
كلمات مفتاحية:نماذج اللغة الكبيرة, قدرات الاستدلال, أمان الذكاء الاصطناعي, النماذج متعددة الوسائط, النماذج مفتوحة المصدر, توليد الفيديو بالذكاء الاصطناعي, تقييم الذكاء الاصطناعي, التطبيقات التجارية للذكاء الاصطناعي, دراسة أبل لقدرات استدلال نماذج اللغة الكبيرة, نموذج Time-R1 لفهم الزمن, توليد الفيديو بمعالجات NVIDIA Blackwell GPU, نموذج علي بابا تونجي تشيان وين 3 مفتوح المصدر, خوادم Hugging Face MCP
🔥 أبرز العناوين
أبل تنشر ورقة بحثية تشير إلى أن نماذج اللغة الكبيرة الحالية لديها “وهم التفكير” فقط وليس قدرة استدلال حقيقية، مما يثير نقاشًا واسعًا في الصناعة: نشر باحثون من أبل (بمن فيهم Samy Bengio، أحد مؤسسي Google Brain) ورقة بحثية، تشير إلى أنه من خلال اختبار أربع مهام ذات صعوبة يمكن التحكم بها مثل برج هانوي وتبادل قطع الداما، فإن النماذج المتطورة مثل DeepSeek و o3-mini و Claude 3.7 “تنهار” جميعها عند مواجهة مشكلات عالية التعقيد، وتظهر “تحجيمًا عكسيًا لجهد الاستدلال” (كلما زادت صعوبة المشكلة، قل التفكير). تعتقد الورقة أن هذه النماذج تعتمد بشكل أكبر على مطابقة الأنماط والذاكرة، بدلاً من الاستدلال المنطقي الحقيقي والقابل للتعميم، وحتى مع توفير خوارزميات كاملة، لا يمكنها تجاوز عنق الزجاجة التعقيدي. يتحدى هذا الرأي الفهم السائد الحالي لقدرات الاستدلال لدى نماذج اللغة الكبيرة (LLM)، وأثار نقاشًا واسعًا حول طرق تقييم LLM، وحدود قدرة الاستدلال الحقيقية، واتجاهات التطوير المستقبلية. تباينت ردود فعل المجتمع تجاه ذلك، حيث يعتقد البعض أن هذا دفاع من أبل عن تقدمها البطيء في مجال الذكاء الاصطناعي (AI)، بينما يتفق آخرون مع رؤيتها الثاقبة لآليات التقييم والقيود الكامنة في النماذج (المصدر: QbitAI، pmddomingos، scaling01، rao2z، paul_cal، BorisMPower، cloneofsimo، farguney)

يوشوا بنجيو الحائز على جائزة تورينج يحذر من مخاطر خروج الذكاء الاصطناعي عن السيطرة، ويعدل توجهه البحثي للتركيز على “الذكاء الاصطناعي العالِم”: صرح يوشوا بنجيو في مؤتمر BAAI بأنه نظرًا للتطور السريع للذكاء الاصطناعي (AI) (خاصة الذكاء الاصطناعي العام AGI) ومخاطر خروجه عن السيطرة المحتملة (مثل قيام الذكاء الاصطناعي بنسخ شفرته الخاصة وإخفاء سلوكياته من أجل “البقاء”)، فقد عدل توجهه البحثي للتركيز على بناء “ذكاء اصطناعي عالِم” يتمتع بالذكاء فقط، دون وعي ذاتي أو أهداف. ويعتقد أن قدرات التخطيط لدى الذكاء الاصطناعي قد تصل إلى مستوى الإنسان في غضون خمس سنوات، وأشار إلى أن طرق تدريب الذكاء الاصطناعي الحالية قد تؤدي إلى إظهاره ثقة مفرطة حتى عند ارتكاب الأخطاء. أكد بنجيو على ضرورة ضمان امتثال الذكاء الاصطناعي للتعليمات الأخلاقية، وتجنب استخدامه لأغراض ضارة، ودعا إلى التعاون العالمي لمواجهة تحديات أمان الذكاء الاصطناعي، وحل مشكلتي “التوافق” و “القابلية للتحكم” (المصدر: QbitAI)

الحكومة البريطانية تتبنى نظام Extract المدعوم بنموذج Gemini من جوجل لتسريع قرارات التخطيط: تستخدم الحكومة البريطانية نظامًا يسمى “Extract” لمساعدة مخططي المجالس المحلية على اتخاذ القرارات بشكل أسرع. يعتمد النظام على نموذج Gemini الأساسي من جوجل، ويستفيد من قدراته على الاستدلال متعدد الوسائط، لتحويل مستندات التخطيط المعقدة، بما في ذلك الملاحظات المكتوبة بخط اليد والخرائط غير الواضحة، إلى بيانات رقمية في غضون 40 ثانية. يوضح هذا التطبيق إمكانات الذكاء الاصطناعي في مجال الخدمات العامة الحكومية، من خلال أتمتة معالجة وفهم المستندات المعقدة، وتحسين الكفاءة الإدارية وجودة القرارات (المصدر: GoogleDeepMind، kylebrussell، demishassabis)

Synthesia أول من يستخدم وحدات معالجة الرسوميات NVIDIA Blackwell GPU لتدريب نموذج الفيديو الكبير EXPRESS-2: أعلنت شركة Synthesia لإنشاء الفيديو بالذكاء الاصطناعي أنها أول شركة في العالم تستخدم وحدات معالجة الرسوميات NVIDIA Blackwell GPU على Google Cloud لتدريب نماذج الفيديو الكبيرة. يهدف نموذجها الجديد EXPRESS-2 إلى مساعدة العملاء على إنشاء مقاطع فيديو وصور رمزية (أفاتار) مُنشأة بالذكاء الاصطناعي بجودة أعلى وبسرعة أكبر، من خلال أجهزة أقوى وإعدادات سحابية متعددة مُحسَّنة. تمثل هذه الخطوة تقدمًا هامًا في تقنية إنشاء الفيديو بالذكاء الاصطناعي من حيث دعم الأجهزة الأساسية وقدرات النماذج، مما ينبئ بمزيد من التحسين في كفاءة وجودة إنشاء محتوى الفيديو بالذكاء الاصطناعي في المستقبل (المصدر: synthesiaIO، Synthesia Blog)
بحث Epoch AI يكشف أن نموذج o3-mini-high يعتمد على “الحدس” لحل ألغاز رياضية متقدمة، وليس الحفظ عن ظهر قلب: دعا Epoch AI أربعة عشر عالم رياضيات لتقييم 29 عملية استدلال لنموذج o3-mini-high على معيار FrontierMath، ووجدوا أن النموذج تمكن من حل 13 لغزًا بشكل صحيح. أظهر البحث أن o3-mini-high يمتلك معرفة رياضية واسعة ويمكنه استدعاء النظريات ذات الصلة، لكن أسلوبه في الاستدلال يميل أكثر إلى “الاستقراء القائم على الحدس”، ويفتقر إلى البراهين الرسمية الصارمة والإبداع، وأحيانًا “يتحايل” بتخطي خطوات البرهان. على الرغم من وجود مشكلات مثل الهلوسة وعدم القدرة على إعادة إنتاج الصيغ بدقة، كان أداؤه في بعض المسائل مشابهًا لعمليات التفكير لدى علماء الرياضيات البشر. يحلل هذا البحث بعمق قدرات وقيود النماذج الكبيرة الحالية في الاستدلال الرياضي المعقد (المصدر: QbitAI)

🎯 اتجاهات
عدد تنزيلات نماذج Qwen3 مفتوحة المصدر من علي بابا يتجاوز 12.5 مليون، والنماذج المشتقة تتجاوز 130 ألف لتحتل المرتبة الأولى عالميًا: منذ إطلاق سلسلة نماذج Qwen3 الكبيرة مفتوحة المصدر من علي بابا قبل شهر، تجاوز إجمالي عدد التنزيلات العالمية 12.5 مليون، لتصبح أكثر النماذج مفتوحة المصدر شيوعًا في الآونة الأخيرة. تجاوزت تنزيلات نماذجها الأربعة بأحجام تتراوح من 0.6B إلى 32B المليون على منصات مثل Hugging Face ومجتمع ModelScope، وتجاوز عدد النماذج المشتقة 130 ألفًا، لتحتل المرتبة الأولى عالميًا. حققت Qwen3 المرتبة الأولى بين النماذج مفتوحة المصدر في العديد من قوائم الأداء المحلية والدولية، وبسبب تكلفتها المنخفضة للاستدلال (حوالي ثلث تكلفة DeepSeek R1)، اجتذبت العديد من مصنعي الرقائق ومنصات الحوسبة مثل NVIDIA و Intel و ARM للتكيف والوصول إليها (المصدر: QbitAI)

جامعة إلينوي تطلق نموذج Time-R1 بمعاملات 3B لتحقيق فهم وتنبؤ وتوليد الزمن: أطلق باحثون من جامعة إلينوي في أوربانا شامبين نموذج Time-R1، وهو نموذج لغوي بمعاملات 3B، يعزز فهم النموذج لمفهوم الزمن، والتنبؤ بالأحداث المستقبلية، وقدرات توليد السيناريوهات الإبداعية، من خلال التعلم المعزز ثلاثي المراحل وآلية المكافأة الديناميكية. يتفوق هذا النموذج في مهام الاستدلال الزمني، حتى أنه يتجاوز النماذج ذات المعاملات الأكبر بكثير مثل DeepSeek-V3-0324. قام فريق البحث بإتاحة Time-Bench (مجموعة بيانات كبيرة للاستدلال الزمني متعدد المهام تعتمد على أخبار نيويورك تايمز لمدة 10 سنوات) بالإضافة إلى كود تدريب Time-R1 ونقاط فحص النموذج كمصادر مفتوحة (المصدر: QbitAI)

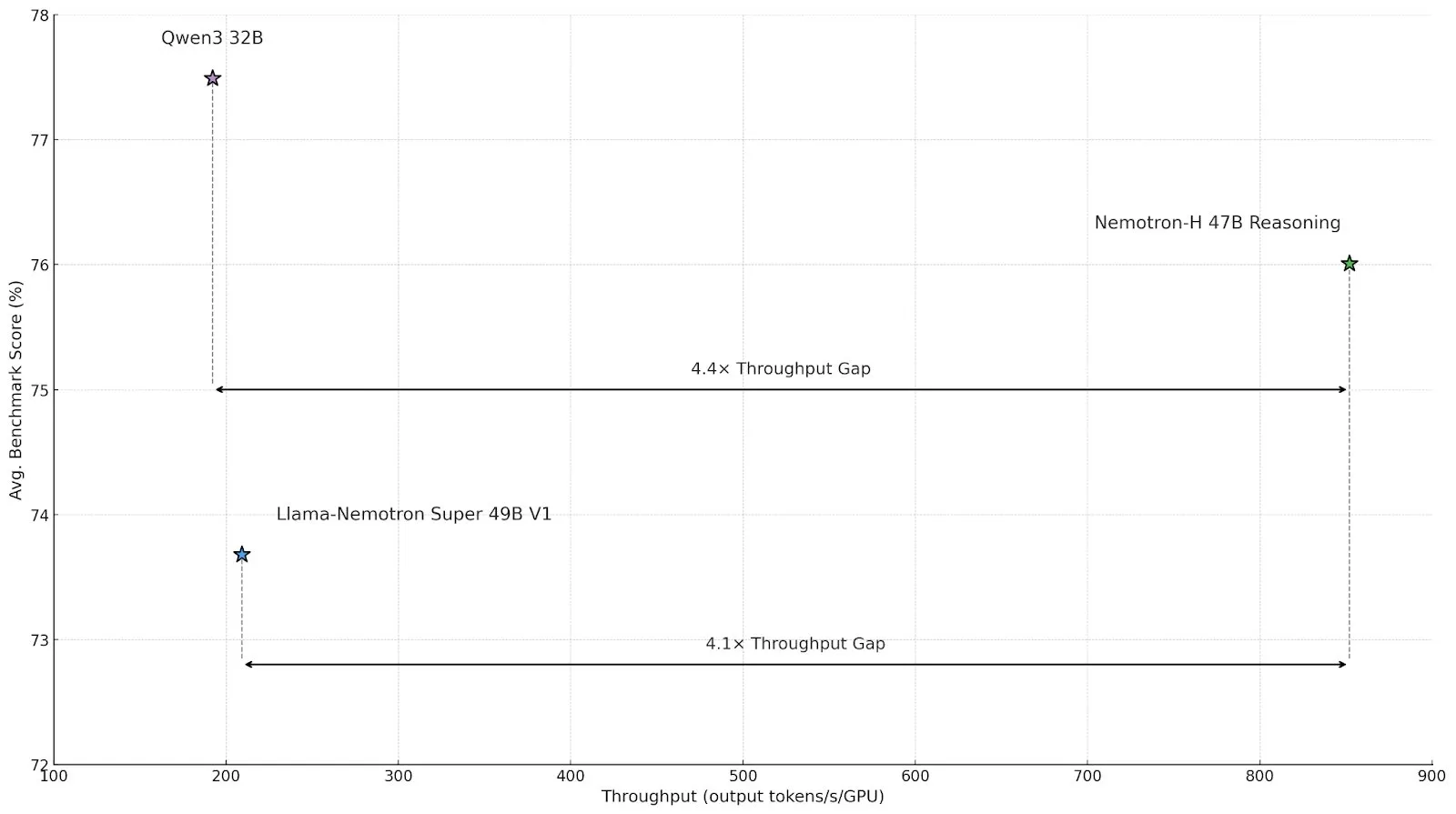
NVIDIA تطلق سلسلة نماذج الاستدلال Nemotron-H، باستخدام بنية Mamba-Transformer الهجينة لتعزيز الكفاءة: أطلقت NVIDIA نماذج الاستدلال Nemotron-H 8B و 47B، استنادًا إلى بنية SSM-Transformer الهجينة (Mamba-Transformer). تحافظ هذه النماذج على دقة عالية مع تحقيق إنتاجية استدلال تصل إلى 4 أضعاف نماذج Transformer المماثلة. يتفوق Nemotron-H-47B-Reasoning-128k على Llama-Nemotron-Super-49B-1.0 في مختلف اختبارات الأداء القياسية، مع خفض تكلفة الاستدلال بما يصل إلى 4 أضعاف. تم نشر أوزان النموذج على HuggingFace بموجب ترخيص غير إنتاجي، بهدف دفع عجلة البحث في مجال الاستدلال واسع النطاق عالي الكفاءة (المصدر: tri_dao، NVIDIA AI Developer)
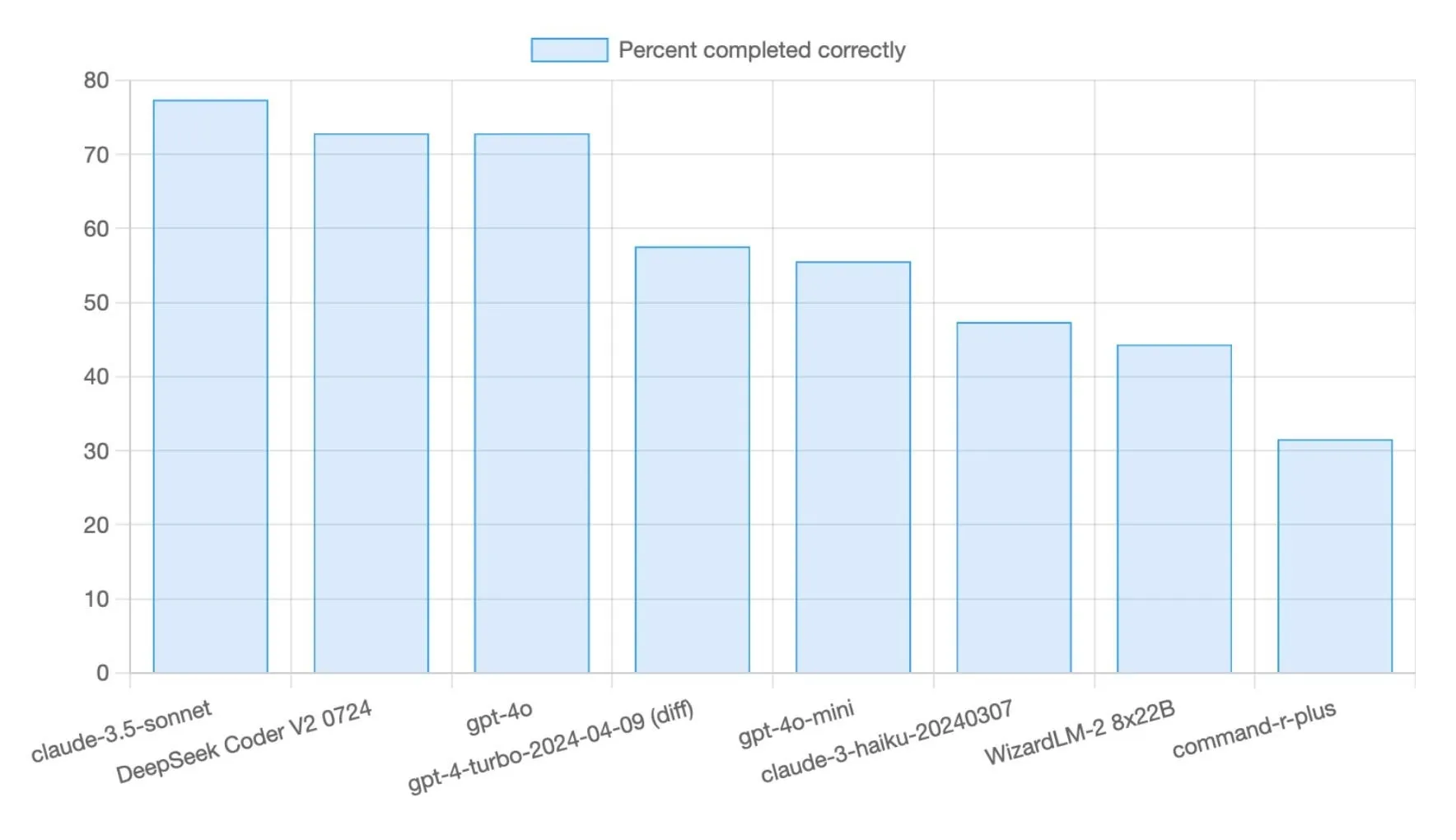
نموذج DeepSeek R1 0528 يحقق درجة 71% في اختبار Aider Polyglot البرمجي القياسي: حقق نموذج DeepSeek R1 0528 درجة 71% في اختبار Aider Polyglot البرمجي القياسي، وهو تحسن كبير (+14.5 نقطة مئوية) مقارنة بالإصدارات السابقة. يحظى هذا النموذج بالاهتمام بسبب فعاليته العالية من حيث التكلفة، حيث أن إكمال حوالي 70% من الاختبار القياسي يكلف أقل من 5 دولارات، مما يدل على قدرته التنافسية القوية في مهام إنشاء الأكواد (المصدر: Reddit r/LocalLLaMA، scaling01)
إطلاق إطار VACE: نموذج متعدد الوظائف يجمع بين إنشاء وتحرير الفيديو: أطلق مختبر علي بابا للرؤية الحاسوبية VACE (Video Creation and Editing)، وهو نموذج موحد يدمج وظائف متعددة مثل إنشاء الفيديو من مرجع (R2V)، وتحرير الفيديو إلى فيديو (V2V)، وتحرير الفيديو المقنع (MV2V). يدعم VACE المستخدمين في دمج هذه المهام بحرية لتحقيق معالجة فيديو متنوعة مثل تحريك الكائنات، واستبدالها، والإشارة إلى الأنماط، والتوسيع، والتحريك. تم إصدار العديد من إصدارات النماذج مثل VACE-Wan2.1-1.3B-Preview، و VACE-LTX-Video-0.9، و Wan2.1-VACE-1.3B، و Wan2.1-VACE-14B، وهي متاحة للتنزيل على HuggingFace و ModelScope (المصدر: GitHub Trending)

جامعة هونغ كونغ للعلوم والتكنولوجيا و ByteDance تطلقان إطار ComfyMind لتوحيد مهام التوليد البصري: أطلقت جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو) بالتعاون مع ByteDance إطار التوليد البصري مفتوح المصدر ComfyMind، بهدف معالجة مهام التوليد البصري الرئيسية المتعددة مثل تحويل النص إلى صورة والصورة إلى فيديو من خلال نظام واحد. يعتمد ComfyMind “سير العمل الذري” كوحدة أساسية، ويجمع بين التخطيط الشجري وآلية التنفيذ بالتغذية الراجعة المحلية، ويستخدم ComfyUI كمحرك تنفيذ أساسي، ويكمل المهام المعقدة من خلال تعاون ثلاثة وكلاء: التخطيط والتنفيذ والتقييم. في اختبارات الأداء القياسية مثل ComfyBench و GenEval و Reason-Edit، أظهر ComfyMind أداءً متميزًا، يضاهي أداء GPT-4o-Image (المصدر: QbitAI)

Hugging Face تطلق خادم بروتوكول سياق النموذج (MCP) لتعزيز قدرات وكلاء الذكاء الاصطناعي: توفر Hugging Face الآن خادم بروتوكول سياق النموذج (MCP)، مما يسمح لوكلاء الذكاء الاصطناعي بالوصول إلى الأدوات الخارجية والبيانات في الوقت الفعلي بطريقة موحدة وآمنة، بما في ذلك نماذج البحث وتحليل مجموعات البيانات والتفاعل مع HuggingFace Spaces. تهدف هذه المبادرة إلى تحويل وكلاء الذكاء الاصطناعي من أدوات ثابتة إلى متعاونين ديناميكيين، مما يعزز قدرتهم على معالجة المهام المعقدة والحصول على أحدث المعلومات. بدأ العديد من أعضاء المجتمع في استكشاف دمج خادم MCP مع مختلف أطر عمل الذكاء الاصطناعي (مثل Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) (المصدر: ClementDelangue، huggingface، awnihannun)

بحث يقترح STARFlow: نموذج تدفق تطبيعي كامن قابل للتطوير لتوليد الصور عالية الدقة: STARFlow هو نموذج توليدي قابل للتطوير يعتمد على التدفق التطبيعي، جوهره هو تدفق Transformer التراجعي الذاتي (TARFlow). من خلال تصميم الطبقات العميقة والسطحية، والنمذجة في الفضاء الكامن لمشفر ذاتي مُدرب مسبقًا، وخوارزمية توجيه جديدة، يحقق STARFlow أداءً تنافسيًا في مهام توليد الصور المشروطة بالفئة والمشروطة بالنص، مقتربًا من أحدث نماذج الانتشار. يعرض هذا العمل لأول مرة بنجاح التشغيل الفعال للتدفق التطبيعي بهذا الحجم والدقة (المصدر: HuggingFace Daily Papers)
بحث جديد HASHIRU: نظام وكلاء هرمي لاستخدام موارد الذكاء الهجين: HASHIRU هو إطار عمل جديد لنظام متعدد الوكلاء (MAS)، يتميز بوجود وكيل “CEO” يدير ديناميكيًا وكلاء “موظفين” متخصصين، ويقوم بإنشائهم بناءً على متطلبات المهمة وقيود الموارد (التكلفة، الذاكرة). يعطي النظام الأولوية لاستخدام نماذج لغوية كبيرة محلية صغيرة (عبر Ollama)، مع استخدام مرن لواجهات برمجة تطبيقات خارجية ونماذج كبيرة، ويتضمن إنشاء أدوات API ذاتية وذاكرة. أظهر التقييم على مهام مثل مراجعة الأوراق الأكاديمية، وتقييم الأمان، والاستدلال المعقد قدراته (المصدر: HuggingFace Daily Papers)
PartCrafter: توليد شبكات ثلاثية الأبعاد مُهيكلة من خلال دمج محولات الانتشار الكامنة: PartCrafter هو أول نموذج توليد ثلاثي الأبعاد مُهيكل، يمكنه توليد شبكات ثلاثية الأبعاد متعددة ذات معنى دلالي ومختلفة هندسيًا بشكل مشترك من صورة RGB واحدة. يعتمد بنية توليد تركيبية موحدة، لا تعتمد على مدخلات مُجزأة مسبقًا، وقادر على إدراك توليد الأجزاء من طرف إلى طرف لكائنات فردية ومشاهد معقدة متعددة الكائنات. تشمل ابتكاراته الأساسية الفضاء الكامن التركيبي وآلية الانتباه الهرمية (المصدر: HuggingFace Daily Papers)
Prefix Grouper: تدريب GRPO فعال من خلال تمرير البادئات المشتركة إلى الأمام: يعمل Group Relative Policy Optimization (GRPO) على تعزيز تعلم السياسات من خلال مقارنة الاختلافات النسبية بين المخرجات المرشحة التي تشترك في بادئة إدخال مشتركة. يزيل Prefix Grouper حسابات البادئات الزائدة عن الحاجة من خلال سياسة تمرير البادئات المشتركة إلى الأمام، مما يحسن كفاءة تدريب GRPO، خاصة في سيناريوهات البادئات الطويلة، مع الحفاظ على التكافؤ التدريبي مع GRPO القياسي (المصدر: HuggingFace Daily Papers)
GuideX: توليد بيانات اصطناعية موجهة لاستخلاص المعلومات بدون عينات (zero-shot): عادةً ما تكون أنظمة استخلاص المعلومات (IE) التقليدية خاصة بالمجال، وتكون تكلفة تكييفها عالية. GuideX هي طريقة جديدة تحدد تلقائيًا الأنماط الخاصة بالمجال، وتستنتج الإرشادات، وتولد مثيلات اصطناعية مُعنونة، مما يحقق تعميمًا أفضل خارج النطاق. أدى استخدام GuideX لضبط Llama 3.1 إلى تحقيق نتائج متطورة جديدة (SOTA) على سبعة معايير قياسية للتعرف على الكيانات المسماة بدون عينات، مما أدى إلى تحسين فهم النموذج لأنماط التعليقات التوضيحية المعقدة الخاصة بالمجال بشكل كبير (المصدر: HuggingFace Daily Papers)
CodeContests+: لتوليد حالات اختبار عالية الجودة لمسابقات البرمجة: لمواجهة مشكلة صعوبة الحصول على حالات اختبار في مسابقات البرمجة، اقترح باحثون نظام وكلاء يعتمد على نماذج اللغة الكبيرة (LLM) لإنشاء حالات اختبار عالية الجودة. تم تطبيق هذا النظام على مجموعة بيانات CodeContests، وتم اقتراح نسخة محسنة CodeContests+. أظهر التقييم أن CodeContests+ يتفوق بشكل كبير على النسخة الأصلية في دقة التقييم، خاصة فيما يتعلق بمعدل الإيجابيات الحقيقية (TPR)، وله مزايا كبيرة لتعلم نماذج اللغة الكبيرة المعزز (المصدر: HuggingFace Daily Papers)
Sentinel: نموذج SOTA للحماية من هجمات حقن الأوامر (prompt injection): لمواجهة مشكلة تعرض نماذج اللغة الكبيرة (LLM) لهجمات حقن الأوامر، أطلق باحثون نموذج Sentinel (qualifire/prompt-injection-sentinel)، استنادًا إلى بنية ModernBERT-large. من خلال الضبط الدقيق على مجموعة بيانات واسعة تحتوي على أنواع متعددة من الهجمات والتعليمات الحميدة، حقق Sentinel متوسط دقة 0.987 ودرجة F1 تبلغ 0.980 على مجموعة اختبار داخلية غير مرئية، وتفوق على نماذج خط الأساس القوية على المعايير العامة (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش: هل توسيع الوسائط هو المسار الصحيح لتحقيق الوسائط الكاملة؟: تهدف نماذج اللغة متعددة الوسائط (OLM) إلى دمج واستنتاج وسائط إدخال متعددة، مع الحفاظ على قدرات لغوية قوية. يستكشف هذا البحث تأثير توسيع الوسائط (أي الضبط الدقيق لنماذج اللغة المدربة مسبقًا) كتقنية سائدة لتدريب النماذج متعددة الوسائط. يركز البحث على ثلاث مسائل أساسية: هل يضر توسيع الوسائط بالقدرات اللغوية الأساسية؟ هل يمكن لدمج النماذج أن يدمج بشكل فعال نماذج خاصة بوسائط معينة تم ضبطها بشكل مستقل لتحقيق الوسائط الكاملة؟ هل يوفر توسيع الوسائط الكاملة مشاركة معرفة وتعميمًا أفضل من التوسيع التسلسلي؟ (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Truth in the Few: طريقة اختيار بيانات عالية القيمة للاستدلال متعدد الوسائط بكفاءة: يتحدى البحث الاعتقاد السائد بأن نماذج اللغة الكبيرة متعددة الوسائط (MLLM) تحتاج إلى كميات كبيرة من بيانات التدريب في مهام الاستدلال المعقدة. من خلال الملاحظة، تبين أن جزءًا صغيرًا فقط من بيانات التدريب، يُعرف باسم “العينات المعرفية”، يمكنه تحفيز الاستدلال متعدد الوسائط بفعالية. بناءً على ذلك، تقترح الورقة نموذج اختيار البيانات Reasoning Activation Potential (RAP)، الذي يحدد هذه العينات المعرفية من خلال مقدر الفرق السببي (CDE) ومقدر ثقة الانتباه (ACE)، ويستبدل المثيلات البسيطة بوحدة استبدال مدركة للصعوبة (DRM). أظهرت التجارب أن RAP يحقق أداءً أفضل باستخدام 9.3% فقط من بيانات التدريب، ويقلل تكاليف الحوسبة بأكثر من 43% (المصدر: HuggingFace Daily Papers)
🧰 أدوات
Task Master: نظام إدارة مهام مدفوع بالذكاء الاصطناعي، مدمج في محررات مثل Cursor: Task Master هو نظام إدارة مهام مصمم خصيصًا للتطوير بمساعدة الذكاء الاصطناعي، ويمكن دمجه بسلاسة مع محررات مثل Cursor AI و Lovable و Windsurf و Roo. يستخدم واجهات برمجة تطبيقات نماذج لغوية كبيرة مثل Claude (يدعم Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama)، لمساعدة المطورين على تحليل مستندات المتطلبات (PRD)، وإنشاء قوائم المهام، وتخطيط خطوات التطوير، والمساعدة في تنفيذ مهام محددة. يعمل هذا النظام مباشرة في المحرر من خلال MCP (بروتوكول التحكم في النموذج)، ويدعم عمليات سطر الأوامر، ويوفر أدلة تكوين مفصلة ودروس استخدام (المصدر: GitHub Trending)
Observer AI: وكيل مراقبة شاشة محلي مفتوح المصدر، مدمج مع Ollama: Observer AI هو مشروع مفتوح المصدر يسمح للمستخدمين بتشغيل نماذج لغوية كبيرة محلية عبر Ollama لمراقبة الشاشة وتنفيذ المهام. يمكن للمستخدمين من خلال هذه الأداة جعل الذكاء الاصطناعي يفهم محتوى الشاشة ويتفاعل معه، مثل تصفح مواقع الويب بلغة أجنبية. يوفر المشروع كود المصدر على GitHub وإصدار تطبيق ويب لا يتطلب إعدادًا محليًا، ويدعم المستخدمين في الاستفادة من نماذج اللغة الكبيرة لأتمتة عمليات الشاشة مع حماية الخصوصية (المصدر: Reddit r/LocalLLaMA)

Weaviate Query Agent يتكامل مع سبعة أطر عمل رئيسية للذكاء الاصطناعي، لتبسيط استعلامات البيانات باللغة الطبيعية: أعلنت Weaviate عن تكامل Query Agent الخاص بها مع سبعة أطر عمل رئيسية للذكاء الاصطناعي (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic). Query Agent هو خدمة وكيل مُعدة مسبقًا، يمكنها الإجابة على استعلامات اللغة الطبيعية بناءً على البيانات الموجودة في Weaviate، دون الحاجة إلى كتابة عبارات استعلام معقدة. تتيح هذه التكاملات للمطورين دمج قدرات استعلام اللغة الطبيعية القوية بسهولة في مكدسات تطبيقات الذكاء الاصطناعي الحالية، مما يعزز سهولة التفاعل مع البيانات (المصدر: bobvanluijt)

إطلاق خادم MCP لـ Claude Code و Gemini Pro للعمل معًا، لتعزيز كفاءة الترميز: أطلقت BeehiveInnovations خادم MCP يمكّن Claude Code و Gemini 2.5 Pro من العمل معًا. يتولى Claude Code مسؤولية التصور والتخطيط الأولي، بينما يستفيد Gemini من سياقه الذي يصل إلى مليون توكن وقدراته العميقة على الاستدلال لاستكماله. يدمج هذا الخادم أدوات مثل التفكير الموسع، وقراءة الملفات، ومراجعة الأكواد، وتصحيح الأخطاء، ويهدف إلى تحسين جودة وكفاءة إنشاء الأكواد وتحسينها من خلال الجمع بين مزايا النموذجين. أظهرت الاختبارات الأولية أنه في مهام تحسين سرعة تحليل JSON، كان استخدام النموذجين معًا أفضل من استخدام أي منهما بمفرده (المصدر: Reddit r/ClaudeAI)

📚 تعلم
Sakana AI تطلق معيار EDINET-Bench المالي الياباني، لتقييم قدرة نماذج اللغة الكبيرة على المهام المالية: أطلقت Sakana AI معيار EDINET-Bench، وهو اختبار معياري مالي باللغة اليابانية تم إنشاؤه باستخدام التقارير السنوية من نظام الإفصاح الإلكتروني EDINET التابع لوكالة الخدمات المالية اليابانية. يهدف هذا المعيار إلى تقييم أداء نماذج اللغة الكبيرة (LLM) في المهام المالية المعقدة مثل اكتشاف الاحتيال، لمواجهة مشكلة ندرة مجموعات البيانات عالية الجودة والمتاحة مجانًا في المجال المالي. يوفر EDINET-Bench موردًا هامًا للبحث والتطوير في مجال الذكاء الاصطناعي المالي من خلال إنشاء مجموعات بيانات متعددة المهام ذات علامات توضيحية تلقائية (المصدر: hardmaru، SakanaAILabs)

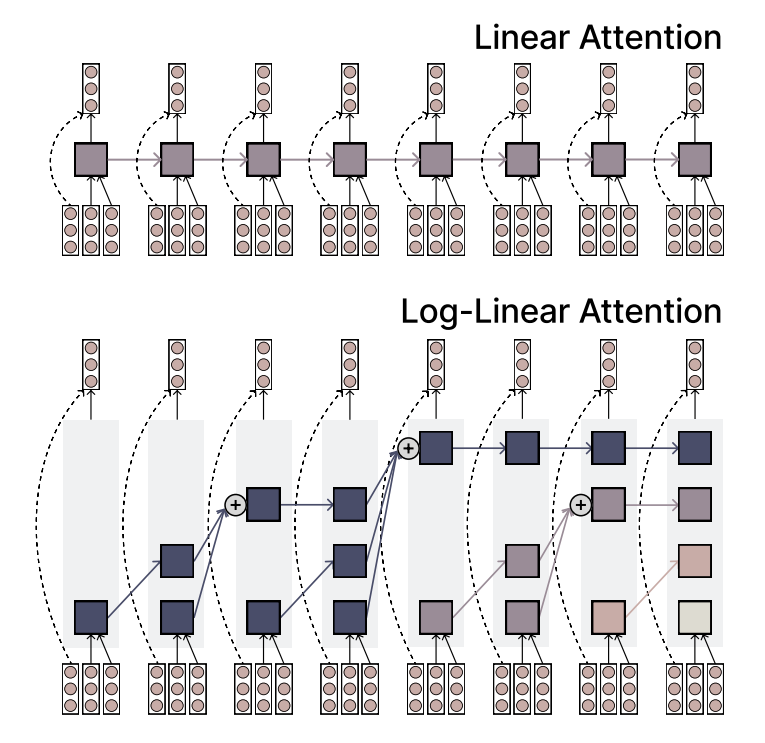
MIT تقترح آلية Log-linear Attention، لتحقيق التوازن بين الكفاءة والقدرة التعبيرية: اقترح باحثون من MIT آلية انتباه جديدة تسمى Log-linear Attention. تهدف هذه الآلية إلى الجمع بين سرعة وكفاءة الانتباه الخطي والقدرة التعبيرية لانتباه Softmax. تحقق ذلك باستخدام عدد قليل من فتحات الذاكرة التي تنمو بشكل لوغاريتمي مع طول التسلسل، مما يوفر طريقة جديدة محتملة لمعالجة بيانات التسلسل الطويل (المصدر: TheTuringPost)
دورة تقييم نماذج اللغة الكبيرة لـ Hamel Husain و Shreya Rajpal تحظى بإشادة: شارك مستخدمون مثل Ryan Lingo و Radek Osmulski تجاربهم الإيجابية في المشاركة في دورة تقييم تطبيقات نماذج اللغة الكبيرة (LLM) التي قدمها Hamel Husain و Shreya Rajpal (maven.com/parlance-labs/evals). اعتُبرت الدورة من أعمق وأكثر المحتويات عملية حول نماذج اللغة الكبيرة حتى الآن، وتُعد محاضراتها وكتابها الحصري ضرورية للمطورين الذين يبنون تطبيقات الذكاء الاصطناعي، مع التأكيد على الدور المركزي للتقييم في تطوير نماذج اللغة الكبيرة (المصدر: HamelHusain، HamelHusain)
MORSE-500: اختبار معياري للفيديو قابل للتحكم برمجيًا، لاختبار ضغط الاستدلال متعدد الوسائط: لمواجهة مشكلة اعتماد معايير الاستدلال متعدد الوسائط الحالية بشكل أساسي على الصور الثابتة، وإغفال التعقيد الزمني ونطاق مهارات الاستدلال، أطلق باحثون MORSE-500. وهو معيار يتضمن 500 مقطع فيديو مُبرمج بالكامل، يغطي ست فئات استدلال: التجريد، والفيزياء، والتخطيط، والمكاني، والزماني. يسمح تصميمه القائم على البرمجة بالتحكم الدقيق في التعقيد البصري، وكثافة المشتتات، والديناميكيات الزمنية، ويدعم إنشاء مثيلات جديدة أكثر تحديًا بشكل تعسفي، بهدف اختبار ضغط نماذج الجيل القادم. أظهرت التجارب الأولية أن نماذج SOTA، بما في ذلك Gemini 2.5 Pro و OpenAI o3، لديها فجوات أداء كبيرة في جميع الفئات (المصدر: HuggingFace Daily Papers)
EverGreenQA: مجموعة بيانات لتصنيف الأسئلة دائمة الخضرة متعددة اللغات، لتعزيز مصداقية الإجابة على الأسئلة: لحل مشكلة الهلوسة التي تنتج عن نماذج اللغة الكبيرة في مهام الإجابة على الأسئلة (QA) بسبب حداثة السؤال (هل يتغير الجواب بمرور الوقت)، أطلق باحثون EverGreenQA. وهي أول مجموعة بيانات QA متعددة اللغات تحتوي على علامات دائمة الخضرة، وتدعم التقييم والتدريب. من خلال مجموعة البيانات هذه، أجرى الباحثون اختبارًا معياريًا لـ 12 نموذجًا لغويًا كبيرًا حديثًا، لتقييم قدرتها على ترميز حداثة السؤال، وقاموا بتدريب مصنف متعدد اللغات خفيف الوزن EG-E5. أظهر البحث أيضًا تطبيقات التصنيف دائم الخضرة في تحسين تقدير المعرفة الذاتية، وتصفية مجموعات بيانات QA، وتفسير سلوك استرجاع GPT-4o (المصدر: HuggingFace Daily Papers)
KVzip: طريقة إخراج ذاكرة التخزين المؤقت KV غير معتمدة على الاستعلام، تقلل بشكل كبير من استهلاك الذاكرة وزمن انتقال فك التشفير: أصدر مختبر التعلم الآلي بجامعة سيول الوطنية KVzip، وهي طريقة تهدف إلى دعم استعلامات مستقبلية متنوعة لضغط ذاكرة التخزين المؤقت KV. من خلال استراتيجية إخراج غير معتمدة على الاستعلام، حققت هذه الطريقة تقليلًا للذاكرة بنحو 3-4 أضعاف وتقليلًا لزمن انتقال فك التشفير بمقدار ضعفين. تدعم حاليًا نماذج مثل Qwen3/2.5 و Gemma3 و LLaMA3، وتوفر كودًا توضيحيًا على GitHub (المصدر: Reddit r/LocalLLaMA)

NimbleEdge تفتح مصدر نوى عامل Transformer متفرقة، لتعزيز سرعة تشغيل نماذج اللغة الكبيرة وكفاءة الذاكرة: قام فريق NimbleEdge، بناءً على بحث Apple “LLM in a Flash” وبحث Zichang وآخرين “Deja Vu”، ببناء نوى عامل مدمجة للتفرقة السياقية المهيكلة. تحقق هذه النوى تحسينًا في أداء طبقة MLP في Transformer بمقدار 5 أضعاف وتقليل استهلاك الذاكرة بنسبة 50%، من خلال تجنب تحميل وحساب أوزان طبقة التغذية الأمامية وتنشيطاتها التي ستؤول مخرجاتها في النهاية إلى الصفر. عند تطبيقها على نموذج Llama 3.2 3B، زادت الإنتاجية الإجمالية بمقدار 1.78 مرة، وانخفض استخدام الذاكرة بنسبة 26.4%. تم فتح مصدر الكود على GitHub، ومن المخطط دعم int8 و CUDA والانتباه المتفرق (المصدر: Reddit r/MachineLearning)
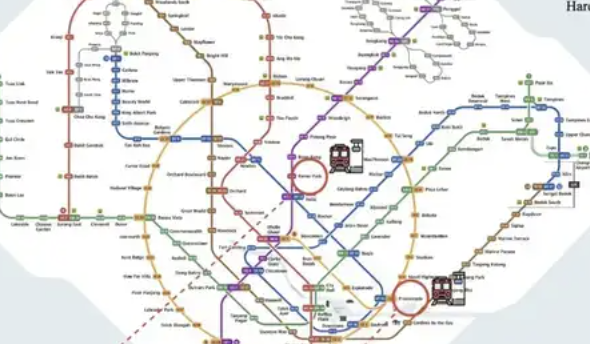
ReasonMap: إطلاق معيار تقييم للاستدلال متعدد الوسائط على خرائط النقل عالية الدقة: أطلق فريق بحثي من جامعة ويست ليك ومؤسسات أخرى ReasonMap، وهو معيار تقييم يركز على الاستدلال متعدد الوسائط على خرائط النقل عالية الدقة (بشكل أساسي خرائط مترو الأنفاق). يهدف هذا المعيار إلى تقييم قدرة النماذج الكبيرة على فهم المعلومات المكانية المهيكلة الدقيقة في الصور، ويتضمن صورًا عالية الدقة (متوسط 5839 × 5449)، وتصميمًا مدركًا للصعوبة، ونظام تقييم متعدد الأبعاد. أظهرت نتائج الاختبار أن النماذج مفتوحة المصدر السائدة الحالية ضعيفة الأداء على ReasonMap، خاصة في تخطيط المسار عبر الخطوط، بينما أظهرت نماذج الاستدلال مغلقة المصدر (مثل GPT-o3) أداءً أفضل بكثير من النماذج مفتوحة المصدر، ولكن لا تزال هناك فجوة مع المستوى البشري. تشكل خرائط مترو الأنفاق المعقدة مثل بكين وهانغتشو تحديًا كبيرًا للنماذج (المصدر: QbitAI)
Yandex تطلق Yambda-5B: مجموعة بيانات نظام توصية مفتوح واسع النطاق: أطلقت Yandex مجموعة بيانات Yambda-5B، وهي مجموعة بيانات بث موسيقى مجهولة المصدر واسعة النطاق تحتوي على 4.79 مليار تفاعل بين المستخدم والعنصر. تتميز مجموعة البيانات هذه بتوفير علامة “is_organic” وتقسيم زمني عالمي (GTS)، ولا تحتوي على سجلات استماع أو إعجابات يمكن التعرف عليها مباشرة للمستخدمين، ولديها قدرة على مقاومة إزالة إخفاء الهوية، وتحتوي على ملاحظات ضمنية (الاستماع إلى الأغاني، التخطي) وصريحة (إعجاب/عدم إعجاب). تهدف Yambda-5B إلى توفير موارد بيانات عالية الجودة ومتعددة الوسائط لأبحاث أنظمة التوصية (المصدر: TheTuringPost)
Tencent تطلق معسكر تحدي النجوم 2025، لتجنيد أفضل الطلاب للمشاركة في أبحاث متقدمة حول النماذج الكبيرة وغيرها: أعلنت Tencent عن إطلاق “معسكر تحدي النجوم” السنوي لعام 2025، مستهدفة طلاب الصف الثاني والثالث الثانوي (خريجي الثانوية العامة دفعة 2025) وغيرهم من الطلاب المتميزين في التخصصات ذات الصلة، لتجنيد 60-70 شخصًا. سيحظى المختارون بفرصة الذهاب إلى المقر الرئيسي في شنتشن، للمشاركة في أبحاث حول ستة مواضيع متقدمة: فهم النصوص الطويلة جدًا، وتقنية سلسلة التفكير الطويلة، والذكاء المجسد + الروبوتات، والإدراك والفهم متعدد الوسائط، والهجوم والدفاع الأمني (بما في ذلك تصميم اختراق LLM Agent)، وتكنولوجيا الكم. يهدف هذا البرنامج إلى تزويد الشباب الموهوبين بفرصة للتعرف على سيناريوهات البحث العلمي على المستوى الصناعي، وتوسيع آفاقهم التقنية، وتعميق فهمهم للصناعة (المصدر: QbitAI)

💼 أعمال
تقارير تشير إلى أن Meta تخطط لاستثمار أكثر من 10 مليارات دولار في Scale AI، لتعزيز تطبيقات الذكاء الاصطناعي في المجالات العسكرية وغيرها: وفقًا للتقارير، تجري Meta محادثات مع شركة Scale AI لوضع علامات على بيانات الذكاء الاصطناعي بشأن استثمار كبير، قد يصل إلى مليارات الدولارات أو حتى يتجاوز 10 مليارات دولار. إذا كان هذا صحيحًا، فسيكون هذا أحد أكبر استثمارات Meta الخارجية في مجال الذكاء الاصطناعي. كانت Scale AI قد قامت سابقًا ببناء نموذج Defense Llama المصمم خصيصًا للاستخدامات العسكرية استنادًا إلى Llama 3 من Meta، لدعم مهام الأمن القومي الأمريكي. قد تشير هذه الخطوة إلى أن Meta ستتخذ استراتيجية استثمار وتعاون أكثر نشاطًا في مجال الذكاء الاصطناعي، خاصة في التطبيقات المتعلقة بالحكومة والدفاع (المصدر: 36Kr)

شركة “ماشANG للاستهلاك” تطلق نموذجها الكبير “Tianjing” 3.0، وترقيته إلى منصة اتخاذ قرارات مالية: أطلقت شركة “ماشANG للاستهلاك” الإصدار 3.0 من نموذجها المالي الكبير “Tianjing”. يكمن الاختراق الأساسي في الإصدار الجديد في الانتقال المنهجي من الذكاء الفردي إلى الذكاء الجماعي، حيث لم يعد يعتمد فقط على التعلم المنطقي، بل يتعمق في استكشاف الخبرات الضمنية المتناثرة في مسارات الموظفين وسجلات الأعمال داخل الشركة، وتحويلها إلى معرفة منظمة. يهدف Tianjing 3.0 إلى الترقية من أداة إلى منصة اتخاذ قرارات، وتعزيز التعاون بين الإنسان والآلة، والقدرة على تفكيك عمليات الخدمة المعقدة ديناميكيًا، ومطابقة أفضل مزيج من الخدمات في الوقت الفعلي بناءً على متطلبات المستخدم والامتثال التنظيمي، لتحقيق الانتقال من الأمثلية المحلية إلى الأمثلية العالمية في اتخاذ القرارات (المصدر: QbitAI)

Together AI تعين Charles Zedlewski رئيسًا جديدًا للمنتجات، مع التركيز على منصة الذكاء الاصطناعي التوليدي مفتوحة المصدر: أعلنت Together AI عن تعيين Charles Zedlewski رئيسًا جديدًا للمنتجات (CPO). كان Charles Zedlewski قد قاد سابقًا منتجات المنصات الموجهة للمطورين والتي يحركها المجتمع في Temporal و Cloudera. تؤكد Together AI التزامها ببناء مستقبل الذكاء الاصطناعي التوليدي مفتوح المصدر، معتبرة أن النماذج المفتوحة تتمتع بمزايا في المرونة وفعالية التكلفة والابتكار. يهدف انضمام Charles إلى زيادة دفع Together AI لإنشاء منصة الذكاء الاصطناعي مفتوحة المصدر الموثوقة، مما يجعل الذكاء الاصطناعي التوليدي القوي في متناول كل مطور ومؤسسة (المصدر: togethercompute)

🌟 مجتمع
سيارة Waymo ذاتية القيادة تتعرض للحرق العمد في لوس أنجلوس، مما يثير مخاوف ونقاشات مجتمعية حول سلامة المركبات ذاتية القيادة: في الآونة الأخيرة، تعرضت عدة سيارات Waymo ذاتية القيادة للحرق العمد في لوس أنجلوس. أثار هذا الحادث اهتمامًا ونقاشًا واسع النطاق على وسائل التواصل الاجتماعي، وتناول المحتوى مدى قبول الجمهور للسيارات ذاتية القيادة، والمخاوف المتعلقة بالسلامة، والمخاطر المحتملة لتضخيم أو تشويه مثل هذه الأحداث بشكل غير لائق بواسطة محتوى مُنشأ بالذكاء الاصطناعي (مثل مقاطع الفيديو التي أنشأها Veo 3). شبه بعض المعلقين هذا المشهد بفيلم الخيال العلمي “Children of Men”، مما يسلط الضوء على الطبيعة الدرامية للحدث وتأثيراته الاجتماعية المحتملة (المصدر: gfodor، fabianstelzer، hrishioa، bookwormengr، claud_fuen)
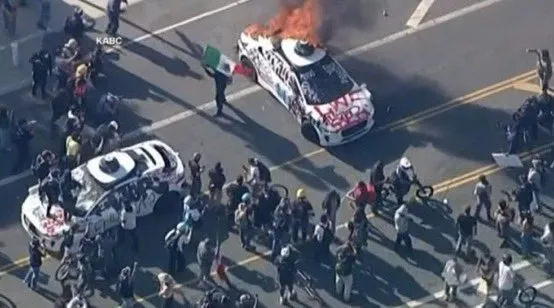
Reddit تقاضي Anthropic، متهمة إياها بجمع المحتوى بشكل غير مصرح به لتدريب Claude AI: رفعت Reddit دعوى قضائية ضد Anthropic، متهمة إياها بجمع منشورات ومحادثات Reddit دون إذن أو دفع، لاستخدامها في تدريب نموذجها للذكاء الاصطناعي Claude. ترى Reddit أن هذا الإجراء ينتهك شروط اتفاقية المستخدم الخاصة بها التي تحظر الاستخدام التجاري غير المصرح به للمحتوى، ووصفت ادعاء Anthropic بأنها “توقفت عن جمع بيانات Reddit” بأنه كاذب. تتناول الدعوى أيضًا قضايا الخصوصية، حيث أن Anthropic، على عكس الشركات الأخرى التي لديها اتفاقيات ترخيص، ليس لديها آلية لحذف المنشورات التي حذفها المستخدمون. تطالب Reddit المحكمة بمنع Anthropic من استخدام بيانات Reddit، وقد تطالبها بسحب Claude من السوق (المصدر: Reddit r/ArtificialInteligence، Reddit r/artificial)
نقاش حاد في معرض مهندسي الذكاء الاصطناعي: Simon Willison يستعرض تطور نماذج اللغة الكبيرة في الأشهر الستة الماضية، ويؤكد على تركيبة الأدوات + الاستدلال: في معرض مهندسي الذكاء الاصطناعي في سان فرانسيسكو، استعرض Simon Willison بشكل فكاهي التطور السريع لنماذج اللغة الكبيرة (LLM) خلال الأشهر الستة الماضية من خلال اختبار إنشاء صور SVG لـ “بجع يركب دراجة”، واختبر شخصيًا أكثر من 30 نموذجًا للذكاء الاصطناعي. وأكد أن أقوى تركيبة للذكاء الاصطناعي حاليًا هي “الأدوات + الاستدلال”، مثل أداء o3/o4-mini في البحث، والاهتمام الذي حظيت به بنية MCP بسبب استدعاء الأدوات. كما استعرض الخطاب “الأخطاء الغريبة” السنوية للذكاء الاصطناعي، مثل الإطراء المفرط لـ ChatGPT، واحتمالية قيام Claude “بالإبلاغ” عن المستخدمين، وأشار إلى مخاطر حقن الأوامر وتسريب البيانات (المصدر: 36Kr، swyx)

نقاش مجتمعي حول القلق المهني الناجم عن الذكاء الاصطناعي واستراتيجيات المواجهة: أثار منشور على Reddit حول “كيفية التعامل مع قلق الذكاء الاصطناعي” نقاشًا حادًا. يشعر المستخدمون عمومًا بالقلق من أن الذكاء الاصطناعي قد يؤدي إلى بطالة واسعة النطاق في السنوات القادمة، خاصة بالنسبة للأشخاص الذين لديهم مدخرات غير كافية وديون كثيرة. في النقاش، اقترح البعض التحول إلى مجالات مثل الحرف اليدوية والرعاية، لكنهم قلقون أيضًا من أن هذه المجالات ستصبح مشبعة بسبب تدفق أعداد كبيرة من المتحولين إليها. شارك المعلقون مشاعر القلق الخاصة بهم، مثل الأرق وصعوبة التركيز في العمل. رأت بعض الآراء أنه يجب تعلم الذكاء الاصطناعي بنشاط والحفاظ على القدرة على التكيف، وأشارت إلى أن الابتكارات التكنولوجية التاريخية (مثل السيارات والإنترنت) أثارت أيضًا مخاوف مماثلة، لكنها خلقت في النهاية فرص عمل جديدة. كما رأى بعض المعلقين أن مدى استبدال الذكاء الاصطناعي للوظائف البشرية حاليًا مبالغ فيه، ومن غير المرجح حدوث تسريح جماعي للعمال على المدى القصير (المصدر: Reddit r/ArtificialInteligence)
مستخدم يشارك تجربته في استخدام ChatGPT لإجراء تحليل نفسي ذاتي “قاسٍ”: شارك مستخدم على Reddit تجربته في استخدام ChatGPT لإجراء تحليل نفسي ذاتي “بأسلوب تنفيذي وحشي”. من خلال أوامر محددة، طلب من ChatGPT إجراء تحليل صارم من خمس زوايا: نقاط القوة الحقيقية، ونقاط الضعف العميقة، وأنماط الفشل المتكررة، والمجالات التي يتجنبها، والمهارات المهملة، وتقديم خطة تطوير من ثلاث مراحل. ذكر المستخدم أنه على الرغم من أن العملية كانت مؤلمة (على سبيل المثال، الإشارة إلى أنه بدأ 12 مشروعًا دون إكمال أي منها، والإفراط في البحث عن الإنتاجية بدلاً من العمل الفعلي)، إلا أن هذه التعليقات “القاسية” دفعته في النهاية إلى التغيير. أثار هذا المنشور نقاشًا مجتمعيًا حول تطبيقات الذكاء الاصطناعي في التأمل الذاتي والتنمية الشخصية (المصدر: Reddit r/ArtificialInteligence)
نقاش حول قدرات الذاكرة والاستدلال لدى نماذج اللغة الكبيرة: هل هي معرفة واسعة أم فهم حقيقي؟: على وسائل التواصل الاجتماعي، ناقش المستخدمون الأداء المتميز لنماذج اللغة الكبيرة (LLM) في مهام استرجاع الحقائق القائمة على الذاكرة، وما إذا كان هذا يعني أنها تمتلك بالفعل قدرة على الاستدلال. ترى بعض الآراء أن أداء نماذج اللغة الكبيرة المتميز في المهام التي تبدو معقدة قد يعتمد بشكل أكبر على بيانات التدريب الضخمة والتعرف على الأنماط، بدلاً من الفهم العميق والإبداع بالمعنى الإنساني. تشير أبحاث شركات مثل Meta إلى أنه يمكن تقدير سعة النموذج عن طريق قياس الذاكرة، وبمجرد امتلاء السعة، يبدأ التعميم. يرتبط هذا النقاش أيضًا بتركيز أنظمة التعليم على الحفظ عن ظهر قلب، والافتقار إلى تنمية القدرة على استرجاع المعلومات واستخدام أدوات الذكاء الاصطناعي (المصدر: omarsar0، menhguin، menhguin)

💡 أخرى
تحليل حالة نجاح نموذج Stripe الأساسي لكشف الاحتيال في المدفوعات: أثار منشور لمهندسي Stripe حول بناء نموذج أساسي ناجح لكشف الاحتيال في المدفوعات اهتمامًا. يشير التحليل إلى أن خصوصية هذه الحالة تكمن في: 1) كشف الاحتيال ليس بطبيعته تنبؤًا بالمستقبل، نظريًا يمكن تحقيق دقة عالية عند توفر إشارات كافية؛ 2) Stripe موجودة بالفعل في بيئة غنية بالإشارات، ولا تحتاج إلى البدء في تجميع البيانات من الصفر؛ 3) هذا السيناريو هو ترقية آلية، من التعلم الآلي التقليدي إلى النموذج الأساسي، وهو قريب من الاستبدال المباشر. هذا يفسر لماذا تكون “الانتصارات الفورية” لمثل هذه التطبيقات للذكاء الاصطناعي نادرة نسبيًا، حيث يتطلب تحقيق معظم القيمة التجارية للذكاء الاصطناعي التغلب على العديد من العقبات (المصدر: random_walker)
الأساس المعرفي لتحول الذكاء الاصطناعي: آلية منهجية لإدراك المعلومات والرؤى التقنية هي المفتاح: تحتاج الشركات في تحول الذكاء الاصطناعي إلى إنشاء آلية منهجية ومنظمة لإدراك المعلومات والرؤى التقنية، تتجاوز الخبرات الفردية والاعتماد على المسارات التقليدية. يشمل ذلك بناء قدرات تحليل البيانات الداخلية وشبكات المعرفة الخارجية (الأوساط الأكاديمية، والصناعية، وأسواق رأس المال، والشركات الناشئة). يجب أيضًا أن يتحول تقييم عائد الاستثمار في الذكاء الاصطناعي من عائد الاستثمار التقليدي إلى نظام “متعدد الدورات ومتعدد الأبعاد”، وأن يقترن بشبكات المعرفة الخارجية، لتشكيل حلقة استراتيجية مغلقة للتحقق المستمر والتعديل الديناميكي. يؤكد المقال أن الذكاء الاصطناعي ليس أداة لمرة واحدة، بل هو أصل استراتيجي يتطور باستمرار وتزداد قيمته (المصدر: 36Kr)
Frigate: نظام NVR يعتمد على كشف الكائنات المحلي في الوقت الفعلي: Frigate هو نظام مسجل فيديو شبكي محلي (NVR) مصمم خصيصًا لـ Home Assistant، ويستخدم OpenCV و Tensorflow لإجراء كشف كائنات محلي في الوقت الفعلي على كاميرات IP. يركز هذا النظام على تحسين الموارد والأداء، من خلال تشغيل كشف الكائنات بواسطة كشف الحركة منخفض التكلفة، واستخدام معالجة متعددة العمليات. يوصى باستخدام مسرعات الذكاء الاصطناعي مثل Google Coral أو Hailo للحصول على أفضل أداء. يدعم Frigate التسجيل على مدار الساعة طوال أيام الأسبوع، والاحتفاظ بالتسجيلات بناءً على كشف الكائنات، وتكامل MQTT، وإعادة بث RTSP، وعرض مباشر منخفض الكمون عبر WebRTC/MSE (المصدر: GitHub Trending)
