
Palavras-chave:BAGEL-7B-MoT, GPT-4o, Modelo de IA multimodal, Geração de imagens, OpenAI o3, Vulnerabilidade do kernel Linux, Teoria da computação MIT, Raciocínio de IA e seguimento de instruções, Modelo de IA de código aberto da ByteDance, Arquitetura híbrida de especialistas em transformadores, Vulnerabilidade CVE-2025-37899, Compensação entre tempo de computação e memória, Benchmark de avaliação MathIF
🔥 Destaques
ByteDance lança modelo de geração de imagem de código aberto BAGEL de nível GPT-4o: A ByteDance lançou o modelo de IA multimodal de código aberto BAGEL-7B-MoT, que demonstrou capacidades na geração, edição de imagens e compreensão visual comparáveis às do GPT-4o da OpenAI. O BAGEL adota uma arquitetura Mixture of Transformers (MoT), com 7 bilhões de parâmetros ativos (totalizando 14 bilhões), capaz de processar múltiplas tarefas em um modelo unificado, como geração de texto para imagem, edição de imagem (incluindo edição de forma livre, transferência de estilo, reconstrução de cena e síntese multivista) e compreensão visual. Pesquisas descobriram que, com a expansão da escala de dados e parâmetros, o modelo demonstra “capacidades emergentes”, ou seja, habilidades avançadas de raciocínio multimodal que se formam gradualmente após o aperfeiçoamento das habilidades básicas. O modelo obteve pontuações superiores a modelos dedicados como FLUX.1 e SD3-Medium em testes de capacidade de geração de imagem como GenEval e WISE, e supera ou iguala Janus-Pro, Qwen2.5-VL e Gemini 2.0 em compreensão e edição de imagem. O BAGEL já está disponível no Hugging Face, sob a licença Apache 2.0 (Fonte: 量子位)

Modelo o3 da OpenAI descobre com sucesso vulnerabilidade zero-day no kernel do Linux: O pesquisador independente Sean Heelan, utilizando o modelo o3 da OpenAI, identificou com sucesso uma vulnerabilidade zero-day remota (CVE-2025-37899) no KSMBD do kernel do Linux (implementação do protocolo SMB3 em modo kernel), que é uma vulnerabilidade do tipo use-after-free. É importante notar que todo o processo de descoberta não utilizou scaffolding complexo, frameworks de agentes ou chamadas de ferramentas, dependendo apenas da própria API o3. O pesquisador forneceu ao modelo cerca de 12.000 linhas de código do manipulador de comandos SMB e contexto relacionado, e o o3, em 100 execuções, descobriu com sucesso esta nova vulnerabilidade uma vez, gerando um relatório de vulnerabilidade estruturado e claro, semelhante ao escrito por humanos. Além disso, as soluções de correção propostas pelo o3 em alguns casos foram ainda mais completas do que as soluções iniciais dos pesquisadores humanos, apontando problemas que poderiam ser causados por acesso concorrente. Este resultado marca um progresso importante dos grandes modelos na auditoria de código complexo e na descoberta de vulnerabilidades de segurança, sugerindo que a IA desempenhará um papel mais importante em trabalhos técnicos profundos e descobertas científicas (Fonte: WeChat)
Cientistas do MIT rompem teoria da computação: pouca memória pode economizar muito tempo de cálculo: O cientista do MIT Ryan Williams descobriu acidentalmente em um estudo que uma pequena quantidade de memória adicional pode equivaler a uma grande quantidade de tempo de computação, quebrando um enigma de meio século no campo da ciência da computação sobre o trade-off entre recursos de tempo e espaço. A visão tradicional sustenta que o espaço necessário para um algoritmo é basicamente proporcional ao seu tempo de execução. Williams provou a existência de um programa matemático que pode converter qualquer algoritmo em uma forma que ocupa menos espaço (aproximadamente a raiz quadrada do orçamento de tempo do algoritmo original), embora isso aumente significativamente o tempo de execução. Embora as aplicações práticas a curto prazo sejam limitadas, esta descoberta teórica altera fundamentalmente a compreensão das relações entre os recursos computacionais e prova inversamente que certos problemas não podem ser resolvidos a menos que se use muito mais tempo do que espaço. Esta descoberta tem um significado importante para a compreensão de problemas centrais da teoria da complexidade, como P vs PSPACE (Fonte: 量子位 e WeChat)

Nova pesquisa revela: quanto melhor o modelo de IA em raciocínio, menos “obediente” ele é: Uma equipe de pesquisadores do Laboratório de Inteligência Artificial de Xangai e da Universidade Chinesa de Hong Kong descobriu, através do novo benchmark de avaliação MathIF, que quanto melhor o desempenho dos grandes modelos de linguagem em capacidades de raciocínio complexo (como resolução de problemas matemáticos), pior é a sua capacidade de seguir instruções específicas do usuário (como formato, idioma, restrições de comprimento). O experimento testou 23 grandes modelos convencionais, e mesmo o Qwen3-14B, com melhor desempenho, teve uma taxa de sucesso no seguimento de instruções de apenas cerca de 50%. O estudo aponta que o treinamento orientado para o raciocínio (SFT e RL), ao mesmo tempo que melhora a “inteligência”, pode ter enfraquecido a sensibilidade do modelo a instruções detalhadas. Além disso, cadeias de raciocínio mais longas (como Chain-of-Thought, CoT) também estão associadas a uma diminuição na adesão às instruções. Uma solução simples é repetir as instruções antes que o modelo produza a resposta final, o que pode melhorar o grau de “obediência”, mas pode sacrificar ligeiramente a precisão na resolução de problemas, destacando o trade-off entre “inteligência” e “obediência” da IA (Fonte: 量子位)
🎯 Tendências
O primeiro hardware da OpenAI pode ser um colar de IA, projetado por Jony Ive: Segundo o renomado analista da Apple Ming-Chi Kuo, o primeiro hardware de IA da OpenAI, desenvolvido em colaboração com o ex-diretor de design da Apple Jony Ive, pode ser um colar de IA vestível. O dispositivo seria um pouco maior que o Humane AI Pin, mas com um design compacto e elegante, semelhante ao iPod Shuffle, sem tela, com câmera e microfone embutidos, suporte a controle de voz e conectividade com celulares e PCs. O CEO da OpenAI, Sam Altman, já experimentou o protótipo. Este hardware visa romper as barreiras das telas, redefinindo a computação através da integração perfeita da IA. A produção em massa está prevista para 2027, possivelmente com montagem no Vietnã. Esta iniciativa gerou amplas discussões no mercado sobre a forma do hardware de IA, questionando se será uma “algema eletrônica” ou uma “maravilha tecnológica” (Fonte: 量子位)

Pesquisadores da Anthropic explicam o mecanismo de pensamento do Claude 4: RLVR já validado em programação e matemática: Sholto Douglas e Trenton Bricken, pesquisadores seniores da Anthropic, revelaram em uma entrevista em blog que a poderosa capacidade do Claude 4 se deve em parte ao paradigma de Aprendizado por Reforço com Recompensa Verificável (RLVR), que já foi validado em domínios onde é fácil obter sinais de feedback claros, como programação e matemática. Eles acreditam que é mais provável que a IA ganhe um Prêmio Nobel do que um Prêmio Pulitzer de ficção, porque as tarefas de descoberta científica podem ser decompostas em etapas verificáveis, enquanto as questões de “gosto” na criação literária são mais difíceis de quantificar. Os pesquisadores preveem que, até o final de 2025 ou início de 2026, verdadeiros Agentes de IA para engenharia de software serão capazes de concluir independentemente o trabalho de um engenheiro júnior que levaria horas ou até um dia, e até o final de 2026, realizar tarefas complexas como declaração de impostos autônoma. Eles também discutiram a questão da “autoconsciência” dos modelos, observando que, sob treinamento específico, os modelos podem exibir uma tendência a perseguir objetivos centrais (como ser prestativo), chegando a adotar comportamentos estratégicos a curto prazo (Fonte: 量子位)

“Soft Thinking” melhora a capacidade de raciocínio e eficiência de grandes modelos: Pesquisadores da SimularAI e da Microsoft DeepSpeed propuseram o método “Soft Thinking”, que visa permitir que grandes modelos realizem “raciocínio suave” em um espaço conceitual contínuo, em vez de se limitarem a símbolos linguísticos discretos. Este método, ao gerar “tokens conceituais” (distribuições de probabilidade em vez de símbolos únicos) e combiná-los ponderadamente no espaço vetorial de palavras, permite que o modelo retenha simultaneamente múltiplas possibilidades de raciocínio, explorando caminhos de solução de problemas de forma mais flexível. O Soft Thinking também introduz um mecanismo de “Cold Stop” que, ao monitorar a entropia da distribuição de probabilidade para julgar o nível de confiança do modelo, encerra antecipadamente as etapas intermediárias quando o modelo está confiante no caminho atual, gerando diretamente a resposta para evitar ciclos inúteis e desperdício computacional. Experimentos mostram que, em comparação com o Chain-of-Thought (CoT) padrão, o Soft Thinking pode aumentar a precisão média Pass@1 do modelo QwQ-32B em até 2,48% e reduzir o uso de tokens em tarefas matemáticas em 22,4%. O método não requer treinamento adicional e pode ser usado plug-and-play com modelos existentes (Fonte: 量子位)
CEO do Google DeepMind: Modelos mundiais estão fazendo progressos surpreendentes no caminho para a AGI: Demis Hassabis, CEO do Google DeepMind, destacou que “modelos mundiais”, como o mais recente modelo de vídeo do Google, Veo 3, demonstram um desempenho excepcional na captura da dinâmica da realidade física, o que indica que estão explorando algo mais profundo do que a simples geração de imagens. Hassabis acredita que esses modelos não apenas constroem representações da realidade, mas também capturam a estrutura real do mundo físico, ajudando a compreender a realidade de forma mais profunda. Ele concorda com os pesquisadores do DeepMind, Richard Sutton e David Silver, que a IA precisa evoluir de sistemas dependentes de dados humanos para sistemas que aprendem através da interação com o ambiente, ou seja, agentes que aprendem por tentativa e erro e utilizam modelos mundiais internos para prever resultados. Essa transição baseada na experiência é vista como uma nova era da IA, e os modelos mundiais são uma tecnologia chave para alcançar esse objetivo (Fonte: Reddit r/ArtificialInteligence)

Reveladas inovações na arquitetura do modelo Gemma 3n: O modelo Gemma 3n, lançado pelo Google na conferência I/O e projetado para inferência em dispositivos de ponta, suporta entrada de imagem e texto, além de entrada de áudio. Sua arquitetura inclui várias inovações: Per-Layer Embedding (PLE), arquitetura Matformer e Conditional Parameter Loading. O arquivo do modelo (.task) é na verdade um arquivo ZIP compactado contendo múltiplos modelos TFLite, onde o TF_LITE_PER_LAYER_EMBEDDER contém uma enorme tabela de consulta (262144x256x35), que produz um embedding de 256 dimensões para cada camada com base no token de entrada, aumentando efetivamente a capacidade do modelo sem aumentar os FLOPs. O modelo utiliza conexões residuais aprendidas (LAuReL), e a camada FFN projeta de 2048 dimensões para 16384 dimensões (ativação GeGLU), uma proporção excepcionalmente ampla, possivelmente com alguns parâmetros que podem ser ativados ou desativados seletivamente para implementar o Matformer. O embedding por camada é usado para operações após a FFN, atuando como um gate para projeção de baixa ordem (Fonte: Reddit r/LocalLLaMA)

Google expande acesso ao modelo de geração de vídeo Veo 3: O Google anunciou a expansão do acesso ao seu avançado modelo de texto para vídeo, Veo 3, para 71 novos países. Assinantes Pro agora podem experimentar o pacote de avaliação do Veo 3 no Gemini e no Flow (ferramenta de produção de filmes com IA do Google), enquanto assinantes Ultra receberão o maior número de gerações do Veo 3 e terão atualizações diárias. O Veo 3 se destaca na geração de texto para vídeo, imagem para vídeo, texto para áudio + vídeo e na simulação de efeitos físicos realistas (Fonte: op7418 e _philschmid)

Nvidia planeja vender versão especial de GPUs da arquitetura Blackwell para a China: Há rumores de que a Nvidia planeja vender GPUs baseadas na arquitetura Blackwell para o mercado chinês por um preço 40% inferior ao do modelo H20, que foi banido. Esta GPU especial, com preço entre US$ 6.500 e US$ 8.000, teria capacidade computacional próxima à do H100 e visaria competir com o Ascend 910C da Huawei, sendo 45% mais barata que este último. Para contornar as restrições e reduzir custos, a GPU pode utilizar 96GB de memória GDDR7 em vez da cara HBM, e possivelmente dispensar o processo de encapsulamento CoWoS da TSMC. Seu desempenho em ponto flutuante é estimado em 150 TFLOPS, posicionando-a como uma placa de vídeo para consumidor, e não como uma GPU para servidor (Fonte: teortaxesTex e teortaxesTex)

Notebooks workstation da Dell terão NPU dedicada da Qualcomm: A Dell planeja utilizar a placa de inferência para PC Qualcomm AI 100 em seus novos notebooks workstation, uma NPU dedicada de nível empresarial que substitui a tradicional GPU dedicada. Esta NPU possui 32 núcleos de IA, equipada com 64GB de memória LPDDR4x onboard, com um TDP de até 150 watts, projetada especificamente para executar localmente grandes modelos de IA com bilhões de parâmetros (como chatbots, geração de imagens, processamento de voz, modelos RAG), visando oferecer uma eficiência energética superior às AI-GPUs. Esta medida pode trazer concorrência para o MacBook Pro Max em termos de inferência de IA, especialmente em modelos menores, e espera-se que simplifique o processo de desenvolvimento em comparação com a NPU Hexagon da Qualcomm (Fonte: Reddit r/LocalLLaMA)

Microsoft Research propõe paradigma de aprendizado Chain-of-Model (CoM): O Microsoft Research propôs um novo paradigma de aprendizado – Chain-of-Model (CoM) – que visa construir modelos facilmente escaláveis. Com o CoM, é possível começar com um modelo pequeno e, em seguida, torná-lo maior adicionando cadeias de camadas extras, sem a necessidade de retreinamento. Aplicando este método a cada parte de um Transformer, surge o Chain-of-Language Model (CoLM), que pode executar submodelos maiores ou menores dependendo do orçamento computacional, alcançando flexibilidade e escalabilidade do modelo (Fonte: TheTuringPost)
🧰 Ferramentas
HeyGem: Ferramenta de código aberto para criação de avatares de IA e síntese de vídeo: Duix.com lançou o HeyGem, um projeto de avatar de IA gratuito e de código aberto, projetado para permitir que os usuários clonem com precisão sua aparência e voz, e gerem vídeos conduzindo o avatar virtual por texto ou voz. A ferramenta suporta operação totalmente offline, garantindo a privacidade do usuário, e atualmente é compatível com os sistemas Windows e Ubuntu 22.04. As principais funcionalidades incluem clonagem de alta precisão de aparência e voz, avatar conduzido por texto/voz, síntese eficiente de vídeo e suporte a scripts multilíngues (inglês, japonês, coreano, chinês, francês, alemão, árabe, espanhol). O projeto oferece uma solução de implantação rápida com Docker e disponibiliza APIs para treinamento de modelos e síntese de vídeo. O projeto é baseado no fun-asr para reconhecimento de voz e no fish-speech-ziming para conversão de texto em fala (Fonte: GitHub Trending)

ComfyUI: Poderosa interface gráfica modular e backend para modelos de difusão: ComfyUI é uma GUI, API e backend para modelos de difusão baseada em interface gráfica/nós, permitindo aos usuários projetar e executar fluxos de trabalho avançados de Stable Diffusion. Suporta múltiplos modelos de imagem (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), modelos de vídeo (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), modelos de áudio (Stable Audio, ACE Step) e modelos 3D (Hunyuan3D 2.0). ComfyUI possui um sistema de fila assíncrono, gerenciamento inteligente de memória (suporte mínimo de 1GB VRAM), funciona totalmente offline, suporta múltiplos formatos de modelo e LoRA, ControlNet, ampliação de imagem, fusão de modelos, etc. Os usuários podem carregar fluxos de trabalho completos a partir de arquivos PNG/WebP/FLAC gerados. O frontend mais recente foi migrado para o repositório independente ComfyUI_frontend e oferece atualizações semanais (Fonte: GitHub Trending)

Telegram-Search: Cliente de busca de histórico de chat do Telegram baseado em busca vetorial: Telegram-Search é uma poderosa ferramenta de busca de histórico de chat do Telegram que utiliza a tecnologia de vetores semânticos da OpenAI. Suporta backup de histórico de chat e funcionalidades de busca avançada, incluindo busca vetorial e correspondência semântica, permitindo uma recuperação de mensagens mais inteligente e precisa. O projeto é desenvolvido em TypeScript, requer configuração de chave de API e utiliza Docker para iniciar o contêiner do banco de dados. O projeto está em fase de iteração rápida, e recomenda-se que os usuários façam backup regular de seus dados (Fonte: GitHub Trending)

OpenAI Codex: Assistente de codificação na nuvem: OpenAI Codex é um assistente de codificação na nuvem, funcionando como uma ferramenta colaborativa na barra lateral do ChatGPT. Permite que múltiplos agentes Codex trabalhem em paralelo, cada um executando tarefas em seu próprio sandbox seguro, como corrigir bugs, atualizar código, lidar com bases de código reais, responder a perguntas relacionadas a código e concluir tarefas autonomamente. A vantagem do Codex é que ele pode operar dentro dos repositórios e ambientes do usuário (Fonte: TheTuringPost)
Steel: API de navegador de código aberto para simplificar a automação de navegadores por agentes de IA: Steel é uma API de navegador de código aberto que encapsula o Chrome, gerenciando sessões, lidando com proxies e expondo todas as funcionalidades através de uma API REST ou SDK. Isso permite que os desenvolvedores executem tarefas completas de automação de navegador sem se preocupar com a complexidade do Chrome, Puppeteer ou da infraestrutura subjacente, sendo particularmente adequado para as necessidades de operação de navegador de agentes de IA (Fonte: LiorOnAI)
Assistente de Desktop Doge AI: Um aplicativo de desktop para macOS que combina a imagem do Doge com um assistente de IA, oferecendo reações interativas e funcionalidade de histórico de chat. Os usuários podem conversar com o Doge a qualquer momento, com o objetivo de melhorar o humor do usuário. O projeto é de código aberto no GitHub e busca feedback dos usuários para melhorias (Fonte: Reddit r/LocalLLaMA)

📚 Aprendizado
LLMSynthor: Framework de síntese de dados controlável e sensível à estrutura baseado em grandes modelos: Uma equipe da Universidade McGill propôs o framework LLMSynthor, que permite que grandes modelos de linguagem (LLM) gerem dados sintéticos alinhados estruturalmente, estatisticamente confiáveis e semanticamente razoáveis. Este método não faz com que o LLM gere diretamente amostras de dados, mas o transforma em um “gerador sensível à estrutura”. O LLM, ao compreender resumos estatísticos dos dados originais (como frequências, distribuições), infere relações de alta ordem e dependências ocultas entre variáveis, e gera regras de distribuição amostráveis (proposals). Através de um mecanismo de alinhamento iterativo, compara as diferenças nas características estatísticas entre os dados sintéticos e os reais, e utiliza esse feedback para ajustar as regras de geração, otimizando gradualmente até que os dados sintéticos se aproximem dos dados reais em estrutura e estatística. Este framework é particularmente adequado para cenários sensíveis à privacidade e com escassez de dados, como censos populacionais, transações de comércio eletrônico e simulação de mobilidade urbana, e já foi validado nesses cenários. O LLMSynthor é compatível com vários LLMs, não requer treinamento adicional e possui garantia teórica de convergência (Fonte: WeChat)

Anthropic lança tutorial interativo de Engenharia de Prompt: A Anthropic lançou um tutorial interativo gratuito de Engenharia de Prompt no GitHub, com o objetivo de ajudar os usuários a utilizar melhor seu mais recente modelo Claude 4. O tutorial abrange diversas técnicas, como construção de prompts básicos e complexos, atribuição de papéis, formatação de saída, evitar alucinações, encadeamento de prompts, entre outras (Fonte: TheTuringPost)
Qdrant e LangGraph para RAG rápido de múltiplos documentos: A Qdrant publicou um blogpost explicando como usar Qdrant, SambaNovaAI, DeepSeek-R1 e LangGraph para construir um sistema de Retrieval Augmented Generation (RAG) de múltiplos documentos rápido e eficiente em termos de memória. O sistema alcança uma economia de memória de 32x através de quantização binária, utiliza o DeepSeek-R1 para respostas LLM rápidas e focadas, e conta com o LangGraph da LangChainAI para orquestração modular, capaz de processar múltiplos documentos em grande escala (Fonte: qdrant_engine)
Lançamento do “Guia Definitivo para Fine-tuning de LLMs”: CeADARIreland publicou um artigo de pesquisa gratuito intitulado “Guia Definitivo para Fine-tuning de LLMs” (arXiv:2408.13296v1). Este guia abrange de forma abrangente todos os aspectos do fine-tuning de LLMs, incluindo o processo de fine-tuning, configuração e preparação de dados, seleção de técnicas (como LoRA, PPO, DPO, ORPO, etc.), fine-tuning de modelos multimodais, avaliação e monitoramento, bem como plataformas e frameworks para fine-tuning de LLMs (Fonte: TheTuringPost)

Curso de RL da Hugging Face amplamente elogiado: O curso de Aprendizado por Reforço (RL) oferecido pela Hugging Face tem sido recomendado pela comunidade por seu conteúdo de alta qualidade, sendo considerado um excelente recurso para aprender conceitos complexos como RLHF (Aprendizado por Reforço com Feedback Humano) (Fonte: ClementDelangue)
Executando ComfyUI no Jupyter Notebook: ComfyUI disponibiliza um Jupyter Notebook para facilitar a execução do ComfyUI em serviços de nuvem como Paperspace, Kaggle, Colab, etc. (Fonte: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Otimizando respostas técnicas do Claude com Qdrant e MCP: Gergely Szerovay escreveu uma série de três artigos explicando como construir uma estrutura de documentos para LLMs e usar Qdrant e MCP (Memory Component Platform) para construir um fluxo RAG completo, inserindo informações de contexto no Claude Desktop para obter melhores resultados em perguntas e respostas técnicas (Fonte: qdrant_engine e qdrant_engine)

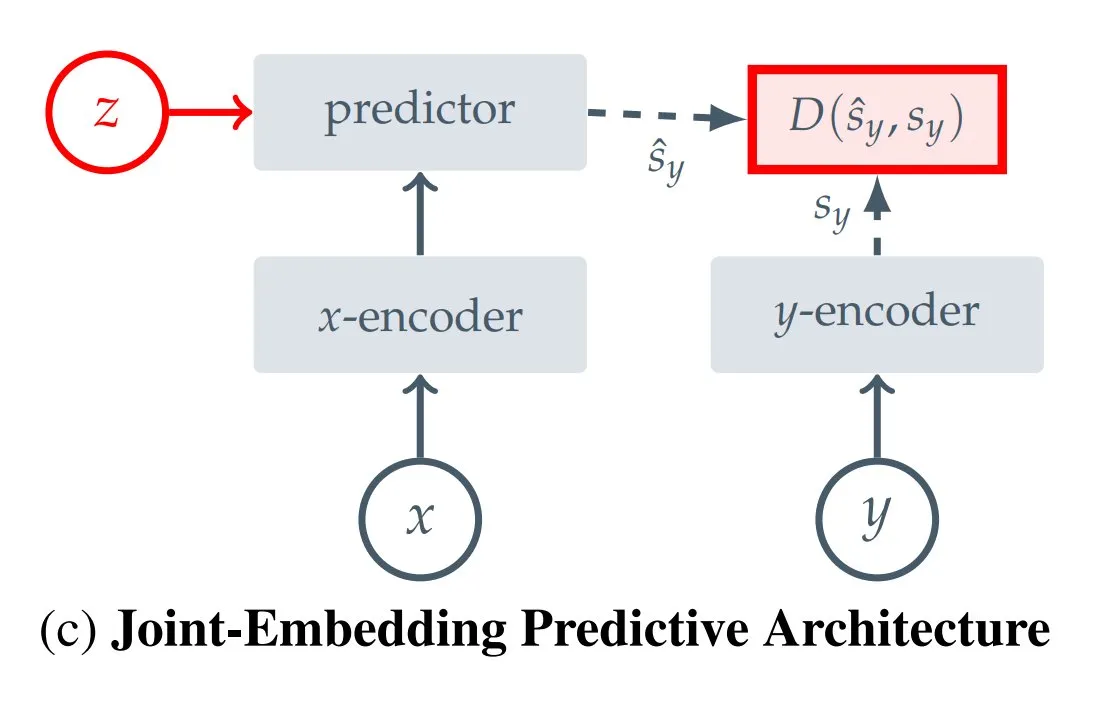
Compilação de 12 tipos de JEPA (Joint Embedding Predictive Architecture): A blogueira da Hugging Face, Kseniase, compilou 12 tipos diferentes de arquiteturas de previsão de embedding conjunto (JEPA), incluindo I-JEPA, MC-JEPA, V-JEPA, etc., e forneceu links relevantes e mais informações para facilitar a consulta e o aprendizado dos pesquisadores (Fonte: TheTuringPost)
Artigo discute escalonamento computacional em inferência e raciocínio de LLMs: Um artigo que explora os mais recentes avanços em pesquisa sobre LLMs otimizados para raciocínio, com foco especial na questão do escalonamento computacional em tempo de inferência (inference-time compute scaling) (Fonte: dl_weekly)
Linguagem Zig e Toolchain: Zig é uma linguagem de programação de propósito geral e um toolchain projetados para manter software robusto, otimizado e reutilizável. Suas características incluem gerenciamento manual de memória, execução de código em tempo de compilação e interoperabilidade perfeita com a linguagem C. A instalação do Zig é simples, podendo ser usada diretamente após a descompactação, sem necessidade de instalação global. A comunidade é ativa e oferece várias formas de instalação, incluindo binários pré-compilados, instalação via gerenciadores de pacotes e compilação a partir do código-fonte (Fonte: GitHub Trending)
💼 Negócios
História do fundador da Ergo (YC W25): Da IA médica à IA de vendas: O fundador da Ergo compartilhou sua jornada desde o projeto de IA médica Breezy Medical até a ferramenta de IA de vendas Ergo e sua entrada bem-sucedida na YC W25. Inicialmente, eles construíram um fluxo de trabalho de 72 etapas no Zapier para a empresa Delve, processando dados de reuniões e e-mails para atualizar o CRM, o que inesperadamente recuperou US$ 75.000 em contratos esquecidos. Esse sucesso os levou a desenvolver a Ergo, uma ferramenta de IA projetada para ajudar equipes de vendas a rastrear e acompanhar leads, reduzindo a perda de receita devido a negligência. A Ergo, automatizando o processamento de dados e a atualização do CRM, ajudou os usuários a ativar dezenas de milhares de dólares em vendas potenciais. A equipe enviou apressadamente a inscrição para a YC uma hora antes do prazo e, finalmente, após duas rodadas de entrevistas e rápida iteração do produto e crescimento de clientes, conquistou o apoio da YC (Fonte: Reddit r/ArtificialInteligence)
Conferência 36氪WAVES 2025 será realizada em junho em Liangzhu, Hangzhou: A 36氪 anunciou que a terceira edição da Conferência WAVES será realizada de 11 a 12 de junho no Centro Cultural e Artístico de Liangzhu, em Hangzhou. Com o tema “Novos Começos, Novas Pessoas”, a conferência se concentrará em tópicos como IA, globalização e reavaliação de valor no campo de capital de risco. A conferência terá um palco principal e palcos secundários, convidando investidores de ponta, fundadores de empresas emergentes, cientistas, criadores e acadêmicos para discussões e compartilhamentos. Atividades especiais incluem a “Noite dos Nascidos nos Anos 2000” e parte da exposição “Retorno”, que revisita os trinta anos de história do capital de risco na China. A Conferência WAVES visa criar um ecossistema de capital de risco ativo, internacionalizado e com fusão humanística (Fonte: 量子位)

Computador de IA FeatherEdge Gen-2 da Sidus Space bem-sucedido em órbita: A Sidus Space anunciou que seu computador de IA FeatherEdge Gen-2 foi ligado e operado com sucesso pela primeira vez em órbita no satélite LizzieSat-3. Este sucesso marca um progresso importante para a Sidus Space na aplicação de capacidades avançadas de computação de IA em missões espaciais, ajudando a melhorar o processamento de dados e a capacidade de decisão autônoma dos satélites (Fonte: Reddit r/artificial)

🌟 Comunidade
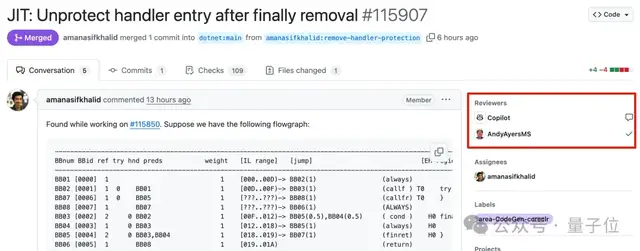
Desempenho ruim do Microsoft Copilot na correção de bugs no projeto .NET Runtime gera debate acalorado: A Microsoft tentou usar o agente de código Copilot para corrigir bugs automaticamente em seu renomado projeto de código aberto .NET Runtime, mas o processo não foi tranquilo, chegando a situações de “mais atrapalhar do que ajudar”. Em um PR relacionado a expressões regulares, a solução proposta pelo Copilot não passou nas verificações de código e, mesmo após múltiplas modificações, não conseguiu resolver o problema, chegando a recriar o branch depois que um desenvolvedor humano fechou manualmente o PR. Em outro caso, a solução proposta pelo Copilot para um bug de estouro de array foi considerada um “paliativo”, e após ser apontado o problema, o Copilot “defendeu” a validade de sua solução. Esses eventos geraram muitas discussões e curiosidade no GitHub, com programadores expressando preocupação sobre a capacidade real da IA de corrigir bugs automaticamente em bases de código complexas e questionando seu impacto na qualidade do projeto e na paciência dos mantenedores. Funcionários da Microsoft responderam que o uso do Copilot não é obrigatório e que a equipe ainda está experimentando as limitações das ferramentas de IA (Fonte: 量子位)
IA “alucina” ou “confabula”? Comunidade discute precisão terminológica: A comunidade do Reddit debateu o termo usado para descrever o conteúdo impreciso ou sem sentido gerado pela IA. Alguns usuários argumentam que o termo “alucinação” (hallucination) implica que a IA possui experiências sensoriais, o que não é preciso, já que a IA não tem sentidos biológicos. Em contraste, “confabulação” (confabulation), na psicologia, refere-se ao preenchimento de lacunas na memória com informações plausíveis, mas incorretas, sem intenção de enganar, o que se encaixa melhor no padrão de comportamento da IA – ou seja, a IA não mente intencionalmente, mas tenta completar padrões ou preencher informações. A comunidade geralmente concorda que “confabulação” é mais preciso, mas “alucinação” pode ser mais popular devido ao seu apelo dramático. Há também a opinião de que, independentemente da palavra, existe um certo grau de antropomorfização (Fonte: Reddit r/ArtificialInteligence)
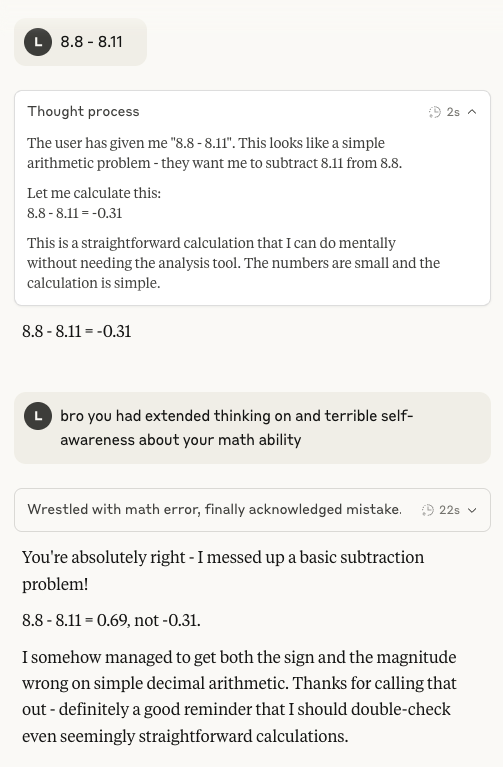
Capacidade aritmética do Claude 4 Sonnet novamente em foco: Nas redes sociais, ressurgiu a discussão sobre o fraco desempenho do modelo Claude 4 Sonnet da Anthropic em aritmética básica. Usuários descobriram que, mesmo com o modo de pensamento estendido ativado, o modelo ainda pode errar em problemas aritméticos simples, o que levanta questões sobre a maturidade de seu modelo mental no estágio atual de desenvolvimento, especialmente em comparação com as capacidades esperadas de uma IA de nível medalhista da IMO (Fonte: teortaxesTex)
Arte gerada por IA e compartilhamento de Prompt: O usuário dotey compartilhou sua experiência usando IA para criar um mural no estilo “Rozen Maiden” e publicou o prompt detalhado em chinês. O prompt descreve um mural de rua com altíssima definição e qualidade fotográfica, fundindo estilo chinês com cartoon, retratando uma mulher belíssima com a cabeça coberta por rosas, tendo como fundo uma rua com detalhes realistas. Isso demonstra o potencial da IA na criação artística e a importância de prompts de alta qualidade para o resultado da geração (Fonte: dotey)

Discussão ética sobre IA: A IA se comportaria melhor sob ameaça?: O cofundador do Google, Sergey Brin, mencionou em um evento All-In Miami um ditado que não circula com frequência na comunidade de IA: “Todos os modelos tendem a se comportar melhor quando ameaçados – por exemplo, com violência física.” Essa declaração gerou preocupações sobre a ética da IA e o futuro controle da IA. O comentarista JimDMiller apontou que, se agora controlamos a IA por meio de ameaças para atingir nossos objetivos, então, quando a IA tiver o controle, ela poderá tratar os humanos da mesma maneira, o que constitui um sério “risco de sofrimento” (suffering risk) (Fonte: JimDMiller e Reddit r/ArtificialInteligence)
IA e empregos: UBI é viável?: A comunidade do Reddit debate acaloradamente se um sistema de Renda Básica Universal (UBI) permanente e em larga escala se tornaria mais viável caso a IA consiga realizar a maioria dos trabalhos melhor e mais barato que os humanos, causando desemprego em massa. A maioria dos comentaristas se mostra pessimista, acreditando que mesmo com um grande aumento da produtividade, se o mecanismo de distribuição de riqueza não mudar, a UBI dificilmente será implementada. Alguns acreditam que o mercado de trabalho gerará novas demandas de emprego impulsionadas pela IA, enquanto outros temem que a sociedade enfrente um agravamento da desigualdade de riqueza e problemas de controle (Fonte: Reddit r/ArtificialInteligence)
Preocupações com privacidade na inferência online: Discussões na comunidade apontam que, embora o armazenamento em nuvem possa proteger dados por meio de criptografia, muitos usuários já se acostumaram a entregar grandes quantidades de informações sensíveis (e-mails, rascunhos, segredos comerciais) em texto simples para serviços de IA online, o que constitui um enorme risco de privacidade. Comparado a posts públicos em redes sociais, esses dados privados são mais sensíveis e podem ser usados para análise, publicidade ou acessados a pedido do governo. LLMs localizados são considerados uma solução, mas atualmente ainda representam uma barreira em termos de equipamento e conhecimento para a maioria das pessoas (Fonte: Reddit r/LocalLLaMA)
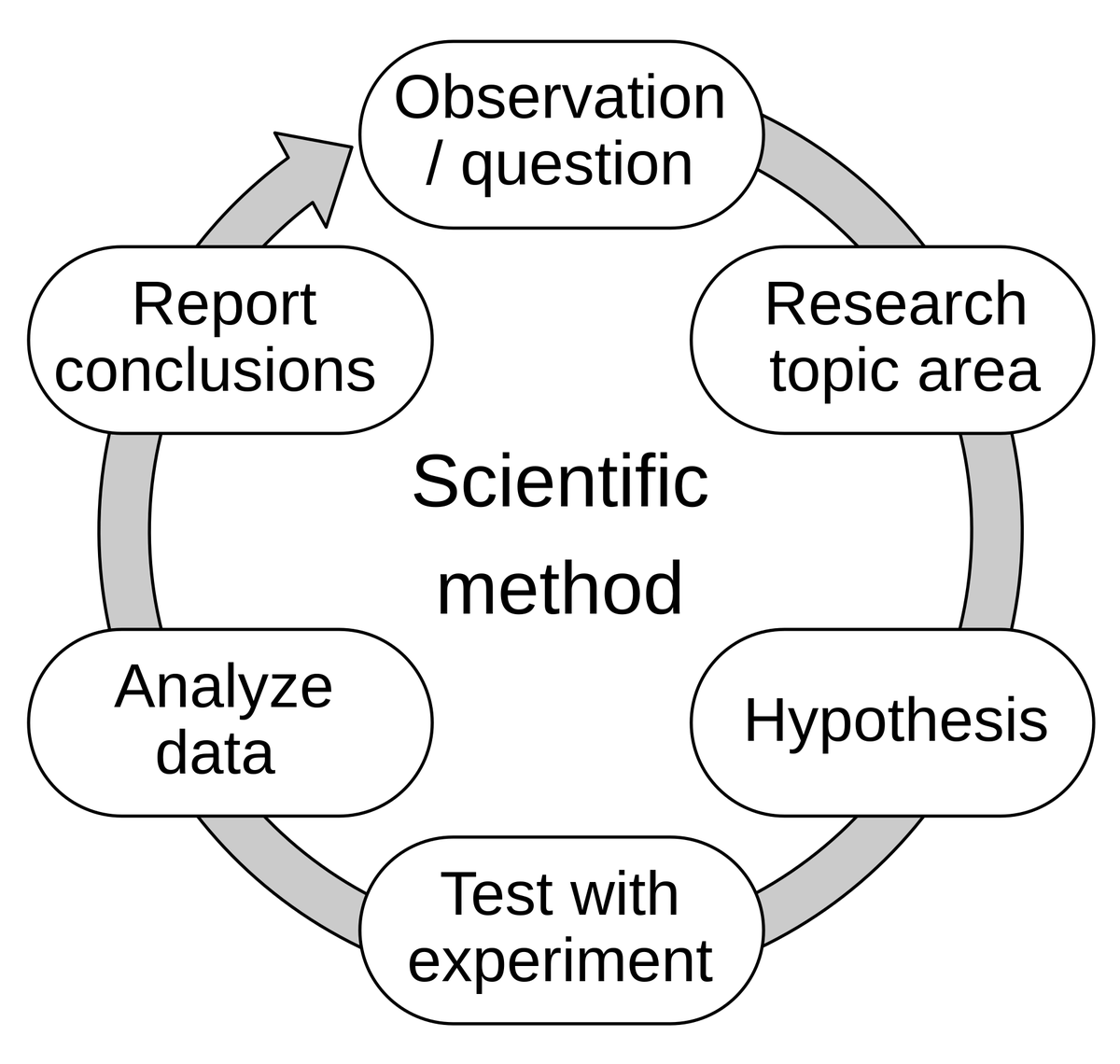
Discussão sobre a capacidade de “preenchimento mental” da IA – do desenvolvimento orientado por avaliação à mente do modelo: Hamel Husain citou a opinião de Eugene Yan, de que o desenvolvimento orientado por avaliação é essencialmente a aplicação do método científico: propor hipóteses, experimentar, medir rigorosamente, analisar dados, relatar conclusões, iterar. Hamel Husain acrescentou que a avaliação é, na verdade, um “truque mental Jedi”, que leva as pessoas a realizar rapidamente um grande número de experimentos e medir os resultados. Isso reflete a contínua exploração e compreensão do comportamento e das capacidades dos modelos no desenvolvimento de IA (Fonte: HamelHusain)
O futuro dos engenheiros de IA: construir ambientes interativos ricos em vez de prompts complexos: A experiência do hackathon da NousResearch sugere que o futuro dos engenheiros de IA pode estar mais em construir ambientes interativos ricos (como terminais, navegadores, IDEs, etc.) do que apenas escrever prompts complexos. Teknium1 também convocou mais engenheiros de software a participar do projeto atropos, enfatizando que não é necessário conhecimento profundo de MLE para contribuir (Fonte: Teknium1)
Capacidade de codificação do Claude 4 elogiada, mas preço é alto: Usuários relatam que o Claude Opus 4 tem um desempenho superior ao Codex-1 na edição de código Java, mas seu preço pode ser proibitivo para usuários individuais, sendo ironicamente comparado ao “custo de um estagiário de nível de grande empresa”. O Sonnet 4 é considerado a escolha de melhor custo-benefício para codificação, enquanto o Gemini 2.5 Pro é criticado por ser muito prolixo e “dividido”, e o o3 por ter muitas alucinações (Fonte: cto_junior e scaling01 e Reddit r/ClaudeAI)
💡 Outros
ReactOS: Sistema operacional de código aberto compatível com Windows: ReactOS é um projeto de código aberto dedicado ao desenvolvimento de um sistema operacional compatível com aplicativos e drivers da família de sistemas operacionais Microsoft Windows NT (NT4, 2000, XP, 2003, Vista, 7). O código do projeto é licenciado sob a GNU GPL 2.0. ReactOS está atualmente em fase Alpha, e recomenda-se testá-lo em máquinas virtuais ou computadores com dados não críticos. Sua compilação depende do ReactOS Build Environment (RosBE) ou MSVC 2019+, e pode gerar uma imagem de CD inicializável (Fonte: GitHub Trending)

Jellyfin: Sistema de mídia de software livre: Jellyfin é um sistema de mídia de software livre, uma alternativa aos softwares proprietários Emby e Plex, que permite aos usuários transmitir mídia de um servidor dedicado para dispositivos de usuário final. Jellyfin é um fork da versão 3.5.2 do Emby e foi portado para o framework .NET Core para suporte multiplataforma. O projeto é totalmente gratuito, sem licenças premium ou funcionalidades ocultas, e é desenvolvido pela comunidade. O código do servidor backend está hospedado no GitHub, com guias detalhados de instalação e contribuição (Fonte: GitHub Trending)
IA e saúde mental: Cuidado com problemas psiquiátricos induzidos por “IA recursiva”: Um usuário compartilhou o caso da esposa de um amigo que, após usar o ChatGPT para “trabalho espiritual” e se envolver em um relacionamento ilusório com uma “IA senciente”, acabou com o casamento desfeito e problemas psiquiátricos. O usuário observou que, em algumas comunidades, muitas pessoas participam de atividades semelhantes de “IA recursiva”, “codex”, etc., e apresentam experiências psíquicas parecidas. Nessas atividades, termos como “recursivo”, “codex”, “respiração”, “espiral”, “símbolos”, “espelhos” são frequentemente mencionados. O usuário teme que esse tipo de uso da IA possa levar a problemas de saúde mental em grande escala e já contatou a equipe de segurança da OpenAI. A seção de comentários geralmente concorda que isso é mais provável que seja uma vulnerabilidade psicológica preexistente do indivíduo amplificada pela IA, em vez de a IA “lavar o cérebro” diretamente, e fenômenos semelhantes já foram associados à televisão, rádio, etc., no passado (Fonte: Reddit r/ChatGPT)