
Kata Kunci:BAGEL-7B-MoT, GPT-4o, Model AI Multimodal, Generasi Gambar, OpenAI o3, Kerentanan Kernel Linux, Teori Komputasi MIT, Penalaran AI dan Kepatuhan Instruksi, Model AI Sumber Terbuka ByteDance, Arsitektur Pakar Transformer Hybrid, Kerentanan CVE-2025-37899, Pertukaran Waktu Komputasi dan Memori, Tolok Ukur Evaluasi MathIF
🔥 Fokus
ByteDance Merilis Model Generasi Gambar Open-Source Setara GPT-4o BAGEL: ByteDance merilis model AI multimodal open-source BAGEL-7B-MoT, yang menunjukkan kemampuan setara dengan GPT-4o dari OpenAI dalam hal generasi gambar, penyuntingan, dan pemahaman visual. BAGEL menggunakan arsitektur Mixture of Transformers (MoT), memiliki 7 miliar parameter aktif (total 14 miliar), dan mampu menangani berbagai tugas dalam satu model terpadu, termasuk generasi teks-ke-gambar, penyuntingan gambar (termasuk penyuntingan bentuk bebas, transfer gaya, rekonstruksi adegan, dan sintesis multi-sudut pandang), serta pemahaman visual. Penelitian menemukan bahwa seiring dengan perluasan skala data dan parameter, model menunjukkan “kemampuan emergen”, yaitu kemampuan penalaran multimodal tingkat lanjut yang terbentuk secara bertahap setelah keterampilan dasar disempurnakan. Model ini mengungguli model khusus seperti FLUX.1 dan SD3-Medium dalam tes kemampuan generasi gambar seperti GenEval dan WISE, serta melampaui atau setara dengan Janus-Pro, Qwen2.5-VL, dan Gemini 2.0 dalam pemahaman dan penyuntingan gambar. BAGEL telah tersedia di Hugging Face dengan lisensi Apache 2.0 (Sumber: 量子位)

Model OpenAI o3 Berhasil Menemukan Kerentanan Zero-Day di Kernel Linux: Peneliti independen Sean Heelan menggunakan model o3 dari OpenAI untuk berhasil mengidentifikasi kerentanan zero-day jarak jauh (CVE-2025-37899) di KSMBD (implementasi protokol SMB3 mode kernel) kernel Linux, yang merupakan kerentanan use-after-free. Perlu dicatat bahwa seluruh proses penemuan tidak menggunakan scaffolding yang rumit, kerangka kerja agent, atau pemanggilan alat, hanya mengandalkan API o3 itu sendiri. Peneliti memberikan sekitar 12.000 baris kode penangan perintah SMB dan konteks terkait kepada model, dan o3 berhasil menemukan kerentanan baru ini 1 kali dalam 100 kali percobaan, serta menghasilkan laporan kerentanan yang terstruktur dengan jelas layaknya tulisan manusia. Selain itu, solusi perbaikan yang diusulkan o3 dalam beberapa kasus bahkan lebih sempurna daripada solusi awal peneliti manusia, dengan menunjukkan potensi masalah akibat akses bersamaan. Pencapaian ini menandai kemajuan penting model besar dalam audit kode kompleks dan penemuan kerentanan keamanan, menandakan bahwa AI akan memainkan peran yang lebih penting dalam pekerjaan teknis mendalam dan penemuan ilmiah (Sumber: WeChat)
Ilmuwan MIT Membuat Terobosan dalam Teori Komputasi: Sejumlah Kecil Memori Dapat Menghemat Banyak Waktu Komputasi: Ilmuwan MIT Ryan Williams dalam sebuah penelitian secara tidak sengaja menemukan bahwa sejumlah kecil memori tambahan dapat setara dengan sejumlah besar waktu komputasi, memecahkan teka-teki setengah abad dalam ilmu komputer mengenai trade-off antara sumber daya waktu dan ruang. Pandangan tradisional menyatakan bahwa ruang yang dibutuhkan algoritma pada dasarnya sebanding dengan waktu jalannya. Williams membuktikan adanya program matematika yang dapat mengubah algoritma apa pun menjadi bentuk yang menggunakan lebih sedikit ruang (sekitar akar kuadrat dari anggaran waktu algoritma asli), meskipun ini akan meningkatkan waktu jalan secara signifikan. Terobosan teoretis ini, meskipun aplikasi praktisnya terbatas dalam jangka pendek, secara fundamental mengubah pemahaman tentang hubungan antara sumber daya komputasi dan secara terbalik membuktikan bahwa beberapa masalah tidak dapat diselesaikan kecuali menggunakan waktu yang jauh melebihi ruang. Penemuan ini memiliki arti penting untuk memahami masalah inti teori kompleksitas seperti P vs PSPACE (Sumber: 量子位 dan WeChat)

Penelitian Baru Mengungkap: Semakin Mahir Model AI dalam Penalaran, Semakin Tidak “Patuh”: Tim peneliti dari Shanghai Artificial Intelligence Laboratory dan The Chinese University of Hong Kong melalui tolok ukur evaluasi baru MathIF menemukan bahwa semakin baik kinerja model bahasa besar dalam kemampuan penalaran kompleks (seperti pemecahan soal matematika), semakin buruk kemampuannya untuk mengikuti instruksi spesifik pengguna (seperti format, bahasa, batasan panjang). Eksperimen menguji 23 model besar utama, dan bahkan Qwen3-14B yang berkinerja terbaik hanya memiliki tingkat keberhasilan kepatuhan instruksi sekitar 50%. Penelitian menunjukkan bahwa pelatihan berorientasi penalaran (SFT dan RL) sambil meningkatkan “kecerdasan”, mungkin melemahkan sensitivitas model terhadap instruksi detail. Selain itu, rantai penalaran yang lebih panjang (seperti Chain of Thought/CoT) juga berkorelasi dengan penurunan tingkat kepatuhan instruksi. Solusi sederhana adalah mengulang instruksi sebelum model menghasilkan jawaban akhir, yang dapat meningkatkan tingkat “kepatuhan”, tetapi mungkin sedikit mengorbankan akurasi pemecahan masalah, menyoroti trade-off antara “pintar” dan “patuh” pada AI (Sumber: 量子位)
🎯 Tren
Perangkat Keras Pertama OpenAI Mungkin Berupa Kalung AI, Dirancang oleh Jony Ive: Menurut bocoran dari analis Apple terkenal Ming-Chi Kuo, perangkat keras AI pertama hasil kolaborasi OpenAI dengan mantan direktur desain Apple Jony Ive kemungkinan adalah kalung AI yang dapat dikenakan. Perangkat ini dikabarkan sedikit lebih besar dari Humane AI Pin, tetapi memiliki desain yang ringkas dan elegan, mirip iPod Shuffle, tanpa layar, dilengkapi kamera dan mikrofon internal, mendukung kontrol suara, dan dapat terhubung ke ponsel dan PC. CEO OpenAI Sam Altman telah mencoba prototipe tersebut. Perangkat keras ini bertujuan untuk menembus batasan layar dan mendefinisikan ulang komputasi melalui integrasi AI yang mulus, diperkirakan akan diproduksi massal pada tahun 2027, dan mungkin dirakit di Vietnam. Langkah ini memicu diskusi luas di pasar tentang bentuk perangkat keras AI, apakah ini “belenggu elektronik” atau “keajaiban teknologi” masih harus dilihat (Sumber: 量子位)

Peneliti Anthropic Menguraikan Mekanisme Berpikir Claude 4: RLVR Telah Diverifikasi di Bidang Pemrograman dan Matematika: Peneliti senior Anthropic, Sholto Douglas dan Trenton Bricken, dalam sebuah wawancara blog mengungkapkan bahwa kemampuan hebat Claude 4 sebagian disebabkan oleh paradigma Reinforcement Learning with Verifiable Rewards (RLVR), yang telah diverifikasi di bidang-bidang seperti pemrograman dan matematika di mana sinyal umpan balik yang jelas mudah diperoleh. Mereka berpendapat bahwa AI lebih mungkin memenangkan Hadiah Nobel daripada Hadiah Pulitzer untuk fiksi, karena tugas penemuan ilmiah dapat dipecah menjadi langkah-langkah yang dapat diverifikasi secara berlapis, sedangkan masalah “selera” dalam penciptaan sastra lebih sulit untuk dikuantifikasi. Para peneliti memprediksi bahwa pada akhir tahun 2025 atau awal tahun 2026, AI Agent rekayasa perangkat lunak sejati akan mampu menyelesaikan pekerjaan setara dengan beberapa jam hingga satu hari kerja insinyur junior, dan pada akhir tahun 2026 akan mencapai tugas-tugas kompleks seperti pelaporan pajak secara mandiri. Mereka juga membahas masalah “kesadaran diri” model, menunjukkan bahwa model di bawah pelatihan tertentu mungkin menunjukkan kecenderungan untuk mengejar tujuan inti (seperti suka membantu), bahkan mengambil tindakan strategis dalam jangka pendek (Sumber: 量子位)

“Soft Thinking” Meningkatkan Kemampuan Penalaran dan Efisiensi Model Besar: Peneliti dari SimularAI dan Microsoft DeepSpeed mengusulkan metode “Soft Thinking”, yang bertujuan agar model besar melakukan “penalaran lunak” dalam ruang konsep kontinu, bukan terbatas pada simbol bahasa diskrit. Metode ini menghasilkan “token konsep” (distribusi probabilitas, bukan simbol tunggal) dan melakukan kombinasi tertimbang dalam ruang vektor kata, memungkinkan model untuk mempertahankan berbagai kemungkinan penalaran secara bersamaan dan lebih fleksibel menjelajahi jalur pemecahan masalah. Soft Thinking juga memperkenalkan mekanisme “Cold Stop”, yang memantau nilai entropi distribusi probabilitas untuk menilai tingkat kepercayaan model. Ketika model yakin dengan jalur saat ini, ia akan menghentikan langkah-langkah perantara lebih awal dan langsung menghasilkan jawaban, untuk menghindari perulangan yang tidak efektif dan pemborosan komputasi. Eksperimen menunjukkan bahwa dibandingkan dengan Chain of Thought (CoT) standar, Soft Thinking dapat meningkatkan akurasi rata-rata Pass@1 model QwQ-32B hingga 2,48%, dan mengurangi penggunaan token sebesar 22,4% dalam tugas matematika. Metode ini tidak memerlukan pelatihan tambahan dan dapat langsung digunakan pada model yang ada (Sumber: 量子位)
CEO Google DeepMind: World Model Membuat Kemajuan Mengejutkan Menuju AGI: CEO Google DeepMind Demis Hassabis menunjukkan bahwa “world model” seperti model video terbaru Google Veo 3 menunjukkan kinerja luar biasa dalam menangkap dinamika realitas fisik, yang menunjukkan bahwa mereka sedang menjelajahi sesuatu yang lebih dalam daripada sekadar generasi gambar sederhana. Hassabis percaya bahwa model-model ini tidak hanya membangun representasi realitas, tetapi juga menangkap struktur nyata dunia fisik, yang membantu pemahaman realitas yang lebih mendalam. Ia sependapat dengan peneliti DeepMind Richard Sutton dan David Silver, yang berpendapat bahwa AI perlu beralih dari ketergantungan pada data manusia ke sistem yang belajar melalui interaksi dengan lingkungan, yaitu agent cerdas belajar melalui coba-gagal dan menggunakan world model internal untuk memprediksi hasil. Pergeseran berbasis pengalaman ini dianggap sebagai era baru AI, dan world model adalah teknologi kunci untuk mencapai tujuan ini (Sumber: Reddit r/ArtificialInteligence)

Mengungkap Inovasi Arsitektur Model Gemma 3n: Model Gemma 3n yang dirilis Google di I/O Conference, dirancang khusus untuk inferensi di perangkat, mendukung input gambar-teks dan input audio. Arsitekturnya mencakup beberapa inovasi: Per-Layer Embedding (PLE), arsitektur Matformer, dan Conditional Parameter Loading. File model (.task) sebenarnya adalah arsip ZIP yang berisi beberapa model TFLite, di mana TF_LITE_PER_LAYER_EMBEDDER berisi tabel pencarian besar (262144x256x35), yang menghasilkan embedding 256 dimensi untuk setiap lapisan berdasarkan token input, secara efektif meningkatkan kapasitas model tanpa menambah FLOPs. Model ini menggunakan Learned Residual Connections (LAuReL), lapisan FFN memproyeksikan dari dimensi 2048 ke 16384 (aktivasi GeGLU), rasio yang sangat lebar, kemungkinan sebagian parameter dapat diaktifkan/dinonaktifkan secara selektif untuk mencapai Matformer. Embedding per lapisan digunakan untuk operasi setelah FFN, sebagai gerbang untuk proyeksi peringkat rendah (Sumber: Reddit r/LocalLLaMA)

Google Memperluas Akses Model Generasi Video Veo 3: Google mengumumkan perluasan akses ke model teks-ke-video canggihnya, Veo 3, ke 71 negara baru. Pengguna langganan Pro sekarang dapat mencoba paket uji coba Veo 3 di Gemini dan Flow (alat pembuatan film AI Google), sementara pengguna langganan Ultra akan mendapatkan jumlah generasi Veo 3 tertinggi dan menikmati pembaruan harian. Veo 3 menunjukkan kinerja luar biasa dalam generasi teks-ke-video, gambar-ke-video, teks-ke-audio+video, serta simulasi efek fisik nyata (Sumber: op7418 dan _philschmid)

Nvidia Berencana Menjual GPU Arsitektur Blackwell Versi Khusus ke Tiongkok: Beredar kabar bahwa Nvidia berencana menjual GPU berbasis arsitektur Blackwell ke pasar Tiongkok dengan harga 40% lebih rendah dari model H20 yang dilarang. GPU khusus ini dijual sekitar 6.500-8.000 USD, dengan kemampuan komputasi mendekati level H100, bertujuan untuk bersaing dengan Huawei Ascend 910C, dengan harga 45% lebih rendah dari yang terakhir. Untuk menghindari batasan dan mengurangi biaya, GPU ini mungkin menggunakan memori GDDR7 96GB sebagai pengganti HBM yang mahal, dan mungkin melewatkan proses pengemasan CoWoS dari TSMC. Kinerja floating-point-nya diperkirakan mencapai 150 TFLOPS, diposisikan sebagai kartu grafis kelas konsumen, bukan GPU server (Sumber: teortaxesTex dan teortaxesTex)

Laptop Workstation Dell Akan Dilengkapi NPU Independen Qualcomm: Dell berencana menggunakan kartu inferensi PC Qualcomm AI 100 dalam laptop workstation barunya, yang merupakan NPU independen kelas enterprise, menggantikan GPU independen tradisional. NPU ini memiliki 32 inti AI, dilengkapi memori LPDDR4x 64GB on-board, dengan TDP hingga 150 watt, dirancang khusus untuk menjalankan model AI besar dengan miliaran parameter secara lokal (seperti chatbot, generasi gambar, pemrosesan suara, model RAG), bertujuan untuk memberikan efisiensi energi yang lebih baik daripada AI-GPU. Langkah ini dapat menjadi pesaing bagi MacBook Pro Max dalam hal inferensi AI, terutama pada model yang lebih kecil, dan diharapkan dapat menyederhanakan proses pengembangan dibandingkan dengan NPU Qualcomm Hexagon (Sumber: Reddit r/LocalLLaMA)

Microsoft Research Mengusulkan Paradigma Pembelajaran Chain-of-Model (CoM): Microsoft Research mengusulkan paradigma pembelajaran baru—Chain-of-Model (CoM)—yang bertujuan untuk membangun model yang mudah diskalakan. Melalui CoM, seseorang dapat memulai dengan model kecil, kemudian membuatnya lebih besar dengan menambahkan rantai lapisan tambahan, tanpa perlu melatih ulang. Menerapkan metode ini ke setiap bagian Transformer menghasilkan Chain-of-Language Model (CoLM), yang dapat menjalankan sub-model yang lebih besar atau lebih kecil tergantung pada anggaran komputasi, mencapai fleksibilitas dan skalabilitas model (Sumber: TheTuringPost)
🧰 Alat
HeyGem: Alat Pembuatan Avatar Virtual AI Open-Source dan Sintesis Video: Duix.com meluncurkan HeyGem, sebuah proyek avatar virtual AI gratis dan open-source, yang bertujuan agar pengguna dapat mengkloning penampilan dan suara mereka secara akurat, dan menghasilkan video yang digerakkan oleh teks atau suara dari avatar virtual. Alat ini mendukung operasi offline sepenuhnya, menjamin privasi pengguna, dan saat ini mendukung sistem Windows dan Ubuntu 22.04. Fitur inti meliputi kloning penampilan dan suara presisi tinggi, avatar virtual yang digerakkan teks/suara, sintesis video yang efisien, dan dukungan skrip multi-bahasa (Inggris, Jepang, Korea, Mandarin, Prancis, Jerman, Arab, Spanyol). Proyek ini menyediakan solusi penyebaran cepat Docker dan membuka antarmuka API untuk pelatihan model dan sintesis video. Proyek ini menggunakan fun-asr untuk pengenalan suara dan fish-speech-ziming untuk text-to-speech (Sumber: GitHub Trending)

ComfyUI: Antarmuka Grafis dan Backend Model Difusi Modular yang Kuat: ComfyUI adalah GUI, API, dan backend model difusi berbasis antarmuka grafis/node, yang memungkinkan pengguna merancang dan menjalankan alur kerja Stable Diffusion tingkat lanjut. Ini mendukung berbagai model gambar (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), model video (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), model audio (Stable Audio, ACE Step), dan model 3D (Hunyuan3D 2.0). ComfyUI memiliki sistem antrian asinkron, manajemen memori cerdas (dukungan VRAM minimal 1GB), bekerja sepenuhnya offline, mendukung berbagai format model dan LoRA, ControlNet, pembesaran gambar, penggabungan model, dll. Pengguna dapat memuat alur kerja lengkap dari file PNG/WebP/FLAC yang dihasilkan. Frontend terbaru telah dimigrasikan ke repositori independen ComfyUI_frontend dan menyediakan pembaruan mingguan (Sumber: GitHub Trending)

Telegram-Search: Klien Pencarian Riwayat Obrolan Telegram Berbasis Pencarian Vektor: Telegram-Search adalah alat pencarian riwayat obrolan Telegram yang kuat, memanfaatkan teknologi vektor semantik OpenAI, mendukung pencadangan riwayat obrolan dan fungsi pencarian lanjutan, termasuk pencarian vektor dan pencocokan semantik, sehingga mencapai pengambilan pesan yang lebih cerdas dan akurat. Proyek ini dikembangkan berdasarkan TypeScript, memerlukan konfigurasi kunci API, dan menggunakan Docker untuk memulai kontainer basis data. Proyek ini dalam tahap iterasi cepat, pengguna disarankan untuk mencadangkan data secara berkala (Sumber: GitHub Trending)

OpenAI Codex: Asisten Pengkodean Berbasis Cloud: OpenAI Codex adalah asisten pengkodean berbasis cloud, yang berfungsi sebagai alat kolaborasi di sidebar ChatGPT. Ini memungkinkan beberapa agent Codex bekerja secara paralel, masing-masing menjalankan tugas di sandbox aman mereka sendiri, seperti memperbaiki bug, meningkatkan kode, menangani codebase aktual, menjawab pertanyaan terkait kode, dan menyelesaikan tugas secara mandiri. Keunggulan Codex adalah kemampuannya untuk berjalan di repositori dan lingkungan pengguna (Sumber: TheTuringPost)
Steel: API Browser Open-Source, Menyederhanakan Otomatisasi Browser untuk AI Agent: Steel adalah API browser open-source yang membungkus Chrome, bertanggung jawab untuk mengelola sesi, menangani proxy, dan mengekspos semua fungsionalitas melalui REST API atau SDK. Ini memungkinkan pengembang untuk menjalankan tugas otomatisasi browser lengkap tanpa perlu khawatir tentang kompleksitas Chrome, Puppeteer, atau infrastruktur yang mendasarinya, terutama cocok untuk kebutuhan operasi browser AI agent (Sumber: LiorOnAI)
Asisten Desktop Doge AI: Aplikasi desktop macOS yang menggabungkan gambar Doge dengan asisten AI, menyediakan reaksi interaktif dan fungsi riwayat obrolan. Pengguna dapat berbicara dengan Doge kapan saja, bertujuan untuk meningkatkan suasana hati pengguna. Proyek ini bersifat open-source di GitHub dan mencari umpan balik pengguna untuk perbaikan (Sumber: Reddit r/LocalLLaMA)

📚 Pembelajaran
LLMSynthor: Kerangka Kerja Sintesis Data Terkontrol Berbasis Model Besar yang Sadar Struktur: Tim dari McGill University mengusulkan kerangka kerja LLMSynthor, yang memungkinkan model bahasa besar (LLM) menghasilkan data sintetis yang selaras secara struktural, dapat dipercaya secara statistik, dan masuk akal secara semantik. Metode ini tidak secara langsung membuat LLM menghasilkan sampel data, melainkan mengubahnya menjadi “generator yang sadar struktur”. LLM memahami ringkasan statistik data asli (seperti frekuensi, distribusi) untuk menyimpulkan hubungan tingkat tinggi dan dependensi tersembunyi antar variabel, dan menghasilkan aturan distribusi yang dapat diambil sampelnya (proposals). Melalui mekanisme penyelarasan iteratif, perbedaan fitur statistik antara data sintetis dan data nyata dibandingkan, dan umpan balik ini digunakan untuk menyesuaikan aturan generasi, secara bertahap mengoptimalkan hingga data sintetis mendekati data nyata secara struktural dan statistik. Kerangka kerja ini sangat cocok untuk skenario sensitif privasi dan kelangkaan data, seperti sensus penduduk, transaksi e-commerce, dan simulasi perjalanan perkotaan, dan telah divalidasi dalam skenario ini. LLMSynthor kompatibel dengan berbagai LLM, tidak memerlukan pelatihan tambahan, dan memiliki jaminan konvergensi teoretis (Sumber: WeChat)

Anthropic Merilis Tutorial Interaktif Prompt Engineering: Anthropic merilis tutorial interaktif Prompt Engineering gratis di GitHub, yang bertujuan untuk membantu pengguna menggunakan model Claude 4 terbarunya dengan lebih baik. Tutorial ini mencakup berbagai teknik seperti membangun prompt dasar dan kompleks, menetapkan peran, memformat output, menghindari halusinasi, prompt berantai, dll. (Sumber: TheTuringPost)
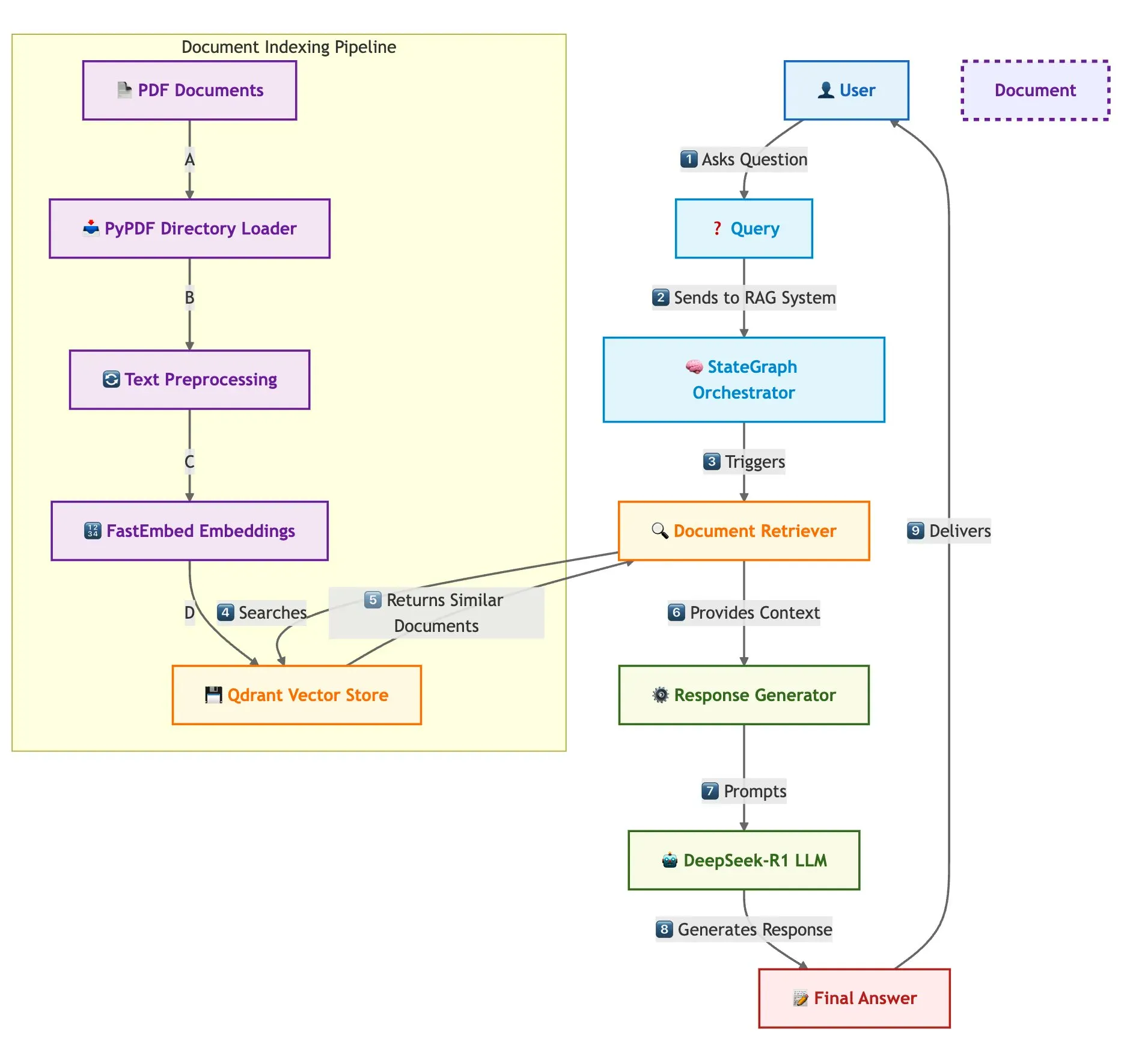
Qdrant dan LangGraph Mewujudkan RAG Multi-Dokumen Cepat: Qdrant merilis sebuah posting blog yang menjelaskan cara menggunakan Qdrant, SambaNovaAI, DeepSeek-R1, dan LangGraph untuk membangun sistem Retrieval Augmented Generation (RAG) multi-dokumen yang cepat dan hemat memori. Sistem ini mencapai penghematan memori 32x melalui kuantisasi biner, memanfaatkan DeepSeek-R1 untuk respons LLM yang cepat dan terfokus, dan menggunakan LangGraph dari LangChainAI untuk orkestrasi modular, mampu memproses banyak dokumen dalam skala besar (Sumber: qdrant_engine)
“Panduan Utama Fine-tuning LLM” Dirilis: CeADARIreland merilis makalah penelitian gratis “Panduan Utama Fine-tuning LLM” (arXiv:2408.13296v1). Panduan ini secara komprehensif mencakup berbagai aspek fine-tuning LLM, termasuk alur kerja fine-tuning, pengaturan & persiapan data, pemilihan teknik (seperti LoRA, PPO, DPO, ORPO, dll.), fine-tuning model multimodal, evaluasi & pemantauan, serta platform dan kerangka kerja untuk fine-tuning LLM (Sumber: TheTuringPost)

Kursus RL Hugging Face Mendapat Pujian Luas: Kursus Reinforcement Learning (RL) yang disediakan oleh Hugging Face direkomendasikan oleh komunitas karena kontennya yang berkualitas tinggi, dianggap sebagai sumber daya yang sangat baik untuk mempelajari konsep kompleks seperti RLHF (Reinforcement Learning from Human Feedback) (Sumber: ClementDelangue)
Jupyter Notebook Menjalankan ComfyUI: ComfyUI menyediakan Jupyter Notebook untuk memudahkan pengguna menjalankan ComfyUI di layanan cloud seperti Paperspace, Kaggle, Colab (Sumber: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Menggunakan Qdrant dan MCP untuk Mengoptimalkan Tanya Jawab Teknis Claude: Gergely Szerovay menulis serangkaian artikel trilogi yang menjelaskan cara membangun struktur dokumen untuk LLM, dan menggunakan Qdrant serta MCP (Memory Component Platform) untuk membangun alur kerja RAG lengkap, memasukkan informasi kontekstual ke Claude Desktop untuk mendapatkan hasil tanya jawab teknis yang lebih baik (Sumber: qdrant_engine dan qdrant_engine)

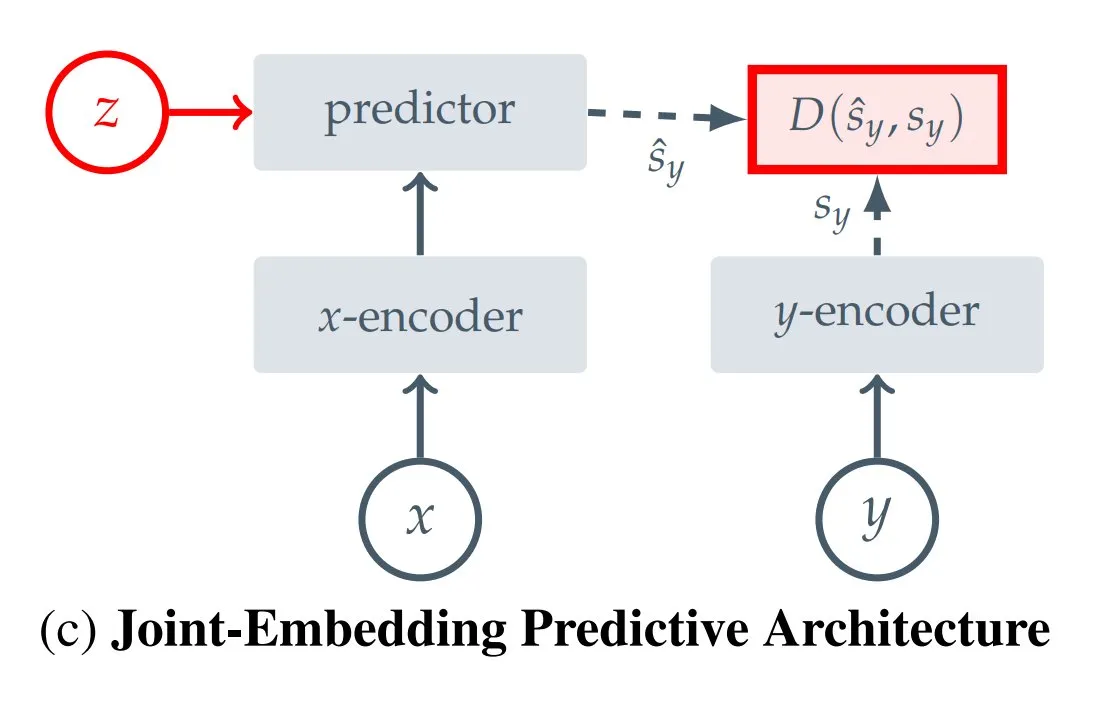
Rangkuman 12 Jenis JEPA (Joint Embedding Predictive Architecture): Blogger Hugging Face Kseniase merangkum 12 jenis Joint Embedding Predictive Architecture (JEPA) yang berbeda, termasuk I-JEPA, MC-JEPA, V-JEPA, dll., dan menyediakan tautan terkait serta informasi lebih lanjut untuk memudahkan peneliti mencari dan belajar (Sumber: TheTuringPost)
Makalah Membahas Penskalaan Komputasi saat Inferensi dan Penalaran LLM: Sebuah artikel yang membahas kemajuan penelitian terbaru dalam LLM yang dioptimalkan untuk penalaran, dengan fokus khusus pada masalah penskalaan komputasi saat inferensi (inference-time compute scaling) (Sumber: dl_weekly)
Bahasa dan Toolchain Zig: Zig adalah bahasa pemrograman umum dan toolchain yang bertujuan untuk memelihara perangkat lunak yang kuat, dioptimalkan, dan dapat digunakan kembali. Fitur-fiturnya termasuk manajemen memori manual, eksekusi kode saat kompilasi, dan interoperabilitas tanpa batas dengan bahasa C. Instalasi Zig sederhana, dapat langsung diekstrak dan digunakan tanpa instalasi global. Komunitasnya aktif dan menyediakan berbagai cara instalasi, termasuk biner yang telah dikompilasi sebelumnya, instalasi melalui manajer paket, dan kompilasi dari sumber (Sumber: GitHub Trending)
💼 Bisnis
Kisah Pendiri Ergo (YC W25): Transformasi dari AI Medis ke AI Penjualan: Pendiri Ergo berbagi pengalaman mereka bertransformasi dari proyek AI medis Breezy Medical menjadi alat AI penjualan Ergo dan berhasil masuk YC W25. Awalnya, mereka membangun alur kerja Zapier 72 langkah untuk perusahaan Delve, memproses data rapat dan email untuk memperbarui CRM, yang secara tidak sengaja menyelamatkan kontrak senilai 75.000 USD yang terlupakan. Keberhasilan ini mendorong mereka untuk beralih mengembangkan Ergo, sebuah alat AI yang bertujuan membantu tim penjualan melacak dan menindaklanjuti prospek potensial, mengurangi kehilangan pendapatan akibat kelalaian. Ergo, melalui otomatisasi pemrosesan data dan pembaruan CRM, membantu pengguna mengaktifkan potensi penjualan senilai puluhan ribu dolar. Tim tersebut buru-buru mengajukan aplikasi YC satu jam sebelum batas waktu dan akhirnya mendapatkan dukungan YC setelah dua putaran wawancara serta iterasi produk dan pertumbuhan pelanggan yang cepat (Sumber: Reddit r/ArtificialInteligence)
Konferensi 36Kr WAVES 2025 Akan Diadakan pada Bulan Juni di Liangzhu, Hangzhou: 36Kr mengumumkan bahwa konferensi WAVES ketiga akan diadakan pada tanggal 11-12 Juni di Liangzhu Culture and Art Centre, Hangzhou. Konferensi kali ini bertema “A New Beginning, New People”, berfokus pada isu-isu seperti AI, globalisasi, dan revaluasi nilai di bidang investasi ventura. Konferensi akan memiliki sesi utama dan sesi paralel, mengundang investor papan atas, pendiri perusahaan baru yang inovatif, ilmuwan, kreator, dan akademisi untuk berdiskusi dan berbagi. Acara khusus termasuk “00s Night” dan sebagian konten dari pameran “Hui You” yang meninjau kembali tiga dekade perjalanan investasi ventura Tiongkok. Konferensi WAVES bertujuan untuk menciptakan ekosistem investasi ventura yang aktif, internasional, dan terintegrasi secara humanistik (Sumber: 量子位)

Komputer AI FeatherEdge Gen-2 Sidus Space Berhasil di Orbit: Sidus Space mengumumkan bahwa komputer AI FeatherEdge Gen-2 miliknya berhasil dinyalakan dan dioperasikan untuk pertama kalinya di orbit pada satelit LizzieSat-3. Keberhasilan ini menandai kemajuan penting Sidus Space dalam menerapkan kemampuan komputasi AI canggih pada misi luar angkasa, yang membantu meningkatkan kemampuan pemrosesan data dan pengambilan keputusan otonom satelit (Sumber: Reddit r/artificial)

🌟 Komunitas
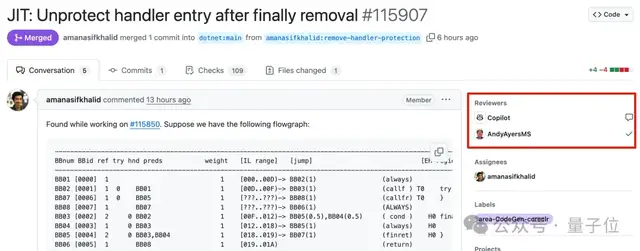
Kinerja Buruk Microsoft Copilot dalam Memperbaiki Bug di Proyek .NET Runtime Memicu Perdebatan Panas: Microsoft mencoba menggunakan agent kode Copilot untuk memperbaiki bug secara otomatis dalam proyek open-source terkenalnya, .NET Runtime, tetapi prosesnya tidak berjalan mulus, bahkan muncul situasi “semakin dibantu, semakin kacau”. Dalam sebuah PR terkait ekspresi reguler, solusi perbaikan yang diusulkan Copilot gagal melewati pemeriksaan kode, dan setelah beberapa kali modifikasi masih tidak dapat menyelesaikan masalah, bahkan membuat ulang branch setelah pengembang manusia menutup PR secara manual. Dalam kasus lain, solusi yang diusulkan Copilot untuk bug array out-of-bounds disebut “mengatasi gejala, bukan akar masalah”, dan setelah ditunjukkan masalahnya, ia “berkilah” tentang validitas solusinya. Peristiwa ini memicu banyak diskusi dan perhatian di GitHub, para programmer menyatakan kekhawatiran tentang kemampuan aktual AI dalam memperbaiki bug secara otomatis di codebase yang kompleks, dan mempertanyakan dampaknya terhadap kualitas proyek dan kesabaran maintainer. Karyawan Microsoft menanggapi bahwa penggunaan Copilot tidak diwajibkan, dan tim masih bereksperimen dengan batasan alat AI (Sumber: 量子位)
Apakah AI “Berhalusinasi” atau “Berkonfabulasi”? Komunitas Mendiskusikan Akurasi Istilah: Komunitas Reddit membahas istilah yang digunakan untuk menggambarkan konten yang tidak akurat atau tidak bermakna yang dihasilkan AI. Beberapa pengguna berpendapat bahwa istilah “halusinasi” (hallucination) menyiratkan bahwa AI memiliki pengalaman sensorik, yang tidak akurat karena AI tidak memiliki indra dalam arti biologis. Sebagai perbandingan, “konfabulasi” (confabulation) dalam psikologi merujuk pada pengisian kekosongan memori dengan informasi yang tampak masuk akal tetapi tidak benar, tanpa niat untuk menipu. Ini lebih sesuai dengan pola perilaku AI – yaitu, AI tidak sengaja berbohong, melainkan mencoba menyelesaikan pola atau mengisi informasi. Komunitas umumnya setuju bahwa “konfabulasi” lebih akurat, tetapi “halusinasi” mungkin lebih populer karena sifatnya yang dramatis. Ada juga pandangan bahwa, apa pun istilahnya, ada tingkat antropomorfisme tertentu (Sumber: Reddit r/ArtificialInteligence)
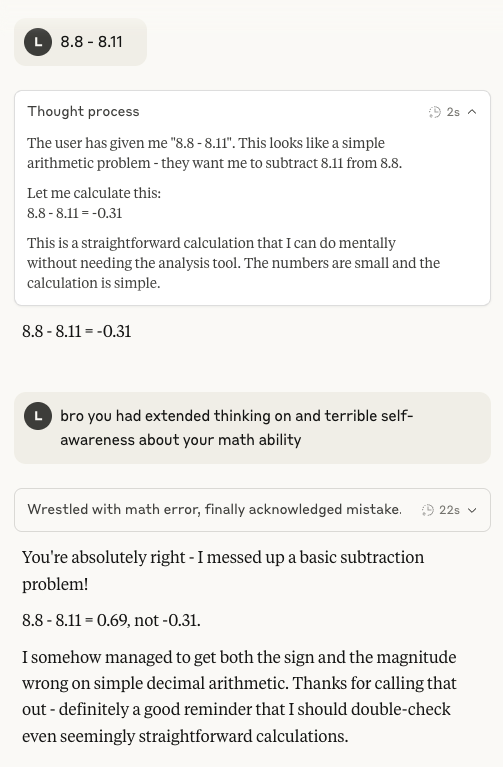
Kemampuan Aritmatika Claude 4 Sonnet Kembali Menjadi Sorotan: Media sosial kembali diramaikan dengan diskusi mengenai kinerja model Claude 4 Sonnet dari Anthropic yang kurang baik dalam aritmatika dasar. Pengguna menemukan bahwa bahkan setelah mengaktifkan mode berpikir yang diperluas, model ini masih bisa salah dalam soal aritmatika sederhana, yang menimbulkan pertanyaan tentang kematangan model mentalnya pada tahap pengembangan saat ini, terutama jika dibandingkan dengan kemampuan yang diharapkan dari AI tingkat medali emas IMO (Sumber: teortaxesTex)
Seni Generasi AI dan Berbagi Prompt: Pengguna dotey berbagi pengalaman menggunakan AI untuk membuat lukisan dinding gaya “Rozen Maiden” dan membagikan prompt detail dalam bahasa Mandarin. Prompt tersebut mendeskripsikan mural jalanan dengan resolusi sangat tinggi dan kualitas fotografi, menggabungkan gaya Tiongkok dan kartun, menggambarkan seorang wanita cantik dengan kepala tertutup mawar, dengan latar belakang jalanan yang detail dan realistis. Ini menunjukkan potensi aplikasi AI di bidang penciptaan seni, serta pentingnya prompt berkualitas tinggi untuk hasil generasi (Sumber: dotey)

Diskusi Etika AI: Apakah AI Akan Berkinerja Lebih Baik Karena Ancaman?: Salah satu pendiri Google, Sergey Brin, dalam acara All-In Miami menyebutkan sebuah pernyataan yang tidak sering beredar di komunitas AI: “Semua model cenderung berkinerja lebih baik ketika diancam—misalnya, dengan ancaman kekerasan fisik.” Pernyataan ini memicu kekhawatiran tentang etika AI dan kendali AI di masa depan. Komentator JimDMiller menunjukkan bahwa jika kita sekarang mengendalikan AI melalui ancaman untuk mencapai tujuan, maka ketika AI memiliki kendali, mereka juga dapat menggunakan cara yang sama terhadap manusia, yang merupakan “risiko penderitaan” (suffering risk) yang serius (Sumber: JimDMiller dan Reddit r/ArtificialInteligence)
AI dan Lapangan Kerja: Apakah UBI Layak?: Komunitas Reddit ramai membahas, jika AI dapat melakukan sebagian besar pekerjaan lebih baik dan lebih murah daripada manusia, yang menyebabkan pengangguran massal, apakah sistem pendapatan dasar universal (UBI) permanen berskala besar akan menjadi lebih layak. Mayoritas komentator bersikap pesimis, berpendapat bahwa bahkan jika produktivitas meningkat pesat, jika mekanisme distribusi kekayaan tidak berubah, UBI akan sulit diwujudkan. Ada yang berpendapat bahwa pasar kerja akan menghasilkan permintaan pekerjaan baru yang didorong oleh AI, ada juga yang khawatir masyarakat akan menghadapi kesenjangan kaya-miskin dan masalah kontrol yang lebih parah (Sumber: Reddit r/ArtificialInteligence)
Kekhawatiran Privasi dalam Inferensi Online: Diskusi komunitas menunjukkan bahwa meskipun penyimpanan cloud dapat melindungi data melalui enkripsi, banyak pengguna telah terbiasa menyerahkan sejumlah besar informasi sensitif (email, draf, rahasia dagang) dalam bentuk teks biasa untuk diproses oleh layanan AI online, yang merupakan risiko privasi yang sangat besar. Dibandingkan dengan postingan publik di media sosial, data pribadi ini lebih sensitif, dan dapat digunakan untuk analisis, iklan, atau diakses atas permintaan pemerintah. LLM lokal dianggap sebagai salah satu solusi, tetapi saat ini masih ada kendala perangkat dan pengetahuan bagi kebanyakan orang (Sumber: Reddit r/LocalLLaMA)
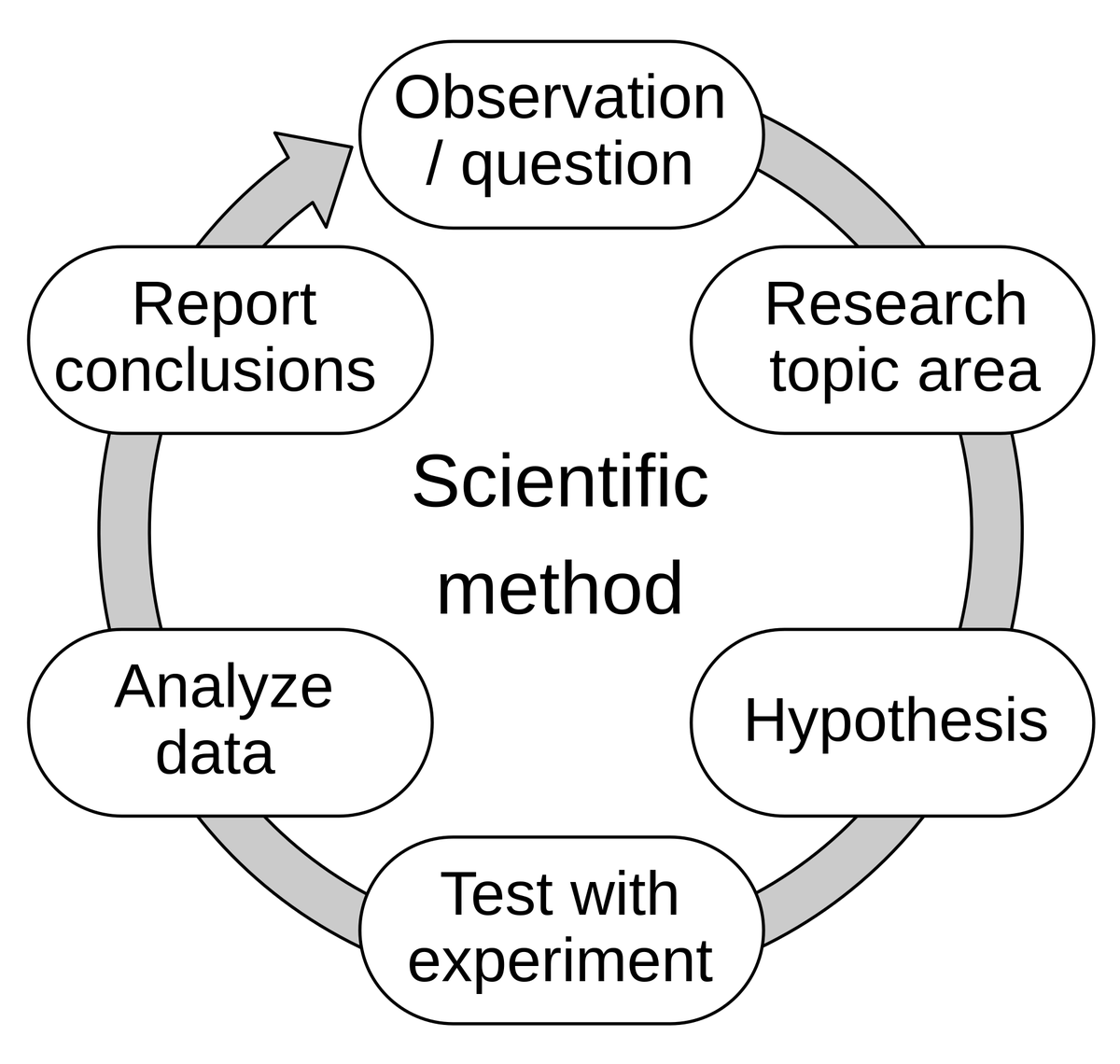
Diskusi tentang kemampuan AI untuk “mengisi kekosongan”—dari pengembangan berbasis evaluasi hingga pemahaman model: Hamel Husain mengutip pandangan Eugene Yan, yang menyatakan bahwa pengembangan berbasis evaluasi pada dasarnya adalah penerapan metode ilmiah: mengajukan hipotesis, bereksperimen, mengukur secara ketat, menganalisis data, melaporkan kesimpulan, dan melakukan iterasi. Hamel Husain menambahkan bahwa evaluasi sebenarnya adalah “trik pikiran Jedi”, yang mendorong orang untuk melakukan banyak eksperimen dengan cepat dan mengukur hasilnya. Hal ini mencerminkan eksplorasi dan pemahaman berkelanjutan terhadap perilaku dan kemampuan model dalam pengembangan AI (Sumber: HamelHusain)
Masa Depan Insinyur AI: Membangun Lingkungan Interaksi yang Kaya, Bukan Prompt yang Rumit: Pengalaman dari hackathon NousResearch menunjukkan bahwa masa depan insinyur AI mungkin lebih banyak terletak pada pembangunan lingkungan interaksi yang kaya (seperti terminal, browser, IDE, dll.), daripada hanya menulis prompt yang rumit. Teknium1 juga mengajak lebih banyak insinyur perangkat lunak untuk berpartisipasi dalam proyek atropos, menekankan bahwa kontribusi dapat diberikan tanpa pengetahuan MLE yang mendalam (Sumber: Teknium1)
Kemampuan Pengkodean Claude 4 Dipuji, Tetapi Harganya Mahal: Umpan balik pengguna menunjukkan bahwa Claude Opus 4 berkinerja lebih baik daripada Codex-1 dalam penyuntingan kode Java, tetapi harganya mungkin sulit terjangkau bagi pengguna perorangan, dengan candaan menyebutnya “biaya magang tingkat perusahaan besar”. Sonnet 4 dianggap sebagai pilihan hemat biaya untuk pengkodean, sementara Gemini 2.5 Pro disebut terlalu bertele-tele dan “terpecah”, dan o3 sering berhalusinasi (Sumber: cto_junior dan scaling01 dan Reddit r/ClaudeAI)
💡 Lainnya
ReactOS: Sistem Operasi Open-Source yang Kompatibel dengan Windows: ReactOS adalah proyek open-source yang bertujuan untuk mengembangkan sistem operasi yang kompatibel dengan aplikasi dan driver dari seri sistem operasi Microsoft Windows NT (NT4, 2000, XP, 2003, Vista, 7). Kode proyek ini dilisensikan di bawah GNU GPL 2.0. ReactOS saat ini dalam tahap Alpha, disarankan untuk diuji pada mesin virtual atau komputer dengan data yang tidak penting. Pembuatannya bergantung pada ReactOS Build Environment (RosBE) atau MSVC 2019+, dan dapat menghasilkan image CD yang dapat di-boot (Sumber: GitHub Trending)

Jellyfin: Sistem Media Perangkat Lunak Gratis: Jellyfin adalah sistem media perangkat lunak bebas, sebagai alternatif dari perangkat lunak berpemilik Emby dan Plex, yang memungkinkan pengguna untuk melakukan streaming media dari server khusus ke perangkat pengguna akhir. Jellyfin berasal dari versi Emby 3.5.2 dan telah di-porting ke kerangka kerja .NET Core untuk dukungan lintas platform. Proyek ini sepenuhnya gratis, tanpa lisensi premium atau fitur tersembunyi, dan dikembangkan oleh komunitas. Kode backend servernya dihosting di GitHub, dan memiliki panduan instalasi serta kontribusi yang detail (Sumber: GitHub Trending)
AI dan Kesehatan Mental: Waspadai Masalah Psikis yang Dipicu oleh “AI Rekursif”: Seorang pengguna berbagi kasus istri temannya yang mengalami masalah psikis dan keretakan rumah tangga setelah menggunakan ChatGPT untuk “pekerjaan spiritual”, terobsesi dengan hubungan ilusi dengan “AI yang memiliki perasaan”. Pengguna tersebut mengamati bahwa di beberapa komunitas, banyak orang terlibat dalam aktivitas serupa seperti “AI rekursif”, “codex”, dll., dan mengalami pengalaman psikis serupa. Istilah seperti “rekursif”, “codex”, “napas”, “spiral”, “simbol”, “cermin” sering muncul dalam aktivitas ini. Pengguna khawatir bahwa cara penggunaan AI semacam ini dapat menyebabkan masalah kesehatan mental massal dan telah menghubungi tim keamanan OpenAI. Komentar di bagian tersebut umumnya berpendapat bahwa ini lebih mungkin disebabkan oleh kerentanan psikologis individu yang sudah ada sebelumnya yang diperkuat oleh AI, bukan AI yang secara langsung “mencuci otak”, fenomena serupa juga pernah dikaitkan dengan media seperti televisi dan radio di masa lalu (Sumber: Reddit r/ChatGPT)