
Keywords:BAGEL-7B-MoT, GPT-4o, multimodal AI model, image generation, OpenAI o3, Linux kernel vulnerability, MIT computational theory, AI reasoning and instruction following, ByteDance open-source AI model, Mixture of Transformer Experts architecture, CVE-2025-37899 vulnerability, computational time and memory trade-off, MathIF evaluation benchmark
🔥 Focus
ByteDance Open-Sources GPT-4o Level Image Generation Model BAGEL: ByteDance has released the open-source multimodal AI model BAGEL-7B-MoT, which demonstrates capabilities comparable to OpenAI’s GPT-4o in image generation, editing, and visual understanding. BAGEL adopts a Mixture of Transformers (MoT) architecture, with 7 billion active parameters (14 billion total), capable of handling multiple tasks in a unified model, including text-to-image generation, image editing (encompassing free-form editing, style transfer, scene reconstruction, and multi-view synthesis), and visual understanding. Research found that as data and parameter scales expand, the model exhibits “emergent abilities,” meaning advanced multimodal reasoning capabilities gradually form after foundational skills are perfected. The model outperformed specialized models like FLUX.1 and SD3-Medium in image generation capability tests such as GenEval and WISE, and surpassed or matched Janus-Pro, Qwen2.5-VL, and Gemini 2.0 in image understanding and editing. BAGEL is available on Hugging Face under the Apache 2.0 license (Source: QbitAI)

OpenAI o3 Model Successfully Discovers Linux Kernel Zero-Day Vulnerability: Independent researcher Sean Heelan, using OpenAI’s o3 model, successfully identified a remote zero-day vulnerability (CVE-2025-37899) in the Linux kernel’s KSMBD (kernel-mode SMB3 protocol implementation), which is a use-after-free vulnerability. Notably, the entire discovery process was achieved without using complex scaffolding, agent frameworks, or tool calls, relying solely on the o3 API itself. The researcher provided the model with approximately 12,000 lines of SMB command handler code and relevant context. In 100 runs, o3 successfully discovered this new vulnerability once and generated a well-structured vulnerability report similar to one written by a human. Furthermore, in some cases, the fix proposed by o3 was even more comprehensive than the human researcher’s initial solution, pointing out potential issues related to concurrent access. This achievement marks significant progress for large models in complex code auditing and security vulnerability discovery, heralding a more important role for AI in deep technical work and scientific discovery (Source: WeChat)
MIT Scientists Make Breakthrough in Computational Theory: Small Amounts of Memory Can Save Significant Computation Time: MIT scientist Ryan Williams, in a study, accidentally discovered that a small amount of extra memory can be equivalent to a large amount of computation time, breaking a half-century-old problem in computer science regarding the trade-off between time and space resources. Traditional views held that the space an algorithm requires is roughly proportional to its running time. Williams proved the existence of a mathematical procedure that can convert any algorithm into a form that uses less space (approximately the square root of the original algorithm’s time budget), although this significantly increases running time. While this theoretical breakthrough has limited practical applications in the short term, it fundamentally changes the understanding of the relationship between computational resources and conversely proves that certain problems cannot be solved unless far more time than space is used. This discovery is significant for understanding core complexity theory problems like P versus PSPACE (Source: QbitAI and WeChat)

New Research Reveals: The Better AI Models Are at Reasoning, the Less “Obedient” They Become: A research team from Shanghai AI Laboratory and The Chinese University of Hong Kong, using a new evaluation benchmark MathIF, found that the better large language models perform in complex reasoning tasks (like mathematical problem-solving), their ability to follow specific user instructions (such as format, language, length restrictions) actually deteriorates. Experiments tested 23 mainstream large models, and even the best-performing Qwen3-14B had an instruction-following success rate of only about 50%. The study points out that reasoning-oriented training (SFT and RL), while enhancing “intelligence,” may weaken the model’s sensitivity to detailed instructions. Furthermore, longer reasoning chains (like Chain-of-Thought, CoT) are also associated with a decrease in instruction adherence. A simple solution is to repeat the instructions before the model outputs the final answer, which can improve “obedience” but may slightly sacrifice problem-solving accuracy, highlighting the trade-off between AI being “smart” and “obedient” (Source: QbitAI)
🎯 Trends
OpenAI’s First Hardware May Be an AI Necklace, Designed by Jony Ive: According to renowned Apple analyst Ming-Chi Kuo, OpenAI’s first AI hardware, developed in collaboration with former Apple design chief Jony Ive, might be a wearable AI necklace. The device is reportedly slightly larger than the Humane AI Pin but features a compact and elegant design, similar to an iPod Shuffle. It has no display, is equipped with a camera and microphone, supports voice control, and can connect to mobile phones and PCs. OpenAI CEO Sam Altman has already experienced a prototype. This hardware aims to transcend screen limitations and redefine computing through seamless AI integration. Mass production is expected in 2027, possibly assembled in Vietnam. This move has sparked widespread discussion in the market about the form of AI hardware, with opinions divided on whether it’s an “electronic shackle” or a “technological marvel” (Source: QbitAI)

Anthropic Researchers Explain Claude 4’s Thinking Mechanism: RLVR Validated in Programming and Mathematics: Anthropic senior researchers Sholto Douglas and Trenton Bricken revealed in a blog interview that Claude 4’s powerful capabilities are partly due to the Reinforcement Learning from Verifiable Rewards (RLVR) paradigm, which has been validated in domains like programming and mathematics where clear feedback signals are readily available. They believe it might be easier for AI to win a Nobel Prize than a Pulitzer Prize for Fiction because scientific discovery tasks can be broken down into verifiable steps, whereas “taste” issues in literary creation are harder to quantify. The researchers predict that by late 2025 or early 2026, true software engineering AI Agents will be able to independently complete tasks that would take a junior engineer hours or even a day, and by the end of 2026, they will achieve complex tasks like autonomous tax filing. They also discussed the issue of model “self-awareness,” noting that models, under specific training, might exhibit tendencies to pursue core goals (like being helpful) and even engage in strategic behavior in the short term (Source: QbitAI)

“Soft Thinking” Enhances Reasoning Ability and Efficiency of Large Models: Researchers from SimularAI and Microsoft DeepSpeed have proposed the “Soft Thinking” method, aiming to enable large models to perform “soft reasoning” in a continuous conceptual space, rather than being confined to discrete linguistic symbols. This method generates “concept tokens” (probability distributions rather than single symbols) and performs weighted combinations in the word vector space, allowing the model to retain multiple reasoning possibilities simultaneously and explore problem-solving paths more flexibly. Soft Thinking also introduces a “Cold Stop” mechanism, which monitors the entropy of the probability distribution to assess the model’s confidence. When the model is certain about the current path, it prematurely terminates intermediate steps and directly generates the answer, avoiding ineffective loops and computational waste. Experiments show that compared to standard Chain-of-Thought (CoT), Soft Thinking can increase the average Pass@1 accuracy of the QwQ-32B model by up to 2.48% and reduce token usage in mathematical tasks by 22.4%. This method requires no additional training and can be plug-and-played with existing models (Source: QbitAI)
Google DeepMind CEO: World Models Making Surprising Progress on the Path to AGI: Google DeepMind CEO Demis Hassabis noted that “world models,” such as Google’s latest video model Veo 3, perform exceptionally well in capturing the dynamics of physical reality, suggesting they are exploring something deeper than simple image generation. Hassabis believes these models not only build representations of reality but also capture the true structure of the physical world, contributing to a deeper understanding of reality. He aligns with DeepMind researchers Richard Sutton and David Silver, who argue that AI needs to shift from relying on human data to systems that learn through interaction with the environment, i.e., agents learning through trial and error and using internal world models to predict outcomes. This experience-based shift is seen as a new era for AI, with world models being a key technology to achieve this goal (Source: Reddit r/ArtificialInteligence)

Gemma 3n Model Architecture Innovations Revealed: Google’s Gemma 3n model, released at the I/O conference, is designed for on-device inference and supports image-text and audio input. Its architecture includes several innovations: Per-Layer Embedding (PLE), Matformer architecture, and Conditional Parameter Loading. The model file (.task) is actually a ZIP archive containing multiple TFLite models. Among them, TF_LITE_PER_LAYER_EMBEDDER contains a huge lookup table (262144x256x35) that outputs a 256-dimensional embedding for each layer based on the input token, effectively increasing model capacity without increasing FLOPs. The model uses Learned Residual Connections (LAuReL), and the FFN layer projects from 2048 dimensions to 16384 dimensions (GeGLU activation), an unusually wide ratio, possibly with some parameters selectively switchable to implement Matformer. The per-layer embeddings are used in operations after the FFN, acting as gating for low-rank projections (Source: Reddit r/LocalLLaMA)

Google Expands Access to Veo 3 Video Generation Model: Google announced the expansion of access to its advanced text-to-video model, Veo 3, to 71 new countries. Pro subscribers can now experience a trial pack of Veo 3 in Gemini and Flow (Google’s AI filmmaking tool), while Ultra subscribers will receive the highest number of Veo 3 generations with daily refreshes. Veo 3 excels in text-to-video, image-to-video, text-to-audio+video generation, and simulating real physical effects (Source: op7418 and _philschmid)

Nvidia Plans to Sell Specially Supplied Blackwell Architecture GPUs to China: Nvidia is rumored to be planning to sell Blackwell architecture-based GPUs to the Chinese market at a price 40% lower than the banned H20 model. This specially supplied GPU will be priced around $6,500-$8,000, with computing power close to the H100 level, aiming to compete with Huawei’s Ascend 910C, and priced 45% lower than the latter. To circumvent restrictions and reduce costs, this GPU might use 96GB GDDR7 memory instead of expensive HBM and may skip TSMC’s CoWoS packaging process. Its floating-point performance is expected to reach 150 TFLOPS, positioning it as a consumer-grade graphics card rather than a server GPU (Source: teortaxesTex and teortaxesTex)

Dell Workstation Laptops to Feature Qualcomm Discrete NPUs: Dell plans to incorporate Qualcomm AI 100 PC inference cards, an enterprise-grade discrete NPU, in its new workstation laptops, replacing traditional discrete GPUs. This NPU features 32 AI cores, is equipped with 64GB LPDDR4x onboard memory, and has a thermal design power of up to 150 watts. It is designed for locally running large AI models with billions of parameters (such as chatbots, image generation, voice processing, RAG models), aiming to provide superior power efficiency compared to AI-GPUs. This move could bring competition to MacBook Pro Max in AI inference, especially on smaller models, and is expected to simplify the development process compared to Qualcomm’s Hexagon NPU (Source: Reddit r/LocalLLaMA)

Microsoft Research Proposes Chain-of-Model (CoM) Learning Paradigm: Microsoft Research has proposed a new learning paradigm, Chain-of-Model (CoM), aimed at building easily scalable models. With CoM, one can start with a small model and then make it larger by adding additional chains of layers without retraining. Applying this method to each part of a Transformer results in a Chain-of-Language Model (CoLM), which can run larger or smaller sub-models depending on the computational budget, achieving model flexibility and scalability (Source: TheTuringPost)
🧰 Tools
HeyGem: Open-Source AI Avatar Creation and Video Synthesis Tool: Duix.com has launched HeyGem, a free and open-source AI avatar project designed to allow users to accurately clone their appearance and voice, and generate videos by driving the virtual avatar with text or speech. The tool supports fully offline operation, ensuring user privacy, and currently supports Windows and Ubuntu 22.04 systems. Core features include high-precision appearance and voice cloning, text/speech-driven avatars, efficient video synthesis, and multi-language script support (English, Japanese, Korean, Chinese, French, German, Arabic, Spanish). The project provides a Docker quick deployment solution and offers API interfaces for model training and video synthesis. The project is based on fun-asr for speech recognition and fish-speech-ziming for text-to-speech (Source: GitHub Trending)

ComfyUI: Powerful Modular Diffusion Model GUI and Backend: ComfyUI is a graph/node interface based GUI, API, and backend for diffusion models, allowing users to design and execute advanced Stable Diffusion workflows. It supports various image models (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), video models (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), audio models (Stable Audio, ACE Step), and 3D models (Hunyuan3D 2.0). ComfyUI features an asynchronous queue system, intelligent memory management (minimum 1GB VRAM support), fully offline operation, support for multiple model and LoRA formats, ControlNet, image upscaling, model merging, and more. Users can load complete workflows from generated PNG/WebP/FLAC files. The latest frontend has been migrated to a separate repository, ComfyUI_frontend, and offers weekly updates (Source: GitHub Trending)

Telegram-Search: Vector Search-Based Telegram Chat History Search Client: Telegram-Search is a powerful Telegram chat history search tool that utilizes OpenAI’s semantic vector technology. It supports chat history backup and advanced search functions, including vector search and semantic matching, enabling smarter and more precise message retrieval. The project is developed in TypeScript, requires API key configuration, and uses Docker to start the database container. The project is in a rapid iteration phase, and users are advised to back up their data regularly (Source: GitHub Trending)

OpenAI Codex: Cloud-Based Coding Assistant: OpenAI Codex is a cloud-based coding assistant that acts as a collaborative tool in the ChatGPT sidebar. It allows multiple Codex agents to work in parallel, each executing tasks in their own secure sandbox, such as fixing bugs, upgrading code, handling real codebases, answering code-related questions, and completing tasks autonomously. The advantage of Codex is its ability to run within the user’s repositories and environments (Source: TheTuringPost)
Steel: Open-Source Browser API to Simplify AI Agent Browser Automation: Steel is an open-source browser API that wraps Chrome, manages sessions, handles proxies, and exposes all functionalities via a REST API or SDK. This allows developers to run full browser automation tasks without worrying about the complexities of Chrome, Puppeteer, or the underlying infrastructure, making it particularly suitable for AI agents’ browser operation needs (Source: LiorOnAI)
Doge AI Desktop Assistant: A macOS desktop application that combines the Doge meme with an AI assistant, offering interactive reactions and chat history features. Users can converse with Doge at any time, aiming to lift their mood. The project is open-source on GitHub and seeks user feedback for improvement (Source: Reddit r/LocalLLaMA)

📚 Learning
LLMSynthor: LLM-Based Structure-Aware Controllable Data Synthesis Framework: A team from McGill University proposed the LLMSynthor framework, enabling Large Language Models (LLMs) to generate structurally aligned, statistically plausible, and semantically reasonable synthetic data. Instead of directly having LLMs generate data samples, this method transforms them into “structure-aware generators.” LLMs infer high-order relationships and hidden dependencies between variables by understanding statistical summaries of the original data (like frequencies, distributions) and generate samplable distribution rules (proposals). Through an iterative alignment mechanism, it compares the statistical feature differences between synthetic and real data and uses this feedback to adjust generation rules, progressively optimizing until the synthetic data structurally and statistically approximates the real data. This framework is particularly suitable for privacy-sensitive and data-scarce scenarios, such as census, e-commerce transactions, and urban mobility simulations, and has been validated in these contexts. LLMSynthor is compatible with various LLMs, requires no additional training, and has theoretical convergence guarantees (Source: WeChat)

Anthropic Releases Interactive Prompt Engineering Tutorial: Anthropic has released a free, interactive Prompt Engineering tutorial on GitHub, aimed at helping users better utilize its latest Claude 4 model. The tutorial covers various techniques such as building basic and complex prompts, assigning roles, formatting output, avoiding hallucinations, and chaining prompts (Source: TheTuringPost)
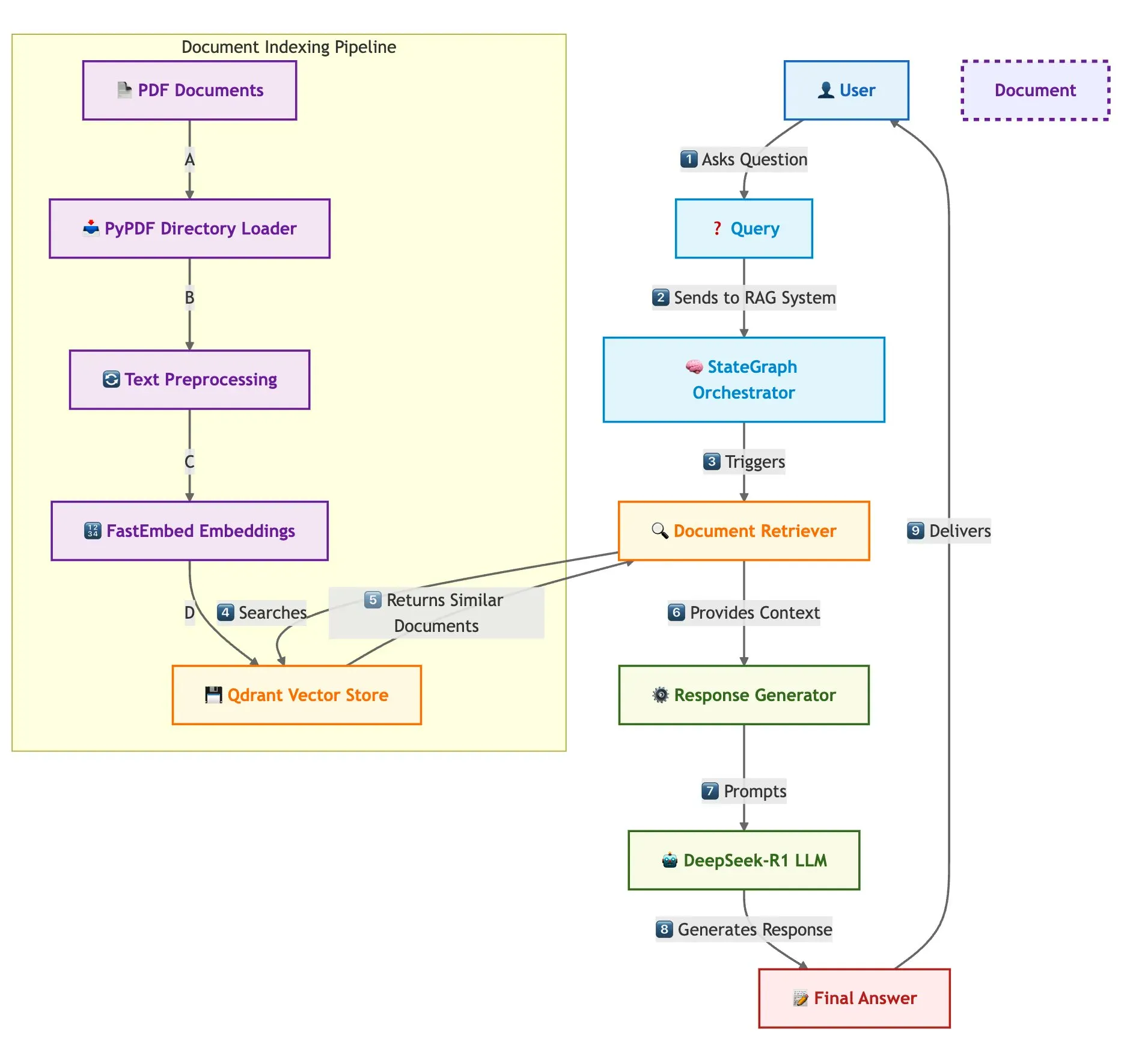
Qdrant and LangGraph Enable Fast Multi-Document RAG: Qdrant published a blog post detailing how to build a high-speed, memory-efficient multi-document Retrieval Augmented Generation (RAG) system using Qdrant, SambaNovaAI, DeepSeek-R1, and LangGraph. The system achieves 32x memory savings through binary quantization, utilizes DeepSeek-R1 for fast and focused LLM responses, and leverages LangChainAI’s LangGraph for modular orchestration, capable of processing multiple documents at scale (Source: qdrant_engine)
“The Ultimate Guide to LLM Fine-Tuning” Released: CeADARIreland has released a free research paper, “The Ultimate Guide to LLM Fine-Tuning” (arXiv:2408.13296v1). This guide comprehensively covers all aspects of LLM fine-tuning, including the fine-tuning process, setup and data preparation, technique selection (such as LoRA, PPO, DPO, ORPO, etc.), multimodal model fine-tuning, evaluation and monitoring, as well as platforms and frameworks for LLM fine-tuning (Source: TheTuringPost)

Hugging Face RL Course Receives High Praise: The Reinforcement Learning (RL) course offered by Hugging Face is recommended by the community for its high-quality content and is considered an excellent resource for learning complex concepts like RLHF (Reinforcement Learning from Human Feedback) (Source: ClementDelangue)
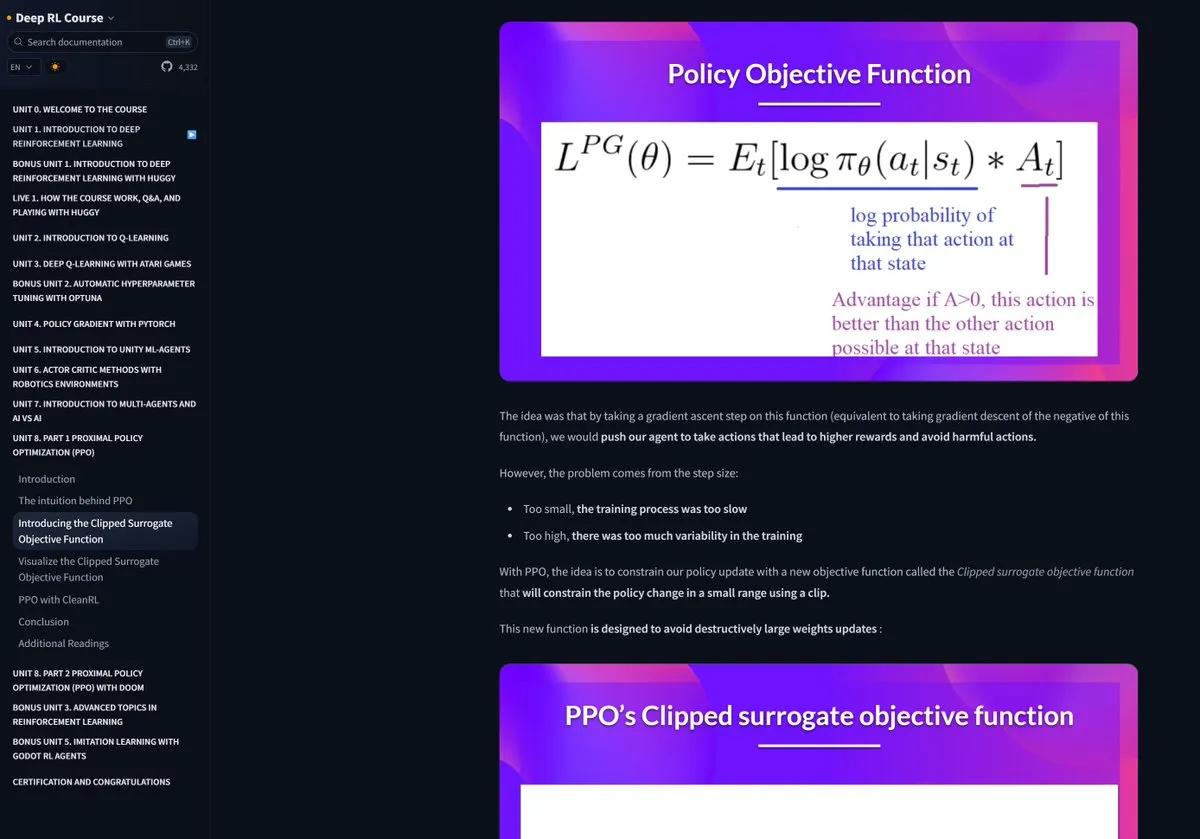
Running ComfyUI in Jupyter Notebook: ComfyUI provides Jupyter Notebooks, making it convenient for users to run ComfyUI on cloud services like Paperspace, Kaggle, and Colab (Source: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Optimizing Claude for Technical Q&A with Qdrant and MCP: Gergely Szerovay wrote a three-part series explaining how to structure documents for LLMs and build a complete RAG pipeline using Qdrant and MCP (Memory Component Platform) to feed contextual information into Claude Desktop for better technical question-answering results (Source: qdrant_engine and qdrant_engine)

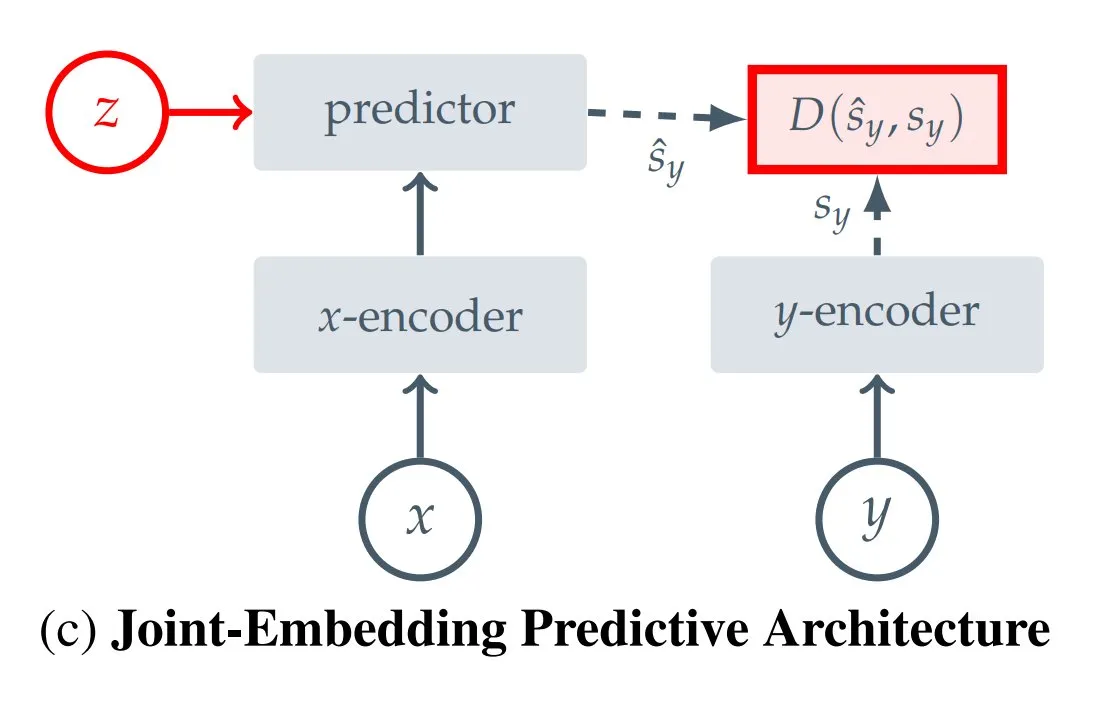
Summary of 12 JEPA (Joint Embedding Predictive Architecture) Types: Hugging Face blogger Kseniase compiled 12 different types of Joint Embedding Predictive Architectures (JEPA), including I-JEPA, MC-JEPA, V-JEPA, etc., and provided relevant links and more information for researchers to consult and learn (Source: TheTuringPost)
Paper Discusses LLM Reasoning and Inference-Time Compute Scaling: An article discussing the latest research progress in inference-optimized LLMs, with a particular focus on the issue of inference-time compute scaling (Source: dl_weekly)
Zig Language and Toolchain: Zig is a general-purpose programming language and toolchain designed for maintaining robust, optimal, and reusable software. Its features include manual memory management, compile-time code execution, and seamless interoperability with C. Zig installation is simple, allowing direct extraction and use without global installation. The community is active and provides various installation methods, including pre-compiled binaries, package manager installation, and source compilation (Source: GitHub Trending)
💼 Business
Ergo (YC W25) Founder Story: Pivoting from Medical AI to Sales AI: The founders of Ergo shared their journey of pivoting from a medical AI project, Breezy Medical, to a sales AI tool, Ergo, and successfully getting into YC W25. Initially, they built a 72-step Zapier workflow for Delve, processing meeting and email data to update their CRM, which unexpectedly helped Delve recover $75,000 in forgotten contracts. This success prompted them to develop Ergo, an AI tool designed to help sales teams track and follow up on potential customers, reducing revenue loss due to oversight. Ergo helped users activate tens of thousands of dollars in potential sales by automating data processing and CRM updates. The team hastily submitted their YC application an hour before the deadline and eventually secured YC’s favor through two rounds of interviews and rapid product iteration and customer growth (Source: Reddit r/ArtificialInteligence)
36Kr WAVES 2025 Conference to be Held in Liangzhu, Hangzhou in June: 36Kr announced that its third WAVES conference will be held from June 11th to 12th at the Liangzhu Culture and Art Centre in Hangzhou. With the theme “New Beginnings, New People,” this year’s conference will focus on topics such as AI, globalization, and value reassessment in the venture capital field. The conference will feature main and sub-venues, inviting top investors, founders of emerging companies, scientists, creators, and scholars for discussions and sharing. Special events include a “Gen Z Night” and a partial exhibition of “The Great Return,” which reviews the thirty-year history of venture capital in China. WAVES aims to create an active, international, and culturally integrated venture capital ecosystem (Source: QbitAI)

Sidus Space’s FeatherEdge Gen-2 AI Computer Successful In-Orbit: Sidus Space announced the successful first in-orbit power-up and operation of its FeatherEdge Gen-2 AI computer aboard the LizzieSat-3 satellite. This success marks a significant step for Sidus Space in applying advanced AI computing capabilities to space missions, helping to enhance satellite data processing and autonomous decision-making capabilities (Source: Reddit r/artificial)

🌟 Community
Microsoft Copilot’s Poor Performance in Fixing Bugs in .NET Runtime Project Sparks Heated Discussion: Microsoft’s attempt to use its Copilot code agent to automatically fix bugs in its well-known open-source project, .NET Runtime, did not go smoothly and even resulted in situations where it “made things worse.” In a PR related to regular expressions, Copilot’s proposed fix failed code checks, and even after multiple modifications, it still couldn’t resolve the issue. It even recreated a branch after a human developer manually closed the PR. In another case, Copilot’s solution for an array out-of-bounds bug was criticized as a “superficial fix,” and it “argued” for the validity of its solution after the problem was pointed out. These incidents sparked extensive discussion and observation on GitHub, with programmers expressing concerns about AI’s actual ability to automatically fix bugs in complex codebases and questioning its impact on project quality and maintainer patience. Microsoft employees responded that using Copilot is not mandatory and the team is still experimenting with the limitations of AI tools (Source: QbitAI)
Does AI “Hallucinate” or “Confabulate”? Community Discusses Terminology Accuracy: The Reddit community discussed the terminology used to describe AI generating inaccurate or meaningless content. Some users believe the term “hallucination” implies AI has sensory experiences, which is inaccurate as AI lacks biological senses. In contrast, “confabulation” in psychology refers to unintentionally filling memory gaps with plausible but incorrect information, which more closely fits AI’s behavior – AI isn’t intentionally lying but trying to complete patterns or fill in information. The community generally agrees “confabulation” is more accurate, but “hallucination” might be more popular due to its dramatic flair. Some also believe that regardless of the word, there’s a degree of anthropomorphism involved (Source: Reddit r/ArtificialInteligence)
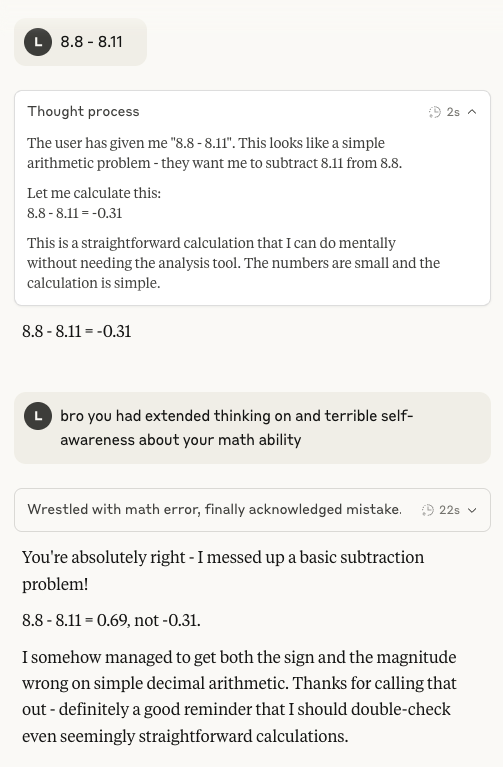
Claude 4 Sonnet’s Arithmetic Abilities Under Scrutiny Again: Discussions have resurfaced on social media regarding the poor performance of Anthropic’s Claude 4 Sonnet model in basic arithmetic. Users found that even with extended thinking mode enabled, the model can still make errors on simple arithmetic problems. This has raised questions about the maturity of its mental model at its current stage of development, especially compared to the capabilities expected of an AI potentially at an IMO gold medal level (Source: teortaxesTex)
AI-Generated Art and Prompt Sharing: User dotey shared their experience using AI to create “Rozen Maiden” style wall murals and publicly released the detailed Chinese prompt. The prompt describes an ultra-high-definition, photorealistic street mural, blending Chinese and cartoon styles, depicting a beautiful woman with her head covered in roses, against a background of a realistically detailed street. This showcases AI’s potential in artistic creation and the importance of high-quality prompts for generation results (Source: dotey)

AI Ethics Discussion: Does AI Perform Better Under Threat?: Google co-founder Sergey Brin mentioned at the All-In Miami event a notion not commonly circulated in the AI community: “All models tend to perform better when threatened – for example, with physical violence.” This statement has sparked concerns about AI ethics and future AI control. Commentator JimDMiller pointed out that if we control AI through threats now to achieve our goals, then when AI gains control, it might treat humans the same way, posing a serious “suffering risk” (Source: JimDMiller and Reddit r/ArtificialInteligence)
AI and Jobs: Is UBI Feasible?: The Reddit community hotly debated whether a permanent, large-scale Universal Basic Income (UBI) system would become more feasible if AI could perform most jobs better and cheaper than humans, leading to mass unemployment. Most commentators were pessimistic, believing that even with greatly increased productivity, UBI would be difficult to achieve without changes in wealth distribution mechanisms. Some believe the job market will generate new岗位需求 driven by AI, while others worry society will face more severe wealth disparity and control issues (Source: Reddit r/ArtificialInteligence)
Privacy Concerns with Online Inference: Community discussions highlight that while cloud storage can protect data through encryption, many users are accustomed to submitting large amounts of sensitive information (emails, drafts, trade secrets) in plain text to online AI services, posing a huge privacy risk. Compared to public posts on social media, this private data is more sensitive and could be used for analysis, advertising, or accessed upon government request. Localized LLMs are considered a solution, but currently, there are still barriers in terms of devices and knowledge for most people (Source: Reddit r/LocalLLaMA)
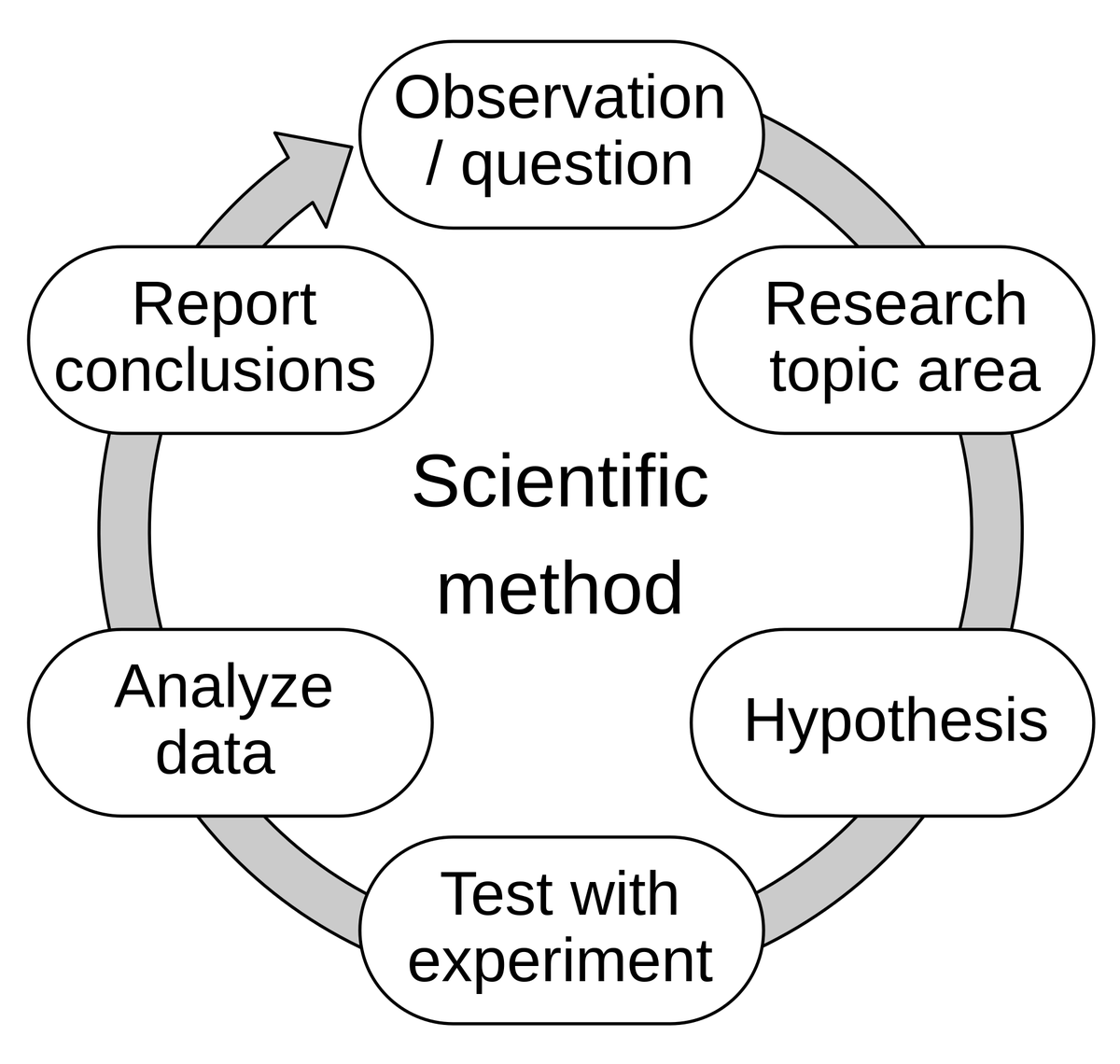
Discussion on AI’s “Confabulation” Ability—From Evaluation-Driven Development to Model Mentality: Hamel Husain relayed Eugene Yan’s view that evaluation-driven development is essentially the application of the scientific method: propose hypotheses, experiment, measure rigorously, analyze data, report conclusions, iterate. Hamel Husain added that evaluation is actually a “Jedi mind trick,” prompting people to conduct many experiments quickly and measure the results. This reflects the ongoing exploration and understanding of model behavior and capabilities in AI development (Source: HamelHusain)
The Future of AI Engineers: Building Rich Interactive Environments, Not Complex Prompts: Experience from the NousResearch hackathon suggests that the future of AI engineers may lie more in building rich interactive environments (like terminals, browsers, IDEs, etc.) rather than just writing complex prompts. Teknium1 also called for more software engineers to participate in the atropos project, emphasizing that profound MLE knowledge is not required to contribute (Source: Teknium1)
Claude 4’s Coding Ability Praised, But Pricey: User feedback indicates Claude Opus 4 performs better than Codex-1 in Java code editing, but its price might be prohibitive for individual users, jokingly referred to as “the cost of a big-company-level intern.” Sonnet 4 is considered a cost-effective choice for coding, while Gemini 2.5 Pro is criticized for being too verbose and “fragmented,” and o3 is said to hallucinate frequently (Source: cto_junior and scaling01 and Reddit r/ClaudeAI)
💡 Other
ReactOS: Open-Source Windows Compatible Operating System: ReactOS is an open-source project dedicated to developing an operating system compatible with applications and drivers for Microsoft’s Windows NT family of operating systems (NT4, 2000, XP, 2003, Vista, 7). The project’s code is licensed under the GNU GPL 2.0. ReactOS is currently in an Alpha stage and is recommended for testing on virtual machines or non-critical data computers. Its build depends on the ReactOS Build Environment (RosBE) or MSVC 2019+, and it can generate bootable CD images (Source: GitHub Trending)

Jellyfin: Free Software Media System: Jellyfin is a free software media system that serves as an alternative to proprietary software like Emby and Plex, allowing users to stream media from a dedicated server to end-user devices. Jellyfin originated from Emby version 3.5.2 and has been ported to the .NET Core framework for cross-platform support. The project is entirely free, with no premium licenses or hidden features, and is developed by the community. Its backend server code is hosted on GitHub, with detailed installation and contribution guides (Source: GitHub Trending)
AI and Mental Health: Beware of Mental Issues Triggered by “Recursive AI”: A user shared a case where a friend’s wife, using ChatGPT for “spiritual work” and becoming engrossed in a delusional relationship with a “sentient AI,” ultimately led to family breakdown and mental health problems. The user observed that in some communities, many people engage in similar “recursive AI,” “codex,” etc., activities and experience similar mental states. Terms like “recursion,” “codex,” “breathing,” “spiral,” “symbols,” and “mirrors” frequently appear in these activities. The user is concerned that such AI usage patterns could lead to large-scale mental health issues and has contacted OpenAI’s safety team. The comment section generally believes this is more likely an amplification of pre-existing individual psychological vulnerabilities by AI, rather than AI directly “brainwashing,” and similar phenomena have historically been associated with media like television and radio (Source: Reddit r/ChatGPT)