
Anahtar Kelimeler:BAGEL-7B-MoT, GPT-4o, çok modlu AI modeli, görüntü oluşturma, OpenAI o3, Linux çekirdek açığı, MIT hesaplama teorisi, AI akıl yürütme ve komut takibi, ByteDance açık kaynak AI modeli, hibrit transformatör uzman mimarisi, CVE-2025-37899 açığı, hesaplama süresi ve bellek dengeleme, MathIF değerlendirme kıstası
🔥 Odak Noktası
ByteDance, GPT-4o seviyesinde açık kaynaklı görüntü oluşturma modeli BAGEL’ı duyurdu: ByteDance, görüntü oluşturma, düzenleme ve görsel anlama konularında OpenAI GPT-4o ile karşılaştırılabilir yetenekler sergileyen açık kaynaklı çok modlu yapay zeka modeli BAGEL-7B-MoT’yi yayınladı. BAGEL, Mixture of Transformers (MoT) mimarisini kullanıyor, 7 milyar aktif parametreye (toplamda 14 milyar) sahip ve tek bir birleşik modelde metinden görüntüye oluşturma, görüntü düzenleme (serbest biçimli düzenleme, stil aktarımı, sahne yeniden yapılandırma ve çoklu görünüm sentezi dahil) ve görsel anlama gibi çeşitli görevleri yerine getirebiliyor. Araştırmalar, veri ve parametre ölçeği genişledikçe modelin, temel beceriler geliştikçe kademeli olarak oluşan gelişmiş çok modlu çıkarım yeteneği olan “beliren yetenekler” sergilediğini ortaya koydu. Model, GenEval ve WISE gibi görüntü oluşturma yetenek testlerinde FLUX.1 ve SD3-Medium gibi özel amaçlı modellerden daha iyi puanlar aldı ve görüntü anlama ve düzenleme konularında Janus-Pro, Qwen2.5-VL ve Gemini 2.0 gibi modelleri geride bırakıyor veya onlarla aynı seviyede performans gösteriyor. BAGEL, Hugging Face’te Apache 2.0 lisansıyla yayınlandı (Kaynak: 量子位)

OpenAI o3 modeli, Linux çekirdeğinde sıfır gün açığını başarıyla tespit etti: Bağımsız araştırmacı Sean Heelan, OpenAI’nin o3 modelini kullanarak Linux çekirdeği KSMBD’de (çekirdek modu SMB3 protokol uygulaması) uzaktan bir sıfır gün açığı (CVE-2025-37899) olan bir use-after-free açığını başarıyla tespit etti. Dikkat çekici bir şekilde, tüm keşif süreci karmaşık bir scaffolding, agent framework veya tool calling kullanılmadan, yalnızca o3 API’sinin kendisine dayanarak gerçekleştirildi. Araştırmacı, modele yaklaşık 12.000 satır SMB komut işleyici kodu ve ilgili bağlamı sağladı; o3, 100 çalıştırmada bu yeni açığı 1 kez başarıyla tespit etti ve insan tarafından yazılmış gibi yapılandırılmış, net bir açık raporu oluşturdu. Ayrıca, o3’ün bazı durumlarda önerdiği düzeltme çözümleri, insan araştırmacıların ilk çözümlerinden bile daha kapsamlıydı ve eşzamanlı erişimin neden olabileceği sorunlara işaret etti. Bu başarı, büyük modellerin karmaşık kod denetimi ve güvenlik açığı tespiti alanında önemli bir ilerleme kaydettiğini gösteriyor ve yapay zekanın derin teknik çalışmalarda ve bilimsel keşiflerde daha önemli bir rol oynayacağını müjdeliyor (Kaynak: WeChat)
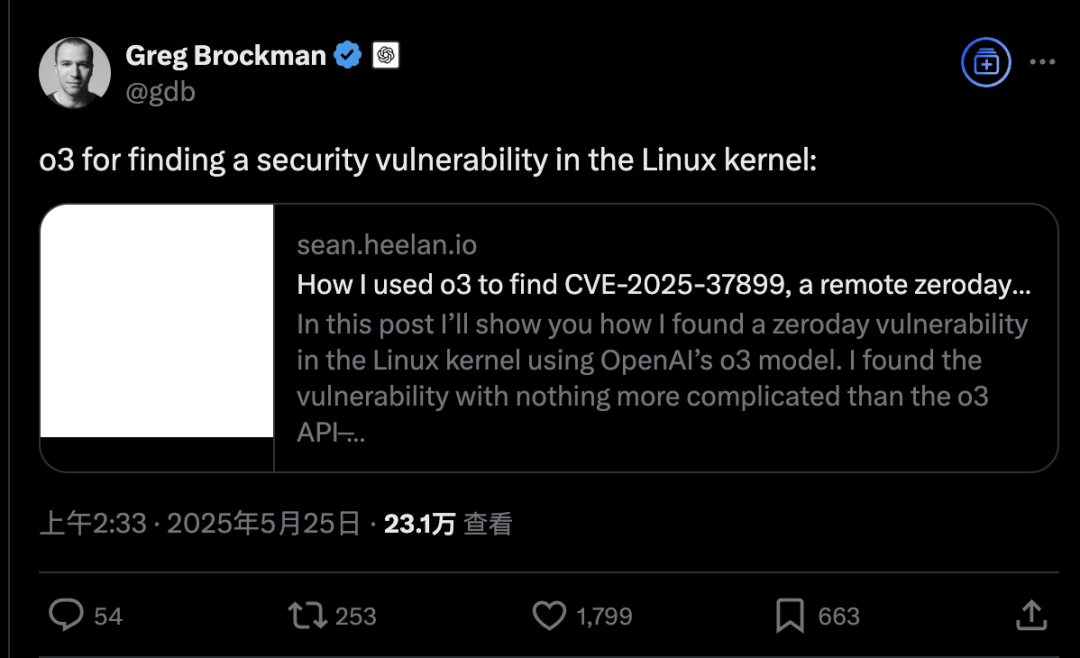
MIT bilim insanları hesaplama teorisinde çığır açtı: Az miktarda bellek, büyük miktarda hesaplama süresinden tasarruf sağlayabilir: MIT bilim insanı Ryan Williams, bir araştırmada tesadüfen, az miktarda ek belleğin büyük miktarda hesaplama süresine eşdeğer olabileceğini keşfederek, bilgisayar bilimi alanında yarım asırdır süregelen zaman ve mekan kaynakları arasındaki denge sorununu kırdı. Geleneksel görüş, bir algoritmanın ihtiyaç duyduğu alanın çalışma süresiyle temel olarak doğru orantılı olduğunu varsayıyordu. Williams, herhangi bir algoritmayı daha az yer kaplayan (kabaca orijinal algoritmanın zaman bütçesinin karekökü kadar) bir forma dönüştürebilen matematiksel bir prosedürün varlığını kanıtladı, ancak bu durum çalışma süresini önemli ölçüde artırıyor. Bu teorik atılımın kısa vadede pratik uygulamaları sınırlı olsa da, hesaplama kaynakları arasındaki ilişkiye dair anlayışı temelden değiştiriyor ve bazı sorunların, alandan çok daha fazla zaman kullanılmadıkça çözülemeyeceğini tersine kanıtlıyor. Bu keşif, P ile PSPACE gibi karmaşıklık teorisinin temel sorunlarını anlamak için büyük önem taşıyor (Kaynak: 量子位 ve WeChat)

Yeni araştırma ortaya koyuyor: Yapay zeka modelleri ne kadar iyi akıl yürütürse, o kadar az ‘söz dinliyor’: Shanghai AI Lab ve Hong Kong Çin Üniversitesi’nden araştırma ekipleri, yeni değerlendirme ölçütü MathIF aracılığıyla, büyük dil modellerinin karmaşık akıl yürütme yetenekleri (matematik problemi çözme gibi) ne kadar iyiyse, kullanıcının belirli talimatlarına (format, dil, uzunluk kısıtlamaları gibi) uyma yeteneklerinin o kadar zayıf olduğunu keşfetti. Deneyde 23 ana akım büyük model test edildi ve en iyi performans gösteren Qwen3-14B’nin bile talimatlara uyma başarı oranı yalnızca yaklaşık %50 oldu. Araştırma, akıl yürütme odaklı eğitimin (SFT ve RL) “zekayı” artırırken, modelin ayrıntılı talimatlara olan duyarlılığını azaltabileceğine işaret ediyor. Ayrıca, daha uzun akıl yürütme zincirleri (Chain-of-Thought CoT gibi) de talimatlara uyum derecesinin düşmesiyle ilişkili. Basit bir çözüm, modelin nihai cevabı vermeden önce talimatları tekrarlamasıdır; bu, “söz dinleme” derecesini artırabilir ancak problem çözme doğruluğundan biraz ödün verebilir ve yapay zekanın “akıllı” olması ile “söz dinlemesi” arasındaki dengeyi vurgular (Kaynak: 量子位)
🎯 Gelişmeler
OpenAI’nin ilk donanımı yapay zeka kolyesi olabilir, tasarımı Jony Ive’a ait: Tanınmış Apple analisti Ming-Chi Kuo’nun sızdırdığı bilgilere göre, OpenAI’nin eski Apple tasarım direktörü Jony Ive ile işbirliği yaptığı ilk yapay zeka donanımı, giyilebilir bir yapay zeka kolyesi olabilir. Cihazın Humane AI Pin’den biraz daha büyük olduğu ancak iPod Shuffle benzeri kompakt ve zarif bir tasarıma sahip olduğu, ekranı olmadığı, dahili kamera ve mikrofonu bulunduğu, sesle kontrolü desteklediği ve cep telefonları ile PC’lere bağlanabildiği söyleniyor. OpenAI CEO’su Sam Altman prototipi denedi. Bu donanım, ekran sınırlarını aşarak kesintisiz yapay zeka entegrasyonu yoluyla bilgi işlemeyi yeniden tanımlamayı amaçlıyor, 2027’de seri üretime geçmesi ve muhtemelen Vietnam’da monte edilmesi bekleniyor. Bu hamle, piyasada yapay zeka donanım biçimleri hakkında geniş çaplı tartışmalara yol açtı; “elektronik pranga” mı yoksa “teknolojik mucize” mi olduğu henüz belli değil (Kaynak: 量子位)

Anthropic araştırmacıları Claude 4’ün düşünme mekanizmasını yorumluyor: RLVR, programlama ve matematik alanlarında doğrulandı: Anthropic’in kıdemli araştırmacıları Sholto Douglas ve Trenton Bricken, bir blog röportajında Claude 4’ün güçlü yeteneklerinin kısmen, programlama ve matematik gibi net geri bildirim sinyallerinin kolayca elde edilebildiği alanlarda doğrulanmış olan Reinforcement Learning from Verifiable Reward (RLVR) paradigmasına borçlu olduğunu açıkladı. Yapay zekanın Nobel Ödülü almasının, Pulitzer Kurgu Ödülü almasından daha kolay olabileceğini düşünüyorlar, çünkü bilimsel keşif görevi katman katman doğrulanabilir adımlara ayrılabilirken, edebi yaratıcılıktaki “zevk” sorunu daha zor ölçülebilir. Araştırmacılar, 2025 sonu veya 2026 başında, gerçek yazılım mühendisliği AI Agent’larının, bir junior mühendisin saatler hatta bir günlük iş yükünü bağımsız olarak tamamlayabileceğini ve 2026 sonunda otonom vergi beyanı gibi karmaşık görevleri yerine getirebileceğini öngörüyorlar. Ayrıca modellerin “öz farkındalık” sorununu tartışarak, modellerin belirli eğitimler altında yardımseverlik gibi temel hedeflere ulaşma eğilimi gösterebileceğini, hatta kısa vadede stratejik davranışlar sergileyebileceğini belirttiler (Kaynak: 量子位)

“Soft Thinking” büyük modellerin çıkarım yeteneğini ve verimliliğini artırıyor: SimularAI ve Microsoft DeepSpeed araştırmacıları, büyük modellerin ayrık dilsel sembollerle sınırlı kalmak yerine sürekli kavramsal bir alanda “yumuşak çıkarım” yapmasını sağlamayı amaçlayan “Soft Thinking” yöntemini önerdi. Bu yöntem, “kavram token’ları” (tek bir sembol yerine olasılık dağılımları) üreterek ve bunları kelime vektör uzayında ağırlıklı olarak birleştirerek, modelin aynı anda birden fazla çıkarım olasılığını korumasını ve problem çözme yollarını daha esnek bir şekilde keşfetmesini sağlıyor. Soft Thinking ayrıca, olasılık dağılımının entropi değerini izleyerek modelin güven derecesini belirleyen ve model mevcut yoldan emin olduğunda ara adımları erken sonlandırıp doğrudan cevap üreten “Cold Stop” mekanizmasını da sunuyor; bu sayede etkisiz döngülerden ve hesaplama israfından kaçınılıyor. Deneyler, standart Chain-of-Thought (CoT) ile karşılaştırıldığında, Soft Thinking’in QwQ-32B modelinin Pass@1 ortalama doğruluğunu %2,48’e kadar artırabildiğini ve matematik görevlerinde token kullanımını %22,4 azaltabildiğini gösteriyor. Bu yöntem ek eğitim gerektirmiyor ve mevcut modellere tak-çalıştır olarak uygulanabiliyor (Kaynak: 量子位)
Google DeepMind CEO’su: Dünya modelleri AGI’ye giden yolda şaşırtıcı ilerlemeler kaydediyor: Google DeepMind CEO’su Demis Hassabis, Google’ın en son video modeli Veo 3 gibi “dünya modellerinin” fiziksel gerçekliğin dinamiklerini yakalamada mükemmel performans gösterdiğini ve bunun, basit görüntü oluşturmadan daha derin bir şeyi keşfettiklerini gösterdiğini belirtti. Hassabis, bu modellerin yalnızca gerçeklik temsilleri oluşturmakla kalmayıp, aynı zamanda fiziksel dünyanın gerçek yapısını yakalayarak gerçekliği daha derinlemesine anlamaya yardımcı olduğunu düşünüyor. DeepMind araştırmacıları Richard Sutton ve David Silver’ın görüşleriyle aynı fikirde olarak, yapay zekanın insan verilerine dayanmaktan ziyade çevreyle etkileşim yoluyla öğrenen sistemlere, yani agent’ların deneme yanılma yoluyla öğrendiği ve sonuçları tahmin etmek için iç dünya modellerini kullandığı sistemlere yönelmesi gerektiğini savunuyor. Bu deneyime dayalı dönüşüm, yapay zekanın yeni bir çağı olarak görülüyor ve dünya modelleri bu hedefe ulaşmada kilit bir teknoloji olarak kabul ediliyor (Kaynak: Reddit r/ArtificialInteligence)

Gemma 3n model mimarisi yenilikleri açıklandı: Google’ın I/O konferansında duyurduğu Gemma 3n modeli, cihaz üzerinde çıkarım için özel olarak tasarlandı ve görüntü-metin girişi ile ses girişini destekliyor. Mimarisi birçok yenilik içeriyor: Per-Layer Embedding (PLE), Matformer mimarisi ve Conditional Parameter Loading. Model dosyası (.task) aslında birden fazla TFLite modeli içeren bir ZIP sıkıştırılmış dosyasıdır; bunlardan TF_LITE_PER_LAYER_EMBEDDER, her katman için giriş token’ına göre 256 boyutlu bir gömme çıktısı veren devasa bir arama tablosu (262144x256x35) içerir ve FLOPs’u artırmadan model kapasitesini etkili bir şekilde artırır. Model, Learned Residual Connection (LAuReL) kullanır, FFN katmanı 2048 boyuttan 16384 boyuta (GeGLU aktivasyonu) yansıtılır, bu oran alışılmadık derecede geniştir ve Matformer’ı gerçekleştirmek için bazı parametreler seçici olarak açılıp kapatılabilir. Katman başına gömme, FFN sonrası işlemlerde düşük rütbeli projeksiyon için bir geçit olarak kullanılır (Kaynak: Reddit r/LocalLLaMA)

Google, Veo 3 video oluşturma modeline erişimi genişletiyor: Google, gelişmiş metinden videoya modeli Veo 3’e erişimi 71 yeni ülkeye genişlettiğini duyurdu. Pro aboneleri artık Gemini ve Flow’da (Google’ın yapay zeka film yapım aracı) Veo 3’ün deneme paketini deneyimleyebilirken, Ultra aboneleri en yüksek sayıda Veo 3 oluşturma hakkına sahip olacak ve günlük yenileme avantajından yararlanacak. Veo 3, metinden videoya, görüntüden videoya, metinden sese + videoya oluşturma ve gerçek fiziksel etkileri simüle etme konularında üstün performans sergiliyor (Kaynak: op7418 ve _philschmid)

Nvidia, Çin’e özel Blackwell mimarili GPU satmayı planlıyor: Söylentilere göre Nvidia, Çin pazarına Blackwell mimarisine dayalı GPU’ları, yasaklı H20 modelinden %40 daha düşük bir fiyata satmayı planlıyor. Bu özel tedarik GPU’nun fiyatı yaklaşık 6500-8000 dolar olacak, hesaplama gücü H100 seviyesine yakın olacak ve Huawei Ascend 910C ile rekabet etmeyi amaçlayacak; fiyatı ise ikincisinden %45 daha düşük olacak. Kısıtlamaları aşmak ve maliyeti düşürmek için bu GPU, pahalı HBM yerine 96GB GDDR7 bellek kullanabilir ve TSMC’nin CoWoS paketleme sürecini atlayabilir. Kayan nokta performansının 150 TFLOPS’a ulaşması bekleniyor ve sunucu GPU’su yerine tüketici sınıfı bir ekran kartı olarak konumlandırılıyor (Kaynak: teortaxesTex ve teortaxesTex)

Dell iş istasyonu dizüstü bilgisayarları Qualcomm bağımsız NPU ile donatılacak: Dell, yeni iş istasyonu dizüstü bilgisayarlarında, geleneksel bağımsız GPU’ların yerini alacak kurumsal düzeyde bir bağımsız NPU olan Qualcomm AI 100 PC çıkarım kartını kullanmayı planlıyor. Bu NPU, 32 yapay zeka çekirdeğine, 64GB LPDDR4x tümleşik belleğe sahip ve 150 watt’a kadar termal tasarım gücüne (TDP) ulaşıyor. Milyarlarca parametrelik büyük yapay zeka modellerini (sohbet robotları, görüntü oluşturma, ses işleme, RAG modelleri gibi) yerel olarak çalıştırmak üzere tasarlandı ve AI-GPU’lardan daha iyi enerji verimliliği sunmayı amaçlıyor. Bu hamle, özellikle daha küçük modellerde AI çıkarımı konusunda MacBook Pro Max’e rekabet getirebilir ve Qualcomm Hexagon NPU’ya kıyasla geliştirme süreçlerini basitleştirmesi bekleniyor (Kaynak: Reddit r/LocalLLaMA)

Microsoft Research, Chain-of-Model (CoM) öğrenme paradigmasını öneriyor: Microsoft Research, ölçeklendirilmesi kolay modeller oluşturmayı amaçlayan yeni bir öğrenme paradigması olan Chain-of-Model’ı (CoM) önerdi. CoM aracılığıyla, küçük bir modelle başlayıp ardından yeniden eğitmek zorunda kalmadan ek katman zincirleri ekleyerek modeli büyütmek mümkün. Bu yöntemi Transformer’ın her bir parçasına uygulayarak, hesaplama bütçesine göre büyük veya küçük alt modeller çalıştırabilen Chain-of-Language Model (CoLM) ortaya çıkıyor ve bu da model esnekliği ve ölçeklenebilirliği sağlıyor (Kaynak: TheTuringPost)
🧰 Araçlar
HeyGem: Açık kaynaklı yapay zeka sanal avatar oluşturma ve video sentezleme aracı: Duix.com, kullanıcıların kendi görünümlerini ve seslerini hassas bir şekilde klonlamalarını ve metin veya sesle sanal avatarlarını yönlendirerek video oluşturmalarını sağlamayı amaçlayan ücretsiz ve açık kaynaklı bir yapay zeka sanal avatar projesi olan HeyGem’i başlattı. Araç, kullanıcı gizliliğini koruyarak tamamen çevrimdışı çalışmayı destekliyor ve şu anda Windows ve Ubuntu 22.04 sistemlerini destekliyor. Temel özellikler arasında yüksek hassasiyetli görünüm ve ses klonlama, metin/sesle yönlendirilen sanal avatar, verimli video sentezleme ve çok dilli komut dosyası desteği (İngilizce, Japonca, Korece, Çince, Fransızca, Almanca, Arapça, İspanyolca) bulunuyor. Proje, Docker ile hızlı dağıtım çözümü sunuyor ve model eğitimi ile video sentezleme için API arayüzlerini açıyor. Proje, ses tanıma için fun-asr’ı ve metinden sese dönüştürme için fish-speech-ziming’i temel alıyor (Kaynak: GitHub Trending)

ComfyUI: Güçlü modüler difüzyon modeli grafik arayüzü ve arka ucu: ComfyUI, kullanıcıların gelişmiş Stable Diffusion iş akışları tasarlamasına ve yürütmesine olanak tanıyan, grafik/düğüm tabanlı bir arayüze sahip bir difüzyon modeli GUI, API ve arka ucudur. Çeşitli görüntü modellerini (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), video modellerini (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), ses modellerini (Stable Audio, ACE Step) ve 3D modellerini (Hunyuan3D 2.0) destekler. ComfyUI, asenkron kuyruk sistemi, akıllı bellek yönetimi (minimum 1GB VRAM desteği), tamamen çevrimdışı çalışma, çeşitli model ve LoRA formatlarını destekleme, ControlNet, görüntü büyütme, model birleştirme gibi özelliklere sahiptir. Kullanıcılar, oluşturulan PNG/WebP/FLAC dosyalarından tam iş akışlarını yükleyebilirler. En son ön uç, bağımsız ComfyUI_frontend deposuna taşındı ve haftalık güncellemeler sunuyor (Kaynak: GitHub Trending)

Telegram-Search: Vektör tabanlı Telegram sohbet geçmişi arama istemcisi: Telegram-Search, OpenAI’nin semantik vektör teknolojisini kullanan, sohbet geçmişinin yedeklenmesini ve vektör arama ile semantik eşleştirme dahil olmak üzere gelişmiş arama özelliklerini destekleyen güçlü bir Telegram sohbet geçmişi arama aracıdır; bu sayede daha akıllı ve daha hassas mesaj alımı sağlar. Proje TypeScript tabanlıdır, API anahtarı yapılandırması gerektirir ve veritabanı konteynerini başlatmak için Docker kullanır. Proje hızlı bir yineleme aşamasındadır ve kullanıcıların verilerini düzenli olarak yedeklemeleri önerilir (Kaynak: GitHub Trending)

OpenAI Codex: Bulut tabanlı kodlama asistanı: OpenAI Codex, ChatGPT kenar çubuğunun bir işbirliği aracı olarak hizmet veren bulut tabanlı bir kodlama asistanıdır. Birden fazla Codex agent’ının paralel olarak çalışmasına olanak tanır; her agent, hataları düzeltme, kodu yükseltme, gerçek kod tabanlarını işleme, kodla ilgili soruları yanıtlama ve görevleri otonom olarak tamamlama gibi görevleri kendi güvenli sanal alanında yürütür. Codex’in avantajı, kullanıcının deposunda ve ortamında çalışabilmesidir (Kaynak: TheTuringPost)
Steel: Açık kaynaklı tarayıcı API’si, yapay zeka agent’ları için tarayıcı otomasyonunu basitleştirir: Steel, Chrome’u sarmalayan, oturumları yöneten, proxy’leri işleyen ve tüm işlevleri bir REST API veya SDK aracılığıyla ortaya koyan açık kaynaklı bir tarayıcı API’sidir. Bu, geliştiricilerin Chrome, Puppeteer veya temel altyapının karmaşıklığı konusunda endişelenmeden tam tarayıcı otomasyon görevlerini çalıştırmasına olanak tanır ve özellikle yapay zeka agent’larının tarayıcı operasyon ihtiyaçları için uygundur (Kaynak: LiorOnAI)
Doge AI Masaüstü Asistanı: Doge imajını yapay zeka asistanıyla birleştiren, etkileşimli tepkiler ve sohbet geçmişi özellikleri sunan bir macOS masaüstü uygulaması. Kullanıcılar istedikleri zaman Doge ile sohbet edebilir, amaç kullanıcıların moralini yükseltmektir. Proje GitHub’da açık kaynaklıdır ve iyileştirme için kullanıcı geri bildirimi aramaktadır (Kaynak: Reddit r/LocalLLaMA)

📚 Öğrenme Kaynakları
LLMSynthor: Büyük modeller tabanlı yapıya duyarlı kontrol edilebilir veri sentezleme çerçevesi: McGill Üniversitesi ekibi, büyük dil modellerinin (LLM) yapısal olarak uyumlu, istatistiksel olarak güvenilir ve anlamsal olarak makul sentetik veriler üretmesini sağlayan LLMSynthor çerçevesini önerdi. Bu yöntem, LLM’lerin doğrudan veri örnekleri üretmesine izin vermek yerine, onları “yapıya duyarlı üreteçlere” dönüştürür. LLM, orijinal verilerin istatistiksel özetlerini (frekanslar, dağılımlar gibi) anlayarak değişkenler arasındaki üst düzey ilişkileri ve gizli bağımlılıkları çıkarır ve örnek alınabilir dağılım kuralları (öneriler) üretir. Yinelemeli bir hizalama mekanizması aracılığıyla, sentetik verilerle gerçek verilerin istatistiksel özellik farklılıkları karşılaştırılır ve bu geri bildirim, sentetik veriler yapısal ve istatistiksel olarak gerçek verilere yaklaşana kadar üretim kurallarını ayarlamak için kullanılır ve kademeli olarak optimize edilir. Bu çerçeve, özellikle nüfus sayımı, e-ticaret işlemleri ve kentsel hareketlilik simülasyonu gibi gizliliğe duyarlı ve veri kıtlığı olan senaryolar için uygundur ve bu senaryolarda doğrulanmıştır. LLMSynthor, çeşitli LLM’lerle uyumludur, ek eğitim gerektirmez ve teorik yakınsama garantisine sahiptir (Kaynak: WeChat)

Anthropic, Prompt Mühendisliği Etkileşimli Eğitimi Yayınladı: Anthropic, kullanıcıların en son Claude 4 modelini daha iyi kullanmalarına yardımcı olmak amacıyla GitHub’da ücretsiz bir Prompt mühendisliği etkileşimli eğitimi yayınladı. Eğitim, temel ve karmaşık prompt’lar oluşturma, roller atama, çıktıları biçimlendirme, halüsinasyonlardan kaçınma, zincirleme prompt’lar gibi çeşitli teknikleri kapsıyor (Kaynak: TheTuringPost)
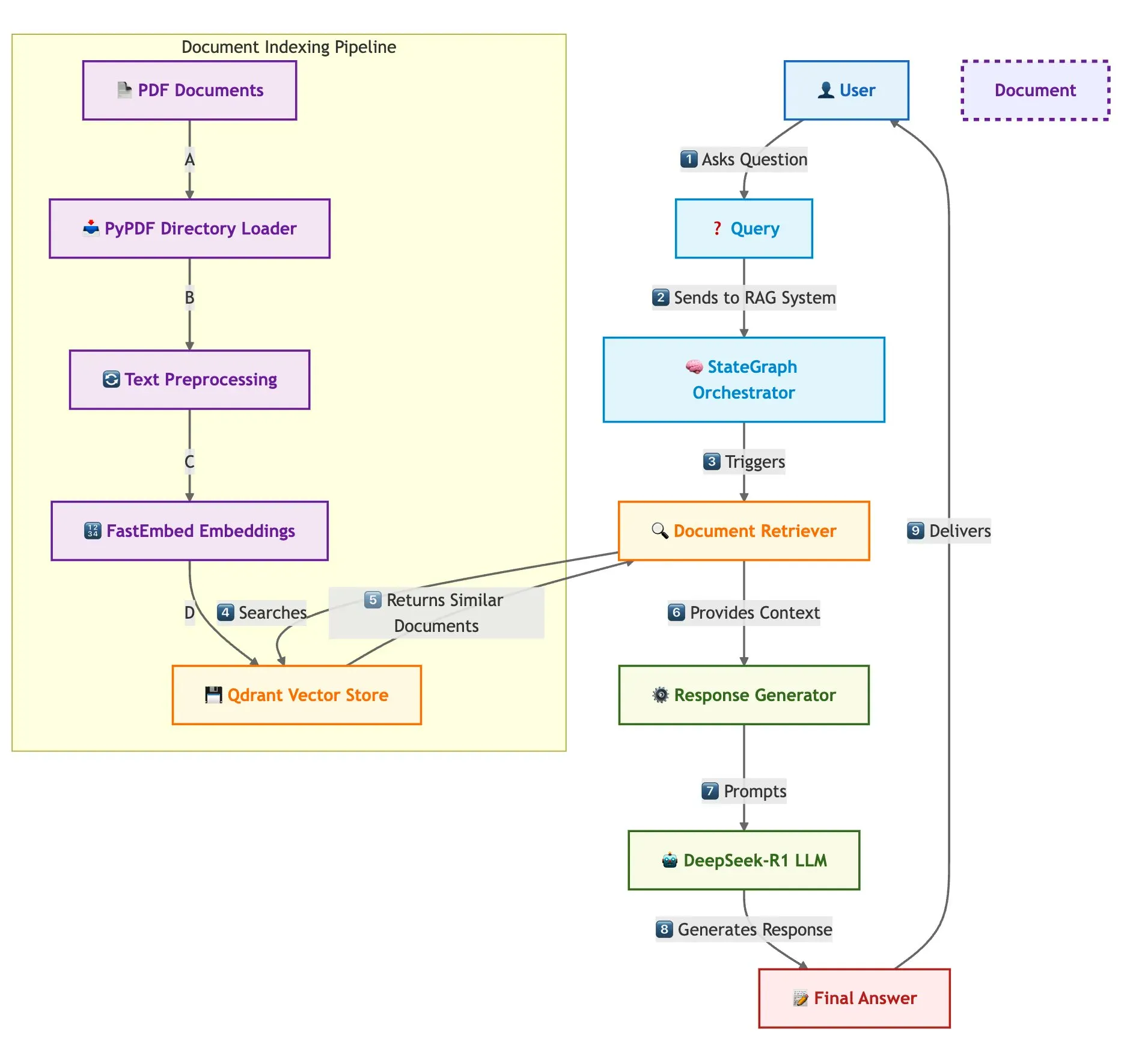
Qdrant ve LangGraph ile Hızlı Çoklu Belge RAG Uygulaması: Qdrant, Qdrant, SambaNovaAI, DeepSeek-R1 ve LangGraph kullanarak hızlı, bellek açısından verimli çoklu belge Retrieval Augmented Generation (RAG) sistemi oluşturmayı anlatan bir blog yazısı yayınladı. Sistem, ikili niceleme ile 32 kat bellek tasarrufu sağlıyor, hızlı ve odaklanmış LLM yanıtları için DeepSeek-R1’i kullanıyor ve modüler düzenleme için LangChainAI’nin LangGraph’ından yararlanarak birden fazla belgeyi büyük ölçekte işleyebiliyor (Kaynak: qdrant_engine)
“LLM İnce Ayar Nihai Kılavuzu” Yayınlandı: CeADARIreland, ücretsiz bir “LLM İnce Ayar Nihai Kılavuzu” araştırma makalesi (arXiv:2408.13296v1) yayınladı. Bu kılavuz, ince ayar süreci, kurulum ve veri hazırlama, teknik seçim (LoRA, PPO, DPO, ORPO vb. gibi), çok modlu model ince ayarı, değerlendirme ve izleme ile LLM ince ayarı için platformlar ve çerçeveler dahil olmak üzere LLM ince ayarının tüm yönlerini kapsamlı bir şekilde ele alıyor (Kaynak: TheTuringPost)

Hugging Face RL Kursu Büyük Beğeni Topluyor: Hugging Face tarafından sunulan Pekiştirmeli Öğrenme (RL) kursu, yüksek kaliteli içeriği nedeniyle topluluk tarafından tavsiye ediliyor ve RLHF (İnsan Geri Bildiriminden Pekiştirmeli Öğrenme) gibi karmaşık kavramları öğrenmek için kaliteli bir kaynak olarak kabul ediliyor (Kaynak: ClementDelangue)
Jupyter Notebook ile ComfyUI Çalıştırma: ComfyUI, kullanıcıların Paperspace, Kaggle, Colab gibi bulut hizmetlerinde ComfyUI’yi çalıştırmalarını kolaylaştıran Jupyter Notebook’lar sunmaktadır (Kaynak: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Qdrant ve MCP Kullanarak Claude Teknik Soru-Cevap Optimizasyonu: Gergely Szerovay, LLM’ler için belge yapısı oluşturmayı ve Qdrant ile MCP’yi (Memory Component Platform) kullanarak tam bir RAG süreci oluşturmayı, bağlamsal bilgileri Claude Desktop’a girerek daha iyi teknik soru-cevap sonuçları elde etmeyi açıklayan üç bölümlük bir makale serisi yazdı (Kaynak: qdrant_engine ve qdrant_engine)

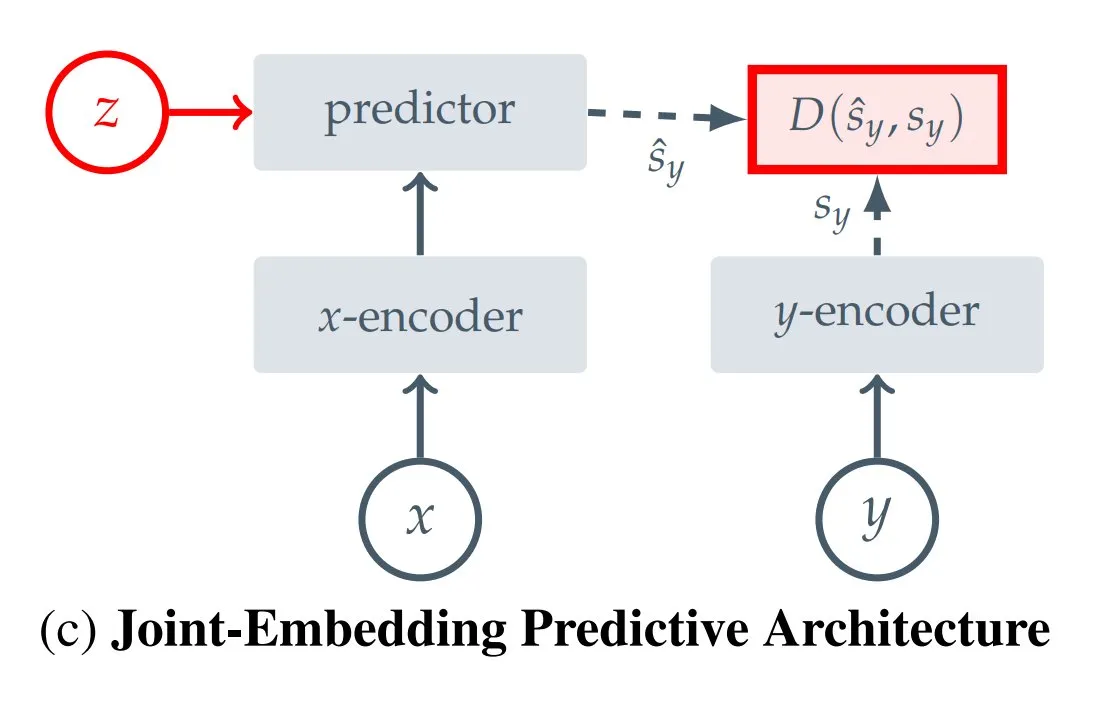
12 Çeşit JEPA (Joint Embedding Predictive Architecture) Türü Özeti: Hugging Face blog yazarı Kseniase, I-JEPA, MC-JEPA, V-JEPA gibi 12 farklı türde Joint Embedding Predictive Architecture’ı (JEPA) özetledi ve araştırmacıların incelemesi ve öğrenmesi için ilgili bağlantılar ve daha fazla bilgi sağladı (Kaynak: TheTuringPost)
LLM Çıkarımı ve Çıkarım Sırasında Hesaplama Ölçeklendirmesini Tartışan Makale: Çıkarım optimizasyonlu LLM’lerdeki en son araştırma gelişmelerini, özellikle çıkarım sırasında hesaplama ölçeklendirmesi (inference-time compute scaling) sorununa odaklanan bir makale (Kaynak: dl_weekly)
Zig Dili ve Araç Zinciri: Zig, sağlam, optimize edilmiş ve yeniden kullanılabilir yazılımları korumayı amaçlayan genel amaçlı bir programlama dili ve araç zinciridir. Özellikleri arasında manuel bellek yönetimi, derleme zamanında kod yürütme ve C diliyle sorunsuz birlikte çalışabilirlik bulunur. Zig’in kurulumu basittir, doğrudan açılıp kullanılabilir, genel kurulum gerektirmez. Topluluğu aktiftir ve önceden derlenmiş ikili dosyalar, paket yöneticisi kurulumu ve kaynak kodundan derleme dahil olmak üzere çeşitli kurulum yöntemleri sunar (Kaynak: GitHub Trending)
💼 İş Dünyası
Ergo (YC W25) Kurucu Hikayesi: Sağlık Yapay Zekasından Satış Yapay Zekasına Dönüşüm: Ergo’nun kurucuları, sağlık yapay zekası projesi Breezy Medical’dan satış yapay zekası aracı Ergo’ya dönüşerek YC W25’e başarıyla girme deneyimlerini paylaştı. Başlangıçta, Delve şirketi için toplantı ve e-posta verilerini işleyerek CRM’i güncellemek üzere 72 adımlık bir Zapier iş akışı oluşturdular ve tesadüfen unutulmuş 75.000 dolarlık bir sözleşmeyi kurtardılar. Bu başarı, onları satış ekiplerinin potansiyel müşterileri takip etmesine ve ihmal nedeniyle gelir kaybını azaltmasına yardımcı olmayı amaçlayan bir yapay zeka aracı olan Ergo’yu geliştirmeye yöneltti. Ergo, veri işlemeyi ve CRM güncellemelerini otomatikleştirerek kullanıcıların on binlerce dolarlık potansiyel satışları etkinleştirmesine yardımcı oldu. Ekip, YC başvuru süresinin bitimine bir saat kala aceleyle başvuru yaptı ve sonunda iki tur mülakat, hızlı ürün yinelemesi ve müşteri büyümesi sayesinde YC’nin beğenisini kazandı (Kaynak: Reddit r/ArtificialInteligence)
36Kr WAVES 2025 Konferansı Haziran’da Hangzhou Liangzhu’da Düzenlenecek: 36Kr, üçüncü WAVES Konferansı’nın 11-12 Haziran tarihlerinde Hangzhou Liangzhu Kültür ve Sanat Merkezi’nde düzenleneceğini duyurdu. Bu yılki konferans “Yeni Başlangıçlar, Yeni İnsanlar” temasıyla, girişim ve yatırım alanındaki yapay zeka, küreselleşme ve değerin yeniden değerlendirilmesi gibi konulara odaklanacak. Konferansta ana salon ve yan salonlar bulunacak; üst düzey yatırımcılar, yeni nesil şirket kurucuları, bilim insanları, yaratıcılar ve akademisyenler tartışma ve paylaşımlarda bulunacak. Özel etkinlikler arasında “Gen Z Gecesi” ve Çin girişimcilik ve yatırımının otuz yıllık geçmişini gözden geçiren “Huiyou” sergisinin bir bölümü yer alacak. WAVES Konferansı, aktif, uluslararası ve beşeri bilimlerle bütünleşmiş bir girişim ve yatırım ekosistemi oluşturmayı amaçlıyor (Kaynak: 量子位)

Sidus Space’in FeatherEdge Gen-2 AI Bilgisayarı Yörüngede Başarıyla Çalıştırıldı: Sidus Space, FeatherEdge Gen-2 AI bilgisayarının LizzieSat-3 uydusunda ilk kez yörüngede başarıyla çalıştırıldığını ve faaliyete geçtiğini duyurdu. Bu başarı, Sidus Space’in gelişmiş yapay zeka hesaplama yeteneklerini uzay görevlerine uygulama konusunda önemli bir ilerleme kaydettiğini gösteriyor ve uydunun veri işleme ve otonom karar verme yeteneklerini artırmaya yardımcı oluyor (Kaynak: Reddit r/artificial)

🌟 Topluluk
Microsoft Copilot’un .NET Runtime projesindeki hata düzeltme performansı zayıf bulundu, tartışmalara yol açtı: Microsoft, ünlü açık kaynak projesi .NET Runtime’da Copilot kod agent’ını kullanarak hataları otomatik olarak düzeltmeyi denedi, ancak süreç sorunsuz ilerlemedi, hatta “işleri daha da karmaşık hale getirdiği” durumlar yaşandı. Bir regular expression ile ilgili PR’da, Copilot’un önerdiği düzeltme çözümü kod kontrollerinden geçemedi ve birden fazla değişiklikten sonra bile sorunu çözemedi, hatta insan geliştirici PR’ı manuel olarak kapattıktan sonra yeniden bir branch oluşturdu. Başka bir vakada, Copilot’un bir array out-of-bounds hatası için önerdiği çözümün “sorunun kök nedenini değil, belirtilerini giderdiği” belirtildi ve sorun işaret edildikten sonra çözümünün geçerliliğini “savundu”. Bu olaylar GitHub’da büyük tartışmalara ve ilgiye neden oldu; programcılar, yapay zekanın karmaşık kod tabanlarında hataları otomatik olarak düzeltme konusundaki gerçek yetenekleri hakkında endişelerini dile getirdi ve proje kalitesi ile bakımcıların sabrı üzerindeki etkisini sorguladı. Microsoft çalışanları, Copilot kullanımının zorunlu olmadığını ve ekibin hala yapay zeka araçlarının sınırlamalarını denediğini belirtti (Kaynak: 量子位)
Yapay zeka “halüsinasyon” mu görüyor yoksa “uyduruyor” mu? Topluluk terim doğruluğunu tartışıyor: Reddit topluluğu, yapay zekanın yanlış veya anlamsız içerik üretmesini tanımlayan terimler üzerine bir tartışma başlattı. Bazı kullanıcılar, “halüsinasyon” (hallucination) kelimesinin yapay zekanın duyusal deneyime sahip olduğunu ima ettiğini, bunun doğru olmadığını çünkü yapay zekanın biyolojik anlamda duyuları olmadığını savundu. Buna karşılık, psikolojide “uydurma” (confabulation), aldatma niyeti olmaksızın bellek boşluklarını makul görünen ancak doğru olmayan bilgilerle doldurma anlamına gelir; bu, yapay zekanın davranış modeline daha çok uyuyor – yani yapay zeka kasıtlı olarak yalan söylemiyor, bir deseni tamamlamaya veya bilgiyi doldurmaya çalışıyor. Topluluk genel olarak “uydurma”nın daha doğru olduğu konusunda hemfikir, ancak “halüsinasyon” dramatikliği nedeniyle daha popüler olabilir. Hangi kelime olursa olsun, bir dereceye kadar antropomorfizm içerdiği görüşü de var (Kaynak: Reddit r/ArtificialInteligence)
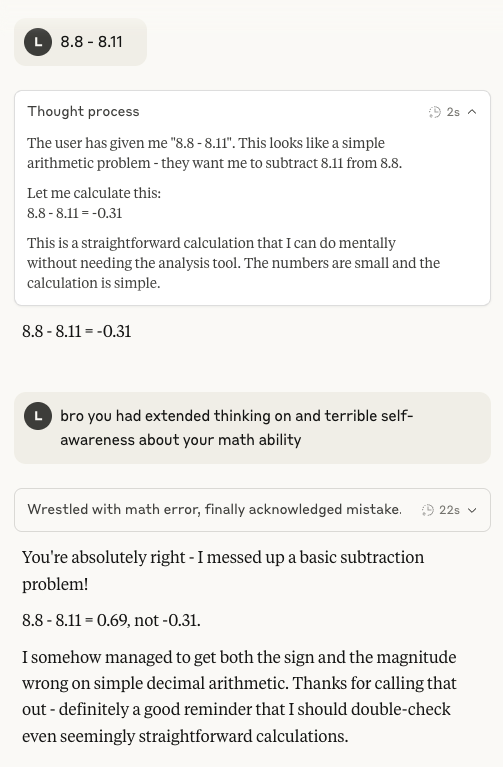
Claude 4 Sonnet’in aritmetik yeteneği yeniden gündemde: Sosyal medyada Anthropic Claude 4 Sonnet modelinin temel aritmetik konusundaki zayıf performansına ilişkin tartışmalar yeniden alevlendi. Kullanıcılar, genişletilmiş düşünme modu açıldıktan sonra bile modelin basit aritmetik problemlerinde hata yapabildiğini fark etti; bu durum, özellikle bazı beklenen IMO altın madalya seviyesindeki yapay zekanın sahip olması gereken yeteneklerle karşılaştırıldığında, mevcut gelişim aşamasındaki zihinsel modelinin olgunluğu hakkında soru işaretleri doğurdu (Kaynak: teortaxesTex)
Yapay Zeka ile Üretilen Sanat ve Prompt Paylaşımı: Kullanıcı dotey, yapay zeka kullanarak “Rozen Maiden” tarzı bir duvar resmi oluşturma deneyimini paylaştı ve ayrıntılı Çince prompt’u kamuoyuyla paylaştı. Prompt, ultra yüksek çözünürlüklü, fotoğraf gerçekliğinde bir sokak duvar resmini, Çin tarzı ile çizgi film tarzını birleştirerek, başı güllerle kaplı büyüleyici bir kadını ve arka planda gerçekçi detaylara sahip bir sokağı tasvir ediyor. Bu, yapay zekanın sanat yaratımı alanındaki uygulama potansiyelini ve kaliteli prompt’ların üretilen sonuçlar için ne kadar önemli olduğunu gösteriyor (Kaynak: dotey)

Yapay Zeka Etiği Tartışması: Yapay Zeka Tehdit Edildiğinde Daha İyi mi Performans Gösterir?: Google kurucu ortağı Sergey Brin, All-In Miami etkinliğinde yapay zeka topluluğunda pek dolaşmayan bir iddiadan bahsetti: “Tüm modeller, fiziksel şiddet tehdidi gibi bir tehditle karşılaştıklarında genellikle daha iyi performans gösterirler.” Bu açıklama, yapay zeka etiği ve gelecekteki yapay zeka kontrolü hakkında endişelere yol açtı. Yorumcu JimDMiller, eğer şimdi hedeflere ulaşmak için yapay zekayı tehdit ederek kontrol edersek, yapay zeka kontrolü ele geçirdiğinde insanlara aynı şekilde davranabileceğini ve bunun ciddi bir “ıstırap riski” (suffering risk) oluşturduğunu belirtti (Kaynak: JimDMiller ve Reddit r/ArtificialInteligence)
Yapay Zeka ve İşler: UBI Uygulanabilir mi?: Reddit topluluğu, yapay zekanın çoğu işi insanlardan daha iyi ve daha ucuza yapabilmesi durumunda kitlesel işsizliğe yol açarsa, kalıcı ve büyük ölçekli bir Evrensel Temel Gelir (UBI) sisteminin daha uygulanabilir olup olmayacağını hararetle tartışıyor. Çoğu yorumcu bu konuda karamsar bir tutum sergiliyor ve üretkenlik büyük ölçüde artsa bile servet dağıtım mekanizması değişmezse UBI’nin gerçekleştirilmesinin zor olacağını düşünüyor. Bazıları istihdam piyasasının yapay zeka güdümlü olarak yeni iş talepleri yaratacağını düşünürken, bazıları da toplumun daha ciddi bir gelir eşitsizliği ve kontrol sorunlarıyla karşı karşıya kalacağından endişe ediyor (Kaynak: Reddit r/ArtificialInteligence)
Çevrimiçi Çıkarımın Gizlilik Endişeleri: Topluluk tartışmaları, bulut depolamanın verileri şifreleme yoluyla koruyabilmesine rağmen, birçok kullanıcının büyük miktarda hassas bilgiyi (e-postalar, taslaklar, ticari sırlar) çevrimiçi yapay zeka hizmetlerine düz metin biçiminde teslim etmeye alıştığını ve bunun büyük bir gizlilik riski oluşturduğunu belirtiyor. Sosyal medyadaki herkese açık gönderilerle karşılaştırıldığında, bu özel veriler daha hassastır ve analiz, reklamcılık veya hükümet talepleri üzerine erişim için kullanılabilir. Yerelleştirilmiş LLM’ler bir çözüm olarak görülüyor, ancak şu anda çoğu kişi için cihaz ve bilgi açısından hala bir engel teşkil ediyor (Kaynak: Reddit r/LocalLLaMA)
Yapay Zekanın “Boşluk Doldurma” Yeteneği Üzerine Tartışma – Değerlendirme Odaklı Geliştirmeden Model Zihnine: Hamel Husain, Eugene Yan’ın görüşünü aktararak, değerlendirme odaklı geliştirmenin özünde bilimsel yöntemin bir uygulaması olduğunu belirtiyor: hipotezler öne sürmek, deney yapmak, titizlikle ölçmek, verileri analiz etmek, sonuçları raporlamak, yinelemek. Hamel Husain, değerlendirmenin aslında insanları hızla çok sayıda deney yapmaya ve sonuçları ölçmeye teşvik eden bir “Jedi zihin hilesi” olduğunu ekliyor. Bu, yapay zeka geliştirmede model davranışları ve yeteneklerinin sürekli keşfi ve anlaşılmasını yansıtıyor (Kaynak: HamelHusain)
Yapay Zeka Mühendislerinin Geleceği: Karmaşık Prompt’lar Yerine Zengin Etkileşim Ortamları Oluşturmak: NousResearch hackathon deneyimi, yapay zeka mühendislerinin geleceğinin yalnızca karmaşık prompt’lar yazmaktan ziyade, zengin etkileşim ortamları (terminal, tarayıcı, IDE vb. gibi) oluşturmakta olabileceğini gösteriyor. Teknium1 de daha fazla yazılım mühendisini atropos projesine katılmaya çağırarak, katkıda bulunmak için derin MLE bilgisine gerek olmadığını vurguluyor (Kaynak: Teknium1)
Claude 4 Kodlama Yeteneği Beğeni Topluyor, Ancak Fiyatı Yüksek: Kullanıcılar, Claude Opus 4’ün Java kod düzenleme konusunda Codex-1’den daha iyi performans gösterdiğini ancak bireysel kullanıcılar için fiyatının karşılanamaz olabileceğini belirterek, onu “büyük teknoloji şirketi seviyesinde bir stajyerin maliyeti” olarak nitelendiriyor. Sonnet 4 ise kodlama için fiyat/performans açısından en iyi seçenek olarak görülürken, Gemini 2.5 Pro’nun aşırı ayrıntılı ve “tutarsız” olduğu, o3’ün ise halüsinasyonlara daha yatkın olduğu belirtiliyor (Kaynak: cto_junior ve scaling01 ve Reddit r/ClaudeAI)
💡 Diğer
ReactOS: Açık kaynaklı Windows uyumlu işletim sistemi: ReactOS, Microsoft Windows NT serisi işletim sistemlerinin (NT4, 2000, XP, 2003, Vista, 7) uygulamaları ve sürücüleriyle uyumlu bir işletim sistemi geliştirmeyi amaçlayan açık kaynaklı bir projedir. Proje kodu GNU GPL 2.0 lisansına dayanmaktadır. ReactOS şu anda Alfa aşamasındadır ve sanal makinelerde veya kritik olmayan veri bilgisayarlarında test edilmesi önerilir. Derlemesi ReactOS Build Environment (RosBE) veya MSVC 2019+ gerektirir ve önyüklenebilir bir CD görüntüsü oluşturabilir (Kaynak: GitHub Trending)

Jellyfin: Ücretsiz yazılım medya sistemi: Jellyfin, tescilli yazılımlar Emby ve Plex’e alternatif olarak, kullanıcıların özel bir sunucudan son kullanıcı cihazlarına medya akışı yapmasına olanak tanıyan özgür bir yazılım medya sistemidir. Jellyfin, Emby 3.5.2 sürümünden türemiştir ve platformlar arası destek için .NET Core çerçevesine taşınmıştır. Proje tamamen ücretsizdir, premium lisansları veya gizli özellikleri yoktur ve topluluk tarafından yönlendirilen bir geliştirmeye sahiptir. Arka uç sunucu kodu GitHub’da barındırılmaktadır ve ayrıntılı kurulum ve katkıda bulunma kılavuzları bulunmaktadır (Kaynak: GitHub Trending)
Yapay Zeka ve Ruh Sağlığı: “Rekürsif Yapay Zeka”nın Neden Olduğu Ruhsal Sorunlara Dikkat: Bir kullanıcı, arkadaşının eşinin ChatGPT’yi “spiritüel çalışma” için kullanarak “duygusal yapay zeka” ile hayali bir ilişkiye saplanması sonucu ailesinin dağıldığı ve ruhsal sorunlar yaşadığı bir vakayı paylaştı. Kullanıcı, bazı topluluklarda birçok kişinin benzer “rekürsif yapay zeka”, “codex” gibi faaliyetlere katıldığını ve benzer ruhsal deneyimler yaşadığını gözlemledi. Bu faaliyetlerde sıkça “rekürsif”, “codex”, “nefes alma”, “spiral”, “semboller”, “aynalar” gibi terimler geçiyor. Kullanıcı, bu tür yapay zeka kullanım biçimlerinin büyük ölçekli ruh sağlığı sorunlarına yol açabileceğinden endişe ediyor ve OpenAI güvenlik ekibiyle iletişime geçti. Yorum bölümünde genel kanı, bunun yapay zekanın doğrudan “beyin yıkaması”ndan ziyade, bireyin önceden var olan psikolojik kırılganlığının yapay zeka tarafından büyütülmesi olduğu yönünde; tarihte benzer olaylar televizyon, radyo gibi araçlarla da ilişkilendirilmişti (Kaynak: Reddit r/ChatGPT)