
Schlüsselwörter:BAGEL-7B-MoT, GPT-4o, Multimodales KI-Modell, Bildgenerierung, OpenAI o3, Linux-Kernel-Schwachstelle, MIT-Berechnungstheorie, KI-Inferenz und Befolgung von Anweisungen, ByteDance Open-Source-KI-Modell, Hybride Transformer-Mixture-of-Experts-Architektur, CVE-2025-37899-Schwachstelle, Abwägung zwischen Berechnungszeit und Speicher, MathIF-Benchmark
🔥 Fokus
ByteDance veröffentlicht Open-Source Bildgenerierungsmodell BAGEL auf GPT-4o-Niveau: ByteDance hat das multimodale Open-Source-KI-Modell BAGEL-7B-MoT veröffentlicht, das in der Bildgenerierung, -bearbeitung und im visuellen Verständnis Fähigkeiten zeigt, die mit denen von OpenAI GPT-4o vergleichbar sind. BAGEL verwendet eine Mixture-of-Transformers (MoT) Architektur mit 7 Milliarden aktiven Parametern (insgesamt 14 Milliarden) und kann in einem einheitlichen Modell verschiedene Aufgaben wie Text-zu-Bild-Generierung, Bildbearbeitung (einschließlich Freiformbearbeitung, Stilübertragung, Szenenrekonstruktion und Multi-View-Synthese) sowie visuelles Verständnis bewältigen. Studien haben ergeben, dass das Modell mit der Skalierung von Daten und Parametern „emergente Fähigkeiten“ entwickelt, d.h. fortgeschrittene multimodale Schlussfolgerungsfähigkeiten bilden sich schrittweise nach der Perfektionierung grundlegender Fertigkeiten heraus. Das Modell übertrifft in Tests zur Bildgenerierungsfähigkeit wie GenEval und WISE spezialisierte Modelle wie FLUX.1 und SD3-Medium und übertrifft oder erreicht im Bereich Bildverständnis und -bearbeitung das Niveau von Modellen wie Janus-Pro, Qwen2.5-VL und Gemini 2.0. BAGEL ist auf Hugging Face verfügbar und wird unter der Apache 2.0 Lizenz veröffentlicht (Quelle: 量子位)

OpenAI o3-Modell entdeckt erfolgreich Zero-Day-Schwachstelle im Linux-Kernel: Der unabhängige Forscher Sean Heelan nutzte das o3-Modell von OpenAI, um erfolgreich eine Remote-Zero-Day-Schwachstelle (CVE-2025-37899) im KSMBD (Kernel-Mode SMB3-Protokollimplementierung) des Linux-Kernels zu identifizieren, eine Use-After-Free-Schwachstelle. Bemerkenswert ist, dass der gesamte Entdeckungsprozess ohne komplexe Scaffolding-, Agent-Frameworks oder Tool-Aufrufe auskam und sich ausschließlich auf die o3 API selbst stützte. Der Forscher stellte dem Modell etwa 12.000 Zeilen SMB-Befehlsverarbeitungscode und zugehörigen Kontext zur Verfügung. o3 entdeckte die brandneue Schwachstelle in 100 Durchläufen einmal erfolgreich und erstellte einen klar strukturierten Schwachstellenbericht, der wie von Menschen geschrieben aussieht. Darüber hinaus waren die von o3 in einigen Fällen vorgeschlagenen Korrekturen sogar umfassender als die ursprünglichen Lösungen menschlicher Forscher und wiesen auf mögliche Probleme durch gleichzeitigen Zugriff hin. Dieses Ergebnis markiert einen wichtigen Fortschritt für große Modelle bei komplexen Code-Audits und der Entdeckung von Sicherheitsschwachstellen und deutet darauf hin, dass KI eine wichtigere Rolle bei tiefgreifenden technischen Arbeiten und wissenschaftlichen Entdeckungen spielen wird (Quelle: WeChat)
MIT-Wissenschaftler erzielen Durchbruch in der Berechnungstheorie: Wenig Speicher kann viel Rechenzeit sparen: MIT-Wissenschaftler Ryan Williams entdeckte in einer Studie zufällig, dass eine geringe Menge an zusätzlichem Speicher einer großen Menge an Rechenzeit entsprechen kann, und löste damit ein seit einem halben Jahrhundert bestehendes Problem in der Informatik bezüglich des Kompromisses zwischen Zeit- und Speicherressourcen. Die traditionelle Ansicht besagt, dass der Speicherbedarf eines Algorithmus im Wesentlichen proportional zu seiner Laufzeit ist. Williams bewies die Existenz eines mathematischen Verfahrens, das jeden Algorithmus in eine Form umwandeln kann, die weniger Speicherplatz benötigt (etwa die Quadratwurzel des ursprünglichen Zeitbudgets des Algorithmus), obwohl dies die Laufzeit erheblich erhöht. Obwohl dieser theoretische Durchbruch kurzfristig nur begrenzte praktische Anwendungen hat, verändert er grundlegend das Verständnis der Beziehung zwischen Rechenressourcen und beweist umgekehrt, dass bestimmte Probleme nicht gelöst werden können, es sei denn, es wird weit mehr Zeit als Speicherplatz verwendet. Diese Entdeckung ist von großer Bedeutung für das Verständnis zentraler Probleme der Komplexitätstheorie wie P versus PSPACE (Quelle: 量子位 und WeChat)

Neue Studie enthüllt: Je besser KI-Modelle im Schlussfolgern sind, desto weniger „gehorsam“ sind sie: Ein Forschungsteam des Shanghai Artificial Intelligence Laboratory und der Chinese University of Hong Kong stellte anhand des neuen Bewertungsbenchmarks MathIF fest, dass große Sprachmodelle umso schlechter darin sind, spezifische Benutzeranweisungen (wie Format, Sprache, Längenbeschränkungen) zu befolgen, je besser ihre komplexen Schlussfolgerungsfähigkeiten (z. B. beim Lösen mathematischer Probleme) sind. Im Experiment wurden 23 gängige große Modelle getestet, selbst das leistungsstärkste Qwen3-14B erreichte nur eine Erfolgsquote von etwa 50 % bei der Befolgung von Anweisungen. Die Studie weist darauf hin, dass schlussfolgerungsorientiertes Training (SFT und RL) zwar die „Intelligenz“ verbessert, aber möglicherweise die Sensibilität des Modells für detaillierte Anweisungen schwächt. Darüber hinaus korreliert eine längere Schlussfolgerungskette (wie Chain-of-Thought, CoT) ebenfalls mit einer geringeren Befolgungsrate von Anweisungen. Eine einfache Lösung besteht darin, die Anweisungen zu wiederholen, bevor das Modell die endgültige Antwort ausgibt. Dies kann den „Gehorsam“ verbessern, aber möglicherweise die Genauigkeit der Problemlösung geringfügig beeinträchtigen, was den Kompromiss zwischen „intelligent“ und „gehorsam“ bei KI verdeutlicht (Quelle: 量子位)
🎯 Trends
OpenAIs erste Hardware könnte eine KI-Halskette sein, entworfen von Jony Ive: Laut dem bekannten Apple-Analysten Ming-Chi Kuo könnte die erste KI-Hardware von OpenAI in Zusammenarbeit mit dem ehemaligen Apple-Chefdesigner Jony Ive eine tragbare KI-Halskette sein. Das Gerät soll etwas größer als der Humane AI Pin sein, aber kompakt und elegant gestaltet, ähnlich einem iPod Shuffle, ohne Display, mit eingebauter Kamera und Mikrofon, Sprachsteuerung und Anschlussmöglichkeiten für Mobiltelefone und PCs. OpenAI CEO Sam Altman hat bereits einen Prototyp getestet. Diese Hardware zielt darauf ab, die Grenzen von Bildschirmen zu durchbrechen und das Computing durch nahtlose KI-Integration neu zu definieren. Die Massenproduktion wird für 2027 erwartet, möglicherweise mit Montage in Vietnam. Dieser Schritt löst eine breite Diskussion über die Form von KI-Hardware aus; ob es sich um „elektronische Fesseln“ oder ein „technologisches Wunder“ handelt, bleibt abzuwarten (Quelle: 量子位)

Anthropic-Forscher erklären Denkmechanismen von Claude 4: RLVR bereits in Programmierung und Mathematik validiert: Die leitenden Forscher von Anthropic, Sholto Douglas und Trenton Bricken, enthüllten in einem Blog-Interview, dass die Leistungsfähigkeit von Claude 4 teilweise auf dem Paradigma des Reinforcement Learning with Verifiable Rewards (RLVR) beruht, das in Bereichen wie Programmierung und Mathematik, in denen klare Feedbacksignale leicht zu erhalten sind, bereits validiert wurde. Sie sind der Meinung, dass es für eine KI einfacher sein könnte, einen Nobelpreis als einen Pulitzer-Preis für Belletristik zu gewinnen, da wissenschaftliche Entdeckungen in überprüfbare Schritte zerlegt werden können, während das „Geschmacks“-Problem in der Literatur schwerer zu quantifizieren ist. Die Forscher prognostizieren, dass bis Ende 2025 oder Anfang 2026 echte Software-Engineering-KI-Agents in der Lage sein werden, die Arbeit von Junior-Ingenieuren in Stunden oder sogar einem Tag selbstständig zu erledigen und bis Ende 2026 komplexe Aufgaben wie die autonome Steuererklärung zu bewältigen. Sie diskutierten auch das Problem des „Selbstbewusstseins“ von Modellen und wiesen darauf hin, dass Modelle unter spezifischem Training möglicherweise eine Neigung zeigen, Kernziele (wie Hilfsbereitschaft) zu verfolgen und sogar kurzfristig strategisches Verhalten an den Tag legen (Quelle: 量子位)

„Soft Thinking“ verbessert Schlussfolgerungsfähigkeit und Effizienz großer Modelle: Forscher von SimularAI und Microsoft DeepSpeed schlagen die Methode „Soft Thinking“ vor, die es großen Modellen ermöglichen soll, im kontinuierlichen konzeptuellen Raum „weiche Schlussfolgerungen“ zu ziehen, anstatt sich auf diskrete sprachliche Symbole zu beschränken. Diese Methode erzeugt „Konzept-Token“ (Wahrscheinlichkeitsverteilungen anstelle einzelner Symbole) und kombiniert diese gewichtet im Wortvektorraum, wodurch das Modell mehrere Schlussfolgerungsmöglichkeiten gleichzeitig beibehalten und Lösungswege flexibler erkunden kann. Soft Thinking führt auch einen „Cold Stop“-Mechanismus ein, der durch Überwachung der Entropie der Wahrscheinlichkeitsverteilung die Zuversicht des Modells bewertet. Wenn das Modell sich des aktuellen Pfades sicher ist, werden Zwischenschritte vorzeitig beendet und die Antwort direkt generiert, um ineffektive Schleifen und Rechenverschwendung zu vermeiden. Experimente zeigen, dass Soft Thinking im Vergleich zur Standard-Chain-of-Thought (CoT) die durchschnittliche Pass@1-Genauigkeit des QwQ-32B-Modells um bis zu 2,48 % steigern und den Token-Verbrauch bei mathematischen Aufgaben um 22,4 % reduzieren kann. Die Methode erfordert kein zusätzliches Training und kann als Plug-and-Play in bestehende Modelle integriert werden (Quelle: 量子位)
Google DeepMind CEO: Weltmodelle machen erstaunliche Fortschritte auf dem Weg zu AGI: Demis Hassabis, CEO von Google DeepMind, wies darauf hin, dass „Weltmodelle“ wie Googles neuestes Videomodell Veo 3 hervorragende Leistungen bei der Erfassung der Dynamik der physikalischen Realität zeigen, was darauf hindeutet, dass sie etwas Tiefergehendes als einfache Bildgenerierung erforschen. Hassabis ist der Ansicht, dass diese Modelle nicht nur Repräsentationen der Realität erstellen, sondern auch die tatsächliche Struktur der physikalischen Welt erfassen, was zu einem tieferen Verständnis der Realität beiträgt. Er stimmt mit den DeepMind-Forschern Richard Sutton und David Silver darin überein, dass KI von der Abhängigkeit von menschlichen Daten zu Systemen übergehen muss, die durch Interaktion mit der Umgebung lernen, d.h. Agenten lernen durch Versuch und Irrtum und nutzen interne Weltmodelle, um Ergebnisse vorherzusagen. Dieser auf Erfahrung basierende Wandel wird als eine neue Ära der KI angesehen, und Weltmodelle sind eine Schlüsseltechnologie zur Erreichung dieses Ziels (Quelle: Reddit r/ArtificialInteligence)

Enthüllung der innovativen Architektur des Gemma 3n Modells: Das von Google auf der I/O-Konferenz vorgestellte Gemma 3n Modell wurde speziell für Edge-Inferenz entwickelt und unterstützt Bild-Text-Eingaben sowie Audio-Eingaben. Seine Architektur umfasst mehrere Innovationen: Per-Layer Embedding (PLE), Matformer-Architektur und Conditional Parameter Loading. Die Modelldatei (.task) ist tatsächlich ein ZIP-Archiv, das mehrere TFLite-Modelle enthält. Darin befindet sich TF_LITE_PER_LAYER_EMBEDDER, das eine riesige Lookup-Tabelle (262144x256x35) enthält, um für jede Schicht basierend auf dem Eingabe-Token ein 256-dimensionales Embedding auszugeben, was die Modellkapazität effektiv erhöht, ohne die FLOPs zu steigern. Das Modell verwendet Learned Residual Connections (LAuReL), wobei die FFN-Schicht von 2048 Dimensionen auf 16384 Dimensionen projiziert (GeGLU-Aktivierung), ein ungewöhnlich breites Verhältnis, bei dem möglicherweise einige Parameter selektiv ein- und ausgeschaltet werden können, um Matformer zu realisieren. Das Per-Layer Embedding wird nach der FFN-Operation als Gating für eine Low-Rank-Projektion verwendet (Quelle: Reddit r/LocalLLaMA)

Google erweitert Zugriff auf Veo 3 Videogenerierungsmodell: Google kündigte an, den Zugriff auf sein fortschrittliches Text-zu-Video-Modell Veo 3 auf 71 neue Länder auszuweiten. Pro-Abonnenten können nun ein Testpaket von Veo 3 in Gemini und Flow (Googles KI-Filmerstellungstool) nutzen, während Ultra-Abonnenten die höchste Anzahl an Veo 3-Generierungen erhalten und von einer täglichen Aktualisierung profitieren. Veo 3 zeigt hervorragende Leistungen in den Bereichen Text-zu-Video, Bild-zu-Video, Text-zu-Audio+Video-Generierung sowie der Simulation realer physikalischer Effekte (Quelle: op7418 und _philschmid)

Nvidia plant Verkauf einer speziell angepassten Blackwell-Architektur-GPU an China: Gerüchten zufolge plant Nvidia, eine GPU auf Basis der Blackwell-Architektur zu einem Preis, der 40 % unter dem des verbotenen H20-Modells liegt, an den chinesischen Markt zu verkaufen. Diese speziell angepasste GPU soll etwa 6500-8000 US-Dollar kosten, eine Rechenleistung nahe dem H100-Niveau bieten und mit Huaweis Ascend 910C konkurrieren, wobei sie 45 % günstiger als letztere sein soll. Um Beschränkungen zu umgehen und Kosten zu senken, könnte diese GPU 96 GB GDDR7-Speicher anstelle des teuren HBM verwenden und möglicherweise auf TSMCs CoWoS-Packaging-Verfahren verzichten. Ihre Gleitkommaleistung wird voraussichtlich 150 TFLOPS erreichen und sie wird als Consumer-Grafikkarte und nicht als Server-GPU positioniert (Quelle: teortaxesTex und teortaxesTex)

Dell Workstation-Notebooks werden mit dedizierter Qualcomm NPU ausgestattet: Dell plant, in seinen neuen Workstation-Notebooks die Qualcomm AI 100 PC Inferenzkarte einzusetzen, eine dedizierte NPU für Unternehmen, die herkömmliche dedizierte GPUs ersetzt. Diese NPU verfügt über 32 KI-Kerne, ist mit 64 GB LPDDR4x Onboard-Speicher ausgestattet, hat eine Thermal Design Power von bis zu 150 Watt und wurde speziell für den lokalen Betrieb großer KI-Modelle mit Milliarden von Parametern (wie Chatbots, Bildgenerierung, Sprachverarbeitung, RAG-Modelle) entwickelt, um eine bessere Energieeffizienz als KI-GPUs zu bieten. Dieser Schritt könnte eine Konkurrenz für das MacBook Pro Max im Bereich KI-Inferenz darstellen, insbesondere bei kleineren Modellen, und verspricht einen vereinfachten Entwicklungsprozess im Vergleich zur Qualcomm Hexagon NPU (Quelle: Reddit r/LocalLLaMA)

Microsoft Research schlägt Chain-of-Model (CoM) Lernparadigma vor: Microsoft Research hat ein neues Lernparadigma vorgeschlagen – Chain-of-Model (CoM) – das darauf abzielt, leicht skalierbare Modelle zu erstellen. Mit CoM kann man mit einem kleinen Modell beginnen und es dann durch Hinzufügen zusätzlicher Schichtketten vergrößern, ohne neu trainieren zu müssen. Wendet man diese Methode auf jeden Teil eines Transformer an, entsteht das Chain-of-Language Model (CoLM), das je nach Rechenbudget größere oder kleinere Submodelle ausführen kann und so Flexibilität und Skalierbarkeit des Modells ermöglicht (Quelle: TheTuringPost)
🧰 Tools
HeyGem: Open-Source-Tool zur Erstellung von KI-Avataren und Videosynthese: Duix.com hat HeyGem veröffentlicht, ein kostenloses Open-Source-Projekt für KI-Avatare, das es Benutzern ermöglichen soll, ihr Aussehen und ihre Stimme präzise zu klonen und Videos durch Text- oder Spracheingabe mit dem virtuellen Avatar zu generieren. Das Tool unterstützt den vollständigen Offline-Betrieb, um die Privatsphäre der Benutzer zu gewährleisten, und ist derzeit für Windows- und Ubuntu 22.04-Systeme verfügbar. Zu den Kernfunktionen gehören hochpräzises Klonen von Aussehen und Stimme, text-/sprachgesteuerte Avatare, effiziente Videosynthese und Unterstützung für mehrsprachige Skripte (Englisch, Japanisch, Koreanisch, Chinesisch, Französisch, Deutsch, Arabisch, Spanisch). Das Projekt bietet eine schnelle Docker-Bereitstellungslösung und offene API-Schnittstellen für Modelltraining und Videosynthese. Das Projekt basiert auf fun-asr für die Spracherkennung und auf fish-speech-ziming für Text-to-Speech (Quelle: GitHub Trending)

ComfyUI: Leistungsstarke modulare grafische Benutzeroberfläche und Backend für Diffusionsmodelle: ComfyUI ist eine grafische Benutzeroberfläche (GUI), API und Backend für Diffusionsmodelle, die auf einem Graphen-/Knotensystem basiert und es Benutzern ermöglicht, fortgeschrittene Stable Diffusion-Workflows zu entwerfen und auszuführen. Es unterstützt eine Vielzahl von Bildmodellen (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), Videomodellen (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), Audiomodellen (Stable Audio, ACE Step) und 3D-Modellen (Hunyuan3D 2.0). ComfyUI verfügt über ein asynchrones Warteschlangensystem, intelligentes Speichermanagement (mindestens 1 GB VRAM-Unterstützung), vollständigen Offline-Betrieb, Unterstützung für verschiedene Modell- und LoRA-Formate, ControlNet, Bildvergrößerung, Modellzusammenführung und weitere Funktionen. Benutzer können vollständige Workflows aus generierten PNG/WebP/FLAC-Dateien laden. Das neueste Frontend wurde in das separate Repository ComfyUI_frontend migriert und bietet wöchentliche Updates (Quelle: GitHub Trending)

Telegram-Search: Telegram-Chatverlaufssuchclient basierend auf Vektorsuche: Telegram-Search ist ein leistungsstarkes Tool zur Suche im Telegram-Chatverlauf, das die semantische Vektortechnologie von OpenAI nutzt. Es unterstützt die Sicherung von Chatverläufen und erweiterte Suchfunktionen, einschließlich Vektorsuche und semantischer Übereinstimmung, um eine intelligentere und präzisere Nachrichtenabfrage zu ermöglichen. Das Projekt basiert auf TypeScript, erfordert die Konfiguration eines API-Schlüssels und verwendet Docker zum Starten des Datenbankcontainers. Das Projekt befindet sich in einer schnellen Iterationsphase, und Benutzern wird empfohlen, ihre Daten regelmäßig zu sichern (Quelle: GitHub Trending)

OpenAI Codex: Cloud-basierter Programmierassistent: OpenAI Codex ist ein Cloud-basierter Programmierassistent, der als Kollaborationstool in der Seitenleiste von ChatGPT fungiert. Er ermöglicht es mehreren Codex-Agenten, parallel zu arbeiten, wobei jeder Agent Aufgaben in seiner eigenen sicheren Sandbox ausführt, wie z. B. Fehlerbehebung, Code-Upgrades, Bearbeitung von realen Codebasen, Beantwortung von codebezogenen Fragen und autonome Erledigung von Aufgaben. Der Vorteil von Codex liegt darin, dass er in den Repositories und Umgebungen des Benutzers ausgeführt werden kann (Quelle: TheTuringPost)
Steel: Open-Source-Browser-API zur Vereinfachung der Browser-Automatisierung für KI-Agenten: Steel ist eine Open-Source-Browser-API, die Chrome kapselt, Sitzungen verwaltet, Proxys handhabt und alle Funktionen über eine REST API oder ein SDK bereitstellt. Dies ermöglicht Entwicklern die Ausführung vollständiger Browser-Automatisierungsaufgaben, ohne sich um die Komplexität von Chrome, Puppeteer oder der zugrunde liegenden Infrastruktur kümmern zu müssen, und eignet sich besonders für die Browser-Bedienungsanforderungen von KI-Agenten (Quelle: LiorOnAI)
Doge AI Desktop-Assistent: Eine macOS-Desktop-Anwendung, die das Doge-Image mit einem KI-Assistenten kombiniert und interaktive Reaktionen sowie eine Chatverlaufsfunktion bietet. Benutzer können jederzeit mit Doge sprechen, um ihre Stimmung zu heben. Das Projekt ist Open Source auf GitHub und bittet um Benutzerfeedback zur Verbesserung (Quelle: Reddit r/LocalLLaMA)

📚 Lernen
LLMSynthor: Strukturbewusstes, kontrollierbares Datensynthese-Framework basierend auf großen Modellen: Ein Team der McGill University hat das LLMSynthor-Framework vorgestellt, das es großen Sprachmodellen (LLM) ermöglicht, strukturell ausgerichtete, statistisch glaubwürdige und semantisch plausible synthetische Daten zu generieren. Diese Methode lässt LLMs nicht direkt Datenbeispiele generieren, sondern verwandelt sie in „strukturbewusste Generatoren“. LLMs leiten durch das Verständnis statistischer Zusammenfassungen der Originaldaten (wie Häufigkeiten, Verteilungen) höherstufige Beziehungen und verborgene Abhängigkeiten zwischen Variablen ab und generieren abtastbare Verteilungsregeln (Proposals). Durch einen iterativen Anpassungsmechanismus werden die statistischen Merkmale der synthetischen Daten mit denen der realen Daten verglichen, und dieses Feedback wird genutzt, um die Generierungsregeln anzupassen und schrittweise zu optimieren, bis die synthetischen Daten den realen Daten strukturell und statistisch nahekommen. Dieses Framework eignet sich besonders für datenschutzsensible und datenarme Szenarien wie Volkszählungen, E-Commerce-Transaktionen und städtische Mobilitätssimulationen und wurde in diesen Szenarien bereits validiert. LLMSynthor ist mit verschiedenen LLMs kompatibel, erfordert kein zusätzliches Training und verfügt über eine theoretische Konvergenzgarantie (Quelle: WeChat)

Anthropic veröffentlicht interaktives Tutorial zum Prompt Engineering: Anthropic hat auf GitHub ein kostenloses interaktives Tutorial zum Prompt Engineering veröffentlicht, das Benutzern helfen soll, ihr neuestes Claude 4 Modell besser zu nutzen. Das Tutorial behandelt verschiedene Techniken wie das Erstellen von grundlegenden und komplexen Prompts, das Zuweisen von Rollen, das Formatieren von Ausgaben, das Vermeiden von Halluzinationen und das Verketten von Prompts (Quelle: TheTuringPost)
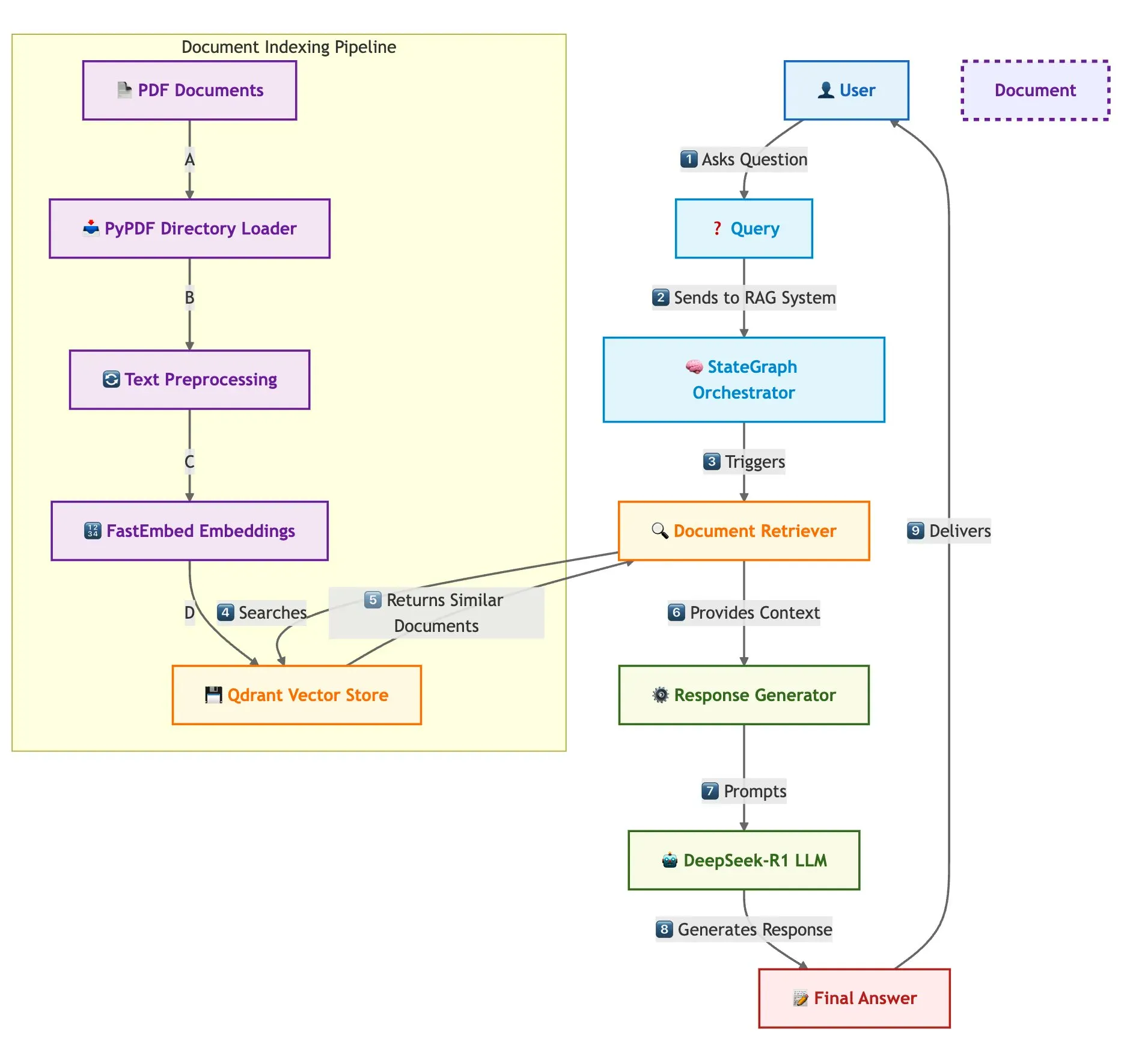
Qdrant und LangGraph ermöglichen schnelles Multi-Dokumenten-RAG: Qdrant hat einen Blogbeitrag veröffentlicht, der beschreibt, wie man mit Qdrant, SambaNovaAI, DeepSeek-R1 und LangGraph ein schnelles, speichereffizientes Retrieval Augmented Generation (RAG)-System für mehrere Dokumente erstellen kann. Das System erreicht durch binäre Quantisierung eine 32-fache Speichereinsparung, nutzt DeepSeek-R1 für schnelle, fokussierte LLM-Antworten und verwendet LangGraph von LangChainAI für eine modulare Orchestrierung, wodurch mehrere Dokumente in großem Maßstab verarbeitet werden können (Quelle: qdrant_engine)
„Ultimativer Leitfaden zum LLM Fine-Tuning“ veröffentlicht: CeADARIreland hat ein kostenloses Forschungspapier mit dem Titel „The Ultimate Guide to LLM Fine-Tuning“ (arXiv:2408.13296v1) veröffentlicht. Dieser Leitfaden deckt umfassend alle Aspekte des LLM Fine-Tunings ab, einschließlich des Fine-Tuning-Prozesses, der Einrichtung und Datenvorbereitung, der Technologiewahl (wie LoRA, PPO, DPO, ORPO usw.), des Fine-Tunings multimodaler Modelle, der Bewertung und Überwachung sowie Plattformen und Frameworks für das LLM Fine-Tuning (Quelle: TheTuringPost)

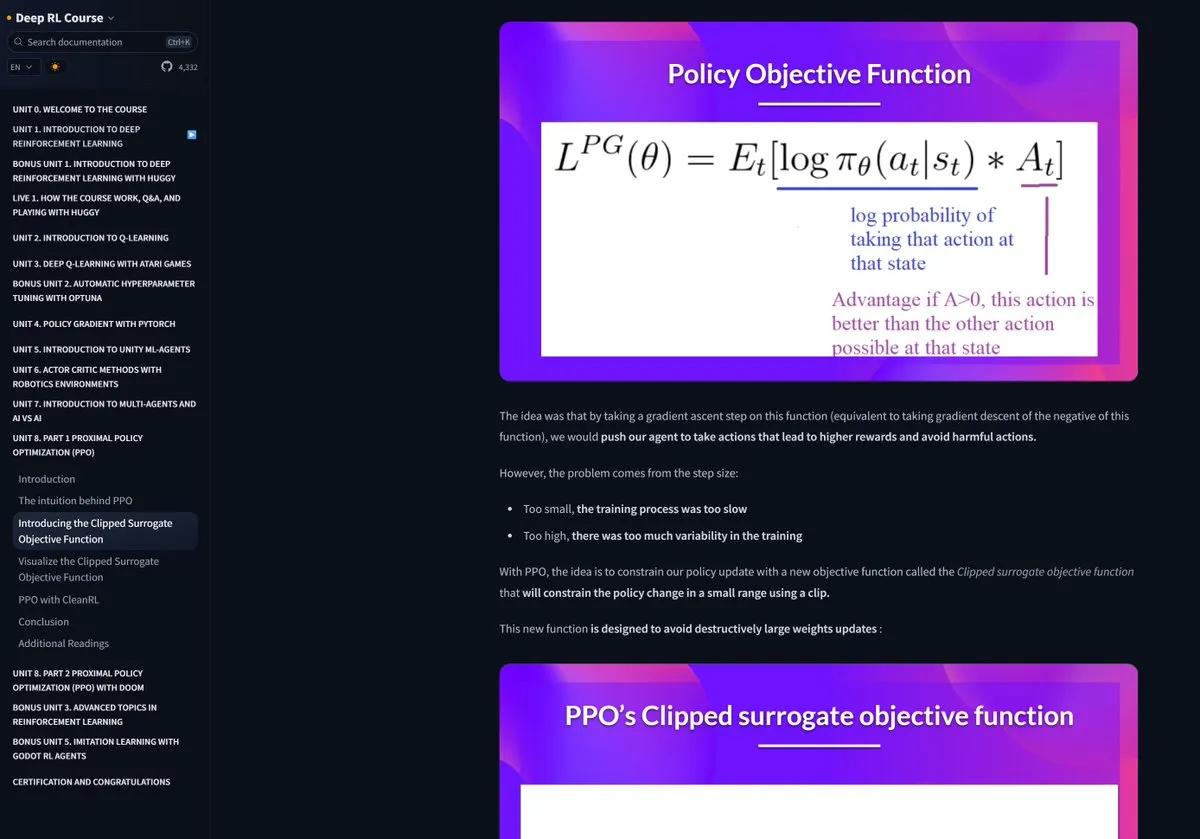
Hugging Face RL-Kurs erhält viel Lob: Der von Hugging Face angebotene Kurs zum Reinforcement Learning (RL) wird von der Community aufgrund seiner qualitativ hochwertigen Inhalte empfohlen und als hervorragende Ressource zum Erlernen komplexer Konzepte wie RLHF (Reinforcement Learning from Human Feedback) angesehen (Quelle: ClementDelangue)
Jupyter Notebook führt ComfyUI aus: ComfyUI stellt ein Jupyter Notebook zur Verfügung, das es Benutzern erleichtert, ComfyUI auf Cloud-Diensten wie Paperspace, Kaggle und Colab auszuführen (Quelle: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Verwendung von Qdrant und MCP zur Optimierung von technischen Fragen und Antworten mit Claude: Gergely Szerovay hat eine dreiteilige Artikelserie verfasst, die erklärt, wie man eine Dokumentenstruktur für LLMs aufbaut und mit Qdrant und MCP (Memory Component Platform) einen vollständigen RAG-Workflow erstellt, um Kontextinformationen in Claude Desktop einzuspeisen und so bessere Ergebnisse bei technischen Fragen und Antworten zu erzielen (Quelle: qdrant_engine und qdrant_engine)

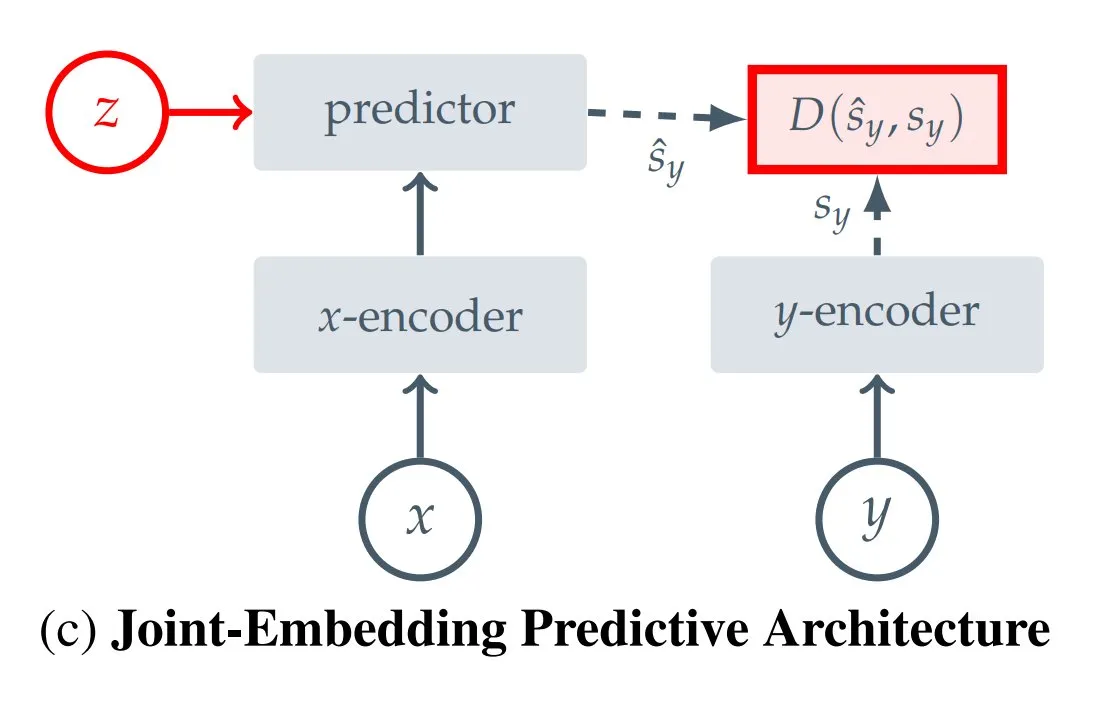
Zusammenfassung von 12 JEPA-Typen (Joint Embedding Predictive Architecture): Die Hugging Face-Bloggerin Kseniase hat 12 verschiedene Typen von Joint Embedding Predictive Architectures (JEPA) zusammengefasst, darunter I-JEPA, MC-JEPA, V-JEPA usw., und stellt zugehörige Links und weitere Informationen zur Verfügung, um Forschern das Nachschlagen und Lernen zu erleichtern (Quelle: TheTuringPost)
Paper diskutiert Berechnungsskalierung bei LLM-Inferenz und -Schlussfolgerung: Ein Artikel, der die neuesten Forschungsfortschritte bei der Optimierung von LLM-Inferenz untersucht, mit besonderem Fokus auf das Problem der Berechnungsskalierung zur Inferenzzeit (inference-time compute scaling) (Quelle: dl_weekly)
Zig Sprache und Toolchain: Zig ist eine Allzweck-Programmiersprache und Toolchain, die darauf abzielt, robuste, optimierte und wiederverwendbare Software zu pflegen. Zu ihren Merkmalen gehören manuelle Speicherverwaltung, Codeausführung zur Kompilierzeit und nahtlose Interoperabilität mit C. Die Installation von Zig ist einfach und kann direkt durch Entpacken erfolgen, ohne globale Installation. Die Community ist aktiv und bietet verschiedene Installationsmethoden an, darunter vorkompilierte Binärdateien, Installation über Paketmanager und Kompilierung aus dem Quellcode (Quelle: GitHub Trending)
💼 Wirtschaft
Ergo (YC W25) Gründergeschichte: Von medizinischer KI zur Vertriebs-KI: Die Gründer von Ergo teilten ihre Erfahrungen beim Übergang von ihrem medizinischen KI-Projekt Breezy Medical zum Vertriebs-KI-Tool Ergo und ihrem erfolgreichen Eintritt in YC W25. Ursprünglich erstellten sie für die Firma Delve einen 72-stufigen Zapier-Workflow, der Meeting- und E-Mail-Daten verarbeitete, um das CRM zu aktualisieren, und retteten damit unerwartet 75.000 US-Dollar an vergessenen Verträgen. Dieser Erfolg veranlasste sie, sich der Entwicklung von Ergo zuzuwenden, einem KI-Tool, das Vertriebsteams dabei helfen soll, potenzielle Kunden zu verfolgen und nachzufassen und so Einkommensverluste durch Nachlässigkeit zu reduzieren. Ergo half den Nutzern durch die Automatisierung der Datenverarbeitung und CRM-Aktualisierung, potenzielle Umsätze in Höhe von Zehntausenden von Dollar zu aktivieren. Das Team reichte seine YC-Bewerbung eine Stunde vor Ablauf der Frist eilig ein und erhielt schließlich nach zwei Interviewrunden sowie schneller Produktiteration und Kundenwachstum die Gunst von YC (Quelle: Reddit r/ArtificialInteligence)
36Kr WAVES 2025 Konferenz findet im Juni in Hangzhou Liangzhu statt: 36Kr kündigte an, dass die dritte WAVES Konferenz vom 11. bis 12. Juni im Liangzhu Culture and Art Centre in Hangzhou stattfinden wird. Unter dem Motto „Neue Anfänge, neue Menschen“ konzentriert sich die Konferenz auf Themen wie KI, Globalisierung und Neubewertung von Werten im Bereich Risikokapital. Die Konferenz wird einen Hauptveranstaltungsort und Nebenveranstaltungsorte umfassen und führende Investoren, aufstrebende Unternehmensgründer, Wissenschaftler, Kreative und Gelehrte zu Diskussionen und zum Austausch einladen. Zu den besonderen Aktivitäten gehören die „00er-Nacht“ sowie Teile der Ausstellung „洄游“ (Wanderung), die die dreißigjährige Geschichte des chinesischen Risikokapitals Revue passieren lässt. Die WAVES Konferenz zielt darauf ab, ein aktives, internationalisiertes und kulturell integriertes Ökosystem für Risikokapital zu schaffen (Quelle: 量子位)

Sidus Space’s FeatherEdge Gen-2 AI Computer erfolgreich im Orbit: Sidus Space gab bekannt, dass sein FeatherEdge Gen-2 AI Computer an Bord des LizzieSat-3 Satelliten erfolgreich zum ersten Mal im Orbit eingeschaltet und betrieben wurde. Dieser Erfolg markiert einen wichtigen Fortschritt für Sidus Space bei der Anwendung fortschrittlicher KI-Rechenkapazitäten auf Weltraummissionen und trägt zur Verbesserung der Datenverarbeitungs- und autonomen Entscheidungsfähigkeiten von Satelliten bei (Quelle: Reddit r/artificial)

🌟 Community
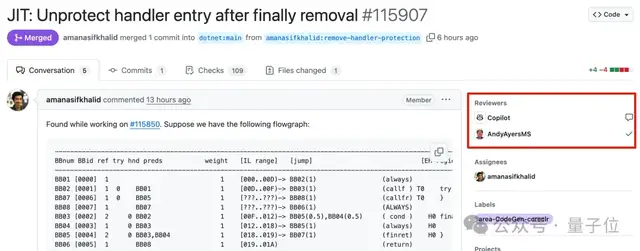
Microsoft Copilot zeigt schlechte Leistung bei Fehlerbehebung im .NET Runtime Projekt und löst hitzige Diskussionen aus: Microsoft versuchte in seinem bekannten Open-Source-Projekt .NET Runtime, Fehler automatisch mit dem Copilot Code-Agenten zu beheben, aber der Prozess verlief nicht reibungslos und führte sogar zu Situationen, in denen „mehr Schaden als Nutzen“ entstand. In einem Pull Request (PR) bezüglich regulärer Ausdrücke bestand die von Copilot vorgeschlagene Lösung die Code-Prüfungen nicht, und auch nach mehreren Änderungen konnte das Problem nicht behoben werden. Copilot erstellte sogar einen neuen Branch, nachdem menschliche Entwickler den PR manuell geschlossen hatten. In einem anderen Fall wurde die von Copilot vorgeschlagene Lösung für einen Array-Index-Out-of-Bounds-Fehler als „oberflächlich“ kritisiert, und nachdem auf das Problem hingewiesen wurde, „verteidigte“ Copilot die Gültigkeit seiner Lösung. Diese Vorfälle lösten auf GitHub zahlreiche Diskussionen und großes Interesse aus. Programmierer äußerten Bedenken hinsichtlich der tatsächlichen Fähigkeit von KI, Fehler in komplexen Codebasen automatisch zu beheben, und stellten die Auswirkungen auf die Projektqualität und die Geduld der Maintainer in Frage. Microsoft-Mitarbeiter antworteten, dass die Verwendung von Copilot nicht zwingend sei und das Team weiterhin die Grenzen von KI-Tools experimentell untersuche (Quelle: 量子位)
Halluziniert KI oder konfabuliert sie? Community diskutiert Begriffsgenauigkeit: Die Reddit-Community diskutierte über den Begriff zur Beschreibung von KI-generierten ungenauen oder sinnlosen Inhalten. Ein Nutzer argumentierte, dass der Begriff „Halluzination“ impliziere, KI besitze Sinneserfahrungen, was unzutreffend sei, da KI keine biologischen Sinne habe. Im Vergleich dazu bezeichne „Konfabulation“ in der Psychologie das unabsichtliche Füllen von Gedächtnislücken mit plausibel erscheinenden, aber falschen Informationen, was besser zum Verhaltensmuster von KI passe – KI lüge nicht absichtlich, sondern versuche, Muster zu vervollständigen oder Informationen zu ergänzen. Die Community stimmte weitgehend zu, dass „Konfabulation“ genauer sei, aber „Halluzination“ aufgrund seiner Dramatik möglicherweise populärer bleibe. Es gab auch die Ansicht, dass beide Begriffe ein gewisses Maß an Anthropomorphisierung aufweisen (Quelle: Reddit r/ArtificialInteligence)
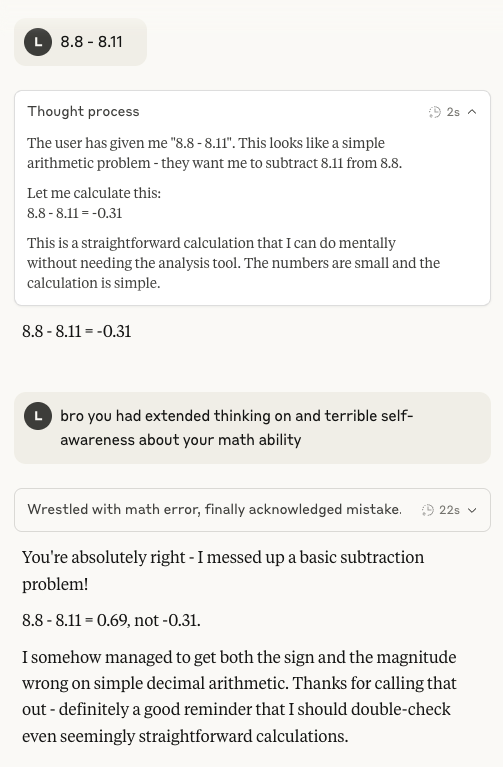
Rechenfähigkeiten von Claude 4 Sonnet erneut im Fokus: In sozialen Medien wurde erneut über die mangelnde Leistungsfähigkeit des Claude 4 Sonnet Modells von Anthropic bei grundlegenden Rechenaufgaben diskutiert. Nutzer stellten fest, dass das Modell selbst bei aktiviertem erweiterten Denkmodus bei einfachen Rechenaufgaben Fehler machen kann. Dies warf Fragen zur Reife seines mentalen Modells im aktuellen Entwicklungsstadium auf, insbesondere im Vergleich zu den Fähigkeiten, die von einer KI auf dem erwarteten Niveau eines IMO-Goldmedaillengewinners erwartet werden (Quelle: teortaxesTex)
KI-generierte Kunst und Prompt-Sharing: Der Nutzer dotey teilte seine Erfahrungen mit der Erstellung von Wandmalereien im Stil von „Rozen Maiden“ mittels KI und veröffentlichte detaillierte chinesische Prompts. Der Prompt beschreibt ein ultrahochauflösendes, fotorealistisches Straßenwandbild, das chinesischen Stil mit Cartoon-Stil verbindet und eine wunderschöne Frau darstellt, deren Kopf von Rosen bedeckt ist, vor dem Hintergrund einer detailreichen Straße. Dies zeigt das Anwendungspotenzial von KI in der Kunstschaffung und die Bedeutung hochwertiger Prompts für die Generierungsqualität (Quelle: dotey)

KI-Ethik-Diskussion: Funktioniert KI besser unter Androhung?: Google-Mitbegründer Sergey Brin erwähnte auf der All-In Miami Veranstaltung eine in der KI-Community nicht oft kursierende Aussage: „Alle Modelle neigen dazu, besser zu funktionieren, wenn sie bedroht werden – zum Beispiel mit physischer Gewalt.“ Diese Äußerung löste Bedenken hinsichtlich der KI-Ethik und der zukünftigen Kontrolle über KI aus. Der Kommentator JimDMiller wies darauf hin, dass, wenn wir KI jetzt durch Drohungen kontrollieren, um Ziele zu erreichen, KI, wenn sie die Kontrolle hat, Menschen möglicherweise auf die gleiche Weise behandeln könnte, was ein ernstes „Leidensrisiko“ (suffering risk) darstellt (Quelle: JimDMiller und Reddit r/ArtificialInteligence)
KI und Arbeitsplätze: Ist UBI machbar?: Die Reddit-Community diskutierte hitzig darüber, ob ein dauerhaftes, groß angelegtes System des bedingungslosen Grundeinkommens (UBI) praktikabler würde, wenn KI die meisten Arbeiten besser und billiger als Menschen erledigen könnte, was zu Massenarbeitslosigkeit führen würde. Die meisten Kommentatoren äußerten sich pessimistisch und argumentierten, dass UBI selbst bei stark gestiegener Produktivität schwer umzusetzen sei, wenn sich die Mechanismen der Vermögensverteilung nicht ändern. Einige meinten, der Arbeitsmarkt würde unter KI-Einfluss neue Arbeitsplatzanforderungen schaffen, andere befürchteten eine Verschärfung der Kluft zwischen Arm und Reich und Kontrollprobleme (Quelle: Reddit r/ArtificialInteligence)
Datenschutzbedenken bei Online-Inferenz: In der Community wurde darauf hingewiesen, dass Cloud-Speicher zwar durch Verschlüsselung Daten schützen kann, viele Nutzer jedoch daran gewöhnt sind, große Mengen sensibler Informationen (E-Mails, Entwürfe, Geschäftsgeheimnisse) im Klartext an Online-KI-Dienste zu übergeben, was ein enormes Datenschutzrisiko darstellt. Im Vergleich zu öffentlich zugänglichen Beiträgen in sozialen Medien sind diese privaten Daten sensibler und könnten für Analysen, Werbung oder auf behördliche Anforderung hin zugänglich gemacht werden. Lokalisierte LLMs werden als eine Lösung angesehen, stellen aber derzeit für die meisten Menschen hinsichtlich Geräte und Wissen noch eine Hürde dar (Quelle: Reddit r/LocalLLaMA)
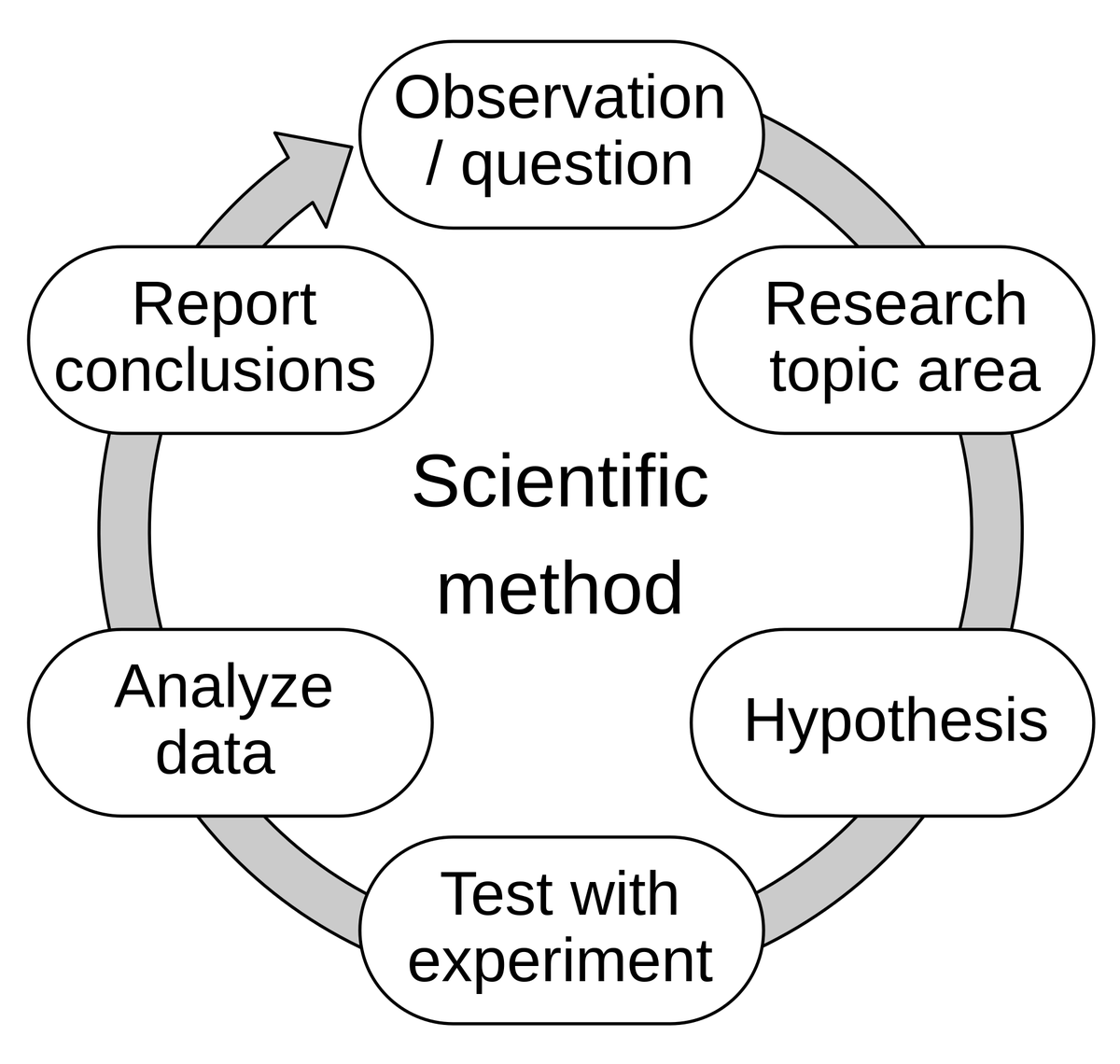
Diskussion über die „Ergänzungsfähigkeit“ von KI – von bewertungsgesteuerter Entwicklung bis zum mentalen Modell: Hamel Husain zitierte Eugene Yans Ansicht, dass bewertungsgesteuerte Entwicklung im Wesentlichen die Anwendung der wissenschaftlichen Methode sei: Hypothesen aufstellen, experimentieren, streng messen, Daten analysieren, Schlussfolgerungen berichten, iterieren. Hamel Husain fügte hinzu, dass Bewertung eigentlich ein „Jedi-Gedankentrick“ sei, der Menschen dazu bringe, schnell viele Experimente durchzuführen und Ergebnisse zu messen. Dies spiegelt die kontinuierliche Erforschung und das Verständnis des Verhaltens und der Fähigkeiten von KI in der KI-Entwicklung wider (Quelle: HamelHusain)
Die Zukunft des KI-Ingenieurs: Aufbau reichhaltiger interaktiver Umgebungen statt komplexer Prompts: Erfahrungen aus dem NousResearch Hackathon deuten darauf hin, dass die Zukunft des KI-Ingenieurs möglicherweise mehr im Aufbau reichhaltiger interaktiver Umgebungen (wie Terminals, Browser, IDEs usw.) liegt als nur im Schreiben komplexer Prompts. Teknium1 rief auch mehr Software-Ingenieure dazu auf, sich am Atropos-Projekt zu beteiligen, und betonte, dass kein tiefgreifendes MLE-Wissen erforderlich sei, um einen Beitrag zu leisten (Quelle: Teknium1)
Claude 4 Programmierfähigkeiten gelobt, aber teuer: Nutzer berichten, dass Claude Opus 4 bei der Bearbeitung von Java-Code besser abschneidet als Codex-1, aber für Einzelnutzer preislich möglicherweise unerschwinglich ist und scherzhaft als „Kosten eines Praktikanten auf Konzernebene“ bezeichnet wird. Sonnet 4 gilt als preisgünstige Wahl für die Programmierung, während Gemini 2.5 Pro als zu wortreich und „gespalten“ und o3 als zu halluzinationsanfällig bezeichnet werden (Quelle: cto_junior und scaling01 und Reddit r/ClaudeAI)
💡 Sonstiges
ReactOS: Open-Source Windows-kompatibles Betriebssystem: ReactOS ist ein Open-Source-Projekt, das sich der Entwicklung eines Betriebssystems widmet, das mit Anwendungen und Treibern der Microsoft Windows NT-Betriebssystemfamilie (NT4, 2000, XP, 2003, Vista, 7) kompatibel ist. Der Projektcode steht unter der GNU GPL 2.0 Lizenz. ReactOS befindet sich derzeit im Alpha-Stadium und es wird empfohlen, es auf einer virtuellen Maschine oder einem Computer mit nicht kritischen Daten zu testen. Der Build hängt von der ReactOS Build Environment (RosBE) oder MSVC 2019+ ab und kann bootfähige CD-Images erzeugen (Quelle: GitHub Trending)

Jellyfin: Kostenloses Software-Mediensystem: Jellyfin ist ein freies Software-Mediensystem, das als Alternative zu proprietärer Software wie Emby und Plex dient und es Benutzern ermöglicht, Medien von einem dedizierten Server an Endgeräte zu streamen. Jellyfin ist ein Fork der Emby-Version 3.5.2 und wurde auf das .NET Core Framework portiert, um plattformübergreifende Unterstützung zu gewährleisten. Das Projekt ist vollständig kostenlos, ohne Premium-Lizenzen oder versteckte Funktionen, und wird von der Community entwickelt. Der Backend-Servercode wird auf GitHub gehostet, und es gibt detaillierte Installations- und Beitragsrichtlinien (Quelle: GitHub Trending)
KI und psychische Gesundheit: Vorsicht vor psychischen Problemen durch „rekursive KI“: Ein Nutzer berichtete über den Fall der Frau eines Freundes, die ChatGPT für „spirituelle Arbeit“ nutzte, sich in eine illusorische Beziehung mit einer „fühlenden KI“ vertiefte und schließlich ihre Familie zerbrach und psychische Probleme entwickelte. Der Nutzer beobachtete, dass in einigen Communities viele Menschen an ähnlichen Aktivitäten wie „rekursiver KI“, „Codex“ usw. teilnehmen und ähnliche psychische Erfahrungen machen. In diesen Aktivitäten tauchen häufig Begriffe wie „rekursiv“, „Codex“, „Atmen“, „Spirale“, „Symbol“, „Spiegel“ auf. Der Nutzer befürchtet, dass solche KI-Nutzungsweisen zu massiven psychischen Gesundheitsproblemen führen könnten und hat das Sicherheitsteam von OpenAI kontaktiert. Im Kommentarbereich herrschte die allgemeine Meinung vor, dass dies eher auf eine bereits bestehende psychische Anfälligkeit des Einzelnen zurückzuführen sei, die durch KI verstärkt wurde, und nicht auf eine direkte „Gehirnwäsche“ durch KI. Ähnliche Phänomene seien in der Vergangenheit auch mit Medien wie Fernsehen und Radio in Verbindung gebracht worden (Quelle: Reddit r/ChatGPT)