um pipeline escalável e um JSON DSL compacto, converte documentos de política em regras atômicas padronizadas, contendo riscos, escopo, condições, exceções, sinais de evidência e proveniência. O P2T aborda o gargalo entre a interpretação de políticas e a execução de ferramentas, especialmente ao lidar com áreas complexas como dados de saúde, podendo reduzir significativamente o tempo necessário para mapear os requisitos da HIPAA para verificações de pipeline de ML, melhorando a eficiência e a verificabilidade da governança de IA. (Fonte: Reddit r/MachineLearning)
GenEnv: Co-evolução de agentes LLM e simuladores de ambiente com alinhamento de dificuldade : GenEnv é uma estrutura que resolve o gargalo de dados de interação do mundo real caros e estáticos ao treinar agentes LLM, estabelecendo um jogo de co-evolução com alinhamento de dificuldade entre agentes e simuladores de ambiente generativos escaláveis. O simulador atua como uma estratégia de currículo dinâmico, gerando continuamente tarefas especificamente adaptadas à “zona de desenvolvimento proximal” do agente, guiado por recompensas de currículo α. GenEnv melhorou o desempenho do agente em até 40,3% em vários benchmarks e igualou ou superou o desempenho médio de modelos maiores com 3,3 vezes menos dados, fornecendo um caminho eficiente em termos de dados para a expansão da capacidade do agente. (Fonte: HuggingFace Daily Papers)
QuCo-RAG: Quantifica a incerteza de corpora pré-treinados para RAG dinâmico : QuCo-RAG propõe quantificar a incerteza a partir de dados pré-treinados para alcançar RAG dinâmico.