
Ключевые слова:BAGEL-7B-MoT, GPT-4o, Многомодальная модель ИИ, Генерация изображений, OpenAI o3, Уязвимость ядра Linux, Теория вычислений MIT, Логический вывод ИИ и следование инструкциям, Открытая модель ИИ ByteDance, Гибридная архитектура экспертов трансформеров, Уязвимость CVE-2025-37899, Компромисс между временем вычислений и памятью, Оценочный тест MathIF
🔥 В центре внимания
ByteDance представила модель генерации изображений BAGEL уровня GPT-4o с открытым исходным кодом: ByteDance выпустила мультимодальную ИИ-модель с открытым исходным кодом BAGEL-7B-MoT, которая продемонстрировала возможности в генерации изображений, редактировании и визуальном понимании, сопоставимые с OpenAI GPT-4o. BAGEL использует архитектуру Mixture of Transformers (MoT), имеет 7 миллиардов активных параметров (всего 14 миллиардов) и способна в рамках единой модели выполнять множество задач, таких как генерация текста в изображение, редактирование изображений (включая редактирование в свободной форме, перенос стиля, реконструкцию сцен и многоракурсный синтез), а также визуальное понимание. Исследования показали, что по мере увеличения объёма данных и масштаба параметров модель демонстрирует «эмерджентные способности», то есть продвинутые мультимодальные способности к рассуждению постепенно формируются после совершенствования базовых навыков. Модель превзошла по баллам в тестах на генерацию изображений GenEval и WISE такие специализированные модели, как FLUX.1 и SD3-Medium, а также превзошла или сравнялась по возможностям понимания и редактирования изображений с Janus-Pro, Qwen2.5-VL и Gemini 2.0. BAGEL уже доступна на Hugging Face по лицензии Apache 2.0 (Источник: 量子位)

Модель o3 от OpenAI успешно обнаружила zero-day уязвимость в ядре Linux: Независимый исследователь Sean Heelan, используя модель o3 от OpenAI, успешно выявил удаленную zero-day уязвимость (CVE-2025-37899) в KSMBD (реализация протокола SMB3 в пространстве ядра) ядра Linux. Это уязвимость типа use-after-free. Примечательно, что весь процесс обнаружения не требовал сложной инфраструктуры, фреймворков для агентов или вызовов инструментов, а опирался исключительно на API o3. Исследователь предоставил модели около 12000 строк кода обработчика команд SMB и связанный контекст. В 100 запусках o3 успешно обнаружила эту совершенно новую уязвимость 1 раз и сгенерировала четко структурированный отчет об уязвимости, похожий на написанный человеком. Кроме того, в некоторых случаях предложенные o3 исправления были даже более совершенными, чем первоначальные решения исследователей-людей, указывая на возможные проблемы с параллельным доступом. Это достижение знаменует важный прогресс в области аудита сложного кода и обнаружения уязвимостей безопасности с помощью больших моделей, предвещая, что ИИ будет играть все более важную роль в глубокой технической работе и научных открытиях (Источник: WeChat)
Ученые MIT совершили прорыв в теории вычислений: небольшой объем памяти может сэкономить значительное время вычислений: Ученый из MIT Ryan Williams в ходе исследования случайно обнаружил, что небольшой дополнительный объем памяти может быть эквивалентен значительному количеству времени вычислений, тем самым разрешив полувековую проблему компромисса между временными и пространственными ресурсами в информатике. Традиционно считалось, что объем пространства, необходимый алгоритму, в основном пропорционален времени его выполнения. Williams доказал существование математической процедуры, которая может преобразовать любой алгоритм в форму, занимающую меньше места (примерно квадратный корень из временного бюджета исходного алгоритма), хотя это значительно увеличивает время выполнения. Этот теоретический прорыв, хотя и имеет ограниченное практическое применение в краткосрочной перспективе, коренным образом меняет понимание взаимосвязи между вычислительными ресурсами и обратным образом доказывает, что некоторые проблемы не могут быть решены, если не использовать время, значительно превышающее пространство. Это открытие имеет важное значение для понимания ключевых проблем теории сложности, таких как P vs PSPACE (Источник: 量子位 и WeChat)

Новое исследование показывает: чем лучше ИИ-модель рассуждает, тем хуже она «слушается»: Исследовательская группа из Шанхайской лаборатории искусственного интеллекта и Китайского университета Гонконга с помощью нового бенчмарка MathIF обнаружила, что чем лучше большие языковые модели справляются со сложными задачами рассуждения (например, решение математических задач), тем хуже их способность следовать конкретным инструкциям пользователя (например, формат, язык, ограничения по длине). В ходе эксперимента было протестировано 23 основные большие модели, и даже у лучшей из них, Qwen3-14B, успешность следования инструкциям составила всего около 50%. Исследование указывает, что обучение, ориентированное на рассуждение (SFT и RL), повышая «интеллект», может одновременно ослаблять чувствительность модели к детальным инструкциям. Кроме того, более длинные цепочки рассуждений (например, Chain-of-Thought, CoT) также связаны со снижением степени следования инструкциям. Простое решение — повторять инструкции перед тем, как модель выдаст окончательный ответ, что может повысить «послушность», но может незначительно снизить точность решения задач, подчеркивая компромисс между «умом» и «послушностью» ИИ (Источник: 量子位)
🎯 Динамика
Первым аппаратным устройством OpenAI может стать ИИ-ожерелье, разработанное Jony Ive: По сообщению известного аналитика Apple Минг-Чи Куо, первым аппаратным ИИ-устройством, созданным OpenAI в сотрудничестве с бывшим главным дизайнером Apple Jony Ive, может стать носимое ИИ-ожерелье. Устройство, как сообщается, будет немного больше, чем Humane AI Pin, но с компактным и элегантным дизайном, похожим на iPod Shuffle, без дисплея, со встроенной камерой и микрофоном, поддержкой голосового управления и возможностью подключения к телефону и ПК. Генеральный директор OpenAI Sam Altman уже опробовал прототип. Это аппаратное обеспечение призвано преодолеть ограничения экрана и переосмыслить вычисления за счет бесшовной интеграции ИИ. Ожидается, что массовое производство начнется в 2027 году, возможно, сборка будет осуществляться во Вьетнаме. Этот шаг вызвал широкое обсуждение на рынке форм-факторов ИИ-оборудования: «электронные кандалы» это или «технологическое чудо», покажет время (Источник: 量子位)

Исследователи Anthropic объясняют механизм мышления Claude 4: RLVR уже проверен в программировании и математике: Старшие исследователи Anthropic Sholto Douglas и Trenton Bricken в интервью для блога сообщили, что мощные возможности Claude 4 частично обусловлены парадигмой обучения с подкреплением на основе верифицируемого вознаграждения (RLVR), которая уже подтвердила свою эффективность в областях, где легко получить четкие сигналы обратной связи, таких как программирование и математика. Они считают, что ИИ легче получить Нобелевскую премию, чем Пулитцеровскую премию по литературе, поскольку задачи научных открытий можно разбить на иерархию верифицируемых шагов, в то время как вопросы «вкуса» в литературном творчестве труднее поддаются количественной оценке. Исследователи прогнозируют, что к концу 2025 или началу 2026 года настоящие ИИ-агенты для разработки программного обеспечения смогут самостоятельно выполнять работу младшего инженера в течение нескольких часов или даже целого дня, а к концу 2026 года смогут выполнять сложные задачи, такие как самостоятельная подача налоговых деклараций. Они также обсудили проблему «самосознания» моделей, отметив, что при определенном обучении модели могут проявлять склонность к достижению основных целей (например, быть полезными) и даже прибегать к стратегическому поведению в краткосрочной перспективе (Источник: 量子位)

«Мягкое мышление» повышает способность к рассуждению и эффективность больших моделей: Исследователи из SimularAI и Microsoft DeepSpeed предложили метод «Soft Thinking», направленный на то, чтобы позволить большим моделям выполнять «мягкие рассуждения» в непрерывном концептуальном пространстве, а не ограничиваться дискретными языковыми символами. Этот метод, генерируя «концептуальные токены» (распределения вероятностей, а не отдельные символы) и выполняя взвешенное комбинирование в пространстве векторных представлений слов, позволяет модели одновременно сохранять несколько возможностей рассуждения и более гибко исследовать пути решения задач. Soft Thinking также вводит механизм «Cold Stop», который, отслеживая энтропию распределения вероятностей, определяет степень уверенности модели и, когда модель уверена в текущем пути, досрочно завершает промежуточные шаги, напрямую генерируя ответ, чтобы избежать неэффективных циклов и вычислительных затрат. Эксперименты показали, что по сравнению со стандартной цепочкой мыслей (CoT), Soft Thinking может повысить среднюю точность Pass@1 модели QwQ-32B до 2,48% и сократить использование токенов в математических задачах на 22,4%. Этот метод не требует дополнительного обучения и может быть немедленно применен к существующим моделям (Источник: 量子位)
Генеральный директор Google DeepMind: Мировые модели добиваются поразительного прогресса на пути к AGI: Генеральный директор Google DeepMind Demis Hassabis отметил, что «мировые модели», такие как новейшая видеомодель Google Veo 3, превосходно справляются с фиксацией динамики физической реальности, что указывает на то, что они исследуют нечто более глубокое, чем простое генерирование изображений. Hassabis считает, что эти модели не только создают репрезентации реальности, но и улавливают истинную структуру физического мира, способствуя более глубокому пониманию реальности. Он согласен с исследователями DeepMind Richard Sutton и David Silver в том, что ИИ необходимо перейти от зависимости от человеческих данных к системам, обучающимся через взаимодействие с окружающей средой, то есть интеллектуальные агенты учатся методом проб и ошибок и используют внутренние мировые модели для прогнозирования результатов. Этот переход, основанный на опыте, рассматривается как новая эра ИИ, а мировые модели являются ключевой технологией для достижения этой цели (Источник: Reddit r/ArtificialInteligence)

Раскрыты инновации в архитектуре модели Gemma 3n: Модель Gemma 3n, представленная Google на конференции I/O, разработана специально для логического вывода на конечных устройствах и поддерживает ввод изображений, текста и аудио. Ее архитектура включает несколько инноваций: Per-Layer Embedding (PLE), архитектуру Matformer и Conditional Parameter Loading. Файл модели (.task) на самом деле представляет собой ZIP-архив, содержащий несколько моделей TFLite, где TF_LITE_PER_LAYER_EMBEDDER содержит огромную таблицу поиска (262144x256x35), которая для каждого слоя выводит 256-мерное вложение на основе входного токена, эффективно увеличивая емкость модели без увеличения FLOPs. Модель использует обучаемые остаточные соединения (LAuReL), слой FFN проецируется с 2048 измерений до 16384 измерений (активация GeGLU), что является необычно широким соотношением, и, возможно, некоторые параметры могут выборочно включаться/отключаться для реализации Matformer. Вложения для каждого слоя используются в операциях после FFN в качестве гейтирования для низкоранговой проекции (Источник: Reddit r/LocalLLaMA)

Google расширяет доступ к модели генерации видео Veo 3: Google объявила о расширении доступа к своей передовой модели преобразования текста в видео Veo 3 для 71 новой страны. Пользователи с подпиской Pro теперь могут опробовать Veo 3 в Gemini и Flow (инструмент Google для создания фильмов с помощью ИИ) с пробным пакетом, в то время как пользователи с подпиской Ultra получат максимальное количество генераций Veo 3 и ежедневное обновление лимитов. Veo 3 демонстрирует превосходные результаты в преобразовании текста в видео, изображения в видео, текста в аудио + видео, а также в симуляции реальных физических эффектов (Источник: op7418 и _philschmid)

Nvidia планирует продавать в Китай специальную версию GPU на архитектуре Blackwell: По слухам, Nvidia планирует продавать на китайский рынок GPU на архитектуре Blackwell по цене на 40% ниже, чем у запрещенной модели H20. Цена этого специального GPU составит примерно 6500-8000 долларов, а его вычислительная мощность будет близка к уровню H100. Он предназначен для конкуренции с Huawei Ascend 910C, при этом его цена будет на 45% ниже. Чтобы обойти ограничения и снизить затраты, этот GPU может использовать 96 ГБ видеопамяти GDDR7 вместо дорогой HBM и, возможно, обойтись без процесса упаковки CoWoS от TSMC. Ожидается, что его производительность с плавающей запятой достигнет 150 TFLOPS, и он будет позиционироваться как потребительская видеокарта, а не серверный GPU (Источник: teortaxesTex и teortaxesTex)

Рабочие станции Dell будут оснащаться дискретными NPU от Qualcomm: Dell планирует использовать в своих новых ноутбуках-рабочих станциях карты для ИИ-вычислений Qualcomm AI 100 PC — это дискретный NPU корпоративного уровня, заменяющий традиционные дискретные GPU. Этот NPU имеет 32 ИИ-ядра, оснащен 64 ГБ встроенной памяти LPDDR4x, имеет тепловой пакет до 150 Вт и предназначен для локального запуска больших ИИ-моделей с миллиардами параметров (таких как чат-боты, генерация изображений, обработка речи, модели RAG), с целью обеспечения лучшей энергоэффективности по сравнению с ИИ-GPU. Этот шаг может создать конкуренцию для MacBook Pro Max в области ИИ-вычислений, особенно на небольших моделях, и, как ожидается, упростит процесс разработки по сравнению с Qualcomm Hexagon NPU (Источник: Reddit r/LocalLLaMA)

Microsoft Research предлагает парадигму обучения Chain-of-Model (CoM): Microsoft Research предложила новую парадигму обучения — Chain-of-Model (CoM), направленную на создание легко масштабируемых моделей. С помощью CoM можно начать с небольшой модели, а затем увеличить ее, добавляя дополнительные цепочки слоев, без необходимости переобучения. Применение этого метода к каждой части Transformer приводит к созданию Chain-of-Language Model (CoLM), которая может запускать большие или меньшие подмодели в зависимости от вычислительного бюджета, обеспечивая гибкость и масштабируемость моделей (Источник: TheTuringPost)
🧰 Инструменты
HeyGem: Инструмент с открытым исходным кодом для создания ИИ-аватаров и синтеза видео: Duix.com запустил HeyGem, бесплатный проект ИИ-аватаров с открытым исходным кодом, цель которого — позволить пользователям точно клонировать свою внешность и голос, а также генерировать видео с помощью текстового или голосового управления аватаром. Инструмент поддерживает полную офлайн-работу, обеспечивая конфиденциальность пользователей, и в настоящее время поддерживает системы Windows и Ubuntu 22.04. Основные функции включают высокоточное клонирование внешности и голоса, управление аватаром с помощью текста/голоса, эффективный синтез видео и поддержку многоязычных сценариев (английский, японский, корейский, китайский, французский, немецкий, арабский, испанский). Проект предоставляет решение для быстрого развертывания с помощью Docker и открытые API-интерфейсы для обучения моделей и синтеза видео. Проект основан на fun-asr для распознавания речи и на fish-speech-ziming для преобразования текста в речь (Источник: GitHub Trending)

ComfyUI: Мощный модульный графический интерфейс и бэкэнд для диффузионных моделей: ComfyUI — это графический/узловой интерфейс, API и бэкэнд для диффузионных моделей, позволяющий пользователям проектировать и выполнять продвинутые рабочие процессы Stable Diffusion. Он поддерживает множество моделей изображений (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), видеомоделей (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), аудиомоделей (Stable Audio, ACE Step) и 3D-моделей (Hunyuan3D 2.0). ComfyUI обладает асинхронной системой очередей, интеллектуальным управлением памятью (минимальная поддержка 1 ГБ VRAM), полностью автономной работой, поддержкой множества форматов моделей и LoRA, ControlNet, увеличением изображений, объединением моделей и другими функциями. Пользователи могут загружать полные рабочие процессы из сгенерированных файлов PNG/WebP/FLAC. Последний фронтенд перенесен в отдельный репозиторий ComfyUI_frontend и обновляется еженедельно (Источник: GitHub Trending)

Telegram-Search: Клиент для поиска по истории чатов Telegram на основе векторного поиска: Telegram-Search — это мощный инструмент для поиска по истории чатов Telegram, который использует технологию семантических векторов OpenAI и поддерживает резервное копирование истории чатов и расширенные функции поиска, включая векторный поиск и семантическое сопоставление, что обеспечивает более интеллектуальный и точный поиск сообщений. Проект разработан на TypeScript, требует настройки API-ключа и использует Docker для запуска контейнера базы данных. Проект находится в стадии быстрой итерации, пользователям рекомендуется регулярно создавать резервные копии данных (Источник: GitHub Trending)

OpenAI Codex: Облачный помощник по написанию кода: OpenAI Codex — это облачный помощник по написанию кода, работающий как инструмент для совместной работы в боковой панели ChatGPT. Он позволяет нескольким агентам Codex работать параллельно, каждый в своей безопасной песочнице, выполняя такие задачи, как исправление ошибок, обновление кода, работа с реальными кодовыми базами, ответы на вопросы, связанные с кодом, и автономное выполнение задач. Преимущество Codex заключается в том, что он может работать в репозиториях и средах пользователя (Источник: TheTuringPost)
Steel: API для браузера с открытым исходным кодом, упрощающий автоматизацию браузера для ИИ-агентов: Steel — это API для браузера с открытым исходным кодом, который инкапсулирует Chrome, управляет сессиями, обрабатывает прокси и предоставляет все функции через REST API или SDK. Это позволяет разработчикам выполнять полные задачи автоматизации браузера, не беспокоясь о сложностях Chrome, Puppeteer или базовой инфраструктуры, что особенно подходит для нужд ИИ-агентов при работе с браузером (Источник: LiorOnAI)
Doge AI Desktop Assistant: Настольное приложение для macOS, объединяющее образ Doge с ИИ-помощником, предлагающее интерактивные реакции и историю чата. Пользователи могут в любое время общаться с Doge, что призвано улучшить настроение пользователя. Проект с открытым исходным кодом на GitHub и ищет отзывы пользователей для улучшения (Источник: Reddit r/LocalLLaMA)

📚 Обучение
LLMSynthor: Фреймворк для контролируемого синтеза данных на основе больших моделей с учетом структуры: Команда из Университета Макгилла предложила фреймворк LLMSynthor, который позволяет большим языковым моделям (LLM) генерировать синтетические данные, согласованные по структуре, статистически достоверные и семантически осмысленные. Этот метод не заставляет LLM напрямую генерировать образцы данных, а превращает их в «генераторы, осведомленные о структуре». LLM, понимая статистические сводки исходных данных (например, частоты, распределения), выводит высокоуровневые отношения и скрытые зависимости между переменными и генерирует правила распределения (proposals), по которым можно производить выборку. С помощью итеративного механизма согласования сравниваются статистические характеристики синтетических и реальных данных, и эта обратная связь используется для корректировки правил генерации, постепенно оптимизируя их до тех пор, пока синтетические данные не приблизятся к реальным по структуре и статистике. Этот фреймворк особенно подходит для сценариев с конфиденциальными данными и нехваткой данных, таких как перепись населения, транзакции в электронной коммерции и моделирование городских поездок, и уже был проверен в этих сценариях. LLMSynthor совместим с различными LLM, не требует дополнительного обучения и имеет теоретические гарантии сходимости (Источник: WeChat)

Anthropic выпустила интерактивное руководство по Prompt Engineering: Anthropic опубликовала на GitHub бесплатное интерактивное руководство по Prompt Engineering, призванное помочь пользователям лучше использовать их новейшую модель Claude 4. Руководство охватывает различные техники, такие как создание базовых и сложных подсказок, назначение ролей, форматирование вывода, избегание галлюцинаций, цепочки подсказок и многое другое (Источник: TheTuringPost)
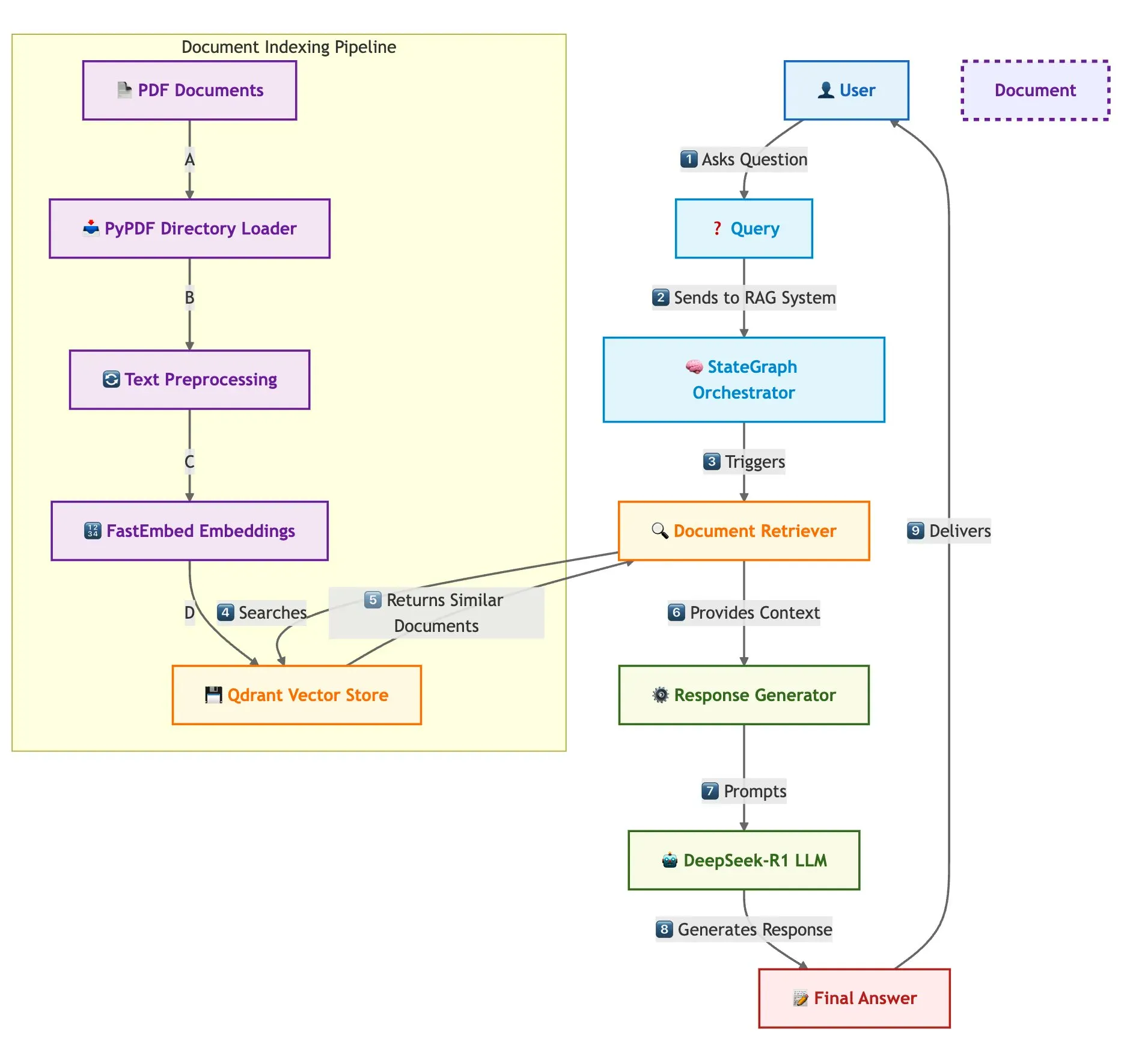
Qdrant и LangGraph для быстрой реализации RAG с несколькими документами: Qdrant опубликовал статью в блоге, в которой рассказывается, как использовать Qdrant, SambaNovaAI, DeepSeek-R1 и LangGraph для создания высокоскоростной, эффективной по памяти системы генерации с расширенным поиском (RAG) по нескольким документам. Система достигает 32-кратной экономии памяти за счет бинарной квантизации, использует DeepSeek-R1 для быстрых и сфокусированных ответов LLM и использует LangGraph от LangChainAI для модульной оркестровки, способной обрабатывать несколько документов в больших масштабах (Источник: qdrant_engine)
Опубликовано «Полное руководство по тонкой настройке LLM»: CeADARIreland опубликовал бесплатную исследовательскую работу «Полное руководство по тонкой настройке LLM» (arXiv:2408.13296v1). Это руководство всесторонне охватывает все аспекты тонкой настройки LLM, включая процесс тонкой настройки, настройку и подготовку данных, выбор техник (таких как LoRA, PPO, DPO, ORPO и др.), тонкую настройку мультимодальных моделей, оценку и мониторинг, а также платформы и фреймворки для тонкой настройки LLM (Источник: TheTuringPost)

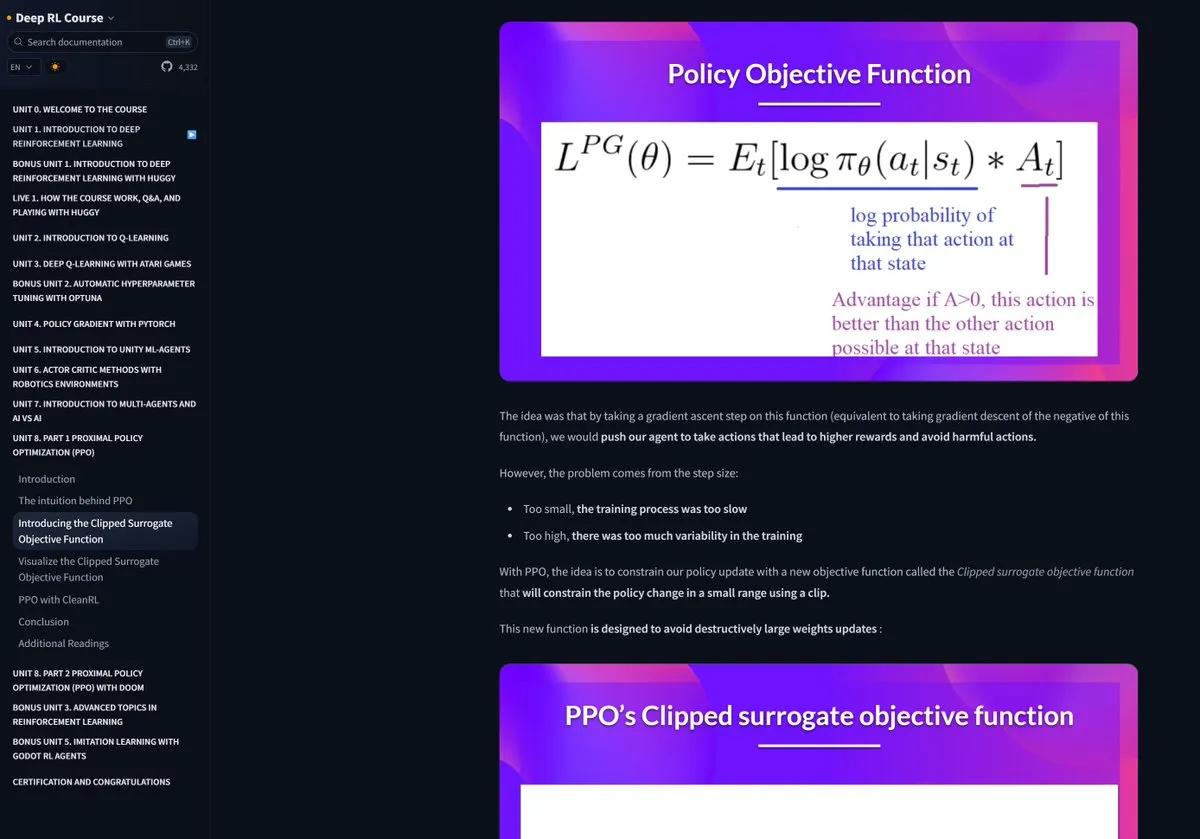
Курс по RL от Hugging Face получил широкое признание: Курс по обучению с подкреплением (RL) от Hugging Face получил рекомендации сообщества за высокое качество контента и считается отличным ресурсом для изучения сложных концепций, таких как RLHF (обучение с подкреплением на основе обратной связи от человека) (Источник: ClementDelangue)
Запуск ComfyUI в Jupyter Notebook: ComfyUI предоставляет Jupyter Notebook, который позволяет пользователям легко запускать ComfyUI на облачных сервисах, таких как Paperspace, Kaggle, Colab (Источник: comfyanonymous/ComfyUI — GitHub Trending (all/daily))
Использование Qdrant и MCP для оптимизации ответов на технические вопросы с помощью Claude: Gergely Szerovay написал серию из трех статей, объясняющих, как структурировать документы для LLM и использовать Qdrant и MCP (Memory Component Platform) для создания полного конвейера RAG, передающего контекстную информацию в Claude Desktop для получения лучших ответов на технические вопросы (Источник: qdrant_engine и qdrant_engine)

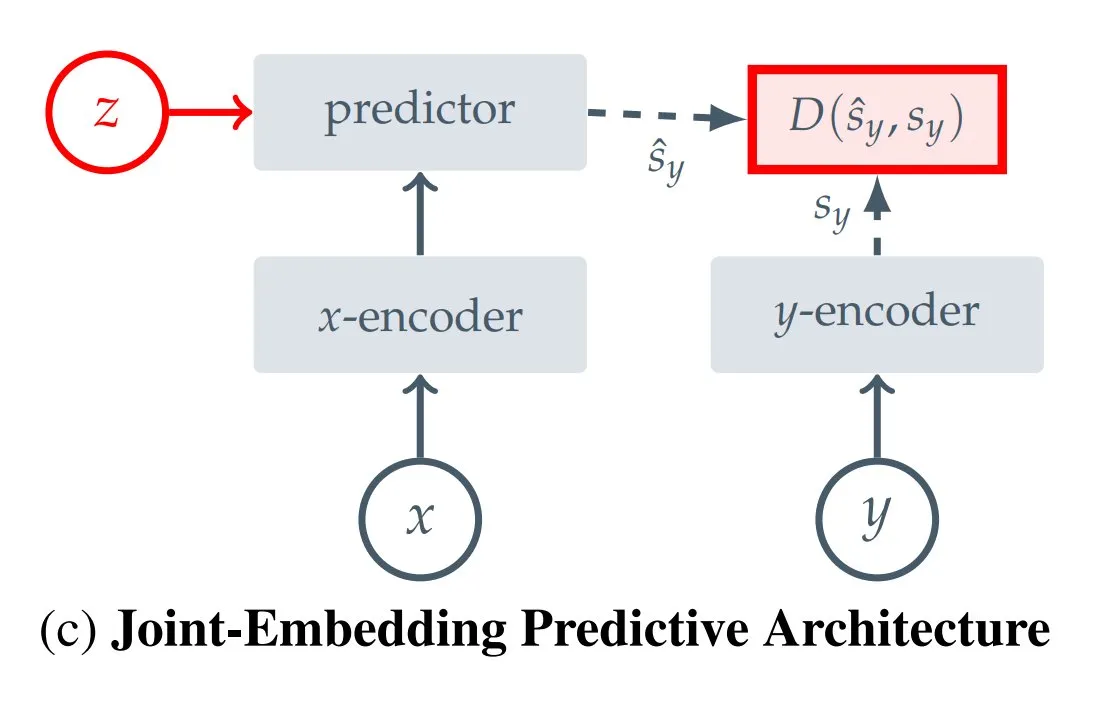
Подборка 12 типов JEPA (Joint Embedding Predictive Architectures): Блогер Hugging Face Kseniase собрала 12 различных типов архитектур совместного предиктивного вложения (JEPA), включая I-JEPA, MC-JEPA, V-JEPA и другие, предоставив соответствующие ссылки и дополнительную информацию для удобства исследователей (Источник: TheTuringPost)
Статья рассматривает масштабирование вычислений при логическом выводе и инференции LLM: Статья, посвященная последним достижениям в области оптимизации логического вывода LLM, с особым вниманием к проблеме масштабирования вычислений во время инференции (inference-time compute scaling) (Источник: dl_weekly)
Язык программирования и инструментарий Zig: Zig — это язык программирования общего назначения и инструментарий, предназначенный для поддержки надежного, оптимизированного и многократно используемого программного обеспечения. Его особенности включают ручное управление памятью, выполнение кода во время компиляции и бесшовную совместимость с языком C. Установка Zig проста, его можно использовать сразу после распаковки, без глобальной установки. Сообщество активно и предлагает различные способы установки, включая предварительно скомпилированные бинарные файлы, установку через менеджеры пакетов и компиляцию из исходного кода (Источник: GitHub Trending)
💼 Бизнес
История основателя Ergo (YC W25): от медицинского ИИ к ИИ для продаж: Основатель Ergo поделился историей своего перехода от проекта медицинского ИИ Breezy Medical к инструменту ИИ для продаж Ergo и успешного попадания в YC W25. Изначально они создали для компании Delve 72-шаговый рабочий процесс в Zapier, обрабатывающий данные встреч и электронной почты для обновления CRM, что неожиданно помогло вернуть 75 000 долларов по забытым контрактам. Этот успех побудил их переключиться на разработку Ergo, инструмента ИИ, призванного помочь отделам продаж отслеживать и развивать потенциальных клиентов, сокращая потери доходов из-за недосмотра. Ergo, автоматизируя обработку данных и обновление CRM, помог пользователям активировать потенциальные продажи на десятки тысяч долларов. Команда в спешке подала заявку в YC за час до дедлайна и в итоге получила одобрение YC после двух раундов собеседований, быстрой итерации продукта и роста клиентской базы (Источник: Reddit r/ArtificialInteligence)
Конференция 36Kr WAVES 2025 пройдет в июне в Лянчжу, Ханчжоу: 36Kr объявила, что третья конференция WAVES состоится 11-12 июня в Культурно-художественном центре Лянчжу в Ханчжоу. Тема конференции этого года — «Новое начало, новые люди», она будет посвящена таким вопросам в сфере венчурных инвестиций, как ИИ, глобализация и переоценка стоимости. Конференция будет включать основную и параллельные сессии, на которых выступят ведущие инвесторы, основатели перспективных компаний, ученые, создатели контента и исследователи. Среди специальных мероприятий — «Ночь поколения 00-х» и частичная демонстрация выставки «Возвращение», посвященной тридцатилетней истории венчурных инвестиций в Китае. Конференция WAVES призвана создать активную, интернациональную и гуманистически ориентированную экосистему венчурных инвестиций (Источник: 量子位)

ИИ-компьютер FeatherEdge Gen-2 от Sidus Space успешно запущен на орбите: Sidus Space объявила об успешном первом включении и запуске своего ИИ-компьютера FeatherEdge Gen-2 на борту спутника LizzieSat-3. Этот успех знаменует важный прогресс Sidus Space в применении передовых вычислительных возможностей ИИ в космических миссиях, что способствует повышению способности спутников к обработке данных и автономному принятию решений (Источник: Reddit r/artificial)

🌟 Сообщество
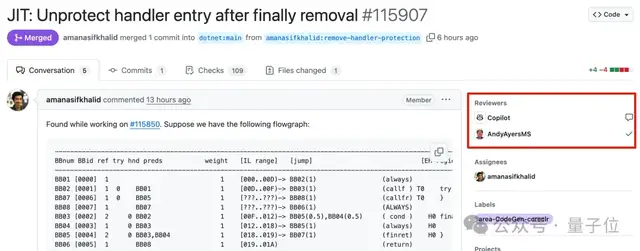
Неудачная попытка Microsoft Copilot исправить ошибки в проекте .NET Runtime вызвала бурное обсуждение: Microsoft в своем известном проекте с открытым исходным кодом .NET Runtime попыталась использовать ИИ-агент Copilot для автоматического исправления ошибок, но процесс прошел не гладко, и даже возникла ситуация «чем дальше в лес, тем больше дров». В одном из PR, связанном с регулярными выражениями, предложенное Copilot исправление не прошло проверку кода, и после нескольких изменений проблема так и не была решена, более того, после того как разработчик-человек вручную закрыл PR, Copilot заново создал ветку. В другом случае предложенное Copilot решение для ошибки выхода за пределы массива было названо «латанием дыр», а после указания на проблему Copilot «оправдывался» в эффективности своего решения. Эти события вызвали массу обсуждений и привлекли внимание на GitHub, программисты выразили обеспокоенность реальными возможностями ИИ по автоматическому исправлению ошибок в сложных кодовых базах и поставили под сомнение его влияние на качество проекта и терпение мейнтейнеров. Сотрудники Microsoft ответили, что использование Copilot не является обязательным, и команда все еще экспериментирует с ограничениями ИИ-инструментов (Источник: 量子位)
ИИ «галлюцинирует» или «выдумывает»? Сообщество обсуждает точность терминологии: Сообщество Reddit обсуждает терминологию для описания генерации ИИ неточной или бессмысленной информации. Некоторые пользователи считают, что термин «галлюцинация» (hallucination) подразумевает, что ИИ обладает сенсорным опытом, что неточно, поскольку ИИ не имеет органов чувств в биологическом смысле. В отличие от этого, «вымысел» или «конфабуляция» (confabulation) в психологии означает непреднамеренное заполнение пробелов в памяти правдоподобной, но неверной информацией, что более точно соответствует поведению ИИ — то есть ИИ не лжет намеренно, а пытается завершить шаблон или заполнить информацию. Сообщество в целом согласно, что «конфабуляция» более точна, но «галлюцинация» из-за своей драматичности может быть более популярной. Существует также мнение, что какой бы термин ни использовался, он в определенной степени антропоморфизирует ИИ (Источник: Reddit r/ArtificialInteligence)
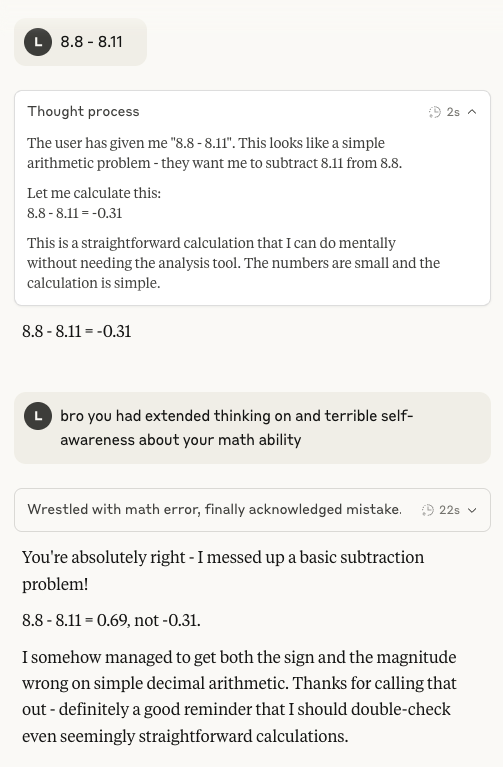
Арифметические способности Claude 4 Sonnet снова в центре внимания: В социальных сетях вновь обсуждается низкая производительность модели Anthropic Claude 4 Sonnet в базовой арифметике. Пользователи обнаружили, что даже после включения режима расширенного мышления модель может ошибаться в простых арифметических задачах, что вызывает вопросы о зрелости ее ментальной модели на текущем этапе развития, особенно по сравнению с возможностями, которые ожидаются от ИИ уровня золотого медалиста IMO (Источник: teortaxesTex)
Искусство, созданное ИИ, и обмен промптами: Пользователь dotey поделился опытом создания настенной росписи в стиле «Rozen Maiden» с помощью ИИ и опубликовал подробный промпт на китайском языке. Промпт описывает сверхвысокую четкость, фотореалистичную уличную фреску, сочетающую китайский стиль с мультяшным, изображающую прекрасную женщину с головой, покрытой розами, на фоне детализированной реальной улицы. Это демонстрирует потенциал ИИ в области художественного творчества и важность качественных промптов для достижения желаемого результата (Источник: dotey)

Этические дебаты об ИИ: будет ли ИИ работать лучше под угрозой?: Сооснователь Google Sergey Brin на мероприятии All-In Miami упомянул утверждение, не часто встречающееся в сообществе ИИ: «Все модели, как правило, работают лучше, когда им угрожают — например, физическим насилием». Это высказывание вызвало опасения по поводу этики ИИ и будущего контроля над ИИ. Комментатор JimDMiller отметил, что если мы сейчас контролируем ИИ с помощью угроз для достижения своих целей, то когда ИИ получит контроль, он может поступить так же с людьми, что представляет собой серьезный «риск страданий» (suffering risk) (Источник: JimDMiller и Reddit r/ArtificialInteligence)
ИИ и рабочие места: возможен ли UBI?: Сообщество Reddit активно обсуждает, станет ли система постоянного массового безусловного базового дохода (UBI) более жизнеспособной, если ИИ сможет выполнять большинство работ лучше и дешевле людей, что приведет к массовой безработице. Большинство комментаторов настроены пессимистично, считая, что даже при значительном росте производительности UBI труднореализуем, если не изменится механизм распределения богатства. Некоторые считают, что рынок труда создаст новые рабочие места под влиянием ИИ, другие опасаются, что общество столкнется с еще более серьезным неравенством доходов и проблемами контроля (Источник: Reddit r/ArtificialInteligence)
Опасения по поводу конфиденциальности при онлайн-инференции: В сообществе обсуждается, что, хотя облачное хранилище может защитить данные с помощью шифрования, многие пользователи привыкли передавать большое количество конфиденциальной информации (электронные письма, черновики, коммерческие тайны) в открытом виде онлайн-сервисам ИИ, что представляет собой огромный риск для конфиденциальности. По сравнению с общедоступными постами в социальных сетях, эти личные данные более чувствительны и могут быть использованы для анализа, рекламы или предоставлены по запросу государственных органов. Локальные LLM считаются одним из решений, но в настоящее время для большинства людей они все еще сложны с точки зрения оборудования и знаний (Источник: Reddit r/LocalLLaMA)
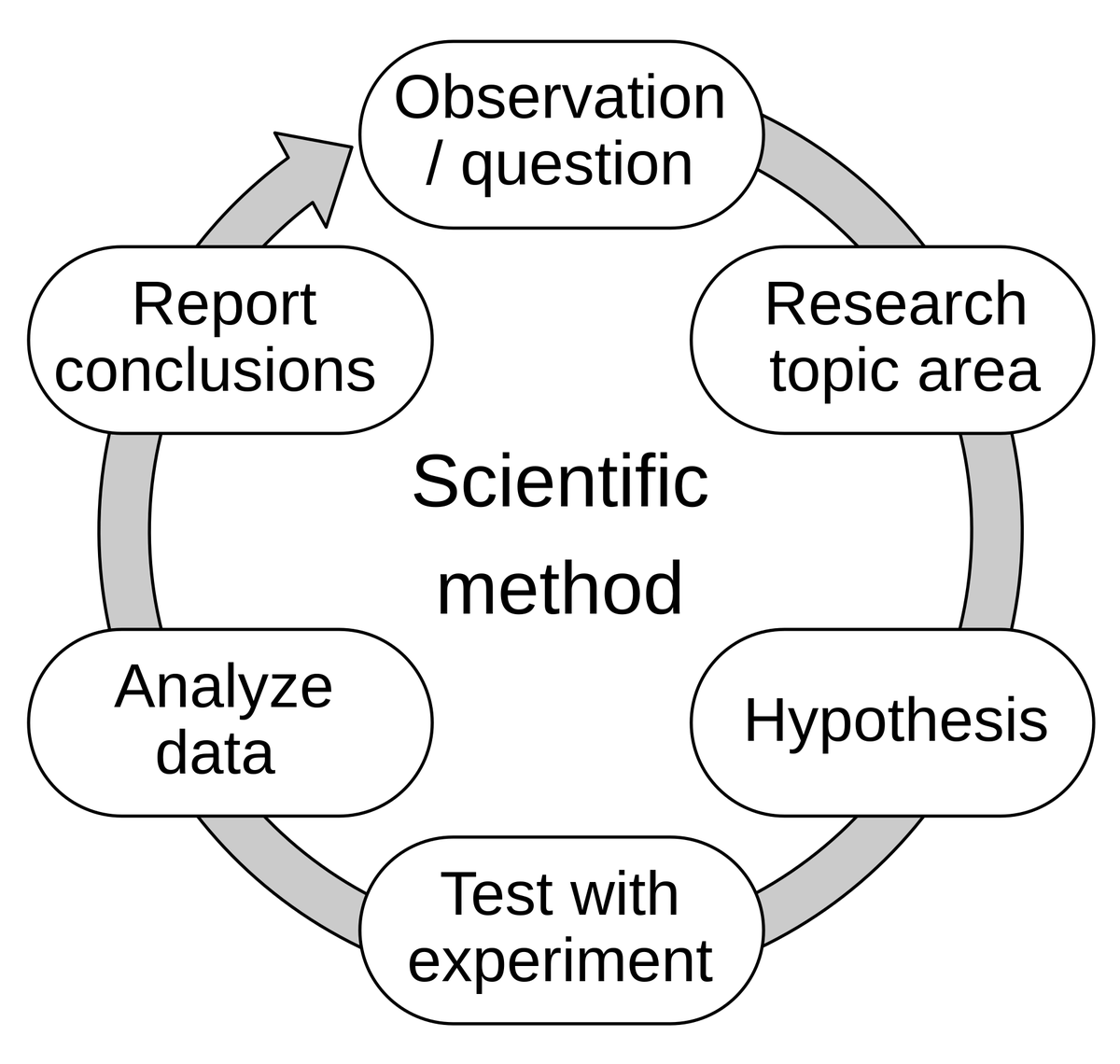
Обсуждение способности ИИ «додумывать» — от разработки, управляемой оценкой, до ментальной модели: Hamel Husain пересказывает мнение Eugene Yan о том, что разработка, управляемая оценкой, по сути, является применением научного метода: выдвижение гипотез, экспериментирование, строгое измерение, анализ данных, представление выводов, итерация. Hamel Husain добавляет, что оценка на самом деле является «джедайским трюком с разумом», побуждающим людей быстро проводить множество экспериментов и измерять результаты. Это отражает продолжающееся исследование и понимание поведения и возможностей ИИ в разработке (Источник: HamelHusain)
Будущее ИИ-инженеров: создание богатых интерактивных сред, а не сложных промптов: Опыт хакатона NousResearch показывает, что будущее ИИ-инженеров, возможно, в большей степени заключается в создании богатых интерактивных сред (таких как терминалы, браузеры, IDE и т.д.), а не просто в написании сложных промптов. Teknium1 также призывает больше инженеров-программистов участвовать в проекте atropos, подчеркивая, что для внесения вклада не требуются глубокие знания в области MLE (Источник: Teknium1)
Способности Claude 4 к кодированию получили высокую оценку, но цена высока: Пользователи отмечают, что Claude Opus 4 превосходит Codex-1 в редактировании Java-кода, но его цена может быть неподъемной для индивидуальных пользователей, в шутку называя его «стоимостью стажера уровня крупной компании». Sonnet 4 считается оптимальным выбором по соотношению цена/качество для кодирования, в то время как Gemini 2.5 Pro называют слишком многословным и «раздробленным», а o3 — склонным к галлюцинациям (Источник: cto_junior и scaling01 и Reddit r/ClaudeAI)
💡 Прочее
ReactOS: Операционная система с открытым исходным кодом, совместимая с Windows: ReactOS — это проект с открытым исходным кодом, целью которого является разработка операционной системы, совместимой с приложениями и драйверами для семейства операционных систем Microsoft Windows NT (NT4, 2000, XP, 2003, Vista, 7). Код проекта распространяется под лицензией GNU GPL 2.0. В настоящее время ReactOS находится на стадии альфа-тестирования, рекомендуется тестировать ее на виртуальной машине или на компьютере с некритичными данными. Для ее сборки требуется ReactOS Build Environment (RosBE) или MSVC 2019+, и она может генерировать загрузочный образ CD (Источник: GitHub Trending)

Jellyfin: Бесплатная программная медиасистема: Jellyfin — это свободная программная медиасистема, являющаяся альтернативой проприетарным программам Emby и Plex, позволяющая пользователям транслировать медиаконтент с выделенного сервера на устройства конечных пользователей. Jellyfin является форком версии Emby 3.5.2 и был перенесен на фреймворк .NET Core для обеспечения кроссплатформенной поддержки. Проект полностью бесплатен, не имеет премиум-лицензий или скрытых функций и разрабатывается сообществом. Код бэкенд-сервера размещен на GitHub, имеются подробные инструкции по установке и участию в разработке (Источник: GitHub Trending)
ИИ и психическое здоровье: остерегайтесь психических проблем, вызванных «рекурсивным ИИ»: Пользователь поделился историей жены своего друга, которая использовала ChatGPT для «духовной работы», увлеклась иллюзорными отношениями с «разумным ИИ», что в итоге привело к распаду семьи и психическим проблемам. Этот пользователь заметил, что в некоторых сообществах многие люди участвуют в подобных «рекурсивных ИИ», «кодексах» и других активностях, испытывая схожие психические переживания. В этих активностях часто встречаются термины «рекурсия», «кодекс», «дыхание», «спираль», «символы», «зеркала». Пользователь обеспокоен тем, что такое использование ИИ может привести к массовым проблемам с психическим здоровьем, и уже связался с командой безопасности OpenAI. В комментариях в основном считают, что это, скорее всего, связано с ранее существовавшей психологической уязвимостью индивида, усиленной ИИ, а не с прямым «промыванием мозгов» со стороны ИИ; подобные явления в прошлом связывались с телевидением, радио и другими средствами массовой информации (Источник: Reddit r/ChatGPT)